
Madoc. Jaargang 2005
(2005)– [tijdschrift] Madoc–
[pagina 24]
| |||||||||
Margit Rem
| |||||||||
Corpus en lokaliseringsprocedureBinnen de Letterenfaculteiten wordt langzamerhand steeds meer gebruik gemaakt van de computer, niet alleen bij het beschrijven van het onderzoek, maar vooral ook bij het onderzoek zelf. Daardoor kunnen andere onderzoeksvragen worden geformuleerd en beantwoord dan in het verleden. In dit artikel wordt een nieuwe onderzoeksmethode en de gebruiksmogelijkheden van deze methode gepresenteerd. Tot nu toe werd de dialectale kleuring van Middelnederlandse teksten bepaald door specialisten die door jarenlange ervaring met deze teksten op basis van hun kennis en intuïtie een uitspraak deden. Het probleem hierbij is niet alleen dat intuïtie niet controleerbaar is, maar ook dat op deze manier maar weinig mensen in staat zijn een uitspraak te doen over de mogelijke herkomst van een tekst. Een computerprogramma dat op basis van dialectkenmerken de mogelijke plaats van herkomst van een tekst berekent, is daarom wenselijk. Zo kan intuïtie meetbaar worden gemaakt en kunnen teksten op grotere schaal worden gelokaliseerd. Aan de Vrije Universiteit van Amsterdam is onder leiding van Piet van Reenen en Maaike Mulder jarenlang gewerkt aan de opbouw van een corpus met veertiende-eeuwse oorkonden (het Corpus veertiende-eeuws Middelnederlands.) Dit corpus wordt nu aan de vua, het Meertens Instituut en de Universiteit van Gent afgerond.Ga naar eindnoot1 Het corpus bestaat uit circa 3000 veertiende-eeuwse oorkonden, die zijn vervaardigd in 342 verschillende plaatsen in het gebied waar in de veertiende eeuw Middelnederlands werd gesproken en vooral ook geschreven. De zuidgrens van dit gebied is niet moeilijk te bepalen; we hebben te maken met een (Franse) taalgrens. Ook de westgrens levert geen problemen op; daar ligt immers de zee. Dit geldt gedeeltelijk ook voor de noordgrens. Er zijn overigens geen Friestalige oorkonden binnen het corpus opgenomen. De oost- | |||||||||
[pagina 25]
| |||||||||
grens is echter zeer lastig te bepalen. Het Middelnederlands gaat vloeiend over in het Duits. Hier is sprake van een dialectcontinuüm. Er is voor gekozen de huidige politieke oostgrens aan te houden. Op basis van dit corpus heeft de auteur van dit artikel samen met de wiskundige Evert Wattel een computerprogramma ontwikkeld, waarmee veertiende-eeuwse teksten van onbekende herkomst toch op taalkundige gronden in een bepaalde plaats of gebied gelokaliseerd kunnen worden.Ga naar eindnoot2 Dit lokaliseringsprogramma vergelijkt dialectkenmerken uit documenten van onbekende herkomst met dialectkenmerken uit de oorkonden uit het Corpus veertiende-eeuws Middelnederlands. Van deze laatste dialectkenmerken is ongeveer bekend in welke plaats ze aan het perkament zijn toevertrouwd. Dit komt omdat er binnen het corpus alleen oorkonden zijn opgenomen waarin lokale aangelegenheden tussen personen of instanties uit één enkele plaats zijn geregeld.Ga naar eindnoot3 Deze personen mogen een niet te hoge maatschappelijke positie vervullen. Aangenomen wordt dan vervolgens dat deze oorkonden door een plaatselijke scribent in het plaatselijke dialect geschreven zijn. Graven, en ook bijvoorbeeld hertogen en bisschoppen, konden door hun bovenregionale contacten en mogelijkheden om personeel van buiten de eigen naaste omgeving te werven, ook oorkonden laten vervaardigen die niet in het plaatselijke dialect geschreven zijn. Deze laatste oorkonden zijn niet toegelaten binnen het Corpus veertiende-eeuws Middelnederlands. Een simpel voorbeeld laat zien hoe de lokaliseringsprocedure in beginsel werkt. Het werkwoord sellen ‘zullen’, met een -e- en dubbel -ll- gespeld, komt vooral rond Utrecht voor. De schrijfwijze van de naam ‘Willem’ met een -a- (Willam) komt veelvuldig voor in de buurt van Utrecht, maar in mindere mate ook daarbuiten. Stel nu dat men een oorkonde wil lokaliseren waarin zowel de vorm sellen als Willam voorkomen en waarin verder geen kenmerken aanwezig zijn die niet rond Utrecht zijn aangetroffen, dan zal deze oorkonde binnen de lokaliseringsprocedure vooral hoge overeenkomsten scoren op materiaal uit (plaatsen rond) Utrecht.
Er zijn verschillende testen ontwikkeld om de betrouwbaarheid van de lokaliseringsprocedure te valideren. Zo is de helft van het taalmateriaal uit een groot aantal plaatsen uit het Corpus veertiende-eeuws Middelnederlands gehaald. Deze oorkonden moesten daarna door de computer gerelateerd worden aan de plaats waar zij geschreven zouden zijn. Dit experiment lukte. Vervolgens is ook nog geprobeerd al het taalmateriaal uit een groot aantal plaatsen te lokaliseren, zonder dat het plaatselijke (of regionale) taalmateriaal in de database aanwezig was. Daarbij zijn bijvoorbeeld, bij wijze van proef, alle oorkonden uit Utrecht tijdelijk uit de database verwijderd. Vervolgens is geprobeerd de dialectkenmerken uit deze Utrechtse oorkonden in de geografische ruimte te plaatsen. De Utrechtse dialectkenmerken blijken in de omgeving van de stad Utrecht gelokaliseerd te worden, zoals op de kaart (Utrecht zonder Utrecht, afb. 3) te zien is. Hoewel er dus geen gegevens uit Utrechtse oorkonden meer in de database aanwezig waren, geeft de toetsing van de Utrechtse oorkonden aan het overige taalmateriaal uit de database aan, dat deze oorkonden in de directe omgeving van Utrecht moeten zijn ontstaan. De achterliggende gedachte bij deze test is dat dialecten geen volledig geïsoleerde entiteiten zijn, maar in grote lijnen geleidelijk in elkaar overgaan. Op grond van dit resultaat mogen twee dingen geconcludeerd worden. Ten eerste geeft de lokaliseringsprocedure voor de stad Utrecht een bevredigend resultaat, zelfs als kenmerken uit die stad niet in de database | |||||||||
[pagina 26]
| |||||||||
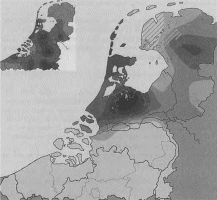 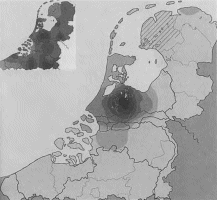
Afb. 1 en 2 Kaartjes van de frequentie van de verschillende spellingsvormen van ‘Willem’ en ‘zullen’ in het Corpus veertiende-eeuws Middelnederlands. Een donkere kleuring op de kaart wil zeggen dat in die regio varianten uit de rechtergroep (Willam, willaem met -a(e)- en sellen met -e- en -ll-) vaker voorkomen dan varianten uit de linkergroep. De kleine inzetkaartjes linksboven laten zien hoe vaak beide varianten (dus de spelling van Willem zowel met -e- als met -a(e)-) in het gehele onderzoeksgebied voorkomen. Hoe donkerder de kleuring, hoe vaker het woord in al zijn varianten in de oorkonden uit dat gebied is aangetroffen. Uit: Rem, De taal van de klerken (noot 2) 234 en 243.
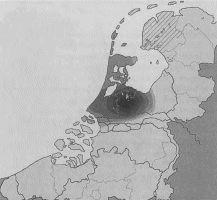
Afb. 3 Kaartje van de selectie ‘Utrecht zonder Utrecht’. Uit: M. Rem, De taal van de klerken (Amsterdam-Münster 2003) 257.
| |||||||||
[pagina 27]
| |||||||||
aanwezig zijn. Ten tweede lijkt het taalgebruik van de stad Utrecht op het taalgebruik uit de omgeving van Utrecht. | |||||||||
Oorkondeschrijvers uit de Hollandse grafelijke kanselarijIn de dissertatie van de auteur van dit artikel staat het taalgebruik centraal van de klerken die werkten in de omgeving van de graaf van Henegouwen, Holland en Zeeland in de periode van 1300 tot 1340.Ga naar eindnoot4 De schrijvers van de graaf produceerden geen plaatselijke oorkonden. De graaf reisde op en neer tussen Holland en Henegouwen. Een gedeelte van de kanselarij, het grafelijke schrijfcentrum, reisde met hem mee. Wanneer de graaf in Holland verbleef, dan verbleef hij vooral in Den Haag, maar het is niet correct om de kanselarij zonder meer in Den Haag te lokaliseren. Daarbij komt dat de graaf juist door zijn reizen de mogelijkheid had om zijn personeel uit verschillende plaatsen te rekruteren. Zo komt Melis Stoke, een belangrijke scribent binnen de kanselarij en schrijver van een gedeelte van de Rijmkroniek van Holland, uit Dordrecht.Ga naar eindnoot5 Het taalgebruik van de schrijvers uit de grafelijke kanselarij is onderwerp van onderzoek geweest. Acht scribenten uit de kanselarij die allen verscheidene oorkonden (minimaal zes stuks) hebben geschreven, zijn geselecteerd en met behulp van de lokaliseringsmethode aan een plaats gekoppeld.Ga naar eindnoot6 Hierbij stonden de volgende vragen centraal:
| |||||||||
Herkomst scribenten uit de kanselarijBij aanvang van het onderzoek bestond de hoop dat van de verschillende grafelijke scribenten een éénduidige plaats van herkomst, of eventueel zelfs een geboorteplaats, aangewezen zou kunnen worden, maar omdat alle grafelijke scribenten in meer of mindere mate gebruik maken van dialectvarianten uit uiteenliggende gebieden, was het niet mogelijk om hun precieze dialectale herkomst te achterhalen. Toch is het taalgebruik van iedere scribent wel globaal in de geografische ruimte te plaatsen. De overeenkomst tussen de dialectkenmerken die een bepaalde scribent gebruikt en de dialectkenmerken uit plaatselijke oorkonden, zijn in grijstinten zichtbaar te maken op een kaart. Zo is op het onderstaande kaartje (afb. 4) de overeenkomst van het taalgebruik van een van de scribenten (Hand 2 genaamd) met het taalgebruik in oorkonden uit bepaalde plaatsen uit het Corpus veertiende-eeuws Middelnederlands gevisualiseerd. We zien dat deze scribent uit de grafelijke kanselarij een westelijk Middelnederlands schrijft dat vooral kan worden geplaatst in het zuidwesten van Holland. Daar vinden we de donkerste kleuring op de kaart. | |||||||||
[pagina 28]
| |||||||||
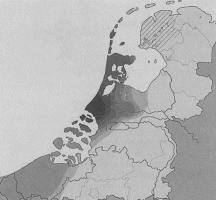
Afb. 4 De lokalisering van het taalgebruik van grafelijke scribent Hand 2. Uit: M. Rem, De taal van de klerken (Amsterdam-Münster 2003) 273.
| |||||||||
Dialect binnen de kanselarij in haar geheelWanneer het taalgebruik binnen de grafelijke kanselarij in haar geheel berekend wordt, dan blijkt dat de taal van de kanselarij vooral op het Dordts lijkt en geografisch in het zuidwesten van Holland geplaatst moet worden. Dordrecht was een politiek en economisch zeer belangrijke stad in het zuiden van Holland, die zeer nauwe banden onderhield met het Hollands-Henegouwse gravenhuis. Op het kaartje (afb. 5) wordt deze overeenkomst tussen het taalgebruik binnen de grafelijke kanselarij en het veertiende-eeuwse Dordts echter niet gevisualiseerd. Dit komt doordat juist het dialect van Dordrecht niet onmiddellijk gerelateerd kan worden aan het taalgebruik in de directe omgeving, maar sterk overeenkomt met het taalgebruik in andere grotere plaatsen in het zuidwesten van Holland. Opmerkelijk is dat het taalgebruik van Gouda hoegenaamd niet lijkt op dat van de grafelijke kanselarij. Op de tweede vraag die hierboven gesteld werd, kan dus geantwoord worden dat men binnen de Hollandse kanselarij Hollands schreef. Bij een aantal scribenten zijn echter ook zeker zuidelijke trekjes aanwijsbaar. De scribenten gebruiken allemaal kenmerken uit verschillende dialecten (door elkaar) en ze gebruiken ook allemaal dialectkenmerken die niet typerend voor Holland zijn. Alle scribenten en de kanselarij in haar geheel zijn dialectaal gezien echter westelijk georiënteerd. 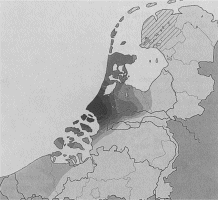
Afb. 5 De lokalisering van het taalgebruik in de grafelijke kanselarij, 1300-1340. Uit: M. Rem, De taal van de klerken (Amsterdam-Münster 2003) 265.
| |||||||||
[pagina 29]
| |||||||||
Het ontstaan van een kanselarijtaalOntstaat er ook al een kanselarijtaal aan het begin van de veertiende eeuw? Na het uitsterven van het Hollandse huis ontwikkelt de kanselarij zich aan het begin van de veertiende eeuw opnieuw tot een professioneel schrijfbureau met een hiërarchische structuur. Er ontstaat een kanselarijdictaat en een nieuw type kanselarijschrift. Ook de keuze voor bepaalde taalvarianten (typerend voor de kanselarij is bijvoorbeeld de schrijfwijze -scip, dortich en dinxendaghes) lijkt kanselarijgebonden te zijn. Daarnaast blijkt ook uit de lokaliseringsprocedure dat de grafelijke scribenten op elkaar lijken in hun schriftelijke taalgebruik. Op de derde vraag luidt het antwoord dat er inderdaad een kanselarijtaal lijkt te ontstaan. | |||||||||
Bovenregionale taalDe vraag of er al een bovenregionale taal ontstaat, is moeilijk te beantwoorden. De schrijvers uit de kanselarij maken allemaal afzonderlijk gebruik van dialectvarianten uit uiteenliggende gebieden. Geen enkele scribent schrijft in een puur lokaal dialect. Zoals gezegd lijken de scribenten op elkaar in hun keuze voor bepaalde dialectvarianten en er kan dus zeker sprake zijn van het ontstaan van een kanselarijtaal. Deze taal mag echter nog niet onmiddellijk een bovenregionale taal genoemd worden, omdat deze gemeenschappelijke taal dan ook buiten de kanselarij gevonden moet worden. Het Dordts lijkt weliswaar op de taal van de grafelijke kanselarij, maar ook op de taal in andere plaatsen in het zuiden van Holland. Het is echter onduidelijk of er al voldoende overeenkomst is tussen de taal van de grafelijke kanselarij en Dordrecht om van een bovenregionale taal te mogen spreken. Dat er belangrijke verbanden waren tussen het Dordtse scriptorium en de grafelijke kanselarij staat echter vast. Zo heeft Melis Stoke zijn invloed in beide schrijfcentra laten gelden.Ga naar eindnoot8 | |||||||||
Verdere gebruiksmogelijkheden van de lokaliseringsprocedureDe lokaliseringsprocedure kan dus worden ingezet om het dialect uit een document van onbepaalde herkomst te lokaliseren. Daarnaast kan met behulp van de lokaliseringsprocedure uitspraken worden gedaan over dialectinvloed binnen een bepaalde groep scribenten. Omdat de lokaliseringsprocedure in de kern eigenlijk een vergelijking maakt tussen de overeenkomsten en verschillen tussen documenten, kan de procedure ook in ruimer verband worden ingezet. Zo blijkt uit een test dat het mogelijk is om scribenten te identificeren met behulp van de lokaliseringsprocedure.Ga naar eindnoot9 Het bewijs hiervoor levert een volgende eenvoudige test: het uitgangspunt is de volledige tekstproductie van de hand van een van de acht grafelijke scribenten. Dit mini-corpus wordt geheel willekeurig in tweeën gedeeld. De ene helft ervan wordt toegevoegd aan de database, het Corpus veertiende-eeuws Middelnederlands, als zou het taalmateriaal uit een fictieve plaats zijn. Als men vervolgens de andere helft van de teksten probeert te lokaliseren met behulp van de lokaliseringsprocedure dan wordt die gekoppeld aan de eerstgenoemde helft, op basis van hun gemeenschappelijke taalkundige kenmerken.Ga naar eindnoot10 Ook onbedoeld bleek de lokaliseringsmethode een oorkonde van een bepaalde scribent te herkennen. Een mooi voorbeeld is een oorkonde die door Vangassen foutief in Naarden gelokaliseerd is.Ga naar eindnoot11 Deze lokalisering was in eerste instantie door de samenstellers van het Corpus veertiende-eeuws Middelnederlands overgenomen. Toen geprobeerd | |||||||||
[pagina 30]
| |||||||||
werd het taalgebruik van Melis Stoke te lokaliseren, bleek dat in Naarden een overeenkomst van 100% gemeten werd. De overeenkomst was weliswaar gebaseerd op zeer weinig gegevens, veroorzaakt door het feit dat Naarden slechts vertegenwoordigd werd door één oorkonde, maar toch. Bij nadere inspectie bleek deze oorkonde geschreven te zijn door een andere grafelijke scribent: een collega van Melis Stoke. Het eigenaardige was echter dat bij lokalisering van deze laatste scribent maar een overeenkomst van 91,4% met Naarden gemeten werd. De oorzaak hiervan werd gevonden in een transcriptiefout van Vangassen. Hij noteert namelijk dertich, waar dortich staat. Melis Stoke gebruikt dertich en scoort daardoor hoger op Naarden dan de andere grafelijke scribent die kiest voor de vorm dortich. Wanneer deze transcriptiefout er niet was geweest, dan had de laatste grafelijke scribent de hoogste score behaald in Naarden. Deze scribent was dan gelokaliseerd op zichzelf. De Naardense oorkonde is verwijderd uit het Corpus veertiende-eeuws Middelnederlands omdat deze geschreven is door een grafelijke scribent en daarom niet thuishoort in het corpus op basis waarvan de vergelijking gemaakt wordt. | |||||||||
Lokalisering van literaire tekstenDe lokaliseringsprocedure is dus niet alleen inzetbaar voor het bepalen van dialectale gekleurdheid en herkomst van documenten, maar kan ook scribenten identificeren. Toch is hier een kanttekening op zijn plaats. Vrijwel alle tot nu toe gelokaliseerde teksten zijn ambtelijk van aard. Daarnaast zijn het stukken die (waarschijnlijk) in origineel zijn overgeleverd en waarin zich geen verschillende dialectlagen bevinden. Literaire teksten zijn vaak kopieën van kopieën en daardoor zijn ze vaak niet in maar ééte bepalen dialect geschreven. Daarnaast zijn de taalkenmerken die gebruikt worden binnen de lokaliseringsprocedure vooral ruim voorhanden in oorkonden (bijvoorbeeld weekdagen en uitgeschreven getallen). Is het nu toch mogelijk om literaire teksten in de geografische ruimte te plaatsen? We hebben de proef op de som genomen en geprobeerd het veertiende-eeuwse afschrift van de Ferguut te lokaliseren.Ga naar eindnoot12 De dissertatie van Willem Kuiper over de Ferguut bevat onder meer een diplomatisch glossarium, waarin de complete woordvoorraad van de Ferguut verwerkt is.Ga naar eindnoot13 Dit bood de mogelijkheid om binnen korte tijd alle taalvormen te excerperen die bruikbaar zijn binnen de lokaliseringsprocedure. Daarnaast heeft Kuiper de taalkenmerken van de Ferguut grondig bestudeerd. Hij komt tot de conclusie dat de kopiist van het veertiende-eeuwse handschrift afkomstig was uit de ‘de Denderstreek, het oosten van Oost-Vlaanderen en het westen van West-Brabant’.Ga naar eindnoot14 Verder zijn er in het afschrift correcties aangebracht die volgens Kuiper wat oostelijker gekleurd zijn dan het afschrift zelf. De legger op basis waarvan de kopie werd afgeschreven was Vlaams. Volgens Kuiper is er sprake van twee auteurs die de oorspronkelijke tekst vervaardigd hebben. De taal van deze auteurs kan gelokaliseerd worden in de buurt van Oudenaarde en Geraardsbergen. De taal van de eerste auteur zou iets westelijker gekleurd zijn dan die van de tweede auteur. Bart Besamusca trekt de (te) verfijnde lokaliseringen van Kuiper in twijfel, maar volgt Kuiper wel in de afwijzing dat de (originele) Ferguut in Brabant zou zijn geschreven, een plaatsbepaling die Besamusca in eerder werk had voorgesteld.Ga naar eindnoot15 In een onlangs verschenen artikel komen Erik Kwakkel en Herman Mulder op basis van codicologisch en filologisch onderzoek tot de conclusie dat de kopiist van de Ferguut werkzaam was in de omgeving van Brussel.Ga naar eindnoot16 Dat wil natuurlijk niet zeggen dat het dialect van de kopiist zonder meer uit de buurt van Brussel afkomstig was, maar een Brabantse dialectale kleuring van het afschrift lijkt toch ook tot de mogelijkheden te behoren. | |||||||||
[pagina 31]
| |||||||||
Men is het er in ieder geval over eens dat de taal van het Ferguut-afschrift zuidelijk is en niet afkomstig uit West-Vlaanderen of Limburg. Wanneer we de tekst nu lokaliseren met behulp van de hierboven beschreven lokaliseringsprocedure, dan hopen we dat het afschrift gelokaliseerd wordt in Oost-Vlaanderen en/of in Brabant. Zou het afschrift met behulp van de computer in West-Vlaanderen of Limburg, of bijvoorbeeld Holland, worden gelokaliseerd, dan is het met de lokaliseringsprocedure blijkbaar niet mogelijk om deze tekst te lokaliseren, tenzij Kuiper en de overige onderzoekers het bij het verkeerde eind hebben, wat niet voor de hand ligt. De door Kuiper verdedigde opvatting dat de oorspronkelijke tekst door twee auteurs geschreven zou zijn, is gerespecteerd en de door Kuiper aangewezen afzonderlijke delen zijn ieder voor zich met de computer gelokaliseerd. Op de volgende kaartjes (afb. 6 en 7) zijn deze lokaliseringen gevisualiseerd. Beide kaartjes verschillen weinig. De lokaliseringsprocedure meet vrijwel geen verschil tussen de eerste en tweede auteur. Daaruit mag echter niet de conclusie worden getrokken dat er sprake zou zijn van maar één auteur. Wat de lokaliseringsprocedure verder meet, is dat de tekst, zoals deze aan ons is overgeleverd, gelokaliseerd moet worden in het zuidelijke grensgebied van Oost-Vlaanderen en Brabant. In grote lijnen is de uitkomst van de lokaliseringsprocedure gelijk aan de uitkomst van Kuipers onderzoek. De uitkomst is ook consistent met de uitkomsten van het onderzoek van Kwakkel en Mulder.
De lokaliseringsprocedure geeft een goede indicatie van de herkomst van het taalgebruik in het afschrift van de Ferguut. Mogelijk wordt het in de toekomst zelfs nog mogelijk om de taal alsook de kopiist van het handschrift scherper te lokaliseren. In het in noot 1 genoemde VNC-project zal het Corpus veertiende-eeuws Middelnederlands met taalmateriaal uit onder meer Oost-Vlaanderen en de Denderstreek aangevuld worden. Daarnaast verzamelen Erik Kwakkel en ik veertiende-eeuws schriftelijk materiaal uit Brussel en omgeving, dat de basis zal vormen voor een onderzoek naar de schrijfcultuur aldaar. 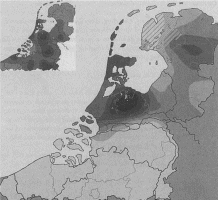 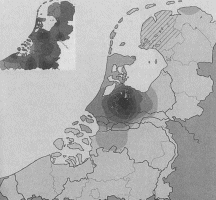
Afb. 6 en 7 De lokalisering van de eerste, respectievelijk tweede auteur van de Ferguut. Ontwerp: Evert Wattel (Wiskunde en Informatica, vu Amsterdam).
| |||||||||
[pagina 32]
| |||||||||
ConclusieEr bestaat sinds kort een computerprogramma waarmee veertiende-eeuwse ambtelijke teksten op basis van taalkenmerken gelokaliseerd kunnen worden. Met behulp van deze methode is het taalgebruik van de scribenten van de graaf van Holland in kaart gebracht. In dit artikel is deze methode ook gebruikt om een literaire tekst te lokaliseren. De resultaten van deze laatste lokalisering zijn bevredigend, maar het is zinvol om de procedure op meer literaire teksten waarvan de ontstaansgeschiedenis min of meer duidelijk is, te testen. De conclusie is dan ook tevens een oproep om dit soort teksten aan te leveren. |
|