
Forum der Letteren. Jaargang 1975
(1975)– [tijdschrift] Forum der Letteren–
[pagina 132]
| ||||||||||||||||||||||
De taalgebruiker in de mens
| ||||||||||||||||||||||
[pagina 133]
| ||||||||||||||||||||||
1. Bouw en werking van de menselijke taalgebruikerNiemand zal moeite hebben met de opsplitsing van de (mondelinge/auditieve) taalgebruiker in de volgende vijf hoofdsystemen (zie Fig. 1): (a) spraakherkenner, (b) zinsontleder, (c) conceptueel systeem, (d) zinsgenerator, (e) articulator.  Fig. 1. De vijf hoofdsystemen van de menselijke taalgebruiker.
Wat deze systemen doen is het gemakkelijkst aan te duiden met vijf werkwoorden: (a) luisteren, (b) ontleden, (c) denken, (d) formuleren, (e) spreken. Onderdelen (a), (b) en (c) zijn nodig voor het verstaan van gesproken taaluitingen; (c), (d) en (e) zijn werkzaam tijdens het produceren van gesproken taal. Wat veel minder voor de hand ligt en meer stof geeft tot nadenken en tot theoretische conflikten is de wijze waarop deze deelsystemen afzonderlijk en in onderling verband funktioneren. | ||||||||||||||||||||||
1.1. Het conceptuele systeem.Het hart van de menselijke taalgebruiker is het conceptuele systeem.Ga naar voetnoot1 Men kan het zich het beste voorstellen als een reusachtig netwerk waarvan de knopen corresponderen met concepten en de verbindingsdraden (pijlen) tussen knopen met relaties tussen concepten. Sinds ongeveer 10 jaar zijn er minstens een dozijn van dergelijke systemen ontwikkeld (zie literatuurlijst van Levelt & Kempen, 1794b), maar hier beperk ik me tot het verst ontwikkelde: Schank's ‘conceptual dependency netwerk’ (1972, 1973). De concepten (knopen) in dit netwerk zijn van vierderlei soort: nominale concepten, actieconcepten, bepalers (modifiers) bij acties, en bepalers bij nominale concepten - resp. N, A, BA, BN. Deze conceptuele categorieën kunnen op welomschreven wijzen met elkaar in verband | ||||||||||||||||||||||
[pagina 134]
| ||||||||||||||||||||||
staan. Schank noemt deze verbanden ‘afhankelijkheden’ (dependencies) want bij de meeste relaties tussen twee concepten is sprake van een asymmetrie. Bv. BA's kunnen niet zelfstandig voorkomen, ze staan altijd in attributieve relatie tot een A-concept. Dit in tegenstelling tot A-concepten die best zonder een BA in het netwerk kunnen figureren. A- en N-concepten zijn van nature ‘regenten’ van een afhankelijkheid, BA en BN zijn van huis uit ‘dependenten’. Pijlen in het netwerk wijzen steeds naar de regent. Bv. kleine Jan zou gerepresenteerd worden als:
 of vereenvoudigd, als  De labels van de pijlen geven het type afhankelijkheidsrelatie aan. Bv. in Jan's hond schuilt het relatietype ‘eigendom van’: 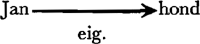 In bepaalde gevallen is er sprake van wederzijde afhankelijkheid, bv. tussen actor en act, 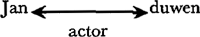 en wanneer een eignschap of lidmaatschap wordt toegekend aan een N.  Tot hiertoe zou men de indruk kunnen hebben dat er een één-op-één relatie bestaat tussen woorden en concepten. Niets is echter minder waar: Schrank is er, meer dan andere ontwerpers van conceptuele netwerken, op uit te laten zien dat de rijkdom van de Woordenschat van een natuurlijke taal te vangen is onder een beperkt aantal elementaire concepten, mits men beschikt over een gedifferentieerd systeem van middelen om deze basisconcepten tot ‘conceptualisaties’ aan elkaar te smeden. Bij wijze van illustratie volgt hier de conceptualisatie van zin (1). | ||||||||||||||||||||||
[pagina 135]
| ||||||||||||||||||||||
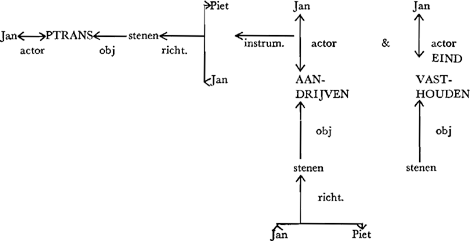 Fig.2 Conceptualisatie behorde bij zin (1).
PTRANS (physische plaatsverandering), AANDRIJVEN en VASTHOUDEN zijn drie van ongeveer een dozijn ‘primitieve actieconcepten’ die Schank ten grondslag legt aan een zeer groot aantal werkwoorden. De plaatsverandering (PTRANS) van Jan naar Piet (richting) waaraan de stenen (object) onder invloed van Jan's optreden onderhevig zijn, wordt bewerkstelligd door (instrument) twee acties van Jan (actor): (1) door te fungeren als krachtbron (AANDRIJVEN) die de stenen naar Piet voortstuwt, en (2) door het VASTHOUDEN van de stenen te beEINDigen, d.w.z. door ze los te laten. We zien tevens dat aan het casusmechanisme (object, richting, instrument) de belangrijke en gecompliceerde taak is toegedacht de primitieve acties op de juiste wijze samen te voegen, hier tot het complexe idee gooien. Dit demonstreert dat het conceptuele systeem in wezen niet-talig is. De relaties tussen de concepten en de woorden van de natuurlijke taal kunnen zeer ingewikkeld zijn; aan de andere kant zijn de concepten het gemakkelijkst op te vatten als codenamen voor de constanten die de wereld van het waarnemen en van het denken bevolken: personen, objecten, eigenschappen, handelingen, gebeurtenissen. Het is van belang het laatste punt verder uit te werken. Stel een onderwijzer ziet een van zijn leerlingen, Jan, een steen gooien naar een klasgenootje, Piet. Hoe zal hij deze episode in zijn lange-termijn-geheugen coderen? Waarschijnlijk zal onze onderwijzer na een paar dagen nog over een voorstellingsbeeld van de episode beschikken. Betekent dit dat | ||||||||||||||||||||||
[pagina 136]
| ||||||||||||||||||||||
hij de episode gedetailleerd heeft geregistreerd, net zoals een filmcamera elk detail op het filmpje vastlegt? Nee, het is voldoende als hij:
Maar hoe kan vanuit zo'n netwerk een voorstellingsbeeld geconstrueerd worden? Hiertoe is een belangrijke extra assumptie nodig, nl. dat het cognitieve systeem beschikt over een ‘voorstellingengenerator’, een systeem dat conceptualisaties tot invoer neemt en deze vertaalt in voorstellingsbeelden. Zo'n systeem zou analoog kunnen werken aan een computer: de conceptualisaties fungeren als programmeertaal; voor elk concept (JAN, VASTHOUDEN, PTRANS etc.) kent het systeem een subroutine; de compiler schakelt de subroutines aaneen tot een serie van instrukties die, bij uitvoering, beelden doen verschijnen op een ‘mentaal beeldstation’. Deze speculatieve uitwijding moge illustreren dat de concepten, hoewel aangeduid (vaak) met alledaagse woorden (JAN, AANDRIJVEN etc.), niet-talige codes zijn die voor allerlei doeleinden gebruikt kunnen worden. Eén ervan hebben we gezien: de voorstellingengenerator vat conceptualisaties op als zinnen van een programmeertaal. Het inferentie-mechanisme ziet de conceptualisaties als databestand: uit de gegevens in bv.Fig. 2 kan dit mechanisme o.m. een antwoord afleiden op de vraag Wie gooide een steen naar Piet; door Fig. 2 in contakt te brengen met een ander stukje netwerk zal het concluderen dat Jan (waarschijnlijk) agressieve bedoelingen had etc. Hoe de taalgebruiker het conceptuele systeem hanteert bij het verstaan en produceren van taaluitingen vormt het onderwerp van de volgende paragrafen. | ||||||||||||||||||||||
1.2. De spraakherkenner.Het spraakverstaan begint met de analyse van het akoustische signaal met als gewenst resultaat een sekwentie van woorden die het gehele signaal dekt. Het staat momenteel wel vast dat dit doel onbereikbaar is zonder syntaktische en semantische (conceptuele) aanwijzingen (vgl. Newell et al. 1973). De spraakherkenner zal van het spraaksignaal in eerste instantie slechts gedeelten kunnen thuisbrengen. Omtrent de iden- | ||||||||||||||||||||||
[pagina 137]
| ||||||||||||||||||||||
titeit van de niet-erkende passages kunnen de zinsontleder en het conceptuele systeem wellicht nadere informatie verschaffen: de herkende woorden suggereren een bepaald syntaktisch schema met bijbehorende funktiewoordjes, of het conceptuele systeem van de luisteraar - dat vele conceptualisaties met de spreker deelt - voorspelt woorden met een bepaalde conceptuele inhoud. Deze syntaktische en conceptuele kennis brengt een enorme beperking aan in wat de spraakherkenner aan woorden kan verwachten, en leidt mogelijkerwijs zelfs tot correctie van fouten die de spraakherkenner in eerste aanleg gemaakt heeft. Hier zien we een uiterst belangrijk kenmerk van de architectuur van de taalgebruiker: de diverse deelsystemen zijn niet in serie achter elkaar geschakeld maar ze werken in wederzijdse afhankelijkheid. In Fig. 1 duiden de dubbele pijlen op het tweerichtingsverkeer in de informatieoverdracht en de procesbesturing. Overigens is nog heel weinig bekend van de manier waarop de spraakherkenner het akoustische signaal verwerkt. De bekendste theorieën (o.a. de motor-theorie, de analyse-door-synthese-theorie) zijn slechts fragmentarisch en bovendien controversieel (zie Campbell, 1974, voor een overzicht en voor verdere literatuur). | ||||||||||||||||||||||
1.3. De zinsontleder.Bij het percipiëren van een taaluiting staat syntaktische ontleding geheel in dienst van het ontdekken van de conceptualisatie die eraan ten grondslag ligt. Het conceptuele systeem beschikt over een uitgebreide inventaris van de typen conceptualisaties waarin elk bekend woord kan voorkomen: het lexicon. Door de lexicale gegevens van de afzonderlijke woorden van de taaluiting, te combineren is vaak een onbetwistbare beslissing mogelijk omtrent de conceptualisatie die de spreker bedoeld heeft: dan namelijk wanneer de conceptuele omgevingen die de woorden vereisen, precies in elkaar passen. In zulke gevallen, en die zijn eerder regel dan uitzondering, is slechts een minimum aan syntaktische ontleding nodig. De uitingen hoeven niet eens grammaticaal te zijn: neem bv. de woordsekwentie stormen-bomen-voetgangers-doden waarin onmiddellijk een conceptualisatie wordt herkend zonder dat - afgezien van de volgorde - syntaktische middelen gebruikt zijn. Zelfs staat van minstens twee woorden de woordsoort niet vast. Het is vooral Schank geweest (1972, 1973) die dit principe naar voren heeft gebracht: de zinsontleder van de menselijke taalgebruiker is sterk | ||||||||||||||||||||||
[pagina 138]
| ||||||||||||||||||||||
woordgeoriënteerd en gaat pas na uitputting van zijn lexicale kennis over tot onderzoek van syntaktische verbanden. Duidelijk spreekt het belang van dit principe als men zich realiseert hoe men een zin als
Bij deze zinnen is vaststelling van de constituentenstruktuur en van de syntaktische relaties tussen de constituenten niet mogelijk zonder conceptuele kennis. Met name de conceptuele casussen die het werkwoord vereist zijn van groot belang (alhoewel niet uitsluitend: vgl. (5) en (6)). De kunstmatige zinsontleder die Schank (1973) heeft gebouwd begint niettemin met een rudimentair stukje syntaktische analyse: hij zoekt de eerste naamwoordsgroep op die niet wordt geregeerd door een voorzetsel, d.w.z. die zou kunnen dienen als onderwerp, en het hoofdwerkwoord (eventueel in combinatie met hulpwerkwoord). Hierna geeft de ontleder het roer onmiddellijk over aan het conceptuele systeem. In geval van zin (2) zal het de met gooien geassocieerde conceptuele struktuur aanreiken. Deze is gelijk aan die van Fig. 2 afgezien van de ‘casushouders’ (Jan, Piet, stenen, etc.) die nog leeg zijn. Raadpleging van het lexicon levert voorts de informatie op dat het object van PTRANS (en van AANDRIJVEN etc.) het eerste FYSISCH OBJECT is dat na de persoonsvorm wordt aangetroffen, eventueel voorafgegaan door met. Het doelwit van het gooien, zo zegt het lexicon, is een FYSISCH OBJECT dat volgt op naar. Is het doelwit een MENS of DIER, dan is een andere volgorde mogelijk: doelwit-met-object. M.b.v. deze regels kan de conceptualisatie voltooid worden door de concepten corresponderend met Jan, stenen, e.d. te deponeren in de casushouders. Blijkt uit dit voorbeeld dat prioriteit van syntaktische boven conceptuele analyse kan leiden tot verregaande inefficiëntie, in sommige situaties, nl. als conceptuele richtlijnen ontbreken, moet van de nood een | ||||||||||||||||||||||
[pagina 139]
| ||||||||||||||||||||||
deugd gemaakt worden. Dit is bv. het geval als de spreker woorden gebruikt die de luisteraar niet kent. Een extreem voorbeeld is Lewis Carroll's ‘wauwelwok’ (ontleend aan Reedijk & Kossman's vertaling van Through the looking glass):
Wauwelwok
't Wier bradig, en de spiraments
Bedroorden slendig in het zwiets:
Hoe klarm waren de ooiefants,
Bij 't bluifen der beriets.
Een zeer aantrekkelijk model voor niet-conceptueel gestuurde zinsontleding bieden de zg. ‘augmented transition networks’ (Woods, 1970; Kaplan, 1972). Bij wijze van voorbeeld schets ik hier een summiere (en onvolledige) grammatica voor de ontleding van zin (9).
De grammatica (zie de drie deelnetwerken van Fig. 3) bestaat uit toestanden (cirkels) en overgangen (pijlen) tussen toestanden. De ontleder start in toestand Sz (start-zin) en probeert deelnetwerk (1) van links naar rechts te doorlopen. Een overgang mag alleen dan gemaakt worden als aan alle voorwaarden die bij die overgang opgesomd staan, voldaan is. Er zijn meerdere soorten voorwaarden:
| ||||||||||||||||||||||
[pagina 140]
| ||||||||||||||||||||||
Verdere bijzonderheden:
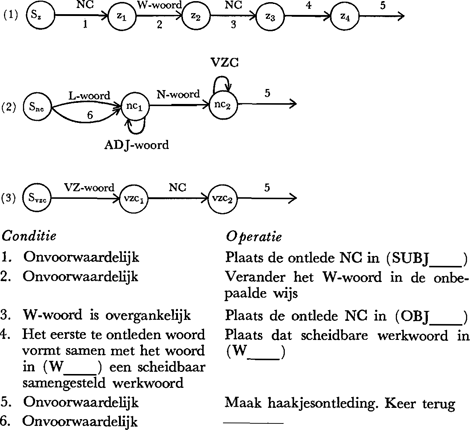 Fig. 3. Een eenvoudige netwerk-grammatica.
Laten we de ontleder stap voor stap volgen. Op overgang 1 komt hij de opdracht ‘zoek een NC’ tegen en springt naar toestand Snc. De eerste overgang die hij hier beproeft is L-woord. Dit lukt, en met als eerste resultaat (L de) gaat hij over op toestand nc1. Het eerstvolgend woord is geen N-woord maar een ADJ-woord zodat de lus wordt doorlopen en (ADJ aardige) resulteert. Dokter is een N-woord en wordt | ||||||||||||||||||||||
[pagina 141]
| ||||||||||||||||||||||
als (N dokter) bewaard. Vervolgens wordt een voorzetselconstituent geprobeerd. Omdat belt echter geen voorzetsel is moet de ontleder onverrichterzake terugkeren van toestand Svzc en gaat nu operatie 5 uitvoeren. Het eerste deel hiervan, ‘Maak haakjesontleding’, voegt de resultaten van het deelnetwerk waarin de ontleder momenteel bezig is, in elkaar tot een haakjesontleding van een bepaald type. Binnen deelnetwerk (2) bv. heeft operatie 5 tot gevolg dat de L-, ADJ-, N- en VZC-resultaten (voor zover aanwezig) geplaatst worden in (NC___), en wel in de aangegeven volgorde. Kwamen meerdere adjectiva voor, dan worden deze eenvoudigweg aan elkaar vastgeknoopt; bv. mooi oud huis wordt (NC (ADJ mooi) (ADJ oud) (N huis)). In deelnetwerk (1) heeft operatie 5 een heel andere uitwerking. De haakjesontleding krijgt nu de vorm
Het tweede deel van operatie 5, ‘Keer terug’, heeft tot gevolg dat de ontleder met de zojuist gefabriceerde haakjesontleding terugkeert naar het punt van oorsprong. Nu is dat overgang 1, en de haakjesontleding is
Conditie 1 wordt nu opgezocht in de lijst. Deze is zonder meer vervuld, maar eerst moet nog de onder 1 vermelde operatie uitgevoerd worden: de ontlede NC wordt ingevoegd in (SUBJ___), d.w.z. wordt opgevat als onderwerp. Via belt, het eerste te ontleden woord, komt hij in z2 na eerst de standaardvorm bellen ingevuld te hebben in (W___). Omdat aan de conditie 3 voldaan is (bellen is bruikbaar als overgankelijk werkwoord) gaat de ontleder opnieuw aan de slag met een NC-opdracht. We slaan nu een paar stappen over en gaan naar toestand nc2. Hier zal de ontleder eerst VZC beproeven en springen naar Svzc. Op is onder meer een voorzetsel, dus de overgang naar vzc1 wordt gemaakt. Omdat de zin nu af is mislukt de VZC-poging. De ontleder laat op nog even zitten, keert terug naar nc2 en neemt nu de overgang 5. Het resultaat,
| ||||||||||||||||||||||
[pagina 142]
| ||||||||||||||||||||||
woord zodat (W bellen) wordt vervangen door (W opbellen). Operatie 5 zet nu de haakjesontleding
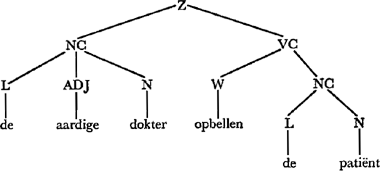 Fig. 4. Ontledingsresultaat van zin (9) m.b.v. de netwerkgrammatica in Fig. 3.
Deze gedetailleerde weergave van het funktioneren van netwerkgrammatica's moge een aantal punten demonstreren, (a) De zinsanalyse verloopt, net als bij de mens, van links naar rechts, (b) De ontleder kiest bepaalde overgangen eerder dan andere en zal dus bij ambigue zinnen slechts met één interpretatie voor de dag komen, net zoals mensen (maar zie ook Lackner & Garrett, 1972). (c) De operaties die bij sommige overgangen worden uitgevoerd hebben het karakter van ‘omgekeerde transformaties’. Een voorbeeld was de samenvoeging van bellen met op. Als de zin passief was geweest dan zou de eerste NC aanvankelijk als ‘logisch’ subjekt zijn aangemerkt (d.w.z. geplaatst in (SUBJ___)) en pas na ontvangst van passief-signalen, bv. een passief hulpwerkwoord, zijn verhuisd naar (OBJ___). Dit laatste vereist natuurlijk een uitbreiding van de grammatica van Fig. 3. Deze paragraaf kort samengevat, in situaties die het conceptuele systeem goed kan overzien zal de menselijke taalgebruiker met een minimum aan syntaktische analyse toekunnen; de behoefte hieraan wordt groter naarmate het conceptuele systeem er minder in slaagt verwachtingen op te bouwen aangaande de inhoud van de binnenkomende boodschap. | ||||||||||||||||||||||
1.4. De zinsgenerator.Taalpsychologisch onderzoek naar het produceren van taaluitingen | ||||||||||||||||||||||
[pagina 143]
| ||||||||||||||||||||||
bestaat nauwelijks. Dit is des te betreurenswaardiger omdat bij het onderzoek naar moedertaal- en vreemdetaalverwerving en naar pathologisch taalgedrag het spreken een centrale plaats inneemt. Hoe moeten we ons het systeem voorstellen dat gedachte- en waarnemingsinhouden omzet in verstaanbare taaluitingen? Zou het transformatiemechanisme van de TGG model kunnen staan voor de zinsgenerator in de menselijke taalgebruiker? In de generatieve semantiek start het generatieproces met een zinsdiagram dat de uit te drukken inhoud weergeeft: de semantische representatie. Via transformatieregels wordt dit aanvankelijke zinsdiagram omgezet tot een zinsdiagram dat oppervlaktestructuur heet. De eindrij van dit laatste zinsdiagram bepaalt dan de uit te spreken zin. Behalve (1) de strikte inhoud, d.w.z. de stand van zaken waarnaar de zin verwijst, zijn er nog andere faktoren die de uiteindelijke vorm van de zin bepalen. In zijn dissertatie brengt van der Geest (1974) ze in drie groepen onder: (2) de attitude, het standpunt van de spreker m.b.t. de strikte inhoud, (3) de uiteindelijke bedoeling die de spreker met het uiten van de zin heeft, en (4) de linguïstische en situationele voorkennis die de spreker (naar hij aanneemt) met de luisteraar deelt. Van der Geest laat uitvoerig zien hoe deze faktoren ingebouwd kunnen worden in de semantische representaties en hun invloed op de vormgeving van de zin doen gelden. (N.B. Onder de term ‘inhoud’ van een zin begrijpen we verderop niet alleen punt (1), maar ook (2), (3), en (4).) Niettemin kleven aan het transformatiemechanisme, indien het dienst zou moeten doen als zinsgenerator in een taalgebruikersmodel, twee hoofdbezwaren.Ga naar voetnoot2 Op de eerste plaats verloopt het generatieproces niet van links naar rechts: de laatste transformatie - die welke de oppervlaktestruktuur als uitvoer geeft - kan de volgorde van de morfemen/woorden helemaal omgooien (bv. de transformatie ‘adjektiefverplaatsing’ die de eindrij een oud vrouwtje stierf afleidt uit de volgorde vrouwtje-oud-sterven). Dit betekent dat de spreker zijn zin pas kan starten nadat het transformationele apparaat de oppervlaktestruktuureindrij kant en klaar heeft afgeleverd. Hetgeen zou impliceren: veel pauzes tussen zinnen, binnen zinnen weinig of geen pauzes; weinig hernemingen en verbeteringen van half afgemaakte zinnen. De mense- | ||||||||||||||||||||||
[pagina 144]
| ||||||||||||||||||||||
lijke taalgebruiker daarentegen begint zijn taaluiting vaak, zo niet gewoonlijk, op een moment dat de woordkeus verderop in de zin nog niet vaststaat. De generator wordt dus op elk moment gestuurd door twee instanties: (a) de inhoud die de spreker wil uitdrukken, en (b) de syntaktische beperkingen die het reeds geproduceerde zinsgedeelte oplegt aan het vervolg. Ten tweede, de impliciete assumptie dat de zinsgenerator volledig onderworpen is aan de beslissingen die het conceptuele systeem neemt ten aanzien van de inhoud van de eerstvolgende zin, is onjuist. In vele gevallen moet aangenomen worden dat syntactische faktoren de inhoud van de eerstvolgende zin medebepalen. Argumenten voor deze stelling zijn te ontlenen aan zowel linguïstische observaties als aan experimenteel taalpsychologisch onderzoek. Hier geef ik er de voornaamste van; voor details zij verwezen naar Kempen (in voorbereiding). De oudste observatie is ongetwijfeld van de denk- en taalspycholoog Selz. Hij wees er al in 1922 op dat iemand die een definitie van een begrip wil geven uit een beperkt aantal syntaktische schema's kan kiezen, zoals een X is een Y die .....; een X is een ..... Y; X bestaat hierin dat ..... Selz draagt zelfs empirisch materiaal uit geheugenproeven aan: deze schema's bevorderen het vinden van een goede definitie voor moeilijke begrippen - een duidelijk geval van syntaktische bepaaaldheid van de inhoud van zinnen. Er zijn grote verschillen tussen talen m.b.t. de genuanceerdheid van het getal-systeem. Het Japans maakt geen onderscheid tussen enkelvoud en meervoud zoals het Nederlands, Engels etc. Het Oud-Grieks kent bovendien een speciale dualisvorm en onderscheidt tussen de aantallen 1, 2, > 2. Het Arabisch gaat zelfs nog verder: 1, 2, 3-10, > 10. Analoge contrasten vindt men op het gebied van beleefdheidsvormen (Ned.: je/jij vs. U; Eng.: alleen You; Japans: een uitgebreid stelsel), en werkwoordstijden (Ned.: onvoltooid en voltooid verleden tijd, tegenwoordige tijd, toekomstige tijd; Bahasa Indonesia: geen tijdsaanduidingen in het werkwoord). Wanneer men, zoals veel gebeurt, ervan uitgaat dat semantische representaties (dieptestrukturen) van zinnen invariant zijn over talen, dan bevat een Japanse, Indonesische, Engelse zin informatie over resp. getal, tijd, en sociale relatie tussen spreker en toegesprokene - informatie die in het transformatieproces eenvoudigweg overboord gegooid wordt. Veel realistischer en efficiënter is de veronderstelling dat de syntaxis van de taal die men spreekt bepaalt welke semantische dimensies onderdeel gaan uitmaken van de ‘dieptestruktuur’ van de zinnen. | ||||||||||||||||||||||
[pagina 145]
| ||||||||||||||||||||||
Een derde argument vloeit voort uit eigen onderzoek over het onthouden en reproduceren van zinnen (Kempen, 1974; Levelt & Kempen, 1974a). De gebruikte basistechniek heb ik ‘parafrastische reproduktie’ genoemd, d.w.z. de proefpersonen moesten zinnen die ze volledig uit het hoofd geleerd hadden, reproduceren in de vorm van een (partiële) parafrase. Bv. (12) is een volledige, (13) een partiële parafrase van (11).
Laat ik één experiment wat meer in detail bespreken. De ene helft van de proefpersonen had 12 zinnen van type (11), allemaal het voegwoord want bevattend, letterlijk van buiten geleerd, de andere helft 12 zinnen van type (12) (steeds met omdat). Daarna begon het eigenlijke experiment: meting van de tijd benodigd om na aanbieding van het onderwerp van één der zinnen zo snel mogelijk het predikaat van die zin hardop op te noemen. Deze reaktietijd werd herhaaldelijk gemeten in vier verschillende condities:
De zinnen die de proefpersonen afmaakten in condities W2, O2 en W1 waren resp. van de typen (11), (12) en (13). In conditie O1 bleven de zinnen syntaktisch onvolledig (zie (14)).
De metingen onder elk der vier condities vonden bloksgewijs plaatsGa naar voetnoot3; bv. de O2-metingen over de 12 zinnen vonden vlak na elkaar plaats, dan kwamen alle W1-metingen etc. (Elke proefpersoon kreeg een andere volgorde van condities.) | ||||||||||||||||||||||
[pagina 146]
| ||||||||||||||||||||||
De gemiddelde reaktietijden vertoonden het patroon W1<W2;O1>O2. In een gangbare redenering (o.a. Johnson, 1970) zou men voorspeld hebben W1<W2; O1<O2: een langere responsie (twee woorden) vergt meer zoektijd door het geheugen en meer responsie-planning dan een kortere responsie (één woord). Men zou ook de tegengestelde voorspelling kunnen opperen, W1>W2; O1>O2. Tijdens het van buiten leren van de zinnen hebben de proefpersonen de twee woorden van elk predikaat tot één geheel verenigd en het kost extra moeite en tijd als die eenheid weer verbroken moet worden (in W1 en O1). De gevonden uitkomst wordt echter voorspeld door een theorie die uitgaat van het grondbegrip ‘syntaktische construktie’. Een syntaktische construktie definiëren we hier als een syntaktisch grondschema dat een samenstel van conceptuele relaties uitdrukt. Bv. het grondschema N1VN2 (naamwoord + werkwoord in bepaalde wijs + naamwoord) kan de conceptuele relatie actor-actie uitdrukken tussen N1 en V, en de relatie actieobject tussen V en N2, zoals in Jan sloeg Piet. Hetzelfde syntaktische grondschema kan ook andere conceptuele relaties weergeven als N2 een tijdsduur aanduidt: Jan sliep uren. Deze voorbeelden maken duidelijk dat een syntaktische konstruktie een combinatie is van een syntaktisch grondschema (dat men kan weergeven als een reeks van woordsoortaanduidingen zoals N, VZ, V etc., evt. ook met funktiewoordjes zoals door in de passief-konstruktie) en een samenstel van conceptuele relaties. Ik neem nu aan dat de taalgebruiker voor elke frekwent voorkomende syntaktische construktie beschikt over een programma dat twee dingen doet: (a) het zoekt in een vooraf aangeduid gedeelte van het conceptuele systeem naar een exemplaar van zijn karakteristieke samenstel van conceptuele relaties, en (b) het giet de gevonden informatie in de vorm van zijn karakteristieke syntaktisch grondschema. Het programma behorende bij het eerste voorbeeld van daarnet zoekt in een concrete conceptualisatie van de vorm actor-actie-objekt (met eventueel verdere casussen en bepalers) precies die informatie die zich laat uitdrukken in het syntaktische patroon N1VN2. Alvorens dit idee nader uit te werken wil ik even terugkomen op de uitkomst van het geheugenexperiment. Tijdens elk blok van reaktietijdmetingen (re)construeerden de proefpersonen steeds meerdere zinnen van dezelfde syntaktische konstruktie. Bv. in conditie W2 vormden ze telkens zinnen van het type XN1VN2 (X staat hier gemakshalve voor de woorden voorafgaande aan het onderwerpssubstantief). De proefpersonen waren hierdoor in de gelegenheid het ‘zoek/formuleer’- | ||||||||||||||||||||||
[pagina 147]
| ||||||||||||||||||||||
programma dat bij die konstruktie hoort, te mobiliseren en effektief te gebruiken: ze wisten dat dit programma feilloos de gevraagde sekwentie van responsiewoorden zou opleveren. In de condities W1 konden ze een eenvoudiger zoek/formuleer-programma XN1V hanteren: alle werkwoorden waren onovergankelijk en de XN1V-zinnen waren partiële parafrasen van de geleerde XN1VN2-zinnen. We mogen hier W1<W2 verwachten, want zowel de op te zoeken conceptuele informatie als de responsieplanning zijn eenvoudiger in het XN1V-programma dan in het XN1VN2-programma. Wat voorspelt deze theorie nu over O1 en O2? Omdat XN1N2 (zie (14)) geen syntaktische konstruktie is kent de taalgebruiker geen zoek/formuleer-programma dat precies past op de eisen die de proefleider in de O1-conditie stelt. De beste taktiek is het XN1N2V-programma toe te passen, dat responsies van het type fietsers beten oplevert, en deze responsies tot één woord in te korten. Dit laatste vergt een extra bewerking zodat de voorspelling luidt: O1gt;O2; hetgeen met de data overeenstemt. De experimentele situatie is minder kunstmatig dan men misschien denkt. In het alledaagse spreken komen opsommingen veelvuldig voor, nl. wanneer men meerdere malen inhouden van hetzelfde type moet formuleren (bv. een reeks sportuitslagen). In dergelijke spreeksituaties ligt de syntaktische vorm van de zin grotendeels vast nog voordat de inhoud vaststaat. Drie argumenten heb ik de revue laten passeren die nopen tot de aanname dat bij het spontane spreken syntaktische faktoren soms de inhoud van de zin meebepalen. Waarmee ik overigens het bestaan van de ‘gewone’ volgorde (conceptie van de inhoud éérst, daarna syntaktische vormgeving) niet wil wegcijferen. Deze argumenten toevoegende aan de hogerop genoemde wenselijkheid van een generator die van links naar rechts werkt, kom ik tot de slotsom dat een transformatiemechanisme naar TGG-voorbeeld niet model kan staan voor de generator in de menselijke taalgebruiker. Fig. 5 vat het contrast tussen TGG-achtige (5a) en taalpsychologisch gewenste (5b) zinsgeneratoren beknopt samen. In Fig. 5a gaat een eenmaal geselekteerde inhoud de generator in die er een grammaticale zin uit tracht te construeren. In Fig. 5b is alleen het globale thema vooraf geselekteerd, bv. het gespreksonderwerp; de gebeurtenis die ik nu waarneem; wat ik gistermiddag heb meegemaakt. De keuze die de inhoudsselektor hieruit maakt voor een nieuw te formuleren zin (pijl no. 1) | ||||||||||||||||||||||
[pagina 148]
| ||||||||||||||||||||||
staat onder invloed van niet slechts inhoudelijke (pijl no. 2) maar ook syntaktische (pijl no. 3) criteria. Het eindprodukt in Fig. 5a is een zin die ‘als één geheel’ wordt afgeleverd; in Fig. 5b komt de zin ‘bij stukjes en beetjes’ (van-links-naar-rechts) tot stand. 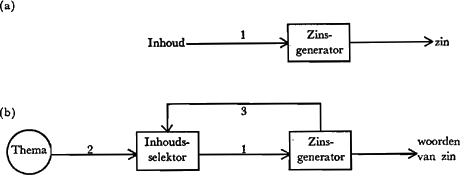 Fig. 5. Stroomdiagram van (a) en TGG-achtige zinsgenerator, en (b) een zinsgenerator die aan de in tekst beschreven taalpsychologische eisen voldoet.
Om te illustreren hoe zinnen van links naar rechts gegenereerd kunnen worden vanuit een voorafgegeven thema volgt nu een (sterk vereenvoudigd) onderdeel van een zinsgenerator die geprogrammeerd werd door Simmons & Slocum (1972). De grammatica die erin gebruikt wordt is een augmented transition network (zie par. 1.3 waar deze netwerken dienst deden als syntaktische ontleders). Fig. 6b geeft een stukje netwerk weer dat naamwoordsgroepen genereert; Fig. 6a is de semantische representatie van de naamwoordsgroep a merry widow in Amsterdam. Ik zal laten zien hoe het genereerprogramma een deel van deze inhoud uitdrukt als a merry widow. De generator kan het semantische netwerk doorlopen; laten we aannemen dat hij zich bevindt bij knoop c2 op het moment dat hij in toestand Snc verkeert. c2 is een concept dat luistert naar de naam widow. dit wordt uitgedrukt door de pijl c2-lex→widow. In toestand Snc onderzoekt de generator de wijze van bepaaldheid van de knoop waarbij hij staat. Hiertoe zoekt hij naar een als ‘bepaler’ gelabelde pijl die uit c2 vertrekt. Aan het eind van die pijl wordt de waarde ‘onbep(aald)’ aangetroffen, zodat grammatica-weg 2 ingeslagen mag worden. De generator produceert nu het eerste woord van de naamwoordsconstituent: a (zie conditie/operatie 2). Vanuit toestand nc1 gaat de generator na of een adjektief geproduceerd kan worden. Dit vereist een wat ingewikkelder zoekproces want er komen geen ‘adj.’-pijlen in het semantische netwerk voor. Voorwaarde 4 stelt dat uitgaande van de knoop waarop de generator | ||||||||||||||||||||||
[pagina 149]
| ||||||||||||||||||||||
momenteel staat (X) een mod(ifier)-pijl doorlopen moet worden en dat de dan bereikte knoop (Y, in dit geval c3) te boek staat als adjektief. Aan deze voorwaarden is voldaan, en merry is het tweede woordje dat wordt uitgesproken. De generator blijft nu in toestand nc1. Om te voorkomen dat hij doorgaat met alsmaar opnieuw merry te zeggen, zullen we afspreken dat een eenmaal verwoord stukje semantisch network wordt uitgeveegd. De rest van de grammatica wijst zich vanzelf. Opgemerkt zij alleen nog dat de operaties die bij de diverse overgangen uitgevoerd moeten worden, vaak complexe funkties zijn die uitgebreid beroep doen op lexicale informatie (bv. in overgang 5 moet opgezocht worden of het naamwoord misschien een onregelmatige meervoudsvorm heeft). 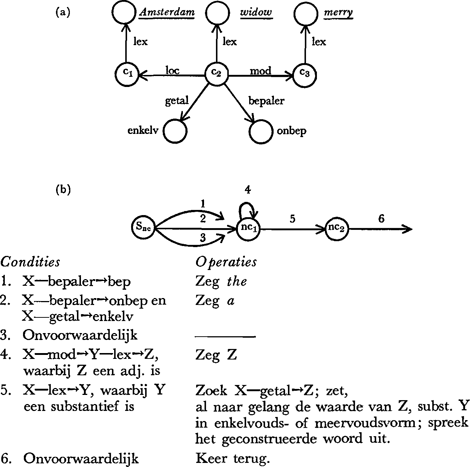 Fig. 6. Een eenvoudige netwerk grammatica voor het genereren van naamwoordsgroepen (b), en een voorbeeld van het type semantische representatie dat als invoer kan fungeren (a).
| ||||||||||||||||||||||
[pagina 150]
| ||||||||||||||||||||||
1.5. De articulator.Het uitspreken van de woordreeksen die de zinsgenerator heeft samengesteld verloopt via een uiterst ingewikkeld proces waarvan ik slechts enkele aspekten wil belichten die betrekking hebben op de sturing van de articulatieorganen. Povel (1974) besteedt hieraan in zijn dissertatie veel aandacht, vooral met het oog op de wijze waarop men leert articuleren, mét of zónder gerichte training. Empirische gegevens maken het, aldus Povel, waarschijnlijk dat het foneem de eenheid van spraakproduktie is, d.w.z. dat fonemen de elementen zijn die de articulatoren achtereenvolgens trachten te realiseren (en niet lettergrepen of woorden). Vervolgens trekt Povel een zeer illustratieve analogie tussen articuleren en fluitspelen: zowel mond als fluit produceren hun diverse geluiden door de resonantiekarakteristieken van een holte te variëren. Op bv. een blokfluit gebeurt dit door met de vingers de gaten open en dicht te maken, bij het spreken door de stand van de articulatieorganen te veranderen. Hoe stuurt de spreker zijn spraakmotoriek ter realisatie van een gewenste fonemenreeks? In beginsel zou de articulator voor elk te realiseren foneem een vast neuraal commando kunnen doorseinen naar de spraakmusculatuur. In de fluit-analogie vertaald: elke toon wordt gemaakt m.b.v. een vaste beweging met de vingers. Dit zou juist zijn als de speler elke toon zou maken vanuit een vaste uitgangspositie van zijn vingers. Maar dit is evident niet het geval: om bv. van f naar g te gaan maakt de blokfluiter een andere vingerbeweging dan wanneer hij een g speelt na een a. Dit brengt ons bij een tweede mogelijke stuurprincipe. Bij elk foneem hoort een vaste doelpositie van de articulatieorganen, en de neurale commando's nodig om deze positie te bereiken zijn verschillend voor elke uitgangspositie (voorafgaand foneem). De werkelijkheid is echter iets ingewikkelder want uit fonetisch onderzoek blijkt dat één en hetzelfde foneem kan worden geproduceerd m.b.v. meerdere configuraties der articulatoren (McNeilage, 1970) - net zoals op een blokfluit één noot vaak met meer dan één configuratie van open en gesloten gaten gemaakt kan worden. Dit betekent dat de perceptuele invariantie van het foneem niet verklaard kan worden vanuit articulatorische invariantie. Omdat ook in de geproduceerde klanken zulk een invariantie niet te vinden blijkt, moet geconcludeerd worden dat het foneem een nogal abstrakte entiteit is. Een soortgelijke situatie treffen we overigens aan op andere terreinen | ||||||||||||||||||||||
[pagina 151]
| ||||||||||||||||||||||
van patroonherkenning en -produktie, niet alleen binnen het taaldomein (o.a. zinsperceptie en -produktie) maar ook daarbuiten. In totaal verschillende foto's herkennen we hetzelfde gezicht, één en hetzelfde figuurtje tekenen we met zeer uiteenlopende bewegingspatronen. Op elk van deze terreinen is waarschijnlijk een systeem nodig bestaande uit een ontleder en een generator dat de complexe relaties beregelt tussen de externe invoer- en uitvoersignalen en de interne eenheden/categorieën/concepten die het cognitieve systeem hanteert. (Een goed voorbeeld van ontleding in het visuele domein staat bekend als ‘scene analysis’. Zie Sutherland, 1974.) | ||||||||||||||||||||||
2. Toepassingen op moedertaal- en vreemdetaalverwervingDeze sektie is gewijd aan het ontstaan van taalgebruikers. | ||||||||||||||||||||||
2.1. Moedertaalverwerving: het leren van grammaticaregels.De moedertaalverwerving kan beginnen zodra het conceptuele systeem concepten bevat voor de objecten, eigenschappen, handelingen, gebeurtenissen die het kind in zijn omgeving waarneemt. Dan kan het associaties gaan vormen tussen concepten en de spraaklabels die personen uit zijn omgeving gebruiken voor objecten, handelingen, etc. waarnaar de concepten verwijzen. Op grond van (aangeboren? vlg. Povel, 1974) kennis van de mogelijkheden der articulatieorganen weet het kind welke de doelposities zijn die het ter imitatie van de spraaklabels zal moeten realiseren. De imitatiepogingen zullen aanvankelijk weinig succesvol zijn omdat de fijne neurale sturing die nodig is om de achtereenvolgende doelposities vlot en vloeiend te bereiken nog ontbreekt. Rond de tijd van zijn eerste verjaardag beschikt het kind niet alleen over ‘losse’ concepten maar ook over conceptualisaties, d.w.z. netwerken waarin de afhankelijkheidsrelaties tussen meerdere concepten worden gespecificeeerd (zie 1.1). We maken nu de grondassumptie dat het kind beschikt over een leermechanisme dat regelmatigheden ontdekt en registreert in paren bestaande uit (a) een conceptualisatie die het kind in een bepaalde situatie maakt, en (b) de reeks woorden die het kind terugkent in een taaluiting die binnen dezelfde situatie tot hem gericht is. Een voorbeeld kan dit verduidelijken. Jessica heeft net een theekopje laten vallen en staat beduusd naar de scherven te kijken. Vader komt binnen en zegt: Heb jij het kopje laten stukvallen? Stel dat Jessica nog | ||||||||||||||||||||||
[pagina 152]
| ||||||||||||||||||||||
alleen de woorden kopje en stuk met de bijbehorende begrippen heeft geassocieerd. Het kent dan in vaders uiting alleen de sekwentie kopje-stuk terug. Omdat op dat moment Jessica de conceptualisatie KOP←attrib→STUK maakt, heeft het leermechanisme gelegenheid te registreren dat in de uiting de attribuutnaam onmiddellijk volgt op de naam van het concept waaraan het attribuut wordt toegekend. Als Jessica meer van deze woordsekwentie-conceptualisatieparen tegenkomt kan haar leermechanisme tot een algemene regel besluiten. Deze regel gaat dan deel uitmaken van de syntaktische ontleder en de syntaktische generator. Als de generator later de conceptualisatie JESSICA-eig→POP←attrib→LIEF aangereikt krijgt (‘Jessica's pop is lief’), dan kan Jessica zeggen Pop lief. Toegegeven, dit voorbeeld is zeer eenvoudig, maar ik zou willen poneren dat zulk een regel-leermechanisme, indien tot in details uitgewerkt, een plausibel taalleersysteem kan opleveren. (N.B. Het leggen van associatieve verbanden tussen spraaklabels en concepten (zie hogerop) is niet het werk van een apart mechanisme maar kan worden opgevat als de eerste manifestatie van het regel-leermechanisme). Zo'n systeem heeft een aantal belangrijke theoretische consekwenties. (1) Kinderen spreken in geen enkele fase van hun taalverwerving in ‘dieptestrukturen’ of semantische representaties. Met name McNeil (1970) heeft verdedigd dat vroege taaluitingen van kinderen vrij direkte weerspiegelingen zouden zijn van dieptestrukturen. Sinds de orthodoxe chomskiaanse dieptestruktuur goeddeels verlaten is en, met name in de generatieve semantiek, vervangen door het begrip ‘semantische representatie’ zou men in het voetspoor van McNeill kunnen opperen dat vroege uitingen heel dicht staan bij semantische representaties. Voorspellingen van dit type zijn op geen enkele wijze afleidbaar uit het hier getekende taalgebruikersmodel. Ons model kent geen semantische representaties maar conceptualisaties en ‘spreken in conceptualisaties’ is een zinloze gedachte: (a) over de concepten die in conceptualisaties optreden is geen volgorde van links naar rechts gedefinieerd (wel over de eindknopen in semantische representaties à la de generatieve semantiek); (b) de concepten zijn met opzet taalvrij (niet-talig) gekozen en hun relaties met de woorden van het lexicon zijn uiterst complex. Ook de vroege taaluitingen, hoe eenvoudig van struktuur ze ook mogen lijken, worden gefabriceerd door de zinsgenerator. (2) Van der Geest snijdt in zijn dissertatie (1974) het probleem aan hoe kinderen, nog slechts over een eenvoudige grammatica beschik- | ||||||||||||||||||||||
[pagina 153]
| ||||||||||||||||||||||
kend, in staat zijn uitingen die volwassenen tot hen richten, te verstaan. Deze uitingen stijgen immers qua syntaktische complexiteit vaak uit boven het niveau van het kind. Dat dit laatste juist is wordt bevestigd door een fraai onderzoek van van der Geest, Snow en Drewes-Drubbels (1974) naar de wijze waarop moeder en kind met elkaar converseren. Zij vonden dat de uitingen van de moeders in syntaktisch opzicht complexer waren dan de uitingen van het kind. Maar een tweede uitkomst is minstens even interessant. De kinder-uitingen waren in semantischcognitief (ik zou zeggen: conceptueel) opzicht meer geavanceerd dan de moeder-uitingen. Het lijkt erop, aldus de auteurs, of het kind aan de moeder de inhouden aanreikt waarover ze zou kunnen praten en dat de moeder dan geschikte syntaktische middelen verschaft om deze inhouden uit te drukken. Als we nu, gewapend met deze data, teruggrijpen naar hetgeen in par. 1.3 gezegd is over zinsontleding, dan blijkt dat de moeder-kind-conversatie een voorbeeld bij uitstek is van een situatie waarin syntaktische ontleding tot een minimum beperkt kan blijven. Syntaktische niveauverschillen tussen moeder en kind hoeven dan geen storing van de communicatie in de hand te werken. Voorts, omdat het kind beschikt over de conceptualisaties die tijdens de conversatie gewoonlijk aan de orde komen vormt dit type gesprekken voor het regel-leermechanisme een ideale vindplaats van conceptueel-syntaktische correspondenties. Dit is m.i. een afdoende oplossing van het probleem dat in dit punt ter sprake is. De oplossing die van der Geest voorstelt en waarin hij een beroep doet op de beperkte onmiddellijk-geheugen-capaciteit van het kind acht ik dan ook overbodig. Hierover meer in punt (4). (3) In de literatuur zijn verschillende mogelijkheden geopperd ter verklaring van de discrepantie tussen de relatief rijke conceptuele (semantische, diepte-) struktuur van kindertaaluitingen en de eenvoud van hun syntaktische (oppervlakte-) struktuur. Bloom (1970) stelt voor dat tot de aanvankelijke grammatica een aantal reduktietransformaties behoren die later echter verdwijnen. Dit heeft iets tegen-intuïtiefs: binnen de TGG-stroming wordt taalontwikkeling gezien als het bijleren van transformaties, niet als het afleren ervan. Voor verdere kritiek zie Schaerlaekens (1973). Brown & Fraser (1963) en van der Geest (1974) leggen de oorzaak van de syntaktische eenvoud van kindertaaluitingen in een meer perifeer mechanisme, het onmiddellijk geheugen. Ze gaan ervan uit dat het transformatiemechanisme dit geheugen nodig heeft om tussenresultaten op te bergen. Als dit klein is zullen bij het | ||||||||||||||||||||||
[pagina 154]
| ||||||||||||||||||||||
uitdrukken van complexe inhouden stukken moeten wegvallen (de minst beklemtoonde stukken het eerst, aldus van der Geest). In punt (4) wordt dit idee geëvalueerd. Een derde verklaringsmogelijkheid wordt naar voren gebracht door Schaerlaekens in haar ‘semantische-relatiemodel’. Sprekend over tweewoordzinnen oppert zij de gedachte dat semantische relaties een vast syntaktisch uitdrukkingspatroon bij zich hebben. Bv. een bezitsrelatie (‘fixed allocation’) wordt weergegeven door de naam van het bezit onmiddellijk te laten volgen door de naam van de bezitter. Zo bezigde een van de door haar onderzochte kinderen de uiting bed Joost voor dit is het bed van Joost. Ter aanduiding van de plaats waar iemand zich bevindt hanteerde ditzelfde kind de omgekeerde volgorde (Joost bed voor Joost is in bed). Dit laatste voorstel past het beste in de zinsgenerator van ons taalgebruikersmodel omdat het geen beroep doet op een transformatiemechanisme. Integendeel, de bedoelde uitdrukkingspatronen vertonen verwantschap met de in par. 1.4 ontwikkelde zoek/formuleer-programma's die eveneens een vaste combinatie vormen van (een samenstel van) conceptuele relaties en een syntaktisch construktieschema. Concretisering en formalisering van Schaerlaeken's voorstel in de vorm van netwerkgrammatica's liggen dan ook voor de hand. Een voorbeeld moge verduidelijken hoe m.b.v. netwerkgrammatica's het aanvankelijke contrast tussen conceptuele rijkdom en syntaktische eenvoud van kindertaaluitingen verklaard kan worden en hoe het geleidelijk aan wordt opgeheven. In de fase van de tweewoordzinnen is het kind in staat, nemen we aan, tot conceptualisaties waarin behalve de actie ook een actor en een objekt figureren. De syntaktische netwerken die het kind tot op dat moment heeft opgebouwd m.b.v. zijn regel-leermechanisme, zijn echter nog beperkt. Bv. het beschikbare syntaktische netwerk zoekt in conceptualisaties van de vorm actor←→actie←objekt alleen actor- en objektconcepten op en plaatst hun lexicale benamingen achter elkaar in de volgorde actor-objekt. In een latere fase van het taalleerproces zal het syntaktische netwerk uitgebreid zijn en ook voor het actie-concept een plaats in de taaluiting inruimen. Merk op dat in deze beschrijving van syntaktische ontwikkeling alleen sprake is van uitbreiding van het regelsysteem en dat geen beroep nodig is op ‘extra’ verklaringsmiddelen zoals een afnemend aantal reduktietransformaties of een groeiend onmiddellijk geheugen. (4) Mijn terughoudendheid ten aanzien van de verklaringen in | ||||||||||||||||||||||
[pagina 155]
| ||||||||||||||||||||||
termen van groei van het onmiddellijk geheugen (short-term memory, STM) is gebaseerd op de uitkomsten van recent onderzoek. Deze suggereren dat de capaciteit van het volwassen STM niet, zoals gewoonlijk wordt aangenomen, in de buurt van 7-8 items ligt maar slechts ongeveer 3 items bedraagt. Zie voor details het overzicht van de experimentele literatuur door Thomassen & Kempen (1974). Met items bedoel ik goed geïntegreerde eenheden (‘chunks’) zoals cijfers, letters, woorden, korte zegswijzen e.d. De geheugenspanne die een normale volwassene weet te behalen is weliswaar 7-8 items, maar dit getal weerspiegelt niet rechtstreeks de STM-capaciteit. Ofschoon hierover het laatste woord nog niet gezegd is wordt steeds waarschijnlijker dat de geheugenspanne het resultaat is van toepassingen van allerlei mnemotechnische hulpmiddelen. Eén ervan is ‘hercodering’: gebruikmakend van eerder verworven kennis slaagt men erin meerdere items tot een hecht geïntegreerde groep te verenigen die slechts één van de ± 3 STM-plaatsen bezet. Bv. het 6-stellige getal 492536 kan m.b.v. worteltrekken worden teruggebracht tot het 3-stellige getal 756. Een ander, machtig, middel tot hercodering is ..... gebruikmaking van syntaktische struktuur. Bv. de nonsens-reeks twier bradi spiramen droor slend zwiets lijkt veel moeilijker te onthouden dan de eerste twee regels van Carroll's Wauwelwok (par. 1.3). Hier dreigt dus het gevaar van verwisseling van oorzaak en gevolg: misschien is de groei van de syntaktische vaardigheid van het kind niet het gevolg van (o.m.) STM-groei, zoals van der Geest en anderen aannemen, maar juist oorzaak (althans één der oorzaken) ervan. Deze mogelijkheid, die in het licht van de recente geheugenpsychologie heel plausibel is, maakt verklaringen zonder STM gewenst. In punten (2) en (3) heb ik gepoogd hiervoor de grondslag te leggen. | ||||||||||||||||||||||
2.2. Vreemdetaalverwerving.In de slotparagraaf wil ik uit het taalgebruikersmodel een drietal gevolgtrekkingen voor vreemdetaalverwerving afleiden. De hypothese van de contrastieve analyse stelt dat contrasterende strukturen (strukturen van de vreemde taal die in de moedertaal geen parallel hebben) de leerling voor grotere problemen zullen plaatsen dan parallelle strukturen. Uit wat in par. 1.2 en 2.1 gezegd is over syntaktische ontleding valt te voorspellen dat deze hypothese niet zal gelden voor het verstaan (luisteren, lezen) van de vreemde taal, tenminste | ||||||||||||||||||||||
[pagina 156]
| ||||||||||||||||||||||
indien het conceptuele systeem beschikt over de concepten waarnaar wordt verwezen door de afzonderlijke woorden van de tekst. Het conceptuele systeem kan dan het ontleedproces in belangrijke mate sturen zodat het er nog weinig toe doet of de lezer/luisteraar de contrasterende struktuur al dan niet beheerst. Ulijn's onderzoek (1974), dat bij mijn weten het enige is waarin de contrastieve hypothese getoetst is aan tekstbegrip, levert gegevens op die met onze voorspelling kloppen. Fouten in de uitspraak van fonemen, woorden, zinnen in de vreemde taal worden gewoonlijk - zonder nadere motivering - toegeschreven aan een onvermogen van de articulatieorganen om de vereiste standen en bewegingen uit te voeren. Ofschoon ik dit niet in zijn algemeenheid wil ontkennen, wijs ik, mede naar aanleiding van Povel's studie (1974), op de mogelijkheid dat uitspraakfouten voortkomen uit een perceptieprobleem. In par. 1.2 is gesteld dat spraakverstaan vaak mogelijk is zonder een nauwkeurige, foutloze analyse van het spraaksignaal omdat syntaktische en conceptuele informatie de tekortkomingen van de spraakherkenner kunnen compenseren. Om het gechargeerd uit te drukken: de (volwassen) taalgebruiker is een goede verstaander maar een slechte luisteraar. Uitspraakfouten zijn dan een onvermogen om de karakteristieke eigenschappen van de vreemdetaalklanken op te pikken. Kinderen, die minder dan volwassenen kunnen vertrouwen op syntaktische en conceptuele kennis, zijn ook bij het verstaan van moedertaalzinnen sterker aangewezen op pure klankinformatie. Ze zullen dan voor het klankaspekt van de vreemde taal een scherper oor hebben. Zich uitdrukken in de vreemde taal vergt van de syntaktische generator méér dan alleen het aanleren van nieuwe construktieschema's. Van minstens even groot belang zijn ‘koppelingen’ tussen conceptualisaties en construktieschema's - koppelingen die misschien de vorm kunnen aannemen van programma's à la Fig. 6b. Het aanleren van zulke programma's vereist minstens twee leerstadia: de syntaktische schema's zelf moeten ingeoefend worden, en ze moeten aan conceptualisaties geassocieerd worden. Struktuuroefeningen (pattern drills) lijken voor het eerste stadium een goede leervorm. Het tweede stadium eist dat de leerling geconfronteerd wordt met telkens wisselende conceptuele inhouden met als taak om uit zijn arsenaal van syntaktische schema's snel het best passende te kiezen. Om te vermijden dat de leerling hierbij moet vertalen is het noodzakelijk die conceptualisatie op een niet-talige manier aan te bieden. Wil men dit leerproces in drill-formaat gieten, dan is men aangewezen op ‘situationele’ of ‘communicatieve’ drills (vgl. het | ||||||||||||||||||||||
[pagina 157]
| ||||||||||||||||||||||
overzicht van Extra, 1973). Een goed voorbeeld hiervan treft men aan in Lipson (1971). | ||||||||||||||||||||||
Referenties
| ||||||||||||||||||||||
[pagina 158]
| ||||||||||||||||||||||
|
|