
Tijdschrift voor Nederlandse Taal- en Letterkunde. Jaargang 88
(1972)– [tijdschrift] Tijdschrift voor Nederlandse Taal- en Letterkunde–
[pagina 284]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Een taalstatistisch onderzoek
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 285]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 2. Het woord als tekst- en lexicale eenheid (p. 24-29). § 3. Statistiek en taal (p. 14-17). § 4. De reductie van een vocabularium (p. 38-48). § 5. Statistische parameters voor de vergelijking van vocabularia (p. 48-58). § 6. De groei van het vocabularium (p. 59-72). § 7. De plaats van de frequentste woorden (p. 72-77). § 8. De verdeling der grammaticale categorieën (p. 81-94). § 9. Plus- en minuswoorden (p. 95-115). Tenslotte geven we in § 11 een lijst van errata bij het boek van Martin. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 2. Het woord als tekst- en lexicale eenheidMartin definieert een woord als een reeks letters, begrensd door blanks en/of interpunctie (p. 25). Daarnaast hanteert hij twee verschillende definities van woordidentiteit: (1) Een grafische definitie: twee woorden zijn hetzelfde (d.w.z. zijn twee ‘tokens’ van hetzelfde ‘type’) als ze grafisch identiek zijn. (2) Een lexicale definitie: twee woorden zijn hetzelfde als ze tot hetzelfde lemma van een woordenboek (i.c. de grote Van Dale) terug te brengen zijn. Op p. 24-27 citeert Martin herhaaldelijk het artikel van P.A.M. Seuren over Het probleem van de woorddefinitie (Tijdschr. voor Ned. taal- en letterk. 82 (1966) 259-293). Seuren wijst er in dit artikel op dat alle gebruikers van alle talen alle zinnen van hun taal in woorden kunnen verdelen, en dat ze dat allemaal op (vrijwel) dezelfde manier doen. De kennis van de plaats van de woordgrenzen behoort dus blijkbaar tot de intuïtie van de taalgebruiker. In geschreven taal worden woordgrenzen gerealiseerd als blanks en/of interpunctie. Seuren noemt deze gegevenheid van het woord als een stukje zin tussen twee woordgrenzen de syntagmatische dimensie van het woord. Martins definitie van het woord is hiermee in overeenstemming. Daarnaast is er volgens Seuren in de taalkunde volkomen ten onrechte steeds weer geprobeerd het woord een paradigmatische dimensie toe te kennen d.w.z. het te beschouwen als een element van taal- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 286]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
bouw. Deze visie impliceert het bestaan van woordidentiteit: eenzelfde ‘woord’ kan voorkomen in verschillende zinnen. Dat het woord steeds ten onrechte een paradigmatische status is verleend, blijkt uit het feit dat geen enkele definitie die er ooit voor het ‘paradigmatische woord’ opgesteld is, in staat is geweest alles te bestrijken wat de taalgebruiker intuïtief als woord aanwijst, en tevens niets anders dan dat. Woorden zijn eenheden uit de oppervlaktestructuur van zinnen. De grammatica van de taal bepaalt waar in de zinnen van die taal woordgrenzen komen te liggen, en wat er tussen twee opeenvolgende woordgrenzen ligt, is automatisch een woord. Wèl een paradigmatische dimensie bezitten o.i. in een taal de morfemen, minimale naar vorm en betekenis konstante eenheden. Elk woord in de oppervlaktestructuur van de zin is een realisering van één of meer morfemen in de dieptestructuur. Het niet samenvallen van woorden en morfemen is de reden van het ontbreken van een paradigmatische dimensie bij het woord. Een consequentie van dit alles is dat een onderzoek naar de betekeniswereld van een tekst of auteur niet gebaseerd dient te worden op paradigmatisch gedefinieerde woorden (de oppervlaktestructuur heeft slechts een zeer indirecte relatie met de betekenis), maar op morfemen die door hun dieptestructurele functie een directe relatie met de betekenis hebben. Het is m.a.w. uiterst riskant op basis van onderzoek op paradigmatisch gedefinieerde woorden uitspraken te doen op het niveau van de betekenis. Martin maakt zich o.i. zowel bij het onderzoek op basis van de grafische definitie van woordidentiteit als bij het onderzoek op basis van de lexicale definitie van woordidentiteit schuldig aan een oncontroleerbare, en daardoor ongeoorloofde interpretatie van zijn resultaten op het niveau van de betekenis. We zullen dit verduidelijken voor beide definities. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(a) De grafische definitie van woordidentiteitEen gevolg van de strikt grafische definitie is dat alle morfologische verschillen tussen woorden (op gelijke wijze) gehonoreerd worden, terwijl veel syntactische en semantische verschillen verwaarloosd wor- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 287]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
den. Zo wordt het verschil tussen grote en groot op dezelfde wijze verwerkt als het verschil tussen grote en werkte. Anderzijds wordt er geen verschil gemaakt tussen trap (ladder), trap (schop: zelfstandig naamwoord) en trap (schop: werkwoord). Onder het opzicht van de betekenis is deze definitie dus volkomen inadequaat. Dat ziet Martin zelf ook wel in en daarom zegt hij dat hij deze definitie alleen zal hanteren bij het onderzoek van de structuur van het vocabularium (zie daarvoor hieronder § 4), omdat daarbij ‘de betekenis van het woord geen rol speelt’ (p. 27). Martin laat echter wel degelijk bij zijn interpretatie het begrip betekenisverschil impliciet een rol spelen door het gebruik van termen als. ‘woordenschat’ (p. 11), ‘woordvoorraad’ (p. 59) en ‘lexicale rijkdom’ (p. 80). In de trant van Martin zou men bijvoorbeeld kunnen zeggen dat een tekst die bestaat uit 9 verschillende vormen van het werkwoord hebben, een even grote ‘woordenschat’ bezit als een tekst die bestaat uit 9 verschillende vormen van 9 verschillende werkwoorden. Dezelfde fout - het ongeoorloofd semantisch interpreteren van strikt grafische gegevens - maakt Martin bij zijn manipulaties met het begrip ‘lexicon’ (zie daarvoor hieronder § 3). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(b) De lexicale definitie van woordidentiteitDoor het gebruik van de lexicale definitie van woordidentiteit worden er meer betekenisverschillen gehonoreerd dan bij het gebruik van de grafische definitie. Maar er gaat dan ook heel wat van de door Martin zo nagestreefde objectiviteit verloren. Op de eerste plaats maakt het verbinden van een woord met een lemma van het woordenboek vaak een subjectieve interpretatie nodig. Dit blijkt bij Martin uit het feit dat nam wel wordt herschreven tot nemen (p. 21), maar verkleinwoorden niet tot hun grondwoord (p. 141). Ook het scheiden van homoniemen op basis van hun context (in dit geval een KWIC-index; p. 21) blijft een subjectieve aangelegenheid, zolang er nog geen volledige en expliciete grammatica van het nederlands tot stand is gekomen. Op de tweede plaats is Martin afhankelijk van de lemmata die Van Dale in zijn woordenboek heeft opgenomen. Wanneer een woord niet direct (bij grafische identiteit met het lemma) of indirect (via boven- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 288]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
genoemde subjectieve interpretatie) bij een lemma kan worden ondergebracht, dan heeft Martin nog drie pijlen op zijn boog: ofwel (1) hij breidt het aantal lemmata uit door andere woordenboeken (i.c. Koenen, Verschueren) te hulp te roepen (p. 116), ofwel (2) hij breidt het woordenboek uit met een aantal samenstellingsregels (b.v. bij aanfloepen; p. 116-117), ofwel (3) hij beschouwt het betreffende woord als neologisme. Wij achten de lexicale definitie niet adequaat voor uitspraken op het gebied van de betekenis. Tussen man en mannetje is er dan evenveel verschil als tussen man en vrouw. Bij een woord als boerendorp aan de ene kant en de woorden boer en dorp aan de andere kant wordt geen enkele betekenisovereenkomst aangegeven. Het zou daarom beter geweest zijn, als Martin nog een stapje verder gegaan was dan de lexicale definitie, en morfemen had aangenomen als eenheid van onderzoekGa naar voetnoot2). Het aantal subjectieve beslissingen was dan weliswaar nog wat toegenomen, maar het onderzoek was in elk geval gebaseerd geweest op eenheden die werkelijk een paradigmatische dimensie hebben. Het lijkt ons altijd nog beter een onderzoek te doen dat misschien ooit zinvol zal blijken te zijn, dan een onderzoek waarvan direct al aan te tonen is dat het zinloos is, omdat het - wanneer er tenminste niet onjuist geëxtrapoleerd wordt - niet tot belangrijke uitspraken kan leiden (met het oog op het onderzoeksdoel). Een betere lezing van het artikel van Seuren had Martin voor deze fundamentele fout kunnen behoeden. Het lijkt ons dat Martin zich in het algemeen erg weinig om problemen als het bovenstaande bekommert, gezien zijn uitspraak: ‘Belangrijk is (.....) niet zozeer welke norm men kiest dan wel überhaupt één (zo eenvoudig mogelijk, wel omlijnde) norm’ (p. 24-25). Het geeft met andere woorden niet waarvoor en hoe de definities opgesteld worden, als het maar expliciet gebeurt. Het is duidelijk dat | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 289]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
een dergelijke methode het object wel afbreuk moet doen. Daarom moet Martins onderzoek vanuit methodologisch oogpunt als zeer twijfelachtig aangemerkt worden. Deze conclusie zal in de volgende §§ ook voor zijn statistiek nog onderstreept worden. In § 4 t/m § 9 zullen we nagaan of Martin op statistisch gebied vermeldenswaardig werk gedaan heeft. We zullen daar zolang aannemen dat als eenheden van onderzoek de morfemen gekozen zijn, omdat anders het zicht op elke door Martin toegepaste statistische bewerking vertroebeld wordt door het foutieve uitgangspunt dat Martin gekozen heeft door de woorden als paradigmatische eenheden te beschouwen. Voor ‘woorden’ leze men in deze praragrafen dus telkens ‘morfemen’. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 3. Statistiek en taalDe Saussure heeft indertijd het onderscheid gemaakt tussen langue en parole, waarmee hij respectievelijk het (supra-individuele) taalsysteem en het gebruik dat er door de individuen van dit systeem gemaakt wordt, aangaf. Dit onderscheid tussen taalsysteem en individueel taalgebruik heeft Martin op p. 15 taalstatistisch proberen te interpreteren: ‘individueel gezien bestaat de “parole” uit linguistische eenheden die resulteren uit een keuze van de taalgebruiker uit de hem ter beschikking staande middelen. Globaal gezien merken we dat het geheel van deze individuele “keuzen” (geheel dat “la langue” wordt geheten) een zulkdanige structuur heeft dat elke keuze kan verklaard worden als het resultaat van een tirage aléatoire uit dit geheel’. We merken op dat Martin het hier in feite over drie verschillende dingen heeft, namelijk: (1) De middelen die de taalgebruiker ter beschikking staan. Deze middelen werden door De Saussure de langue genoemd. (2) Datgene wat Martin als langue aanduidt: een verzameling van individueel taalgebruik. Het is niet duidelijk of Martin de verzameling van alle taalgebruik van alle individuen bedoelt, dan wel de verzameling van alle taalgebruik per afzonderlijk individu; uit het woord ‘globaal’ in het bovenstaande citaat is dat niet op te maken. Wat Martin langue | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 290]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
noemt is en blijft echter taalgebruik, en valt daardoor onder het Saussuriaanse begrip parole. (3) Datgene wat Martin als parole aanduidt: het actuele taalgebruik van een individu. Dit valt eveneens onder het Saussuriaanse begrip parole. Het lijkt ons dat het invoeren van begrip (2) vanuit statistisch oogpunt zeer zinvol kan zijn, maar we hebben er ernstige bezwaren tegen dat de begrippen (1) en (2) door elkaar gebruikt worden, zoals Martin in zijn boek doet. Tussen (1) en (2) bestaat nog steeds het verschil van taalsysteem en taalgebruik. Dat mag een taalstatisticus zeker niet uit het oog verliezen. Dat Martin op een tweeslachtige manier het begrip langue hanteert, blijkt uit zijn behandeling van de relatie tussen het lexicon en het vocabularium. Na op p. 15 (zie boven) de langue gedefinieerd te hebben als een verzameling van taalgebruik, definieert hij het lexicon (dat hij, als we zijn verhaal goed begrepen hebben, tot de langue rekent) als: ‘de potentiële woordvooraad of anders geformuleerd de woordvoorraad die de schrijver ter beschikking staat’ (p. 48), waarmee het lexicon ingelijfd wordt bij de middelen die de taalgebruiker ter beschikking staan: het taalsysteem. Het vocabularium van de tekst levert, als de actuele woordvoorraad die de schrijver in de tekst gebruikt heeft, en als zodanig behorend tot de parole, geen terminologische verwarring op. Wanneer we zouden verwachten dat Martin de term lexicon steeds in zijn taalsystematische betekenis gebruikt, komen we bedrogen uit. Op p. 48-49 en p. 77-78 komt Martin namelijk op basis van o.a. een onderzoek van de z.g. hapax legomena (V1-woorden: woorden met frequentie 1) tot de conclusie, dat Michiels bij het schrijven van Het boek Alfa zijn lexicon bewust ingekrompen heeft ten opzichte van het lexicon dat aanwezig was bij het schrijven van Het afscheid. Op p. 80 beweert hij zelfs dat het lexicon per passage verandert (omdat het aantal V1-woorden per passage wisselt). Dit nu is onmogelijk bij een lexicon als taalsystematisch gegeven. Het lexicon (van een individu in dit geval) blijft in de tijd constant of wordt groter, tenzij factoren als vermoeidheid, geheugenverlies of ouderdom een remmende rol spelen (p. 48-49). Bij Michiels is niet het lexicon veranderd, maar het | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 291]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
gebruik dat de auteur van zijn lexicon maakt. De schrijver kan bewust besluiten bepaalde woorden niet te kiezen. Wanneer Martin zijn conclusie op deze wijze geformuleerd had, zou zijn onderzoek taalkundig gezien minder onaanvaardbaar geworden zijn. Tevens was dan duidelijk geworden dat er nog een andere verklaring mogelijk is voor het verschil tussen de vocabularia van beide onderzochte werken, namelijk dat Michiels bij de behandeling van het thema van Het afscheid over meer voor dat thema bruikbare lexicale items beschikt dan bij de behandeling van het thema van Het boek Alfa. Het lijkt niet zo vreemd te veronderstellen dat Michiels bijvoorbeeld niet beschikt over een uitgebreide voorraad legertermen, lexicale items die hij in Het boek Alfa zeer goed had kunnen gebruiken. Dat zou verklaren, dat er in Het boek Alfa maar weinig verschillende legertermen gebruikt worden, maar tevens dat de legertermen die gebruikt worden, een relatief hoge frequentie hebben (p. 110). We maken tenslotte nog twee opmerkingen over het lexicon (in de betekenis van de voor een individu beschikbare voorraad woorden, of morfemen). (a) Herhaaldelijk (p. 30, 53-54, 77-78, 92-93) betoogt Martin dat de hapax legomena een belangrijke aanwijzing geven voor de uitgebreidheid van het lexicon van de taalgebruiker. Hij merkt op p. 53-54 wel terecht op, dat V1 sterk afhankelijk is van de tekstlengte (omdat het lexicon in de praktijk eindig is; zie hieronder), maar daar houdt hij bij zijn conclusies geen rekening meer mee. Dit is erg gevaarlijk, zoals blijkt uit het volgende. Als we de tekstlengte van 1 laten toenemen tot oneindig, zal V1 aanvankelijk toenemen. Op het moment echter dat V (het aantal verschillende woorden) begint te naderen tot L (de grootte van het lexicon, of liever de grootte van het voor het thema bruikbare deel van het lexicon) zal V1 gaan dalen, omdat er weinig nieuwe woorden meer bijkomen en er daardoor veel woorden uit V1 zullen overgaan naar een hogere frequentieklasse. Bij een bepaalde tekstlengte zal V1 = o zijn. De waarde van V1 lijkt alleen een geschikte indicatie voor (het bruikbare deel van) L, wanneer V1 nog niet over zijn top heen is, maar die top moet wel eerst vastgesteld worden. Martin heeft dit nagelaten, zodat de resultaten van zijn V1-onder- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 292]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
zoek twijfelachtig zijn. De twijfelachtigheid van de interpretatie van die resultaten, die we hierboven al gesignaleerd hebben, wordt hierdoor dus nog vergroot. Voor de verdeling van V1-woorden in grammaticale categorieën zie hieronder § 8. (b) Martin zegt op p. 39 dat ‘het lexicon van de taalgebruiker, practisch gezien, eindig is’, waarbij hij in de voetnoot opmerkt, dat ‘het lexicon van een persoon (...) daarentegen, theoretisch gezien, niet te meten’ is. Inderdaad zou een ‘lexicon’ dat bestaat uit woorden, oneindig zijn, omdat het onmogelijk is het langste woord aan te wijzen dat de taalgebruiker zou kunnen construeren (denk aan woorden als hottentottententententoonstellingsterreinen...etc.) Een lexicon bestaat echter uit morfemen en moet eindig zijn, omdat de geheugencapaciteit van elke taalgebruiker eindig is. Via regels is de taalgebruiker in staat op basis van dit eindige aantal morfemen een oneindig aantal woorden te construeren. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 4. De reductie van een vocabulariumOm twee teksten te kunnen vergelijken moeten beide even lang zijn. Om dit te bereiken dient de langste tekst gereduceerd te worden tot hij de lengte heeft van de kortste tekst. Martin stelt voor de methode van Muller te gebruiken voor het reduceren van het vocabularium in Het afscheid, omdat deze methode de grootste garantie biedt voor het behoud van de structuur van de frequentieverdeling (p. 37-38). De definitie van structuur ontbreekt, zodat deze uitspraak niet geverifieerd kan worden. Later (p. 47) blijkt, dat de juistheid van de reductie moet volgen uit ten eerste het gelijkblijven van de K-factor en ten tweede hetzelfde dalingspatroon van het effectief van de frequentieklassen bij Het afscheid en het reductie resultaat van Het afscheid (Afscheid-R), hoewel deze eis niet essentieel is. Wij stellen hierbij de volgende vragen. (a) Hoe is bepaald, dat de K-factor belangrijker is dan het genoemde dalingspatroon? (b) Waarom is de K-factor zo belangrijk, gezien de juiste opmer- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 293]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
king (p. 37), dat de K-factor slechts één aspekt van de frequentiedistributie weergeeft? (c) Is de K-factor wel gelijk gebleven? Hij daalt van 109.77 naar 108.72. (d) Is het niet beter de juistheid van de reductiemethode theoretisch te bewijzen uit de gebruikte formules en het gestelde doel nl. behoud van (goed gedefinieerde) structuur? Overigens is ondanks alle ‘bewijzen’ (p. 41, 47-48) de gebruikte formule onjuist, hetgeen moge blijken uit het volgende eenvoudig na te rekenen voorbeeld (notatie op p. 40). Neem de tekst: Wie is Wie. Hiervoor geldt:
effectief van frequentieklasse 1 = V1 = 1 (het woordje is) effectief van frequentieklasse 2 = V2 = 1 (het woordje wie)
Als deze tekst op welke wijze ook gereduceerd wordt tot een tekst ter lengte 1 dan moet het nieuwe aantal tokens N' = 1 zijn en het nieuwe aantal typen V' ook 1, dus V'1 = 1 en V'2 = 0.
Toepassing van de formule (p. 43) levert met p = N'/N = 1/3, q = 1-p = 2/3, V1 = 1 en V2 = 1
Dit resultaat stemt niet overeen met de verwachting.
Wat Muller wilde is het volgende. Een tekst moet gereduceerd worden van lengte N tot lengte N'. Dit kan gebeuren door uit de tekst aselekt woorden weg te laten tot de lengte N' is bereikt. De frequentieverdeling van de aldus ontstane (onleesbare) tekst wordt door het toeval bepaald. Immers als nu nog eens de oorspronkelijke tekst gereduceerd wordt tot de lengte N' door aselekte trekking, ontstaat een | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 294]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
andere (onleesbare) tekst met een andere frequentieverdeling. Als dit proces (oneindig) vaak herhaald wordt zal de frequentieverdeling, ontstaan door het gemiddelde te nemen van alle verkregen frequentieverdelingen, op den duur constant worden. Muller wilde nu deze (verwachte) frequentieverdeling, die niet meer van het toeval afhankelijk is, berekenen. Zoals het proces beschreven is zal het er niet toe doen of we de tekst eerst reduceren tot een lengte N1 (N>N1>N') en daarna tot de lengte N'. Immers alle tussenliggende aantallen worden automatisch bereikt bij de trekking. De formule van Muller geeft echter een ander resultaat als de reductie in meerdere stappen uitgevoerd wordt. Dit komt omdat Muller geen rekening houdt met het feit, dat tijdens het reductieproces de kans een bepaald woord te trekken groter wordt. Er wordt namelijk zonder teruglegging getrokken. De juiste formule voor het verkrijgen van de verwachte frequentieverdeling gaat dan ook niet uit van de binomiale verdeling, maar van de hypergeometrische verdeling. We verwijzen hiervoor naar het in § 2 genoemde Eindverslag no. 2 van de Projektgroep ‘Kwantitatieve benadering van moderne poëzie’. De formules zijn:
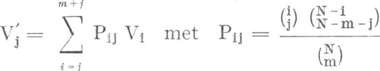 Hierin is:
 Opgemerkt dient dat voor grote N en kleine m/N beide formules ongeveer hetzelfde resultaat geven. De resultaten van p. 44-46, waar het gaat over frequentiedistributies, zullen wel goed zijn (m/N = 0,22), | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 295]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
maar de resultaten van p. 65, waar het gaat over de groei van het vocabularium en waarbij m/N kan oplopen tot 0.94, lijken ons onbetrouwbaar. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 5. Statistische parameters voor de vergelijking van vocabulariaMartin vergelijkt de uitkomsten van een aantal statistische parameters. Om de beoordelingswijze te analyseren geven we zijn resultaten in tabel 1. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 1Samenvatting van de resultaten en conclusies van het onderzoek van Martin naar enkele statistische parameters.
We maken hierover de volgende opmerkingen:
(1) Het doel van de onderzoeksmethode ‘objectivering van de esthetische beoordeling’ (p. 11) komt hier in het gedrang. Immers | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 296]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de conclusies die Martin trekt uit de getallen zijn subjectief, vooral wanneer hij de gevonden verschillen gaat voorzien van predicaten als: ‘aanzienlijk’, ‘duidelijk’ enz. De beoordeling is dan ook weinig esthetisch als niet aangegeven wordt hoe de beoordeling tot stand komt (b.v. waarom zijn de verschillen in N en in de reële belastingsklasse D verwaarloosbaar, en de verschillen elders niet?).
(2) Door het ontbreken van goede criteria is het te verklaren dat er bij de beoordeling tegenstrijdige opmerkingen gemaakt worden, b.v.: a) Op p. 48 wordt gesproken van een aanzienlijke inkrimping van V, terwijl op p. 57 gesteld wordt, dat N en V globaal gelijk zijn voor beide werken. b) De beoordeling van de Vl-woorden blijkt op een andere wijze te moeten geschieden dan de beoordeling van de andere parameters. Hier zegt Martin dat de cijfers alleen slechts tot een vermoeden kunnen leiden. De definitieve beslissing laat hij over aan een (significantie)toets (p. 54). Deze inconsequentie is te verklaren uit het feit dat Martin voor de andere parameters geen toets kon vinden. Dit geeft hem echter niet het recht de conclusies voor de niet te toetsen parameters met zo'n grote stelligheid te trekken als hij doet. c) Ook daar waar wel duidelijke criteria bestaan, nl. bij het toetsen, hanteert Martin willekeurige normen (p. 71, voetnoot 2).
(3) De toets voor het vergelijken van de percentages Vl-woorden, gevonden bij Miclau (p. 54-55, voetnoot), is een zeer ongebruikelijke variant van de toets in de 2 × 2-tabel. De χ2-toets, die normaal gebruikt wordt en ook aan Martin bekend is (p. 85), hoeft zijn plaats niet af te staan aan deze formule. Overigens werd de toets niet uitgevoerd op het percentage Vl-woorden onder de types (Vl/V), zoals uit de tekst zou zijn op te maken, maar op het percentage Vl-woorden onder de tokens (Vl/N). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 6. De groei van het vocabulariumHet idee om de gevonden groei (p. 59-62) van het vocabularium te vergelijken met de theoretische groei ervan (p. 63, 64) is goed. Mar- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 297]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
tin merkt op dat zowel de χ2-test als de z-waarden-methode bruikbaar is voor de analyse (p. 68). De χ2-test kan hooguit tot de uitspraak leiden, dat er verschil is tussen de gevonden en de theoretische groei. Met de z-waarden kan ook nog gezegd worden hoe de afwijkingen voorkomen (p. 68, 71, 72). Dit voordeel heeft waarschijnlijk de keuze op de z-waarden-methode laten vallen. De z-waarden zijn echter bedrieglijk en wel op de volgende gronden. (1) Er wordt per curve meer dan één toets toegepast. Voor Het afscheid b.v. worden 22 z-waarden getoets. Als nu de werkelijke groei geheel volgens verwachting verloopt, kan men op grond van het toeval enkele significante verschillen verwachten. De χ2-test echter beoordeelt de afwijkingen als geheel. In Het afscheid is χ2 = 30.25 bij 21 vrijheidsgraden. De kritische waarde van de χ2 bij 21 vrijheidsgraden bij 5% is 33.67. Dus wijkt de gevonden groeicurve niet significant af van de theoretische groeicurve. De significante z-waarde(n) (p. 71) kunnen dus door toeval ontstaan zijn. De z-waarden-methode wordt om o.a. deze reden in de mathematische statistiek niet aanvaard. (2) De z-waarden zijn onderling afhankelijk. Hoe deze afhankelijkheid de conclusies zal beïnvloeden is niet vast te stellen, hetgeen aan de hand van het volgende voorbeeld is duidelijk te maken. Beschouw een volgens verwachting groeiend vocabularium. Neem b.v. de theoretische groei van Het boek Alfa. Voeg aan dit werk 1 deel van 2000 woorden normaal opgebouwde tekst toe in een vreemde taal (er treedt dus geen ‘overlap’ op met het boek Alfa wat betreft de typen). Omdat het toegevoegde stuk normaal is opgebouwd, kan verondersteld worden dat het ook circa 712 nieuwe woorden zal bevatten, evenals het eerste deel van het theoretische Alfa. Het aldus ontstane werk zal 3800 + 712 = 4512 typen bevatten en 17 + 1 = 18 delen. Voor het ‘vreemde werk’ werd een frequentiestructuur aangenomen en opgeteld bij de frequentiestructuur van Het boek Alfa. Uit de resulterende frequentiestructuur werd met behulp van reductieformules de theoretische groei berekend voor het gehele werk (zie tabel 2, kolom 1). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 298]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 2Uitwerking van de z-waarden-methode voor een voorbeeld. De z-waarde van een fragment is gedefinieerd als z = d/σ waarin d = het verschil tussen de theoretische groei en de waargenomen groei en σ = de standaardafwijking van d, volgens de formule σ = √npq met n = het aantal tokens = 4512, p. = de theoretische groei gedeeld door n en q = l-p. De toetsingsgrootheid voor de χ2-toets is de som van de kwadraten van de z-waarden, indien σ gewijzigd wordt in σ = √np. De z-waarden kunnen getoetst worden met de normale verdeling. De z-waarden, die significant zijn bij een drempel van 5%, hebben in kolom c een *-teken.
Bij deze theoretische waarden behoren volgens de formule van p. 70 (voetnoot 1) de σ-waarden van kolom 2. Al naar gelang de plaats van het ‘vreemde werk’, dat, waar dan ook geplaatst, altijd voor een toename van 712 typen zal zorgen, worden kolom 3 en kolom 4 ge- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 299]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
vonden voor de groei, z-waarden en significantieniveau. De getallen uit kolom 3a en 4a zijn, afgezien van de onderbreking tengevolge van het vreemde werk, de theoretische groeiaantallen uit Martins tabel op p. 70. Indien het vreemde werk als 1e deel is geplaatst, zien we toch de meest afwijkende z-waarde bij het 2e deel (kolom 3b). Verder wordt ook door de afhankelijkheid het 3e deel significant. De conclusie die uit de z-waarden getrokken zou worden, nl. dat het 2e deel vreemd is, is niet juist. Indien het vreemde deel op de 8e plaats gezet wordt, komt men tot de juiste conclusie dat dit deel vreemd is, echter alle voorgaande delen zijn ook significant afwijkend van de verwachting. Er worden dus veel niet interpreteerbare significanties geïntroduceerd door de afhankelijkheid van de z-waarden. Zelfs het aantal significante z-waarden is niet relevant te noemen. Als tenslotte het vreemde werk op de 2e plaats zou staan, krijgt men weer kolom 3b als z-waarden. De conclusie dat het 2e deel vreemd is, is nu wel correct, echter de andere significanties (1e en 3e deel) zijn niet interpreteerbaar. Op deze manier zijn ook voorbeelden te construeren waarbij het vreemde werk niet significant is en ‘normale’ delen wel. In al deze gevallen zou de χ2-test leiden tot de juiste conclusie dat er een significant verschil bestaat tussen de gevonden en de theoretische groei. Een nadere specificatie is dan niet mogelijk, maar men wordt wel behoed voor onjuiste conclusies. Het genoemde voorbeeld is weliswaar niet realistisch, doch geeft wel een inzicht in de moeilijkheden bij de interpretatie van zowel de significante z-waarden als zodanig, als van het aantal significante z-waarden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 7. De plaats van de frequentste woordenMartin wil de lengte van de tekst berekenen, waarbinnen met 95% zekerheid een zeer frequent woord voor het eerst optreedt, onder de voorwaarde van een aselecte woordvolgorde. Hij komt zowel voor Het afscheid als voor Het boek Alfa tot een lengte van 4000 woorden (p. 75). Hierbij is het volgende op te merken. (1) Door zijn indeling in porties van 1000 woorden maakt Martin het zich nodeloos moeilijk en zijn de resultaten te onnauwkeurig. Immers de kans dat een woord voor het eerst optreedt in de i-de portie | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 300]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(i = 1, 2, 3, 4), is niet relevant gezien de doelstelling. De formules kunnen daarom beperkt blijven tot die van p. 73 bovenaan. Wat berekend moet worden is het volgende. Stel de gevraagde grens = g en de totale lengte van de tekst = N, dan geldt:
(2) De grenzen zijn zodanig gekozen, dat de zeer frequente woorden een kans van 5% hebben om een uitzondering te worden. Bij 200 woorden zijn op grond van toeval 5% van 200 = 10 uitzonderingen te verwachten. Bij Het Afscheid worden slechts 8 uitzonderingen gevonden (in werkelijkheid 6). Zijn dit nu toch bijzondere woorden, die de moeite van het vermelden waard zijn? (3) Waarom al dit rekenwerk, als in de uiteindelijke conclusie (p. 77) de grens zonder meer op 5000 wordt gesteld? Wegen deze 1000 extra woorden voor beide werken even zwaar? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 8. De verdeling der grammaticale categorieënWe zullen hier niet uitgebreid ingaan op de toename van de oncontroleerbaarheid, wanneer woorden op de traditionele wijze in woordsoorten ingedeeld worden. Martin is zich wel bewust van deze subjectiviteit (p. 81), maar dat brengt hem toch niet tot een duidelijk relativerende houding ten aanzien van de resultaten van dit deel van het onderzoek. We beperken ons met betrekking tot zijn onderzoek van deze grammaticale categorieën tot 2 punten. (1) Op p. 90 wordt de belangrijke betekenis van het woordje en | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 301]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
besproken. Hierbij waagt Martin zich aan een zeer gevaarlijke extrapolatie van de steekproefgegevens naar de gegevens voor de gehele tekst. Het aantal voegwoorden in Het boek Alfa resp. Het Afscheid wordt geschat op 4266 resp. 4012. Bij deze aantallen wordt het verwachte aantal voegwoorden in Het boek Alfa bij een gelijkmatige verdeling van de voegwoorden over beide werken, mede gezien de tekstlengten, gesteld op 3626, zodat er een surplus van 640 voegwoorden geconstateerd wordt. Reeds eerder was berekend dat Het boek Alfa een surplus van 441 aan het woordje en heeft. Het surplus aan voegwoorden wordt voor ⅔ toegeschreven aan het woordje en. Op deze schatting wordt de verdere conclusie gebaseerd. Dit zijn goede schattingen. Er zijn echter vele goede schattingen te bedenken. Laten we het aantal voegwoorden in Het boek Alfa en Het Afscheid schatten op 4500 resp. 3800. Het verwachte aantal voegwoorden in de steekproeven van 5000 woorden is dan 672 resp. 443. Als er nu 637 resp. 468 voegwoorden gevonden worden, dan zijn de verschillen door toeval te verklaren. Bij deze aantallen is het verwachte aantal voegwoorden in Het boek Alfa op grond van een gelijkmatige verdeling over beide werken gelijk aan 3640, zodat er nu een surplus van 860 voegwoorden is. Het woord en, dat ongeveer de helft van het aantal voegwoorden uitmaakt (2214 van de 4500), maakt nu ook ongeveer de helft van het surplus uit (441 van de 860). Er mag dus aangenomen worden dat ‘een onderzoek naar de syntactische valentie van dit woord en naar de functie ervan in de ritmische structuur van de zin’ (p. 90) wellicht tijdverspilling zal zijn. (2) Martin verdeelt ook de Vl-woorden, die volgens hem een indicatie voor het lexicon zijn, in grammaticale categorieën (p. 92-93). Daarbij veronderstelt hij impliciet, dat een lexicon inderdaad grammaticale categorieën bevat en wel de door hem gepostuleerde. Dit wordt tegenwoordig nogal aangevochten. Maar zelfs wanneer waar zou zijn wat Martin veronderstelt, dan nog zou hij voor iedere categorie afzonderlijk moeten onderzoeken of het aantal gebruikte woorden daarin nadert tot de grootte van het ‘lexicon’ van deze categorie. We lichten dit toe aan de hand van een voorbeeld voor de categorie ‘lidwoorden’ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 302]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(lidwoorden horen weliswaar niet in een lexicon thuis omdat ze geen lexicale betekenis hebben, maar ze hebben voor dit voorbeeld de prettige eigenschap, dat ze een zeer kleine categorie vormen). Stel er zijn twee teksten: Tekst 1 heeft aan lidwoorden 4 × de, 1 × het en 1 × een Tekst 2 heeft aan lidwoorden 2 × de, 2 × het en 2 × een De conclusie op grond van de V1-woorden zou zijn, dat tekst 1 een grotere lexicale potentie aan lidwoorden heeft dan tekst 2. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 9. Plus- en minuswoorden(1) Martin heeft gelijk als hij stelt dat door toeval, onderwerpgebondenheid, etc. woorden voorkomen, die een ongewone frequentie vertonen in het ‘grote sampel van 20 auteurs’. Het idee om de frequenties te corrigeren naar het aantal bronnen is goed. Martin gebruikt de U-waarde (p. 97), als gecorrigeerde frequentie, om de meest gebruikte woorden in het grote sampel te vinden. Dat hij later bij de berekeningen weer terugvalt op de oorspronkelijke versmade frequenties, is inconsequent. Dit moge blijken uit het volgende voorbeeld, dat inhaakt op het voorbeeld met hoofd en leraar (p. 97-99).
In dit voorbeeld komt leraar te weinig voor in de tekst van 60.000 woorden, omdat zijn Ecart Reduit kleiner is dan -5. Het woord hoofd komt normaal voor. Bezien we echter de U-waarden dan verwachten we voor hoofd en leraar een verhouding van 193/65, welke verhouding ook in de realisatie (45/14) terug te vinden is, zodat op grond van de U-waarden geconcludeerd mag worden, dat beide woorden normaal voorkomen. (2) Een ander bezwaar tegen de definitie van minuswoorden moge blijken uit de volgende beschouwing. Er worden twee soorten minuswoorden onderscheiden (p. 100): a) negatieve sleutelwoorden zijn woorden met een Ecart Reduit | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 303]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
kleiner dan -5 met als voorwaarde, dat de waargenomen frequentie minimaal 10 is. b) negatieve outsiders zijn woorden die op de basislijst wel voorkomen (bij minimaal 18 van de 20 auteurs) en in het onderzochte werk niet voorkomen. Bij de keuze van deze criteria kan zich het volgende voordoen. Stel een woord heeft op grond van het ‘grote sampel’ een verwachte frequentie van 49. Stel de frequentie van dit woord in de tekst is:
De discontinuïteit geïntroduceerd door de criteria is ontoelaatbaar. Ieder woord in het basisvocabularium heeft een U-waarde groter dan 20. De frequentie van zo'n woord in het ‘grote sampel’ zal groter zijn dan 20. Stel dat een woord een frequentie 25 heeft. De verwachting in een tekst ter lengte 34.000 is 3,4. Stel het woord komt in de onderzochte tekst niet voor. Het kan dan een negatieve outsider zijn, echter zijn Ecart-Reduit = (0-3,4)/√ 3,4 = -1,85. De eis voor een negatief sleutelwoord (E.R. < -5) is dus aanzienlijk sterker dan voor een negatieve outsider. Pas bij een frequentie van 180 is het ‘grote sampel’ en een frequentie van o in de onderzochte tekst (lengte = 34.000) wordt het E.R. gelijk aan -5. Bij alle negatieve outsiders die Martin gevonden heeft, lag het E.R. aanzienlijk dichter bij nul. (3) Het is uiteraard toegestaan de plus- en minuswoorden te rangschikken naar dalend E.R. Men bedenke echter dat het E.R. slechts een maat is voor de zekerheid waarmee men kan besluiten dat een woord uitzonderlijk is, maar geen maat voor de afwijking van de norm zelf. Hiervoor zou men b.v. de verhouding tussen de gevonden frequentie en de op grond van het basisvocabularium verwachte frequentie kunnen nemen. (4) De opmerking van de auteur (p. 99, voetnoot 2) dat de eisen voor plus- en minuswoorden niet belangrijk zijn voor het vergelijken van | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 304]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de twee boeken, is zeer twijfelachtig als men bedenkt dat sommige eisen oncontroleerbare consequenties hebben. Overigens is het, gezien het soort conclusies, dat de schrijver trekt uit de gevonden plus- en minuswoorden (p. 115), de vraag of niet de frequenties van Het boek Alfa en Het Afscheid direct vergeleken moeten worden in plaats van deze indirecte analyse, en beide werken te samen vergeleken moeten worden met het basisvocabularium. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 10. ConclusiesWanneer we alle kritiek uit de voorafgaande paragrafen op het taalstatistische onderzoek van Martin overzien, moeten we tot de conclusie komen dat dit onderzoek noch taalkundig, noch statistisch op een bijzonder hoog peil staat. Martin heeft in zijn computer-enthousiasme zijn object wel erg links laten liggen. Dit onderzoek had bij de huidige stand van de taalkunde en de statistiek stukken beter gekund. Het boek moet dan ook zeer kritisch gelezen worden en is niet geschikt om er methoden uit over te nemen. We kunnen ons daarnaast echter afvragen of het überhaupt wel mogelijk is om wetenschappelijk verantwoord (op zijn minst expliciet) taalstatistisch onderzoek te doen. Aan de ene kant zitten we namelijk met een taalkunde die nog maar pas in de kinderschoenen staat, en die nog niet in staat is haar object en de onderdelen daarvan ‘goed’ te definiëren (vergelijk de subjectieve manier waarop morfemen vastgesteld moeten worden), en aan de andere kant is de statistiek nog niet op de uiteindelijk door de taalkunde gedefinieerde eenheden toegepast, zodat nog helemaal niet duidelijk is of er niet geheel nieuwe statistische technieken ontwikkeld zullen moeten worden. Omdat de taalkunde geen goed gedefinieerde eenheden levert, en de statistische modellen, die op basis van subjectief gevonden eenheden ontwikkeld worden, een goede kans maken onbruikbaar te zijn, lijkt taalstatistiek een frustrerende bezigheid te zijn. Nochtans kunnen er argumenten zijn waarom statistisch onderzoek van gebruikte taal zeker zinvol geacht kan worden. (1) Vooreerst bestaat de mogelijkheid, dat taalstatistisch onderzoek | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 305]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
en taaltheorievorming elkaar gunstig zullen beïnvloeden in de snelheid van hun ontwikkeling. (2) We hebben gesteld, dat de statistische modellen, die op basis van onderzoek op ‘slecht’ gedefinieerde eenheden in gebruikte taal ontworpen worden, wellicht nooit bruikbaar zullen blijken. Maar er is natuurlijk ook een zekere kans, vooral wanneer de eenheden in gebruikte taal intuïtief zo adequaat mogelijk vastgesteld worden, dat de opgedane kennis en ervaring wel van nut kan zijn bij de bewerking van taaleenheden, die vanuit een expliciete en volledige taaltheorie misschien ooit als zodanig aangewezen zullen worden. (3) Het belangrijkste argument voor taalstatistisch onderzoek ligt in de maatschappelijke noodzaak van onderzoek naar gebruikte taal. Deze noodzaak komt niet voort uit luxueuze problemen als de esthetische beoordeling van literaire werken, maar veeleer uit urgente problemen betreffende taalvaardigheid, taaldidactiek, klassebepaald taalgebruik e.d. De maatschappelijke noodzaak van een onderzoek kan ons ertoe dwingen enkele - maar zo weinig mogelijke - wetenschappelijke eisen te laten vallen. We kunnen niet wachten met onderzoek van gebruikte taal tot eindelijk een redelijke taaltheorie ontworpen is. Tegen deze achtergrond moeten we concluderen dat het onderzoek van Martin, dat wetenschappelijk beneden de maat is, feitelijk een onderzoeksmethode in diskrediet brengt, die mits serieus toegepast, zeer goed tot belangrijke resultaten zou kunnen leiden bij de bestudering van maatschappelijk relevante objecten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 11. Lijst van errata bij het boek van MartinHieronder volgen enige errata, speciaal in formules, getallen en definities.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 306]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
M. van 't Hof (statisticus) F. Jansen (neerlandicus) Universiteit Nijmegen |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


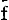 , wordt:
, wordt: