|
| |
| |
| |
Psychologische theorieën over het lexicon R. Schreuder W.J.M. Levelt
1. Inleiding
In dit artikel worden theorieën en experimenten over het ‘menselijk lexicon’ besproken. Het is duidelijk dat het in deze omvang niet volledig kan zijn; veel interessant onderzoek zal onbesproken moeten blijven. Ook zal na lezing duidelijk zijn dat er niet zoiets is als een echte psychologische theorie over de betekenis van woorden. Sommige psycholinguisten menen zelfs dat er geen psychologische theorie over betekenis kan zijn voordat (formele) semantici duidelijk maken waar zo'n theorie nu eigenlijk een theorie over is (Fodor, Bever en Garrett, 1974). Anderen menen dat, relatief onafhankelijk van andere wetenschappen, de psychologie toch een eigen bijdrage kan leveren. Een markant punt wat dit betreft, is het onlangs verschenen werk van Miller en Johnson-Laird (1976) dat een uitgebreid overzicht geeft over wat de auteurs ‘psycholexicologie’ noemen. Zij trachten hierin bovendien een psychologisch gefundeerde theorie over het lexicon te geven, die later nog ter sprake zal komen. Als eerste kunnen wij ons afvragen: ‘wat betekent het wanneer men een woord kent?’ Globaal kan men zeggen dat dit inhoudt dat men van het betreffende woord kent (zie ook Fillmore, 1971):
| (1) | betekeniseigenschappen; |
| (2) | fonologische en morfologische eigenschappen; |
| (3) | syntactische eigenschappen; |
| (4) | orthografische eigenschappen. |
In de linguistiek zien we vooral problemen bij het vinden van een afbakening van (1) en (3) terwijl in de taalpsychologie relatief weinig aandacht wordt besteed aan (3).
Tezamen vormen de woorden die wij kennen het ‘mentale lexicon’ (M.L.). De mens bezit echter niet alleen een mentaal lexicon, maar ook een ‘mentale encyclopedie’ (M.E.). Eén van de mogelijke toegangen van de M.E. is het M.L. Via het woord kat kunnen wij bijvoorbeeld in de M.E. de volgende kennis vinden:
| (1) | uiterlijk: (klein, harig, staart, etc.) |
| (2) | functie: (huisdier) |
| (3) | typisch gedrag: (spinnen, miauwen, op muizen jagen, ...) |
| (4) | origine: (siamees) |
| (5) | andere feiten: (mijn zus heeft een kat enz.) |
Zo'n lijst kan natuurlijk in principe enorm uitgebreid worden (Clark en Clark, 1977, p. 411). Men zou kunnen stellen dat al deze kennis ook tot het M.L. behoort en het onderscheid tussen M.E. en M.L. laten vervallen. In het M.L. wordt dan bij kat in feite
| |
| |
alle kennis over katten en het woord kat opgeslagen. Er zijn echter argumenten tegen het zonder meer gelijkstellen van M.E. en M.L. De encyclopedische kennis is voor iedereen enigszins verschillend; we nemen echter aan dat de betekenis van woorden in onze taal toch voor iedereen min of meer hetzelfde is. Het lijkt daarom verstandig om onder het M.L. in ieder geval gemeenschappelijke kennis te verstaan. Verder is het zo dat er een enorme hoeveelheid informatie in de M.E. is opgeslagen waarvoor géén woorden in de taal voorhanden zijn om naar te verwijzen. Mensen die door hersenletsel hun taalvermogen hebben verloren, hebben nog wel een M.E. evenals bijvoorbeeld prélinguistische kinderen. (zie ook Fodor, 1975).
Een precieze afbakening van M.E. en M.L. is echter moeilijk, of zoals Clark en Clark (1977, p. 412) zeggen: ‘... the M.L. is parasitic on the M.E.’. Bij het proces van begrijpen van taaluitingen zal men bovendien dikwijls gebruik maken van kennis uit de M.E. (‘Gelukkig hebben we hier geen last van muizen of ratten, ik houd niet zo van gif strooien, en van katten nog minder’.). In dit artikel zullen wij ons bezighouden met het M.L. en psychologische theorieën en experimenten daarover.
De volgende onderwerpen zullen besproken worden:
| (1) | De betekenis van woorden en de manier waarop die in het M.L. opgeslagen zou kunnen zijn. |
| (2) | Opslag van fonologische en morfologische eigenschappen van woorden. |
| (3) | Toegangsprocessen tot het lexicon: ‘Hoe wordt lexicale informatie opgezocht?’ |
| |
2. Betekenis van woorden
2.1. ‘Semantische ruimte’
In de psycholinguistiek heeft de theorie der semantische velden, een type theorie dat in de linguistiek reeds lang bekend is, een tijd lang een relatief grote rol gespeeld. In de semantische velden theorie houdt men zich bezig met lexicale structuur, dat wil zeggen de structuur van het vocabulaire. Men houdt zich niet bezig met de designata, maar met de betekenis van lexemen t.o.v. andere lexemen in hetzelfde systeem (Lyons, 1977, p.251).
In de psycholinguistische benadering gaat men niet alleen uit van de intuïties van de onderzoeker zelf, maar men verzamelt op systematische wijze de intuïties van meerdere proefpersonen. Deze intuïties hebben dan betrekking op betekenisovereenkomst tussen lexemen. De resultaten van zo'n systematische verzameling van intuïties worden dan met geavanceerde mathematische technieken geanalyseerd. Men hoopt hiermee meer ‘objectieve’ gegevens te verkrijgen en deze methoden maken het ook mogelijk om semantische velden te onderzoeken waarover de onderzoeker zelf geen duidelijke intuïties heeft. Wanneer het om n woorden gaat, dan kan men de n (n-1)/2 mogelijke woordparen laten schalen op betekenisovereenkomst. Een andere manier is de z.g. sorteermethode (Miller, 1969): ieder woord uit de lijst van te bestuderen woorden wordt apart op een kaartje getypt. Het pakje kaarten wordt aan een proefpersoon gegeven en deze wordt gevraagd de kaarten in stapeltjes te verdelen op basis van betekenisovereenkomst. Woorden die in betekenis veel op elkaar lijken komen samen in een stapel. Nadat een aantal proefpersonen dit gedaan heeft, wordt voor ieder paar van woorden na- | |
| |
gegaan hoe vaak deze twee samen in één stapel terecht zijn gekomen. Deze getallen worden dan beschouwd als een maat voor de semantische gelijkenis of nabijheid.
Vervolgens worden mathematische analyses toegepast om in deze matrix een onderliggende structuur te herkennen (multidimensioneelschalen, cluster-analyse). In de meest gebruikte techniek, multidimensioneel schalen, worden de woorden in een ‘semantische ruimte’ afgebeeld. Deze afbeelding wordt zó gekozen dat deze zoveel mogelijk de gelijkenisrelaties in de datamatrix weerspiegelt. Als in de afbeelding punt A dichter bij punt B dan punt C ligt, dan moet liefst uit de oorspronkelijke gegevens blijken dat woord A meer in betekenis op woord B dan op woord C lijkt. Deze schaalmethoden zijn op veel semantische velden toegepast, waaronder diernamen, kleurnamen, verwantschapsnamen, voorzetsels, beoordelingswerkwoorden etc. (Zie b.v. Henley (1969) voor diernamen en Fillenbaum en Rapoport (1971) voor een uitgebreid literatuuroverzicht en een weergave van diverse technieken in allerlei domeinen). Als voorbeeld van zo'n afbeelding moge figuur 1 dienen. Hierin is het resultaat van een multidimensionele schaling van een gelijkenismatrix van Nederlandse bewegingswerkwoorden weergegeven. Het betreft hier werkwoorden die voortbeweging ter land aanduiden. De data zijn verkregen met de eerder genoemde sorteermethode (45 proefpersonen).
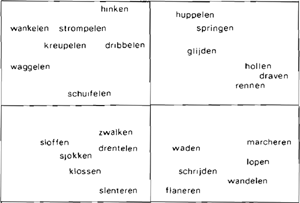
Fig. 1: Twee-dimensionele representatie van enkele bewegingswerkwoorden (voortbeweging ter land).
In figuur 1 zien we het resultaat van een multidimensionele schaalanalyse voor twee dimensies, van de datamatrix met gelijkenismaten. Enige beschouwing laat ons zien dat men de horizontale as zou kunnen interpreteren als een aanduiding van snelheid. De verticale as lijkt iets aan te geven als een soort afwijking van het standaard looppatroon. (flaneren: geen afwijking, hinken: maxinale afwijking van het standaard looppatroon, op perceptuele eigenschappen berust). Vaak is het echter veel moeilijker om dimensies van een ‘label’ te voorzien. Wanneer de analyse de wenselijkheid aangeeft van weergave in drie of meer dimensies wordt interpretatie van de resultaten nog problematischer. Toch laten dit soort semantische ruimtes goed de continue aard van bepaalde concepten zien (cf. Clark en Clark, 1977, p. 436) zoals hier snelheid en afwijking van looppatroon. Een aanhanger van een strikte scheiding tussen M.L. en M.E. zou wel als bezwaar
| |
| |
kunnen aanvoeren dat bij de gelijkenisbeoordelingen zeer waarschijnlijk ook kennis over de fenomenen die door de woorden worden aangeduid, een rol speelt. En daar is weinig tegen in te brengen.
| |
2.2. Affectieve betekenis
De alweer enige tijd geleden ontwikkelde methode der ‘semantische differentiaal’ om ‘affectieve’ betekenis van woorden te meten (Osgood, Suci, en Tannenbaum, 1957) mag hier niet onvermeld blijven.
Aan proefpersonen wordt gevraagd een groot aantal woorden te schalen op een aantal bipolaire adjectief schalen als goed - slecht, hard - zacht en langzaam - snel. Deze beoordelingen worden daarna met behulp van factoranalyse geanalyseerd. Uit de resultaten bleek steeds weer dat er drie groepen van schalen een verschillende factor of aspect van de affectieve betekenis weergaven. Deze drie factoren werden als volgt benoemd:
Evaluatie (zoals in goed - slecht);
Potentie (zoals in sterk - zwak);
Activiteit (zoals in snel - langzaam).
Met de semantische differentiaal hebben Osgood en zijn medewerkers de toepasbaarheid en stabiliteit van de z.g. E.P.A. factoren in de woorden van vele talen aangetoond. De semantische differentiaal geeft, behalve over de ‘affectieve’ kant, echter weinig informatie over andere aspecten van de betekenisinhoud.
| |
2.3. Semantische componenten
In de componentiële analyse beschouwt men de betekenisinhoud van een woord als een bundel componenten (elementair-primitief). Die componenten worden soms beschouwd als proposities, bestaande uit een predikaat met één of meer argumenten. Deze proposities zijn identiek aan diegene die gebruikt worden om de betekenis van zinnen weer te geven. De componentiële analyse is vooral door antropologen tot ontwikkeling gebracht; het betrof dan voornamelijk analyses van verwantschapstermen die zich hiertoe goed blijken te lenen (b.v. Romney en d'Andrade, 1964). In de psycholinguisistiek is de componentiële analyse ook dikwijls het onderwerp van onderzoek geweest. Het betreft hier echter meestal geen onderzoek naar de assumptie van componenten, maar eerder tracht men op allerlei manieren componenten op te sporen. Ook worden componenten vaak gebruikt in z.g. procesmodellen die trachten weer te geven hoe de mens met betekenisinformatie omgaat. Alleen psychologisch onderzoek zal hier vermeld worden. Osgood (1968) trachtte, met behulp van factoranalytische technieken, semantische componenten te ontdekken in de oordelen van proefpersonen over de passendheid van woordcombinaties (adjectieven met nomina, adverbia met werkwoorden). Dit blijkt echter een omslachtige procedure die niet altijd even duidelijke resultaten oplevert. Een goede indruk van deze methode kan men krijgen in Noordman en Levelt (1970, 1977).
Een bekend onderzoek is dat van Miller (1972) naar de betekeniscomponenten van bewegingswerkwoorden. Miller komt uiteindelijk tot twaalf componenten waaruit de betekenisrepresentaties van bewerkingswerkwoorden zouden zijn opgebouwd. Die componenten zijn: Motion, Reflexive-Objective, Causative, Permissive, Propellent. Directorial, Medium, Instrumental, Inchoative, Change-of-Motion, Deictic en Velocity.
| |
| |
Miller vond deze componenten met behulp van de ‘methode van onvolledige definities’. Deze methode houdt in dat men van werkwoorden die in betekenis op elkaar lijken, het gezamenlijk gedeelte van de betekenis tracht weer te geven in een onvolledige definitie. De definitie is bevredigend wanneer een eenvoudige zin (enkelvoudig, bevestigend, geen negatie of kwantoren) waarin het werkwoord voorkomt, de zin impliceert waarin het werkwoord is vervangen door de onvolledige definitie. Miller onderzoekt de plausibiliteit van zijn componenten door middel van de sorteermethode (zie 2.1.). Wanneer hij echter aan zijn proefpersonen vraagt de werkwoorden te sorteren op basis van betekenisovereenkomst, dan onderzoekt hij alleen of hun intuïtie overeenstemt met zijn eigen opvattingen. In feite staat dit los van de wijze waarop de betekenisovereenkomst in de onvolledige definities wordt verantwoord. Een groter bezwaar tegen de analyse van Miller is echter dat het verband tussen verschillende betekeniselementen niet duidelijk wordt gemaakt. We zullen nu een voorbeeld geven van onderzoek waarbij semantische componenten niet opgespoord worden, maar gebruikt worden om bepaalde (psychologische) verschijnselen te kunnen verklaren.
Het betreft hier de zeer uitgebreide reeks gegevens die er in de loop der jaren verzameld zijn over woord associaties. Clark (1970) heeft een aantal regels voorgesteld die het merendeel van paradigmatische associaties kunnen verklaren. De drie belangrijkste zijn:
(1) Minimum-contrast regel, die in termen van semantische componenten luidt: ‘verander maar één component’. Dit treedt vooral op bij polaire adjectieven als lang - kort; goed - slecht; ook bij nomina: alleen de ‘Male’ component wordt bijvoorbeeld veranderd bij associaties als man - vrouw, hij - zij; werkwoorden: geven - nemen; gaan - komen. Bovendien lijkt het er op dat er een hierarchie van componenten is. Man krijgt zelden als associatie: jongen, dat wil zeggen dat bijvoorkeur de geslachtscomponent wordt veranderd.
(2) Feature-deletie, en-toevoegingsregels. Deletie: appel - fruit; toevoeging: bloem - tulp. Deletie blijkt veel vaker op te treden dan toevoeging.
(3) Categorie-instandhoudings regel. In feite een negatieve regel: vervang niet de weinig informatie dragende componenten als (+ nomen). Clark veronderstelt dat een proefpersoon dit soort ‘strategieën’ gebruikt wanneer er associaties op woorden gegeven moeten worden. Het gaat hier dus niet om onderzoek naar de status van componenten zelf maar zij worden (tezamen met de strategieën) als verklarend principe gebruikt.
Een ander, laatste voorbeeld waarbij in feite van een componentiële analyse uitgegaan wordt, betreft eigen onderzoek naar de (semantische) struktuur van (Nederlandse) bewegingswerkwoorden. Een onderdeel hiervan was het onderscheid maken tussen die werkwoorden die verplaatsing aanduiden en die werkwoorden die meer beweging op één plaats (trillen) of binnen een beperkt gebied aanduiden (cirkelen). Het gaat hier dus om een verplaatsings-component. Hierbij werd niet van eigen intuiïtie gebruik gemaakt over het al dan niet toekennen van een component aan een werkwoord, maar er werden intuïties van een aantal informaten hierover ingewonnen. Een linguistische test werd hiervoor gebruikt. Proefpersonen moesten zinnen van het volgende type completeren: ‘Zij (werkwoord) x via ..........’, waarbij op de punten een plaats (indien mogelijk) diende te worden ingevuld.
Bijvoorbeeld: ‘zij gooien de bal via het raam naar buiten’. De optionele x is voor het
| |
| |
invullen van objecten bij transitieve werkwoorden. Bij verplaatsing is er altijd sprake van dat het thema van de verplaatsing op één moment op de ene plaats is en na afloop ervan op een andere plaats. In dit geval moet het thema in de tussentijd ook op een andere plaats geweest zijn. (Jackendoff, 1976). Twintig personen trachtten ieder een lijst met 157 bewegingswerkwoorden aan te vullen (dit waren de bewegingswerkwoorden die voortkomen in de gelemmatiseerde lijst van Uit den Boogaart, 1975). Figuur 2 geeft een samenvatting van de resultaten. Voor de meeste werkwoorden konden (bijna) alle,
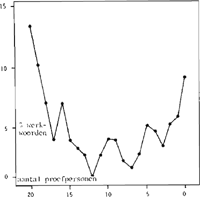
Fig. 2.: Percentage werkwoorden dat als verplaatsingswerkwoorden werd beoordeeld per aantal subjecten (+ verplaatsing o.a.: bereiken, brengen, duwen, gaan, klimmen, kruipen, lopen, naderen, reizen, rennen, roeien, schuifelen, slenteren; - verplaatsing o.a.: beven, buigen, gapen, huiveren, knielen, krimpen, rekken, remmen, rillen, scheiden, splijten, vouwen, zwellen.)
of (bijna) geen van de proefpersonen een passende completering vinden. Deze test leidt dus tot een goede dichotomizering van de verzameling werkwoorden in termen van een component die aanduidt dat er sprake is van verplaatsing.
Het betreft hier dus een poging om (met behulp van een aantal informanten) een component bij een groot aantal werkwoorden op te sporen. (Zie ook Levelt, Schreuder en Hoenkamp, 1977).
| |
2.4. Procedurele semantiek
Het basis idee van procedurele semantiek is dat de betekenisinhoud van een woord een procedure is, een verzameling ‘mentale’ operaties nodig om te kunnen beslissen of een woord op iets van toepassing is of niet (Johnson-Laird, 1975). Deze procedures vormen de bouwstenen van de (interne) representatie van zinnen, die ook als een procedure wordt opgevat. Dat kan een serie operaties zijn die nodig zijn om de zin te verifiëren of een procedure om bepaalde informatie uit het geheugen op te halen (‘herinner je je die man van gisteren nog?’) etc. Miller en Johnson-Laird (1976) hebben dit type theorie vanuit de psycholinguistiek verder ontwikkeld (maar zie ook Catlin, 1975). Twee belangrijke elementen hebben zij er aan toegevoegd. Ten eerste stellen zij dat het begrijpen van een taaluiting niet inhoudt dat automatisch de bijbehorende procedures uitgevoerd worden, maar dat deze alleen beschikbaar worden gemaakt. (Vergelijkbaar in computertermen met het onderscheid compileren - uitvoeren van een programma).
| |
| |
Fodor's (1975) ideeën zijn hieraan sterk gerelateerd hoewel hij het zeker niet helemaal eens is met Miller en Johnson-Laird. Ten tweede zijn de uiteindelijke ‘primitieve’ concepten in hun procedures z.g. perceptuele predicaten. Dit zijn (relatief) eenvoudige perceptuele oordelen of constateringen waartoe het menselijk organisme in staat is. (enige voorbeelden uit Miller en Johnson-Laird: Red(x), Above(x,y), Greater(x,y), Travel(x)). Zij trachten op zeer expliciete wijze zo een relatie te leggen tussen taal en waarneming. In feite hoort ook deze aanpak tot de componentiële analyse, maar semantische procedures zijn soms flexibeler. Een punt van kritiek op semantische componenten is namelijk onder andere dat niet alle woorden gedefinieerd kunnen worden in termen van noodzakelijke condities. Sommige woorden vereisen disjunctieve regels en andere combinaties van conjunctieve en disjunctieve regels. De weergave hiervan is in procedurele vorm veel eenvoudiger. Wanneer Miller en Johnson-Laird de betekenis van een woord beschrijven, dan geven zij de naam van de procedure met de variabelen, de waarheidscondities en soms presupposities. We vermeldden reeds het perceptuele predicaat Travel (x) dat overeenkomt met de waarneming van beweging. We zullen nu een voorbeeld geven van de procedure TRAVEL (x), een meer conceptuele vorm, omdat beweging ook afgeleid kan worden zonder dat beweging is gezien. Zij geven de volgende semantische procedure (p. 533): ‘TRAVEL (x): something x “travels” from time to to time tm if for each ti such that to<ti<tm, there is a place Y such that:
| I | Rti (AT (X,Y)) |
| II | Rti+1 (AT (X,Z)) |
| III | F (Y,Z).’ |
Hierbij geeft Rt het predicaat aan dat op tijd t het ingebedde predicaat gerealiseerd is. AT(X,Y) is het conceptuele predicaat dat object X op plaats Y is. (Hier wordt opnieuw niet een perceptueel predicaat verondersteld, omdat dit oordeel uit ander dan perceptuele ervaring geveld kan worden). F(Y,Z) tenslotte, is een predicaat dat de ongelijkheid van Y en Z aangeeft. Miller en Johnson-Laird geven ook voorbeelden van procedures die andere procedures als argument hebben. Voor het werkwoord rise stellen zij als semantische procedure (UPWARD (TRAVEL)) (x) voor. De procedure UPWARD wordt eerst uitgevoerd op TRAVEL en met het resultaat daarvan kunnen tests met betrekking tot het object x worden uitgevoerd. De procedure UPWARD verandert in de procedure TRAVEL, F(Y,Z)in OVER (Y,Z), het oordeel dat Z hoger is dan Y.
Het zou te ver voeren om hier nu uitgebreid op deze theorie in te gaan, die in zo'n kort bestek niet tot zijn recht kan komen. Vermeld kan nog worden dat zij deze theorie op een groot aantal semantische velden trachten toe te passen. Wat betreft punten van kritiek kunnen we onder andere noemen dat procedures zoals ze beschreven worden, nogal inflexibel zijn. De procedure MALE (x), als onderdeel van man moet deze op heel andere perceptuele eigenschappen kontroleren dan bij b.v. haan. Ook categorienamen zullen problemen geven (zijn tomaten fruit of groente?). Een verdere uitwerking van deze theorie is nodig om hem empirisch toetsbaar te maken.
| |
2.5. Namen van categorieën en de structuur van het mentale lexicon
Het is reeds lang problematisch wat de betekeniscomponenten (of procedures) van categorienamen zouden kunnen zijn. Niemand heeft tot nu toe de noodzakelijke of voldoende criteria kunnen vinden om iets als meubelstuk, vogel, fruit, etc. te kunnen clas- | |
| |
sificeren. In de laatste tien jaar is er in de psychologie een enorme hoeveelheid onderzoek gedaan naar de manier waarop mensen van hun kennis van categorieën gebruik maken. Op grond van hierbij gevonden resultaten worden modellen opgesteld over de opslag van dit soort kennis. (Dit gebied staat bekend onder de naam ‘Semantisch Geheugen’ hoewel hier ook dikwijls veel ruimere kennisbestanden mee bedoeld worden). Twee typen theorieën kunnen onderscheiden worden. In de netwerk benadering worden namen van categorieën opgevat als knopen in een netwerk die door middel van benoemde takken met elkaar verbonden zijn. In het verzamelingsmodel wordt aangenomen dat iedere categorienaam gekenmerkt wordt door een verzameling van semantische componenten.
| |
Semantische netwerken
Iedere categorienaam is een lid van een taxonomie, de naam van die taxonomie is weer lid van andere taxonomieën. Ieder woord behoort zo tot een netwerk van woorden en wordt gedefinieerd door de relaties met andere woorden. Soms worden deze taxonomieën hierarchisch weergegeven. Dit maakt mogelijk dat de waarheid van een uitspraak als: een tulp is een bloem, gevonden kan worden door in de hierarchie één of meer stappen omhoog te gaan. De onwaarheid van uitspraken als een hond is een insect kan gevonden worden door, vanuit hond omhooggaand, in een zijtak insect te vinden. (Zie figuur 3).
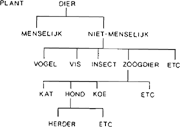
Fig. 3: Voorbeeld van hierarchische representatie van categorienamen.
In zeer schematische vorm is dit de essentie van het werk van Collins en Quillian (1969, 1972). (Zie ook Rumelhart, Lindsay en Norman, 1972).
Zij stelden voor dat het ‘semantische geheugen’ van de mens in zo'n type netwerk gerepresenteerd zou kunnen worden en dat mensen uitspraken over categorieën beoordelen met behulp van diverse zoekprocessen in de hierarchie. In deze benadering wordt geen enkel onderscheid gemaakt tussen het M.L. en de M.E. Men beschouwt de concepten waar woorden naar verwijzen als de knopen in het net, de takken refereren naar relaties (is-een; is-een-deel-van) of operaties. De betekenis van een concept wordt beschouwd als de verzameling van alle concepten waarmee dat concept op een of andere manier gerelateerd kan worden. De betekenis van een concept is dus onbeperkt en wordt alleen door procescapaciteit en zoekprocedures beperkt; betekenis is dan geen statische entiteit maar hangt af van de context die het zoeken naar relaties bepaalt (Frijda, 1972). Psychologische experimentatie houdt meestal de verificatie van het type zinnen in als: een alligator is een reptiel, of: een alligator is een dier. De tijd die nodig is om deze uitspraak op juistheid te controleren (reactietijd, RT) wordt gemeten. Voorspeld wordt dat het
| |
| |
langer zal duren om de tweede zin te beoordelen, omdat verder in het netwerk gezocht moet worden. Dit soort resultaat werd inderdaad gevonden. Later onderzoek leerde echter dat de zaken wat moeilijker lagen (Conrad, 1972; Smith, Shoben, en Rips, 1974). Het blijkt bijvoorbeeld dat binnen één categorie verschillen optreden. Een kanarie is een vogel wordt sneller geverifieerd dan een kip is een vogel. In de netwerk theorie tracht men dit resultaat te verklaren door aan te nemen dat sommige takken in het net ‘langer’ zijn of aangegeven als minder belangrijk. Wat op die wijze echter weer niet verklaard kan worden is dat de zojuist genoemde resultaten omdraaien wanneer de relatie hoger in het netwerk gevonden kan worden (Dat wil zeggen een kanarie is een dier duurt langer om te verifiëren dan een kip is een dier; Smith et al., 1974, Smith, Rips en Shoben, 1974). De resultaten van dit soort experimenten lijken echter beter verklaard te kunnen worden door de component modellen. De netwerk theorie is echter nog steeds van belang, vooral daar waar men computerprogramma's tracht te ontwerpen die natuurlijke taal kunnen verwerken.
| |
Componentverzameling theorieën
Deze theorieën werden voornamelijk ontwikkeld door Smith, Shoben en Rips 1974, Shoben, 1976; Smith, 1977 en door Rosch (1973, 1975); Rosch en Mervis (1975). Zij stellen dat categorieën een interne structuur hebben die niet in een hierarchisch model kan worden weergegeven. In een hierarchisch model krijgen in het algemeen pinguins, mezen, adelaars en kippen een gelijke status als vogels. Ook intuïtief zal het wel duidelijk zijn dat sommige meer typisch zijn voor de categorie dan andere. Een struisvogel zal niet als een typische vogel worden beschouwd. Voor veel categorieën zijn op grond van experimenteel onderzoek, lijsten samengesteld met een ordening van meest tot minst typische leden (althans voor de Engelse woorden die categorieën aanduiden). Bijvoorbeeld: (Categorie: typisch lid-niet-typisch lid) ‘Furniture: chair - cupboard; Fruit: apple - coconut; Clothing: pants - hat’, uit Rosch (1975). Wanneer er zo'n ordening van a-typisch tot typisch is, dan kunnen we ons ook voorstellen dat er een soort prototype element is in een categorie, dat van alle het meest typisch is voor die categorie. Rosch (1977) concludeert dat er zo'n prototype is en dat mensen dit in feite meestal bedoelen wanneer zij bijvoorbeeld het woord vogel gebruiken. Zij liet proefpersonen zinnen genereren met categorienamen als vogel, fruit etc. De proefpersonen vormden zinnen als: ‘ik hoorde een vogel piepen; er zaten twee vogels op een tak; een vogel vloog naar beneden en begon te eten’. Daarna verving zij de categorienaam in de gegenereerde zinnen door verschillende leden van de categorie en liet andere proefpersonen de zo verkregen zinnen op betekenisvolheid beoordelen. Wanneer we bij dit soort zinnen vogel door mees vervangen, dan past dit nog wel, maar kip geeft al een
merkwaardig resultaat. Hoe typischer een lid voor een categorie was, hoe gemakkelijker deze de categorienaam kon vervangen; dat wil zeggen, volgens Rosch, dat naarmate een lid typischer is, het meer lijkt op het prototype van die categorie. Enigszins vergelijkbaar hiermee geven Anderson et al. (1976) evidentie dat bij het begrijpen en onthouden van zinnen met categorienamen deze vaak vervangen worden door een typisch lid of door een lid zoals dat door de context geïnduceerd wordt.
Het feit dat in een categorie ‘typische’ leden voorkomen wordt door Smith en zijn
| |
| |
collega's als volgt verklaard: volgens Smith, Rips en Shoben kan de semantische representatie van het woord vogel gezien worden als een verzameling van tests voor wat zij definiërende en karakteristieke ‘features’ noemen. De definiërende features komen voor bij alle woorden die vogels aanduiden (anders waren het geen vogels). Alle vogels hebben veren, leggen eieren. Maar vogels bezitten ook karakteristieke eigenschappen, zoals het kunnen vliegen, het hebben van korte pootjes. Deze eigenschappen komen zo vaak voor dat deze ook in de representatie van vogel vermeld worden als karakteristieke features. De verificatieresultaten zoals wij die besproken hebben worden door hen nu als volgt verklaard. Eerst vindt een globale vergelijking plaats van de twee verzamelingen van features. Wordt een grote overeenkomst aangetroffen (mees - vogel; er zijn niet alleen veel gemeenschappelijke definiërende maar ook veel gemeenschappelijke karakteristieke features), dan wordt meteen aangenomen dat het hier inderdaad om een lid van de categorie gaat. Wanneer deze overeenkomst laag is dan treedt een proces in werking dat precies controleert of de definiërende componenten van vogel overeenkomen met die van mees. Aangezien dit pas gebeurt ná het berekenen van een globale overeenkomst zal dit meer tijd kosten. In het geval van een zeer kleine overeenkomst kan meteen ontkennend geantwoord worden, maar bij een zekere mate van overeenkomst moeten de definiërende eigenschappen precies onderzocht worden. (De RT op het falsifiëren van een mees is een auto is inderdaad korter dan die bij een vleermuis is een vogel). Dit zogenaamde twee-stadium model kan ook goed de resultaten van andere typen experimenten over het vergelijken van
woordbetekenissen beschrijven. Recentelijk heeft Noordman-Vonk (1977) een twee-stadium model ontwikkeld (een verificatiestadium - gevolgd door een falsificatiestadium), dat niet alleen deze zelfde gegevens verklaart, maar bovendien voor het eerst verklaart dat ‘onwaar’-antwoorden meer tijd kosten dan ‘waar’-antwoorden. Zie voor een uitgebreid overzicht Smith, Rips en Shoben (1974) en voor een kritische discussie over de status van dit type model versus het netwerk model Glass en Holyoak (1976).
Veel van de theorieën en experimenten zoals die tot nu toe beschreven zijn gaan uit van semantische decompositie. In vrijwel iedere vorm van een componentiële theorie is de betekenis van een lexeem de decompositie ervan in een stel componenten die als de ‘atomen’ der woordbetekenis beschouwd kunnen worden. Een heel ander type theorie is dat waarin semantische verschijnselen verklaard worden met behulp van betekenispostulaten of betekenisregels. Een recent pleidooi hiervoor komt van Fodor, Fodor en Garrett (1975) en Fodor (1975). Betekenisregels zijn een wat flexibelere vorm van betekenispostulaten, zij kunnen informatie bevatten die moeilijk in de vorm van postulaten gegeven kan worden. Vanuit de psycholinguistiek is nog vrijwel niets aan de theoretische kant bijgedragen. Kintsch (1974) geeft echter enige evidentie dat er geen lexicale decompositie optreedt bij het begrijpen en onthouden van zinnen. Verder kan nog Stillings (1975) genoemd worden, die betekenisregels bespreekt voor werkwoorden die bezitsoverdracht aanduiden, en deze experimenteel tracht te onderzoeken. Wellicht moet echter dit soort kennis niet in het M.L. maar in de M.E. verantwoord worden.
| |
| |
| |
3. Fonologische en morfologische eigenschappen
Hoe zijn woorden in het permanent geheugen opgeslagen? Bij het construeren van een articulatie-programma maken sprekers natuurlijk gebruik van hun fonologische kennis van woorden in het geheugen. Het werkwoord plagen bijvoorbeeld, is op een of ander nivo in het geheugen zeker weergegeven als een enkele eenheid, met een semantische representatie, als een reeks fonologische segmenten gereed om in een articulatieprogramma geplaatst te worden. Maar plaagde, de verleden tijd van plagen? Op zijn minst zijn twee manieren van representatie mogelijk. Het zou één enkele eenheid plaagde kunnen zijn met daaraan toegevoegd de informatie dat het de verleden tijd van plagen is. Of het zou uit twee eenheden kunnen bestaan plagen + [VT], die door een later proces in het articulatie-programma in de juiste fonologische codering worden omgezet. Deze twee theorieën zouden in hun extreme vorm de directe en abstracte theorieën van het woordvormings proces genoemd kunnen worden.
Diverse onderzoekingen naar versprekingen lijken erop te wijzen dat de representatie nogal abstract is. (Zie voor een recente samenvatting van de literatuur over versprekingen Fromkin, 1973). Fromkin meent bijvoorbeeld dat woorden als imprecise, disregard en unclear met behulp van het abstracte negatieve prefix [NEG] gerepresenteerd zijn (b.v. [NEG]+ precise). Zij citeert daartoe het volgende type versprekingen: I regard this as imprecise → I disregard this as precise en If there was anything that was unclear → If there was nothing that was clear. In beide gevallen is het veronderstelde element [NEG] naar voren geplaatst.
Een andere vorm van versprekingen treedt op bij werkwoorden met een onregelmatige verleden tijd. MacKay (1976) liet proefpersonen zo snel mogelijk de verleden tijd van werkwoorden produceren. Regelmatige vormen werden sneller geproduceerd dan onregelmatige. Belangrijker nog echter waren de vele fouten die optraden bij het produceren van de verleden tijd van onregelmatige werkwoorden. Deze werden regelmatig gemaakt (dig - digged i.p.v. dug; teach - teached i.p.v. taught). De hypothese dat verledentijds vormen onafhankelijk zijn opgeslagen kunnen dit soort versprekingen moeilijk verklaren, immers deze vormen komen dan in het lexicon helemaal niet voor. Wij zijn er hier stilzwijgend vanuit gegaan dat, wanneer de semantische representatie van een woord bekend is, de fonologische representatie dat ook is. ledereen is echter bekend met het z.g. ‘Tip of the Tonge’ fenomeen, het verschijnsel dat we de betekenis van een woord wel kunnen specificeren, maar het woord zelf niet. Brown en McNeill (1969) veroorzaakten dit soort gewaarwordingen bij proefpersonen door de definities van laag frequente woorden voor te lezen en ze te vragen het bedoelde woord te noemen, (b.v. Aziatische boottype, platte bodem = sampan). Aan die proefpersonen die in een ‘Tip of the Tongue’ toestand geraakten, werd gevraagd hoeveel syllaben het gezochte woord volgens hen bevatte, met welke letter het begon, hoe het ongeveer klonk en naar woorden die er in betekenis op leken.
Hoewel de proefpersonen het woord zelf niet konden vinden, wisten zij toch in 57% van de gevallen het aantal syllaben correct te schatten. Beginletters werden in 62% van de gevallen correct geschat. Wat betreft de vraag naar woorden met klankovereenstemming kwamen bijvoorbeeld bij het gezochte woord sextant antwoorden als secant, sextet, sexton. Dit soort resultaten lijken er op te wijzen dat fonologische representaties soms niet (als geheel) toegankelijk zijn en dat in de fonologische code syllabepatroon en
| |
| |
intonatiepatroon wellicht relatief onafhankelijk opgeslagen zijn.
| |
4. Toegang tot het lexicon
4.1. Hoe zoeken wij de woorden in ons ‘interne woordenboek’ op? (Er zijn schattingen dat men een passieve kennis van zeker 50.000 woorden bezit, Oldfield, 1963). In de psychologie, waar sedert de laatste 10 jaar het onderzoek naar allerlei mentale processen enorm is opgebloeid, heeft deze vraag tot een grote hoeveelheid onderzoek geleid. Wanneer wij woorden horen of lezen dan is het meestal nodig de betekenis ervan op te zoeken. Twee typen van modellen hierover zullen besproken worden: van Morton (1970) en forster (1976).
Het z.g. logogenmodel van Morton zal niet tot in de mathematische details besproken worden, maar er zal alleen een globaal overzicht van gegeven worden. Het model heeft als belangrijkste aanname dat één eenheid verantwoordelijk is voor het beschikbaar komen van een lexicaal element, ongeacht de informatie die daartoe aanleiding gaf. Het element vis kan opgeroepen worden door het zien van een vis, het lezen van het woord vis, door context zoals in: ‘hij voelde zich als een ... op het droge’. Het is steeds dezelfde identifikatie-eenheid die het woord vis beschikbaar maakt. Een dergelijke eenheid wordt een logogen genoemd. Een logogen wordt gekarakteriseerd door fonologische, visuele en semantische attributen. Aangenomen wordt dat homonymen (bank) met verschillende logogens corresponderen vanwege het verschil in semantische attributen (Experimentele evidentie hiervoor o.a. in Jastrzembski en Stanners, 1975).
Wanneer nu een of ander attribuut wordt gedetecteerd, ongeacht of dit nu visueel, semantisch of iets anders van aard is, dan wordt dit door alle logogens geregistreerd die dat attribuut in hun karakteristieke verzameling hebben. Cumulatieve tellingen van het door een logogen geregistreerde aantal attributen binnen een bepaalde periode, komen overeen met iets dat we de ‘activatie-toestand’ van het logogen zouden kunnen noemen. Dit activatienivo neemt af wanneer er geen nieuwe informatie binnenkomt. Zo gauw echter het activatienivo hoog genoeg is (een bepaalde drempel heeft overschreden), geeft het logogen zijn response vrij. Ook wordt aangenomen dat, als een logogen net ge respondeerd heeft, de drempel ervan (tijdelijk) wat lager wordt. Hiermee kan verklaard worden dat een woord gemakkelijker wordt herkend wanneer het kort te voren al eens werd geactiveerd. Wanneer een logogen heel vaak geactiveerd wordt, leidt dit tot een permanente drempel verlaging van het logogen. Hiermee kan het model verklaren dat hoogfrequente woorden makkelijker herkend worden dan laagfrequente (zie b.v. Neisser, 1967, pag. 116 e.v.). Ook context (woordgroepen, zinnen, eerder waargenomen woorden etc.) is via semantische attributen van invloed op het activatienivo. Semantisch verwante logogens lijken hun activatie aan elkaar door te geven (Meyer en Schvaneveldt, 1971; Meyer, Schvaneveldt en Ruddy, 1974 a; Schmidt, 1976). Wellicht geven ook fonologisch verwante logogens informatie aan elkaar door (Fay en Cutler, 1977). Onderzoek van Osgood en Hoosain (1974) maakt aannemelijk dat de eenheid waarmee het logogen correspondeert zeker niet de syllabe of het morfeen is, maar eerder het (niet-samengestelde) woord (zie ook Levelt en Kempen, 1976).
Forster (1976) bespreekt twee belangrijke problemen voor de logogen theorie. Ten
| |
| |
eerste moet er voor gezorgd worden dat de juiste detector als eerste zijn response afgeeft. Bij een drempelverschil tussen hoog- en laagfrequente woorden kunnen problemen ontstaan bij laagfrequente woorden die veel op hoogfrequente woorden lijken. In normale omstandigheden worden bij identificatie hiervan vrijwel nooit fouten gemaakt die de logogen-theorie wel zou voorspellen. Een tweede en belangrijker probleem noemt Forster het lexicale decisie proces. (Hij heeft het hier over een momenteel popu lair experimenteel paradigma, waarbij aan proefpersonen wordt gevraagd zo snel mogelijk te beslissen of een aangeboden letterreeks al dan niet een bestaand woord is. De reactietijd wordt gemeten). Hierbij dient opgemerkt te worden dat lexicale decisietijden relatief lang zijn en enigszins buiten het bereik van Morton's model vallen. Resulta ten uit lexicale decisie experimenten kunnen tot een aanvulling leiden van het logogen model, maar slechts zelden tot een weerlegging.
Lexicale decisie zou, uitgaande van een logogen model,als volgt kunnen geschieden. Bij het decisieproces zou er sprake kunnen zijn van een tijdslimiet, dat wil zeegen dat wanneer binnen een bepaalde tijd nog geen detector heeft gerespondeerd, de beslissing wordt genomen dat het hier géén bestaand woord betreft. Dit heeft echter weer als bezwaar dat er toch gevallen zijn dat niet-lexicale eenheden woorddetectors kunnen activeren voor de tijdslimiet is bereikt. Niet-lexicale elementen die op bestaande woorden lijken kosten meer tijd om te verwerpen dan andere niet-lexicale elementen. (Zo'n moeilijk verwerpbaar niet-lexicaal element zou b.v. aaradbei kunnen zijn of difstal, et. Taft en Forster, 1975). Het is nogal implausibel om dit soort effecten trachten te verklaren zonder aan te nemen dat in dit soort gevallen de detectors niet op minstens drempelnivo geactiveerd worden. Forster stelt daarom voor om van het passieve detectiemodel van Morton een gedeeltelijk actief model te maken. Hij stelt een detectorsysteem voor dat in feite alleen een verzameling plausibele hypotheses genereert over het element, hypotheses die dan nog onderzocht moeten worden door de grafische of fonologische code in de mogelijke lemma's te vergelijken met de aangeboden informatie. Na passieve detectie van de mogelijke ‘kandidaten’ (eventueel in een door frequentie geordende lijst) vindt dus nog een actieve vergelijking en vervolgens selectie plaats. (Zie b.v. ook Becker, 1976). Er zijn aanwijzingen dat deze vergelijkingsprocedure niet noodzakelijkerwijs op representaties van het hele woord berust. Taft en Forster (1975) geven enige experimentele evidentie dat woorden met een prefix gedecomponeerd worden en dat voornamelijk de stam gebruikt wordt bij het opzoeken in het lexicon, (c.f. Jarvella en Snodgrass, 1974 en ook Murrel en Morton, 1974). In het geval
van polymorfemische woorden met twee stammen zoals bij samengestelde woorden als dagdroom en fietspomp, lijkt het er ook op alsof alleen het eerste morfeem bepaalt welke verzameling van woorden in aanmerking komt. Taft en Forster (1975) vonden dat het langer duurde om te beslissen dat woorden als voetbrik en stofdrul niet tot het lexicon behoorden dan woorden als trifpaard en pargluf Binnen elk van deze klassen werd geen verschil gevonden.
Een van de mogelijke toegangen tot het interne lexicon is via het geschreven of gedrukte woord. Een aantal onderzoekers heeft de hypothese onderzocht dat de toegang tot het lexicon bij lezen via fonemische hercodering zou gaan. (Tenminste voor orthografische systemen die zich daartoe lenen). Men vond onder andere dat het langer duurde om een letterreeks die geen bestaand woord vormde, af te wijzen wanneer deze reeks
| |
| |
een homofoon was van een wel bestaand woord. (Rubenstein, Lewis en Rubenstein, 1971; zie ook Meyer, Schvaneveldt en Ruddy, 1974 b).
Experimentele evidentie tegen de hercoderingshypothese is onder andere te vinden in Green en Shallice (1976). Marshall (1976) geeft een goed overzicht van deze problematiek en geeft ook vanuit klinische gegevens (afasie) sterke argumenten voor het bestaan van zowel een fonologische hercodering als ook een direkte visuele toegang tot het lexicon, waarbij deze twee systemen eventueel parallel kunnen werken.
Hieraan gerelateerd is de vraag of woorden als geheel herkend worden ( op grond van globale en visuele eigenschappen) of dat er sprake is van een herkenningsproces waarbij iedere letter afzonderlijk een rol speelt. De meest extreme positie (serieële verwerking van letters) zoals bijvoorbeeld in het model van Gough (1972) wordt steeds minder plausibel. (Een goed overzicht over de problematiek van het leesproces is te vinden in Kavanagh en Mattingly, 1972). Een groot aantal experimenten toonde bijvoorbeeld aan, dat het langer duurt om subcomponenten van woorden zoals letters of fonemen te detecteren, dan om de aanwezigheid van het woord zélf te detecteren. (Ball, Wood, en Smith, 1975; Foss en Swinney, 1973; McNeil en Lindig, 1973). Dit zou er op kunnen wijzen dat de codering van woorden voltooid is voordat de samenstellende letters of fonemen volledig gecodeerd zijn. Op dit moment is het echter niet helemaal duidelijk of deze resultaten het gevolg zijn van een bepaalde coderingswijze of dat deze resultaten een gevolg zijn van het vergelijkingsproces dat in dit soort experimenten ook plaats moet vinden. (Sloboda, 1976; zie ook Massaro en Klitzke, 1977).
In de beschrijving van het model van Morton is al naar het verschijnsel van lexicale homonymie verwezen. Het is duidelijk dat semantische context gebruikt kan worden om te disambigueren, maar vooralsnog is het onduidelijk hoe dit precies gebeurt en hoe de betekenisinhouden van ambigue woorden opgezocht worden.
Vele experimenten toonden aan dat zinnen met ambigue woorden moeilijker te verwerken zijn (b.v. MacKay, 1966). Foss en Swinney (1973) vonden dat het aanbieden van een semantische context geen invloed had op de verwerkingstijd van ambigue en niet ambigue woorden. (Volgens Morton en Long (1976) hebben Fossen Swinney echter niet in de goede range gemeten.) Foss en Swinney concluderen dat meer betekenissen, niet selectief, toegankelijk worden gemaakt en dat de extra betekenissen verwerkingstijd aan ambigue woorden toevoegen. Die extra tijd zou echter kunnen resulteren uit het opzoeken van nieuwe betekenissen of het opnieuw ophalen van eerder afgewezen mogelijkheden. Schvaneveldt, Meyer en Becker (1976) vonden in een lexicaal decisie experiment evidentie voor selectieve toegankelijkheid. Tussen de letterseries waarvan beslist moest worden of het bestaande woorden waren zaten tripletten van het type: save, bank, money, waarin het eerste en derde woord gerelateerd waren via éénzelfde betekenis van het ambigue tweede woord. De beslissingstijd voor het derde woord nam dan af. Maar wanneer het eerste en derde woord aan verschillende betekenissen gerelateerd waren (river-bank-money) verschilde de reactietijd voor het derde woord niet significant met de reactietijd uit een controle serie. Ook uit geheugen-experimenten blijkt dat maar één van de betekenissen onthouden wordt (Winograd en Raines, 1972).
4.2. Een geheel andere toegang tot het interne lexicon treffen we aan bij het benoemen van objecten. Wanneer een naam geselecteerd moet worden, dan moet eerst het te
| |
| |
benoemen object geïdentificeerd worden, en vervolgens moet een passend woord gezocht worden. De passendheid van een woord kan van de context afhangen. Oldfield en Wingfield (1965) lieten proefpersonen een plaatje zien van een object en vroegen ze dit object zo snel mogelijk te benoemen. Er waren plaatjes van gewone dagelijkse voorwerpen (boek, typemachine, bloem) en van meer zeldzame objecten als een microscoop of xylofoon. Gemiddeld werden de wat gebruikelijker objecten ca. 0.5 seconde sneller benoemd. Kwam dit omdat zeldzame voorwerpen moeilijker te identificeren zijn, of omdat het moeilijker is een passende naam te kiezen? Volgens Wingfield (1967) ligt het aan het tweede stadium. Wanneer bijv. de categorie gevraagd wordt, dan blijkt dat een trommel en een xylophoon even snel een muziekinstrument worden genoemd. Wat bepaalt nu hoe vlug een naam geselecteerd wordt? Het aantal mogelijke namen is misschien van invloed (rijksdaalder, munt, geld, poen, knaak, ...). Een ander punt is de fonologische toegankelijkheid (zie 3.): men kan een woord kennen, maar de fonologische vorm niet direkt vinden. Carroll en White (1973) vonden dat objecten sneller werden benoemd, naarmate de naam ervoor eerder door het kind geleerd was in de jeugd. Natuurlijk is het zo dat als een woord vroeg geleerd wordt het later meestal ook een frequenter woord in de taal zal zijn, wat goed aansluit bij het resultaat van Oldfield en Wingfield dat meer frequente woorden sneller geproduceerd worden als naam van een object. Maar Carroll en White toonden ook aan dat de leeftijd waarop men een woord had geleerd, de benoemingstijd nog beter voorspelde dan de frequentie waarmee het woord in de taal voorkomt.
| |
5. Conclusie
Getracht is een globaal overzicht te geven over psycholinguistisch onderzoek betreffende het menselijk lexicon. Daarbij zijn niet alleen binnen de wel vermelde onderwerpen allerlei belangrijke zaken onvermeld gebleven, maar ook zijn twee relatief grote onderwerpen niet ter sprake gekomen. Het betreft hier respectievelijk de ontogenese van het lexicon en de pathologie ervan. Hiervoor verwijzen wij naar Clark (1977) en Marshall (1977) die goede inleidingen hierover verschaffen. In het verwante gebied der Artificiële Intelligentie worden ook voorstellen gedaan hoe een lexicon ten behoeven van taalverwerkende programma's er uit zou kunnen zien. (Zie b.v. Schank en Colby, 1973). De psychologische waarde van deze voorstellen is moeilijk te schatten; wel gaat er een stimulerende invloed op nieuw onderzoek van uit.
| |
Literatuur
Anderson, R.C., Pichert, J.W., Goetz, E.T., Schallert, D.L., Stevens, K.U. & Trollip, S.R.
1976 Instantation of general terms. Journal of Verbal learning and Verbal Behaviour, 15, 667-679. |
Ball, F., Wood, C., & Smith, E.E.
1975 When are semantic targets detected faster than visual or acoustic ones? Perception & Psychophysics, 17, 1-8. |
| |
| |
Becker, C.A.
1976 Allocation of attention during visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 2, 556-566. |
Brown, R., & McNeil, D.
1966 The ‘tip of the tongue’ phenomenon. Journal of Verbal Learning and Verbal Behaviour, 5, 325-337. |
Carroll, J.B., & White, M.N.
1973 Word frequency and age of acquisition as determiners of picture naming latency. Quarterly Journal of Experimental Psychology, 25, 85-95. |
Catlin, J., & Micham, D.
1975 Semantic representations as procedures for verification. Journal of Psycholinguistic Research, 4, 209-225. |
Clark, E.V.
1977 First language acquisition. In J. Morton & J.C. Marshall (eds.) Psycholinguistic Series Vol. I; Developmental and Pathological. London: Elek Science. |
Clark, H.H.
1970 Word associations and linguistic theory. In J. Lyons (ed.), New horizons in linguistics. Harmondsworth: Pinguin Books. |
Clark, H.H. & Clark, E.V.
1977 Psychology and language. New York:-Harcourt, Brace, Jovanovich. |
Collins, A.M., & Quillian, M.R.
1969 Retrieval time from semantic memory. Journal of Verbal Learning and Verbal Behaviour, 8, 240-248.
1972 How to make a language user. In E. Tulving & W. Donaldson (eds.), Organization of memory. New York: Academie Press. |
Conrad, C.
1972 Cognitive economy in semantic memory. Journal of Experimental Psychology, 92, 149-154. |
Fay, D., & Cutler, A.
1977 Malapropisms and the structure of the mental lexicon. Linguistic Inquiry, 8, 505-520. |
Fillenbaum, S.A., & Rapoport, A.
1971 Structures in the subjective lexicon. New York: Academie Press. |
Fillmore, C.J.
1971 Types of lexical information. In: Steinberg D.D. & Jakobovits, L.A., (eds.), Semantics, Cambridge University Press. |
Fodor, J.A.
1975 The language of thought. New York: Thomas Y. Crowell Company. |
Fodor, J.A., Bever, T.G., & Garrett, M.F.
1974 The psychology of language. New York: McGraw-Hill. |
Fodor, J.D., Fodor, J.A., & Garrett, M.F.
1975 The psychological unreality of semantic representations. Linguistic Inquiry, 6, 515-531. |
Forster, K.I.
1976 Accessing the mental lexicon. In: R.J. Wales, & E. Walker (eds.) New approaches to language mechanisms. Amsterdam: North-Holland. |
Foss, D.J., & Jenkins, C.M.
1973 Some effects of context on the comprehension of ambiguous sentences. Journal of Verbal Learning and Verbal Behaviour, 12, 577-589. |
Foss, D.J., & Swinney, D.A.
1973 On the psychological reality of the phoneme. Journal of Verbal Learning and Verbal Behaviour, 12, 246-257. |
| |
| |
Frijda, N.H.
1972 Simulation of long term memory. Psychological Bulletin, 77, 1-31. |
Fromkin, V., (ed.)
1973 Speech errors as linguistic evidence. Den Haag: Mouton. |
Gough, P.B.
1972 One second of reading. In: J.F. Kavanagh & J.G. Mattingly, Language by ear and by eye. Cambridge: MIT press. |
Green, D.W., & Shallice, T.
1976 Direct visual access in reading for meaning. Memory & Cognition, 4, 753-758. |
Glass, A.L., & Holyoak, K.J.
1976 Alternative conceptions of semantic theory. Cognition, 3, 313-339. |
Henley, N.M.
1969 A psychological study of the semantics of animal terms. Journal of Verbal Learning and Verbal Behaviour, 8, 176-184. |
Jackendoff, R.
1976 Toward an explanatory semantic representation. Linguistic Inquiry, 7, 89-150. |
Jarvella, R.J., & Snodgrass, J.G.
1974 Seeing ring in rang and retain in retention: On recognizing stem morphemes in printed words. Journal of Verbal Learning and Verbal Behaviour, 13, 590-598. |
Jastrzembski, J., & Stanners, R.
1975 Multiple word meanings and lexical search speed. Journal of Verbal Learning and Verbal Behaviour, 14, 534-537. |
Johnson-Laird, P.N.
1975 Meaning and the mental lexicon. In A. Kennedy & A. Wilkes (eds.), Studies in long term memory, London: Wiley. |
Kavanagh, J.F., & Mattingly, I.G. (eds.)
1972 Language by ear and by eye. Cambridge: The M.I.T. Press. |
Kintsch, W.
1974 The representation of meaning in memory. Hillsdale, N.J.: Lawrence Erlbaum Associates. |
Levelt, W.J.M., & Kempen, G.A.M.
1976 Taal. In: J.A. Michon, E.G.J. Eijkman & L.F.W. de Klerk (eds.), Handboek der Psychonomie, Deventer: Van Loghum Slaterus. |
Levelt, W.J.M., Schreuder, R., & Hoenkamp, E.C.M.
1977 Structure and use of verbs of motion. In: R. Campbell & P. Smith (eds.), Proceedings of the Psychology of Language Conference, June 1976. New York: Plenum Press. |
Lyons, J.
1977 Semantics, Cambridge University Press. |
Mackay, D G.
1966 To end ambiguous sentences. Perception & Psychophysics, 1, 426-436.
1976 On the retrieval and lexical structure of verbs. Journal of Verbal Learning and Verbal Behaviour, 15, 169-182. |
Marshall, J.C.
1976 Neuropsychological aspects of ortographic representation. In: R.J. Wales & E.
Walker (eds.), New approaches to language meachnisms, Amsterdam: North-Holland.
1977 Disorders in the expression of language. In: J. Morton & J.C. Marshall (eds.), Psycholinguistic Series Vol. I: Developmental and Pathological. London: Elek Science. |
Massaro, D.W., & Klitzke, D.
1977 Letters are functional in word recognition. Memory & Cognition, Vol. 5, 3, 292-298. |
McNeil, D., & Lindig, K.
1973 The perceptual reality of phonemes, syllables, words and sentences. Journal of
|
| |
| |
| Verbal Learning and Verbal Behaviour, 12, 419-430. |
Meyer, D.E., & Schvaneveldt, R.W.
1971 Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. Journal of Experimental Psychology, 90, 227-234. |
Meyer, D.E., Schvaneveldt, R.W., & Ruddy, M.C.
1974a Loci of contextual effects on visual word recognition. In: P. Rabbitt (ed.), Attention and Performance V. New York: Academie Press.
1974b Functions of the graphemic and phonemic codes in visual word recognition.
Memory & Cognition, 2, 309-323. |
Miller, G.A.
1969 A psychological method to investigate verbal concepts. Journal of Mathematical Psychology, 6, 169-191.
1972 English verbs of motion: a case study in semantics and lexical memory. In: A.W. Melton & E. Martin, Coding processes in human memory, Washington D.C.: V.H. Winston & Sons. |
Miller, G.A., & Johnson-Laird, P.N.
1976 Language and Perception. Cambridge Mass.: The Belknap Press. |
Morton, J.A.
1970 A functional model for memory. In: D.A. Norman, (ed.), Models of human memory. New York: Academie Press. |
Morton, J., & Long, J.
1976 Effect of word transitional probability on phoneme identification. Journal of Verbal Learning and Verbal Behaviour, 15,43-51. |
Murrell, G.A., & Morton, J.
1974 Word recognition and morphemic structure. Journal of Experimental Psychology, 102, 963-968. |
Neisser, U.
1967 Cognitive Psychology, New York: Appleton - Century - Crofts. |
Noordman-Vonk., W.
1977 Retrieval mechanisms of semantic memory. Dissertatie, Groningen. |
Noordman, L.G.M., & Levelt, W.J.M.
1970 Noun categorization by noun-verb intersection for the Dutch languahe. Rapport HB-70-59 EX, R.U. Groningen.
1977 The noun-verb intersection method for the study of word meanings. Methodology & Science, (in press). |
Oldfield, R.C.
1963 Individual vocabulary and semantic currency: a preliminary study. British Journal of Social and Clinical Psychology, 2, 122-130. |
Oldfield, R.C., & Wingfield, A.
1965 Response latencies in naming objects. The Quarterly Journal of Experimental Psychology, 17, 273-281. |
Osgood, C.E., Suci, G.J., & Tannenbaum, P.H.
1957 The measurement of meaning. Urbana: University of Illinois press. |
Osgood, C.E.
1968 Toward a wedding of insufficiencies. In: T. Dixon & D. Horton (eds.), Verbal behaviour and general behaviour theory. Englewood Cliffs, N.J.: Prentice Hall. |
Osgood, C.E., & Hoosain, R.
1974 Salience of the word as a unit in the perception of language. Perception & Psychophysics, 15, 168-192. |
Rommey, A.K., & d'Andrade, R.G.
1964 Transcultural studies in cognition. American Anthropologist, 66, (3, Pt. 2), 146-170. |
| |
| |
Rosch, E.
1973 On the internal structure of perceptual and semantic categories. In. T.E. Moore (ed.), Cognitive development and the acquisition of language. New York: Academie Press.
1975 Cognitive representations of semantic categories. Journal of Experimental Psychology: General, 104, 192-233.
1977 Human categorization. In: N. Warren (ed.), Advances in cross-cultural psychology (Vol. 1), London. Academie Press. |
Rosch, E., & Mervis, C.B.
1975 Family resemblances: Studies in the internal structure of categories. Cognitive Psychology, 7, 573-605. |
Rubenstein, H., Lewis, S.S., & Rubenstein, M.A.
1971 Evidence for phonemic recoding in word recognition. Journal of Verbal Learning and Verbal Behavior, 10, 645-657. |
Rumelhart, D.E., Lindsay, P.H., & Norman, D.A.
1972 A process model for longterm memory. In: E. Tulving & W. Donaldson (eds.), Organization of memory, New York: Academie Press. |
Schank, R.C., & Colby, K.M.
1973 Computer models of thought and language, San Francisco: Freeman. |
Schmidt, R.
1976 On the spread of semantic excitation, Psychological Research, 38, 333-353. |
Schvaneveldt, R.W., Meyer, D.E., & Becker, C.A.
1976 Lexical ambiguity, semantic context and visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 2, 243-256. |
Shoben, E.J.
1976 The verification of semantic relations in a same-different paradigm: An assymetry in semantic memory, Journal of Verbal Learning and Verbal Behavior, 15, 365-379. |
Sloboda, J.A.
1977 The locus of the word-priority effect in a target-detection task. Memory & Cognition, 5, 371-376. |
Smith, E.E.
1977 Theories of semantic memory. In: W.K. Estes (eds.), Handbook of learning and cognitive processes. (Vol. 5). Hillsdale, N.J.: Lawrence Erlbaum Associates. |
Smith, E.E., Rips, L.J., & Shoben, E.J.
1974 Semantic memory and psychological semantics. In: G. Bower (ed.), The Psychology of Learning and Motivation, Vol. 8, New York: Academie Press.
1974 Structure and processes in Semantic Memory: a featural model for semantic decisions. Psychological Review, 81, 214-241. |
Stillings, N.A.
1975 Meaning rules and systems of inference for verbs of transfer and possession. Journal of Verbal Learning and Verbal Behavior, 14, 453-470. |
Taft, M., &. Forster, K.I.
1976 Lexical storage and retrieval of polymorphic and polysyllabic words, Journal of Verbal Learning and Verbal Behavior, 15, 607-620. |
Uit den Boogaart, P.C.
1975 Woord frequenties, Utrecht: Oosthoek, Scheltema & Holkema. |
Wingfield, A.
1967 Perceptual and response hierarchies in object identification, Acta Psychologica, 26, 216-226. |
Winograd, E., & Raines, S.R.
1972 Semantic and temporal variation in recognition memory, Journal of Verbal Learning and Verbal Behavior, 11, 114-119. |
|
|
