|
| |
| |
| |
Encyclopedisch deel:
enkele grondbegrippen van de taalstudie
| |
| |
Enkele grondbegrippen van de taalstudie
| Afasie. Verzamelnaam voor stoornissen in het auditieve en mondelinge taalgebruik die zijn veroorzaakt door hersenletsel (t.g.v. verwondingen, tumoren, beroerte). De benaming afasie wordt alleen toegepast voor taalgebruiksstoornissen die primair zijn, dus niet het gevolg van andere stoornissen, bijv. gehoorgestoordheid. Afasie uit zich soms in articulatie* -stoornissen, maar niet alle neurologische articulatiestoornissen (vaak samengevat in te term disartrie) zijn afatisch van oorsprong. Afasie kan gepaard gaan met stoornissen in het visuele taalgebruik: alexie (lezen) en agrafie (schrijven). |
| Agrafie. Zie: afasie. |
| Alexie. Zie: afasie. |
Ambiguïteit. Zinnen of zinsdelen waaraan méér dan één betekenis kan worden toegekend, heten ambigu. Binnen de stroming van de TGG* onderscheidt men drie soorten ambiguïteit.
| 1 | Lexicale* ambiguïteit treedt op als één of meer woorden in de zin meer betekenissen hebben. Bijv. je wilde kussen waarin je een persoonlijk (jij) of een bezittelijk voornaamwoord (jouw) kan zijn; wilde een bijvoeglijk naamwoord (‘wild’), een hulpwerkwoord (‘willen’) of een hoofdwerkwoord (‘verlangen’); kussen een werkwoord of een zelfstandig naamwoord. Andere naam: semantische ambiguïteit. |
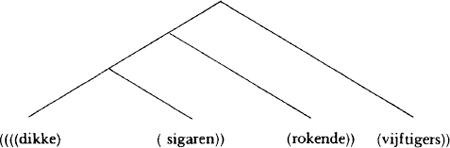
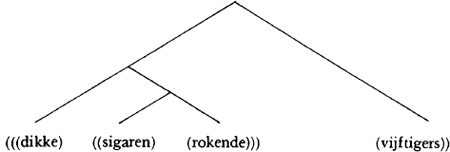
| 2 | Syntaktische ambiguïteit treedt op als op een zin of zinsdeel méér dan één haakjesontleding* van toepassing is. Bijv. dikke sigaren rokende vijftigers: |
lezing 1
|
| |
| |
lezing 2
| (Dikke hoort bij vijftigers in lezing 1, bij sigaren in lezing 2). Andere namen: grammatische ambiguïteit of oppervlaktestruktuurambiguïteit. |
| 3 | Dieptestruktuurambiguïteit treedt op als een zin(sdeel) twee of meer patronen van dieptestruktuur* -relaties uitdrukt. Bijv. het pesten van leraren kan uitdrukken ‘iemand-pest-leraren’ of ‘leraren-pesten-iemand’. Voor de eerste lezing geldt dat in de dieptestructuur de grammatische relatie* ‘lijdend voorwerp’ gespecificeerd is tussen pesten en leraren, voor de tweede lezing de relatie ‘onderwerp’. In TGG-termen: twee dieptestrukturen zijn door toepassing van bepaalde transformatieregels samengevallen in één en dezelfde oppervlaktestruktuur. Andere naam: transformationele ambiguïteit. (In de terminologie van deze tekst zou men kunnen spreken van casus* -ambiguïteit). |
|
| Articulatie. Zie: fonetiek. |
Automaat. Automaten zijn de tegenhangers van grammatica's* . Een grammatica bevat ‘recepten’ om de zinnen van een taal te maken, d.w.z. produceert zinnen van de taal als uitvoer. Een automaat neemt symboolreeksen als invoer en zegt a.h.w. ‘OK’ zodra hij een symboolreeks ingevoerd gekregen heeft die een zin is uit de taal. Voor elke grammatica is een automaat te construeren die precies de verzameling zinnen accepteert (er ‘OK’ tegen zegt) die door die grammatica wordt gegenereerd. De tegenhangers van reguliere grammatica's heten ‘finite-state automaten’ of ‘eindige automaten’. Met type-0-grammatica's corresponderen zg. Turing-machines.
Als voorbeeld volgt hier een eindige automaat die letterreeksen bestaande uit a's en b's tot invoer neemt, bijv. bab, aab, abba, abaaa. (Fig. 5). De automaat is een netwerk bestaande uit toestanden (states) en overgangen (transitions) tussen toestanden. De starttoestand is
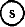 . Begint de letterreeks met een a, dan gaat de automaat over in toestand t1: dit is de betekenis van deelnetwerk . Begint de letterreeks met een a, dan gaat de automaat over in toestand t1: dit is de betekenis van deelnetwerk
|
| |
| |
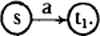 Algemeen gesteld: elke invoerletter doet de automaat overgaan van de gegeven toestand in een nieuwe toestand, volgens de pijlen in het netwerk. Deze automaat is in staat te beslissen, of een letterreeks behoort tot de taal die wordt gegenereerd door de reguliere grammatica in punt 12 van het trefwoord grammatica* . Tot deze taal behoren o.a. de reeksen ab, abb, abbb, abab, ababb, abbab, maar niet de reeksen ba, a, b, aba, aab, abba. Een reeks wordt geaccepteerd, indien na verwerking van de laatste letter van de reeks de automaat zich in toestand Algemeen gesteld: elke invoerletter doet de automaat overgaan van de gegeven toestand in een nieuwe toestand, volgens de pijlen in het netwerk. Deze automaat is in staat te beslissen, of een letterreeks behoort tot de taal die wordt gegenereerd door de reguliere grammatica in punt 12 van het trefwoord grammatica* . Tot deze taal behoren o.a. de reeksen ab, abb, abbb, abab, ababb, abbab, maar niet de reeksen ba, a, b, aba, aab, abba. Een reeks wordt geaccepteerd, indien na verwerking van de laatste letter van de reeks de automaat zich in toestand 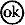 bevindt. Is hij op dat moment in een andere toestand, dan wordt dit geïnterpreteerd als verwerping. bevindt. Is hij op dat moment in een andere toestand, dan wordt dit geïnterpreteerd als verwerping. |
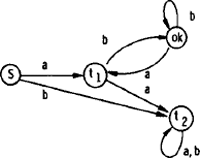
Fig. 5. Een eenvoudige eindige automaat.
Casus (letterlijk: naamval). In verscheidene theorieën over het weergeven van de inhoud van zinnen wordt uitgegaan van het basisbegrip relatie. Bijv. de zin Jan slaat Piet specificeert de relatie slaan tussen Jan en Piet. (N.B. Dit wijkt af van Schank's theorie; zie par. 1.2). Dit is echter nog niet voldoende: de wijze waarop Jan en Piet in deze relatie verwikkeld zijn, behoeft nog nadere explicatie. Hiervoor gebruikt men casussen; in het voorbeeld vervult Jan de rol van agens bij de relatie slaan. Piet de rol van patiens. (Agens = handelende instantie; patiens = instantie die de handeling ondergaat).
Andere casussen zijn:
Locatief (plaatsbepaling).
\ Instrumentalis (het instrument waarmee een handeling verricht wordt). In Schank's theorie (par. 1.2) heeft deze term een ietwat andere betekenis. |
Recipiënt (de ontvangende partij bij een bezitsoverdracht, bijv. geven aan...).
De term casus wordt meestal gebezigd voor het weergeven van semantische (conceptuele) verbanden. Dit in tegenstelling tot ‘grammatische relatie’, een term die syntaktische verbanden aanduidt, bijv. onderwerp, meewerkend voorwerp. Er bestaat geen één-op-één-relatie tussen casus- en grammatische relaties. Bijv. in Ik heb
|
| |
| |
| een boek gekregen vervult ik de semantische rol van recipiënt maar is grammatisch onderwerp. |
| Competentie. Zie: intuïtie. |
| Constituent. Zie: regeltypen. |
| Dieptestruktuur. Zie: transformationeel-generatieve grammatica. |
Distinktieve kenmerken (distinctive features). Die eigenschappen van spraakklanken die in talen gebruikt worden om morfemen* (woorden) van elkaar te onderscheiden. Bijv. lot en rot zijn in het Nederlands verschillende morfemen; dit verschil schrijft de fonologie* toe aan het feit dat de eerste spraakklank van lot het kenmerk ‘continu’ heeft, maar de eerste spraakklank van rot het kenmerk ‘discontinu’. De /l/ en de ‘rollende’ /r/ verschillen uitsluitend in dit opzicht en zijn wat alle andere kenmerken betreft gelijk. Distinktieve kenmerken worden benoemd in fonetische* termen (‘nasaal’, ‘stemhebbend’, ‘continu’, etc.) en hebben hun plaats in zowel fonologie als fonetiek. Dit betekent dat niet alleen spraakklanken (in fonetische zin) maar ook fonemen* kunnen worden beschreven als bundels (combinaties) van distinktieve kenmerken. Bijv. de /p/ wordt gevormd door de combinatie van de kenmerken ‘ploffer’, ‘labiaal’, ‘stemloos’.
Veelal wordt aangenomen dat heel de mensheid slechts ongeveer 15 distinktieve kenmerken kent, die in sommige talen allemaal, in andere slechts voor een deel gebruikt worden. Sommige auteurs geven er de voorkeur aan de distinktieve kenmerken te benoemen d.m.v. termen uit de akoestische fonetiek. Bijv. ‘compact’ betekent: op het geluidsspektrogram zien we concentratie van geluidsenergie in dicht bij elkaar gelegen frekwentiegebieden. Andere auteurs prefereren benamingen uit de articulatorische fonetiek. Bijv. ‘coronaal’: uitgesproken met de punt van de tong. Men kiest de kenmerken het liefst dichotoom, d.w.z.: een continuum wordt in twee gebieden verdeeld, een kenmerk is aanwezig (+) of afwezig (-). |
| Eindknoop. Zie: zinsdiagram. |
| Eindrij. Zie: zinsdiagram. |
Foneem. Een klasse van spraakklanken die wordt samengesteld volgens deze regels:
| a | de spraakklanken die tot dezelfde klasse behoren, moeten fonetische* gelijkenis vertonen; |
| b | het verschil tussen twee spraakklanken die tot dezelfde klasse behoren, mag in de gegeven taal nooit tussen twee morfemen* (of woorden) differentiëren. |
Bijv. de eerste /k/ in zakdoek wordt anders uitgesproken dan de /k/ van zak (‘zachte’ vs. ‘harde’ k). Deze k's lijken fonetisch gezien sterk
|
| |
| |
op elkaar, en bovendien zijn er in het Nederlands geen twee verschillende morfemen (of woorden) te vinden die in alles gelijk zijn behalve dat het ene de ‘zachte’, het andere de ‘harde’ k bevat. Beide spraakklanken behoren dus tot het (Nederlandse) foneem /k/. (Fonemen worden altijd met schuine streepjes aangeduid). De term ‘foneem’ behoort tot de wetenschap der fonologie*, niet tot de fonetiek* .
De verschillende varianten (spraakklanken, realisaties) van een bepaald foneem worden allofonen genoemd (vgl. de term (‘allomorf’ onder morfeem* ). Elk foneem wordt gekarakteriseerd door een typerende combinatie van distinktieve kenmerken. Dit veroorzaakt de hierboven onder a genoemde fonetische gelijkenis.
Er bestaan overigens spraakklanken die allofonen zijn van méér dan één foneem. Dit vormt een belangrijk probleem voor theorieen over foneemherkenning: hoe kan uit spraakklanken afgeleid worden tot welk foneem ze behoren? |
| Fonetiek bestudeert de relaties tussen de fysische eigenschappen van spraak en de linguïstische eenheden (fonemen*, woorden, zinnen enz.) waarmee de spreker/luisteraar opereert. Bijv. de foneticus kan bestuderen wat de typerende eigenschappen zijn van de geluidsgolven die worden geproduceerd wanneer een aantal mensen het foneem /p/ van pot realiseert, en in welk opzicht deze eigenschappen afwijken van de realisaties van de /p/ van pet, of van de /b/ van bot, enz. De articulatorische fonetiek houdt zich bezig met de aktiviteiten van de spraakorganen tijdens het spreken en met de wijze waarop deze aktiviteiten worden bestuurd door de articulator (par. 1.6). De akoestische fonetiek bestudeert de geluidsgolven die door de spreker geproduceerd worden. |
Fonologie (van het Nederlands, van het Engels, etc.) bestudeert de spraakklanken van de taal in kwestie (Nederlands, Engels, etc.) voor zover deze relevant (funktioneel) zijn voor het communiceren in die taal. Bijv. in het Nederlands is het verschil tussen de ‘zachte’ en de ‘harde’ k niet functioneel (zie foneem* ) wel in het Engels (vgl. curl met girl). Fonologie staat tegenover fonetiek* .
Fonologie neemt twee verschillende vormen aan:
| a | Studie van het systeem van fonemen van een bepaalde taal, en van de regels welke het combineren van fonemen tot morfemen* en woorden bepalen; bijv. in het Nederlands komt /fl/ nooit aan het eind van een woord voor (andere benaming voor dit type fonologie: ‘fonematiek’). |
| b | In de transformationeel-generatieve grammatica* de studie van de regels die bepalen hoe oppervlaktestrukturen* fonetisch gereali- |
|
| |
| |
| seerd (uitgesproken) moeten worden, d.w.z. van de regels die bepalen welke de precieze opeenvolging van spraakklanken zal zijn in de te genereren zin, welke zijn intonatiepatroon, hoe de accentverdeling etc. Bijv. als in een oppervlaktestruktuur de reeks VT + vang + PLUR voorkomt, d.w.z. het morfeem vang moet in de Verleden Tijd en in de meervoudsvorm, dan zorgen fonologische regels ervoor, dat deze reeks fonetisch gerealiseerd gaat worden als vingen. |
|
| Formant. Een formant is een concentratie van geluidsenergie (hoge amplitudo's) in een vrij nauwe frekwentieband. Elke klinker laat zich beschrijven als een combinatie van twee formanten die in karakteristieke frekwentiegebieden gelegen zijn. Formanten zijn als donkere horizontale banen in geluidsspectogrammen af te lezen (term uit de fonetiek* ). |
| Frasestruktuur. Zie: regeltypen. |
| Funktiewoord. Woorden die als voornaamste taak hebben de syntaktische verbanden binnen zinnen aan te geven, heten funktiewoorden: voegwoorden, hulpwerkwoorden, voorzetsels, lidwoorden. Het aantal funktiewoorden in een taal is klein en vormt een vaste, moeilijk uit te breiden verzameling. De term funktiewoord staat tegenover inhoudswoord* . |
Grammatica (een stukje formele taaltheorie).
| 1 | Benodigdheden om een taal te definiëren:
| a | Verzameling van eindsymbolen: VE (de eindwoorden, het ‘alfabet’). |
| b | Verzameling van hulpsymbolen: VH (de hulpwoorden, het hulpvocabulair). |
| c | Regels (zie 9). |
|
| 2 | De verzameling van alle mogelijke reeksen die gemaakt kunnen worden uit VE noemen we V* .
Voorbeeld: als VE = a, b dan, in alfabetische volgorde,
V* = ø, a, b, a, aa, aaa........, aab, aabbb,...., bbb,.....
N.B.: ø is de reeks bestaande uit nul symbolen (de ‘nulreeks’). |
| 3 | V+ = V* - ø (d.w.z. V+ is ‘ V* behalve de nulreeks’). |
| 4 | Elk lid van verzameling V* is een zin.
Dus, (zie (2)), ø, aaa, bab, etc. zijn zinnen. |
| 5 | Definitie van taal:
Elke (deel)verzameling uit V* is een taal. |
| 6 | Vele talen bevatten een oneindig aantal zinnen.
Bijv. T1 = ab, abb, abbb, abbbb,.... |
| 7 | Voorlopige omschrijving van het begrip grammatica: een grammatica is een eindige karakterisering van een taal.
|
|
| |
| |
|
N.B.: ‘karakterisering van een taal’: een omschrijving of specificatie waaruit moet blijken welke zinnen tot de taal behoren;
‘eindig’: de karakterisering moet een keer ‘af’ zijn (ook al is de taal zelf oneindig).
Bijv. G (T1) = ‘een zin moet beginnen met één a die moet worden gevolgd door één of meer b's’. |
| 8 | Enkele handigheidjes en wenselijkheden bij het opstellen van een grammatica.
| a | Geef in de karakterisering de structuur aan van de zinnen.
VH is handig daarbij.
Bijv.: ‘de zinnen van T1 bestaan uit een A-stuk gevolgd door een B-stuk’. |
| b | Doe alsof zinnen ontstaan zoals een stamboom ontstaat, d.w.z. er is een oorsprong, en er worden takken en nakomelingen voortgebracht (gegenereerd). |
| c | Het pijl-teken ‘→’, bijv. A→ B, geeft aan dat symboolreeks B ontstaat uit A (‘A wordt herschreven tot B’). |
| d | Neem één symbool uit VH als oorsprong (start): S. Dus: elke voortbrenging begint vanuit S. |
|
| 9 | Voorbeeld van een grammatica voor T1:
VE = a, b
VH = S, A, B
startsymbool: S
regels: |
|
| S → AB |
(N.B. Regels niet beginnend met S kunnen in willekeurige volgorde worden uitgevoerd, mits toepasbaar.) |
| A → a |
|
| B → bB |
|
| B → b |
|
| 10 | Elke grammatica bevat de volgende typen van informatie:
| a | VE; b VH; c S; d de verzameling regels R.
G = (VH, VE, S, R). |
|
| 11 | Typen van grammatica's:
3) finite-state grammatica's (type-3, eindige machine);
2) kontekstvrije grammatica's;
1) kontekstgevoelige grammatica's;
0) onbeperkte grammatica's.
De typen onderscheiden zich in de vorm van hun herschrijfregels. |
| 12 | Type-3:
Regelvorm:
A → aB
of
A → a
|
| |
| |
|
waarbij A en B willekeurige symbolen uit VH zijn, en a een willekeurig symbool uit VE.
Voorbeeld:
S → aB
B → bB
B →bS
B → b
|
| 13 | Type-2:
Regelvorm: A → X, waarbij A één symbool is uit VH; en X een symbool of symboolreeks samengesteld uit VH, en/of VE.
Voorbeeld:
S → aSb
S → ab |
| 14 | Type-1:
Regelvorm: X → Y, waarbij geldt:
X is ... (zie 13)
Y is ... (zie X)
en: het aantal symbolen van X ≤ aantal symbolen van Y.
Voorbeeld:
AB → CB
AD → ED
Dus: A gevolgd door B wordt C, maar A gevolgd door D wordt E: kontekstgevoelig. |
| 15 | Type-0:
Regelvorm: elke herschrijfregel is toegelaten (behalve herschrijving vanuit de nulreeks).
Voorbeeld: ABcD → Ef
aD → ø |
| 16 | De zogenaamde Chomsky-hiërarchie van grammatica's: Fig. 6. |

Fig. 6. De Chomsky-hiërarchie.
| D.w.z. de reguliere grammatica's zijn een deelverzameling van de kontekstvrije, de kontekstvrije een deelverzameling van de kontekstgevoelige, enz. |
| 17 | Een taal voortgebracht door een grammatica van een bepaald type (bv. ‘type-1’, ‘regulier’, etc.) heet zelf ook naar dat type. Dus:
|
| |
| |
| een taal voortgebracht door een kontekstvrije grammatica heet een kontekstvrije taal. Er is bovendien bewezen dat de Chomsky-hiërarchie niet alleen geldt voor grammatica's maar ook voor de talen die ze voortbrengen (bijv. reguliere talen zijn tevens kontekstvrije, etc.). |
| Grammatische relatie. Zie: casus. |
Haakjesontleding. Er zijn twee, onderling gelijkwaardige, manieren om aan te duiden, hoe een zin via frasestruktuur* -regels is gegenereerd. De ene manier is een zinsdiagram*, de andere is een haakjesontleding. Om de haakjesontleding te maken die hoort bij het zinsdiagram van de kat vangt de muis (voor de gehanteerde regels, zie regeltypen* ) gaan we als volgt te werk. Met elk hulpwoord in het zinsdiagram correspondeert een paar van linker- en rechterhaakjes waaraan het hulpwoord als subscript is toegevoegd, bijv. (z,)z, (nc, enz. Elk paar van aldus gelabelde haakjes wordt geplaatst aan weerszijden van de eindrij waartoe het desbetreffende hulpwoord werd herschreven. Begin hierbij met de laagste knopen van het zinsdiagram en plaats de haakjes die corresponderen met een hogere knoop buiten de haakjes die corresponderen met lagere knopen. Resultaat:
(z (nc (l de)l (n kat)n)nc (vc (w vangt)w (nc (l de)l (n muis)n)nc)vc)z
Men verkrijgt een kortere en handiger notatie als men de hulpwoorden vlak achter de bijbehorende linkerhaakjes plaatst:
(NC(L de) (N kat)) enz.
Dit is de notatie die overal in deze tekst is gebezigd. |
| Inhoudswoord. Woorden die als voornaamste taak hebben de betekenis van de zin te specificeren, heten inhoudswoorden: zelfstandige en bijvoeglijke naamwoorden, werkwoorden, bijwoorden. Het aantal inhoudswoorden in een taal is groot en er komen voortdurend nieuwe bij. |
Intuïtie. Taalintuïties (linguïstische intuïties) zijn reflekties op een taaluiting als taaluiting. Ze kunnen zich uitdrukken in oordelen die een spreker van een taal geeft over aan hem voorgelegde taaluitingen. (Zie ook het Nawoord.) Er zijn intuïties over allerlei aspekten van uitingen:
| a | Syntaktische intuïties:
| 1 | Grammaticaliteits-intuïtie: is woordreeks ‘...’ een zin van de taal? Bijv. is Waar heb dat nou voor nodig goed Nederlands? |
| 2 | Parafrase-intuïtie: draagt zin ‘...’ dezelfde betekenis als zin ‘...’? |
| 3 | Cohesie-intuïtie: hoe nauw horen de verschillende woorden van
|
|
|
| |
| |
|
| een zin bij elkaar? Bijv. hoort in de zin Jan is ziek het woordje is meer bij Jan dan bij ziek? |
|
| b | Semantische intuïties: over synonymie, hyponymie, etc. |
| c | Fonologische intuïties. Bijv. Nederlandstaligen zullen van oordeel zijn, dat de tweede spraakklank in op en in opmaken tot hetzelfde foneem* behoren, ondanks grote akoestische verschillen (de p van opmaken ‘ploft’ niet, wél de p van op). |
| d | Fonetische intuïties. Bijv. de eerste a in materiaal dient korter te duren dan de a in mateloos (Nooteboom, 1972). |
| e | Morfologische intuïties. Bijv. de eerste lettergrepen in resp. vingen en vangen behoren tot hetzelfde morfeem.
De linguïstiek baseert zich onder meer op dergelijke oordelen; het zijn voor haar empirische gegevens die zij tracht te beschrijven (karakteriseren) en te verklaren (interpreteren). Zulke karakteriseringen nemen de vorm aan van (syntaktische, semantische, fonologische enz.) regels van een grammatica* (bijv. de TGG* ). Over de psychologische processen via welke taaloordelen tot stand komen, valt vooralsnog weinig met zekerheid te zeggen. |
|
| Lexeem. Zie: lexicon. |
Lexicon. Elke grammatica* kent een verzameling eindwoorden (VE). In grammatica's voor natuurlijke talen komen veel regels voor die specifiek zijn voor één woord of op een beperkt aantal woorden betrekking hebben. Bijv. het woord bedenken mag alleen dan in een zin ingevoegd worden als die zin een onderwerp én een lijdend voorwerp heeft (het is een ‘transitief’ werkwoord). Voorts geldt dat het in de verleden tijd uitgesproken wordt als bedacht(en). Een ander type informatie dat specifiek is voor een woord, is zijn betekenis. Een lexicon kan het best gezien worden als een vergaarbak van al dergelijke specifieke regels.
Het is gebruikelijk de gegevens die men wil opnemen in een lexicon te ordenen volgens lexemen. Bijv. leerboek, leerboeken en leerboekjes zijn weliswaar drie verschillende woorden, maar ze behoren tot hetzelfde (abstrakte) lexeem. Als (concreet) trefwoord ten behoeve van het lexicon kiest men dan één van die woorden, bijv. de enkelvoudsvorm voor zelfstandige naamwoorden, de onbepaalde wijs voor werkwoorden. |
| Morfeem. De kleinste taaleenheden die nog een semantische of syntaktische funktie vervullen, heten morfemen. Bijv. geleerdheid bestaat uit vier morfemen: ge-, leer, -d en -heid. Sommige andere definities zijn niet geheel korrekt, bijv. ‘morfemen zijn de kleinste betekenisdragende eenheden’. Wat is immers de betekenis van het genoemde morfeem ge-? Dit morfeem vervult wel een syntaktische
|
| |
| |
rol. Ook is een morfeem niet het kleinste betekenisdragende ‘onderdeel’ van een woord. Bijv. beter bevat de morfemen goed en -er, meer bevat veel en -er.
Uit de laatste twee voorbeelden blijkt tevens dat een morfeem op meerdere wijzen gerealiseerd kan worden: goed, bet(er) en be(st) zijn verschillende realisaties van hetzelfde morfeem. Verschillende realisaties van hetzelfde morfeem zijn allomorfen (vgl. de term allofoon onder foneem* . Allomorfen zijn ook de verschillende realisaties van het meervoudssuffix: -en in huizen, -s in duivels, -eren in kinderen, -a in musea enz. |
| Morfologie is de leer van het combineren van morfemen*, en geeft dus regels voor het combineren van morfemen/allomorfen (bijv. tot woorden) in een bepaalde taal. |
| Oppervlaktestruktuur. Zie: transformationeel-generatieve grammatica. |
Overgangsnetwerken zijn ontworpen als procedures voor zinsontleding (Woods, 1970; Kaplan, 1972, 1973). Het basisprincipe van hun werking is te vinden in de eindige automaten* . Men kan overgangsnetwerken zien als ‘opgevoerde’ eindige automaten met een capaciteit die kan reiken tot die van Turing-machines.
Hier volgt een gedetailleerde bespreking van een netwerk dat zinnen als (27) kan ontleden (Fig. 7).
27 De aardige dokter belde de patiënt op.
De ontleder start in toestand Sz (startzin) en probeert deelnetwerk (l) te doorlopen.
Een overgang mag alleen dan gemaakt worden als aan alle voorwaarden die bij die overgang opgesomd staan, voldaan is. Er zijn meerdere soorten voorwaarden:
| - | de cijfers 1, 2, 3, etc. verwijzen naar de condities die in het lijstje onder de figuur vermeld staan; |
| - | L-woord, N-Woord, W-woord etc. betekenen dat het eerstvolgende woord van de zin moet behoren tot de woordsoort lidwoord, zelfstandig naamwoord, werkwoord, etc; |
| - | een voorwaarde zoals NC of VZC omvat de opdracht om een constituent van een bepaald type, hier een naamwoordsgroep of een voorzetselgroep, te gaan opzoeken in het eerstvolgende gedeelte van de zin. Om bijv. de opdracht (subroutine) NC te vervullen springt de ontleder rechtstreeks over naar toestand Snc in het tweede deelnetwerk van Fig. 7. Hij werkt zich vooruit naar het einde van dit deelnetwerk en keert met de gevonden naamwoordsgroep terug naar
|
|
| |
| |
| de plaats waar hij de NC-opdracht had ontvangen. Omdat nu aan de NC- voorwaarde is voldaan mag de desbetreffende overgang gemaakt worden.
Verdere bijzonderheden: |
| - | de ontleder leest de woorden van de zin in volgorde van links naar rechts; |
| - | als uit een toestand meerdere pijlen vertrekken worden ze kloksgewijs beproefd; |
| - | elk deelresultaat wordt weergegeven m.b.v. haakjesnotatie; bijv. als een L-woordovergang wordt geprobeerd met de als in te lezen woord, zal het succesvolle resultaat aangeduid worden als (L de). |
|
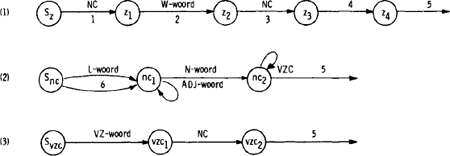
Fig. 7. Een eenvoudig overgangsnetwerk.
| Conditites |
Operaties |
| |
| 1. Geen |
1. Plaats de ontlede NC in (SUBJ_) |
| 2. Geen |
2. Verander hei W-woord in de onbepaalde wijs |
| 3. W-woord is overgankelijk |
3. Plaats de ontlede NC in (OBJ_) |
| 4. Het eerste te ontleden woord vormt samen met het woord in (W_) een scheidbaar samengesteld werkwoord |
4. Plaats dat scheidbare werkwoord in (W_) |
| 5. Geen |
5. Maak haakjesontleding; keer terug |
| 6. Geen |
6. Geen |
| |
| |
| Laten we de ontleder stap voor stap volgen. Op overgang 1 komt hij de opdracht ‘zoek een NC’ tegen en springt naar toestand Snc. De eerste overgang die hij hier beproeft is L-woord. Dit lukt, en met als eerste resultaat (L de) gaat hij over op toestand nc1. Het eerstvolgende woord is geen N-woord maar een ADJ-woord zodat de lus wordt doorlopen en (ADJ aardige) resulteert. Dokter is een N-woord en wordt als (N dokter) bewaard. Vervolgens wordt een voorzetselconstituent geprobeerd. Omdat belt echter geen voorzetsel is moet de ontleder onverrichterzake terugkeren van toestand Svzc en gaat nu operatie 5 uitvoeren. Het eerste deel hiervan, ‘Maak haakjesontleding’, voegt de resultaten van het deelnetwerk waarin de ontleder momenteel bezig is, in elkaar tot een haakjesontleding van een bepaald type. Binnen deelnetwerk (2) bijv. heeft operatie 5 tot gevolg, dat de L-, ADJ-, N- en VZC-resultaten (voor zover aanwezig) geplaatst worden in (NC_), en wel in de aangegeven volgorde. Kwamen meerdere adjektiva voor, dan worden deze eenvoudigweg aan elkaar vastgeknoopt; bijv. mooi oud huis wordt (NC (ADJ mooi) (ADJ oud) (N huis)). In deelnetwerk (1) heeft operatie 5 een heel andere uitwerking. De haakjesontleding krijgt nu de vorm |
(Z (NC_)(VC (W_)(NC_))),
waarbij de eerste NC afkomstig is uit (SUBJ_), de tweede uit (OBJ_).
Het tweede deel van operatie 5, ‘Keer terug’, heeft tot gevolg dat de ontleder met de zojuist gefabriceerde haakjesontleding terugkeert naar het punt van oorsprong. Nu is dat overgang 1 en de haakjesontleding is |
(NC (L de) (ADJ aardige) (N dokter)).
Conditie 1 wordt nu opgezocht in de lijst. Deze is zonder meer vervuld, maar eerst moet nog de onder 1 vermelde operatie uitgevoerd worden; de ontlede NC wordt ingevoegd in (SUBJ_), d.w.z. wordt opgevat als onderwerp. Via belt, het eerste te ontleden woord, komt hij in z2 na eerst de standaardvorm bellen ingevuld te hebben in (W_). Omdat aan conditie 3 voldaan is (bellen is bruikbaar als overgankelijk werkwoord), gaat de ontleder opnieuw aan de slag met een NC-opdracht.
We slaan nu een paar stappen over en gaan naar toestand nc2. Hier zal de ontleder eerst VZC beproeven en springen naar Svzc. Op is onder meer een voorzetsel, dus de overgang naar vzc1 wordt gemaakt.
|
| |
| |
| Omdat de zin nu af is, mislukt de VZC-poging. De ontleder laat op nog even zitten, keert terug naar nc2 en neemt nu de overgang 5. Het resultaat, |
(NC (L de)(N patiënt)),
wordt (zie conditie/operatie 3) geplaatst in (OBJ_). Vanuit de huidige toestand, z3, wordt conditie 4 getoetst. Het eerste te ontleden woord, op, vormt samen met bellen een scheidbaar samengesteld werkwoord zodat (W bellen) wordt vervangen door (W opbellen). Operatie 5 zet nu de haakjesontleding
(Z(NC (L de) (ADJ aardige) (N dokter)) (VC (W opbellen)(NC (L de) (N patiënt)))) in elkaar, die er als zinsdiagram uitziet als Fig. 8. |
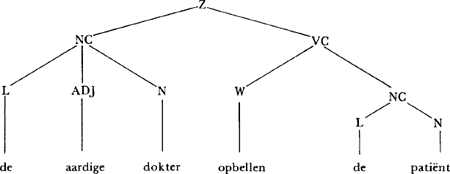
Fig. 8. Ontledingsresultaat van zin (27) m.b.v. het overgangsnetwerk in Fig. 7.
Deze gedetailleerde weergave van het funktioneren van overgangsnetwerken moge een aantal punten demonstreren.
| a | De zinsanalyse verloopt, net als bij de mens, van links naar rechts. |
| b | De ontleder kiest bepaalde overgangen eerder dan andere en zal dus bij ambigue zinnen slechts met één interpretatie voor de dag komen, net zoals mensen doen (maar zie'ook Lackner & Garrett, 1972). |
| c | De operaties die bij sommige overgangen worden uitgevoerd hebben het karakter van ‘omgekeerde transformaties’. Een voorbeeld was de samenvoeging van bellen met op. Als de zin passief was geweest, dan zou de eerste NC aanvankelijk als ‘logisch’ subjekt zijn aangemerkt (d.w.z. geplaatst in (SUBJ_)) en pas na ontvangst van passiefsignalen, bijv. een passief hulpwerkwoord, zijn verhuisd naar (OBJ_). Dit laatste vereist natuurlijk een uitbreiding van het netwerk van Fig. 7. |
|
| |
| |
| Wanner & Maratsos (1975) beschrijven enkele verdere accessoires waarmee overgangsnetwerken uitrustbaar zijn, en de resultaten van het eerste experimenteel-psychologische onderzoek dat op overgangsnetwerken is geïnspireerd. |
| Prosodie is het geheel van klankeigenschappen van een taaluiting die niet rechtstreeks samenhangen met de reeks van fonemen* waaruit de uiting bestaat. Tot dit geheel worden o.a. gerekend: klemtoon (nadruk, accent), toonhoogte, intonatie, pauze, tijdsduur. |
Regeltypen (met het oog op natuurlijke talen).
| a | Frasestruktuurregels
In grammatica* punt 13, is de algemene regelvorm van eenkontekstvrije grammatica weergegeven. Een alternatieve regelvorm is deze:
A → BC
of
A → b
waarbij A, B en C symbolen zijn uit VH en b een symbool uit VE. Met elk van de twee regelvormen kunnen alle kontekstvrije talen gegenereerd worden.
Een grammatica die geheel aan deze alternatieve regelvorm beantwoordt, heet ook een frasestruktuur- of constituentengrammatica (frase = constituent = zinsdeel). Dit omdat deze regels goed laten zien, uit welke zinsdelen een gegenereerde zin is opgebouwd. Voorbeeld van een constituentengrammatica: |
|
| Z → NC VC |
(Z is het startsymbool; Z, N, NC, VC e.d. zijn hulpwoorden; de, kat e.d. zijn eindwoorden; C = constituent; V = W = verbum (werkwoord), N = naamwoord, L = lidwoord) |
| NC → L N |
|
| VC → W NC |
|
| L → de |
|
| N → kat |
|
| N → muis |
|
| W → vangt |
|
Zie zinsdiagram* voor een weergave van de frasestruktuur van één der zinnen die door deze grammatica worden gegenereerd.
| b | Transformatieregels
In deze regels staat links van de pijl steeds een haakjesontleding*; rechts van de pijl is gespecificeerd, hoe deze haakjesontleding veranderd mag worden. Omdat een haakjesontleding ook als zinsdiagram* weergegeven kan worden, geldt ook de omschrijving dat transformatieregels zinsdiagrammen in andere zinsdiagrammen
|
|
| |
| |
| omzetten. Alle soorten veranderingen zijn hierbij toegestaan: onderdelen van zinsdiagrammen mogen worden weggelaten, door andere vervangen, van volgorde verwisseld, en er mogen nieuwe onderdelen worden toegevoegd.
Voorbeeld: een soort vraagtransformatie.
(Z (NC X1) (VC (V X2) (NC X3))) ⇒ (Z (V X2) (NC X1) (NC X3))
Als we hier invullen voor X1 (L de) (N kat),
voor X2: vangt,
en voor X3: (L de) (N muis),
dan zet deze regel de kat vangt de muis om in vangt de kat de muis.
Omdat voor de symbolen X1, X2, X3 etc., die in transformatieregels vaak voorkomen, allerlei woordreeksen kunnen worden ingevuld, staat een transformatieregel eigenlijk voor een hele groep transformaties. |
|
| TGG. Afkorting van transformationeel-generatieve grammatica* . |
Transformationeel-generatieve grammatica (TGG). In een TGG vindt de generatie van een zin plaats in twee fasen:
| 1 | generatie van een zinsdiagram* dat alle gegevens bevat voor de semantische interpretatie van de te genereren zin; |
| 2 | zodanige transformatie van dit zinsdiagram dat de resulterende eindrij*, op toepassing van fonologische* regels na, overeenkomt met de zin zoals deze wordt uitgesproken.
Het eindresultaat van fase 1 heeft dieptestruktuur van de zin, het eindresultaat van fase 2 is de oppervlaktestruktuur. De regeltypen* die in fasen 1 en 2 gebruikt worden, zijn resp. frasestruktuur- en transformatieregels.
Fase 2 bestaat gewoonlijk uit een hele reeks transformaties: er is dus sprake van een stapsgewijze omvormingsproces, met na elke stap een nieuw zinsdiagram. Bij elke stap wordt het laatst-gegenereerde zinsdiagram bekeken om na te gaan welke transformatie(s) erop toepasbaar is (zijn).
Waarom is de dieptestruktuur-fase nodig, waarom wordt niet rechtstreeks de oppervlaktestruktuur gegenereerd? Semantische overwegingen spelen hier de hoofdrol, zoals onder meer:
| - | De betekenisovereenkomst van een aktieve en passieve zin kan in de grammatica uitgedrukt worden door de twee zinnen af te leiden uit dezelfde dieptestruktuur (vgl. de sektie over parafrasen in par. 1.2). |
| - | De ambiguïteit* van een constructie als het nafluiten van de meisjes berust op het feit dat de meisjes zowel onderwerp als lijdend
|
|
|
| |
| |
|
| voorwerp van nafluiten kan zijn (dieptestruktuur-ambiguïteit). De grammatica kan dit uitdrukken door deze konstruktie van twee verschillende dieptestrukturen af te leiden: in de ene is de meisjes het onderwerp, in de andere het lijdend voorwerp.
Genoemde twee fasen in het genereren van een zin komen tot stand door toepassing van regels uit resp. de basis- en de transformationele gedeelten van de syntaxis. Behalve deze syntaxis bevat een TGG nog een semantische component die aan dieptestrukturen betekenissen toekent (semantische interpretatie), en een fonologische* component die bepaalt hoe oppervlaktestrukturen fonetisch weergegeven moeten worden. Zie Fig. 9. |
|
|
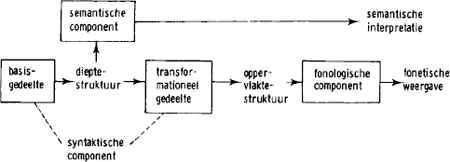
Fig. 9. Opbouw van de chomskiaanse transformationeel-generatieve grammatica.
| Verbaal transformatieëffekt. Een auditieve waarnemingsillusie die optreedt als men langdurig (minutenlang) luistert naar een alsmaar herhaalde taaluiting (woord, kort zinnetje). Men kan het effekt demonstreren m.b.v. een bandrecorder en een geluidsband die een groot aantal kopieën van dezelfde taaluiting bevat (intervallen tussen kopieën bijv. ½ seconde). In een demonstratie-experiment heb ik o.a. deze voorbeelden van illusoire spraakperceptie geobserveerd (4 proefpersonen). |
| Stimulus woord |
Waargenomen ‘woorden’ |
| merk |
mirrik, merre kie, nerks, melk, maar ik, merrie sss; |
| rotzak |
brodzak, rondzag, broodzak, balzak, mehousak, brokzak; |
| kopje |
kom je, kom hier, pompje, kopj'n, krepeer'n, kom Pierre; |
| vuurpijl |
zuurpijl, bezuurpijan, zuur bij Jan, kozuurpijl. |
| Zinsdiagram. Zinsdiagrammen (phrase-markers) zijn figuren die aangeven welke frasestruktuur* -regels zijn toegepast bij het genereren van een woordenreeks. Het zijn zijn boomvormige diagrammen met een ‘oorsprong’, ‘takken’ en ‘knopen’. De knopen waaruit geen
|
| |
| |
verdere takken ontspringen heten eindknopen. Een reeks van eindknopen heet een eindrij (bijv. de eindwoorden (zie grammatica, punt 1) in het zinsdiagram beneden: de, kat enz.). De knopen van een zinsdiagram zijn voorzien van labels: de eindknopen zijn geetiketteerd met eindwoorden, de overige met hulpwoorden. De oorsprong draagt het etiket Z (‘zin’); de takken staan voor de toegepaste herschrijvingen.
Voorbeeld: de generatie van de kat vangt de muis m.b.v. de regels vermeld onder regeltypen* (zie ook haakjesontleding* ). Zie Fig. 10. |
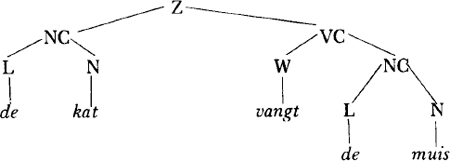
Fig. 10. Een zinsdiagram volgens de frasestruktuurregels vermeld onder regeltypen.*
| |
Beknopt Register op het Encyclopedisch Deel
Cursief gedrukte getallen: pagina waar de definitie van het begrip begint.
Overige getallen: pagina's waar het begrip in de tekst gebruikt wordt.
| afasie 50-53, 57 |
| agrafie 57 |
| alexie 57 |
| ambiguïteit 24, 57, 72 |
| articulatie 39-40, 52, 57, 58 |
| automaat 58, 67 |
| casus 20, 29, 33, 35, 58, 59 |
| competentie 60, 75-77 |
| constituent 29, 47, 60, 67, 71 |
| dieptestruktuur 32, 33, 44, 46, 60 |
| distinktief kenmerk 26, 39, 60, 61 |
| eindknoop 45, 46, 60 |
| eindrij 31, 32, 60, 72 |
| foneem 17, 26, 39, 48, 51, 52, 60, 66 |
| fonetiek 26, 39, 40, 43, 52, 53, 60, 61, 62 |
| fonologie 26, 50, 60, 61, 72, 73 |
| formant 26, 62 |
| frasestruktuur 62, 65, 73 |
| funktiewoord 26, 27, 35, 62 |
| grammatica 62, passim |
| grammatische relatie 21, 29, 58, 65 |
| haakjesontleding 57, 65, 68, 69, 71 |
| inhoudswoord 52, 53, 62, 65 |
| intuïtie 65, 75-77 |
| lexeem 15, 28, 66 |
| lexicon 66, passim |
| morfeem 26, 28, 60, 61, 66 |
| morfologie 25, 28, 32, 67 |
| oppervlaktestruktuur 31, 32, 46, 47, 61, 67 |
| overgangsnetwerk 28, 37-39, 46, 47, 67 |
| prosodie 27, 71 |
| regeltypen 31, 65, 71, 72 |
| TGG 31-32, 37, 57, 61, 72 |
| transformationeel-generatieve grammatica, zie TGG |
| verbaal transformatieëffekt 49, 73 |
| zinsdiagram 31, 65, 70, 71, 73 |
|
|
