
Forum der Letteren. Jaargang 1981
(1981)– [tijdschrift] Forum der Letteren–
[pagina 26]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De productiviteit van woordvormingsregels
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (a) | Instemming wordt betuigd met de volgende opmerkingen van Karcevsky (1932:85): (al) ‘ce qui est mort peut être identifié par le nombre, et vice versa: ce qui peut être compté n'est plus productif’ en (a2) ‘par contre, ce qui est vivant ne comporte pas d'expression numérique’. |
| (b) | Uit het voorafgaande wordt afgeleid dat een adequate morfologische descriptie bestaat uit regels waarmee de per definitie productieve procédés kunnen worden beschreven en lijsten waarop de uitzonderingen op deze regels kunnen worden opgesomd. Ook de woorden die volgens een niet meer productief procédé zijn gevormd, horen tot de uitzonderingen. |
| (c) | Productiviteit mag niet zonder meer gelijkgesteld worden met de mogelijkheid om nieuwe woorden te vormen; alleen onopzettelijke nieuwvormingen komen in aanmerking. |
| (d) | Onderzoek naar productiviteit vereist (d1) interviews en experimenteel onderzoek met veel informanten, in combinatie met (d2) een zorgvuldige analyse van feitelijk taalgebruik. |
Het is de bedoeling van deze bijdrage te laten zien dat, in tegenstelling tot wat uitspraak (a2) mogelijk suggereert, een kwantitatieve benadering van het verschijnsel productiviteit wel degelijk zinvol is.Ga naar voetnoot2. Een dergelijke aanpak maakt het niet alleen mogelijk om het feitelijk taalgebruik zorgvuldig te analyseren (d2), waarbij tevens marginale en normale gevallen kunnen worden onderscheiden (c). Ook ontstaat zodoende een meer genuanceerd beeld van de morfologische component van een grammatica dan in (a) en (b) wordt geschetst: er blijkt geen absolute tegenstelling te bestaan tussen productiviteit (regels) en improductiviteit (lijsten met uitzonderingen); sommige regels zijn productiever dan andere. Hieruit volgt dat een adequate morfologie naast deterministische regels en lijsten met uitzonderingen ook regels moet bevatten waarvan de toepassingswaarschijnlijkheid groter is dan 0, maar kleiner dan 1.
Het betoog is als volgt opgebouwd: in deel 2 wordt ingegaan op de materiaalverzamelingen die de morfoloog ter beschikking staan, in 3 komen variaties in taalgebruik ter sprake, in deel 4 wordt de relatie tussen taalgebruik en productiviteit aan de orde ge-
steld, terwijl in het laatste deel uit een en ander conclusies worden getrokken. Het geheel wordt toegelicht aan de hand van Nederlandse en Franse nomina actionis.
2. Steekproeven van taalgebruik
Een analyse van feitelijk taalgebruik zal slechts bij uitzondering op al het relevante materiaal kunnen worden toegepast. Meestal volstaat de linguïst met een steekproef uit de feitenverzameling. In de praktijk van het morfologisch onderzoek blijkt hij ofwel van een woordenboek ofwel van een corpus taaluitingen gebruik te maken. Het is daarom van belang het een met het ander te vergelijken.
Allereerst moet worden opgemerkt dat een corpus meer informatie verschaft dan een woordenboek, omdat er niet alleen uit kan worden afgeleid dat een bepaalde woordvorm (‘type’) gebruikt wordt, maar ook hoeveel maal hij in de steekproef voorkomt (het aantal ‘tokens’ van dat ‘type’). Als het corpus bovendien taaluitingen van een aantal verschillende personen bevat, en deze uitingen eventueel ook nog in verschillende situaties tot stand zijn gekomen, dan ontstaat de mogelijkheid om verbanden te onderzoeken tussen de taalfeiten aan de ene kant en de factoren die de structuur van het corpus bepalen (situationele of sociale variabelen, b.v.) aan de andere kant.
Tevens kunnen gevallen van incidenteel of persoonsgebonden taalgebruik gemakkelijker worden onderkend. Indien een corpus tenslotte uit taaluitingen van verschillende, elkaar opvolgende periodes is opgebouwd, zoals b.v. bij de Trésor de la Langue Française het geval is, dan wordt het ook mogelijk om op verantwoorde wijze de expansie of de regressie van bepaalde verschijnselen te bestuderen. Al deze corpuseigenschappen komen in een onderzoek naar het begrip productiviteit van pas, zoals wij zullen laten zien.
In een woordenboek daarentegen wegen alle ingangen in principe even zwaar. Toegevoegde labels als ‘zeldzaam’, ‘schrijftalig’, ‘ironisch’ of ‘regionaal’ geven wel enige indicatie omtrent de feitelijke gebruiksmogelijkheden, maar ook niet meer dan dat. Als men bereid is het onvermijdelijke achterlopen van een woordenboek voor lief te nemen, dan kan onderzoek naar nieuwvormingen ook aan de hand van de opeenvolgende drukken van b.v. Van Dale plaatsvinden. Een betrouwbaar totaalbeeld van het eigentijds taalgebruik verkrijgt men daarmee echter nog niet. Uit een vergelijking tussen Van Dale (1970) enerzijds en de subcorpora 1 (dagbladen) en 2 (opiniebladen) van Uit den Boogaart (1975) en het spreektaalcorpus van de Jong (1979) anderzijds blijkt dat Van Dale m.b.t. nomina actionis op -age, -atie en -ering twee typische tekortkomingen vertoont:
| - | van de 29 woorden op -ering uit het dagbladcorpus staan er 3 niet in Van Dale, terwijl er van de 42 woorden op -ering uit de opiniebladen 8 niet in voorkomen; |
| - | Van Dale ‘dekt’ weliswaar alle woorden op -age uit de corpora, maar vermeldt daarnaast tal van woorden die totaal in onbruik zijn geraakt, zoals b.v. boelage, kijvage, kwellage en lullage, waardoor het eerder op een taalmuseum lijkt dan op een inventaris van het hedendaagse Nederlands. |
Kortom, een woordenboek als Van Dale is geen representatieve steekproef en dus een slechte steekproef. Daarmee is niet gezegd dat een corpus taaluitingen per definitie
een goede steekproef is, maar het kan het zijn, mits aan de eis van een aselecte samenstelling is voldaan. Als wij in het vervolg van deze beschouwing dan ook aan woordenboeken refereren, dan is dat uitsluitend omdat de momenteel beschikbare corpora niet alle wenselijk geachte kenmerken vertonen die hierboven zijn opgesomd.Ga naar voetnoot3.
3. Variaties in taalgebruik
Talen kunnen verschillen in de mate waarin zij gebruik maken van gelede woorden om concepten uit te drukken; de alternatieven zijn uiteraard het ongelede woord en de omschrijving. Dit verschil tussen talen kan twee oorzaken hebben. In de eerste plaats kan de ene taal over meer woordvormingsprocédés beschikken dan de andere, in de tweede plaats kunnen de beschikbare woordvormingsprocédés veel of weinig gebruikt worden. De vraag is nu wat onder ‘gebruik’ moet worden verstaan en hoe het gemeten kan worden. De term ‘gebruik’ kan nl. gemakkelijk aanleiding geven tot misverstand. Uit het schrijftaalcorpus van Uit den Boogaart (1975) kan b.v. zowel worden afgeleid dat substantiva 52,23% als dat zij 22,42% in beslag nemen. In het eerste geval heeft men het over het aandeel van de substantiva in de lijst van ‘types’ (41 191 op 78859), in het andere geval over ‘tokens’, d.w.z. het aantal types vermenigvuldigd met de frequentie waarmee zij in het corpus voorkomen (135815 op 605733). Hoewel er verschillende situaties denkbaar zijn waarbij het nuttig lijkt de tokens mede in de beschouwingen te betrekkenGa naar voetnoot4., zal in het vervolg, tenzij expliciet anders vermeld, steeds van types sprake zijn. Met andere woorden, een procédé X wordt meer gebruikt dan een procédé Y als er meer verschillende woordvormen zijn die door X worden beschreven dan door Y.
Wij zullen nu twee voorbeelden geven van analyses van feitelijk taalgebruik die o.i. in dit kader relevant zijn. Het eerste heeft betrekking op verschillen in het gebruik van de drie al eerder genoemde procédés waarmee Nederlandse nomina actionis beschreven kunnen worden, het tweede gaat over diachrone variaties in het gebruik van vier Franse nominalisatie-procédés.
Op grond van gegevens die in Uit den Boogaart (1975) en De Jong (1979) voorkomen, kan het volgende vergelijkende overzicht worden opgesteld (tabel 1, p. 29).
| nomina actionis op | overige | ||||
|---|---|---|---|---|---|
| -age | -atie | -ering | nomina | totaal | |
| dagbladen | 9 | 55 | 29 | 10373 | 10466 |
| opiniebladen | 5 | 67 | 42 | 10169 | 10283 |
| gezinsbladen | 7 | 61 | 12 | 9142 | 9222 |
| romans/novellen | 4 | 37 | 9 | 9585 | 9635 |
| pop.wet.proza | 6 | 102 | 46 | 9472 | 9626 |
| spreektaal | 0 | 14 | 6 | 3028 | 3048 |
| _____ | _____ | _____ | _____ | _____ | _____ |
| totaalGa naar voetnoot5. | 31 | 336 | 144 | 51769 | 52280 |
D.m.v. een Chi-kwadraat toets - voor verklaring en toepassingsvoorwaarden van deze toets, zie b.v. Wijvekate (1976, deel III) - kunnen uit deze tabel de volgende conclusies getrokken worden:
| - | Binnen het geheel van de substantiva worden er significant minder nomina actionis gebruikt in romans en novellen dan in de andere genoemde situaties (p< 0,001), terwijl er in populair wetenschappelijk proza significant meer gebruik van wordt gemaakt (p eveneens < 0,001). De overige geconstateerde verschillen zijn niet significant. |
| - | Van de drie bekeken suffixen wordt -atie in gezinsbladen significant meer gebruikt (0,02 < p < 0,05) tegen -ering significant minder (0,001 < p < 0,01), terwijl dit laatste suffix in opiniebladen significant meer gebruikt wordt (0,01 < p < 0,02). Andere verschillen zijn niet significantGa naar voetnoot6., hetgeen o.a. inhoudt dat het ‘tekort’ in romans en novellen niet aan één van de drie genoemde suffixen afzonderlijk is toe te schrijven en dat het ‘overschot’ in populair wetenschappelijk proza evenmin aan één van de 3 suffixen afzonderlijk is te danken. |
Wij zullen niet proberen in het bestek van deze verkenning een verklaring te zoeken voor deze verschillen, en merken slechts op dat de toepassingswaarschijnlijkheid van enkele regels waarmee in het Nederlands nomina actionis worden afgeleid mede afhankelijk is van de situationele kontekst. Een soortgelijke factor wordt genoemd door Pauwels (1964) en Noë (1976), nl. die van de regio: in België kiest men onder overigens vergelijkbare omstandigheden gauwer voor -atie dan voor -ering. Vergelijk:
België: constatatie, annulatie
Nederland: constatering, annulering
Het literaire corpus teksten van de Trésor de la Langue Française telt ongeveer 71 miljoen tokens, verdeeld over 71.415 lemrmata. In de tijd strekt het corpus zich uit van 1789 tot 1964, een periode die als volgt in vier stukken verdeeld kan worden:
(1) 1789-1849, (2) 1850-1879, (3) 1880-1918 en (4) 1919-1964. Teneinde te kunnen vaststellen of er zich m.b.t. de derivatie van Franse nomina actionis in de loop der tijd
veranderingen hebben voorgedaan, werd uit de lijst van 50232 lemmata waarvan het aantal tokens tenminste 2 bedraagt een aselecte steekproef getrokken van 990 lemmata. Voor elk lemma werd nagegaan of het een nomen actionis was, gevormd volgens één van de volgende procédés: -age, aison, -ement en -tion, en zo ja in welke van de vier onderscheiden tijdvakken het gebruikt was. Zodoende kon tabel 2 worden opgesteld.
| 1789-1849 | 1850-1879 | 1880-1918 | 1919-1964 | totaal | |
|---|---|---|---|---|---|
| -age | 5 | 8 | 9 | 12 | 34 |
| -aison | - | - | - | - | - |
| -ement | 19 | 21 | 26 | 24 | 90 |
| -tion | 25 | 23 | 23 | 25 | 96 |
| overige lemmata | 652 | 656 | 734 | 803 | 2845 |
| _____ | _____ | _____ | _____ | _____ | _____ |
| totaal | 701 | 708 | 792 | 864 | 3065 |
Het totaal aantal verschillende nomina actionis op de 990 onderzochte woorden bedroeg 70, als volgt over de drie procédés verdeeld: 12 op -age, 29 op -ement en 29 op -tion. Op grond van de vergelijking van tabel 2 met de theoretische, normale verdeling en de toetsing van de geconstateerde verschillen d.m.v. een Chi-kwadraat toets, kunnen de volgende conclusies worden getrokken:
| - | De onderlinge verhouding van de onderzochte suffixen heeft zich tussen 1789 en 1964 niet significant gewijzigd: -ement en -tion houden elkaar in evenwicht, -age blijft daarbij achter, terwijl -aison marginaal was en blijft. |
| - | Ook de verhouding tussen het totaal van de nomina actionis op -age, -ement en -tion enerzijds en het totale aantal lemmata anderzijds verandert niet significant. De waarschijnlijkheid dat een lemma uit een literair corpus een nomen actionis is, gevormd volgens één van deze drie procédés, kan geschat worden op 0,07 met een schattingsinterval van ± 0,02 (p < 0,01). |
Dat de tijd in andere gevallen wel een factor van belang is komt b.v. naar voren uit een globale vergelijking van Middelnederlandse data met die van het hedendaagse Nederlands. In het corpus Gysseling (1977), dat teksten tot 1300 bevat (in totaal ongeveer 850.000 tokens), komt op de ± 44.000 types geen enkel nomen actionis op -ering voor, tegen 5 op -atie. Het Middelnederlands Woordenboek (Van den Berg 1972), dat ongeveer 75.000 ingangen telt, bevat één woord op -ering tegen 28 op -atie.Ga naar voetnoot7. Als wij dit gegeven vergelijken met de huidige situatie (zie tabel 1), dan mag men ondanks de kleine getallen daaruit wel afleiden dat er een verschuiving in de relatieve toepassingswaarschijnlijkheid van beide suffixen is opgetreden, en wel ten gunste van -ering.
Wij menen dit deel van onze bijdrage te mogen besluiten met de conclusie dat factoren
als ‘kontekstuele situatie van een taaluiting’ en ‘tijd’ van invloed zijn op het daadwerkelijk gebruik van woordvormingsregels.
4. Taalgebruik en productiviteit
4.1 Inleiding
Hoewel er ontegenzeggelijk een verband bestaat tussen taalgebruik en productiviteit is het niet zo dat de graad van productiviteit van een woordvormingsprocédé alleen op grond van zijn rendement berekend zou kunnen worden, waarbij onder rendement wordt verstaan de verhouding tussen het aantal door die woordvormingsregel beschreven types en het totaal aantal types van een steekproef (met het bijbehorende schattingsinterval). Zodoende zou men nl. twee dingen over het hoofd zien. In de eerste plaats is er het feit, om met Uhlenbeck (1979:14) te spreken, ‘dat iedere taal verandert en de synchronische beschrijving altijd rekening moet houden met de omstandigheid dat een taal voorlopig eindpunt is van een historische ontwikkeling’. Op dit punt wordt nader ingegaan in paragraaf 4.3. In de tweede plaats moet worden opgemerkt dat voor de bepaling van de productiviteit van een procédé niet alleen de verhouding tussen de d.m.v. dat procédé gevormde types en het totaal aantal types van belang is, maar ook de verhouding tussen de d.m.v. dat procédé gevormde types en het aantal dat daarmee gevormd had kunnen worden, het aantal mogelijke types. Hierover gaat de volgende paragraaf.
4.2 Beperkingen op woordvormingsregels en graden van productiviteit
De gedachte om de graad van productiviteit van een woordvormingsregel te berekenen door het aantal bestaande woorden van een bepaald soort te delen door het aantal mogelijke woorden van datzelfde soort, wordt o.a. door Aronoff (1976:36) verdedigd. Een regel is dan productiever naarmate de breuk groter is. De grootte van de klasse mogelijke woorden van een bepaald soort is in principe gelijk aan het aantal beschikbare grondwoorden die voldoen aan de absolute eisen die de woordvormingsregel aan zijn grondwoorden stelt. Die eisen kunnen syntactisch, morfologisch of fonologisch van aard zijn. Enkele voorbeelden van zulke eisen zijn:
| - | het suffix -iteit kan alleen worden aangehecht aan adjectieven; |
| - | het suffix -te kan alleen worden aangehecht aan ongelede adjectieven (Booij 1977:129-130); |
| - | het meervoudssuffix -s kan niet worden aangehecht aan grondwoorden eindigend op -s. |
Deze wijze van berekenen brengt echter wel een aantal problemen met zich mee. Deze betreffen zowel de notie ‘bestaand woord’ (zie ook Booij 1979:9-10, 163-170) als de berekening van de klasse ‘mogelijke woorden’. Dit laatste omdat het aantal mogelijke basiswoorden van een regel niet vaststaat: als basis van het Nederlandse suffix -heid kunnen b.v. alle bestaande adjectieven optreden, maar ook mogelijke adjectieven, omdat woordvormingsregels rechtstreeks op de output van andere woordvormingsregels kunnen werken, b.v. olie → olieachtig → olieachtigheid, geel → gelig → geligheid. Het werken met representatieve steekproeven vergemakkelijkt de oplossing van deze problemen. Men kan er immers bij de analyse van zo'n steekproef vanuit gaan dat de werke-
lijkheid er zo goed mogelijk in gerepresenteerd is. In deel 3 hebben wij vastgesteld op grond van een steekproef van 990 lemmata, dat de kans om in een bepaald soort Frans op een nomen actionis te stuiten gelijk is aan 0,07. Nu kunnen wij daaraan het volgende toevoegen. In de steekproef kwamen 96 werkwoorden voor waarvan in beginsel nomina actionis hadden kunnen worden afgeleid. Van deze 96 mogelijke nomina actionis waren er in de steekproef slechts 58 gerealiseerd. Op grond van deze gegevens schatten wij de verhouding tussen bestaande en mogelijke Franse nomina actionis - in literaire teksten -, d.w.z. de graad van productiviteit van alle procédés tezamen, in de zin van Aronoff (1976), op 0,60 ± 0,125 (p < 0,01). Het schattingsinterval - in dit geval 0,125 - wordt berekend met behulp van de formule 2,5 √pq / n, waarbij p de gevonden verhouding in de steekproef aangeeft (0,60), q het complement daarvan (0,40) en n gelijk is aan het aantal waarnemingen (96). Uit de formule blijkt dat het schattingsinterval kleiner wordt naarmate de steekproef groter is, en dat het bij een gelijkblijvende n kleiner wordt naarmate ❘ p - 0,5 ❘ groter is. Een soortgelijke steekproef, uitgevoerd op het corpus Uit den Boogaart (1975) leverde een geschatte verhouding tussen bestaande en mogelijke Nederlandse nomina actionis op van 0,65 ± 0,09 (p < 0,01), waarbij echter moet worden aangetekend dat dit corpus mogelijk te klein is voor een dergelijk onderzoek (de hapax legomena spelen een te grote rol). Het gevolg hiervan kan zijn dat de verhouding tussen bestaande en mogelijke nomina actionis in het Nederlands in werkelijkheid hoger ligt dan hier wordt gesteld.
Een tweede probleem voor Aronoff's definitie van graden van productiviteit is dat hij daarbij alleen rekening houdt met absolute en niet met - eveneens bestaande - variabele beperkingen op woordvormingsregels. Zo kan het Nederlandse suffix -atie heel gemakkelijk worden aangehecht aan werkwoorden op -iseer, maar heel moeilijk aan werkwoorden op -eer die van een nomen zijn afgeleid. Evenzo wijst Aronoff (1976:63) erop dat de productiviteitsgraad van het negatieve prefix un- in het Engels varieert met de morfologische structuur van het basisadjectief. Naast de in paragraaf 3 genoemde factoren - tijdsvak en situationele kontekst - waarvan wij hebben vastgesteld dat zij in dit verband relevant zijn, kan ook gedacht worden aan pragmatische factoren en aan het verschijnsel ‘blokkering’. Zo geldt voor het maken van composita de pragmatische regel dat de twee woorden die samengevoegd worden in een compositum, bij voorkeur een niet-toevallige relatie hebben. Een woord als appelsapstoel met de betekenis ‘stoel waarvoor op tafel een glas appelsap staat’ is weliswaar niet onmogelijk, en kan in een bepaalde kontekst ook wel gebruikt worden, maar zulke composita zijn toch vrij zeldzaam en zullen terecht nooit in een woordenboek worden opgenomen (Downing 1977). Blokkering is het verschijnsel dat als een bepaald geleed woord eenmaal bestaat, van hetzelfde grondwoord niet nog een ander synoniem geleed woord wordt afgeleid. Omdat b.v. komst bestaat, is er geen behoefte aan koming. Maar blokkering is geen absoluut principe, hetgeen blijkt uit woordparen als vergeving ~ vergiffenis, fabricage ~ fabricering ~ fabricatie en industrialisering ~ industrialisatie of, in het Frans, affaitage ~ affaitement, dessalage ~ dessalement. Tenslotte blijkt vooral daar waar twee of meer suffixen elkaar beconcurreren, dat men met tendenzen eerder dan met absolute voorwaarden te maken heeft. Deze tendenzen vinden hun weerslag in de relatieve toepassingswaarschijnlijkheid van de betrokken procédés.
Wij lichten dit toe aan de hand van de volgende woordvormingsregels in het Nederlands:
| (1) | V → [V + ing]N | (2) | V → [V + atie]NGa naar voetnoot8. |
| conditie: V = [X + eer]V | |||
Het concurrerend karakter van deze regels blijkt hieruit, dat het gedeelte links van de pijl identiek is. Door de aan (2) toegevoegde conditie concurreren -atie en -ing alleen bij werkwoorden op -eer. Het suffix -ing kan ook aan inheemse werkwoorden worden aangehecht. Vergelijk:
| (i) | roep | roeping | *roepatie |
| bestel | bestelling | *bestellatie | |
| (ii) | noteer | notering | notatie |
| industrialiseer | industrialisering | industrialisatie |
De suffixen -eer en -iseer maken een werkwoord uitheems, omdat het uitheemse suffixen zijn, hetgeen blijkt uit hun vermogen zich te hechten aan uitheemse grondwoorden (b.v. code ~ codeer, stabiel ~ stabiliseer).
Er zijn nu een aantal factoren die de keuze tussen -ing en -atie beïnvloeden. Hieronder geven wij aan wat o.i. de belangrijkste factoren zijn:
(a) -atie treedt niet op als bij het grondwerk woord al een ander, synoniem nomen bestaat dat eindigt op een niet productief uitheems suffix (blokkering)Ga naar voetnoot9.:
| reageer | reaktie | reagering | reagatie |
| garandeer | garantie | garandering | *garandatie |
| correspondeer | correspondentie | correspondering | *correspondatie |
| componeer | compositie | componering | *componatie |
| bombardeer | bombardement | bombardering | *bombardatie |
Uiteraard is de vorm op -atie wel mogelijk bij betekenisverschil tussen beide afgeleide nomina:
| noteer | notitie | notering | notatie |
| vaceer | vacantie | vacering | vacatie |
(b) Het optreden van -atie wordt sterk afgeremd als in het grondwoord -eer direct achter een lexicaal morfeem staat. Bij werkwoorden op -iseer is dat per definitie niet het geval, omdat -is- grondwoord en -eer scheidt; vandaar dat -atie naar verhouding meer optreedt bij werkwoorden op -iseer dan bij werkwoorden op -eer. Vergelijk b.v. de volgende reeksen gerelateerde woorden:
| diftong | diftongeer | diftongering | ?diftongatie | diftongisatie |
| nasaal | nasaleer | nasalering | ?nasalatie | nasalisatie |
(c) Het suffix -ing heeft de voorkeur boven -atie als het grond woord uit slechts twee syllaben bestaat. Vergelijk b.v.:
| saneer | sanering | ?sanatie |
| fouilleer | fouillering | ?fouillatie |
Pro memorie noemen wij nog de factor die al in deel 3 aan de orde is geweest, nl. die
van de regio. Aangezien kwantitatieve gegevens hieromtrent ontbreken, laten wij deze variabele verder buiten beschouwing.
Wij kunnen nu de relatieve toepassingswaarschijnlijkheid van de regels (1) en (2) berekenen met het volgende multiplicatieve model van beperkende factoren (zie Cedergren & Sankoff 1974):
| (3) | p2 = po × a × b × c |
waarbij geldt dat p2 de toepassingswaarschijnlijkheid van regel (2) voorstelt en p0 de beginwaarschijnlijkheid, d.w.z. de waarde van p2 als er geen beperkende factoren in het geding zijn. De overige letters staan voor de zoëven opgesomde beperkende factoren (a), (b) en (c). De toepassingswaarschijnlijkheid van regel (1) is gelijk aan:
| (4) | p1 = 1 - p2 |
Elk van de beperkende factoren heeft de waarde 1 bij afwezigheid. De volgende kwantitatieve gegevens betreffende de woordenschat geregistreerd in Van Dale (1970) zijn nu basis voor de berekening van de waarde van de variabelen (tabel 3)Ga naar voetnoot10.:
| geen beperkende factor (p0) | alleen factor (b) | alleen factor (c) | factoren (b) en (c) | |
|---|---|---|---|---|
| woorden op -atie: | 344 | 13 | 22 | 3 |
| woorden op -ering: | 209 | 69 | 55 | 23 |
| p2 (-atie). | 0,622 | 0,159 | 0,286 | 0,115 |
| p1 (-ing): | 0,378 | 0,841 | 0,714 | 0,885 |
| p1:p2 | 0,608 | 5,289 | 2,496 | 7,696 |
De toepassingswaarschijnlijkheid p2 wordt berekend door het aantal woorden op -atie in een bepaalde kolom te delen door het totaal van het aantal woorden op -atie en het aantal woorden op -ering. Dus, b.v., 344:(344 + 209) = 0,622. Uit tabel 3 kunnen nu de waarden van de factoren (b) en (c) worden afgeleid. Het gewicht van (b) is gelijk aan 0,159:0,622 = 0,256 en dat van (c) is gelijk aan 0,286:0,622 = 0,460. Het gewicht van factor (a) - blokkering - is uiteraard 0. Hierdoor bereiken wij immers dat p2 gelijk wordt aan 0. Als factor (a) aanwezig is, dan zijn (b) en (c) verder niet meer van belang; het procédé op -atie is geblokkeerd. Uit tabel 3 kan ook worden geconcludeerd dat de factoren (b) en (c) niet onafhankelijk zijn, aangezien er in dat geval in de laatste kolom voor p2 een waarde van 0,159 × 0,286 = 0,045 had moeten staan (i.p.v. 0,115). Essentieel is echter dat uit de laatste regel van tabel 3 blijkt hoezeer de relatieve toepassingswaarschijnlijkheid van de beide suffigeringsregels varieert, afhankelijk van de in
deze beschouwing betrokken factoren. Wij concluderen (1) dat de graad van productiviteit van een woordvormingsregel kan variëren met de aard van de grondwoorden, de aanwezigheid van concurrerende woorden en concurrerende woordvormingsprocessen, en (2) dat volgens het hier geschetste model voor de berekening van p de concurrentie van woordvormingsregels ook formeel tot uitdrukking kan worden gebracht.
Tot besluit van dit deel nog een opmerking over de relatie tussen de productiviteit van een woordvormingsprocédé - in de zin van Aronoff (1976) - en zijn rendement, het percentage types dat d.m.v. dat procédé beschreven wordt. Uit het voorafgaande kunnen wij nl. concluderen dat de productiviteit van een woordvormingsregel hoog kan zijn, terwijl zijn rendement, door het grote aantal beperkingen op die regel, laag is. Aangezien het omgekeerde niet denkbaar is, kunnen wij stellen dat een hoge graad van productiviteit in de zin van Aronoff een noodzakelijke maar niet voldoende voorwaarde is voor een hoog rendement. Met andere woorden, uit een hoog rendement kunnen wij afleiden dat de productiviteit van een procédé groot is, maar indien het rendement laag is, kan daar niet zonder meer uit worden geconcludeerd dat de productiviteit gering is.
4.3 Productiviteitsveranderingen
Gegeven het feit dat woordvormingsregels kunnen verschillen in de mate van productiviteit die zij bezitten, dan is een mogelijk type taalverandering dat een woordvormingsregel meer of minder productief wordt. In deel 3 hebben wij daar ook een voorbeeld van gegeven (woorden op -ering zijn nu t.o.v. woorden op -atie waarschijnlijker dan in het Middelnederlands). Een ander suffix dat in dit verband nadere bespreking verdient is het suffix -age dat evenals -atie aan het Frans is ontleend. De woorden op -age die in Van Dale (1970) zijn geregistreerd, vallen uiteen in de volgende typen:
| (i) | leen woorden, zonder bijbehorend werkwoord op -eer, b.v. affutage, bagage; |
| (ii) | uitheemse nomina, met bijbehorend werkwoord op -eer, b.v. appreteer ~ appretage, arbitreer ~ arbitrage, agioteer ~ agiotage (in totaal 46 woorden); |
| (iii) | nomina met een substantief als grondwoord, als in bosschage, dierage (‘gedierte’), klerage (‘de kleren’), enz. |
| (iv) | nomina gehecht aan een inheems werkwoord, b.v. brekage, dijkage, plakkage, stoppage, strijkage (totaal 26 woorden). |
De groep die ons hier interesseert is groep (iv). In het Frans werd -age oorspronkelijk toegevoegd aan nomina, maar later door morfologische herinterpretatie ook aan verba (Fleischman 1977), en in het huidige Frans wordt -age nog uitsluitend bij verba productief gebruikt. Groep (ii) vormt geen betrouwbare evidentie voor het productief gebruik van -age in het Nederlands: waarschijnlijk zijn verbum en nomen beide aan het Frans ontleend. Het opmerkelijke van groep (iv) is dat -age toegevoegd wordt aan inheemse grondwoorden, terwijl de algemene tendens in het Nederlands is, dat dit niet mogelijk is (zie Booij 1977:131-9).Ga naar voetnoot11. Dit verklaart mogelijk de beperkte omvang van de groep. Opmerkelijk is voorts dat -age alleen voorkomt bij ongelede werkwoorden.
Dit correleert met het door Van Haeringen (1971) opgemerkte feit dat -ing gemakkelijker optreedt bij gelede dan bij ongelede werkwoorden. Het suffix -age is dus, zo zou men kunnen denken, een heel kleine concurrent van -ing, bij inheemse verba. De toepassingswaarschijnlijkheid van de -age regel zou, indien berekend op de wijze die in paragraaf 4.2 is gedemonstreerd, de waarde 0 weliswaar dicht benaderen, maar toch niet gelijk zijn aan 0. Dit is intuïtief onbevredigend, omdat de kans op een nieuw woord op -age wél gelijk is aan 0.
Hiermee zijn wij teruggekeerd bij een aspekt van de notie productiviteit dat in paragraaf 4.1 al even n.a.v. een citaat van Uhlenbeck aan de orde is geweest, en waar de definitie van Aronoff - graad van productiviteit = bestaande woorden gedeeld door mogelijke woorden - geheel aan voorbij gaat. Om deze dynamische dimensie van het verschijnsel productiviteit te kunnen verantwoorden, is het noodzakelijk om twee soorten woordvormingsregels te onderscheiden (zie ook Van Marle 1978). Er zijn enerzijds regels die alleen een analyserende functie hebben: een bepaald gedeelte van de bestaande woordvoorraad, zoals die in een steekproef tot uitdrukking komt, kan ermee worden beschreven. Hun rendement en hun graad van productiviteit in de zin van Aronoff kunnen worden berekend, maar hun voorspellende waarde is nihil, aangezien deze procédés niet worden gebruikt bij de vorming van nieuwe woorden. Anderzijds zijn er regels die naast een analyserende ook nog een predictieve functie hebben. Voor deze regels kan behalve het rendement en de productiviteit in de zin van Aronoff ook nog worden vastgesteld welk percentage nieuwvormingen ermee wordt bestreken. Beide typen regels horen thuis in de morfologische component van een grammatica, maar slechts de regels die zowel een analyserende als een voorspellende functie hebben kunnen echt productief genoemd worden. Deze verzameling is een deelverzameling van de regels waaraan Aronoff het predicaat ‘productief’ toekent.Ga naar voetnoot12. Er moet worden opgemerkt dat de graad van productiviteit van de procédés met voorspellende waarde wederom een variabele is. Deze conclusie kan zowel op grond van exploratie van een in de tijd gestructureerd corpus taaluitingen worden bereikt als door de vergelijking van enkele successieve edities van een woordenboek. Bij een corpus betrekt men uiteraard alleen die woorden in de beschouwing die in het ene tijdvak nog niet voorkomen en in het daaropvolgende wel. M.b.t. het Frans komt men dan b.v. op grond van de in deel 3 besproken steekproef tot de conclusie dat de procédés -age, -ement en -tion alle drie naast een analyserende ook een voorspellende waarde hebben. Dit wordt bevestigd door het recentelijk uitgekomen neologismen-woordenboek van Gilbert (1980), waarin ongeveer 370 ‘nieuwe’ nomina actionis zijn opgenomen, waarvan ± 62% op -tion, 28% op -age en 10% op -ment. Indien men meerdere edities van een woordenboek als materiaalverzameling wenst te gebruiken, dan kan men b.v. volgens de methode van Dubois (1962) te werk gaan. Deze vergelijkt twee edities van de Petit Larousse: L1 en L2, en gaat daarbij na hoeveel woorden van een bepaald soort zowel in L1 als in L2 voorkomen (stabiliteit), hoeveel er alleen in L2 voorkomen (expansie) en hoeveel er alleen in L1, staan (regressie). Op basis van deze gegevens kunnen dan de volgende coëf-
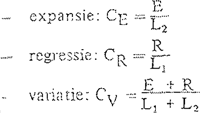
Indien men de methode Dubois toepast op de 7e, 8e en 9e druk van Van Dale, dan constateert men dat de CE van -age gelijk is aan 0, hetgeen dus inhoudt dat dit Nederlandse suffix momenteel geheel improductief is.
5. Conclusies
| 5.1 | Als steekproef van taalgebruik is een corpus te verkiezen boven een woordenboek. |
| 5.2 | Een statistisch verantwoorde analyse van taalgebruik maakt het mogelijk absolute zowel als niet absolute beperkingen op de productiviteit van woordvormingsregels op te sporen, op grond waarvan de toepassingswaarschijnlijkheid van deze regels kan worden bepaald. |
| 5.3 | Er moet een onderscheid gemaakt worden tussen het rendement van een regel en zijn productiviteit, waarbij kan worden aangetekend dat een grote productiviteit een noodzakelijke voorwaarde is voor een hoog rendement. |
| 5.4 | Een procédé is improductief als er geen nieuwe woorden meer worden gevormd volgens dat procédé. Alle andere procédés zijn productief, maar hun graad van productiviteit varieert van bijna 0 tot 1. |
| 5.5 | In Aronoff's definitie van het begrip productiviteit (bestaande gedeeld door mogelijke woorden) worden nieuwvormingen - en daarmee de diachronische dimensie - ten onrechte niet betrokken. Hierdoor dreigt het aantal productieve procédés systematisch te worden overschat. Met andere woorden, de ‘echt’ productieve procédés vormen een deelverzameling van de verzameling procédés waaraan Aronoff een graad van productiviteit toekent. |
Vakgroep Franse taalkunde
Vrije Universiteit
Instituut voor Neerlandistiek
Universiteit van Amsterdam
Bibliografie
| Al, B.P.F. |
| 1973 ‘Thesaurus en taalkundig onderzoek’, Forum der Letteren 19, 118-126 |
| Aronoff, M. |
| 1976 Word Formation in Generative Grammar, Cambridge Mass. |
| Berg, B. van den |
| 1972 Retrograde woordenboek van het Middelnederlands, Den Haag |
| Booij, G.F. |
| 1977 Dutch Morphology. A Study of Word Formation in Generative Grammar, |
| Dordrecht |
| 1978 ‘Woordvormingsregels als probabilistische regels’, Forum der Letteren 19, 248-251 |
| Booij, G.E. (red.) |
| 1979 Morfologie van het Nederlands, Amsterdam |
| Cedergren, H.J. & Sankoff, D. |
| 1974 ‘Variable rules: Performance as a statistical reflection of competence’, Language 50, 333-355 |
| Dale, van |
| 1970 Groot woordenboek der Nederlandse taal, Den Haag9 (7e druk van 1950, 8e druk van 1961) |
| Downing, P. |
| 1977 ‘On the creation and use of English compound nouns’, Language 53, 810-842 |
| Dubois, J. |
| 1962 Etude sur la dérivation suffixale en Français moderne et contemporain, Paris |
| Fleischman, S. |
| 1977 Cultural and Linguistic Factors in Word Formation. An Integrated Approach to the Development of the Suffix -age, Berkeley and Los Angeles |
| Gilbert, P. |
| 1980 Dictionnaire des mots contemporains, Paris |
| Gysseling, M. |
| 1977 Corpus van Middelnederlandse teksten (tot en met het jaar 1300). Reeks 1: Ambtelijke Bescheiden, Den Haag |
| Haeringen, C.B. van |
| 1971 ‘Het achtervoegsel -ing: mogelijkheden en beperkingen’, Nieuwe Taalgids 64, 449-468 |
| Jong, E.D. de (red.) |
| 1979 Spreektaal. Woordfrequenties in gesproken Nederlands, Utrecht |
| Karcevsky, S. |
| 1932 ‘Autour d'un problème de morphologie’, Annales Academiae Scientiarum Fennicae B 27, 84-91 |
| Marle, J. van |
| 1978 ‘De taken van het lexicon’, Forum der Letteren 19, 7-19 |
| Noë, J. |
| 1976 [-atie of -ering], Nu nog 24, 27-29 |
| Pauwels, J.L. |
| 1964 ‘Woorden op -atie en -ering in het Nederlands’, Verslagen en Mededelingen van de Koninklijke Vlaamse Academie voor Taal- en Letterkunde, 205-210 |
| Pichon, E. |
| 1939 ‘L'enrichissement lexical dans le français d'aujourd'hui’, Le français moderne 7, 317-328 |
| Uhlenbeck, E.M. |
| 1977 ‘The concepts of productivity and potentiality in morphological description and their psycholinguistic reality’, Salzburger Beiträge zur Linguistik 4, 379-391 |
| 1978 Studies in Javanese morphology, Den Haag |
| 1979 ‘Hoe een linguïst omgaat met ambassadrices en masseuses, een kritische vergelijking van morfologische theorie en descriptieve praktijk’, in T. Hoekstra & H. van der Hulst (eds.), Morfologie in Nederland, Leiden, 7-20 (Glot-special) |
| Uit den Boogaart, P.C. (red.) |
| 1975 Woordfrequenties in gesproken en geschreven Nederlands, Utrecht |
| Wijvekate, M.L. |
| 1976 Verklarende statistïek, Utrecht/Antwerpen15 (Aula 39) |
| Zwanenburg, W. |
| 1971 Franse afleidingsmanoeuvres, Leiden |
- voetnoot1.
- Zie ook Uhlenbeck (1978, 1979).
- voetnoot2.
- Dit artikel bouwt voort op een in het kader van Forum der Letteren gevoerde discussie over de aard van woordvormingsregels (zie Al 1978:124 en Booij 1978). Het aandeel van de eerstgenoemde auteur kwam tot stand gedurende een verblijf op het N.I.A.S. te Wassenaar.
- voetnoot3.
- Voor het Nederlands is er zowel voor de gesproken als voor de geschreven taal een corpus beschikbaar. Het is echter niet in de tijd gestructureerd, terwijl bovendien de omvang van de steekproeven vrij beperkt is. Voor het Frans bestaan ook zowel voor de gesproken als voor de geschreven taal corpora. Het laatste is zelfs zeer groot en tevens in verschillende tijdstranches onderverdeeld, maar is literair van aard, waardoor de representativiteit twijfelachtig is. Ongeacht de omvang van het gebruikte corpus geldt dat informatie over laagfrequente woordvormen aangevuld dient te worden met resultaten uit experimenteel onderzoek.
- voetnoot4.
- Bij een werkelijk groot corpus zou men kunnen besluiten dat alleen de types die door meer dan één persoon zijn gebruikt in het onderzoek mogen worden betrokken, dit om zuiver incidentele gevallen uit te sluiten. Een ander interessant punt zou zijn om te bezien of de in Zwanenburg (1971) beschreven Franse afkeer van gelede woorden - een type-probleem - ook tot uitdrukking komt in de gemiddelde frequentie van die woorden in vergelijking met b.v. het Nederlands.
- voetnoot5.
- De uitkomsten van de verticale optellingen corresponderen niet met de gegevens betreffende het totale corpus, aangezien de subcorpora hier geheel onafhankelijk van elkaar zijn geanalyseerd.
- voetnoot6.
- Over de rol van de verschillende in het corpus De Jong geregistreerde variabelen voor de hier besproken gelede woorden vallen geen betrouwbare conclusies te trekken vanwege het beperkte aantal relevante woorden dat in dit corpus voorkomt.
- voetnoot7.
- Van de woorden op -atie zijn alleen die geteld waarbij in het Middelnederlands woordenboek ook een werkwoord op -eer geregistreerd staat (zie paragraaf 4.2).
- voetnoot8.
- De wijze waarop regel (2) is geformuleerd, impliceert dat -eer door een truncatieregel wordt verwijderd na de aanhechting van -atie. Een alternatief zonder truncatie is:
(2) [x + eer]V → [x + atie]N
waarbij de woordvormingsregel -atie substitueert voor -eer. Voor de in dit artikel aan de orde gestelde problematiek is een keuze tussen beide oplossingen niet van belang.
- voetnoot9.
- Woorden op -age, die wij hier buiten beschouwing laten om het betoog niet nodeloos te compliceren, hebben dit blokkerend effect niet, ondanks het feit dat -age een uitheems suffix is (vgl. fabricatie ~ fabricage). In paragraaf 4.3 komt nog een ander uitzonderlijk kenmerk van dit suffix ter sprake.
- voetnoot10.
- De reden dat in dit geval Van Dale en niet het corpus Uit den Boogaart gebruikt wordt, is van uitsluitend praktische aard. Op het moment dat deze passage geschreven werd was er geen complete retrograde lijst van het corpus Uit den Boogaart voorhanden.
- voetnoot11.
- Vgi. ook de bijdrage van Zwanenburg in deze bundel, die Pichon (1939:319) aanhaalt: ‘les radicaux “savants” admettent, en effet, couramment les suffixes de souche française authentique (...). Au contraire, il y a toujours de la gaucherie à attacher un suffixe savant à un radical de la souche authentique’.
- voetnoot12.
- Uhlenbeck's voorstel om in een beschrijving naast productieve regels slechts lijsten met uitzonderingen op te nemen, vinden wij niet aantrekkelijk, aangezien een lijst o.i. slechts gebruikt zou moeten worden voor de opsomming van a-systematische gevallen. Die zijn er uiteraard, maar daarnaast valt er in dat deel van de woordvoorraad dat niet door ‘echt’ productieve regels kan worden beschreven toch wel degelijk regelmaat te ontdekken. Dit is het domein van regels met een uitsluitend analyserende functie.