
De Nieuwe Taalgids. Jaargang 70
(1977)– [tijdschrift] Nieuwe Taalgids, De–
[pagina 222]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Frequenties van beginconsonanten en beginconsonantclusters in het NederlandsAanleiding tot de analyse van statistische gegevens van beginconsonanten en beginconsonantclusters was het onderzoek naar de relatie tussen statistische taalgegevens in het algemeen en wat genoemd wordt ‘linguistic expectancy’. Onder linguistic expectancy verstaan we de intuïtieve kennis van de taalgebruiker van statistische eigenschappen van de taal. We mogen namelijk stellen, dat het leren van een taal zich niet beperkt tot het zich eigen maken van de betekenissen van woorden en hun korrekte grammatikale inpassing in het taalsysteem als geheel, maar dat tijdens het proces van taalverwerving ook de waarschijnlijkheden van voorkomen van de verschillende taaleenheden aangeleerd worden. Aangezien de mogelijkheden van voorkomen van bepaalde structuren meer waarschijnlijk zijn dan die van andere structuren mogen we aannemen dat linguistic expectancy het decoderingsproces van de ontvanger van een spraaksignaal beïnvloedt. Deze hypothese is al eerder getoetst. Zo hebben Miller et al. (1951) getoond, dat betekenisdragende woorden beter verstaan worden in een context van grammatikaal correcte zinnen, dan wanneer ze in gerandomiseerde volgorde gesproken worden als items van een lijst. Dit onderscheid werd toegeschreven aan de contextuele reductie in het aantal van alternatieve woorden waaruit de ontvanger te kiezen heeft. Hoe kleiner het aantal van alternatieven werd, des te gemakkelijker was het een bepaald woord te identificeren. Door Miller et al. (1963) werd aangetoond, dat grammatikaal korrekte zinnen, die per definitie een grotere waarschijnlijkheid van voorkomen hebben, meer resistentie hebben tegen omgevingslawaai (10-20db) dan ongrammatikale zinnen. Howes en Solaman (1954) hebben bewezen, dat frequente woorden met groter gemak begrepen worden dan infrequente. In een experiment van Miller, Bruner and Postman (1954) bleek, dat pseudo-woorden die in bouw dichter staan bij de statistische structuur van woorden gemakkelijker verstaan worden. In een eigen experimenteel onderzoek (Gil, 1974) werd nagegaan in hoeverre de frequentie van voorkomen van Engelse beginconsonantclusters invloed heeft op de perceptie en productie van spraak van Engelse native speakers. De resultaten daar lieten zien, dat wat de waarneming betreft
Wat de productie betreft bleek:
Het stimulusmateriaal voor deze testen werd ontleend aan A. Hood Roberts (1965), die met behulp van een computer een corpus van 10'000 woorden geanalyseerd heeft met als resultaat uitgebreide kwantitatieve gegevens over de segmentele opbouw van het Engels. Het nu lopende onderzoek concentreert zich behalve op het verschijnsel linguistic expectancy in de moedertaal ook op de vraag of deze regelmatigheden ook in een | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 223]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
vreemde, later aangeleerde taal verworven worden en of derhalve het kwantificeren van linguistic expectancy een objectieve maat kan vormen van graden van beheersing van een vreemde taal. Aangezien er daarom met twee talen, t.w. Engels en Nederlands parallel gewerkt wordt, was er behoefte om ook aan statische gegevens over de segmentale opbouw - in het bijzonder wat betreft beginconsonanten en beginconsonant-clusters - in het Nederlands te komen. De rest van dit artikel zal gewijd zijn aan de beschrijving van de procedure ter verkrijging van het stimulusmateriaal en de presentatie daarvan. Als uitgangspunt werd de Al lijst van Uit den Boogaart (1975) gebruikt. Deze lijst bevat alle woordvormen (met hun grammatikale code) die meer dan eenmaal in het totale corpus voorkomen en waarvan de lengte niet die van 25 tekens overschrijdt. De frequenties in deze lijst zijn per subcorpus en totalen gespecificeerd. Voor deze compu-terwerkzaamheden werd op de Technische Hogeschool te Eindhoven de IBM 360.30 van de afdeling Elektrotechniek en de Burrough's van het Rekencentrum gebruikt. De computerprogramma's werden daar in PL/1 geschreven. Ter verkrijging van onze eigen data werd een computerprogramma in Fortran IV geschreven, dat uit de bovengenoemde Al lijst en met gebruikmaking van de CDC 6500 van het AcademischComputer Centrum Utrecht de volgende gegevens opleverde:Ga naar voetnoot1 per consonant het totale aantal verschillende woorden beginnende met deze consonant, gesplitst naar voorkomen in geschreven en gesproken taal; per consonant de totaal-frequentie van woorden beginnende met deze consonant; gegeven werden het totaal schrijftaal, het totaal spreektaal, het absolute totaal en het relatieve totaal;Ga naar voetnoot2 per consonantcluster het aantal verschillende woorden beginnende met dit cluster, het totaal schrijftaal, het totaal spreektaal, het absolute totaal en het percentage t.o.v. het aantal woorden beginnende met het eerste segment van het cluster; per consonantcluster de totaal-frequentie van woorden beginnende met dit cluster; gegeven werden het totaal schrijftaal, het totaal spreektaal, het absolute totaal, het relatieve totaal en het percentage t.o.v. de totaal-frequentie van woorden beginnende met het eerste segment van het cluster. De hieronder volgende lijsten geven de kwantitatieve gegevens voor Nederlandse beginconsonanten en beginconsonantclusters
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 224]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
CONSONANTEN ALFABETISCH
CONSONANTEN GERANGSCHIKT NAAR TOTAAL GEBRUIKSFREQUENTIE
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 225]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
CONSONANT CLUSTERS ALFABETISCH
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 226]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
CONSONANT CLUSTERS GERANGSCHIKT NAAR TOTAAL GEBRUIKSFREQUENTIE
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 227]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Correlatie tussen rangordes van beginclusters aan de hand van het totaal aantal verschillende woorden, lexicale frequentie (types) en van het aantal daadwerkelijk aangetroffen woorden in het corpus, gebruiksfrequentie (tokens) leverde een rangordecorrelatiecoiëfficient van 0.90 op bij een significantieniveau van kleiner dan 0.00003. Hieruit mogen we concluderen dat, wat woorden betreft die met een consonantcluster beginnen, een grote maat van overeenstemming bestaat tussen de rangordes van lexicale- en gebruiksfrequentie. Het lijkt ons beslist de moeite waard om dit soort vergelijkingen ook op andere linguistisch gedefinieerde categorieën woorden toe te passen. Figuur 1 laat deze correlatie grafisch zien. De onderbroken lijn geeft de hypothetische één tot één relatie aan en de doorlopende lijn de algemene charasteristic van de puntenwolk. Op deze lijn kan men ook voor een gegeven x-waarde de verwachte y-waarde aflezen. 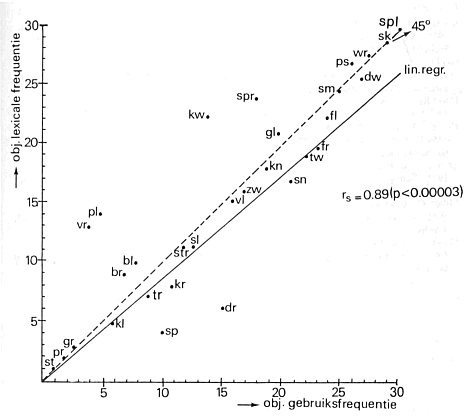
Fig. 1: relatie tussen rangordes van lexicale en gebruiksfrequentie van beginconsonantelusters.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 228]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De hier gepresenteerde resultaten waaruit blijkt dat in de notie ‘linguistic expectancy’ zeker ook ‘kennis’ van frequentie van voorkomen bij taalgebruikers besloten is, maakt het aantrekkelijk nader onderzoek in deze richting uit te voeren. Als mogelijke uitbreiding zou men kunnen denken aan toepassing van de gebruikte technieken van productie-en perceptietesten op ander linguistisch gedefinieerd materiaal dan beginclusters. Dit soort onderzoek zou kunnen leiden tot het in kaart brengen van wat er al zo, in de vorm van linguistic expectancy, aan taalgebruikers van hun eigen taal ‘bekend’ is. Als mogelijke toepassing van dit soort onderzoek kan men denken aan het vreemde-talenonderwijs waarin de mate van aanwezigheid van linguistic expectancy een indicatie zou kunnen zijn voor de graad van gevorderdheid in de beheersing van een vreemde taal.
Fonetisch Instituut, Utrecht, Oudenoord 6 d. gil-günzburger | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Referenties
|