|
| |
| |
| |
A.M. Duinhoven
Filologie en computer
N.a.v. Josephie Brefeld, A Guidebook for the Jerusalem Pilgrimage in the Late Middle Ages: A Case for Computer-Aided Textual Criticism. Hilversum: Verloren, 1994.
ISBN 90-6550-257-2 Prijs: ƒ 45, -
Abstract - Method and working practice in philology are essentially the same today as they were a hundred years ago. It would be a big step forward if we could profit more from modern technology. In her dissertation Ms. Brefeld proposes and demonstrates the use of a statistical program in textual criticism. This review tries to describe and evaluate her interesting approach.
Bovengenoemd boek, als proefschrift aan de R.U. te Groningen verdedigd, is voor de neerlandistiek om twee redenen van belang. Object van onderzoek vormen onder meer Middelnederlandse reisverslagen van pelgrims naar het Heilig Land. Bovendien wordt een statistische benadering beproefd, die voor de tekstkritiek in het algemeen waardevol zou kunnen blijken. Vanwege dit methodologische aspect verdient de studie een uitvoerige bespreking, waarin duidelijk moet worden in hoeverre het nieuwe hulpmiddel dat wordt aangereikt, voor de Middelnederlandse filologie van nut kan zijn.
| |
Het filologische handwerk
Het boek is doorzichtig gestructureerd; het bestaat uit een zestal steeds specifiekere hoofdstukken (p. 9-152), een addendum van methodologische aard (p. 153-178), samenvattingen in Engels en Nederlands en twee appendices. Het eerste hoofdstuk bevat algemene informatie over de bedevaarten naar Jerusalem tussen 1300 en 1600. Jaarlijks trokken duizenden pelgrims naar het Heilig Land, vanuit alle uithoeken van Europa te paard of te voet naar Venetië vooral, en vandaar over zee. Wanneer de pelgrims na een tocht van maanden voet aan wal zetten, werden zij opgevangen door Franciscaanse monniken, die hen in hoog tempo langs de heilige plaatsen gidsten en na een dag of tien weer op de boot zetten.
De reis is door vele pelgrims beschreven; er zijn honderden reisverslagen bewaard. Door vele onderzoekers opgemerkt is het frappante feit, dat de opsommingen van heilige plaatsen en zelfs sommige formuleringen zeer gelijkend zijn, ongeacht de taal waarin het verslag is geschreven. Dat heeft reeds meer dan een eeuw geleden tot de veronderstelling geleid, dat de efficiënt opererende Franciscanen de pelgrims een geschreven reisgids ter beschikking stelden. Deze hypothese wordt in hoofdstuk 2 nader bezien. Verzameld worden aanwijzingen in de verslagen zelf, die de conclusie onontkoombaar maken dat de reisbeschrijvingen steunden op een schriftelijke bron. De rest van het boek zoekt een antwoord op de vraag, wat voor tekst dat moet zijn geweest.
| |
| |
Het is interessant de auteur aan het werk te zien. Haar werkwijze wordt bepaald door de aard van de tekstoverlevering. Er is een overvloed aan reisverslagen overgeleverd, die in een wat gedrongen stamboom moeten samenhangen: iemand heeft een lijst van heilige plaatsen opgesteld, welk origineel in een aantal onpersoonlijke voorbeeldteksten moet zijn vermenigvuldigd. Deze hebben als basis gediend voor vele persoonlijke reisverslagen:
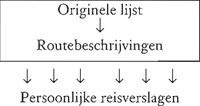
Hoe nu greep te krijgen op materiaal en materie?
Om te beginnen tracht de auteur in hoofdstuk 3 een representatieve selectie te maken uit de 130 verslagen die zij onder ogen heeft gehad. Zij kiest voor achttien teksten, zo goed mogelijk verdeeld naar tijd (1300-1561), herkomst en taal (Latijn, Duits, Frans, Engels en Nederlands); het corpus bevat drie typen: pure opsommingen van heilige plaatsen, persoonlijke verslagen van de reis, en teksten van gemengde aard. De achttien teksten worden kort beschreven, misschien wat al te summier. Het is voor de lezer van het boek moeilijk zich een voorstelling te maken van de aard van het materiaal.
Een aanduiding van de omvang, een cruciaal gegeven bij tekstvergelijking, zou welkom zijn geweest. Op p. 77 bijvoorbeeld wordt plotseling opgemerkt dat anglure en lannoy lange teksten zijn, maar een maatstaf ontbreekt. Alleen via de bibliografie (p. 215-216) kan uit de paginering van de uitgaven de lengte van sommige bronnen bij benadering worden afgeleid. Bij menige tekst blijkt het slechts om een paar pagina's te gaan. In hoofdstuk 6 wordt één van de opsommende teksten uitgegeven; maar dat weet de lezer in hoofdstuk 3 nog niet.
Een tweede vereenvoudiging betreft de punten van vergelijking. De auteur beperkt zich ertoe het al dan niet voorkomen te noteren van de (in totaal 369) heilige plaatsen. Overeenkomsten en verschillen in de volgorde en in de bewoordingen blijven buiten beschouwing. Daar het in deze reisverslagen in essentie gaat om een opsomming van de locaties, lijkt deze start verantwoord.
De vergelijking nu van telkens twee verslagen leidt tot een ‘similarity-index’ waarin voor elk paar teksten is aangegeven hoeveel procent van de in deze twee bronnen genoemde plaatsen de twee teksten gemeenschappelijk hebben. Dat geeft al een ruwe aanduiding van de onderlinge samenhang. Zo blijken sessa en gent voor 99% overeen te stemmen. Er zijn twee clusters van gelijkende verslagen te herkennen: van 4 resp. 3 teksten. Kijkt men alleen naar de 227 plaatsen binnen het Heilig Land, de standaard-tour, dan nemen de overeenkomsten in het algemeen toe en worden de clusters minder opvallend; maar ze zijn toch nog herkenbaar.
Op grond van het voorkomen der plaatsaanduidingen kunnen dus binnen de selectie van achttien reisverslagen twee groepen worden onderkend, die wat de
| |
| |
genoemde plaatsen betreft in hoge mate overeenkomen. Met deze gegevens zonder meer kan men nog niet erg veel doen. Om meer inzicht te verkrijgen in de aard van de samenhang, zou men de overeenkomsten en verschillen nader kunnen bestuderen. Er zijn andersoortige scheidingen aan te brengen die het materiaal toegankelijker maken. De bronnen kunnen worden gegroepeerd naar tijd van ontstaan; de drukken vormen daarbij een categorie op zichzelf; de reisverslagen kunnen worden gerangschikt naar de verschillende routes die ze beschrijven; er zijn verhalende ooggetuigeverslagen en zakelijke en onpersoonlijke opsommingen.
De laatste categorie maakt uiteraard de grootste kans tot de kern van voorbeeldteksten te hebben behoord, waarop de persoonlijke reisverslagen zijn gebaseerd; het feit dat de meeste van deze opsommende teksten in het Latijn gesteld zijn, versterkt die indruk. Het is zeker niet uitgesloten, dat een studie van de gemeenschappelijke veranderingen een beeld van de ontwikkeling der voorbeeldteksten zal opleveren. Zou inderdaad blijken, dat er in de loop van de tijd weinig in de gids is veranderd, dan is dat een feit van belang. Elke willekeurige opsommende tekst is dan een goed voorbeeld van de door de Franciscanen beschikbaar gestelde reisroute.
De hierboven beschreven onderzoeksweg heeft mevrouw Brefeld echter niet gevolgd. Omvang en aard van het materiaal maken volgens haar een filologische, tekstkritische analyse moeilijk uitvoerbaar; zeker voor een Assistent of Onderzoeker In Opleiding, zou men daaraan kunnen toevoegen, die zijn of haar promotieonderzoek en het schrijven van een dissertatie in luttele jaren moet afronden. Daar filologisch werk ervaring en veelzijdigheid vereist, tijdrovend is en op korte termijn geen bruikbare resultaten garandeert, is het begrijpelijk dat naar andere wegen wordt gezocht om het doel te bereiken. Daar de computer bij uitstek geschikt is om grote hoeveelheden data te verwerken, hoopt de auteur met behulp van een statistische bewerking, bekend als ‘factoranalyse’, resultaten te boeken. En die boekt zij ook, maar zijn het resultaten waar de filologie iets aan heeft?
| |
De computer aan het werk
In hoofdstuk 4, de kern van het proefschrift, wordt uitgelegd, wat ‘factoranalyse’ is en hoe deze statistische techniek in dit geval wordt toegepast. Het al (1) dan niet (0) voorkomen van elk der 369 genummerde plaatsaanduidingen in de 18 genummerde bronnen is in een matrix ingevoerd (afgedrukt als appendix 2). Daarin staan achter elk plaatsnummer 18 nullen en enen, en onder elk tekstnummer 369 nullen en enen. Het gebruikte statistische programma nu berekent ten aanzien van elk paar teksten de overeenkomsten (1:1 resp. 0:0) en verschillen (1:0 en 0:1) in een correlatie-coëfficiënt, die loopt van 1 (d.i. volledig overeenstemmend), via 0 (evenveel overeenstemmingen als verschillen, dus geen correlatie) naar -1 (volledig tegengesteld).
Dit lijkt een nauwkeuriger berekening dan de bovenbeschreven ‘similarity-index’, die alleen op de enen berust. Bovendien wordt de tekstvergelijking niet gebaseerd op de steeds wisselende verzameling plaatsen die in telkens twee teksten voorkomen, doch op het totale corpus van 369 heilige plaatsen. Door deze constante kunnen ook allerlei andere berekeningen worden uitgevoerd. De statistische benadering betekent
| |
| |
dus in rekenkundige zin een grote stap vooruit. Wie echter gewend is te denken in termen van genealogische verwantschap, zal moeite hebben met het feit dat overeenkomsten en verschillen elkaar opheffen. Wanneer tekst A en B 50% van hun plaatsnamen gemeenschappelijk hebben en voor 50% niet overeenstemmen, is er in statistisch opzicht geen correlatie. De kans dat een willekeurige plaats al dan niet in beide bronnen voorkomt, is immers niet meer dan 50%, wat bij een keuze uit twee de uitgangspositie vormt.
Toch vormt het feit dat de twee teksten voor de helft overeenstemmen, een belangrijke verbindende factor. De overeenkomsten bewijzen een gemeenschappelijke herkomst, althans voor een deel van de tekst. Doch op de vaststelling daarvan is het computerprogramma en daardoor ook de auteur niet gericht. Wat is dan de aard van het resultaat? De ‘rekenaar’ is in staat in grote hoeveelheden cijfermateriaal correlaties vast te stellen, samenhangen te ontdekken. De computer kan daarmee een groot aantal variabelen herleiden tot een kleiner aantal onderliggende factoren, causale verbanden van de een of andere aard.
In het dagelijks leven zijn we met dit soort berekeningen vertrouwd. Wordt er opvallend vaak ingebroken in huizen met een garage, significant meer dan in huizen zonder in- of oprit, dan zal niet alleen de verzekeringspremie voor deze categorie woningen omhoog gaan. De experts zullen ook zoeken naar een verklaring, die tot preventie kan leiden. Het is aan de onderzoeker de verbindende factor te identificeren: gemakkelijke toegankelijkheid, grotere buit, sociale rancune? De computer geeft slechts aan, dat er een of meer factoren aanwezig zijn die een groter of kleiner deel van de samenhang zouden kunnen verklaren.
Het principe van factoranalyse is duidelijk, al wordt het een en ander niet glashelder uitgelegd, in hoofdstuk 4 noch in appendix 1, dat voor de vakman overbodig en voor de doelgroep van leken ontoegankelijk is. De berekeningen op zichzelf zijn van wiskundige aard en in principe steeds hetzelfde. De methode is door statistici ontworpen en in de praktijk getest. Er is geen enkele reden aan nut en betrouwbaarheid van het instrument te twijfelen en voor het gebruik van het computerprogramma zijn geen wiskundige vaardigheden vereist. Hoe kan er dan nog iets mis gaan?
Hoe verbluffend veelomvattend, nauwkeurig en snel het rekenwerk van de computer ook zij, er wordt van de gebruiker toch nog wel enig denkwerk gevergd. (1) Voor alle computerbewerkingen geldt dat de invoer van gegevens de waarde van de resultaten bepaalt; in statistisch jargon: ‘garbage in, garbage out’. (2) De interpretatie van de factoren bovendien blijft aan de onderzoeker voorbehouden. In het abstracte cijfermateriaal herkent het programma correlaties en factoren; de computer brengt verbanden aan het licht; om de oorzakelijke factor te bepalen wordt vindingrijkheid en overleg, en vooral kennis van de werkelijkheid gevergd, begrip van de zaken die in het geding zijn. (3) Vóór alles echter moet de onderzoeker beseffen, wat voor resultaten de statistische bewerkingen opleveren, en overwegen of dit soort resultaten voor zijn onderzoek van nut kan zijn. Op deze drie punten zullen we het werk van mevrouw Brefeld dus moeten beoordelen. Schetsen we eerst echter het verloop van het onderzoek.
| |
| |
| |
Verloop van het onderzoek
De precieze berekeningen kunnen we hier buiten beschouwing laten. Ingevoerd zijn van 18 teksten alle plaatsnamen. De computer berekent de correlatiecoëfficiënt van elk paar teksten. Deze 153 coëfficiënten worden niet afgedrukt, hoewel het aardig zou zijn geweest ze met de similarity-index te vergelijken. Gepresenteerd worden de resultaten van verdere berekeningen. Er blijken in de matrix twee oorzakelijke factoren aan te wijzen, die de distributie van de plaatsnamen in de 18 teksten bepalen; factor 1 doet dat voor 55,5% van de heilige plaatsen, factor 2 voor 10,7%. Het gaat bij dit soort berekeningen om gemiddelden en percentages. Hoewel het zeker is, dat een deel van de plaatsnamen in beide factoren een rol speelt, kan niet worden vastgesteld welke plaatsen factor 1 vormen en welke factor 2.
Wel is het mogelijk aan te geven in hoeverre de factoren in de verschillende teksten werkzaam zijn, en welk percentage van elke tekst door de twee factoren te zamen wordt bestreken (overzicht p. 90). Voor enkele teksten is dat meer dan 80%, voor andere nog geen 40%. Dat houdt dus in, dat sommige teksten zeer veel plaatsaanduidingen met de overige gemeenschappelijk hebben, terwijl andere teksten sterk van het gemiddelde afwijken. De twee groepen teksten die de similarity-index opleverde, blijken opnieuw te herkennen. Dat is begrijpelijk, daar het steeds om dezelfde plaatsnamen gaat. Vier handschriften scoren hoog op factor 1, drie andere op factor 2. Op basis van de gezamenlijke invloed der twee factoren kan de mate van overeenkomst tussen de 18 teksten worden bepaald (clusteranalyse), hetgeen in een tweetakkige boomstructuur kan en is vastgelegd (p. 93).
De belangrijkste factor 1 labelt mevrouw Brefeld als ‘invloed van een Latijnse voorbeeldtekst’, we zullen hieronder zien hoe zij daartoe komt. Zij bekijkt nu drie van de teksten die het hoogst scoren op factor 1, waaronder sessa, een incunabel gedrukt te Venetië in 1491. Het boek is een gids voor pelgrims, heeft een klein formaat, bevat geen enkele persoonlijke aantekening. Het boekje lijkt aan alle voorwaarden te voldoen die men aan een voor pelgrims bestemde voorbeeldtekst kan stellen. Tevreden stelt de auteur dan ook vast: ‘with sessa I have come very close to the text I have been looking for’ (p. 118). De opsomming in sessa ‘closely resembles’ een lijst van plaatsnamen in het reisverslag van Johannes van Frankfurt uit 1426-1427, welke lijst in Jerusalem is overgeschreven. ‘What more “proof” may one hope to be able to muster?’ (p. 119).
In hoofdstuk 5 dringt zij door tot ‘The Heart of the Matter’. Met sessa worden vijf op het oog sterk gelijkende teksten vergeleken. Factoranalyse brengt weer twee factoren aan het licht, op grond waarvan een subgroep van 3 teksten wordt geïdentificeerd, drie incunabelen, sessa, rome en new york, alle te Venetië gedrukt tussen 1470 en 1491. Op grond van ‘ouderwetse’ filologische argumenten zoekt de auteur nu naar de beste tekst, met de minste evidente fouten. Tenslotte wijst zij new york aan als de meest exemplarische vertegenwoordiger van het corpus. In hoofdstuk 6 geeft zij de Latijnse tekst (263 regels) diplomatisch uit, met wat tekstkritische aantekeningen, doch zonder vertaling.
| |
| |
| |
Vooruitgang in de filologie?
De filologie, de studie van taal en letteren in het algemeen, is een ouderwets soort wetenschap. Terwijl de exacte vakken en de technologische disciplines zich razendsnel ontwikkelen en, met geavanceerde apparatuur en steeds vernieuwde methodes, verbluffende resultaten behalen, zijn de taal- en letterkundigen nog in discussie met hun voorgangers uit de vorige eeuw. Filologische kennis en ervaring is nauwelijks over te dragen. Elke onderzoeker in spe moet weer vooraan beginnen. Nieuwe tekstedities zijn kwalitatief vaak minder dan de oude; de meeste studies betekenen slechts kwantitatieve winst.
We mogen voor menig terrein binnen de filologie al blij zijn dat het wetenschappelijk werk voortgang vindt; vooruitgang wordt er nauwelijks geboekt. In methodologisch opzicht gebeurt er weinig. Het conserveren van de verzamelde kennis vergt van de weinige actieve filologen zoveel tijd en inspanning, dat zij op vernieuwingen ook niet bijzonder gebrand zijn. Het zou dan ook een verheugende doorbraak betekenen, wanneer de filologie kon profiteren van moderne technieken en methoden, zodat voortgang ook vooruitgang betekende. Jonge onderzoekers zouden dan op een hoger niveau van wetenschap beginnen dan de vorige generatie. Hoeveel aantrekkelijker en interessanter zou de tekststudie voor nieuwe beoefenaars zijn, wanneer zij niet met uiterste inspanning het werk van voorgangers in stand behoefden te houden doch met verbeterde inzichten en hulpmiddelen op het gedane werk konden voortbouwen.
Met grote interesse heb ik dan ook van deze dissertatie kennis genomen, waarin naar nieuwe mogelijkheden voor de tekstkritiek wordt gezocht. Het onderzoek vormt een boeiend en nuttig experiment. Het voor de letteren uitzonderlijke gebruik van een statistisch computerprogramma geeft het proefschrift een modern en vernieuwend karakter. Het boek is ook zorgvuldig en met gevoel voor effect gecomponeerd. De auteur weet bij de lezer de indruk te wekken, dat mens en machine tezamen, stap voor stap, op een moeilijk te bereiken doel afgaan, dat zij met vernuft en volharding uiteindelijk ook weten te bereiken. Bij een eerste lezing is men geneigd het enthousiasme van de auteur te delen en de expeditie als een succes te beschouwen: ‘Aan het eind van een selectieproces van veel plussen en minnen slaagt Brefeld erin de hand te leggen op een tekst die rond 1480 in Venetië, haven van inscheping voor veel pelgrims, gedrukt werd en waarschijnlijk model heeft gestaan voor een groot aantal 15de- en 16de-eeuwse verslagen’ (Samuel de Lange in NRC-Handelsblad 9-7-1994).
Jammer genoeg blijkt de statistische benadering bij nadere beschouwing voor de tekstkritiek geen echte doorbraak te betekenen, de wat belerende uiteenzetting in het addendum ten spijt. Vooral in de eerste hoofdstukken vindt men wel nuttige informatie over het genre, de teksten en de bronnen. Lof verdient ook de introductie van de methode, die misschien bij andersoortig filologisch onderzoek nog wel eens van nut kan zijn. Het oordeel over de kern van het onderzoek echter moet tot mijn spijt negatief zijn. De essentie van het proefschrift, de gefaseerde selectie van new york als beste voorbeeldtekst, is, naar ik meen, voor de filologie van nul en generlei waarde.
| |
| |
| |
Evaluatie
Boek en tekst waren al bekend. In die zin is er van geen ontdekking sprake. De incunabel blijkt ook niet cruciaal voor de tekstgeschiedenis; de geselecteerde bron was en blijft een onbelangrijke schakel in het geheel van de tekstoverlevering. Maar geven de berekeningen dan niet onomstotelijk aan, dat new york de meest karakteristieke tekst van het onderzochte corpus is? Zelfs dat is niet het geval, want volgens de tabel op p. 130 zou dat sessa moeten zijn; maar daar zitten een aantal fouten in, die new york en rome missen. In het laatste stadium van haar selectie durft de auteur niet vast te houden aan de pure statistische resultaten en is zij erop uit te bepalen ‘which of these three texts is older’ of tenminste correcter ‘in grammatical or biblical terms’ (p. 135).
Maar ook wanneer het resultaat niet op deze wijze zou zijn geretoucheerd, is de selectie verwonderlijk, zelfs voor de auteur: ‘It follows that sessa, rome and new york are better representatives of the prototype guide than london is. One wonders to what extent it is coincidental that sessa, rome and new york are the incunables’ (p. 133). De drie incunabelen, alle drie te Venetië gedrukt, vertonen onderling slechts kleine verschillen. Zij vormen binnen het corpus een hecht blok en beïnvloeden daardoor sterk het gemiddelde, [...] zodat zij daarmee ook de meeste overeenkomst vertonen. Dat alleen al maakt duidelijk, hoe de uitkomst bepaald wordt door de invoer. De selectiemethode levert, op wiskundig verantwoorde wijze weliswaar, steeds de tekst op die van de onderzochte teksten en wat betreft de ingevoerde eigenschappen het dichtste ligt bij het gemiddelde.
Het corpus van 18 teksten is vrij willekeurig gekozen. Zouden de sterk verwante bronnen sessa en gent bijvoorbeeld buiten de eerste selectie zijn gelaten, dan had dat een ander gemiddelde opgeleverd, en zeker ook andere topscorers. Zelfs wanneer men alle overgeleverde teksten zou invoeren, vormen die nog slechts een toevallige deelverzameling van alle teksten die er zijn geweest. De willekeurige samenstelling van het corpus staat in schril contrast tot de nauwkeurigheid van de berekeningen, die daardoor geen nut heeft.
Niet alleen het corpus bepaalt de uitkomst, ook de aard van de ingevoerde data. Wanneer men andere bijzonderheden uit de teksten licht, de presentatie en de volgorde en de onderlinge afhankelijkheid der elementen in het onderzoek betrekt, kunnen steeds andere teksten representatief blijken. Het beeld kan al sterk veranderen, wanneer men de ingevoerde plaatsen categoriseert. Nu krijgen alle plaatsnamen één 1 of 0 en daardoor een even groot belang. We zouden ze echter ook kunnen groeperen op grond van inhoudelijke factoren (belangrijke tegenover bijkomstige voorvallen in het leven van Jesus, plaatsen in het Heilig Land en daarbuiten, bijbelse en apocriefe gebeurtenissen). Plaatsen in het Heilig Land, in de bijbel genoemd en in verband staand met een belangrijk voorval, die een grote kans maken tot de voorbeeldtekst te behoren, zouden zo hoger scoren dan plaatsen die een, twee of drie van deze kenmerken missen. Dit soort verfijningen van de input bepalen de output, en kunnen telkens andere teksten naar voren brengen.
Maar is het dan niet van belang, dat we nu, hoe dan ook, over een tekst beschikken die toch in zeker opzicht exemplarisch mag heten voor de Franciscaanse voorbeeld- | |
| |
teksten? Nee, want die globale kennis hadden we al. Hoe de voorbeeldteksten er ongeveer uitzien, kan iedereen constateren die van de tekstoverlevering kennis neemt. Een ruim aantal teksten zijn als voorbeeld even geschikt. Dat het om onpersoonlijke, Latijnse of op het Latijn gebaseerde, opsommende teksten gaat, weten we niet op grond van het statistische onderzoek. De oppositie ten opzichte van de persoonlijke, verhalende reisverslagen blijkt reeds bij een eerste verkenning van de bronnen.
Deze op conventionele wijze verkregen kennis heeft het de auteur ook mogelijk gemaakt de twee factoren (deelverzamelingen van namen) te interpreteren die het computerprogramma in de teksten aanwijst. De grootste deelverzameling stelt zij, vanzelfsprekend en terecht, op rekening van de Latijnse bron; met andere woorden: die zijn uit de schriftelijke teksttraditie afkomstig. Dat een aantal reisverslagen behalve deze kern van namen een kleinere deelverzameling van secundaire heilige plaatsen gemeenschappelijk hebben, schrijft zij toe aan mondelinge informatie. Tijdens de rondtocht zullen aanvullende, saillante en apocriefe, bijzonderheden zijn verteld. Een bescheiden orale traditie lijkt mij een plausibele veronderstelling, al is het mogelijk dat een nadere genealogische studie nog wat ondergeschikte schrijftradities aan het licht zal brengen.
| |
Doel en methode
Zelfs wanneer van de hele tekstoverlevering alle mogelijke kenmerken werden ingevoerd, zou de identificatie van de meest karakteristieke tekst binnen het corpus voor het filologisch onderzoek zonder belang zijn. Men is er in de tekstkritiek niet op uit een modeltekst te construeren en de tekst te bepalen die het gemiddelde het dichtst benadert. De constructie van een modeltekst is een manier om de overgeleverde teksten te beschrijven, maar vertelt niets over de tekstontwikkeling en helpt ons niet bij de reconstructie van oudere fasen. Een voorbeeld kan dat verduidelijken.
In het algemeen bestaat de tekstoverlevering grotendeels uit jongere kopieën, handschriften en incunabelen, die door hun numerieke overwicht in hoge mate het gemiddelde, de modeltekst, bepalen. Tegenover deze meerderheid zal een enkele bron die nauwer bij het origineel aansluit, in het niet vallen. Zou men op deze statistische wijze de overlevering analyseren van een verhaal als de Renout van Montalbaen, dan zal de exemplarische tekst die het dichtst bij de berekende modeltekst aansluit, ongetwijfeld een druk van de prozaroman De vier Heemskinderen zijn, waartegenover de fragmenten van de oudere berijmde versie een insignificante minderheid vormen.
Om misverstanden te voorkomen is het misschien goed te onderstrepen, dat in het voorliggende boek niet alleen de methode maar mede daardoor ook de doelstelling afwijkt van wat in de filologie gebruikelijk is. Het uiteindelijk doel van alle filologische activiteiten is het begrip en de verklaring van oude teksten. Twee omstandigheden dwingen daarbij tot tekstkritiek. (1) Er zijn vaak verschillende redacties van een en dezelfde tekst overgeleverd, waardoor men telkens gedwongen wordt te overwegen welke variant de oudere lezing vormt. (2) Wanneer er maar één exemplaar is bewaard, zijn daarin meestal sporen van tekstverandering aan te wijzen. Ook dan wordt de filoloog gedwongen tot reconstructie van oudere fasen in de tekstgeschiedenis.
| |
| |
De tekstkritiek dient dus de tekstinterpretatie, maar steunt daar ook op, doordat een zorgvuldige analyse duidelijk moet maken waar er in de tekst iets schort, welke variant de voorkeur geniet en hoe de oudere lezing er moet hebben uitgezien. Tekstinterpretatie en tekstkritiek zijn nauw met elkaar verbonden, naar mijn mening zelfs onlosmakelijk. Hoe men in de tekstkritiek zijn doel ook wil bereiken, men streeft naar reconstructie: getracht wordt al dan niet bewaarde lezingen te bepalen vanwaaruit de overgeleverde varianten te verklaren zijn. Een stamboom, die de familieverwantschap van de bronnen in beeld brengt, kan daarbij als hulpmiddel dienen. Het resultaat dus van de vergelijking van een verzameling varianten of van een corpus overgeleverde teksten is een hypothetische oudere lezing of tekst, die buiten de verzameling of het corpus ligt en daaraan voorafgaat.
Op tekstreconstructie is de auteur echter niet uit. Haar statistische bewerkingen van een corpus teksten leveren een modeltekst op waarin de geselecteerde eigenschappen van de individuele teksten gemiddeld zijn. Zoals de niet bestaande gemiddelde Nederlander de abstractie is van alle Nederlanders, zo is deze gemiddelde tekst het abstracte model voor het hele corpus. Bepaald kan nu worden welke tekst het meest op de modeltekst lijkt. Deze overgeleverde tekst is dan te beschouwen als de meest typische vertegenwoordiger van de groep. Het prototype behoort echter tot het corpus en gaat niet aan de overlevering vooraf. Van reconstructie is geen sprake.
Het is van belang doel en methode in de beschouwing gescheiden te houden. Wie kritiek heeft op de doelstelling, twijfelt aan het nut van het beoogde en geboekte resultaat, behoeft geen bestrijder te wezen van de statistische methode, niet wars te zijn van rekenkundige bewerkingen of zelfs een tegenstander van ‘computer-aided textual criticism’, waarvan de auteur mij tot mijn verbazing beticht (p. 163n). Gelukkig deel ik deze reprimande met de vermaarde filoloog A. Dain en de professionele alfa-informaticus B. Salemans. Gedrieën krijgen wij deze retorische veeg uit de pan (p. 154): ‘Are those that maintain that computers cannot think and that the “real” textcritical work is for the human mind only, right in keeping a healthy distance, or are they missing out on an opportunity to develop the possibilities and improve the achievements of textual criticism?’.
| |
Methodologische discussie
Het is in principe mogelijk van elke teksttraditie de meest typische vertegenwoordiger te bepalen. Maar wat is daarvan het nut? Hoe kan de auteur menen, dat de tekstreconstructie daarmee gediend zou zijn? Hoewel zij zich in haar Addendum (p. 153-178) stevig afzet tegen de traditionele, op tekststudie gerichte filologie, maakt zij niet duidelijk waarom haar op analyse van getallen gerichte benadering te prefereren zou zijn. Zij toont niet aan, in welke gevallen of in hoeverre een statistische, generaliserende benadering de analyserende, reconstruerende methode zou kunnen verbeteren of vervangen. In plaats daarvan neemt zij haar toevlucht tot enkele kunstgrepen.
Om de zwakte van de oude filologie aan te tonen en de kracht van haar eigen benadering te onderstrepen, laat zij in extenso zien hoe beperkt het menselijke brein is, hoe selectief we waarnemen en onthouden, en hoe slecht we rekenen. Met welbekende
| |
| |
voorbeelden uit de psychologie wordt aangetoond wat niemand zal weerspreken: het menselijk denken is zeer onvolmaakt. Maar bijzonder dom is wel de (vermeende) ‘aversion some textual critics have towards the use of computers in textual criticism’ (p. 162). Volgt een loflied op de rekenaar die, nog maar aan het begin van zijn ontwikkeling, reeds veel intelligenter zou zijn dan de mens, krachtiger, sneller, betrouwbaarder. Wie probeert mevrouw Brefeld hier te overtuigen? De computer kan inderdaad grote verzamelingen data ordenen, regelmatigheden ontdekken, correlaties, gemiddelden en factoren aanwijzen. Dat bestrijdt geen mens. De vraag die positief beantwoord zou moeten worden is: hebben we bij tekstreconstructie behoefte aan deze mogelijkheden, en zo ja, in welke gevallen?
De auteur creëert welbewust tegenstanders, die zij allerlei domheden in de schoenen schuift. Hun tekstkritisch werk leidt tot imperfecte resultaten, zij weten niet wat zij met contaminatie aan moeten en met parallellisme (p. 154). Zij overschatten hun eigen verstandelijke vermogens, zijn wars van vernieuwing, afkerig van getallen; ‘textual critics’, gericht als zij zijn op woorden en tekst, hebben weinig gevoel voor statistische waarschijnlijkheid (p. 166). Daar steekt haar eigen werkwijze bijzonder gunstig bij af: zij laat zich niet misleiden door ‘the false law of small numbers’ doch gehoorzaamt aan de ‘law of large numbers’ (p. 158); zij zet talige gegevens om in getallen en werkt daardoor ‘blind’ en vrij van vooroordeel (p. 165). Zo weet zij de teksten op basis van onderlinge overeenkomsten te groeperen en van elke cluster de beste vertegenwoordiger aan te wijzen. Alleen: wat moeten we daarmee?
Nu lijkt ook de traditionele filologie geen nuttig doel na te streven, volgens mevrouw Brefeld althans: ‘In textual criticism the ultimate goal usually is the construction of a stemma’ (p. 169). Deze typering getuigt van onvoldoende bekendheid met het vakgebied. De tekstkritiek omvat behalve de recensio ook de emendatio; en doel van alle tekstkritiek is tekstreconstructie, de vaststelling van oudere lezingen, waarbij een stemma van nut kan zijn. Het opstellen van een stamboom is dus geen doel maar middel. De auteur doet de genealogische methode bovendien onrecht, wanneer zij geen onderscheid wenst te maken tussen overeenkomsten en gemeenschappelijke veranderingen (waaronder gemeenschappelijke fouten): ‘I feel, however, that it is not useful to differentiate between similarities and/or differences on the one hand and mistakes on the other as a mistake is a difference that is interpreted in causal terms’ (p. 171n). Maar om oorzakelijke verhoudingen gaat het nu juist bij afstamming.
Wil men de filologie hervormen door de introductie van ‘a New Observational Theory’ (p. 153), dan zal men zich eerst terdege vertrouwd moeten maken met het vakgebied. Bovenal zal men scherp moeten zien, wat er precies wordt nagestreefd. Alle filologische bedrijvigheid is gericht op het begrip en de verklaring van (oude) teksten. Tekstanalyse echter speelt in deze studie geen rol. De reisverslagen worden gepresenteerd als een opsomming van heilige plaatsen, en gereduceerd tot een verzameling van enen en nullen. De interne samenhang, de inhoud van de teksten, is in deze benadering van geen belang. Dat werpt licht op een andere eigenaardigheid in dit boek. Daar de auteur niet op het begrip van de tekst gericht is, laat zij citaten uit Latijnse, oude Duitse, Franse, Italiaanse en Nederlandse teksten zonder enige argumentatie onvertaald (vgl. p. 7). Zelfs bij de interpretatie van de in hoofdstuk 6 uitgegeven Latijnse tekst, de enige bron waarvan de lezer kennis kan nemen, wordt geen hulp geboden.
| |
| |
Men zou met deze weinig tekstvriendelijke, onfilologische houding vrede kunnen hebben, wanneer de toepassing van de statistische methode tot resultaten had geleid die de interpretatie van de tekst uiteindelijk ten goede komen. De factoranalyse, de clustering van teksten en de selectie van representanten echter vergroten het begrip van de tekst niet, vormen geen hulpmiddel bij de interpretatie, helpen niet de verwantschap der teksten te bepalen, dragen op geen enkele wijze bij tot de vaststelling van oudere lezingen. Kortom, de statistische methode is prachtig en zal ook voor de studie der letteren hier en daar voordelig kunnen zijn. De hier beschreven toepassing echter heeft voor de filologie geen zin.
Afgezien van het addendum is het boek te beschouwen als een nuttig experiment. Dat het geen verbetering van de filologische methode oplevert, doet daaraan niets af, want ook een negatief resultaat is positief.
Adres van de auteur: Instituut voor Neerlandistiek U.v.A., Spuistraat 134, NL-1012 VB Amsterdam
| |
| |
| |
Reactie van de auteur
Duinhoven heeft mijn boek meermalen gelezen en wijdt er een zeer uitgebreide bespreking aan. Dat hij mijn werk serieus neemt, en dan met name de ambitie die ik ermee heb om te komen tot een methodologische vernieuwing in het vakgebied, doet me deugd. Echter, hij oordeelt dat ik in die ambitie niet geslaagd ben. Dat doet hij omdat hij mijn boek niet begrepen heeft. Ik wil mij hier beperken tot het maken van drie opmerkingen.
In de eerste plaats heeft Duinhoven jammer genoeg niet begrepen wat factoranalyse doet. In zijn commentaar op mijn gebruik van die statististische methode hanteert hij vaak het begrip ‘gemiddelde’. Zo zou ik slechts een gemiddelde, een modeltekst opgespoord hebben. Factoranalyse heeft echter helemaal niets te maken met gemiddelden. Factoranalyse is een techniek die gebruikt wordt om de invloeden op te sporen die voor correlaties tussen series metingen gezorgd hebben.
Op p. 70 beweert Duinhoven dat mijn methoden van nut zouden kunnen zijn ‘bij andersoortig filologisch onderzoek’. Dit bestrijd ik. Ik doe immers niets meer dan iets toevoegen aan het arsenaal beschikbare analysemethoden van de filologie. Op pp. 176-177 van mijn boek ga ik op dit onderwerp in. De wetenschapsfilosofische literatuur voorspelt dat een vakgebied zal reageren op vernieuwingen in methoden door het onderzoeksobject van het vernieuwende onderzoek te bestempelen tot uitzonderingsgeval, precies zoals Duinhoven doet.
In de derde plaats wil ik nog opmerken dat ik het jammer vind dat Duinhoven voorbijgaat aan wat ikzelf de nuttigste bijdrage van mijn onderzoek vind. Op p. 69 schrijft hij: ‘Hoewel het zeker is, dat een deel van de beide plaatsnamen in beide factoren een rol speelt, kan niet worden vastgesteld welke plaatsen factor 1 vormen en welke factor 2’. Ook hier heeft Duinhoven mij niet begrepen. Op pp. 94-96 laat ik wel degelijk zien hoe uitgerekend kan worden welke stukken tekst een doorslaggevende rol hebben gespeeld bij de totstandkoming van de waargenomen verhoudingen tussen de teksten in het corpus, anders gezegd: welke stukken tekst factor 1 vormen en welke factor 2. Bij mijn keuze van variatieplaatsen beroep ik mij op waarschijnlijkheidsberekening. Niet omdat ik niet beter zou kunnen, maar omdat dat de beste manier is.
Josephie Brefeld
| |
| |
| |
Nawoord van de recensent
Het is jammer dat mevrouw Brefeld niet de gelegenheid heeft benut om met argumenten aan te tonen, dat de resultaten van haar onderzoek voor de filologie wel degelijk belangrijk zijn. Als auteur is zij het beste in staat haar werkwijze toe te lichten en bedenkingen uit de weg te ruimen. Zij beoogt met haar proefschrift een methodologische vernieuwing te bewerken binnen een vakgebied met een lange traditie. Zo iets gaat niet zonder slag of stoot; dat vergt wetenschappelijke discussie.
| |
Opmerkingen
Misschien kan ik naar aanleiding van haar korte reactie een paar opmerkingen maken die ons verschil van inzicht verduidelijken. Om met de laatste alinea te beginnen. Wanneer men tekstelementen eenmaal door cijfers heeft vervangen en daarmee aan het rekenen slaat, is een terugkoppeling naar de tekst niet meer mogelijk. Dat is geen bezwaar, maar een constatering. Vervangt men de heilige plaatsen door enen en nullen, dan valt niet meer vast te stellen over welke plaatsnamen men spreekt. Daardoor is het ook niet mogelijk de plaatsnamen op te sommen die door de factoren 1 en 2 worden opgeroepen. Dit wordt niet weersproken door wat de auteur op p. 94-96 betoogt.
Van de plaatsnamen, zo zet zij uiteen, kan worden vastgesteld, hoe groot de kans is dat het voorkomen in de verschillende bronnen (de afwisseling van nullen en enen in de regel) niet in overeenstemming is met de trend in de hele matrix. De auteur geeft die percentages niet; in 71 (ongespecificeerde) gevallen is de waarschijnlijkheid ≤ 5%; in alle andere gevallen is de kans groter. Niet alleen geven deze kanspercentages geen zekerheid; ook bij volkomen overeenstemming met de trend in de matrix zou het voorkomen van een naam nog steeds in wisselende kanspercentages worden veroorzaakt door factor 1 (schriftelijke overlevering), factor 2 (mondelinge traditie) of door factoren van andere aard. De constatering blijft dus waar: we kunnen niet precies bepalen welke namen aan welke factoren moeten worden toegeschreven.
Alinea 3 van het weerwoord bevat, naar ik meen, een denkfout. De wetenschapsfilosofen zouden voorspellen: vakgebied wijst nieuwe methode af en bestempelt succes van gedemonstreerde toepassing als een toevalstreffer. Deze stereotype geldt niet voor mijn recensie van mevrouw Brefeld's boek. Precies het tegengestelde is betoogd: er is waardering voor de methode en voor de introductie daarvan, doch twijfel aan het nut van de specifieke toepassing.
| |
Het gemiddelde
Die twijfel is niet weggenomen door de stellige verzekering in alinea 2, dat factoranalyse niets met gemiddelden te maken heeft. Dat is slechts waar zolang twee sets van data worden vergeleken. De oorzakelijke factor geldt dan herkenbare overeen- | |
| |
komsten, in dit geval een bepaalde distributie van plaatsnamen, die in beide teksten volledig aanwezig is. Wanneer de computer echter drie of meer teksten vergelijkt, brengt hij de verschillende correlaties met elkaar in verband; het programma zoekt naar het beste compromis tussen alle correlaties, een soort gemiddelde. Dit gemiddelde is een rekenkundige grootheid die niet meer correspondeert met een reële distributie van plaatsnamen. Het resultaat, dat dus niet kan worden verwoord, is in geen enkele bron compleet aanwezig. Dat verklaart dat elke bron voor een zeker percentage op de factor ‘scoort’.
Men kan zich een tekst voorstellen die voor 100% scoort; deze imaginaire, abstracte modeltekst ligt dan midden in het corpus. En de teksten die hoog scoren, liggen daar dicht bij. Dat mevrouw Brefeld zich wel van deze verhoudingen bewust is, blijkt op bladzijde 130, waar ze zegt dat new york behoort tot ‘the texts at the centre of this small corpus’. Wij zijn het er dus over eens, dat new york exemplarisch is voor het geselecteerde corpus voorzover het gaat om de in het corpus aanwezige factoren. Daarvan is factor 1 de belangrijkste.
| |
Wat is factor 1?
Factor 1 bestrijkt het grootste deel van de in de reisgidsen voorkomende plaatsaanduidingen. Het is daardoor alleszins acceptabel, dat de auteur het voorkomen van deze plaatsnamen toeschrijft aan de schriftelijke teksttraditie. Doordat alle teksten teruggaan op dezelfde groep routebeschrijvingen en uiteindelijk op één en dezelfde lijst, hebben ze veel plaatsnamen gemeenschappelijk. Mevrouw Brefeld typeert factor 1 als ‘de invloed van een geschreven, Latijnse, brontekst’ (p. 111). De vraag is nu, wat we moeten verstaan onder invloed van het origineel.
Het computerprogramma kan ons hier niet meer helpen; de waardering van de factor is, zoals de auteur zelf benadrukt, een taak voor de onderzoeker. Bij de interpretatie nu van factor 1 maakt mevrouw Brefeld een gedachtensprong. Wanneer new york het hoogst scoort, dus meer dan andere teksten door het origineel is beïnvloed, dan lijkt new york volgens haar ook het meest op het origineel. Ongemerkt vervangt zij ‘invloed van de brontekst’ door ‘brontekst’.
Het misverstand wordt in de hand gewerkt door de definitie van factor 1 als ‘invloed van het origineel’. Minder verwarrend zou zijn ‘invloed van de schriftelijke overlevering’. Daarin ligt zowel de bijdrage van het origineel als die van de tussenstadia, de bewerkingen, besloten. Zoals in elke tekstoverlevering zijn de correlaties tussen de bewaard gebleven bronnen veroorzaakt niet uitsluitend door het origineel maar door het geheel van de voorgaande teksttraditie. Alleen wanneer er geen tussenstadia zijn, is er een direct verband tussen origineel en kopie. Het is echter uit te sluiten, dat new york, als jonge incunabel in een teksttraditie van eeuwen, direct van het origineel nagedrukt zou zijn. De overeenkomsten met de andere bronnen zijn voor een deel toe te schrijven aan opeenvolgende bewerkers, kopiisten en drukkers. In factor 1 liggen dus verschillende invloeden besloten.
De situatie is nog ingewikkelder, doordat in de analyse die tot factor 1 heeft geleid, teksten zijn betrokken met telkens een andere voorgeschiedenis: ‘invloed van
| |
| |
de schriftelijke overlevering’ is dus geen constante. Verandert men het corpus, dan verandert ook factor 1. Dat ziet men in mevrouw Brefeld's studie ook gebeuren. Binnen het eerste corpus scoorde bijvoorbeeld sessa voor 88% op factor 1 (zie p. 90), binnen het tweede corpus voor 96% (p. 130). Aan sessa is niets veranderd, ook niet aan het origineel. Dat bewijst dat de factor van het corpus afhankelijk is.
Dat de bronnen, waaronder sessa, in het tweede corpus hoger scoren, komt doordat deze bronnen hier niet alleen het origineel gemeenschappelijk hebben maar ook een groter stuk tekstgeschiedenis. Hoe hoger de score, des te groter is binnen factor 1 de invloed van de tekstontwikkeling, en des te geringer het aandeel van het origineel. Terwijl de auteur op de brontekst denkt aan te stevenen, raakt zij steeds verder van koers. Factoranalyse is voor de tekstkritiek een onbetrouwbaar kompas, dat we maar het beste over boord kunnen gooien.
A.M. Duinhoven |
|
