
Forum der Letteren. Jaargang 1975
(1975)– [tijdschrift] Forum der Letteren–
[pagina 200]
| |||||||||||
De computer in de taal- en letterkunde
| |||||||||||
InleidingHet vermogen van de mens door middel van de taal een abstractie van de realiteit te maken en die aan anderen over te dragen blijft iets wonderbaarlijks. Het schrift heeft het verder versterkt doordat de communicatie daarmee de tijd is gaan overbruggen. Een brief, een manuscript, kan bovendien reizen. Maar een werkelijke overbrugging van de ruimte kwam pas met de boekdrukkunst. Men zou deze verbreiding van de menselijke gedachten kunnen vergelijken met een zwak diersoort. In de evolutie kan het zich handhaven door hoge geboorte-aantallen. Misschien kan het zelfs bezit nemen van een groot areaal. En een natuurlijk evenwicht ontstaat dan door de beperktheid van het voedsel en de strijd met de natuurlijke vijanden. De populatie van door de mens geproduceerde documenten lijkt nog steeds te groeien. De enige werkelijke effectieve vijanden zijn de verveling en de economie. De verveling die je bekruipt bij het te vaak onder ogen krijgen van dezelfde frasen garandeert een broodwinning aan journalisten en litteratoren. Hun produkten krijgen een kans om de oude te verdringen en die door overstelping te doen vergeten. De economie, als leer van de maatschappelijke voortbrenging, maakt duidelijk dat er grenzen zijn aan iedere groei. Niet alleen wordt de aanwas van nieuwe publicaties | |||||||||||
[pagina 201]
| |||||||||||
geremd, bijvoorbeeld door de stijging van de drukkosten, maar ook het toegankelijk maken van bestaande geschriften wordt steeds moeilijker, al was het alleen maar om de aantallen. Dit was het toneel waar plotseling een nieuwe variëteit verscheen in de vorm van computer-gedragen informatie. In het begin leek dit resultaat van menselijk vernuft niets met de taal- of letterkunde van doen te hebben. Maar vandaag weten wij dat het een mutant is die enorm veel beter uitgerust is tegen de bekende bedreigingen van de habitat. Het ruimtebeslag is miniem: het ongeveer kwart miljoen tekens (blanco's meegeteld) dat in dit nummer van Forum der Letteren leesbaar is afgedrukt kan op minder dan een meter magneetband geregistreerd worden. De economie van overdracht wordt steeds gunstiger: om de inhoud van dat stukje band in de machine over te nemen kost ऒ 1,25 en het duurt minder dan 10 seconden, het afdrukken van de tekst in regels gebeurt binnen de twee minuten en kost nog geen twintig gulden. Wel heb je daarvoor geen prettig leesbaar boekje in je hand, maar de abstracties, de taal, de begrippen, kortom de wezenlijke boodschappen staan tot je beschikking. Het gaat bij de twee genoemde operaties (magneetband lezen, resp. regels drukken) nog om mechanische apparatuur. Inwendig zijn de elektronische afhandelsnelheden bijna onvoorstelbaar geworden, per seconde worden er tussen een miljoen en een miljard manipulaties verricht! Waar deze ontwikkeling technisch toe zal leiden is niet te overzien. Door transmissie over het telefoonnet en draadloos via straalzenders en satellieten wordt nu al een bijna momentane gegevensverbreiding over de hele wereld bereikt. Een ware zondvloed van berichten staat ons te wachten, een mogelijke ‘information pollution’ waar de materiële milieuvervuiling bij in het niet kan zinken..... De meeste computer-gedragen signalen behoren natuurlijk niet tot de echte litteratuur. Administratieve informatie, zakelijke boodschappen, wetenschappelijke gegevens, televisiebeelden, ruimtevaartsignalen en dergelijke, zij hebben hun eigen kring van belangstellenden. Maar het feit dat zij uit ketens van symbolen bestaan, dat aan hun onderlinge ordening een betekenis is verbonden en dat de automatische verwerking daarvan een gestruktureerd stel opdrachten vereist, legt een nauwe relatie tussen theoretische computerkunde en theoretische taalkunde. Omgekeerd kunnen taal- en letterkunde, waarvan de objecten ook de vorm van geordende symbolenketels hebben, in de computer een machtig hulpmiddel vinden. Immers zullen veel studies zowel als prak- | |||||||||||
[pagina 202]
| |||||||||||
tische verwerkingstaken in feite het manipuleren van grote hoeveelheden van die symbolen met zich meebrengen. Het is over al deze dingen dat dit artikel handelt. | |||||||||||
Begrippen rond de computerIn het spraakgebruik, vooral het Engelstalige, is de term computer erg centraal komen te staan. Het is waar dat zonder de nieuwe technologie geen van de genoemde ontwikkelingen had kunnen plaatsvinden en dat wij ons daardoor pas echt bewust zijn geworden van zulk soort zaken als de betekenis van informatie in de organisatie. Ook zouden de natuurwetenschappen niet de verbluffende vlucht van. deze laatste decennia hebben kunnen nemen zonder computers, en evenmin hadden de economische, sociale, medische en andere wetenschappen hun huidige niveau bij benadering kunnen bereiken zonder geautomatiseerd rekenwerk. Maar er is meer dan alleen het computer-georiënteerde aspect.
Men moet op zijn minst de volgende onderscheidingen maken:
Het eerste begrippengebied moet nadrukkelijk los gezien worden van de praktische uitvoering. In de praktijk wordt informatie overgedragen door middel van continue of discrete signalen. De spraak, als continue geluidstroom, hoort tot de ene groep, het schrift, met zijn discrete symbolenketens, tot de andere. Wanneer wij over de computer praten bedoelen wij altijd een machine die ‘digitaal’ (dus discreet) vastgelegde symbolen verwerkt.Ga naar voetnoot1 Nu kan men over de struktuur van een symbolenverzameling of over de handelingen bij het manipuleren en omvormen daarvan nadenken zonder de technische verwezenlijking erbij te betrekken. Codering, strukturering en verwerking zijn daarom belangrijke onderwerpen die afzonderlijk bekeken moeten worden. Zij vormen het kerngebied van een nieuwe discipline die bij ons de naam informatica heeft gekregen. Wij zullen er dadelijk op terugkomen. | |||||||||||
[pagina 203]
| |||||||||||
Het tweede begrippengebied betreft de problemen die wèl met de feitelijke technologie te maken hebben. De term ‘automatisering’ komt hierbij naar voren omdat de verwerkende apparatuur met zulke enorme snelheden kan werken dat het onzinnig zou zijn als de gebruiker de afzonderlijke stappen telkens afzonderlijk op gang moest brengen. Bijna alle verwerkingsprocessen vinden herhaaldelijk toepassing, zij het iedere keer met andere gegevens (denk aan administraties, wetenschappelijke berekeningen, enz.). Het ligt dan ook voor de hand een rij ‘opdrachten’ vast te leggen op dusdanige manier dat de machine zo'n ‘programma’ zelf kan volgen. Het klassieke mechanische voorbeeld is het draaiorgel: de geperforeerde band heeft gaatjes die eenmalig worden aangebracht; daarna kan het afspeelapparaat deze zonder meer aftasten, wanneer men maar wil. Het bijzondere van de elektronische computer is dat men de opdrachten binnen de machine zelf opslaat. Het aftasten van de instructies kan dan inderdaad met electronische snelheden gebeuren. De codering van de verschillende bewerkingsstappen is een typisch taalkundig probleem. Ook dat is een onderwerp waar we dieper op in moeten gaan. Het derde begrippengebied is een zaak die van de gebruiker afhangt. Wanneer hij natuurwetenschappelijke berekeningen wil maken heeft hij behoefte aan numeriek wiskundige methoden, wanneer hij de sociale wetenschappen beoefent zal hij zich van statistische methodieken bedienen en de lezers van dit artikel zullen in het algemeen meer baat vinden bij taalkundige uitgangspunten. Twee dingen maken dat zij niettemin een paar aspecten gemeen hebben. Ten eerste weet de computer niet wat de betekenis is van de symbolen die hij manipuleert. Dat maakt dat de algemene informatie-problematiek voor iedere gebruiker dezelfde is en daarmee de informatica een gemeenschappelijke hulpwetenschap. Ten tweede heeft de computer bepaalde sterke kanten (de reeds genoemde snelheid en het vermogen gegevens compact op te slaan), maar ook zekere zwakheden (hij benadert de mens zelfs niet in zijn associatief vermogen en heeft meer dan het bekende halve woord van de goede verstaander nodig). Zo heeft hij zich ontwikkeld tot een hulpmiddel voor nogal specifieke taken, speciaal die waarin exactheid en struktuur optreden. Waar die ontbreken, en eigenlijk ook waar zij wel aanwezig zijn maar dan in mindere mate, wordt men met flexibiliteitsproblemen geconfronteerd. De formuleringen die men zoekt hebben ook weer een nadrukkelijk taalkundig element dat in de verdere discussie telkens weer naar voren zal komen. | |||||||||||
[pagina 204]
| |||||||||||
InformaticaHet ontstaan van nieuw jargon is altijd boeiend om aan te zien. Het is ook vaak van invloed op de verdere ontwikkeling van het gebied. De Angelsaksische voorkeur voor de benaming ‘computer science’ heeft er misschien niet toe geleid dat de beoefenaren alleen in termen van technische realisatie gingen denken, maar wel heeft hij ertoe bijgedragen dat een grote kloof is ontstaan tussen de praktische gebruikers (die hun activiteit ‘data processing’ noemen) en de nogal abstract ingestelde vaktheoretici. In Europa is de naam ‘formatica’ gebruikelijk geworden (door ZoutendijkGa naar voetnoot2 in zijn oratie gesuggereerd in 1964, door de Académie Française als ‘l'informatique’ in 1966 officieel gedefinieerd en in het Duits als ‘die Informatik’ bekend). Het accent dat daarmee op het element informatie wordt gelegd is van veel belang, want al leven ook bij ons de theoretici en pragmatici in enigszins gescheiden werelden, er is een voortdurende discussie wie nu het meeste recht op het woord heeft. De daarbij benutte argumentatie heeft een niet onaanzienlijk kruisbestuivings-effect. De meest wezenlijke aspecten van de informatica vloeien voort uit de volgende, heel simpele, beschrijving van het proces van ‘gegevensverwerking’: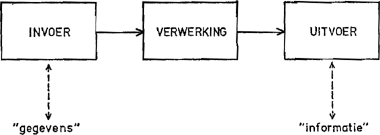 Figuur 1: Gegevensverwerking.
De termen ‘gegevens’ en ‘informatie’ zijn hier in een speciale betekenis gebruikt. De eerste betreft de signalering of registratie van feiten of toestanden zonder meer. Bij de tweede gaat het om geordende, geïnterpreteerde of omgevormde gegevens, bedoeld om betekenis te hebben. Er is dus een ‘zender-drager-ontvanger’ situatie. De benadering typeert het gebruik van informatie in onderneming en bestuur. Maar men kan haar direct overbrengen op de wetenschap: | |||||||||||
[pagina 205]
| |||||||||||
uitgaande van zeker materiaal (waarnemingen, tekst, enz.) bewerkt en ordent men de representatieve symbolen dusdanig dat men zijn inzicht vergroot (strukturele analyse, statistische analyse, e.d.). De formulering van de desbetreffende wetenschap wordt door de computer in daden omgezet. Maar hoe moet men nu die taak zo omschrijven dat dit hulpapparaat dat goed doet? In de eerste plaats geldt dat de te verwerken gegevens geordend ter beschikking moeten staan. Bij wetenschappelijke metingen en in financiële administraties betekent dat het netjes op een rijtje, of in een rij van rijtjes plaatsen van gestandaardiseerde cijfers en coderingen. Bij taalkundige problemen levert dat nog al eens praktische moeilijkheden op, maar men kan zich toch wel keurig voorbereide tabellen of een achter elkaar ingevoerde rij van woorden uit de tekst als ‘input’ voorstellen. Dan komt de bewerking, het herkennen, tellen, omzetten, enzovoort. Daarbij wordt dus gerekend, maar een belangrijk deel van de stappen bestaat uit het trekken van logische conclusies (‘Zijn twee woorden hetzelfde? Zo ja, verhoog teller, zo nee, vergelijk volgende twee’ of ‘Hebben we het laatste woord al bekeken? Zo ja, beëindig de analyse, zo nee, probeer het volgende woord’ ...) en bovenal worden de gegevens of delen daarvan telkens verplaatst (plaatsing in een vergelijkingsregister, uitsplitsen of samenvoegen van symbolen-ketens, sorteren in een zekere volgorde, tijdelijk opslaan van tussenresultaten, enz.). Het is de combinatie van reken-, logische en verplaatsings-opdrachten die het bewerkingsschema bepalen. Dit kan met potlood en papier uitgevoerd worden of zelfs gewoon in het hoofd en dan is een algemene aanduiding voldoende. Maar wanneer je het door een computer wil laten doen moeten de stappen precies omschreven zijn. Men noemt zo'n schema een algoritme (naar de 9e eeuwse Arabische wiskundige Abu Jafar Mohammed Ibn Musa al Khowarizmi). Nadat het gewenste resultaat verkregen is komt de laatste stap, het zichtbaar maken ervan (‘output’). Daarmee is het schema rond. Duidelijk is dat een algoritme waarmee één soort bewerking herhaaldelijk moet worden uitgevoerd zich prettig compact laat opstellen met behulp van een of meer tellers, zoals in het voorbeeld van figuur 2. Dat illustreert het bepalen van de woordlengtefrequentie in een tekst. Het is ook duidelijk dat een toets op het einde van zo'n herhaalde bewerking essentieel is, anders zou de computer maar door blijven gaan! De informatica kent drie fundamentele probleemgebieden: de ge- | |||||||||||
[pagina 206]
| |||||||||||
gevens-ordening (‘data-strukturen’), de verwerkingslogica (‘algoritmiek’) en het nog niet aangeroerde onderwerp van de codering van de algoritme dusdanig dat die door een computer kan worden begrepen. Dat is het probleem van de programmeertaal. Om dat te begrijpen is het nodig even een kijkje te nemen in het binnenste van de computer zelf.  Figuur 2: Algoritme voor het bepalen van woordlengte-frequenties (tekst staat in posities TXT(1), TXT(2),... met aan het eind een sluitsymbool; T1 wijst eerste letter van een woord aan, T2 tast naar de laatste; de frequenties worden geteld door F(1),..., F(10); in de laatste tellen meer dan 10-letterige woorden mee).
| |||||||||||
[pagina 207]
| |||||||||||
AutomatiseringOp zijn eenvoudigst kan men zich de machine voorstellen als een enorm stuk ruitjespapier, waarvan alle hokjes genummerd zijn, met een paar speciale registers daaraan gekoppeld. Het papier dient voor het opslaan van de te bewerken gegevens, zowel als van de gecodeerde instrukties die het programma vormen. Het ruitjespapier noemt men daarom het ‘geheugen’ en de hokjes ‘geheugencellen’ (zie figuur 3). 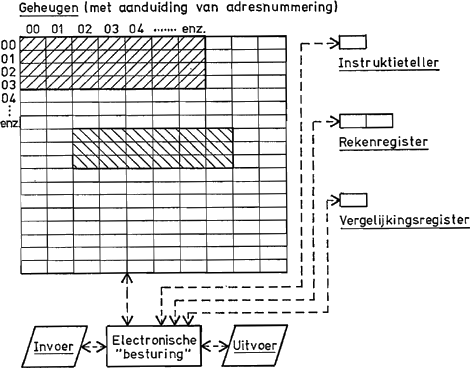 Figuur 3: Schematische struktuur van een computer; geheugengebruik bv. als aangegeven:
▨ programma ▧ gegevens □ onbenut Het mechanisme dat de automatische verwerking mogelijk maakt wordt verschaft door een teller, die men eenmalig van buiten af instelt op dat vakje waar zich de eerste opdracht bevindt. Deze wordt uitgevoerd waarna de ‘instruktie-teller’ één omhoogspringt. Normaal wordt dan de opdracht in het volgende hokje uitgevoerd. Moet een | |||||||||||
[pagina 208]
| |||||||||||
serie opdrachten herhaald worden of een elders opgeslagen stel worden uitgevoerd dan moet dat in de laatste opdracht worden voorbereid door de instruktieteller te verzetten. Maar dat is een soort opdracht dat niet verschilt van optellen en aftrekken! De vorm van de opdrachten in het algemeen hangt natuurlijk erg af van de feitelijke constructie van de machine. Meestal bestaat een instruktie uit een operatiecode (XX) en een adrescode (yy):
De operatiecode geeft aan wat er met de gegevens moet gebeuren en de adrescode duidt de plaats aan waar ze vandaan komen of naar toe moeten gaan. Zoals uit de beginselen van de algoritimiek volgt zijn er vier soorten operaties:
In de praktische uitvoering worden operatie- en adrescode beide door getallen gevormd. Voor de eerste kiest de ontwerper een handige nummering, bij de tweede gaat het om de ‘adressen’ van de geheugencellen. Hun aantal kan tegenwoordig in de miljoenen lopen, maar ook aan een kleine hypothetische machine, met niet meer dan bv. 1000 cellen, laten de principes zich al heel goed illustreren. Wanneer die een optelregister (‘accumulator’), een vergelijkingsregister (inhoud: + of - of =) en een instruktieteller bezit, benevens een invoer- en uitvoerorgaan (bv. één getal of woord tegelijk ‘inlezen’, resp. ‘schrijven’) dan heeft men daarmee een primitieve, maar toch volledig automatische computer. Dat dit tot zeer omvangrijke programma's aanleiding geeft is evident. Het voorbeeld van figuur 4, waarin het voorkomen van een gegeven naam op een in de machine aanwezige standaardlijst wordt gecontroleerd, toont dit duidelijk aan. Maar dat is nog niet het ergste. De moderne computer met zijn grote geheugen en snelle werking weet daar wel raad mee. Erger is het moeizame gebruik van een dergelijke ‘taal’. Niet alleen moet men de betekenis van de numerieke operatiecodes onthouden, men moet ook de preciese locatie van de programmastappen en de gegevens weten. Het volgende taalkundige probleem is daarom een ‘hogere taal’ te definiëren waarin de taakformulering eenvoudiger is en waarbij het routinematige omzetten van verbale instructies in | |||||||||||
[pagina 209]
| |||||||||||
 Figuur 4: Een programma in de ‘machinetaal’ van een hypothetische computer (naam zoeken in lijst); in een ‘hogere taal’ kunnen de 17 programmastappen al in ca. 5 worden weergegeven.
| |||||||||||
[pagina 210]
| |||||||||||
numerieke machinecode en het bijhouden van de adresseringsadministratie door de computer zelf gedaan worden. | |||||||||||
Hogere talenEen korte manier van aanduiden dat de getallen in de hokjes A en B moeten worden opgeteld en dat de som in het hokje B moet worden achtergelaten is:
Uit het voorbeeld van fig. 4 blijkt onze primitieve machine daarvoor steeds drie instructies nodig te hebben. Wij moeten nog wel vaststellen welke adressen met ‘A’ en ‘B’ bedoeld worden. Dat kan bijvoorbeeld in de eerste fase van het vertaalproces gebeuren, hetzij door expliciet een paar hokjes toe te wijzen, hetzij door de vertaler een keus te laten uit een aan te wijzen gebied. Eenmaal bepaald en in een verwijzingstabel geplaatst zijn de feitelijke adressen altijd weer terug te vinden, wanneer het programma opnieuw iets met A of B wil doen. Zo wordt het programmeren als een stuk gemakkelijker. Nog eenvoudiger wordt het wanneer men zo'n optelling in de vorm van de gewone formule:
Het succes van zulke kunsttalen, waarvan er inmiddels honderden zijn ontwikkeld, hangt volledig af van de mogelijkheid ze te gebruiken | |||||||||||
[pagina 211]
| |||||||||||
en dus of er een vertaler (in computerjargon ‘compiler’) op je eigen machine beschikbaar is. Van belang is ook of je elders geschreven programma's kunt overnemen (‘portability’). Van de vele algemene of speciale talen hebben vooral de drie genoemde een grote verbreiding gekregen. Het leren beheersen van een nieuwe computertaal is overigens niet zo moeilijk dat de potentiële gebruiker afgeschrikt zou moeten worden doordat hij met andere dan de hem bekende talen of ‘dialecten’ (speciale versies daarvan) zou worden geconfronteerd. Het grote probleem is het formuleren van de taken als zodanig, niet het opschrijven van de uiteindelijke expressies. Een amusant (en leerzaam) boek over de geschiedenis van dit gebied is door Jean Sammet geschreven.Ga naar voetnoot4 Op de omslag staat een toren van Babel..... | |||||||||||
Formele definitiesIn het bovenstaande is de pragmatische kant van het computertaalgebruik het sterkst naar voren geschoven. Voor wij ons concentreren op de ondersteuning die daarmee aan taal- en letterkundige studies gegeven kan worden is een enkele opmerking over de semantische en syntactische aspecten op zijn plaats. Brandt CorstiusGa naar voetnoot5 merkt op dat de benaming wiskundige taalkunde als verzamelterm voor drie nogal verschillende studiegebieden gebruikt wordt:
| |||||||||||
[pagina 212]
| |||||||||||
Het is dit laatste, nogal abstracte gebied waar de theoretische computerkundige en de theoretische taalkundige elkaar ontmoeten. De grote baanbreker was uiteraard Chomsky.Ga naar voetnoot6 Diens hypothese dat alle natuurlijke talen door zg. transformationeel-voortbrengende grammatica's beschreven kunnen worden wordt misschien niet door iedereen aanvaard, maar zijn benadering vormt het enige echt uitgewerkte systeem om de syntaxis van een zin in een mechanisch stelsel uit te drukken. De theoretici die zich met de meest fundamentele aspecten van computertalen bezighouden, hebben in Chomsky's aanpak een zeer bruikbaar uitgangspunt gevonden voor hun specifieke gebied. Diverse praktisch zeer bruikbare talen zijn in feite niet zuiver gedefinieerd, wat tot dubbelzinnigheden en vooral ondoorzichtige uitdrukkingsvormen leidt. Vanwege de eerder genoemde zwakte van de computer om aan een half woord niet genoeg te hebben en de menselijke zwakte zich daar nu juist vaak van te bedienen is een effectieve samenwerking zeer gediend met een heldere taal die logisch functioneert en goed leesbare ‘teksten’ oplevert. ALGOL was een groepsresultaat van grote betekenis, het rapport$3 waarin de omschrijving gegeven is staat nog steeds model voor de wijze waarop men een sluitend geheel kan opstellen. Het nadere onderzoek naar de mogelijkheden van computertaalontwerp en vooral het formele definiëren van programmeertalen is geen eenvoudige zaak. Ten aanzien van de syntactische definitie (welke ‘zinnen’ kunnen worden geconstrueerd?) gaat men algemeen uit van de genoemde formalismen van Chomsky en het ALGOL-rapport. Het is ook nuttig zich bezig te houden met de semantiek, want juist weer bij de slecht begrijpende computer is het van belang dat eventuele betekenisloosheid van een grammaticaal correcte constructie aangetoond wordt voor er moeilijkheden ontstaan. Er zijn al genoeg flauwe moppen over ‘domme’ computers (lees ‘domme computerprogrammeurs’). Eén methode voor een semantische definitie is het formuleren van een mechanisme dat in staat is te bepalen (te ‘berekenen’) wat een programma in een bepaalde taal doet, gegeven een beginsituatie. Men noemt dat een automaat. Het is echter geen eenvoudig onderwerp om over te lezen. Wie dat toch wil doen wordt verwezen naar een recent | |||||||||||
[pagina 213]
| |||||||||||
artikel van Ollongren en Terpstra.Ga naar voetnoot7 De kwantitatieve en de computertaalkunde zijn gebieden die misschien het meest overeenkomen met wat de titel van het voor u liggende artikel suggereert: wat voor nut heeft de computer nu voor taal- en letterkunde en waar kan men daar meer over lezen? Zoals in vele andere wetenschapsgebieden is veel litteratuur in het Engels gesteld. Bij het zoeken naar interessante boeken en artikelen is de term ‘computational linguistics’ een van de vruchtbaarste trefwoorden. | |||||||||||
Computational linguisticsIn het Engels klinkt ‘informaties’ onnatuurlijk, in onze moedertaal doet ‘computer-linguistiek’ gekunsteld aan. Het dekt bovendien een nogal heterogeen stel zaken, die wij beter apart kunnen aanduiden. Donald HayesGa naar voetnoot8 heeft het bijvoorbeeld over: ‘.... the growing art of computer linguistics, a body of techniques that make the computer an effective, workable tool for language processing.’ Het gemeenschappelijke gebied is de ‘taal-verwerking’ en Hayes behandelt daarbij technieken voor automatisch zoeken in woordenlijsten, het automatisch ontleden van zinnen, het opstellen van concordanties, gecomputeriseerde documentatiesystemen, automatische vertaling. Het is een karakteristieke greep uit de onderwerpen die men in dit soort litteratuur tegenkomt. Een echte ordening is nog niet tot stand gekomen, vermoedelijk omdat het hele gebied nog teveel in beroering is. Ik wil daarom hier een poging wagen een bruikbare klassificatie op te stellen. Het uitgangspunt daarbij vormen de objecten die verwerkt worden, resp. die door die verwerking kunnen ontstaan. Alle taal is uiteraard abstractie, de objecten van belang kunnen echter ook weer iets over de taal zelf zeggen en zijn daarmee abstracties van abstracties. Aldus:
| |||||||||||
[pagina 214]
| |||||||||||
De doelstellingen van de computer-linguisten worden door allerlei combinaties van deze aspecten gekarakteriseerd. Als doelstelling van de dienst-verlenende informaticus geldt het beschikbaar maken van hulpmiddelen om dit automatisch te doen. Men vindt daarom relevante artikelen in tijdschriften zoals Mechanical Translation, Information Storage and Retrieval, Library Resources and Techniques, ASLIB Proceedings, maar bovenal in het zeer aanbevelenswaardige Computers and the Humanities (uitgave Queens College Press, New York, officiële afkorting CHum.). Verder is het altijd de moite waard om in de Social Sciences Citation Index te zoeken naar publicaties die voortbouwen op bekende computer-linguistische bronnen of die gerubriceerd zijn onder geschikte trefwoorden. Maar u moet daarbij een beetje op uw gevoel afgaan. De Massificatie die ik hieronder zal ontwikkelen wordt nog niet gebruikt en ‘computational linguistics’ blijft het vruchtbaarste trefwoord. | |||||||||||
Een klassificatieDe vijf soorten van objecten die ik hierboven noemde lenen zich alle als invoer zowel als uitvoer van een gecomputeriseerd proces. In wezen is dat in het schema van Figuur 1 (‘gegevensverwerking’) vervat, met dien verstande dat invoer en uitvoer beide meervoudig kunnen zijn. Het eenvoudigste voorbeeld daarvan is het bijwerken respectievelijk raadplegen van een ‘databank’ of andere verzameling (magnetisch vastgelegde) gegevens. De invoer bestaat dan uit twee stromen, nl. de nieuwe gegevens die toegevoegd moeten worden en de codering van de vraag die men stelt, samen met de bestaande gegevens in de verzameling zelf. Ook de uitvoer is tweeledig, nl. de bijgewerkte gegevensverzameling aan de ene kant en het gevraagde uittreksel (‘rapport’) aan de andere: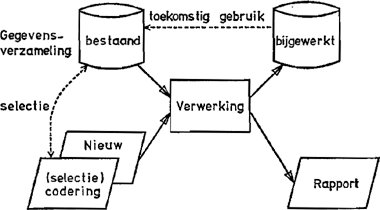 Figuur 5: Gegevensverwerking met bijwerken.
| |||||||||||
[pagina 215]
| |||||||||||
Het algemene karakter van een linguistisch gegevensverwerkingsproces wordt dus gekenmerkt door het schema: één of meer invoerobjecten → één of meer uitvoerobjecten Omdat men in principe oneindig veel malen een der elementen kan invoeren of door herhaling van de verwerking kan laten uitvoeren (vb. constructies van het soort ‘ik weet dat jij weet dat ik weet....’) moet men zich bij het opstellen van de klassificatie los maken van het aantal elementen van elk soort dat in de invoer of uitvoer voorkomt. Toch blijven er dan 31 mogelijkheden aan beide zijden, dus 961 categorieën over! Wij zullen daarvan alleen de voornaamste bespreken. Ten dele zullen dat de processen van praktisch belang zijn en ten dele juist degene die niet (of nog niet) succesvol zijn toe te passen: | |||||||||||
a) Tekst in/tekst uitDe eerste toepassing waar men aan denkt is het automatisch vertalen. Die mogelijkheid is een oude droom, die nog maar zeer beperkt verwezenlijkt is. Een algemene vertaler die bv. een Engelse tekst in een Russische kan omzetten wordt tegenwoordig niet meer als een realistisch doel gezien. Wel kan gecomputeriseerde analyse het begrip een eind op weg helpen (maar dan zit men eigenlijk in categorie c). Ook is een haast natuurlijk gesprek op te bouwen door mens/machine-interactie, waarbij de computer op zinnen reageert door selectie uit een voorgeprogrammeerd stel associaties; bijvoorbeeld:
De reactie volgt uit de herkenning van het persoonlijk voornaamwoord ik en het zelfstandig naamwoord mes; bij het laatste horen de mogelijkheden scherp en doen die in de tevoren gegeven associatielijst voorkomen....... Van deze associatieve gespreksopbouw is in de naaste toekomst al veel te verwachten, al blijft het nog wel even experimenteel. Volkomen routinematig is in deze categorie het geautomatiseerde zetproces, dat door de meeste kranten - en talloze boekdrukkerijen wordt toegepast. De zetter voert de tekst alinea voor alinea in, de computer voegt de juiste hoeveelheid wit in met een toegestaan minimum en maximum bij de gegeven regellengte. Past een rij woorden op | |||||||||||
[pagina 216]
| |||||||||||
geen manier dan wordt het laatste woord automatisch afgebroken. Op het oog lijkt dit een moeilijke taak, maar dat valt erg mee (zie Brandt CorstiusGa naar voetnoot9). De aldus in kolommen gezette tekst kan als strookproef afgedrukt worden, vaak met de regelnumers erbij, maar blijft ook in het geheugen bewaard. Het corrigeren kan dan uit enkele simpele verwijzingen bestaan (dus ‘gezette tekst’ + ‘tekstcorrecties’ in, ‘gecorrigeerde tekst’ uit). Het hier beschreven proces lijkt mij de voorbode van een gecomputeriseerde relatie auteur-boek. Zelf schrijf ik deze tekst met potlood op papier; een secretaresse maakt daar nette kopij van; de zetter van Forum der Letteren maakt het zetsel en de pers drukt het af. De diverse correctiefasen laat ik nog even buiten beschouwing. Straks zet ik mij aan een toetsenbord dat met een computer is verbonden en breng zelf mijn tekst in het geheugen; op een beeldscherm kan ik zien hoe het in kolommen zal worden gezet met lay-out, bladzijdenummering en al; correcties, inhoudelijke incluis, zijn eenvoudig aan te brengen - met electronische snelheid wordt de zaak in het geheugen opgeschoven; is alles klaar dan druk ik, of de uitgever, op de knop die de produktie in werking zet. Gaat het om een tijdschriftartikel dan kan de redactie de vorderingen van de auteur volgen (als hij dat toestaat) en de diverse bijdragen geordend samenvoegen. | |||||||||||
b) Tekst in/Samenvatting uitDit is een proces dat moeilijk automatiseerbaar is. Het probleem is dat de relevantie van de diverse begrippen vaak sterk context-gevoelig is, iets wat een deskundige er direct aan herkent, maar waar geen eenvoudige regels en dus geen praktische algoritme voor op te stellen is. | |||||||||||
c) Tekst in/Strukturen uitAutomatisch ontleden volgens Chomsky - of ‘post-Chomsky’-methoden is zeer goed mogelijk. Het vormt de basis voor het onder a) genoemde conversationele werk. Het is ook een zeer geschikte techniek om grote stukken tekst op stijl en taalgebruik te analyseren en hoort als zodanig in de kwantitatieve hoek thuis. | |||||||||||
[pagina 217]
| |||||||||||
d) Tekst in/Identificaties uitDit is een triviale operatie wanneer de tekst de identificatie, in de vorm van de bibliografische gegevens, al bevat. De omgekeerde operatie, het opvragen van een tekst op grond van de identificatie, is ook een beetje triviaal: het te leen vragen van een boek via een geautomatiseerde administratie. Verre van trivaal is de tekstaanvraag wanneer deze vastgelegd is in een ander medium. Het bekijken van een tekst door de onder a) genoemde toekomstige auteur is een voorbeeld. Actueler is het snel opsporen van op microfiche o.i.d. geregistreerde gegevens zoals een informatiedienst nodig heeft. | |||||||||||
e) Tekst in/Kenmerken uitHieronder valt het automatisch opbouwen van concordanties en andere woordlijsten. Indien het om het zuivere voorkomen gaat is het een eenvoudig proces, al is het computerverwerkbaar maken (verponsen) zeer bewerkelijk. Een moeilijker proces is het toepassen van statistische ‘overeenkomsten’, waarmee men een tekst automatisch van (tevoren niet vastliggende) trefwoorden voorziet of de relevantie van meerdere teksten door overeenkomst in het voorkomen van trefwoorden bepaalt. Interessante litteratuur op dit gebied vormen de publicaties van Gerard Salton.Ga naar voetnoot10 Het omgekeerde proces is de meest bekende vorm van information retrieval; door één of meerdere trefwoorden te geven kan men relevante teksten opsporen. In feite gaat het daarbij meestal om het proces Kenmerk in/Identificatie uit of Kenmerk in/Samenvatting uit. Heeft men die informatie, dan is de beslissing het volledige ‘document’ op te vragen een kwestie van menselijk oordeel (zg. ‘document retrieval’). Echt lezen via terminals en kanalen van willekeurige litteratuur zal voorlopig wel achterwege blijven. Het is nog relatief erg duur in vergelijking met het over de post uitlenen van een boek. | |||||||||||
f) Samenvattingen in/Kenmerken + Identificatie uitIk noem deze categorie afzonderlijk omdat daarin twee bijzonder elegante samenwerkingsvormen van mens en machine vallen, nl. de | |||||||||||
[pagina 218]
| |||||||||||
KWIC-index en de Citation Index. Elegant zijn zij beide omdat de computer het domme massawerk doet met als resultaat een geordende verzameling gegevens waarin de mens in een enkele oogopslag patronen herkent, de relevantie waarvan de machine ontgaat. KWIC staat voor Key-Word-In-Context en houdt in dat een stuk tekst van ca 10 woorden wordt afgedrukt met in het midden het daarin voorkomende trefwoord. Door zulke tekstdeeltjes voor een groot aantal documenten op trefwoord gesorteerd onder elkaar te zetten, met daarnaast de verwijzing naar het document van herkomst verkrijgt men een veel nuttiger index dan de ‘gewone’, waarin de trefwoorden geïsoleerd verschijnen, zoals in de gebruikelijke zakenregisters in een boek. Het stukje zin waarin het trefwoord voorkomt zegt door de context immers veel en veel meer dan het voorkomen als zodanig. Het is voor een computer erg gemakkelijk om een KWIC-index te maken, en dit zou ook met volledige teksten gedaan kunnen worden. Het voorbereiden daarvan kost echter veel tijd, terwijl de trefwoorden maar vrij zeldzaam zullen optreden. Dat maakt dat toepassing op samenvattingen (‘abstracts’) het effectiefst is. Een Citation Index is een merkwaardig zoekmiddel omdat het niet op onderwerp maar op citaten ontsluit. Het samenstellen is eenvoudig: men dient de computer van een tijdschriftartikel de bibliografische gegevens toe benevens de in het artikel voorkomende verwijzingen. Dit doet men voor alle artikelen in een jaargang van de belangrijkste tijdschriften op een samenhangend gebied (bijv. natuur- en levenswetenschappen, sociale en geesteswetenschappen) en laat de computer sorteren op de namen van de geciteerde auteurs. Het resultaat is een lijst waaruit blijkt wie bepaalde auteurs uit voorgaande jaren citeren en dus vermoedelijk het desbetreffende onderwerp verder bestudeerd hebben. Een erste kennismaking bv. met de Social Sciences Citation Index, die in 1974 2552 tijdschriften verwerkte, met daarin 83.055 artikelen waarin tesamen 871.576 citaten voorkwamen, leert al gauw hoe sommige artikelen in een bepaald jaar erg in de belangstelling staan om daarna weer in de vergetelheid weg te zakken. Iemand die met de vroegere litteratuur bekend is kan zo snel bijkomen. De redacties van dergelijke helaas erg dure en daarom maar in een paar bibliotheken beschikbare publicaties laten aan ieder bronartikel overigens ook een paar trefwoorden verbinden. Daardoor is een ‘gewone’ indexering op onderwerp ook beschikbaar. Deze klassificatie laat zich willekeurig uitbreiden. Dat kunt U voor | |||||||||||
[pagina 219]
| |||||||||||
U zelf doen zodra U de vraag hebt beantwoord welk element voor U een gegeven is en welk aspect U daaruit zou willen voortbrengen. Dat specificeert hetgeen een computer (misschien) voor U zou kunnen doen. In principe kan alles eruit gehaald worden wat in de ingevoerde tekst of tekstenverzameling besloten is. Maar het is goed te bedenken dat ook aan de capiciteit van een computer grenzen zijn. Terwijl de mens een patroon zonder aarzeling herkennen kan, moet een computer dat inzicht moeizaam opbouwen door een stel vergelijkingen te maken. De vraag ‘komt woord W op deze bladzijde voor?’ kan hij snel oplossen, maar ‘voor hoeveel % zijn twee teksten gelijk?’ vereist al een onprettig aantal stappen. Ook kan het verstandig zijn eerst enkele algemene ordenende werkzaamheden door de computer te laten verrichten. In gesorteerd materiaal ontdekt men vaak het patroon waar de computer dan een geselecteerde verwerkingsoperatie op kan verrichten. Je weet dat nooit van te voren. Een gesprek met een computerdeskundige, die zelf wel handig zal zijn maar nu juist niet thuis is in echte linguistische problemen, is een eerste vereiste. Als dit artikel de weg daarvoor heeft helpen effenen is aan de doelstelling van deze auteur voldaan.
N.I.A.S., Wassenaar, augustus 1975 |
|