|
| |
| |
| |
Informatieteorie en literatuurteorie
I. Inleiding
Het verschijnen van het boekje van Max Bense, Einführung in die Informationstheoretische Ästhetik. Grundlegung und Anwendung in der Texttheorie (Hamburg: Rowohlt, 1969) is een geschikte aanleiding voor een terugblik op de relaties die de afgelopen tien jaar zijn gelegd tussen informatieteorie en (literaire) tekstteorie. Een dergelijk inleidend en zeer globaal overzicht zal aan de ene kant het belang van het begrip ‘informatie’ voor de teorie van het literaire kommunikatieproces onderstrepen, maar aan de andere kant niet nalaten te wijzen op de tekortkomingen van de bestaandeliteraire-estetische toepassingen van de informatieteorie. Met name de generatief-transformationele grammatika heeft het belang van de - statistisch georiënteerde - informatieteorie voor de linguïstiek, en dus voor de teorie van de (literaire) tekst, op enkele punten sterk gerelativeerd. Deze kritiek geldt, zoals we zullen zien, vooral met betrekking tot de bestudering van het regelsysteem van de taal, de z.g. competence, en niet zozeer voor de studie van het konkrete psycho-sociale kommunikatieproces, de zg. performance.
Dit overzicht van de estetische informatieteorie - met name gericht op de ‘school’ van Bense in Stuttgart - kan slechts zeer fragmentair zijn. In het kader van deze vluchtige uiteenzetting is het bijvoorbeeld niet mogelijk een bevredigende weergave te geven van de technische (matematische) aspecten van het begrip ‘informatie’ en de begrippen die daarmee in verband staan. We zullen ons vooral richten op die elementen die ‘overdraagbaar’ zijn op andere wetenschapsgebieden, in dit geval dat van de literatuurteorie. Voor details zal er verwezen worden naar de meer gespecialiseerde vakliteratuur of naar eenvoudige inleidingen.
| |
2. De informatieteorie
De informatieteorie is een relatief jonge wetenschap. In strikte zin is zij eigenlijk pas twintig jaar oud, d.w.z. sinds haar wiskundige grondslagen gelegd zijn in de monografieën van Shannon en Weaver (1949 - zie bibliografie) en Wiener (1948). Dit wil niet zeggen dat het begrip ‘informa- tie’ pas toen ontstond. Twintig jaar eerder had Hartley (zie Pierce, 1966: 55) reeds enkele aspecten belicht van het overbrengen van ‘informatie’.
| |
| |
De informatieteorie is afkomstig uit de telekommunikatietechniek, en bij een extrapolering naar andere gebieden, bv. de menswetenschappen, moet steeds deze ‘technische’ oorsprong in gedachte worden gehouden. Al te licht is men geneigd parallellen te zien of kritiekloos bepaalde matematische procedures te volgen in de toepassingen op de bestudering van kommunikatieprocessen in andere wetenschappen. Het ging de genoemde ingenieurs en matematici erom te berekenen hoe men zo effektief mogelijk een boodschap - bv. door een telefoonleiding - moet ‘overbrengen’. We zullen zien dat zij daarbij slechts rekening hielden met de konkrete ‘signalen’ van zo'n boodschap, en met hun waarschijnlijkheid, en niet met de semantische ‘inhoud’ van de overgebrachte woorden.
Men kan de informatieteorie (ook wel kommunikatieteorie genoemd) beschouwen als een onderdeel van een meer omvattende wetenschap: de cybernetika, ook al worden beide begrippen vaak als synoniemen gebruikt. Het begrip ‘informatie’ is weliswaar fundamenteel in de cybernetika, maar kenmerkt niet direkt alle aspekten ervan. De cybernetika, de wetenschap van het ‘sturen’, houdt zich o.a. ook bezig met de uitwerking van begrippen als ‘terugkoppeling’, dat ruwweg wil zeggen: het ‘aanpassen van een (re-)aktie, van mens en machine, na een gekonstateerde verandering. Een bekend voorbeeld is de termostaat: op een gemeten informatie ‘(te) hoge temperatuur’ zal bv. in een ijskast de koelmotor in werking worden gesteld om de ‘gewenste’ lagere temperatuur weer te herstellen (voor details zie Bok, 1966 en Von Cube, 1967). Ook in talloze andere wetenschappen bleken de begrippen ‘informatie’ en ‘terugkoppeling’ van toepassing te zijn: de (leer)psychologie, de neurologie, de biologie, de ekonomie, de sociologie, etc., waarin het over het algemeen niet ging om een ‘terugkoppeling’ (feed-back) op een machine maar op de mens (een groep mensen) en op zijn fysische en psychische aspekten. In de estetika en de literatuurwetenschap lijkt het begrip vooralsnog alleen van toepassing op het kognitieve leerproces t.o.v. estetische objekten. We zullen ons dan ook voornamelijk beperken tot een uiteenzetting van het begrip ‘informatie’.
| |
3. Het begrip ‘informatie
Zoals gezegd is het begrip ‘informatie’ in zijn precieze, technische betekenis afkomstig uit de telekommunikatietechniek. De talrijke psychologische, filosofische en biologische interpretaties die er later aan zijn gegeven zijn direkt of indirekt op deze technische, matematische betekenis terug te voeren. Het woord ‘informatie’ uit onze dagelijkse omgangstaal heeft hier bijzonder weinig mee te maken: daar betekent het nl. iets als ‘inlichting’, ‘voorlichting’, etc. Deze betekenis van het dagelijkse woord ‘informatie’ legt dus de nadruk op het semantische aspekt, dit in tegen- | |
| |
stelling tot het technische gebruik van de term waarin van de ‘inhoud’, van de betekenis, van een bepaalde (woord) teken wordt geabstraheerd. Het gaat daarbij slechts om het konkrete woordteken zelf, d.w.z. om het materiële signaal.
Toch is er een zekere relatie tussen het dagelijkse en het technische begrip ‘informatie’. In beide gevallen heeft ‘informatie’ nl. een analoog effekt op degene die de informatie ontvangt (de ‘ontvanger’): zij heft een bepaalde onzekerheid of onwetendheid op. Een boodschap die ‘informatie’ bevat brengt een bepaalde hoeveelheid onverwacht en onvoorspelbaar nieuws over. In de technische betekenis echter gaat het daarbij niet om wat er gezegd wordt, d.w.z. om wat de woorden betekenen, maar om hoe het gezegd wordt, d.w.z. om de manier waarop de woordtekens met elkaar zijn gekombineerd, om het aantal malen dat een bepaald woordteken voorkomt, om de hoeveelheid woorden (of letters) van de boodschap, etc. ‘Informatie’ heeft te maken met de onverwachtheid van die kombinaties of die frekwenties. Het spreekt vanzelf dat een begrip als ‘onverwachtheid’ (of ‘onvoorspelbaarheid’) relatief van karakter is. In de eerste plaats kan men zich afvragen ‘voor wie’ een bepaalde informatie ‘onverwacht’ is; immers, als iemand een bepaalde boodschap, laten we zeggen een gedicht, al vaker gelezen heeft zal hem die boodschap veel minder ‘nieuw’ voorkomen, en voor hem persoonlijk dus minder ‘informatief’ zijn. In relatie tot de ontvanger-lezer van een boodschap kan men dan ook van subjektieve informatie spreken. Daar zullen we nog op terug komen. Het begrip ‘onverwachtheid’ - van een bepaald woord bv. - is echter ook nog relatief in een ander opzicht, nl. ten opzichte van de andere tekens (woorden, letters, etc.) van een bepaalde taal. Het is intuïtief gemakkelijk te begrijpen dat een woord dat, bv. in de dagelijkse omgangstaal, heel vaak voorkomt heel wat minder ‘onverwacht’ en
‘nieuw’ is, dan een woord dat bijna nooit wordt gebruikt. Men zegt dat het woord dat men vaker in een taal tegenkomt een hogere waarschijnlijkheid heeft dan de woorden die men minder vaak tegenkomt. Statistisch onderzoek kan nu vaststellen wat de gemiddelde waarschijnlijkheid is, d.w.z. de kans, dat een bepaald woord door de sprekers van een taal gebruikt zal worden. (Natuurlijk hangt dit ook af van het type boodschappen dat men wil beschrijven: bij de berekening van de waarschijnlijkheid van een woord gaat het echter om een zeer algemene, globale waarschijnlijkheid berekend op basis van duizenden teksten van een verschillend type: kranten, omgangstaal, artikelen, toespraken, etc.). Welnu, men heeft ontdekt dat de hoeveelheid informatie van een bepaald teken (een letter, een woord, etc.) in matematisch verband staat met de waarschijnlijkheid van dat teken in een taal: nl. hoe groter de waarschijnlijkheid is des te kleiner is de hoeveelheid informatie die zo'n teken bezit. Aangezien de waarschijnlijkheid van een teken, d.w.z. het aantal malen dat bv. een woord op het totaal van de gebruikte woorden voorkwam, objektief is te
| |
| |
berekenen, hebben we hier te maken met een objektief aspekt van het begrip ‘informatie’. Dus: de waarschijnlijkheid (p) van een teken is het aantal malen (frekwentie: f) dat het teken op het totaal aantal tekens (n) voorkomt: p = f/n. In een alfabet komt iedere letter één maal op de 26 letters voor, zodat de waarschijnlijkheid p van iedere letter gelijk is, nl. 1/26. We zien daarbij ook dat de som van 26 letters met een p van 1/26 precies 1 is. Dit is, zoals we nog zullen zien, slechts een ideale situatie: in werkelijkheid, d.w.z. in het konkrete taalgebruik, zullen bepaalde letters vaker voorkomen dan anderen, een e bv. vaker dan een x. In werkelijkheid is (buiten de abstraktie van het alfabet) de waarschijnlijkheid van een e groter dan die van een x. Zoals we hierboven gezien hebben impliceert dit dat de informatie van een e kleiner is dan die van de x. Die feit hebben de ingenieurs uitgebuit om boodschappen zo snel en effektief mogelijk over te brengen. Daarbij gingen zij uit van het feit dat vaakvoorkomende tekens, d.w.z. tekens met weinig informatie, het kortst in een bepaalde kode moesten worden omgezet, bv. in een kode van stroomimpul-(voor een draad). Omgekeerd zullen tekens die minder vaak voorkomen (dus een lagere waarschijnlijkheid bezitten) - en dus door een taalgebruiker a.h.w. met meer ‘moeite’ zijn geselekteerd temidden van de andere mogelijke tekens van de taal - een langere vorm krijgen in de gebruikte kode om de signalen (tekens) over te brengen. We zijn hier op een belangrijk punt aangeland: men heeft nl. gesteld dat de informatie-hoeveelheid van een teken gelijk is aan de ‘moeite’ die het kost om het teken te koderen, d.w.z. aan het aantal stappen dat men moet doen om het zo effektief mogelijk in kode
om te zetten.
Het koderen van de over te brengen letters of woorden gebeurt over het algemeen op binaire wijze. Zo'n binaire kodering kan men als volgt illustreren: Laten we aannemen dat we een bepaalde letter van een alfabet willen koderen; om zo'n letter ondubbelzinnig te identificeren, d.w.z. vast te stellen dat het juist om die letter ging, kunnen we een aantal vragen stellen over bv. de plaats waar de letter zich in het alfabet bevindt: bevindt hij zich in het eerste deel?, waarop slechts twee antwoorden mogelijk zijn: JA of NEE. Bij ieder antwoord weten wij iets meer over de plaats van de letter in het alfabet, d.w.z. onze onwetendheid over de identiteit van de letter stap voor stap door ieder antwoord verminderd. We hebben echter al gezien dat juist ‘informatie’ samenhangt met deze ‘onwetendheid’: bij ieder antwoord JA of NEE krijgen wij een hoeveel- heid informatie over een bepaald teken (i.c. een letter van het alfabet). Men heeft bepaald dat de hoeveelheid informatie juist, per antwoord, 1 bedraagt. De maat van de hoeveelheid noemde men bit, een afkorting van ‘binary digit’: immers men krijgt precies 1 bit informatie wanneer men één binair antwoord (JA of NEE, of ook vaak 1 of o geschreven) krijgt. In een alfabet met 32 tekens (punt, komma, spatie, etc. meegeteld) moet men op deze wijze 5 antwoorden krijgen om een bepaald teken te
| |
| |
identificeren: in de eerste zestien, daarvan het tweede achttal, etc. Na deze antwoorden heeft men dus 5 eenheden informatie gekregen omtrent een letterteken: 5 bit. Dit kan men ook zeer snel zien door het totale aantal waaruit men moet kiezen als een macht van 2 te schrijven: 32 = 25, waarbij de exponent juist gelijk is aan het aantal binaire (JA of NEE) antwoorden, d.w.z. aan de hoeveelheid informatie van één van de 32 tekens. Bij een alfabet, of in het algemeen: een repertoire, van 64 tekens is de informatie die men nodig heeft om één teken te identificeren gelijk aan de macht van twee om dat getal te krijgen: 26, dus 6 bit. Bij de kodering krijgt men dan bijvoorbeeld een signaal als: 101001 of 110001 (waarbij er natuurlijk weer 64 mogelijkheden zijn nullen en enen op deze zes plaatsen te kombineren). In het algemeen heeft men dus x bit informatie nodig om een element uit 2x elementen te selekteren. Als het totaal aantal elementen n bedraagt schrijft men dit het gemakkelijkst als een logaritme met het grondtal 2:x = 2log n, d.w.z. de hoeveelheid informatie is gelijk aan het getal waartoe men 2 moet verheffen om n te verkrijgen. Zo is de informatie die nodig is om een teken uit een repertoire van 8 verschillende tekens te selekteren gelijk aan 2log 8=2log 23=3 bit.
Deze zeer simpele manier om de informatie van een teken uit een bepaald repertoire te bepalen is in de praktijk echter niet van toepassing op bv. onze (natuurlijke) taal. Daar komen letters, woorden, etc. nl. niet - net als in de voorbeelden hierboven - even vaak voor: hun relatieve frekwentie is verschillend, dus ook hun waarschijnlijkheid en hun informatie. Zo zal een e in werkelijkheid een informatie bezitten die kleiner is dan 5 bit en een x een informatie die groter is dan 5 bit. Met dit feit zullen we dan ook bij de berekening van de informatie van een teken rekening moeten houden. We zeggen dan dat de informatie (I) van een teken meer in het algemeen de macht van 2 (dus 2log) van zijn onwaarschijnlijkheid is (zoals we al eerder intuïtief hadden gekonstateerd), d.w.z. het omgekeerde van zijn waarschijnlijkheid p in de taal:
| (1) |
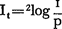
|
| Dit is het zelfde als 2log p-1, en dit is hetzelfde als: |
| (2) |
It = - 2log p (bit)
|
| Dit is natuurlijk ook in overeenstemming met het voorbeeld van het alfabet van 32 tekens met allen dezelfde waarschijnlijkheid 1/32: vult men dit in in formule (1) dan krijgt men inderdaad: |
|
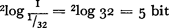
|
| Een ander, zeer eenvoudig, voorbeeld: We nemen een ‘boodschap’ van 8 letters in totaal gevormd met behulp van vier verschillende letters a, b, c en d: |
| (3) | a a b a b c a d
Hierin komt de a 4X voor op de acht letters, zijn waarschijnlijkheid p is
|
| |
| |
| dus gelijk aan 4/8 = ½. Wanneer we p = ½ invullen in (1) of (2) dan vinden we voor de informatie van a (Ia): |
| (4) |
| Ia |
= |
- 21og ½ |
| |
= |
- 2log 2-1 |
| |
= |
2log 2 |
| |
= |
1 bit |
|
| Op dezelfde wijze vinden we de informatiewaarde voor b, waarvan de waarschijnlijkheid p gelijk is aan de frekwentie (2) gedeeld door het totaal aantal letters (8): 1/4. Wanneer men nu invult in een der formules vindt men voor b: Ib = 2 bit. Voor c en d, die allebei slechts één maal voorkomen dus een p hebben van 1/8 vinden we zo een informatie van 3 bit ieder. |
| Nu we de informatiewaarde van de verschillende letters kennen is het gemakkelijk de hoeveelheid informatie voor de hele boodschap te berekenen: iedere a draagt daartoe 1 bit bij - samen dus 4 bit -, iedere b 2 bit - samen dus ook 4 bit - en de c en de d ieder 3 bit; de totale hoeveelheid informatie is dus 14 bit. We zien dat de totale informatie van iedere verschillende letter zijn frekwentie is maal zijn informatie als afzonderlijke letter: |
| (5) |
Il = f. -2log p
|
| Maar aangezien - zie blz. 4 - de frekwentie van een teken gelijk is aan zijn waarschijnlijkheid maal het totaal aantal tekens, dus p.n, mag men schrijven: |
| (6) |
I letter = p.n.-2log p
|
| Om nu de totale informatie van de hele boodschap te berekenen hoeft men slechts de som van de informaties van ieder teken te nemen. Dit schrijft men als volgt: |
| (7) |
I tekst = ∑p.n.-2log p
|
| (voor een preciezere afleiding van deze formule, zie o.a. Herdan, 1966: 260 sqq.) Hierna kunnen we eventueel ook nog berekenen wat de gemiddelde informatie van de tekens van deze tekst is; we hoeven dan alleen maar te delen door n: |
| (8) |
I teken = -∑p. 2log p
|
| Op deze nogal vereenvoudigde manier hebben we in (7) de beroemde formule van Shannon afgeleid. We zien daarin duidelijk dat de totale informatie van een tekst groter wordt a) wanneer de waarschijnlijkheid p van zijn tekens kleiner wordt en b) wanneer die tekst meer tekens bevat, dus langer wordt. |
| |
Het begrip ‘entropie’
Opvallend was nu dat de formule van Shannon een frappante analogie vertoonde met een bekende formule uit de termodynamika, nl. die welke
| |
| |
de ‘toestand’ van een gas karakteriseert. Deze toestand noemt men entropie en drukt een gepaalde maat van ongeordendheid uit van de elementen (gasmolekulen )in een bepaalde ruimte. De entropie wordt groter naarmate de elementen meer willekeurig verspreid zijn, op meer ongeordende wijze zijn vermengd. In dat geval is de plaats van een bepaald element minder gemakkelijk te voorspellen, en dus - zie boven - met meer ‘moeite’ te lokaliseren, d.w.z. ieder element heeft een hogere informatie. We zien dus dat ‘informatie’ en ‘entropie’ analoge begrippen zijn: we kunnen de toestand van een gas (met gasmolekulen) vergelijken met die van een tekst (met tekens); een maximale ongeordendheid van het gas (maximale entropie) korrespondeert met een maximale informatie, en omgekeerd; wanneer de entropie laag is, d.w.z. de elementen gemakkelijker voorspelbaar, geordend, zijn dan is ook de informatie laag. Een systeem waarvan de elementen allemaal dezelfde waarschijnlijkheid hebben (zoals bv. in het gegeven voorbeeld van het alfabet), nl.1/n, waarin p van ieder teken dus zo laag mogelijk is, is de entropie maximaal: er heerst een zo groot mogelijke ongeordendheid en onverwachtheid van de elementen, dus ook de informatie is maximaal.
In de konkrete teksten van de taal hebben de letters en de woorden, zoals reeds vaker gezegd, niet allemaal dezelfde waarschijnlijkheid, en dus ook niet dezelfde informatie. Daar komt nog iets bij. De tekens van een tekst staan niet zomaar los en onafhankelijk naast elkaar, maar hebben bepaalde relaties tot elkaar. Deze worden o.a. bepaald door de morfofonologische, syntaktische en semantische regels van de taal. Deze zullen er voor zorgen dat de voorspelbaarheid van bv. een woord in de kontekst toeneemt: wanneer we een zin hebben als ‘Ik lees een...’ dan weet men bijna zeker dat men een woord als ‘boek’, ‘krant’, of ‘tijdschrift’ daarna zal tegenkomen. Aangezien de onverwachtheid van deze woorden door het zinsverband kleiner is geworden is ook informatie kleiner geworden. Dit geldt voor bijna alle letters en woorden van een tekst, en des te meer naar mate de tekst langer wordt. Door de invloed van de kontekst wordt de totale informatie van de tekst (de entropie) dus minder dan de reeds eerder berekende som van zijn tekens. Door een (ingewikkelde) berekening van de waarschijnlijkheden waarmee een bepaald teken y na een teken x komt, en een teken z na de kombinatie xy, etc. d.w.z. door het berekenen - in een bepaalde taal - wat de zg. overgangswaarschijnlijkheden kan men toch de totale informatie van een tekst berekenen. Tenminste: in theorie, want hoe langer een tekst wordt, des te minder statistische gegevens bezitten we over deze overgangswaarschijnlijkheden. We komen daar nog op terug.
| |
| |
| |
5. Het begrip ‘redundantie’
Tenslotte, na de begrippen ‘informatie’ en ‘entropie’ nog een derde begrip van de informatieteorie dat van belang is in de tekstteorie, nl. het begrip ‘redundantie’. We zeggen dat een tekst ‘redundant’ is wanneer hij meer tekens bevat dan een tekst met dezelfde hoeveelheid informatie. De gemiddelde informatie van een teken is daardoor kleiner (omdat n groter is) in de redundante tekst dan in de meer optimaal gekodeerde tekst. Deze redundantie is gemakkelijk te berekenen, nl. door het verschil van de maximale en de werkelijke informatie te delen op de maximale informatie:
| (9) |
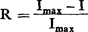
|
| |
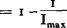
|
We zien daarbij direkt dat als de informatie I van een tekst gelijk is aan de maximale informatie Imax R gelijk is aan nul, terwijl wanneer de informatie van een tekst nul is (d.w.z. al zijn elementen zijn te voorspellen) de redundantie zo groot mogelijk is, nl.1.
Redundantie kan men zien als een soort ‘overbodigheid’ van elementen in een tekst. In de gewone taal is deze redundantie vrij sterk: in veel konstrukties komt men een bepaald element tweemaal tegen, terwijl we ook niet nalaten volledig voorspelbare letters, als in ‘morge...’, toch te schrijven. Deze redundantie is nodig voor de verstaanbaarheid van de teksten: om een tekst zonder redundantie te lezen zouden we teveel moeite moeten doen, juist omdat er (bv. per sekonde) ‘teveel’ informatie wordt aangeboden. En omdat bij het konkrete spreken ook veel informatie verloren gaat door storende invloeden van buitenaf (noise). We zullen zien dat in sommige poëtische teksten juist deze redundantie geëlimineerd kan worden.
Van de hierboven staande uiteenzetting van enkele begrippen uit de informatieteorie moeten we vooral onthouden:
| - | de informatie van een element (een teken, bv.) is gekorreleerd met de (negatieve 2log van de) waarschijnlijkheid van dat element |
| - | de informatie van een tekst is gekorreleerd met het aantal elementen daarvan en met de waarschijnlijkheid van die elementen |
| - | informatie en entropie (van een tekst bv.) hebben te maken met de ongeordendheid (van de tekst), d.w.z. de onverwachtheid, onvoorspelbaarheid van zijn elementen |
| - | de redundantie van een tekst is omgekeerd gekorreleerd met zijn informatie (entropie) en heeft te maken met een ordening, verwachtheid, voorspelbaarheid, regel-maat. |
| - | de geformuleerde begrippen hebben vooralsnog uitsluitend betrekking
|
| |
| |
| op objektieve (statistische) waarschijnlijkheden die berusten op relatiev frekwenties berekend op basis van een bestaand corpus (sample) van taalteksten. |
(Zie ook voor al deze begrippen: Van Peursen, Bertels, Nauta, 1968.)
| |
6. Het begrip ‘informatie’ in de literatuurteorie en de estetika
Reeds aan de gegeven voorbeelden hebben we nierboven gezien dat de begrippen uit de informatieteorie ook van toepassing zijn op teksten, hetgeen natuurlijk niet verwonderlijk is wanneer men bedenkt dat de informatieteorie in eerste instantie is ontworpen voor de kodering van taalboodschappen. De relatie met de linguïstiek ligt dan ook voor de hand, en sommige veronderstellingen uit de informatieteorie lijken bevestigd door taalfeiten. Men heeft namelijk gekonstateerd dat de taal zelf reeds schijnt te gehoorzamen aan enkele koderingskriteria: de meest frekwente woorden (die dus met een hoge waarschijnlijkheid) blijken inderdaad de kortere woorden van een taal te zijn, terwijl bovendien hun semantische ‘inhoud’ het minst ‘gespecificeerd’ is, d.w.z. relatief weinig ‘informatie’ (hier in semantische zin geïnterpreteerd) bevat, en omgekeerd. Verder zijn ‘boodschappen’ in gewone omgangstaal een soort ‘gulden middenweg’ tussen entropie (informatie, onverwachtheid) en redundantie (regel-maat). Reeds in de vorige paragraaf konstateerden we daarbij dat bv. in moderne poëzie er van deze redundantiegraad (die voor de verschillende talen verschillend is) kan worden afgeweken. Dit gebeurt bijvoorbeeld door een afwijking van de ‘gewone’ grammatikale regels die de vorming van zinnen en teksten determineren. Op die manier zijn de elementen van de literaire tekst minder ‘voorspelbaar’ geworden, en wordt de entropie van die tekst dus groter, hetgeen - onder bepaalde andere voorwaarden - een estetisch effect op een interpreterend subjekt kan hebben. Hoewel de estetische interpretatie van deze ‘verschillen’ met de dagelijkse omgangstaal funktie zijn van een relatie tussen het objekt: de tekst, en het subjekt: de lezer, moeten we ons rekenschap geven van het feit dat deze
‘verschillen’ kenmerk zijn van het objekt zelf, en dus ‘objektief’ zijn in die zin dat zij statistische feiten weerspiegelen.
De grotere entropie (informatie) van moderne poëtische teksten wordt in de werkelijkheid van het hele literaire kommunikatieproces dat zich tussen schrijver en lezer via de tekst voltrekt toch weer voor een deel teniet gedaan. Immers, door een regelmatig kontakt met zulke teksten zullen bepaalde afwijkingen of de aanwezigheid van andere regels steeds minder ‘onverwacht’ zijn, jazelfs als kenmerk voor zulke teksttypen in zekere zin verwacht worden. Door een bepaald leerproces bij zowel schrijver als lezer wordt de oorspronkelijke objektieve informatie - die
| |
| |
bij het eerste kontakt idealiter gelijk was aan de subjektieve informatie - omgezet in een steeds kleiner wordende subjektieve informatie. Zo ook kan men verklaren dat men de stilistische kenmerken van de teksten van een bepaalde schrijver of van een bepaalde periode kan herkennen. Dit herkennen van bepaalde elementen van een kunstwerk in het algemeen komt overeen met een ordening, een strukturering van dat kunstwerk door degene die het beschrijft (interpreteert), en daardoor wordt dat kunstwerk subjektief steeds redundanter, er wordt - zoals o.a. Bense zegt - als het ware een negatieve entropie gevormd.
Vaak wordt de ‘ordening’, de strukturering, van een kunstwerk in verband gebracht met zijn estetische aspekt. De matematikus Birkhoff heeft in dit verband een ‘maat’ voor dit estetische aspekt van objekten vastgesteld en ging daarbij uit van de veronderstelling dat die maat gekorreleerd was met de mate van geordendheid van dat objekt en omgekeerd gekorreleerd met de ‘ongeordendheid’ of kompleksiteit ervan: M = O/C. Dat deze ‘maat’ een al te eenvoudige weergave van het estetische aspekt van een objekt is, heeft Rul Gunzenhäuser in een monografie (1962) over estetische redundantie aangetoond. Hij vervangt daarin de begrippen ‘Ordening’ en ‘Kompleksiteit’, die zuiver numeriek en relatief arbitrair een ‘waarde’ kregen toegekend, door informatieteoretische begrippen, waarin ‘ordening’ als redundantie en ‘kompleksiteit’ als entropie worden geïnterpreteerd. Ondanks dat ontsnapt hij niet geheel aan de willekeurigheid van de kriteria volgens welke een bepaald element van een estetisch objekt als ‘ordeningselement’ of als ‘informatief’ element moet worden geïnterpreteerd.
Dat de problemen niet zo eenvoudig liggen blijkt al uit het onmiskenbare feit dat het ordeningsprincipe als belangrijk (positief) estetisch kriterium niet voor alle kunstrichtingen opgaat. De regelmaat, de redundantie, mag wellicht een belangrijk aspekt zijn van de ‘klassieke’ kunst en literatuur, voor de barok en het surrealisme geldt dit estetisch principe in ieder geval niet. Programmatisch werd er zelfs door de surrealisten op gewezen dat ‘le hasard’ - hoogstens gedeterimineerd door het onderbewuste - de grondslag vormt van hun literaire teksten. Dit ‘toeval’ bij de selektie van tekstelementen is identiek aan een hoge informatie- en entropiewaarde.
Hieruit blijkt dat een manipulering van informatieteoretische principes in de estetika en in de literatuurwetenschap met grote omzichtigheid moet gebeuren. Positieve estetische ‘informatie’ blijkt soms gekorreleerd met zowel geordendheid (redundantie) als met ongeordendheid (entropie). We mogen wellicht zelfs van een zekere dialektiek spreken: herkenning, strukturering, etc. zijn kondities voor de interpreteerbaarheid van estetische objekten, terwijl het innovatieve (informatieve) t.o.v. van de bekende regels van de taal of van de kunst juist het individuele kunstwerk definiëren, nl. als een verzameling operaties (met woorden, verf of ander ‘mate- | |
| |
riaal’) waarvan de waarschijnlijkheidsverdeling eenmalig en dus ‘oorspronkelijk’ is. Deze dialektiek is weliswaar door de informatieteoretici niet onopgemerkt gebleven, een teoretisch bevredigende oplossing hebben zij echter nog niet kunnen geven.
Het lezen en interpreteren van teksten gaat zoals gezegd gepaard met het ontdekken van bepaalde regelmatigheden en strukturen waardoor de entropie van een tekst kleiner wordt. Dit is het gevolg van wat de Duitse informatieteoretici ‘Superzeichenbildung’ hebben genoemd (cf. ook Moles, 1968:207 sqq). Het blijkt nl. dat de tekens, van een tekst bv., niet afzonderlijk worden waargenomen maar als onderdeel van grotere strukturen: zinnen, een tematiek, etc., die men ‘tekens-gevormd-uit-tekens’ kan noemen: Superzeichen, zoals ook woorden al Superzeichen zijn t.o.v. de lettertekens waaruit ze bestaan. Er zijn kennelijk meerdere nivoos van Superzeichen, en het is gebleken - o.a. in de eksperimentele waarnemingspsychologie (cf. Hörmann, 1967:65 sqq, 97 sqq) - dat deze samenhangende tekenkonfiguraties als ‘Gestalte’ minder informatie overbrengen dan de som van hun konstitutieve tekens. Iedere waarneming - dus ook die van estetische objekten - zal er volgens de informatieteoretische psychologie naar streven de in het objekt aangeboden informatie te verminderen door ‘klassifikatie’ (herkenning) en het vormen van strukturen die als een ‘geheel’ kunnen worden geïnterpreteerd (cf. Riedel, 1968:51-63). Dit is noodzakelijk omdat ons bewustzijn van de enorme hoeveelheid informatie die onze zintuigen ‘waarnemen’ slechts ongeveer 16 bit per sekonde kan ‘verwerken’, en deze in de onmiddellijke herinnering slechts 10 sekonde kan ‘opbergen’: dus in het totaal 160 bit. En hiervan wordt slechts maximaal 0,6 bit/sek. opgeslagen in het geheugen. Bij de direkte waarneming zal men dus onbewust trachten zo ‘optimaal’ mogelijk, d.w.z. met zoveel mogelijk informatie in zo kort mogelijke tijd, de elementen van een tekst te appercipiëren, en dit gebeurt door het lezen van groepen woorden tegelijk, bv. van een korte zin of van
syntagmata: de grammatische analyse in ‘syntagmen’ heeft kennelijk een psychologische realiteit (cf. Franke, 1968:137-143 en Hörmann, 1967:246-277).
Deze feiten zijn alle relevant voor de beschrijving van het kommunikatieve proces waarin de literaire tekst zich manifesteert. We moeten echter bedenken dat het daarbij om de empirische aspekten van de tekstteorie gaat, nl. om bepaalde waarschijnlijkheidsverdelingen in teksten ten opzichte van andere teksten in de taal en ten opzichte van een interpreterend bewustzijn, en niet om de logisch-grammatische aspekten van de tekstteorie, de zg. competence, d.w.z. het systeem van abstrakte regels dat ten grondslag ligt aan de vorming van die teksten. Juist in het kader van de bestudering van het konkrete psycho-sociale kommunikatieproces van de literatuur en de kunst, d.w.z. de performance, ligt de waarde van het estetisch onderzoek van de informatieteoretici als Bense, Moles, Gunzenhäuser, Frank, Franke, e.a. (cf. van Dijk, verschijnt).
| |
| |
Voordat we nader zullen ingaan op het boekje van Bense eerst een ogenblik de aandacht voor degene die waarschijnlijk als eerste de informatieteoretische begrippen toepaste in de estetika, nl. Abraham Moles.
Moles, in zijn beroemde monografie: Théorie de l'information et perception esthétiëue (1958), legde een verband tussen het technische begrip ‘informatie’ en het estetische begrip ‘originaliteit’, dat in dit perspektief geïnterpreteerd wordt als ‘onverwachtheid’ ten opzichte van bekende, konventionele patronen. Moles legt er terecht de nadruk op dat het natuurlijk niet eenvoudig is precies te bepalen welke patronen - en in welke mate - bij een subjekt (een ontvanger van de estetische boodschap) bekend zijn, en dat het daarom ook niet eenvoudig is te berekenen wat de subjektieve informatie (entropie) van het estetische objekt is. Hoewel er kennelijk een verband bestaat, moet men dus metodologisch een scheiding zien tussen statistisch-informationele ‘originaliteit’ en estetische ‘oorspronkelijkheid’, alleen al omdat deze laatste - zie boven - vaak berust op de redundante aspekten van het objekt. Hiervan uitgaand maakt Moles een ander typisch onderscheid, nl. tussen ‘semantische’ en ‘estetische’ boodschappen, een onderscheid dat in de literaire kritiek, onder andere benamingen, ook vaak is gemaakt. Semantische boodschappen zijn logisch gestruktureerd, vertaalbaar, etc., terwijl estetische boodschappen in principe onvertaalbaar zijn (bv. door de niet-arbitraire relatie tussen semantische ‘inhoud’ en fonisch-grafische ‘vorm’) terwijl de selektieve informatie van die teksten een andere waarschijnlijkheidsverdeling vertegenwoordigt als die van de teksten uit de dagelijkse omgangstaal (cf. ook Moles, 1963:23 sqq.). De estetische boodschap (musikaal, literair, etc.) is ‘intentie-loos’, slechts een ‘uiting’ van een ‘innerlijk schema’ dat in het kanaal (de tekst, de boodschap) zelf haar uiteindelijke ‘doel’ vindt. Ook voor iemand als Jakobson (1960)
wordt de ‘poëtische funktie’ van de taal gedefinieerd als het richten van de aandacht op de vorm van de boodschap zelf - bij zowel schrijver als lezer - in plaats van op zijn semantische ‘inhoud’ en zijn pragmatische implikaties. Estetische informatie voor Moles wordt gekreëerd door het uitbuiten van de vrijheids-marge in het taalgebruik. Hoewel deze ‘definities’ van het estetische en het literaire niet principieel onjuist zijn, kan men moeilijk volhouden dat zij in deze vorm precies genoeg zijn om te kunnen worden geïntegreerd in een wetenschappelijke terminologie en teorie. Weliswaar is de berekening van de statistische ‘informatie’ empirisch gezien niet onaanvaardbaar, de teoretische interpretatie van de resultaten blijft bijzonder vaag en dubbelzinnig. Op talrijke punten zullen een taal- en literatuurteorie deze opmerkingen moeten preciseren.
| |
| |
| |
7. Bense's informatieteoretische opvatting van de kunst
Na Birkhoff - en zijn interpretator Gunzenhäuser -, Moles en enkele anderen, is Bense ongetwijfeld degene die het meest tot een informatieteoretische estetika en tekstteorie heeft bijgedragen. In tegenstelling tot de genoemde figuren, richt hij echter met meer nadruk de aandacht op. de tekstteorie, zoals zijn Theorie der Texte van 1962 reeds heeft aangetoond. Hij benadert daarin, zoals ook in het tweede deel van zijn Einführung... de (literaire) tekst op een fundamenteel andere manier als de linguïst of de traditionele literatuurbeschouwer. Leggen Saussure, de strukturalisten en, met Chomsky, de transformationalisten de nadruk op de beschrijving van het abstrakte taal-systeem - bij Chomsky expliciet in regels in een grammatika vastgelegd -, Bense gaat uit van een konkreter, materialistischer standpunt. Zoals voor de eerste informatieteoretici is een boodschap, een tekst, in de eerste plaats voor hem een op een bepaalde wijze geordende verzameling tekens. Dit geldt overigens voor alle estetische objekten. Zowel zijn estetika als zijn tekstteorie zijn dan ook opgebouwd op twee teoretische pijlers: een matematische en een semiotische (d.w.z. tekenteoretische). De wiskundige benadering bestaat grotendeels uit de hierboven geschetste statistische en informatieteoretische interpretatie van het kommunikatieproces, en verder uit een meer algebraïsche verzamelingsteoretische (tekst is een verzameling tekens) en topologische (tekst is een samenhangende, geordende, verzameling tekens) benadering.
Dit opteren voor de bestudering van het konkrete, empirische objekt houdt een afwijzing in van de spekulatieve en metafysische estetika, en tegelijkertijd een abstraheren van de subjektieve aspekten van het estetische teken-proces. De beschrijving zelf wordt gegeven in de abstrakte taal van een rationele teorie. Het volgende citaat laat geen twijfel bestaan omtrent de doelstellingen van een dergelijke estetische teorie:
‘Nur eine solche rational-empirische, objektiv-materiale Ästhetik-konzeption kann das allgemeine spekulative Kunstgeschwätz der Kritik beseitigen und den pädagogischen Irrationalismus unserer Akademien zum verschwinden bringen.’ (p. 8)
Dat deze ondubbelzinnige, historisch goed te verklaren, uitspraak niet dogmatisch van aard is, bewijzen de regels die erop volgen. Daarin wordt betuigd dat de rationele estetische teorie zijn filosofische grondslagen heeft, en zoals iedere teorie ‘open’ moet zijn, kontroleerbaar, weerlegbaar en ‘aanvulbaar’, kriteria waaraan iedere wetenschappelijke teorie moet voldoen.
In de ‘Einleitung’ van zijn boekje preciseert Bense de implikaties van zijn rationele, materiële estetische teorie. Het is hem begonnen om een teorie van estetische ‘Zustände’ (‘states’) van objekten en gebeurtenissen, en niet om een interpretatie daarvan door een (subjektieve) beschou- | |
| |
wer, lezer, luisteraar. Hij onderstreept daarbij wel dat zo'n empirische beschrijving zelf niet ‘objektief’ kan zijn. Zoals in iedere waarneming en iedere ken-teoretische relatie, hebben we ook hier te maken met een subjekt-objekt relatie. De relatie tussen het teoretische bewustzijn en het te beschrijven (estetische) objekt is echter niet direkt, onmiddelbaar van aard Onze kennis van de wereld en zijn objekten - en in de wetenschap is dat een voorwaarde - is in taal geformuleerd, d.w.z. gekodeerd in tekens en tekensystemen. Het denken, en dus zeker het expliciete wetenschappelijke denken, ontsnapt niet aan het middel, nl. het teken, dat de taal ons biedt om überhaupt over die wereld en dat objekt te kunnen spreken. Hoewel Bense deze kennisteoretische feiten niet onvermeld laat - alleen al omdat ze een voortvloeisel zijn uit zijn semiotische teorie - had hij wellicht iets meer de nadruk moeten leggen op het feit dat de ‘objektiviteit’ van zijn benadering - hoewel alweer historisch verklaarbaar - per definitie onmogelijk is door te voeren, temeer wanneer wij veronderstellen dat estetische interpretatie, zoals iedere interpretatie, funktie is van de relatie objekt-subjekt. Daarentegen merkt Bense terecht op dat deze relatie gebaseerd is op de objektieve (statistische) eigenschappen van de ‘estetische toestand’ zelf. Hij vergeet daarbij echter dat de klassifikatie (en herkenning) van die eigenschappen van het objekt als estetische eigenschappen plaats vindt in de objekt-subjekt
relatie.
Het estetische kommunikatieproces voor Bense - en hier volgt hij Hegel - berust op tekens. In het eerste hoofdstuk geeft hij dan ook een korte uiteenzetting van de semiotiek of tekenteorie. Enkele begrippen daarvan liggen ten grondslag aan de indeling van de meeste teoretische begrippen van zijn boek, hoewel men zich - ondanks deze konsekwentie - mag afvragen wat de teoretische waarde is van het interpreteren van alle wetenschappelijke begrippen in het semiotisch model. We zullen ons in het kader van deze uiteenzetting niet direkt bezig houden met de semiotische aspekten van de estetika en de literatuurteorie, het gaat ons vooral om de informatieteoretische aspekten daarvan - ook al zijn die nauwelijks los te denken van de semiotische (zie ons ‘Semiotiek en literatuur’, 1970a).
De semiotische teorie van Bense, die zich voor een deel hier inspireert op zijn medewerkster Elisabeth Walther (cf. Walther, 1965), berust bijna geheel op die van de amerikaanse logicus Charles Sanders Peirce, die na honderden jaren (Locke, Leibniz, Hegel) weer de ideeën van o.a. de stoïsche en middeleeuwse tekenteorieën nieuw leven inblies en trachtte uit te breiden en te preciseren. Zijn teken-opvatting, zoals overigens in de meeste semantische en semiotische teorieën, is triadisch van aard, d.w.z. het teken is funktie van een drievoudige relatie, nl. tussen ‘betekend objekt’, ‘het betekenende middel’ (het konkrete teken zelf) en een ‘interpreterend bewustzijn’ (‘interpretant’ genoemd):
| |
| |
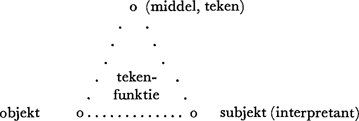
(fig. 1)
Teken, zegt Bense, is alles wat tot teken ‘verklaard’ wordt. Dit wil zeggen - vgl. ook Saussure (die de ‘sémiologie’ als een allesomvattende teken-wetenschap zag) - een teken is konventioneel, het produkt van een arbitraire stilzwijgende afspraak van een (taal)gemeenschap. Peirce, en zijn adepten Morris en Bense beperken zich allerminst tot het taalteken, maar denken ook aan verkeerstekens, gebaren, geluiden, kortom alles wat waarneembaar is en wijst op iets anders dan zichzelf. Teken is teken ‘van iets’, ‘voor iemand’. Om tekens te kunnen klassificeren brengt Peirce (en dus Bense) een aantal verdere onderscheidingen aan binnen de drie genoemde relaties. In zijn objekt-relatie heeft het teken (opgevat als ‘materiëel signaal’):
1. niets met zijn objekt gemeen (en is dus willekeurig, zoals het taalteken) - in dat geval heet het teken een ‘symbool’
2. een vorm of een struktuur die analoog is aan die van het objekt (een portret bv.) - in dat geval heet het teken ‘ikoon’
3. een direkte, materiële, kausale, etc. relatie met het objekt, of heeft daar enkele elementen mee gemeen (rook als teken van bv. een trein) - in dat geval heet het teken ‘index’.
Men kan in het kort zeggen: een symbool ‘betekent’, een ikoon ‘verbeeldt’ en een index ‘verwijst’. Dit is een indeling van alle tekentypes op basis van hun relatie met het objekt.
Op dezelfde wijze kan men het teken als ‘middel’ als basis nemen, en weer een driedeling maken:
| 1. | het teken is ‘kwalitatief’ (inkt, geluid, kleur, etc.).
- en heet dan ‘qualisign’ (volgens de terminologie van Peirce) |
| 2. | het teken is algemeen van aard en duidt een klasse aan (is dus abstrakt
- en heet dan ‘legisign’ |
| 3. | het teken is ‘bijzonder’ van aard, en wordt als eenmalig objekt beschouwd: dit ene konkrete teken
- het heet dan ‘sinsign’ (afk. v. ‘singular sign’). |
De laatste twee onderscheidingen worden ook elders, bv. in de taalfilosofie gemaakt, men spreekt dan van resp. een type en een token.
Tenslotte kan men het teken ook nog een driedeling geven op basis van de relatie met het interpreterend bewustzijn (men zou kunnen zeggen de ‘betekenis’ van het teken voor iemand):
| 1. | het teken staat op zichzelf zonder relatie met andere tekens (bv. een woord) - het heet dan een ‘rhema’. |
| |
| |
| 2. | het teken vormt een relatief onafhankelijke en gesloten eenheid (bv. een zin, een propositie) - het heet dan ‘dicent’ |
| 3. | het teken vormt een op zichzelf staand, afgesloten geheel (bv. een heel logisch bewijs, een paragraaf, etc.)
- het heet dan ‘argument’. |
Een dergelijke klassifikatie van de verschillende tekenrelaties biedt mogelijkheden voor een typologisering van tekens en tekensystemen. Het woord van de gewone taal is zo bv. een ‘symbolisch-rhematisch-legisign’.
Herhaalde triadische indelingen op basis van de genoemde driedelingen worden steeds door Bense volgehouden. Hij tracht de meeste van zijn teoretische of filosofische termen te passen in de semiotische driehoek. Dat hij daarbij wel eens geforceerd te werk moet gaan is onvermijdelijk. Men kan zich afvragen wat het teoretisch belang is van deze terminologische parallellen met het schema van Peirce. Hoewel vaststaat dat de semiotiek een belangrijke rol kan vervullen als meta-wetenschap, omdat zij alle tekensystemen - dus ook die van de al dan niet formele wetenschappelijke ‘talen’ - kritisch kan bestuderen, heeft men bij Bense vaak de indruk dat zijn triadische her-interpretaties eerder een inventief spelletje zijn dan een verklarende hypotese: en daar zal men in een estetische of literaire teorie op af moeten werken, of van uit moeten gaan. En juist door dit gebrek aan teoretische funktionaliteit en praktische verklarings-kracht kan men de juistheid van de indelingen ook moeilijk door toetsing aantonen of bestrijden. Ook door de beknoptheid van de uiteenzetting is niet altijd uit te maken wat Bense met zo'n indeling precies wil. Op blz. 14 bv. vinden we een nadere indeling van de drie tekenrelaties (objekt, middel, interpretant) - resp. opgevat hier als ‘realisatie’, ‘kommunikatie’, ‘kodering’ -nl.: disjunktiv, selektiv, kontinuierlich; konstruktiv, präsentativ, repräsentativ; analog, digital, kopulativ. Zonder een geëxpliciteerde omschrijving en regels voor een eventuele toepassing kan men deze indelingen hoogstens beschouwen als interessante filosofische aperçus.
Na deze zeer gedrongen ‘abstrakte semiotiek’ (die hij ook al, wat uitgebreider, in een kleine monografie van 1967 had gegeven) begint Bense met de beschrijving van de verschillende fasen van het kommunikatieproces dat op basis van tekens en tekenkombinaties mogelijk is geworden.
In de eerste plaats komt dan een ‘repertoireteorie’ ter sprake. Tekens, signalen, voordat zij geselekteerd, gekodeerd en verzonden kunnen worden komen uit een repertoire. Voor de taal is dat het woordenboek, voor de schilder zijn verzameling tubes verf, etc. Ieder teken, volgens Bense, wordt op drie wijzen bepaald, nl. door zijn ‘substantie’, zijn ‘vorm’ en zijn ‘intensiteit’, een hjelmleviaanse indeling die nogal globaal en vaag is. Het repertoire bestaat uit diskrete elementen, is eindig, en heeft vaak - voor de selektie - toch al een bepaalde voor-ordening ondergaan, in het woordenboek bv. door de ordening van lettertekens in morfemen/grafe- | |
| |
men of door een in de spreektaal bepaalde waarschijnlijkheid van de elementen. Traditiegetrouw kent Bense tenslotte het teken een ‘materiëel’ en een ‘ideëel’ (of ‘semanteem’) aspekt toe. Deze beide kunnen de dragers zijn van estetische ‘toestanden’. Dit lijkt al een afwijking van het oorspronkelijke exklusief materiële standpunt van het begin van het boek. Dit standpunt blijft hij echter in zoverre getrouw dat we inderdaad van de semantische aspekten van het estetisch proces niet veel meer horen. Door deze beperking tot een overdreven behavioristisch materialisme, moet Bense schijnt het afzien van één van de belangrijkste estetische aspekten van de tekst-kommunikatie, nl. van de betekenisstruktuur van de tekst (en van de interpretatie daarvan). Dat hij daarmee dezelfde onnodige reduktionistische fout begaat als de amerikaanse strukturalisten en de eerste transformationalistische studies, zal direkt blijken. Deze verwaarlozing van de semantisch-interpretatieve aspekten is des te meer bevreemdend, omdat hij daarmee één der hoekpunten (nl. die van de interpretant) uit zijn semiotische driehoek vergeet.
De driehoek reduceert zich in dat geval tot de rechte lijn. Door het zg. ‘subjektieve’ te willen vermijden, vergeet hij dat ook de betekenis-toekenning aan een teken zijn inter-subjektieve, dus ‘objektieve’, aspekten heeft die als zodanig ook formeel zijn te beschrijven.
(Om terminologische verwarring te voorkomen moeten we erbij vermelden dat voor Bense ‘semantisch’ inde meeste gevalleneen betekenis heeft zoals bij de semioticus Morris - 1938, 1964 - en bij vele logici en taalfilosofen: nl. betrekking hebbend op de relatie tussen materiëel teken en het betekende objekt (de fiktieve of werkelijke wereld, de denotata), en niet op de relatie tussen teken en interpreterend bewustzijn of het subjekt, een relatie die door Morris e.a.‘ pragmatisch’ wordt genoemd. De relaties tussen tekens onderling - de enige die in formele talen van belang zijn - worden ‘syntaktisch’ genoemd. Ook het formeel-linguistische aspekt van ‘semantisch’ betrekt Beuse niet in zijn overwegingen).
Na deze opmerkingen over een repertoireteorie, komt dan het eigenlijke kommunikatieproces zelf ter sprake. Hij volgt daarbij het bekende schema van Meyer-Eppler:
(Z(ender) - Kanaal - W(aarnemer) (Ontvanger) waarin Z en W een al dan niet geheel gemeenschappelijk repertoire van tekens (en regels) gemeen moeten hebben om een kommunikatie tot stand te kunnen brengen. De Zender selekteert tekens uit het repertoire - daarbij min of meer ‘gestuurd’ door de waarschijnlijkheden van de tekens in de taal - kodeert ze, bv. in geschreven letters, en voegt ze samen tot grotere eenheden: ‘Konnexe’ of ‘Kontexte’, zoals Bense ze noemt.
Zoals reeds eerder opgemerkt is het overbrengen van informatie in een boodschap identiek met het opheffen van een zekere onwetendheid. Dit geldt natuurlijk ook voor de wetenschappelijke en teoretische kennisverwerving en voor alle andere manieren van kennen. Om deze manieren van ‘kennen’ te typologiseren past Bense nogmaals een triadisch schema
| |
| |
toe. De teoretische kennis, die geen direkte relatie heeft met zijn objekt, noemt hij ‘symbolisch’, de kennis die gebaseerd is op analogie, vanzelfsprekendheid en beeldendheid, noemt hij ‘ikonisch’, terwijl de kausaalempirische kennis ‘indexikaal’ wordt genoemd. Op dezelfde wijze onderscheidt hij tussen drie vormen van informatie, nl. strukturele informatie (die ikonisch is, bv. de informatie die we krijgen uit een model, een raster, een plattegrond, etc.), selektieve informatie (die symbolisch is, en kenmerkend voor abstrakte teorieën) en metrische informatie (die indexikaal is en kenmerkend voor onze empirische, metende, ervaring). Op die wijze probeert Bense de kennisteorie (die zelf natuurlijk digitaal en selektief is, nl. een ‘taal’) in het kader van de informatieteorie te interpreteren.
Doorbordurend op dit kennisteoretische aspekt van deze relatie tussen semiotische driehoek en informatieteorie, komt Bense - zijn vroegere filosofische aspiraties getrouw - onvermijdelijk uit op een (materiële) ontologie (en inspireert zich daarbij vooral op Ujomov en Lesniewski. De band met de verschillende tekenrelaties ligt voor de hand wanneer hij, met Ujomov, al het zijnde als volgt indeelt en definiëert:
het ding is een relatie van eigenschappen; de eigenschap is een relatie van dingen; de relatie is een eigenschap van dingen
deze ontologische definities weet Bense handig in zijn teken-schema in te passen en te vertalen. Wanneer het teken - als ding - de relatie tussen de eigenschappen ‘middel-te-zijn’, ‘op-een-objekt-betrokken-te- zijn’ en ‘op-een-interpretant-betrokken-te-zijn’ blijkt te hebben, dan vraagt men zich af of een linguïstische benadering in dit geval niet preciezere en teoretisch meer interessante eigenschappen van het teken had kunnen geven, nl. (ook evt. triadisch!) als relatie van syntaktische, semantische en fonologische eigenschappen (i.c. kategorieën). De verdere filosofische implikaties van Bense's semiotische interpretaties moeten we hier buiten beschouwing laten. We kunnen slechts zeggen dat, hoe interessant zijn uiteenzetting vaak is, de relaties met de estetische teorie niet altijd voor de hand liggen, en dat deze zeker niet - als ze al bestaan - aannemelijk worden gemaakt: een verstrengeling van semiotiek, informatieteorie en ontologie levert nu eenmaal niet direkt een estetika of een kennisteorie. Daar heeft men een heel systeem van ‘interpretaties’ - overgangsregels - voor nodig, die de relaties tussen de meer abstrakte en de minder abstrakte teorie aangeven (voor verdere relaties met de filosofie, cf. Steinbuch & Moser, Hrsg., 1970).
In dit kennisteoretische perspektief ligt ook het onderscheid, fundamenteel bij Bense, tussen de fysische en de estetische wereld: de eerste is gegeven en als zodanig sterk kausaal gedetermineerd, de tweede is ‘gemaakt’ en zwak gedermineerd. Overigens is deze determinering gradueel: een taal- | |
| |
tekst is zwak gedetermineerd (door de regels van de grammatika en door het repertoire), maar een poëtische is nog zwakker gedetermineerd, omdat daar zelfs de taalregels kunnen worden opgeheven. Echter, ook hier geldt dat slechts datgene kan worden ‘her-kend’ en geïdentificeerd dat reeds een zekere ‘ordening’ heeft ondergaan (een ‘superzeichen-vorming’), en deze ordening is een gevolg van de determinering. Het niet gedetermineerde bestaat uit de selektie van (in de kontekst toegestane) tekens en de kombinatie daarvan in de tekst: hier ligt dan ook het gebied van de evt. estetische ‘innovatie’ (informatie) - zie Moles - nl. die van de specifieke distributie van de tekens in de tekst. Daarbij kan van de objektief of subjektief ‘verwachte’ schema's worden afgeweken, waarbij ieder schema bij Bense natuurlijk weer als een bepaald type ‘teken’ kan worden geïnterpreteerd. We zullen zien dat de selektie uit het woordenboek ook gedetermineerd is, nl. door onderliggende tekstsstrukturen.
Een ander belangrijk onderscheid dat Bense maakt is dat tussen de mikro- en makro-estetische aspekten van het objekt. Het eerste heeft betrekking op het proces van selektie en kombinatie van tekens (op basis van bepaalde waarschijnlijkheden), terwijl het tweede betrekking heeft op de globale vorm van de hele tekst, op zijn ‘Gestalt’ zou men kunnen zeggen. Het eerste betreft de vorming van de tekst zoals die zich stap voor stap voltrekt, en wordt dan ook ‘generatief’ genoemd, het tweede de vorm van de voltooide tekst en wordt ‘formeel’ genoemd. Dit laatste aspekt was, zoals we reeds gezien hebben, met name het objekt van de onderzoekingen van Birkhoff, bij wie het ging om een karakterisering van de globale konfiguraties: rijmschema's, allerlei vormen van symmetrie, de tematiek (waar Birkhoff en Bense niet over spreken), etc. De mikro-estetische aspekten zijn statistisch en informatie-teoretisch van aard: door selektie en kombinatie wordt er een proces in werking gesteld dat loopt van een ‘chaogene’ toestand tot een ‘strukturele’ toestand. Daarbij blijft de dialektiek tussen redundantie en innovatie bestaan. Het vormen van ‘begrijpelijke’ Superzeichen (betekenissen, herkende figuren, etc.) doet de totale informatie zoals reeds werd aangetoond afnemen. De schilderkunst na Kandinsky vermijdt dergelijke betekenis-volle figuren, waardoor de innovatieve informatie-hoeveelheid kan worden vergroot; in de niet-figuratieve schilderkunst heeft men vaak meer ‘moeite’ om bepaalde strukturen te ontdekken - waarbij bovendien deze strukturen geen traditionele semantische interpretatie kunnen krijgen (man, vrouw, huis, boom, etc.) - hetgeen een bewijs is van een groot informatie-aanbod; zoals gezegd hebben informatiepsychologen berekend hoeveel informatie men maximaal per sekonde kan verwerken.
In het kader van deze mikro-estetische informatieteorie ligt ook de meer aktieve relatie tussen objekt en subjekt, nl. de zg. Generative Ästhetik. Deze gaat van de teoretisch voor de hand liggende gedachte uit, dat wanneer men een repertoire van elementen bezit en een aantal regels
| |
| |
(voor Bense zijn dat de gegeven waarschijnlijkheden) men niet alleen een tekst kan analyseren, maar ook kan syntetiseren, bv. door hem te simuleren met behulp van een komputer. Met name in de muziek, de grafiek en de design zijn dergelijke ideeën met wisselend sukses gerealiseerd. Om het proces niet totaal door het programma gedetermineerd te laten verlopen (hetgeen het estetisch kriterium van de zwakke determinering zou tegenspreken) gebruikt men daarbij een zg. ‘toevalsgenerator’. Deze zorgt ervoor dat, binnen het kader van het programma en de regels/repertoire, talloze ‘vrije’ kombinaties worden geproduceerd. We zullen straks terugkomen op de zg. ‘syntetische’ teksten.
Het eerste deel van zijn boekje sluit Bense af met enkele opmerkingen over een ‘Wertästhetik’, die hij zeer duidelijk niet heeft willen geven, omdat zij niet betrekking heeft op het kunstwerk als ‘middel’ (teken) maar op de relatie met de interpretant van een subjekt. Maar ook deze interpretatieve relatie - die zich weerspiegelt in een verzameling ‘beschrijvende uitspraken’ (waarvan de ‘oordelende’ uitspraken slechts een deelverzameling zijn) is gebaseerd op de kodering van tekens (nl. op die van de beschrijvende taal), zodat ook hier de informatieteorie van pas zou kunnen komen. Het gaat er daarbij om enkele overgangsregels vast te stellen tussen objekt en subjekt, d.w.z. zekere niet-dubbelzinnige relaties te ontdekken tussen een bepaalde tekenkonfiguratie en een bepaalde al dan niet evaluerende beschrijving. We hebben reeds opgemerkt dat ook de wetenschappelijke beschouwer zich niet aan dat proces kan onttrekken. Weliswaar kan hij het hele kommunikatieproces ‘van buiten af’ bestuderen - dus ook de relatie tussen objekt en subjekt -, maar zodra hij zelf het objekt (in zijn expliciete wetenschappelijke taal) wil beschrijven kan ook hij zich niet onttrekken aan een selektie van aspekten van dat objekt, en aan een ‘interpretatie’ van zijn ‘feiten’. Dit geldt minstens zolang hij geen ‘mechanische procedure’ bezit voor een dergelijke beschrijving. Zoals gezegd had Bense wellicht meer nadruk moeten geven aan dit kennisteoretische probleem. In ieder geval verdedigt hij zich al bijvoorbaat - en in sommige opzichten terecht - tegen eventuele beschuldigingen van ‘reduktionisme’ of tegen een verwijt als zou hij een ‘verdingelijkte-technologische’ estetika willen propageren. Ten eerste voert hij aan dat altans in de beeldende kunst de matemarische denkwijzen vaker tot belangrijke vernieuwingen hebben geleid dat
‘inhoudelijk-metafysische’. Bovendien, zo zegt hij, is iedere teoretische kennis, nadat zij zich heeft los gemaakt uit een metaforisch stadium, matematisch van aard. Dit leidt dan tot de volgende filosofische konklusie van het eerste deel:
‘Nur antizipierbare Welten sind programmierbar, nur programmierbare sind konstruierbar und human bewohnbar’ (p. 72)
| |
| |
| |
8. Bense's tekstteorie
Dit heilige geloof in de matematische beheersing van de wereld en dus ook van de estetische wereld, karakteriseert ook de ‘Kleine Texttheorie’ die hij in het tweede deel van zijn boekje geeft. In de eerste plaats moeten we hier de aandacht vestigen op het feit dat Bense met zijn Theorie der Texte in 1962 een der eersten was die het belang van een wetenschappelijk tekstteorie inzag, in tegenstelling tot veel linguïsten die zich tot de formele bestudering van de ‘zin’ beperkten. Pas de laatste jaren konstateert men - voor het eerst uit de strukturalistische (harrissiaanse) hoek - een hernieuwde belangstelling voor een tekstteorie ook bij de linguïsten. Een tekstteorie is in de eerste plaats fundamenteel voor een literatuurteorie en voor een tekstestetika (cf. van Dijk 1970b, 1971a, b; Schmidt, Hrsg. 1970).
Zoals hij ook het teken benaderde, tracht Bense de tekst te definiëren. Dit taalprodukt is zowel ‘materieël’ als ‘geistig’ van aard, en men mag van Bense verwachten dat hij vooral aandacht voor het eerste aspekt zal hebben, want dit is het gemakkelijkst matematiseerbaar. Deze ‘materiële tekst’ of ‘Textur’ bestudeert hij achtereenvolgens op basis van een a) tekststatistiek b) een tekstalgebra (verzamelingenleer) en c) topologie. Pas dan kan men overgaan tot de andere aspekten van de tekstsemiotiek: een tekstsemantiek en een tekstpragmatiek. Zich in zijn definitie inspirerend op Mandelbrot is een tekst - heel breed opgevat - een ‘räumlich angeordnete Menge von materiale, diskrete Elemente, die als Zeichen fungieren können, auf Grund gewisser Regeln zu Teilen oder zu einer Ganzheit zusammengefasst’ (p. 76).
De eerste stap in de beschrijving van dit materiële objekt baseert hij op het begrip ‘Menge’ van de definitie. Als een tekst een verzameling tekens is kan men de verzamelingenleer te hulp roepen. Het idee ligt voor de hand, maar wat doet Bense ermee? Hij begint met een korte inleiding in enkele basisbegrippen en - operaties van de verzamelingenleer (element, verzameling, deelverzameling, snijden van verzamelingen, lege verzamelingen, etc.) en zegt dan: ‘Wenn die Elemente Wörter sind heissen die Menge Texten’ (p. 76), en hij herhaalt dan enkele algebraïsche operaties: deel-tekst, snijden van teksten, etc. Helaas laat hij na aan te geven wat het tekstteoretisch nut is van deze automatische ‘vertaling’ in de verzamelingenleer. Het gebruik maken van abstrakte matematische operaties lijkt in ieder geval pas dan zinvol wanneer men reeds een bepaalde terminologie, een bepaald probleem of een hypotese heeft geformuleerd. Bense doet in feite niets anders dan het evidente feit aantonen dat men voor de variabelen van een verzamelingenleer ook tekens als elementen kan ‘invullen’.
Vervolgens gaat het erom aan te tonen dat een tekst niet zomaar een verzameling is van tekens, maar een geordende verzameling en dat er dus
| |
| |
bepaalde relaties bestaan tussen de tekens onderling. Ook deze noodzakelijke aanvulling geeft hij zeer summier in een symbolische notatie. In zekere zin kan men het konstateren van deze relaties (ekwivalentie, symmetrie, transitiviteit, refleksiviteit, volgt op, gaat vooraf, etc.) en hun formele uitdrukking zien als een rechtvaardiging van het tehulp roepen van de verzamelingenleer. Toch blijft zijn uiteenzetting eerder een inleiding in de algebra dan in de tekstteorie, temeer daar hij zoals gezegd helemaal niet aangeeft hoe zijn symbolische notering gebruikt kan worden om literatuur- of tekstteoretische problemen op te lossen. Hoewel het een onloochenbaar feit is dat een tekst een ‘geordende verzameling’ tekens is, moet men zich echter afvragen of die ‘ordening’ inderdaad zich uitput in de materiële ‘oppervlakte’ relaties waar Bense over spreekt. We zullen zien dat het ‘verband’ (lattice) waarover hij het heeft in feite op een ‘dieper’ en abstrakter nivo ligt, en dat de oppervlakterelaties slechts een aspekt zijn van de materiële ‘manifestatie’ van de tekst. Alleen het feit al dat men dezelfde tekst vaak zowel kan schrijven als kan uitspreken lijkt er een bewijs voor dat de materiële manifestatie niet het belangrijkste kenmerk is van de tekst als tekst, nl. als samenhang. Wanneer Bense op blz. 83 betoogt dat deze ‘materiële’ tekst slechts dient ter overbrenging van de semantische informatie geeft hij een absoluut noodzakelijke aanvulling.
Op hetzelfde ‘materiële’ vlak ligt natuurlijk de meer bekende tekststatistiek, die al door velen voor hem was beoefend: Yule, Zipf, Guiraud, Fucks, e.a. Deze statistische bestudering is gebaseerd op de ‘telbaarheid’ van de diskrete materiële elementen van de tekst: letters, woorden, lettergrepen, zinnen, etc. en richt zich op een precieze berekening van de gemiddelde of afwijkende waarschijnlijkheidsverdelingen daarvan in verschillende teksten. Op deze wijze is men in staat om een precieze basis te geven aan de beschrijving van de stijl van een bepaalde auteur of van een bepaalde periode (groepen auteurs). Een juiste en teoretische bevredigende interpretatie van de gegevens blijkt daarbij vaak te ontbreken.
Hier ligt ook de relatie met de informatieteoretische aspekten van de tekst. Bense, in navolging van sommige informatieteoretici (zoals Shannon), veronderstelt dat een tekst gedefiniëerd kan worden op basis van zijn statistische overgangswaarschijnlijkheden. Bense realiseert zich daarbij weliswaar dat deze o.a. het resultaat zijn van de syntaktische en semantische regels van de grammatika, maar houdt vol dat de kombinaties van woorden ook onderworpen zijn aan de wetten van de waarschijnlijkheid: niet alleen een woord A heeft een bepaalde waarschijnlijkheid, en niet alleen een woord B, maar ook de kombinatie AB heeft een waarschijnlijkheid, een waarschijnlijkheid die kleiner is dan de som van die van A en B, nl. de waarschijnlijkheid van A maal de waarschijnlijkheid van ‘B-volgend-op--A’ (zie Cherry, 1966: 184 sqq,). Deze totale
| |
| |
informatie wordt natuurlijk kleiner naarmate de tekst langer wordt en de elementen daardoor meer door de kontekst voorspelbaar worden.
Men kan niet ontkennen dat in de konkrete kommunikatie er een bepaalde waarschijnlijkheidsverdeling van zekere woordgroepen bestaat, maar dit wil zeker niet zeggen dat men daarmee adekwaat een tekst als samenhangend geheel kan beschrijven, zoals dat wel door een evt. tekstgrammatika gedaan zou kunnen worden. Wanneer Shannon voor steeds grotere groepen woorden de waarschijnlijkheid in een taal - en dus hun gemiddelde frekwentie in een tekst - wil berekenen, en zo automatisch resp. digrammen, trigrammen ... n-grammen wil produceren, vergeet hij het elementaire (linguïstische) feit dat men met slechts enkele elementen en enkele regels een oneindig aantal zinnen kan genereren. Zelfs van alle bestaande zinnen (waartoe de linguïstische grammatika zich zeker niet toe wil beperken) zal de frekwentie vaak niet veel hoger liggen dan 1. In praktijk bleek men inderdaad niet veel verder te komen dan de statistische distributie van 5e of 6e orde benaderingen tot een ‘gewone’ tekst: d.m.v. het laten ‘raden’ van een 5e of 6e woord wanneer resp. 4 of 5 woorden reeds gegeven zijn. Bovendien, wat erger is, niet-bestaande zinnen zouden op deze wijze nooit geproduceerd kunnen worden, hetgeen met de pricipiële ‘kreativiteit’ (Chomsky) van de taal in tegenspraak is.
Alleen al de kompleksiteit van een statistische berekening van de overgangswaarschijnlijkheden van langere series woorden doet vermoeden dat een statistische ‘definitie’ van een koherente, grammatikale tekst vooralsnog tot de onmogelijkheden behoort. De formule van Shannon geldt dan ook slechts voor een ‘bron’ waarvan de diskrete elementen geen verband met elkaar hebben, de berekening van de informatie van koherente tekstgedeelten stuit op talloze moeilijkheden omdat de determinerende faktoren zo gevariëerd zijn, niet alleen semantisch, syntaktisch en morfo-fonologisch - d.w.z. kenmerkend voor het producerende systeem (de taal) - maar wellicht ook stilistisch (bij herhalingen, inversies, rijmschema's en andere ‘literair-stilistische operaties) of referentieel (men verwacht woorden in een kontekst bij elkaar waarvan de denotata ook spatio-temporeel met elkaar in verband staan: stoel/tafel, etc.). Deze immense kompleksiteit van de determinerende faktoren - voor zover daar al een informatieteoretische ‘maat’ voor te vinden is - verhindert nu juist de eksaktheid die de materiële tekstteorie van Bense nastreeft, en een flinke dosis skepticisme is dan ook op zijn plaats: in ieder geval zullen er heel wat meer aspekten mede worden beschouwd, met name de linguïstische (semantische).
Interessant als ‘idee’ maar onbevredigend in zijn uitwerking is de invoering van een teksttopologie om het fundamentele begrip van de ‘samenhang’ beter te kunnen definiëren. De tekst wordt in dit perspektief niet langer gezien als een verzameling (diskrete) tekens, maar als een woordruimte, waarin de omgeving van een woord (de ‘kontekst’) van essentiëel
| |
| |
belang is. Een tekst wordt dan ‘samenhangend’ genoemd wanneer het niet mogelijk is hem in twee open of gesloten teksten te scheiden. Een dergelijke definitie is niet onjuist, maar is een al te mechanistische ‘vertaling’ van het topologische begrip (cf. Simmons: 1963:142 sqq) omdat Bense niet de (linguïstische of andere) kriteria geeft waarop die samenhang of scheiding zouden moeten berusten. Zijn teorie van de samenhang had Bense moeten uitstellen tot zijn hoofdstuk ‘Textsemantik’, omdat zij bepaald wordt door de semantische-linguïstische ‘dieptestruktuur’ (in generatief-transformationele zin) van de tekst, en niet door de arbitraire syntaktische en morfo-fonologische oppervlaktestruktuur. Maar zelfs de teoretische diskrete elementen van die dieptestruktuur (de semantische katagoriën ofsemen, vgl. Greimas, Katz, Gruber, Weinreich, Bierwisch, McGawley, Lakoff, e.a.) had hij met dezelfde matematische, verzamelingsteoretische en/of logische middelen kunnen bestuderen; in ieder geval zou hij met de bestudering van deze semantische relaties veel verder gekomen zijn bij zijn tekstdefinitie.
Als schakel met de niet-materiële aspekten van de tekst fungeert het hoofdstukje over tekstsemiotiek. De terminologische en teoretische uiteenzettingen van het begin van het boek zijn hier natuurlijk ook van kracht, en dezelfde klassifikaties zijn voor de tekst en de diverse aspekten daarvan door te voeren. Wat echter voor de typologie van de verschillende tekensystemen (waaronder dat van de taal er slechts één is) geldt, hoeft echter niet direkt op te gaan bij het karakteriseren van taalteksten. Bense maakt hier, ons inziens, een aantal fundamentele vergissingen (die voor een deel terug gaan op Peirce, en die ook Walther al had gemaakt). In de eerste plaats worden de woorden van de natuurlijke taal in hun objekt-relatie symbolen genoemd (dus: in de semiotische betekenis van arbitraire tekens) omdat zij met dat objekt geen enkele formele of materiële band of gelijkenis hebben. Des te verwonderlijker is het te konstateren, dat de dwang van de triadische indeling zich toch echter ook binnen de taal (en de tekst) - bestaande uit symbolen - doet gelden. Zo worden aanwijzende en betrekkelijke voornaamwoorden indices genoemd, omdat zij naar hun ‘objekt verwijzen’, i.c. een ander teken. Weliswaar stemt dit in zekere zin overeen met de definitie van een indexikaal teken, en weliswaar kan men zeggen dat demonstrativa, relativa (maar dan óók pronomina, etc.) ‘staan voor’ het woord waarnaar zij ‘verwijzen’, maar dit grammatikale woord ‘verwijzen’ is misleidend in zoverre dat er slechts een bepaalde relatie tussen demonstrativum, etc. en het ‘woord waarnaar verwezen wordt’ bestaat; deze relatie is een grammatikale, dus abstrakt-teoretische relatie, zodat demonstrativa, etc. slechts ‘symbolen’ genoemd kunnen worden, net als alle andere woorden, konstrukties, etc.
van de taal. Er is nl. niets, en daar gaat het om, aan demonstrativa, etc. zèlf (dus in hun klank- of schrijfvorm: dus het materiële teken waarover Bense spreekt) dat hen indices zou kunnen maken, zoals een pijl een index kan
| |
| |
zijn, noch is er een ‘kausale’ of andere konkrete relatie tussen deze woorden en de woorden waarnaar ze verwijzen. Immers zou dit zo zijn, dan zouden alle woorden van de taal, die immers in een tekst alle een bepaalde relatie hebben met andere woorden, indices zijn.
De vergissing ligt dachten we in het feit dat Bense niet langer het typologiseringskriterium doet berusten op het karakter van het (konkrete, materiële) teken zelf, maar op zijn (semantische) betekenis of op aspekten daarvan (‘deictisch’, etc.) of zelfs op de betekenis van de grammatikale termen waardoor ze worden aangeduid. Juist die relatie met de interpretant was bij de typologisering uitgeschakeld omdat het ging om een karakterisering van de relatie tussen objekt en materiëel teken.
Dit geldt wellicht nog eerder bij de zg. ikonische tekens van een tekst, zoals het beeld, de metafoor. Ook hier wordt ten onrechte de deHnitie van ‘ikonische tekens’ bijna metaforisch geïnterpreteerd. Immers, de woorden (morfemen) die een metafoor, een ‘beeld’ (?), een beschrijving ‘verbeelden’ of konstitueren hebben natuurlijk zelf geen elementen of een vorm gemeen met dat wat zij verbeelden, etc. daar zijn het arbitraire taaltekens (dus: symbolen) voor. Men zou evenwel kunnen zeggen dat in de metafoor het verbeeldende woord (dus dat wat in de tekst de metafoor heet) ‘eigenschappen’ (bv. semantische) gemeen heeft met het niet in de tekst genoemde verbeelde woord, omdat op die grond de woorden voor elkaar ‘in de plaats gezet konden worden’ - zoals de traditionele metafoorteorieën dat plegen uit te drukken. Echter, dit moge wellicht globaal niet onjuist zijn, de tekens (woorden) worden daar zelf nog geen ‘ikonen’ om, want in dat geval zou ieder woord dat eigenschappen met een ander gemeen heeft - d.w.z. alle semantisch met elkaar in verband staande woorden van de tekst - ikonen moeten zijn. Blijft alleen het feit dat het verbeeldende woord inderdaad ‘in plaats van het andere’ schijnt te staan: het is echter de vraag of dit wel een bevredigende beschrijving van een metafoor genoemd mag worden, aangezien het zeker niet altijd mogelijk is het ‘verbeelde’ woord te identificeren (en zeker niet zonder dubbelzinnigheid) en het bovendien de vraag is of dat wel zou moeten. Het gaat slechts om de aanwezigheid van een woord (betekenis) dat in een bepaalde semantische struktuur van een zin ‘ongrammatikaal’ genoemd moet worden, en zeker niet om een woord (betekenis) dat men ‘verwacht’ (door zijn koherentie met de tekst), anders zou iedere afwijkende struktuur en ieder stilistikum een
‘ikoon’ zijn van de elementen die men had ‘verwacht’. Deze herhaalde typologisering - binnen de taal - van de woord-tekens op grond van hun betekenis is dus niet in overeenstemming met de materiële basis van de tekentypologiseringskriteria die oorspronkelijk waren gesteld.
Hieruit blijkt de fundamentele misvatting van Bense: i.p.v. een abstrakt-teoretische benadering van zijn objekt (zoals de systeem- of competence beschrijving van de linguïst) geeft hij een empirisch- | |
| |
fenomenologische beschrijving van taalgebruik (performance) om achter de wetmatigheden van teksten te komen.
Ook in het korte hoofdstuk over tekstsemantiek trekt Bense geen lering uit de verworvenheden van de (linguïstische) semantiek - die slechts door hem wordt genoemd. Zijn semiotische uitgangspunt krijgt ook hier de overhand, zonder dat hij zich bewust is van het feit dat ook de linguïstiek een onderdeel is van die semiotiek, én een onderdeel dat bijzonder ver ontwikkeld is: het tehulp roepen ervan voor de beschrijving van teksten bestaande uit taaltekens is dan ook noodzakelijk. In het kader van zijn semiotische driehoek wordt de betekenis gezien in relatie met de ‘interpretant’; hij manipuleert dan begrippen als ‘Ausdruck’ (relatie met het subjekt) en ‘Aussage’ (relatie met het objekt), etc. begrippen die 40 jaar geleden al door Bühler waren gebruikt, en waarvan de linguïstische implikaties opzijn minst betrekkelijk genoemd moeten worden. De topologische ‘definitie’ van de metafoor als ‘oneigenlijke samenhang’ moge globaal gezien niet onjuist zijn, maar wanneer Bense verzuimd precies te beschrijven wat nu precies die onsamenhangendheid veroorzaakt (nl. de afwezigheid van bepaalde semantische features) dan blijft zijn definitie, ondanks de topologische terminologie, dezelfde als die welke 2000 jaar geleden al door Indische linguïsten werd gegeven (cf. van Dijk, 1970c).
Ook de teksttypologie, die begrippen als ‘Ausdruck’, etc. zouden kunnen funderen, (en Morris doet dat reeds heel wat preciezer en uitgebreider - cf. 1946:123 sqq), kan op basis van een grondige semantische teorie worden opgebouwd. De konstatering dat er (in de interpretant-relatie: rhema, dicent, argument - zie boven) ‘open teksten’ (woorden) ‘gesloten teksten’ (atomaire zinnen) en ‘volledige teksten’ (een verzameling zinnen met een logische band) bestaan, is slechts elementair fenomenologisch van karakter, temeer wanneer men in de praktijk ziet dat een imperatief als ‘Kom!’ in dat geval in alle drie de klassen thuis zou horen. Bovendien is de ‘indeling’ natuurlijk geen tekstindeling: het woord is een eenheid van het leksikon, de zin een formele eenheid van de grammatika, en de paragraaf (etc.) een formele eenheid van een (nog niet bestaande) tekstgrammatika, Ook hier schijnt Bense slechts aan de ‘oppervlakte’ van een materiële tekst te willen blijven wanneer hij deze Zeichen en Superzeichen (in zijn hoofdstuk over semantiek!) in de interpretant-relatie karakteriseert. Dat daarbij toch ongemerkt semantische overwegingen worden betrokken blijkt uit het feit dat de koherentie van zowel een dicent (bv, een zin) als van een argument (bv. paragraaf) slechts semantisch, en niet ‘materieel’ van aard is.
Wanneer Bense in de laatste hoofdstukken van zijn boek overgaat tot de estetische bestudering van de tekst, heeft hij zoals uit het hierboven staande mag blijken, maar een bijzonder wankele basis. Men hoeft niet te ontkennen dat een semiotische of informatieteoretische benadering
| |
| |
bruikbaar kan zijn, met name wanneer het erom gaat meerdere tekensystemen (meerdere kunsttypen) onder één teoretische en terminologische noemer te vatten, maar wanneer we op het linguïstisch niveau van de tekst niet de specifieke semiotische beschrijving, toepassen die we ‘grammatika’ noemen - evt. door deze een ruimere interpretatie te geven - dan leidt dat ongetwijfeld tot een onbevredigende beschrijving van dat objekt, van die tekst. Deze inadekwaatheid wordt zeker niet gemoti- veerd door het brede perspektiefdat de semiotiek aan een tekstteorie zou verlenen. De informatieteoretische estetika wordt direkt overgedragen op de tekst, zonder een definitie of een beschrijving van het karakter van de elementen in de tekst waarop begrippen als ‘ordening’ (redundantie) en ‘kompleksiteit’ (entropie) betrekking zouden moeten hebben: tekens, betekenissen, betekenisstrukturen (tematiek), klanken, of alles tegelijk? Wat betreft de mikro-estetische aspekten (selektieve informatie, over- gangswaarschijnlijkheden, etc. in de stapsgewijze ‘opbouw’ van de tekst) verwijzen we naar wat we daarover reeds hierboven hebben betoogd. Bovendien mag men veronderstellen dat de statistische karakterisering van de tekst in feite een makro-estetische aspekt is, aangezien het gaat om de als frekwenties gerealiseerde waarschijnlijkheidsverdeling in de gehele tekst (in de formule van Shannon staat nl. al een variabele voor het totaal aantal tekens van de tekst). Over de (andere) makro-estetische aspekten - gebaseerd op Birkhoff - zoals rijmschema's (de tematiek is niet materiëel, maar abstrakt en zou dus buiten de kriteria vallen), etc. wordt nauwelijks gesproken. Dat begrippen als ‘symmetrie’, etc. - die wellicht in de visuele kunsten met een zekere precisie zijn te definiëren (overigens niet zonder willekeurigheid wat betreft de keuze zijn de kriteria) - niet
zo belangrijk zijn voor taalteksten - hoogstens voor de moderne konkrete visuele poëzie - lijkt wel duidelijk.
De gesignaleerde beperkingen komen ook aan het licht in de ‘automaten-teorie’ en de ‘generatieve (syntetische) tekstteorie’, hoe interessant die op zich ook mogen wezen. Zoals gezegd kan men het struktureringsproces van een tekst niet uitputtend, en zeker niet formeel, beschrijven op basis van de (overgangs) waarschijnlijkheden van zijn woorden, d.w.z. in zg. ‘Markov-chains’ (cf. Kawano, 1968). Deze verdeling geldt nl. voor de gehele bestaande ‘taal’, d.w.z. het corpus van bestaande teksten, en dus aposteriori voor de tekst die men nu konstitueert. Het voorbeeld van de ‘black box’ uit de automatenteorie is bijzonder relevant. Het gaat er inderdaad om te expliciteren wat de regelmechanismen zijn die ervoor zorgen dat uit een eindig aantal leksikale eenheden een samenhangende tekst wordt gevormd. En de teorie die expliciet rekenschap geeft van deze regelmechanismen (die mentaal zijn vastgelegd) is een uitgebreide generatieve grammatika zoals o.a. Chomsky en de generatieve semantici die hebben ontworpen. Daarom zal men bij het syntetiseren van teksten ook de regels van die grammatika moeten mee- | |
| |
programmeren, wil de geproduceerde tekst überhaupt ‘taal’ zijn, en niet een willekeurige verzameling van min of meer samenhangende syntagmen die gelicht zijn uit bestaande teksten. De eksperimenten die Bense vermeldt zijn interessant inzoverre dat zij bewijzen wat een automatisch geproduceerde tekst (zoals die van Gunzenhäuser, Stickel, Lutz, e.a.) niet heeft als gevolg van een gebrek aan voldoende grammatikale - en vooral semantische - regels. Bovendien is het interessant te zien dat dergelijke teksten, juist door het echte gebrek aan regels, lijken op bestaande (niet-automatische) poëzie waarin de bestaande taalregels ook buiten werking kunnen worden gesteld, of andere (optioneel)
worden ingevoerd. In de automatische teksten zijn enkele zeer eenvoudige regels (voor de relatie objekt-predikaat en de relatie verbum-(in) direkt objekt) meegeprogrammeerd, zodat men het idee heeft dat er zinnen zijn geproduceerd. Echter, door een gebrek aan expliciete semantische koherentieregels (geldend voor een hele tekst) is de relatie tussen de zinnen totaal afwezig, zodat er niet sprake kan zijn van een tekst maar hoogstens van een lineaire verzameling zinnen. Binnen de zin kan het ontbreken van semantische restriktieregels leiden tot de produktie van (toevallig) interessante metaforen (zoals dat door het toeval ook bij de surrealisten gebeurde), maar het ontbreken van relaties tussen de zinnen van de tekst resulteert in een totale ordeloosheid. De (zeer hoge) entropie van de tekst die daar een gevolg van is, zal slechts bij uitzondering een estetisch effekt kunnen hebben (temeer daar juist in literaire teksten bv. de tematische strukturering - dus redundantie - als belangrijk estetisch kriterium kan worden beschouwd (cf. Exakte Astetik, 5 (1967, passim). Zoals gezegd voltrekt de generering (die formeel en abstrakt van aard is) van de (semantische) samenhang van de tekst zich in de abstrakte dieptestruktuur van de tekst zoals hij - voor de zin - door de generatieve grammatika wordt gedefiniëerd. Zonder de generering van deze dieptestruktuur is het onmogelijk een tekst in eigenlijke zin (in zijn ‘materiële’ oppervlaktestruktuur) te produceren. Dat sommige teksten in de voorbeelden van Bense toch een zekere samenhang hebben komt omdat men van te voren reeds het meegeprogrammeerde leksikon samengesteld had op basis van bepaalde tema's: liefdesgedicht, etc. Het zou pas interessant worden als de computer zelf in staat was deze selektie uit een heel woordenboek te maken, bv. aan de hand van een zeer abstrakte en globale semantische dieptestruktuur als programma (zie Van Dijk, igyob). Zonder een expliciete formulering
van een semantisch regelsysteem is dat vooralsnog echter onmogelijk. Hetzelfde geldt natuurlijk voor de ‘produktie’ van de estetische aspekten van de tekst: ook hier zou men een expliciete literaire teoric moeten hebben die precies aangeeft welke (optionele) regels er ten grondslag liggen aan de diverse fonisch-grafische, syntaktische en semantische operaties die de literaire tekst formeel kenmerken. Bense had wellicht zich meer rekenschap moeten geven dat alle aspekten van de
| |
| |
tekst (ook de estetische) in de eerste plaats formeel door een abstrakt regelsysteem worden gegenereerd en dat de (vrije) selektiemogelijkheden (of afwijkingen) daarvan slechts zeer zwak (zoals hij zelf zegt) statistisch zijn gedetermineerd door psycho-sociale factoren. De tekst die hij beschouwt is de konkrete, bestaande tekst van de performance (parole). Zoals bekend, ligt aan deze performance tenminste ook de competence (d.w.z. het abstrakte regelsysteem) ten grondslag (cf. Baumgärtner, 1968, 39 Miller & Chomsky, 1963). Maar zelfs de psycho-sociale en semiotische wetmatigheden zijn niet direkt statistisch maar vaak formeelabstrakt van karakter (zoals bv. de ‘regels’ die bepaalde teksttypen, genres, etc. produceren). De informatie-teorie kan slechts de konkrete feiten van produktie en receptie van teksten (globaal) bestuderen, en vooral de algemene principes ervan (de precieze berekening van entropie en informatie bleken op onoverkomelijke moeilijkheden te stuiten) zijn niet onbelangrijk voor het begrip van de aspekten van het hele (literaire) kommunikatieproces (cf. van Dijk, verschijnt).
Ook in het laatste hoofdstuk blijkt deze algemene waarde van de informatieteorie: tekstproduktie is een sociaal proces van kommunikatie, dat zoals iedere proces gekarakteriseerd wordt door bepaalde statistische regelmatigheden; zo ook zijn de semiotische grondslagen van iedere kennisteorie onloochenbaar. Dat er een algemene ‘Versprachlichung’ (symbolisch, digitaal, etc.) van de wetenschaps‘talen’ te konstateren valt kan men reeds zien aan het toenemend aantal formele talen. Dit wil echter niet zeggen dat de studie van de natuurlijke taal en de teksten die zij genereert met haar regels niet in de eerste plaats ‘grammatikaal’ moeten worden bestudeerd. Pas dan kan men erachter komen wat precies het karakter is van bepaalde estetisch-literaire tekstoperaties. De (globale) statistische (dus atomistische) berekening van de waarschijnlijkheid van letters, lettergrepen, woorden en zinnen, kan hiervan niet funktioneel rekenschap afleggen. De details van ‘ordening’ (redundantie) en ‘innovatie’ - en eker van de grondslagen daarvan - zijn nog allerminst duidelijk: de paradox van de estetische kriteria blijft bestaan: welke van twee, of onder welke omstandigheden beide, en in welke mate, zijn ordening en ongeordendheid bepalend voor een bepaalde estetische waarde? Een nauwkeurige bestudering van de precieze relaties tussen objekt en subjekt (de overgangsregels) is daarbij een eerste vereiste.
Met dit voorbehoud, en gelet op de gesignaleerde beperkingen (die overigens voor een deel zelf waren opgelegd) is het boekje van Bens eeen nuttige bijdrage tot de bestudering van het konkrete estetische objekt zelf, en van de konkrete, materiële aspekten van het estetische kommunikatie-proces. Blijft dus de taak hiervoor een formeel-linguïstische grammatika als basis te konstrueren.
T.A. van Dijk
(Seminarium Literatuurwetenschap) Amsterdam, december 1969
| |
| |
| |
Biografische verwijzingen
| Baumgärtner, Klaus, 1968 ‘Sprache und Automat’, in: Moser & Schmidt, hrsg, pp. 39-50. |
| Bense, Max, 1962 Theorie der Texte. Eine Einführung in neuere Auffassungen und Methoden. Köln: Kiepenheuer und Witsch. |
| Bense, Max, 1967 Semiotik. Allgemeine Theorie der Zeichen. Baden-Baden: Agis Verlag. |
| Bense, Max, 1969 Einführung in die Informationstheoretische Ästhetik. Grundlegung und Anwendung in der Texttheorie. Hamburg: Rowohlt. |
| Bok, S.T., 1958 Cybernetica. Utrecht-Antwerpen: Het Spectrum (1966: Aula4) |
| Cherry, Colin, 1957 On Human Communication. Cambridge, Mass.: The MIT Press. |
| Dijk, T.A. van, 1970a ‘Semiotiek en literatuur’. Raster 4 200-225. |
| Dijk, T.A. van, 1970b ‘Tekstgenerering en tekstproduktie’. Studia Neerlandica 1/4. |
| Dijk, T.A. van, 1970c ‘Theorie en praktijk van de semantische analyse van literaire teksten’. Nieuwe Taalgids, 64 340-355. |
| Dijk, T.A. van, 1971a ‘Some Problems of Generative Poetics’. Poetics 2. |
| Dijk, T.A. van, 1971b ‘Aspekten van een tekstgrammatika’. Lezing voor de Nederlandse Lnguïstendag. Januari 1971. |
| Dijk, T.A. van, verschijnt ‘Text and Context. Towards a Theory of Literary Performance’. In: F. Miko & James S Holmes, eds. Text and Context, (preprint, 85 p.) |
| Exakte Asthetik, 5 1967 ‘Kunst aus dem Computer’. Stuttgart: Nadolski. |
Franke, Herbert W., 1968, ‘Grundriss einer kybernetischen Ästhetik’, in: In-
S. Moser & S.J. Schmidt. Hrsg. pp. 137-143. |
| Gunzenhäuser, Rul, 1962 Ästhetisches Mass und ästhetische Kommunikation. Einfürung in die Theorie G.D. Birkhoffs und die Redundanztheorie ästhetischer Prozesse. Quickborn: Schnelle Verlag. |
| Herdan, G., 1966 The Advanced Theory of Language as Choice and Chance. Heidelberg-New York: Springer Verlag. |
| Hörmann, Hans, 1967 Psychologie der Sprache. Berlin Heidelberg New York: Springer Verlag. |
| Jakobson, Roman, 1960 ‘Linguistics and Poetics’, in: Th.A. Sebeck, ed., Style in Language, Ccambridge, Mass.: MIT Press, 350-377. |
| Miller, George A. P Chomsky, Noam, 1963 ‘Finitary Models of Language Users’. In: R.D. Luce & R.R. Bush & E.E. Galanter, eds. Handbook of Mathematical Psychology. New York: Wiley, 3 vols. II: pp. 419-91. |
| Moles, Abraham, 1958 Théorie de l'information et perception esthétique. Paris: Flammarion (Eng. vert.: Information Theory and Esthetic Perception, by Joel E Cohen. Urbana: University of Illinois Press, 1966). |
| Moles, Abraham, 1963 ‘Les bases de la théorie de l'information et leur application aux langages’, in: Communications et Langages, éd. par Abraham A. Moles et Bernard Vallancien. Paris: Gauthier-Villars, 1963: pp. 15-31. |
| Moles, Abraham, 1968 ‘Zeichen und Superzeichen als Elemente der Wahrnehmung’, in: Hans Ronge, Hrsg. pp. 207-17. |
| Morris, Charles, 1938 Foudations of the Theory of Signs. International Encyclopedia of Unified Science. Chicago: Chicago U.P. |
| Morris, Charles, 1946 Signs, Language and Behavior. New York: Prentice Hall. |
| Moser, Simon & Schmidt, Siegfried J., Hrsg., 1968 Information und Kommunikation. München & Wien: Oldenbourg. |
| Kawano, Kiroshi, 1968 ‘The Asthetics for Computer Art’, in BIT (Zagreb) 2, 22-28. |
| Peursen, C.A. van, Bertels, C.P., Nauta, D., 1968, Informatie. Een interdisciplinaire studie. Utrecht-Antwerpen: Het Spectrum. |
| Pierce, J.R., 1961 Symbols, Signals and Noise. New York: Harper and Brothers
|
| |
| |
| (Ned. vert.: Symbolen en signalen. Utrecht-Antwerpen: Het Spectrum, 1966). |
| Riedel, Harald, 1968 ‘Einführung in die Informationspsychologie’, in: Ronge, Hrsg., pp. 51-63. |
| Ronge, Hans, Hrsg. 1968 Kunst und Kybernetik. Köln: Dumont Schauberg. |
| Schmidt, Siegfried J., Hrsg. 1970 Text. Bedeutung. Asthetik. München: Bayerischer Schulbuchverlag. |
| Shannon, Cl. and Weaver, W., 1949 The Mathematical of Communication. Urbana: University of Illinois Press. |
| Simmons, George F., 1963 Introduction to Topology and Modern Analysis. New York, etc.: McGraw Hill. |
| Steinbuch, Karl & Moser, Simon, Hrsg. 1970 Philosophie und Kybernetik. München: Nymphenburger. |
| Von Cube, F., 1967 Was ist Kybernetik? Grundbegiffe. Methoden. Anwendungen. Bremen: Schünemann. |
| Walther, Elisabeth, 1965 ‘Semiotische Analyse’, in: R. Gunzenhäuser & H. Kreuzer, Hrsg., Mathematik und Dichtung. München: Nymphenburger, pp. 143-158. |
| Walther, Elisabeth, 1965 Francis Ponge. Eine Ästhetische Analyse. Köln: Kiepenheuer und Witsch |
| Wiener, Norbert, 1948 Cybernetics. New York. |
|
|
