Tijdschrift voor Nederlandse Taal- en Letterkunde. Jaargang 90
(1974)– [tijdschrift] Tijdschrift voor Nederlandse Taal- en Letterkunde–
[pagina 251]
| |||||||||||||||||||||||||
Opmerkingen bij ‘Een taalstatistisch onderzoek’Ga naar voetnoot*)In een vorige aflevering van dit tijdschrift (deel 88, 1972, 284-306) verscheen een vrij uitvoerige bespreking (23 pp.) van mijn boek ‘Analyse van een vocabularium met behulp van een computer’ (Brussel, AIMAV, 1970, 219 pp.) onder de titel ‘Een taalstatistisch onderzoek’. Een dergelijke uitgebreide reactie kon mij in principe slechts verheugen: naast de talrijke (bij mijn weten een tiental) reeds verschenen kortere recensies, die alle het werk positief beoordeelden, zou een ruimere voorstelling de linguïst en literatuurwetenschapper een duidelijk beeld kunnen bijbrengen niet alleen van het werk zelf, maar ook van de kwantitatieve taalkunde in het algemeen. Het bleek echter vrij spoedig dat het de schrijvers van het artikel helemaal niet om duidelijke en brede informatie te doen was. Meer zelfs, als lezer kon men geen staat maken op de feiten zoals de recensenten die voorstelden. Ik achtte het dan ook een primair recht én een primaire plicht deze foutieve voorstellingen te weerleggen, a fortiori daar het ging om critici die zich als competent in het vakgebied voorstelden. Wat volgt zijn derhalve een aantal kritische opmerkingen bij het door M. Van 't Hof en F. Jansen geschreven review-artikel. Hierbij worden, gezien het plaatsgebrek, slechts de voornaamste punten behandeld. Deze lijken mij echter voldoende representatief voor het gehele stuk. Voor een ruimere, meer gedetailleerde en vollediger uiteenzetting verwijs ik naar een interne publikatie (paper) van het Departement Linguïstiek, LeuvenGa naar voetnoot1). | |||||||||||||||||||||||||
[pagina 252]
| |||||||||||||||||||||||||
1. In de eerste paragraaf stippen V. en J. zeer summier de opzet van mijn werk aan en vragen zich daarbij af ‘of het wel juist is dat er voor een onderzoek ten bate van de esthetische beoordeling van literatuur zoveel geld en mankracht wordt uitgetrokken, terwijl er op het gebied van taalgebruik nog zoveel maatschappelijk veel belangrijker onderzoek te doen is’ (Ts., 284)Ga naar voetnoot2). V. en J. menen immers dat het hier om een maatschappelijk weinig relevant object gaat, maar eerder om ‘luxueuze problemen’ (Ts., 305). Het is dan ook hoogst bevreemdend te merken dat mensen die zich zo diep bewust zijn van de geringe maatschappelijke relevantie van mijn ‘Analyse’, zo veel tijd en mankracht besteden aan de bespreking ervan. Even merkwaardig is trouwens dat V. en J. zich blijkbaar zelf met dergelijke ‘luxueuze problemen’ actief hebben ingelaten, als we tenminste de twee verwijzingen naar (hun) werk in een ‘Projektgroep kwantitatieve benadering van moderne poëzie’ in die zin mogen interpreteren (Ts., 288 en 294). Dergelijke inconsequenties in houding en argumentering zullen we bij deze recensenten vaker aantreffen. Dit neemt nochtans niet weg dat de vraag naar de maatschappelijke relevantie van mijn boek een zinnige vraag blijft die een antwoord verdient. Ik zou daarom kort het volgende willen stellen: bij hun denigrerende uitlatingen omtrent de maatschappelijke relevantie van mijn boek hebben V. en J. twee belangrijke zaken over het hoofd gezien. Allereerst miskennen zij de rol van de cultuur, en meer speciaal van de literatuur in de maatschappij: het maatschappelijk-relevante wordt bij hen beperkt tot het eng-sociaal utilitaire. Vervolgens vergeten zij dat een gericht wetenschapsonderzoek (i.c. stijlonderzoek) toch altijd stoelt op een vrij, wetenschappelijk onderzoek (i.c. een kwantitatieve taaltheorie: inzichten omtrent kwantitatieve aspecten van taal en taalgebruik) en van daaruit weer andere richtingen kan uitgaan. In die optiek is de z.g. kloof tussen de ‘luxueuze’ (literaire) problemen en de meer ‘urgente problemen betreffende taalvaardigheid, taaldidactiek, klassebepaald taalgebruik, e.d.’ (Ts., 305) helemaal niet zo | |||||||||||||||||||||||||
[pagina 253]
| |||||||||||||||||||||||||
groot als V. en J. het voorstellen. Zo kunnen modellen (zoals b.v. het reductiemodel) die ik heb voorgesteld en gebruikt ter verklaring van literaire problemen (i.c. ter bepaling van de relatieve omvang van vocabularia van romans met verschillende lengte), evengoed van nut zijn bij meer sociaal-linguïstisch gericht onderzoek (b.v. ter vergelijking van de grootte van de woordvoorraad bij subjecten of groepen afkomstig uit verschillende sociale milieus).
2. Een der voornaamste vragen die wij ons bij ons onderzoek stelden was deze naar de relatieve omvang of grootte van een literair werk: hoe kan men de grootte van het vocabularium, het aantal verschillende gebruikte woorden (= V), uit verschillende teksten bepalen? Wij gingen hierbij uit van woordvormen of grafische eenheden waarbij één string van grafemen gelijkgesteld werd aan één woord. Omtrent deze werkhypothese maken V. en J. heel wat misbaar: deze definitie zou onder het opzicht van de betekenis volkomen inadequaat zijn; het verschil tussen grote en groot zou op dezelfde wijze verwerkt worden als het verschil tussen grote en werkte; anderzijds zou er geen verschil gemaakt worden tussen trap (ladder), trap (schop: zelf-standig naamwoord) en trap (schop: werkwoord) (Ts., 287). Dat onze werkhypothese ondanks dit misbaar toch juist was en de gebruikte woorddefinitie derhalve operationeel adequaat was, kan met een eenvoudig kwantitatief proefje gemakkelijk gedemonstreerd worden. Hieruit blijkt dat de verhouding woordvorm-lemma (waarbij met alle bovengenoemde verschillen wel rekening wordt gehouden) constant is (als men een voldoende hoeveelheid tekst beschouwt). Deze constante impliceert dan meteen dat, als men b.v. de omvang van het vocabularium van verschillende werken met elkaar vergelijkt, hetzelfde resultaat wordt bekomen of men nu met woordvormen dan wel met lemmata werkt. Zo vindt men in Alfa 3.800, in Afscheid 4.641 verschillende woordvormen. In Alfa waren er 2.919 verschillende lemmata (hun aantal bekomt men door de frequentielijsten op pp. 143-193 van mijn ‘Analyse’ te raadplegen), in Afscheid 3.614. Welnu, de verhouding woordvormen-lemmata blijkt voor beide werken constant te zijn, nl. | |||||||||||||||||||||||||
[pagina 254]
| |||||||||||||||||||||||||
Dit wil dus zeggen dat de relatieve omvang van het vocabularium in Alfa en Afscheid dezelfde blijft of men die nu meet via woordvormen (die minder rekening houden met de betekenis) dan wel via lemmata (waar betekenisonderscheidingen wel worden gemaakt). Het is dus helemaal niet ongeoorloofd zoals V. en J. beweren, conclusies i.v.m. de grootte van de woordenschat (en m.m. met de groei) te maken aan de hand van woordvormen. Daarenboven menen we dat, daar het gebleken is dat deze hypothese niet alleen bij deze twee werken opgaat, maar ook voor andere werken empirisch bevestigd kan worden, hiermee zowel voor de theorie als voor de praktijk van de lexicale statistiek een fundamenteel gegeven gedetecteerd isGa naar voetnoot3).
3. Het uitgangspunt bij de discussie omtrent ‘statistiek en taal’ vormt een citaat uit mijn boek op p. 15: ‘(Anders geformuleerd): individueel gezien bestaat de “parole” uit linguïstische eenheden die resulteren uit een keuze van de taalgebruiker uit de hem ter beschikking staande middelen. Globaal gezien merken we dat het geheel van deze individuele “keuzen” (geheel dat “la langue” wordt geheten) een zulkdanige structuur heeft dat elke keuze kan verklaard worden als resultaat van een tirage aléatoire uit dit geheel’. Volgens V. en J. gaat het mij hier om het ‘onderscheid tussen taalsysteem en taalgebruik’ (Ts., 289). Alleen een oppervlakkige lectuur, die enkel rekening houdt met de termen langue-parole (en dan nog in Saussuriaanse zin), kan tot een dergelijke conclusie leiden. In feite moet men dit citaat in zijn oorspronkelijke context lezen. Het gaat hier om een deel van een parafrase van het citaat van Muller dat onmiddellijk voorafgaatGa naar voetnoot4), nl.: | |||||||||||||||||||||||||
[pagina 255]
| |||||||||||||||||||||||||
‘Essayer les méthodes statistiques sur le vocabulaire d'un texte, c'est avouer une croyance ou tout au moins ne pas refuser une hypothèse: celle d'après laquelle le choix des mots, dans l'exercice du langage relève des lois du hasard et peut être assimilé à un tirage aléatoire. Cela tout au moins quand on considère une étendue suffisante de texte, et qu'on l'envisage comme une masse en faisant abstraction de l'ordre d'apparition de ses éléments’ (Analyse, 14-15). Ik heb de uitdrukking ‘exercice du langage’ opzettelijk gecursiveerd om duidelijk te maken dat de dichotomie waarvan sprake er niet een is tussen taalsysteem en taalgebruik. Wel wordt hier, binnen het taalgebruik zelf, de tegenstelling tussen populatie (globaal, geheel) en sample (individueel, onderdeel) weergegeven. M.a.w., daar de frequentie van sommige taalobjecten stabiel blijkt te zijn binnen verschillende samples of steekproeven, wordt aangenomen dat dit taalgebruik kan voorgesteld worden als afkomstig uit een groter overkoepelend geheel, een populatie, een verzameling (finiet of infiniet) van taalgebruik, en wel als een blinde toevalstrekking uit die populatie (cf. het beeld van de urne in de statistiek). Dat hierbij voor de term ‘sample’ in de kwantitatieve taalkunde ‘parole’ gebruikt wordt, zal niet zoveel verwondering baren. Daarentegen is de term ‘langue’ voor ‘populatie’ voor niet-geïnitieerden misschien nieuw, maar dit zou de twee recensenten toch moeten bekend zijn. Daar dit niet het geval blijkt te zijn mogen we hen misschien dan ook het boek van Muller ‘Initiation à la statistique linguistique’ (Paris, Larousse, 1968, 248 pp.) aanbevelen en speciaal p. 91 en vlg. waar hij het heeft over ‘la langue d'un texte, (...) la population parente dont ce texte est un échantillon, et dont on ne connait les caractères qu'à travers ce texte’. Op het vlak van de lexemen wordt de tegenstelling populatie-sample in mijn boek dan ook verder doorgetrokken in de termen lexicon-vocabularium. V. en J. lezen wel dat ik lexicon definieer als ‘de potentiële woordvoorraad of anders geformuleerd de woordvoorraad die de schrijver ter beschikking staat’ (Analyse, 48), maar weigeren dit te interpreteren als de taalgebruikspopulatie, het gaat hier volgens hen ‘om de middelen die de taalgebruiker ter beschikking staan: (dus) het taalsysteem’ (Ts., 290.) Dat alle groten van de hedendaagse lexicale | |||||||||||||||||||||||||
[pagina 256]
| |||||||||||||||||||||||||
statistiek (zoals G.U. Yule, P. Guiraud, G. Herdan en Ch. Muller) de tegenstelling lexicon-vocabularium wel als een tegenstelling tussen populatie en sample op het vlak van het woordgebruik interpreteren blijkt ten overvloede uit hun werkGa naar voetnoot5). Het gaat hier trouwens niet om een secundair, maar om een basisgegeven van de kwantitatieve taalkunde. Als woorden niet als random variabelen kunnen worden aangezien d.i. als variabelen die op een populatie teruggaan en derhalve een vaste probabiliteit hebben, bestaat er ook geen lexicale probabiliteitsstructuur en verliest de lexicale statistiek derhalve haar studieobject. Het feit dat V. en J. van deze voor de taalstatistiek zo fundamentele notie geen weet hebben, getuigt dan ook allerminst voor de degelijkheid van hun taalstatistische inzichten.
4. Daar het in mijn Analyse om de vergelijking van twee vocabularia van ongelijke lengte gaat, en de meeste lexico-statistische grootheden afhankelijk zijn van de tekstlengte, is een essentieel punt in mijn betoog de reductie van vocabularia tot gelijke lengte, i.c. de reductie van de lengte van Afscheid (ruim 42.000 tokens) tot die van Alfa (ruim 33.000 tokens). De methode (reduceren van een vocabularium op basis van een binomiaal model) werd uitvoerig door mezelfGa naar voetnoot6) toegelicht. De recensenten proberen nu o.m. de onjuistheid van de formule te bewijzen aan de hand van ‘een eenvoudig na te rekenen voorbeeld’ (Ts., 293). Dit blijkt echter alras een karikatuur van elke primaire statistische bewijsvoering te zijn. Immers, dat de gebruikte formule onjuist is, concluderen V. en J. uit het feit dat er in een tekst (Wie is wie) bestaande uit 3 tokens en 2 types en te reduceren tot 1 token volgens | |||||||||||||||||||||||||
[pagina 257]
| |||||||||||||||||||||||||
het gebruikte model 8/9 types verwacht worden, terwijl er uiteraard bij een tekst van 1 token, 1 type wordt waargenomen. Daar de verwachting (8/9) niet overeenstemt met het resultaat (9/9) is de gebruikte formule fout volgens V. en J. Dit is echter helemaal niet het geval. Wat V. en J. constateren is een verschil tussen geobserveerde en geëxpecteerde (op het model gebaseerde) waarden. Het is echter niet omdat er een verschil is dat we daarom concluderen dat het model niet deugt: we moeten alleen te weten komen of het hier al dan niet om een significant verschil gaat; in dit laatste geval is het verschil tussen model en observatie niet langer door het toeval te verklaren. Welnu in het bovenstaande voorbeeld is het geobserveerde verschil gelijk aan 0,11 (9/9-8/9). De standaarddeviatie is gelijk aan 0,70 (volgens de formule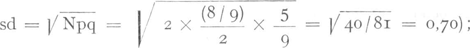 z is derhalve gelijk aan 0,11/0,70 = 0,157. De kans om door het toeval alleen een dergelijke z-waarde en dus een dergelijk verschil tussen observatie en model te bereiken en te overtreffen = 88%. Significante verschillen worden meestal slechts voor z-waarden met een probabiliteit ≤ 5% aangenomen. Het is dus duidelijk dat het voorgestelde model in het voorbeeld helemaal niet in tegenspraak is met het geobserveerde resultaat. Dat blijken V. en J. even verder ook wel in te zien - hoe sterk dit dan ook in tegenspraak moge zijn met hun zoëven geformuleerde uitlatingen - als ze uiteindelijk toegeven dat de resultaten van de reductie bij Afscheid ‘wel goed zullen zijn’ (Ts., 294).
5. Op pp. 295-296 van hun artikel brengen V. en J. een tabel waarin een aantal statistische grootheden van Alfa en Afscheid-R (gereduceerd) worden samengebracht en gecommentarieerd. Zij komen voornamelijk tot de slotsom dat de conclusies die ik uit deze getallen trek subjectief en tegenstrijdig zijn (Ts., 296). Hoewel ik, gezien de gebrekkige argumentatie van V. en J. (zoals verder zal blijken) voor dit punt beslist | |||||||||||||||||||||||||
[pagina 258]
| |||||||||||||||||||||||||
geen uitvoerige discussie nodig acht, wil ik toch op beide facetten even ingaan: a) Het wordt mij kwalijk genomen dat ik bij de vergelijking van diverse grootheden (o.m.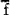 , v, C en R)Ga naar voetnoot7) de waarden ‘verbaliseer’: d.w.z. dat ik ze als ‘groter’ in Alfa dan in Afscheid - of omgekeerd - bestempel. Ik ben mij niet bewust hierdoor in subjectiviteit te vervallen: de cijfers blijven de primaire data. Daar het om secundaire (b.v. , v, C en R)Ga naar voetnoot7) de waarden ‘verbaliseer’: d.w.z. dat ik ze als ‘groter’ in Alfa dan in Afscheid - of omgekeerd - bestempel. Ik ben mij niet bewust hierdoor in subjectiviteit te vervallen: de cijfers blijven de primaire data. Daar het om secundaire (b.v. 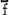 , C en R zijn een parafrase van V) of voor ons onderzoek minder relevante grootheden gaat (b.v. v) zie ik mij niet genoodzaakt hier telkens significantietoetsen te gebruiken. , C en R zijn een parafrase van V) of voor ons onderzoek minder relevante grootheden gaat (b.v. v) zie ik mij niet genoodzaakt hier telkens significantietoetsen te gebruiken.
b) V. en J. wijzen erop dat ik tegenstrijdige opmerkingen zou maken, daar ‘op p. 48 gesproken wordt van een aanzienlijke inkrimping van V, terwijl op p. 57 gesteld wordt, dat N en V globaal gelijk zijn voor beide werken’ (Ts., 296). De recensenten zouden er toch maar beter aan doen de tekst eerst aandachtig te lezen alvorens op ketterjacht te gaan: op p. 48 gaat het om N en V van het totale werk, op p. 57 om N en V van drie frequentieschijven (A, B, C samen: woorden met f ≥ 100). (Analyse, p. 57, pt. 2).
6. In de volgende paragraaf wordt de gevolgde methode (z-waarden) bij het onderzoek naar de groei van het vocabularium aangevochten. V. en J. beweren dat de door ons gebruikte z-waarden bedrieglijk zijn omdat ze ‘onderling afhankelijk zijn’ (Ts., 297). De bewijsvoering die V. en J. hierbij volgen, doet echter niet ter zake. Ten eerste steunen zij op fictieve voorbeelden die teksten uit twee verschillende talen met elkaar amalgameren, hoewel het model waaraan gerefereerd wordt duidelijk de tekst als één homogene monoliet behandelt. Ten tweede is het gegeven voorbeeld oncontroleerbaar (de frequentiestructuur van de ‘vreemde tekst’ is niet gegeven, de theoretische groei van het gehele | |||||||||||||||||||||||||
[pagina 259]
| |||||||||||||||||||||||||
werk kan derhalve niet worden berekend). Ten derde is de mogelijke afhankelijkheid van z-waarden op een veel eenvoudiger manier te verduidelijken. Immers het is klaar dat wanneer een geobserveerde frequentie (fo) t.o.v. een geëxpecteerde frequentie (fe) een grote afwijking vertoont, dit zijn repercussie kan hebben op de fo uit andere fragmenten. Stel dat een fragment een surplus aan V vertoonde t.o.v. fe, dan zou het volgende fragment dit normalerwijze met een deficit van fo t.o.v. fe moeten compenseren. Er kwamen immers meer nieuwe woorden voor dan verwacht; er is dus minder kans dat het volgende fragment nieuwe woorden oplevert. Daar de z-waarden berekend worden als fo-fe / sd is het ook zonder oncontroleerbare fictieve voorbeelden gemakkelijk duidelijk te maken dat de z-waarden afhankelijk van elkaar kunnen zijn. Dat wij ze toch gebruiken, had een dubbele reden:
Juist die twee fenomenen hebben zich voorgedaan: Afscheid vertoonde geen clustering van significante afwijkingen, wel een regelmatig verloop. Alfa daarentegen vertoonde deze clustering wel. Eén van deze clusters kon o.i. op een zinnige manier worden verklaard, vandaar de conclusie dat in Alfa vermoedelijk het ontbreken van een klassiek exposé zijn repercussie had op het deficitaire groei-begin van V. Wij schreven vermoeden omdat wij Alfa enkel met Afscheid konden vergelijken. Hadden V. en J. zinvol werk willen doen, dan hadden zij b.v. dit vermoeden kunnen verifiëren. Wij hebben het inmiddels gedaan voor Mei van Gorter. Net zoals in Afscheid ontbrak hier een clustering van significant-negatieve z-waarden. Wij vonden immers de volgende distributie: | |||||||||||||||||||||||||
[pagina 260]
| |||||||||||||||||||||||||
Bij α = 0,05 vindt men enkel vanaf z ≥ 1,96 significantie. Voortgaande op werken als Afscheid en Mei waar het verhaal door een klassiek exposé op gang wordt gebracht, en waar de groei van het vocabularium in de beginsegmenten niet significant deficitair verloopt, kunnen wij derhalve de hypothese dat het significant deficitaire verloop in de beginsegmenten van Alfa op het ontbreken van dit exposé teruggaat, nu nog sterker affirmeren.
7. V. en J. vinden dat ik het mij bij mijn berekening van de plaats der frequentste woorden nodeloos moeilijk maak en stellen een eenvoudiger formule voor. Misschien is mijn methode inderdaad omslachtig maar ze heeft het voordeel dat zij niet verkeerd kan geïnterpreteerd worden, wat niet gezegd kan worden van de formule die V. en J. voorstellen. Als qf = (1-g/N)f (Ts., 300) de kans moet voorstellen dat een woord met een frequentie f niet bij de eerste g woorden voorkomt, dan is het uit de formule niet duidelijk of het gaat om 1 - g / N of om 1- g / N. Daar de laatste interpretatie in dit geval de enig juiste is, moet de formule herschreven worden als qf = (1 - g / N)f of als qf = (N - gf / N) of als qf = (1 - (g/N))f.
8. Een der vragen die wij ons in het begin van dit werk stelden was deze naar het kwantitatieve gebruik van grammaticale categorieën in een tekst (Analyse, 81-94). Bij de discussie daaromtrent spannen V. en J. zich erg in om duidelijk te maken dat het zinloos zou zijn voor iedere woordcategorie V1 (het aantal hapaxen) als afspiegeling van L (grootte van het lexicon van deze categorie) te beschouwen: men zou toch ‘voor iedere categorie afzonderlijk moeten onderzoeken of het | |||||||||||||||||||||||||
[pagina 261]
| |||||||||||||||||||||||||
aantal gebruikte woorden daarin nadert tot de grootte van het “lexicon” van deze categorie’ (Ts., 301). Dit zou inderdaad nodig zijn bij woordcategorieën waar L vrij klein is en er dus kans bestaat dat V = L. In zo'n geval zou V1 geen betrouwbare parameter voor de grootte van L meer kunnen zijn omdat er in een dergelijke woordcategorie geen nieuwe V's meer zouden kunnen komen, wat uiteindelijk tot het verdwijnen van de V1-klasse voor deze categorie zou kunnen leiden. Bij ons onderzoek doet zich echter deze moeilijkheid niet voor, daar wij voor dit gedeelte van het onderzoek enkel werkten met z.g. open of infiniete (of door hun uitgebreidheid als infiniet voorkomende) woordklassen, nl. adjectieven, substantieven, werkwoorden en bijwoorden. Het voorbeeld met de lidwoorden dat de recensenten opgeven (waarbij de grootte van L tot 3 woorden is beperkt in het Nederlands) is dus volledig naast de kwestie.
9. Bij de behandeling van plus- en minuswoorden wilden wij die woorden opsporen ‘die qua frequentie een significante afwijking vertoonden in het werk van de auteur in vergelijking met het gemiddelde literair taalgebruik’ (Analyse, 95). Om dit gemiddelde literair taalgebruik te benaderen, gebruikten we een corpus van 20 fragmenten uit moderne Nederlandse romans, elk bestaande uit 12.500 tokens. Daar elk subsample uit evenveel tokens bestond, en de afzonderlijke frequentie per subsample voor elk woord bekend was konden wij voor elk woord i.p.v. zijn totale frequentie (som der frequenties der subsamples) een gecorrigeerde frequentie berekenen(U(sage)-waarde) die rekening hield met de verdeling (spreiding) der frequenties over het aantal bronnen. Achteraf echter werd voor berekening van de eventuele deviaties (ER-waarden)Ga naar voetnoot8) van Alfa resp. Afscheid t.o.v. dit basisvocabularium voor geschreven fictie niet op deze gecorrigeerde frequenties, maar op de oorspronkelijke een beroep gedaan. Dit vinden V. en J. inconsequent. Zij stellen het daarbij voor alsof men de gecorrigeerde frequenties uit het basisvocabularium zou mogen vergelijken met de ongecorrigeerde frequenties uit Alfa resp. Afscheid. | |||||||||||||||||||||||||
[pagina 262]
| |||||||||||||||||||||||||
Zo wordt bij hen het woord hoofd met U-waarde 193 in het basisvocabularium vergeleken met de f-waarde van hetzelfde woord in Alfa (f = 45). Er wordt geconstateerd dat de ER-waarde in dit geval niet significant is (ER = -0.15). Welnu, dit is een oncontroleerbare uitspraak. Immers, twee incompatibele waarden worden met elkaar vergeleken. Of om het anders te formuleren: de bovenstaande uitkomst kan slechts juist zijn indien de f-waarde in Alfa samenvalt met de U-waarde van ditzelfde woord in Alfa. Dit zou dus de meer dan onwaarschijnlijke hypothese inhouden dat de frequentie van hoofd in de desbetreffende roman volledig homogeen (want pas dan is d (dispersie) = 1 en U wordt berekend als f × d waarbij d varieert van o naar l, van totale ongelijke naar totale evenredige spreiding der frequenties) over het gehele boek zou gespreid zijn. V. en J. vervallen op die manier in oncontroleerbare en inconsequente uitspraken. Als men de U-waarden wil gebruiken, is het duidelijk dat men dat voor beide te vergelijken teksten moet doen (zowel voor het basisvocabularium als voor de te onderzoeken tekst). Dat wij van de U-waarden hebben afgezien en enkel f-waarden met elkaar hebben vergeleken, heeft dan ook niets met inconsequentie te maken, wel met het feit dat men om de U-waarden te berekenen moet vertrekken van fragmenten van dezelfde grootte: deze waren voor het basisvocabularium, bij een vroeger onderzoek aan het ITL, op 12.500 tokens vastgesteld. Daar noch de tekstlengte van Alfa (33.489 tokens), noch deze van Afscheid (42.865 tokens) een veelvoud van 12.500 uitmaakten konden wij noch voor Alfa noch voor Afscheid tot U-waarden komen die compatibel zouden zijn met de U-waarden van het basisvocabulariumGa naar voetnoot9). Het leek ons dan ook veiliger, i.p.v. in controleerbare uitspraken te vervallen, f-waarden boven U-waarden te verkiezen voor de vergelijking tussen tekst en basisvocabularium.
10. Tot slot nog een woord over de auteurs van dit artikel. Een harde kritiek is beter dan geen kritiek. Wie een kritek schrijft, moet | |||||||||||||||||||||||||
[pagina 263]
| |||||||||||||||||||||||||
echter berekend zijn op zijn taak, een coup d'essai is hier niet gepermitteerd. Ik meen dat het uit mijn opmerkingen ten overvloede is gebleken dat deze coups d'essai bij V. en J. zo vaak voorkwamen en daarbij zo dikwijls misslagen bleken te zijn dat het inderdaad begrijpelijk is dat de door hen bedreven ‘taalstatistiek een frustrerende bezigheid’ (Ts., 304) zal geweest zijn.
Instituut voor Toegepaste Linguïstiek K.U. Leuven W. Martin |
|