
Spektator. Jaargang 4
(1974-1975)– [tijdschrift] Spektator. Tijdschrift voor Neerlandistiek–
[pagina 499]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Leesbaarheidsformules voor informatieve
Nederlandse teksten
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| C% | = | 62.862 | - 0.518x7 | - 0.323x9 | ||||
| C% | = | 40.082 | ± 0.422x2 | - 0.391x7 | - 0.344x9 | |||
| C% | = | 136.067 | - 0.462x1 | ± 1.535x3 | - 0.479x7 | - 0.364x9 | ||
| C% | = | 258.767 | - 1.125x1 | ± 3.915x3 | - 0.778x4 | - 0.605x9 | - 1.331x13 | ± 1.717x17 |
1. Inleiding
In hoeverre kan de lezer de tekst begrijpen? Dat is een vraag waarop het leesbaarheidsonderzoek een precies en betrouwbaar antwoord kan geven. Het is mogelijk de begrijpelijkheid van een tekst te bepalen op het ogenblik dat hij wel al geformuleerd, maar r og niet geïnterpreteerd is. De leesbaarheidspredictie gebeurt met behulp van een leesbaarheidsformule.
De toepasbaarheid van een bepaalde formule is bepaalde formule is beperkt tot één soort teksten en één soort lezers. We onderscheiden een aantal tekstsoorten naar het intrinsieke doel dat de schrijver met zijn tekst heeft. Dat doel kan zijn: de lezer informatie en/of commentaar verstrekken; zijn oordeel en/ of zijn gedrag beinvloeden; hem vermaken. We onderscheiden dus informatieve, commentariërende, persuasieve, directieve en diverterende teksten. Heel wat teksten zijn echter mengvormen. Reclame ziet er soms op het eerste geziht uitsluitend informatief uit, maar is persuasief bedoeld. Fictie wordt soms aangewend om het oordeel en dus ook het gedrag van de lezer te beinvloeden of om hem een zekere kennis bij te brengen (cfr. vele kinder- en jeugdboeken). Journalistieke teksten zijn soms louter informatief, soms commentariërend, soms beide samen. Zijn ze commentariërend, dan zijn ze veelal ook persuasief (cfr. de opiniebladen).
We onderscheiden soorten lezers naar de grootte van hun leesvaardigheid. Omdat die niet gradueel toeneemt, kan men de lezers arbitrair in veel of weinig groepen indelen. Hoe talrijker de groepen, hoe homogener: de twaalfjarigen vormen qua lees
vaardigheid een homogenere groep dan de lezers van tien tot veertien jaar. De grootte van de leesvaardigheid wordt vooral bepaald door het aantal leerjaren dat de lezer doorlopen heeft.
2. De leesbaarheidstest
In dit artikel stellen we vier leesbaarheidsformules voor waarmee het mogelijk is te bepalen hoe begrijpelijk informatieve teksten zijn voor lezers met middelbareschoolopleiding. Bij de leesbaarheidspredictie gaat men uit van de leesbaarheidsmeting: door middel van een leesbaarheidstest meet men hoe begrijpelijk een aantal teksten van een bepaalde soort zijn voor een aantal lezers met een bepaalde leesvaardigheid; vervolgens veralgemeent men de uitslag naar andere teksten van dezelfde soort en andere lezers met dezelfde leesvaardigheid toe. Voor de constructie van de formules die we wensen voor te stellen, hebben we gebruik kunnen maken van de uitslagen van een leesbaarheidstest, geconstrueerd, toegediend en geïnterpreteerd door R. van Remoortele (1974). Die test heeft betrekking op honderdtwintig proefpersonen en zestien tekstfragmenten. De proefpersonen waren leerlingen laatste en voorlaatste jaar middelbaar onderwijs. Het waren meer bepaald jongens en meisjes uit het laatste en voorlaatstejaar oude en nieuwe humanioraGa naar eind1. De tekstfragmenten, elk ongeveer 200 woorden lang, werd ontleend aan de volgende werken:
Argyris, C., Het individu geïntegreerd in de organisatie, Utrecht-Antwerpen, Het Spectrum (Mai ka), 1967.
Bally, P.J.H., Inkooppolitiek en voorraadbeheer, Utrecht-Antwerpen, Het Spectrum (Marka), 1968.
Berlin, I., Karl Marx, Zijn leven en tijd, Amsterdam, Arbeiderspers (Kleine Floret), 1968.
Clark, G., Jagers uit de steentijd, Amsterdam-Brussel, Elsevier, 1967.
Dunn, L.C. & Dobzhansky, Th., Erfelijkheid, ras en maatschappij, Doornik, Desclée, 1968.
Elston, D.R., Israël. De wording van een moderne staat, Utrecht-Antwerpen, Het Spectrum (Prisma), 1967.
Jones, H., Alcoholisme, Utrecht-Antwerpen,Het Spectrum (Aula), 1966.
Jones, H., Misdaad in een veranderende samenleving, Utrecht-Antwerpen, Het Spectrum (Aula), 1968.
Manchester, W., De dood van een president, Utrecht-Antwerpen, A.W. Bruna & Zoon, 1967.
Noroney, M.J., Feiten uit ciffers, Utrecht-Antwerpen, Het Spectrum (Aula), 1967.
Myer, J.N., Het financiële verslag, Utrecht-Antwerpen, Het Spectrum (Marka), 1967.
Rose, R. & Farr, D.E., Bestuursinformatie voor topmanagement, Utrecht-Antwerpen, Het Spectrum (Marka), 1967.
Sayles, L.R., De taak van de leider in de onderneming, Utrecht-Antwerpen, Het Spectrum (Marka), 1967.
Simpson, G.G., De betekenis van de evolutie, Utrecht-Antwerpen, Het Spectrum (Aula), 1968.
Woodward, E.L., Geschiedenis van Engeland, Utrecht-Antwerpen, Het Spectrum (Prisma), 1967.
Om te meten hoe leesbaar te tekstpassages voor de proefpersonen waren, heeft Van Remoortele de ‘cloze procedure’ gebruikt. Een clozetest construeren, afnemen en interpreteren gebeurt als volgt: men laat in de tekstpassages elk vijfde woord weg en vervangt de weggelaten woorden door spaties die even lang zijn, zodat de lengte van de spaties het raden niet kan beïnvloeden; men laat de proefpersonen de weggelaten woorden invullen; als juiste antwoorden beschouwt men de
woorden die, op eventuele spellingsfouten na, overeenstemmen met de weggelaten woordenGa naar eind2. Wanneer we elk vijfde woord weglaten, hoeft dat niet hoofdzakelijk het vijfde, tiende, vijftiende enz. te zijn: het kan ook bv. het zesde, elfde, zestiende enz. of het zevende, twaalfde enz. zijn. Van Remoortele heeft aldus van iedere tekst vijf testversies geconstrueerd. Met het oog op de distributie van de 16 teksten en de 16 × 5 = 80 testversies over de proefpersonen, heeft hij de 120 leerlingen ingedeeld in twintig groepen van zes. Elke groep kreeg 80:20= 4 testversies, zo gekozen dat het verschillende versies van verschillende teksten waren. De clozetest leverde voor elke tekst 30 uitslagen op (per tekst vijf versies, elk ingevuld door zes proefpersonen). Het gemiddelde van die dertig uitslagen drukt uit hoe leesbaar de tekst is voor de proefpersonen, het is een criterium, een operationele definitie van de leesbaarheid.
De leesbaarheidstest licht ons in over de begrijpelijkheid van de criteriumteksten voor onze proefpersonen en ook over de leesvaardigheid van die proefpersonen. In tabel I geven we voor elk der zestien teksten de gemiddelde clozetest-uitslag en de standaardafwijkingen.
Tabel I
Gemiddelde clozetest-uitslagen voor zestien informatieve teksten en de bijhorende standaardafwijkingen (N=30)
| Nummers tekst | Gemiddelde clozetest-uitslag | Standaard-afwijking |
|---|---|---|
| 1 | 37,441 | 5,07 |
| 2 | 37,427 | 5,31 |
| 3 | 38,093 | 5,77 |
| 4 | 38,726 | 8,29 |
| 5 | 38,336 | 7,00 |
| 6 | 44,673 | 9,62 |
| 7 | 34,376 | 7,59 |
| 8 | 34,383 | 7,82 |
| 9 | 36,343 | 6,79 |
| 10 | 40,706 | 4,49 |
| 1l | 38,740 | 6,39 |
| 12 | 30,976 | 6,47 |
| 13 | 37,186 | 4,16 |
| 14 | 20,363 | 5,76 |
| 15 | 47,046 | 5,97 |
| 16 | 33,353 | 5,21 |
Uit tabel I blijkt dat de gemiddelde clozetest-uitslagen slechts een geringe spreiding vertonen. De breedte, d.i. het verschil tussen de hoogste en de laagste gemiddelde uitslag is 47,046 - 20,363 = 26,683. De variatiebreedte berust op slechts twee clozetestgemiddelden, waarvan er toevallig één zeer laag uitvalt ten opzichte van de andere. Een beter beeld van de spreiding geeft ons de standaardafwijking van het gemiddelde van de gemiddelde clozetest-uitslagen. Die standaardafwijking bedraagt slechts 5,90228. Als de criteriumteksten representatief zijn voor popularise
rend informatief proza moeten we uit de geringe spreidingsbreedte besluiten dat informatieve teksten qua begrijpelijkheid niet erg van elkaar verschillen.
Zo groot als de overeenkomst van de gemiddelde clozetestuitslagen voor de verschillende criteriumteksten is, zo klein is de overeenkomst van de clozetest-uitslagen waaruit elke gemiddelde clozetest-uitslag berekend is. De standaardafwijkingen schommelen tussen 4,16 en 8,29. Bij een normale verdeling wijkt de clozetestuitslag van een derde van de proefpersonen naar gelang van de tekst dus meer dan 4,16 tot 8,29 af van de gemiddelde clozetest-uitslag voor die tekst.
Een tekst vertoont kenmerken die verband houden met zijn leesbaarheid. Het gemiddeld aantal woorden per zin is één van die kenmerken. Het gemiddeld aantal woorden per zin verschilt van tekst tot tekst: het is een veranderlijke, een variabele. Omdat zo'n variabele een kenmerk van de formulering is, spreken we van een linguïstische variabele. We hebben de zestien teksten geanalyseerd met betrekking tot twintig linguïstische variabelen, waarvan we vermoedden dat ze met de leesbaarheid in verband staan. Die linguïstische variabelen worden opgesomd in Tabel II.
Tabel II
| Linguïstische Variabelen | |
|---|---|
| x1 | lettergrepen per honderd woorden |
| x2 | éénlettergrepige woorden per honderd woorden |
| x3 | woorden met meer dan drie lettergrepen per honderd woorden |
| x4 | woorden per zin |
| x5 | woorden per T-eenheid |
| x6 | lettergrepen per zin |
| x7 | lettergrepen per T-eenheid |
| x8 | tangconstructies per honderd woorden |
| x9 | woorden in de tangconstructies per honderd woorden |
| x10 | gemiddeld aantal woorden per tangconstructie |
| x11 | substantieven per honderd woorden |
| x12 | woorden in de voorbepalingen bij substantieven per honderd woorden |
| x13 | voorzetsels per honderd woorden |
| x14 | persoonsvormen van het werkwoord per honderd woorden |
| x15 | voltooide deelwoorden per honderd woorden |
| x16 | infinitieven per honderd woorden |
| x17 | infinitiefconstructies per honderd woorden |
| x18 | nevenschikkende voegwoorden per honderd woorden |
| x19 | onderschikkende voegwoorden per honderd woorden |
| x20 | anaforische pronomina per honderd woorden |
In deze tabel bedoelen we met woord: een opeenvolging van letters of cijfers voorafgegaan en gevolgd door een witspatie. Verbindingen als binnen- en buitengaan hebben we dus als drie woorden geteld. Afstandscomposita als sloeg...af zijn twee woorden. Voorzetseluitdrukkingen als naar aanleiding van hebben we geteld als drie woorden, maar de verkorting n.a.v. als één. Eigennamen als Jan de Hartog bestaan uit drie woorden. Verkortingen als o.a. en telwoorden in cijfers hebben we beschouwd als eenlettergrepige woorden.
Een zin is een geheel waarvan het eerste woord met een hoofdletter geschreven
wordt en dat gevolgd wordt door een punt, een uitroepteken of een vraagteken. Volgens de grammatici bestaat een zin uit één of meer subject-predikaatsverbindingen. Vooral als twee of meer subject-predikaatsverbindingen samen een hiërarchische structuur vormen, in geval van onderschikking dus, vormen zij een hechte verbinding. Een zin die bestaat uit één enkele subject-predikaatsverbindling is onafhankelijke zin; een zin die bestaat uit twee of meer subjects-predikaatsveriïdingen die samen een hiërarchische structuur vormen is een samengestelde zin met een hoofdzin en één of meer bijzinnen. Zowel de onafhankelijke zin als de verbinding van een hoofdzin en zijn bijzin(nen) noemen we een T-eenheid (Eng. Terminable unit).De grenzen van de typografische zin, vallen niet altijd samen met die van de T-eenheid. De volgende zin bestaat uit twee T-eenheden.
Onze oucers deden met ons wat hun verstandig en nodig leek en zij konden moeilijk rekening houden met wat elk van ons voor zichzelf gewild had.
Evenzeer als een typografisch gekenmerkte zin twee of meer T-eenheden kan bevatten, komt het voor dat een T-eenheid zich uitrekt over twee of meer typografisch gekenmerkte zinnen. Vb.
Toen ik thuiskwam, stopte ik het plantje van de zoldereremiet in een bloempot die ik onder de achterste zitplaats van mijn auto verstopte. Omdat ik mij een beetje schaamde. En omdat ik hoopte dat de plant daar wel spoedig en tevens ongemerkt zou verkwijnen.
In een, Nederlandse zin staan de delen die naar de betekenis bij elkaar horen niet altijd naast elkaar.
Vergelijk:
Engels: I have met your sister this afternoon.
Frans: J'ai renconiré ta soeur cet après-midi.
Nederlands: Ik heb vanmiddag je zus ontmoet.
De woorden vanmiddag, je en zus dringen als een wig tussen de delen van het werkwoordelijk gezegde. Omgekeerd ,orden vanmiddag, je en zus door heb en ontmoet omsloten als door de grijpers van een tang. Vandaar de benaming tangconstructie. Fangconstructies komen voor in ce hoofdzin, de bijzin en in de beknopte bijzin met een infinitief als kern. In de hoofdzin is één van de twee grijpers altijd de persoonsvorm van het werkwoord. De andere grijper kan zijn:
- het niet-werkwoordelijk deel van een scheidjkar samengesteld werkwoord;
Ze deelden ons gisteren hun bevindingen mee;
- het niet-werkwoordelijk deel van een werkwoordelijke uitdrukking;
Hij leidde de politie om de tuin.
- de infinitief die deel uitmaakt van het werkwoordelij, gezegde;
Ik zal nu toch wel niet langer snijbonen moeten eten.
- het voltooid deelwoord dat deel uitmaakt van het werkwoordelijk gezegde;
Ik heb nu al drie weken elke middag snijbonen gegeten.
- het naamwoordelijk deel van het gezegde;
Dat mes is in geen geval van Rik.
- het specificerend complement;
Dit huis kostte vóór de oorlog al ƒ 50.000.
- de predikatieve bepaling of het complement van ‘maken’ en ‘vinden’;
Hij verft de deur voor de tweede keer groen.
Jan loopt zijn schoenen altijd scheef
Zij maakt de kamer voor de gelegenheid gezellig.
Ik vind haar nu niet meer zo mooi.
- het direct object;
Ik schrijf je direct na mijn aankomst een kaart.
- het voorzetselvoorwerp;
Ik hou onuitsprekelijk veel van je.
- de aanvulling bij werkwoorden die een voortbeweging uitdrukken;
De minister reist ter ondertekening van het verdrag naar Parijs.
- de aanvulling bij werkwoorden die een verblijven uitdrukken;
Hij logeert met zijn gezin bij een vriend.
In de bijzin is de ene grijper de persoonsvorm, de andere het onderwerp.
Ik blijf erbij dat zij niet ouder dan zeventien is.
In een infinitiefconstructie wordt de tang gevormd door het voorzetsel (na, zonder, om...) en te ± infinitief.
Na elf dagen bewusteloos in het ziekenhuis gelegen te hebben...
Dit probleem biedt voldoende stof om er onze aandacht aan te wijden.
Het voorzetsel om ‘ontbreekt’ soms, maar het kan dan meestal toegevoegd worden:
Hij voelde de neiging (om) hard te gaan schreeuwen.
In samengestelde zinnen met nevenschikkend verband leidt contractie er soms toe dat de eerste en/ of de tweede grjper van de tang in de tweede nevengeschikte ‘zin’ weggelaten wordt. Ook de woorden in de tang worden soms niet alle herhaald. We hebben in geval van samentrekking alleen die woorden in de tang geteld die er
werkelijk staan en slechts dan als alleen de eerste grijper weggelaten is. Voorbeelden (de getelde woorden zijn onderlijnd):
Als we twaalfinkoopordersper dag hebben, moeten we een inkoper aanstellen en een aparte afdeling maken.
Zijn opvatting wijkt niet af van de algemeen gangbare betekenis van het woord, maar hij bedient zich van een begripsomschrijving die het mogelijk maakt over waarschijnlihkheidsvaagstukken niet alleen vage beschouwingen ten beste te geven, doch ook numerieke uitspraken te doen.
Of, tenslotte, herbergen de krachten der evolutie misschien een principe dat zowel de materie als het leven te boven gaat, een kracht die een voortgaan teweegbrengt naar een vooraf uitgestippeld doel en die daarmee de materiële wet van oorzaak en gevolg niet alleen ontkent maar zelfs omkeert, zodat het gevolg aan de oorzaak vooraf gaat?
Het is bijvoorbeeld onbekend of de West-Saksen via de Theems binnengedrongen zijn, of dat zij op de oostkust aan land zijn gegaan en langs de leknield Road naar de omgeving van Wallingford in de centrale Theemsvallei zijn gekomen.
Wat hun afkomst ook is, deze vroege avonturiers zijn van groot belang, omdat zij de eerste grondleggers waren van het koninkrijk Wessex en uiteindelijk van het koninkrijk Engeland.
In de laatste voorbeeldzin is het woord ‘uiteindelijk’ niet geteld omdat de tweede grijper, nl. ‘waren’, niet herhaald is.
Een bijzondere soort tangconstructie vormt de substantiefsgroepGa naar eind3 van het type determinator ± voorbepaling(en) ± substantief:
de vorige woensdag bij gelegenheid van de tiende verjaardag van het bedrijf gehouden receptie.
De grijpers van de tang zijn de determinator en het substantief. Omdat wij de woorden in de voorbepalingen bij substantieven apart geteld hebben (cfr infra x12), zijn we aan deze soort tangconstructie voorbijgegaan. Alleen als de woorden in de tang duidelijk een beknopte bijzin vormen, die tussen de determinator en het substantief is geplaatst, hebben we ze geteld als ‘woorden in de tang’. Dus wel in
een met zekerheid te voorspellen resultaat
deze, na zorgvuldig onderzoek, wel toegelaten conserveermiddelen
de breder wordende corridor
maar niet in
deze, voor het tot stand komen van een nauwere Europese samenwerking erg belangrijke vergadering.
Binnen in een tangconstructie kan nog een tweede en daarin nog een derde tangconstructie gevormd worden. In de onderstaande zin hebben we het aantal tangen waarin de woorden voorkomen aangegeven met haakjes: ( (( ((( ))) )) ).
Nadat Frankrijk en Groot-Brittannië het in 1916 eens waren geworden (Palestina, dat ((tot het (((aan de zijde van Duitsland strijdende))) Ottomaanse Rijk)) behoorde, na de oorlog onder Brits mardaat) te plaatsen, schreef de Britse minister van buitenlandse zaken, Lord Balfour, in een brief aan lord Rotschild dat de Britse regering gunstig stond tegenover de oprichting van een joods nationaal tehuis in Palestina.
Bij het tellen van de ‘woorden in de tangconstructie’ hebben we geen rekening ge
houden met de ‘tang in de tang’. We hebben alle woorden in de eerste tang slechts eenmaal geteld ook als ze in een tweede of derde tang voorkwamen.
De linguïstische variabelen x11, tot en met x20 hebben te maken met woordsoorten. Tot de substantieven hebben we ook gereken d, de substantieven die samen met andere woorden een werkwoordelijke uitdrukking of een voorzetseluitdrukking vormen. Vb. Om de tuin leiden, met betrekking tot.
Met x12 bedoelen we alle woorden die deel uitmaken van een voorbepaling bij een substantief behalve het lidwoord.
Tot de voorzetsels hebben we ook gerekend om en te in de constructie om (...) te ± ihfinitief. Aangezien we voorzetseluitdrukkingen zoals ‘naar gelang van’ als drie woorden geteld hebben, lag het voor de hand dat we ‘naar’ en ‘van’ als voorzetsels beschouwd hebben.
Met ‘infinitiefconstructies’ bedoelen we naast de zgn. beknopte bijzinnen met een infinitief als kern ook de beknopte subjects- en objectszinnen met een infinitief als kern. De volgende zinnen bevatten dus elk een infinil fconstructie. Na uit de bus gestapt te zijn, werd hij door een wagen aangeredeN. Altijd maar karweitjes op te moeten knappen, stond me op den duur tegen. Hij geloofde, nu de grote stap wel te kunnen wagen. Maria hoorde haar zoontje saxofoon spelen. Ze is er nog niet aan gewend, zoveel geld te moeten beheren. -
Als anaforische pronomina, hebben we geteld: a) aanwijzende voornaamwoorden, bijvoeglijk of zelfstandig gebruikt, bv. deze, dit, die, dat; b) persoonlijke voornaamwoorden 3e persoon: zij (mv), ze, zij, haar, hij het; c) bezittelijke voornaamwoorden 3e persoon: zijn, hun, haar; d) betrekkelijke voornaamwoorden: die, dat wat; e) voornaamwoordelijke bijwoorden: ervan, hiervan, daartegenover, etc.
3. De correlatieberekening
De waarden die de twintig linguïstische variabelen in de zestien teksten aannamen, hebben we gecorreleerd met elkaar en met de gemiddelde clozetest-uitslagen. De correlatiecoëfficiënten kunnen worden afgelezen van de matrix in Tabel III.
Met x1 (lettergrepen per honderd woorden), x2 (éénlettergrepige woorden per honderd woorden) en x3 (woorden met meer dan drie lettergrepen per honderd woorden) hebben we de woordlengte willen meten. 1ange woorden hebben meestal een complexe bouw: ze zijn polymorfematisch en de morfemen vormen samen een hiërarchische structuur. Lange woorden hebben meestal ook een precieze betekenis: ‘houtskooltekening’ is preciezer dan ‘tekening’. Woorden met een precieze betekenis kunnen in minder teksten gebruikt worden dan woorden met een vrage betekenis. De woordlengte staat dus ook in verband met de woordfrequentie: korte woorden zijn hoogfrequent, lange woorden daarentegen langfrequent. De correlatie met het criterium van de leesbaarheid is voor de drie variabelen nagenoeg even hoog: -0.40 voor x1, 0.42 voor x2 en -0.40 voor x3. Onderling correleren ze, zoals verwacht heel hoog.
De variabelen x4 (woorden per zin) en x5 (woorden per T-eenheid) hebben we gekozen om er de syntactische complexiteit mee te meten, in zoverre die tot uiting komt in de lengte. De lengte van de T-eenheid blijkt een duidelijker nevenverschijnsel van de complexiteit te zijn dan de zinslengte.
Als we met x1, x2 en x3 de ‘morfologische lengte’ meten en met x4 en x5 de ‘syntactische lengte’, dan drukken we met x6 (lettergrepen eprzin) en x7 (lettergrepen per T-eenheid) misschien wel de ‘morfologisch-syntactische lengte’ uit. Het gaat hier inderdaad om variabelen die een hoge correlatie met de leesbaarheid vertonen: x6 correleert hoger met de leesbaarheid dan x4; x7 hoger dan x5.
De syntactische complexiteit kan ook anders gemeten worden dan langs de lengte van de zin of de T-eenheid om. Een Nederlandse zin, in de betekenis van subject-predikaatsverbinding, vertoont meestal een zekere spanning, doordat een aantal woorden geklemd zitten in een tang. De grijpers van die tang zijn woorden die naar de betekenis bij elkaar horen. De tangvorming is eigen aan het Nederlands. Ze komt in veel subject-predikaatsverbindingen (persoonsvormconstructiesGa naar eind4, Eng. clauses) voor. Vandaar de hote positieve correlatie (±0.66) tussen het aantal tangconstructies per honderd woorden (x8) en het aantal persoonsvormen van het werkwoord per honderd woorden (x14). Ook in de beknopte bijzin is tangvorming gewoon. De correlatie tussen x8 en x17 (infinitiefconstructies per honderd woorden) bedraagt dan ook ±0.62. De leesbaarheid van een tekst lijdt niet onder de aanwezigheid van tangconstructies, als die niet overspannen zijn. De variabele x8 correleert positief met de leesbaarheid. De variabelen ‘woorden in de tangconstructies’ en ‘woorden per tangcontructue’ correleren negatief met de leesbaarheid. Het aantal woorden dat in een tangconstructie voorkomt, kan groot zijn, omdat de tangconstructies talrijk zijn. Vandaar wellicht de lage correlatie van x9 met de leesbaarheid. Het gemiddeld aantal woorden per tangconstructie drukt beter uit hoe groot de spanning is in de persoonsvorm- of infinitiefconstructie. Een van de grijpers van de tang is in de hoofdzin en de reguliere bijzin altijd de persoonsvorm. Hoe groter het aantal woorden in de tang, hoe kleiner dus het aantal persoonsvormen. Dat blijkt uit de hoge negatieve correlatie tussen x10 en x14. Overspannen tangconstructies komen blijkens de hoge positieve correlatie tussen x10 en x15 vooral in lange T-eenheden voor. Wat de T-eenheid lang maakt, is de lengte van de persoonsvorm- en infinitiefconstructies waaruit ze bestaat, niet hun aantal. Dat blijkt uit de hoge negatieve correlatie tussen x5 (woorden per T-eenheid) en x14 (persoonsvormen per 100 worden). We verwijzen in dat verband ook naar de hoge negatieve correlatie tussen x5 en x8 (tangconstructies per honderd woorden).
Met de variabelen x11 tot en met x20 hebben we willen nagaan in welke mate de aanwezigheid van bepaalde syntactisch of syntactisch-morfologisch gekenmerkte categorieën en/ of subcategorieën van woorden in de teksten, met de leesbaarheid correleert. Bij de keuze van de categorieën en subcategorieën hebben we ons laten leiden door de vaststelling dat de stuijlboekjes altijd zinnen als de volgende hebben afgekeurd:
Met het beschikbaar komen van grote koelmachines en huishoudkoelkasten heeft ook de toepassing van koude op grote schaal haar intrede gedaan bij het conserveren van voedingsmiddelen. Geregeld gebruik van bevroren voedingsmiddelen en systematische bewaring in de huishouding van bederfelijke voedingsmiddelen beneden 5o C vereisen uiteraard de aanwezigheid in huis van een elektrische koelkast.
Deze zinnen zijn voorbeelden van wat in de stijlboekjes ‘naamwoordelijke stijl’ heet. In de gecursiveerde substantiefgroepen is de relatie tussen de kern en de nabepaling te vergelijken met de relatie persoonsvorm-subject of persoonsvorm-direct object.
Table III
CorrelatiematrixGa naar voetnoot*
| variabele | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 1 | - | -895 | 872 | -172 | -019 | -010 | 120 | -147 | -017 | -010 | 164 | 550 | -193 | -107 | 303 | 417 | -122 | -299 | 086 | -303 | -403 |
| 2 | -895 | - | -718 | 039 | -051 | -092 | -170 | 118 | 109 | 045 | -099 | -566 | 273 | 040 | -246 | -417 | 159 | 315 | -058 | 267 | 416 |
| 3 | 872 | -718 | - | 110 | 203 | 244 | 315 | -266 | 020 | 182 | 127 | 367 | 149 | -347 | 395 | 264 | -123 | -180 | -133 | -406 | -398 |
| 4 | -172 | 039 | 110 | - | 815 | 961 | 792 | -523 | -224 | 404 | 085 | -052 | 434 | -388 | 182 | -455 | -401 | 533 | -373 | -004 | -468 |
| 5 | -019 | -051 | 203 | 815 | - | 780 | 962 | -609 | -155 | 618 | 415 | 039 | 610 | -639 | 120 | -404 | -309 | 404 | -562 | 058 | -659 |
| 6 | -010 | -092 | 244 | 961 | 780 | - | 832 | -566 | -241 | 396 | 080 | 083 | 402 | -361 | 304 | -493 | -502 | 480 | -306 | -052 | -549 |
| 7 | 120 | -170 | 315 | 792 | 962 | 832 | - | -651 | -190 | 591 | 396 | 164 | 576 | -594 | 238 | -462 | -418 | 360 | -494 | 013 | -730 |
| 8 | -147 | 118 | -266 | -523 | -609 | -566 | -651 | - | 365 | -577 | -642 | -365 | -409 | 660 | -118 | 313 | 620 | -467 | 218 | 378 | 415 |
| 9 | -017 | 109 | 020 | -224 | -155 | -241 | -190 | 365 | - | 445 | -334 | 262 | -299 | 143 | -046 | 063 | 180 | -245 | 361 | 340 | -260 |
| 10 | -010 | 045 | 182 | 404 | 618 | 396 | 591 | -577 | 445 | - | 362 | 429 | 281 | -623 | 038 | -225 | -368 | 287 | -080 | 001 | -598 |
| 11 | 164 | -099 | 127 | 085 | 415 | 080 | 396 | -642 | -334 | 362 | - | 244 | 303 | -563 | 112 | -109 | -361 | 307 | -246 | -079 | -199 |
| 12 | 550 | -566 | 367 | -052 | 039 | 083 | 164 | -365 | 262 | 429 | 244 | - | -401 | -021 | 019 | 034 | -515 | -085 | 588 | -210 | -502 |
| 13 | -193 | 273 | 149 | 434 | 610 | 402 | 576 | -409 | -299 | 281 | 303 | -401 | - | -688 | 189 | -268 | 166 | 004 | -708 | -258 | -095 |
| 14 | -107 | 040 | -347 | -388 | -639 | -361 | -594 | 660 | 143 | -623 | -563 | -021 | -688 | - | -073 | -094 | -018 | -155 | 598 | 344 | 265 |
| 15 | 303 | -246 | 395 | 182 | 120 | 304 | 238 | -118 | -046 | 038 | 112 | 019 | 189 | -073 | - | -142 | -253 | 095 | -083 | 243 | -240 |
| 16 | 417 | -417 | 264 | -455 | -404 | -493 | -462 | 313 | 063 | -225 | -109 | 034 | -268 | -094 | -142 | - | 567 | -461 | 062 | -319 | 224 |
| 17 | -122 | 159 | -123 | -401 | -309 | -502 | -418 | 620 | 180 | -368 | -361 | -515 | 166 | -018 | -253 | 567 | - | -660 | -246 | -053 | 377 |
| 18 | -299 | 315 | -180 | 533 | 404 | 480 | 360 | -467 | -245 | 287 | 301 | -085 | 004 | -155 | 095 | -461 | -660 | - | -119 | 320 | -112 |
| 19 | 086 | -058 | -133 | -373 | -562 | -306 | -494 | 218 | 361 | -080 | -246 | 588 | -708 | 598 | -083 | 062 | -246 | -119 | - | -037 | 126 |
| 20 | -303 | 267 | -406 | -004 | 058 | -052 | 013 | 378 | 340 | 001 | -079 | -210 | -258 | 344 | 243 | -319 | -053 | 320 | -037 | - | -210 |
| 21 | -403 | 416 | -398 | -468 | -659 | -549 | -730 | 415 | -260 | -598 | -199 | -502 | -095 | 265 | -240 | 224 | 377 | -112 | 126 | -210 | - |
We kunnen de zinnen als volgt herschrijven:
Doordat grote koelmachines en huishoudkoelkasten beschikbaar geworden zijn, is men op grote schaal kou gaan toepassen om voedingsmiddelen te conserveren. Wie geregeld bevroren voedingsmiddelen wil gebruiken en bederfelijke voedingsmiddelen systematisch in de huishouding wil bewaren beneden 5oC, moet uiteraard een elektrische koelkast in huis hebben.
Een vergelijking van de oorspronkelijke met de herschreven zinnen, leert ons dat de laatste samen zeven substantieven minder en drie persoonsvormen meer tellen, te weten resp. 10 i.p.v. 17 en 5 i.p.v. 2. De herschreven zinnen zijn nochtans niet langer dan de oorspronkelijke, integendeel ze zijn maar 46 woorden lang i.p.v. 52.
Wat de stijlboekjes schrijven over de onleesbaarheid van de naamwoordelijke stijl, wordt door het kwantitatief onderzoek bevestigd: de correlatie van variabele x11 (substantieven per honderd woorden) met de leesbaarheid is negatief (-0.20); de correlatie van x14 (persoonsvormen per honderd woorden) met de leesbaarheid is positief (±0.26). Onderling vertonen x11 en x14, zoals men kan verwachten, een vrij hoge negatieve correlatie (-0.56).
In een substantiefsgroep wordt de nabepaling met de kern verbonden door een voorzetsel. Vb.: het antwoord op mijn vraag. Als de nabepaling op haar beurt een kern en een nabepaling bevat, stapelen de voorzetsels zich op. Vb.: het overwegen van het gebruik van kernenergie bij de levensmiddelenconservering. Als we een tekst zo herschrijven dat het aantal substantieven kleiner en het aantal persoonsvormen groter wordt, neemt het aantal voorzetsels af en het aantal onderschikkende voegwoorden toe. In de twee herschreven zinnen komen zes voorzetsels voor, (tegenover twaalf in de oorspronkelijke zinnen), en één onderschikkend voegwoord (in de oorspronkelijke zinnen geen enkel). Het ligt alweer geheel in de lijn der verwachtingen dat x13 (voorzetsels per honderd woorden) negatief met de leesbaarheid correleert (-0.09) en x19 (onderschikkende voegwoorden per honderd woorden) daarentegen positief (±0.13). De hoge negatieve correlatie tussen x13 en x14 (-0.69) en tussen x13 en x9 (-0.71) zal ook wel niemand verwonderen. Het aantal voorzetsels per honderd woorden hebben we in verband gebracht met het aantal nabepalingen bij het substantief, maar wat met de voorbepalingen? Variabele x12 (woorden in de voorbepalingen bij de substantieven per honderd woorden) geeft een negatieve correlatie met de leesbaarheid te zien (-0.50). Uit de correlatiematrix kan men afleiden dat schrijvers zich bedienen van voorbepalingen of nabepalingen, maar niet van beide: de correlatie tussen x12 en x13 is negatief (-0.40). Er is een hoge positieve correlatie tussen x13 en x5, nl. ±0.61, maar tussen x12 en x5 is er slechts een heel lage correlatie: ±0.04. Het zijn dus niet zozeer de voorbepalingen die de T-eenheid lang maken, maar vooral de nabepalingen. Dat blijkt ook nog uit de hoge positieve correlatie tussen x12 en x19 : ±0.59. We treffen de voorbepalingen dus vooral aan in teksten met korte T-eenheden, want het aantal onderschikkende voegwoorden per honderd woorden correleert hoog en negatief met het aantal woorden per T-eenheid (-0.56). Gemakkelijk te verklaren is ook de vrij hoge correlatie tussen x12 en x17 (infinitiefconstructies per honderd woorden). De reguliere bijzin is een subject-predikaatsverbinding. In de beknopte bijzin is het onderwerp niet uitgedrukt. Het onderwerp bestaat veelal uit een substantiefsgroep waarin voorbepalingen voorkomen. Als het onderwerp in de infinitiefconstructie niet uitgedrukt wordt, is de kans vanzelfsprekend gering dat de constructie een substantief met voorbepaling bevat. Wordt de ‘syntactische lengte’ nauwe
lijks beïnvloed door de woorden in de voorbepalingen bij de substantieven dan kan niet hetzelfde gezegd worden van de ‘morfologische lengte’: tussen x12 en x1 is er een vrij hoge positieve correlatie (±4.55), tussen x12 en x2 een vrij hoge negatieve correlatie (-0.57). De woorden in de voorbep alingen bij substantieven zijn bijvoeglijke voornaamwoorden, telwoorden en adjectieven. Vooral adjectieven zijn soms vrij lang.
Tussen onderschikkende en nevenschikkende voegwoorden is er een voor ons belangrijk verschil: de eerste verbin len alleen persoonsvormconstructies, de tweede daarnaast ook woordgroepen en woorden. iariabele x18 (nevenschikkende voegwoorden per honderd woorden) correleert positief met x4 (woorden per zin) en x5 (woorden per T-eenheid). Twee nevengeschikt verbonden subject-predikaatsverbindingen beschouwen we als een enkele zin, maar als twee afzonderlijke T-eenheden. Dat verklaart dat x18 hoger correleert met x4 (±0.53) dan met x5 (±0.40). Op welke manier is het verband tussen het aantal nevenschikkende voegwoorden en de lengte van de zinnen en de T-eenheden te verklaren? Als het aantal nevenschikkende voegwoorden groot is, zijn de tangconstructies weinig talrijk, maar het gemiddeld aantal woorden ‘in de tang’ is vrij, groot: in de tang komen dan nevenschikkend verbonden woorden en woordgroepen voor. Len en ander blijkt uit de negatieve correlatie tussen x18 en x8 (tangconstructies per 100 woorden) en uit de positieve correlatie tussen x18 en x10 (gemiddeld aantal woorden per tangconstructie). Het aantal onderschikkende voegwoorden per honderd woorden (xl9) vertoont een negatieve correlakic met x4 en x5. Dat wijst erop dat het niet het aantal subject-predikaatsverbindingen is dat de zin en de T-eenheid lang maakt, maar het aantal woorden per subject-predikaatsverbinding.
Om een idee te krijgen van het verband tussen de leesbaarheid en de aanwezigheid van werkwoordvormen in de tekst, hebben we behalve de persoonsvormen ook de voltooide deelwoorden en de infinitieven bij ons onderzoek betrokken. Het aantal voltooide deelwoorden per honderd woorden (x5) correleert negatief met de leesbaarheid, het aantal infinitieven per honderd woorden (x16) positief. Zowel infinitieven als voltooide deelwoorden zijn meestal lange woorden (cfr. de correlaties van x15 en x16 met x1, x2 en x3). Dat x16 toch positief met de leesbaarheid correleert, ligt o.a. daaraan dat de infinitief behalve in het werkwoordelijk gezegde van de persoonsvormconstructie ook voorkomt als kern van een infinitiefconstructie. De correlatie van x17 (infinitiefconstructies per honderd woorden) met de leesbaarheid is positief (±0.38). Merkwaardig is echter dat x4 (woorden per zin) en x5 (woorden per T-eenheid) hoger met x16 (infinitieven per honderc: woorden) correleren dan met x17 (infinitiefconstructies per 100 woorden). Dat x17 een positieve correlatie met de leesbaarheid vertoont, hoeft ons niet te verwonderen. Een gedeeltelijke verklaring hebben we hierboven gegeven waar we gewezen hebben op de negatieve correlatie van x17 met x11 (substantieven per honderd woorden) en x12 (woorden in de voorbepalingen bij de substantieven per honderd woorden).
Blijft tenslotte x20 (anaforische pronomina per honderd woorden) te bespreken. Voor de negatieve correlatie met de leesbaarheid (-0.21) is in de correlatiematrix geen bevredigende verklaring te vinden. Anaforisch pronomina zijn korte woorden. Dat blijkt bv. uit de negatieve correlatie van x20 met x3 (woorden met meer dan drie lettergrepen per honderd woorden). Met x4 en x5, de varinbelen ,waarmee we de syntactische lengte hebben willen meten, houdt x20 merkwaardig genoeg nauwelijks verband. Misschien hadden we apart moeten tellen enerzijds de aanwijzende, persoonlijke en bezittelijke voornaamwoorden anderzijds de betrekkelijke voornaamwoorden en de voornaamwoordelijke bijwoorrden. Met
geen enkele van de resterende variabelen vertoont het aantal anaforische pronomina per honderd woorden een noemenswaardige correlatie.
4. De regressieberekening
Om een leesbaarheidsformule te ontwikkelen hebben we nodig: 1. de gemiddelden x1, x2,..., x21 van de waarden die de variabelen voor de 16 tekstpassages aannemen en de standaardafwijkingin s1, s2,..., s21 van die gemiddelden, 2. de correlaties uit tabel III. De correlatie tussen tween variabelen bv. x1 en x2 duiden we aan als r12. Leesbaarheidsformules zijn multipele of meervoudige regressievergelijkingen. Bij het opstellen ervan maken we gebruik van de partiële correlatierekening. De partiële correlatiecoëfficiënt geeft de correlatie aan tussen twee variabelen, als alle variatie in de andere variabelen is onderdrukt. De partiële correlatie van x1 en x2 met uitschakeling van x3, x4,..., xn wordt aangeduid door x12.34...n; de nummers van de consdtant gehouden variabelen staan achter de punt. De multipele regressievergelijking is een regressievergelijking met ten minste drie variabelen: de afhankelijk variabele x1 en de onafhankelijk variabelen x2 en x3. Als de correlatie tussen de afhankelijk veranderlijke en de onafhankelijk veranderlijken lineair is, heeft de vergelijking met drie variabelen de vormx1 =a1.23 x2 + 13.2 x3
daarin is
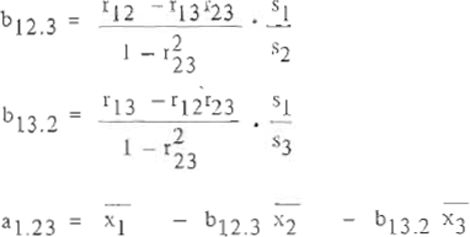
De b-coëfficiënten geven de absolute gewichten, die de onafhankelijk veranderlijken bij de bepaling van de afhankelijk veranderlijke via de regressievergelijking bezitten: de waarden van deze coëfficiënten worden mede beïnvloed door de eenheden waarin de onafhankelijk veranderlijken zijn gemeten.
Met een meervoudige regressievergelijking is het dus mogelijk de waarde van de afhankelijk veranderlijke of te verklaren variabele te schattne uit de waarden van de onafhankelijk veranderlijken of verklarende variabelen. In een leesbaarheidsformule is de te verklaren variabele het criterium van de leesbaarheid; de verklarende variabelen zijn de linguïstische variabelen. We zijn er bij dit onderzoek van uitgegaan dat del inguistische variabelen in lineaire relatie staan tot het criterium van de leesbaarheid maar dat ze onderling lineair onafhankelijk zijn. Die vooronderstellingen werden getoetst.
De formules die we ontwikkeld hebben, maken het mogelijk de leesbaarheid met vrij grote nauwkeurigheid te voorspellen uit de waarde van twee, drie, vier of zes linguistische variabelen.
De eerste formule luidt:
C% = 62.862 - 0.418x7 - 0.323x9waarin C%= het clozepercentage, d.i. het percentage juiste antwoorden dat leerlingen laatste en voorlaatste jaar humaniora zouden geven, als we ze over de tekst een clozetest afnamen;
x7 = lettergrepen per T-eenheid;
x9 = woorden in de tangconstructie per honderd woorden.
De nauwkeurigheid van de voorspelling wordt uitgedrukt door de grootheid R, die we de ‘multipele correlatiecoëfficiënt’ noemen. Het is de maat voor de correlatie tussen de gemiddelde clozetestitslagen van onze proefpersonen, leerlingen voorlaatste en laatste jaar humaniora, en de formule-uitslagen voor de 16 tekstpassages. De multipele R van deze formule is 0.836. Honderdmaal R2 geeft aan hoeveel procent van de veranderlijkheid in het criterium van de leesbaarheid verklaard wordt door de veranderlijkheid in de linguïstische variabelen. Voor deze formule is R2 = 0.698. Aangezien de formule gebaseerd is op slechts 16 observaties, de 16 teksten waarover de proefpersonen een clozetest werd afgenomen, hebben wij R2 gecorrigeerd voor het aantal vrijheidsgraden. Het aantal vrijheidsgraden voor een formule = het aantal observaties - het aantal linguïstische variabelen in de formule - 1.
We berekenen de gecorrigeerde R2 met de formule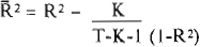
waarin
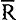 2 - de gecorrigeerde R2
2 - de gecorrigeerde R2
K = het aantal verklarende variabelen in de formule
T = het aantal observaties
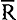 2 = 0.651, wat betekent dat de variabiliteit van de leesbaarheid voor 65 procent verklaard wordt door de variabiliteit van de linguïstische variabelen. De standaardfout van de schatting S.F. = 3.479 d.w.z. dat deze formule, toegepast op de testpassages, scores oplevert die in ±- twee derde van de gevallen niet meer dan 3.479 cloze units (juist ingevulde woorden) van de testscores afwijken.
2 = 0.651, wat betekent dat de variabiliteit van de leesbaarheid voor 65 procent verklaard wordt door de variabiliteit van de linguïstische variabelen. De standaardfout van de schatting S.F. = 3.479 d.w.z. dat deze formule, toegepast op de testpassages, scores oplevert die in ±- twee derde van de gevallen niet meer dan 3.479 cloze units (juist ingevulde woorden) van de testscores afwijken.
De vooronderstellingen bij de keuze van het formule-model werden getoetst. Dat de linguïstische variabelen in lineaire relatie staan tot het criterium van de leesbaarheid, blijkt daaruit dat de waarde van F(2.13)= 15.081. De hypothese dat de verklarende variabelen onderling lineair onafhankelijk zijn is getoetst met een F-toets. Alle variabelen hebben een significantieniveau < 0.02.
In tabel IV geven we voor elke verklarende variabele in de formule: de regressiecoëfficiënt b, de standaardfout SF, de F-waarde en het significantieniveau P.
Tabel IV
Statistische gegevens over de linguïstische variabelen in de eerste formule
| Variabele | Coëfficiënt | SF | F | P |
|---|---|---|---|---|
| 7 | -0.417 | 0.080 | 27.244 | 0.0001 |
| 9 | -0.322 | 0.120 | 7.125 | 0.0192 |
De tweede formule bevat drie linguïstische variabelen: de twee uit de eerste formule en x2 = éénlettergrepige woorden per honderd woorden. Deze formule luidt:
C% = 40.082 ± 0.422x2 - 0.391x7 - 0.344x9R = 0.898,
 2 = 0.757, SF = 2.896 en F(3.12) = 16.760
2 = 0.757, SF = 2.896 en F(3.12) = 16.760
In tabel V geven we weer voor elke variabele in de formule: de regressiecoëfficiënt b, de standaardfout SF, de F-waarde en het significantieniveau P.
Tabel V
Statistische gegevens over de linguïstische variabelen in de tweede formule
| Variabele | Coëfficiënt | SF | F | P |
|---|---|---|---|---|
| 2 | 0.421 | 0.162 | 6.757 | 0.0232 |
| 7 | -0.390 | 0.067 | 33.585 | 0.00008 |
| 9 | -0.343 | 0.101 | 11.573 | 0.0052 |
In de derde formule is x2 vervangen door x1 (lettergrepen per honderd woorden) en x3 (woorden met meer dan drie lettergrepen per honderd woorden). In de matrix (Tabel III) zijn deze twee variabelen sterk gecorreleerd. Dat ze toch in de vergelijking ingevoerd kunnen worden ligt daaraan dat ze niet sterk partieël gecorreleerd zijn: gegeven variabelen x7 en x9 is de correlatie tussen xl en x3 niet groot. De derde formule luidt:
C% = 136.067 - 0.462x1 ± 1.535x3 - 0.479x7 - 0.364x9R = 0.942,
 2 = 0.846, SF = 2.305 en F(4.11) = 21.832 Voor de statistische gegevens over de linguïstische variabelen verwijzen we naar Tabel VI.
2 = 0.846, SF = 2.305 en F(4.11) = 21.832 Voor de statistische gegevens over de linguïstische variabelen verwijzen we naar Tabel VI.
Tabel VI
Statistische gegevens over de linguïstische variabelen in de derde formule
| Variabele | b-coëffiënt | SF | F | P |
|---|---|---|---|---|
| 1 | -0.462 | 0.113 | 16.605 | 0.0018 |
| 3 | ±1.534 | 0.516 | 8.825 | 0.0127 |
| 7 | -0.479 | 0.060 | 63.741 | 0.0000 |
| 9 | -0.364 | 0.081 | 19.997 | 0.0009 |
In deze formule hebben alle variabelen een significantieniveau < 0.02 zoals in de eerste formule. Als het significantieniveau op 0.05 gesteld wordt, is het mogelijk een formule te construeren die de leesbaarheid nog iets nauwkeuriger voorspelt. Hij bevat echter zes verklarende variabelen, wat betekent dat er maar 9 vrijheidsgraden meer overblijven. Deze vierde formule komt tot stand door aan x1 , x3, x7 en x9 achtereenvolgens xl3 en x17 toe te voegen en dan x7 uit de vergelijking te verwijderen.
De vierde formule luidt:
C% =258.767 1.125x1 ± 3.915x3 - 0.778x4 - 0,605x9 1.331x13 ± 1.717x17De multipele R, van deze formule: 0.963; de
 2 = 0.881.
2 = 0.881.
De SF- van de schatting = 2.034 en F (6,9) = 19.539.
In Tabel VII geven we weer voor elke onafhankelijk veranderlijke in de formule: de regressiecoëfficiënt b, de standaardfout SF, de F-waarde en het significantieniveau.
Tabel VII
Statistische gegevens over de linguïstische variabelen in de vierde formnule
| Variabele | Coëffiënt | SF | F | P |
|---|---|---|---|---|
| 1 | -1.125 | 0.156 | 51.869 | 0.0000 |
| 3 | ±3.915 | 0.670 | 34.096 | 0.0002 |
| 4 | -0.778 | 0.125 | 38.509 | 0.0001 |
| 9 | -0.605 | 0.085 | 49.787 | 0.0000 |
| 13 | -1.331 | 0.278 | 22.783 | 0.0010 |
| 17 | ±1.717 | 0.719 | 5.693 | 0.0408 |
Als we een keuze moeten maken tussen de vier besproken formules, kiezen we de derde. Hij verklaart 85% van de veranderlijkheid in het leesbaarheidscriterium. Dat is nagenoeg 10% meer dan de tweede formule en 20% meer dan de eerste. De vierde formule voorspelt de leesbaarheid nog wel iets nauwkeuriger dan de derde, maar daar staat tegenover dat de vierde formule, met zijn zes linguïstische variabelen veel moeilijker is dan de derde.
Dat we de variabiliteit in ons criterium voor 85 en zelfs 90% kunnen voorspellen is verwonderlijk, gezien de kleine leesbaarheidverschillen tussen de criteriumteksten (cfr. de kleine spreidingsbreedte van de gemiddelde clozetest-uitslagen in Tabel I) Het blijkt dus mogelijk te zijn om heel nauwkeurig kleine leesbaarheidsverschillen te voorspellen met vrij gemakkelijke formules.
5. Factoranalyse
Omdat we willen weten, in hoeverre onze linguïstische variabelen verschillende dimensies van de leesbaarheid bepalen, hebben we een factoranalyse uitgevoerd. De factoranalyse is een statistische techniek waarmee we de variantie van de variabelen kunnen ontlï,den in gemeenschappelijke en specifieke dimensies ‘factoren’ genoemd. Het uitgangspunt van de factoranalyse vormen de geobserveerde correlaties tussen de linguïstische variabelen; het resultaat is een aantal factoren en de mate waarin die factoren voorkomen in elke variabele. De gevonden factoren interpreteert men, rekening houdend met de variabele(n) waarin ze voorkomen.
De totale variantie is de som van de getallen op die diagonaal van decorrelatiemarix. In ons geval bedraagt die som 20. Het deel van die variartie dat door een variabele verklard wordt, is de eigenwaarde voor die variabele. Do correlatiematrix
die als uitgangspunt van de factoranalyse diende, was overbepaald: van de totale variantie wordt 94% verklaard door dertien factoren; de veertiende t.e.m. de twintigste factor hebben echter een negatieve eigenwaarde. Onze bespreking is beperkt tot de acht factoren waarvan de eigenwaarde groter is dan 0.50. De factoren zijn niet gecorreleerde basisvariabelen. Men kan ze voorstellen als orthogonale vectoren. De acht factoren die het voorwerp zijn van onze bespreking, stelle men zich voor als acht orthogonale vectoren in een achtdimensionale ruimte. De mate waarin een factor in een variabele voorkomt, wordi uitgedrukt door de partiële correlatie tussen de factor en de variabele, het is de lading die de variabele op de factor heeft.
Door de factor te roteren kan men de hoge factorladingen nog hoger en de lage nog lager maken. In geval van orthogonale rotatie zijn de factoren ook na de rotatie nog ongecorreleerd. Wat het principe van de orthogonale rotatie is, hebben we trachten te verduidelijken met de grafische voorstelling van een fictief voorbeeld
Figuur VIII
Orthogonale factorrotatie
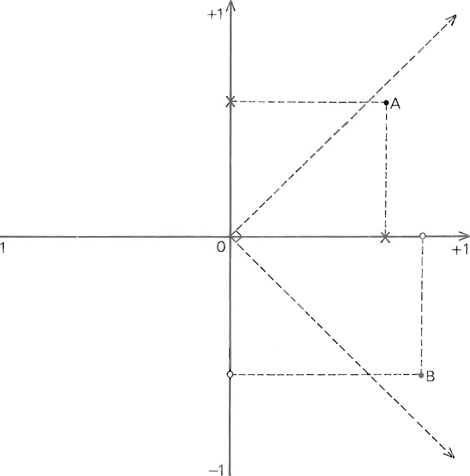
In figuur VIII stellen we twee variabelen, A en B, voor in een tweedimensionale factorruimte. De ladingen van A op de niet geroteerde factors zijn aangegeven met een kruisje op iedere as. De afstanden van het punt waar de assen elkaar snijden naar de kruisjes stellen voor hoe hoog de ladingen zijn. De ladingen van variabele B zijn aangegeven met cirkeltjes op de assen. De beide variabelen hebben een zeer hoge positieve lading op de niet geroteerde eerste factor. Op de niet geroteerde tweede factor heeft variabele A een vrij hoge positieve lading en variabele B een vrij hoge negatieve lading. Na de rotatie van de factors krijgen we totaal verschillende ladingen. Variabele A heeft een zeer hoge positieve lading op de geroteerde factor II, maar een zeer lage positieve lading op de geroteerde factor I. Met variabele B is het net andersom: hij heeft een hoge positieve lading op de geroteerde factor I en een lage positieve lading op de geroteerde factor II.
Voor de orthogonale rotatie van de acht factoren hebben we de VARIMAX-methodeGa naar eind5 gebruikt. De niet-geroteerde factorladingen geven we in tabel IX, de factorladingen na de rotatie in tabel X. de matrix in tabel X is gesorteerd: ladingen van minder dan 0,25 zijn vervangen door nul. Ter wille van de duidelijkheid zijn de variabelen zo onder elkaar geschikt dat de variantie, verklaard door de factoren, gegeven wordt van hoog naar laag.
Tabel IX
De factorladingen van de linguïstische variabelen vóór de rotatie
| Factoren | ||||||||
|---|---|---|---|---|---|---|---|---|
| Variabelen | I | III | III | VI | V | VI | VII | VIII |
| 1 | 0.052 | 0.936 | -0.060 | -0.125 | 0.215 | 0.164 | 0.026 | 0.033 |
| 2 | -0.071 | -0.879 | 0.013 | 0.210 | -0.260 | -0.060 | 0.176 | 0.160 |
| 3 | 0.304 | 0.786 | -0.198 | -0.027 | 0.297 | 0.005 | 0.152 | 0.257 |
| 4 | 0.814 | -0.221 | 0.093 | -0.124 | 0.254 | -0.335 | -0.190 | 0.061 |
| 5 | 0.917 | -0.101 | -0.068 | 0.143 | 0.175 | -0.005 | -0.166 | -0.209 |
| 6 | 0.838 | -0.071 | 0.156 | -0.190 | 0.304 | -0.349 | -0.055 | 0.052 |
| 7 | 0.936 | 0.029 | 0.002 | 0.056 | 0.220 | -0.027 | -0.024 | -0.233 |
| 8 | -0.818 | -0.196 | -0.088 | 0.050 | 0.426 | -0.023 | -0.039 | -0.049 |
| 9 | -0.292 | 0.058 | 0.319 | 0.818 | 0.303 | -0.087 | 0.074 | 0.135 |
| 10 | 0.630 | 0.098 | 0.236 | 0.691 | -0.115 | -0.009 | -0.029 | -.092 |
| 11 | 0.512 | 0.163 | -0.036 | 0.012 | -0.443 | 0.512 | 0.033 | -0.123 |
| 12 | 0.132 | 0.718 | 0.556 | 0.217 | -0.203 | -0.094 | 0.013 | -0.232 |
| 13 | 0.625 | -0.262 | -0.638 | -0.107 | -0.003 | -0.032 | 0.403 | -0.043 |
| 14 | -0.706 | -0.135 | 0.474 | -0.343 | 0.229 | -0.144 | 0.114 | -0.150 |
| 15 | 0.248 | 0.169 | 0.069 | -0.164 | 0.378 | 0.236 | 0.315 | 0.179 |
| 16 | -0.450 | 0.471 | -0.428 | 0.105 | -0.046 | 0.064 | -0.377 | 0.162 |
| 17 | -0.527 | -0.142 | -0.734 | 0.284 | 0.183 | -0.059 | -0.136 | -0.084 |
| 18 | 0.519 | -0.375 | 0.444 | -0.226 | -0.139 | 0.203 | -0.222 | 0.351 |
| 19 | -0.486 | 0.255 | 0.633 | 0.051 | -0.193 | -0.229 | 0.112 | 0.011 |
| 20 | -0.111 | -0.491 | 0.442 | 0.134 | 0.548 | 0.601 | -0.079 | -0.103 |
| Verklaarde variantie (eigenwaarde) | ||||||||
| 6.561 | 3.728 | 2.706 | 1.652 | 1.550 | 1.085 | 0.635 | 0.519 | |
Table X
Gesorteerde factorladingen na de rotatie (varimax)
| Factoren | ||||||||
|---|---|---|---|---|---|---|---|---|
| Variabelen | I | II | III | IV | V | VI | VII | VIII |
| 6 | 0.946 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.252 | 0.0 |
| 4 | 0.937 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7 | 0.874 | 0.0 | 0.409 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 0.862 | 0.0 | 0.466 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.959 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.889 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | -0.887 | 0.0 | -0.271 | 0.0 | 0.0 | 0.0 | 0.0 |
| 11 | 0.0 | 0.0 | 0.801 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 14 | -0.343 | 0.0 | -0.789 | 0.323 | 0.274 | 0.0 | 0.0 | 0.0 |
| 8 | -0.458 | 0.0 | -0.626 | 0.0 | 0.302 | 0.0 | -0.340 | 0.0 |
| 10 | 0.423 | 0.0 | 0.569 | 0.0 | 0.0 | 0.630 | 0.0 | 0.0 |
| 12 | 0.0 | 0.412 | 0.0 | 0.854 | 0.0 | 0.0 | 0.0 | 0.0 |
| 19 | -0.379 | 0.0 | -0.382 | 0.667 | 0.0 | 0.0 | 0.0 | 0.0 |
| 17 | -0.353 | 0.0 | 0.0 | -0.607 | 0.0 | 0.0 | -0.615 | -0.254 |
| 13 | 0.425 | 0.0 | 0.466 | -0.555 | 0.0 | 0.0 | 0.0 | 0.471 |
| 20 | 0.0 | 0.0 | 0.0 | 0.0 | 1.031 | 0.0 | 0.0 | 0.0 |
| 9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.921 | 0.0 | 0.0 |
| 18 | 0.370 | -0.273 | 0.0 | 0.0 | 0.0 | 0.0 | 0.756 | 0.0 |
| 16 | -0.469 | 0.410 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -0.516 |
| 15 | 0.0 | 0.408 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.381 |
| Verklaarde variantie (eigenwaarde) | ||||||||
| 4.681 | 3.194 | 2.859 | 2.292 | 1.610 | 1.545 | 1.429 | 0.825 | |
De variabelen 6 (lettergrepen per zin) en 4 (woorden per zin) hebben heel hoge ladingen op Factor I en geen belangrijke ladingen op de andere factoren. Ook de variabelen 7 (lettergrepen per T-eenheid) en 5 (woorden per T-eenheid) hebben hoge ladingen op Factor I, ofschoon ook Factor III op deze variabelen een vrij belangrijke invloed uitoefent. Het is duidelijk dat Factor I te maken heeft met de syntactische moeilijkheid voor zover ze tot uiting komt in de lengte.
Factor II is de enige die in belangrijke mate voorkomt in de variabelen 1 (lettergrepen per honderd woorden), 3 (woorden met meer dan drie lettergrepen per 100 woorden) en 2 (eenlettergrepige woorden per woorden). Factor II heeft te maken met de woormoeilijkheid, voor zover ze tot uiting komt in de lengte.
De variabelen 11 (substantieven per 100 woorden) en 14 (persoonsvormen van het werkwoord per honderd woorden) hebben hoge ladingen op Factor III en lage op de andere factoren. De elementen 8 (tangconstructies per 100 woorden) en 10 (gemiddeld aantal woorden per tangconstructie) hebben hoge ladingen of Factor III, maar in deze variabelen komt ook Factor I in vrij hoge mate voor. Om Factor III te kunnen interpreteren mogen we niet uit het oog verliezen dat een enkel voudife zin een subject-predikaatsverbinding is en dus minimaal een nomen en een persoonsvorm van het werkwoord bevat. Samengestelde zinnen bestaan uit twee of meer subject-predikaatsverbindingen. Vooral in geval van onderschikking is
het verband tussen de subject-predikaatsverbindingen niet oppervlakkig: de elementen 7 (lettergrepen per T-eenheid) en 5 (woorden per T-eenheid) hebben dan ook vrij hoge ladingen op deze factor. In een subject-predikaatsverbinding die bestaat uit meer dan een nomen en een persoonsvorm. wordt een tang gevormd waarvan de persoonsvorm één der grijpers is. Factor I heeft te maken met de syntactische complexiteit van een tekst, zoals die tot uiting komt in de structuur van de ‘clause’, de subject-predikaatsverbinding. Die syntactische complexiteit is groter naar gelang het aantal persoonsvormen kleiner en het aantal substantieven groter is of nog naar gelang het aantal tangconstructies kleiner is en het aantal woorden in de tang groter.
Op Factor IV hebben de variabelen 12 (woorden in de voorbepalingen bij de substantieven) en 19 (onderschikkende voegwoorden per 100 woorden) een hoge positieve lading; de variabelen 17 (infinitiefconstructies per 100 woorden) en 13 (voorzetsels per 100 woorden) hebben een hoge negatieve lading op deze factor. Een mogelijke interpretatie is dat deze factor vooral verband houdt met voorbepalingen bij substantieven die als subject fungeren. Het subject van een zin is een nominale constituent die veelal bestaat uit een substantief met een voorbepaling. Zo'n substantiefgroep komt niet alleen in onafhankelijke zinnen en hoofdzinnen, maar ook in bijzinnen voor. Als bijzinnen echter de vorm aannemen van een infinitiefconstructie wordt het onderwerp niet uitgedrukt. Reguliere bijzinnen worden met de hoofdzin veelal verbonden door een voegwoord, ‘infinitiefzinnen’ door een voorzetsel.
Factor V is een doublure van variabele 20 (anaforische pronomina per 100 woorden). Op deze variabele, de enige met een hoge lading op Factor V, oefenen geen andere factoren een noemenswaarde invloed uitGa naar eind6.
Op Factor VI heeft variabele 9 (woorden in tangconstructies per 100 woorden) een hoge lading. Variabele 10 (gemiddeld aantal woorden per tangconstructie) heeft een vrij hoge lading op deze factor, die duidelijk te maken heeft met de spanning die in de Nederlandse zin wordt teweeggebracht als woorden ver van elkaar staan, ofschoon ze naar betekenis samenhoren.
Factor VII houdt verband met nevenschikking. Variabele 18 (nevenschikkende voegwoorden per 100 woorden) heeft er een hoge positieve lading op. Variabele 17 (infinitiefconstructies per 100 woorden) heeft een hoge negatieve lading op deze factor, doordat ‘infinitiefzinnen’ bijzinnen zijn en dus geassocieerd moeten worden met onderschikking en niet met nevenschikking.
Op Factor VIII ten slotte heeft variabele 16 (infinitieven per 100 woorden) een vrij hoge negatieve lading en variabele 15 (voltooide deelwoorden per 100 woorden) een minder hoge positieve lading. We zouden daaruit kunnen besluiten dat Factor VIII te maken heeft met de niet-persoonsvormen van het werkwoord. Op de genoemde variabelen oefent'ook Factor II invloed uit. Factor VIII zou daarom alleen verband houden met het syntactisch aspect van de niet-persoonsvormen van het werkwoord. Een kleine moeilijkheid bij de interpretatie van I-actor V I blijft echter dat hij ook voorkomt in variabele 13 (voorzetsels per 100 woorden), waarvoor geen bevredigende verklaring te vinden is.
Het blijkt dat onze factoranalyse acht factoren heeft opgeleverd, die we tentatief als volgt kunnen etiketteren:
| I: | syntactische lengte |
| II: | morfologische lengte |
| III: | structuur van de subject-predikaatsverbinding |
| V: | voorbepalingen in de subjects-NC's |
| V: | anaforische pronomina |
| V1: | spanning van de tangconstructies |
| VII: | nevenschikking |
| VIII: | syntactisch aspect van de niet-persoonsvorm van het werkwoord |
De belangrijkste factor heeft te maken met de syntactische moeilijkheid, de opéén-na belangrijkste met de woordmoeilijkheid. Er is maar één variabele met een lading van meer dan 0.30 op beide factoren, namelijk x16 (infinitieven per honderd woorden). De variabelen met een lading van rieer dan 0.30 op Factor III hebben alle, behalve x11 (substantieven per honderd woorden) eveneens ladingen die ten minste even hoog zijn op Factor I. Ook de overige factoren kunnen gemakkelijker met de syntacu:ische moeilijkheid in verband gebracht worden, dan met de woordmoeilijkheid.
6. Besluit
Bij wijze van besluit willen we laten zien in welke mate de verschillende variabelen in de formules ook verschillende factors representeren.
Variabele x7 (lettergrepen per T-eenheid), de eerste variabele die we in de stapsgewijze regressieberekening ingevoerd hebben, heeft een hoge lading op Factor I en een vrij hoge op Factor III. Onze verwachting dat we met die variabele behalve de syntactische lengte ook de morfologische lengte meten is maar gedeeltelijk uitgekomen: cfr de lage lading van x7 op Factor II. Met x9 (woorden in de tangconstructies per honderd woorden) is Factor VI in de formales vertegenwoordigd, die zoals Factor I duidelijk gerelateerd is aan de syntactische complexiteit. Vanaf de tweede formule is ook Factor II vertegenwoornigd: in de tweede formule met x2 (éénlettergrepige woorden per honderd woorden) en in de derde en vierde formule met xl (lettergrepen per honderd woorden) en x3 (woorden met meer dan drie lettergrepen per honderd woorden). Dat x1 en xsub, ondanks hun hoge ladingen op dezelfde factor, samen in een formule kunnen optreden, is maar mogelijk doordat ze eerst na x7 en x9 in de stapsgewijze regressieberekern ag ingevoerd zijn. Gegeven x7 en x9 is de partiële correlatie tussen x1 en x3 klein. De onafhankelijke bijdrage van elk van die variabelen is m.a.w. zo groot, dat ze beide in de regressievergelijking ingevoerd kunnen worden. In de vierde formule is facter I niet langer vertegenwoordigd met x7, (lettergrepen per T-eenheid) maar met x4 (woorden perzin). Doordat x7 uit de vergelijking verdwijnt, kunnen x13 (voorzetsels per honderd woorden) en xl7 (infinitiefconstructies per honcerd woorden) erin opgenomen worden. Met x7 was Factor III in de formule vertegenwoordigd, maar met x4 niet meer. Die leemte wordt opgevuld door de variabele x13, die een even hoge lading op Factor III heeft als x7. Zijn hoogste ladingen heeft x13 echter op Factor IV en Factor VIII Met x17 (infinitiefconstructies per honderd woorden) komt ten slotte Factor VII aan bod (en daarnaast nog eens Factor IV). In de formule met zes linguïstische variabelen is dus allen van Factor V geen spoor te vinden.
Bibliografie
Van Remoortele, Roland, Contribution to the measurement of readability of Dutch popular sciernific texts translated from English, Onuitgegeven licentiaatsscriptie, Hoger Instituut voor Vertalers en Tolken, Gent, 1974.
- eind1
- Het voorlaatste en laatste jaar oude en moderne humaniora in België corresponderen grosso modo met het voorlaatste en laatste jaar V.W.O. en H A.V.O. in Nederland
- eind2
- Voor een uitvoerige behandeling van de cloze procedure verwijzen we naar P. van Hauwermeiren, Het leesbaarheidsonderzoek, Groningen, H.D. Tjeenk Willink bv. 1975, p. 77-88, waar achtereenvolgens besproken worden: de theoretische basis van de cloze procedure; de validiteit en de betrouwbaarheid van de clozetest; het methodologisch onderzoek betreffende de constructie en het afnemen van de test alsook betreffende het berekenen en interpreteren van de uitslag.
- eind3
- Zie Rijpma, E. en Schuringa, F.G., Nederlandse spraakkunst, bewerkt door J. van Bakel, Eenentwintigste druk, Groningen, J.B. Wolters, 1968, p. 194-195.
- eind4
- Zie Rijpma, E. en Schuringa, F.G., Nederlandse spraakkunst, bewerkt door J. van Bakel, Eenentwintigste druk, Groningen, J.B. Wolters, 1968, p. 222-226.
- voetnoot*
- In deze correlatiematrix zijn ter wille van de overzichtelijkheid allen decimalen opgenomen. De eenentwintigste variabele is de afhankelijk veranderlijke.
- eind5
- Wij bedienden ons van het computerprogramma BMDP4M -Factor Analysis-Double Precision Version, Health Sciences Computing Facility, University of California, Los Angeles. Wij danken Mevr. M. Vuylsteke-Wauters, Wetenschappelijk medewerkster aan het Rekencentrum van de Universiteit Leuven voor haar gewaardeerde medewerking.
- eind6
- Factorladingen variëren van ± 1 tot - 1. Dat we als lading van variabele 20 op factor V 1.031 krijgen, is te wijten aan een afrondingsfout.