
Tijdschrift voor Taalbeheersing. Jaargang 27
(2005)– [tijdschrift] Tijdschrift voor Taalbeheersing–
[pagina 106]
| |||||||||||||||||||||||||||||||||
Bert Meuffels en Huub van den Bergh
| |||||||||||||||||||||||||||||||||
1. InleidingEen truïsme - zo zal menige lezer de (hoofd)titel van dit artikel kenschetsen: natuurlijk is de ene tekst de andere niet! Hoeft dat nog enig betoog? Kennelijk wel, tenminste als men afgaat op het gekozen design en de daarbij aansluitende statistische data-verwerking in het empirisch-tekstuele onderzoek waarover door taalbeheersers de afgelopen dertig jaar in dit Tijdschrift voor Taalbeheersing is gerapporteerd. Het tekstuele aspect van dat betreffende empirisch onderzoek vatten we hier heel ruim en divers op: het kan gaan om empirisch onderzoek waarin woorden centraal staan (bijvoorbeeld onderzoek naar de spelling van bepaalde woordvormen), zinnen (bijvoorbeeld onderzoek naar de verwerking van retorische vragen), korte teksten (bijvoorbeeld onderzoek naar de begrijpelijkheid van bijsluiters) of lange teksten, qua omvang variërend van voorlichtingsfolders die een paar pagina's beslaan (bijvoorbeeld onderzoek naar het persuasieve effect van anti-alcoholcampagnes van de overheid) tot complete boekwerken als computerhandleidingen (bijvoorbeeld onderzoek naar de snelheid waarmee onervaren gebruikers in staat zijn het betreffende apparaat aan te sluiten en ‘aan de praat te krijgen’). De evidente fouten die in dit breed geconcipieerde onderzoeksveld keer op keer worden gemaakt - fouten zowel wat | |||||||||||||||||||||||||||||||||
[pagina 107]
| |||||||||||||||||||||||||||||||||
betreft de keuze van een adequaat onderzoeksontwerp als de keuze van een verantwoorde statistische toetsingsgrootheid (meestal een of andere vorm van F-ratio) - impliceren in feite de ontkenning van het adagium: ‘de ene tekst is de andere niet’, en introduceren daarmee een enorme hoeveelheid ruis in het betreffende onderzoeksveld. Immers, op grond van de door een onderzoeker verzamelde empirische data, data die nu juist worden verzameld met het oog op confirmatie dan wel falsificatie van een theorie/hypothese, kan als gevolg van methodologisch feilen in de onderzoeksopzet en/of inadequate data-verwerking onmogelijk gediscrimineerd worden tussen (pseudo-) falsificatie en (pseudo-) confirmatie van de betreffende theorie/hypothese, ook al mag dan de onderzoeker zelf met grote stelligheid beweren dat zijn data eenduidig wijzen in de richting van confirmatie (of falsificatie). De hier gewraakte fouten die in het licht van de ontwikkeling van een onderzoeksveld zonder meer als catastrofaal gekenschetst kunnen worden, komen zo frequent voor dat een aparte behandeling van de daarmee samenhangende methodologische en statistische problematiek ons meer dan wenselijk lijkt.
In 1973 verscheen er in het tijdschrift Journal of Verbal Learning and Verbal Behavior een inmiddels klassiek geworden artikel van de hand van de psycholinguïst Clark, waarin deze openlijk en zonder omwegen taalonderzoekers (door hem getypeerd als ‘investigators of words, sentences, and other language materials’) ervan beschuldigde dat zij zich in hun kwantitatief-empirisch onderzoek bezondigden aan wat hij betitelde als ‘the-language-asfixed-effect fallacy’: een drogreden dus. Clark's kritiek beperkte zich niet tot incidentele wetenschappers, maar betrof in feite de gehele taalwetenschappelijke discipline. In antwoord op de door hemzelf gestelde vraag hoeveel taalwetenschappers in de jaren vijftig en zestig zich dan wel schuldig zouden maken aan deze language-as-fixed-effect fallacy, deze grove wetenschappelijke denkfout, stelde Clark even kort als krachtig: ‘The answer, sad to say, is almost everyone.’ (Clark 1973: 355). Daar kon het forum van wetenschappelijke taalonderzoekers het mee doen. Ook al treft men de door Clark geïntroduceerde drogreden nimmer aan op de canonieke lijstjes van drogredenen die traditioneel, bij wijze van conventie, door argumentatietheoretici als ‘bedrieglijke redenering’, ‘valse zet’ of ‘denkfout’ worden gecategoriseerd, de languageas-a-fixed-effect drogreden is niet meer weg te denken uit het merendeel van de methodologisch en statistisch georiënteerde literatuur: in vrijwel elk handboek treft men wel enkele paragrafen of hoofdstukken aan die gewijd zijn aan Clark's vernietigende analyse van de toenmalige taalwetenschappelijke onderzoekspraktijk die volgens hem gebukt ging onder de terreur van een evidente drogreden (zie bijvoorbeeld Keppel 1982 voor een puur statistische beschouwing, met name Appendix C (Analysis of Designs with Random Factors); zie voor een meer methodologisch getinte analyse: Jackson 1992). Ook in dit tijdschrift, het Tijdschrift voor Taalbeheersing, treft men niet zelden verwijzingen aan naar Clark's invloedrijke publicatie (vooral wanneer het gaat om de statistische analyse van de onderzoeksgegevens, en daarbij de toetsingsgrootheden F1, F2 of het zogenaamde F1 x F2 criterium worden gehanteerd). Zo'n drie decennia na het verschijnen van Clark's geruchtmakende artikel echter blijken diens ideeën alsmede zijn voorstellen tot verbetering van de door hem verguisde praktijk merkwaardigerwijze niet, althans naar ons oordeel onvoldoende te zijn doorgedrongen tot de wetenschappelijke gemeenschap, inclusief de kwantitatief-empirisch georiënteerde taalonderzoekers die de afgelopen jaren in dit tijdschrift publiceerden. Het gaat bij deze fixedeffect fallacy kennelijk om een hardnekkig en weerbarstig probleem. | |||||||||||||||||||||||||||||||||
[pagina 108]
| |||||||||||||||||||||||||||||||||
In een analytisch-beschrijvend (meta-)onderzoek van empirische artikelen die in de periode 1979-2003 in dit tijdschrift verschenen zijn, zullen we de omvang van de methodologische en statistische problematiek die verbonden is aan de language-as-a-fixed-effect fallacy, over de afgelopen twee decennia proberen vast te stellen. De deplorabele resultaten van dit analytisch-beschrijvend onderzoek kunnen gezien worden als een legitimering van de noodzaak tot deze publicatie. Het is - het zij met nadruk gesteld - in het geheel niet onze bedoeling om aan de hand van de resultaten van dit meta-onderzoek contemporaine onderzoekers die de afgelopen jaren in dit tijdschrift over de resultaten van hun taalwetenschappelijk onderzoek hebben gepubliceerd, aan de schandpaal te nagelen - integendeel: de teneur van deze bijdrage is positief en constructief. Anders dan Clark die op enigszins malicieuze wijze individuele onderzoekers de oren waste, zullen wij ons van elk (negatief) commentaar op individuele, met naam en toenaam genoemde onderzoekers onthouden, behalve wanneer het ons zelf betreft. Het primaire doel van onze bijdrage ligt toch ook wat op een ander niveau dan het louter inventariseren, beschrijven en becommentariëren van eerder verricht empirisch taalbeheersingsonderzoek waarin al of niet sprake is van de language-as-a-fixed-effect fallacy. In dit artikel willen wij met name een poging doen om in zo begrijpelijk mogelijke termen de door Clark geïntroduceerde fallacy uiteen te zettenGa naar eind1, alsmede de consequenties van deze fallacy te belichten voor de interne en externe validiteit van empirisch taalwetenschappelijk onderzoek. Daarbij zal de door Clark geïntroduceerde fallacy gedissocieerd worden in: 1. een fallacy van methodologische aard, en 2. een fallacy van statistische aard. In deze bijdrage zullen voornamelijk de methodologische implicaties aan de orde worden gesteld; voor een goed begrip is specialistische voorkennis niet vereist. In de bespreking van de methodologische implicaties zullen her en der concrete, toepasbare oplossingen op het vlak van design worden aangereikt waarmee de door Clark gewraakte drogreden in empirisch taalwetenschappelijk onderzoek vermeden kan worden. | |||||||||||||||||||||||||||||||||
2. De language-as-a-fixed-effect fallacyOnze beschouwingen over de language-as-a-fixed-effect fallacy (voortaan kortheidshalve: fixed-effect fallacy) beperken zich tot dat type kwantitatief-empirisch onderzoek waarbij inferentieel-statistische methoden en technieken worden toegepast om de in een steekproef verkregen talige of tekstuele resultaten (betreffende ‘words, sentences, and other language materials’) te generaliseren naar een groter geheel: de populatie. In de regel worden er in kwantitatief-empirisch onderzoek twee verschillende soorten statistiek toegepast: (1) beschrijvende statistiek (ook wel descriptieve statistiek genoemd) en (2) inferentiële statistiek (ook wel getypeerd als inductieve statistiek). Het doel van het eerste type statistiek, de beschrijvende statistiek, is het reduceren van een groot aantal empirische gegevens (‘data’) tot slechts een paar inzichtelijke statistische grootheden of tot slechts tot één enkele inzichtelijke statistiek. Het gemiddelde, de range, de standaarddeviatie, enzovoort, het zijn allemaal prototypische voorbeelden van beschrijvende (data-reducerende) statistieken. De empirisch onderzoeker die descriptieve statistiek op zijn data wil toepassen, ziet zich gesteld voor een keuzeprobleem. Hét kardinale probleem bij de toepassing van beschrijvende statistiek is immers de keuze van een ‘unbiased’ statistiek: welke beschrijvende statistische grootheid is in staat de data zo spaarzaam en zo inzichtelijk mogelijk te beschrijven, zonder | |||||||||||||||||||||||||||||||||
[pagina 109]
| |||||||||||||||||||||||||||||||||
dat daarbij de oorspronkelijke gegevens al te zeer geweld aangedaan worden en zonder dat de werkelijkheid al te zeer vertekend wordt? Het is al tijden genoegzaam bekend dat men met statistieken kan manipuleren en de argeloze buitenstaander een verwrongen, gekleurd en bevooroordeeld beeld van de werkelijkheid kan voorspiegelen (zie voor een aantal fraaie voorbeelden: Huff 1954).Ga naar eind2 In dit kader wordt wel vaker verwezen naar de climactische uitspraak van de Britse staatsman en schrijver Benjamin Disraeli (1804-1881): ‘There are three kinds of lies: lies, damned lies and statistics!’. Verwijzingen als deze worden niet zelden als argument gebruikt om de (overigens onjuiste) stelling te verdedigen dat je met statistiek zowat alles kunt bewijzen, om het even wat.
Ook bij de fixed-effect fallacy is er ongetwijfeld sprake van een statistische ‘truc’, wellicht zelfs van een ‘leugen’. Ter nuancering van de typering ‘leugen’ moet als verzachtende omstandigheid worden aangevoerd dat degenen die zich in hun taalwetenschappelijk werk aan deze fixed-effect fallacy schuldig maken, zich door de bank genomen in het geheel niet bewust zijn van het feit dat zij ook een kapitale denkfout - een drogreden - begaan. Van bewuste misleiding of manipulatie is dus bij deze drogreden absoluut geen sprake, wat de betreffende drogreden misschien wel des te venijniger maakt! Met de door Clark geïntroduceerde term ‘fixed-effect fallacy’ wordt niet verwezen naar een van de vele, ook bij het grote publiek min of meer bekende trucs en machinaties binnen de beschrijvende statistiek, maar juist gedoeld op een drogreden binnen de inferentiële statistiek: een drogreden waarvan het bestaan zelfs binnen het toenmalige forum der wetenschappers - de ingewijden en de ter zake kundig geachten bij uitstek - vrijwel onbekend was. Een empirisch taalonderzoeker zal zich in de statistische analyse en verwerking van de gegevens zelden willen beperken tot uitsluitend beschrijvende technieken: in de regel immers wil hij de empirische resultaten, verkregen bij een specifieke groep proefpersonen aan wie responsies zijn ontlokt op basis van specifiek talig materiaal, generaliseren naar een groter domein (zowel wat proefpersonen als wat talig materiaal betreft). Op dat groter domein immers heeft zijn onderzoekshypothese - die als wetenschappelijke bewering in de vorm: ‘Als A, dan (waarschijnlijk) B’, qualitate qua generiek, dus niet-singulier van aard is - in feite betrekking. Inductieve statistiek helpt de onderzoeker bij deze sprong van (onderzochte) steekproef naar (niet-onderzochte) populatie. De fixed-effect fallacy nu duidt op een statistische fout die bij dit generaliseren, bij deze inductieve sprong van steekproef naar populatie gemaakt wordt. Elke toepassing van inductieve statistiek resulteert in een waarschijnlijkheidsuitspraak die de mate van (on) zekerheid kwantificeert waarmee de resultaten, verkregen binnen een specifieke steekproef, naar de bedoelde populatie gegeneraliseerd kunnen worden (‘de kans dat de gevonden resultaten in de steekproef van toepassing verklaard mogen worden op de populatie, is zus en zo groot’). In het gebruikelijke statistische jargon wordt deze kans aangeduid als statistisch significantieniveau (en ook wel als alpha-niveau of kans op een fout van de eerste soort). Een onderzoeker die een statistisch significant resultaat in zijn onderzoek heeft behaald, mag de resultaten die behaald zijn in een steekproef - gegeven de onzekerheidsmarges gedicteerd door het conventionele significantieniveau - van toepassing verklaren op en generaliseren naar de (niet-onderzochte) populatie; dat hij in die generalisatie in 5 van de 100 gevallen toch een fout maakt, wordt door het wetenschappelijk forum bij conventie als een acceptabel foutenniveau beschouwd. | |||||||||||||||||||||||||||||||||
[pagina 110]
| |||||||||||||||||||||||||||||||||
Precies zoals het geval is bij de beschrijvende statistiek, zijn er ook in de inferentiële statistiek vele trucs mogelijk die al dan niet bewust kunnen worden ingezet om de werkelijkheid naar iemands hand te zetten. Het meest bekende voorbeeld in dit verband is het vergroten van de steekproef: als je de steekproef maar groot genoeg maakt, kan je elk verschil of elke samenhang (hoe klein en triviaal ook) statistisch significant maken. Concreet voorbeeld: in een steekproef van 10 personen dient een correlatie (i.c.: pmc) minstens .632 te zijn om tot een statistisch significant resultaat te kunnen worden uitgeroepen (getoetst op een alpha-niveau van 0.05, tweezijdig), maar bestaat de steekproef uit 1000 personen, dan is opeens een triviale correlatie van 0.062 al voldoende om de vlag uit te hangen. Degenen die enigszins vertrouwd zijn met de methoden en technieken van de inductieve statistiek, laten zich door dergelijke uitkomsten niet misleiden: zij weten immers dat een statistisch significant resultaat niet verward mag worden en in definitorische zin niet gelijk gesteld mag worden aan een in praktisch opzicht significant resultaat, en dat het inductief-statistische begrip ‘statistische significantie’ slechts dan adequaat geïnterpreteerd kan worden, indien rekening wordt gehouden met drie andere parameters: 1. steekproefgrootte 2. eenzijdige versus tweezijdige toetsing 3. effect-grootte. Waar precies zit nu de generalisatiefout bij de fixed-effect fallacy? Kort samengevat: taalonderzoekers die zich schuldig maken aan deze drogreden, claimen dat hun specifieke talige materiaal, verkregen in een experimentele situatie bij een specifieke groep proefpersonen, gegeneraliseerd mag worden naar taal-in-het-algemeen, maar de inductief-statistische informatie die deze taalonderzoekers ten bewijze van deze claim verstrekken, is niet alleen inadequaat - sterker, die is helemáál niet relevant voor de rechtvaardiging van deze claim.Ga naar eind3 | |||||||||||||||||||||||||||||||||
3. De kern van de fixed-effect fallacyHoe kan, als we Clark mogen geloven, de gemeenschap van taalwetenschappers zich unaniem zo ernstig vergissen? Deze vraag is niet of nauwelijks in deterministische, niet-speculatieve termen te beantwoorden; wat daarentegen wellicht wel met enige zekerheid beantwoord kan worden, is de vraag waar de kern (‘de bron’, de ‘oorzaak’) van de fixed-effect fallacy gelokaliseerd moet worden: de oorsprong van de fixed-effect fallacy moet gezocht worden in een conceptuele verwarring van gefixeerde met random factoren. Het onderscheid tussen gefixeerde en random factoren is een van oudsher bekende dichotomie die onder meer relevant is voor de kwantitatief-statistische analyse van empirisch-experimentele onderzoeksgegevens (via bijvoorbeeld variantie-analyse). Ten onrechte worden bij de fixed-effect drogreden in de (inductief-) statistische analyse de random (talige) factoren opgevat als gefixeerde factoren. De dramatische consequentie van deze misclassificatie is wat in statistische kringen getypeerd wordt als ‘positieve bias’: de berekende kansen (uitgedrukt in termen van statistisch significantieniveau, alpha-niveau of kans op een fout van de eerste soort) duiden zonder meer op de mogelijkheid tot generalisatie, terwijl bij nadere beschouwing en analyse blijkt dat een dergelijke mogelijkheid geheel en al afwezig is.Ga naar eind4 Anders uitgedrukt: de berekende kansen suggereren dat de onderzoeker ervan mag uitgaan dat het door hem in de steekproef aangetroffen verschil tussen bijvoorbeeld het leesgemak van twee verschillende teksten (bijvoorbeeld een abstracte tekst versus een concrete tekst) gegeneraliseerd mag worden en dus ook voor de populatie geldt (d.w.z. voor andere representanten van abstracte teksten in het algemeen en andere representanten | |||||||||||||||||||||||||||||||||
[pagina 111]
| |||||||||||||||||||||||||||||||||
van concrete teksten in het algemeen), terwijl in feite in de bedoelde populatie geen enkel verschil tussen het leesgemak van beide typen teksten kan worden aangetroffen. Kortom, de fixed-effect fallacy leidt als gevolg van het feit dat random factoren (ten onrechte) worden opgevat als gefixeerde factoren, tot wat in statistische kringen ook wel genoemd wordt: alpha-inflatie. Onderzoekers claimen op grond van de berekende kansen (p-waarden) dat hun hypothese door de empirische gegevens ondersteund wordt, terwijl dat in feite in het geheel niet het geval is. | |||||||||||||||||||||||||||||||||
4. Gefixeerde en random factorenHet is gebruikelijk om in experimentele proefopzetten (in jargon: designs) een onderscheid te maken tussen gefixeerde en random factoren (ook wel a-selecte of toevallige factoren genoemd). Het onderscheid tussen deze twee typen factoren kan wellicht het best worden verduidelijkt aan de hand van wat voorbeelden - definities (er zijn er verschillende die onderling nogal uiteenlopen) helpen in dit opzicht niet zo veel. Stel dat een onderzoeker in een effectonderzoek wil nagaan of een door hem ontwikkelde schrijfdidactiek superieur is aan een conventionele schrijfdidactiek. Hij kiest voor een conventioneel two-group, experimental-control-group design waarin de ene klas gedurende een bepaalde periode - zeg een jaar - de experimentele didactiek gaat volgen bij leerkracht A, terwijl de andere klas in die periode wordt onderwezen door leerkracht B via een conventionele schrijfdidactiek (in dit ontwerp zijn de twee klassen random, d.w.z. op grond van het toeval toegewezen aan een van beide didactieken)(zie figuur 1). 
Figuur 1: Two-group, experimental-control group design, met aard van de didactiek als gefixeerde factor
In dit ontwerp staat de variabele: ‘aard van de didactiek' te boek als gefixeerde factor (met 2 niveaus: niveau 1=experimentele didactiek; niveau 2=controle didactiek). De variabele ‘aard van de didactiek’ wordt gefixeerd genoemd doordat de niveaus van deze factor precies dát contrast belichamen waarin de onderzoeker in theoretische zin geïnteresseerd is. Variabelen die in theoretisch opzicht belangrijk zijn, worden gemeenlijk opgevat als gefixeerd; ze worden ook wel omschreven als ‘explanatory’ variabelen. Verschillen in schrijfprestaties tussen de twee schrijfdidactieken kunnen in het gehanteerde design - om de metafoor door te trekken - dan ook toegeschreven worden aan c.q. ‘verklaard’ worden door de variabele ‘aard van de didactiek’, aangenomen dat de experimentele didactiek na een jaar inderdaad tot betere schrijfprestaties leidt. Op dit - in de jaren zestig en zeventig frequent gebruikt design, vooral in de onderwijsresearch - is uiteraard methodologische kritiek mogelijk: de interne validiteit van het onderzoek is belabberd, dat wil zeggen: in het gehanteerde design worden plausibele alternatieve | |||||||||||||||||||||||||||||||||
[pagina 112]
| |||||||||||||||||||||||||||||||||
verklaringen van een positieve uitkomst (i.c. de experimentele didactiek is superieur aan de standaarddidactiek) niet of althans in onvoldoende mate uitgesloten. Een geconstateerde superioriteit van de experimentele didactiek kan, bijvoorbeeld, ook worden toegeschreven aan de superieure didactische kwaliteiten van de specifieke leerkracht die nu net deze experimentele didactiek onderwezen heeft (A is enthousiast, weet te inspireren, enzovoort; B daarentegen loopt tegen zijn pensioen en is niet van zins zich nog ooit ergens druk over te maken). Het methodologische probleem met dit ontwerp is dat de aard van de didactiek ‘confounded’ (verstrengeld) is met de variabele ‘leerkracht’. Om nu de invloed van beide variabelen (dus zowel de aard van de didactiek als de didactische kwaliteiten van de leerkracht) op de schrijfprestaties van de leerlingen te ontknopen en uiteen te rafelen, kan een ander - voor de hand liggend - ontwerp gekozen worden waarin de leerkracht als random variabele wordt geïncorporeerd.Ga naar eind5 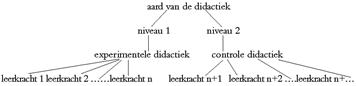
Figuur 2: Two-group, experimental-control group design, met aard van de didactiek als gefixeerde factor en leerkracht als random factor
Anders dan het in figuur 1 weergegeven design waarin aan elk niveau van de gefixeerde variabele ‘aard van de didactiek’ slechts één leerkracht is toegewezen, wordt in dit design op elk van de twee niveaus van de gefixeerde factor een aantal leerkrachten, zeg 5, 10 of 20 ingeschakeld (het precieze aantal leerkrachten dat een van de twee didactieken moet implementeren, is uiteraard afhankelijk van puur praktische kwesties als beschikbaarheid, praktische uitvoerbaarheid, enzovoort). De leerkracht figureert in dit ontwerp - weergegeven in figuur 2 - als random factor. Juist het incorporeren van deze random factor in het onderzoeksontwerp optimaliseert de interne validiteit. In scherp contrast met gefixeerde factoren gaat de theoretische belangstelling van de onderzoeker bij random factoren in het geheel niet uit naar eventuele verschillen tussen de niveaus van die random factoren. Zo is de schrijfvaardigheidsonderzoeker in ons voorbeeld, zo nemen we gemakshalve even aan, ook helemaal niet geïnteresseerd in eventuele verschillen in schrijfprestaties tussen verschillende docenten - nee, het gaat hem primair om verschillen tussen de didactieken, ongeacht de wijze waarop die didactiek via een ‘toevallige’ leerkracht geïmplementeerd is. Anders uitgedrukt: de niveaus van een random variabele zijn - beschouwd vanuit het onderzoeksdoel van een onderzoeker - arbitrair, ze representeren noch concretiseren specifieke researchdoeleinden. Een en ander betekent dat het onderscheid tussen gefixeerde en random factoren geen ‘clear cut’, ondubbelzinnige en onveranderlijke classificatie behelst maar een analytischfunctioneel onderscheid is waarbij het onderzoeksdoel van doorslaggevende betekenis is voor de typering van variabelen als fixed of random: een variabele die in het ene onder- | |||||||||||||||||||||||||||||||||
[pagina 113]
| |||||||||||||||||||||||||||||||||
zoek als random factor opereert, kan in een ander onderzoek best als gefixeerd worden beschouwd. Zo zou men in bovenstaand voorbeeld de leerkracht als gefixeerde variabele in het design kunnen invoeren (althans specifieke eigenschappen die worden toegekend aan de leerkracht), bijvoorbeeld wanneer men in theoretische zin veronderstelt dat de wijze van lesgeven (leerkracht: inspirerend versus niet-inspirerend) van doorslaggevend belang is voor de kwaliteit van schrijfprestaties. Ook in dit laatste voorbeeld echter blijft het dan overigens raadzaam omwille van de interne validiteit de gefixeerde factor ‘type leerkracht’ (met als niveaus: inspirerend versus niet-inspirerend) door een random factor ‘specifieke leerkracht’ te vertegenwoordigen. Het prototypische voorbeeld van een random factor in gedrags- en taalwetenschappelijk onderzoek vormt uit de aard der zaak de variabele ‘proefpersoon’. De belangstelling van de modale onderzoeker gaat zelden tot nooit uit naar de (min of meer als toevallig beschouwde) verschillen tussen de proefpersonen in de getrokken steekproef - integendeel, het gaat hem primair om (de verschillen tussen de niveaus van) de ‘explanatory’ variabelen, om verschillen tussen condities/treatments die hij met behulp van inductieve methoden wil generaliseren naar een grotere, niet-onderzochte populatie waaruit de getrokken steekproef slechts een deelverzameling vormt. Een heel ander criterium dat in praktische zin gebruikt kan worden om te bepalen of een factor als random of gefixeerd beschouwd moet worden, is de zogenaamde ‘vervangingstoets’ of ‘substitutietoets’ (Shavelson & Webb 1991). Indien een specifiek niveau door een willekeurig ander niveau van dezelfde factor vervangen kan worden zonder dat die ingreep enige inhoudelijke consequenties heeft voor het onderzoeksprobleem, dan moet de betreffende factor als een random factor worden opgevat. Zo kan leerkracht 1 in figuur 2 probleemloos worden vervangen door leerkracht 2 (en omgekeerd) zonder dat dit enig gevolg heeft voor de aard van het onderzoeksprobleem - maar dat geldt nu juist niet voor niveau 1 en niveau 2 van de factor ‘aard van de didactiek’; zouden we de experimentele didactiek vervangen door de controle didactiek, verandert het onderzoeksprobleem radicaal. Er zijn in de literatuur nog verscheidene andere criteria voorgesteld om te bepalen of een factor als een random of als een gefixeerde factor moet worden geclassificeerd (bijvoorbeeld de ‘betekenisvolheidtoets’: indien aan elk niveau van een factor een betekenisvolle, inhoudelijke conclusie kan worden verbonden, beschouw de factor dan als gefixeerd), maar de hier genoemde mogen volstaan om het bedoelde onderscheid tussen de twee typen factoren voldoende te verduidelijken.Ga naar eind6 | |||||||||||||||||||||||||||||||||
5. Methodologische implicaties van de fixed-effect fallacyWat is nu het belang van bovenstaande exercitie? Het in methodologisch opzicht cruciale punt waar het hier om draait, is dat talig materiaal (‘words, sentences, and other language materials’ in de woorden van Clark) als random factoren in taalwetenschappelijke designs geïncorporeerd moeten worden teneinde de interne en - en zoals verderop betoogd zal worden - de externe validiteit te optimaliseren. Een van de concrete remedies die Clark voorstelt om de fixed-effect fallacy te vermijden, luidt: kies het juiste onderzoeksontwerp. Hij besteedt aan de methodologische problematiek hieromtrent - om overigens begrijpelijke redenen - betrekkelijk weinig aandacht en concentreert zich verder louter op de, nogal gecompliceerde, statistische kant van de zaak. | |||||||||||||||||||||||||||||||||
[pagina 114]
| |||||||||||||||||||||||||||||||||
Voor Clark is de fixed-effect fallacy dan ook vooral een statistische drogreden: hij gaat in zijn kritische beschouwing al zonder meer uit van de vooronderstelling dat in experimenteel onderzoek waarin hypothesen over taal/teksten/woorden worden getoetst, het talig materiaal als random factor in een design is opgenomen. Deze vooronderstelling is alleszins begrijpelijk en ook terecht als men beseft dat Clark's kritiek in eerste instantie gericht was op de gemeenschap van psycholinguïsten. In de van oudsher sterk experimenteel gerichte psycholinguïstiek was het immers al sinds jaar en dag standaardgebruik (‘tacit knowledge’) om in taalexperimenten de niveaus van de gefixeerde, verklarende (linguïstische) variabelen te representeren door een veelvoud aan talig materiaal (‘words, sentences, and other language materials’), kortom te representeren door een random factor ‘taalmateriaal’ teneinde een confounding van verschillende effecten te vermijden. Ter toelichting het volgende voorbeeld: geen psycholinguïst zou het ooit in zijn hoofd halen - toen niet, in de jaren vijftig en zestig van de vorige eeuw, en nu niet - om een experiment op te zetten naar bijvoorbeeld verschillen in verwerkingscomplexiteit tussen actieve zinnen en hun passieve pendanten (dus ‘zinstype’ fungeert in dit voorbeeld als gefixeerde factor) waarbij hij aan de proefpersonen slechts één actieve en slechts één passieve zin zou aanbieden waarvan hij vervolgens, bijvoorbeeld via een reactietijdmeting, de verwerkingscomplexiteit zou vaststellen. De psycholinguïstische theorie immers heeft betrekking op een klasse, op een categorie die in beginsel oneindig groot is (actieve versus passieve zinnen), terwijl de experimentele implementatie van die categorie in het gegeven voorbeeld uit slechts één, min of meer toevallige idiosyncratische instantiatie van die categorie bestaat. Bij toeval kan juist die ene actieve zin die in het experiment is aangeboden, lastiger blijken dan de passieve zin (bijvoorbeeld doordat de zin qua topic vrij abstract is) terwijl op categoriaal niveau in theoretisch zin precies het omgekeerde is voorspeld en - zo nemen we hier voor ‘the sake of argument’ even aan - ook ‘in werkelijkheid’ het geval is: die werkelijkheid (namelijk dat passieve zinnen lastiger te verwerken zijn dan actieve) zou pas aan het licht (kunnen) komen wanneer grote aantallen min of meer toevallige instantiaties in de experimentele setup zouden worden betrokken. Geconfronteerd met bovenstaande onverwachte uitkomst (de actieve zin is lastiger dan de passieve) concludeert de onderzoeker die gebruik maakt van slechts één instantiatie van de bovengeordende categorie vervolgens ten onrechte dat de oorspronkelijke theorie gefalsifieerd moet worden. Kortom: pseudo-falsificatie! De ene zin is de andere niet, de ene tekst is de andere niet - een truïsme volgens velen dat verder geen rechtvaardiging of nadere uitleg behoeft. De wetenschappelijke praktijk zoals die naar voren komt in dik twintig jaar empirisch-taalwetenschappelijk onderzoek waarover in dit tijdschrift is gepubliceerd, staat echter haaks op datgene wat kennelijk met de mond beleden wordt. Wanneer talig materiaal niet als random factor in een design wordt opgenomen, kan - zoals betoogd - pseudo-falsificatie het gevolg zijn; maar ook het omgekeerde -pseudo-confirmatie - wordt door het gehanteerde design in het geheel niet uitgesloten: de toevallige instantiatie werkt zo uit dat de in het experiment aangeboden actieve zin makkelijker te verwerken blijkt dan de passieve, terwijl op abstract-categoriaal niveau er -anders dan voorspeld - in werkelijkheid helemaal geen verschillen zijn - verschillen die ook niet aan het licht gekomen zouden zijn wanneer toevallig een hele reeks andere instantiaties uit het potentiële domein van actieve en passieve zinnen getrokken zouden zijn. De onderzoeker concludeert in deze situatie ten onrechte dat zijn theorie geconfirmeerd is (dus pseudo-confirmatie). | |||||||||||||||||||||||||||||||||
[pagina 115]
| |||||||||||||||||||||||||||||||||
Het probleem bij de hier gegeven voorbeelden is natuurlijk dat we ‘de werkelijkheid’ niet kennen - daarom wordt nu juist empirisch onderzoek opgezet en uitgevoerd. De hypothetische situaties maken echter duidelijk dat het gebruik van inadequate designs waarin via slechts één talige instantiatie het niveau van een verklarende linguïstische factor is gerepresenteerd, in het geheel niet uitsluiten dat er ruis in een onderzoeksveld wordt geïntroduceerd - sterker, men kan zich afvragen wat überhaupt de zin is van zulk empirisch onderzoek indien de verzamelde data niet kunnen discrimineren tussen 4 verschillende mogelijkheden: 1. reële falsificatie 2. pseudo-falsificatie 3. reële confirmatie en 4. pseudo-confirmatie. Veel, veel meer dan thans het geval is zouden empirisch-kwantitatief georiënteerde taalbeheersers die over hun onderzoek in dit tijdschrift publiceren, moeten (leren) denken in termen van random factoren wanneer het om de concreet-experimentele implementatie van talig materiaal gaat. Wat in de psycholinguïstiek sinds jaar en dag in methodologisch opzicht ‘taken for granted’ is, moet in de taalbeheersing kennelijk nog worden bevochten. Denken in termen van random factoren bij talig materiaal - daar is ongetwijfeld een cultuuromslag voor nodig.
Laten we, ter verduidelijking van (althans een deel van) bovenstaande abstract-hypothetische situaties, de methodologische problematiek waar het hier in feite om draait - interne validiteit - illustreren aan de hand van concreet-empirisch materiaal uit eigen onderzoek, in dit geval empirisch onderzoek naar de beoordeling van drogredenen. De betreffende illustratie zal hopelijk verduidelijken dat het bij de hier aan de orde zijnde problematiek niet alleen om strikt hypothetische kwesties gaat. In een van de vele onderzoeken binnen een wat grootschaliger project (waarin telkens verschillende soorten drogredenen werden onderzocht) moesten proefpersonen (middelbare scholieren van 5-6 vwo) de (on) redelijkheid van tekstfragmenten beoordelen waarin door een discussiant soms wel, soms niet een drogreden werd begaan. Een van de onderzochte drogredenen betrof het argumentum ad hominem. In het hier te bespreken onderzoek werden de drie bekende, traditioneel onderscheiden varianten van deze drogreden onderzocht: de abusive, de circumstantial en de tu quoque-variant, alsmede tekstfragmenten waarin door een van de discussianten helemaal geen drogreden werd begaan. Kortom, in dit onderzoek fungeerde de afwezigheid/aanwezigheid van een drogreden als ‘explanatory’ variabele. Wij concentreren ons hier op de laatste variant, de zogenaamde ‘jij ook’ - bak. Een voorbeeld van een door ons geconstrueerd tekstfragment waarin deze tu quoque -drogreden optreedt en dat gesitueerd werd in de context van een zogeheten wetenschappelijke discussie, is het volgende:
De proefpersonen in dit experimentele onderzoek werd verzocht bij elk tekstfragment (in totaal 48) hun oordeel over de redelijkheid c.q. onredelijkheid van de laatste discussiebijdrage (dus de bijdrage van B) uit te drukken op een 7-punts schaal, variërend van 1=zeer onredelijk tot 7=zeer redelijk. In een van de condities van het experiment was deze tu quoque-drogreden vertegenwoordigd door 4 tekstfragmenten, 4 instantiaties dus; 4 andere gelijksoortige fragmenten werden geconstrueerd waarin door B juist niét drogredelijk werd geargumenteerd. Wij als onderzoekers voorspelden onder andere - op grond van theoretische overwegingen - dat proefpersonen de tu quoque-drogreden minder redelijk zouden vinden dan niet-drogredelijke argumentatie. | |||||||||||||||||||||||||||||||||
[pagina 116]
| |||||||||||||||||||||||||||||||||
In dit design vormt de variabele ‘aard van de discussiebijdrage’ de verklarende, gefixeerde variabele (met 2 niveaus: niveau 1=wel drogreden (i.c. tu quoque); niveau 2= geen drogreden); de random factor ‘tekstfragment’ (i.c. ‘talig materiaal’; instantiatie) kent 4 niveaus en is genestGa naar eind7 binnen elk niveau van deze verklarende, gefixeerde variabele. In onderstaande tabel staan de empirisch verkregen beschrijvende statistieken (gemiddelden + sd's) voor de niveaus van de variabele waar het hier om draait: de random variabele ‘tekstfragment’/instantiatie:
Tabel 1: Gemiddelden (met tussen haakjes: sd) voor elk niveau van de random variabele ‘tekstfragment’ (‘instantiatie’); de random variabele is genest binnen elk niveau van de gefixeerde variabele ‘aard van de discussiebijdrage’ (met 2 niveaus: wel vs. geen drogreden); fr=fragment/instantiatie.
Wat in tabel 1 ogenblikkelijk opvalt, is dat de concrete tekstuele instantiaties van de tu quoque-drogreden binnen elk niveau van de gefixeerde variabele ‘aard van de discussiebijdrage’ afwijkingen vertonen ten opzichte van elkaar, en in incidentele gevallen nogal forse afwijkingen ook. Maar dat is nu precies het kardinale punt waar het in deze methodologische exercitie om draait: random, dat wil zeggen min of meer toevallige, niet-systematische afwijkingen (‘fluctuations due to sampling’) ten opzichte van elkaar manifesteren zich in de data, ongeacht de inspanningen van de onderzoekers op het vlak van testconstructie om zoveel mogelijk potentieel storende variabelen onder controle te houden teneinde er voor te zorgen dat de realisaties/tekstfragmenten in feite equivalent zijn. Wie enige ervaring heeft met het opnemen van talig materiaal (als random factor) in een design, wéét dat zulke fluctuaties in de data eerder regel dan uitzondering zijn. De niveaus van de gefixeerde factor ‘aard van de discussiebijdrage’ (namelijk wél versus geen drogreden), zijn natuurlijk op een legio aantal manieren via tekst instrumenteel te realiseren (er is immers sprake van niet-gesloten klassen), maar kennelijk is de ene realisatie (het ene tekstfragment) de andere niet. De in tabel 1 weergegeven getalsmatige fluctuaties zijn, samenvattend, een uitdrukking van het empirische feit dat de ene tekst de andere niet is - net zo min als de ene proefpersoon de andere is: zulke in de praktijk van het empirisch onderzoek telkens weer aangetroffen fluctuaties zijn het gevolg van random sampling. Proefpersonen en tekst/talig experimenteel materiaal verschillen onderling, zij het op nietsystematische wijze (zo mogen we aannemen); dat impliceert dat beide variabelen random factoren vormen. Tabel 1 maakt voorts duidelijk welke warwinkel en kluwen van misverstanden er kunnen ontstaan wanneer onderzoekers zich in hun experimenten beperken tot slechts één instantiatie van het tekstuele materiaal waarop de hypothese betrekking heeft. Laten we aannemen dat wij als onderzoekers uitsluitend fragment 3 (als operationalisatie voor niveau 1) en fragment 3a (als operationalisatie voor niveau 2 van de gefixeerde variabele) aan de proefpersonen ter beoordeling aangeboden zouden hebben. Zouden we in dit geval onze onderzoekshypothese op de in de steekproef aangetroffen verschillen tussen de redelijkheidsoordelen voor de 2 niveaus van de verklarende variabele ‘wel versus geen drogreden’ statistisch toetsen, dan zouden we op grond van de toetsingsgrootheid tot de conclusie moeten komen dat er | |||||||||||||||||||||||||||||||||
[pagina 117]
| |||||||||||||||||||||||||||||||||
tussen deze 2 niveaus - anders dan verondersteld - in de populatie helemaal geen verschillen zijn, en dat dus de oorspronkelijke theoretische inzichten verworpen moeten worden. Zouden we daarentegen bijvoorbeeld alleen fragment 2 als representatie voor niveau 1 en fragment 1a als representatie voor niveau 2 hebben geconstrueerd, dan zouden we in statistische zin moeten concluderen dat de data in overeenstemming zijn met de hypothesen, en dat er dus in de populatie een verschil in redelijkheid is tussen de twee niveaus van de gefixeerde factor.
Precies zoals het geval is bij het onderzoeksontwerp uit figuur 1 waarbij sprake is van confounding (als gevolg waarvan de intrinsieke effecten van de didactiek niet meer onderscheiden kunnen worden van de effecten van de toevallige leerkracht), zo ook is er in bovenstaande voorbeelden van taalwetenschappelijk onderzoek sprake van confounding: de effecten op abstract, categoriaal niveau kunnen niet meer onderscheiden worden van de specifieke effecten van de concrete, toevallige, min of meer unieke experimentele talige instantiatie van die bovengeordende categorie. Veel - en wellicht zou men in evaluatieve zin daaraan moeten toevoegen: teveel - experimenteel-taalwetenschappelijk onderzoek waarover in artikelen in taalwetenschappelijke tijdschriften is gepubliceerd, is behept met dit methodologische manco. Zoals eerder betoogd: wat is eigenlijk de zin van een empirisch taalwetenschappelijk onderzoek dat juist wordt opgezet en uitgevoerd met de bedoeling om de aanvaardbaarheid van een theorie te toetsen, terwijl datzelfde onderzoek - ongeacht de uitkomst - door feilen in de opzet onmogelijk kan discrimineren tussen (pseudo-) falsificatie en (pseudo-) confirmatie van die theorie? | |||||||||||||||||||||||||||||||||
6. Burden of proof; single versus multiple message designsHet incorporeren van talig materiaal als random factor in taalwetenschappelijke designs is niet alleen van belang voor het optimaliseren van de interne validiteit, maar ook voor het maximaliseren van de externe validiteit (d.w.z. de mate waarin het toevallige taalmateriaal dat gebruikt is in een experiment, gegeneraliseerd kan worden naar een buiten-experimentele ‘talige’ situatie, kortom naar taal-in-het-algemeen). Stel dat een onderzoeker twee soorten reclameteksten op effectiviteit en overtuigingskracht wil onderzoeken: advertenties waarin expliciet het aangeprezen product wordt vergeleken met soortgelijke producten van de concurrent, en advertenties waarin een dergelijke expliciete vergelijking juist achterwege blijft (type reclametekst moet in dit voorbeeld, in het licht van het gestelde onderzoeksdoel, beschouwd worden als een gefixeerde factor, met twee niveaus). Stel voorts dat de onderzoeker de twee niveaus van de betreffende gefixeerde factor instrumenteel realiseert door slechts één instantiatie, bijvoorbeeld een reclametekst waarin een BMW wordt aangeprezen die in het ene geval wel, in het andere geval niet expliciet wordt vergeleken met zijn Japanse concurrenten. Niet alleen uit het oogpunt van interne validiteit is een dergelijk design, zoals betoogd, defectief, ook met de externe validiteit van dit zogeheten single message design is het nogal droevig gesteld: hoeveel verschillende soorten producten kunnen er op categoriaal niveau van de advertentietekst-in-het-algemeen wel niet onderscheiden worden? Naarmate meer van die producten (auto's, wasmachines, koffiezetapparaten, videorecorders, enzovoort) in het design als (niveaus van de) random factor ‘in de advertentie aangeprezen product’ zijn ondergebracht, neemt de generaliseerbaarheid toe - even aangenomen dat de uitkomsten | |||||||||||||||||||||||||||||||||
[pagina 118]
| |||||||||||||||||||||||||||||||||
per niveau van de random factor allemaal in min of meer dezelfde richting wijzen. Kortom, multiple message designs zijn uit het oogpunt van zowel de interne als de externe validiteit voor taalwetenschappelijk onderzoek een conditio sine qua non. Sommige onderzoekers trachten hun gebruik van single message designs niettemin te rechtvaardigheden - of wellicht beter uitgedrukt: te rationaliseren - met het argument dat andere onderzoekers die zo nodig twijfel moeten uiten aan de generaliseerbaarheid van hun resultaten, dan maar via eigen replicatieonderzoek waarin andere messages worden aangeboden, moeten uitzoeken hoe de vork precies in de steel zit. Niet alleen wordt in dit argument de methodologische problematiek betreffende interne validiteit miskend, daar komt nog bij dat dit argument als een echte drogreden (in argumentatietheoretische zin) gekarakteriseerd moet worden: de drogreden van het verschuiven van de bewijslast. Andere onderzoekers verdedigen nog wel eens het standpunt dat de resultaten van individuele studies noodgedwongen beperkt zijn (om het even of het single message of multiple message designs betreft) en op grond van die omstandigheid altijd gecombineerd moeten worden in een zogenaamde meta-analyse. Omdat in verschillende studies zowel de afhankelijke als de onafhankelijke variabele vaak op een iets andere manier geoperationaliseerd zijn, kan op grond van een dergelijke meta-analyse pas écht gegeneraliseerd worden, zo is de gedachtegang. In deze optiek wordt de hele generalisatieproblematiek naar de meta-analyse verschoven, waardoor de ‘language-as-a-fixed-effect fallacy’ - discussie aan methodologisch belang inboet. Zowel op principiële als op praktische gronden is deze laatste opvatting moeilijk te handhaven. Immers, ten principale ligt de bewijslast (voor een categorische claim/hypothese) bij de individuele onderzoeker - deze kan en mag zich niet zomaar verschuilen achter een meta-analyse die wellicht ooit (maar misschien ook wel nooit) op een later tijdstip door een ander wordt uitgevoerd. Op de resultaten van individuele studies kan, uitgaande van deze meta-analyse optiek, dan ook geen staat meer gemaakt worden omdat generalisatie over zinnen, teksten, items of andere talige eenheden niet langer relevant geacht wordt - wat zou resten, zijn slechts studies waarin voor één eenheid aangetoond wordt dat er al dan niet een effect is. Ook praktisch gezien kleven er vaak veel meer haken en ogen aan een meta-analyse dan op het eerste gezicht lijkt. Wanneer bijvoorbeeld in de ene studie een effect wordt aangetoond van treatment T en in de andere studie niet, dan kan dat onder meer toegeschreven worden aan de diversiteit en heterogeniteit in de operationalisaties van het stimulusmateriaal, in de operationalisaties van de vragen, enzovoort, maar ook aan interacties met kenmerken van de steekproeven. Een fraai voorbeeld hiervan levert de meta-analyse van Holleman (2000), uitgevoerd in het kader van haar proefschrift naar verschillen in responsies ten gevolge van vraagformulering. In die meta-analyse blijken diverse geconstateerde effecten totaal oninterpreteerbaar als gevolg van verschillen tussen de geanalyseerde studies, en moet door een gebrek aan manipulatie tussen de studies de causaliteitsvraag noodgedwongen onbeantwoord blijven (Holleman 1997: 431). Elke onderzoeker die een taalwetenschappelijk experiment opzet om een hypothese/ theorie te toetsen, brengt impliciet of expliciet een claim naar voren. Wie claimt, moet bewijzen. De ‘burden of proof’, de bewijslast (die er hier op neer komt dat de empirische data gezien moeten worden als argument voor de aanvaardbaarheid van de claim) rust ten principale op de schouders van de onderzoeker die claimt: de onderzoeker zélf zal aannemelijk moeten maken dat de empirische gegevens een ondersteuning of een ontkrachting vormen | |||||||||||||||||||||||||||||||||
[pagina 119]
| |||||||||||||||||||||||||||||||||
van zijn claim, hij zelf zal met bewijzen moeten komen dat zijn data gegeneraliseerd kunnen worden, zowel naar taal-in-het-algemeen als naar proefpersonen-in-het-algemeen. Het gebruik van een single message design in taalwetenschappelijk onderzoek is in feite equivalent met de volgende argumentatieve zet, een zet overigens die in normatief opzicht net zo deficiënt is: stel dat een persoon claimt dat vrouwen geen gevoel voor humor hebben en, uitgedaagd door een antagonist die twijfelt aan de aanvaardbaarheid van die claim, daarvoor als argument zijn eigen vrouw Brigitte opvoert: ‘Je weet toch dat ze geen gevoel voor humor heeft!’. Slechts weinigen zouden overtuigd zijn door dit argument (in feite een empirische n=1 case study), tenzij de protagonist van de naar voren gebrachte claim via referentie aan andere data, bijvoorbeeld grootscheeps empirisch onderzoek, aannemelijk zou kunnen maken dat Brigitte's gevoel voor humor karakteristiek (representatief/kenmerkend/ typerend) is voor dat van haar seksegenoten in het algemeen - maar daarmee is men in feite weer terug bij een multiple message design.Ga naar eind8 | |||||||||||||||||||||||||||||||||
7. Een analyse van kwantitatief-empirisch taalwetenschappelijk onderzoek in het Tijdschrift voor Taalbeheersing 1977-2003Wordt de fixed-effect fallacy onder taalwetenschappers vaak begaan, zo vroeg Clark zich in zijn geruchtmakende artikel af. Wie van deze taalwetenschappers maakt zich zoal schuldig aan deze drogreden? Zijn even kernachtige als vernietigende antwoord luidde: ‘Sad to say, practically everyone’. Zo'n 30 jaar na dato stellen wij opnieuw dezelfde vraag, nu echter toegespitst op de empirische taalwetenschappelijke artikelen die de afgelopen 25 jaar in dit tijdschrift zijn verschenen; daarbij zullen we de fixed-effect fallacy dissociëren in een designfout en in een statistische fout. Anders dan Clark die - zoals betoogd om begrijpelijke redenen -de fixed-effect fallacy reserveerde voor een puur statistische drogreden die optreedt bij de (inductief-statistische) generalisatie van empirisch-experimentele bevindingen naar een grotere populatie, hebben wij in dit artikel deze fallacy gedissocieerd in:
Nogmaals, bovenstaande dissociatie was voor Clark die zijn beschouwingen beperkte tot de discipline psycholinguïstiek, niet relevant: in dat vakgebied immers kwam, anders dan in de taalbeheersing, de betreffende methodologische feilen helemaal niet voor. We beperken onze beschouwingen en analyses die tot een antwoord moeten leiden op de vraag: ‘Hoe frequent komt de fixed-effect fallacy voor?’ tot artikelen die verschenen zijn in jaargang 1 (1977) tot en met jaargang 23 (2003) van dit tijdschrift. | |||||||||||||||||||||||||||||||||
[pagina 120]
| |||||||||||||||||||||||||||||||||
Een tweede beperking betreft de specifieke aard van de geanalyseerde artikelen: het gaat ons in eerste instantie uitsluitend om kwantitatief-empirisch onderzoek, onderzoek dus waarin talige, tekstuele verschijnselen gekwantificeerd zijn en waarin dus statistiek is toegepast. Dat betekent dat alle artikelen waarin gerapporteerd wordt over empirisch onderzoek dat niet-kwantitatief, maar kwalitatief van aard is (bijvoorbeeld conversatie-analytisch of discourse-analytisch onderzoek waarin voorbeelden (‘cases’) worden gebruikt als argument ten gunste van bepaalde typen claims) buiten beschouwing blijven. Deze beperking is niet principieel, maar praktisch van aard: hoewel de fixed-effect fallacy als design-fout in beginsel ook in kwalitatief-empirisch onderzoek kan optreden, is het bijzonder lastig eenduidige criteria op te stellen aan de hand waarvan ondubbelzinnig bepaald kan worden of er in een concreet geval van empirisch-kwalitatief onderzoek al dan niet sprake is van de fixed-effect fallacy. Een derde beperking - evenmin van principiële aard - betreft de specifieke aard van de geanalyseerde kwantitatief-empirische artikelen: alle artikelen over kwantitatief onderzoek dat correlationeel van aard is - dat wil zeggen onderzoek waarin niet zozeer causale relaties, als wel samenhangen worden beschreven en geïnventariseerd - blijven buiten beschouwing. Dat impliceert dat onze beschouwingen zich beperken tot experimenteel onderzoek, onderzoek dus waarin sprake is van de manipulatie van een onafhankelijke (meestal tekstuele) variabele en de meting van een afhankelijke variabele. Daarmee wil niet gezegd zijn dat de fixed-effect fallacy noodzakelijkerwijze beperkt blijft tot experimenteel onderzoek, integendeel: ook in correlationeel onderzoek treft men deze drogreden aan, zij het dat men in dit type onderzoek (niet zelden van het type ‘ex post facto research’) vaker wat meer moeite zal hebben de gefixeerde en random factoren eenduidig te benoemen. Juist deze specifieke beperking tot experimenteel onderzoek maakt dat mogelijke interpretatieverschillen (bijvoorbeeld over het specifieke doel van het onderzoek, en dus ook over de cruciale vraag of een variabele als random of als gefixeerd moet worden beschouwd) radicaal zijn uitgesloten. Artikelen immers waarin over experimenteel onderzoek wordt gerapporteerd, hebben door de bank genomen een vrij vaste, gefixeerde structuur: het probleem wordt geschetst, de theorie en daaruit afgeleide hypothesen worden uiteengezet, de onafhankelijke en afhankelijke variabele worden gedefinieerd, het aangeboden talige materiaal wordt besproken, de specifieke methode van aanbieding wordt uit de doeken gedaan, de aard van de onderzochte proefpersonen wordt toegelicht, waarna vervolgens de data worden geanalyseerd (doorgaans via een of andere vorm van variantie-analyse); tot slot volgt een discussie en een samenvattende eindconclusie. Een dergelijke vaste structuur levert ons als analysator de benodigde objectieve gegevens voor de meta-analyse, zonder dat we daarbij in twijfelachtige ad hoc interpretaties hoeven te vervallen. Uit de experimentele artikelen valt immers precies en eenduidig te achterhalen, welke factor als ‘explanatory’ - dus als gefixeerde factor - beschouwd moet worden: de onafhankelijke variabele. Daar kan geen misverstand of interpretatieverschil over bestaan, net zo min als over de vraag of de niveaus van deze gefixeerde variabele gerepresenteerd zijn door een random talige factor. De beperking tot experimentele studies heeft echter ook een schaduwzijde: de aard en frequentie van het fixed effect-fallacy probleem wordt, net zoals het geval is bij bovenstaande beperking tot kwantitatieve studies, onderschat. Verder blijven alle overzichtsartikelen over experimenteel onderzoek, ook die waarin de resultaten van inductieve statistische technieken worden gerapporteerd, buiten beschouwing; zonder de oorspronkelijke artikelen te screenen is het vaak niet te achterhalen of er in het beschreven onderzoek talige, random factoren opereren. Het gaat ons dus om zelfstandig verricht, nieuw onderzoek. | |||||||||||||||||||||||||||||||||
[pagina 121]
| |||||||||||||||||||||||||||||||||
De laatste beperking betreft onze telling van de fixed-effect fallacy: het komt wel vaker voor (met name in de eerste jaargangen van dit tijdschrift) dat in één en hetzelfde artikel de opzet en de resultaten van meerdere experimenten worden gerapporteerd, soms zelfs van vijf! Komt in al die experimenten onveranderlijk de fixed-effect fallacy voor, dan tellen we dat niet als vijf fouten, maar enkel als één fout. Dat betekent dat wij in onze meta-analyse de individuele, publicerende experimentele onderzoeker als analyse-eenheid beschouwen. Deze inperking leidt, net zoals bovenstaande beperkingen, vermoedelijk tot een onderschatting van de werkelijke omvang van de fixed-effect fallacy. In tabel 2 staan de resultaten.
Tabel 2: Frequentie van single message vs multiple message designs in experimenteel onderzoek, gerapporteerd in TvT jaargang 1 t/m 23
In de eerste 23 jaargangen van dit tijdschrift is er 94 maal over experimenteel taalwetenschappelijk onderzoek gepubliceerd, een respectabel aantal. In iets meer dan de helft van het gerapporteerde onderzoek wordt een, vanuit methodologisch perspectief beschouwd, inadequaat design gehanteerd. In welke gevallen gaat het nu typisch goed, wanneer typisch fout? Zijn er binnen de taalbeheersing misschien onderzoeksdomeinen te traceren waarbinnen het multiple message design, wellicht als gevolg van traditie en conventie, schering en inslag is? Het prototypische voorbeeld van onderzoek waarin het door de bank genomen goed gaat, betreft het experimentele onderzoek naar problemen op het vlak van spelling: de onderzochte theoretische categorieën worden consequent door meerdere woorden (instantiaties) geoperationaliseerd. Het prototypische onderzoek waarin het doorgaans fout gaat, betreft het meer cognitiefgeöriënteerde functieleerachtige onderzoek naar de verwerking van teksten (bijvoorbeeld: zijn doorlopende teksten, zonder veel structuur, moeilijker te onthouden/verwerken dan teksten met veel structuur?). Vrijwel zonder uitzondering worden in dit onderzoeksveld de theoretisch relevante categorieën door slechts één enkele tekst geoperationaliseerd. Wellicht zijn omstandigheden van experimenteel-praktische aard verantwoordelijk voor dit verschil tussen beide onderzoeksvelden: het is in praktisch opzicht relatief eenvoudig een schrijver binnen de beperkte tijd van een experimentele sessie (zeg zo'n 45 à 60 minuten) een flink aantal woorden te laten spellen, terwijl het - zeker in repeated measurement designs - in praktisch opzicht vrijwel uitgesloten is een lezer te confronteren met meerdere (vaak lange) teksten waarover door de proefpersoon ook nog eens een flink aantal (begrips-of geheugen) vragen beantwoord moeten worden. Dat laat echter onverlet dat er ook andere ontwerpen dan repeated measurement designs gekozen kunnen worden waarbij de gewraakte feilen niet optreden. Hoe staat het met de frequentie van de fixed-effect fallacy (in inductief-statistische zin), de drogreden die Clark in feite op het oog had? Hoe vaak worden de talige random factoren in de statistische analyse ten onrechte als gefixeerd opgevat, hoe vaak wordt daarmee een geflatteerde, te positieve indruk van het alpha-niveau gepresenteerd? Voordat we deze vraag concreet beantwoorden, eerst een paar opmerkingen vooraf. In de eerste plaats vooronderstelt de beantwoording van deze vraag dat de data ook in induc- | |||||||||||||||||||||||||||||||||
[pagina 122]
| |||||||||||||||||||||||||||||||||
tief-statistische zin geanalyseerd zijn. Dat is echter merkwaardigerwijze vaak niet het geval, vooral in het onderzoeksdomein dat zich richt op de spellingsproblematiek: niet zelden vindt daar helemaal geen statistische toetsing plaats! Impliciet geeft de onderzoeker daarmee te kennen dat de aangetroffen talige resultaten enkel en alleen geldig zijn voor de specifieke groep onderzochte personen, en alleen voor die groep, en enkel en alleen geldig voor de onderzochte spelproblemen, en alleen voor die groep. Maar hoe kunnen resultaten verkregen bij die specifieke groep ooit relevant zijn voor een wetenschappelijke (spelling) theorie die immers betrekking heeft op een generische klasse van personen en van spelproblemen? Het zijn nu juist de methoden van de inductieve statistiek die de onderzoeker helpen bij de beantwoording van de vraag of en in hoeverre de resultaten verkregen binnen een specifieke groep proefpersonen en verkregen bij specifiek talig materiaal, met enig vertrouwen gegeneraliseerd mogen worden naar een groter geheel. Door af te zien van dergelijke methoden, of althans door af te zien van een beantwoording van de generalisatie-vraag, wordt in feite de bewijslast ontdoken. In de tweede plaats worden door sommige onderzoekers helemaal geen toetsingsgrootheden gerapporteerd, alleen p-waarden. En er zijn ook gevallen waarin de uitkomsten van (inductief-statistische) toetsingen alleen in verbale zin worden weergegeven: ‘dit resultaat bleek bij toetsing significant’. Dat deze bedenkelijke praktijk betreffende de rapportage van uitkomsten van inductief-statistische technieken de controleerbaarheid van wetenschappelijk onderzoek niet bepaald ten goede komt, staat wel vast. In de derde plaats wordt in een enkel geval door een onderzoeker expliciet gesteld dat in alle statistische analyses die in het kader van het door hem verrichte experimentele onderzoek zijn uitgevoerd, verschillen tussen teksten genegeerd zijn; daaraan wordt dan ook nog eens toegevoegd dat de kwantitatieve resultaten niet generaliseerbaar naar andere teksten zijn! De drie bovenstaande opmerkingen hebben uit de aard der zaak tot gevolg dat het feitelijke aantal onderzoeken dat überhaupt geanalyseerd kan worden op het optreden van de statistische fixed-effect fallacy, niet meer betrekking heeft op het oorspronkelijke aantal onderzoeken dat gekarakteriseerd kan worden als een multiple message design (43 in totaal), maar op een behoorlijk kleiner aantal: het oorspronkelijke aantal van 43 reduceert tot 34. In liefst 32 van die 34 studies figureert de door Clark gewraakte drogreden: de fixedeffect fallacy. Concreet voorbeeld: in een artikel van Van den Bergh (Slijkerman & Van den Bergh 1992) wordt de invloed van een samenvatting vooraf op het begrip van speelfilms bij prelinguaal doven onderzocht. In dit artikel wordt onder andere geconcludeerd dat ‘prelinguaal dove leerlingen die een (eenvoudige) samenvatting lezen voordat zij naar een film kijken, deze film beter begrijpen dan leerlingen die niet de beschikking over een dergelijke samenvatting hebben’ (o.c.p. 299). Kortom, in deze boude conclusie wordt zonder enige terughoudendheid gegeneraliseerd naar films in het algemeen (en naar daaraan voorafgaande tekstuele samenvattingen), terwijl in het betreffende experiment slechts twee instantiaties van de bedoelde, bovengeordende categorie figureerden; generalisatie op grond van een steekproef van twee elementen is toch wel wat al te kort door de bocht. Daar komt nog bij dat in de toegepaste inferentiële statistiek de fixed-effect fallacy wordt begaan: op basis van een statistische toetsingsgrootheid op grond waarvan alleen naar personen gegeneraliseerd kan worden (F1), wordt zonder enige terughoudendheid de generalisatiestap naar films (inclusief de daaraan voorafgaande samenvatting) gezet. Gezien deze deficiënties is de reikwijdte van deze studie nogal beperkt. Zonder overdrijving kan gesteld worden dat vele studies met deze beide manco's behept zijn, en dat dus generalisatie op grond van deze studies kwestieus is. | |||||||||||||||||||||||||||||||||
[pagina 123]
| |||||||||||||||||||||||||||||||||
Het gaat bij de fixed-effect fallacy kennelijk - zoals eerder betoogd - om een hardnekkig en weerbarstig probleem, een probleem overigens dat in het geheel niet beperkt blijft tot het Nederlandse taalgebied. In het Journal of Memory and Language (jaargang 32-37) werden, blijkens de resultaten van een aldaar uitgevoerd meta-onderzoek, in 120 artikelen (op een totaal van 220) toetsingsgrootheden gerapporteerd waarbij de fixed-effect fallacy (althans een variant daarop: de zogenaamde F1 x F2 fallacy) zou kunnen worden begaan: slechts 4 van die 120 artikelen bevatten correcte, niet-drogredelijke toetsingsgrootheden (Raaijmakers, Schrijnemakers & Gremmen 1999). In een volgende bijdrage hopen we in te kunnen gaan op de statistische en computationele implicaties van de fixed-effect fallacy. | |||||||||||||||||||||||||||||||||
[pagina 125]
| |||||||||||||||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||||||||||||||