
Spektator. Jaargang 15
(1985-1986)– [tijdschrift] Spektator. Tijdschrift voor Neerlandistiek–
[pagina 123]
| |||||||||||||||||||||||||||||||||||||||||||
Over Nederlandse lettergreep- en klemtoonstruktuurGa naar eindnoot*
| |||||||||||||||||||||||||||||||||||||||||||
[pagina 124]
| |||||||||||||||||||||||||||||||||||||||||||
duidelijkheid niet vergroot doordat H de neiging heeft verschillende benaderingswijzen (inklusief zijn eigen) door elkaar te behandelen. We zullen beneden proberen zo veel mogelijk H's eigen voorstellen uit de tekst te destilleren en kunnen er daarbij niet onderuit van een aantal begrippen uit de niet-lineaire fonologie bekendheid bij de lezer te veronderstellen. | |||||||||||||||||||||||||||||||||||||||||||
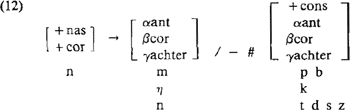
Deel II: Syllable StructureH's hoofdstuk 2, het algemene hoofdstuk, stelt drie zaken aan de orde, nl. (i) ‘to characterize the sequence of segments that constitute a wellformed syllable (the linear structure)’, (ii) ‘to determine wheter and, if so, how these segments are grouped into sybsyllabic units (the hierarchical structure)’, en (iii) ‘the issue of syllabification’ (p. 37). Om met dit laatste punt (iii) te beginnen, gegeven taalfeiten als in (1)
zijn volgens H syllabifikatiedomeinen in het Nederlands de volgende: het ongelede woord (type (1a)), het ongelede woord dat samen met bepaalde suffiksen één geheel vormt (type (1b)), bepaalde suffiksen an sich (1c), en prefiksen (1d). Wat welgevormde Nederlandse lettergrepen zijn zal in de rest van het betoog dan ook gebaseerd zijn op mogelijke sekwenties binnen deze domeinen, want ‘[t]he set of syllables that occur in underived and uncompounded stems is a proper subset of the set of syllables that occur in (complex) words. By characterizing the larger set we characterize the smaller set as well’ (p. 66). Van (i), de lineaire struktuur van de lettergreep, neemt H aan dat deze het best wordt gekarakterizeerd met behulp van een absolute sonoriteitsschaal, dit in tegenstelling tot eerdere voorstellen zoals een relatieve schaal (de ‘sonoriteitshierarchie’) of een binair kenmerk ([± sonorant]). H stelt in feite voor een meerwaardig feature [sonoriteit] te gebruiken om, binnen een lettergreep bepaalde links-rechts en rechts-links verhoudingen toe te laten of uit te sluiten. De precieze invulling van dit feature voor het Nederlands, oftewel welke klank of klasse klanken heeft welke waarde, is onderdeel van hoofdstuk 3, en komt beneden aan de orde. Wat betreft (ii) kiest H voor een hierarchische struktuur van de lettergreep, met verwerping van in de literatuur bestaande (Clements, Keyser) niet-hiërarchische oplossingen, waarop we hier niet in zullen gaan. H stelt twee varianten van de hiërarchische struktuur voor als adekwaat: de metrische, die syllabekonstituenten als onset, nucleus en coda kent, en de mora-theorie à la Hyman (1983), waar lettergrepen bestaan uit konstituenten die ‘weight units’ of ‘morae’ genoemd worden. Omdat vertakkingen binnen de lettergreep in het algemeen een bepaalde vorm van lettergreep-zwaarte aangeven, en omdat lettergreep-zwaarte in het algemeen interakteert met (klem)toongevoeligheid, zijn zowel de metrische als de mora-theorie in staat het licht/zwaar onderscheid uit te drukken, zoals uit (2) blijkt, zij het op een onderling iets verschillende manier: | |||||||||||||||||||||||||||||||||||||||||||
[pagina 125]
| |||||||||||||||||||||||||||||||||||||||||||
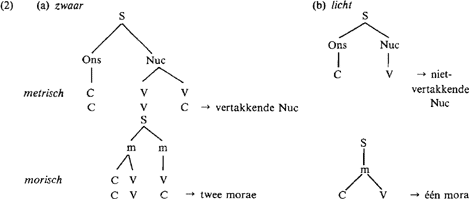 Van deze twee hiërarchische varianten kiest H er niet expliciet een, maar in de meeste gevallen wordt de morische aangehouden, en de claim is dat zijn voorstellen binnen deze theorie ook gelden voor de metrische. Beneden zullen wij derhalve ook de morische analyse gebruiken, hoewel we wel af en toe potentiële problemen binnen het metrische alternatief zullen aanstippen.
In hoofdstuk 3 vervolgens, worden de stellingnames van hoofdstuk 2 ingevuld met taalfeiten uit het Nederlands. Begonnen wordt met een invulling van de lineaire struktuur van de lettergreep met mogelijke klanksekwenties. Gegeven dat afgeleide woorden input zijn van deze lineaire struktuur en gegeven dat konsonant-clusters van drie het maksimale begin van een lettergreep vormen, heeft een mogelijk Nederlands afgeleid woord negen posities in haar representatie,
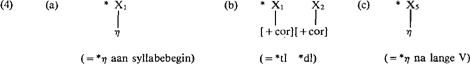 Dissimilarity conditions drukken hele sets opeenvolgingsbeperkingen uit in termen van ‘sonoriteitsafstand’. Aangenomen dat (klassen) segmenten een bepaalde waarde van het meerwaardige feature [sonoriteit] hebben, zoals op de schaal in (5) | |||||||||||||||||||||||||||||||||||||||||||
[pagina 126]
| |||||||||||||||||||||||||||||||||||||||||||
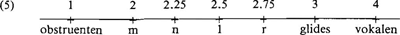 en aangenomen dat X0 altijd het segment s is, kan men bepaalde invullingen van X1-X5 uitsluiten met dissimilarity conditions van de volgende vorm:
Conditie (6a) sluit bijvoorbeeld twee obstruenten aan lettergreepbegin uit, evenals de sekwentie obstruent-nasaal en nasaal-liquid. Conditie (6b) geldt voor postvokalische sekwenties. Als X3 enkel door vokalen opgevuld mag worden (i.e. X3 = 4), dan kunnen op X4 zowel vokalen (lange vokalen worden als een opeenvolging van twee korte beschouwd) als konsonanten, en op X5 slechts konsonanten voorkomen; d.w.z. dat X4 en X5 ‘vrij’ zijn in hun sonoriteitskeuze. Echter, wat op die posities bijvoorbeeld niet mag zijn twee identieke konsonanten (-rr, -nn, etc.) en de sekwenties -rl, -ln, -nm, terwijl -rn, -rm, en -lm okee zijn. Daarom zijn de waarden van de nasalen en liquidae zo gekozen, dat de afstand 0.5 tussen X4 en X5 de foute uitsluit en de goede toelaat. Twee verdere aannames zijn naast het bovenstaande nodig. Gezien het feit dat Nederlandse lettergrepen kunnen beginnen met en eindigen op een vokaal, is de eerste dat de posities voor konsonanten optioneel zijn. Met als tweede aanname dat syllabes niet kunnen eindigen op een korte vokaal (tenzij dit de schwa is) betekent dit dat alle posities optioneel zijn behalve X3 en X4. Dit geldt ook woordintern, i.e. als korte vokalen daar voorkomen dan enkel in gesloten lettergreep. H claimt derhalve, dat een intervokalische konsonant na een korte vokaal ambisyllabisch is, gerepresenteerd als in (7a) of (7b): (Hoe precies in (7b) de dubbele C-positie die geassocieerd wordt met de enkele f tot stand komt, is niet duidelijk).
Het is wellicht nuttig op dit punt in de weergave van H's voorstellen een paar opmerkingen te plaatsen. Deze hebben betrekking op kleine onvolledigheden en, naar onze mening, grotere problemen, en wat daar tussen kan liggen, waarbij we aan de lezer zelf overlaten tot welke kategorie ze behoren. Op pp. 89-92 leidt een uit Moulton (1962) ontleend overzicht van o.a. de (kombinatie-)mogelijkheden van Nederlandse obstruenten H ertoe het filter in (8) te formuleren, dat stemhebbende obstruenten uitsluit uit alle posities behalve syllabe-initiële: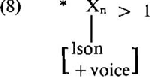 | |||||||||||||||||||||||||||||||||||||||||||
[pagina 127]
| |||||||||||||||||||||||||||||||||||||||||||
Het is onduidelijk of H het pregeneratieve karakter van Moulton's kader over het hoofd ziet (waarin (8) geldt), of dat (8) het effekt van de regel van Auslautverhärtung uitdrukt. De generatieve fonologie maakt sinds 1959 gebruik van onderliggende representaties als /hard/ , /perz/ , etc. om hard-e te onderscheiden van hart-en, perz-en van pers-en, etc. Het kan toch nooit H's bedoeling zijn dit onderscheid weer te neutralizeren, en het zou de duidelijkheid ten goede zijn gekomen als hij een uitspraak had gedaan over de status van filter (8). Dit is niet het enige filter waar problemen mee rijzen. Op p. 78 vinden we filter (4a), dat in z'n algemeenheid zou willen uitdrukken dat een bepaalde medeklinker, in dit geval η, nooit ‘in de onset’ van een lettergreep kan voorkomen. H verwerpt echter voor zijn mora-variant metrische begrippen zoals onset en coda (id.), en hoopt toch via kondities op X-posities vergelijkbare resultaten te boeken. (4a) is echter duidelijk niet in staat η uit te sluiten uit de posities, die in de metrische variant onset heten, omdat de vraag zich opwerpt waarom bij eventuele optionele afwezigheid van X1, η niet alsnog de X2-positie zou kunnen bezetten. Eenzelfde moeilijkheid zou zich voordoen bij het uitsluiten van postvokalische h, die door H onbesproken gelaten wordt: uitsluiten uit X5 zou niet voldoende zijn, het moet X4 én X5 zijn, wat in de metrische variant simpelweg ‘coda’ heet. Vervolgens is het ons onduidelijk welk effekt conditie (4a) heeft op de door H gepropageerde ambisyllabische medeklinker van een woord als hengel: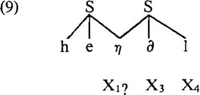 Raadsels dienen zich overigens toch aan bij H's behandeling van de h, die volgens hem ‘the realization of an empty X1 slot’ (wederom wordt X2 over het hoofd gezien) is. Dit is moeilijk te rijmen met twee verdere mededelingen: in de eerste plaats lezen we op p. 114 dat ‘no use is made of “empty slots”’, een reden voor H zijn voorstellen te verkiezen boven andere, die dat wel doen; en in de tweede plaats, als h de, naar wij veronderstellen fonetische, invulling is van deze lege positie, is het moeilijk een filter te interpreteren als (10) 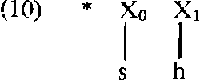 waar h gewoon genoemd wordt. De postvokalische konsonant-clusters in (11a) moeten volgens H uitgesloten worden m.b.v. het filter in (11b):  | |||||||||||||||||||||||||||||||||||||||||||
[pagina 128]
| |||||||||||||||||||||||||||||||||||||||||||
Wat aan (11b) schort zijn twee dingen: de klasse nasalen kan niet gekarakterizeerd worden door [2son], maar een range is nodig (omdat η niet op de sonoriteitsschaal voorkomt kunnen we niet precies zien welke); bovendien, door een verkeerd gebruik van Griekse variabelen, pakt het filter slechts 2 kombinaties uit (11a) mee, nl. nk en nx. Van deze twee wordt nk op zich overbodig uitgesloten (net zo min als np uitgesloten zou moeten worden), omdat deze sekwentie altijd aan de oppervlakte zal verschijnen als ηk (en np als mp) door de uitzonderingsloze regel van Nasaal-Assimilatie (zie (14) beneden). Al deze opmerkingen hebben betrekking op filters, en de lezer zal het met ons eens zijn dat deze waarschijnlijk wel te herformuleren zullen zijn tot empirisch korrekte versies, alhoewel we van sommige nog niet zo een-twee-drie zien hoe dat zou moeten met behoud van het gewenste inzicht. Een principiëler punt van kritiek betreft echter H's strategie om syllabifikatie-beperkingen te definiëren op woordnivo (inklusief afgeleide woorden) en niet op onafgeleide woorden. Men zou verwachten, dat H's syllabe-theorie dan ook inderdaad afgeleide woorden syllabificeert, en korrekt syllabificeert. Op beide punten rijzen echter vragen. Om met het laatste te beginnen, H's theorie levert de volgende syllabifikaties op van markten en barsten:
Met name de positie van s als begin van de tweede syllabe wordt afgedwongen door twee principes: syllabes hebben een ‘maksimale onset’; en st- is toegestaan, en kt- niet. Dit levert dus voor deze vormen verschillende syllabifikaties op. Wat ons betreft is dit niet erg, ware het niet dat H passim de nadruk legt op de kwalijkheid van ‘geometrical distinctions’ in strings, die qua opbouw erg op elkaar lijken. Ambisyllabiciteit (zie (7)) zal de zaak niet recht kunnen trekken want in beide gevallen is de eerste syllabe met de korte vokaal gesloten. In de tweede plaats heeft H. bij het opstellen van zijn strategie om te generaliseren over onafgeleide én afgeleide woorden, zich blijkbaar onvoldoende gerealizeerd hoever de mogelijkheden van de laatste reiken. Weliswaar motiveert hij de verplichte woordfinaliteit van de posities X6-X8 door gevallen zoals in (13a), maar hij realizeert zich blijkbaar tegelijkertijd niet, dat er bij verdere afleidingen ook andere mogelijkheden ontstaan, zie (13b): Als argument zal niet aangevoerd kunnen worden dat juist daarom de omkaderde dentale plosieven vaak gedeleerd worden, want ten eerste vindt H deze regel optioneel (p. 99), en ten tweede werkt hij ook binnen monosyllabische vormen die wél integraal binnen de lineaire struktuur passen (13a), i.e. niet-passen is | |||||||||||||||||||||||||||||||||||||||||||
[pagina 129]
| |||||||||||||||||||||||||||||||||||||||||||
niet de trigger voor deletie (id.). Wat blijkbaar nodig is, is het beschikbaar stellen van X6 voor syllabe-einde, en deze positie niet beperken tot woord-einde. Dat de voorspelde (maar niet bestaande) overgenerering in niet-afgeleide woorden - die al bestond bij X5 - dan wel heel massaal wordt, behoeft waarschijnlijk geen betoog. Een ander probleem, dat we hebben met H's analyse heeft betrekking op effekten van de sonoriteitsschaal (5). De waarden op deze schaal zijn absoluut. Gegeven nu, dat bijvoorbeeld obstruenten, d.w.z. de klasse [-son]-segmenten, 1 zijn, betekent dat dan dat het feature [son] als binair feature in de grammatika overbodig wordt? Waarschijnlijk wel, want H zegt zelf dat ‘a more redundant theory that makes use of both the traditional major class features and a cover feature [sonority]’ minder ‘simple and homogeneous’ (p. 50) is dan een systeem dat dat niet heeft, en daarom geen voorkeur verdient. Maar impliceert het dan ook dat bijvoorbeeld het feature [nasaal] redundant is. Gegeven het feit dat elke nasaal zijn eigen uitputtende sonoriteitswaarde heeft, lijkt deze konklusie haast onoverkomelijk. Bovendien zijn features van artikulatieplaats voor deze klasse dan niet verder nodig. Dus, waar voorheen n gekarakterizeerd werd door de feature-bundel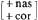 zou nu 2.25 voldoende zijn, en hetzelfde - maar dan met nog iets meer winst - geldt voor m (=2) en zou nu 2.25 voldoende zijn, en hetzelfde - maar dan met nog iets meer winst - geldt voor m (=2) en 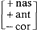 . Omdat H zelf een filter noemt, dat naar sonoriteitswaarde refereert, en niet naar [+ nasaal](= 11b)), zullen we er inderdaad van uitgaan, dat [nasaal] uit de grammatika verdwenen is. Maar hoe moet nu de werking van een regel als Nasaal-Assimilatie ‘gelezen’ worden? Tot nu toe werd een dergelijke regel gerepresenteerd als bijvoorbeeld in (14): . Omdat H zelf een filter noemt, dat naar sonoriteitswaarde refereert, en niet naar [+ nasaal](= 11b)), zullen we er inderdaad van uitgaan, dat [nasaal] uit de grammatika verdwenen is. Maar hoe moet nu de werking van een regel als Nasaal-Assimilatie ‘gelezen’ worden? Tot nu toe werd een dergelijke regel gerepresenteerd als bijvoorbeeld in (14):
 Stel, we substitueren de feature-bundel voor n door 2.25, hoe weet de ‘te ontstane nasaal’ (i.e. het gedeelte rechts van de pijl) nu dat hij nasaal moet zijn? En hoe wordt de palatale nasaal (in Joure), die alleen door assimilatie ontstaat, en geen onderdeel uitmaakt van de onderliggende konsonantverzameling van het Nederlands, verkregen? Wellicht is het feature [nasaal], hoewel redundant, dan toch niet overbodig in de grammatika van het Nederlands. Geldt datzelfde dan ook voor het feature [lateraal], dat er alleen voor dient om onder de liquidae de r van de l te onderscheiden? Het zijn deze en soortgelijke vragen, die door H's voorstellen opgeroepen worden, maar waar het boek geen antwoord op geeft.
Zoals boven gezegd hangt H een hiërarchische theorie over de Nederlandse lettergreep aan, maar daar is tot nu toe bij onze opmerkingen nog niet veel van gebleken. Zijn claim is dat er weinig verschil is tussen de metrische en morische | |||||||||||||||||||||||||||||||||||||||||||
[pagina 130]
| |||||||||||||||||||||||||||||||||||||||||||
varianten qua empirie. Wij volgen hier kort zijn uitleg van de morische theorie en besluiten dit lettergreep-gedeelte met een aantal opmerkingen daarover, voornamelijk aan de hand van het door H besproken verschijnsel van diminutiefvorming in het Nederlands. Volgens H wordt een Nederlandse lettergreep als volgt in morae of ‘weight units’ opgebouwd: de sonority peak (=vokaal) met een maksimale welgevormde sekwentie konsonanten ervoor is één mora; ieder segment volgend op deze mora is óók een mora. Om een illustratie te geven: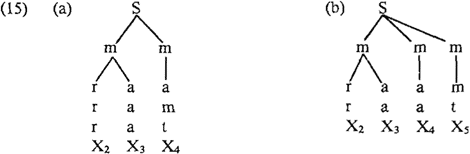 Gegeven het feit dat lettergrepen nooit op een korte vokaal eindigen, maar dat óf een lange vokaal dan wel een korte gevolgd door een konsonant (i.e. de verplichte aanwezigheid van X3 en X4) het minimum is, betekent dit eigenlijk dat iedere syllabe tenminste bimorisch is, en dit impliceert dat het Nederlands geen lichte lettergrepen zou hebben (vergelijk (2b)), maar alleen zware en extrazware. Hierop is één duidelijke uitzondering: lettergrepen met schwa als vokaal lijken in zoverre verplicht licht, dat ze nooit klemtoon op zich kunnen hebben, een eigenschap waar we in het tweede deel van deze recensie nog op terug zullen komen. De notie ‘verplicht licht’ wordt door H uitgedrukt door twee stipulaties over lettergrepen met schwa: (i) voor deze lettergrepen geldt niet dat X3 en X4 verplicht zijn (maar X4 is zelfs verplicht afwezig); en (ii) alle X-posities na schwa worden verplicht bij de schwa-mora getrokken. Dit kan worden gerepresenteerd als in (16):  Merk echter op dat hiermee ram en bezem (hoewel segmenteel voor H hetzelfde, i.e. korte vokaal plus m) verschillende arboreale representaties hebben, iets dat H, zoals boven al gezegd, kwalijk vindt. Op grond van de bovengenoemde aannames over lettergreepstruktuur behandelt H vervolgens een syllabegevoelig verschijnsel van het Nederlands, nl. diminutiefvorming. Het hete hangijzer in alle beschrijven van dit proces is altijd geweest de distributie van -etje (na korte vokaal (behalve schwa) + één sonorante konsonant = ram-metje) vs. die van -pje/ -kje/ -tje in de komplementaire klassen: korte vokaal + twee sonorante konsonanten (arm-pje), lange vokaal + sonorante konsonant ( = raam-pje), en schwa + sonorante konsonant ( = bezem-pje). Over dit fenomeen bestaat lite- | |||||||||||||||||||||||||||||||||||||||||||
[pagina 131]
| |||||||||||||||||||||||||||||||||||||||||||
ratuur van tientallen jaren, en daar onder bevinden zich ook analyses die gebruik maken van hierarchische syllabe-opbouw. Gegeven deze eerdere voorstellen wil H aantonen dat zijn strukturen dit fenomeen ook kunnen behandelen, iets wat hij met de volgende regels probeert:
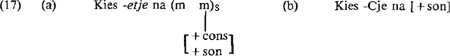 De lezer zal begrijpen dat (17a) alléén twee-morische lettergrepen meepakt, en geen andere. Regel (17b), die zich als ‘elsewhere’-geval verhoudt tot (a), zou nu alle overige gevallen moeten meenemen (met C geïnterpreteerd als homorgaan aan de voorafgaande sonorant), maar elke evaluatie van de pros en cons van deze voorstellen wordt overbodig gemaakt door het feit dat in H's theorie het major class feature [ + son] niet bestaat, zoals eerder aangegeven. We weten niet of dit makkelijk of moeilijk te herstellen is. Weglating van dit kenmerk is in ieder geval een onmogelijkheid, want het dient in de formulering van (17a) cruciaal om ram en rat (vergelijk (15a)) te onderscheiden (zoals [ + cons] dient voor het onderscheid tussen ram en raa), terwijl het er in (17b) voor zorgt, dat in de ‘elsewhere’-gevallen de obstruenten niet met de regel meegaan. We hebben boven geprobeerd aan de lezer een indruk te geven wat de opbouw van H's voorstellen over de Nederlandse lettergreep is in SSSD. Afgezien van de vraag of we kritische aanmerkingen kunnen maken op dit of dat idee, is het voor ons uiteindelijk teleurstellend dat tot op dit punt van het proefschrift de verschillende komponenten van wat één analyse zou behoren te zijn hun logische verbanden missen. Zo wil H op zich syllabestruktuur beschrijven op het nivo van afgeleide woorden; hij toont aan dat dat mogelijkerwijs kán, maar niet waarom het beter is om het zo te doen, en ook niet waarom het zo móet. Het verschil in extra struktuur, dat afgeleide woorden blijkbaar opleveren speelt vervolgens geen rol in de behandeling van diminutiefvorming, en zal, zoals we straks zullen zien, ook geen rol spelen in de behandeling van klemtoon in het derde deel van het boek. Kortom, er is geen rode draad die deze drie onderdelen bindt, of ze uit elkaar laat volgen, en zoals al gezegd, wordt deze rode draad ook verder niet duidelijk. We hebben over klemtoon hierboven incidenteel al wat aangestipt, maar zullen er nu dieper op ingaan. | |||||||||||||||||||||||||||||||||||||||||||
Deel III: StressIn hoofdstuk 4 van Deel III geeft H een overzicht van de verschillende nietlineaire theorieën van woordklemtoon, zoals die zijn voorgesteld in de literatuur. In H's visie verschillen deze theorieën onderling slechts in de mate waarin klemtoonrepresentaties binnen woorden vervat zijn in termen van konstituenten. Ruwweg gezegd zijn de graden van konstituentschap aan de ene pool de s-w gelabelde boom uit de metrische variant, en aan de andere pool de gridtheorie, die helemaal geen konstituenten erkent. H's centrale vraag is dan ook in hoeverre woordklemtoon-theorieën echt gebruik maken van konstituentschap, en zijn voorstel, dat we hier beneden zullen behandelen, moet derhalve gezien worden als een potentieel antwoord op deze vraag. Zijn idee is om deze uitersten - welke ‘both..succeed in accounting for the | |||||||||||||||||||||||||||||||||||||||||||
[pagina 132]
| |||||||||||||||||||||||||||||||||||||||||||
known variety of wordstress systems’ en ‘also make use of a highly comparable “machinery”, to an extent that one is tempted to speak of “notational variants”’ (p. 144) - elkaar te laten ontmoeten door een beperkt gebruik van konstituenten: alle talen hebben minimaal één konstituent, de zgn. ‘stress foot’, waarbinnen zich óf uiterst links (= (18a)) óf uiterst rechts (=(18b)) de hoofdklemtoon (=s) bevindt. Deze konstituent is niet-binair vertakkend:
 Talen kunnen vervolgens verschillen in het al of niet aanwezig zijn van een tweede konstituent, de zgn. ‘antipole stress foot’. Deze korrespondeert met de aanwezigheid van een sterk sekundair begint-aksent, en deze konstituent is eveneens niet-binair vertakkend. De antipole stress foot wordt via een aparte konventie opgeleverd, d.w.z. niet door iteratieve toepassing van de regel die de stress foot bouwt. Een labelings-konventie draagt zorg voor de s-w- verhoudingen tussen de stress foot en de antipole foot: de stress foot is altijd s. 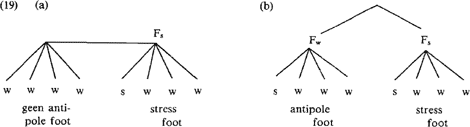 Het Nederlands is volgens H een voorbeeld van een type (19b)-klemtoontaal. Voor die talen - waaronder wederom het Nederlands - waarin buiten deze twee klemtonen nog gedetailleerdere prominentie-aspekten voorkomen (bijv. alternantie van sterke en zwakke lettergrepen), merkt H op (in navolging van Prince 1983), dat deze alternantie in de rest van het woord afhankelijk is van de positie van de hóofdklemtoon; H werkt dit uit door de hoofdklemtoon het startpunt te laten vormen waarvandaan de alternantie ‘fonetisch echoot’. Deze aanpak leidt dus bijklemtoon af van de hoofdklemtoon, i.t.t. bestaande metrische woordklemtoon-analyses, waarin één van de bijklemtonen wordt gepromoveerd tot hoofdklemtoon. Op de details van dit ‘derde type klemtoon’ zullen we hier verder niet ingaan, hoewel een verdere uitwerking van H's idee ons zeker de moeite van verder onderzoek waard lijkt.
Deze klemtoonaannames worden vervolgens in hoofdstuk 5 aangewend bij de beregeling van de klemtoonfeiten in Nederlandse woorden. Volgens de al bestaande analyses lijken de volgende vier eigenschappen van lettergrepen een rol te spelen:
| |||||||||||||||||||||||||||||||||||||||||||
[pagina 133]
| |||||||||||||||||||||||||||||||||||||||||||
Met name punt (iv) wordt door H - gestuurd door zijn mora-theorie die VV en VC gelijkwaardig struktureert - in twijfel getrokken als relevant. Daarom ligt de nadruk bij de bespreking van de taalfeiten bij dit onderscheid. Uitgangpunt voor zijn voorstellen is de volgende inperking van zijn feitenmateriaal: ‘I will in principle propose a stress rule that accounts for the patterns that are in the majority, the dominant patterns’ (p. 215) en bovendien dat ‘the notion “dominant pattern”..must be followed to the letter’ (p. 217). Gegeven de dominante patronen in het feiten-materiaal, lijken de rolpatronen in (i) - (iii) door het Nederlandse korpus wel bevestigd te worden. Wat betreft rolpatroon (iv): van alle twee- of meersyllabische woorden leiden met name de tweesyllabische tot de konstatering dat ‘stress is predominantly prefinal...and...the difference between VV and VC syllables is of little significance’ (p. 221). Bij de meersyllabische zijn er twee sekwenties die het zojuist gekonstateerde prefinale patroon verstoren. Deze sekwenties, i.e. VV-VV-VC en VC-VV-VC, vertonen initieel aksent als het dominante patroon, en zijn niet onder een of andere subregelmatigheid te verenigen, en suggereren een onderscheid tussen VV en VC in lettergreep-zwaarte.
Voordat we H's voorstellen voor de beregeling van de dominante klemtoonpatronen zullen bespreken, willen we eerst een paar opmerkingen maken, die voornamelijk betrekking hebben op de data-verzameling. Allereerst betreft dit de indeling van woorden op grond van hun lettergreepstruktuur. Naast een aantal foute indelingen (bijv. angora, maizena, angina, en maskara onder VV-VV-VV) is er een aantal onduidelijkheden, dat de cijfers van H wat onbetrouwbaar maakt. Bijvoorbeeld, in de klassen VV-VV-VC (60-20-35) en VC-VV-VC (40-9-17) is, gegeven de cijfers, het dominante patroon op de voor-voorlaatste (i.t.t. de voorlaatste), zoals we net al gezegd hebben. Echter, bij de voorbeelden die H geeft (p. 226 en p. 228) blijkt bij de telling van de taalfeiten de sekwentie -ium (stadium, calcium) als VV-VC te tellen, terwijl op p. 130 wordt gesteld dat u in -ium-woorden (ondanks de spelling u) een schwa is. Aangezien VC in H's model een andere behandeling krijgt als schwa-C, zoals we straks zullen zien, en omdat bovendien -ium-woorden nogal talrijk zijn in het Nederlands, vragen we ons af of hier de cijfers (60 en 40) niet een vertekend beeld geven. Ook hadden we verwacht dat H op dit punt in het proefschrift - mede gezien de doorslaggevende rol van ambisyllabische konsonanten bij verkrijging van het cijfermateriaal - aangegeven zou hebben hóe precies ambisyllabiciteit verkregen en geïnterpreteerd moet worden, en dit voor zowel de morische als de metrische aanpak. Kan bijvoorbeeld in het metrische kader de ambisyllabische f van koffie (zie (7)) zowel tot een nucleus als tot een onset behoren en/of welke representatie in (7) sluit het beste aan bij de morische variant. Het is ons inziens een nalatigheid, dat de lezer dit zelf maar moet uitzoeken.
Voor zijn op grond van cijfers verkregen indeling van het Nederlandse korpus in dominant en niet-dominant, gebruikt H vervolgens de voeten genoemd in (18) en (19) plus de mora-zwaarte van hoofdstuk 3 om de dominante klemtoon- | |||||||||||||||||||||||||||||||||||||||||||
[pagina 134]
| |||||||||||||||||||||||||||||||||||||||||||
patronen te beregelen. Twee verdere stress foot-beperkingen zijn nodig: de eerste is dat op de s-positie minimaal een zware, i.e. bimorische oftewel beklemtoonbare, lettergreep moet staan. Dit dient om ervoor te zorgen, dat schwa niet s wordt, d.w.z. de hoofdklemtoon krijgt. De tweede beperking moet er voor zorgen dat er niet te veel syllabes in de stress foot terecht komen. Dit effekt wordt als volgt verkregen: H neemt aan dat ‘each prosodic category is assigned an index that specifies its weight’ (p. 244); deze index kan als volgt afgeleid worden: (i) voor lettergrepen uit het aantal morae dat deze bevat (dus één, twee, of drie) en (ii) voor voeten door de indices van de lettergrepen waaruit hij bestaat op te tellen. De beperking op voeten luidt dan, dat ze ‘an upper limit, being [4]’ (p. 245) hebben:
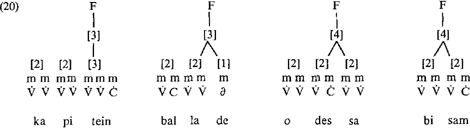 De voorbeelden in (20) geven de maksimale stress voeten aan; wanneer méér syllabes bij de voet zouden worden betrokken, zou het maksimum van [4] overschreden worden. Blijkens de strukturen die H zelf geeft van de woorden in (20) moeten deze als volgt afgemaakt worden: 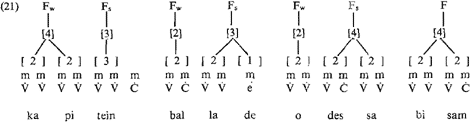 Binnen de stress foot in het Nederlands ligt de s-positie uiterst links (waarbij wel aangenomen dient te worden dat de stress foot aan de rechterkant van het woord wordt toegekend). De bovengeschetste principes beregelen de dominante klemtoonpatronen van het Nederlands: (i) superzware finale lettergrepen hebben finaal aksent (kapitéin); (ii) lettergrepen met schwa dragen nooit aksent, en een finale lettergreep met schwa krijgt meteen klemtoon vóór zich (balláde); (iii) twee- of meersyllabische woorden hebben prefinale klemtoon (odéssa, bísam).
In woorden met de vorm VX-VV-VC (almanak, abraham etc.) ligt als dominant patroon klemtoon op de vóor-voor-laatste lettergreep, i.t.t. het voorspelde (à la odéssa) prefinale patroon. Daarom moeten deze in het lexicon opgenomen worden met een extrametrische laatste lettergreep: ze krijgen daarmee de struktuur van bísam en de laatste lettergreep wordt later aangebouwd, zonder de klemtoon te beínvloeden. | |||||||||||||||||||||||||||||||||||||||||||
[pagina 135]
| |||||||||||||||||||||||||||||||||||||||||||
Dit is in een notedop H's behandeling van de Nederlandse dominante klemtoonpatronen. De voorbeelden in (21) laten zien, dat H niet alleen de stress foot, maar ook de antipole foot indiceert. Echter, daarmee rijzen dan wel wat vragen, met name betreffende voet-bouwerij en indexering. Laten we eens een woord nemen van het type kapitein, maar dat één lettergreep langer is, zoals anakoloet. Na bouw van de stress foot moeten vervolgens de resterende lettergrepen in een antipole stress foot worden opgenomen. Dit geeft voor anakoloet de volgende struktuur:
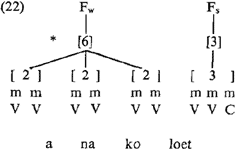 Deze antipole stress foot heeft echter een index die hoger is dan het maksimaal toegestane: [4]. Als H vast wil houden aan het maksimum [4] zou dit voor anakoloet niet struktuur (22) betekenen, maar een van de strukturen uit (23): 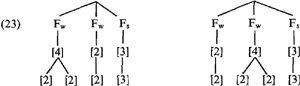 Deze strukturen kunnen echter alleen ontstaan als we iteratieve voet-toekenning toelaten: er moeten immers meerdere antipole voeten gekreëerd worden. Maar dit is niet kompatibel met H's opmerking dat ‘making use of weight indices and the notion of upper weight for feet allows me to retain the idea that footassignment is non-iterative’ (p. 246). Omdat H zelf alleen maar vóorbeelden geeft van onafgeleide woorden met meer dan drie lettergrepen, maar geen bóomstrukturen, blijft deze kwestie van ‘óf toch meer dan [4] voor de antipole’ / ‘óf toch maar iteratief’ onduidelijk. De aanname dat een voet maksimaal een index van [4] heeft, heeft nog een merkwaardige konsekwentie. Het komt er nu namelijk op neer dat dit voor stress voeten inhoudt, dat ze in bijna alle gevallen of monosyllabisch of hooguit bisyllabisch zijn (tenzij er twee schwa's volgen na een volle vokaal in de voor-voor-laatste lettergreep, maar deze laatste komen eigenlijk alleen voor bij afgeleide woorden, waar we straks nog op terug zullen komen). Dit betekent in de praktijk dat de hoofdklemtoon altijd op de voorlaatste lettergreep zal vallen, tenzij de laatste extrazwaar ([ = 3]) is. Dit betekent ook, dat alle hoofdklemtonen op de voor-voor-laatste lettergreep via additionele mechanismes, zoals extrametriciteit, verkregen worden. Dit was bijvoorbeeld het geval met almanak, een lid van de dominante klasse VX-VV-VC, die beginklemtoon heeft. Nu is het verkrijgen van beginklemtoon via extra mechanismes voor al die gevallen, die dit als niet-dominant patroon hebben, natuurlijk aanvaardbaar: als taalbeschrijver verwacht men dat uitzonderlijke vormen ook via uitzonderlijke me- | |||||||||||||||||||||||||||||||||||||||||||
[pagina 136]
| |||||||||||||||||||||||||||||||||||||||||||
chanismes verkregen worden. H zelf noemt zijn behandeling van de klasse almanak het missen van ‘what seems to be a rather marginal generalization’ (p. 249). Echter deze klasse is géén geïsoleerd geval. Ook de klasse X-∂-X, waar de tweede X een bimorische lettergreep is, vertoont dominant initieel aksent: álgebra, zéppelin, etc. Voor deze gevallen zou H foutief eindklemtoon voorspellen; de weight indexen van deze vormen zijn [2] [1] [2], en omdat de mediale schwa nooit s mag zijn binnen de stress foot, krijg je strukturen als in (24):
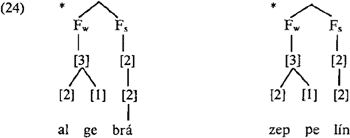 Eén stress foot voor deze gevallen, waarmee wél beginklemtoon zou worden voorspeld, kan ook niet, want dan wordt het maksimum van [4] overschreden: *[5]. Om hier de korrekte klemtoon te verkrijgen, zal H de laatste lettergreep als extrametrisch moeten markeren, d.w.z. er is wederom, net als bij almanak, een extra ingreep nodig voor deze gevallen, die binnen hun klasse dominant zijn (terwijl het niet-dominante patroon met eindklemtoon - dat H overigens niet wil beregelen - uit zijn voorstellen als regelmatig tevoorschijn zou komen; envelóp). Deze voorbeelden maken duidelijk dat voor H botsingen tussen cijfermateriaal (dominant of niet) én voorspellingen van zijn theorie altijd beslist worden ten gunste van het cijfermateriaal. Dit betekent een lastenverzwaring van de theorie door de noodzaak tot invoering van additionele mechanismes om het dominante patroon te kunnen beregelen. Voor ons is een volgende grote vraag hoe H's klemtoonanalyse nu precies interakteert met de syllabifikatiedomeinen; de laatste werden gedefinieerd op het zgn. ‘fonologische woord’, d.w.z. de domeinen genoemd onder (la) - (ld). Daardoor vormen in bepaalde gevallen suffiksen mét de stam één geheel. In zijn boek merkt H passim op dat de output van syllabifikatie als het ware de input voor klemtoon is, bijvoorbeeld door opmerkingen als ‘It seems that both the mora theory and the metrical theory are satisfactory, in that both theories allow us...to distinguish between the classes of syllables that show different behavior with respect to stress assignment’ (p. 109), en ‘I maintain that the syllable structure analysis that I have proposed provides an adequate basis for approaching stress assignment in Dutch’ (p. 214). In het klemtoondeel echter beperkt H zich ineens vrijwel uitsluitend tot ongelede woorden, alhoewel de suggestie gewekt wordt dat bepaalde gelede woorden - nl. die met twee schwa's in de laatste twee lettergrepen - wel meegaan met de klemtoonanalyse: | |||||||||||||||||||||||||||||||||||||||||||
[pagina 137]
| |||||||||||||||||||||||||||||||||||||||||||
Zelfs langere afgeleide woorden worden behandeld. Omdat deze binnen de stress foot het maksimum [4] overschrijden, merkt H op dat ‘In those cases where more than two schwas occur it is possible to apply several rules that delete certain schwas. For example gezamelijke can easily be pronounced as gezamølijke. In the case of verschrikkelijkere we find an alternative form verschrikkølijkerø’ (p. 241). Echter, wanneer nou precies een geleed woord wél en wanneer níet als klemtoondomein mag gelden blijft totaal onduidelijk. Omdat voor bepaalde gevallen de klemtoonkonsekwenties nogal groot zijn, zoals uit (26) blijkt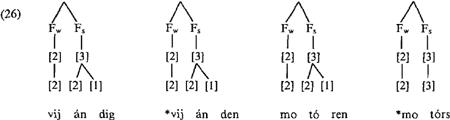 en omdat het voor andere gevallen onduidelijk is óf het tellen van morae überhaupt tot resultaten kan leiden (bijv. beroemdst heeft gegeven de mora-teldefinitie maar liefst een finale lettergreep van [6], waarmee het maksimum [4] ruim overschreden is) zou het de transparantie van H's boek ten goede zijn gekomen als hij definitievere uitspraken gedaan zou hebben over klemtoondomeinen dan ‘The present analysis is incomplete in the sense that I have said little about the placement of stress in the derived vocabulary’ (p. 251). We zouden de volgende konklusies aan H's proefschrift willen verbinden. Zoals we boven al hebben opgemerkt, hebben we ons bij deze bespreking ingeperkt, door niet H's ‘algemene hoofdstukken’ 1, 2, en 4 te bespreken, die uitgebreide literatuur-overzichten bevatten. Zou iemand bijv. een kollege ‘niet-lineaire fonologie’ willen verzorgen, dan zou hij/zij een grote hoeveelheid informatie en verwijzingen uit deze hoofdstukken kunnen putten. Binnen SSSD zelf wordt echter de uitgebreide tekst van deze hoofdstukken niet ten volle gerechtvaardigd door een cruciaal verband met hoofdstuk 3 en 5. Zoals verder uit het bovenstaande duidelijk zal zijn, heeft de inhoud van de laatste twee ons op verschillende punten niet overtuigd. We kunnen niet overzien of de slordigheden en fouten in H's behandeling van de lettergreep, die we in het eerste deel van deze bespreking hebben aangestipt, op een inzichtelijke manier kunnen worden hersteld. Maar met name zijn we niet overtuigd dat voor de Nederlandse lettergreep het afgeleide woord als basis moet dienen. Deze stellingname leidt tot een heel groot empirisch bereik, en dit bereik wordt slechts ten dele benut en uitgewerkt voor de klemtoon-voorstellen. Verder wordt H's hele analyse gestuurd door de drang het gedrag van de schwa te verklaren, zowel qua syllabeeigenschappen als qua klemtoon-karakteristieken. Uiteindelijk wordt dit bereikt door een aantal stipulaties, waardoor de schwa zich gaat onderscheiden van alle andere vokalen, waaronder (i) schwa is ‘verplicht licht’, (ii) consonanten na schwa tellen als het ware niet mee, en (iii) een s-positie = *schwa. Omdat deze stipulaties nergens uit volgen zijn we van mening dat H wat betreft deze vokaal iets te los het woord ‘verklaring’ gebruikt. Ook omdat schwa's als veelvoorkomende suffiks-vokalen, een belangrijke rol spelen in het ‘derived lexicon’, rijst voor ons bovenal de vraag of het afgeleide woord nu wel een goed | |||||||||||||||||||||||||||||||||||||||||||
[pagina 138]
| |||||||||||||||||||||||||||||||||||||||||||
uitgangspunt vormt voor een analyse, die zowel lettergreep-struktuur als klemtoon-struktuur wil bestrijken. | |||||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||||||||||||||||||||||||