
Tijdschrift voor Nederlandse Taal- en Letterkunde. Jaargang 110
(1994)– [tijdschrift] Tijdschrift voor Nederlandse Taal- en Letterkunde–
[pagina 2]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wim Zonneveld
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. InleidingHet doel van dit artikel is om een overzicht te geven van de stand van zaken in de studie van de Nederlandse fonologie. Voor zover het niet gaat om puur observationeel of descriptief werk, maar om werk met in bepaalde mate een theoretische inslag, is er op dit vakgebied verregaand sprake van een homogeen theoretisch kader: dat van de generatieve fonologie Ik zal de stand van zaken dan ook vanuit dat perspectief bekijken. Ik kan daarbij op geen enkele manier volledigheid nastreven, maar richt mijn tekst in met als leidraad een aantal onderdelen van de huidige fonologie, die bekend staan als, respectievelijk, metrische fonologie (voor klemtoon en syllabestructuur), autosegmentele fonologie (voor assimilatie), lexicale fonologie (voor de interactie met de morfologie), en prosodische fonologie (voor sandhi). Voor elk van deze onderdelen gaat het om ontwikkelingen na en uit Chomsky & Halle (1968) (beneden SPE). Steeds zal ik proberen per onderdeel de bron van zijn ontstaan te schetsen, en vervolgens de Nederlandse fonologie te behandelen, waarin men zich overigens niet in dezelfde mate met elk onderdeel bezig houdt. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. Ontwikkelingen in de fonologische theorievormingDe taak van een fonoloog-taalkundige in de jaren zeventig was het ontwerpen van een taalspecifieke grammatica, en te laten zien hoe deze activiteit bijdroeg aan het inzicht in het verschijnsel taal (in de eigenschappen van de ‘universele grammatica’), liefst ook in het proces van ‘taalverwerving’. Deze taak is in de jaren tachtig niet en wel veranderd: níet, omdat in deze globale bewoordingen de taak nog steeds hetzelfde is gebleven; wél, omdat het begrip ‘grammatica’ een andere invulling heeft gekregen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 3]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Het is nogal een verschil - in de woorden van Chomsky (1986:146) zelfs een ‘conceptual shift’ vergelijkbaar met de invoering van de transformationeel-generatieve grammatica in de jaren vijftig en zestig - om eerst een grammatica (en de componenten daarvan) te zien als een regel-systeem, en daarna als het ideaal te formuleren dat het proces van kindertaalverwerving bestaat uit ‘parameter-setting’, met de eruit voortvloeiende grammatica als een verzameling vastgestelde parameters. Het is ook nogal een verschil om in essentie een fonologische component te zien als een set geordende, soms uiterst complex geformuleerde, fonologische regels met in principe allemaal dezelfde status, werkend op een input-representatie en een output-representatie afleverend; en daarna te denken in termen van complexe hierarchische structuren waarvoor één simpele instructie (bijvoorbeeld ‘assimileer’) grote gevolgen kan hebben. Laat me illustreren wat een regel-grammatica inhoudt aan de hand van een voorbeeld van Trommelen & Zonneveld (1979a, b), en Zonneveld (1983), een drietal analyses in een veel grotere hoeveelheid literatuur die zich heeft gericht op stemassimilatie. In het SPE-model werkt de fonologische ‘component’ van een transformationeel-generatieve grammatica op de output van de syntaxis (op de ‘oppervlaktestructuur’), en zijn de fonologische regels netjes ‘lineair’ na elkaar geordend, 1...n, waarin n het aantal regels is van de taal in kwestie: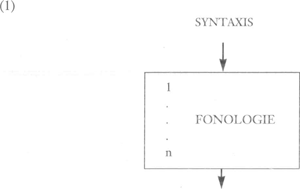 Regel 3 kan een klemtoon-regel zijn, regel 8 d-deletie, regel 12 stem-assimilatie, etc. De output van deze nette component bestond uit de fonetische representatie, idealiter een groep pasklare instructies aan de spraakorganen. Elke fonologische regel had de volgende vorm:
Hierin is A het klank-segment dat veranderd wordt, B de gespecificeerder verandering, en C en D de context waarin de verandering plaatsvindt. We kunnen ook zeggen dat CAD de input van de regel is (zelf weer de output van een voorafgaande regel), en CBD de output (zelf weer de input van de volgende regel, enz.). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 4]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De illustratie die ik geef, behelst stem-assimilatie, een bekend verschijnsel in de Nederlandse fonologie. De basisobservatie is dat Nederlandse obstruent-clusters altijd overeenkomen in hun waarde voor het kenmerk [stem]. Dat is zo binnen woorden, dat is zo bij affigering, en dat is zo over woordgrenzen heen. In (3) geef ik voorbeelden van deze drie situaties:Ga naar eind1
Uit (a) is duidelijk dat binnen ongelede woorden niet alleen obstruent-clusters in de waarde voor [stem] overeenkomen, maar dat clusters in deze situatie bovendien altijd stemloos zijn. Dit wordt verantwoord door een ‘morfeemstructuur-conditie’ van de volgende vorm:
De taak van zo'n conditie is tweeledig: hij drukt de bedoelde generalisatie uit,Ga naar eind2 maar het is net zo goed de bedoeling dat de achter ‘dan’ genoemde kenmerken niet meetellen bij een evaluatie van de grammatica: ze zijn wel aanwezig in de lexicale representaties van de betrokken woorden, maar zijn ‘voorspelbaar’ of ‘redundant’. De situatie in (b) en (c) is iets anders, want nu komen ook stemhebbende clusters voor. Er blijken twee patronen te heersen, afhankelijk van de aard van de tweede obstruent in het cluster: - als de rechter obstruent een fricatief is, is het hele cluster stemloos; - als de rechter obstruent een plosief is, bepaalt zijn [stem]-waarde die van het cluster. In fonologische regels van het type (2) kunnen we dat als volgt uitdrukken: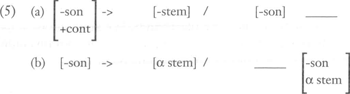 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 5]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Regel (5a) zorgt ervoor dat bijvoorbeeld in de geaffigeerde vorm mis-vormd en de samenstelling straf-zaak de fricatief rechts stemloos wordt. Regel (5b) zorgt ervoor dat in de geaffigeerde vorm raad-sel en de samenstelling hand-palm de linker obstruent stemloos wordt; dezelfde regel zorgt ervoor dat in de geaffigeerde vorm zes-de en de samenstelling strop-das de linker obstruent stemhebbend wordt. Ze kunnen ook als duo opereren: in de geaffigeerde vorm raad-zaam en de samenstelling rond-vaart werkt eerst (5a) en vervolgens (5b). Merk op dat de omgekeerde volgorde verkeerde output zou opleveren: bijvoorbeeld *stra-[vs]-aak en *raa-[ds]-aam. Deze analyse, inclusief de formulering van de regels en het volgorde-argument, zijn typisch voor zeventiger-jaren SPE-fonologie. We kunnen nu de twee regels in (5) opnemen, als bijvoorbeeld regels genummerd 12 en 13 (ik noem maar twee getallen) in de fonologische component van (1). We kunnen vervolgens andere feiten bij de analyse betrekken, daarvoor nieuwe fonologische regels formuleren, en die ordenen ten opzichte van de zojuist genummerde twee. Een voor de hand liggende gedachte is om te kijken hoe de regel van Auslautverhärtung zich gedraagt ten opzichte van de twee in (5). Feiten zoals die in (6) laten zien dat de regel geformuleerd moet worden met een context zoals in (7).
De regel heeft twee contexten: de betrokken obstruent kan onmiddellijk voor een medeklinker staan (a); of hij kan onmiddellijk voor een zogenaamde ‘woordgrens’ staan, d.w.z. aan het eind van een woord zoals intern in een samenstelling (c), of voor een suffix dat zich in dit opzicht als een apart woord gedraagt (b). Over woordgrenzen straks meer,Ga naar eind3 nu observeren we in elk geval dat de regel geordend moet worden vóór (5b), om niet output als *stro-[pd]-as te genereren. Enzovoort: een zo gecreëerde en beargumenteerde, lineair geordende lijst van 13 fonologische regels kan gevonden worden aan het eind van hoofdstuk 9 van Trommelen & Zonneveld (1979a). Ontegenzeggelijk zijn in dit model voortreffelijke analyses van natuurlijke talen geproduceerd, en is er veel inzicht verkregen in de universalia die in zulke analyses terugkeren. Niettemin zijn in de reacties erop, op zich uitingen van ontevredenheid, twee grote lijnen te ontdekken. De eerste heeft te maken met de kijk op, en de evaluatie van, een grammatica als zodanig, waarvan de fonologische component een onderdeel is; de tweede met de specifiek in de fonologie gebruikte regels en representaties. Op het eerste punt ben ik al heel uitvoerig ingegaan in Zonneveld (1988), en ik zal het belangrijkste daarvan slechts kort herhalen. Over het tweede punt zal in feite de rest van dit artikel gaan. Bij elke analyse van een fonologisch verschijnsel hoort een evaluatie, die uitmaakt of we met het voorgestelde resultaat ook inderdaad de beste sub-grammatica voor dat verschijnsel geproduceerd hebben. Die evaluatie was in het SPE-kader vastge- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 6]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
legd in een ‘evaluatie-procedure’ van een tamelijk simpele vorm: de correcte analyse is de kortste, met kortheid gedefinieerd in termen van verbruikte symbolen (kenmerken, grenssymbolen, enz.). We zouden dus (5) moeten prefereren boven een analyse die meer kenmerken gebruikt voor het dekken van dezelfde verschijnselen, maar moeten laten vallen als blijkt dat er een nog eenvoudiger voorstel bestaat. Deze evaluatie-procedure was gemotiveerd vanuit de eerste taalverwerving. Dat is een opvallend snel en relatief gemakkelijk verlopend proces, terwijl de taak uiterst complex is. Als het kind steeds maar weer hele reeksen mogelijke grammatica's moet uitproberen voor de hem op dat moment bekende feiten, is een verklaring nagenoeg onmogelijk. Als de evaluatie-procedure hem stuurt om steeds de ‘eenvoudigste’ grammatica te kiezen, worden de snelheid en het relatieve gemak al begrijpelijker. Op twee manieren is deze visie vervolgens gestrand. Het eenvoudscriterium speelde in de dagelijkse fonologische praktijk nauwelijks een rol - maar wel bijvoorbeeld het empirische bereik van een analyse, of een intuïtieve inzichtelijkheid, hoe vaag die laatste notie vaak ook was. Verder kwam er geen evidentie uit eerste taalverwerving dat die inderdaad langs de geschetste lijnen verliep. Op de grens van de jaren zeventig en tachtig werden deze ideeën daarom verlaten en kwam de ‘parameter’-benadering op, waar ik zometeen op zal ingaan. Wat betreft de regels en representaties kwam er een reactie op het stricte ‘lineaire’ karakter van de analyses in het SPE-kader, waarmee niet de regelordening werd bedoeld, maar het feit dat de gehanteerde representaties bestonden uit ‘links-rechts’ opeenvolgingen van klank-segmenten en grens-symbolen. De onderliggende representatie van de samenstelling diep-zee bijvoorbeeld, waarop regel (5a) werkt, ziet er als volgt uit:
De #-symbolen (‘woordgrens-symbolen’) bakenen de twee woorden van de samenstelling af. Daartussen bestaat elk klanksegment uit een bundel fonologische kenmerken. Regel (5a) verandert in het vierde klanksegment van links [+stem] in [-stem], en de output is precies hetzelfde soort representatie, die in één kenmerkwaarde afwijkt van de input. De claim van SPE was dat elk fonologisch verschijnsel door middel van dit soort representaties, en de daarbij behorende fonologische regels als in (5) (d.w.z. volgens het abstracte schema in (2)) te vangen moest zijn: klemtoon, assimilatie, dissimilatie, epenthese, diphtongering, clusterreductie, enzovoort, enzovoort. De reactie betoogde dat deze claim niet kón, en vooral ook niet móest, worden waargemaakt. Tot de allereerste, en duidelijkst geformuleerde, kritieken op deze in SPE geformuleerde visie behoren die van Anderson (1975) en Goldsmith (1976). Zij beschouwen - in de woorden van de laatste - consequent dóór de fonologie volgehouden representaties zoals (8) als het resultaat van een veel te stringent toegepaste | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 7]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
‘Absolute Slicing Hypothesis’, die eist dat kenmerken overal binnen de grenzen van afzonderlijke klank-segmenten worden ondergebracht. Anderson bespreekt het geval van de plosief-epenthese in woorden als in het Engels warm[p]th - in het Nederlands bijvoorbeeld (hij) kom[p]t. Hoe implausibel ‘Absolute Slicing’ daarbij is, probeert hij als volgt weer te geven:
Omdat op de nasaal een plosief volgt, gaat ‘anticiperend’ het zachte gehemelte omhoog; hierdoor wordt gedurende korte periode een plosief-achtig element gevormd, dat de stemhebbendheid van zijn mede-plosief overneemt. Anderson merkt op dat dit proces niet, op de klassieke manier, kenmerken verandert, maar alleen hun ‘scope’ wijzigt. Deze redeneertrant heeft alles van de latere autosegmentele fonologie, hoewel die een andere notatie zou gaan gebruiken, zoals we beneden nog zullen zien. Het zal ook niet moeilijk zijn in te zien dat via zulke argumentatie de fonologie in feite ‘fonetischer’ wordt: segmentering van het lopende spraaksignaal leidt tot abstracties als (8), die lang niet onder alle omstandigheden nodig of gewenst zijn. In deze zin is er in de post-SPE fonologie zeker sprake van een ombuiging richting fonetiek.Ga naar eind4 Metrische fonologie ontwikkelde zich, met zijn eigen representaties, als theorie over klemtoon en daaraan verwante verschijnselen. Autosegmentele fonologie kwam er voor assimilatie (of voor een geval als de zojuist besproken epenthese met aan assimilatie verwante eigenschappen). Lexicale fonologie voor de interactie met de morfologie, inclusief de visie op grenssymbolen. Prosodische fonologie voor de interactie met de syntaxis, d.w.z. typisch voor sandhi-verschijnselen. Dat zijn de belangrijkste gebieden van het hedendaagse fonologische onderzoek, en elk heeft zich ontwikkeld vanuit het idee dat fonologische representaties aanzienlijk verrijkt moeten worden ten opzichte van de zeer simpele voorstelling van zaken in (8). Daarnaast ontwikkelde zich de parameter-theorie als nieuwe poging het verband tussen taalspecifieke analyses, de universele theorie en moedertaal-verwerving te verduidelijken. Vooral door taaltypologisch werk in de syntaxis van de Romaanse talen kwam rond 1980 het idee op dat talen op subtiele manieren van elkaar verschillen, verschillen die formaliseerbaar zijn door ze te gieten in termen van ja/neevragen: staan in deze taal de bijvoeglijke naamwoorden voor of na het zelfstandig naamwoord? Laat deze taal toe dat persoonlijke voornaamwoorden als subject achterwege worden gelaten of niet? Het verband met de moedertaalverwerving was daarna snel gelegd, zie de volgende passage uit Chomsky (1986: 146): | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 8]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The parameters must have the property that they can be fixed by quite simple evidence, because this is what is available to the child [...]. Once the values of the parameters are set, the whole system is operative [...]. [W]e may think of UG as an intricately structured system, but one that is only partially ‘wired up’. The system is associated with a finite set of switches, each of which has a finite number of positions (perhaps two). Experience is required to set the switches. When they are set, the system functions. Dientengevolge is het typisch moderne fonologie om een klemtoonanalyse voorgeschoteld te krijgen in termen van metrische representaties, die het gevolg zijn van als parameters geformuleerde eigenschappen van die representaties. En vergelijkbaar met de andere gebieden (hoewel de studie van klemtoon relatief ver op dit terrein is gevorderd). In de volgende secties zal ik vanuit deze optiek de vier genoemde deelgebieden gaan bespreken. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Metrische FonologieEen van de meest spectaculaire veronderstellingen van SPE was dat ‘zelfs’ typisch prosodische kenmerken, zoals toon en klemtoon, in het lineaire model verantwoord konden worden: ook regels en representaties voor déze verschijnselen moesten het uiterlijk hebben van (2) en (8). De daaruit voortvloeiende hoofdklemtoonregel voor het Engels kan in al zijn complexiteit opgezocht worden in SPE (p. 240), en recent heeft Kaye (1989: 139) het met een understatement een ‘fairly discouraging result’ genoemd. In het begin van de jaren zeventig werd in een grote hoeveelheid werk van M.I.T.-leerlingen van Halle betoogd dat dit zeker voor [toon] niet waar kon zijn: Goldsmith, Haraguchi, Leben en Williams zijn de belangrijkste namen die bij die ontwikkeling horen. Klemtoon volgde vlak daarna, met een ‘niet-lineaire’ heranalyse van de oorspronkelijke SPE-voorstellen voor het Engels, door Liberman, uitgewerkt in het klassieke artikel van Liberman & Prince (1977). Hun nieuwe klemtoonbenadering werd bekend als metrische fonologie. De grote verdienste van het daaropvolgende werk van Hayes (1980) en Prince (1983) is dat zij een combinatie van de metrische theorie met de parameter-theorie mogelijk maken. De geschiedenis aanzienlijk condenserend (en ook afziend van de meest recente ontwikkelingen), zal ik in deze sectie nu illustreren hoe een analyse van Nederlandse woordklemtoon er in zo'n parametrische metrische theorie uitziet. Daarbij verlaat ik me eerst op ideeën van Hayes en Prince, daarna voor het Nederlands op die van Kager e.a. (1987), Trommelen & Zonneveld (1989) en Kager (1989). Laten we er ten eerste van uitgaan dat klemtoon wordt toegekend aan lettergrepen, in alle natuurlijke talen; ten tweede dat dat kan gebeuren volgens een aantal vaste patronen, waaronder de jambe en de trochee; en ten derde dat hoofdklemtoon een eigenschap van beklemtoonde lettergrepen aan de rand is. Tot de op deze manier gegenereerde klemtoonpatronen van natuurlijke talen behoren die in (10), waarbij ik gebruik maak van de metrische grid voor de wijze van representeren: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 9]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Configuratie (10(i)) representeert een taal met beginklemtoon, en bijklemtoon op elke even lettergreep rechts daarvan; (10(ii)) een taal met hoofdklemtoon op de tweede lettergreep, en bijklemtoon op elke even lettergreep rechts daarvan; en (10(iii)) een taal met hoofdklemtoon uiterst rechts, en bijklemtoon op elke lettergreep links daarvan. Deze patronen worden, als de literatuur klopt, gebruikt in respectievelijk het Maranungku (Noord-Australië), Southern Paiute (Utah, V.S.) en het Weri (Australisch Nieuw Guinea). Patroon (10(iv)) komt voor in het Warao (Venezuela), en is ook het basispatroon van het Engels en het Nederlands. Daar zal ik zometeen op ingaan, maar laat me eerst het volgende opmerken. In de eerste plaats heeft de theorie die ondermeer de patronen in (10) genereert, de interessante eigenschap, dat hij dat lijkt te doen via een aantal twee-keuze vragen, en wel de volgende:
Het zijn precies deze twee-keuze vragen die de parameters van de metrische klemtoontheorie uitmaken. Als het waar is dat het basispatroon van het Engels en het Nederlands (iv) is, wordt dat dus bereikt door de volgende drie parameter-keuzes: (11) - trochee, vanaf rechts, hoofdklemtoon rechts. Dat is inderdaad heel wat anders dan de oerwoud-achtige fonologische regels die in lineaire beschrijvingen figureren (en misschien is het verband tussen trochee vanaf rechts plus hoofdklemtoon vanaf rechts ‘ongemarkeerd’, zodat alleen de eerste twee mededelingen zouden volstaan). In de tweede plaats is er een tamelijk directe band tussen deze parameter-theorie, en beschrijvingen van de universele eigenschappen van klemtoon in de pre-generatieve periode, met name die van de ‘Praagse School’. Voor Troubetzkoy golden als belangrijke eigenschappen van klemtoon dat hij heel vaak demarcatief was, en culminatief, waarmee hij het volgende bedoelde: de hoofdklemtoon wordt heel vaak gevonden aan de rand van het woord, links of rechts; en er is altijd per woord maar één lettergreep met hoofdklemtoon, hoewel er meerdere bijklemtonen kunnen zijn. Beide observaties zijn in de metrische beschrijvingswijze ingebakken.Ga naar eind5 Hoe komen we nu vanaf (10(iv)) tot een adequate klemtoonbeschrijving van het Nederlands? De gegeven procedure geeft onmiddellijk het goede klemtoonpatroon voor hele reeksen woorden met prefinale hoofdklemtoon, zoals de volgende: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 10]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Een groot deel van de Nederlandse woordenschat kan op deze manier gedekt worden. Alleen zijn er twee bekende patronen die er niet onder vallen: eind-klemtoon (vulkáan, augúrk) en pre-prefinale klemtoon (cánada, álcohol). Daarvoor zijn een aantal aanvullende maatregelen nodig, die op zich weer uit een parametrische aanpak kunnen volgen. In de overgrote meerderheid van de gevallen gaat het bij eind-klemtoon om zogenaamde superzware lettergrepen, dat wil zeggen, lettergrepen aan het eind van woorden met de vorm -(C)VVC (lange klinker gevolgd door medeklinker: vulkáan) of - (C)VCC (korte klinker gevolgd door meerdere medeklinkers: augúrk). Door hun opbouw zijn zij in elk geval altijd ‘gesloten’, d.w.z. ze eindigen op een medeklinker. Nu blijken er in het algemeen reeksen talen te zijn waarin de opbouw van de lettergreep een rol speelt bij klemtoontoekenning, met lettergrepen gerangschikt naar ‘zwaarte’. Zulke talen heten dan ook ‘zwaartegevoelig’, en het is opnieuw niet moeilijk deze eigenschap in een parameter-vorm te gieten, met als mogelijk antwoord voor een taal ‘ja’ of ‘nee’. Laten we aannemen dat het Nederlands tot de ja-zeggende talen behoort, en gesloten lettergrepen als ‘zwaar’ beschouwt. Dit kunnen we in de grid uitdrukken door zulke zware lettergrepen per definitie een extra grid-markering te geven, en we bereiken daarmee representaties als de volgende:
In vulkáan hebben twee gesloten lettergrepen een extra grid-markering gekregen (hier onderstreept), die niet het gevolg is van de toekenning van een trocheïsch patroon; dat opereert hier dan ook helemaal niet. De hoofdklemtoon komt daarna op de meest rechtse beschikbare positie te liggen. In ledikánt en proletariáat wordt de finale gesloten lettergreep gemarkeerd, en vanaf dat punt wordt het trocheïsch patroon naar links uitgewerkt; opnieuw komt de hoofdklemtoon uiterst rechts te liggen. Als we nu met een zwaartegevoelige blik kijken naar de oorspronkelijke feiten in (12), dan zien we dat deze eigenschap van het Nederlands daar geen effect heeft (zwaartegevoeligheid of trochee doen hetzelfde), behalve voor één voorbeeld, rododéndron: we voorspellen zelfs finale klemtoon voor dit woord. Het verschil tussen dit woord en die in (13) is echter duidelijk: het eindigt op een gesloten lettergreep, maar niet een ‘superzware’. Voor deze situatie heeft de metrische theorie een formele uitwerking gevonden in zogenaamde ‘extrametriciteit’, die talen in staat stelt in hun klemtoonsysteem lettergrepen te negeren. Laten we zeggen dat het Nederlands ‘relatief lichte gesloten lettergrepen’ (-(C)VC) aan het eind van woor- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 11]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
den negeert, voor de klemtoon-instructie ‘hoofdklemtoon rechts’. Het effect, hier aangegeven met ‘/’, is als volgt:
Extrametriciteit is een belangrijk begrip geworden in de beschrijvingen van klemtoonsystemen van natuurlijke talen, en het lijkt onderhevig te zijn aan een zeer algemene restrictie: dat hij alleen geldt voor elementen aan de rand van woorden, zoals hier de laatste VC-lettergreep. Welk effect dat kan hebben, blijkt als we nagaan dat extrametriciteit en zwaartegevoeligheid samen een voorspelling doen met betrekking tot pre-prefinale klemtoon, die we nog niet hebben behandeld gezien: als in woorden die eindigen op -VC de voorlaatste lettergreep ‘open’ is (niet eindigt op een medeklinker), is hoofdklemtoon pre-prefinaal:
Men kan voor zichzelf nagaan hoe ‘zwaartegevoeligheid’, ‘trochee-vorming’, ‘hoofdklemtoontoekenning’ en ‘extrametriciteit’ met elkaar interacteren. Vooral met betrekking tot de laatste eigenschap blijkt nu een belangrijk feit: hij stelt de metrisch fonoloog in staat in een fundamenteel binair alternerend systeem, hoofdklemtoon te genereren op pre-prefinale lettergrepen. Het Nederlands heeft dat gemeen met bijvoorbeeld het Engels en het Latijn. Dit is in kort bestek een impressie van een metrische klemtoonanalyse van het Nederlands. Ik zou er nog graag drie opmerkingen bij maken. In de eerste plaats gaat het hier uitdrukkelijk om regelmatige patronen in de taalfeiten, die echter, zoals iedereen weet, lang niet uitzonderingsloos zijn. We hebben naast máraton ook capuchón, naast bikíni ook rímini, en naast presidént ook ólifant. Ik zal deze gevallen niet allemaal gaan bespreken, maar merk wel op dat de bovenstaande theorie ook beoordeeld wordt op zijn vermogen de uitzonderlijke patronen als zodanig te beschrijven. Zo kan capuchón tamelijk gemakkelijk gevangen worden door dit woord uit te rusten met een uitzonderingskenmerk [-ex] voor ‘geen extrametriciteit’, waardoor automatisch het gewenste patroon met finale klemtoon wordt opgeleverd. Vergelijkbare voorstellen zijn in de literatuur gedaan voor de andere gevallen. In de tweede plaats moet worden aangetoond dat de genoemde patronen ook inderdaad creatief worden gehanteerd door de sprekers van de taal, d.w.z.: we moeten laten zien dat niet het klemtoonpatroon simpelweg per woord wordt geleerd, waarbij de ‘regels’ alleen maar statistische tendenzen beschrijven. En we moeten laten zien dat niet voor nieuwe woorden simpelweg het klemtoonpatroon uit de | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 12]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
leentaal wordt overgenomen. Er zijn aanwijzingen dat klemtoonintuïties op de gewenste manier regelgebonden zijn. Laat me één voorbeeld geven, dat gebruik maakt van plaatsaanduidingen van het Zuidamerikaanse continent. Beschouw de woorden Antofagasta ‘havenstad in Noord Chili’, Tiahuanaco ‘stad in Bolivia’ en Cristobal ‘plaats genoemd naar Columbus’, met hun ‘Nederlandse’ klemtoonpatronen:
Het eerste patroon is hetzelfde in de leentaal: Zuidamerikaans Spaans. Het kan in het Nederlands zo zijn overgenomen, of bestaan omdat de simpele trochee in het Nederlands een ‘ongemarkeerd’ patroon zou kunnen zijn. Het tweede woord gaat tegen de eerste mogelijkheid in: het heeft oorspronkelijk klemtoon op de laatste lettergreep. Het derde woord tenslotte gooit beide theorieën in de war. Het Spaanse patroon is Cristóbal. Dat wordt niet overgenomen, en de trochee wordt vervangen door pre-prefinale klemtoon, precies volgens de Nederlandse regels voor klemtoon in woorden met deze opbouw: hánnibal, cárnaval, etc. Dit is dus een aanwijzing dat klemtoontoekenning productief is. Tenslotte het begrip syllabestructuur. Ik heb in deze uiteenzetting voetstoots aangenomen dat klemtoon wordt toegekend aan lettergrepen. Maar dat is niet onproblematisch gezien de geschiedenis van de lettergreep in de generatieve fonologie. Met name in SPE speelt de lettergreep geen rol, en wordt klemtoon toegekend aan klinkers, in bepaalde lineaire configuraties. Onder de verdiensten van de niet-lineaire fonologie kan echter ook de (her-)invoering van de lettergreep worden gerekend, eerst in het M.I.T.-proefschrift van Kahn uit 1976, daarna in een aantal verschillende vormen in een grote hoeveelheid literatuur. Het meest gebruikelijk is om de lettergreep weer te geven in een binair vertakkende boomstructuur, hoewel de namen van de daarin figurerende knopen vaak verschillen, nog afgezien van de vraag of de (of alle) knopen wel namen hébben. Zonder die vragen te bediscussiëren geef ik hier (17):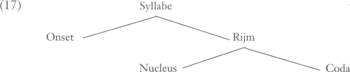 Gegeven zo'n structuur is een manier om over klemtoontoekenning te praten de volgende. Universeel, voor alle natuurlijke talen, wordt aangenomen dat de aard van de ‘onset’ (alles in de lettergreep links van de klinker) irrelevant is voor klemtoontoekenning. Zwaartegevoeligheid in het Nederlands heeft dan te maken met de inhoud van het rijm: als er een Coda is, is de lettergreep ‘zwaar’, als die er niet is, is de lettergreep ‘licht’. Natuurlijk houdt de studie van lettergreepstructuur niet uit- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 13]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
sluitend verband met klemtoon. Kaye (1989: 55) bespreekt een parametrische syllabetheorie die voor elke constituent C van (16) de vraag stelt: ‘vertakt C?’. Talen variëren dan in hun antwoorden op deze vragen. Auslautverhärtung kan nu worden geformuleerd als opererend ‘in de Coda’. Trommelen (1983) laat zien dat Nederlandse verkleinwoordvorming afhankelijk is van syllabestructuur. Verdere voorstellen voor de Nederlandse lettergreep zijn te vinden in Van der Hulst (1984), Kager & Zonneveld (1986) en Kager (1989).Ga naar eind6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Autosegmentele FonologieSPE bevat grote stukken analyses van het Engels, maar daarnaast net zo goed gedeelten waarin wordt geprobeerd de universele theorie te illustreren met materiaal uit andere, vaak exotische talen. Zo wordt voor het verschijnsel vocaalharmonie de West-Afrikaanse taal Igbo gebruikt. Vocaalharmonie is het verschijnsel waarbij alle klinkers binnen een domein, vaak het woord, voor een gegeven fonologisch kenmerk dezelfde waarde hebben - bijvoorbeeld allemaal [+achter] of juist [-achter]. Deze harmonische waarde kan zich op twee manieren door het woord verspreiden: vanuit de stam naar de affixen toe (zgn. symmetrische of ‘root-controlled’ harmonie), of met een bepaalde richting, van links naar rechts door het woord of andersom (zgn. directionele harmonie). In het Igbo is vocaalharmonie symmetrisch, en in het lineaire kader van SPE zijn er drie, samen redelijk complexe, regels nodig om harmonie te vangen:Ga naar eind7 In 1980 publiceerde Clements, een oorspronkelijk Engelse fonoloog die in de Verenigde Staten was gaan werken en kenner was van Afrikaanse talen, een ‘autosegmentele’ analyse van het Igbo die er (op z'n slechtst) zo uitzag: (19) Associeer Het zal duidelijk zijn dat er in die 12 jaar drastische dingen zijn gebeurd. In Zonneveld (1986) ben ik daar voor het Igbo al tamelijk gedetailleerd op in gegaan, en wie wil kan de lineaire analyse daar nalezen. Ik geef hier nu de cruciale feiten, en de ‘autosegmentele’ analyse. Daarna zal ik in deze sectie weer terugkomen op het Nederlands: stem-assimilatie kan immers gezien worden als een soort ‘harmonie’, van het kenmerk [stem], in het domein van het obstruent-cluster. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 14]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De basisfeiten voor de Igbo vocaalharmonie zijn die in (20) (SPE geeft overigens geen voorbeelden, alleen maar een schematische voorstelling van zaken; ze kunnen echter gevonden worden in werk over deze taal van Green & Igwe en Ringen):
De onderstreepte klinkers in de woorden links zijn [+ATR], waar ATR staat voor ‘advanced tongue root’: een beweging naar voren van de tongwortel in de mond die, uitgedrukt als fonologisch kenmerk, geschikt is zijn om dit verschijnsel te beschrijven. Bij de klinkers in de woorden rechts ontbreekt deze eigenschap. We zien dat steeds alle klinkers door het woord heen dezelfde waarde hebben: allemaal [+ATR] of allemaal [-ATR]. Dit is de normale stand van zaken. Toch kan zich in zulke systemen een onregelmatigheid voordoen, die bekend staat als ‘opaakheid’. Daarmee wordt bedoeld dat bepaalde klanksegmenten, of bepaalde affixen, de spreiding van het harmonische kenmerk kunnen blokkeren. Dat verschijnsel doet zich ook voor in het Igbo, en (21) geeft een indicatie waar het om gaat:
De bovenste vorm is een perfecte harmonievorm, met de suffixen -wa en -ghi. Uit de tweede vorm blijkt dat het suffix -si uitzonderlijk niet aan harmonie deelneemt. De laatste vorm illustreert dat harmonie -ghi niet kan bereiken óver -si heen: het is alsof bij het uitzonderlijke -si een nieuw harmonie-domein naar rechts toe begint. Er is niets in een aanpak zoals (18) waar dat uit volgt, hoewel het verschijnsel van opaakheid zeer wijdverbreid is. Wat gebeurt er in een autosegmentele analyse? De centrale eigenschap van een autosegmentele analyse is het ‘autosegmentaliseren’, iets simpeler gezegd ‘apart zetten’, van het harmoniekenmerk op een apart ‘nivo’ of (Engels) ‘tier’. Een autosegmentele representatie van regelmatige vocaalharmonie in het Igbo ziet er als volgt uit: Zulke representaties worden afgeleid uit onderliggende vormen waarvoor wordt aangenomen dat het autosegmentele kenmerk als het ware los (voor een symmetrische taal) boven de stam zweeft, en affixen ongespecificeerd zijn voor het kenmerk:
Het verschil tussen deze twee representaties zit hem in de ‘associatie-lijnen’ die worden getrokken volgens de zogenaamde Well Formedness Condition op autosegmentele representaties. Deze is universeel en heeft de volgende vorm: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 15]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Nu kan [+ATR] nooit lettergepen rechts van het uitzonderlijke suffix bereiken, omdat associatielijnen nooit mogen kruisen (24c). De gewenste richting van de spreiding wordt beregeld door (24d).  De taalspecifieke informatie bestaat nu uit de mededeling dat -si een opaak suffix is (ge-pre-associeerd is), en dat [ATR] een autosegmenteel kenmerk is. Op welk punt vervolgens (19) in werking treedt, nl. de simpele instructie te gaan associëren volgens de universele WFC, zal afhangen van de vraag of het nodig is (19) in de taalspecifieke grammatica op te nemen (bijvoorbeeld als geordende regel). Als dat niet nodig is, bestaat zelfs (19) in stricte zin niet, en kunnen per definitie alleen vormen het onderliggende niveau verlaten die aan de WFC voldoen. Dit voorbeeld laat zien hoe ontwikkelingen uit SPE nogal drastisch van het oorspronkelijke kader kunnen verschillen, en ten opzichte ervan empirische en conceptuele winst boeken: van (18) naar (19) bijvoorbeeld, plus een inzichtelijke analyse voor opaakheid. Aan de andere kant is er geen reden te verdoezelen dat de winst niet altijd zo spectaculair is als in dit voorbeeld, en dat het autosegmentele kader volop in beweging is. Wie daar een overzicht van wil hebben kan bij voorbeeld terecht in de bundels van Van der Hulst & Smith (1988a, b). Ik zal hier nu terugkeren naar het Nederlands, en het door mij in sectie 3 behandelde voorbeeld van stem-assimilatie, dat zich natuurlijk ook leent voor een autosegmentele analyse. Die zou ongeveer als volgt kunnen lopen.Ga naar eind8 Een eerste belangrijke observatie met betrekking tot de Nederlandse vorm van stem-assimilatie is dat er weliswaar consequent overeenkomst van stem in obstruentclusters voorkomt, maar dat lang niet alles daarvan aantoonbaar het resultaat is van actieve assimilatie met een veroorzaker (‘trigger’) en een focus (‘victim’). Dat laatste gebeurt maar in een heel beperkte hoeveelheid van de taalfeiten, nl. wanneer rechts een stemhebbende plosief staat en links een stemloze obstruent. Voorbeelden: ze[z]de, stro[bd]as, sto[vb]ril, enz. In alle andere gevallen komen stemloze clusters | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 16]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
voor, die kunnen worden toegeschreven aan de regel die fricatieven stemloos maakt aan woordbegin, aan Auslautverhärtung, en aan de eis dat binnen ongelede woorden clusters stemloos zijn. We kunnen zeggen dat die laatste regels deel uit maken van een soort samenzwering die uiteindelijk altijd leidt tot stem-homorganische clusters, maar assimilerend als zodanig zijn ze niet. Dat betekent dat we een autosegmentele spreidings-analyse in eerste instantie inrichten voor de eerstgenoemde feiten. In het Igbo hebben we gezien hoe het ‘domein’ waarbinnen harmonie plaatsvindt het woord is, en dat daarbinnen de individuele ATR-waarde van de stam als trigger fungeert (opake suffixen daargelaten). In Nederlandse stem-assimilatie zijn beide eenheden kleiner: het domein van stem-assimilatie is het (obstruent-)cluster, de trigger is een individuele obstruent met zijn stem-waarde. Net als stammen in het Igbo dus met hun eigen kenmerk onderliggend gerepresenteerd zijn, kunnen we aannemen dat in het Nederlands elke obstruent met zijn eigen stem-waarde gerepresenteerd is. Het relevante gedeelte van de zojuist genoemde woorden dat ons nu bezighoudt, is het volgende: Het is duidelijk wat in deze configuraties onze wens is, en wat het probleem: de wens is om het autosegment [+stem] met de linker-obstruent te verbinden, het probleem is dat die bezet is met [-stem]. Om dat te verhelpen, nemen we aan dat een regel nodig is die het linker autosegment ontkoppelt. Omdat het vervolgens nergens naar toe kan, wordt het automatisch gedeleerd. Even automatisch spreidt [+stem] zich naar links. Er zijn een aantal formuleringen mogelijk van de ‘ontkoppelingsregel’ die deze gang van zaken aanzwengelt, en uit die mogelijkheden kies ik de onderstaande, om een reden die vlak daarna duidelijk zal worden: (28) Ontkoppel voor een obstruent het autosegment voor [stem] aan het eind van een lettergreep. Door de regel zo te formuleren ontstaat de mogelijkheid een verband te leggen met een tweede fonologische regel uit de lineaire analyse: Auslautverhärtung in (7). Stem-assimilatie kan gezien worden als een vorm van fonologische kenmerk-‘neutralisatie’ ten faveure van een kenmerk dat uit de context wordt toegeleverd. Auslautverhärtung is neutralisatie ten faveure van de waarde [-stem], een waarde die moeiteloos universeel als ongemarkeerd voor obstruenten kan worden beschouwd. Het scenario is dus dit: aan het eind van een lettergreep wordt [stem] ontkoppeld. Als er een nieuwe waarde voor [stem] uit de context kan worden gehaald, wordt die gebruikt. Als dat niet lukt, wordt [-stem] als ongemarkeerde waarde ingevoerd. Regel (28) kan zowel het een als het ander veroorzaken. In alle gevallen waarin specifiek de waarde [-stem] assimileert, zoals raa[t]-sel en han[t]-palm uit (3), kan (28) zowel worden gevolgd door assimilatie als door [-stem] invulling, dat maakt niet uit. Voorbeelden zoals doo[t]-s laten zien dat (28) een subtiele herformulering behoeft: we willen hier graag de ‘onderliggende’ d ontkoppe- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 17]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
len, maar die staat strikt genomen niet op het eind van een lettergreep. Een in dit opzicht verbeterde formulering van (28) maakt gebruik van de interne structuur van de lettergreep die we aan het eind van sectie 4 zijn tegengekomen: ontkoppel het autosegment [stem] in de Coda. Voor het cluster aan het eind van doo-ds is er daarna geen assimilatie-trigger meer aanwezig, en het wordt in zijn geheel automatisch [-stem]. Met assimilatie van [+stem] gebeurt iets dergelijks in het totale cluster van de samenstelling tekst-boek: eerst wordt het autosegment voor ‘stem’ gedeleerd uit de gehele coda van te-kst, daarna wordt [+stem] uit de rechter-context gehaald. Blijft over de autosegmentele pendant van regel (5a), voor de stemloosheid van de initiële fricatief in stop-[f]erf en dergelijke samenstellingen (zie (3c)). Deze regel kan - voor zover ik zie - niet tot iets algemeners worden teruggebracht. Hij blijft bestaan, en de formulering kan worden bereikt door op de plaats van [-stem] in de structurele verandering van de regel nu ‘ontkoppel’ te zeggen. De goede waarde volgt daarna weer automatisch. In zijn geheel ziet de ‘ontkoppelingsregel’ er tenslotte als volgt uit:
Voor zover ik weet speelt opaakheid geen rol in de analyse van Nederlandse stemassimilatie. Dit verschijnsel is bij ons dan ook veel meer recht-toe-recht-aan dan in talen als het Russisch en het Pools, die óók assimilatie en Auslautverhärtung, maar waarin lettergreepstructuur en ook sonorante medeklinkers een veel belangrijker rol spelen. Wie daarover wil lezen, verwijs ik naar resp. Kiparsky (1985) en Gussmann (1992).Ga naar eind9 Wat ik nog niet besproken heb met betrekking tot Nederlandse assimilatie is de generalisatie dat een (ongeleed) woord als tekst zelf, en alle andere in (3a), stemloze obstruent-clusters hebben. Op zich is het niet moeilijk ook in een autosegmentele analyse gewoon conditie (4) te handhaven. Toch zijn er wellicht redenen om dat niet te doen. Conditie (4) noemt de [-stem]-waarde. Maar net zo goed is dat in het Nederlands de ingevoerde stemwaarde in niet-assimilatiecontexten (Auslautverhärtung en de regel voor stemloze fricatieven), én het is de universeel ongemarkeerde stemwaarde voor obstruenten. Het eerste proberen we al te vangen door een regel inderdaad [-stem] te laten invoegen als assimilatie niet plaatsvindt, en het tweede kan worden uitgedrukt door in de onderliggende vorm de obstruent-clusters ongespecificeerd te laten voor [stem]. Zodra ze echter het onderliggende niveau verlaten, wordt [-stem] ingevuld, als ongemarkeerde waarde. Deze laatste ideeën, als ze tenminste langs deze lijnen uitvoerbaar blijken, zouden moeten worden uitgewerkt in een theorie over onderspecificatie, die onderzocht wordt in nauw verband met de autosegmentele fonologie, en waarvan verschillende varianten beschikbaar zijn. Redundante informatie wordt dan niet alleen voorspeld en ‘weggeëvalueerd’ via redundantieregels als (4), maar is letterlijk in de onderliggende representaties afwezig. Deze theorie is ook verwant aan ontwikkelingen in de Praagse School die leidden tot ‘arche-phonemen’ en het begrip ‘gemarkeerdheid’, en aan redundantie en gemarkeerdheid in de vroege fonologie tot en met SPE. Ik zal er hier niet verder op ingaan, maar verwijs de geïnteresseerde lezer naar de inleiding van het proefschrift van De Haas (1988). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 18]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Een fenomeen dat zich uitermate goed leent tot een autosegmentele analyse is dat van ‘toon’. Typisch voor toontalen is in de eerste plaats het feit dat niet per woord een culminatieve piek voorkomt, zoals bij klemtoon, maar dat woorden zijn voorzien van melodieën, waarbij op klinkers de toon omhoog of omlaag kan gaan, iets wat verschillende malen per woord kan gebeuren. En in de tweede plaats is toonhoogte in zulke talen woordonderscheidend te gebruiken, zoals bij ons bijvoorbeeld [stem] (hart vs. hard). Volgens Hyman (1975) heeft het Igbo vier woorden akwa, met verschillende toon-melodieën; zo betekent bijv. àkwá ‘ei’ en ákwà ‘kleed’. Nu is het Nederlands geen toontaal, maar intonatie speelt wel een belangrijke rol.Ga naar eind10 Autosegmentele analyses daarvan kunnen gevonden worden in het werk van Gussenhoven. In Gussenhoven (1987, 1988) geeft hij een overzicht van Nederlandse intonatie-patronen, waarbij hij overigens erkent dat hij veel dank verschuldigd is aan het fonetisch onderzoek van Collier en 't Hart. Hij leidt de bekende intonatiecontouren af van drie basispatronen: HL, HLH, en LH. De linker hiervan wordt, in een zin of frase, verbonden met een beklemtoonde lettergreep, de tweede wordt gespreid over een zo groot mogelijk domein, en de derde (als die er is) wordt aan het eind vastgemaakt. Dat ziet er in Gussenhovens notatie als volgt uit: Op deze basispatronen kunnen een reeks van bewerkingen worden uitgevoerd, die formeel heel simpel kunnen worden geformuleerd, gegeven het autosegmentele model, en die zorgen voor een rijk geheel aan Nederlandse intonatiecontouren. Ik verwijs daarvoor verder naar Gussenhovens werk. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5. Lexicale FonologieIn de SPE-theorie werd het lexicon gezien als een opslagplaats van ‘morfemen’ of ‘lexicale items’ (ongelede woorden, affixen) met hun karakteristieke, niet voorspelbare, eigenaardigheden. Dat idee had traditionele pendanten, die worden opgemerkt in Chomsky (1965: 214): ‘Recall Bloomfield's characterization of a lexicon as the list of basic irregularities of a language (1933, p.274). The same point is made by Sweet (1913, p.31), who holds that “grammar deals with the general facts of language, lexicology with the special facts”.’ Deze kijk op het lexicon werd in de generatieve taalkunde ondersteunt door de in sectie 3 vermelde poging de evaluatieprocedure te verbinden aan het aantal in een grammatica gebruikte symbolen. Alle, ten onrechte in het lexicon opgenomen informatie pleitte tegen de voorgestelde grammatica, en wat voorspeld kon worden, kon er dus beter worden uitgelaten, of via redundantieregels ‘onzichtbaar’ gemaakt voor evaluatie. Om een bekend voorbeeld te noemen: het is weliswaar niet voorspelbaar dat een morfeem, bijv. straal, met een medeklinker begint, want morfemen kunnen ook met klinkers beginnen, maar als een morfeem met drie medeklinkers begint, weten we | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 19]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
meteen dat de eerste een s is, want zo zijn Nederlandse initiële clusters nu eenmaal opgebouwd. Het enige lexicaal meetellende kenmerk van de eerste klank van straal is dus [+cons]. Lexicale of onderliggende vormen werden als zodanig ingevoerd in syntactische structuur door het proces van ‘lexicale insertie’, waarvan de morfemen nu ‘eindknopen’ waren. De syntactische boom werd vervolgens weergegeven als een haakjesstructuur, en dergelijke ‘platte’ structuren dienden als input voor de fonologische component. Zij vormen de ‘oppervlaktestructuren’ waarvan sprake was bij (1) aan het begin van sectie 3. Fonologische regels kwamen dus pas in actie als eenmaal input als in (31) beschikbaar was: (31) [S[NP[NHennie]] [VP[Vkoop[+O] + te] [NP[Det een] [Nauto + tje]]]] Tot de vroegste fonologische regels (d.w.z. de regels die het eerst aan de beurt kwamen in de fonologische component van (1)) behoorden de zogenaamde ‘readjustment rules’. Een voorbeeld is de regel die koop+vt omzette in kocht, op grond van de informatie dat dat een [+O(nregelmatig)] werkwoord is. Een belangrijke taak van deze regels is ook het invoeren, en zonodig manipuleren, van zogenaamde woordgrenssymbolen: aan de ‘binnenkant’ van elk haakje uit de haakjesstructuur wordt automatisch een # toegevoegd als het om een lexicale categorie (N, A, V) of frase (NP, VP, S) gaat. Onderdeel van (31) worden dan bijvoorbeeld de volgende frases, wanneer we ze voorzien van grenssymbolen:
De rationale achter deze procedure was dat deze woordgrenssymbolen konden figureren in de context van fonologische regels, zoals Auslautverhärtung; en dat ook het aantal grenssymbolen tussen morfemen relevant zou kunnen zijn voor fonologische processen, zoals ‘sandhi’: wél tussen kleine woorden (lidwoorden, voorzetsels, etc.) en echte woorden, níet tussen twee woorden onderling, enzovoort. Ik kom daar in de volgende sectie op terug. Tot de latere fonologische regels behoorden regels voor klemtoon, assimilatie, enz. In Halle (1973) werd vervolgens een poging gedaan dit plaatje op te schonen door alle morfologie te ordenen vóór lexicale insertie. Het lexicon werd op dat moment dus aanzienlijk uitgebreid, en ook onregelmatige werkwoordsvormen als kocht maakten er nu deel van uit, plus morfologische regels voor inflectie en derivatie. Het argument was het volgende: nagenoeg alle morfologische processen (in de zin van: combineringen van morfemen) brengen hun specifieke eigenaardigheden mee: uitzonderingen, ablaut, augmenten, allomorfie, afwijkende semantiek, enz. Dat legt een heel zware last op de schouders van de readjustment rules, die bovendien heel andere taken krijgen dan werkelijk fonologische regels: het is heel wat anders dan koop-te om te zetten in kocht, dan twee obstruenten te assimileren qua [stem]. De readjustment rules voeren operaties uit die te maken hebben met idiosyncratieën, die we eigenlijk liever in het lexicon zouden situeren. Dus moet de morfologie naar het lexicon. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 20]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Niet lang hierna werd het lexicon opnieuw uitgebreid, dit keer met een deel fonologie, nl. voor zover die door de morfologie wordt beïnvloed. In SPE werd al een indeling gemaakt in twee soorten affixatie, afhankelijk van het fonologische gedrag van de affixen in kwestie. (Dit greep ook terug op ouder werk, zie bijv. de ‘primary’ vs. ‘secondary’ morfologie van Bloomfield 1933.) We kunnen via een herbeschouwing van klemtoon verduidelijken hoe dat loopt. De Nederlandse klemtoonregels van sectie 4 gelden voor ongelede woorden alsook voor een aanzienlijke hoeveelheid gelede:
Deze groep suffixen wordt ‘klemtoon-gevoelig’ genoemd. Daarnaast is er echter een groep suffixen die zich niets van de klemtoonregels aantrekt. Voorbeelden hiervan zijn de suffixen in de volgende woorden:
Alle generalisaties met betrekking tot Nederlandse woordklemtoon worden door deze formaties geschonden. De hoofdklemtoon kan verder naar links liggen dan de derde lettergreep van rechts, wat ‘normaal’ eigenlijk niet kan. Finale ‘superzware’ lettergrepen vangen geen hoofdklemtoon. Prefinale gesloten lettergrepen laten zich gemakkelijk passeren voor hoofdklemtoon. Dit, terwijl de echte generalisatie gemakkelijk te formuleren is: deze groep suffixen is zogenaamd klemtoonneutraal, en automatisch blijft de hoofdklemtoon op zijn oorspronkelijke plek. Om dit onderscheid in twee typen affixen uit te drukken, stelt SPE het volgende voor. Klemtoonneutrale affixen worden als zodanig gemarkeerd door ze te laten voorafgaan door een speciaal teken, het ‘grenssymbool’ #. Dit gebeurt door een readjustment rule die deze operatie uitvoert (en dus een regel is die grenssymbolen manipuleert, zoals boven vermeld). Voor klemtoongevoelige affixen worden geen speciale maatregelen genomen: die worden slechts voorafgegaan door de grens die altijd twee morfemen van elkaar scheidt: ‘+’. We krijgen nu de volgende soorten representaties:
Aan het #-grenssymbool wordt vervolgens een klemtoonregel-blokkerende eigenschap toegekend. Een woord waarin dit symbool verschijnt, mag niet de woordklemtoonregels ondergaan. De +-grens, aan de andere kant, wordt feitelijk onzichtbaar verklaard, en klemtoon kan worden toegekend als een woord deze grens bevat, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 21]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
precies zoals gewenst. De eigenschap toegedicht aan de #-grens lijkt er slechts toe te leiden dat woorden met zulke affixen helemaal géén klemtoon krijgen toegekend. Maar dat effect wordt omzeild door een interessante aanname: toekenning van woordklemtoon verloopt cyclisch, van binnen naar buiten in een structuur, met als gids de morfologische opbouw van het woord. Deze stap blijkt precies het gewenste resultaat te hebben om het verschil in klemtoongedrag tussen de twee groepen affixen te verklaren:
De opzet in (38) is zeer goed te combineren met het standpunt dat morfologie deel uitmaakt van het lexicon: in elk geval werken de klemtoonregels op morfologisch complexe structuren. Het idee dat ook een deel van de fonologie zich in het lexicon bevindt, d.w.z. opereert voor lexicale insertie, is te danken aan het proefschrift van Siegel (1974). Voor ‘klemtoongevoelig’ en ‘klemtoonneutraal’ voert zij de terminologie ‘Klasse I’- en ‘Klasse II’-affixen in, en zij stelt voor de klemtoonregel en affigering ten opzichte van elkaar te ordenen volgens het volgende model:
Dit alles ín het lexicon. Elk ongeleed woord en alle gelede woorden met een Klasse I-affix ondergaan de klemtoonregels, wat verklaart waarom de laatste zich aan de klemtoonregels voor ongelede woorden houden. Daarna kan nog Klasse II-affigering volgen, maar klemtoon is dan al toegekend; dit verklaart waarom deze suffixen klemtoonneutraal zijn. De aan het eind van de procedure opgeleverde woorden ondergaan lexicale insertie. Een scepticus zal zeggen dat (37) er misschien schematisch beter uitziet, maar dat er verder nog niet duidelijk is wat er beter is aan (37) ten opzichte van (36). Maar het Siegel-model heeft een bonus: het doet de voorspelling dat in sequenties van suffixen klemtoongevoelige nooit buiten klemtoonneutrale zullen voorkomen. Dat is een uitkomst die helemaal niet volgt uit het SPE-model, en hij is dus de moeite waard na te gaan. Voor het Nederlands komen we er in elk geval een heel eind mee:
Volgordes waarbij de affixen zijn omgekeerd, ontbreken. Wat ook opvalt zijn twee andere zaken. In de eerste plaats is het grenssymbolen-verschil tussen affixen (# vs. +) overbodig. Dat is een conclusie die Siegel zelf overigens (nog) niet trok, maar die niet al te lang na haar door andere onderzoekers wel werd gezien (zie met name Strauss 1979, Selkirk 1980a). Het tweede punt is dat, gegeven model (39), cyclische toepassing van de klemtoonregel niet meer nodig lijkt: het hele probleem, door de | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 22]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
aanwezigheid van het #-symbool in een string gecreëerd, is geëlimineerd. Ik kom daar zometeen op terug. Het Siegel-model is in het begin van de jaren tachtig vooral uitgewerkt in de theorie van ‘Lexical Phonology and Morphology’, door Kiparsky (1982a, b) en een reeks andere onderzoekers. Daarbij worden er drie grote onderzoeksvragen aangeroerd:
Laten we deze vragen stuk voor stuk kort bekijken. Gewoonlijk worden niet-lexicale fonologische regels aangeduid als post-lexicale, omdat ze typisch werken na lexicale insertie, met als input de syntactische oppervlaktestructuur, als vanouds. Het gaat dan typisch om regels die werken in verschillende soorten woordgroepen, en ik zal daar in sectie 6 op terugkomen. Het is overigens niet verboden voor een fonologische regel om zowel lexicaal als post-lexicaal te opereren. Kiparsky (1985) noemt onder de kenmerkende eigenschappen van lexicale fonologische regels de volgende (in vergelijking met post-lexicale fonologische regels). In de eerste plaats kunnen lexicale regels cyclisch werken, en zijn post-lexicale niet-cyclisch. Het eerste is onverwacht gezien wat we boven geconcludeerd hebben over affigering in het Siegel-model. In de tweede plaats zijn ze structuur-behoudend, wat wil zeggen dat ze als regelgroep gebruik maken van een vaste inventaris aan klanken, die in het lexicon zelf niet gewijzigd mag worden. Dit betekent bijvoorbeeld dat allofonie-regels post-lexicaal moeten zijn. Een voorbeeld is de bekende Nederlandse regel die voor verschillende k's zorgt, al naar gelang de articulatieplaats van de volgende klinker: kies, koos, kaas. Ten derde mogen post-lexicale regels, en lexicale regels niet, ‘gradient’ zijn. Nederlandse stem-assimilatie bijv. zou best wel eens zowel een lexicale als een post-lexicale regel kunnen zijn: hij werkt in elk geval zowel binnen woorden als over woordgrenzen heen (Het schi[b] deint...). In het laatste geval is het effect van de regel gradient in die zin dat het afneemt naarmate de afstand tussen de te assimileren klanken toeneemt (als in Tekst drukken..., etc.). De vraag of het systematische onderscheid tussen Klasse I- en Klasse II-affigering de tand van gedegen empirisch onderzoek doorstaat, is het gebied van de zogenaamde ‘ordeningsparadoxen’, d.w.z. gevallen waarbij het er in eerste instantie op lijkt dat de volgorde tussen affixen wel degelijk die is die de opzet verbiedt. Voor het Engels wordt in een grote hoeveelheid literatuur het klasse-onderscheid verworpen op grond van dergelijke gevallen, hoewel het lexicale model als zodanig niet (zie bijv. Fabb 1988, Halle & Vergnaud 1987). Een klassiek voorbeeld voor het Nederlands is het suffix-paar dat optreedt aan het eind van een woord als vriend-schapp-elijk, omdat aantoonbaar -schap klemtoonneutraal lijkt, en -elijk klemtoongevoelig. Een heranalyse van zulke voorbeelden wordt voorgesteld in Trommelen & Zonneveld (1992), waarbij het probleem wordt omzeild door te ontkennen dat -schap een suffix is. Tenslotte de vraag hoe fonologie en morfologie met elkaar interacteren, een onderwerp dat sterk verbonden is met de lang niet opgeheven cyclus. In SPE | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 23]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
bestond de morfologie uit een combinatie van lexicale insertie van morfemen in syntactische structuren en de schemerige readjustment rules samen. Als Halle (1973) de morfologie als gebied naar het lexicon verwijst doet hij dat om dat vak principieel te scheiden van de fonologie. Er ontstaat dan ook behoefte aan een theorie over ‘woordvormingsregels’; de discussie over de aard daarvan loopt door tot op de dag van vandaag, maar zal mij hier niet bezighouden.Ga naar eind11 De introductie van een deel van de fonologie in het lexicon lijkt weer afbreuk te doen aan Halle's scheiding, maar op het ogenblik worden fonologie en morfologie beschouwd als twee onafhankelijk naast elkaar staande systemen (‘modules’), die (a) kunnen worden aangestuurd door informatie vanuit lexicale items (sterk werkwoord, uitzondering op een woordvormingsregel, etc.), en (b) interacteren op een manier die universeel is vastgelegd. Een concreet en populair voorstel over hoe men zich dit laatste kan indenken is gedaan in Strauss (1983), en het loopt als volgt. Stel we willen klemtoon toekennen aan het gelede Nederlandse woord referentN-ieN-eelA. Bij die wens hoort dan de volgende schematische opzet:
Het lexicale item referent kan als zodanig klemtoon krijgen. Op de output kan een woordvormingsregel werken, bijv. nominalisering met -ie. Vervolgens werkt automatisch de klemtoonregel. Daarna kan weer een woordvormingsregel werken, in dit geval adjectivisering met -eel. Dan werkt automatisch de klemtoonregel. Enzovoort. Klemtoonneutraliteit kan worden uitgedrukt via een Klasse-onderscheid, maar daar zijn eventueel ook andere middelen voor. Een dergelijk model heet ‘Cyclic’ Lexical Phonology, en is het verst uitgewerkt door Rubach, bijvoorbeeld in Booij & Rubach (1986). Het idee is dat morfologie en fonologie gescheiden ‘pre-lexicale insertie’ systemen zijn, die interacteren doordat de toevoeging van een affix onmiddellijk de fonologie aanroept. De cyclus is in zo'n systeem geen aparte veronderstelling over de manier waarop fonologische regels opereren, gegeven gelede woorden, maar volgt uit een universele aanname over de manier waarop morfologie en fonologie - hoe verschillend ze eventueel ook zijn - interacteren. Het model wordt ook wel ‘inherent cyclisch’ genoemd. Maar merk op dat de cyclus op zich niet wordt afgedwongen door onze wens gelede woorden correct klemtoon te geven, als in het SPE-model. We zouden ogenschijnlijk net zo goed eerst het gelede woord totaal morfologisch kunnen opbouwen, en vervolgens klemtoon toekennen, waarom niet? Het antwoord is dat er in de jaren tachtig een nieuw empirisch verschijnsel werd ontdekt dat model (41) ondersteunt: dit model voorspelt dat er affixen kunnen bestaan die alleen kunnen worden toegevoegd onder bepaalde klemtooncondities, bijv. ‘eindklemtoon op de input’; een alternatief met ‘alle morfologie-eerst’ kan een dergelijke situatie per definitie niet behappen. Ook het Nederlands lijkt een of meer dergelijke suffixen te hebben: Trommelen & Zonneveld (1989) noemen nominaliserend -ie dat altijd graag eindklemtoon in zijn | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 24]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
basiswoord wil hebben. Als dergelijke voorbeelden kloppen, ondersteunen zij het ‘inherent cyclische’ variant van Lexical Phonology, en zijn we al doende een heel eind gekomen vanaf SPE's readjustment rules. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6. Prosodische FonologieProsodische Fonologie is het vakgebied dat zich bezig houdt met de klankverschijnselen die zich afspelen in de structuren die beschikbaar zijn na lexicale insertie. Het gaat dan om sandhi, intonatie, en dergelijke. Op verschillende plaatsen in SPE wordt het begrip fonologische frase gebruikt in een losse betekenis die ook de auteurs, zoals ze zelf zeggen, niet geheel duidelijk is. Ik heb hier tot nu toe, met betrekking tot de schematische weergave in (1), en tot de voorbeeldzin in (3), voorgewend alsof de syntactische oppervlaktestructuur direct wordt ingevoerd in de fonologische component, eventueel met wat wijzigingen door ‘readjustment rules’ in idiosyncratische gevallen. Maar op p. 13 van SPE wordt tussen neus en lippen door het volgende gezegd: ‘The readjustment rules will modify the surface structure in various ad hoc ways, demarcating it into phonological phrases, eliminating some structure....’. Pas op p. 372 wordt dan enigszins gepreciseerd wat hier wordt bedoeld, zij het op bescheiden wijze, aan de hand van de volgende zin met meervoudige inbedding: (40) This is [the cat that caught [the rat that stole [the cheese]]] De auteurs observeren dat de intonatie van deze zin in het geheel niet de syntactische structuur volgt, maar dat er ‘breuken’ liggen achter cat en rat. Ze vervolgen dan: ‘This effect could be achieved by a readjustment rule which converts [42], with its multiply embedded sentences, into a structure where each embedded sentence is sister-adjoined in turn to the sentence dominating it.[...] But it can certainly be argued plausibly that this “flattening” of the surface structure is simply a performance factor, related to the difficulty of producing right-branching structures.[...] Hence it certainly can be argued that these problems do not belong to grammar - to the theory of competence - at all.’ En: ‘Similar questions arise in connection with the notion of “phonological phrase”, which we have mentioned several times. It is clear that the rules of the phonological component do not apply to strings that exceed a certain level of complexity or a certain length, and that therefore certain readjustment rules must apply to the syntactically generated surface structure to demarcate the strings to which the rules are limited, that is, the strings that we have called “phonological phrases”. [These rules] will have to take account of syntactic structure, but they will also involve certain parameters that relate to performance....’. Ze verwijzen tenslotte naar Bierwisch (1966) voor pogingen voor het Duits om dergelijke procedures op te stellen, maar ‘[w]e have nothing to add to his proposals, and we therefore omit any further discussion of phonological phrases’. Daarmee ging dit onderwerp geruime tijd in de ijskast. De linguïst die zich in de jaren na SPE het meest met sandhi bezighield was de Amerikaanse Selkirk. Zij behandelde de Franse liaison in een aantal publikaties (1972, 1974), maar wel in het SPE-read- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 25]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
justment kader: grenssymbolen spelen een uiterst belangrijke rol in die analyse. Pas aan het eind van de jaren zeventig komt daarin verandering, en wel uit de hoek van de romanistiek, door nieuw werk van Nespor over het Italiaans, en een herinterpretatie van haar eigen werk over het Frans door Selkirk. In deze sectie volg ik deze twee lijnen, die uiteindelijk uitkomen bij de theorie van Prosodische Fonologie. Aan het eind zeg ik nog iets over de prosodische fonologie van het Nederlands. Een uitermate fascinerend verschijnsel uit de fonologie van het Italiaans, is de zogenaamde Raddoppiamento Sintattico, een verlenging van de beginmedeklinker van een woord, als het voorafgaande woord op een beklemtoonde klinker eindigt: la cittá v[:]ecchia ‘de oude stad’. Napoli & Nespor (1979) bespreken uitgebreid een aantal analyses van dit verschijnsel, waaronder een met SPE-achtige readjustment rules en woordgrenzen. Maar hun commentaar daarop is tamelijk kernachtig negatief, en bevat uitdrukkingen als ‘highly arbitrary’, ‘no independent support’ en ‘lack of empirical testability’. Ze komen vervolgens met het voorstel voor dit verschijnsel readjustment rules te negeren, en syntactische structuur onmiddellijk in te voeren in de fonologische component. Dat gaat als volgt in zijn werk: we observeren eerst dat in het Italiaans in (41a) wél RS optreedt, en in (41b) niet (de plaats van potentiële RS wordt onderstreept):
Napoli & Nespor's conclusie is dat het volgende de regelmaat is achter RS in het Italiaans:
Dat klopt positief voor (41a), en negatief voor (41b). Maar de fonologische operatie wordt nu wel onmiddellijk op de syntactische structuur uitgevoerd, zonder tussenkomst van readjustment regels, of verwijzing naar grenssymbolen. Aan het eind van hun artikel speculeren de auteurs dan nog als volgt: ‘Why should the left branch and not the right one, the first constituent and not the last one, be crucial? Perhaps the traditional grammarians [...] were on the right track when they talked of “phrases”, or “united” words and “groups”. What RS tends to do is to signal the listener that a new constituent has started. [...] We leave these suggestions for further research.’ Tegelijkertijd werkt Selkirk voor een deel langs dezelfde lijnen, maar voor een deel ook langs andere, d.w.z. meer fonologische, met daardoor ook een ander resultaat. In Selkirk (1980a, b) wordt de theorie van readjustment rules en grenssymbolen ook door haar zwaar onder vuur genomen, en geëlimineerd. Maar ervoor in de plaats komt niet een theorie van ‘directe verwijzing’ (‘direct reference’) naar syntac- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 26]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
tische structuur, maar een waarin ‘fonologische domeinen’, zoals SPE's ‘phonological phrase’ direct zijn geïncorporeerd.Ga naar eind12 Zij demonstreert haar theorie aan een reeks van talen, waaronder het Engels, het Sanskrit en het Frans in een heranalyse van haar eigen onderwerp, ‘liaison’. Ik zal deze voorbeelden niet bespreken, maar doorgaan met het Italiaans, omdat Selkirk's voorstellen onmiddellijk op RS werden toegepast door Nespor & Vogel (1982). Voor dat verschijnsel doen die auteurs de volgende voorstellen. Laten we nog steeds aannemen dat (43) de doorsnee syntactische structuur van het Italiaans weergeeft. Dan woorden fonologische frases, of ‘fi's’ (ϕ) gebouwd volgens de volgende instructie:
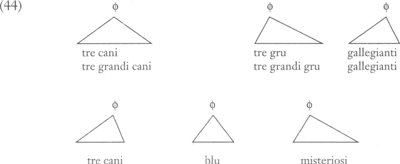 RS vindt nu plaats ‘binnen een fi’. We zouden kunnen zeggen dat (43) de plaats inneemt van de readjustment rules van SPE, met daarbij twee opmerkingen. Er is in de eerste plaats een aanzienlijk conceptueel verschil: readjustment rules konden elke gewenste taak uitvoeren die nodig was om syntaxis en fonologie aan elkaar te lijmen. De regels in (43), daarentegen, leveren prosodische structuren die verder consequent in de fonologie van de taal in kwestie de zaken moeten opknappen: ze beperken de mogelijkheden eerder dan dat ze die uitbreiden. En in de tweede plaats heeft (43) geen idiosyncratische-taalspecifieke status, maar (idealiter) juist een universele. Daarover zal ik zometeen iets meer zeggen. Het zal misschien zijn opgevallen dat (44) voor een deel een andere voorspelling doet dan (41), met name voor de ‘kraanvogel’-zinnen. Nespor & Vogel zien hier een pré voor de fi-analyse. Zij veronderstellen heranalyse van de fi-structuur als een niet-vertakkende fi wordt voorafgegaan door een vertakkende, tot één grotere vertakkende. Daarna volgt alsnog RS. Dit volgt niet uit de oorspronkelijke, op syntaxis gebaseerde, analyse. Doordat alleen niet-vertakkende ϕ's adjungeren, wordt voorspeld dat er geen RS is in het laatste geval van (44), wat correct is, en in een geval als [tre cani][molto belli], wat klopt met de feiten. Op deze manier drukt de analyse uit dat de ‘lengte’ van het B-woord er in de configuratie voor RS toe doet, wat intuïtief juist lijkt te zijn. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 27]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Onderdeel van de Selkirk/Nespor-theorie van Prosodische Fonologie is ook dat ϕ's kunnen worden samengenomen in ‘intonationele frases’ (I's), die bijvoorbeeld een rol spelen in de gewenste opdeling van (40). Deze worden vervolgens weer samengevoegd in een ‘utterance’ (U). Twee opmerkingen passen hierbij. In de eerste plaats kan de theorie van Prosodische Fonologie beschouwd worden als een antwoord op SPE's nogal onzekere opmerkingen over de status van categorieën als ‘intonatie-domein’ en ‘fonologische frase’. Het domein ϕ volgt rechtstreeks uit de syntactische structuur van een taal; ϕ's liggen dan ook vast. De regel die niet-vertakkende ϕ's adjungeert, is aan de ene kant grammaticaal bepaald (‘niet-vertakkend’ is een grammaticale notie), maar de optionaliteit ervan zou best te maken kunnen hebben met bijvoorbeeld spreektempo en stijl. Datzelfde geldt voor de verschillende manieren waarop ϕ's tot I's kunnen worden samengenomen. Dit is lang niet in alle detail uitgewerkt, maar wel een belangrijke stap verder. In de tweede plaats wordt voor het proces van ϕ-vorming in (43) (en I- en U-vorming) ook een hoge mate van universaliteit verondersteld. Voor ideeën hierover verwijs ik naar Nespor & Vogel. Een bekend proces dat in een reeks van talen plaatsvindt, waaronder het Nederlands, en opereert in het ϕ-domein, is Klemtoonverschuiving. Ik geef eerst een voorbeeld uit het Italiaans en het Engels. 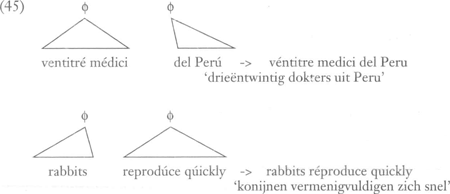 Klemtoonverschuiving wordt veroorzaakt door twee vlakbij elkaar liggende hoofdklemtonen; de linker ervan verschuift naar links. Het domein van het proces is de ϕ. In het Italiaanse voorbeeld is die geconstrueerd op grond van de syntaxis. In het Engels gebeurt dat net zo goed (thirtéen mén → thírteen mén, achromátic léns → áchromatic léns), maar in het hier gegeven voorbeeld is de relevante (rechter) ϕ ontstaan uit adjunctie van een niet-vertakkende ϕ naar links. Vervolgens vindt verschuiving plaats. In Nespor & Vogel (1982) is de Italiaanse zin in feite langer, want:
Klemtoonverschuiving vindt ook nog plaats aan het eind van de zin, waar het resultaat is: tríbu nórdiche. Maar cruciaal níet in het midden van de zin, ondanks de twee | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 28]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
bij elkaar staande klemtonen: maar die staan niet in dezelfde ϕ, dus geen verschuiving. Het Nederlands doet mee met de verschuivende talen. Het proces van klemtoonverschuiving wordt onderzocht in Visch (1990), zij het dat het prosodische domein daar niet wordt onderzocht.Ga naar eind13 Nederlandse voorbeelden van Adjectief-Zelfstandig Naamwoord combinaties (één ϕ) zijn de volgende:
 De twee botsende klemtonen zijn in een vierkant aangegeven; deze situatie wordt gewoonlijk met ‘stress clash’ aangeduid. Als we de ϕ-gevoeligheid van Klemtoonverschuiving willen aantonen, zou dat op de volgende manier kunnen. Beschouw de zinnen in (52):
Dit lijkt inderdaad conform de gangbare intuïties. De raiddelste zin is in feite een stap interessanter dan hij op het eerste gezicht lijkt, want hij heeft twee interpretaties. In de interpretatie (Hij sprak) ‘urgent zoals Italianen dat doen’ is er van het begin af aan al sprake van één ϕ, en verschuiving moet daarin relatief gemakkelijk zijn. In de betekenis (Hij sprak) ‘het Italiaans urgent uit’, kan er alleen sprake van verschuiving zijn door adjungering. Iets anders geformuleerd: de zin mét verschuiving zou het gemakkelijkst de eerste betekenis moeten losmaken, die zónder de tweede. Ook dat lijkt te kloppen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7. EpiloogIn dit artikel heb ik gepoogd een overzicht te geven van de stand van zaken in de studie van de fonologie van het Nederlands. Maar in feite heb ik meer en minder dan dat gedaan. Ik heb meer gedaan in die zin dat in dit sterk theoretisch georiënteerde | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 29]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
en geïnternationaliseerde vakgebied het Nederlands niet in isolatie bestudeerd wordt. Voorstellen voor het Italiaans of Igbo kunnen direct relevant zijn voor het Nederlands en andersom. Daarom hebben zulke talen ook, als introductie in een bepaald verschijnsel, een rol gespeeld. Ik heb minder gedaan op twee manieren. In de eerste plaats kan ik helemaal niet de pretentie hebben, zoals ik al in de introductie al heb toegegeven, volledigheid te benaderen. Er is veel en veel meer geschreven in de Nederlandse fonologie, door meer onderzoekers dan de nu genoemde. Dat volgt nu eenmaal uit de aard van een artikel als dit. Ik kan alleen maar hopen dat de selectie aan zijn doel heeft beantwoord. In de tweede plaats zijn sommige specifieke onderdelen van de Nederlandse fonologie niet geheel aan hun trekken gekomen. Ik denk daarbij aan een aantal vakgebieden. Ten eerste de dialectologie, die net zo goed in het generatieve kader wordt beoefend (in bijvoorbeeld werk van Hinskens, Nijen Twilhaar en Taeldeman); en de relatie tussen fonetiek en fonologie (Quené, Slootweg, e.a.). De historische fonologie genoot in de jaren zeventig uitermate grote populariteit, vanwege het idee, specifiek geuit door Kiparsky, de grote historisch taalkundige uit deze periode, dat historisch onderzoek zou kunnen dienen als evidentie voor de ‘psychologische realiteit’ van taalkundige analyses, d.w.z. als ‘a window on the form of linguistic competence’ (1968: 174). Maar daarover ontstond langzamerhand grote skepsis, niet in het minst bij Kiparsky zelf, die in het voorwoord van de verzamelbundel ‘Kiparsky (1982c)’ dan ook concludeert dat ‘linguistic change is not as direct a “window” on linguistic structure as one might have hoped’. Sindsdien is historische generatieve fonologie niet meer het speciale vak dan het toen was. Internationaal wordt er wel onderzoek gedaan naar de klankstructuur van oudere taalstadia, waarom niet, maar onderzoek dat zich richt op historische ontwikkelingen is als vakgebied teruggevallen. In Nederland wordt historische generatieve fonologie op het ogenblik slechts spaarzaam beoefend. Sinds vanaf de jaren tachtig wordt geprobeerd een directer verband te leggen tussen theoretische beweringen en de uitkomsten van onderzoek naar eerste taalverwerving, komt ook in de Nederlandse fonologie dit vakgebied op gang. Het is jong, er is nog weinig gepubliceerd, maar ik noem in elk geval Van Zonneveld (1988). In Leiden en Utrecht lopen AIO-projecten met als onderwerp resp. het fonologisch segment en syllabestructuur (Fikkert & Levelt) en klemtoon (Nouveau). De Nederlandse fonologen vormen een kleine, maar tamelijk coherente groep, die over het algemeen goed van elkaars werk op de hoogte is. Maar wat onmiddellijk opvalt is het volgende:Ga naar eind14 de studie van de Nederlandse fonologie vindt nagenoeg steeds plaats buiten de context van de universitaire opleidingen Nederlands. Hij wordt beoefent op instituten voor Algemene Taalwetenschap, Anglistiek en Romanistiek. Men vergelijkt Engelse lexicale fonologie met de Nederlandse, Engelse intonatie met de Nederlandse, Romaanse epenthese met de Nederlandse, en de gehele groep voorziet de Neerlandistiek van analyses van het Nederlands. De Neerlandistiek zelf lijkt de Nederlandse fonologie een beetje te hebben losgelaten, zeker in de universitaire aanstellingen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 30]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Adres van de auteur Onderzoeksinstituut voor Taal en Spraak R.U.U. Trans 10 3512 JK Utrecht | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 31]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 32]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 33]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||