
Tijdschrift voor Taalbeheersing. Jaargang 28
(2006)– [tijdschrift] Tijdschrift voor Taalbeheersing–
[pagina 323]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bert Meuffels en Huub van den Bergh
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. De fixed-effect fallacy gedissocieerdIn een vorige aflevering van dit tijdschrift zijn methodologische implicaties van de door Clark geïntroduceerde fixed-effect fallacy besproken (Meuffels & Van den Bergh 2005).Ga naar eind1 Clark zelf beschouwde deze fout (waaraan vrijwel de gehele gemeenschap van toenmalige kwantitatiefempirisch georiënteerde taalonderzoekers zich volgens hem in de jaren zestig en zeventig schuldig maakte) als een puur statistische fout. De door Clark geïntroduceerde drogreden is echter in de vorige bijdrage door ons gedissocieerd in twee typen fouten:
1. Een fallacy van methodologische aard; deze design-fout manifesteert zich wanneer in taalwetenschappelijk onderzoek de niveaus van de categoriale, gefixeerde variabele (de ‘explanatory’ variabele) waarnaar de theoretisch-inhoudelijke interesse van de taalwetenschappelijke onderzoeker uitgaat, in instrumenteel-operationele zin slechts gerepresenteerd wordt door één instantiatie: één tekst (of één zin, één woord, letter, kortom één talig element). In een dergelijk design, een single message design genoemd, kan niet gediscrimineerd worden tussen de effecten op specifiek-instrumenteel niveau en de effecten op generiek, categoriaal-abstract niveau. Omdat beide soorten effecten in een single message design verstrengeld (‘confounded’) zijn, wordt zowel de interne als de externe validiteit van zulk soort taalwetenschappelijk onderzoek aangetast. Wat de interne validiteit van een dergelijk single message design betreft: een ondubbelzinnig onderscheid tussen (pseudo-) confirmatie en (pseudo-) falsificatie van de onderzoekshypothese is als gevolg van de verstrengeling niet goed mogelijk. Wat de externe validiteit van een dergelijk design betreft: een generalisatie van de steekproefgegevens naar een populatie van gelijksoortige proefpersonen én naar een populatie van gelijksoortig talig materiaal, is - op grond van de omstandigheid dat slechts één talig element werd onderzocht - dubieus. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 324]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. Een fallacy van inductief-statistische aard; deze statistische fout treedt op in een multiple message design waarbij er in de statistische analyse ten onrechte vanuit gegaan wordt dat de random factor ‘talige/tekstuele instantiatie’ (die in taalwetenschappelijk onderzoek vaak genest is binnen de categoriale, gefixeerde ‘explanatory’ variabele) een gefixeerde factor, en niet een random factor, zou zijn. Het gevolg van deze misclassificatie is dat de - op basis van een F-ratio - geschatte alpha-fout (type I-fout) geflatteerd is, dat wil zeggen een ‘positieve bias’ vertoontGa naar eind2. Dat heeft weer tot gevolg dat de kans dat ten onrechte de bevindingen vanuit de steekproef naar de populatie gegeneraliseerd worden, groter is dan het door de betreffende empirisch onderzoeker gerapporteerde nominale niveau van 5%. Hoeveel groter is doorgaans onbekend - soms echter kan die grootte vrij nauwkeurig geschat worden, onder andere met behulp van simulatie-studies. Uit studies als deze blijkt dat onder extreme condities de positieve bias die optreedt wanneer random factoren ten onrechte in de data-analyse als gefixeerde factoren worden behandeld, soms de grootte van een factor 10 aanneemt (Forster & Dickinson 1976). In de praktijk komt dit laatste op het volgende neer: de taalwetenschappelijke onderzoeker rapporteert een p-waarde (een alpha-fout) van p < 0.05, denkt dan op grond van het conventioneel bepaalde significantieniveau van 5% de nulhypothese: ‘geen verschil tussen gemiddelden van de niveaus van een treatment in de populatie’ te kunnen verwerpen en dus de resultaten te kunnen generaliseren naar de populatie (zowel naar de populatie ‘proefpersonen’ als naar de populatie ‘taal’), terwijl in feite het significantieniveau minstens. 50 bedraagt. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. DoelIn deze bijdrage waarin kennis van statistische nulhypothese-toetsing en van variantie-analyse wordt voorondersteld, gaan we in eerste instantie in algemene, niet-technische zin in op de onder punt 2 genoemde statistische fout (technisch commentaar van statistische aard wordt in de voetnoten opgenomen). Wat houdt deze statistische fout waarvoor Clark de in retorisch opzichtGa naar eind3 zo toepasselijke naam ‘fixed-effect fallacy’ introduceerde, nu in feite in? Inzicht in het antwoord op deze vraag is niet zonder enig praktisch belang: in het Tijdschrift voor Taalbeheersing treft men de fixed-effect fallacy immers regelmatig aan, zo bleek uit een door ons uitgevoerde meta-analyse van experimentele artikelen die de afgelopen 23 jaargangen in dit tijdschrift verschenen zijn. In 32 van de 34 mogelijke gevallen werd de door Clark gewraakte drogreden aangetroffen (Meuffels & Van den Berg 2005: 121-122) - alle reden dus om er aandacht aan te besteden. De fixed-effect fallacy vooronderstelt het gebruik van een multiple message design. Na een niet-technische uitleg van de fixed-effect fallacy gaan we in op de statistische verwerking van data die zijn verkregen aan de hand van zulk soort multiple message designs. Met behulp van dit type designs (designs dus waarin de categoriale, gefixeerde ‘explanatory’ variabele in instrumentele zin gerepresenteerd is door niet één, maar door verschillende talige instantiaties) is de taalwetenschappelijke onderzoeker in beginsel in staat om de verstrengeling (de ‘confounding’) van effecten op abstract-categoriaal niveau en op specifiek-instrumenteel niveau te ontrafelen. Daardoor is de interne validiteit - op dit punt althans - gewaarborgd; en het spreekt voor zich dat de externe validiteit van dergelijke designs vele malen groter is dan die van de daarmee concurrerende single message designs. In dezelfde, door ons uitgevoerde meta-analyse van experimentele artikelen in de eerste | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 325]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
23 jaargangen van het Tijdschrift voor Taalbeheersing bleek dat in iets meer dan de helft van het gerapporteerde experimenteel-taalwetenschappelijk onderzoek (namelijk in 51 van de in totaal 94 gevallen) een, vanuit methodologisch perspectief beschouwd, inadequaat design gehanteerd werd, namelijk een single message design. En ‘inadequaat’ moet hier nadrukkelijk niet in absolute zin geïnterpreteerd worden, als wel in relatieve zin: inadequaat namelijk in het licht van de door de empirisch-taalwetenschappelijke onderzoeker zélf naar voren gebrachte claim (i.c. de in het betreffende empirisch taalwetenschappelijk onderzoek te toetsen hypothese) die, gezien de generieke aard ervan, niet zozeer betrekking heeft op één specifiek talig element (één min of meer toevallige instantiatie), maar veeleer op een meer abstracte, bovenliggende categorie die een klasse van talige verschijnselen bestrijkt waarvan het onderzochte talige specimen slechts een min of meer toevallige verbijzondering betreft.
Multiple message designs mogen dan wel voor empirisch-taalwetenschappelijk onderzoek op grond van methodologische overwegingen betreffende interne en externe validiteit superieur zijn aan single message designs, dat neemt niet weg dat zulke multiple message designs nogal gecompliceerd zijn. Dat zijn ze niet alleen qua opzet en praktische uitvoering, maar vooral ook wat betreft de statistische analyse via bestaande computerprogramma's. Anders dan voor single message designs bestaan er voor vele multiple message designs (bijvoorbeeld het specifieke design aan de hand waarvan Clark de fixed-effect fallacy bespreekt) tot op heden geen kanten-klare, computer-gegenereerde oplossingen die probleemloos de gewenste toetsingsgrootheid (F-ratio) opleveren. De onderzoeker zal in zulke specifieke gevallen zelf via een aantal computerruns en - uiteindelijk - via een zakrekenmachine de gewenste F-ratio moeten berekenen. Hierbij moet hij uitgaan van het statistisch model dat aan het gehanteerde multiple message design ten grondslag ligt; het genereren van zo'n statistische model (via algoritmische procedures) is echter bepaald geen sinecure.Ga naar eind4 Om de praktische bruikbaarheid van deze bijdrage te vergroten, presenteren we een viertal multiple message designs inclusief de daarbij behorende statistische analyse. Voor elk design wordt het daaraan ten grondslag liggende statistische model geëxpliciteerd, wordt de vorm en structuur van de relevante F-ratio (ter toetsing van treatment-effecten) vermeld, en bij elk design geven we aan de hand van gefingeerde datasets steeds aan hoe de betreffende data in SPSS verwerkt worden. De vier te bespreken multiple message designs (hierna te noemen: design I, design II, III en IV) zijn overigens niet willekeurig gekozen uit het grote potentieel aan mogelijke designs: anders dan design I en II die een binnen-proefpersonen ontwerp betreffen, vormen design III en IV tussen-proefpersonen ontwerpen. Design I is het ontwerp waar Clark in zijn bespreking van de fixed-effect fallacy van uitgaat - uit de aard der zaak kan dit ontwerp in dit artikel niet onbesproken blijven. Bovendien behelst dit design een ontwerp dat aanleiding geeft tot de constructie van een geheel afwijkend type F-ratio (namelijk een quasi F). Design II is wat complexer en betreft in feite een generalisatie van design I: is er in design I sprake van slechts één treatment, in II spelen twee onafhankelijke variabelen en hun eventuele interactie een rol. Overigens, net als design I treft men ook dit design in het Tijdschrift voor Taalbeheersing aan. Design III en IV (de tussen-proefpersonen ontwerpen) zijn als illustratieve voorbeelden van multiple message designs gekozen omdat in de praktijk van alledag vaak gekozen zal moeten worden tussen één van beide configuraties die als het ware elkaars spiegelbeeld vormen: III komt met name in aanmerking wanneer de beschikbaarheid van grote aantallen proefpersonen geen al te groot probleem vormt terwijl de constructie of ‘sampling’ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 326]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
van grote aantallen talige instantiaties nogal lastig is (bijvoorbeeld wanneer met advertenties met en zonder woordspelingen op persuasieve kracht met elkaar wil vergelijken, dan zal de eerste categorie - met woordspelingen - moeizaam te implementeren zijn). IV daarentegen komt juist in de omgekeerde situatie in aanmerking: grote aantallen instantiaties kunnen gemakkelijk uit een gespecificeerd domein gegenereerd worden (bijvoorbeeld wanneer men dialoogjes wil construeren waarin al dan niet ad verecundiam drogredenen optreden) terwijl het samenstellen van steekproeven met grote aantallen proefpersonen tot de praktische onmogelijkheden behoort. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. De fixed-effect fallacyIn empirisch-taalwetenschappelijk onderzoek wordt vaak gebruik gemaakt van de inductiefstatistische techniek die bekend staat onder de naam: variantie-analyse. Toepassing van deze statistische analyse resulteert in een toetsingsgrootheid: de zogenaamde F-ratio, met behulp waarvan nagegaan kan worden of het verschil tussen twee of meer ‘treatment’-gemiddelden dat in een steekproef is aangetroffen, geen toevalstreffer is maar een ‘echt’, substantieel verschil dat met vertrouwen - dat wil zeggen binnen de grenzen van conventioneel bepaalde waarschijnlijkheidsmarges - naar de populatie gegeneraliseerd mag worden. Het is deze toetsingsgrootheid F, oorspronkelijk in de jaren dertig door de Engelse mathematisch-statisticus en geneticus Fisher ontwikkeld (vandaar de naam: F-toets) waarop Clark zijn pijlen afvuurde - althans, op het naar zijn oordeel drogredelijk (‘fallacious’) gebruik van deze F. De onderstaande niet-technische beschouwingen over de fixed-effect fallacy zijn dus gecentreerd rond deze F-toets. De toetsingsgrootheid F is vanuit structureel oogpunt bekeken in feite een getalsmatige uitdrukking van de verhouding van de grootte van een signaal ten opzichte van de grootte van de ruis: hoe sterker het signaal ten opzichte van de ruis, hoe groter (in absolute waarde) F en - als regel - hoe makkelijker de bevindingen in de steekproef gegeneraliseerd kunnen worden naar de populatie:
Is F gelijk aan of kleiner dan 1, dan kan de nulhypothese (‘er is geen verschil tussen de treatment-gemiddelden in de populatie’) nooit verworpen worden ten gunste van de door de onderzoeker geliefkoosde alternatieve hypothese (‘er is wel een verschil tussen de treatmentgemiddelden in de populatie’). In dat geval immers is de ruis (de ‘error’) minstens zo groot is als het signaal. In het algemeen geldt: hoe groter de numerieke waarde van F, hoe groter de kans dat de nulhypothese verworpen en de alternatieve hypothese geaccepteerd kan worden, dus hoe groter ook de kans dat de bevindingen in de steekproef met vertrouwen naar de populatie gegeneraliseerd kunnen worden. De teller van de F-ratio bestaat dus uit het signaal, anders uitgedrukt: uit het effect dat de onderzoeker wil aantonen (i.c. het verschil tussen gemiddelden), de noemer van de F-ratio bestaat uit een ruis-of errorterm. In het meest eenvoudige design, het één-factor experiment, bestaat de toetsingsgrootheid F uit de ratio van variantie tussen de groepen en (‘gepoolde’) variantie binnen de groepen (ofwel: de ratio van variantie tussen de treatments en van variantie binnen de treatments).Ga naar eind5 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 327]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De aldus opgebouwde F-ratio heeft als rationale dat naarmate de variantie van de steekproefgemiddelden groter is ten opzichte van de in de steekproef aangetroffen ruis (de error-term, i.c. de gepoolde variantie binnen de groepen) de nulhypothese dat alle gemiddelden in de populatie aan elkaar gelijk zijn, sneller verworpen wordt.  Verschillen tussen de proefpersonen binnen de treatments worden in de variantie-analyse van het één-factor experiment dus opgevat als error, te wijten aan steekproeffouten (‘sampling error’). Het punt waar het nu bij de fixed-effect fallacy in feite om draait, is dat in een multiple message design waarin de taalwetenschappelijke variabele (de treatment) is vertegenwoordigd door een random factor ‘talige instantiaties’, de error-term van de betreffende F-ratio niet uit slechts één component bestaat (namelijk uit de error die te wijten is aan steekproeffouten bij het trekken van personen uit de populatie) maar uit twee: namelijk óók uit een component die error representeert die het gevolg is van steekproeffouten bij het trekken van de talige instantiaties (de ‘messages’) uit een gespecificeerd domein:  Vat men nu - ten onrechte overigens - de talige instantiaties op als een gefixeerde, en niet als een random factor, dan wordt de noemer van de F-ratio kunstmatig verkleind (men abstraheert dan immers van de sampling error die aan de messages kan worden toegeschreven). Een aldus kunstmatig verkleinde noemer leidt - bij gelijkblijvend teller, dus bij gelijkblijvend effect - tot een kunstmatig vergrote F-ratio. Dit is, in niet-technische termen uitgedrukt, de fixed-effect fallacy. Wat is nu het gevolg van dit kunstmatig vergroten van de F-ratio? Als een F-ratio kunstmatig vergroot wordt, dan wordt de kans op het ten onrechte verwerpen van de nulhypothese (de alpha-fout) kunstmatig vergroot en gaat dus het nominale alpha-niveau afwijken van het werkelijke alpha-niveau. De toetsingsgrootheid F vertoont onder deze omstandigheden een ‘positieve bias’: de onderzoeker concludeert dat het aangetroffen verschil in treatmentgemiddelden, gelet op de met de toetsingsgrootheid F geassocieerde p-waarde die kleiner is dan 5%, met vertrouwen gegeneraliseerd mag worden. De feitelijke p-waarde echter (die p-waarde die verkregen zou zijn indien de random talige factor niet als gefixeerde, maar juist als random factor in de analyse verdisconteerd zou zijn) is vele malen groter is en zou juist tot een tegengestelde conclusie moeten leiden: geen verschil in treatment-gemiddelden in de populatie. Volgens Clark bleef de language-as-fixed-effect fallacy niet beperkt tot een incidentele taalwetenschappelijke onderzoeker. In antwoord op de door hemzelf gestelde vraag hoeveel taalwetenschappers in de jaren vijftig en zestig zich dan wel schuldig zouden maken aan deze fixed-effect fallacy stelde Clark even kort als krachtig: ‘The answer, sad to say, is almost everyone.’ (Clark 1973: 355). Gelet op de frequentie van voorkomen van de (statistische) fixed-effect fallacy in het Tijdschrift voor Taalbeheersing lijkt Clark's antwoord drie decennia na dato nog even actueel. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 328]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Design I: woorden genest binnen treatment, respondenten gekruist met woorden en treatmentHet multiple message design dat in deze paragraaf besproken wordt, betreft het design aan de hand waarvan Clark de fixed-effect fallacy bespreekt. In dit multiple message design is er sprake van een gefixeerde treatment T, waarvan de niveaus worden gerepresenteerd door (een random steekproef aan) verschillende woorden w, die op hun beurt genest zijn binnen elk niveau van de treatment (w(T)). De respondenten (r) krijgen elk woord in elke treatment conditie aangeboden waarop zij moeten reageren. Een concreet voorbeeld van een dergelijk design (besproken door Clark in diens artikel, en aldaar Study 5 genoemd (Clark 1973: 337-338)) betreft het volgende: in het kader van een reeks psycholinguïstische experimenten (uitgevoerd in de jaren zeventig) waarin wordt nagegaan hoe snel proefpersonen beslissen of een reeks letters een woord dan wel een nietwoord vormt, werden homofonen vergeleken met niet-homofonen. In het betreffende experiment werden 25 homofonen vergeleken met 24 niet-homofonen (een voorbeeld van een (Engels) homofoon is het woord bear, een woord dat net zo wordt uitgesproken als bare, maar dat verschillend wordt gespeld en dat qua betekenis niet-identiek is). De homofonen en niet-homofonen werden één-voor-één aangeboden (overigens lukraak afgewisseld met ‘nonword filler items’); van elk woord werd de herkenningstijd (wel woord/geen woord) in milliseconden gemeten. Alle proefpersonen reageren op alle 49 aangeboden woorden. Dit design kent dus drie factoren: (1) Homofonie, een gefixeerde factor met 2 niveaus; (2) Woorden genest binnen Homofonie, bestaande uit een random steekproef uit de populatie: alle mogelijke homofonen en niet-homofonen; en (3) Respondenten, bestaande uit een random steekproef uit alle mogelijke respondenten. Dit specifieke design betreft dus een repeated measurement design (een binnen-proefpersonen design) waarin de random factor ‘proefpersoon’ (r) gekruist is met zowel de gefixeerde treatment factor T als met de random factor ‘woorden binnen treatment’ (w(T)). Vanuit methodologisch oogpunt beschouwd is dit design (ook wel een gemengd hiërarchisch drie-factor design genoemd) een bijzonder sterk design: aangetroffen effecten van de treatment kunnen niet worden toegeschreven aan verschillen tussen proefpersonen (zoals soms in een tussen-proefpersonen design): elke proefpersoon wordt immers geobserveerd onder alle treatment-condities en fungeert derhalve als zijn ‘eigen controle’. Bovendien - maar dit geldt in feite voor álle multiple message designs - is een uiteenrafeling van effecten van de treatment op categoriaal niveau en op instrumenteel niveau mogelijk. De keerzijde van de medaille is echter dat het statistisch model voor dit design en de constructie van een adequate F-ratio verre van eenvoudig is (zie tabel 1). Immers, de F-ratio die voor de toetsing van deze treatment geconstrueerd moet worden, is geen reguliere F-ratio maar een zogenaamde quasi F-ratio (symbolisch weergegeven als F’).Ga naar eind6 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 329]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 1: Verwachtingswaarden van MS-termen in design I: woorden genest binnen treatment, respondenten gekruist met woorden en treatment (N.B. t is het aantal treatment-niveaus, w is het aantal replicaties per treatment-niveau, en r is het totale aantal respondenten).
Zijn de verschillende variantiebronnen gedefinieerd, dan kan de quasi F geconstrueerd worden en wel zo dat bij toetsing van het effect van Treatment het verschil tussen de teller en de noemer van de F-ratio alleen de variantie van Treatment bevat, én dat in de noemer (ook) de verschillen tussen woorden binnen Treatment (w(T)) tot uitdrukking komen. Voor design I voldoet de volgende quasi F-ratio aan deze eisen:
Niet alleen moet deze F-ratio handmatig berekend worden (zij het dat men via een aantal computer-runs over de benodigde MS-termen kan beschikken), dat geldt evenzeer voor de bijbehorende vrijheidsgraden:
Een van de karakteristieke aspecten van een quasi F-ratio betreft het feit dat de daarbij behorende vrijheidsgraden niet meer exact zijn, maar moeten worden benaderd.Ga naar eind8 Een andere problematische eigenschap van quasi F-ratio's is dat deze, anders dan reguliere F-ratio's, niet uniek zijn: voor hetzelfde design kunnen andere quasi F-ratio's geconstrueerd worden die tot andere toetsingsuitkomsten aanleiding kunnen geven.Ga naar eind9 Uit simulatie-onderzoek is overigens gebleken dat quasi F-ratio's in het algemeen redelijke toetsingsgrootheden vormen waarop men staat kan maken (Forster & Dickinson 1976; Santa, Miller & Shaw 1979; Maxwell & Bray 1986); ze zijn echter licht conservatief. Tot slot: in lang niet alle gevallen is het hier besproken ‘ideale’ design ook in praktische zin toepasbaar. Veronderstelt een onderzoeker bijvoorbeeld oefen-effecten (‘practice’-effecten die maken dat een proefpersoon door de herhaalde blootstelling aan de afhankelijke variabele tijdens de duur van het experiment beter gaat presteren - of juist slechter ten gevolge van vermoeidheid), dan kan het gebruik van dit design bezwaarlijk zijn. Zou hij de treatment-condities, inclusief de instantiaties, allemaal in precies dezelfde volgorde aan de proefpersonen aanbieden, dan is hij niet meer in staat de treatment- van de oefeneffecten te onderscheiden: beide effecten zijn dan immers met elkaar verstrengeld (‘confounded’). De standaardoplossing voor dit probleem bestaat eruit de messages in verschillende volgordes aan verschillende proefpersonen aan te bieden, wat meestal in de praktijk bewerkstelligd wordt door het zogenaamde ‘counterbalancing’. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 330]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Een tweede moeilijkheid met dit design betreft de mogelijkheid van differentiële ‘carryover’-effecten. Anders dan ‘practice’-effecten die algemeen van aard zijn en alle treatment-condities gelijkelijk beïnvloeden, zijn ‘carryover’-effecten onveranderlijk specifiek. Stel dat een experiment drie treatment-condities bevat (a1, a2 en a3) die qua moeilijkheid sterk verschillen (a1 het makkelijkst, a3 het moeilijkst). De drie condities worden in twee verschillende volgorden aangeboden: a1, a2 en a3 en a3, a2 en a1: zullen nu proefpersonen die aan de moeilijkste conditie als eerste worden blootgesteld (dus aan a3), op precies dezelfde wijze reageren op de treatment-conditie waarvan verondersteld wordt dat deze middelmatig moeilijk is (dus op a2), als de proefpersonen die eerst de gemakkelijkste treatment-conditie (dus a1) moesten doorlopen? Indien het antwoord op de gestelde vraag nee is, dan hebben we te maken met een voorbeeld van differentiële carryover-effecten. Weer een ander potentieel bezwaar tegen dit design betreft de mogelijkheid dat proefpersonen, juist door de herhaalde blootstelling aan eenzelfde type stimuli, achter het eigenlijke doel van het experiment komen waardoor de ecologische validiteit aangetast kan worden - vooral in het sociaal-psychologisch georiënteerde persuasie-onderzoek kan deze factor een sterk contaminerende invloed uitoefenen. En het in deze paragraaf besproken design is al helemáál uitgesloten indien de talige instantiaties, de ‘woorden’ (de messages) in fysieke zin niet uit ‘levensechte’ woorden bestaan die slechts een korte verwerkingstijd vergen (bijvoorbeeld woorden in een dictee), maar uit bijvoorbeeld volledige teksten die elk een aantal pagina's of zelfs hele boekwerken beslaan (zoals voorlichtingsfolders of computerhandleidingen). In louter praktische zin zou dan een repeated measurement design zoals hier besproken, uitgesloten zijn. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.1 De verwerking van data in design ILaten we aan de hand van onderstaande (fictieve) dataset de berekening van de quasi F in design I illustreren. We gaan uit van een gefixeerde factor T (met twee niveaus: T1 en T2), waarbinnen een random factor ‘woorden’ (w, met vier niveaus) genest is. Verder nemen we aan dat er 8 proefpersonen (r) aan het experiment deelnemen; deze proefpersonen vormen eveneens een random factor die volledig gekruist is met de random factor ‘woorden’ en de gefixeerde factor T.
Tabel 2: Fictieve dataset voor design I (woorden genest binnen treatment, respondenten gekruist met woorden en treatment).
Met behulp van onderstaande SPSS-setup kunnen de vijf variantie-bronnen (i.c. MS-termen) in het statistisch model van design I achterhaald worden. Dan is men er overigens nog niet: de betreffende MS-termen dienen in de formule voor de quasi F ingevuld te worden, zodat deze F' (handmatig) berekend kan worden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 331]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De setup voor de analyse van de gegevens in Tabel 2 bestaat uit drie delen. In het eerste deel worden de data gedefinieerd, in het tweede en derde deel worden twee aparte analyses gespecificeerd.Ga naar eind10
Tabel 3: SPSS-setup voor de analyse van de gegevens uit tabel 2.
De eerste run met manova levert drie van de in totaal vijf benodigde MS-termen voor design I op: (1) de MS-term voor Treatment (die 43.89 bedraagt, bij 1 vrijheidsgraad), (2) de MS-term voor Respondent (ter grootte van 6.18, bij 7 vrijheidsgraden) en (3) de MS-term voor de interactie van Respondent en Treatment (7.85 bij 7 vrijheidsgraden).Ga naar eind11
Tabel 4: Resultaten van de eerste MANOVA voor design I.
De tweede run met MANOVA waarin de variantie van woorden binnen Treatment geschat wordt (w(T)) en waarin wordt aangegeven dat ‘woorden’ genest zijn binnen Treatment, levert de twee resterende MS-termen voor het statistisch model van design I: de MS-term voor woorden binnen Treatment (i.c. w(T), die bij 6 vrijheidsgraden 5.43 bedraagt, en de MS-term voor de interactie tussen Respondent en ‘woorden’ binnen Treatment (groot: 3.29 bij 42 vrijheidsgraden). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 332]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 5: Resultaten van de tweede manova voor Design I.
Met behulp van 4 van deze 5 MS-termen kan vervolgens de quasi F voor de toetsing van het Treatment-effect berekend worden: 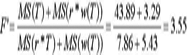 Vervolgens moeten de aantallen bij deze quasi F behorende (niet-exacte) vrijheidsgraden berekend worden. Dat leidt tot: 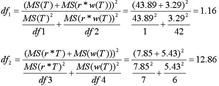 De vrijheidsgraden moeten worden afgerond op het dichtstbijzijnde gehele getal, met als resultaat: F' = 3.55; df1 = 1; df2 = 13. Dit levert een overschrijdingskans op van 0.08. Naar conventionele maatstaven gemeten (alpha <5%) kan het verschil tussen de beide condities niet gegeneraliseerd worden naar de geïntendeerde populatie van subjecten en van woorden. Zou men echter, ten onrechte overigens, uitgegaan zijn van een statistische analyse waarbij de variatie tussen woorden buiten beschouwing gelaten wordt - dus zou men zich schuldig maken aan de door Clark verguisde fixed-effect fallacy - dan zouden de toetsingsuitkomsten wél significant zijn geweest en zou men wél tot generalisatie van steekproefuitkomsten naar populatie zijn overgegaan.Ga naar eind12 De fixed-effect fallacy geeft dus een te optimistisch beeld. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5. Design II: woorden genest binnen de interactie van de twee gefixeerde treatments, respondenten gekruist met woorden en treatmentsDit design, dat net zoals design I een repeated measurement design is, betreft in feite een generalisatie van design I: anders dan in design I figureert in dit design niet slechts één onafhankelijke variabele, maar twee. Dit design kent twee gefixeerde, volledig met elkaar gekruiste factoren (treatments) en twee random factoren: woorden/messages en respondenten. De woorden/messages zijn genest binnen de interactie van de twee factoren, de respondenten zijn volledig gekruist met alle overige (random en gefixeerde) factoren. Ter illustratie van dit design een concreet voorbeeld, ontleend aan een van de experimentele artikelen in het Tijdschrift voor Taalbeheersing. In het betreffende artikel werd de invloed van | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 333]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
twee factoren (namelijk van woordfrequentie en van zinscontext) op het spellingsgedrag van intuïtieve spellers bij zwakke prefixwerkwoorden (zoals: verandert/veranderd) nagegaan. Er werden drie zinscontexten gemanipuleerd: (1) neutraal (d.w.z. context biedt geen aanknopingspunten voor de juiste spelling voor spellers die geen regels tot hun beschikking hebben); (2) context werkt mee (d.w.z. context biedt optimale aanknopingspunten om tot juiste spelling te komen); (3) context werkt tegen. Daarnaast werden drie typen woordfrequenties gemanipuleerd die, zo luidde althans de veronderstelling, (1) een correcte spelling tegenwerkten (bijvoorbeeld: ‘geloofd’, een relatief weinig frequent voorkomende woordvorm die de intuïtieve speller die op het woordbeeld vertrouwt, op het verkeerde been zal zetten); (2) een correcte spelling juist ondersteunden (bijvoorbeeld: ‘gelooft’); en (3) een neutrale uitwerking op het spellingsgedrag hadden (bijvoorbeeld: ‘gebeurd’, een woordvorm die qua frequentie min of meer overeenkomt met ‘gebeurt’). In totaal werden er aan 253 proefpersonen 72 zinnetjes in de vorm van een dictee voorgelegd (zoals: ‘Ik weet dat hij bepaal_heeft, dat niemand zijn auto mag gebruiken’ en ‘Weet je, dat ik jarenlang Jan geloof_heb?’). Aan de proefpersonen de taak de ontbrekende letter bij de 72 prefixwerkwoorden correct in te vullen. Dit multiple message design kent vier factoren: (1) Zinscontext, een gefixeerde factor met 3 niveaus; (2) Woordfrequentie, eveneens een gefixeerde factor met drie niveaus; (3) Woorden genest binnen de interactie van Zinscontext en Woordfrequentie, bestaande uit een random steekproef van 8 te spellen prefixwerkwoorden uit de betreffende populatie; (4) Respondenten, bestaande uit een random steekproef uit alle mogelijke respondenten. Dit specifieke design betreft, zoals gezegd, een repeated measurement design (een binnenproefpersonen design) waarin de random factor ‘proefpersoon’ (r) gekruist is met zowel de gefixeerde treatment factor Zinscontext als de gefixeerde factor Woordfrequentie en tevens gekruist is met de random factor ‘woorden genest binnen de interactie van de treatments Zinscontext en Woordfrequentie’ (w(Z x WF)). Het statistisch model voor dit design staat in onderstaande tabel (waarbij we de twee gefixeerde treatment-factoren met A en B aanduiden, de random factor ‘woorden’ met w(AB) en de random factor ‘proefpersoon’ met r).
Tabel 6: Verwachtingswaarden van MS-termen in design II: woorden genest binnen de interactie van treatment A en B, respondenten gekruist met woorden en treatments (N.B. a is het aantal niveaus van treatment A, b het aantal niveaus vantreatment B, w is het aantal replicaties per A × B interactie, en r is het totale aantal respondenten).
Uit bovenstaande verwachtingswaarden voor de 9 variantiebronnen in dit statistisch model valt af te leiden dat een reguliere F-ratio voor toetsing van A, B of de interactie van A en B niet voorhanden is. Net zoals bij design I zal ook hier een quasi F-ratio berekend moeten worden. De drie quasi F's voor de toetsing van A, B respectievelijk de interactie tussen A en B zijn successievelijk: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 334]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
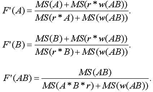 De bij deze drie quasi F-ratio's behorende vrijheidsgraden moeten - alweer - benaderd worden via de daartoe geëigende formules (zie paragraaf 4). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5.1 De verwerking van data in design IIDe berekening van de drie quasi F's in design II lichten we weer toe aan de hand van een concreet (getallen) voorbeeld. We gaan uit van twee gefixeerde factoren A en B (elk met twee niveaus); de random factor ‘woorden’ (w, met twee niveaus) is genest binnen de interactie van A en B. Verder nemen we aan dat er 8 proefpersonen (r) aan het experiment deelnemen; deze proefpersonen vormen eveneens een random factor die volledig gekruist is met de random factor ‘woorden’ en de twee gefixeerde factoren A en B.
Tabel 7: Fictieve dataset voor design II: woorden genest binnen de interactie van treatment A en B, respondenten gekruist met woorden en treatments.
Ook voor dit design zijn weer twee SPSS-runs nodig.Ga naar eind13
Tabel 8: SPSS-setup voor de analyse van design II (zie ook tabel 7).
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 335]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 9: Resultaten van de eerste MANAVO voor Design II.
De eerste run van manova levert 6 van de in totaal 8 MS-termen op die nodig zijn bij de berekening van de drie quasi F's in design II: MS(A) ter grootte van 43.89 bij 1 vrijheidsgraad, MS(B) ter grootte van 19.14 bij 1 vrijheidsgraad en MS(AB): deze bedraagt 1.89 bij 1 vrijheidsgraad. De drie daarbij behorende error-termen MS(r x A), MS(r x B) en MS(r x A x B) bedragen respectievelijk 7.85, 1.75 en 4.00, elk met 7 vrijheidsgraden.Ga naar eind14 In de tweede MANOVA-run wordt gespecificeerd dat de items/woorden/messages genest zijn binnen de interactie van beide treatments (wsdesign). Deze run levert de twee andere MS-schattingen op die nodig zijn voor de berekening van de drie quasi F's: MS(w(AB)) bedraagt 2.89 bij 4 vrijheidsgraden, MS(r x w(AB)) wordt geschat op 3.50 bij 28 vrijheidsgraden (zie uitkomsten Tabel 10).
Tabel 10: Resultaten van de tweede MANOVA voor Design II.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 336]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De twee runs hebben de ingrediënten opgeleverd met behulp waarvan de drie quasi-F's berekend kunnen worden: 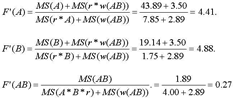 De vrijheidsgraden (voor F'(A)) bedragen: 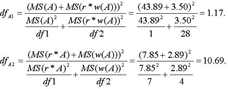 Voor het effect van treatment A geldt: F' = 4.41 (bij dfA1 = 1, dfA2 = 11; p = 0.06). We moeten derhalve concluderen dat - strikt genomen - de verschillen tengevolge van treatment A niet gegeneraliseerd kunnen worden. Voor treatment B en het interactie-effect krijgen we na enig rekenwerk respectievelijk: F'(B) = 4.88 (dfB1 = 1, dfB2 = 9; p = 0.054), en F'(AB) = 0.27 (dfAB1 = 1, dfAB2 = 11; p = 0.61). Dus noch het effect van treatment A, noch dat van B, noch het interactie-effect kan met vertrouwen gegeneraliseerd worden. Zouden we daarentegen uitgaan van een fixedeffect analyse (vgl noot 14), dan blijken de effecten van treatment A en B - ten onrechte overigens - wél gegeneraliseerd te kunnen worden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6. Design III: woorden genest binnen treatment, respondenten genest binnen woordenIn dit design, een tussen-proefpersonen ontwerp, figureert één onafhankelijke variabele (een gefixeerde factor) en twee random replicatiefactoren (woorden en respondenten) die hiërarchisch ten opzichte van elkaar geordend zijn: de woorden zijn genest binnen elk niveau van de treatment, de respondenten zijn genest binnen elk woord - met dien verstande dat elke persoon slechts één woord/message binnen een niveau van de treatment krijgt aangeboden. Een hypothetisch voorbeeld van een dergelijk design betreft het volgende: stel dat een persuasie-onderzoeker de overtuigingskracht van advertenties met en zonder woordspelingen wil onderzoeken (=gefixeerde factor). In de dagbladen en media treft hij slechts 5 advertenties met woordspelingen aan; deze contrasteert hij met 5 (door hemzelf gemanipuleerde) niet-woordspelige advertenties. Aan onafhankelijke, grote groepen proefpersonen vraagt hij | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 337]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
nu telkens één advertentie te beoordelen op een aantal relevante beoordelingsschalen (overtuigend? prikkelend? aardig? enzovoort). Dit design, een recht-toe-recht-aan ‘single-factor independent-group’ design, is in het bijzonder geschikt voor die situaties waarin een onderzoeker gemakkelijk over grote aantallen proefpersonen kan beschikken, terwijl de voorraad messages waaruit geput kan worden, beperkt is. Nog een voorbeeld van dit type design, nu uit een geheel andere discipline dan die van het taalwetenschappelijk bedrijf: de onderwijsresearch (het betreffende voorbeeld is eerder door ons uitvoerig toegelicht aan de hand van het two-group, experimental-control group design (o.c. 2005: 111-112). Stel dat een onderwijsresearcher de effectiviteit van een nieuw ontwikkelde didactiek wil toetsen, en deze contrasteert met een conventionele. Om een ‘confounding’ van de effecten van de (aard van de) didactiek met de onderwijskwaliteiten van de twee docenten die de experimentele respectievelijk de controle-didactiek implementeren te vermijden, introduceert de onderwijsonderzoeker in dit design een random variabele ‘docent’ die genest is binnen de aard van de didactiek - de leerlingen zijn verder genest binnen elke docent. De ‘woorden’ zijn in dit design dus vervangen door ‘docenten’, de respondenten door ‘leerlingen’. In ons eerste voorbeeld van dit design is sprake van drie variantiebronnen: 1. een gefixeerde variabele ‘Advertentietype’, met twee niveaus: 1. met woordspelingen 2. zonder woordspelingen; 2. een replicatiefactor ‘woorden/messages’ (in dit geval de 5 advertenties); 3. een replicatiefactor ‘proefpersoon’. Beide replicatiefactoren worden verondersteld random factoren te zijn. Het statistisch model voor dit design is als volgt:
Tabel 11. Verwachtingswaarden van MS-termen in design III: woorden genest binnen treatment, respondenten genest binnen woorden. (N.B. w is het aantal replicaties per treatment-niveau; r is het aantal respondenten per woord).
Met behulp van de volgende (reguliere) F-ratio kan het effect van de treatment getoetst worden:  waarbij t het aantal niveaus van de treatment-variabele en w het aantal message-replicaties per niveau van de treatmentvariabele betreft
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6.1 De verwerking van data in design IIITer illustratie van de berekening van de F-ratio voor design III gebruiken we dezelfde numerieke gegevens als die in de vorige analyses; alleen worden in dit design alle woorden aan andere steekproeven respondenten zijn voorgelegd. Er wordt gebruik gemaakt van acht steekproeven van acht respondenten, zodat de totale steekproef uit 64 respondenten bestaat. In tabel 12 is dit design III schematisch weergegeven voor het geval er vier woorden (of vier advertenties of docenten) per conditie aanwezig zijn. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 338]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 12: Schematische weergave van Design III (n=aantal observaties per woord).
In dit voorbeeld wordt uitgegaan van 4 woorden/messages per conditie. De getallen aan de hand waarvan de berekening van de F-ratio geïllustreerd wordt, zijn overigens dezelfde als die uit tabel 2, met dien verstande dat de eerste vier items (woorden) in conditie 1 geobserveerd zijn en de tweede vier in conditie 2. De SPSS-setup voor design III is in principe simpelGa naar eind15, hoewel er wel (weer) enig handmatig rekenwerk verricht moet worden. In de eerste run wordt naast de gemiddelden en de standaarddeviatie per conditie ook de variantie tussen condities uitgerekend; in de tweede en derde run wordt per conditie de (teller van de) variantie geschat. Tezamen geven deze de variantie tussen woorden binnen condities.
Tabel 13: SPSS-setup voor de analyse van Design III.
In de tweede en derde run wordt de variantie tussen woorden per conditie uitgerekend. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 339]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Deze runs leveren de volgende resultaten.
Tabel 14: Resultaten van de runs voor design III.
De teller van de variantie tussen items binnen condities kan uitgerekend worden als de som van de betreffende kwadratensommen (26.094 + 4.618), hetgeen de waarde 5.12 (30.712/6) oplevert als schatting van de variantie tussen items binnen condities. Rekening houdend met de toevalsverschillen tussen items door deze als een random factor te conceptualiseren krijgt men:
Met 1 vrijheidsgraad voor de teller en [2* (4-1) =] 6 vrijheidsgraden voor de noemer, levert dit een overschrijdingskans van 0.16 op.Vat men - ten onrechte overigens - de verschillen tussen items/woorden/messages op als een gefixeerd effect, dan blijkt het verschil tussen de beide condities - precies zoals bij de vorige analyses - wél significant (p = .002). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7. Design IV: woorden genest binnen respondenten, respondenten genest binnen treatmentDe keuze voor design III versus design IV (beide tussen-proefpersonen ontwerpen) is onder meer afhankelijk van de vraag of de onderzoeker makkelijker aan messages dan aan proefpersonen kan komen; is het eerste het geval, dan ligt design IV voor de hand, is het laatste het geval, dan zal de keuze op III vallen. Precies zoals design III is ook design IV een hiërarchisch design waarbij de ene replicatiefactor genest is in de andere, zij het dat nu - anders dan in design III waar de proefpersonen genest zijn binnen de messages - de messages juist genest | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 340]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
zijn binnen de proefpersonen. Elke persoon in dit design wordt blootgesteld aan zijn eigen, ‘unieke’ message-set. Uiteraard heeft deze configuratie consequenties voor het statistisch model en de daaruit af te leiden F-ratio:
Tabel 15: Verwachtingswaarden van MS-termen in design IV: woorden genest binnen respondenten, respondenten genest binnen treatment (N.B. r is het aantal proefpersonen per treatment-niveau, w is het aantal replicaties/woorden per proefpersoon)
De (reguliere) F-ratio ter toetsing van het treatment-effect heeft de volgende vorm:
df1 = t - 1, df2 = t (r-1), waarbij t het aantal niveaus van de treatment-variabele en r het aantal respondenten per treatment-niveau betreft | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7.1 De verwerking van data in design IVDe gegevens waarop we ons baseren, zijn weer dezelfde als die in de eerdere voorbeelden, met dien verstande dat alle respondenten nu andere ‘woorden’ voorgelegd krijgen (in feite wordt dus tabel 2 in SPSS gebruikt). Hoewel de setup ook voor dit voorbeeld redelijk eenvoudig is, moet er naderhand toch weer het één en ander met de hand berekend worden.
Tabel 16: SPSS-setup voor de analyse van design IV
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 341]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Dit levert (o.a.) de volgende output:
Tabel 17: Resultaten voor design IV
Nu de variantie per conditie bekend is, kan de ‘gepoolde’ kwadratensom uitgerekend worden:Ga naar eind16 deze bedraagt 24.56 (nl.: 2.669*7+0.839*7). De gemiddelde kwadratensom is dan 1.75 (nl.: 24.56/(2*(8-1)). Nu kan de toetsingsgrootheid F berekend worden volgens:
met dfteller = 2-1 en dfnoemer = 14. De hierbij behorende overschrijdingskans is 0.001, zodat de nulhypothese verworpen kan worden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
8 ConclusiesIn deze bijdrage is geïllustreerd dat voor multiple message designs de constructie van een correcte F-ratio (en dus een correcte toetsing van het treatment-effect) bepaald géén eenvoudige zaak is. Het is verstandig om hiermee rekening te houden voordat een experiment opgezet wordt; dit kan veel problemen en frustraties voorkomen. Wellicht bieden de in dit artikel besproken designs, die redelijk frequent voorkomen, afdoende aanknopingspunten voor de berekening van een correcte toetsingsgrootheid. De gegeven design-voorbeelden zijn echter geenszins in generaliserende zin toe te passen op soortgelijke, op het oog verwante onderzoeksontwerpen: de onderzoeker zal zich er telkens van moeten vergewissen dat het door hem gekozen specifieke onderzoeksontwerp de facto identiek is aan dan wel een verbijzondering betreft van de in dit artikel gegeven voorbeelden. Immers, marginale verschillen in onderzoeksontwerp kunnen leiden tot grote verschillen in de te berekenen toetsingsgrootheden. Tot slot: het verdient aanbeveling om voor de feitelijke uitvoering van een experiment het betreffende design door te rekenen met behulp van gefingeerde data-sets. Deze procedure kent twee grote voordelen: (1) de wijze van data-analyse is al bekend vóórdat de gegevens verzameld zijn - statistische ad hoc-oplossingen worden daardoor voorkomen; (2) er wordt informatie verkregen over de power van de toets, hetgeen aanleiding kan zijn om meer dan wel minder gegevens te verzamelen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 345]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||