
Forum der Letteren. Jaargang 1981
(1981)– [tijdschrift] Forum der Letteren–
[pagina 229]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Taalverwerving en probabilistische grammatika's Bob VisserSamenvatting | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1De laatste decennia heeft het onderzoek naar eerste en tweede taalverwerving belangrijke ontwikkelingen gekend. Nadat zowel het behavioristische stimulus-response model (van vooral Skinner) als het mentalistische model (Chomsky) verworpen waren, kreeg het denkbeeld dat taalverwerving een differentiatie-proces is, de overhand: ‘Taalontwikkeling manifesteert zich als een proces waarbij er in de hiërarchische deelkomponenten van het taalsysteem sprake is van een steeds verdere uitbouw of differentiatie van het regelsysteem van het kind in de richting van het regelsysteem van de volwassene. In hun taalgebruik maken kinderen slechts gebruik van die regels waarover zij in een bepaalde fase van taalontwikkeling beschikken’ (Van Els e.a. 1977: p. 121). Dit idee van een geleidelijke overgang van de ene naar de andere fase kan men op het ogenblik op verschillende terreinen van de taalkunde constateren. Vooral door het werk van Labov is de al te statische opvatting van Chomsky vervangen door, c.q. aangevuld met, een meer dynamisch element: de variabele regel. De variabele regel maakt het mogelijk taalverwerving te beschrijven als een dynamisch proces. Een nadeel van de variabele regel is evenwel, dat de toepassing ervan beperkt blijft tot het fonologische en morfologische niveau. Er is behoefte aan een méér omvattend instrument, een soort ‘variabele grammatika’, waarmee ook het syntactische niveau beschreven kan worden. Een ander nadeel van veel onderzoekingen naar eerste en tweede taalverwerving (maar ook van sociolinguïstisch onderzoek) is, dat er geen overeenstemming is over het te hanteren regelsysteem. Hierdoor maakt iedere onderzoeker van zijn eigen regels gebruik om een bepaald corpus taal te analyseren, hetgeen onderlinge vergelijkingen vrijwel onmogelijk maakt én de praktische toepasbaarheid van de resultaten tot vrijwel nihil reduceert. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 230]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Het zou ideaal zijn als er één ‘overkoepelende’ grammatika zou bestaan, waarmee onderzoekers konden werken, dat wil zeggen waarmee onderzocht kon worden in hoeverre er van die grammatika gebruik wordt gemaakt. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2Het gebruik van de variabele regel vindt men voorlopig alleen in de sociolinguistiek. Hoewel men pretendeert iets te zeggen over niet-linguïstische ‘constraints’ op het taalgebruik, komt de meeste literatuur over de variabele regel toch niet verder dan het analyseren van linguïstische ‘beperkingen’ of condities op het taalgebruik. Zo bezien is de variabele regel-methode een methode om te onderzoeken hoe en in welke mate het voorkomen van een verschijnsel beïnvloed wordt door de linguïstische omgeving; hierbij maakt men gebruik van kwantitatieve gegevens, die omgezet worden in waarschijnlijkheden. Hoewel de nadruk bij de variabele regel dus vooral op taalgebruikcondities ligt en bij de PG op de taalontwikkeling, moeten we constateren dat beide methodes in grote lijnen hetzelfde zijn. De verschillen zijn historisch gegroeid: de sociolinguistiek hield zich voornamelijk met fonologische en morfologische verschijnselen bezig, terwijl het taalverwervingsonderzoek altijd sterk syntactisch georiënteerd was. Waarom het gebruik van een PG in veel mindere mate voorkomt dan het gebruik van de variabele regel, is minder eenvoudig te verklaren. Waarschijnlijk speelt hierbij een rol, dat de variabele regel veel minder data en dataverwerking vereist dan de PG. De eisen die een PG aan een corpus stelt zijn dusdanig, dat men het eigenlijk niet zonder automatische ontleding kan stellen (zie ook paragraaf 13). Hoe waardevol het gebruik van een PG kan zijn, blijkt uit het boek Developing Grammars van Klein/Dittmar (1979), dat het eindverslag is van een groot onderzoek naar de taalontwikkeling van buitenlandse werknemers in Duitsland (zie voor een bespreking: B.J. Visser, in een volgend nummer van Forum). In dit boek vindt men het bewijs van de stelling dat het gebruik van een PG het mogelijk maakt taalverwerving te beschrijven als een dynamisch proces, overigens zónder gebruik te maken van een longitudinaal onderzoek. De ‘differentiatie van het regelsysteem’ kan met een PG exact vastgelegd worden. De toename van de taalbeheersing kan aan de hand van het afnemen en toenemen van de frequentie van diverse grammatikaregels geïllustreerd worden. Dit maakt het bijvoorbeeld mogelijk de taalbeheersing van een tweede taal-leerder te bepalen aan de hand van slechts énkele (of zelfs maar één) grammatikaregels (zie ook Anne Vermeer 1981 voor een praktische toepassing vanuit een voorwetenschappelijke hoek). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3Een variabele regel is veelal een herschrijfregel met een getal. Dat getal geeft aan in welke mate er van die regel gebruik wordt gemaakt. Het ‘variabele’ wordt uitgedrukt door de waarde van dat getal; naarmate de regel meer wordt gebruikt, is dat getal groter. Het getal dat aan een regel wordt toegevoegd heet de regelwaarschijnlijkheid, aan | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 231]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
te duiden met een ‘p’. Indien de regel in het geheel niet wordt toegepast, stellen we: p = 0; wordt de regel altijd toegepast, dan: p = 1 (zie voor een inleiding tot de variabele regel Dittmar 1978: H 5.2.1, Van Hout 1981 of meer uitgebreid Sankoff 1978). Een ‘variabele grammatika’ heet officieel een probabilistische grammatika (PG). In het vervolg van dit artikel zullen we onder een PG verstaan: een verzameling herschrijfregels met voor iedere regel een regelwaarschijnlijkheid, ter beschrijving van het syntactische niveau van natuurlijke taal.Ga naar voetnoot1 De formele definitie luidt: Een probabilistische grammatika is een geordend viertal (Vn, Vt, S, P), waar:
Minder formeel komt dit erop neer dat we, via de herschrijfregels, niet alleen aangeven welke taalbouwsels grammatikaal zijn, maar tevens binnen de grammatika verantwoorden wat de kans is op de toepassing van de onderscheiden regels en daarmee de kans op een sequentie van regels, vormende een bepaald zinstype van de taal die de PG beschrijft. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4Het idee van een PG is nauw verbonden met wat wel de corpus-taalkunde wordt genoemd. Dat is taalkundig onderzoek dat geschiedt op basis van (grote) verzamelingen taalmateriaal. De onderzoeker laat zich liever leiden door empirische onderzoekstrategieën dan door grammatikaliteitsuitspraken en intuïties. van native speakers. In sommige gevallen (bij onderzoek van dode of exotische talen, van kindertaal of van pathologisch taalgebruik) zijn deze laatste zelfs niet voor handen en is men wel op corpusanalyse aangewezen. De corpus-taalkunde baseert haar uitspraken dus in eerste aanleg op de taalfeiten zélf. Een verschil met bijvoorbeeld mentalistisch georiënteerd taalonderzoek is, dat de notie ‘aantal’ een belangrijke rol speelt. Voor de corpustaalkundige is het al of niet grammatikaal zijn alléén niet voldoende; hij wil graag nuanceringen aanbrengen in de zin van: beide constructies zijn mogelijk, maar er is een sterke voorkeur voor één van de twee. Het was pas aan het eind der 60-er jaren dat er ook in de praktijk (nadat de conceptie van een PG reeds lang theoretisch onderzocht was, vooral door mathematici en | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 232]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
informatici) met PG'sgewerkt werd, door onder andere Suppes, Salomaa en Grenander. De PG bleek een adequaat instrument om er taalverwerving mee te beschrijven, aangezien een PG precies kan verantwoorden hoe het taalgebruik zich ontwikkelt en dat op volstrekt expliciete wijze. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5Het werken met een PG zal nu aan de hand van een klein voorbeeld worden toegelicht. Stel dat een grammatika de volgende regels bevat:
Middels deze twee regels is het mogelijk alle sequenties van nul of meer adjectieven gevolgd door een nomen te genereren. Door de recursiviteit van regel 2a is zo'n grammatika veel krachtiger én eleganter dan een grammatika van de vorm:
Deze vorm van enumeratie heeft bovendien nog het nadeel dat men ergens op moet houden (het aantal regels dient eindig te zijn), wat het taalkundig onacceptabele feit inhoudt, dat er een absoluut langste rij van adjectieven zou zijn. Een nadeel van een regel als 2a is evenwel dat hij té krachtig is: er is geen enkele rem op de lengte van de rij adjectieven; een nomen met één adjectief is voor die grammatika even ‘grammatikaal’ als een nomen voorafgegaan door 1001 adjectieven. Een grammatika met dergelijke regels beschrijft (bij definitie) wel de competence maar leidt in de praktijk tot over-generatie en verantwoordt op geen enkele wijze het (grammatikaal) steeds marginaler worden van de constructies naarmate het aantal adjectieven toeneemt. Willen we het principe van de recursiviteit behouden en tóch de kracht van de grammatika beteugelen, dan kennen we een waarschijnlijkheid toe aan de regels, bijvoorbeeld:
Dit betekent dat in negen van de tien gevallen een NP herschreven wordt als een N. Aangezien we de kansen vermenigvuldigen, krijgen we de volgende verdeling: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 233]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Hoewel de kansen bij een groeiend aantal adjectieven steeds kleiner worden, zijn deze nooit nul. Dit lijkt in eerste instantie een aanvaardbare formalisering van de taalkundige intuïtie, hoewel uit corpus-onderzoek blijkt dat de hier genoemde verhoudingen niet kloppen.Ga naar voetnoot2 Bij de contructie van een PG streeft men naar zoveel mogelijk empirisch vaststellen (door middel van tellingen in een corpus) van de verschillende p-waarden bij de regels van de grammatika. Als we zo'n p-waarde een parameter noemen, dan heet het toekennen van die waarden de parameterschatting van de PG. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6Er zijn drie belangrijke problemen bij het opstellen van een PG:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ad 1, het corpus:Er is nog weinig theorievorming met betrekking tot de problematiek van corpora en steekproeven uit verzamelingen natuurlijke taal. Absolute criteria voor de noodzakelijke omvang van een corpus zijn er nog niet, maar men kan wel empirisch vaststellen of deze groot genoeg is. Dat is namelijk het geval als de regelwaarschijnlijkheden niet of nauwelijks meer veranderen, ook al worden er nieuwe data ingevoerd. Men kan hier een zekere marge hanteren, bijvoorbeeld 1% (d.w.z. we achten de steekproef groot genoeg als de kansen niet meer dan 1% veranderen, ondanks invoer van nieuwe zinnen.Ga naar voetnoot3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 234]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ad 2, de grammatika:In principe kan iedere expliciete grammatika verrijkt worden met een parameterschatting. Tot nu toe hebben echter alleen de grammatika's uit de zogenaamde Chomsky hiërachie (zie Levelt: deel 1, p. 11) als kern voor een PG gediend en dan nog voornamelijk de contextvrije. Doch zelfs als men zich tot een contextvrije grammatika beperkt, blijven er nog zeer veel keuzemogelijkheden. Een eerste belangrijke keuze betreft het bereik of het voortbrengend vermogen van de grammatika: tracht men de grammatika zo ruim mogelijk te maken of stelt men haar zodanig op, dat zij precies het corpus beschrijft en niet meer dan dat. Het moge uit hiervoor gemaakte opmerkingen duidelijk zijn dat ik pleit voor een zo krachtig mogelijke grammatika; dit met het oog op de bruikbaarheid en vergelijkbaarheid. Het is onwenselijk om voor iedere fase in de taalverwerving een aparte grammatika te hanteren. Het ‘naar het corpus toeschrijven’ van de grammatika dient vermeden te worden (vergelijk ook Brandt Corstius' slogan: ‘itereer op verse tekst’; 1978: p. 151). Een tweede, heel wat complexere keuze, betreft de beschrijving van taalafhankelijkheden en het hiermee verband houdende gebruik van recursieve regels. Aangezien dit probleem sterk interfereert met de kansberekening, kom ik hier eerst later op terug. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ad 3, het kansberekeningsmodel:De meest eenvoudige manier om de p-waarden te schatten is de volgende:
Deze methode wordt de onafhankelijke kansberekening genoemd, aangezien de kansen alleen berekend worden aan de hand van het totale voorkomen van een regel, onafhankelijk van de context waarin die regel optreedt. Zo'n onafhankelijke berekening zegt wel iets over de kansverdeling, doch die informatie is vaak veel te globaal. Bovendien is de premisse die er aan ten grondslag ligt, nl. dat taalelementen onafhankelijk van elkaar optreden, onjuist. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7Hoewel de onafhankelijke kansberekening ontoereikend is, legt zij wél bloot waar de taalafhankelijkheden liggen, namelijk daar, waar het model foute voorspellingen doet. Een voorbeeld moge één en ander verduidelijken. Stel dat we een grammatika met de volgende regels hebben:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 235]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Stel we vinden van de vier mogelijke typen die de grammatika beschrijft de volgende frequenties:
Dit levert de volgende verwachtingen voor de vier typen:
Daar klopt dus niet zo veel van. Hoe komt dat nu? De NP vóór de V heeft niet dezelfde vorm-kansen als de NP erna. Dit kan het hier gehanteerde model echter niet verantwoorden. Wat zijn nu de mogelijkheden om tot een adequate beschrijving te komen? In het kader van de doelstelling te komen tot een kansberekening voor grammatikaregels, zijn dat er twee: 1 de grammatika kan veranderd worden en wel zodanig dat de taalafhankelijkheden in de regels zélf verantwoord worden, bijvoorbeeld:
2 het kansberekeningsmodel wordt uitgebreid; i.p.v. één kans bij één regel geven we iedere regel meerdere kansen, waarvan de waarden afhankelijk zijn van de erna toegepaste regel. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 236]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
8In dit voorbeeld is het vrij eenvoudig om de grammatika zodanig te veranderen, dat de taalafhankelijkhedenGa naar voetnoot6 verantwoord worden. Maar het zal duidelijk zijn dat, naarmate de grammatika omvangrijker wordt en grotere delen natuurlijke taal gaat beschrijven, de hoeveelheid afhankelijkheden ook sterk zal toenemen. Om dit nog op regelniveau te verantwoorden zal een veelvoud van het oorspronkelijke aantal regels nodig zijn. Naast dit praktische bezwaar is er ook nog een principieel bezwaar te maken. Het grote voordeel van een generatieve grammatika is, dat men met een eindig aantal regels een in principe oneindig aantal zinnen kan voortbrengen, door gebruik te maken van recursieve regels. Dit wordt de ‘kracht’ van zo'n grammatika genoemd. Nu zijn het echter juist die recursieve regels die wat betreft de kansberekening problemen opleveren. Hierdoor hebben linguïsten die zich met een PG bezig houden de neiging dit soort regels uit de grammatika te weren. Deze neiging de taalafhankelijkheden in de grammatika zélf te willen verantwoorden zal evenwel tot gevolg hebben dat recursieve regels (en mogelijkheden tot coördinatie) uit de grammatika geweerd moeten worden, waardoor:
Deze nadelen wegen mijns inziens veel zwaarder dan het voordeel van een eenvoudige parameterschatting. Er is bovendien nog een ander argument: bovengenoemde werkwijze houdt namelijk in dat de grammatika naar het corpus toegeschreven zal worden. Ik ben echter van mening dat de potentie van een grammatika groter dient te zijn dan het (min of meer toevallig) gehanteerde corpus. Het is juist het grote voordeel van een PG dat de kansverdeling precies aangeeft, hóe en in welke mate er van de grammatika gebruik wordt gemaakt, d.w.z. wat de verdeling van de herschrijfregels is. Het zijn de verschillen in kansverdeling die aangeven in hoeverre groepen sprekers van elkaar verschillen (in de sociolinguïstiek) of hoe en in welke richting zich het taalvermogen onwikkelt, om een paar voorbeelden te noemen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
9Als het alternatief van het aanpassen van de regels verworpen wordt, blijft derhalve het uitbreiden van het kansberekeningsmodel over. In plaats van een onafhankelijke wordt een conditionele kansberekening toegepast; de conditie is in dit geval de regel (of regels) die voor of na de regel waarvoor we de kans willen berekenen, wordt toegepast. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 237]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Zo kan men een indeling maken van de diverse modellen (zie bijvoorbeeld Levelt 1973: H. 14):
Over de eerste twee benaderingen is al gesproken, we gaan nu kijken hoe de 2e-orde-benadering werkt. Als we in een grammatika k regels hebben en we willen de kans op toepassing van een regel af laten hangen van de ervoor toegepaste regel, dan krijgt iedere regel k kansen (want in principe kan iedere grammatikaregel vooraf gaan); de gehele grammatika omvat dan k × k kansen. Deze worden opgeslagen in een zogenaamde overgangsmatrix (zie Bisher/Drewes 1970: H. 20). De kansen worden dan ook wel overgangswaarschijnlijkheden genoemd, omdat ze de kans aangeven dat de éne regel overgaat naar (gevolgd wordt door) een andere. Toegepast op het voorbeeld van par. 7 krijgen we het volgende:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 238]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
10In dit voorbeeld is het voldoende om alleen met de direct voorafgaande regel rekening te houden, aangezien de grammatika zeer eenvoudig is. Het is echter zeker niet ondenkbaar dat, naarmate de grammatika omvangrijker wordt, een hogere orde-benadering noodzakelijk zal worden. Dit gaat gepaard met het toenemen van het aantal kansen. Zo levert een 4e-orde-benadering van een grammatika met 30 regels 304, dat is een kleine miljoen, overgangswaarschijnlijkheden, waarvan er overigens zeer vele nul zullen zijn. Over de vraag hoe diep men moet gaan om tot een adequate beschrijving te komen tast men nog in het duister. Een analyse hoger dan de 2e-orde is mij, wat natuurlijke taal betreft, niet bekend. Men kan evenwel een ad-hoc-beslissing nemen: men gaat net zo ‘diep’ totdat er juiste voorspellingen gedaan worden (vergelijk ook het voorbeeld van de vorige pagina: een 1e-orde-benadering bleek niet goed, dus werd een 2e-orde geprobeerd; deze bleek wel een juiste beschrijving te geven, zodat er gestopt kon worden). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
11Een ander belangrijk punt bij het opstellen van een PG is de evaluatie-procedure om te bepalen of de gekozen grammatika wel de juiste is. Dit is des te belangrijker, aangezien er veelal met een contextvrije grammatika (CFG) gewerkt wordt, een type grammatika die een zekere vrijblijvendheid niet ontzegd kan worden (die vrijblijvendheid speelt vooral bij de beschrijving van coördinatie; een CFG geeft de taalbeschrijver zeer vele mogelijkheden om één, min of meer complexe zin te beschrijven; zie voor de beschrijvende inadequaatheid van CFG's Levelt 1973: p. 31-35, deel 2). Net als voor een ‘gewone’ (d.w.z. niet-probabilistische) grammatika, zijn er voor een PG drie criteria (Levelt 1973: p. 8 e.v., deel 2):
Hiermee zijn we er echter nog niet wat een PG betreft. Een PG is immers au fond de weerslag van een steekproef uit een populatie. Statistisch gezien heeft de PG de status van een hypothese. Net als bij iedere andere steekproef heeft men ook hier te maken met het inferentie-probleem: in hoeverre is het geoorloofde op basis van een eindige steekproef uitspraken te doen over de populatie? Het inferentie-probleem heeft voor taalkundigen twee kanten:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 239]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Het is van groot belang dat de hypothese, de PG, getoetst wordt. Die toetsing houdt in het bekijken of de PG juiste voorspellingen doet. Dit doen we door, nadat de regelwaarschijnlijkheden geschat zijn, ‘terug te gaan rekenen’, door de kansen van alle (of in ieder geval de meest frequente) typen die de grammatika voortbrengt, te vermenigvuldigen met de corpus-grootte, opdat de zo verkregen verwachtingen vergeleken kunnen worden (eventueel met behulp van een statistische toets als de chi-quadraat) met de geobserveerde data. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
12Uit het voorafgaande moge duidelijk geworden zijn, dat het gebruik van een PG de nodige voorzichtigheid behoeft. Die voorzichtigheid is voornamelijk geboden omdat we nauwelijks iets weten over steekproefgedrag van natuurlijke taal. Vóórdat de PG dan ook op grotere schaal gehanteerd kan worden, is het noodzakelijk dat we weten a) of het opstellen van een PG überhaupt mogelijk is en b) of het zinvol is. Als uit onderzoek blijkt dat alleen een zeer hoge orde-benadering een adequate beschrijving oplevert, dan is daarmee in feite het vonnis over de PG geveld. Niettemin kan men nu al (evenwel onder het nodige voorbehoud) met een PG aan de slag. In het voorafgaande is voornamelijk over het gebruik van een PG gesproken ten behoeve van de beschrijving van taalverwerving; dit omdat haast alle literatuur zich op dat terrein begeeft. Hierbij kan men opmerken dat de PG niet alleen voor de beschrijving dienst kan doen, maar ook het (tweede-) taal-onderwijs belangrijke perspectieven biedt. Naast de (basis)woordenlijsten kent men sinds kort ook de (basis) structuurlijsten (zie bijv. Van Els e.a. 1977: p. 284 e.v.). Voor het opstellen van zo'n structuurlijst is een PG het uitgelezen middel. Op het gevaar af speculatief te zijn, biedt de PG het volgende perspectief: de (Nederlandse) syntaxis is met behulp van een PG in kaart gebracht, we weten precies hoe vaak de mogelijk structuren voorkomen. Via een niet te grote steekproef van een taalleerder (bijv. 100 zinnen) kunnen we nu precies bepalen welke structuren deze leerder wel, niet, gedeeltelijk of incorrect beheerst; hier kan men dan het onderwijs op afstemmen. Daarnaast kan men het onderwijs aan beginnende tweede-taalleerders aanvangen met de meest voorkomende structuren (vergelijkbaar met het aanleren van woorden: ook hier begint men veelal met de meest frequente). Naast een praktische heeft een PG ook een theoretische waarde. Allereerst voor de ‘zuivere’ syntactici, doch wellicht nog meer voor dialectologen en sociolinguïsten. Naast het registreren van syntactische verschillen tussen groepen sprekers, is het mogelijk om met behulp van een PG die verschillen te correleren met niet-linguïstische factoren, analoog aan de variabele regel-methode. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
13Tot besluit nog een enkel woord over de praktijk van het hanteren van een PG. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 240]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Aangezien we met frequenties werken moeten we gaan tellen. Dit is tijdrovend en secuur werk. Net als bij de vervaardiging van frequentie-woordenlijsten ligt het voor de hand dit tellen te automatiseren. Automatische zinsontleding is echter aanzienlijk ingewikkelder dan woorden tellen. Op het ogenblik is volledige automatische zinsontleding (nog) niet mogelijk. Er bestaan echter wel programma's die delen van zinnen, vooral nominale groepen, kunnen ontleden. Het is te verwachten dat in de toekomst onderzoek naar PG's vaak samen zal gaan met de ontwikkeling van automatische ontleding (zie voor een inleiding Dik Bakker 1981). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 241]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
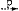 β
β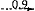 N
N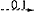 ADJ + NP
ADJ + NP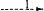 NP + V + NP
NP + V + NP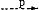 DET + N
DET + N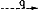 DET + ADJ + N
DET + ADJ + N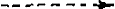 NP1 + V + NP2
NP1 + V + NP2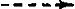 DET + N
DET + N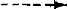 DET + ADJ + N
DET + ADJ + N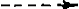
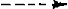 DET + ADJ + N
DET + ADJ + N