|
| |
| |
| |
Contrastieve fraseologie Nederlands-Frans
Jean-Pierre Colson, Institut libre Marie Haps & Université catholique de Louvain
1. Fraseologie: theoretische achtergrond
Zowel fraseologie (de vaste verbindingen in de brede zin) als het daaraan verwante verschijnsel figuurlijke taal staan in een aantal recente taalkundige theorieën centraal. In het kader van de corpuslinguïstiek wees John Sinclair (1991) er al op dat er sprake is van het idiom principle (idioomprincipe): ongeveer de helft van alle teksten bestaat uit vaste verbindingen. Ook binnen de cognitieve semantiek (Lakoff, 1988) en de cognitieve linguïstiek (Langacker, 1999, 2000; Taylor, 2002) wordt ruimschoots aandacht besteed aan de beschrijving van metaforen, die veel raakpunten vertonen met fraseologie.
Er bestaat weliswaar geen echte theorie van de fraseologie, maar het aantal publicaties die n.a.v. de activiteiten en colloquia van Europhras, de Europese Vereniging voor Fraseologie, tot stand kwam, is indrukwekkend. Burger (1998) en Burger et al. (2007) bieden een uitgebreid overzicht van alle theoretische vragen en ook praktische problemen op dat gebied. De grondgedachte van deze linguïstische stroming is dat vaste verbindingen in de brede zin geen uitzondering zijn, zoals lang gedacht werd onder invloed van de generatieve grammatica, maar eerder de hoekstenen vormen van taalstructuur. Het gaat daarbij onder meer om de volgende hoofdcategorieën:
| - | communicatieve vaste verbindingen (zeg het maar, ga zitten, prettig weekend) |
| - | grammaticale vaste verbindingen (tot en met, nu en dan, met behulp van) |
| - | semantische vaste verbindingen (collocaties: hevige kritiek; halfidiomen: een beroep doen op iemand; idiomen: de kat uit de boom kijken) |
In het theoretisch onderzoek van de laatste tien jaar legt de constructiegrammatica (Goldberg, 1995; Croft, 2001; Tomasello, 2003) ook de nadruk op het idiomatische aspect van het taalgebruik, in tegenstelling tot de traditionele syntactische theorieën. Volgens M. Hüning (2007) kan de constructiegrammatica zelfs als een ‘verlengstuk van de fraseologie’ beschouwd worden.
| |
| |
Ook het inspirerende boek van Dobrovol'skij & Piirainen (2005) wijst op de complexe wisselwerking tussen fraseologie en figuurlijke taal: niet alle vaste verbindingen zijn figuurlijk, maar de basis van de idiomaticiteit is het bestaan van mentale beelden die ook verband houden met de cultuur.
| |
2. Uitgangspunt van de contrastieve fraseologie
Gaat men ervan uit dat fraseologie en figuurlijke constructies wezenlijke aspecten zijn van het taalgebruik en van de taalstructuur, dan ligt het ook voor de hand om vaste verbindingen uit verschillende talen met elkaar te vergelijken. Contrastieve studies vormen daarom een belangrijk onderdeel van het fraseologisch onderzoek, al staan in de literatuur vooral het Duits en het Engels in contrast met één of meer andere talen.
Wie in deze studies een grootste gemene deler zoekt, komt zeer zeker met een korte lijst uit de bus. Tot nu toe heeft niemand trouwens kunnen aantonen dat fraseologie universeel is, maar alles wijst er toch op dat de wisselwerking tussen lexicon, morfologie, syntaxis, figuurlijke taal en vaste verbindingen voor alle (tot nu toe onderzochte) talen geldt. Ieder vogeltje zingt bovendien zoals het gebekt is, en het is dan ook geen wonder dat de juiste combinatie tussen deze verschillende elementen taalafhankelijk is. Verder hoeft het ook geen betoog dat taal en cultuur in nauw verband staan met elkaar, zodat fraseologie en metaforen de weerspiegeling zijn van een aantal culturele kenmerken van een bepaalde taalgroep. Het blijkt bv. dat er onderscheid kan worden gemaakt tussen maritieme en continentale culturen, en dit geldt o.a. voor het Frans en het Russisch aan de ene kant; het Engels en het Nederlands aan de andere. Zoals bekend, zijn in het geval van het Nederlands de vaste verbindingen ontleend aan de scheepstaal schering en inslag: iets in de wacht slepen, tussen wal en schip vallen, schoon schip maken met, driemaal is scheepsrecht, enz.
| |
3. Praktische toepassingen van de contrastieve fraseologie
Zoals gezegd, zijn de corpuslinguïstiek, de constructiegrammatica en de fraseologie tot de conclusie gekomen dat taal veel meer is dan de verbinding van lexicale elementen d.m.v. syntactische regels: de meeste constructies hebben een min of meer idiomatisch karakter, en maken deel uit van frequente patronen die niet op voorhand te voorspellen zijn.
| |
| |
Alle gevorderde leerders van een vreemde taal weten ook hoe moeilijk het is om in de doeltaal te schrijven. Taaldocenten worden dagelijks met het verschijnsel geconfronteerd, dat studenten zinnen of uitingen produceren, die weliswaar grammaticaal zijn, maar die kunstmatig aandoen, omdat geen enkele moedertaalspreker die zin op die manier geformuleerd zou hebben.
Studenten attent maken op de vastheid van de meeste taalconstructies is pas dan mogelijk, als ze enig inzicht hebben in contrastieve fraseologie. Het traditionele talenonderwijs heeft daar weinig aandacht aan besteed, behalve misschien voor de frequente communicatieve vaste verbindingen. De meeste studenten hebben daarom geen idee van het belang van de fraseologie, en hun pogingen om in de vreemde taal eenvoudige teksten te schrijven, worden zelden met succes bekroond, omdat ze in hun eigen moedertaal blijven denken. Het lezen in beide talen van parallelle teksten die rijk zijn aan fraseologie is een praktische vorm van contrastieve fraseologie die uitkomst kan bieden.
Ook in het kader van de vertaaltheorie en de vertaalpraktijk is de contrastieve fraseologie onontbeerlijk. In de literatuur is het probleem van translationese al vaak aan de orde gekomen (Tirkkonen-Condit, 2002): kunstmatige vertalingen die ergens te situeren vallen tussen bron- en doeltaal, met een gebrekkige fraseologie als één van de hoofdoorzaken.
Zowel in het vreemdetalenonderwijs als in de vertaalopleidingen zijn de leerkrachten (soms onbewust) met contrastieve fraseologie bezig: ‘Die zin klinkt een beetje vreemd’, ‘Dat zou je anders moeten formuleren’, enz. Op zijn taalgevoel afgaan is weliswaar belangrijk, maar in onze tijd van multimedia en internet kan dit toch met meer recente technieken aangevuld worden.
| |
4. Contrastieve fraseologie: methodologische problemen
In de literatuur zijn veel voorbeelden te vinden van fraseologische verschillen die te herleiden zijn tot culturele contrasten. In de regel zijn de voorbeelden sterk idiomatische constructies, de bekende idiomen of idiomatische uitdrukkingen: constructies die gekenmerkt worden door gefixeerdheid maar ook door niet-compositionaliteit van de betekenis.
Dobrovol'skij & Piirainen (2005, p. 39) beschouwen ze zelfs als ‘the central and most important class of phrasemes’ (de centrale en belangrijkste categorie binnen de vaste verbindingen). Dit stelt ons voor een methodologisch probleem, want corpusonderzoek wijst er integendeel op dat het gros van de
| |
| |
fraseologie uit communicatieve en grammaticale vaste verbindingen bestaat. De gehanteerde methodologie is met andere woorden sterk afhankelijk van het nagestreefde doel van het contrastief onderzoek. Wil men aandacht besteden aan culturele verschillen, dan is cognitief geïnspireerd onderzoek naar idiomen en metaforen weliswaar de aangewezen weg. Is het de onderzoeker of de leerkracht eerder te doen om een breder overzicht van contrasten in taalgebruik en taalsystematiek, dan moet hij op zoek gaan naar een methodologie die hem in staat stelt zijn intuïtie te objectiveren.
In het geval van het Nederlands en het Frans springen de fraseologische verschillen in het oog. Het Nederlands is een West-Germaanse taal, die zoals het Engels en het Duits veel gebruik maakt van de combinatiemogelijkheden tussen basiswerkwoorden en grammaticale elementen (bv. door elkaar halen, uit elkaar houden), terwijl het Frans als Romaanse taal liever een beroep doet op abstracte woorden en Latijnse of Griekse etymologie (in dit geval resp. mélanger, confondre; distinguer). Naast het anekdotische karakter van dergelijke voorbeelden, is het zozeer de vraag welke invloed dergelijke subtiele verschillen hebben op het volledig fraseologisch gebruik van het Nederlands en het Frans, en ook of ze wel degelijk met bewijsmateriaal kunnen worden gestaafd.
Een beroep doen op de traditionele corpuslinguïstiek zet meestal geen zoden aan de dijk, want uit onderzoek blijkt (Moon, 1998, 2007; Colson 2004, 2007) dat de meeste vaste verbindingen (zelfs in het Engels) een frequentie hebben van minder dan één per miljoen woorden. Zo vertonen frequente Engelse idiomen als spill the beans, kick the bucket, rain cats and dogs een aantal treffers van resp. 311, 52 en 39 op een Engels corpus van 450 miljoen woorden (Moon, 2007, p. 1050), en dit valt dus samen met frequenties van 0.69, 0.12 en 0.09 per miljoen woorden.
Een concreet voorbeeld moge het bovenstaande toelichten. Stel dat we onderzoek willen doen naar de fraseologische omgeving van het Nederlandse werkwoord grijpen en een van de hoofdvertalingen ervan, saisir. Op een corpus (één jaar) van NRC-Handelsblad en van de Belgische krant Le Soir gaan we in dit eenvoudige voorbeeld op zoek naar alle combinaties waarin grijpen gevolgd werd door de of het, zowel in SOV- als in SVO-volgorde. Het programma (JP Colson) zorgt dan voor een frequentielijst van alle woorden die net op de of het volgden. Er werd ook rekening gehouden met de vervoegde vormen van het werkwoord. Al die elementen kunnen gemakkelijk in een reguliere expressie worden gegoten, bijvoorbeeld met behulp van de Perl-programmeertaal. Voor het Frans werd een soortgelijke methode gevolgd, alleen voor SVO uiteraard.
| |
| |
Tabel 1 Frequentielijst (fragment) van substantieven na ‘grijpen’ en ‘saisir’ op een krantencorpus
|
| GRIJPEN |
SAISIR |
| 11 |
hart |
9 |
occasion |
| 11 |
leven |
4 |
balle |
| 11 |
lucht |
4 |
marché |
| 9 |
macht |
3 |
comité |
| 8 |
kans |
2 |
commission |
| 3 |
pen |
2 |
dimension |
| 2 |
afgevaardigden |
2 |
perche |
| 2 |
hand |
2 |
taureau |
| 2 |
telefoon |
1 |
bonheur |
| 1 |
algemeen |
1 |
chambre |
| 1 |
andere |
1 |
chance |
| 1 |
basgitaar |
1 |
coccinelle |
| 1 |
beest |
1 |
cohérence |
| 1 |
bende |
1 |
complexité |
| 1 |
bezoeker |
1 |
conférence |
| 1 |
broekspijpen |
1 |
conseil |
| 1 |
bureaucraten |
1 |
énorme |
| 1 |
clubs |
1 |
évolution |
| 1 |
divisie |
1 |
film |
| 1 |
drugs |
1 |
fonctionnement |
| 1 |
drugsmaffia |
1 |
justice |
| 1 |
erotiek |
1 |
manière |
| 1 |
fractie |
1 |
monde |
| 1 |
gelegenheid |
1 |
opportunité |
| 1 |
gesprek |
1 |
parquet |
| 1 |
hongerstaking |
1 |
périple |
| 1 |
hoteliers |
1 |
petit |
| 1 |
kano |
1 |
pied |
| 1 |
keel |
1 |
poids |
| 1 |
kind |
1 |
politique |
| 1 |
kladden |
1 |
pourquoi |
| 1 |
kraag |
1 |
réalité |
| 1 |
land |
1 |
sainte |
| 1 |
lipstick |
1 |
sens |
| 1 |
luchtledige |
1 |
sensualité |
| 1 |
microfoon |
1 |
travail |
| |
1 |
tribunal |
| |
| |
Uit tabel 1 blijkt in de eerste plaats dat de oogst wat magertjes is. Zelfs de frequentste treffers liggen rond het cijfer 10. Verder is de verleiding groot om er iets achter te zoeken, en op het eerste gezicht bevestigt dit eenvoudige voorbeeld al dat de fraseologische kloof tussen het Nederlands en het Frans groot is. Zo stelt men bv. vast dat de Nederlandse substantieven hoofdzakelijk concreet zijn, terwijl het Franse fragment meer abstracte woorden biedt (bonheur, cohérence, complexité, évolution...); dit komt waarschijnlijk doordat saisir in die gevallen eerder met begrijpen, snappen correspondeert. Ook valt het op dat de eerste drie treffers voor het Nederlands geen voorbeelden zijn van collocaties bij het werkwoord grijpen, maar idiomen, namelijk uit het hart / uit het leven / uit de lucht gegrepen. De volgende drie elementen in de Nederlandse reeks (grijpen in combinatie met macht, kans, pen) zijn halfidiomen (de betekenis blijft gedeeltelijk compositioneel). Onder de zes eerste voorbeelden vinden we dus géén enkele gewone collocatie, maar alleen idiomen en halfidiomen. In het Frans daarentegen vinden we onder de zes eerste resultaten vier gewone collocaties (saisir in combinatie met marché, comité, commission, dimension), één halfidioom (saisir l'occasion) en één idioom (saisir la balle, als afkorting van saisir la balle au bond).
Aan de ene kant levert deze methodologie interessante resultaten op, maar aan de andere is toch enige voorzichtigheid geboden bij de interpretatie ervan, omdat de treffers zo weinig frequent zijn, dat de statistische waarde ervan gering is. De onderzoeker die i.v.m. contrastieve fraseologie veel meer voorbeelden aangeboden wil krijgen, is eigenlijk op Internet aangewezen. Sinds het verschijnen van het themanummer ‘Web as Corpus’ van het tijdschrijft Computational Linguistics (Kilgariff & Grefenstette, 2003) is het namelijk duidelijk geworden dat het Web best als taalkundig corpus mag worden gebruikt, op voorwaarde dat men rekening houdt met de specifieke kenmerken ervan. Ook voor de contrastieve fraseologie opent deze methode heel wat nieuwe perspectieven.
| |
5. Contrastieve fraseologie Nederlands-Frans: experimenten met een webcorpus
Willen we een objectief beeld proberen te krijgen van fraseologische verschillen tussen twee talen, dan moeten we enerzijds een gigantisch corpus tot onze beschikking hebben, en anderzijds een geautomatiseerde methode die ons in staat stelt het kaf van het koren te scheiden, i.c. gewone combinaties van vaste verbindingen te onderscheiden.
| |
| |
In de corpus- en computerlinguïstiek wordt al jaren geprobeerd collocaties automatisch uit corpora te extraheren. Op basis van statistische scores zoals t-score, log-likelihood, mutual information en vele andere werden tot nu toe acceptabele resultaten bereikt, al bestaat er bij de specialisten nog geen eensgezindheid, noch over de ideale score, noch over de statistische fundering van deze methode. Voor een overzicht, zie bv. Evert (2004) en ook de webpagina van de auteur, www.collocations.de.
Het nadeel van deze statistische scores is o.a. de traagheid waarmee ze werken, want het hele corpus moet eerst in reeksen van twee woorden worden gesplitst, de zgn. bigrammen, en pas dan worden die aan de statistische score onderworpen. Voor heel grote corpora is dat onbegonnen werk, behalve natuurlijk als de volledige berekeningen op voorhand beschikbaar zijn gemaakt op een cd-rom met het corpus, zoals dat het geval is met het British National Corpus (http://www.natcorp.ox.ac.uk/).
Zo'n methode op het Web toepassen is uiteraard toekomstmuziek, al heeft de zoekmachine Google een experiment gedaan met een Engels corpus van niet minder dan één biljoen woorden, waarvan alle n-grammen werden gehaald (voor meer informatie: http://www.ldc.upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC2006T13).
In plaats van het hele corpus te doorlopen bestaat er een andere, veelbelovende mogelijkheid: de macht van de zoekmachine zelf benutten. Met behulp van de zoekmachine AltaVista werd geprobeerd om een aangepaste versie van de mutual information score op bigrammen toe te passen (Turney, 2001; Baroni & Vegnaduzzo, 2004):
Tabel 2 ‘Web-based mutual information’ voor bigrammen
|
| WMI(w1, w2) = log2 N hits(w1 NEAR w2) / hits(w1)hits(w2) |
Dit leest als volgt: de WMI-score (‘web-based mutual information’) van twee grammen w1 en w2 is de logaritme (grondtal 2) van N (het totaal aantal woorden in het corpus), vermenigvuldigd door het aantal treffers waarbij de twee bigrammen naast elkaar stonden (met de operator NEAR), gedeeld door de vermenigvuldiging van het respectievelijke aantal treffers van beide bigrammen. Het probleem met deze formule is dat ze een beroep deed op de
| |
| |
‘NEAR’-operator van de zoekmachine AltaVista, en die is niet meer beschikbaar. Bovendien is het werken met bigrammen weliswaar heel interessant, vooral als men op zoek gaat naar collocaties zoals Substantief + Adjectief, maar dit geeft toch geen algemeen beeld van het fraseologisch gebruik. Een beroep doen op hogere n-grammen, in de eerste plaats trigrammen, is daarom aangeraden.
Helaas bestaat er voor trigrammen, viergrammen en andere nog geen algemeen aanvaarde statistische methodologie: ‘If the mathematics of word pair statistics is based on the well-understood 2×2 contingency table, an extension to higher dimensions (three, four,... words) is not yet fully understood even theoretically.’ (Heid, 2007, p. 1042).
Daar staat tegenover dat het Web als corpus een goudmijn is voor fraseologische studies (zie Colson, 2007). Voor de eerste keer sinds het ontstaan van taalkundig onderzoek heeft men vandaag bliksemsnel toegang tot een corpus dat zelfs voor talen als het Nederlands miljarden woorden groot is. Voor het eerst ook kunnen concurrerende taaltheorieën blootgesteld worden aan de vuurproef van het bijna oneindig taalmateriaal. Zo bleek dat de hierboven beschreven statistische extractie van significante bigrammen, die tot nu toe acceptabele resultaten opleverde op corpora van redelijke omvang, heel wat te wensen overliet als het om het Web ging. Deze vaststelling bevestigt het argument dat taal geen statistisch verschijnsel is, maar eerder een combinatie van semantische en structurele verschijnselen. Dit lijkt een waarheid als een koe, maar corpuslinguïstiek, constructiegrammatica en fraseologie kunnen precies beschouwd worden als nieuw bewijsmateriaal voor het structuralisme (zie ook Hüning, 2007).
Met al die elementen voor ogen doe ik momenteel experimenteel onderzoek naar alternatieve methoden die objectieve fraseologische verschillen tussen twee of meer talen kunnen laten zien. De eerste stap is het vinden van een algoritme met een structurele basis voor de automatische extractie van gefixeerde trigrammen uit elektronische corpora. Zoals gezegd, zijn trigrammen immers een goed compromis tussen collocaties en bredere structuren. Zij kunnen bovendien een collocatie bevatten. Als hypothese gaan we ervan uit dat het aantal vaste trigrammen uit een tekst een objectief beeld geeft van het algemeen fraseologisch niveau van deze tekst.
Op basis van de bovenvermelde studies over bigrammen en van de informatietheorie heb ik een werkalgoritme voor trigrammen ontworpen, de ‘web log ratio (WLR)’, die gebruik maakt van de Google API (de geautomatiseerde
| |
| |
versie van de bekende zoekmachine, die toegankelijk is voor computerprogramma's).
Tabel 3 ‘Web Log Ratio’ voor trigrammen
|
| T=Trig(G1,G2,G3) |
| T#=Trig(G1,*,G3) |
| WLR=100 ln(f T)/ln(f T#) y (G1,G2,G3) |
T is een trigram en T# staat voor een trigram waarbij het centrale element vervangen wordt door de ster van de zoekmachine Google (dit symbool vervangt in principe één woord, soms twee of drie). De WLR-score is dan 100 maal de natuurlijke logaritme van de frequentie van T, gedeeld door de natuurlijke logaritme van de frequentie van T#, vermenigvuldigd door de gamma-factor voor deze grammen. Deze gamma-factor correspondeert met de natuurlijke associatie van deze drie grammen door de Google zoekmachine. Op die manier wordt vermeden dat heel frequente trigrammen systematisch als een fraseologische structuur worden beschouwd. Dit werkalgoritme heeft geen zuiver statistische fundering: het gaat eerder om een vertaling voor de computer van het feit dat een bepaalde structuur door een moedertaalspreker als gefixeerd beschouwd zal worden. Omdat het Googlezoekalgoritme precies op zoek gaat naar alle frequente combinaties tussen gevraagde elementen, biedt zo'n formule interessante resultaten. Nogmaals dient onderstreept te worden dat deze score experimenteel is. Na experimenten met een tiental andere formules bleek deze het dichtst te liggen bij wat intuïtief (d.i. op basis van moedertaalcompetentie) als een gefixeerde trigram beschouwd zou moeten worden. Een gefixeerde trigram kan uiteraard meer zijn dan een idioom: het kan om een collocatie gaan met een bijkomend element (die hevige kritiek), of ook om een eigennaam die uit drie woorden bestaat (De Lage Landen), of nog om een samengestelde term (raad van bestuur).
Zo'n score (die zeker nog voor verbetering vatbaar is) kan op verschillende manieren benut worden voor contrastief fraseologisch onderzoek. Een eerste methode bestaat erin vergelijkbare teksten in twee talen te verzamelen. Laten we opnieuw een eenvoudig voorbeeld gebruiken. Hieronder volgt een fragment van hetzelfde nieuws (30 april 2008) in een Vlaamse krant (De Tijd) en een Franstalige krant (Le Soir). Het ging om de bekende communautaire
| |
| |
heisa van België, waarachtig een onuitputtelijke bron van contrastieve fraseologie Nederlands-Frans.
Leterme: ‘Er is geen crisis’ Volgens premier Yves Leterme is er geen sprake van een regeringscrisis. Dat verklaarde hij in de wandelgangen van de Senaat. De eerste minister benadrukte dat zijn kartel niet alleen de stemming van de Vlaamse splitsingsvoorstellen vraagt, maar ook wil onderhandelen. Er zal sowieso moeten worden onderhandeld, zelfs met een stemming, herhaalde de premier.(belga) - De regeringsleider (foto) beklemtoonde ook dat het kartel het kartel is en dat hij als eerste minister zal zien hoe de situatie best wordt aangepakt. Leterme pleitte tot slot nogmaals voor een sereen klimaat. ‘Dat moet mogelijk zijn als iedereen het hoofd koel houdt’, luidde het. De uitspraken van Leterme volgden op de vergadering van de CD&V/N-VA-kamerfractie eerder op de dag. CD&V/N-VA blijft bij het standpunt dat het politiek bestuur maandag over Brussel-Halle-Vilvoorde innam: de Vlaamse voorstellen om de kieskring te splitsen moeten volgende week op de agenda van de plenaire Kamer komen, maar tegelijkertijd moet er ruimte blijven voor onderhandelingen.
De vergadering van de fractie kwam er vlak na de briefing die premier Leterme gaf na afloop van het kernkabinet. Daar liet de eerste minister weten dat het parlement meester van is van zijn agenda, maar voegde hij er ook aan toe dat eenzijdige handelingen de onderhandelingen over de verdere staatshervorming in gevaar kunnen brengen. Hij stelde ook nog van plan te zijn zijn partijgenoten duidelijk te maken wat hij denkt over de kwestie.
Op de vergadering van de CD&V/N-VA-fractie heerste naar verluidt eensgezindheid over het pad dat de volgende dagen moet worden bewandeld. Het kartel blijft bij het standpunt dat het politiek bestuur maandag innam. Toen liet CD&V-voorzitter ad interim Wouter Beke weten dat zijn partij de parlementaire behandeling van het BHV-wetsvoorstel wil voortzetten en het dus volgende week wil agenderen, maar tegelijkertijd ook ruimte laat voor onderhandelingen. De fractie sloot zich ook woensdag unaniem bij deze houding aan.
Premier Leterme - die op de fractievergadering aanwezig was, maar naar verluidt niet tussenkwam - verklaarde dinsdag dat er de komende dagen niet wordt onderhandeld over BHV en dat op korte termijn dus ook geen oplossing te verwachten valt. De onderhandelingen over de tweede ronde in de staatshervorming, en dus ook over BHV, beginnen pas midden mei.
| |
| |
Volgens de woordvoerder van de premier zijn er dit weekend geen vergaderingen voorzien. Maandag en dinsdag trekt Leterme respectievelijk naar Parijs en Berlijn in het kader van zijn ‘aantredingsbezoeken’. (De Tijd, 30 april 2008)
Il n'y a pas de crise pour Leterme Pour le Premier ministre, il n'y a pas de crise. ‘Il faut créer un climat serein’, a-t-il dit. Ce mercredi, le CD&V/N-VA a réaffirmé sa volonté de mettre à l'ordre du jour la proposition de scission de l'arrondissement de BHV la semaine prochaine. Pour éviter que la proposition de loi des partis flamands sur la scission de BHV ne court-circuite le travail gouvernemental et ne provoque une crise dans la majorité, faisons en sorte que le parlement ne se réunisse pas, et le tour est joué. Il suffisait d'y penser. Cela n'a pas échappé aux chefs de groupe de la pentapartite: CD&V, VLD, MR, PS et CDH. Les cinq se sont retrouvés tôt mardi matin et sont convenus de défendre une position commune en conférence des présidents un peu plus tard, avant midi, laquelle devait décider de l'ordre du jour des travaux en assemblée plénière ce mercredi à la Chambre. Faisons l'impasse sur cette plénière (la veille de l'Ascension, du Premier mai, tout ça...), retrouvons-nous dans une semaine. Et le tour est joué. Les carottes étaient cuites déjà: la veille, en comité ministériel restreint, Yves Leterme avait désamorcé provisoirement la ‘bombe’ BHV en annonçant le début des négociations sur la seconde phase de la réforme de l'Etat, la convocation imminente du groupe Octopus (majorité + opposition, si possible), et en traçant les grandes lignes d'un schéma institutionnel qu'il doit compléter et soumettre à ses vice-Premiers ce mercredi, en principe. La réunion des chefs de groupes, mardi vers 11 heures, autour d'Herman Van Rompuy, s'est déroulée sans éclats. Comme prévu, les
représentants du Vlaams Belang, de la liste Dedecker et du SP.A ont réclamé que la Chambre se réunisse en plénière ce mercredi, et, comme prévu encore, ceux de la majorité leur ont répliqué en substance: ‘Non merci’, évitant de la sorte que les premiers ne relancent le débat sur la scission de BHV. Yves Leterme obtient un délai d'une semaine. Jusqu'à la prochaine conférence des présidents des groupes parlementaires, mardi prochain, 6 mai, appelée à fixer l'ordre du jour des travaux de la séance plénière de la Chambre du 7 mai, consacrée au vote de la loi-programme du gouvernement, cela avant une autre plénière, très ‘à risques’ celle-là, le lendemain, 8 mai, jour de... la Libération, et néanmoins voué à l'affrontement Nord-Sud si, entre-temps, Yves Leterme
| |
| |
n'a pas convaincu ses troupes de laisser une chance à la négociation, et de garder au frigo leur proposition de loi sur la scission de BHV. La séquence politique des 6-7-8 mai s'annonce donc comme extrêmement délicate - on a l'habitude. Le Premier s'active comme un beau diable pour éviter l'enfer. (Le Soir, 30 april 2008)
De gemiddelde WLR-score bedroeg voor de Nederlandse tekst 45.74 en voor de Franse 42.41. Als men er rekening mee houdt dat de score op een logaritmische schaal berust, is dat verschil niet gering. Andere experimenten met soortgelijke teksten wezen ook in dezelfde richting: de gefixeerdheid van de trigrammen (en dus als hypothese het algemeen fraseologisch gebruik) bleek in dergelijke krantenartikelen hoger te liggen voor het Nederlands dan voor het Frans.
Deze benadering kan met een andere methodologie aangevuld worden: het vergelijken van vertalingen. Om er zeker van te zijn dat teksten uit twee of meer talen met elkaar vergeleken kunnen worden op basis van hun fraseologische kenmerken, ligt het beroep op meertalige vertalingen voor de hand. Wel moet ervoor gezorgd worden dan het om kwaliteitsvertalingen gaat, zoals bv. de officiële documenten van de Europese Unie.
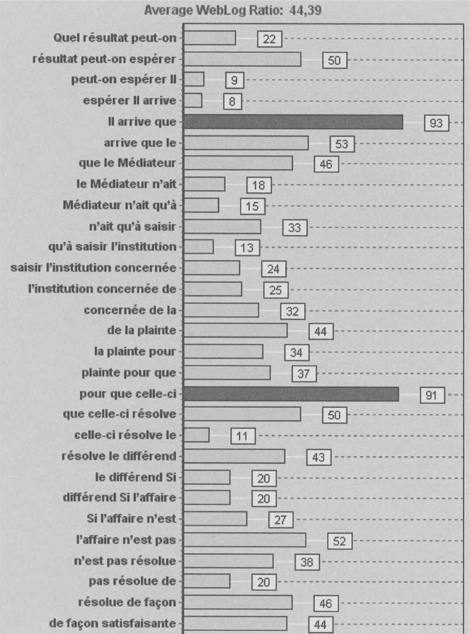
Ter illustratie van deze methode wordt in de tabel hieronder de WLR-score aangegeven voor resp. de Nederlandse en de Franse versie van het EU-document over The European Ombudsman (fragment).
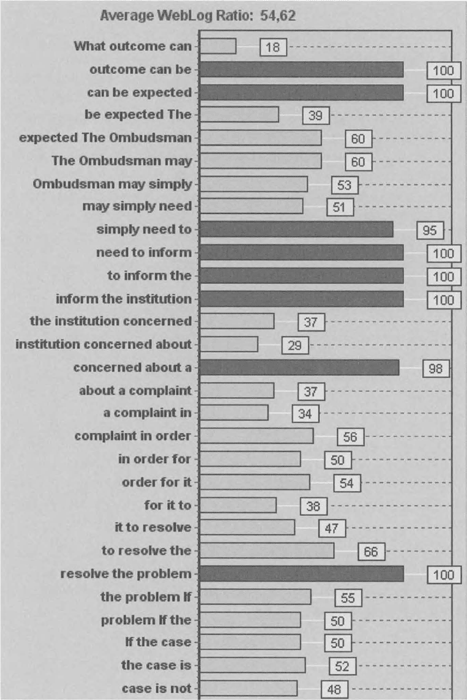
Uit dit voorbeeld blijkt opnieuw dat de gefixeerdheid van de trigrammen sterker is in de Nederlandse tekst dan in de Franse: de WLR-score bedraagt 48,29 voor het Nederlands en 44,39 voor het Frans. Met het nodige voorbehoud kunnen we in het kader van de contrastieve analyse de hypothese formuleren dat journalistieke teksten in het Nederlands rijker zijn aan fraseologie dan in het Frans, althans wat het gebruik van bestaande patronen betreft. Het Frans lijkt bovendien veel meer te steunen op metaforen (in het Franse artikel bv. La bombe BHV), en clichés (créer un climat serein, les carottes étaient cuites). Interessant is ook een vergelijking met de Engelse versie, waarvan de WLR-score nog veel hoger ligt.
Met een gemiddelde score van 54,62 blijkt de fraseologische densiteit in deze Engelse tekst nog veel hoger te liggen. Opnieuw moet men voorzichtig zijn met de interpretatie van die cijfers, die van een nog te verfijnen werkalgoritme afhangen, maar deze tekst blijkt koren op de molen te zijn van de vaakgehoorde stelling dat het Engels de meest idiomatische taal is: om dezelfde
| |
| |

Tabel 4 ‘Web Log Ratio’ voor een Nederlandse en een Franse vertaling van een EU-document
| |
| |
| |
| |
| |
| |
inhoud uit te drukken werd in het fragment een beroep gedaan op een meerderheid van structuren die sterk gefixeerd zijn.
Laten we in verband met deze EU-documenten tenslotte opmerken dat de Europese vertalers weliswaar de opdracht krijgen om vrij neutrale teksten samen te stellen, zonder te veel idiomaticiteit. Maar dit weerspiegelt alleen de verspreide misvatting dat fraseologie vooral of zelfs alleen uit idiomatische uitdrukkingen bestaat. Bewust of onbewust valt elke vertaler in zijn moedertaal terug op patronen die voor hem vanzelfsprekend zijn, omdat ze precies deel uitmaken van fraseologie in de brede zin. Het gaat hier niet om idiomen, maar om een resem grammaticale, communicatieve, redactionele vaste verbindingen en om collocaties. Deze dragen precies in hoge mate bij tot het algemeen fraseologisch gebruik, en zijn voor anderstaligen heel moeilijk te beheersen.
| |
6. Bij wijze van conclusie
Contrastief fraselogisch onderzoek is heel interessant voor het ontdekken van culturele verschillen, maar het heeft ook gevolgen voor het vreemdetalenonderwijs, de natuurlijke taalverwerking (NLP), de vertaaltheorie en de vertaalpraktijk.
Is het de bedoeling om objectieve verschillen in het fraseologisch gebruik van twee of meer talen te ontdekken, dan is het ontwikkelen van een betrouwbare methodologie voor dit vrij recente onderzoeksgebied een prioriteit. In dat verband kan de intuïtie van de taalkundige beter aangevuld worden door corpusonderzoek, geautomatiseerde computermethodes en statistiek.
Met alle voorbehoud blijkt uit onze eerste experimenten dat de Nederlandse fraseologie (evenals de Engelse, maar toch in mindere mate) een sterk beroep doet op bestaande vaste verbindingen, die een hoge onderlinge gefixeerdheid vertonen. Het Frans daarentegen werkt meer met contextuele metaforen en clichés om in vergelijkbare teksten voor stijleffecten te zorgen.
| |
Literatuurlijst
| Baroni, M. & S. Vegnaduzzo (2004). ‘Identifying subjective adjectives through webbased mutual information.’ In Buchberger, E. (red.), Proceedings of KONVENS 2004. Vienna: ÖGAI, p. 17-24. |
| |
| |
| Burger, H. (1998). Phraseologie. Eine Einführung am Beispiel des Deutschen. Berlin: Erich Schmidt Verlag. |
| Burger, H., Dobrovol'skij, D., Kühn, P. & N.R. Norrick (red.) (2007). Phraseologie / Phraseology. Ein internationales Handbuch der zeitgenössischen Forschung / An International Handbook of Contemporary Research. Berlin, New York: Walter de Gruyter. |
| Colson, J.-P. (2003). ‘Corpus Linguistics and Phraseological Statistics: a Few Hypotheses and Examples.’ In Burger, H., Häcki Buhofer, A. & G. Gréciano (red.) Flut von Texten - Vielfalt der Kulturen. Ascona 2001 zu Methodologie und Kulturspezifik der Phraseologie. Baltmannsweiler: Schneider Verlag Hohengehren, p. 47-59. |
| Colson, J.-P. (2004). ‘Phraseology and computational corpus linguistics: from theory to a practical example.’ In Bouillon, H. (red.), Langues à niveaux multiples. Hommage au Professeur Jacques Lerot à l'occasion de son éméritat. Bibliothèque des Cahiers de l'Institut de Linguistique de Louvain, 113. Louvain-la-Neuve, Peeters, p. 35-45. |
| Colson, J.-P. (2005). ‘Computationele corpuslinguïstiek voor germanisten en vertalers: toekomstmuziek?’ In Hiligsmann, Ph., Janssens, G. & J. Vromans (red.) Woord voor woord, zin voor zin. Liber Amicorum voor Siegfried Theissen. Gent: Koninklijke Academie voor Nederlandse Taal- en Letterkunde, p. 49-58. |
| Colson, J.-P. (2007). ‘The World Wide Web as a corpus for set phrases.’ In Burger, H., Dobrovol'skij, D., Kühn, P. & N.R. Norrick (red.) Phraseologie / Phraseology. Ein internationales Handbuch der zeitgenössischen Forschung / An International Handbook of Contemporary Research, Volume 2. Berlin, New York: Walter de Gruyter, p. 1071-1077. |
| Colson, J.-P. (2008). ‘Cross-linguistic phraseological studies: an overview.’ In Granger, S. & F. Meunier (red.) Phraseology: an interdisciplinary perspective. Amsterdam, Philadelphia: John Benjamins, p. 191-206. |
| Croft, W. (2001). Radical construction grammar. Syntactic theory in typological perspective. Oxford: Oxford University Press. |
| Dobrovol'skij, D. & E. Piirainen (2005). Figurative Language. Cross-Cultural and Cross-Linguistic Perspectives. Amsterdam: Elsevier. |
| Evert, S. (2004). The statistics of word cooccurrences - word pairs and collocations. Ph.D. Dissertation, University of Stuttgart. |
| Goldberg, A.E. (1995). Constructions: a construction grammar approach to argument structure. Chicago: University of Chicago Press. |
| Heid, U. (2007). ‘Computational linguistic aspects of phraseology II.’ In Burger, H., Dobrovol'skij, D., Kühn, P. & N.R. Norrick (red.) Phraseologie / Phraseology. Ein internationales Handbuch der zeitgenössischen Forschung / An International Handbook of Contemporary Research, Volume 2. Berlin, New York: Walter de Gruyter, p. 1036-1044. |
| |
| |
| Hüning, M. (2007). ‘Constructiegrammatica als verlengstuk van de fraseologie.’ In Moerdijk, F., Van Santen, A. & R. Tempelaars (red.) Leven met woorden. Opstellen aangeboden aan Piet Sterkenburg bij zijn afscheid als directeur van het Instituut voor Nederlandse lexicologie en als hoogleraar Lexicologie aan de Universiteit Leiden. Leiden: INL/Koninklijke Brill, p. 377-384. |
| Kilgariff, A. & G. Grefenstette (2003). ‘Web as Corpus. Introduction to the Special Issue.’ Computational Linguistics 29: 1-15. |
| Lakoff, G. (1988). ‘Cognitive semantics.’ In Eco U., Santambrogio M. & P. Violi (red.) Meaning and mental representations. Bloomington, Indianapolis: Indiana University Press, p. 119-154. |
| Langacker, R.W. (1999). ‘Assessing the cognitive linguistic enterprise.’ In Janssen T. & G. Redeker (red.) Cognitive Linguistics: Foundations, Scope and Methodology. Berlin, New York: Mouton de Gruyter, p. 13-59. |
| Langacker, R.W. (2000). Grammar and Conceptualization. Berlin, New York: Mouton de Gruyter. |
| Moon, R. (1998). Fixed Expressions and Idioms in English. Oxford: Clarendon Press. |
| Moon, R. (2007). ‘Corpus linguistic approaches with English corpora.’ In Burger, H., Dobrovol'skij, D., Kühn, P. & N.R. Norrick (red.) Phraseologie / Phraseology. Ein internationales Handbuch der zeitgenössischen Forschung / An International Handbook of Contemporary Research, Volume 2. Berlin, New York: Walter de Gruyter, p. 1045-1059. |
| Sinclair, J. (1991). Corpus, Concordance, Collocation. Oxford: Oxford University Press. |
| Taylor, J.R. (2002). Cognitive Grammar. Oxford: Oxford University Press. |
| Tirkkonen-Condit, S. (2002). ‘Translationese - a myth or an empirical fact?’ Target 14: 207-220. |
| Tomasello, M. (2003). Constructing a language. A usage-based theory of language acquisition. Cambridge (Mass.): Harvard University Press. |
| Turney, P. (2001). ‘Mining the Web for Synonyms: PMI-IR versus LSA on TOEFL.’ Lecture Notes in Computer Science 2167: 491-502. |
|
|