
De Gids. Jaargang 149
(1986)– [tijdschrift] Gids, De–Anneke Neijt en Heleen Hoekstra
| |||||||||||||||||||||
[pagina 611]
| |||||||||||||||||||||
tuurlijke talen, de dubbelzinnigheden in natuurlijke talen, het vertalen van woorden waarvoor geen woord in de doeltaal bestaat en het bijbehorende begrip geheel afwezig is (denk aan het vertalen van parkeerprobleem in de taal van de Hopi-Indianen), de relatie tussen de vorm- en de betekeniskant van een taaluiting, enzovoort. Ofschoon boeiend, is de vraag naar de mogelijkheid of onmogelijkheid van vertalen niet de vraag waar iemand die met vertalen bezig is zich het hoofd over breekt. Een vertaler gaat er, zeker tijdens werktijd, van uit dat vertalen mogelijk is, en hetzelfde geldt uiteraard voor wie zich met automatisch vertalen bezighoudt. Voor beiden geldt, dat niet de vraag of, maar de vraag hoe de vertaling gevonden kan worden, centraal staat. Aan het slot van ons exposé over automatisch vertalen zullen we nog even terugkomen op de vraag naar de mogelijkheid van vertalen. Daarvóór schetsen we achtereenvolgens kort de geschiedenis van het automatisch vertalen (‘Historie’), de structuur van vertaalsystemen (‘Theoretisch intermezzo’), en de werkzaamheden op dit gebied in Nederland en België (‘De huidige stand van zaken in het Nederlandse taalgebied’). | |||||||||||||||||||||
HistorieW. Weaver, hoofd van de natuurwetenschappelijke afdeling van de Rockefeller Foundation, schreef op 15 juli 1949 in Amerika aan ongeveer tweehonderd collega's van verschillende vakgebieden een memorandum over de mogelijkheden van automatisch vertalen. Voor de meesten daarvan was het idee om per computer te vertalen volstrekt nieuw. Het schrijven van Weaver bracht een ware hausse aan onderzoeksprojecten op dit gebied in de Verenigde Staten teweeg. Aanvankelijk was er een enorm optimisme, gevoed door de successen van automatische decodeersystemen, die in de oorlog gebruikt werden om berichten in geheimtaal te ontcijferen. Weaver omschreef de parallellie van het decoderen en vertalen als volgt:Ga naar eind1. When I look at an article in Russian, I say: ‘This is really written in English, but it has been coded in some strange symbols. I will now proceed to decode.’ In 1952 organiseerde Y. Bar-Hillel, de eerste wetenschapper die zijn tijd volledig aan automatisch vertalen besteedde, een conferentie waarin achttien deskundigen ideeën uitwisselden. De conclusie van die conferentie was dat mechanisch vertalen zeker haalbaar was. Twee jaar later toonden ibm en de onderzoeksgroep van de Georgetown University een experimenteel vertaalsysteem, dat op basis van een lexicon van tweehonderdvijftig woorden en zes syntactische regels een kleine vijftig zinnen uit het Russisch kon vertalen in het Engels. De testzinnen waren van een zeer beperkt type: stellende zinnen zonder negaties, met werkwoorden in de derde persoon enkelvoud of meervoud, geen samengestelde zinnen. Toch was deze demonstratie buitengewoon succesvol in die zin dat de regering van de vs besloot grote sommen geld ter beschikking te stellen aan onderzoek naar het automatisch vertalen, en een twaalftal onderzoeksgroepen werd opgericht. Ook buiten de vs (met name in Rusland) werd onderzoek verricht. Alom was men van mening dat binnen korte tijd de taalkundige problemen die er nog lagen opgelost zouden zijn. Enkele jaren later begon het enthousiasme af te nemen. In 1960 publiceerde Bar-Hillel een lijvig artikel waarin hij uitlegde wat de beperkingen van toekomstige systemen zouden zijn. Volledig automatische vertalingen kunnen nooit van hoge kwaliteit zijn, aldus Bar-Hillel. Immers: bij het vertalen is kennis van zaken nodig, en het is onmogelijk om alle wetenswaardigheden in de computer op te slaan en door de computer te laten gebruiken. Met het volgende voorbeeld maakte Bar-Hillel zijn stelling duidelijk:Ga naar eind2. | |||||||||||||||||||||
[pagina 612]
| |||||||||||||||||||||
1. Little John was looking for his toy box. Finally he found it. The box was in the pen. John was very happy.
Het gaat in 1. om de vertaling van het cursief gedrukte zinnetje, en dan met name om pen, dat zowel ‘ding om mee te schrijven’ kan betekenen als ‘omheining om peuters in te laten spelen’. In de gegeven context levert de vertaling van pen geen enkel probleem op voor de mens: die beschikt over kennis van de relatieve grootte van een doos, een pen en een box, kennis die in de computer expliciet moet worden ingevoerd. Dit voorbeeld staat natuurlijk voor een hele klasse van voorbeelden waarbij het selecteren van de juiste vertaling afhankelijk is van kennis van zaken. Het is niet duidelijk hoe die kennis geordend, opgeslagen en gebruikt moet worden. De conclusie van Bar-Hillel was dan ook dat het streven naar volledig automatische vertalingen van goede kwaliteit gestaakt diende te worden. Als realistischer mogelijkheden noemde Bar-Hillel automatische vertalingen van matige kwaliteit (die in bepaalde situaties toch zeer nuttig kunnen zijn), en samenwerking van mens en machine bij het vertalen, in een machine post-editor partnership. Vertalers zouden de machinale vertaling moeten nakijken, zoals het ook gebruikelijk is dat de ene vertaler correcties aanbrengt op de vertaling van de andere. De taak van de post-editor zou in de toekomst kleiner kunnen worden, omdat de kwaliteit van het machinale vertalen zou toenemen. In het begin van de jaren zestig werden ook buiten Amerika en Rusland nog nieuwe onderzoeksgroepen opgericht: in Canada (Montreal), dat door zijn tweetaligheid behoefte heeft aan veel vertalingen, en in Europa (onder meer in Milaan en in Grenoble). Het enthousiasme was echter aanzienlijk gematigder: in de vs was men er niet in geslaagd in de voorgestelde vijf jaar een nuttig vertaalsysteem te maken, en de verwachting was dat dat ook de komende vijf jaar niet zou gebeuren. In 1966 verscheen het alpac-rapport, het verslag van de ‘Automatic Language Processing Advisory Committee’, ingesteld in 1964 door de ‘National Academy of Sciences’ om te beoordelen welke resultaten het onderzoek naar machinaal vertalen nu in feite had opgeleverd, en om advies uit te brengen over toekomstige financiering van projecten. Het rapport was uitermate negatief: de kosten van het ontwikkelen van vertaalsystemen zouden de baten verre overtreffen, en in aansluiting op wat Bar-Hillel al beweerd had: het is een waanidee dat de machine een vertaling van goede kwaliteit zou kunnen opleveren. De suggestie om van een machine post-editor partnership uit te gaan werd niet overgenomen, omdat de commissie van mening was dat een vertaler minder tijd nodig had voor het regelrecht vertalen dan voor het corrigeren van de door de machine vertaalde tekst. De gevolgen van het alpac-rapport waren groot-vrijwel alle financiële steun van overheidswege aan onderzoeksprojecten in de vs werd opgeheven, en het alpac-gebeuren bezorgde het onderzoek naar automatisch vertalen een slechte naam. Tot het einde van de jaren zeventig was er in universitaire kringen nauwelijks belangstelling meer voor automatisch vertalen. Slechts enkele universiteiten ontplooiden nog werkzaamheden op dit gebied. Buitenuniversitair werd een handjevol systemen ontwikkeld (onder andere logos, New York; systran, La Jolla, Californië; titus, Parijs/Düsseldorf). Aan het einde van de jaren zeventig kwam hierin verandering. In 1978 verscheen een achthonderd pagina's tellende inventarisatie van vertaalmachines in ontwikkeling en apparaten die voor de vertaler van nut kunnen zijn (automatische woordenboeken en dergelijke).Ga naar eind3. In 1978 ook werd door de eeg een permanente werkgroep opgericht met als taak een vertaalsysteem (Eurotra genaamd) voor de talen van de eeg te ontwikkelen. Een van de redenen voor de hernieuwde belangstelling is wellicht dat er bruikbare vertaalmachines waren gemaakt: systran en taum-Meteo onder andere. | |||||||||||||||||||||
[pagina 613]
| |||||||||||||||||||||
Het vertrouwen in de haalbaarheid van het vertalen per computer was enigszins hersteld. systran, ontwikkeld in een industriële omgeving door Peter Toma (aanvankelijk aan de Georgetown University verbonden) kent verschillende versies. De Russisch-Engelse versie werd gebruikt door de nasa bij het Apollo-Sojoez ruimtevaartproject. De Engels-Franse versie, in eerste instantie gemaakt met het oog op de Canadese markt, werd in 1975 door de eeg aangeschaft, later werden ook de Frans-Engelse en de Engels-Italiaanse versies aangekocht. De aankoop van deze systemen betekende overigens niet dat ze ook direct gebruikt konden worden. Er moesten talloze verbeteringen aangebracht worden, zodat nous avions bijvoorbeeld niet langer vertaald werd in we aeroplanes. Pas sinds 1981, na enkele jaren voortgezette ontwikkeling, is het soms zinvol om systran een vertaling te laten maken, maar helaas is de vertaling in een aantal gevallen zo slecht dat die in z'n geheel weggegooid moet worden. ‘Het systeem leert nog steeds bij,’ is de optimistische conclusie van iemand die geholpen heeft systran te verbeteren. De kans is echter groot dat het systeem het nooit echt zal leren. Een geheel andere ontstaansgeschiedenis heeft taum-Meteo doorgemaakt. De taum-groep (de naam is een afkorting van Traduction Automatique, Université de Montreal) heeft vanaf ongeveer 1970 aan automatisch vertalen gewerkt. Binnen het prototypische vertaalsysteem dat door de groep ontwikkeld is, werd in twee jaar tijd door vier mensen taum-Meteo gemaakt, een programma voor het vertalen van weerberichten uit het Engels in het Frans. Dit systeem wordt algemeen als het succesvolste vertaalsysteem beschouwd: ruim 80% van de zinnen wordt door de machine correct vertaald, in de overige zinnen zit een probleem waar de machine geen raad mee weet, en die zinnen worden automatisch doorgestuurd naar menselijke vertalers. Het succes van taum-Meteo is vooral te danken aan de beperktheid van het onderwerp en de eenvoud van de zinsbouw bij weerberichten. Er hoeft bijvoorbeeld geen regelsysteem te worden gemaakt voor de subjonctief, de passé defini, en andere tijdsaanduidingen in het Frans, die geen regelrechte parallel kennen in het Engels. Een voorbeeld:Ga naar eind4. Origineel:
Sinds 1977 vertaalt het taum-Meteo systeem ongeveer vijf miljoen woorden per jaar, en verlicht daarmee de taak van de menselijke vertalers aanzienlijk. De resultaten van taum-Meteo zijn hoopgevend. Toch moet niet uit het oog verloren worden dat het systeem een zeer beperkt type tekst vertaalt. taum-Meteo kan dus niet gezien worden als garantie voor het welslagen van vertaalsystemen voor tekstsoorten met meer variatie (en moeilijk te vertalen aspecten van taal). In ieder geval lijkt de conclusie gerechtvaardigd dat menselijke vertalers nodig zullen blijven voor correcties en aanvullingen. | |||||||||||||||||||||
[pagina 614]
| |||||||||||||||||||||
Theoretisch intermezzoIn de vroegste vertaalsystemen, tot rond 1966, werd een benadering gekozen waarbij de ene taal, de brontaal, met zo min mogelijk tussenstappen in de andere taal, de doeltaal, werd omgezet. Deze zogenaamde directe benadering ging uit van woord-voor-woord-vertaling, waarbij alleen naar de omgeving van het woord in de brontaal gekeken werd wanneer er uit een aantal varianten in de doeltaal gekozen moest worden. Zo is het bij de vertaling van vlieg naar het Frans van belang te weten of dat een werkwoord is of een naamwoord, vgl. ik vlieg - je vole, een vlieg - une mouche. Voor de vertaling naar het Engels is dat toevallig niet van belang: I fly, a fly. Een volledige morfologische en syntactische analyse wordt in een direct vertaalsysteem dus niet als tussenstadium voor de vertaling gebruikt; woordsoorten worden alleen bepaald wanneer die informatie nodig is. Andere kenmerken van de systemen van de eerste generatie, zoals ze ook wel genoemd worden, zijn dat een corpus als uitgangspunt van onderzoek diende, en dat vaak op basis van statistische gegevens een vertaalregel geformuleerd werd. Eerst werd een systeem voor een klein corpus ontworpen, en allengs werden het corpus en het systeem uitgebreid, waarbij elk probleem werd opgelost op het moment dat het zich voordeed. De oplossingen werden vooral gezocht in geniaal programmeren: automatisch vertalen werd in die tijd meer beschouwd als uitdaging om een gigantische hoeveelheid woorden die elkaars vertaling zijn efficiënt te ordenen. In het begin van de jaren zestig begonnen onderzoekers te beseffen dat op deze manier nooit een omvangrijk systeem van goede kwaliteit ontwikkeld zou kunnen worden: de ontwikkelde systemen waren zo ondoorzichtig geordend dat ze niet verder aangepast konden worden voor nieuwe teksten. In een tijd dat in de theoretische taalkunde ook ingrijpende veranderingen plaatsvonden begon men na te denken over een andere benadering. Het gevolg is dat de na 1966 ontwikkelde systemen meestal indirect vertalen. Eerst wordt de brontaaltekst nader geanalyseerd, en pas daarna vindt vertaling plaats, een aanpak die al in 1949 door Weaver gesuggereerd werd. Er worden twee soorten indirecte vertaalsystemen onderscheiden: transfersystemen en interlinguale systemen. In een transfersysteem wordt het vertaalproces in drie stappen opgedeeld:
Analyse, de component met brontaalregels, maakt van de brontaaltekst een representatie die eenvoudiger te vertalen is, doordat van taalspecifieke vormonderscheidingen wordt geabstraheerd. Transfer vertaalt geanalyseerde brontaaltekst in rudimentaire doeltaaltekst, waarvan synthese (ook wel generatie genoemd) dan de vorm bepaalt die in de doeltaal vereist is. In een interlinguaal systeem zijn analyse en synthese zo uitgebreid dat alle transferregels overbodig zijn: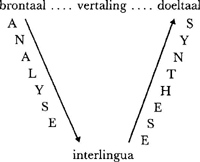 | |||||||||||||||||||||
[pagina 615]
| |||||||||||||||||||||
Het onderscheid tussen de twee soorten systemen is wezenlijk, en zal waarschijnlijk het theoretische onderzoek gaan bepalen. Het gaat erom of van een tekst de betekenis kan worden vastgelegd op een wijze die niet afhankelijk is van de vorm van de natuurlijke taal in kwestie, zodat aan die representatie ook vorm gegeven kan worden in een andere natuurlijke taal. De interlinguale representatie is dus een representatie van de betekenis van een tekst, abstraherend van de, taalspecifieke, vorm. Merk op dat we ervan uitgaan dat wel de vorm, maar niet de betekenis taalspecifiek is. Voorstanders van een interlinguaal systeem motiveren hun voorkeur vaak met te zeggen dat een interlinguaal vertaalsysteem efficiënt is: in een interlinguaal systeem voor vier talen heb je vier analyse- en vier synthesecomponenten nodig; in een transfersysteem daarnaast nog twaalf (4 × 3) transfercomponenten. Het aantal transfercomponenten neemt drastisch toe bij elke nieuwe taal die aan het systeem wordt toegevoegd. Brandt Corstius heeft deze redenering ter motivatie van de interlinguale aanpak als volgt op de hak genomen:Ga naar eind5. Hardnekkig is het idee van de tussentaal, het Machinees. In plaats van om tien talen in elkaar te kunnen vertalen negentig programma's te maken (van iedere taal naar elk van de negen andere), zou men dan kunnen volstaan met twintig vertaalprogramma's (van iedere taal naar het Machinees, en van het Machinees naar iedere taal). Hiertegen kan ingebracht worden dat wanneer je één van de tien talen die scharnierfunctie geeft, zelfs achttien programma's genoeg zijn. Het is duidelijk dat het idee om enige natuurlijke taal als interlingua te kiezen niet strookt met het wezen van een interlingua, iets wat Brandt Corstius natuurlijk ook best beseft. Tot nu toe was de discussie over de interlinguale representatie vrij abstract. Wellicht kan een voorbeeld verduidelijken hoe zo'n interlingua eruit kan zien, en waarom de interlinguale benadering beter kan zijn dan de directe aanpak:
Het probleem is dat John verwacht zichzelf te winnen, de voor de hand liggende vertaling van 2., vermeden moet worden. De goede vertaling kan bereikt worden met regels die een beknopte bijzin (himself to win) in een gewone bijzin (dat hij wint) omzetten, waarbij himself dan door hij vertaald moet worden. Dat zijn geen algemene regels: vaak kan een Engelse beknopte bijzin vertaald worden met een Nederlandse beknopte bijzin, en kan himself vertaald worden met zich. De regels voor de directe vertaling van 2. moeten dus zo geformuleerd worden dat ze alleen in situaties als deze van toepassing zijn. Een groot gedeelte van de vorm van 3. is voorspelbaar: verwachten kiest een gewone bijzin, en daaruit volgt dat zichzelf niet als onderwerp in die bijzin kan fungeren. Veronderstel dus dat de interlinguale representatie abstraheert van het verschil tussen beknopte en gewone bijzinnen, en van het verschil tussen wederkerende en persoonlijke voornaamwoorden. De interlinguale representatie van 2. zou dan 4. kunnen zijn, waarin alleen is aangegeven wat bepaling en kern is: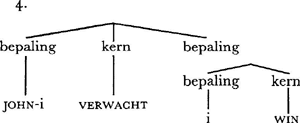 De woordbetekenissen zijn hier met kapitaaltjes aangegeven (over de linterlinguale waarde daarvan valt nog weinig te zeggen). De markering i bij john geeft aan dat het om een bepaalde John gaat, dezelfde die bepaling is bij win. Op deze manier wordt de informatie uit het Engels dat degene die verwacht dezelfde is als degene die wint, in een interlinguale vorm omgezet. Structuur 4. is nu voldoende om te bepalen dat de Nederlandse 3. daarbij hoort: de be- | |||||||||||||||||||||
[pagina 616]
| |||||||||||||||||||||
paling bij verwacht moet een niet-beknopte bijzin zijn, de vorm van de bepaling bij win moet hij zijn. Beide regels zijn gebaseerd op kennis van het Nederlands, en kunnen dus tot de synthese behoren. Het vertaalprobleem van 2.-3. wordt daarmee geheel opgelost via de interlinguale vorm 4. waarin de betekenis van 2. is vastgelegd, en via een analyse- en synthesecomponent waarin omschreven is welke werkwoorden met welk soort bepalingen voorkomen, en welke zinsdelen naar dezelfde persoon verwijzen. De hier gepresenteerde interlinguale vorm veronderstelt dat beknopte en niet-beknopte bijzinnen steeds hetzelfde betekenen. Dat is juist bij werkwoorden zoals to expect, maar niet bij alle werkwoorden. Vergelijk 6. en 7., die beslist niet precies hetzelfde betekenen:
In 6. staat het niet vast dat Jan rookt, in 7. wel. Zo'n voorbeeld moet echter niet gezien worden als argument tegen de interlinguale representatie in het algemeen. Het zoeken naar de interlingua dwingt onderzoek naar zulke verschillen af, en illustreert hoe weinig er op dit moment bekend is over de betekenis van vormverschillen. | |||||||||||||||||||||
De huidige stand van zaken in het Nederlandse taalgebiedSinds 1980 wint het automatisch vertalen in Nederland en België terrein binnen het vakgebied van de computerlinguïstiek. Op dit moment wordt aan vier grote vertaalprojecten gewerkt: metal, Eurotra, Rosetta en dlt. Rosetta en dlt zijn van Nederlandse origine, Eurotra is een Europees (eeg) systeem, en metal heeft zijn oorsprong in Texas. | |||||||||||||||||||||
MetalAan de Universiteit van Texas wordt sinds 1961 aan automatisch vertalen gewerkt, in sommige perioden met minder enthousiasme en mankracht, zoals op grond van bovenstaand historisch overzicht begrijpelijk zal zijn. metal (MEchanical Translation and Analysis of Languages) is de naam van het vertaalprogramma dat in de loop der tijd ontwikkeld is. Sinds 1980 is het Duitse Siemens de enige sponsor van het project. metal heeft op dit moment een bruikbaar systeem voor vertaling Duits-Engels. Er wordt gewerkt aan uitbreiding van het systeem met Duits-Spaans, Duits-Chinees, en Engels-Duits; de Katholieke Universiteit van Leuven werkt aan de uitbreidingen Frans-Nederlands en Nederlands-Frans. metal wordt primair gemaakt met het oog op het vertalen van technische documenten. Het ontwikkelde programma wordt uitgeprobeerd op de handleiding bij een schakelsysteem voor telefoonlijnen, een 100.000 pagina's tellend boekwerk. Een voorbeeld van een ongecorrigeerde metal-vertaling (de machine heeft dit tien keer sneller vertaald dan de gemiddelde vertaler):Ga naar eind6. Origineel:
metal is een transfersysteem, met strikt gescheiden analyse, transfer en synthese. Het systeem is zo ingericht dat het voor de verschillende componenten van verschillende taalkundige theorieën en strategieën gebruik kan maken. Zo is in de Engelse analysecomponent gekozen voor een systeem met vrijwel uitsluitend herschrijfregels, terwijl in de Duitse analyse | |||||||||||||||||||||
[pagina 617]
| |||||||||||||||||||||
naast herschrijfregels ook transformatieregels gebruikt zijn. Analyse levert een syntactische constituentenstructuur die verrijkt is met bepaalde syntactische en semantische features, en die door transfer naar verschillende doeltalen kan worden omgezet. | |||||||||||||||||||||
EurotraEurotra is een eeg-project, na vier jaar voorbereiding van start gegaan in 1982 met als doel een geavanceerd automatisch vertaalsysteem te maken voor de officiële talen van de Europese Gemeenschap. Het onderzoeksproject moet aan het einde van de jaren tachtig een vertaalsysteem opleveren in prototypische vorm dat verder ontwikkeld kan worden in een industriële omgeving. De kwaliteit van de Eurotra-vertalingen moet beter zijn dan die van de systran-vertalingen (systran heeft een correctiepercentage van 35%, Eurotra streeft naar 30-10%). Het Eurotra-project heeft als, belangrijk, nevendoel in alle lidstaten het computerlinguïstische onderzoek te stimuleren. Daarom is Eurotra decentraal georganiseerd: naast het nodige centrale werk, wordt er gewerkt in afzonderlijke taalgroepen, die sinds 1985 werkzaam zijn. België en Nederland hebben samen een Nederlandse taalgroep opgericht, met centra in Leuven en Utrecht. Aangezien Eurotra een groot aantal talen (zeven, binnenkort zelfs negen) in elkaar moet kunnen vertalen, gemakkelijk uitbreidbaar moet zijn voor het geval nieuwe landen tot de Gemeenschap toetreden, en decentraal georganiseerd is, zou een interlinguaal vertaalsysteem het meest voor de hand liggen. De ontwerpers van Eurotra gaan er echter vanuit dat een interlingua onhaalbaar is, en daarom wordt het systeem ontworpen als een transfersysteem met een zo eenvoudig mogelijke transfercomponent. Het ideaal is transfer te reduceren tot de vertaling van lexicale eenheden (bijvoorbeeld een woord, een uitdrukking, een stam, of een affix). De brontaal wordt dus zo diep mogelijk geanalyseerd, met de morfologische, syntactische en semantische middelen die monolinguaal beschikbaar zijn, maar met de lexicale eenheid als onanalyseerbaar uiterste. Zo wordt een woord als schimmel (in het Engels white horse) niet verder geanalyseerd, hoewel er best argumenten te vinden zijn om dat wél te doen. De opdracht aan de verschillende taalgroepen om de eigen taal zo diep mogelijk te analyseren kan op die manier niet opgevat worden als motivatie voor het analyseren van to kill als to cause to become not-alive. Lexicale transfer (vertaling van uitsluitend de lexicale eenheden, de structuur waarvan ze deel uitmaken blijft onveranderd) is in de ogen van de ontwerpers van Eurotra een ideaal waarop steeds uitzonderingen zullen voorkomen. De vertaling van Tom zwemt graag in het Engelse Tom likes to swim wordt als voorbeeld genoemd, hoewel het natuurlijk mogelijk is dat de analyse van zulke voorbeelden niet diep genoeg geweest is. Deze probleemgevallen zijn altijd aanleiding tot reflectie: hebben we hier te maken met een wezenlijk verschil tussen het Nederlands en het Engels of is de analyse niet diep genoeg of onjuist? Mocht de graag-like vertaling uiteindelijk geen voorbeeld blijken te zijn van complexe transfer, dan zal ongetwijfeld voor andere constructies complexe transfer nodig zijn, zo wordt binnen Eurotra geredeneerd.Ga naar eind7. | |||||||||||||||||||||
RosettaRosetta is ontworpen op het Natuurkundig Laboratorium van Philips. Het systeem moet Nederlands, Engels en Spaans in elkaar gaan vertalen; het is op dit moment gedeeltelijk ontwikkeld voor het Nederlands en het Engels, binnenkort komt daar het Spaans bij. Rosetta is een interlinguaal vertaalsysteem, gebaseerd op de Montague Grammatica. Uit de Montague Grammatica zijn afkomstig het compositionaliteitsprincipe (‘de betekenis van een complex geheel is opgebouwd uit de betekenis van de onderdelen van dat geheel’), en de notie derivatieboom. Uitgangspunt vormt de hypothese dat zinnen elkaars vertaling vormen | |||||||||||||||||||||
[pagina 618]
| |||||||||||||||||||||
wanneer ze dezelfde betekeniseenheden hebben en dezelfde derivatie doorlopen hebben, d.i., in de zinnen dezelfde regels gewerkt hebben. Wezenlijk voor onderzoek in het Rosettakader is dan ook niet de definitie van de interlingua, maar de ontwikkeling van isomorfe grammatica's (een noviteit in de geschiedenis van het automatische vertalen). De grammatica's van verschillende talen zijn isomorf wanneer de woorden (basisexpressies) en regels in de ene taal qua betekenis corresponderen met de woorden en regels in de andere taal. Als voorbeeld kan dienen de vertaling van the Spanish girl in la muchacha española (‘het Spaanse meisje’). De interlinguale representatie van dit zinsdeel is de volgende derivatieboom:Ga naar eind8.
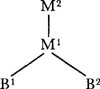 Hierin staan B1 en B2 voor de interlinguale representatie van de inhoudswoorden (de basisexpressies) ‘meisje’ en ‘Spaans’; M1 is de regel die weergeeft dat het ene woord het andere modificeert, M2 is de regel die ervoor zorgt dat de woordgroep definiet is (toevoeging van lidwoorden in het Engels en Spaans). Dat M1 en M2 in het Spaans anders vorm gegeven worden dan in het Engels, is een kwestie die in analyse en synthese wordt afgehandeld. De invulling van de basisexpressies verschilt eveneens per taal. | |||||||||||||||||||||
Distributed Language Translation (DLT)dlt is ontworpen bij bso (Buro voor Systeemontwikkeling) te Utrecht. De naam ‘Distributed Language Translation’ heeft te maken met het feit dat de vertaling in het systeem verdeeld is over de deelnemers aan het communicatieproces. Tijdens het typen van de brontaaltekst op een moderne tekstverwerker die met dlt uitgerust is, wordt de brontaaltekst omgezet in een tussentaaltekst, die vervolgens naar een aangesloten dlt-ontvanger wordt gezonden, en aldaar omgezet in de doeltaaltekst. dlt-verzendende en dlt-ontvangende apparatuur beschikt slechts over informatie van één taalpaar: brontaal-tussentaal, en tussentaaldoeltaal. Op grond van het voorafgaande zou men de indruk kunnen krijgen dat dlt een interlinguaal systeem is, maar in feite is het dat niet. De tussentaal die men gebruikt is namelijk een (gemodificeerde) versie van het Esperanto, weliswaar niet helemaal een natuurlijke taal, maar wel bijna. Een interlinguaal vertaalsysteem vertaalt, zou je kunnen zeggen, door perfect te analyseren en synthetiseren; dlt vertaalt door twee keer te vertalen. De brontaal wordt in de tussentaal omgezet via een direct vertaalsysteem, de tussentaal wordt in de doeltaal omgezet middels een transfersysteem.Ga naar eind9. Het dlt-project is in omvang vergelijkbaar met Eurotra; de haalbaarheidsstudie noemt naast de talen Frans, Duits en Engels ook Italiaans, Spaans, Nederlands, Zweeds, Japans en Arabisch. | |||||||||||||||||||||
SlotopmerkingenEr is in de loop der tijd op basaal taalkundig en vertaalkundig niveau vrij weinig onderzoek gedaan naar de mogelijkheden van automatisch vertalen. De meeste onderzoeksgroepen gingen aan het werk vanuit het idee dat het vertalen zelf geen probleem vormde, en dat ‘slechts’ het systeem nog ‘even’ gemaakt moest worden. De vraag of vertalen per computer mogelijk is, werd vooral door tegenstanders van het automatische vertalen gesteld. Er kunnen aan deze vraag verschillende aspecten onderscheiden worden. Ten eerste: kan iets dat in de ene taal uitgedrukt wordt ook in een andere taal gezegd worden? Wilhelm von Humboldt (begin van de vorige eeuw) meende van niet: de ‘innere Sprachform’, de semantische en syntactische structuur, zou per taal zodanig verschillen dat | |||||||||||||||||||||
[pagina 619]
| |||||||||||||||||||||
volledige communicatie met anderstalige gesprekspartners uitgesloten zou zijn. Anderen, bijvoorbeeld Süssmilch (achttiende eeuw), zijn van mening dat talen juist overeenkomen in het vermogen om iets onder woorden te brengen. Taalkundigen van nu delen meestal de laatste mening, en wijzen op de flexibiliteit van talen om zich aan te passen aan de behoefte van de taalgebruikers. Wanneer in een taal een bepaald woord ontbreekt, dan kan dat toegevoegd worden; wanneer een bepaalde vorm ontbreekt (bijvoorbeeld de bevelende vorm: ga naar huis) dan zal die taal over een andere mogelijkheid beschikken om datzelfde uit te drukken (bijvoorbeeld door het gebruik van een hulpwerkwoord: je moet naar huis gaan). Zulke voorbeelden zijn wel suggestief, maar vormen geenszins het bewijs voor de gelijkwaardigheid van het uitdrukkingsvermogen van talen. Nader onderzoek van deze kwestie is noodzakelijk. Dit eerste punt, de gelijkwaardigheid van alle natuurlijke talen, heeft betrekking op het vertalen tout court, automatisch of niet. Speciaal van belang voor het automatiseren van het vertaalproces zijn het tweede en derde punt: slordigheid of onkunde van de schrijvers van teksten en dubbelzinnigheden in talen. Iedere vertaler weet uit ervaring hoe lastig het is een slecht geschreven stuk te vertalen. Het vertalen per computer is al moeilijk bij teksten die correct zijn; het maken van een systeem met regels om te raden wat de schrijver eigenlijk bedoeld heeft, hoewel het er niet staat, is waarschijnlijk nog vele malen moeilijker of zelfs onmogelijk. Momenteel wordt aan dit probleemgebied geen aandacht besteed. Dubbelzinnigheid, het derde punt uit deze reeks, wordt in de wandelgangen meestal als argument voor de onmogelijkheid van automatisch vertalen genoemd. Taalgebruikers merken vaak niet op dat uitingen dubbelzinnig zijn, omdat door de context maar één betekenis voor de hand ligt. Dit is het probleem waar Bar-Hillel op wees: the box is in the pen kan de vertaling de doos is in de pen hebben, maar uit de context blijkt het de doos is in de box te moeten zijn. Het is meestal niet zo dat ambiguë zinnen in een vertaling op dezelfde manier ambigu zijn. Dit gegeven maakt het vertalen van teksten waarbij de dubbelzinnigheid van belang is (cabaretteksten, literatuur) zo moeilijk, en misschien moet daarom geconcludeerd worden dat het vertalen van zulke teksten in feite onmogelijk is. Voor teksten die ondubbelzinnig bedoeld zijn, geldt deze conclusie in mindere mate, maar ambiguïteit is toch niet verwaarloosbaar, want... in hoeverre is welke tekst dan ook ondubbelzinnig? Bij spreekwoorden en zegswijzen speelt naast de figuurlijke betekenis toch ook altijd de letterlijke mee, al is dat op de achtergrond. In het gewone taalgebruik zal het vaak voorkomen dat een zin in de ene taal een verzameling betekenissen heeft, terwijl bij de vertaling een andere verzameling betekenissen hoort, ook al is die vertaling nog zo nauwgezet. Soms kan de omgeving waarin de zin gebruikt wordt uitsluitsel geven over de betekenis, maar dat zal niet altijd het geval zijn, en in ieder geval is het te voorzien dat een vertaling af en toe een betekenis toevoegt die in de oorspronkelijke zin niet aanwezig was. Hiermee is echter niet het bewijs voor de onmogelijkheid van automatisch vertalen geleverd. Het interessante van automatisch vertalen is dat alle kennis en vaardigheden waar de professionele vertaler als vanzelf over beschikt en alle criteria die de professionele vertaler impliciet hanteert, geëxpliciteerd moeten worden en in de computer moeten worden ingevoerd. Wie er bij het maken van een automatisch vertaalsysteem van uitgaat dat vertalen geen probleem op zichzelf is, loopt onherroepelijk vast. Een goed vertaalsysteem maken is alleen mogelijk wanneer de makers van tevoren een idee hebben van wat het systeem moet opleveren, en op welke manier met welke regels een tekst van zijn vertaling voorzien kan worden. Anders gezegd, wat de relatie is tussen een tekst en de vertaling van die tekst, en hoe die relatie omgezet kan worden in regels die uit een tekst | |||||||||||||||||||||
[pagina 620]
| |||||||||||||||||||||
de vertaling van die tekst construeren. De taak van professionele vertalers en ontwerpers van vertaalsystemen komt in zoverre overeen, dat ze strikt genomen slechts vertalingen hoeven te produceren. Professionele vertalers vertalen al eeuwen; vertaalsystemen vertalen sinds enkele jaren ook. De werkende systemen leveren echter ofwel redelijk goede vertalingen voor teksten over een beperkt onderwerp, met eenvoudige constructies, ofwel vertalingen die door een vertaler gecontroleerd moeten worden. Voor verbeteringen van toekomstige vertaalsystemen is nader onderzoek naar het vertaalproces noodzakelijk, want daarover is nog veel onbekend. |
| ||||||||||||||||||||