
De Nieuwe Taalgids. Jaargang 77
(1984)– [tijdschrift] Nieuwe Taalgids, De–
[pagina 30]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
SF: Contouren van een toegepaste fonologieGa naar voetnoot*Jip Wester0 InleidingSinds een aantal jaren is het denken over op grote schaal toepasbare ‘sprekende machines’ niet meer voorbehouden aan de Science Fiction cultuur alleen. Ook de feitelijke wetenschap neemt, mede door de grote vlucht van de computertechnologie en de daarmee samenhangende stand van de moderne fonetiek, de mogelijkheden op dit terrein volledig serieus. Dingen als ‘sprekende dashboards’ zijn inmiddels een gegeven geworden, en veel meer soortgelijke toepassingen staan op stapel. Van een aantal van die toepassingen kan men zich afvragen of de mensheid er echt mee gediend zal zijn. Die twijfel geldt niet voor één van de meer geavanceerde machines uit deze generatie, de zgn. ‘voorleesautomaat’, een apparaat dat vanuit normale geschreven tekst tot redelijk normale spraak kan komen, bijvoorbeeld ten dienste van blinden en slechtzienden. Dat deze voorleesmachines steeds dichter binnen het bereik komen, hangt behalve met de genoemde ontwikkelingen in de computerkunde en de fonetiek, echter ook samen met de voortschrijdende theorievorming binnen de moderne taalkunde, in de richting van steeds elegantere en verder uitgewerkte (‘mechanisch’ toepasbare) grammaticasystemen. In dit artikel willen we stilstaan bij de relevantie van deze modern-taalkundige inzichten voor tekst-naar-spraak-omzetting, dat wil zeggen, we zullen kijken naar een aantal eigenschappen van geavanceerde theoretische grammatica's die ook voor een efficiënte tekst-naar-spraak-omzetting nodig zullen zijn. We zullen er hierbij vanuit gaan dat de parallellen tussen de modern-taalkundige en de toegepaste grammatica's zijn terug te voeren tot wat we hier zullen noemen het gemeenschappelijk ‘transformationele principe’, het principe om vanuit ‘onderliggende vormen’ via veranderingsregels tot concrete taaluitingen te komen. In de eerste sectie zullen we kijken naar de relevantie van theoretische inzichten voor de inrichting van toegepaste transformationele grammatica's. Met name de theoretische verhouding van dieptestructuur en transformaties, de relatie fonologie-fonetiek, en de notie ‘modulariteit’ zullen voor de tekst-tot-spraak-taalkunde worden uitgewerkt. Vervolgens zullen we in Sectie 2 stilstaan bij het waarom van het transformationele principe binnen de theoretische en de toegepaste variant. Het zal blijken dat het verschil in doelstelling tussen beide varianten in de praktijk ook een aantal verschillen in de aanpak van concrete taalkundige problemen met zich mee zal brengen. We zullen bij dit alles, in het korte bestek van dit artikel niet naar volledigheid streven; | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 31]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
ons doel is bereikt wanneer we erin slagen enigszins aan te geven welke taalkundige ‘issues’ er bij de constructie van een efficiënt tekst-tot-spraak-systeem kunnen spelen. Wanneer we in dit artikel ingaan op de ‘taalkundige kant’ van tekst-naar-spraak-conversie, zullen we daarbij overigens afzien van syntactische en semantische aspecten; ‘taalkunde’ is voor ons doel fonologie (en voor zover van belang ook morfologie). Deze componenten zullen verder op een voor taalkundigen bekende manier worden benaderd, d.w.z. dat we zullen uitgaan van een zo ‘regulier’ mogelijk fonologisch model, gebruikmakend van de bekende fonologische features, afkortingsconventies, etc. De strategie is als het ware als volgt: wat zou een gewone transformationeel-generatieve fonologie doen met de Nederlandse orthografie als uitgangsstructuur. Deze aanpak is niet ongelijk aan de strategie die in Hertz (1979, 1982) gevolgd wordt voor een vergelijkbare Amerikaanse tekst-naar-spraak-grammatica. | |||||||||||||||||||||||||||||||||||||||||||||||||||
1. Inrichting van een toegepaste fonologische componentEvenals de theoretische fonologie (hierna TF), kent ook de tekst-tot-spraak-fonologie (hierna SF) een natuurlijke opdeling in een aantal stappen of ‘blokken’. TF en SF lopen, omdat ze beide geënt zijn op het transformationele principe, bijvoorbeeld parallel in de inrichting, zoals schematisch is weergegeven in (1) 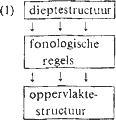 waarin de ‘dieptestructuur’ staat voor de input-structuur voor fonologische regels, en de ‘oppervlaktestructuur’ voor de output van de fonologische component: de structuur waar de fonetische component op zal inhaken. Uitgaande van schema (1), geldt voor TF vervolgens dat behalve het blok fonologische regels ook de dieptestructuur (in het vervolg: DS) ‘gemanipuleerd’ kan worden, dat is: onderwerp zal zijn van hypothesevorming. En dat het juist het samenspel van deze beide soorten manipulaties is die tot efficiënte en inzichtelijke theorieën leidtGa naar voetnoot1. De TF lijkt zich hier op het eerste gezicht van SF te onderscheiden, immers, waar voor TF het lexicon en in zekere zin ook de morfologie in principe variabele blokken zijn, is voor SF de geschreven tekst (orthografie) als input een onveranderlijk, niet te manipuleren gegeven. Dit verschil tussen SF en TF is echter bij nadere beschouwing veel minder groot dan het lijkt. Ook voor SF is in principe een variable DS mogelijk, zij het niet via hypothesevorming, maar via veranderingsregels binnen de grammatica zelf, op grond van de volgende observatie. Het belangrijke gegeven is, dat er binnen SF altijd sprake zal zijn van een te definiëren | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 32]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
‘mapping’ van orthografie naar DS, al was het alleen maar in de instructie dat die orthografie inderdaad als DS, d.w.z. als het relevante uitgangsnivo voor de set fonologische regels gebruikt zal worden (de mapping is in dat geval 1:1). Immers, je zult hoe dan ook minstens de keuze moeten maken of de tekst-karakters (de ‘letters’ van de geschreven tekst) binnen je systeem een één-op-één-correspondentie zullen hebben met de fonemen die ‘toevallig’ traditioneel óók door deze zelfde karakters worden gesymboliseerd. Een toegepaste grammatica zal zo dus een principiële mapping-fase vóór de fonologische input kennen, waarmee een vollediger schema voor SF komt op (2): 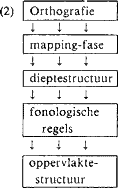 Merk op dat deze principieel aanwezige ‘mapping-fase’ vervolgens ook voor SF de beginstructuur op een natuurlijke manier manipuleerbaar maakt: je hoeft alleen andere dan 1:1-relaties tussen letters en ‘begin-fonemen’ te specificeren. De belangrijke vraag bij dit alles is natuurlijk, of het fonologisch gezien ook zinvol is om de mapping-fase uit te bouwen tot een geëxpliciteerde component, waarin andere dan 1:1-relaties tussen tekst-letters en foneem-karakters worden gespecificeerd. Of, met andere woorden de argumenten voor een samenspel tussen onderliggende vorm en fonologische regels zoals die binnen TF gelden, ook voor SF opgaan. Een motivatie voor een uitgewerkte mapping-component voor SF is het onderwerp van de volgende paragraaf. | |||||||||||||||||||||||||||||||||||||||||||||||||||
1.1 De ‘mapping-component’ - modulariteitHet nut van het werken met een apart ‘mapping-blok’ binnen SF loopt parallel met het algemene nut van een zgn. ‘modulaire aanpak’, zoals dat ook in de theoretische taalkunde wordt gesignaleerd. Deze modulaire aanpak komt, kort gezegd, neer op de strategie om een aantal complexe processen te ‘ontwarren’, d.w.z. te verantwoorden d.m.v. een reeks van op zich eenvoudige, niet-complexe systemen. Een erg duidelijk voorbeeld van dit streven is, natuurlijk, de recente ontwikkeling in de theoretische syntaxis, in de richting van een verantwoording van grammaticale processen d.m.v. aan de ene kant een qua inrichting uiterst eenvoudige (en eenvoudig te beperken) zgn. ‘Move α’-module, en aan de andere kant een gescheiden module die alleen de conditionering van dit Move α-blok voor zijn rekening neemt. De voordelen van deze modulaire aanpak kunnen gegeven worden als winst aan inzicht in het grammaticasysteem, endaarmee samenhangend - de mogelijkheid om een grotere efficiëntie te bereiken. Precies deze voordelen blijken ook op te gaan bij de modulaire benadering van | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 33]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
mapping-regels en transformaties, binnen de toegepaste fonologie. Hieronder zullen we beide voordelen kort uitwerken voor een aantal representatieve, concrete SF-processen.
Eén van de meest elementaire taken waarvoor een SF zich gesteld ziet, is het beregelen van de lengte van klinkers op grond van geschreven tekst. De fonologie moet, concreet, opleveren dat de a in schapen bijvoorbeeld lang wordt, en die in schappen kort. Laten we er vanuit gaan dat alle klinkers onderliggend lang zijn, en dat de beregeling van de lang-kort-variatie dus door middel van een selectieve verkortingsregel moet gebeuren (zie voor deze strategie Sectie 2). De snelste weg tot dit doel is, om te werken vanuit het gegeven dat de SF-context voor de korte variant, zeg maar: de ‘gespelde dichte syllabe’, herkenbaar is als (globaal) een CC-sequentie direct rechts van de klinker in kwestie. Een generale veranderingsregel voor verkorting van klinkers zou er daarmee, wat de rechtercontext betreft, bijvoorbeeld uit kunnen zien als in (3) (de zaak is voor 't voorbeeld iets vereenvoudigd voorgesteld) (3) [+ voc] → [-lang] / ─ [+ cons][+ cons] Vergelijk nu echter een geschreven woord als taxonomie. Wanneer we inderdaad deze geschreven vorm als de directe input voor fonologische veranderingsregels zouden nemen, d.w.z. wanneer we geen uitgewerkte ‘mapping’-module zouden hebben, zou er voor deze vorm iets heel wezenlijks misgaan. Als we even afzien van de slot-ie (zie hieronder): de beide o's zouden, observationeel juist, lang blijven; de a zou echter ten onrechte door regel (3) worden overgeslagen. Het bijsturen van dit soort missers op het nivo van de betreffende veranderingsregel zelf, zou betekenen dat een regel als (3) alleen voor dit ene geval al een aparte, oninzichtelijke uitbreiding mee moet krijgen: de bestaande omgevings-specificatie van de dubbele consonant zou moeten worden samengeklapt met een specificatie die x in rechteromgeving noemt. Tot de veranderingsregels zou zo in principe een onnodige ‘wildgroei’ van onoverzichtelijke, lastig te implementeren en tijdrovende uitzonderingen worden toegelaten; uitzonderingen die veel eenvoudiger gewoon als spellings-generalisaties beregeld kunnen worden door een voorafgaande mapping-component. Immers, met alleen een generale mapping-regel als (4) (4) x → ks zou het probleem met de geschreven x letterlijk en figuurlijk aan de basis onderschept worden: de relevante input voor veranderingsregel (4) wordt daarmee taksonomie, het gedrag van de o vóór de zo ‘klaargelegde’ CC-sequentie ks blijft gewoon regelmatig, en de fonologische regel (3) kan in zijn generale, inzichtelijke vorm gehandhaafd blijven. Merk echter op dat mapping-regel (4) behalve inzicht in het systeem ook efficiëntie oplevert, omdat hij ook onafhankelijk van het besproken lengte-proces kan worden gebruikt. Nederlandse geschreven x zal immers inderdaad op dezelfde manier verklankt moeten worden als de sequentie ks, waarvan de beide afzonderlijke fonemen k (ktachel) en s (stoel) toch al nodig zijn binnen een Nederlandse SF. Het bestaan van een onafhankelijke regel als (4) nu, ontslaat je van de verplichting een apart ‘foneem’ x aan de Nederlandse SF toe te voegen. | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 34]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Het voorgaande voorbeeldje taxonomie, of liever taksonomie, kan nog op een tweede manier het goede samenspel tussen een mapping- en een veranderings-component illustreren. Vergelijk hiervoor het probleem dat zojuist al even werd aangestipt: de behandeling van de slot-ie als lange i. Wat opvalt, is dat de e in deze grafie vanuit spellings-oogpunt gezien vreemd is: hij ‘staat’ noch voor (korte of lange) /e/ noch voor schwa, maar heeft alleen betekenis als lengte-indicator voor de voorafgaande i. Inderdaad een afwijking van het normale Nederlandse geval, waarin geëxpliciteerde lengte van een klinker wordt aangegeven met verdubbeling van hetzelfde segment: aa, ee, oo, uu. Een mapping-regel als (5) nu, zou ook lange i in dit opzicht tot een regelmatig geval maken waardoor het vervolgens mogelijk wordt één generale veranderingsregel te geven die indentieke, adjacente V's omzet in Vø. (Een regel die dan op zijn beurt weer gegeneraliseerd kan worden over zowel V's als C's - vgl. het proces van ‘degeminatie’ in het Nederlands: schappen → schappen; vissen → vissen, etc). (5) ie → ii Ook voor deze regel (5) geldt overigens dat-ie in principe op meerdere punten in de afleiding gemotiveerd kan worden. Vergelijk bijvoorbeeld het proces van GLIDE-INSERTIE (boa → bowa; beo → bejo, etc). GLIDE-INSERTIE in het Nederlands werkt tussen vocalen, maar wat je natuurlijk uit wilt sluiten, is dat ook tussen de twee delen van één lange vocaal glide-insertie optreedt (boot ↦ bowot; buurt ↦ bujurt, etc). De meest generale manier om dit te beregelen, is in de eis dat de vocalen waartussen glides geïnserteerd worden niet identiek mogen zijn, schematisch als (6):Ga naar voetnoot2 (6) ø → glide / Vi ─ Vj Het zal duidelijk zijn dat regel (6) in deze algemene gedaante alleen kan bestaan wanneer ook lange i op grond van mapping-regel (5) tot een regelmatig geval gemaakt is. Immers, zonder (5) zou de generale regel (6) op een zeer omslachtige ad hoc manier moeten worden aangepast om ook gevallen als taksonomie → taksonomije uit te sluiten. Ook in dit geval blijkt het dus inzichtelijk zowel als efficiënt om een aparte mapping-regel aan te nemen, die de meest generale, eenvoudige DS voor de daarop volgende fonologische component kan ‘klaarleggen’. Het laat zich denken dat op grond van overeenkomstige redeneringen nog veel meer mapping-regels te construeren zijn - in feite voor ieder geval van een context-vrije spellings-generalisatie één. Het ‘context-vrije’ karakter van de mapping-regels, kan daarbij overigens ook op een eigen manier de geschetste modulaire benadering motiveren. Het feit immers, dat binnen het mapping-blok geen fonologische omgevingen in de beschouwing hoeven worden betrokken, betekent dat ook de zoekinstructies voor de computer binnen deze module systematisch beperkt kunnen worden tot alleen de ‘focus’ van de verandering, wat de snelheid van de operaties ten goede komt. In de volgende paragraaf zullen we ingaan op de inrichting van de ‘contextgevoelige’ component van de SF-grammatica. | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 35]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
1.2. Fonologische regels - transformaties en prosodieHet blok regels na de mapping-component, zal naast de fonologische transformaties ook prosodische regels (bijvoorbeeld klemtoonregels) bevatten. Ook deze splitsing tussen transformaties en prosodie zullen we modulair benaderen, zoals in (7): 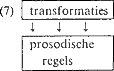 Merk op dat er tussen de beide blokken in (7) een vaste ordeningsrelatie wordt aangehouden: prosodische regels haken in op de output van de transformationele component. De reden hiervoor is, dat deze volgorde de meest efficiënte formulering van de processen mogelijk maakt, met name van de prosodische. Wanneer klemtoontoekenning bijvoorbeeld geordend is na de regels die e in de juiste contexten omzetten in schwa (∂) (boete → boet∂; betoog → b∂toog), kan ten tijde van deze prosodische regel in een belangrijk aantal gevallen worden volstaan met de fonologische generalisatie dat schwa in het Nederlands ‘automatisch’ de laagste stress heeft. Er is echter ook een geval in het Nederlands waarbij de ordeningsrelatie in (7) tot problemen leidt: een situatie waarbij een fonologische transformatie al kijkt naar in (7) pas later beschikbare prosodische informatie. Vergelijk hiervoor gevallen van vocaalreductie als in (8)
Slechts wanneer klemtoon-informatie al beschikbaar zou zijn ten tijde van de regel VOCAALREDUCTIE, zou deze transformatie gebruik kunnen maken van de generalisatie dat alleen onbeklemtoonde vocalen in principe reductie kunnen ondergaan (vgl. bijvoorbeeld Neyt en Zonneveld (1982)) - waarmee zowel de correcte als de stervormen in (8) direct verklaard kunnen worden. Deze zgn. ‘ordeningsparadox’ kan echter op de volgende manier worden weggewerkt. Het belangrijke gegeven is, dat de output van de fonologische VOCAALREDUCTIE in (8) met schwa in de gereduceerde vormen, voor ons toegepaste doel soms te ‘grofmazig’ kan zijn. Wat we met onze uiteindelijke machine willen is immers zo dicht mogelijk naderen tot de fonetische werkelijkheid, waarin gereduceerde a, u en o in een aantal gevallen nog van elkaar te onderscheiden zijn. Wanneer we nu dit uiteindelijk nodige onderscheid al in onze fonologische component zouden neutraliseren, zouden we de latere fonetische component de onmogelijke taak opleggen om in een concreet geval vanuit schwa een keuze te maken voor ‘een beetje meer, a, e af o’. De oplossing is duidelijk: VOCAALREDUCTIE kan binnen ons toegepaste kader overgeheveld worden van de fonologische component naar te fonetische, waar de regel als ‘détailregel’ aan de ene kant de subtiele fonetische veranderingen aankan, terwijl ook - en daar was het ons wat de fonologie betreft om begonnen - de cruciale ordening van dit proces na de klemtoonregels gewaarborgd is. Het feit dat het prosodische blok binnen de fonologische component geordend is na de transformaties, betekent overi- | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 36]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
gens niet dat alle prosodie binnen ons systeem ook fonologisch zal zijn, d.w.z. afgeleid zou moeten worden door de betrekkelijk ‘grofmazige’ fonologische regels. Wanneer het om subtielere prosodische processen gaat, zullen ook deze zonder bezwaar als ‘fonetisch détail’ behandeld kunnen worden. Wat de fonologische prosodie - bijvoorbeeld woordklemtoon - betreft, kunnen we tenslotte opmerken dat een aantal recente inzichten binnen de zgn. ‘metrische fonologie’ ook voor ons toegepaste doel zeer bruikbaar lijken (vgl. bijv. Neyt en Zonneveld (1982), en, in het verlengde daarvan, Kager en Visch (1983)). | |||||||||||||||||||||||||||||||||||||||||||||||||||
1.3. De relatie fonologie-fonetiekIn de voorgaande paragrafen werd een modulaire inrichting bepleit voor de toegepast-fonologische component, waarbij we uiteindelijk drie grammaticale eenheden onderscheidden; in volgorde van ordening de mapping-fase, het transformationele blok, en het prosodische. Ook de fonologische component zelf kan echter weer beschouwd worden als een module in het uiteindelijke systeem, als onderscheiden van bijvoorbeeld het fonetische blok. Hieronder zullen we deze tot nu toe min of meer impliciet gebleven betrekking tussen fonologie en fonetiek binnen het tekst-naar-spraak-systeem iets nader uitwerken. De toegepast-taalkundige reden voor een formele scheiding van fonologie en fonetiek is in feite terug te voeren op een observatie die ook binnen het theoretisch kader vaak gemaakt is, namelijk dat wat voor een fonologie de meest efficiënte, inzichtelijke aannames zijn niet altijd een direct fonetisch correlaat hebben. Binnen het theoretische kader heeft deze observatie, zoals bekend, aanleiding gegeven tot ‘abstracte’ analyses in de fonologie, waarbij de verhouding tussen fonologisch en fonetisch inzicht in feite als volgt gezien wordt: de abstract-cognitieve, psychische realiteit van fonologische eenheden mag een andere zijn dan de fonetische werkelijkheid van het fysische spraaksignaal, voor zover de relatie tussen beide in de grammatica formeel verantwoord kan worden. De Nederlandse schwa mag, om een voorbeeld te noemen, in deze optiek fonologisch tot de klasse van de lange vocalen gerekend worden (vgl. Trommelen (1982)), mits deze eigenschap op een bepaald moment in de derivatie, via regels, fonetisch kan worden uitgewist. Precies deze taalkundig efficiënte verhouding tussen fonologie en fonetiek kan ook voor onze tekst-naar-spraak-grammatica worden aangehouden. De modulaire scheiding maakt dat ook binnen ons toegepaste model ruimte zal zijn voor ‘abstracte fonologie’, voor zover dit de - letterlijke - efficiëntie van het systeem ten goede komt. Wanneer we binnen onze SF bijvoorbeeld uitgaan van een lengteverschil als het kenmerkende onderscheid tussen de klinkers [ce] (mussen) en [ü] (muzen), is dat niet vanuit een naïeve kijk op de fonetische werkelijkheid, maar op grond van het toegepastfonologisch gedrag van deze vocalen, d.w.z. omdat deze aanname als toegepastfonologische generalisatie een eenvoudiger regelsysteem mogelijk maakt. Dit betekent echter wel, dat we, eveneens analoog aan de theoretische situatie, ergens in de grammatica de relatie tussen fonologische en fonetische eenheden moeten specificeren. In ons geval echer niet omdat een verantwoording van de betrekking tussen taal en spraak in de toegepaste grammatica thuis zou horen, maar heel praktisch, omdat de vaak abstracte fonologische eigenschappen van klanksegmenten niet bruikbaar zullen zijn | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 37]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
voor de fonetische defenitie van klanken, zoals die dient ter sturing van de uiteindelijke spraaksynthetisator. We zullen hiertoe, aan het begin van de toegepast-fonetische component een eenvoudige herdefinitie van de feature-waarden van klanksegmenten veronderstellen; aan de détails van deze ‘mapping’ van fonologische naar fonetische werkelijkheid zullen we hier echter verder geen aandacht besteden.
Een modulaire scheiding van fonologie en fonetiek kan overigens ook op niettaalkundige gronden gemotiveerd worden. Voor de respectievelijke blokken zullen, vanwege de aard van de processen, zeer verschillende typen regels gelden; binnen de fonologische component bijvoorbeeld, zijn de veranderingen gedefinieerd in termen van binaire kenmerken, terwijl binnen de fonetische fijnere, glijdende schalen gebruikt zullen worden. Formele loskoppeling van de beide componenten betekent dat de machine per blok zo efficiënt mogelijk geïnstrueerd kan worden over de relevante ‘regelsyntaxis’, zodat een groot aantal voorspelbaar overbodige, ‘loze’ procedures vermeden kunnen worden. | |||||||||||||||||||||||||||||||||||||||||||||||||||
2. ‘Toegepaste generalisaties’ - verschillen tussen TF en SFIn de vorige sectie zagen we dat het gemeenschappelijke ‘transformationele principe’ (in het vervolg tp) een duidelijke parallel in de inrichting van TF en SF met zich meebrengt. Als we echter kijken naar de achterliggende redenen voor het tp in beide fonologiëen, blijken er ook een aantal fundamentele verschillen tussen de theoretische en de toegepaste variant te bestaan, verschillen die hun stempel kunnen drukken op de benadering van concrete fonologische problemen. In deze sectie zullen we een aantal van dit soort verschillen bespreken, en laten zien op welke manier ze doorwerken in de regels en regelsystemen van de Nederlandse SF. Zoals bekend, is het tp in de theoretische taalkunde geïntroduceerd ter verantwoording van linguïstische intuïties van moedertaalsprekers, met name intuïties over overeenkomsten en verschillen tussen uitingen en eigenschappen daarvan. Het tp kan zo bijvoorbeeld worden ingezet voor de verantwoording van de intuïtieve kennis dat zinnen als (9a) en (9b) in semantisch opzicht ‘hetzelfde’ zijn, hoewel ze syntactisch verschillen: (9b), zeggen we is de lijdende vorm van (9a). (9) De strategie bij de theoretische verantwoording van deze ‘eenheid in verscheidenheid’ is als volgt: de eenheid wordt gedekt door beide zinnen dezelfde dieptestructuur toe te kennen, de verscheidenheid door de zinnen vervolgens een verschillende afleidingsgeschiedenis mee te geven: er zijn bij (9a) en (9b) verschillende transformaties in het spel geweest. Het blijkt zo dat het tp binnen de theoretische syntaxis een plaats heeft, omdat het kan worden ingezet bij een adequate verantwoording van een bepaald soort intuïties van moedertaalsprekers.Ga naar voetnoot3 | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 38]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Precies hetzelfde geldt voor de theoretische fonologie. Ook hier geldt dat het tp zijn bestaansrecht ontleent aan de intuïtieve kennis van moedertaalsprekers over talige relaties en verschillen. Vergelijk bijvoorbeeld fonologische paren als (10a) en (10b):
Nederlanders weten dat de stammen in (10a) weliswaar verschillen van de corresponderende stammen in (10b), maar dat er tegelijkertijd toch ook steeds sprake is van inderdaad corresponderende stammen. Dat er, met andere woorden, sprake is van een fonologische verscheidenheid binnen een semantische relatie. Wat de fonologie indeze gevallen doet, is net als de syntaxis één onderliggende vorm van beide stammen aannemen (de (lOb)-vorm), om vervolgens het verschil te be-regelen via de bekende regel AUSLAUTVERHARTUNG (11) die obstruenten op woordeinde stemloos maakt. (11) [-son] → [-stem] / ─ # Als we kijken naar wat SF hier zou doen, blijkt dat deze fonologie precies dezelfde regel kent - maar ook, en dat is belangrijk, dat deze parallel fonologisch gezien op toeval berust. Ook SF heet, om van geschreven bed en lob naar resp. [bεt] en [lɔp] te komen, ergens in de afleiding een regel (11) nodig, echter niet omdat een verantwoording van intuïties tot de taken van deze fonologie zou behoren, maar omdat despelling hier niet direct de uitspraak volgt, terwijl ze dat bij pet en top wel doet, bijvoorbeeld. Dat beide fonologieën hier dezelfde regel zullen kennen, laat zich echter verklaren uit het feit dat de spellingen bed en lob berusten op argumenten, die analoog zijn aan de fonologische argumenten om [bεt] en [lɔp] in de DS een stemhebbende obstruent mee te geven: bed en lob hebben een d resp. b omdat bedden en lobbig die ook hebben. De fonologische redenering loopt in dit geval parallel met het ‘principe der gelijkvormigheid’ in de Nederlandse spelling. Er zijn echter ook een groot aantal gevallen waarin dit niet zo is, en waarin het verschil in doelstelling tussen de beide fonologieën ook in concrete regels tot uitdrukking zal komen. Twee representatieve gevallen zullen hiervoor worden beschreven. | |||||||||||||||||||||||||||||||||||||||||||||||||||
A. Lengte-alternanties bij klinkersVoor het eerste voorbeeld van hoe het verschil in doelstelling tussen TF en SF zal doorwerken in concrete fonologische regels, zullen we stilstaan bij de afleiding van langkort-alternanties van klinkers binnen de beide fonologieën. Als uitgangspunt kunnen we nemen de vormen (12a) en (12b).
| |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 39]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Precies zoals in de gevallen (10a) en (10b) hiervóór, is ook hier bij de vormen tussen vierkante haken sprake van paren, gebaseerd op semantische overwegingen. En ook voor deze gevallen zal TF steeds één onderliggende vorm aannemen, om de verschillen vervolgens via (onder andere) fonologische lengte-regels af te leiden. De vraag is echter, welke vorm wat deze lengte betreft als de onderliggende beschouwd moet worden. Immers, bij het beregelen van dit soort lang-kort-alternanties zijn in principe twee strategieën denkbaar. Je kunt de klinkers onderliggend lang maken en vervolgens selectieve verkorting toepassen, of andersom: je begint met de korte varianten en neemt daarbij verlengingsregels in je grammatica op. Welke van beide strategieën in een concrete TF de beste zal zijn volgt uit taalspecifieke gegevens. Voor de Nederlandse TF geldt zo, dat in de praktijk alleen de verlengingsstrategie in aanmerking komt. De noodzaak voor deze verlengings-aanpak, volgt uit het naast elkaar voorkomen van zowel [sxIp] -[sxep∂] als [spεl] - [spel∂] in (12), met beide een lange e in de rechter vorm. Je kunt, kort gezegd, binnen de Nederlandse fonologie wel ‘mechanisch’ vanuit zowel korte i als korte e naar lange e komen, maar niet omgekeerd: je kunt niet op een fonologisch zinvolle manier vanuit lange e een keuze maken voor óf korte i (schip) óf korte e (spel). Merk echter op dat deze problemen voor SF nooit zullen spelen, omdat een taalkundige verantwoording voor de relaties in (12) voor deze toegepaste fonologie niet aan de orde is. Het gaat bij SF niet om een verantwoording van eventuele linguistische relaties als tussen schip en schepen, maar om een observationeel juiste beregeling van lengte-verschillen als tussen schepen en schèppen, vanuit de de geschreven vormen. Dit betekent dat voor SF opnieuw, rekening houdend met de eigen doelstelling, een eigen keuze gemaakt moet worden voor de verlengings- of verkortingsstrategie in het geval van één gespelde klinker, onafhankelijk van de Nederlandse TF. Zoals elders al even aan de orde kwam, hebben we in onze SF gekozen voor de tweede benadering: verkorten. Eén van de redenen voor deze keuze zal hieronder worden gereconstrueerd. Een belangrijk argument voor de verkortingsstrategie is dat een verkortingsregel zelf, efficiënter te formuleren is dan een verlengingsregel. Laten we beide mogelijkheden eens nalopen. Een verlengingsregel zal in de eerste plaats moeten werken in wat je kunt noemen de ‘gespelde open syllabe’: een CV-sequentie of een woordgrens direct rechts van de klinker in kwestie (tuba #;, Plato #, etc). De kern van de regel zal dus in ieder geval de volgende informatie moeten bevatten: (13) (13) [+ voc] → [+ lang] / _____ {[+ cons#][+ voc]} Merk echter op dat met deze regel (13), in de open syllabe-context ook het tweede lid van een dubbel geschreven klinker wordt meegenomen: zeel #, roodachtig #, etc. Om in een later stadium álle identieke dubbele vocalen, op een beetje generale manier als één lange aan de oppervlakte te krijgen, zul je vervolgens ook in dichte syllaben het tweede lid van een dubbel geschreven klinker moeten verlengen. Regel (13) zal met andere woorden moeten worden uitgebreid met de specificatie dat de syllabe niet per sé dicht hoeft te zijn, in het geval er een identieke V voor de klinker in kwestie staat. De snelste manier om deze nieuwe informatie in de verlengingsregel onder te brengen is als in (14) 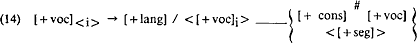 | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 40]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
waarbij de eis dat de vocalen identiek moeten zijn dient om te voorkomen dat ook het tweede lid van een diftong door de regel wordt meegenomen. Dit zou elders in de fonologie moeilijkheden opleveren.
Een volgend gegeven is, dat de uiteindelijke verandering van een dubbel geschreven klinker tot één lange, verreweg het gemakkelijkst kan gebeuren wanneer de beide leden van zo'n dubbele vocaal lang zijn, ten tijde van de toch al nodige ‘degeminatie-regel’, die voor dit doel over zowel identieke consonanten als identieke vocalen kan worden gegeneraliseerd (zie par. 1.1.). Dit houdt in, dat behalve het tweede lid van een dubbele vocaal, ook het eerste lid verlengd moet worden, ongeacht de linker-context. De verlengingsregel moet, met andere woorden, uitgebreid worden met de volgende informatie (15): (15) [+ voc]i → [+ lang] / _____ [+ voc]i We zien dat een verlengingsregel zo onderhand volstrekt oninzichtelijk en onimplementeerbaar dreigt te worden. De enige praktische oplossing is hier in feite nog, om de afleiding te laten gebeuren door een aantal regels; een weinig efficiënte situatie.
De verkortingsstrategie kent deze problemen niet. Dubbel geschreven lange klinkers bijvoorbeeld, zijn bij deze aanpak al gewoon lang, en hoeven dus ook geen verandering te ondergaan. De enige klinkers die onder de verkortingsstrategie in feite beregeld hoeven worden zijn enkel geschreven klinkers in dichte syllaben zoals in dakpan, boktor, etc. voor ons doel schematisch te noteren als (16): (16) [+ voc]i → [-lang] / [+ seg]j_____[+ cons] {[-#son]} Een regel die tenslotte nog vereenvoudigd kan worden, wanneer we binnen ons fonologische systeem behalve de obstruenten, ook de woordgrens # het feature -sonorantisch meegeven: de accolade-specificatie in (16) kan daarmee worden vervangen door alleen de ‘gemene deler’ [-son], zodat de regel kan worden gereduceerd tot (16'): (16') [+ voc]i → [-lang] / [+ seg]j_____[+ cons] [-son] B. De rol van morfologische informatie Een tweede representatief verschil met TF, dat voor de constructie van SF-regels van belang is, kan gevonden worden in de rol die morfologische informatie in beide fonologieën speelt, en de manier waarop zulke informatie in spelling en theoretische DS ‘gecodeerd’ is. Zoals bekend, is een groot deel van de morfologie van het Nederlands binnen het theoretische kader ook fonologisch relevant. Een eenvoudig voorbeeld is de fonologische transformatie die schwa deleert in gevallen als syllabe + isch → syllabisch, als onderscheiden van syllabe + informatie → syllabe - informatie. Het ligt voor de hand om voor dit onderscheid tussen beide vormen gebruik te maken van het morfologische onderscheid tussen affixen en woorden: een suffix (-isch) laat schwa-deletie toe, een woord (informatie) niet. Dit voorbeeldje laat echter ook direct het fundamentele verschil zien tussen TF en SF, op het punt van deze morfologische informatie. Voor SF | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 41]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
zal deze morfologisch geconditioneerde SCHWA-DELETIE irrelevant zijn, omdat de theoretische reden ervoor (weer: de verantwoording van linguistische ‘eenheid in verscheidenheid’) in deze fonologie ontbreekt. De enige gevallen waar SF in feite mee te maken zal krijgen zijn de oppervlaktevormen syllabisch en syllabe-informatie, wat je zou kunnen noemen de gespelde output van TF. Ook hier geldt zo dat het verschil in doelstelling tussen de beide fonologieën doorwerkt als een discrepantie tussen spelling en theoretische DS.
Wanneer we op grond van de syllabe-gevallen kunnen vaststellen dat het voor SF niet nodig is naar morfologie te kijken omdat TF dat ook doet, kunnen we ons vervolgens afvragen in welke situaties morfologische generalisaties voor SF binnen het eigen kader, op onafhankelijke gronden zinvol zijn. Voor een antwoord op deze vraag zullen we kijken naar het representatieve onderscheid prefix-woord, waarbij we ons zullen beperken tot de prefixen zonder hoofdaccent, waarvan er onder (17) een beperkt aantal gegeven zijn. (17) prefixen zonder hoofdaccent: be-, ge-, ver-, her-, on-, re-, de-, ont-, etc. Bij een aantal leden van deze klasse, lijkt (al dan niet ‘historische’) affix-informatie voor SF op het eerste gezicht noodzakelijk om een proces als SCHWA-REDUCTIE te conditioneren. Vergelijk bijvoorbeeld vormen met be- en ge-: wanneer het hier om prefixen gaat, zal SF de geschreven e moeten reduceren tot schwa; vlg. betekenen naast beven, geteken naast geven, begeleiden naast begeren, etc. Deze gevallen zullen echter voor een groot deel fonologisch benaderd kunnen worden, vanuit - schematisch - de volgende strategie: be en ge mogen gelden als prefixen, tenzij op fonologische gronden het tegendeel blijkt. Of, beter gezegd: e mag in de gevallen be en ge reduceren, tenzij de resulterende schwa om fonologische redenen onmogelijk is. Een benadering die we kort kunnen illustreren aan de hand van de bovengenoemde vormen. De uitspraak van de gespelde woorden betekenen, beven, geteken etc. leert, dat de Nederlandse SF in ieder geval een regel moet kennen die e voor n omzet in schwa; schematisch als (18), met als resultaat (19).
Wanneer we nu de output in (19) bekijken, kunnen we de volgende regelmaat ontdekken: de gevallen waarin be en ge géén prefixen zijn (beven, geven, begeren), zijn fonologisch te herkennen, namelijk als precies die gevallen waarin reductie tot g∂ en b∂ zou leiden tot vormen met schwa 's als enige klinkers. Waar we hier in feite op stuiten, is de bekende fonologische generalisatie dat Nederlandse stammen wat de vocalen betreft niet uit alleen schwa's mogen bestaan. Een generalisatie die we vervolgens binnen SF kunnen inzetten, door voor de be/ge-regel een niet-schwa-klinker in rechter omgeving te eisen, schematisch als (20), waarmee de volledige afleiding wordt als in (21).
| |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 42]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Op dit punt aangekomen, kunnen we iets dieper ingaan op onze achterliggende strategie bij de benadering van morfologische (en andere ‘spelling-externe’) informatie. Wat opvalt, is dat we ten behoeve van de be/ge-afleiding geen formele ‘morfologische component’ hebben ontwikkeld, zoals bijvoorbeeld een fase waarin pré- en suffixen worden gescheiden van hun stammen door insertie van een ‘+’-grens (zgn. ‘affix-stripping’). Regel (20) bijvoorbeeld, kijkt niet naar morfologie. Het enige dat in het voorgaande in feite gezegd werd is dat de be/ge = b∂/g∂ - regelmaat in het Nederlands voldoende groot is om er een aparte fonologische regel aan te wijden; het feit dat de oorzaak van deze regelmaat ligt in de produktiviteit van een affix wordt daarbij strikt genomen genegeerd. Dit is met opzet. De achterliggende reden voor deze benadering is, dat in het Nederlands slechts één onafhankelijke regel van deze expliciete affixinformatie gebruik zou maken (namelijk inderdaad de be/ge → b∂/g∂-regel), en in zo'n geval zou explicitering van morfologie niets meer opleveren dan een onnodige extra stap. Immers, de informatie op grond waarvan je zou besluiten dat be of ge in een concreet geval een prefix is, en dus een ‘+’ in rechter omgeving moet krijgen ten dienste van schwa-reductie, kan ook direct gebruikt worden als context-specificatie van de regel SCHWA-REDUCTIE zèlf, zoals in (20) in feite ook gebeurd is. Explicitering van morfologische of ander spelling-externe informatie is voor een SF alleen zinvol indien dat elders in de grammatica tot duidelijke generalisaties leidt. Bijvoorbeeld wanneer het om context-specificaties gaat die in meerdere SF-regels gebruikt moeten worden. Dit betekent niet dat het principe van ‘affix-stripping’ voor onze SF onbruikbaar wordt geacht, maar wel dat de theoretische-taalkundige vraag om ‘onafhankelijke argumenten’ als methodologische eis, ook voor de toegepaste variant op een zinvolle manier gehanteerd kan worden. Zulke onafhankelijke evidentie tenslotte, is bijvoorbeeld wel te vinden voor een prefix als on- in (17): insertie van een grens na # on zou zowel voor een proces als klinkerverkorting zinvol zijn (vgl. onedel met [ ɔ ], naast bonafide met [o]), als voor het proces dat ng omzet in η (vgl. ongans met [ɔ : γ] naast wrongel met [η]). Deze grens zou vervolgens ook kunnen worden ingezet voor de beregeling van een sequentie als lijk in gevallen als ongelijk naast degelijk: gegeven een schematische lijk → l∂k-regel als (22) en de reeds bestaande regel (20), kan de afleiding worden als onder (23)
Wanneer on- hier gescheiden wordt van de stam, kan met andere woorden ook voor het suffix- lijk gebruik gemaakt worden van de fonologische generalisatie dat Nederlandse stammen minstens één volle vocaal moeten bevatten. | |||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 43]
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
|