
Streven. Vlaamse editie. Jaargang 48
(1980-1981)– [tijdschrift] Streven. Vlaamse editie–
[pagina 810]
| |
Computers in de taalkunde
| |
Hoe gaan taalkunde en computers samen?Van oudsher is taalkunde beschouwd als één van de mens- of geesteswetenschappen. Bijgevolg is het zeer de vraag voor niet-ingewijden hoe de taalkunde en computers verenigbaar zijn en meer nog, hoe een discipline | |
[pagina 811]
| |
als computertaalkunde (vanaf nu: CT) überhaupt kan bestaan. Inderdaad, intuïtief kan men een computer definiëren als een programmeerbare rekenmachine; als zodanig werd hij immers voor het eerst gebruikt door mathematici. Oorspronkelijk waren alle problemen die door de computer moesten worden opgelost van numerieke of kwantitatieve aard zodat hij uitsluitend werd aangewend in de exacte of positieve wetenschappen. Voor de humane wetenschappen leek het gebruik van computers veel onzekerder, temeer daar de problemen er minder kwantificeerbaar waren en dus minder geschikt voor automatische verwerking (i.e. door middel van een computer). Op deze manier zou de opkomst van de computer in het midden van de jaren veertig een kloof veroorzaakt hebben tussen de humane wetenschappen (waaronder taalkunde) en de exacte wetenschappen. Wat de taalkunde betreft, werd deze kloof snel gedicht omdat binnen deze discipline een stroming groeide van toenemende ‘mathematisatie’. De invloed van de mathematica (en daarmee samengaand die van de informatica) was zo groot dat het taalkundig onderzoek op een meer exacte en formele manier geschiedde dan voorheen gebruikelijk was. Meteen waren het taalkundig onderzoek en de taalkundige problemen ‘computer-fähig’ (i.e. geschikt voor verwerking door een computer). Het onmiddellijk resultaat van deze methematisatie van de taalkunde waren de opkomst in het midden van de jaren vijftig van de eerste twee sub-disciplines binnen de CT: (1) statistische taalkunde en (2) machinale of mechanische vertaling. De eerste sub-discipline zal hieronder behandeld worden. Aan de machinale vertaling zal in een afzonderlijk hoofdstukje aandacht besteed worden. Voor buitenstaanders is de statistische taalkunde meestal de enige vorm van CT die zij kennen. De computer wordt hier gebruikt als een classificeer- en/of rekenmachine. Hij is vooral nuttig omdat hij grote hoeveelheden taalmateriaal gesorteerd kan aanleveren door ze uit teksten, woordenboeken of andere bronnen te halen en voor ons te rangschikken. Typische voorbeelden van gesorteerd taalmateriaal zijn woordindexen (een alfabetische lijst van woorden samen met de plaats waar deze woorden voorkomen) en concordanties (woordindexen met context). Dit taalmateriaal leent zich bijzonder goed voor statistische taalverwerking; de belangrijkste taalstatistische toepassing is het nagaan van de frequentie van een taalelement. De volgende voorbeelden beogen deze toepassing te illustreren. Dr. W. Martin (KUL) promoveerde op een computeranalyse van het vocabula- | |
[pagina 812]
| |
rium van de romans Het afscheid en Het boek AlfaGa naar voetnoot1. Na statistisch onderzoek van het vocabularium bleek dat de auteur in zijn evolutie zijn woordenschat drastisch had gereduceerd om tot een soort van basis-nederlands te komen. Zo wordt de computer ook gebruikt voor de behandeling van religieuze geschriften als de Bijbel, de Koran en de geschriften van St.-Thomas van Aquino. Wat de studie van de Bijbel betreft, werkt men reeds heel wat jaren aan een computerbijbel, die bestaat uit concordanties van de boeken van het Oude en Nieuwe Testament. Zulk een computerbijbel vormt een erg geschikt instrument voor bijbelstudie omdat hij de exegeet laat beschikken over een enorme verscheidenheid aan geklasseerde empirische gegevens. Meteen kunnen deze gegevens ook efficiënter behandeld worden zodat een meer empirische, exhaustieve, statistische en bijgevolg meer wetenschappelijke studie van de Bijbel mogelijk wordt. M.a.w. de inhoudsanalyse van de Bijbel kan steunen op een meer solide, wetenschappelijke basis. R. BusaGa naar voetnoot2 stelde een Index Thomisticus op: een concordantie van alle woorden die Thomas van Aquino gebruikte om de wetenschapslui die zijn geschriften bestudeerden in staat te stellen, langs zijn woordgebruik zijn denksysteem te achterhalen. Samengevat, in de statistische taalkunde primeert het resultaat en niet de manier waarop dat resultaat werd bereikt. De computer is er enkel een hulpmiddel: zijn gebruik draagt niet bij tot één of andere taalkundige theorie. Toch is hij een niet te onderschatten hulpmiddel. Taken die vroeger menselijk gesproken onuitvoerbaar waren (b.v. door het enorme aantal uit te sorteren gegevens) worden nu zeer elegant door een computer verricht. | |
Machinale vertaling: tot mislukking gedoemdZoals gezegd was de snelle ontwikkeling van de informatietheorie van groot belang voor alle takken van de wetenschap; ook de taalkunde kon zich niet aan deze invloed onttrekken. Dat die invloed niet noodzakelijk negatief was mag blijken uit het voorgaande. Niet-taalkundigen gingen daarbij echter ook het terrein van de taalkunde betreden. Meer bepaald in | |
[pagina 813]
| |
de machinale vertaling (vanaf nu: MV) werden werkwijzen toegepast die tot mislukking gedoemd waren. De vertaalmachine is natuurlijk niet een ding, maar het is een computerprogramma dat het mogelijk maakt om een willekeurige tekst geschreven in een taal A om te zetten in een taal B. Onderzoek in MV-projecten werd gestart in de jaren vijftig. Door de komst van de computer en diens eerste successen werden in die roes heel wat wilde dromen geformuleerd (en ook gefinancierd). Vooral de regering van de VSA scheen er heel wat brood in te zien om zulke projecten te steunen (meestal niet om strict wetenschappelijke redenen). De verwachtingen waren hoog gespannen: men geloofde immers dat met het nodige geld, de nodige werklust en snelle computers vlug een degelijk programma zou kunnen ontwikkeld worden om correcte vertalingen af te leveren. Men kan natuurlijk de zaak verder ridiculiseren door een geschiedenis van gekke zinnetjes te schrijven (bvb. ‘The Spirit is willing, but the flesh is weak’ werd vertaald tot ‘de whiskey is wel smakelijk, maar de biefstuk is maar slapjes’). De beginjaren waren echter gekenmerkt door een echt en eerlijk enthousiasme: (1) men ging ervan uit dat de computer alles kon; (2) uit schrik voor Rusland wou men al wat daar verscheen direct vertaald hebben (de jaren vijftig is immers de periode van de koude oorlog); (3) het eventueel welslagen van het MV-project was voor de computermaatschappijen van enorm commercieel belang; (4) zoals reeds aangestipt, was er een stroming die de taalkunde formeler en exacter maakte. Men verwachte veel van MV, maar het project werd een hopeloze flop. De voornaamste oorzaken van dit falen liggen voor de hand. MV werd initieel niet beschouwd als een linguïstisch onderzoek, maar veeleer als een praktische manier om de kloof van de vertaling te overbruggen. Ten onrechte werd MV beschouwd als een computerprobleem en niet als een taalkundig probleem. Men had (of wilde) immers geen inzicht in woordbetekenissen, dubbelzinnigheden, enz.; m.a.w. men had zich niet verdiept in de structuur en de werking van de taal. Een belangrijk keerpunt in de ontwikkeling van de CT is het zogenaamde ‘Black Book’ of het ALPAC-rapport (Automatic Language Processing Advisory Committee), dat verscheen in 1966. Het rapport stelde dat ‘...nuttige MV niet onmiddellijk in het vooruitzicht kon gesteld worden en zelfs niet voorspeld.’ (p. 32). Bovendien gaf het een nieuwe richting aan CT: ‘...computertaalkunde dient beschouwd te worden als een deel van de taalkunde...’, zodat de aandacht binnen CT werd gericht op: ‘...de studie van syntactische ontleding,..., taalkundige structuren, semantiek, statistiek en ook vertaalexperimenten, met of zon- | |
[pagina 814]
| |
der machinale hulp. De taalkunde moet gesteund worden als een wetenschap en dient niet beoordeeld te worden op zijn onmiddellijk voorspelbare bijdrage tot praktische vertaling. Belangrijk hierbij is dat voorstellen worden geëvalueerd door mensen die competent genoeg zijn om linguïstisch werk te beoordelen en die voorstellen evalueren op basis van hun wetenschappelijke waarde en verdienste.’ (p. 34)Ga naar voetnoot3,Ga naar voetnoot4. Door deze stellingen wordt het accent in CT verlegd van machinale vertaling (dat niet altijd strikt wetenschappelijke doeleinden had), naar basisonderzoek in de taalkunde. Dit impliceert dat een CT-project zou worden beoordeeld op zijn taalkundige verdienste. Samengevat kan men stellen dat het ALPAC-rapport de malaise onder woorden bracht die er al gedurende enkele jaren in de MV heerst en terzelfdertijd catalysator was van een nieuwe richting binnen CT. De band tussen de taalkunde en de computer werd meer aangehaald; men gaf toe dat een beter inzicht in de structuur van de taal de eerste voorwaarde was voor fundamenteel taalkundig onderzoek met behulp van de computer. | |
Computertaalkunde na het MV-tijdperkUit dit stukje geschiedenis blijkt dat kennis van taalkundige processen fundamenteel is voor de vooruitgang van computertoepassingen. Voor wat MV betreft zou men hieruit kunnen afleiden dat men eerst een volledig inzicht in het vertaalproces dient te hebben voor men pas aan MV kan toekomen. Volgens deze opvatting wordt CT volledig triviaal, want dan zou zij enkel mogen herhalen wat het menselijk brein voor haar heeft gepresteerd. Het CT-onderzoek wordt echter wel relevant wanneer de CT-benadering een mogelijke weg suggereert om tot theoretische kennis (van het natuurlijke taalsysteem) te komen. Hierin ligt zijn belangrijkste verdienste (naast de interessante nevenresultaten van de computer als statistische machine). In deze optiek is CT nuttig, m.a.w. blijft niet langer een ingenieus spelletje wanneer de computer in de taalkunde wordt gebruikt als een ‘simulatiemachine’. Dit betekent dat de onderzoeker een geformaliseerd model (i.e. aangepast voor computerverwerking) tracht te vinden realiteit simuleert. Wanneer dit geformaliseerd model dezelfde output dat werkt net als (een deel van) de realiteit of m.a.w. (een deel van) de | |
[pagina 815]
| |
levert als de realiteit, dan kan het op die manier een theorie zijn voor die realiteit of bijdragen tot de theorievorming omtrent die realiteit. Zo kan de taalkundige die de betekenis van taalelementen (zijn realiteit) onderzoekt, de computer voor fundamenteel taalkundig onderzoek inschakelen. Wanneer zijn computerprogramma (i.e. zijn geformaliseerd model, zijn simulatie van zijn realiteit) eveneens de betekenis vindt van de taalelementen die de taalkundige onderzoekt, dan kan dit model gebruikt worden als een betekenistheorie voor die taalelementen. Het wordt nu ook duidelijk dat, precies omdat de computer zulk een rigoureus apparaat is, de taalkundige verplicht is zijn analyse zo nauwkeurig mogelijk te definiëren. Wanneer zijn analyse of zijn verklaring voor (een deel van) het taalkundig systeem met positief gevolg door een computer getest wordt, heeft de taalkundige een erg krachtig werkmiddel waarmee hij de gezochte verklaring rigoureus kan onderlijnen. Wanneer we stelden dat CT zich bezighoudt met het opstellen van een model dat (een deel van) het taalsysteem simuleert en op die manier een bijdrage kan leveren tot het onderzoek naar de werking van het taalsysteem, gaven we impliciet aan wat het impact is van het CT-onderzoek op taalkundig onderzoek. Reeds jaren discussiëren de linguïstische scholen over de mogelijke vorm van een grammatica van de natuurlijke taal (i.e. de werking van het natuurlijke taalsysteem). De invloed van CT op het taalkundig onderzoek kunnen we als volgt samenvatten: wanneer een taaltheorie wordt getest binnen het kader van CT, en vervolgens blijkt dat de onvolkomenheden van de testresultaten te wijten zijn aan de theorie zelf (en niet zozeer aan het computerprogramma), leidt dit tot de herziening van die taaltheorie tot een nauwkeurige en betrouwbare theorie is bereikt. De verdere evolutie van CT (na het MV-tijdperk) reflecteert enigszins de evolutie binnen de theoretische taalkunde. Op het ogenblik van de publikatie van het ALPAC-rapport was de meest invloedrijke taaltheorie die van Noam Chomsky (voor het eerst gepubliceerd in 1957 in Syntactic Structures). Deze theorie was op zijn beurt eveneens beïnvloed door de toenemende drang naar een exacte en formele taaltheorie. Wij willen de Transformationeel Generatieve Grammatica (TGG) van Chomsky hier niet omstandig beschrijven. Wel dient aangestipt dat voor Chomsky de syntactische beschrijving van de zinnen centraal staat. Zelf wil hij niets te maken hebben met CT (waarschijnlijk omdat hij het debâcle van MV voor ogen had). Toch staat vast dat op het einde van de jaren zestig de automatische syntactische analyse in CT centraal staat. Een van de belangrijkste | |
[pagina 816]
| |
onderzoekers op dit gebied is Woods die het systeem van ‘transition networks’ ontwierp. Het resultaat van zulke analyse is dat de computer automatisch kan aangeven dat in de voorbeeldzin ‘Jan vliegt naar Rome’ ‘Jan’ een naamwoord is en bovendien het onderwerp van de zin, ‘vliegt’ het werkwoord en ‘naar Rome’ voorzetselvoorwerp is. Wij hebben deze fase enkel kort geschetst omdat wij aan een meer belangrijke fase in CT willen toekomen. Alhoewel veel vooruitgang werd geboekt in de automatische syntactische analyse, toch werd hiermee niet verholpen aan het grootste struikelbolk van MV, nl. de betekenis van woorden en zinnen. Een machine zal immers alleen van een taal A in een taal B kunnen vertalen als het de twee talen kan verstaan of begrijpen. De interesse vanuit CT voor de betekenis van de taal gaat weer samen met de vernieuwde interesse in de taalkunde voor semantiek (i.e. de betekenisleer). Voor automatische betekenisanalyse spreekt men niet zozeer van CT, maar men ziet het als een onderdeel van Artificiële Intelligentie (vanaf nu, AI). AI is een term die gebruikt wordt om het kader aan te duiden waarin een poging wordt gedaan om menselijk intelligent gedrag te simuleren. Het automatisch analyseren van de betekenis van taalelementen simuleert menselijk intelligent gedrag. Tot AI hoort b.v. ook computerschaak en het automatisch herkennen van voorwerpen (‘vision’), wat alle simulaties zijn van menselijk intelligent gedrag. D.m.v. gesimuleerd taalvermogen in de boven beschreven zin, kan de computer een betekenisrepresentatie van aangeboden zinnen of van een volledig verhaal produceren. Voor het grootste gedeelte gebeurt dit onderzoek binnen het Angelsaksische taalgebied. Binnen de automatische betekenisanalyse kan men nog bezwaarlijk spreken van een leidinggevende theorie. Het gaat hier eerder om aparte projecten, waarbij het ene onderzoek kan profiteren van de resultaten van een ander. Kenmerkend voor de aanpak vanuit AI is dat men zich weer verder gaat verwijderen van taalkundige inzichten. Zo stelt men dat een computer een tekst of een zin begrepen heeft wanneer hij hem kan omzetten in een representatietaal (die vaak nog weinig met natuurlijke taal te maken heeft). Zo wordt in Schanks systeemGa naar voetnoot5 ‘Jan ging naar New York’ als volgt gerepresenteerd: 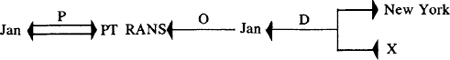 | |
[pagina 817]
| |
Deze formule betekent dat Jan een fysische transitie (=gaan) heeft uitgevoerd, waarvan hijzelf het object is (i.e. Jan gaat zelf); de richting (D) van die transitie is van een onbepaalde plaats X naar New York. Zoals reeds aangestipt bestaat de geschiedenis van AI uit een opeenvolging van individuele projecten. Toch kan men spreken van een zekere vooruitgang. In 1971 slaagde T. Winograd erin met een computer te converseren over een beperkte blokjeswereldGa naar voetnoot6. Andere belangrijke onderzoekers binnen het Angelsaksische taalgebied zijn Schank (Yale), Woods (Bolt, Beranek and Newman, Inc.), Bobrow (Xerox) en Wilks (Essex). Verder gebeurt op MIT in de VSA ook erg veel belangrijk onderzoek. Het grote bezwaar dat men kan opperen tegen de aanpak van AI is dat taalkundige inzichten er dikwijls zoek zijn. Soms krijgt men de indruk dat het motto luidt: ‘Hoe minder taalkundige ballast, hoe beter’! Het is een aanpak die wel resultaat oplevert, maar die ook gepaard gaat met een vals optimisme (net zoals bij MV). De grote moeilijkheid voor MV en voor elk onderzoek van de betekenis van de taal met behulp van de computer: hoe definieer ik een formeel model zodat de computer natuurlijke taal verstaat - het grote struikelblok van MV - is nog steeds niet opgelost. Voorlopig moeten we ons tevreden stellen met enkele partiële resultaten. | |
Computertaalkunde in België en NederlandHet overgrote deel van CT-onderzoek wordt verricht in de Angelsaksische landen (waar de computer trouwens voor het eerst werd gebruikt). De geschiedenis van CT in België en Nederland is niet erg lang. Aan de universiteiten wordt nergens CT als een volwaardige richting onderwezen. Het blijft bij een sporadisch inleidend vakje hier en daar. CT-onderzoek wordt in Vlaanderen vooral verricht aan het Instituut voor Toegepaste Taalkunde in Leuven (Dr. Dirk Geens, Prof. Dr. L.K. Engels, Prof. Dr. W. Martin) en aan de Universitaire Instelling Antwerpen (vroeger L. Steels, nu vooral K. De Smedt). In Nederland is vooral Prof. Dr. Brandt Corstius een leidinggevende figuur. Binnen AI wordt belangrijk onderzoek verricht aan de Universiteit van Nijmegen (Prof. Dr. G. Kempen). Verder is ook het Instituut voor | |
[pagina 818]
| |
Toegepaste en Computerlinguïstiek van de Rijksuniversiteit Utrecht van belang. Er wordt in België en Nederland meer CT-onderzoek verricht dan uit deze lijst mag blijken, maar toch wordt dit onderzoek (ten onrechte) nog stiefmoederlijk behandeld. Wij hopen dat hier vlug verandering in mag komen. |
|