
Tabu. Jaargang 19
(1989)– [tijdschrift] Tabu–
[pagina 149]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Digitale fonologie: het vocaalmodel
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 150]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Figuur (1) geeft een simplistische voorstelling van zaken. Stel dat carrier C in (1) de articulatieplaats voor de vocaal /e/ aangeeft, en modulator M de modulatie <lax> (=ongespannen); dan houden de opties AC en AD in het schakelsysteem in, dat het model geen vocaal genereert. Als de carrier niet in actie is gezet, doet modulatie niets meer ter zake. Modulator M is immers niet rechtstreeks met de output verbonden; <lax> kan de output slechts bereiken via een geactiveerde carrier C. De metafoor van het stroomschema bewijst hier zijn waarde: zowel wanneer de met de modulator verbonden carrier niet geactiveerd is, als wanneer het pad input-modulator in het schakelsysteem onderbroken is, krijgt de modulator de waarde 0 in de output-code. Schakelstand BC activeert wel de carrier, maar niet de modulator; de output is de ongemoduleerde vocaal /e/. Schakelstand BD daarentegen activeert beide modules, zodat er sprake is van een gemoduleerde, en daarom meer gemarkeerde, vocaal in hetzelfde articulatiedomein: /ε/. 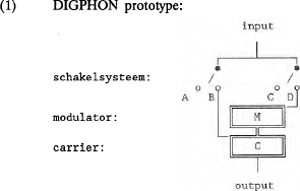 DIGPHON definieert eigenlijk een verzameling mogelijke paden, en voor elke afzonderlijke taal een deelverzameling van die paden, de actuele paden. Dit artikel is als volgt opgebouwd: in paragraaf 1 behandelen we de bouwstenen van DIGPHON, waarna in paragraaf 2 een handleiding volgt om met die bouwstenen het universele vocaalmodel samen te stellen. Tevens geven we in paragraaf 2 aan, hoe taalspecifieke modellen van het universele model kunnen worden afgeleid. Paragraaf 3 is -net als deze inleiding- bedoeld om de lezer ervan te overtuigen dat DIGPHON niet een soort bouwpakket voor een transistorradio is, maar dat hier wel degelijk sprake is van een fonologische onderneming, en wel een op het terrein van de non-lineaire fonologie. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1 Bouwstenen van DIGPHON.1.1 Het digitaliseren van vocalenIn DIGPHON geven we vocalen weer door middel van bytes, codes die bestaan uit combinaties van 0-en en 1-en. Een positie in een code wordt een bit genoemd en kan de waarde 0 of 1 hebben. Digitalisering van het vocaalsysteem | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 151]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
houdt in dat de vocaaldriehoek wordt ‘bemonsterd’ ofwel ingedeeld in domeinen. Het aantal bits dat nodig is om per taal de vocalen van elkaar te onderscheiden is daarbij afhankelijk van het aantal vocalen in de taal.Ga naar eind2. Het meest voorkomende taalsysteem bestaat uit vijf vocalen: /i,e,a,o,u/. Dit geldt voor 27% van alle talen; als voorbeeld kan hier het Latijn dienen. Als we het Latijnse vocaalsysteem willen coderen, is een 2-bits-codering onvoldoende. Met twee bits kunnen we immers slechts vier vocalen van elkaar onderscheiden: 00; 01; 10; 11. Een 3-bits-codering is daarom noodzakelijk. Elke vocaal representeren we als een code die uit drie bits bestaat. We benutten daarbij de posities van de bits zo, dat uit de gegeven codes articulatieplaatsen af te lezen zijn. Zo staat de combinatie 010 voor /a/, 100 voor /i/, 001 voor /u/, 110 voor /e/ en 011 voor /o/. Wanneer de eerste bit de waarde 1 heeft, is het feature <front> aanwezig; waarde 1 voor de tweede bit geeft <central> aan, en waarde 1 voor de derde bit staat voor <back>. Deze codering vertoont sterke overeenkomsten met de vocaalrepresentatie in het werk van Kaye et al. (1985) en Van der Hulst (te verschijnen). De harde kern van beide analyses is het uitgangspunt van drie basiselementen A, I en U. Deze elementen staan voor fonologische segmenten. Hierbij geldt dat een segment dat door een combinatie van elementen beschreven wordt gemarkeerder is -dat wil zeggen minder vaak voorkomt in natuurlijke talen- dan een segment dat door een enkel element gerepresenteerd wordt. A staat voor het foneem /a/ en I voor /i/, maar bijvoorbeeld de combinatie I.A voor /e/. De code 110 voor /e/ in DIGPHON kan op vergelijkbare wijze ook gezien worden als een combinatie van de codes 100 voor /i/ en 010 voor /a/. Laten we aannemen dat het vocaalsysteem van taal X uit zestien vocalen bestaat. Een 4-bits-codering is dan voldoende om alle vocalen van elkaar te onderscheiden. Maar het is ook onze bedoeling om de onderlinge samenhang tussen de bits (lees: features) te verdisconteren. Pas dan is het mogelijk om generalisaties te maken over klassen van fonemen en om fonologische processen in de vorm van codeveranderingen op inzichtgevende wijze weer te geven. Zo delen /i/ en /y/ de articulatieplaats en kunnen ze van elkaar onderscheiden worden door middel van de articulatorische operatie ‘lipronding’. Hetzelfde geldt voor /e/ en /ø/. Om dergelijke generalisaties te verantwoorden, onderscheiden we in DIGPHON carriers en modulators. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.2 CarriersDe carriers vatten we op als de basisfeatures. Op basis van deze carriers wordt de vocaaldriehoek in domeinen verdeeld en daarmee wordt ook de articulatieplaats van de vocalen voorgoed vastgelegd. In elke code voor een foneem staan de eerste drie bits voor de articulatieplaats. Voor een 3-bits-codering betekent dit, dat er 23 = 8 articulatiedomeinen onderscheiden kunnen worden. Dat we er daarvan niet meer dan zes gebruiken, heeft te maken met de interpretatie van de bits. De eerste staat voor articulatie met gesloten onderkaak en tongpositie voor: <gesloten/voor>; de tweede voor <open/centraal>; de derde voor <gesloten/ achter>. Combinaties van de eerste of derde bit met de tweede bit geven articulatie met half gesloten onderkaak aan. De theoretisch mogelijke 3-bits-combinaties 111 en 101 moeten we echter op praktische gronden uitsluiten, | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 152]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
aangezien bij de articulatie van een vocaal de tong niet gelijktijdig achter en voor kan zijn. De eerste en de derde bit mogen dus niet gelijktijdig de waarde 1 (=geactiveerd) hebben. De combinatie 000 geeft aan, dat er geen enkele carrier geactiveerd is; het articulatorisch correlaat voor deze combinatie is dus min of meer ongearticuleerdheid. De combinatie 000 staat dan ook voor de vocaal schwa.Ga naar eind3. In elk van de zes domeinen moeten meerdere vocalen kunnen worden gegenereerd. Dit gebeurt door middel van beïnvloeding, ofwel modulatie, van de carriers. (2) toont de articulatorische domeinen plus een selectie van de belangrijkste vocalen. 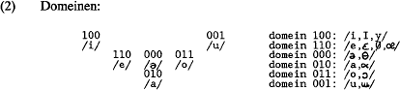 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.3 ModulatorsDe manier waarop de beïnvloeding van de carriers in zijn werk gaat, is geïnspireerd op de manier waarop met een Yamaha DX 7 synthesizer geluid wordt opgewekt.Ga naar eind4. De DX 7 kent twee soorten operators: carriers voor het basisgeluid en modulators voor de beïnvloeding van dit basisgeluid. De operators worden algoritmisch met elkaar verbonden; een voorbeeld van zo'n DX 7 algoritme, namelijk algoritme 17, wordt hier in beeld gebracht. 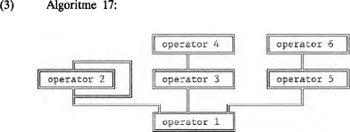 Hoe moeten we de werking van zo'n algoritme nu begrijpen? In (3) fungeert operator 1 als carrier en fungeren de andere operators als modulator. Operator 1 bepaalt de toonhoogte en de luidheid van het signaal en de andere operators bepalen de klankkleur. Modulators kunnen behalve een carrier ook andere modulators moduleren: 4 moduleert 3, en 6 moduleert 5. We kunnen in (3) zien, dat algoritme 17 zodanig is samengesteld, dat operator 4 het carriersignaal | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 153]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
slechts indirect kan beïnvloeden en wel slechts dan als operator 3 geactiveerd is. Verder zien we dat operator 2 naast de carrier ook zichzelf kan moduleren; deze laatste vorm van modulatie wordt ‘feedback’ genoemd. Algoritme 17 staat, primitief als het is, ook al een fonologische interpretatie toe. Beschouw operator 1 als articulatieplaats-bepaler van een vocaal en operator 2 als een feature dat de articulatiewijze aanduidt. Feedback maakt dan gradaties in de waarde van dit feature mogelijk. Een voorbeeld: het Fries kent gradaties in duur, hier geïllustreerd aan de hand van wyt /i/ (wit); wiid /i:/ (wijd) en wiet /iə/ (nat).Ga naar eind5. Stel dat operator 3 voor feature X staat en operator 4 voor feature Y. Algoritme 17 kan dan het vocaalmodel van een imaginaire taal zijn die slechts vocalen met het kenmerk Y heeft, die al kenmerk X hebben, aangezien modulator Y de carrier slechts dan kan beïnvloeden als modulator X actief is. Een dergelijke situatie doet zich in het Frans voor, waar slechts korte vocalen genasaliseerd worden. In een Frans vocaalmodel zou operator 4 <nasal> kunnen aanduiden en operator 3 <lax>. Het zal duidelijk zijn dat niet alleen het aantal combinaties, maar ook de interpretatie van de operators een welhaast onbeperkt aantal mogelijkheden biedt. Hoe moeten we nu een DIGPHON-model construeren ? Het DIGPHON-vocaalmodel moet zowel economisch als effectief zijn. In de fonologie van de laatste jaren heeft zich, net als in de syntaxis overigens, een verandering in het paradigma voorgedaan: men heeft nu meer interesse voor principes en parameters, dan voor regels. In vergelijking met de fonologie van Chomsky & Halle (1968) (verder: SPE) besteedt de fonologie de laatste jaren minder aandacht aan het weergeven van fonologische processen in de vorm van regels. We kunnen immers ook regels formuleren voor denkbare processen die zich in geen enkele natuurlijke taal voordoen. Dat duidt erop dat het regelmodel in verklarend opzicht tekortschiet: het kan te veel, het is te ‘powerful’. Daarom richt het fonologisch onderzoek zich steeds meer op het ontwerpen van modellen die -in termen van verklarende waarde- hoger scoren. In de vigerende visie moet een fonologisch model aan in elk geval de volgende criteria voldoen: de natuurlijkheid van bepaalde fonologische processen moet uit de inrichting van het model blijken. Verder moet een ideaal model zodanig ingericht zijn, dat het een voorspellende waarde heeft voor de inventaris van foneemsystemen. Op basis ervan moet kunnen worden aangegeven waarom bijvoorbeeld /a/ vaker dan /y/ voorkomt; en waarom er wel vocaal-systemen met alleen /a,i,u/ worden aangetroffen, maar geen vocaalsystemen met alleen /y,ɛ,/∧/. Clements (1989) geeft een vijftal criteria waaraan een fonologisch model idealiter moet voldoen. In paragraaf 3 gaan we daar nader op in. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.4 Plaatsmodulatie en polariteit1.4.1 PlaatsmodulatieIn het voorafgaande hebben we erop gewezen dat de DIGPHON-vocaaldriehoek bemonsterd wordt met behulp van drie articulatieplaats-bepalende carriers. In het vocaalmodel geven we deze carriers weer als een drieëenheid van horizontaal, op één rij, gerangschikte modules. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 154]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Als het vocaalmodel uit slechts deze drie carriers zou bestaan, zouden we er de volgende, ongemoduleerde vocalen mee kunnen afleiden: /ə/ in domein 000 als geen enkele carrier geactiveerd wordt; /a/ in domein 010, /i/ in domein 100 en /u/ in domein 001 als één carrier geactiveerd wordt; en tenslotte /e/ in domein 110 en /o/ in domein 011 als twee carriers geactiveerd worden. Door modulatie toe te passen scheppen we echter per domein de mogelijkheid meerdere vocalen te genereren. In een eerdere versie van DIGPHON (Gilbers (1989)) hebben we modulators als <round> en <tense> voorgesteld om bijvoorbeeld /I,i,y/ van elkaar te kunnen onderscheiden in domein 100. Hier zien we af van een modulator <tense>, omdat dit feature zich niet goed articulatorisch laat definiëren. In DIGPHON willen we elk feature van een passend fonetisch correlaat voorzien; een feature mag niet slechts een fonologisch label zijn om fonemen van elkaar te onderscheiden. Wat is er mis met dit fonologische feature <tense>? Om ‘lengteverschillen’ tussen vocalen, als bijvoorbeeld in hol - holen; dakdaken, te kunnen beschrijven werd in de fonologie aanvankelijk gebruik gemaakt van het feature <long>. Er bleek echter geen overeenstemming te zijn tussen fonologen en fonetici over de status van dit feature (zie o.a. Streekstra & de Graaf (1979)). We zullen dit hier aan de hand van twee voorbeelden verduidelijken. Volgens de Nederlandse fonotaxis gedragen fonemen als /i,y,u/ zich als lange vocalen. Net als bijvoorbeeld /e,o,a/ kunnen /i,y,u/, in tegenstelling tot /ɛ,ɔ,α/, aan het einde van een woord voorkomen: nee, zo, la; zie, nu, toe. Ondanks het feit dat fonologisch gezien /i,y,u/ zich als lange vocalen gedragen, leveren fonetische duurmetingen voor deze vocalen geen andere resultaten op dan voor vocalen als bijvoorbeeld /ɛ,ɔ,α/. Dus moeten we het idee opgeven om het feature <long> fonetisch in termen van duur te definiëren. Morfonologisch gezien vereist een Nederlandse korte vocaal voor een sonorant het diminutiefsuffix -etje: zon - zonnetje; ster - sterretje. Indien nu /i,y,u/ kort zouden zijn, dan zouden we verwachten dat de verkleinvormen voor zoen, bier en kuur respectievelijk * zoenetje, * bieretje en * kuuretje zijn. Ook hier weer gedragen /i,y,u/ zich net als /a,o,e/ als lange vocalen: zoentje, biertje, kuurtje; haantje, boortje, keeltje. Om toch te voldoen aan de algemeen aanvaarde eis dat ieder feature van een adequaat articulatorisch correlaat is voorzien, heeft men het feature <long> vervangen door het feature <tense>. Halle & Clements (1983): Tense vowels are produced with a tongue body or tongue root configuration involving a greater degree of constriction than that found in their lax counterparts; this greater degree of constriction is frequently accompanied by greater length. Deze fonetisch gezien weinig precieze definitie maakt duidelijk dat de naam van het feature er eigenlijk niet toe doet, als het feature maar het effect | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 155]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
heeft dat er een fonologisch onderscheid gemaakt kan worden tussen vocalen zoals bijvoorbeeld /i,u,e,o,a/ en hun respectievelijke tegenhangers /I,U,ɛ,ɔ,α/. De fonologische motivatie voor dit feature was de hoofdzaak. Dat het articulatorische correlaat slechts bijzaak was, bleek overduidelijk toen in Afrikaanse talen fonologische processen ontdekt werden die betrekking hebben op gespannen vocalen, maar waarbij /a/ zich als ongespannen vocaal gedraagt. Die ontdekking had tot gevolg dat nu de vocalen /i,u,e,o/ onderscheiden moesten worden van /I,U,ɛ,ɔ,a/ en er zat dus niets anders op dan ad hoc een nieuw feature te introduceren, <ATR> (=advanced tongue root), voor alle gespannen vocalen behalve /a/. Halle en Clements (1983): As its name implies, this feature is implemented by drawing the root of the tongue forward, enlarging the pharyngeal cavity and often raising the tongue body as well; <-ATR> sounds do not involve this gesture. Daarmee is de zaak uiteraard nog niet opgelost. Vergelijking van de definitie voor <tense> met die voor <ATR> maakt niet duidelijk waarom /a/ wel aan de eerste articulatorische beschrijving voldoet, maar niet aan de tweede. Daarbij is het merkwaardig, dat er om /ɔ/ en /o/;/ɛ/ en /e/ te onderscheiden maar liefst drie features ter beschikking zijn. Halle & Clements (1983) is deze situatie niet ontgaan, maar zij tillen niet zo zwaar aan deze luxueuze voorraad features, aangezien <tense> en <ATR> nooit beide in één taal distinctief zijn. Het zijn dus varianten van eenzelfde feature, dat in de ene taal als <ATR> verschijnt en in de andere als <tense>. In DIGPHON blijft bij toepassing van een modulator <tense> om bijvoorbeeld /I/ en /i/ te onderscheiden de articulatieplaats ongewijzigd; slechts de wijze van articulatie verandert. Fonetisch gezien is dit niet correct. De articulatieplaatsen van /I/ en /i/; /ɛ/ en /e/; /β/ en /a/ zijn verschillend. Vergelijking van de formantwaarden van de genoemde vocalen wijst uit dat het onderscheid tussen gespannen en ongespannen eigenlijk geen verschil in articulatiewijze betreft, maar een licht verschil in articulatieplaats.Ga naar eind6.  | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 156]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Om in bijvoorbeeld domein 100 /I/ van /i/ te onderscheiden worden daarom lengtemodulators, zoals <long>; <tense> en <ATR>, vervangen door plaatsmodulators die lichte verschillen in de articulatieplaats veroorzaken. Uit (5) blijkt dat op één na alle traditioneel als kort gekenmerkte vocalen ten opzichte van hun ‘lange’ tegenhangers lager, dat wil zeggen met een iets verder geopende onderkaak, gearticuleerd worden. Enige uitzondering vormt /α/, waarbij juist sprake is van een iets meer gesloten onderkaak ten opzichte van de articulatie van /a/. In het model kan deze plaatsmodulatie als in (6) verwerkt worden. 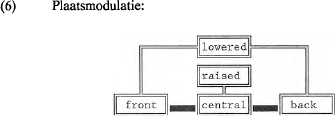 Alleen de carriers zijn verbonden met de output. <raised>, bijvoorbeeld, kan slechts dan met de waarde 1 tot de output doordringen als <central> geactiveerd is. Zoals <raised> afhankelijk is van <central>, zo is <lowered> afhankelijk van de carriers <front> en <back>; <lowered> kan alleen van invloed zijn in de domeinen 100; 110; 001 en 011 en werkt derhalve niet in domein 010. <raised> is niet van toepassing in de domeinen 100 en 001. Plaatsmodulatie is dus ongeveer hetzelfde als centralisatie; /a,i,u/ blijven de extreem perifere articulatieposities in de vocaaldriehoek bezetten. Met deze visie op plaatsmodulatie is niet alleen het onderscheid tussen vocalen zoals bijvoorbeeld /i,u,e,o,a/ en hun respectievelijke tegenhangers /I,U,ɛ,ɔ,α/ voorzien van een passend, dat wil zeggen meetbaar, articulatorisch correlaat, ook het fonologische onderscheid tussen <tense> en <ATR> kan verantwoord worden: ‘ongemoduleerd’ staat voor <tense>; elke vorm van plaatsmodulatie staat voor <lax> (=ongespannen); alleen <lowered> staat voor <-ATR>. <ATR> en <tense> moeten daarom niet als realisatievormen van hetzelfde feature beschouwd worden, en zo nemen we dus afstand van Halle & Clements (1983). De overeenkomst zit in de modulatie van de articulatieplaats; het verschil in de richting van die modulatie. De vervanging van features als <long>, <tense> en <ATR> door plaatsmodulatie brengt ook een nieuwe kijk met zich mee op het fonotactisch gezien eigenaardige gedrag van de schwa in het Nederlands. Op enkele interjecties na, als bah en hè, kunnen in het Nederlands slechts lange vocalen aan het woordeinde voorkomen. Getuige woorden als ze, me, deze en oase gedroeg de fonetisch korte schwa zich daarbij als een fonologisch lange vocaal. In termen van DIGPHON is de schwa echter een ongemoduleerde vocaal, net als een uit de reeks /a,i,y,u,e,ø,o/. Fonotactisch gezien neemt schwa dus geenszins een uitzonderingspositie in. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 157]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.4.2 R-reverseIn tegenstelling tot het onderscheid lang: kort behelst het onderscheid rond : ongerond ondubbelzinnig een oppositie in articulatiewijze. Ronde vocalen worden met getuite lippen gearticuleerd. De vraag is hier hoe dit feature <round> als operator in het model moet worden opgenomen. In Gilbers (1989) is het feature in het model verwerkt als een modulator die niet rechtstreeks de output-code kan beïnvloeden. Dit levert weliswaar een adequate beschrijving van een vocaalsysteem op, maar de moderne fonologie wil meer: een beschrijvingsmodel moet verklarende waarde hebben. Hoe moeten we bijvoorbeeld op inzichtgevende wijze verantwoorden dat de geronde achtervocaal /u/ vaker voorkomt dan zijn ongeronde tegenhanger /ɯ/; en dat daarentegen de ongeronde voorvocaal /i/ vaker voorkomt dan zijn geronde tegenhanger /y/? Dergelijke gemarkeerdheidsverschillen kunnen we niet verklaren met het in- of uitschakelen van een modulator <round>. <round> modulatie is van een andere orde dan bijvoorbeeld modulatie als <nasal>, <clicked> en <breathy>. Voor deze laatste drie, actieve, modulators geldt dat alle gemoduleerde vocaalafleidingen gemarkeerder zijn dan de niet gemoduleerde. <round> daarentegen is een volledig passief, ondergespecificeerd, feature; de waarde van <round> is afhankelijk van de carrierinstelling. We kunnen <round> het beste beschouwen als een soort eigenschap van de articulatiedomeinen, net als bijvoorbeeld het feature <high>. Zoals <high> impliciet in de domeinen 100 en 001 aanwezig en in domein 010 afwezig is, zo is <round>, in het ongemarkeerde geval, in domein 100 afwezig en in domein 001 aanwezig. Om het passieve karakter van <round> tot uitdrukking te laten komen, nemen we het feature, voorzien van een polariteitsschakelaar (R-reverse), naast de carrier-drieëenheid in het model op. <round> is dan niet als modulator, maar als eigenschap van de carrier-drieëenheid met de output van het model verbonden. Het schakelsysteem moet zo worden ingericht dat in positief-polaire stand onder andere de ongeronde /i/ en geronde /u/ kunnen worden afgeleid, en in negatief-polaire stand de geronde /y/ en de ongeronde /ɯ/. Negatief-polair is gemarkeerder dan positief-polair. 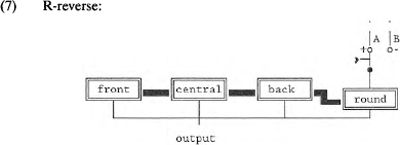 In (7) geeft schakelaar AB in de stand A de ongemarkeerde waarde voor <round> aan. Dit betekent dat <round> ondergespecificeerd is voor <back>. Stand B geeft de ‘reverse’ (=meer gemarkeerde) waarde voor <round> van het te genereren foneem aan. In stand B is <round> juist ondergespecificeerd voor | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 158]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
<front>. Round-reverse kan gezien worden als een spiegeling van de waarde voor <round> in een denkbeeldige verticale as in de vocaaldriehoek.  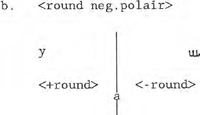 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.4.3 HL-reverseDe polariteitsschakelaar voor <round> is gemotiveerd door gemarkeerdheidsgegevens. Dezelfde motivatie geldt voor de introductie van een tweede passieve operator, namelijk <HL-reverse>, die hoog-laagpolariteit aangeeft. De vocaaldriehoek is eigenlijk een fysisch model voor de articulatiemogelijkheden van het menselijke spraakkanaal met als oriëntatiepunten /a,i,u/, respectievelijk open-centraal; gesloten-voor en gesloten-achter. Toch zijn er talen bekend die juist de complementaire posities van deze belangrijkste articulatieplaatsen in de vocaaldriehoek benutten. Zo kennen talen als Russisch en Khmer een lage (=open) ongeronde voorvocaal: /a̟/; talen als Frans en Hongaars een lage geronde achtervocaal: /ɐ/; en talen als Laps en Kurdisch een hoge (=gesloten) ongeronde centrale vocaal: /ɨ/. Om enerzijds dergelijke vocalen te kunnen genereren en anderzijds hun gemarkeerde status te kunnen verantwoorden, maken we in DIGPHON gebruik van een operator voor HL-reverse. 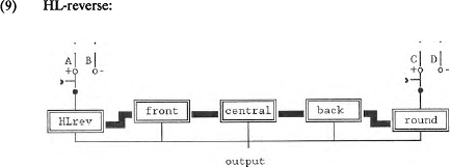 Bij een positief-polaire stand van de operator voor HL-reverse is het model in staat vocalen als /a,i,u/ te genereren; bij een negatief-polaire stand: /ɨ,a̟,ɒ/. Deze operator verandert de interpretatie van de codes. Hoog wordt negatiefpolair laag; laag wordt hoog; en wat de plaatsmodulators betreft: <lowered> | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 159]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
wordt <raised> en <raised> wordt <lowered>. Zoals Round-reverse de vocaaldriehoek ‘verticaal’ spiegelde, zo spiegelt HL-reverse de driehoek in een denkbeeldige horizontale as. Deze /e/-/o/ as zelf geeft het middengebied aan, dat bij HL-reverse uiteraard onveranderd blijft. Het effect van plaatsmodulatie brengt wel veranderingen met zich mee. Daarover meer bij de opbouw van een model voor de universele vocaal.  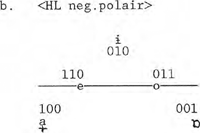 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.5 Schakelsysteem1.5.1 Operator-externe schakelingenAls laatste onderdeel van een DIGPHON-model behandelen we in deze paragraaf het schakelsysteem. Een stroomschema verbeeldt de manier waarop elke operator in het model geactiveerd kan worden. De verbinding van de input met een operator geeft deze operator de waarde 1. Is het pad onderweg onderbroken, dan heeft de operator de waarde 0. Dit systeem zorgt er in de eerste plaats voor dat articulatorisch gezien onmogelijke featurecombinaties worden uitgesloten. Zo is hierboven gesteld dat de carrier <front> niet gelijktijdig met de carrier <back> aan de input verbonden mag zijn. Een keuzeschakelaar (11) in het schakelsysteem maakt een dergelijke koppeling onmogelijk, en daarmee het afleiden van de ongewenste domeinen 101 en 111. Schakelaar (11) gebruiken we om disjunctie aan te geven. 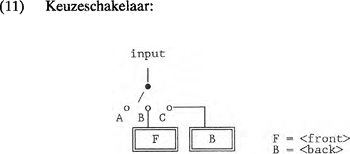 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 160]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Verder geeft het schakelsysteem taalspecifieke implicaties weer. In het Nederlands komen, in tegenstelling tot bijvoorbeeld het Russisch, geen ongeronde achtervocalen voor, met andere woorden, in het Nederlands impliceert het feature <back> (B) het feature <round> (R). Een implicatielijn als in (12), die in stand C zowel module (B) als module (R) met de input verbindt, gebruiken we om conjunctie aan te geven. 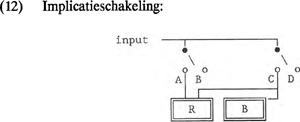 Bij de constructie van een vocaalmodel voor het Russisch zal de verbindingslijn die <round> activeert als de rechter keuzeschakelaar in (12) in stand C staat, achterwege blijven. Om implicaties van het type ‘Als X dan Y, tenzij Z’ in het schema te verwerken, wordt gebruik gemaakt van dubbelpolige omschakelaars: 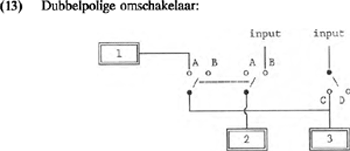 Volgens (13) wordt in de stand C operator 1 gelijk met operator 3 geactiveerd, tenzij operator 2 geactiveerd is door middel van de dubbelpolige keuzeschakelaar in stand B. Stel dat 1 in taal X voor modulator <nasal> staat; 2 voor modulator <breathy voiced> en 3 voor carrier <back>, dan kunnen in taal X alleen nasale achtervocalen voorkomen die niet <breathy voiced> zijn. Met keuzeschakelaars, dubbelpolige omschakelaars en implicatielijnen kunnen we elke taalspecifieke vorm van onderspecificatie in het schakelsysteem verwerken. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 161]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.5.2 Operator-interne schakelingenOperator-interne schakelingen zorgen ervoor dat de waarde 1 van een ingeschakelde modulator de output-code van het te genereren foneem alleen dan kan bereiken als de carrier waarmee deze modulator verbonden is, geactiveerd is. Simpeler gezegd: als de carrier het niet doet, heeft modulatie daarop ook geen zin. In (14a) wordt de interne schakeling van een carrier gegeven en in (14b) de interne schakeling van een modulator. Om de metafoor van het stroomschema vol te houden: iedere operator wordt met behulp van een relais (RL) geactiveerd. In voorbeeld (14) staat C voor de bit die in de foneemcode de waarde voor de carrier <central> aangeeft; Ra staat voor modulator <raised> en Fb voor <feedback on raised>. 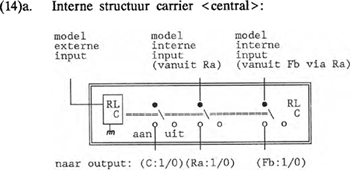 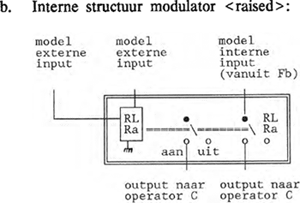 Tot zover de bouwstenen van het DIGPHON-model. In paragraaf 2 gaan we met deze bouwstenen aan het werk. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 162]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2 Vocaal-modellen2.1 Modaal vocaalmodelNu we alle bouwstenen van DIGPHON in handen hebben, kunnen we beginnen met de opbouw van de modellen. Als voorbeeld wordt in dit hoofdstuk een model gegeven van het meest voorkomende vocaalsysteem: /a,i,u,e,o/. Niet alle bouwstenen zijn nodig voor dit ‘modale’ vocaalmodel. Aangezien er slechts geronde achtervocalen en ongeronde voorvocalen in dit systeem zitten, kan R-reverse achterwege blijven. Hetzelfde geldt voor HL-reverse en plaatsmodulatie. Ook het schakelsysteem is eenvoudig: aangezien er alleen geronde achtervocalen zijn, is een implicatielijn als (12), die <round> activeert als en slechts als <back> ingeschakeld wordt, voldoende om de gewenste en slechts de gewenste fonemen te genereren. Om de schwa uit te sluiten kunnen we eventueel een verbindingslijn tussen A en <central> in (15) toevoegen, waardoor het onmogelijk wordt geen enkele operator te activeren. In DIGPHON gaan we er echter van uit dat neutrale ‘voicing’ -de schwa- universeel is. De uit 0-en bestaande output-code geeft deze ongearticuleerde stemhebbendheid aan. Of aan deze code het foneem schwa gekoppeld moet worden is een kwestie van interpretatie. We kunnen immers evengoed stellen dat de 0-output aangeeft dat er geen vocaal gegenereerd is. Er is immers geen enkele module geactiveerd. Dat het niet eenvoudig is om voor een bepaalde taal vast te stellen of de schwa inderdaad een foneem, dat wil zeggen een fonologisch contrastief klanksegment, is, moge blijken uit het geringe aantal minimale paren waarin de schwa in het Nederlands contrastief is: katterig - katterug, de bul - dubbel, Thebe's - theebus. Zo wordt in SPE de schwa niet als een foneem, maar als een door fonologische regels afgeleid klanksegment beschouwd. Voor een non-native speaker/onderzoeker van, bijvoorbeeld, het Yurak of het Osmanli (zie Maddieson (1984)) zal het dan ook niet altijd even duidelijk zijn of de schwa wel of niet deel uitmaakt van het te beschrijven vocaalsysteem. 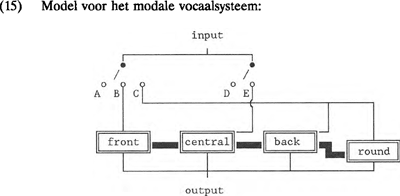 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 163]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.2 Universeel vocaalmodelConsequente toepassing van de opbouwprincipes uit paragraaf 1 stelt ons in staat om modellen van alle mogelijke taalsystemen te construeren en met elkaar te vergelijken. Alle modellen zijn uiteindelijk afgeleid van één universeel vocaalmodel dat idealiter in staat is alle in natuurlijke talen voorkomende vocalen te genereren. Extra implicaties in het schakelsysteem en afstoting van bepaalde operators zorgen voor de opbouw van taalspecifieke modellen. Het grootste probleem bij de constructie van het universele vocaalmodel is het antwoord op de volgende empirische vraag: welke vocalen zijn er? In dit hoofdstuk wordt gebruik gemaakt van twee verzamelingen van fonemen: het corpus in Ruhlen (1976) en het corpus in Maddieson (1984). Vergelijking van in beide verzamelingen voorkomende taalsystemen leert dat het determineren van een taalsysteem een subjectieve aangelegenheid is. Zo kent volgens Ruhlen het Japans de vocalen /a,i,u,e,o/. Volgens Maddieson (1984) bestaat het Japanse vocaalsysteem echter uit de vocalen /a,i,ɯ,ɛ,ɔ/. In DIGPHON worden twee klanksegmenten pas als universele fonemen erkend als ze binnen één taal woordonderscheidend zijn. Op grond van het Nederlands kunnen we bijvoorbeeld de klanken /æ/ en /ɛ/ als allofonen beschouwen. Toch zijn het fonemen, getuige de fonologische oppositie in het Engels tussen head en had. Als nu een bepaald taalsysteem deze klanken als allofonen heeft, valt het niet mee vast te stellen welke van beide klanken als foneem beschouwd moet worden. Vaak is de keuze afhankelijk van het oordeel van de fonoloog of foneticus die het taalsysteem beschrijft. Vandaar ook dat er nogal wat verschillen worden aangetroffen in Maddieson (1984) en Ruhlen (1976) inzake de vocaalinventaris van één en dezelfde taal, zoals we hierboven hebben laten zien. Ook zijn de verzamelingen op zichzelf niet altijd consistent. Zo vermeldt Maddieson (1984) dat de talen Ostyak, Mongolian, Somali, Ket en Yukaghir een geronde tegenhanger van de schwa in hun systeem hebben, terwijl deze talen noch in de lijst van talen met een schwa, noch in de lijst van talen met /œ/ voorkomen. De foneemstatus van deze geronde midden centrale vocaal /θ/ is dus gegeven het corpus in Maddieson (1984) enigszins dubieus. Verder geeft Maddieson (1984) in zijn segmentindex onder andere het foneem /θ̞/, een verhoogde midden centrale geronde vocaal, die echter in de taalsysteem-voorbeelden nergens terugkeert. Het antwoord op de vraag wat wel en wat niet als foneem moet worden beschouwd blijkt met name in het centrum van de vocaaldriehoek nogal arbitrair te zijn. Ondanks deze reserves wordt hier voor de opbouw van het universeel vocaalmodel uitgegaan van het corpus van Maddieson (1984). In het model wordt in eerste instantie geabstraheerd van wat in Clements (1985) ‘laryngale knoop’ wordt genoemd. De features onder deze knoop zijn in DIGPHON modulators die bij de input van het schakelsysteem geactiveerd worden. Ze bewerkstelligen onder andere de afleiding van <voiceless>; <breathy voiced>; <pharyngealized> en <retroflexed> vocalen, die met diacritische tekens worden aangegeven: /ḁ,a̤, as,ar/. Door in het schakelsysteem een onderscheid te maken tussen laryngale en supralaryngale features verwerken we Clements' groepering van features (Clements (1985) (1989)) in DIGPHON (zie ook paragraaf 3). In (16) worden alle fonemen in natuurlijke talen uit de verzameling van Maddieson (1984) in schema gezet. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 164]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(16) Segment IndexGa naar eind7.:
In (16) staat tevens per articulatiedomein de carriercode vermeld. De normale vorm van de vocaaldriehoek vinden we terug bij een HL positief-polaire stand; en de driehoek op zijn kop bij een HL negatief-polaire stand. In eerste instantie maakt de HL-waarde niets uit voor het genereren van de vocalen in de domeinen 110 en 011. Deze domeinen vormen immers de horizontale as waarlangs de driehoek omgeklapt wordt. Pas als er sprake is van plaatsmodulatie speelt ook de HL-modulator in deze domeinen een rol. Bij een HL positiefpolaire stand zorgt <lowered> voor het genereren van <lowered mid> vocalen; bij een HL negatief-polaire stand verandert <lowered> in <raised> en kunnen de <higher mid> vocalen afgeleid worden. De vijf gaten (*) in (16) moeten via het schakelsysteem uitgesloten worden.Ga naar eind8. Verder richten we het schakelsysteem zodanig in, dat bij een R positiefpolaire stand alle en slechts alle achtervocalen automatisch gerond worden; en bij een R negatief-polaire stand alle en slechts alle voorvocalen. Blijft over het genereren van de vijf middenvocalen in domein 000 in (16). Aangezien modulator <round> niet met de carriers verbonden is, kan /θ/ bij een negatief-polaire stand in domein 000 afgeleid worden. Plaatsmodulatie is in 000 echter onmogelijk, omdat <lowered> en <raised> hun waarde niet via de uitgeschakelde carriers aan de output-code kunnen doorgeven. Hierboven zijn vraagtekens geplaatst bij het onderscheiden van zo veel verschillende centrale middenvocalen. Toch is het mogelijk de vocalen /˅,ə̞,θ̞/ te genereren, en wel met behulp van de feedbackmogelijkheid op modulator <raised>. Bij een HL positief-polaire stand kan /Ȝ/ en bij een HL negatief-polaire stand kunnen /ə̞/ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 165]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
en /θ̞/ vanuit domein 010 gegenereerd worden. In het eerste geval is er dan sprake van een extra verhoogde /a/ in domein 8; en in het tweede geval, als <raised> vanwege HL- <lowered> is geworden, van een extra verlaagde /ɨ/ of, in geval van R-, een extra verlaagde /ʉ/ in domein 2. Om feedback in de output-code tot uitdrukking te laten komen wordt een extra modulator op de modulator <raised> aangebracht. Deze opsomming van samenstellingen en schakelingen vraagt om een alles verduidelijkende illustratie. Het uiteindelijke model dat alle vocalen uit (16) kan genereren ziet er als volgt uit: 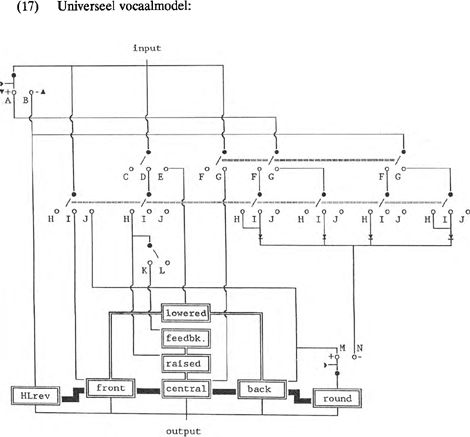 Model-interne schakelingen zorgen ervoor dat <raised> de output-code niet kan bereiken als <central> niet geactiveerd is en dat <lowered> de output-code niet kan bereiken als de verbinding van de input met zowel <front> als <back> onderbroken is. Hoe moeten we model (17) interpreteren? In (17) wordt gebruik gemaakt van acht operators: drie carriers en vijf modulators. Elke natuurlijke vocaal kan in | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 166]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de vorm van een uit acht bits bestaande byte worden gerepresenteerd. Elke bit staat voor één van de operators in het model en kan de waarde 1 (= actief) of 0 ( = passief) hebben. De polariteit van <high/low rev.> en <round> wordt geregeld door middel van respectievelijk de schakelaars AB en MN. Schakelstanden G; I en J activeren rechtstreeks de carriers <central>; <front> en <back>. De modulator <lowered> kan door middel van stand E rechtstreeks met de input worden verbonden en wordt daarom een onafhankelijke modulator genoemd. <raised> is een afhankelijke modulator. Activering van deze modulator vereist zowel stand D als stand H. Het verschil tussen afhankelijke en onafhankelijke modulators speelt een rol bij gemarkeerdheidssequenties van afgeleide vocalen. Bij het inschakelen van <feedback> zijn zelfs drie schakelaars betrokken. In het model zijn de schakelaarposities D; H en K noodzakelijk om de zwaar gemarkeerde fonemen die van de optie <feedback> gebruik maken, voort te brengen. In (18) staan de paden die in (17) gevolgd moeten worden om de juiste vocalen af te leiden. De eerste drie bits in elke code staan voor respectievelijk de carriers <front> (=F); <central> (=C) en <back> (=B). De tweede drie bits staan voor <lowered> (=1); <raised> (=r)en <feedback on raised> (=f). De voorlaatste bit staat voor <round> (=R). De waarde voor R volgt automatisch uit de implicatielijnen in het model; R is dan ook een passieve modulator. De waarde van de laatste bit geeft de polariteit van de eveneens passieve modulator <high/low rev.> (=HL) aan. Daarbij staat 0 voor ongemarkeerd, dat wil zeggen positief-polair, en 1 voor gemarkeerd, negatief-polair.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 167]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In (18) staan alle codes gegeven alle mogelijke paden in (17). Mocht er een taalsysteem ontdekt worden met bijvoorbeeld een geronde verhoogde open voorvocaal, de geronde tegenhanger van /æ/, dan zou het schakelsysteem | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 168]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
aangepast moeten worden. Het model is niet in staat meer dan zeven articulatiehoogtes te onderscheiden. Mocht er een taalsysteem ontdekt worden met naast bijvoorbeeld /I/ en /e/ een foneem dat qua articulatiehoogte tussen /I/ en /e/ ligt, dan zal het model moeten worden aangepast. In beide gevallen is er dan wel sprake van een nieuwe ontdekking, gegeven het corpus uit Maddieson (1984). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.3 Japans vocaalmodelVan het universele vocaalmodel kunnen we de taalspecifieke modellen afleiden. Niet alle vocaalmodellen zijn echter zo eenvoudig te construeren als het modale uit paragraaf 2.1. Als we bijvoorbeeld het Japanse vocaalsysteem, zoals beschreven in Maddieson (1984), bekijken, dan vallen twee dingen op: in vergelijking met het modale vocaalsysteem met /e/ en /o/ heeft het Japans alleen de ‘verlaagde’ (=ongespannen) tegenhangers en in plaats van /u/ de ongeronde tegenhanger /ɯ/.
In het model voor het Japans moeten we dus de modulator <lowered> opnemen. Het model in (20) maakt het mogelijk alle en slechts alle vocalen in het Japans te genereren. Een keuzeschakelaar, zoals (11), maakt het onmogelijk om <front> en <back> tegelijkertijd te activeren. Dat is precies wat we willen, want een <front/back> vocaal is een articulatorische onmogelijkheid. Het schakelsysteem is verder zodanig ingericht, dat bij inschakeling van <central> <lowered> automatisch volgt. Een implicatielijn, zoals in (12), die met <central> <lowered> in de stand E activeert, maakt het genereren van /e/ en /o/ onmogelijk. Daarnaast moeten de schakelingen ronding in 011 verplicht en in 001 onmogelijk maken. Dit kan op de meest eenvoudige wijze door middel van een schakeling, zoals (13), die gegeven C (impliceert <+back>) <round> activeert, tenzij D (impliceert <-central>). In (20) impliceert <central> <lowered> (stand E). Aangezien de modulator <lowered> in het model niet verbonden is met de carrier <central>, wordt <lowered> terecht uitgesloten in domein 010. Immers, als <front> en <back> uitgeschakeld zijn, kan de modulator <lowered> zijn waarde 1 niet aan de output doorgeven. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 169]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
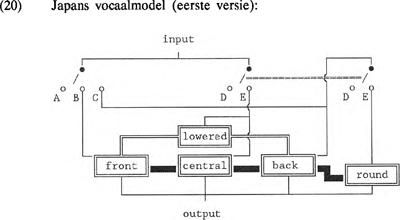 Toch voldoet model (20) niet. Weliswaar kunnen de beoogde vocalen en slechts de beoogde vocalen gegenereerd worden, maar het model is niet uitgerust om de gemarkeerdheidssequenties van vocalen te verklaren. Het gegeven dat het Japans zowel een geronde als een ongeronde achtervocaal kent, vereist een modulator <R-reverse> in het model. Er zijn meerdere modellen mogelijk die een juiste beschrijving van een bepaald systeem geven, maar een correct verklarend model voldoet aan de basisprincipes zoals in paragraaf 1 geschetst. De meer bevredigende versie van het Japanse vocaalmodel is (21). 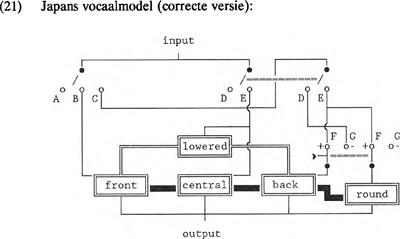 Om dezelfde redenen moet in het model voor het Abkhazische vocaalsysteem, dat slechts uit de vocalen /a/ en /ɨ/ bestaat, een HL-reverse modulator worden opgenomen. Aangezien we er vanuit gaan dat de schwa onderdeel is van elke natuurlijke taal, is (22) eveneens voorzien van een keuzeschakelaar CD die de | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 170]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
input al dan niet met <central> verbindt. Laten we deze laatste schakelaar weg, dan is een uit O-en bestaande output-code onmogelijk. 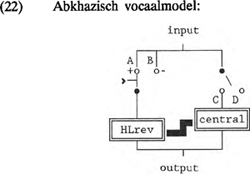 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.4 Nederlands vocaalmodel(23) toont het Nederlandse vocaalsysteem inclusief tussen haakjes drie leenvocalen.
 In Gilbers (1989) wordt een model voor de Nederlandse vocaal (versie 1.0) voorgesteld waarmee het mogelijk is om alle vocalen uit (23) te beschrijven. Dit model biedt echter geen verklaring voor gemarkeerdheidssequenties van de te genereren vocalen. Hier volgt dan ook een versie met meer verklarende kracht. Het Nederlands kent geen enkele vocaal uit (18c en d). Een modulator voor <HL-reverse> kan dus achterwege blijven. Ook een modulator <feedback> is onnodig, aangezien /ɜ/ in het Nederlandse vocaalsysteem ontbreekt. Elk taalspecifiek model is een vereenvoudiging, een uitgeklede versie, van het universele vocaalmodel. Daarentegen is het goed mogelijk, dat in een taalspecifiek schakelsysteem ingewikkeldere schakelingen voorkomen dan in het universele. Met het universele vocaalmodel kunnen bijvoorbeeld zowel geronde als ongeronde achtervocalen gegenereerd worden, terwijl in het Nederlandse vocaalsysteem slechts geronde achtervocalen voorkomen. Het Nederlandse vocaalmodel vereist dus ten opzichte van het universeel vocaalmodel bij R- polariteit een extra implicatielijn die bij geactiveerd <back> <round> inschakelt. (24) toont het model voor de Nederlandse vocaal exclusief de drie leenvocalen. Zoals we in paragraaf 2.2 hebben vermeld, worden de modulators voor | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 171]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
laryngale features als <long> in DIGPHON geactiveerd vanaf een schakelpunt dat hoger ligt dan de input voor het universele model (17). Deze wijze van schakeling roept herinneringen op aan de feature-groepering die voor het eerst is voorgesteld in Clements (1985) en Sagey (1986). Wij abstraheren van de niet supra-laryngale features. Een kleine aanpassing van (24) maakt het echter mogelijk om ook de fonemen /ɛ:,œ:,ɔ:/ te genereren. Een modulator <long> moet dan in het model op de modulator <lowered> geplaatst worden. Een extra schakelaar, die de output met deze modulator via het pad CGE verbindt, voorziet vervolgens in de mogelijke afleiding van deze drie vocalen. Om ook verlengde vocalen te kunnen genereren als /i:/ in surprise en /y:/ in centrifuge (zie Smith e.a. (1989)) zou de modulator parallel aan de modulator <lowered> in het model moeten worden verbonden met <front> en <back>, uiteraard met de nodige aanpassingen in het schakelsysteem. Hier worden dergelijke verlengingen voor het Nederlands als allofoonvariatie beschouwd, omdat we van het standpunt uitgaan dat een klank pas een foneem van een bepaalde taal is als deze klank in die taal in fonologische oppositie staat met een andere klank. De klank moet woordonderscheidende betekenis hebben in die taal. Dit geldt voor /ɛ:,œ:,ɔ:/, getuige frèle en freule, zône en Zijne, maar niet voor /i:/ en /y:/, die niet voorkomen in woorden waarmee in het Nederlands een minimaal paar gevormd kan worden met een ander woord. 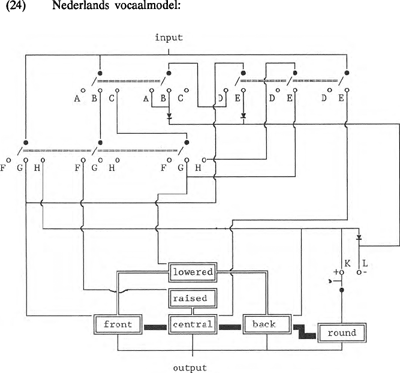 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 172]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3 DIGPHON en fonologische theorievormingIn paragraaf 2 hebben we een voorstel gedaan voor een digitaal fonologische vocaalrepresentatie. Volgens de in paragraaf 1 vastgelegde opbouwprincipes hebben we een model voor de universele vocaal samengesteld uit carriers en modulators en voorzien van een schakelsysteem waarmee deze carriers en modulators in werking kunnen worden gezet. Taalspecifieke modellen leiden we van dit universele model af; ze kunnen daarom onderling en met het universele model vergeleken worden. In deze paragraaf wordt in het kort ingegaan op de waarde van deze vorm van vocaalrepresentatie voor de fonologische theorievorming. Volgens Clements (1989) betreft een theorie over fonologische features het ontdekken en verklaren van generalisaties over het fonologische gedrag van fonologische segmenten, al dan niet in geïsoleerde positie. Hij stelt de volgende criteria vast waaraan zo'n theorie moet voldoen:
(25a) geeft aan dat een featuretheorie idealiter alle en slechts alle contrastieve fonemen moet kunnen onderscheiden. Om de genererende kracht van het DIGPHON-model zo sterk mogelijk te maken, hebben we voor een groot corpus fonemen gekozen: alle fonologisch contrastieve vocalen volgens Maddieson (1984) (zie (16)). De samenstelling van de modules in het model en het schakelsysteem garanderen dat slechts alle fonologisch contrastieve vocalen kunnen worden gegenereerd, met andere woorden, ‘onmogelijke’ bundles of features kunnen niet worden voortgebracht. Door het schakelsysteem zijn onderspecificatie en segmentele redundantieregels op een natuurlijke wijze in de representatie ingebouwd (zie Gilbers (te verschijnen)). DIGPHON beantwoordt dus aan (25a). (25b) houdt in dat elk feature van een fonetisch correlaat moet zijn voorzien. De vervanging in DIGPHON van <tense> en <ATR> door plaatsmodulatie brengt met zich mee, dat het onderscheid tussen bijvoorbeeld /e/ en /ɛ/ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 173]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
acoustisch kan worden vertaald in een gewijzigde waarde van de eerste formant, en articulatorisch in een gewijzigde stand van de onderkaak. De problemen bij het fonetisch definiëren van features als <long>, <tense> en <ATR> keren in DIGPHON dus niet meer terug. De carriers <front>, <central> en <back> geven in combinatie met <high/low rev.> de plaats van de tong aan, en modulator <round> vindt zijn articulatorisch correlaat in de stand van de lippen. Aan criterium (25b) wordt dus eveneens beantwoord. Het articulatorische correlaat van features speelt ook een rol bij criterium (25c). De features <con> (=consonantisch), <syl> (=syllabisch) en <son> (=sonorant) worden traditioneel beschouwd als de kenmerken die fonemen kunnen onderverdelen in natuurlijke klassen. Voor de fonologische theorievorming is het van belang dat in DIGPHON deze natuurlijke klasse features niet als operators terugkeren. De pogingen in de generatieve fonologie om alle features van articulatorische definities te voorzien leverden met name problemen op bij deze vooral op fonologische gronden gemotiveerde features. Volgens SPE worden sonorante klanken gekenmerkt door spontane stembandtrillingen, maar deze articulatorische definitie lijkt nauwelijks houdbaar, gezien het bestaan van stemloze nasalen, zoals /m̥/ en /n̥/ in talen als Klamath en Hopi. Ook stemloze liquidae komen voor: /r̥/ in bijvoorbeeld het Sedang en /l̥/ in het Klamath. Halle & Clements (1983) beschrijven sonorant als (...) produced with a vocal tract configuration sufficiently open that the air pressure inside and outside the mouth is approximately equal. Hun definitie van consonantisch is wellicht nog vager: Consonantal sounds are produced with a sustained vocal tract constriction at least equal to that required in the production of fricatives. Voor syllabisch wordt zelfs geen articulatorisch correlaat meer gegeven: Syllabic sounds are those that constitute syllabic peaks (...) Syllabic sounds are typically more prominent than contiguous nonsyllabic sounds. Dit feature <syl> is fonologisch gemotiveerd; overwegingen van taalstructurele aard bepalen wat syllabisch is en wat niet. Het zal duidelijk zijn dat het niet eenvoudig is deze natuurlijke klasse-features van een passend articulatorisch correlaat te voorzien. Ook wat de representatie van natuurlijke klasse-features betreft lopen de meningen uiteen. Volgens Clements (1985) moet het feature <son> onder de ‘manner’-knoop van zijn model worden ondergebracht, volgens Sagey (1986) hoger in de feature-hiërarchie, onder de ‘root’-knoop, en volgens Pulleyblank (1988) samen met <nasal> onder een aparte knoop tussen de ‘root’-knoop en de ‘manner’-knoop in. In DIGPHON keren de natuurlijke klasse-features niet als aparte foneemkenmerken terug, maar als schakelpunten in het stroomschema. Zo is de mate van sonoriteit van een foneem terug te vinden in de mate van inbedding in het model: hoe meer rechtsvertakkend het pad in (26), des te minder sonorant het afgeleide foneem. Net als bij Dogil (1987) wordt sonoriteit teruggevonden in de structuur. Problemen met het niet binaire (=tweewaardige) karakter van dit | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 174]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
feature in SPE zijn daarmee uit de wereld, aangezien <son> geen feature in de traditionele zin van het woord is, maar een schakelpunt in het model. Daarbij moeten we in acht nemen dat het vocaalmodel onderdeel vormt van een foneemmodel. In (26) vormt de output bij <syl> de input voor het in paragraaf 2 behandelde vocaalmodel. 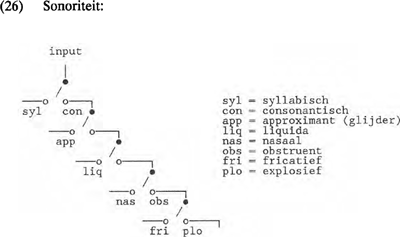 De natuurlijke klassen in de fonologie vinden we dus terug in de mate van inbedding in het schakelsysteem. Op deze wijze voldoet DIGPHON, voor wat de natuurlijke klasse-features betreft, zowel aan criterium (25c) als aan criterium (25b). De inbedding van natuurlijke klassen in het schakelsysteem bewijst zijn waarde bij het beschrijven van fonologische processen. Om bijvoorbeeld een fonologisch proces als ‘final devoicing’ in DIGPHON te beschrijven is het niet nodig om alle relevante consonanten te markeren als <-son>. De verandering van één schakelaar is voldoende om de obstruenten van alle sonoranten te onderscheiden. De natuurlijke groepering van features die gezamenlijk functioneren in bepaalde fonologische regels, kunnen we in het DIGPHON-schakelsysteem terugvinden. Daarbij is gebruik gemaakt van de inzichten uit de non-lineaire fonologie van Sagey (1986) en Clements (1985, 1989). Het uiteindelijke doel van DIGPHON is één model waarbij de drie-bits carrier combinatie zowel de basis voor vocalen als voor consonanten vormt. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 175]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
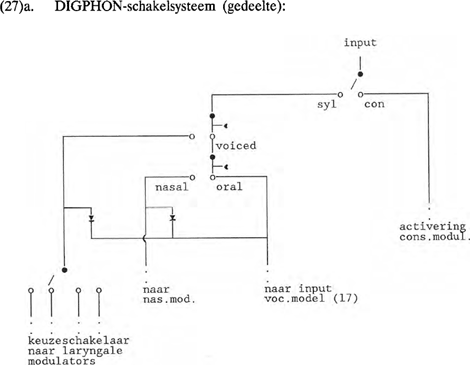 De in (27) voorgestelde wijze van schakeling scheidt diverse vormen van laryngale modulatie af van nasale modulatie. Verder worden onder ‘oral’ de in paragraaf twee behandelde vocaal-modulators gegroepeerd en onder ‘con’ de consonant-modulators. Nader onderzoek moet uitwijzen in hoeverre DIGPHON met het implementeren van Clements' indeling voldoet aan (25d). Blijft over criterium (25e). Een artikel over DIGPHON en gemarkeerdheid is in voorbereiding. Op grond van structurele principes wordt daarin een preferentieregel-hiërarchie voorgesteld voor de afleiding van fonemen in het model. Het verband tussen de complexiteit van de schakelingen en de diverse vormen van gemarkeerdheid in de fonologie zal vervolgens worden uiteengezet. Door de digitale codering van het fonologische systeem boeken we op twee terreinen winst. In de eerste plaats kunnen de moderne fonologische inzichten nu vertaald worden in een voor de computer leesbare vorm, waardoor DIGPHON een rol kan spelen in de verdere ontwikkeling van text-to-speech programma's. In de tweede plaats is er sprake van methodologische winst. Kas (1989) biedt een programma in de computertaal LISP waarmee de adequaatheid van DIGPHON-modellen kan worden getest; het betreft een programma dat nagaat of een bepaald model inderdaad alle en slechts alle gewenste fonemen kan genereren. De computer hoeft in DIGPHON niet alleen een controlerende taak te vervullen; hij kan zijn ware kunstmatige intelligentie tonen bij de afleiding van taalspecifieke modellen van het universeel vocaalmodel en bij de samenstelling van het schakelsysteem voor een consonantmodel. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 177]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||