
Forum der Letteren. Jaargang 1979
(1979)– [tijdschrift] Forum der Letteren–
[pagina 497]
| |
Bepaling van de herkomst van Oudfranse literaire teksten aan de hand van oorkondengegevens A. Dees en J.A. de VriesSamenvatting Het oud-Frans wordt gekenmerkt door een grote mate van dialectale verscheidenheid. De Oudfranse taalkunde, voornamelijk beoefend aan de hand van literaire teksten van onzekere herkomst, is er maar zeer ten dele in geslaagd greep te krijgen op deze verscheidenheid. Een beter inzicht in de ruimtelijke aspecten van het middeleeuwse Frans veronderstelt immers bekendheid met de herkomst van het aangewende documentatiemateriaal, hetgeen slechts bij uitzondering - en dan nooit anders dan met een zekere mate van aannemelijkheid - het geval is. Bij gebrek aan mogelijkheden tot oriëntatie op een niet-talige werkelijkheid moet derhalve, voor het overgrote deel van de literaire teksten, worden teruggevallen op vergelijking met de spaarzame teksten waarvan de herkomst als bekend wordt gepostuleerd. De vergelijking zelf verloopt volgens een procedure die als zeer ontoereikend moet worden beschouwd: aangezien het vrijwel uitgesloten is dat twee teksten door precies dezelfde serie karakteristieken worden gekenmerkt, zal onduidelijk blijven welke conclusies kunnen worden verbonden aan de in een bepaald geval aangetroffen constellatie van overeenstemmingen en tot welke gevolgtrekkingen de - meestal verwaarloosde - verschillen aanleiding geven. Het is, gelet op de geschetste benadering, begrijpelijk dat de onzekerheid met betrekking tot problemen van herkomst en dialectale geaardheid van taalgebruik tot uitdrukking wordt gebracht in de voorwoorden van talloze tekstedities. In het kader van het onlangs in dit tijdschriftGa naar eind1 beschreven project ‘Taalkundig onderzoek aan de hand van Franse oorkonden van de 13e eeuw’ werden enkele honderden kaarten vervaardigd die regionale verschillen vastleggen van de meest frequente taalverschijnselen (voornamelijk grafische reflexen van fonetische en morfologische variaties), zoals die worden aangetroffen in dateerbare en localiseerbare oorkonden uit de 13e eeuw. Aangezien de plaats van herkomst van de 3300 oorkonden waarop deze kaarten zijn gebaseerd is vastgesteld aan de hand van niet-talige criteria, kon een groter nauwkeurigheid worden bereikt bij het bepalen van het spreidingsgebied van de beschreven verschijnselen dan tot nog toe mogelijk was. | |
[pagina 498]
| |
Er zijn, voor wat de 13e eeuw aangaat, geen gronden aanwezig om te veronderstellen dat de ruimtelijke spreiding van deze verschijnselen zich in literaire teksten principieel anders zou manifesteren dan in oorkonden (de verderop te bespreken proeftekst weerspreekt eveneens een dergelijke veronderstelling). Er is derhalve aanleiding om te menen dat thans een goede basis is gevonden voor pogingen om, door vergelijking met de oorkonden, te geraken tot redelijk betrouwbare hypothesen inzake de herkomst van literaire teksten van de 13e eeuw. Met een dergelijke localisering komt, naar mag worden verwacht, de mogelijkheid binnen bereik om een zodanige ordening aan te brengen in het geheel van Oudfranse teksten dat een beter uitgangspunt wordt verkregen voor de bestudering van de regionale aspecten van het middeleeuwse Frans.
Parallel aan het vervaardigen van de door de computer berekende kaarten voor de Atlas des formes et des constructions des chartes françaises du 13e siècleGa naar eind2, werd een localiseringsprocedure ontwikkeld, die thans als operationeel kan worden aangemerkt. Alvorens de werking van het localiseringsprogramma te beschrijven lijkt het dienstig in herinnering te brengen op welke wijze het basismateriaal, gevormd door de beschrijving van 268 voor localisatie te gebruiken verschijnselen, tot stand is gekomen. In verband met de soms lange reeksen uiteenlopende schrijfwijzen voor één en hetzelfde woord in het oud-Frans moest er, bij het in kaart brengen van de verschillen, van af worden gezien deze vormen individueel te presenteren. In plaats daarvan werd gekozen voor een dichotomische benadering die hierin bestaat dat de gevonden schrijfwijzen worden verdeeld over twee klassen, waarvan de eerste wordt gedefinieerd door een of meer kenmerken die de tweede klasse niet heeft. Voor een onderzoek naar de regionale variaties in de spellingen van ‘maison’ (maisom, maison(s), maisonz, maisoun(s), maisson(s), maissum, maissun(s), maisun(s), maixon(s), maizon(s), maizoun(s), mason(s), masun(s), maxon(s), mayson(s), maysson(s), meisom, meison(s), meisson(s), meisum, meisun(s), mesom, meson(s), messon(s), messum, mesum, mesun(s), meyson(s)) kan onder andere worden nagegaan de aard van de klinker of tweeklank in de beginlettergreep. Een voor de hand liggende dichotomische verdeling plaatst de schrijfwijzen met -e-, -ei-, -ey- in de eerste klasse, terwijl de complementaire klasse in dit geval wordt gekenmerkt door -a-, -ai-, -ay-. De berekening van de absolute en van de relatieve frequenties van deze twee klassen levert per gebied een bepaald percentage op voor de aanwezigheid van het kenmerk -e-, -ei-, -ey- en een complementair percentage voor de aanwezigheid van -a-, -ai-, -ay-. De percentages van de eerste klasse worden door de computer op een kaart van Frankrijk ingetekend en geven aldus inzicht in de ruimtelijke verdeling van de schrijfwijze -e-, -ei-, -ey- tegenover de schrijfwijze -a-, -ai-, -ay-. Het onderzoek naar de beginlettergreep van ‘maison’ kan worden voortgezet door op een nieuwe kaart de verdeling van bij voorbeeld -e- versus -ei-, -ey- in beeld te brengen. De dichotomische benadering, in eerste instantie bedoeld om, door een woud van spellingen heen, een zo nauwkeurig mogelijke schatting te kunnen maken van het verloop van belangrijke isoglossen, leverde aldus als interessant bijproduct een grote hoeveelheid kwantitatieve informatie op, die gebruikt kan worden voor de getalsmatige vergelijkingen in de localiseringsprocedure. Deze kwantitatieve gegevens zijn zo georganiseerd dat in principe op 85 meetpunten (steden of gebieden waarvoor voldoende informatie beschikbaar is), verspreid over het gebied van het oud-Frans, te weten Noord-Frankrijk en Franstalig België, voor 268 verschijnselen een percentage voorhanden is;dit percentage legt voor elk meetpunt de frequentie vast van die verschijnselen | |
[pagina 499]
| |
uit de Atlas die, zoals het voorkomen van -e-, -ei-, -ey- in de spelling van ‘maison’, als localiseringscriterium in aanmerking zijn genomen. Voor het uitvoeren van de vergelijking van taalvormen uit een literaire tekst met het zojuist beschreven basismateriaal is het noodzakelijk de relevante vormen uit die tekst te inventariseren teneinde de tekstpercentages van de 268 verschijnselen te kunnen bepalen. Daartoe worden de aangetroffen vormen, met hun absolute frequenties, ingevoerd in de computer, die voor elk van de verschijnselen zorg draagt voor de verdeling van de vormen over de twee gedefinieerde klassen en vervolgens de relatieve frequenties van deze klassen berekent. De reeks van 268 tekstpercentages, die de frequentie aangeven van de eerste klasse van elk verschijnsel, vormen de tekstbeschrijving, die nu kan worden vergeleken met de analoog ingerichte oorkondenbeschrijving op elk van de 85 meetpunten. In de aanvankelijke (intussen sterk gewijzigde) vorm van het programma werd daartoe, bij voorbeeld op het meetpunt Arras, het verschil bepaald tussen het tekstpercentage en het meetpuntpercentage voor elk van de verschijnselen. Het gemiddelde van de 268 zo verkregen verschillen drukt in één getal uit hoe sterk de taalvormen van de literaire tekst verschillen van die van het onderzochte meetpunt. Door dit getal af te trekken van 100 wordt, op een schaal lopend van 0 tot 100, een getal verkregen dat de mate van overeenstemming tussen tekst en meetpunt vastlegt. Wanneer op deze wijze de mate van verwantschap van een tekst met elk van de meetpunten is bepaald, wordt door de computer een kaart getekend waarop de gevonden overeenstemmingsgetallen bij de betreffende meetpunten worden aangegeven. In een gewijzigde versie van het programma wordt aan de telkens gevonden verschillen tussen tekstpercentage en meetpuntpercentage een andere vertaling gegeven teneinde, gemakshalve, te kunnen werken met een systeem van positieve en negatieve argumenten. Bij een meer of minder sterke overeenstemming tussen tekstpercentage en meetpuntpercentage, dat wil zeggen bij een verschil liggend tussen 0% en 50%, wordt een positieve score toegekend, terwijl gebrek aan overeenstemming (verschil groter dan 50% en oplopend tot 100%) negatief wordt gewaardeerd. Aan de mate van overeenstemming of verschil wordt recht gedaan door maximale overeenstemming en maximaal verschil te tellen als 3 x 100, respectievelijk -3 x 100, terwijl de daartussen liggende mogelijkheden worden gehonoreerd met getallen die liggen tussen 3 x 100 en -3 x 100 (de keuze van de factor 3 moet worden bezien in samenhang met de verderop te introduceren alternatieve berekeningsmethode). De becijfering van de verschillende uitkomsten kan worden weergegeven met het schema van figuur 1 (zie bladzijde 500). Dit schema veronderstelt dat een bepaald meetpuntpercentage wordt uitgezet op de X-as en het daarmee te vergelijken tekstpercentage op de Y-as. Het snijpunt van de frequentielijnen ligt, indien beide percentages gelijk zijn, op de diagonaal en levert dan 3 x 100 op; bij tegengestelde percentages (0% voor meetpunt en 100% voor tekst of omgekeerd) ligt het snijpunt respectievelijk in de linkerbovenhoek of in de rechterbenedenhoek, in welke situatie -3 x 100 wordt toegekend, terwijl de verschillen die liggen tussen de genoemde hoofdwaarden volgens een glijdende schaal worden omgerekend tot waarden die liggen tussen 3 x 100 en -3 x 100 (in het bijzonder valt bij een verschil van precies 50% het snijpunt op de aangegeven 0-lijnen, welk geval, met 0 x 100, geen positief of negatief argument oplevert).
Eerste ervaringen met het zojuist beschreven programma werden opgedaan aan de hand van de Jeu de saint Nicolas, een dertiende-eeuwse tekst die vrijwel zeker uit Arras afkomstig is. De resultaten van de berekening, hoewel onmiskenbaar in de juiste richting | |
[pagina 500]
| |
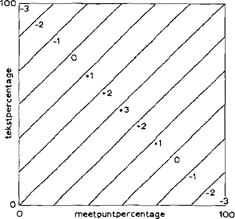
figure 1
wijzend, vertoonden een aantal oneffenheden in de verdeling van de overeenstemmingsgetallen over het gehele gebied die leken te wijzen op onvolkomenheden in de procedure. Aan de hand van een reeks experimenten konden deze onvolkomenheden worden opgespoord en hun storende invloed goeddeels teniet gedaan. Vier tekortkomingen in het programma moesten nader worden bezien en waar mogelijk verholpen, tekortkomingen die samenhangen met achtereenvolgens de soms ontoereikende documentatie, het niet geheel onproblematisch vergelijken van individueel tekstgedrag en collectief oorkondengedrag, het gewicht van de argumenten die kunnen worden ontleend aan het al of niet overeenstemmen van tekstpercentages en meetpuntpercentages in verschillende situaties en tenslotte berekeningsmoeilijkheden die zich voordoen indien de meetpuntpercentages voor een bepaald verschijnsel niet een maximale spreiding vertonen met waarden lopend van 0% tot 100%.
Wat betreft de omvang van de benodigde documentatie, in de Atlas is als norm gehanteerd dat geen uitspraak wordt gedaan over relatieve frequenties indien deze niet kunnen worden berekend op grond van tenminste zes getuigenissen. Het zou bevredigend zijn als deze norm ook kon worden gehandhaafd voor het berekenen van de tekstpercentages. Dit houdt evenwel in dat, om bij voorbeeld het woord ‘maison’ in aanmerking te kunnen nemen, minstens zes voorkomens van dat woord moeten kunnen worden geregistreerd in de literaire tekst. Aangezien dit in vele gevallen niet gelukt, ontstaat een deelvergelijking op basis van de meest frequente verschijnselen in de literaire tekst, waarbij een niet onaanzienlijke hoeveelheid informatie wordt verwaarloosd. Mede in het belang van de onderlinge vergelijkbaarheid van de resultaten voor verschillende teksten werd als tussenoplossing gekozen dat het vereiste aantal voorkomens afhankelijk wordt gemaakt van het gedrag van het verschijnsel in de literaire tekst. Indien de tekst voor een gegeven verschijnsel een consequent gedrag vertoont, dat wil zeggen indien het tekstpercentage 0 of 100 bedraagt, wordt genoegen genomen met drie voorkomens; indien twee contrasterende schrijfwijzen gelijkelijk worden aangetroffen (inhoudend dat het tekstpercentage 50 bedraagt) wordt de oude norm gehanteerd, terwijl voor tekstpercentages liggend tussen de twee uitersten van 100 en 50 of 0 en 50 een tussennorm wordt berekend van vier of vijf voorkomens. Het resultaat is dat ge- | |
[pagina 501]
| |
woonlijk, voor een tekst van gemiddelde omvang, verreweg de meeste verschijnselen voor vergelijking in aanmerking kunnen komen. Soortgelijke moeilijkheden, maar dan met ernstiger consequenties, doen zich voor op sommige niet al te sterk gedocumenteerde meetpunten. Het ontbreken van voldoende gegevens voor de minder frequente verschijnselen op bepaalde meetpunten leidt tot vergelijkingen die niet meer voor de 85 meetpunten als onderling gelijkwaardig kunnen worden beschouwd, met het risico dat zich voor een bepaalde tekst onregelmatigheden, ja zelfs vertekeningen voordoen in de verdeling van de overeenstemmingsgetallen. Een ietwat gedurfde, maar naar onze mening verantwoorde, oplossing nam dit risico weg; deze oplossing bestaat hierin dat, indien minder dan zes oorkonden het betreffende verschijnsel kunnen documenteren op een bepaald meetpunt, een beroep wordt gedaan op drie of vier naburige meetpunten, waarvan als het ware enkele oorkonden worden overgeheveld naar het onderzochte meetpunt teneinde - zo mogelijk - voldoende documentatie te verkrijgen. Aangezien door deze ingreep de 85 becijferingen in belangrijke mate onderling vergelijkbaar zijn geworden, behoeft geen beduchtheid te bestaan dat de resultaten door toevallige lacunes sterk beïnvloed worden, terwijl anderzijds controle leerde dat de grootste correcties ten opzichte van de oorspronkelijke berekening tot enkele eenheden beperkt blijven.
Een moeilijk adequaat op te lossen problematiek hangt samen met het vergelijken van één individuele tekst met een collectief van teksten, te weten het geheel van oorkonden op een bepaald meetpunt. Is het wel voor de hand liggend om, zoals gebeurt bij vergelijking van tekstpercentages en meetpuntpercentages, er van uit te gaan dat de individuele kopiist in zijn gedrag altijd een afspiegeling vormt van het doorsneegedrag van een verzameling kopiisten? Zal bij voorbeeld, als in een overgangsgebied de helft van de oorkondenschrijvers opteert voor een bepaalde schrijfwijze en de andere helft voor de contrasterende spelling, de tekstschrijver geneigd zijn zijn voorkeuren te verdelen volgens dezelfde verhouding? Mag van zijn individueel gedrag niet meer consistentie worden verwacht dan van het groepsgedrag? Enige tijd is, in de hoop een uitweg te hebben gevonden uit de moeilijkheden, gewerkt met een programma dat abstraheerde van de middenpercentages, hetzij in de tekst, hetzij op de meetpunten. De methode van de duidelijke gevallen die aldus ontstaat vergelijkt uitsluitend op basis van extreme percentages, bij voorbeeld liggend onder de 20% en boven de 80%. In deze benadering, die beoogde de problematiek van de overgangsgebieden te elimineren, krijgt men een duidelijk negatieve score bij conflict tussen tekstpercentage en meetpuntpercentage en een duidelijk positieve score bij samentreffen van beide hetzij in de lage, hetzij in de hoge regionen van de percentageschaal. Positieve en negatieve overeenstemming kunnen worden gewaardeerd met toekenning van respectievelijk 100 en -100. De eigenlijke moeilijkheid wordt op deze wijze evenwel niet opgelost: het blijft immers mogelijk dat een tekst met een consistent gedrag toch uit een overgangsgebied afkomstig is; de methode van de duidelijke gevallen levert in dit geval geen argument op voor het bedoelde gebied (dat immers met zijn middenpercentage buiten de berekening wordt gehouden), terwijl de toekenning van positieve punten normaal doorgang vindt voor wat betreft de kerngebieden van het bestudeerde verschijnsel. Het is niet onaannemelijk dat de totale schade van dergelijke vertekeningen beperkt blijft; bedacht mag immers worden dat per gebied maar een deel van de verschijnselen een middenpercentage oplevert, terwijl daarnaast troost kan worden geput uit de overweging dat eventuele vertekeningen niet systematisch in dezelfde richting werken, zodat met een op- | |
[pagina 502]
| |
heffingseffect mag worden gerekend. Voorts is het natuurlijk niet zo dat de tekstschrijver nooit zou verraden dat hij voor wat betreft een bepaald verschijnsel uit een overgangsgebied afkomstig is; het middenpercentage dat op dit overgangskarakter wijst bewerkt dat dit argument voor alle gebieden buiten beschouwing blijft, zodat vertekening niet plaats vindt. Het is intussen wel duidelijk dat deze alternatieve methode bezwaarlijk zijn voornaamste bestaansgrond kan ontlenen aan de geschetste problematiek. Wanneer aan deze methode, in gewijzigde vorm, niettemin een belangrijke rol is voorbehouden in de localiseringsprocedure, dan is dat om andere redenen, waarop nu nader kan worden ingegaan.
Het hangt met de aard van het basismateriaal samen - en hiermee komen we tot het probleem van het gewicht dat mag worden toegekend aan het al of niet overeenstemmen van tekstpercentages en meetpuntpercentages - dat niet aan alle uitkomsten van de vergelijking hetzelfde belang kan worden gehecht. Het komt in een groot aantal gevallen voor dat het spreidingsgebied van de onderzochte verschijnselen beperkt van omvang is. Overeenstemming van tekst en meetpunt in het niet kennen van een dergelijk verschijnsel zal veelvuldig voorkomen en is weinig leerrijk. Wanneer een groot aantal van deze gevallen wordt samengenomen dreigt datgene wat de meetpunten van elkaar onderscheidt overstemd te worden door datgene wat ze gemeen hebben. Concreet manifesteerde een ongedifferentieerde benadering, die aan alle argumenten hetzelfde gewicht toekent, zich in overeenstemmingsgevallen die voor de verschillende meetpunten te weinig uiteenliepen en zich op de schaal van 0 tot 100 concentreerden in het interval van bij voorbeeld 50 tot 100. In overeenstemming met het principe dat argumenten te waardevoller zijn naarmate ze preciezere conclusies toelaten lijkt het redelijk, ingeval een gegeven verschijnsel slechts op een beperkt gebied voorkomt, de positieve overeenstemming die slaat op aanwezigheid van dit verschijnsel zwaarder te laten wegen dan de positieve overeenstemming die slaat op de afwezigheid ervan. In hetzelfde perspectief behoort negatieve overeenstemming sterker in aanmerking te worden genomen dan de positieve overeenstemming voortvloeiend uit het ontbreken van het verschijnsel met beperkt spreidingsgebied. Aan het principe van de weging van argumenten conform de aangegeven uitgangspunten wordt vorm gegeven in het in figuur 2 afgebeelde model, dat een aangepaste versie is van de methode van de duidelijke gevallen (zie bladzijde 503). Dit model heeft een gunstige uitwerking in situaties waarin het spreidingsgebied van een verschijnsel beperkt is. Drie mogelijkheden moeten worden onderscheiden: a) de tekst kent het bedoelde verschijnsel niet of nauwelijks; het snijpunt van tekstpercentage en meetpuntpercentage wordt derhalve aangetroffen aan de onderzijde van het vierkant; indien het meetpuntpercentage laag is (hetgeen het veel voorkomende en weinig interessante geval oplevert van overeenstemming tussen tekst en meetpunt in het niet kennen van het verschijnsel) vindt in de linker benedenhoek normale honorering plaats met toekenning van 1 x 100. Naarmate, naar rechts gaande, de meetpuntpercentages hogere waarden aannemen, ontstaan situaties waarin een steeds sterkere tegenstelling aan de dag treedt tussen tekst en meetpunt; het corresponderende negatieve argument krijgt het maximale gewicht bij een meetpuntpercentage van 100%, in welk geval de toegekende -100 drie keer wordt geteld; b) de tekst kent het verschijnsel uitsluitend of vrijwel uitsluitend; het snijpunt van tekstpercentage en meetpuntpercentage komt terecht aan de bovenzijde van het vier- | |
[pagina 503]
| |

figuur 2
kant. In gebieden die het verschijnsel niet kennen (snijpunt van tekst en meetpunt in linker bovenhoek) ontstaat een conflictsituatie, ook hier gewaardeerd met het gewicht -3, terwijl de (zeldzame) hoge meetpuntpercentages in de rechterbovenhoek resulteren in een vijf keer geteld positief argument; c) de tekst kent zowel het bedoelde verschijnsel als het daarmee contrasterende verschijnsel, beide vertegenwoordigd met een middenpercentage. De methode van de duidelijke gevallen behoort nu niet te worden toegepast; het snijpunt valt midden in het veld, zodat geen argument wordt verkregen (zoals verderop zal blijken kan dit geval (gedeeltelijk) worden overgenomen door de alternatieve methode volgens het model van figuur 1). De werking van dit model lijkt intuitief bevredigend, uiteraard op voorwaarde dat de toepassing ervan slechts plaats vindt in die gevallen waarvoor de methode is ontworpen, te weten voor verschijnselen met een beperkt spreidingsgebied. In deze selectieve toepasbaarheid wordt voorzien door het gemiddelde van de meetpuntpercentages voor een gegeven verschijnsel te berekenen: hoe beperkter het spreidingsgebied, hoe lager dit gemiddelde zal uitvallen. Het model van de duidelijke gevallen in de zojuist beschreven gewijzigde vorm wordt ingezet, indien het gemiddelde van de meetpuntpercentages valt beneden de empirisch vastgestelde grens van 20%.
Een laatste moeilijkheid moet thans onder ogen worden gezien. Kennisname van de volgens de oorspronkelijke methode uitgevoerde berekeningen leerde dat vergelijking van tekstpercentage en meetpuntpercentage in sommige gevallen een averechtse conclusie opleverde. Dit falen van de oorspronkelijke methode hangt samen met de omstandigheid dat de 85 meetpuntpercentages, die de frequentie van het verschijnsel over het gehele gebied vastleggen, niet noodzakelijk lopen van 0% tot 100%. In een aantal gevallen blijft het maximum van de gevonden frequenties steken bij bij voorbeeld 50%. Een literaire tekst met een frequentie van 100% voor een dergelijk verschijnsel zou uiteraard met een krachtig argument moeten worden toegeschreven aan het kerngebied met 50%, terwijl in werkelijkheid een aanzienlijk verschil in percentages wordt geregistreerd; een tekst met een frequentie van 30% zou zelfs krachtiger worden toegeschreven aan het kerngebied dan de tekst met 100%. De localiseringsmethode moet kennelijk gevoelig worden gemaakt voor de maximumfrequentie die voor ieder verschijnsel is gevonden. | |
[pagina 504]
| |
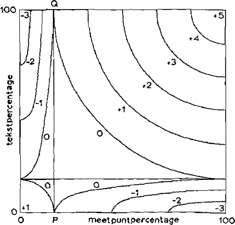
Dit wordt bereikt door het model van figuur 2 zodanig asymetrisch te maken dat de omslag van relatief lage naar relatief hoge meetpuntpercentages vroeger kan inzetten dan bij de 50%-grens (zie figuur 3):
figuur 3
Het verloop van de lijn PQ wordt bepaald door het gemiddelde van de meetpuntpercentages van een gegeven verschijnsel als punt P uit te zetten op de X-as; deze lijn vormt de nieuwe grens tussen de relatief lage waarden (tot nog toe: kleiner dan 50%) en de relatief hoge waarden (tot nog toe: groter dan 50%) van de meetpuntpercentages. Daarnaast wordt het vierkant zo ver versmald als nodig is om de rechterzijde te doen gelijk vallen met de lijn die het maximum van de meetpuntfrequenties aangeeft; hierdoor wordt bereikt dat een tekst met een hoge frequentie toch een maximale score kan opleveren (enkele kleine correcties op deze versmalling worden hier buiten beschouwing gelaten).
Aan de besproken aspecten van de localiseringsproblematiek wordt naar onze mening zo goed mogelijk recht gedaan door in de procedure twee formules te laten samenspelen. De eerste formule is, zoals boven is gebleken, een afgeleide van de oorspronkelijke vergelijking van tekstpercentages en meetpuntpercentages en werd in beeld gebracht in figuur 1. Deze formule wordt gehanteerd indien het gemiddelde van de meetpuntpercentages 50% bedraagt. Dit (zeldzame) hoge gemiddelde is een aanwijzing dat enerzijds het spreidingsgebied groot is, terwijl anderzijds het maximum van de meetpuntpercentages hoog moet zijn en waarschijnlijk in de buurt van 100% ligt. In deze situatie is er geen aanleiding om niet de oorspronkelijke benadering te kiezen. De tweede formule, weergegeven in figuur 3, wordt in stelling gebracht indien hetzij een klein spreidingsgebied, hetzij een lage maximumwaarde van de meetpuntpercentages, hetzij beide, resulteren in een laag gemiddelde van deze percentages. Zoals in het voorgaande is betoogd is er nu mogelijkheid de resultaten duidelijker te laten uitkomen door de argumenten te wegen en/of aanleiding om corrigerend op te treden om onjuiste werking van de vergelijkingsmethode tegen te gaan. Met deze tweede formule wordt gewerkt indien het gemiddelde van de meetpuntpercentages minder dan 20% bedraagt. Voor de resterende gevallen, waarbij het gemiddelde van de meetpuntpercentages valt in het interval van 20% tot 50%, wordt volgens een glijdende schaal berekend welk aan- | |
[pagina 505]
| |
deel toevalt aan beide methoden: vanaf 20% tot 50% wordt in toenemende mate de tweede formule vervangen door de eerste tot bij 50% het aandeel van de methode van de duidelijke gevallen tot nul is gereduceerd.
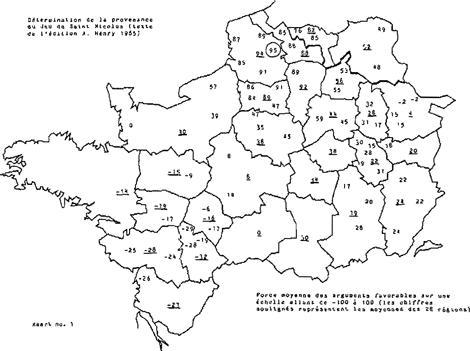
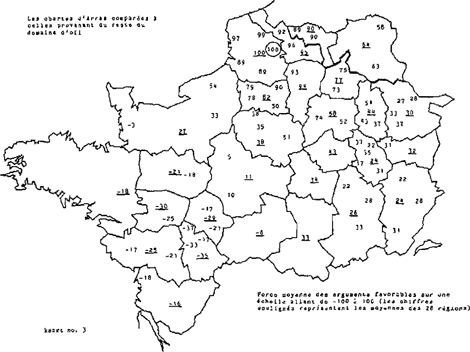
Het resultaat van de toepassing van de ontwikkelde methode op de Jeu de saint Nicolas wordt gegeven op kaart no. 1, die enerzijds duidelijk maakt hoezeer de bestudeerde verschijnselen in de literaire tekst overeenstemmen met de in de oorkonden uit Arras gebruikelijke vormen en anderzijds leert dat de overeenstemming geleidelijk afneemt naarmate de afstand tot het centrum Arras groeit. Op indirecte wijze wordt aldus aannemelijk gemaakt dat de in de oorkonden aangetroffen vormen sterk plaatselijk bepaald zijn en dat, vanuit een bepaald centrum gezien, de verschillen in alle richtingen accumuleren. Op meer directe wijze kon dit geleidelijk afnemen van verwantschap binnen het geheel van oorkonden in beeld worden gebracht door het localiseringsprogramma te laten werken op de verzameling oorkonden die van een bepaald meetpunt afkomstig zijn. Behalve dat aldus de werking van het localiseringsprogramma werd gecontroleerd ontstond zodoende inzicht in de mate waarin bij voorbeeld de oorkonden uit Arras overeenstemmen met de uit andere gebieden afkomstige oorkonden (zie kaart 3). Nu deze exercitie is uitgevoerd voor elk van de 85 meetpunten kan de algemene conclusie worden getrokken dat, zoals Arras zich onderscheidt zelfs van naburige meetpunten, ook de overige punten individueel kunnen worden beschreven als gekenmerkt door een specifieke dosering van regionale trekken. Daarmee lijkt niet alleen een wijdverbreide misvatting te worden weerlegd volgens welke er enkele grote streektalen bestaan die niet intern differentieerbaar zijn, maar wordt ook voldaan aan een noodzakelijke voorwaarde voor de uitvoerbaarheid van localiseringspogingen als nu worden ondernomen.
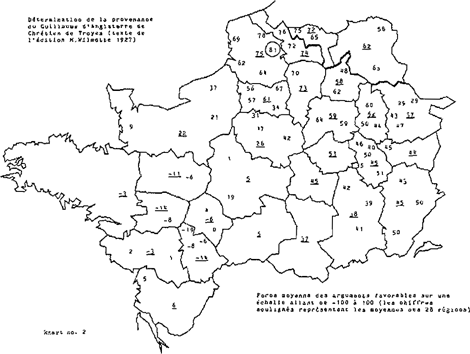
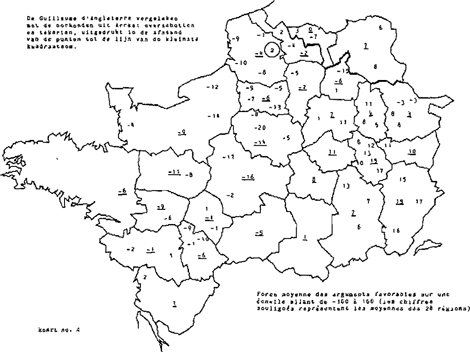
Het toepassen van de localiseringsmethode op de oorkonden zelf opent nog andere perspectieven. Stel dat een literaire tekst gevonden zou worden die precies dezelfde taalvormen zou hebben als die welke worden aangetroffen in de verzameling oorkonden uit Arras. De localisering van deze literaire tekst zou uiteraard leiden tot dezelfde constellatie van overeenstemmingsgetallen als kaart no. 3 te zien geeft. Vergelijking van kaart no. 1 met kaart no. 3 toont aan dat de Jeu de saint Nicolas een geheel van getallen oplevert dat sterk lijkt op het beeld dat de oorkonden uit Arras vertonen, waardoor nog eens wordt bevestigd dat deze literaire tekst in belangrijke mate voldoet aan de verwachting die men op grond van de oorkonden kan hebben van een tekst die in die stad geschreven is. Andere literaire teksten leveren een minder gunstig beeld op. Op kaart no. 2 is het resultaat te zien dat werd verkregen voor de Guillaume d'Angleterre die, naar wordt aangenomen, weliswaar in het Noorden is afgeschreven, maar afkomstig is uit een gebied ten Oosten van Parijs (de tekst wordt veelal toegeschreven aan Chrétien de Troyes). Verondersteld mag worden dat de Picardische afschrijver de oorspronkelijke tekst in belangrijke mate heeft gepicardiseerd, zodat Arras als plaats van herkomst wordt aangewezen, maar daarnaast ook oorspronkelijke vormen (bij voorbeeld aan het eind van de versregel met het oog op het rijm) heeft behouden. Het spreekt vanzelf dat deze tekst, met vormen die niet eenduidig in een bepaalde richting wijzen, minder hoog kan scoren dan een tekst als de Jeu de saint Nicolas: een teveel aan niet-Picardische vormen bewerkt dat het overeenstemmingsgetal bij 81 blijft steken, terwijl de Jeu de saint Nicolas tot 95 komt. Anderzijds leert vergelijking van de kaarten 1, 2 en 3 dat ten Oosten van Parijs op kaart 2 getallen worden aangetroffen die wijzen op een grotere verwantschap met dit gebied dan het geval is voor de Jeu de saint Nicolas en voor de oor- | |
[pagina 506]
| |
konden uit Arras. Aldus wordt de aanwezigheid van een restant van oostelijke vormen in de Guillaume d'Angleterre bevestigd. Om dergelijke restanten uit andere gebieden duidelijk aan het licht te brengen wordt gezocht naar een methode die overschotten en verschillen ten opzichte van gelocaliseerde oorkonden in beeld brengt. Hoewel deze methode zich nog in een stadium van ontwikkeling bevindt en met name nog uitvoerig getest moet worden aan de hand van een groter aantal gelocaliseerde teksten, kan kaart no. 4 nu reeds een indruk geven van de resultaten die verwacht mogen worden van deze benadering.
Hierboven is gesteld dat een geheel van gelocaliseerde literaire teksten een geschikt uitgangspunt biedt voor nauwkeuriger bestudering van de regionale aspecten van het middeleeuwse Frans. De lijnen waarlangs een dergelijk onderzoek zich kan voltrekken beginnen reeds duidelijk te worden. Het zal met betrekkelijk geringe middelen mogelijk zijn om, analoog aan wat is gebeurd voor de oorkonden, een inventarisatie van literaire teksten te ondernemen die beoogt regionale variaties op te sporen zoals die zich manifesteren in literair taalgebruik. De beperkingen van de reeds vervaardigde atlas, die samenhangen met het vrij specifieke taalgebruik in oorkonden, zouden aldus op afzienbare termijn kunnen worden overwonnen door het tot stand brengen van een uitgebreider atlas die zal zijn gebaseerd op de - rijkere - literaire taal.
Amsterdam | |
[pagina 507]
| |
 Provenance de textes littéraires du moyen-ȃge d'après le témoignage des formes trouvées oans les chartes
 Provenance de textes littéraires du moyen-ȃge d'après le témoignage des formes trouvées dans les chartes
| |
[pagina 508]
| |
 Provenance de textes littéraires du moyen-ȃge d'après le témoignage des formes trouvées dans les chartes
 Provenance de textes littéraires du moyen-ȃge d'aprés le témoignage des formes trouvées dans les chartes
|