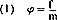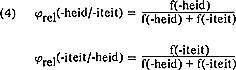len. Als namelijk het aantal basiswoorden waarop de ene regel van toepassing is, groter is dan het aantal waarop de andere van toepassing is, dan kan ondanks verschil in frequentie van de twee typen gelede woorden toch de toepassingswaarschijnlijkheid van beide regels gelijk zijn. Het suffix -
iteit kan, op enkele uitzonderingen na, alleen worden aangehecht aan adjectieven van vreemde, Romaanse oorsprong, terwijl -
heid aan alle soorten adjectieven kan worden aangehecht:
absurdheid, absurditeit en
gekheid zijn welgevormde woorden, maar *
gekkiteit niet (cf. Booij 1977: 131-39). Als het aantal vreemde adjectieven in de Nederlandse woordenschat b.v. de helft zou zijn van het totale aantal adjectieven, en het aantal nomina op -
iteit in een gegeven corpus de helft van het aantal nomina op -
heid, dan zou toch de toepassingswaarschijnlijkheid van beide regels dezelfde zijn, omdat het aantal toepassingsmogelijkheden van de -
iteit-regel de helft is van het aantal toepassingsmogelijkheden van de -
heid-regel:
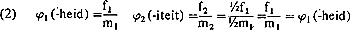
Een tweede voorbeeld betreft het al eerder genoemde suffix -heid en het suffix -te dat eveneens abstracte nomina afleidt van adjectieven. Maar voor -te gelden absolute beperkingen die niet gelden voor -heid: -te kan alleen worden aangehecht aan ongelede adjectieven van inheemse, niet-Romaanse oorsprong (cf. Booij 1977: 129). Vergelijk:
| (3) |
stil |
stilte |
| |
muisstil |
*muisstilte |
| |
absurd |
*absurdte |
Ook hier geldt dus weer, dat het aantal toepassingsmogelijkheden voor -te veel geringer is dan dat voor -heid. Daarmee moet rekening gehouden worden bij het bepalen van de toepassingswaarschijnlijkheid.
De hier gegeven voorbeelden betreffen regels die hetzelfde soort abstracte nomina afleiden. Als we regels gaan vergelijken die woorden met verschillende syntactische categorieën afleiden, ontstaan er allerlei complicaties. Omdat b.v. in een corpus waarschijnlijk veel meer nomina dan adjectieven en verba voorkomen, krijgen de verschillende typen gelede nomina dus ook meer kansen om op te treden. Ook de betekeniscategorie van de verschillende typen gelede woorden en het al of niet bestaan vanongeleden woorden met soortgelijke betekenis zullen een rol spelen. Bovendien is het zeer moeilijk een betrouwbare berekening te maken van het aantal woorden dat geschikt is voor een bepaald affix. Gezien deze complicaties, lijkt het vrijwel onmogelijk de absolute toepassingswaarschijnlijkheid van een woordvormingsregel te berekenen. Beter is het daarom, de toepassingswaarschijnlijkheid van regels te onderzoeken voor die domeinen, waarin ze met elkaar concurreren. De frequenties van de suffixen -heid en -iteit worden dan alleen vergeleken, voorzover ze voorkomen in woorden afgeleid van adjectieven van Romaanse oorsprong, en de frequenties van -heid en -te alleen, voorzover ze voorkomen in van niet-gelede, inheemse adjectieven afgeleide nomina. We berekenen zo dus alleen relatieve toepassingswaarschijnlijkheden. Deze vergelijking van elkaar beconcurrerende affixen is ook, wat Al blijkens zijn artikel (p. 1 25) voor ogen staat. De relatieve toepassingswaarschijnlijkheid van de regel voor -heid ten opzichte van die voor -iteit en omgekeerd kan nu als volgt worden berekend: