|
| |
| |
| |
Met de ritmische hangmat in de metrische boom
Ron van Zonneveld
0. Enkele jaren geleden dacht ik dat het erg eenvoudig was om regels te geven voor de aksentverhoudingen in woorden en woordgroepen.
Woorden ontvangen het hoofdaksent via een regel, lijkend op de Main Stress Rule uit de Sound Pattern of English, die ervoor zorgt dat de laatste vokaal wordt uitgekozen, tenzij die vokaal deel uitmaakt van een zogeheten zwakke cluster. Dat laatste is het geval met woorden als motor, dollar, perzik en koning en met alle woorden die een laatste lettergreep met de sjwa als kern hebben, als bodem en haven. Eindaksent komt dus toe aan woorden die buiten deze categorie vallen, als paradijs, kotelet, proces, kasteel en fonologie. Het niet onaanzienlijke aantal woorden dat niet aan deze regel voldoet krijgt het etiket ‘uitzondering’.
Daartoe behoren bijvoorbeeld horizon en divan, gegeven het eindaksent in balkon en tiran.
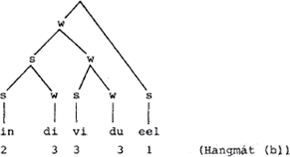
Aan deze regel voor het hoofdaksent zou een regel voor bijaksenten moeten worden toegevoegd. Kiparsky (1966) had al een regel voor secundair aksent in het Duits weergegeven, welke regel naar mijn idee ook opging voor het Nederlands. Die regel zegt dat secundair aksent aan het begin van een woord terecht komt als het primaire aksent aan het eind valt, en vice versa. Vergelijk 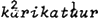 en 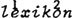 . Dezelfde regel voorziet in de distributie van aksentoppen in woordgroepen. Bezie de alternantie in een 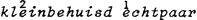 en het 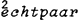 is is 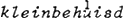 . Aan de maximale distantie van de aksentoppen dankt de regel voor nevenaksent de naam ‘ritmische Hangmat’. Een formalisering daarvan, in de traditie van de segmentele fonologie, is opgenomen in Van Zonneveld (1980).
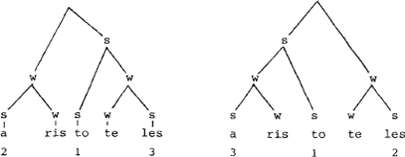
Onder invloed van Liberman & Prince (1977) heeft de segmentele, lineaire benadering van aksentkwesties het veld geruimd voor een non-lineaire. Het verschil laat zich gemakkelijk optisch illustreren: een lineaire representatie vermeldt de relatieve aksentwaarden met cijfers, een nonlineaire doet dat met boomdiagrammen waar s en w (voor strong en weak) zusterknopen zijn. Vergelijk 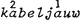 en
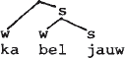
| |
| |
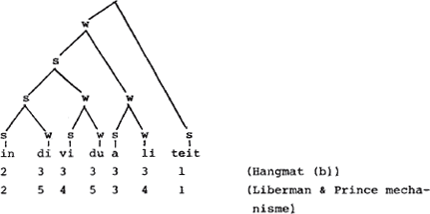
De superioriteit van de non-lineaire ten opzichte van de lineaire aanpak dient natuurlijk gezocht te worden in de ‘verklarende’ waarde van de bomentheorie. Deze theorie zou automatisch kunnen zorgen voor de toekenning van relatieve waarden, weergegeven met cijfers, en deze cijferpatronen bovendien moeten afleiden uit ‘parameters’ die de konstruktie van metrische bomen bepalen. Liberman & Prince leveren dan ook een maniertje om aksent-bomen te vertalen in cijferwaarden, ongeveer als volgt: tel in het boompje voor kabeljauw de topknoop mee en stel vast dat ka door twee kopen wordt gedomineerd en bel door drie. Alleen door s gedomineerde knopen krijgen het cijfer 1, hetgeen jauw ten deel valt. Het cijferpatroon 2 3 1 is zo af te leiden uit het w w s patroon, waar de laatste w plus s zusters zijn en de eerste w een zuster is van de s die de laatste s plus w domineert.
Van deze non-lineaire benadering zeggen Neijt & Zonneveld (1981) dat de regels er eenvoudig door worden gehouden, terwijl de representaties ingewikkeld zijn (namelijk boomdiagrammen). Het omgekeerde zou volgens hen gelden voor de traditionele aanpak: ingewikkelde regels, maar eenvoudige representaties (namelijk cijfers).
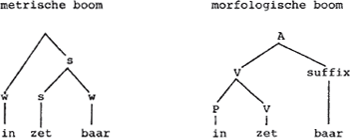
Ik denk dat de non-lineaire fonologie in geen enkel opzicht een vereenvoudiging betekent. Hieronder zal ik deze gedachte uitwerken. Mijn argwaan ten opzichte van metrische bomen berust vooral op de volgende overwegingen. Ook in de metrische fonologie is er een segmenteel gefundeerde Main Stress Rule, of een variant daarvan, nodig. De non-lineaire aanpak is dus geen alternatief voor de lineaire, maar ten hoogste een complement ervan. Principes voor boomkonstruktie, vervolgens, doen eveneens een beroep op segmentele informatie. Zie daarvoor bijvoorbeeld de principes voor de distributie van sterke en zwakke voeten in Neijt & Zonneveld. Volgens hen is de laatste lettergreep van kabeljauw een vertakkende monosyllabische voet, vanwege de kwaliteit van de au. Deze ingreep staat toe om dit woord als volgt te struktureren:

Het eindaksent van kabeljauw lijkt nu een gevolg van de hiërarchische struktuur, aangenomen dat de laatste voet met s is ge- | |
| |
labeld volgens het Liberman & Prince principe dat van twee zusterknopen de rechter voor s wordt geselekteerd als deze zich vertakt (‘Lexical Category Prominence Rule’, een regel die, opererend op compositum-niveau, van toepassing is op zijn eigen naam, met als gevolg woordaksent op prominencel. Ik kan het weer niet anders zien dan dat het feit dat kabeljauw nu eenmaal eindaksent heeft, verantwoordelijk is voor de s-labeling van de rechtervoet, en dat de vertakking er om zo te zeggen is binnengesmokkeld om in de pas te blijven met een klaarblijkelijk aanvaard principe om bomen te bouwen.
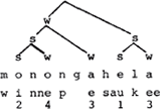
In dit geval bepaalt dus niet de bomentheorie het patroon van kabeljauw, maar precies andersom: het feit dat kabeljauw eindaksent heeft zorgt ervoor dat de rechtervoet s is. Met een zelfde achterdocht dient ook de konstruktie van metrische bomen in Liberman & Prince te worden beoordeeld. Ook zij maken gebruik van een - overigens ook zeer ingewikkelde - variant van de Main Stress Rule uit de Sound Pattern of English, door hen English Stress Rule genoemd. Deze regel bezit een interatieve kracht en distribueert plussen en minnen over een woord. In een lang woord als Monongahela werkt hij drie keer. Laat ik al simplificerend zeggen dat deze regel bij elke werking een plus gevolgd door een min toekent, en als er slechts een vokaal in aanmerking komt een plus. De eerste toepassing geeft dan 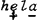 , de tweede 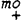 en de derde 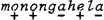 .
Eindresultaat: 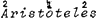 .
Hoe trekken Liberman & Prince vervolgens een metrische boom op? De plussen en minnen worden geassocieerd met s en w, overeenkomstig het principe dat een min (= -stress) niet met een s kan worden verbonden.
Alleen nonga en hela komen voor s-w alternantie in aanmerking, in dit stadium, omdat dit zusterkonstituenten zijn op het laagste niveau: in een later stadium krijgt mo een w omdat deze lettergreep als zusterkonstituent fungeert van de twee erop volgende voeten. De eerste stap is dus deze:

De volgende stap wordt gedikteerd door de al vermelde Lexical Category Prominence Rule: de twee met s en w gelabelde voeten worden op hun beurt gelabeld met s en w, en wel zo dat de laatste
| |
| |
voet, omdat die vertakt, de s ontvangt. Resultaat;
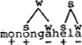
Dezelfde regel (LCPR) zorgt tenslotte voor nat eindresultaat: (M = Mot)
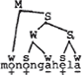
Vanwaar nu de reserves ten opzichte van deze procedure? Net als in het geval van kabeljauw, waarvan ik beweerd heb dat het akseritpatroon de boom bepaalt, en niet andersom, is de boom voor Monongahela gekonstrueerd op basis van het feit dat dit woord penult hoofdaksent draagt. Met verwijzing naar de English Stress Rule stel ik dat bij iteratieve toepassing de eerste toepassing het hoofdaksent levert, en de erop volgende toepassingen de bijaksenten. Met verwijzing naar bovenstaande boom stel ik dat de s van de laatste voet op het laagste niveau afkomstig is van de English Stress Rule en dat om die reden de hogere voetniveaus die de drager van het woordaksent domineren ook met s gelabeld moeten worden. De Lexical Category Prominence Rule doet dus niets anders dan wat de English Stress Rule ook al doet: de penulte vokaal selekteren voor het hoofdaksent. Dit wijst erop dat er geen onafhankelijke principes om bomen te construeren in het geding zijn, waar de aksentpatronen uit kunnen worden afgeleid. Het is eerder andersom: gegeven de English Stress Rule en zo de positie van het hoofdaksent, is de metrische struktuur af te leiden op basis van segmentele informatie. Ik zal in de volgende paragraaf eenzelfde stelling betrekken met betrekking tot het Nederlands. De overtuiging dat de positie van het hoofdaksent het uitgangspunt is bij het konstrueren van een metrische boom is nog enigszins in de pas met Liberman & Prince: zij erkennen althans het belang van de English Stress Rule, maar voegen er een - naar mijn idee overbodig - extra principe aan toe, namelijk de Lexical Category Prominence Rule. Deze overtui- | |
| |
ging is echter volledig in strijd met het onderzoeksprogramma van Selkirk (1980), een extensie van Liberman & Prince, dat zich ten doel stelt om aan te tonen dat ‘the proper representation of the patterns of stress in English doe a not involve the phonological feature
[± stress]’ (p. 563). Het laat zich nu natuurlijk al raden dat datgene waar het gewraakte feature voor staat, in haar theorie weer via een achterdeur binnensluipt, zodat de lezer weliswaar niet rechtstreeks meer kan lezen welke vokaal door de English Stress Rule aangewezen zou zijn als drager van het hoofdaksent (en bij iteratieve toepassing als drager van nevenaksent), maar dat via een omweg kan afleiden. Een dergelijk onderzoeksprogramma zal dan ook ongetwijfeld, opgeblazen als het al is, binnenkort als een zeepbel uiteen spatten. Ik zal de lezer op de hoogte houden.
In de volgende paragraaf zal ik nog wat boomkonstruktieprincipes aan de orde stellen, uit Wheeler (1981) en uit de oratie van Booij (1982). Ik zal, laten zien dat het niet alleen mogelijk is om cijferwaarden af te leiden uit boomdiagrammen, als gedemonstreerd door Liberman & Prince, maar ook andersom, boomdiagrammen te konstrueren op basis van cijferwaarden. Er ontstaat een klein ‘empirisch’ konflikt over de relatieve waarden van nevenaksenten. De ritmische Hangmat kan namelijk nevenaksenten distribueren van gelijke waarde (twee tweetjes of twee drietjes), wat niet steeds kan in de metrische theorie. Dat konflikt zal worden opgelost door de Hangmatregel bij konjunktie toepassing te ordenen, wat in termen van de metrische fonologie betekent dat er in die gevallen voor rechtsvertakkende bomen wordt gekozen.
1. Er bestaat volgens sommigen (zie Wheeler (1981, par. 4.1.)) een korrelatie tussen de richting waarin een metrische boom vertakt en de relatieve prominentie van de knopen in de boom. Een voorbeeld daarvan is de al besproken Lexical Category Prominence Rule. Neem anecdotal, verleen de penulte vokaal een plus omdat die de drager is van het woordaksent, geef de overgeslagen slotvokaal een min. Doe hetzelfde nog een keer, maar dan niet meer op dotal maar op anec en stel tevreden vast dat de English Stress Rule een mooie alternantie + - + - verschaft. De Lexical Category Prominence Rule ziet vervolgens dat dit woord aan zijn eisen voldoet: de laatste knoop (voet) vertakt,
| |
| |
dus onderstaande boom is de juiste metrische representatie van anecdotal:
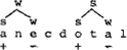
Neem vervolgens anecdote, stel vast dat het hoofdaksent op de eerste vokaal valt, verleen die vokaal een plus en de twee overgeslagen vokalen een min. Konkludeer dat de Lexical Category Prominence Rule niet van toepassing is en bouw een linksvertakkende boom.

Nu is het aksentsysteem van het Engels niet gelijk aan dat van het Nederlands: het Engelse anecdote heeft beginaksent en het Nederlandse pendant penult. Omdat de slotsjwa in het Nederlands wordt uitgesproken (de Engelstaligen hebben dit segment alleen in de orthografie behouden), zou er kunnen worden vastgesteld dat de rechterknoop in anekdote vertakt, waardoor aan dit woord dezelfde metrische boom kan worden toegekend als aan het Engelse anecdotal (zie boven). Zo simpel werkt het echter allemaal niet. Het Nederlands kent ook vele woorden met finaal aksent, van het type individu, kotelet en kabeljauw, waar niet tot een vertakkende laatste knoop kan worden besloten (zie echter Neijt-Zonneveld, die uit het feit dat de slotvokaal hier aksent draagt, afleiden dat er dus vertakking is). Wat is nu de ‘juiste’ metrische representatie van woorden als individu, gegeven dat de LCPR het hier laat afweten?
Booij wijdt in zijn oratie enige aandacht aan deze kwestie. Hij presenteert eerst enige parameters, die ik hieronder overneem.
| (i) |
Een voet bestaat uit maximaal twee syllaben (problematisch zijn woorden van het type Groningen, Batavia en Gymnasium, omdat die in aanmerking komen voor een analyse in termen van driesyllabige voeten) |
| (ii) |
De labeling is ‘strong’-‘weak’ |
| (iii) |
De voetregel werkt van links naar rechts |
| |
| |
Aan deze konventies voegt Booij nog een instruktie toe voor een labeling op woordniveau: de labeling is ‘strong’-‘weak’ bij inheemse woorden, en ‘weak’-‘strong’ bij uitheemse woorden. De konventies worden gedemonstreerd aan de hand van het uitheemse woord fonologie, dat natuurlijk metrisch hetzelfde is als individu. Blinde toepassing van (i), (ii) en (iii) geeft de foute boom:
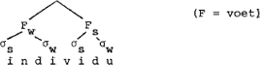
Deze fout wordt vervolgens hersteld via een ‘specifieke, lexikaal bepaalde regel’ die ervoor zorgt dat er van rechts naar links monosyllabische voeten worden toegekend in woorden van het type fonologie en individu (door Booij ‘Frans-Griekse woorden’ genoemd). Vervolgens worden van links naar rechts iteratief voeten toegekend, uitmondend in de volgende boom.
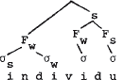
Hier begrijp ik niets van. Het aksentpatroon van individu wijst uit dat er iets mis is met de drie gegeven parameters, en wel met (ii) en (iii). (Dat ook (i) wellicht onjuist is doet hier niet terzake). De ‘specifieke’ regel die Booij voor woorden van het type individu opvoert ontbeert echter de noodzakelijke toelichting, zodat ik er niet op in kan gaan.
De moraal van deze demonstratie is dat er geen algemene principes in de literatuur te vinden zijn die in acht genomen dienen te worden bij de konstruktie van metrische bomen. Wheeler maakt gebruik van de Lexical Category Prominence Rule, die het laat afweten als er finaal aksent is en Booij geeft enkele principes die voor dezelfde kategorie (eindaksent en meer dan twee syllaben) tekort schieten, alsmede een ‘specifieke’ regel die ik eenvoudigweg onbegrijpelijk vind.
Zowel Wheeler als Booij omarmen de hypothese dat er een korrelatie bestaat tussen dominantie en vertakking: in een links- | |
| |
vertakkende struktuur N1 N2 is N1 sterk, en in een rechtsvertakkende struktuur N1 N2 is N2 sterk. (Merk op dat hier de Lexical Category Prominence Rule op zijn kop gezet wordt). Booij licht toe dat linksvertakking voor een woord als fonologie of individu tot een verkeerde voorstelling van de feiten leidt (lo komt dan sterker uit de hus dan fo, c.q. vi sterker dan in):
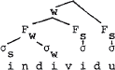
Waarom is in in deze boom zwakker dan lo? Denk aan de manier waarop Liberman & Prince cijfers uit bomen afleiden: tel alle knopen vanaf de laagste w. De resulteert in: 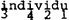 .
Doe nu hetzelfde voor de boom die eerder gegeven werd (de tweede) en stel vast dat het resultaat is. (Dit ondanks de vermelding van Booij dat de tweede syllabe het minst prominent zou zijn: dat valt niet via de Liberman & Pince manier af te leiden: di en vi worden, vanaf de laagste w door in totaal drie knopen gedomineerd). Het verschil in de cijferwaarden, 2 3 3 1 naast 3 4 2 1, lijkt inderdaad te pleiten tegen de linksvertakkende variant. Maar dat komt niet doordat die variant linksvertakkend is, maar door de eigenaardige distributie van s'jes en w'tjes. Een goede representatie, gemeten naar de cijferwaarden dier ermee korresponderen, is namelijk de volgende boom, struktureel overeenkomend met de hierboven gegeven linksvertakkende boom.
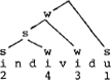
Ik neem aan dat het duidelijk is dat deze boom, hoewel hij de korrekte cijferwaarden scoort, niets van doen heeft met de parameters van Booij en dat er evenmin een beroep is gedaan op de Lexical Category Prominence Rule (ik heb de geaksentueerde slotvokaal immers niet als vertakkend weergegeven).
De laatste individu-boom is een soort derivaat van de seg- | |
| |
menteel ingerichte ritmische Hangmat, die ik zo simpel mogelijk als volgt kan weergeven (zie voor details, uitwerking en formalismes Van Zonneveld (1980)).
| Ritmische Hangmat: |
| V |
→ |
2 |
aksent |
/ |
X |
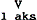 |
Y |
- |
Z |
(a) |
X en Z zijn variabelen voor segmentreeksen (mogelijk nul) |
| |
/ |
X |
- |
Y |
|
Z |
(b) |
en Y is een variabele voor een segmentreeks tussen en 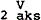 , welke reeks alle tussenliggende vokalen herbergt (mogelijk nul) , welke reeks alle tussenliggende vokalen herbergt (mogelijk nul) |
Hoe werkt deze regel?
Op eensyllabige woorden is hij natuurlijk niet van toepassing, en tweesyllabige woorden, waarbij de variabele Y in de Hangmatkontekst geen vokalen maar alleen konsonanten (mogelijk nul) herbergt, ontvangen ‘triviaal’ via de Hangmat sekundair aksent ten dienste van de vokaal die niet voorzien is van primair aksent. Ik neem overigens aan dat 1 aksent wordt toegekend door een Hoofd Aksent Regel, die hier verder niet ter sprake komt. De trivialiteit van de Hangmat voor tweesyllabige woorden schuilt hierin, dat in dergelijke woorden de verst van de primair geaksentueerde vokaal tegelijkertijd de enige resterende vokaal is: de Hangmat heeft daar dus geen keus (zoals de Hoofd Aksent Regel ook ‘triviaal’ monosyllabische woorden voorziet van primair aksent). Pas bij woorden van drie of meer lettergrepen manifesteert zich het ritmische patroon waaraan de regel zijn naam dankt: volgens (a) valt er sekundair aksent op de laatste vokaal van woorden als lexikon en bruikbaarheid en volgens (b) ontstaat het omgekeerde patroon in kabeljauw en interessant.
Wil ik deze Hangmat nu ten nutte maken voor de non-lineaire fonologie, dan kan ik dat als volgt doen: evenals het bekende principe dat zusters in een metrische boom altijd met s - w of als w - s gelabeld dienen te zijn, erkent de Hangmat w - s en s - w verhoudingen, respektievelijk via (a) en via (b). Zie de patronen 1 3 2 voor lexikon en 2 3 a voor kabeljauw. Ik wil natuurlijk verschillende bomen optrekken voor deze twee patronen.
| |
| |
Daartoe stel ik het volgende principe voor:
| Principe |
(1): De voet die de primair geaksentueerde vokaal bevat (of: is) is de s-zus van de rest. De rest wordt gedomineerd door w. |
Principe (1) maakt een rechtsvertakkende boom van het patroon 1 3 2 en een linksvertakkende van 2 3 1. In het eerste patroon is 2 de s-zus van w-zus 3 en in het laatste patroon eveneens, maar dan in spiegelbeeld.
Zo bepaalt de Hangmat dus de vertakkingsrichting; rechts via (a) en links via (b). Omdat principe (1) melding maakt van een voet ben ik het de lezer verschuldigd om daar even over uit te weiden. Ik onderscheid één- en tweelettergrepige voeten. Eenlettergrepige zijn altijd s, tweelettergrepige s - w of w - s. De laatste individu-boom geeft aanleiding om voeten van meer dan twee lettergrepen te erkennen: indivi zou kunnen worden gezien als de w-zustervoet van de eenlettergrepige s-voet du. Ik heb echter mijn twijfels aan de status van een dergelijk objekt: de s - w - w struktuur van indivi valt niet los te zien van de s die aan du is toegekend. Het is met andere woorden zo, dat toevallig in mijn boompje indivi als een drielettergrepige voet zou kunnen worden beschouwd, als gevolg van de principes die ik hanteer om een boomstruktuur te bouwen.
Maar het is natuurlijk denkbaar dat een kollega-fonoloog toch het liefst voor een kombinatie van twee tweelettergrepige voeten zou kiezen of voor nog iets anders (zie Booij's ingewikkelde boom voor individu, waarin drie voeten te onderscheiden zijn, namelijk indi, vi en du.). Erg belangrijk is deze kwestie in dit verband overigens niet: Principe (1) spreekt alleen over de voet die de primair geaksentueerde vokaal bevat (of: is) en die voet is ofwel eenlettergrepig, als in kontrakt, ofwel tweelettergrepig, als in chokolade. Zodra zich een drielettergrepige rechtsvertakkende struktuur voordoet, als in lexikon en Aristoteles (stoteles), is er weer een eenlettergrepige s-voet en een tweelettergrepige w - s voet te onderscheiden. Tot zover de toelichting bij de term ‘voet’ in Principe (1).
Omdat ik niet wil afwijken van de algemene gewoonte om metrische bomen alleen binair te vertakken, zal ik (a) en (b) van de Hangmat moeten ordenen.
Zoals later zal blijken zijn hier ook ‘empirische’ argumenten voor.
| |
| |
Principe (2); Hangmat (a) gaat voor Hangmat (b)
De lezer bedenke zich intussen dat ik deze twee principes niet opvoer om de non-lineaire metrische fonologie een dienst te bewijzen. Ik ben er juist op utt om te laten zien dat segmenteel verkregen cijferreeksen door verschillende bomen kunnen worden gerepresenteerd (vergelijk mijn boompjes maar met die van de kanonieke fonologen). Als me dat lukt, dan heb ik de vermeende meerwaarde van de metrische bomentheorie tot nul gereduceerd. Als immers verschillende vlaggen (= bomen) dezelfde empirische lading kunnen dekken, dan blijft er van de verklarende waarde die metrische bomen zouden hebben natuurlijk weinig over.
Laat ik de twee principes maar eens aan het werk zetten, te beginnen met de ‘echte’ alternerende Hangmat-patronen. Zoals steeds is de waarde 1 afkomstig van een Hoofd Aksent Regel, 2 van de Hangmat en 3 wordt toegekend aan vokalen die noch 1 noch 2 ontvangen hebben. Later zullen er nog drietjes hun opwachting maken die ontstaan via tweevoudige toepassing van de Hangmat.
Patroon 1 3 2 (als in lexikon, bruikbaarheid, koningschap, appeltje, etc.)
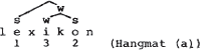
Toelichting: principe (1) zorgt voor rechtsvertakking. Principe (2) werkt enigszins loos, want alleen Hangmat (a) is van toepassing. Volgens Hangmat (a) is de laatste vokaal sterker dan de voorlaatste, wat de zusters w - s oplevert. Dat deze voet de w-zus is van de eerste s-voet wordt gedikteerd door Principe (1).
Patroon 2 3 1 (als in kabeljauw, potentaat, filosoof, Canadees, etc.)
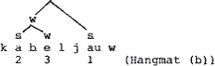
Toelichting: mutatis mutandis als voor lexikon. Principe (1) zorgt voor linksvertakking. Ook hier werkt Principe (2) enigszins loos, want alleen Hangmat (b) is van toepassing. Volgens Hangmat (b) is de eerste vokaal sterker dan de tweede, wat de zusters s - w oplevert. Dat deze voet de w-zus is van de laatste
| |
| |
s-voet wordt gedikteerd door Principe (1).
Voor individu (filosofie, fonologie enz) verloopt de zaak op vergelijkbare wijze. De slotvokaal wordt van 1 aksent voorzien door een Hoofd Aksent Regel, Hangmat (a) is niet van toepassing, Hangmat (b) maakt de beginvokaal s. De tweede vokaal is dus w. Deze s - w voet (indi) is de sterke zus van de resterende konstituent (vi), welk geheel de zwakke zus is van de voet die gevormd wordt door de slotkonstituent (du), volgens Principe (1).
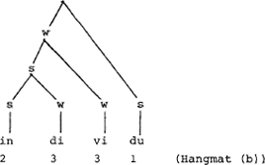
Merk op dat de cijferwaarden afgeleid op de Liberman & Prince manier, op 2 4 3 1 uitkomen. Een mooiere alternantie dan in individu is te zien in individueel, omdat de zwakke zus van eel zich laat opsplitsen in twee s - w voeten.
Het knopen-tel-mechanisme van Liberman & Prince levert cijferpatroon 2 4 3 4 1 op, wat mij een reële uitkomst lijkt. Ditzelfde mechanisme geeft echter wat minder realistische waarden
| |
| |
bij nog langere woorden. Neem individualiteit en trek een boom op in overeenstemming met de twee gegeven principes.
Ik zou hier wel voelen voor een opwaardering van 5 en 4 tot 4 en 3, met als resultaat 2 4 3 4 1. De hoge (niet realistische) cijferwaarden van individualiteit zijn uiteraard te wijten aan Principe (1), dat verplicht tot de gegeven analyse, waarbij individuali de w-zus is van teit. Zou ik dit principe laten vallen, waartoe ik niet bereid ben, dan zou het gewenste resultaat bereikt kunnen worden door de w-voet ali als zuster van teit te analyseren:
Ik zal ruiterlijk erkennen dat dit een aardig boompje is, maar ik vind cijferwaarden lager dan 3 van te weinig belang om Principe (1) daarover te laten struikelen. Dat Principe (1) heeft immers de verdienste om de patronen 2 3 1 en 1 3 2 als
| |
| |
elkaars spiegelbeeld te representeren. Vergelijk, de linksvertakkende boom van Afrikaan met de rechtsvertakkende boom van Afrika.

Principe (1) garandeert dus verschillende boomstrukturen voor 1 3 2 en 2 3 1 patronen, hoewel de vertakkingsrichting zelf niet verantwoordelijk is voor de cijferwaarden. Konstrueer voor Afrikaan maar een rechtsvertakkende boom en stel vast dat ook die de waarden 2 3 1 oplevert.
Het ‘empirische’ konflikt dat zich voordoet bij konjunkte toepassing van de Hangmat (dus, zowel (a) als (b) toepassen) laat zich demonstreren aan de hand van woorden met de metrische struktuur s w S w s, waar de kapitaal S de drager is van het hoofdaksent. Voorbeelden: Aristoteles, onnadenkendheid en overdraagbaarheid. Volgens de Hangmat wordt in dit soort woorden tweemaal sekundair aksent verleend, eenmaal via (a) en eenmaal via (b), resulterend in 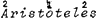 . Geen boom die dit patroon kan produceren. Immers, de twee mogelijke bomen voor Aristoteles geven ofwel 2 1 3 ofwel 3 1 2, afhankelijk van de vorm van de inbedding:
| |
| |
Mij lijkt het eerste patroon reëler, wat betekent dat de Hangmat bij konjunkte toepassing een ordening moet worden opgelegd. Regel (a) moet voorafgaan aan regel (b), waarna een ‘Stress Subordination Convention’ (zie Sound Pattern) ervoor moet zorgen dat het tweetje, geproduceerd door (a), gereduceerd wordt tot een drietje wanneer ook (b) heeft gewerkt. Het is niet onbelangrijk om op te merken dat de lezer die 2 1 2 korrekter vindt dan 2 1 3 zich verder niet met de nonlineaire metrische fonologie hoeft in te laten: daar is 2 1 2 geen mogelijke uitkomst. Dit laatste natuurlijk onder de aanname dat de Liberman & Prince methode om cijfers uit bomen af te leiden - binnen de metrische theorie - goed is.
Het Aristoteles-probleem doet zich ook voor bij woorden als inzetbaar en produktschap. Het hoofdaksent valt in het midden en de twee nevenaksenten grenzen daar direkt aan. De Aristotelesoplossing is dat na toekenning van 1 aksent aan zet en dukt 2 aksent via Hangmat (a) wordt gelokaliseerd op baar en schap en daarna via Hangmat (b) op in en pro, resulterend in 2 1 3 patronen (de 3 is weer afkomstig van de Stress Subordination Convention). Opmerkenswaardig is dat de metrische boom voor dit patroon rechtsvertakkend is, terwijl de morfologische struktuur bij woorden van het type inzetbaar beantwoordt aan een linksvertakkende boom.
Ik zal niet ingaan op de patronen van woorden met sjwa's: vergelijk inzetbaar met betaalbaar. In dat laatste lijkt de eerste vokaal niet sterker dan de slotvokaal. Het 2 1 3 patroon voldoet hier dus niet. Wellicht is dit manco te ondervangen door een losse sjwa helemaal geen cijferwaarde toe te kennen (in te- | |
| |
genstelling tot niet-losse sjwa's, als in vergelijk en eindelijk, waar de perifere sjwa's wel degelijk nevenaksent dragen).
Laat ik tot slot van deze paragraaf ook eens demonstreren dat de Hangmat, met de twee gegeven principes voor boomkonstruktie, universele trekjes vertoont door bomen te konstrueren voor Monongahela en Winnepesaukee. Deze beide paradepaardjes vertonen dezelfde metrische struktuur:
penult 1 aksent en initieel 2 aksent. Dat Monongahela een regél voor ‘initial destressing’ zou ondergaan (Liberman & Prince, p. 279), mag in dit verband worden veronachtzaamd.
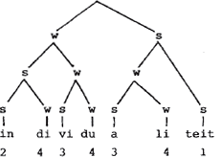
Neem als voorbeeld Monongahela. Een Hoofd Aksent Regel verleent de penulte vokaal 1 aksent. De Hangmat werkt twee keer: eerst op hela en dan op mononga. Omdat he 1 aksent draagt is hela de s-zuster van de rest, mononga. De Hangmat heeft daar mo aangewezen, die dus s is. Samen met non is dat een (binaire) s - w voet, te verbinden met ga, dat daar de w-zuster van is (ga is door geen enkele aksent-regel uitverkoren en wordt met monon geassocieerd op de wijze die eerder voor individu is besproken).
Vergelijk deze boom nu eens met die van Liberman & Prince en stel vast dat twee via verschillende principes opgetrokken bomen (Liberman & prince passen de English Stress Rule iteratief toe en doen een beroep op de Lexical Categroy Prominence Rule. Zie de uiteenzetting daarover aan het begin van dit verhaal) beide een redelijke afspiegeling geven van een cijferpatroon. Alleen op het niveau van 3 en 4 aksent treden er variaties op: in mijn boom is de tweede lettergreep zwakker dan de derde en in die van Liberman & Prince is het net andersom.
Liberman & Prince versie
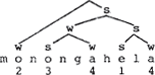
| |
| |
Het zou natuurlijk aardig zijn als er, naast de licht variërende cijferwaarden, nog andere criteria voorhanden zouden zijn om de twee bomen te vergelijken. Een eerste criterium dat me te binnen schiet is dit: s'jes zouden hogere aksentwaarden moeten aanwijzen dan w'tjes. Met dit criterium wint mijn boompje het glansrijk van dat van Liberman & Prince. De laatste labelen immers s en w takken zondere enige acht te slaan op de cijferwaarden die daarmee korresponderen. Neem de eerste lettergreep: ondanks het feit dat hij 2 aksent draagt is hij met w gelabeld. De tweede lettergreep daarentegen is minder geaksentueerd dan de eerste, maar hij is niettemin met s gelabeld. Een ander criterium zou te destilleren kunnen zijn uit welgevormdheidskondities op voeten: ik vind bijvoorbeeld een monosyllabische zwakke voet maar een raar ding (mo in de boom hierboven). Een dergelijke voet is ook niets anders als een toevalstreffer: de English Stress Rule is verantwoordelijk, werkend van rechts naar links, voor de voeten hela en nonga; de LCPR maakt dat die twee voeten een w - s struktuur krijgen en de w-status van de eerste lettergreep, als zus van de rest, is dan onontkoombaar. Bevatte dit woord echter een lettergreep meer, zeg Gemonongahela, dan zouden ge en mo samen een zwakke voet vormen en mo zou de w-zus zijn van ge. De s-status van mo in mijn boom is niet arbitrair: dat is immers een gevolg van de Hangmat. Ik zal deze overwegingen hier echter niet uitwerken. De bedoeling is geweest om te laten zien dat de segmentele aanpak ‘restriktiever’ is dan de hiërarchische, door erop te wijzen dat er meerdere boomstrukturen in aanmerking komen voor één en hetzelfde cijferpatroon. Er zijn danook meerdere principes denkbaar om de ‘goede’ bomen op te trekken.
2. Een van de belangrijkste slogans ter verbreiding van de non-lineaire fonologie is de stelling dat aksent een relationele eigenschap is.
Een losse s of een losse w is dus oninterpreteerbaar. In de Sound Pattern traditie zou deze eigenschap niet onderkend zijn. Daar is het immers gewoon om een monosyllabisch woord automatisch van 1 aksent te voorzien: de Hoofd Aksent Regel heeft het dan makkelijk, omdat er geen rivaliserende vokalen zijn. Dit nu lijkt mij typisch een verbale kwestie. Het is ten eerste geboden om de cijferwaarden, net als s'jes en w'tjes, relatief te interpreteren:
| |
| |
1 betekent niets anders dan ‘relatief sterkst geaksentueerde vokaal’, 2 ‘op een na sterkst geaksentueerde vokaal’, enzovoorts. Ik wil overigens niet ontkennen dat er in de Sound Pattern wel degelijk aanleiding wordt gegeven tot een ‘absolute’ interpretatie van de cijferwaarden (zie Van Zonneveld (1980)). Een goede raad: zie toch in dat een niet-relatieve interpretatie van cijferwaarden onzin is. Zet vervolgens ook de stap om de waarde 1 in een monosyllabisch woord te interpreteren als relatief sterkste vokaal, ongeveer zoals een hardloopwedstrijd met slechts één deelnemer wel een winnaar, maar geen verliezer oplevert. Het zal dan nog weinig moeite kosten om het wat opgeblazen dispuut over lineaire versus non-lineaire fonologie door te prikken: het is nog steeds niet zo moeilijk om aksentregels te maken.
(Vakgroep Nederlandse Taalkunde, RU Groningen)
|
|
