
Forum der Letteren. Jaargang 1989
(1989)– [tijdschrift] Forum der Letteren–
[pagina 255]
| |||||||||||||||||||||
Over het automatisch zetten van zinsaccenten
| |||||||||||||||||||||
1. InleidingDe laatste jaren hebben Nederlandse onderzoekers veel aandacht besteed aan de plaats van zinsaccenten. Behalve door taalkundig geïnteresseerden is het probleem ook aangevat door onderzoekers die tot doel hebben om een tekst-naar-spraaksysteem te ontwikkelen: een computersysteem dat een gedrukte tekst als input heeft en de gesproken versie van die tekst als output. Daarbij zijn accenten een probleem omdat in een gedrukte tekst niet staat aangegeven welke woorden geaccentueerd zijn, terwijl een zonder accenten gesproken tekst klinkt zoals de taal van een robot in een science fiction film, en dat vindt men niet mooi genoeg. Ter verhoging van de natuurlijkheid van (synthetische) computerspraak wil men ergens tussen gedrukte input en gesproken output accenten toevoegen. Dat zou je kunnen doen door een typist(e) te instrueren om een teken, zeg ‘^’, te zetten op ieder woord dat in de gesproken versie van een zin een accent heeft; een bijbehorend computerprogramma zou dan het teken ‘^’ moeten lezen als de instructie: ‘spreek hier een accent uit’. De vorige zin zou dan de computer ingaan als: dat zôu je kunnen dôen door een typîst(e) te instru
Computermensen zijn uiteraard geneigd dergelijke benaderingen als uitgangspunt te nemen, in de veronderstelling dat hun eigen probleem althans in de verte iets te maken heeft met het taalkundige probleem. Helaas, die vlieger gaat (nog steeds) niet op. Dit artikel probeert uiteen te zetten waarom die vlieger niet opgaat, en ook niet kan opgaan. De conclusie luidt dat in het meeste tot nog toe verrichte onderzoek naar automatische accentplaatsing één belangrijk ding ontbreekt: begrip voor het feit dat wat men wil eigenlijk niet kan. | |||||||||||||||||||||
[pagina 256]
| |||||||||||||||||||||
2. Waarom het eigenlijk niet kanIn een eerder artikel in dit tijdschrift (Keijsper 1982) heb ik betoogd dat het onmogelijk is accent te voorspellen op grond van de context waarin een zin optreedt: in een gegeven context zijn vaak meerdere accentuaties mogelijk. Bijvoorbeeld (op.cit.: 44):
De spreker van (1a) zet na het accent op tv geen verder accent meer in de zin. In de gegeven context kan de hoorder daaruit opmaken dat de spreker het begrip ‘naar een wedstrijd kijken’ geïmpliceerd acht in het (al in de context aanwezige) begrip ‘naar Ajax gaan’. De spreker van (1b) geeft de informatie dat voor hem (op de tv naar een wedstrijd) kijken een nieuwe ontwikkeling is in de dialoog, bijvoorbeeld omdat je op de Ajax-tribune niet zoveel van de wedstrijd kunt zien, of omdat het gaan naar Ajax meer omvat dan het kijken naar de wedstrijd (zingen, vechten, bier drinken, enzovoort). Zowel (1a) als (1b) delen mee dat het begrip ‘wedstrijd’ geïmpliceerd is in het begrip ‘naar Ajax gaan’ (door de afwezigheid van een accent op wedstrijd). Dat is anders in (1c): de spreker van deze zin weet bijvoorbeeld dat de wedstrijd van Ajax afgelast was, of hij vindt de verrichtingen van Ajax te slecht om daaraan het woord wedstrijd vuil te maken, etc.; in ieder geval geeft hij de informatie dat het begrip ‘wedstrijd’ niet geïmpliceerd is in het voorafgaande. Het essentiële punt in dit voorbeeld is dat de betreffende informatie gegeven wordt door de accentuatie in de zin die gesproken wordt, en dat die informatie niet bekend was vóór die tijd. Als de zin eenmaal gesproken is lijkt het weliswaar alsof de gekozen accentuatie logisch uit de context volgt, maar de manier waarop die coherentie gecreëerd zal worden valt niet te voorspellen, omdat er meerdere mogelijkheden zijn. Anders gezegd, de informatie dat bepaalde elementen ‘nieuw’ zijn en andere ‘oud’ is zelf nieuwe informatie. Die informatie wordt door accentuatie toegevoegd aan datgene wat al uit de context bekend was. En dat precies is het probleem bij automatische accentuering: het feit dat accentuatie informatie toevoegt is in tegenspraak met het idee dat een computer accenten zou kunnen zetten, want een computer heeft van huis uit niet de neiging om iets te willen zeggen. | |||||||||||||||||||||
3. Twee taalkundige benaderingenDe observatie dat in een gegeven context veelal meerdere accentuaties mogelijk zijn heeft er, althans bij Nederlandse onderzoekers, toe geleid dat niemand meer serieus volhoudt dat accentuatie rechtstreeks uit de context volgt: | |||||||||||||||||||||
[pagina 257]
| |||||||||||||||||||||
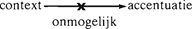 Maar over de vraag of accent voorspeld kan worden kan en moet worden lopen de meningen uiteen. Eén benadering (Gussenhoven 1983; 1984) beoogt regels te geven voor accentplaatsing (d.w.z. accent te voorspellen), een andere benadering (Keijsper 1985) verlaat dat idee. Beide benaderingen zijn onder andere gebaseerd op de observatie dat er geen 1-op-1-relatie bestaat tussen de informatiewaarde van zinselementen en accentuatie. Het duidelijkst kan die observatie gedemonstreerd worden aan de hand van ongeaccentueerde zinselementen. In een zin als
Vergelijk: Wat is er aan de hand? of Wat is er verdwenen? Staat er daarentegen een accent op verdwenen:
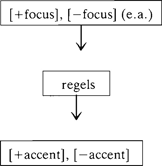 De regels zorgen er onder andere voor dat een zin wordt verdeeld in zogenaamde focusdomeinen: in de ene lezing van (2) (‘alles nieuw’) bestaat de zin uit één focusdomein, in de andere lezing (met zijn verdwenen als ‘oude’ informatie) bestaat de zin uit twee focusdomeinen. Zin (3) bestaat uit twee focusdomeinen. Gegeven de verdeling van (2) en (3) in [+focus] en [-focus], en gegeven de verdeling in focusdomeinen, kan de plaats van het accent in (2) en (3) voorspeld worden: een [-focus] focusdomein krijgt geen accent, een [+focus] focusdomein krijgt een accent op een door regels gespecificeerde plaats, hier op sleutels. | |||||||||||||||||||||
[pagina 258]
| |||||||||||||||||||||
Mijn conclusie uit dezelfde observaties ten aanzien van (2) en (3) is dat [+focus] en [-focus] (of ‘nieuw’ en ‘oud’, enz.) niet de inhouden zijn die door accent (of de afwezigheid van accent) tot uitdrukking worden gebracht. Beter gezegd, deze inhouden bestaan niet op betekenisniveau, maar alleen op interpretatieniveau. Een betekenis is de inhoud die rechtstreeks, zonder tussenliggende regels, door een vorm tot uitdrukking wordt gebracht; een interpretatie is wat je krijgt als je de betekenis van een bepaalde vorm (hier: van [+accent] of [-accent]) combineert met de betekenissen van andere vormen, en met de informatie die je uit de context haalt. Om tot de interpretaties [+focus] en [-focus] te komen heb je, naast de betekenis van accent, ook de informatie nodig die weerspiegeld is in Gussenhoven's focusdomeinen en die ik, om redenen die hier niet terzake doen, noteer met behulp van pijltjes:
 Ga naar eind1 Mijn schema ziet er dan als volgt uit: 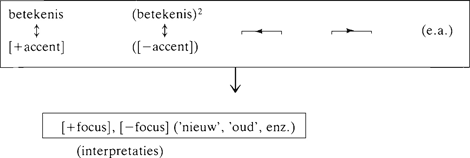 Ga naar eind2 Dit schema keert dus Gussenhoven's schema om en voegt er betekenissen aan toe. Wat Gussenhoven doet is, in mijn terminologie, het geven van regels die specificeren welke interpretaties gecorreleerd zijn aan welke vormen. Het is niet zijn bedoeling om te verklaren waarom die correlaties zijn zoals ze zijn. Dat laatste is wel mijn bedoeling: de verklaring zit in de voorgestelde betekenissen. Wat ik doe is het afleiden van interpretaties uit vorm-betekenis-complexen. Het is niet mijn bedoeling om regels te geven die de plaats van accenten voorspellen. Dat laatste is wel Gussenhoven's bedoeling: zijn verklaring van accent bestaat in het geven van regels die interpretaties en vormen aan elkaar relateren. De twee geschetste benaderingen vloeien voort uit een verschillende opvatting over wat een verklaring is. Gussenhoven's aanpak speelt zich af binnen het denkraam van (een versie van) de Transformationeel-Generatieve Grammatica, dat het geven van regels die accent voorspellen gelijk stelt aan een verklaring van accent. Binnen mijn Vorm-Betekenisaanpak hebben die regels de status van observaties die verklaard (moeten) worden op betekenisniveau. | |||||||||||||||||||||
[pagina 259]
| |||||||||||||||||||||
4. Hebben we daar iets aan bij het automatisch plaatsen van accenten?Op het eerste gezicht lijkt het schema van Gussenhoven het meest geschikt om toegepast te worden bij automatische accentplaatsing: het geeft regels die de plaats van accenten voorspellen, en dat is precies wat we nodig hebben voor een automatische voorlezer. Het enige wat er (bewust) aan ontbreekt is een relatie tussen voorafgaande context en de inhouden [+focus] en [-focus]. Als nu op een mooie dag ook nog iemand uitlegt hoe je van de context van een zin komt tot die inhouden, dan lijkt het probleem opgelost: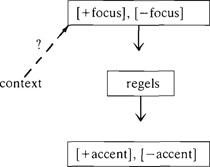 Mijn schema biedt geen hoop, omdat het in omgekeerde richting werkt: het voorspelt, op basis van (o.a.) de betekenis van accent en van syntactische informatie, hoe een zin met gegeven accentuatie aansluit bij de context:Ga naar eind3 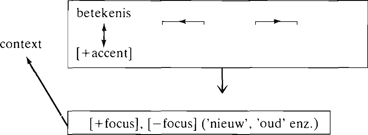 Het ligt dus voor de hand dat Baart (1987a)Gussenhoven's schema als uitgangspunt neemt. De zinnen (2) en (3) zien er in Baart's representatie als volgt uit (Baart 1987b: 299; s staat voor strong, w voor weak): 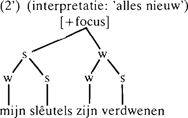 | |||||||||||||||||||||
[pagina 260]
| |||||||||||||||||||||
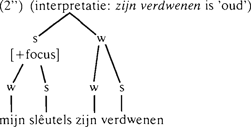 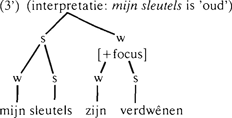 Deze prosodische bomen worden op hun beurt afgeleid van de verdeling van een zin in (onder andere) subjecten, hoofden, complementen en specificeerders. Bijvoorbeeld (Baart 1987b: 300-301; ter vergelijking zet ik mijn pijltjes ernaast):
 ). In (6) en (8) daarentegen specificeert het tweede element van de constructie (een appel (6) / uit Frankrijk (8)) welke van de mogelijke eetsituaties bedoeld wordt (6) / naar welke wijn de spreker wil verwijzen (8) (
). In (6) en (8) daarentegen specificeert het tweede element van de constructie (een appel (6) / uit Frankrijk (8)) welke van de mogelijke eetsituaties bedoeld wordt (6) / naar welke wijn de spreker wil verwijzen (8) (
 ). Ook in (7), tenslotte, moet het eerste element van de constructie (Franse) eerst aangevuld worden (wat hier gebeurt door wijn) voordat duidelijk is welke referent de spreker op het oog heeft (
). Ook in (7), tenslotte, moet het eerste element van de constructie (Franse) eerst aangevuld worden (wat hier gebeurt door wijn) voordat duidelijk is welke referent de spreker op het oog heeft (
 ).
).
In plaats van de pijltjes en hun semantisch correlaat gebruikt Baart een s/w verdeling, plus een aantal syntactische begrippen. Wat lost dat nu op? Ik zou | |||||||||||||||||||||
[pagina 261]
| |||||||||||||||||||||
zeggen: helemaal niets. We weten nu, hetzij in termen van focusdomeinen (Gussenhoven), hetzij in pijltjesnotatie (Keijsper), hetzij in termen als s/w en subject, hoofd, complement, specificeerder (Baart), welke ongeaccentueerde elementen kunnen vallen onder het bereik van een accent elders (welke ongeaccentueerde elementen geïnterpreteerd kunnen worden als ([+focus]). Andersom gezegd, we weten nu dat je niet door de computer moet laten zeggen:
Ja, maar, zullen sommige mensen nu tegenwerpen, dat probleem laten we even rusten: op een mooie dag zal iemand uitleggen hoe je de verdeling van [+focus] en [-focus] kunt voorspellen. Voorlopig doen we gewoon alsof iedere zin helemaal uit ‘nieuwe’ informatie bestaat (helemaal [+focus] is). Dan kunnen we toch op basis van de syntactische structuur (die we automatisch zullen bepalen) de plaats van accenten voorspellen? Nee, helaas niet, want we weten ook niet wanneer een tekst incoherent wordt als de computer zegt
Beide zijn in de focusbenadering geheel [+focus]. Niettemin betekenen ze iets heel verschillends, getuige de man die de Londense ondergrondse binnenkwam, een bordje las met de tekst
| |||||||||||||||||||||
[pagina 262]
| |||||||||||||||||||||
in plaats van
Het enige wat de syntactische analyse doet is zeggen welke ongeaccentueerde elementen kunnen vallen onder het bereik van een accent elders (geïnterpreteerd kunnen worden als [+focus]), maar het probleem is dat we niet kunnen voorspellen wanneer het de bedoeling is dat ze dat ook doen: dat hangt er van af wat iemand wil zeggen:
Zolang niemand kan uitleggen hoe je kunt voorspellen welke [+focus] elementen een accent moeten krijgen om een tekst coherent te maken, en welke juist niet, kunnen we geen accent voorspellen, zelfs niet als we doen alsof alle elementen van een zin [+ focus] zijn. Er is één regel voor accentuering: als het de bedoeling is om de betekenis van accent uit te drukken, zet dan een accent; als het niet de bedoeling is om de betekenis van accent uit te drukken, zet dan geen accent. Aan zo'n regel heeft een computer natuurlijk niets, want die weet niet wanneer het al dan niet de bedoeling is om de betekenis van accent uit te drukken. De focusbenadering verandert niets aan dit feit, want die lost alleen een probleem op dat door de benadering zelf wordt gecreëerd, op de volgende manier. Iemand die automatisch accenten wil zetten begint met een rijtje ongeaccentueerde woorden. Hij moet dat rijtje omzetten in 1. geaccentueerde woorden, 2a. ongeaccentueerde woorden die onder het bereik van een accent elders vallen, en 2b. ongeaccentueerde woorden die niet onder het bereik van een accent elders vallen. De focusbenadering neemt 1 en 2a bij elkaar in de input: beide heten [+focus]; 2b heet [-focus]. De verdeling in focusdomeinen, of in s en w, of in subjecten, hoofden, complementen en specificeerders, scheidt dan 1 weer van 2a, en voegt 2a weer bij 2b: 1 heet in de output [+accent], 2a en 2b heten [-accent]. Deze exercitie is alleen nodig omdat eerst 1 en 2a bij elkaar waren genomen, en 2a was gescheiden van 2b: de fout in de input moet hersteld worden. Die input is fout omdat de scheiding tussen 2a en 2b al volgt uit de syntactische informatie (focusdomeinen, pijltjes, s en w, subjecten, hoofden, enzovoort): die scheiding hoeft niet nog een keer gemaakt te worden door de zin te verdelen in [+focus] en [-focus]. Die verdeling is ook nog fout omdat een geaccentueerd element (1) niet hetzelfde is als een ongeaccentueerd element dat valt onder het bereik van een accent elders (2a): zie de voorbeelden (9)-(11). Samenvattend vertaalt de focusbenadering alleen het probleem: | |||||||||||||||||||||
[pagina 263]
| |||||||||||||||||||||
Ook hieraan heeft een computer natuurlijk niets, want die weet nog steeds niet wanneer iets al dan niet de bedoeling is. | |||||||||||||||||||||
5. Wat voor soort probleem is het eigenlijk?De gedachte dat we bij automatische accentplaatsing iets hebben aan de focusbenadering berust naar mijn mening op een verkeerde inschatting van de aard van het probleem. Een vergelijking kan die mening wellicht verduidelijken. We beginnen met een Russische tekst en willen de gegeven Cyrillische letters omzetten in Latijnse: a → a, c → s, p → r, enzovoort. De transliteratie van de tekst kan aan een computer worden uitbesteed, omdat je er niet voor hoeft te kunnen denken: een bepaalde (Cyrillische) codering van informatie moet worden omgezet in een andere codering van diezelfde informatie; er hoeft geen informatie te worden toegevoegd. Nu nemen we een gedrukte tekst en willen die voorlezen, met accenten. Dat zou een probleem zijn van hetzelfde type als de Cyrillisch-Latijn-omzetting als het zo zou zijn dat de informatie die door accent wordt uitgedrukt al, op een andere manier, in de gedrukte tekst aanwezig was. Maar dat is niet het geval: het feit dat in een gegeven context veelal meerdere accentuaties mogelijk zijn wil zeggen dat accentuatie informatie toevoegt aan een gedrukte tekst, dat de informatie die door accent wordt uitgedrukt er niet is voordat de accenten er zijn (zie paragraaf 2 hierboven). Het verwarrende van de focusbenadering, en in het algemeen van benaderingen die accent proberen af te leiden van de inhoud die door accent wordt uitgedrukt, is dat ze doen alsof die inhoud bestaat onafhankelijk van de bijbehorende vorm: [-focus]/[+focus], ‘oud’/‘nieuw’, topic/comment, thema/rhema → accent Het lijkt dan dus alsof accentuatie een gevolg is van de aanwezigheid van de inhoud: de schijn wordt gewekt dat het probleem van automatische accentuering bestaat in het omzetten van een inhoudscodering in een vormcodering, analoog aan de Cyrillisch-Latijn-omzetting. Maar hoe kom je aan die inhoudscodering? De gedachte dat iemand die vraag op een mooie dag zal beantwoorden, en dat we dan tenminste alvast de rest van het probleem (van inhoud naar vorm) hebben opgelost, is een misvatting: de inhoud is niet aanwezig voordat de accenten gezet zijn (paragraaf 2), en de rest van het probleem bestaat alleen als je perse iets wilt hebben om alvast op te lossen (paragraaf 4). Het probleem van automatische accentuering bestaat niet in het omzetten van een gegeven codering van informatie in een andere codering van dezelfde informatie, maar in het toevoegen van ontbrekende informatie. Het probleem kan daarom vergeleken worden met het lezen van een tekst waarin sommige woorden zijn weggevallen: | |||||||||||||||||||||
[pagina 264]
| |||||||||||||||||||||
Om ... uur ging ... naar ... Onderweg ... hij ... tegen. Die ...: ‘Benje ... nog naar ... geweest?’ ... antwoordde:‘...’. Toen ... thuis ... gaf hij zijn ... een ... en vroeg: ‘Is het ... al ...?’ Enzovoort. Als we zo'n tekst proberen te lezen zijn we bezig om ontbrekende informatie te raden op grond van andere informatie. Zo kun je uit de zinsnede Om ... uur afleiden dat op de plaats van de puntjes een getal moet staan. Op dezelfde manier zijn mensen die een gedrukte tekst lezen voortdurend bezig te ‘raden’ wat de schrijver van die tekst vermoedelijk wilde zeggen, dat wil zeggen, in ons geval, welke elementen hij vermoedelijk geïnterpreteerd wil hebben als [-focus], en welke als [+focus]. Verschillende mensen zullen enigszins verschillende inschattingen maken van de bedoeling van de schrijver, en dus enigszins verschillende accentuaties kiezen. Een computer kan ons dit niet echt nadoen zolang die de tekst niet begrijpt en geen kennis van de wereld heeft. Willen we toch het leesproces in zoverre simuleren dat althans één van de mogelijke accentuaties automatisch wordt gegenereerd, dan moeten we uitgaan van de informatie die voor een computer in de gedrukte tekst aanwezig is, dat wil zeggen juist niet van de informatie die door accent wordt uitgedrukt ([+focus]/[-focus] etc): die informatie is er niet, die gaan we aan de tekst toevoegen. In de literatuur over accent en woordvolgorde staan veel dingen vermeld die je kunt gebruiken om tot een redelijke accentuatie te komen. Je kunt denken aan het verschil tussen inhoudswoorden en functiewoorden (de eerste zijn vaker geaccentueerd dan de laatste), aan lijsten woorden zoals dit, dergelijke, zulke, volgende, dezelfde, die veelal gecombineerd worden met een ongeaccentueerd substantief (bijvoorbeeld: Marîetje neemt de vôlgende trein, zonder accent op trein), het type werkwoord, de lengte en complexiteit van constructies, en zo kun je nog een aantal trucs verzinnen (Baart 1987a: 56-58, Kageren Quené 1989). Eén van deze trucs (niet een alternatief ervoor) is voor een menselijke lezer natuurlijk de context van een zin: je kunt redelijkerwijs aannemen dat de te accentueren tekst coherent moet worden, zodat niet alle theoretisch mogelijke accentuaties redelijke inschattingen zijn van de bedoeling van de schrijver. Maar juist deze truc is moeilijk te leren aan een computer, omdat die de tekst niet begrijpt. Het aantal beter bruikbare mogelijkheden is nog lang niet uitgeput. Met name zou naar mijn mening meer aandacht moeten worden besteed aan het feit dat lezers de neiging hebben om het laatste accent aan het einde van de zin te plaatsen, en dat goedgeschreven teksten rekening houden met deze neiging (zie b.v. Bolinger 1965; Baart 1983; Keijsper 1985: 37-60). Zo is de volgende zin slecht geschreven, omdat de woordvolgorde de lezer op het verkeerde been zet:
De meeste lezers zullen geneigd zijn het woord Kemenade beide keren te accentueren, waardoor ten onrechte de suggestie ontstaat dat er twee personen in het geding zijn. Om dit woordvolgorde-effect te vermijden zou een constructie | |||||||||||||||||||||
[pagina 265]
| |||||||||||||||||||||
moeten worden gekozen waarin van Kemenade de tweede keer niet aan het einde van de zin staat. De volgende zin, ook uit het NRC, is eveneens moeilijk te lezen, omdat de woordvolgorde niet duidelijk maakt welke accentuatie is bedoeld:
Als we ervan uitgaan dat een automatische accentzetter meestal te maken zal hebben met goedgeschreven teksten dan kunnen we woordvolgorde gebruiken om een voor de hand liggende accentuatie toe te voegen. Wat je met deze aanpak kunt bereiken is een accentuering die vaker goed is dan fout (?Marîetje gaat nîet met die krakkemikkige âuto, ze neemt liever de vôlgende trein), en die, als er meerdere mogelijkheden zijn, één lezing weet te geven (vergelijk Van Bezooijen 1989). Het genereren van een foutloze accentuering is natuurlijk niet simpel, net zo min als het simpel is om door een computer een gatentekstje te laten invullen. Men zou vermoedelijk alleen beginnen aan het opslaan van alle kennis die daarvoor nodig is als er grote economische belangen mee gemoeid zijn. Evenzo zou men zich mijns inziens ernstig af moeten vragen of het wel de moeite loont om een automatische accentzetter te ontwikkelen, en zeker of zo'n accentzetter alleen bijvoorbeeld weerberichten moet kunnen voorzien van accenten, of ook Roodkapje en Carmiggelt. Gaat het alleen om weerberichten of andere teksten met een simpele structuur en een beperkt lexicon, dan kun je een heel eind komen met grof (computer)geweld (lijsten woorden, en dergelijke). Voor een aantal mogelijke toepassingen is toch misschien een goede typist(e) wel handig. En is het onaanvaardbaar als mensen die Roodkapje en Carmiggelt voorgelezen willen krijgen moeten luisteren naar een monotoon sprekende robot en zelf de bedoeling van de schrijver moeten raden, zoals ze ook doen als ze de tekst (kunnen) lezen? Het feit dat dergelijke vragen niet worden gesteld vloeit, denk ik, voort uit een ernstige onderschatting van het probleem. Te veel is tot nog toe geprobeerd om uit te komen onder het feit dat accent betekenis heeft. En dat kan niet. | |||||||||||||||||||||
[pagina 266]
| |||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||
 ren om een t
ren om een t
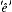 ken... Zolang computerinvoer getypt moet worden is deze oplossing vermoedelijk de beste en de goedkoopste, hoewel de betreffende typist(e) iets meer in huis zou moeten hebben dan een typediploma, maar niet zo heel veel meer. De ontwikkeling van scanners die zonder menselijke tussenkomst een gedrukte tekst kunnen opslaan in een computer doet echter naar meer verlangen: zouden we niet aan de computer kunnen leren wat een enigszins intelligente typist(e) kan, namelijk die accenten zetten? Dat nu is een heel probleem, want een computer is, in tegenstelling tot onze enigszins intelligente typist(e), oliedom: hij begrijpt niets van wat hij leest. Taalkundige theorieën over accentplaatsing lossen dit probleem niet op, hoewel sommige benaderingen pretenderen accent te kunnen voorspellen.
ken... Zolang computerinvoer getypt moet worden is deze oplossing vermoedelijk de beste en de goedkoopste, hoewel de betreffende typist(e) iets meer in huis zou moeten hebben dan een typediploma, maar niet zo heel veel meer. De ontwikkeling van scanners die zonder menselijke tussenkomst een gedrukte tekst kunnen opslaan in een computer doet echter naar meer verlangen: zouden we niet aan de computer kunnen leren wat een enigszins intelligente typist(e) kan, namelijk die accenten zetten? Dat nu is een heel probleem, want een computer is, in tegenstelling tot onze enigszins intelligente typist(e), oliedom: hij begrijpt niets van wat hij leest. Taalkundige theorieën over accentplaatsing lossen dit probleem niet op, hoewel sommige benaderingen pretenderen accent te kunnen voorspellen.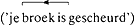
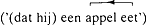
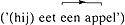
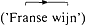
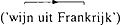
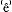 mers zijn in N
mers zijn in N
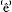 derland nog âltijd te vînden.
derland nog âltijd te vînden.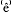 derland zijn nog âltijd g
derland zijn nog âltijd g
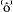 ede ondernêmers te vinden.
ede ondernêmers te vinden.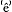 mers zijn nog âltijd te vînden, in Nederland.
mers zijn nog âltijd te vînden, in Nederland.