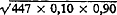|
| |
| |
| |
Distributie van ‘nieuwe woorden’ in Mei van Herman Gorter
0. Inleiding
De bedoeling van dit artikel is de spreiding van ‘nieuwe woorden’ in het gedicht Mei van H. Gorter te onderzoeken.
Deze woorden definiëren wij hier voorlopig als vroeger niet bestaande, hoewel misschien bestaanbare, woorden uit de Nederlandse taalvoorraad.
Het creëren van nieuwe woorden is niet het monopolie van een dichter, iedere taalgebruiker kan op elk ogenblik gebruik maken van de taaldynamiek die hem in staat stelt nieuwe woorden te vormen. Algemeen echter wordt aangenomen dat ‘de dichter overvloediger dan wie ook gebruik maakt van de hem door de taal geschonken dynamische vrijheid’Ga naar voetnoot1. Als deze bewering juist is kunnen wij de creatie van nieuwe woorden typisch dichterlijk noemen. Anders geformuleerd: een van de kenmerken van poëtisch taalgebruik (in tegenstelling tot de dagelijkse omgangstaal b.v.) is zijn significant meer-gebruik van nieuwe woorden.
Aangezien onze stijlbenadering mathematisch-statistisch is en wij de statistiek als la science des écarts kunnen bestempelen, wordt stijl in deze optiek, als écart par rapport à une norme begrepenGa naar voetnoot2.
Dit betekent dan dat wij de auteur of de taalgebruiker zien als enerzijds onderworpen aan bepaalde normen of conventies, anderzijds ervan bevrijd, omdat zovele regels optioneel zijn. Juist door deze keuzemogelijkheid is er fluctuatie van de norm mogelijk en kan de auteur een bepaald effect nastreven. Is deze fluctuatie (statistisch) -significant dan kunnen wij spreken van een stijlverschil, tenminste indien wij van een (stilistisch) representatieve norm kunnen uitgaan.
Meestal ligt precies hier de grote moeilijkheid: genuanceerde frequentietellingen waarbij o.m. rekening wordt gehouden met onderwerp, situatie (dialoog of monoloog b.v.), structuur (proza, poëzie, genres), gesproken of geschreven taal, milieu of streek van de auteur (b.v.Zuid- tgo. N.-Nederland) enz. en die de probabiliteit van diverse linguïstische objecten als fonemen, morfemen, woorden, woordgroepen en zinnen weergeven bestaan immers vrijwel nog niet. Zolang die er niet zijn zal het moeilijk blijven de literatuur- en stijlstudie exacter en objectiever te maken.
Wat het gebruik van nieuwe woorden in Gorters Mei betreft: we kunnen slechts van een (Gorteriaans) stijlkenmerk spreken, als we konden aantonen dat Gorter afwijkt van het verwachte aantal nieuwe woorden (gebaseerd op een objectief en representatief taalsample) voor een tekst van dezelfde grootte. Dit is niet mogelijk, aangezien een dergelijk sample niet bestaat. Daarom moeten wij de hier bekomen ratio (aantal verschillende nieuwe woorden (= n) / totaal aantal verschillende woorden (= V)), op grond van deelresultaten en eigen subjectieve ervaring als significant-afwijkend bestempelenGa naar voetnoot3. Deze n/V-ratio bedraagt ruim 8%: 460 verschillende nieuwe woorden/
| |
| |
5666 verschillende woordvormenGa naar voetnoot1. Wij troosten ons daarbij met de gedachte dat het soms gemakkelijker is deviatie van de norm te onderkennen, dan de norm zelf te bepalen. Aanvaarden wij het gebruik van nieuwe woorden als typerend stijlkenmerk in Mei dan sluit dat niet uit dat dit werk nog door andere (stijl-) criteria gekenmerkt wordt. In de statistische benadering die wij voorstaan is stijl trouwens de som van de individuele opties die de auteur maakt van de lexicale, morfologische en syntactische keuzemogelijkheden in de taal. Aldus wordt hier geen exhaustieve stijlstudie van Gorters Mei geboden, maar enkel één aspect van Gorters stijl in Mei onderzocht.
Uitgaande van het feit dat het gebruik van nieuwe woorden een stijlkenmerk is van Gorters Mei, onderzoeken wij de distributie van deze woorden, om daaruit conclusies te kunnen trekken over de al- of niet-homogeniteit van het werk. Gegeven het stijlcriterium nieuwe woorden gaat het om de volgende alternatieven:
- ofwel is hun aantal over het hele werk homogeen verdeeld, en dan hebben we te maken met een stijlkenmerk dat het gehele werk door constant blijft;
- ofwel is hun aantal over het hele werk niet-homogeen verdeeld.
De vraag is dan hoe de verdeling is en waarom.
De werkwijze die wij bij dit onderzoek volgen kunnen wij in vier punten samenvatten:
| 1. | de detectie van nieuwe woorden |
| 2. | toepassing van 1 op Mei |
| 3. | statistisch onderzoek van de distributie van die woorden |
| 4. | interpretatie van 3 |
| |
1. Detectie van nieuwe woorden
De definitie waarvan wij uitgingen was: nieuwe woorden zijn vroeger niet bestaande, hoewel misschien bestaanbare, woorden uit de Nederlandse taalvoorraad.
Deze definitie stelt ons nochtans voor een moeilijkheid: zij schiet namelijk tekort indien wij ze aan de computer geven en hem vragen aan de hand daarvan in een willekeurige tekst de nieuwe woorden op te sporen. Daar dit laatste in onze bedoeling lag, hebben wij, om onze bepaling computer-geschikt te maken, niet met een linguistisch-inhoudelijke definitie gewerkt, maar met een formeel, machine-georiënteerd adekwaat. Daarbij bepaalden wij nieuwe woorden als woorden die nog niet van de Nederlandse taalvoorraad deel uitmaakten en die wij dus als lexicologische innovaties konden beschouwen. De Nederlandse taalvoorraad zagen wij dan als de verzameling woorden opgenomen in de volgende woordenboeken en -lijsten:
| 1. | van Dale, Groot Woordenboek der Nederlandse Taal, bewerkt door dr. C. Kruyskamp, 's-Gravenhage, 8e druk, 1961. |
| 2. | L. Brouwers, Het juiste Woord, Brussel-Turnhout, 4e druk, 1965. |
| |
| |
| 3. | Frequentielijst I.T.L., niet-gepubliceerd, ter inzage op het Instituut voor Toegepaste Linguïstiek, LeuvenGa naar voetnoot1. |
| 4. | K.R. Gallas, Nieuw Frans-Nederlands Nederlands-Frans Woordenboek, deel II Nederlands-Frans, Zutphen, 3e druk, z.j. |
| 5. | L. Grootaers' Nieuw Nederlands-Frans Woordenboek, Leuven-Brussel, 17de druk, 1970. |
| 6. | C.B. van Haeringen, Kramers' Woordenboek Nederlands, Den Haag-Brussel, 13de druk, 1968. |
| 7. | H. Jansonius, Groot Nederlands-Engels Woordenboek, Leiden, 3 delen, 1950-1959. |
| 8. | M.J. Koenen - J. Endepols, Verklarend Handwoordenboek der Nederlandse taal, Groningen, 26e druk, 1966. |
| 9. | J. Linschoten, De la Court's Frekwentietelling van Nederlandse Woorden, Utrecht, 1963. |
| 10. | Verschuerens Modern Woordenboek en Atlas, Turnhout-Brussel, 2e druk, 1965. |
| 11. | Winkler Prins Woordenboek, 2 delen, A'dam-Brussel, 1967. |
| 12. | Woordenboek der Nederlandse Taal, 's-Gravenhage-Leiden, 1882-. |
Het lijkt ons nuttig hierbij enige toelichting te geven omtrent:
| 1. | de taalopvatting die met een dergelijke operationele definitie gepaard ging; |
| 2. | de wijze waarop de nieuwe woorden in de praktijk werden bekomen. |
Ad I:
- Wanneer wij aan ‘nieuw woord’ de karakteristiek: nog niet voorkomend woord uit de Nederlandse taalvoorraad toekennen, dan betekent dit dat wij deze taalvoorraad dynamisch zien: nieuwe woorden kunnen, mits het volgen van bepaalde regels, gevormd worden. Vervolgens bestaat zij niet alleen uit ongelede maar tevens uit gelede elementen.
De taalvoorraad bestaat immers uit woorden. Wij aanvaarden hier de opvatting die MattensGa naar voetnoot2 onlangs verdedigde. Om in zijn terminologie te blijven: nieuwe woorden behoren niet tot de Nederlandse taalvoorraad, zijn geen taalvoorraadfixaties. De meeste woordenboeken aanvaarden trouwens impliciet dit onderscheid tussen virtueeel en geactualiseerd taalgebruik. Anders zou het geen zin hebben verder ‘bestaanbare’ woorden op te nemen en ze zelfs met citaten te stavenGa naar voetnoot3. Op basis daarvan zouden wij jongensloos als nieuw woord bestempelen, kinderloos, dat tenminste latent in de voorraad van iedere taalgebruiker aanwezig is, niet. M.a.w. jongensloos is een bestaanbaar woord: zowel de lexicale elementen als de bouwregels nodig om én oppervlakte- én dieptestructuur te genereren zijn reeds in het Nederlands aanwezig. Nieuw betekent hier dus dat het woord niet eerder in het Nederlands werd gerealiseerd, in de taalvoor- | |
| |
raad gefixeerd. Zo ook b.v. konden wij enkele jaren geleden kijkgeld als een nieuw woord aanzien, hoewel het volkomen ‘bestaanbaar’ was.
- Om nu de taalvoorraadfixaties te bepalen hebben wij een beroep gedaan op een aantal woordenboeken en -lijsten. In de inleiding van deze werken wordt er meestal op gewezen, dat de opgetekende woordvoorraad niet volledig is. Toch dunkt ons dat de cumulatie van de door ons opgestelde lijsten een thesaurus vormt die bij benadering een goede weergave is van de bestaande Nederlandse woorden. Er werd naar gestreefd om de foutenmarge hierbij de 10%-grens niet te laten overschrijden. Wij zouden het zo kunnen stellen dat de lijst in 2 ‘nieuwe woorden’ bevat met de volgende restricties:
| 1. | met een foutenmarge van 10% moet worden gerekend, d.w.z. dat op de 460 opgetekende gevallen er een 50-tal kunnen ingeslopen zijn die in andere dan de hier geciteerde bronnen voorkomen of die gewoon nergens opgetekend staan, hoewel ze bestaan. Deze foutenmarge zal o.i. ook bij minder formele, meer intuïtieve criteria blijven bestaan. |
| 2. | de lijst bevat zowel woorden die reeds vroeger bestaanbaar waren als woorden die dat niet waren, zo b.v. bosvijver tgo. blosrood. |
Als gemeenschappelijk kenmerk hebben ze echter dat ze beide niet eerder in het Nederlands werden gerealiseerdGa naar voetnoot1.
In deze optiek is een verdere nuancering in de ‘nieuwe woorden’ mogelijk, misschien reserveert men daarbij het best de term neologisme voor vroeger onbestaanbare woorden. Met deze verdere indelingsmogelijkheid wordt hier (nog) geen rekening gehouden.
Ad II:
Over de realisatie van de in 2 gegeven lijsten kunnen wij kort zijn: d.m.v. een computer-programma werden de woorden uit Mei met de woorden van Van Dale's Zakwoordenboekje, uitgave 1964, vergelekenGa naar voetnoot2. Beide corpora stonden immers op elektronische band en werden reeds voor ander onderzoek gebruiktGa naar voetnoot3.
Na deze eerste machinale zifting gebeurde de rest manueel. Dit betekende dat na vergelijking met de grote van Dale ongeveer 550 woordenGa naar voetnoot4 overbleven. Deze werden bron na bron verder tot 460 gezift.
| |
| |
| |
2. Nieuwe woorden in Mei van Gorter
De principes uit 1 in acht genomen bekwamen wij de volgende lijsten (in alfabetische orde)Ga naar voetnoot1:
| AANDOMEN |
BLOOTVOET'GE |
| AKKERVOGELS |
BLOSROOD |
| AVONDGROEN |
BOKAALKLANK |
| AVONDZEE |
BOMEHAGEN |
| BADKOUD |
BOMENLICHTGETOVER |
| BEDDINGZAND |
BOMENPAAN |
| BEEKDOORADERDE |
BOOMBEPLANT |
| BEEKIJS |
BOOMBOS |
| BEEKVAL |
BOOMNEST |
| BEELDEDROM |
BOOMVOLK |
| BERGVLIET |
BOSKRUINEN |
| BLADERSCHADUW |
BOSVIJVER |
| BLADERSCHERM |
BOSWIND |
| BLADERWOUDEN |
BROEIMUUR |
| BLADGERIL |
BUITENWIND |
| BLADWUIVING |
BUREDEUREN |
| BLANK-ROOD |
DAGAVOND |
| BLANKZWART |
DEURESLUIS |
| BLAUWGEVEERDE |
DICHTGESCHULPTE |
| BLIKSEMGETROFFEN |
DODENGEZICHTJES |
| BLOEMEKINDEREN |
DONKERFLONKENDE |
| BLOEMELANDEN |
DONKERKOE |
| BLOEMENAT |
DOODKOEL |
| BLOEMERANK |
DOODSROFFEL |
| BLOEMENSCHEPPING |
DOODSTWEESPALT |
| BLOEMESCHOOL |
DOODSWOLK |
| BLOEMEVATEN |
DOODVERDRONKEN |
| BLOEMEWEI |
DOODZWART |
| BLOEMGESCHOMMEL |
DOORBLOEMDE |
| BLOEMHONINGHARTEN |
DROMEHEG |
| BLOEMKLEUREN |
DROMELIED |
| BLOEMKLOKKENSPEL |
DROMESCHAAR |
| BLOEMVIOLEN |
DROMESPEL |
| BLOEMVOLLER |
DROOMGESUS |
| BLOEMWONING |
DUIKLAART |
| BLOEMWOORDEN |
DUINVIJVER |
| |
| |
| DUIVEKENGERUCHT |
GOUDZADEN |
| DUIVEKLEUR |
HALSZUIL |
| DUIZELSPRONG |
HANDGESTROOK |
| DUNGESTEELD |
HARSPARELS |
| EIKESTERKEN |
HARTEWARMTE |
| ELVEKINDEREN |
HEENDONKEREN |
| ELVENMEISJES |
HEENFLIKKEREN |
| ELVENSPEL |
HEENSPREIDT |
| ENGELENELFJES |
HEENWIEKTEN |
| ETHERBRAND |
HEENZWEMEND |
| FIJNGESTEELDE |
HEIHEUVELS |
| GEBEKERTE |
HEIKAMP |
| GEESTENTROEP |
HEIL'GENISSEN |
| GEGLIJ |
HEIMWEEËND |
| GEHIP |
HEMELBRAUW |
| GEHUIVER |
HEMELHAL |
| GELAAIER |
HEMELKOLKEN |
| GELEROZE-STRUIK |
HEMELLICHTZEE |
| GEPLUIM |
HEMELNEVELINGEN |
| GEREP |
HEMELSTER |
| GESMELT |
HEMELWAAS |
| GESPIE |
HEMELWEI |
| GESTAP |
HEMELZOMEN |
| GESTRUISVEERD |
HENEWIEGEN |
| GETINK |
HERFSTBOSSEN |
| GEURDOORTROKKEN |
HOEFSLAANDE |
| GEUREDAMP |
HOOGGETROKKEN |
| GEVACHT |
HOUTDOFFER |
| GEWEMER |
HOUTVLAM |
| GEZWING |
HUWELIJKSUUR |
| GLIMLACHING |
INDROOM (ww.) |
| GLOEDBRON |
JONGENSGESCHREEUW |
| GODENDANS |
KARRESNIJWERK |
| GODENDROMEN |
KERMISBAAN |
| GODENDROMENLIED |
KINDERNAGELS |
| GODENGEDAANTEN |
KLANKENRIJKDOM |
| GODENLAND |
KLEURBOGEN |
| GODENOGEN |
KLEURENLICHT |
| GODENPAAR |
KLEUREZWEVEN |
| GODESSENSCHAAR |
KLEURVERTIER |
| GODINNEHAAR |
KOEJONG |
| GOLVEKLOKKEN |
KOEPELBOOG |
| GOLVEMOMP'LEN |
KOMING |
| GOLVEVLEUGELS |
KONINGSTROTS |
| GOUDDAMP |
KORFRAND |
| GOUDGEWELF |
KOUDROOD |
| GOUDSCULPTUREN |
KRONKELTONGEN |
| GOUDSPECHTEN |
KROONSCHAT |
| GOUDSPLINTERS |
KUSTESTRAND |
| GOUDVLOKKEN |
LANDSGOD |
| |
| |
| LELIEHUID |
MONDEKELK |
| LENTEBEELDEN |
MORGENGOLVEN |
| LENTEBLOED |
MURMELWINDEN |
| LENTEVOGELBEK |
MUURROOD |
| LEVENDLICHTE |
MUZIEKBALLONS |
| LICHTGEFLIKKER |
MUZIEKGALEIEN |
| LICHTGESCHOEID |
MUZIEKGORDIJNEN |
| LICHTSCHITTER |
MUZIEKWOLKEN |
| LICHTVLOEDEN |
NAAMGESCHAL |
| LICHTVROLIJK |
NACHTDROEFENIS |
| LICHTWATERVAL |
NACHTEGAALGEKLAAG |
| LIEFDEWELLUST |
NACHTORKAAN |
| LIJSTERVINK |
NACHTZIEK |
| LIS-BOS |
NELKEN (sb.) |
| LOKGELUID |
NEVELDRADEN |
| LOKKENVRACHT |
NEVELDROM |
| LOOFBELAAN |
NEVELDRUPPEN |
| LUCHTGEKLAG |
NEVELKUSSENS |
| LUCHTVERSTOORDER |
NEVELLOMMER |
| LUCHTVONKEN |
NEVELVENSTER |
| LUCHTWEMELING |
NEVELWIT |
| MAANGOUD |
OASELANEN |
| MAANLAMP |
OCHTENDROOK |
| MAANSTROOM |
OEVERAARD |
| MAANVROUW |
OGENLICHT |
| MANBEELD |
OGENWACHT |
| MANEMERRIE |
OLIËNGEUR |
| MANNE-KLEUR |
OMGONZEN |
| MANNEMOMPELEN |
OMSCHRIJDEND |
| MANNENGEDAANTEN |
ONDERZOOM |
| MANNENMOND |
ONSTAGEN (a.) |
| MANNENRIJ |
ONWEERSVRACHTEN |
| MARMERPALEIZEN |
OOGGLANZEND |
| MAT-GOUD |
OPBLAFTEN |
| MEERPLASSEN |
OPBRONDE |
| MEERVLAK |
OPENLACHT' |
| MEI-JEUGD |
OPGEBLOEI |
| MEILEVEN |
OPGEDOEM |
| MEILIPPEN |
ORKANESTEM |
| MEIMIDDAG |
OVERROOD |
| MEISJESBEELD |
PIJNBOMENGEJAMMER |
| MEISJESVOETEN |
REISVOGELTJES |
| MENSEKAMER |
REUKBELADEN |
| MENSENGEJUICH |
REUKWATERGEUREN |
| MIDDAGSTEE |
RIJZENIS |
| MIDWINTERNACHT |
RINKELTAMBOERIJN |
| MIJNGRAVERSLAMPEN |
RIVIERGRAS |
| MISTBEWEGING |
RIVIERIG |
| MISTGELUID |
ROODGELIPTE |
| MOEDERMAAN |
ROODGOUD |
| |
| |
| ROOMGEEL |
UITGEDOOI |
| ROOSBOSJE |
UITGESCHATER |
| ROTSGEZICHT |
UITTJUIKTE |
| ROTSRAVIJN |
UITWAZEN |
| ROZEFESTOENEN |
UITWUIVEND |
| RUNDEREBULKEN |
VERESCHACHT |
| SCHADUWLICHT |
VERGLINSTERT |
| SCHADUWNEVELINGEN |
VERRITSELEN |
| SCHADUWSTREEK |
VERROODDE |
| SCHAPENHEER |
VERSNEEUWEN |
| SCHELLEPKRANS |
VERSTREMDE |
| SCHEMERVUUR |
VERSTROOMT |
| SCHEPEZEILEN |
VERWOLKTE |
| SCHIJNARMOEDE |
VINGERTRILLINGEN |
| SCHIMMENAFBEELDSELS |
VIOOLPRIEEL |
| SCHUIMDROPPEN |
VLAMVLAAG |
| SCHUIMFONTEINEN |
VLERKGEKLEPPER |
| SCHUIMGEVECHT |
VLIEGEVLEUGELS |
| SLAAPSCHADUW |
VOETGESCHUIF |
| SLEEPGORDIJNEN |
VOETGETREE |
| SNEEUWBLEEK |
VOGELDONS |
| SNEEUWGERUIS |
VOGELDOS |
| SNEEUWLAKEN |
VOGELKELEN |
| SNUISTERIJENKRAMEN |
VOGELSCHAAR |
| SPINGEWEMEL |
VOLGEBEITELD |
| SPINWEBDRUPPEN |
VOORTKLAAGT |
| SPREEUWGEKWETTER |
VROUWEJAMM'REN |
| STARGEKROONDE |
VRUCHTEVELLEN |
| STARRENRIJ |
VUURBAD |
| STEMGEAAI |
VUURPRIEEL |
| STERRENGRUIS |
WAAIIG |
| STOM-STIL |
WALLESCHANSEN |
| STRAALGEBREEK |
WASBLANK |
| STRAALGEKROOND |
WATERGESPEEL |
| STRANDELOOS |
WATERGOUD |
| STROMELINT |
WATERGRACHT |
| STROOMGOUD |
WATERGROEN |
| STROOMSTRAAT |
WATERHEUVELS |
| STROOMVAZEN |
WATERSPEL |
| STROOMVROUW |
WATERWEMEL |
| STRUIKENSCHADUW |
WATERWIEG |
| TEMPELSCHAUW |
WEERSCHEMERDEN |
| TINKELING |
WEIDEGEUR |
| TOEDEINEN |
WELWELLUST |
| TONENTREINEN |
WENSBLOESEM |
| TOVERIGE |
WIEGEKAMER |
| TRANENBRON |
WIEGEWICHT |
| TRANENDAMPEN |
WIEGEWINDSELS |
| TUIGSCHELLEN |
WIJDGEMOND |
| UITBELEEND |
WIJDUIT |
| |
| |
| WIJDVERGULDE |
WOUDLAAN |
| WIJNDROPPEL |
WRAAKGEROCHEL |
| WIJNWATER |
WUIVELEN |
| WILLENSWOEDE |
ZAALMUREN |
| WINDADEM |
ZEEËFLUISTREN |
| WINDBEWOGEN |
ZEEGELAAT |
| WINDBRUIN |
ZEEMELODIJ |
| WINDELOEIEN |
ZEEPSOPBELLEN |
| WINDESTROMEN |
ZEEZILTE |
| WINDEWIEK |
ZEEZOOM |
| WINDGETIJ |
ZEILEWIEK |
| WINDHENGST |
ZIELEPOORT |
| WINDKOELT(E) |
ZIELSBEWEGINGEN |
| WINDLAWAAI |
ZIELSVERBEELDINGEN |
| WINDPAARD |
ZILVERSTAART |
| WINGERDTAK |
ZOMERACHTERMIDDAGEN |
| WINTEREVENING |
ZOMERBLIKSEMS |
| WINTERMIST |
ZOMERBLOEMEGROEPEN |
| WINTERNACHTHEMEL |
ZOMERMIDDAGUUR |
| WITGEBLOEMDEN |
ZOMEROORD |
| WITTEROZESCHIJN |
ZOMERROOD |
| WOLKEKRING |
ZOMERWEIDE |
| WOLKENDAUW |
ZONMIDDAG |
| WOLKENHEIR |
ZONNEBERG |
| WOLKENHONING |
ZONNEHEIL |
| WOLKENIJS |
ZONNEKRUIN |
| WOLKENKADE |
ZONNEMEEL |
| WOLKENPUIM |
ZONNEMOORD |
| WOLKENSPREI |
ZONNENOEN |
| WOLKENTROEP |
ZONNEPIJL |
| WOLKESPINSTER |
ZONNETOORTS |
| WOLKGEDAAL |
ZONOGIG |
| WOLKMARMER |
ZONSCHIP |
| WOLKMOERAS |
ZONVERLICHTE |
| WOLKSCHERMEN |
ZONVONKENGESPROEI |
| WOLKZOMEN |
ZUIDERZUCHT |
| WOLVEHUILEN |
ZUILWOUD |
| WOLZIJ |
ZUSTERRIJ |
| WONDER-WONDERBAAR |
ZWAARGESTAMDE |
| WONDERDROOM |
ZWALUWGEVLIEG |
| WOORDETREIN |
ZWANEPAAR |
| WOORDGEBRUIS |
ZWARTDORRE |
| WOORDGERAAS |
ZWARTGEBORENE |
| WOUDGERONK |
ZWARTGEHANDE |
| |
3. Distributie der nieuwe woorden in Mei
Dat de distributie van stilistische fenomenen een interessant object kan zijn voor stijlstudie noteerde reeds St. Ullmann, nochtans geen fervent aanhanger van een statistische approach: ‘Numerical data may in some cases reveal a striking anomaly in the
| |
| |
distribution of stylistic elements, and may thus raise important problems of aesthetic interpretation’Ga naar voetnoot1.
Als wij aanvaarden dat nieuwe woorden een uiting zijn van de scheppingskracht van de auteur kunnen wij ons afvragen hoe dit creatief vermogen over het werk is verdeeld. Met dit doel deelden wij eerst het werk op in 10 gelijke delen van 3.000 occurences elk. Mei telt immers 32.231 woorden tekst. Het laatste onvolledige segment lieten wij daarbij buiten beschouwing. Indien de auteur nu zijn nieuwe woorden homogeen over het ganse werk had verspreid dan zouden wij er in elk segment even veel dus:
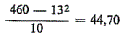 verwachten.
Ga naar voetnoot2
De werkelijke verdeling zag er uit als volgt:
| N |
n |
|
| 1-3.000 |
30 |
- |
| 3.001-6.000 |
30 |
- |
| 6.001-9.000 |
48 |
0 |
| 9.001-12.000 |
69 |
+ |
| 12.001-15.000 |
69 |
+ |
| 15.001-18.000 |
54 |
0 |
| 18.001-21.000 |
56 |
0 |
| 21.001-24.000 |
31 |
- |
| 24.001-27.000 |
27 |
- |
| 27.001-30.000 |
33 |
0 |
| 30.001-32.231 |
13 |
|
In deze tabel duidt N de doorlopende tekst aan, n het aantal nieuwe woorden per tekstsegment. Normaal gesproken zou een tekst die ingedeeld is in gelijke delen, per deel een zelfde aantal nieuwe woorden moeten hebben. Deze hebben hier immers op enkele uitzonderingen naGa naar voetnoot3 allen frequentie = 1. Welnu de kans op voorkomen in een tekst van woorden met f = 1 is, in tegenstelling met de woorden met f > 1, overal gelijk. Delen wij een tekst op in 10 delen dan zal de probabiliteit van woorden met f = 10 om voor het eerst op te treden groter zijn in deel X, dan in deel X + 1, en die op haar beurt groter dan in deel X + 2, enz.
De mathematische verwachting van de woorden met f = 1 (en dus van vrijwel alle nieuwe woorden) is echter overal gelijk.
Per segment verwachten wij dus 447/10 = 44,7 neologismen. Door het toeval alleen
| |
| |
reeds is echter een zekere deviatie mogelijk. Deze wordt standaarddeviatie geheten en als σ aangeduid. Waarden die 1,96 σ hoger of lager liggen dan de verwachte worden (bij p = 0,05) als significant afwijkend beschouwd (voor lezers die minder vertrouwd zijn met statistiek verwijzen wij naar voetnootGa naar voetnoot1. σ was hier gelijk aan 6,32Ga naar voetnoot2. Waarden die hoger dan of gelijk waren aan 44,70 + (1,96 × 6,32) = 57 of lager dan (gelijk aan) 44,70 - (1,96 × 6,32) = 32 konden wij dus als significante afwijkingen beschouwen. Vandaar onze aanduidingen in de 3e kolom van de tabel: - duidt een significant-negatief verschil aan, 0 duidt aan dat er geen verschil is (of beter dat het verschil tussen geobserveerde en geëxpecteerde waarde door het toeval te verklaren is), + duidt een significant-positief verschil aan.
Wij constateren dus allereerst dat de nieuwe woorden in Mei niet homogeen verdeeld zijn maar dat wij het grosso modo zo kunnen stellen dat er in de aanvang en op het einde een significant deficit is, tegenover een significant surplus ongeveer in het midden.
Het valt echter onmiddellijk op dat deze afwijkingen vooral in het vierde en vijfde segment grote afmetingen aannemen (+ 12 in het vierde en vijfde deel; tegenover de negatieve afwijkingen -2 (1e segment en 2e segment), -1 (8e segment) en -5 (9e segment)). Wij hebben dan ook allereerst dit gedeelte (N: 9.000-15.000) onder de loep genomen. Hierin werd onze aandacht getrokken op het lied van Balder dat voorkomt op het einde van het vierde segment en aan het begin van het vijfde (N = 11.848-12.102 en 12.199-12.732). Zoals men weet verandert Gorter hierin zijn rijmschema van parende rijmen tot vijf- en zesregelige verzen. Deze zang is daardoor alleen reeds iets aparts. Bij telling bleek dat Gorter in dit tekstgedeelte van 789 woorden 42 nieuwe woorden gebruikte, daar waar er slechts 44,70 verwacht worden op 3.000 woorden.
De afwijking is meteen overduidelijk.
Wanneer wij nu het werk opnieuw in 10 delen (van 3.000 woorden elk) opdelen met weglating van Balders lied (N = 11.848-12.102 en 12.199-12.732) bekomen wij de volgende verdeling:
| |
| |
| N |
n |
|
| 1-3.000 |
30 |
0 |
| 3.001-6.000 |
30 |
0 |
| 6.001-9.000 |
48 |
0 |
| 9.001-11.847} |
60 |
+ |
| 12.103-12.198} |
60 |
+ |
| 12.733-12.789} |
60 |
+ |
| 12.790-15.789 |
51 |
0 |
| 15.790-18.789 |
57 |
+ |
| 18.790-21.789 |
42 |
0 |
| 21.790-24.789 |
34 |
0 |
| 24.790-27.789 |
25 |
- |
| 27.790-30.789 |
32 |
0 |
| 30.790-32.231 |
9 |
|
Per segment verwachten wij nu 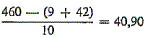 nieuwe woorden.
De standaardafwijking is gelijk aan 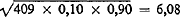 . Significante afwijkingen vinden wij dus bij waarden die gelijk zijn aan of hoger dan 40,90 + (1,96 × 6,08) = 52,80, resp. gelijk aan of kleiner dan 40,90 - (1,96 × 6,08) = 29,10.
Zelfs wanneer wij het lied van Balder uit het gedicht abstraheren is het aantal nieuwe woorden nog steeds niet homogeen over het werk verdeeld. Hoewel het aantal significante afwijkingen van 6 naar 3 is geslonken blijft er toch een significant surplus in het midden van het werk, een significant tekort naar het einde toe. Om dit verder te toetsen delen wij het werk nu in 3 delen, corresponderend met de 3 door de auteur opgegeven zangen.
| N |
no |
ne (proc. tekstlengte) |
v |
| 1-9.914 |
116 |
142 (30,75%) |
26 |
| 9.915-26.342 |
295 |
234 (50,96%) |
61 |
| 26.343-32.231 |
49 |
84 (18,27%) |
35 |
| |
----- |
----- |
|
| |
460 |
460 |
|
| |
Tabel a (Balders lied inclusief) |
|
|
| N |
no |
ne (proc. tekstlengte) |
v |
| 1-9.914 |
116 |
132 (31,53%) |
16 |
| 9.915-26.342 |
253 |
209 (49,73%) |
44 |
| (- Balders zang = 789 woorden) |
|
|
|
| 26.343-32.231 |
49 |
78 (18,72%) |
-29 |
| |
----- |
----- |
|
| |
418 |
418 |
|
| |
Tabel b (met weglating van Balders lied) |
|
|
| |
| |
In deze tabellen staat N opnieuw voor de doorlopende tekst (de zangen uitgedrukt in aantal woorden); no is het geobserveerde aantal nieuwe woorden per zang, ne is het daarmee corresponderende geëxpecteerde aantalGa naar voetnoot1, v is het verschil tussen no en ne.
Om te weten of de drie delen significant verschillen, kunnen wij een Chi-Square-test toepassenGa naar voetnoot2. Uit de over-all-test bleek zowel voor Tabel a als voor Tabel b een significant verschil dat terugging op zang twee en drieGa naar voetnoot3.
| |
4. Interpretatie
De conclusies die wij op basis van het cijfermateriaal in 3 menen te mogen trekken zijn de volgende:
| a. | De nieuwe woorden in Mei van Herman Gorter zijn niet homogeen verdeeld: naast passages die in overeenstemming zijn met de verwachting vinden wij er andere die een significant-negatieve, nog andere die een significant-positieve afwijking vertonen. |
| b. | Wat de ligging van de afwijkingen betreft:
| - | allereerst vinden wij een significant surplus aan nieuwe woorden in het lied van Balder: het maakt dit gedeelte exuberanter dan de rest van het werk. |
| - | daarenboven weerspiegelt de nieuwe-woordenspreiding de klassieke bouw van het werk (vooral als Balders lied buiten beschouwing wordt gelaten); zang één kent een licht (doch niet-significant) deficit tegenover de verwachting, zang twee heeft een significant surplus aan nieuwe woorden, zang drie een significant tekort: in zang één is de dichter niet zo uitbundig als in zang twee maar groeit er naar toe, het hoogtepunt ligt in de tweede zang, deze intensiteit neemt af naar de derde zang toe. |
|
| |
5. Besluit
| a. | In de inleiding hadden we voor de distributie der nieuwe woorden twee alternatieven aangeduid, de feiten hebben ons voor de tweede mogelijkheid doen kiezen, deze woorden zijn in Mei niet homogeen over het werk verdeeld, maar corres- |
| |
| |
| ponderen met de uitzonderingspositie die Balders lied in het gedicht krijgt en met de drieledige bouw van het werk. |
| b. | Daarmee wensen wij geen appreciatie uit te spreken. De bedoeling was een stijlfacet te analyseren, niet te appreciëren. |
| c. | Wij ontdekten o.m. dat één bepaalde stijlkarakteristiek correleerde met de bouw die de auteur aan zijn werk gaf. Wij spreken ons hierbij niet uit over oorzaak of gevolg: daarvoor zouden wij o.i. niet over één stilistische factor maar over een complex van dergelijke factoren moeten beschikken. |
| d. | Wij hoeven er niet de nadruk op te leggen dat wij hier slechts één aspect i.v.m. nieuwe woorden onderzochten. Andere aspecten als morfologische structuur, motiefstudie, invloed van rijmwoorden, vergelijking met andere auteurs e.d. lijken ons de moeite voor verdere studie waardGa naar voetnoot1. |
Leuven, Instituut voor Toegepaste Linguïstiek
w. martin
|
-
voetnoot1
- W.H.M. Mattens, De indifferentialis, Van Gorcum, Assen, 1970, p. 25.
-
voetnoot2
- P. Guiraud, Problèmes et Méthodes de la Statistique linguistique, Reidel, Dordrecht, 1959.
-
voetnoot3
- In Analyse van een vocabularium met behulp van een computer (AIMAV, Brussel, 1970) onderzochten wij o.m. reeds nieuwvormingen in 2 werken van Ivo Michiels. De n/V ratio was in beide gevallen zeer klein: in Het Boek Alfa = 24/2784 of kleiner dan 1%, in Het Afscheid = 64/3467 of nauwelijks 2%.
-
voetnoot1
- Deze ratio zou heel wat hoger liggen als wij niet met woordvormen maar met lemmata werkten (wat in de onderzochte romans van Michiels het geval was). Bij de nieuwe woorden is de verhouding woordvorm - lemma (op een paar uitzonderingen na, cfr. noot 3 p. 172) 1 : 1. Bij de andere woorden echter is de proportie niet meer gelijk: er zijn heel wat minder gelemmatiseerde woorden dan woordvormen. Daar n vrijwel stabiel blijft (460 - 3 = 457), V echter gevoelig daalt, zal de n/V - ratio gevoelig stijgen.
-
voetnoot1
- Frequentielijst gebaseerd op 500.000 occurrences. Voor verdere inlichtingen verwijzen wij naar ons eerder verschenen werk De inhoud van krant en roman (Plantijn, Antwerpen, 1968), p. 8 en vlg.
-
voetnoot1
- D.w.z. niet in onze thesaurus voorkomen. Een woord als vogelschaar b.v. treft men bij Gezelle aan; ook voor andere zal dat het geval zijn. Wij hebben echter een foutmarge van 10% toegelaten, daarom werd met geen andere bronnen meer rekening gehouden.
-
voetnoot2
-
van Dale's Zakwoordenboekje der Nederlandse Taal, 17e herziene druk door dr. C. Kruyskamp, Nijhoff, 's-Gravenhage, 1964. Dit woordenboekje is gebaseerd op de grote van Dale en bevat 16.453 woorden.
-
voetnoot3
- Van Mei werd o.m. een woordindex vervaardigd (Standaard Wetenschappelijke Uitgeverij, Antwerpen, 1969); met behulp van van Dale's Zakwoordenboekje werd een onderzoek ingesteld naar ‘de evolutie van de woordenschat in het huidige Nederlands’ (Revue des Langues Vivantes, XXXV (1969), pp. 67-76).
-
voetnoot4
- Toen dit werk werd uitgevoerd stond de grote van Dale nog niet alfabethisch (wel invert) op band. Na de voltooiing van dit onderzoek (juli 1970) was dit wel het geval. Het te vergelijken corpus kan aldus makkelijk machinaal tot 1/10 herleid worden (550 te onderzoeken woorden op 5666 in Mei).
-
voetnoot1
- Alle woordvormen uit Mei werden tot lemmata herleid en met de lemmata uit onze thesaurus vergeleken. Eliminatie gebeurde wanneer gelijkheid voorkwam.
Hierbij werd geen rekening gehouden met louter formele verschillen. Zo b.v. werd ‘veldegod’ (Mei) geschrapt als ‘veldgod’ in onze bronnen voorkwam.
Bij vergelijking met het W.N.T. werd rekening gehouden met een datum post quem: werd het woord opgegeven in het W.N.T. maar gedateerd na 1889 (eerste verschijnen van Mei) dan werd het niet in onze lijst geschrapt. Zo b.v. avondzee (1920), getink (1937), reisvogeltjes (1946), tinkeling (1916).
Voorts worden de woorden opgegeven in de vorm zoals ze in de tekst voorkwamen.
-
voetnoot1
- St. Uhlmann, Language and Style, Blackwell, Oxford, 1966, pp. 120-121.
-
voetnoot2
- 460 wordt met 13 verminderd omdat wij het laatste segment buiten beschouwing laten.
-
voetnoot3
- Nl. avondzee (f = 2), boombos (f = 2), hemelhal (f = 2), koningstrots (f = 2), lijstervink (f = 2), oliegeur (f = 2; oliëngeur + oliegeur), omschrijden (f = 2; omschrijdend + omschreed), tinkeling (f = 2), uitgeschater (f = 2), vogelkelen (f = 2), watergracht (f = 2), wolkzoom (f = 2, wolkzomen + wolkezoom), zeepsopbellen (f = 2), zeezoom (f = 3), zomerrood (f = 3), zonverlichte (f = 2).
-
voetnoot1
- Om de waarde van een hypothese te testen vertrekt men in de statistiek gewoonlijk van de zgn. nulhypothese. Hierbij wordt verondersteld dat de massa's die met elkaar vergeleken worden homogeen zijn, d.w.z. dat zij steekproeven zijn van een zelfde populatie. In het gunstigste geval zouden er dan geen verschillen tussen de onderscheiden samples te noteren vallen (m.a.w. het verschil zou gelijk zijn aan nul, vandaar de naam nulhypothese); of zo die er wel zouden zijn, zouden die volkomen aan het toeval te wijten zijn. In dit geval zullen deze verschillen binnen bepaalde grenzen vallen.
Welnu, wanneer σ ≽ 1,96 dan is er nog slechts 5% kans dat het toeval hiervoor verantwoordelijk is. Het 5%-significantiegebied wordt dan ook gewoonlijk als drempelwaarde aanvaard.
-
voetnoot2
- Werkt men niet met gemiddelden maar met massa's dan wordt σ berekend als
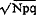
waarbij N het aantal uitkomsten, p de theoretische probabiliteit van voorkomen en q de complementaire probabiliteit van niet-voorkomen aanduidt. In ons geval was σ overal gelijk nl.
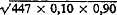
.
-
voetnoot1
- ne = totaal n × procentuele tekstlengte.
-
voetnoot2
- D.m.v. deze test kunnen wij twee verdelingen, een experimentele (de observatie) en een theoretische (het model) met elkaar vergelijken.
De formule luidt χ2 = (fo - fe)2/fe, waarbij fo het geobserveerde, fe het geëxpecteerde effectief aanduidt. Deze waarde moet opgezocht worden in een χ2-tabel ,die, met in achtname van de vrijheidsgraden, de probabiliteit aanduidt waarbij een dergelijke uitkomst kan voorkomen. Gewoonlijk wordt de significantiegrens bij 5% gelegd. D.w.z. dat bij deze waarde slechts 5 kansen op 100 bestaan dat het toeval er de oorzaak van is. Is de gevonden uitkomst hieraan gelijk of groter dan neemt men doorgaans aan dat niet het toeval maar een andere factor hiervoor verantwoordelijk is.(Voor meer uitleg, zie mijn artikel: Statistiek en Linguistiek in ITL, I (1968), p. 15 en vlg.).
-
voetnoot3
- χ2 voor Tabel a = 262/142 + 612/234 + 352/84; wat groter is dan 5, 991 (de significantiegrens bij p = 0,05 voor 2 vrijheidsgraden).
χ2 voor Tabel b = 162/132 + 442/209 + 292/78. Wat eveneens groter is dan 5,991. Daarbij is voor Zang 1 afzonderlijk χ2 in Tabel b < 3,841 (de significantiegrens bij p = 0,05 voor één vrijheidsgraad).
-
voetnoot1
- Wij staan erop Prof. Dr. L.K. Engels en Drs. R. Eeckhout hartelijk te danken voor de waardevolle opmerkingen die zij bij de lectuur van het manuscript maakten.
|