
Forum der Letteren. Jaargang 1968
(1968)– [tijdschrift] Forum der Letteren–
[pagina 152]
| |||||||||||||||||||||||||||||||||
Mens en machine in het vertaalproces§ 1. Inleiding.Het probleem dat we hier aan de orde willen stellen, heeft twee aspecten: (a) in hoeverre geven moeilijkheden bij het vertalen informatie over taal en taaltheorie en omgekeerd (b) in hoeverre kunnen taaltheoretische onderzoekingen een bijdrage leveren in een grotere adequaatheid van het vertalen. Ons uitgangspunt bij deze problematiek is een menselijke vertaling: deze vertoont echter zodanige tekortkomingen, dat een vergelijking met de machinale vertaling zich bijna opdringt, temeer omdat de tekorten onmiskenbaar gelijkenis vertonen met die van de computervertaling. Daar komt nog bij dat juist de machine, in positieve of negatieve zin, eigen-aardigheden belicht van de betrokken talen, die bij menselijke tussenkomst veelal verborgen blijven. In eerste instantie is het hierbij van belang te benadrukken, dat we ons beperken tot natuurlijke talen; geen mechanische talen en zeker geen specificatietalen van mechanische talen.Ga naar eind1. De zin van de mechanische vertaling, hoezeer ook aangevochten in ons taalgebied, stellen we niet discutabel. Ook wij zijn van mening ‘dat waardevolle nieuwe inzichten over de taal voortkomen uit het fundamentele structuuronderzoek’Ga naar eind2. zoals dat bij de computervertaling wordt verricht. Trouwens, bij vele centra is men er zich, na de eerste onzekere pogingen, terdege van bewust geworden, dat het onderzoek in de eerste plaats op linguïstische basis geschieden moetGa naar eind3. en de taalkunde zou zichzelf belangrijke mogelijkheden ontnemen door de ‘mathematische linguïstiek’ niet in haar gebied op te nemen. In het korte bestek van deze voordracht is het niet mogelijk alle systemen aan de orde te stellen, die gevolgd worden in het nog jonge, experimentele stadium van de machinale vertaling. We signaleren er slechts een drietal, om duidelijk te maken dat de linguïstische kennis inderdaad wordt toegepast, en dat bovendien geen mogelijkheid onbenut gelaten wordt. Het structuralisme (1) vormt met name in Rusland de grondslag van de mechanische vertaling, waaraan de materialistische beschouwingswijze, die we veelal aantreffen in de wetenschappelijke benadering daar, niet vreemd zal zijn. ‘Juist omdat de regels, die dit onderscheid [te weten: van de nuances in het denken] toestaan, formeel uitgedrukt zijn, is de mechanische vertaling mogelijk.’Ga naar eind4. In de Verenigde Staten treft men, naast een structurele benadering, meer en meer een generatieve ‘approach’ (2) aan, niet alleen bij het | |||||||||||||||||||||||||||||||||
[pagina 153]
| |||||||||||||||||||||||||||||||||
M.I.T. maar ook elders. ‘Het systeem voor het construeren van zinnen’, zegt b.v. Yngve, ‘lijkt tot op zekere hoogte op de suggestieve wijze, waarop Chomsky zinnen genereert, al is er een belangrijk verschil. Terwijl het genereren van zinnen belang heeft bij een volledige representatie van de zinnen van een taal, worden bij het construeren van zinnen (in de machine) gespecificeerde zinnen slechts een voor een opgebouwd.’Ga naar eind5. De derde methode wordt gevolgd door diegenen, die een interlingua (3) trachten te vormen, ter vergemakkelijking van de overgang van grondtaal naar vertaling. In een betrekkelijk vroeg stadium is dat geprobeerd met een strikt logische interlingua,Ga naar eind6. hetgeen wel op een mislukking moest uitlopen, zoals aan het slot van deze verhandeling moge blijken. Vruchtdragender lijken daarom de gedachten van Harris, die voorstelde de te vertalen zinnen te ontleden in ‘kernel sentences’, deze te vertalen en vervolgens te transformeren tot hele zinnen.Ga naar eind7. En Dinneen tenslotte zoekt het in de vertaling op een abstract niveau, dus niet van de woorden, maar van de zogenaamde ‘specifiers’, de syntactische mechanismen die het grondpatroon van een zin genereren: ‘liever dan te vertalen op woord-niveau of zelfs op het niveau van syntactische structuren, zouden we willen vertalen op een meer abstract niveau, nl. dat van de ‘specifiers’.Ga naar eind8. Zijn er nu geen overeenkomsten in problematiek en werkwijze bij de verschillende machine-vertalingen? Die blijven er natuurlijk toch. Simpel gesteld beschikt immers in al die gevallen de computer over (1) een tweetalig woordenboek, (2) de grammatica van de grondtaal en (3) de grammatica van de tweede taal.Ga naar eind9. Op welke wijze een machine dit materiaal verwerken kan, is op heldere wijze geschematiseerd door Yngve. Hoewel zijn schema niet representatief is voor iedere methode (zeker niet voor die met de interlingua) willen we het hier toch (iets vereenvoudigd) weergeven, omdat het ook een waardevolle steun biedt bij de analyse van onze menselijke vertaling.Ga naar eind10. 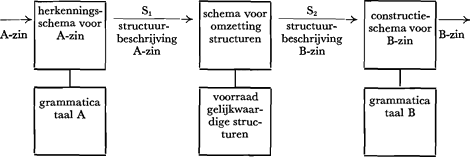 De bovenste reeks in dit schema bevat de vertaalprocessen, de onderste reeks de opgeslagen kennis. Als we, links boven, een zin uit taal A in- | |||||||||||||||||||||||||||||||||
[pagina 154]
| |||||||||||||||||||||||||||||||||
voeren, wordt deze in de eerste ‘box’ geanalyseerd overeenkomstig de eronder staande grammatica. Hierbij wordt de structuurbeschrijving (S1) vastgesteld: deze S1 bevat dus alle informatie van de A-zin, maar wat in de zin impliciet besloten ligt, wordt nu geëxpliciteerd. Aangezien de structuren van taal A afwijken van die van taal B, hebben we een ‘statement of the equivalences’ nodig; deze wordt geraadpleegd en zo kan in de tweede ‘box’ S1 omgezet worden in S2. Het constructieschema verwerkt nu S2 overeenkomstig de grammatica van taal B en rechtsboven wordt een nieuwe zin gegenereerd. De hypothetische vertaalmachine die we hier voor ons zien, biedt een aantal waardevolle informaties over het vertaalproces. Daarbij zullen de ‘mechanische’ regels ook van belang blijken voor de niet-machinale vertaling. Laten we de directe, feitelijke moeilijkheden terzijde, die niet afleesbaar zijn uit dit schema, dan schakelen we al direct o.m. uit homonymie, synonymie, idiomatische verschillen en het probleem van de woordgroep.Ga naar eind11. Als problemen van algemene orde blijven dan toch bestaan: a) de vertaalmachine is uitsluitend aangewezen op datgene wat formeel uitgedrukt is in de grondtaal of wat in een bewerking vooraf van de grondtekst, de zogenaamde ‘pre-editing’, is geformaliseerd; b) contextuele informatie is veelal formeel vastgelegd, maar de secundaire informatie die de situatie verstrekt, is niet linguaal uitgedrukt en zou hoogstens alleen weer in de ‘pre-editing’ toegevoegd kunnen worden; c) taal A en taal B beschikken elk over een eigen structureringsproces; dat geldt niet alleen voor de opbouw van de zin, maar ook voor die van kleinere eenheden als de woordgroep en eventueel ook het woord; d) voor de vertaling, hier te beschouwen als een reeks samenhangende herschrijfregels, is een structuuranalyse van taal A evenzeer essentieel als een structuuranalyse van taal B. In hoeverre gelden deze vier moeilijkheden nu ook bij de menselijke vertaling en waar distancieert die zich van de computer? In eerste instantie kan men veronderstellen, dat de menselijke vertaling dichter bij de machinale zal staan - ook in resultaten - naarmate de ‘kennis’aspecten zwakker zijn ten aanzien van een van beide talen, de input en/of de output. Dat is heel goed zichtbaar in een onlangs verschenen Reisgids voor Italië, die hier verder met de naam van de uitgever zal worden aangeduid als enit.Ga naar eind12. Blijkens ingewonnen informatie hebben we hier te doen met een vertaling en wel een niet-machinale. (Inhoeverre daarbij het Duits als ‘hulpmiddel’ een rol heeft gespeeld, is niet duidelijk geworden.) We treffen daarin drie typen zinnen aan: 1) een beperkt aantal grammaticaal en informatief aanvaardbare, die we hier verder buiten beschouwing laten; 2) moeilijk te begrijpen zinnen en 3) zinnen die niet begrijpelijk zijn zonder kennis van de grondtekst. Voor 2), maar | |||||||||||||||||||||||||||||||||
[pagina 155]
| |||||||||||||||||||||||||||||||||
vooral voor 3) geldt hetzelfde als voor de (meeste) machinale vertalingen: dat ze ‘nog niet van zodanige kwaliteit (zijn), dat ze herschreven kunnen worden door een vertaler zonder gebruikmaking van het origineel’.Ga naar eind13. We laten hier enige zinnen volgen in een aaneengesloten tekst, waarvan we de moeilijkheid, respectievelijk onbegrijpelijkheid aanduiden met 2) en 3): 2) Maar natuurlijk is het beter er met enkele erkenningen door te reizen [te weten: Italië], om de aanstoten, de eerste mogelijke misverstanden. een of andere achteloosheid te vermijden. En dat is echt hetzij voor de toeristen die hun reis van dag tot dag uit de lucht grijpen hetzij voor diegenen die er eerst over nadenken, een voorontwerp en een beknopte kostvooruitzicht stellen. 2-3) Wijdbekend is ons land herbergzaam - en dat ook tot zijn nut - en nogal met voldoende inrichtingen welgesteld. 3) De enen en de anderen kunnen ontvangen en verdragen worden en, gezien onder de enen en de anderen zijn er enkelen die Italië nooit bezochten, hebben wij er gezorgd voor dit beperkte handboek voor hen toe te bereiden. (p. 4) Refereren we nu, zonder in details te treden, aan de vier problemen zoals genoemd door Yngve, dan noteren we het volgende parallellisme: we nemen aan, dat de grondtaal bekend of voldoende bekend was aan de vertalerGa naar eind14. en punt a) vervalt dus. Ook punt b) is hier niet relevant, aangezien dat primair de grondtekst (taal A) betreft, maar voor c) geldt, dat het structureringsproces van taal B zozeer onbekend is, dat het herhaaldelijk ongenuanceerd geïndentificeerd is met dat van taal A. Wat d) betreft willen we aannemen, dat de structuuranalyse voor taal A geschied is, maar voor taal B is dat zeker niet het geval. Wat de schematische vertaalmachine betreft, deze toont nog duidelijker de tekortkomingen en de oorzaken ervan in deze B-tekst; het proces kan eigenlijk alleen maar ontwikkeld worden tot en met S1; de tweede groep boxen is of functioneert onvolledig en datzelfde geldt, in versterkte mate, voor S2 en het constructieschema met de grammatica van taal B (de derde groep boxen). De winst die geboekt is ten opzichte van de machinale vertaling, zelfs in het onvolmaakte stadium waarin de laatste zich nu bevindt en nog wel enige decennia zal blijven bevinden,Ga naar eind15. is gering. De inderdaad moeizame en moeilijke arbeid van structurering op syntactisch niveau en interpretatie op semantisch niveau in taal A kan achterwege blijven.Ga naar eind16. Voorzover structurering van taal A zou moeten geschieden met het oog op structurering en structuurbeschrijving van taal B, zou deze winst echter al weer beschouwd kunnen worden als een rem voor een uiteindelijk volledig welslagen van de vertaling. Wat kan nu onze eerste conclusie zijn ten aanzien van de machinale vertaling en deze menselijke vertaling? Het komt ons voor, dat afwijkingen van Yngves schema onjuistheden kunnen opleveren, maar deze kunnen van verschillende aard zijn. Oppervlakkige beschouwing van de | |||||||||||||||||||||||||||||||||
[pagina 156]
| |||||||||||||||||||||||||||||||||
eerste reeks voorbeelden uit de enit-tekst toont immers al, dat er graden van onjuistheid zijn. Aangezien deze zowel de structuur van een taal per se alsook de door een taal (of talen) opgeroepen ‘voorstellingen’ kunnen betreffen, dienen we enkele niveaus van adequaatheid te onderscheiden. Ook al omdat de machinale vertaling voorlopig nog wel genoegen zal moeten nemen met ‘onelegante maar begrijpelijke resultaten’,Ga naar eind17. is een dergelijk onderscheid voor een nadere beschouwing van belang. | |||||||||||||||||||||||||||||||||
§ 2. Niveaus van adequaatheid.Wat we in de eerste paragraaf terloops enkele malen gedaan hebben, willen we in het vervolg voortzetten: we spreken niet meer van een grondtaal (input, source language, languesource) maar van taal A, en niet meer van vertaling (output, target language, langue-cible) maar van taal B. Dit om duidelijk te maken, dat beide talen uiteindelijk zelfstandig moeten kunnen functioneren en niet in dienst van de andere. Met name in c) en d) hierboven is gebleken, dat de talen moeten functioneren overeenkomstig hun eigen structuurprincipes, al zal, idealiter, de ‘doorsnee’ van de verzamelingen A en B gelijk zijn, in casu het door de taal aangeduide, het betekende. We onderscheiden nu: I. Het niveau van grammaticaliteit. Hierbij moet voldaan worden aan de volgende voorwaarden: a) taal B is informatief functioneel, dat wil zeggen de overgebrachte informatie moet als zinvol en autonoom (los van taal A) ervaren worden door de taalgebruiker.Ga naar eind18. b) De voortgebrachte zinnen van B zijn grammaticaal correct en stemmen overeen met de voor deze taal geldende code in zijn ruimste zin. We zien, dat hier de relatie met taal A, ondanks de secondariteit van B, niet in het geding is. Men kan niet laten gelden, dat deze voorwaarden pas vervuld zijn bij de volmaakte vertaling; integendeel, er kunnen zeer sterke verschillen tussen A en B bestaan. We stellen overigens reeds vast dat de hierboven geciteerde enit-tekst niet voldoet aan de voorwaarden van niveau I. II. Het niveau van overeenkomst. Het stelsel van voorwaarden hier is al aanmerkelijk gecompliceerder. Om te beginnen moeten a) de eisen van het eerste niveau vervuld zijn. b) Dezelfde voorwaarden gelden nu ook voor taal A, met dien verstande, dat nog niet een directe relatie tussen A en B gelegd is. Beide talen zijn begrijpelijk en grammaticaal correct, maar hun gemeenschappelijkheid komt pas aan de orde in een volgend punt. We menen overigens dat bij incorrectheid of informatieve onduidelijkheid van taal A geen vertaalproces ondernomen kan worden en a) en b) zijn daardoor fundamenteel voor c): formele gelijkwaardigheid van taal A en taal B. Hieronder verstaan we een correspondentie met name op het vlak van de structuren en de structuurelementen (tempus, getal, vraag of mededeling, zin en niet-zin enz.). d) Correlatie van de | |||||||||||||||||||||||||||||||||
[pagina 157]
| |||||||||||||||||||||||||||||||||
betekenisrelaties van taal A en taal B, waarbij we de betekenisrelaties voorlopig omschrijven als: de in woorden en constructies gegeven informatieve functies. We spreken in d) dus nog niet over het totale, geordende ‘beeld’ dat erdoor wordt opgeroepen buiten de taal, al zijn we ons bewust van de nauwe samenhang tussen de betekenende en de betekende orde. III. Het niveau van gelijkwaardigheid. a) De voorwaarden van niveau I en II zijn vervuld. b) Niet alleen - zoals in II - zijn de betekenisrelaties correlatief, maar de interpretatie van de betekenismechanismen in B dient te corresponderen met de interpretatie van de betekenismechanismen in taal A. We bedoelen hier met interpretatie de ‘projection rule’, de contextuele component die duidelijk maakt of door het woord bal een ‘feest’ dan wel ‘speelgoed’ wordt aangeduid.Ga naar eind19. c) Het door de betekenisstructuur opgeroepen begripspatroon van taal B dient een optimale overeenkomst te bezitten met het begripspatroon van taal A; hoever die overeenkomst gaat en of er ooit van identiteit sprake kan zijn, zoals door propagandisten van de logische interlingua is gesuggereerd, moge in de slotparagraaf blijken. De bovenstaande indeling roept talloze vragen op, die lang niet alle worden opgelost door de voorwaarden die gesteld zijn bij de drie niveaus. Men kan zelfs deze indeling verwerpen op grond van het feit, dat de enit-tekst niet voldoet aan de voorwaarden van niveau I, terwijl er dikwijls toch wel een zekere overeenkomst schijnt te bestaan tussen taal A en taal B; en dat zou suggereren dat althans ten dele wel van een niveau van overeenkomst sprake is. Men zal echter moeten inzien, dat niveau I ‘ook wel eens’ bereikt wordt, maar geenszins volledig en niet in zijn totaliteit. De driedeling maakt echter wel duidelijk wat o.i. te vaak verwaarloosd is in de onderzoekingen en de eerste pogingen bij het machinale vertalen. Veelvuldig wordt het accent tot nu toe gelegd op analyse en grammaticale beschrijving van taal A; daarbij tracht men veelal een volledige grammatica op te stellen en een ‘glossary’, waarin de equivalenten van taal B secundair zijn.Ga naar eind20. De vraag mag echter gesteld worden of niet eerst getracht moet worden taal B te formaliseren, waarna de formalisering van A voorzover mogelijk zou kunnen geschieden op basis van B.Ga naar eind21. Gelijkwaardigheid immers berust niet op volledigheid, maar uiteindelijk op de kwaliteit van de zinnen, zoals ze in taal B worden gegenereerd. We willen overigens deze vraag hier niet verder behandelen en ons beperken tot enkele problemen, die door de bovengenoemde voorwaarden acuut kunnen worden. Volledigheid streven we niet na; eerder willen we een aantal essentialia uit de theoretische linguïstiek confronteren met enkele vertaalproblemen, ons daarbij afvragend inhoeverre de hier aangetroffen vertaalproblemen ons iets omtrent de structuur en het | |||||||||||||||||||||||||||||||||
[pagina 158]
| |||||||||||||||||||||||||||||||||
functioneren van de taal leren en in hoeverre de linguïstiek uitkomsten tonen kan, die kunnen bijdragen in een gunstiger ontwikkeling van het vertaalproces. | |||||||||||||||||||||||||||||||||
§ 3. Juist en onjuist in taalgebruik.De ‘grammaticatiteit’, die we voor niveau I centraal stelden, heeft twee aspecten: dat van de informatie en dat van de vormgeving. Moeten we nu de vertalingen die afwijkingen te zien geven van de oorspronkelijke tekst, analyseren naar deze twee aspecten? En zo ja, moeten we afwijkende structuren (hebben wij er gezorgd voor - enit p. 4) dan classificeren als formeel incorrect, en onjuist geïnterpreteerde woorden ((dit handboek) toe te bereiden - enit p. 4) als informatief incorrect? Of doen we er beter aan de ‘general classification of errors’ te volgen en b.v. categorieën te onderscheiden als ‘multiple meanings and ambiguities’ en ‘word order rearranged’?Ga naar eind22. Het komt ons voor dat we, alvorens te classificeren, dienen na te gaan wat we kunnen aanvangen met discriminerende termen als ‘onjuist’ en ‘incorrect’. Als Bach b.v., bij confrontatie van de zinnen Deze bewering berust op een vergissing en Jij berust op een vergissing, concludeert dat de tweede zin niet welgevormd is, dan gaat hij daarmee o.i. te ver en liever volgen we hem als hij verklaart dat de zin in ieder geval zo bijzonder is, dat hij verbazing of verwarring wekt.Ga naar eind23. Het vraagstuk van juist en onjuist is hiermee echter niet opgelost als we de opvatting van Yngve er tegenover stellen, die na een machinale generatie van zinnen constateert: ‘De voortgebrachte zinnen waren voor het merendeel helemaal correct, hoewel, natuurlijk, zonder betekenis’.Ga naar eind24. Onjuist naar de vorm, onjuist naar de inhoud. Of moeten we nog verder gaan en spreken van ‘onjuist’ in woordkeus, in structuur, in betekenis, in opgeroepen begrippen? En wat ‘onjuist’ is voor de taalbeschouwer, is dat voor de ervaring van de taalgebruiker ook ‘onjuist’? Vast staat, wat het laatste betreft, dat in het taalgebruik heel wat informatieve vormelementen gemist kunnen worden en ook worden weggelaten, zonder dat dit de communicatie op hinderlijke wijze beïnvloedt. Evenals ‘de context en de situatie ons toestaan een hoog percentage te verwaarlozen van de distinctieve eigenschappen, fonemen en foneemcombinaties in de binnenkomende “message” zonder dat de verstaanbaarheid in gevaar wordt gebracht’,Ga naar eind25. kunnen we - althans in het directe, gesproken taalgebruik - afwijkingen van de gecodificeerde constructieregels voor woorden en groepen, afwijkingen van gecodificeerde (‘letterlijke’) betekenisverwijzingen, registreren die toch de verstaanbaarheid niet verstoren. Toch, anderzijds, zijn we ons ervan bewust, dat er zinnen zijn die ons voorkomen als welgeschapen, terwijl we ook geconfronteerd kunnen worden met uitingen, die ons in meerdere of mindere mate storen. En we moeten inderdaad wel ‘graden van grammaticaliteit’ onderscheiden, | |||||||||||||||||||||||||||||||||
[pagina 159]
| |||||||||||||||||||||||||||||||||
zodat b.v. zinnen als: (1) Kleurloze groene ideeën slapen woedend eerder te aanvaarden zijn dan zinnen van het type (2) Jan vond droevig en (3) Jan verstreek dat Wim zal komen.Ga naar eind26. We voegen hieraan nu nog toe zinnen als (4) Nadat hij ingegaan zal zijn, tegenover de meesterstukken, zal hij vanzelf doen, (ENIT, 108) waar de informatie fundamenteel gestoord is bij de overdracht, en (5) Strijdonderwerp in de Middeleeuwen Genua en Pisa, nadat ze zelfstandige regeringswijzen, onder wie de een van de eigenardigste politische instellingen in de Middeleeuwen; de ‘giudicato’ ontwikkeld had, kwam zij met de Aragon's tot het Spaans invloedsgebied over (ENIT, 102), waar de verstoring eerder in een structurele orde schijnt te liggen. De volgorde van (1), (2), (3), (4) en (5) mag hier inderdaad wel gelden als een reeks, waarin de ‘afwijkendheid’ steeds toeneemt, maar anderzijds zijn de oorzaken ervan en de wijze waarop de afwijkingen tot stand komen zo uiteenlopend, dat we deze ordening verder niet bruikbaar achten. Wel echter kunnen we enkele (nogal negatieve) conclusies trekken naar aanleiding van bovenstaande zinnen.
Het bovenstaande dwingt ons ertoe een onderscheid, dat we en passant aangaven, iets scherper te stellen. Als we spreken over de ‘message’, de ‘boodschap’, de ‘voorstelling’, schijnen we ons buiten de directe orde van de taal te bewegen, al zijn deze voorstellingen ten nauwste met de taal verbonden. We zouden voor het onderscheid met de taalmechanismen die deze voorstellingen oproepen, een beroep kunnen doen op Bally, en zijn termen thema en propos weer invoeren. Propos is dan datgene wat gezegd wordt, de informatie, en thema de manier waarop dit gebeurt: de betekenis.Ga naar eind28. Het merkwaardige is namelijk dat incorrecte informatie alleen maar als incorrect ervaren kan worden, doordat het medium waarmee ze tot ons wordt gebracht, goed heeft gefunctioneerd. Willen we kunnen oordelen over het al- of niet-juistzijn van informatie, dan moet het taalgebruik (zowel grammaticaal als semantisch) overeenkomen met de code. Als dus onjuiste informatie van taal A een gelijkelijk onjuiste | |||||||||||||||||||||||||||||||||
[pagina 160]
| |||||||||||||||||||||||||||||||||
informatie van taal B tengevolge heeft, impliceert dat dan niet dat èn de vorm èn de betekenis het niveau van gelijkwaardigheid hebben bereikt? En als we tweemaal twee is vijf informatief onjuist achten, kunnen we dat dan niet alleen maar op grond van het feit, dat de zin hier grammaticaal en semantisch volkomen correct functioneert? Voorlopig concluderen we hieruit dat niet alleen Jij berust op een vergissing een correcte zin is, maar ook (1) Kleurloze groene ideeën slapen woedend. Dat de informatie in deze zinnen eigenaardig is, kunnen we buiten beschouwing laten. We doen dit met temeer overtuiging, omdat de enit-tekst ons duidelijk maakt dat er talloze vormen in het taalgebruik zijn, die een botsing laten zien van ‘performance’ en ‘competence’ in het semantische vlak. Structurele en semantische afwijzingen van de code lopen vaak in elkaar over, zijn niet steeds principieel te scheiden, terwijl informatieve afwijkingen (van de werkelijkheid?) duidelijk in een andere orde liggen. De hier volgende zinnen bewijzen o.i. dat met name voor het vertaalproces (dus ook voor de mechanische vertaling) de termen juist-onjuist terzijde gelaten kunnen worden en dat we moeten spreken van grammaticaal en ongrammaticaal, met daartussen eventueel overgangsvormen en ‘degrees’. Dat men in de ongrammaticale typen soms duidelijk structurele dan wel semantische tekortkomingen kan onderscheiden lijkt ons, althans voor de hier waargenomen gevallen, van secundair belang. De vijf typen die ongrammaticaal zijn in de enit-tekst betreffen de volgende grammaticale aspecten:
Zelfs dit geringe aantal voorbeelden (overigens ad libitum uit te breiden) maakt al duidelijk, dat we inderdaad graden van (on)grammaticaliteit moeten erkennen. Twee linguïstische verschijnselen spelen hierbij met name een rol: om te beginnen is er de dynamiek en de creativiteit van het taalgebruik (gebaseerd uiteraard op de principes | |||||||||||||||||||||||||||||||||
[pagina 161]
| |||||||||||||||||||||||||||||||||
zoals gegeven in de code). Ook in de enit treffen we constructies aan, in de woord- en in de woordgroeporde, die enerzijds als ongewoon ervaren worden, anderzijds niet in strijd hoeven te zijn met woordbouwprincipes (het Oostdeel van de stad) of met de semantische functionaliteit (dan rijden we naar Trieste voort) behalve een afwijking (...) naar het Adriatisch haventje Caorle ... (30). In de tweede plaats is er dan het verschijnsel dat wij aangeduid hebben als modaliteit. Het betekenismechanisme modaliteit kan structuren van lagere orde (b.v. de woordgroep) gedeeltelijk herinterpreteren, zodat een nieuwe betekenisstructuur ontstaat. Zo kan de grammaticaal bijzondere woordgroep (John frightened sincerity) door combinatie met het modaliteitsprincipe ervaren worden als een metafoor, een ironische zinswending, en daardoor grammaticaal correct functioneren. In de moderne poëzie is het dit modale mechanisme met name, dat een woord of woordgroep semantisch her-structureert; ‘dit hangt samen met het feit, dat in deze derde laag van betekenis een personaal, individualiserend aspect uitgedrukt is’:Ga naar eind30. het badzand is nu kolengruis het water is een winterdak en dichters dragen micatranen in een winkeljas (Lucebert). Als het eerste noch het tweede creatieve aspect uit de modale orde bedoeld zijn, en er zijn afwijkingen van de code te constateren in taal B, kan men eventueel spreken van ongrammaticaal en van graden van ongrammaticaliteit; we menen dat de vijf bovengenoemde typen inderdaad ongrammaticaal zijn. | |||||||||||||||||||||||||||||||||
§ 4. Taalgebruik en code.Zoëven hebben we gezinspeeld op de verhouding tussen taalgebruik en code, met name waar het de ongrammaticale uitingen betrof. Hoewel het onderscheid dat Chomsky maakt tussen ongrammaticaal (in strijd met de code) en onaanvaardbaar (overeenkomstig de code, maar strijdig met het taalgebruikGa naar eind31.) zeer bruikbaar is, is het in het vertalen minder actueel. Wat ons interesseert zijn primair de ongrammaticale vormen, omdat deze met name in de vertaling zo veelvuldig voorkomen. Daarbij doet zich echter een merkwaardig feit voor. Wat gebeurt er namelijk als we, zoals hierboven, het zorg ongrammaticaal noemen? Enerzijds erkennen we het zorg als een groep uit het taalgebruik, maar anderzijds gebruiken we deze term in een veel beperkter zin, namelijk als realisatie van in de code gegeven regels. Het is duidelijk dat er hier een verwarring optreedt van twee termen:
Deze verwarring kan aanleiding geven tot ernstige misverstanden en we stellen daarom voor alleen voor a) te spreken van taalgebruik en voor b) van spraak. Het taalgebruik is dus ingebed in de spraak, de spraak is | |||||||||||||||||||||||||||||||||
[pagina 162]
| |||||||||||||||||||||||||||||||||
dus taalgebruik + individualiteit. En in dat laatste met name vangen we de mislukking, de afwijking, de ontsporing, kortom alles dat niet gegeven is in en met de code. We bepalen ons nu weer tot de enit en wel tot de uiting (de Renaissance die) langzaam door een eeuwendurend gescharreld voorbereid werd naarmate om de weerherstelling van een diepe geestevenwicht ook tot een ontteffing van de verstiptheid van de Middeleeuwen uit kwam (39). Om deze uiting, die duidelijk onder de maat van niveau I - grammaticaliteit - blijft, te kunnen analyseren, moeten we het taalgebruik, de code en ten derde de spraak-aspecten onderzoeken. Zorgvuldige lezing, ook van de voorafgaande en volgende uitingen, geeft echter niet de mogelijkheid om het taalgebruik uit de spraak los te weken, omdat hier klaarblijkelijk de code in al zijn aspecten is aangetast. In termen van de machinale vertaling omgezet, constateren we ernstige stoornissen op de volgende onderdelen:
Twee interessante verschijnselen vallen hierbij in het oog:
Wat a) betreft, met name ‘woorden’ als weerherstelling, geestevenwicht, verstiptheid wijzen in deze richting. Men kan deze woorden immers ongrammaticaal noemen, omdat de grammaticale (= woordbouw-) valentie van de erin geconcretiseerde morfemen doorbroken is. Maar hoe zou men de valentie van een morfeem wel tot de code kunnen rekenen en dat morfeem zelf niet? Trouwens, het opslagorgaan van de computer kan niet toe met instructies in het algemeen, maar dat moeten instructies zijn voor modellen, en deze modellen dienen evenzeer opgenomen te zijn als de ermee verbonden programma's. Dat we in de code wel regels en modellen blijven onderscheiden, behoeft overigens geen betoog. Wat b) betreft eerst het volgende. Als we een vorm als geestevenwicht stellen naast het gebruikelijke geestesevenwicht moeten we eerst al vaststellen, dat het morfeem / geest / blijkbaar al evenzeer variabel is als | |||||||||||||||||||||||||||||||||
[pagina 163]
| |||||||||||||||||||||||||||||||||
zijn valentie. We zien dat bevestigd in vrijwel iedere vorm van taalgebruik. Wel is het centrale morfeem van nestje (lees nesje) / nest /, maar dat morfeem moet toch variabel genoeg zijn, vaag genoeg, om grondslag te zijn voor de realisaties nest en nes-. Moeten we dan ook in de code een zekere ‘onvastheid’ veronderstellen? We putten weer uit onze rijke enit-tekst, die vermeldt dat onder de kleindorpmatige, verwilderde aanschijnen nog een stukje van de droom van vroeger te vinden is (16). In deze spraakgroep kan een van de volgende taalgebruiksvormen schuil gaan: onder het kleinsteedse uiterlijk of ondanks de schijn van dorpsheid. Als we nu zien dat we, afgezien van de betekenis en de daarmee samenhangende interpretatie, hier zoeken naar taalgebruik en daardoorheen naar een code, dan is een onvariabele eenvormigheid in beide systemen niet erg denkbaar. Klaarblijkelijk is de mens, intermediërend tussen beide, essentieel, zoals het (menselijk) algoritme en de programmering ook onmisbaar zijn voor de werking van de vertaalmachine. Het is wel duidelijk, dat we hiermee de ‘universele eigenschappen’, de ‘invariabelen van de taal’, zoals Weaver die in gelijke mate in elke taal meent aan te treffen,Ga naar eind33. afwijzen. Als zelfs één taal niet over onveranderlijken beschikt, hoe zouden die dan in iedere taal gelijk kunnen zijn? Ons lijkt eerder de code:
Bezien we op deze basis nog eens de woordvormen de aanschijnen (in plaats van het aanschijn), kleindorps, dan wordt de aarzeling tussen grammaticaal en ongrammaticaal duidelijker. De dynamiek en creativiteit van het taalgebruik moeten hun invloed hebben op de code, die we niet anders leren zien dan als een min of meer vast complex van min of meer vaste regels en modellen. Die principiële onvastheid van de code wordt nog bevorderd door het feit, dat de code correlatief verbonden is met de realisatie en iedere nieuwe impuls vanuit de geconcretiseerde gebruiksvormen absorbeert en idealiseert. Aangezien deze injecties voortdurend plaatsvinden, is de code - in tegenstelling tot De Saussures opvatting - voortdurend in beweging. Iedere nieuwe vorm, iedere nieuwe regel betekent immers een wijziging van de gehele code. De conclusie die we trokken ten aanzien van juist en onjuist in de orde van de taal wordt hier dus bevestigd. De grenzen tussen grammaticaal en ongrammaticaal zijn niet scherp, en wel doordat de categorieën van de code principieel onscherp zijn. Daardoor moet men erkennen dat er 1) afwijkingen zijn van het normenstelsel (=code) die niet meer aanvaardbaar of zelf onverstaanbaar zijn en 2) afwijkingen zijn, die men ervaren zal als persoonlijk, maar die nog wel aanvaardbaar zijn. Alleen | |||||||||||||||||||||||||||||||||
[pagina 164]
| |||||||||||||||||||||||||||||||||
door de code een zekere beweeglijkheid toe te kennen, te beschouwen als een stelsel van normen, zijn de ‘degrees of grammaticalness’ geheel te verklaren; inderdaad ‘behoren ze tot het terrein van de code’,Ga naar eind35. maar ze geven tevens een aanduiding van het karakter van die code: abstract, ‘idealistisch’, met een zekere inwendige flexibiliteit. | |||||||||||||||||||||||||||||||||
§ 5. Vorm en betekenis.Een van de meest karakteristieke werkhypotheses van het structuralisme is altijd geweest, dat linguistïsch relevante verschillen uitgedrukt moeten worden in het taalgebruik.Ga naar eind36. Dat kan op velerlei wijze gebeuren en de distributie, de syntactische valentie, de morfologische valentie spelen hierbij evenzeer een rol als de woordvorm per se. Simplificerend mogen we stellen, dat één vorm één betekenis heeft. Het is duidelijk, dat de automatische vertaling, ondanks de invloed die zij in verschillende centra ondergaan heeft van Chomsky's school, tot op zekere hoogte aan dit principe is blijven vasthouden, met dien verstande dat men ieder relevant betekenisverschil geëxpliciteerd heeft in formele schema's. Dat met name deze formalisering een van de grote problemen vormt van de machine-vertalingGa naar eind37. doet aan de noodzaak ervan niet af. Men zou nu, bij oppervlakkige beschouwing, geneigd zijn te veronderstellen, dat een woord van taal A ook slecht één equivalent in taal B heeft, op grond van die stelling: één vorm - één betekenis. En blijkens zijn tekst heeft de enit-vertaler ook in deze geest gewerkt. Dat daarbij moeilijkheden moesten ontstaan is begrijpelijk als we weten dat bij de vertaling Russisch-Engels 30% van de Russische woorden tenminste drie equivalenten in het Engels bezitten, waartussen gekozen moet worden, en dat is nog niet eens een hoge schatting.Ga naar eind38. Wat kunnen wij nu voor algemeen-linguïstische conclusies trekken uit de grammaticale ontsporingen die de enit ons biedt?
Bezien we alleen de feiten zoals ze zich hier aanbieden, dan constateren we: 1. de ‘onbegrijpelijkheid’ van de hier aangegeven woorden van taal B doet veronderstellen, dat ze niet correleren met de ermee verbonden woorden van taal A; 2. de ‘onbegrijpelijkheid’ is van dien aard, dat men toch een zekere verwantschap in betekeniswaarde veronderstelt tussen de woorden van A en B; 3. krachtens de syntactische correctheid van de hier gepresenteerde zinnen mag men aanemen, dat de klasse-kenmerken in beide talen juist beoordeeld zijn. Zoeken we nu naar de oorzaken van deze vertaal-fouten - en daarbij willen we wat dieper gaan dan de constatering: het glossarium is niet goed gebruikt - dan merken we het volgende op. Om te beginnen zijn | |||||||||||||||||||||||||||||||||
[pagina 165]
| |||||||||||||||||||||||||||||||||
taal A en B in zoverre geïdentificeerd, dat alleen niet-principiële, haast toevallige vormverschillen zijn onderkend. Dat in taal A de betrekkingen tussen vorm, betekenis en informatie kunnen verschillen van die in taal B, is niet ervaren. In feite wordt hier dezelfde fout gemaakt die Weaver beging toen hij een Russisch artikel, in verband met de decodering, beschouwde als een artikel ‘dat in feite geschreven (was) in het Engels, maar dat men gecodeerd (had) met behulp van vreemde symbolen’.Ga naar eind39. Een tweede onjuistheid die ten grondslag ligt aan de grammaticale afwijkingen van de enit, betreft de bouw van het woordmodel. De vertaler is zich in onvoldoende mate bewust geweest van het feit, dat de semantische grenzen van het morfeem alleen te bepalen zijn in samenhang met die van andere morfemen, zodat taal A nooit representatief kan zijn voor het bereik van morfemen uit taal B. Dat daardoor in het semantisch aangeduide begripsveld verschillende subnoties kunnen liggen en dat (om met Katz en Fodor te spreken) de ‘markers’ en de ‘distinguishers’ niet parallel kunnen lopen in twee talen, moest hem wel ontgaan. Zelfs als we vertalen zouden simplificeren tot het schema: taalA→informatie→taal B, dan nog zou het bovenstaande ons dwingen tot de erkenning, dat in dat informatieveld door de mechanismen uit taal A andere noties geïndiceerd worden dan door de correlerende mechanismen uit taal B. Terwijl x uit taal A de begripsconstellatie ‘x’ 1, 2, 4, 7 zal dekken, zal x' uit taal B representatief zijn voor de begripsstructuur ‘x’ 1, 3, 7, 9.
We bevinden ons met het bovenstaande nog op het betrekkelijk overzichtelijke niveau van woord en morfeem. Op een hoger informatieniveau is onze vertaling echter ook belangwekkend, zoals blijkt uit de voorbeelden: (De Marken en de Abruzzen zijn de streken van Italië) die de internationale toerisme het minst bekent (60). In deze spraakuitingen kunnen twee taalgebruiksgroepen schuil gaan en
Zijn regelmatige net rechte straten (5) is zelfs vatbaar voor drieërlei uitleg, waarbij de eerste, de grammaticaal correcte, de minst waarschijnlijke is:
De grammaticale incorrectheid, zoals hierboven gedemonstreerd, is niet alleen van lexicale aard; ook de functionaliteit van de betrokken zinsdelen komt niet voldoende duidelijk tot uitdrukking, d.w.z. onder één (incorrecte) oppervlaktestructuur gaan verschillende dieptestructuren schuil.Ga naar eind40. Het komt ons voor dat met name door deze vertaalpro- | |||||||||||||||||||||||||||||||||
[pagina 166]
| |||||||||||||||||||||||||||||||||
blemen duidelijk wordt, dat functionaliteit evenzeer een semantisch mechanisme is als lexicaliteit, ook al bevinden zij zich op verschillend niveau. Argumenten voor een semantische verklaring van het functionaliteitsbegrip zijn:
Dat men toch weer steeds huiverig is om de syntactisch functionaliteit te erkennen als een betekenismechanisme moet geweten worden aan het feit, dat niet zozeer gedacht is vanuit de opgeroepen informatie - deze is toch weer sterk gebonden aan de betekenis en dus aan de linguïstische mechanismen - als wel vanuit de door de informatie bedoelde wereld van objecten. De wijze waarop taal A en taal B geprogrammeerd moeten worden voor een machinale vertaling bevestigt de overeenkomst in semantische functionaliteit van woord en structuurprincipe (en overeenkomst wil niet zeggen: gelijkheid; er is een hiërarchie); de algoritmen die men maken moet voor bepaalde syntactische herschrijvingen wijken niet wezenlijk af van de algoritmen van woordvertalingen: zie b.v. het algoritme dat Oettinger vermeldt voor de vertaling van het Engelse voorzetsel of in het Russisch, waarbij niet minder dan 22 instructies moeten worden ingevoerd.Ga naar eind41. In wezen wijkt dat niet af van het deelprogramma voor de keuze tussen subject en object na bepaalde Russische werkwoorden bij vertalingen in het Engels: de 26 instructies die hiervan deel uitmaken, presenteren zich op precies gelijke wijze als die van het genoemde voorzetsel.Ga naar eind42. Volgens onze, elders verdedigde, theorieGa naar eind43. zouden we nog een derde niveau van betekenis moeten onderscheiden, nl. de zinsbetekenis, waarin de (functionele) woordgroepbetekenis besloten ligt, die op haar beurt de (lexicale) woordbetekenis omsluit. We menen echter, dat deze tekst te weinig gegevens bevat om hier voldoende bewijsmateriaal in te vinden. Om te beginnen zijn de zogenaamde modale aspecten, die in dit mechanisme een rol spelen, in elke geschreven tekst zoveel mogelijk geëlimineerd en bovendien ligt hun functie eerder in het veld van het gesproken taalgebruik alsook in dat van de literaire tekst. Over de actualiteit ervan bij het simultaan vertalen en het vertalen van literair taalgebruik kunnen we in dit beknopte bestek geen verdere opmerkingen maken. | |||||||||||||||||||||||||||||||||
[pagina 167]
| |||||||||||||||||||||||||||||||||
§ 6. Betekenis en begrip.Als uitgangspunt kiezen we weer een spraakuiting van de enit, dus een tekst uit een B-taal: de gewoonlijke grenzen (16). In de vorige paragraaf hebben we kunnen constateren, dat de begripsvelden die door de corresponderende woorden van taal A en taal B worden opgeroepen, elkaar maar ten dele dekken. Voor dit geval kunnen we dat aldus schematiseren: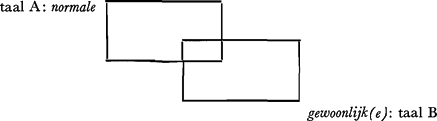 Het komt ons echter voor dat met dit schema toch een simplificatie is ingevoerd, die niet voldoende recht doet wedervaren aan de verhouding betekenis-informatie. Een inadequate vertaling A→B kan namelijk niet alleen berusten op een divergentie van de betekenissen, maar ook op een onderscheiden begrenzing van de opgeroepen begrippen. Als we het geval buiten beschouwing laten, zoals dat boven gesteld is (ongelijkheid van betekenis, ongelijkheid van begrip), dan is het mogelijk, dat
Het eerste treedt met name op binnen één taalgemeenschap: de ene taalgebruiker kan het woord vrijheid met een ander, d.w.z. ten dele afwijkend begrip verbinden dan zijn gesprekspartner. Sprekend is dat ook bij een woord als Demokratie, dat in Oost-Duitsland een andere begripsbegrenzing zal krijgen dan in West-Duitsland. Van b) schijnen talloze structuren te getuigen in de transformationele grammatica: een dieptestructuur kan door een transformatie tot een oppervlaktestructuur worden omgezet, die zich formeel onderscheidt van de oppervlaktestructuur die samenvalt met de dieptestructuur. De begripsconstellatie kan men daarbij opvatten als gelijkwaardig, terwijl de betekenisstructuren uiteenlopen, althans in het taalgebruik. Een voorbeeld in het vertaalproces van deze verhouding zien we bij ‘herschrijving’ van het Engelse I love her tot ik bemin haar; willen de betekenisstructuren van A en B hier corresponderen, dan lijkt de vertaling ik houd van haar adequater. Een analyse van deze verhoudingen voert ons tot een van de wezenlijke problemen van het vertalen. We stellen voor een nadere begrenzing van dat probleem hier als werkhypothese vast, dat betekenis is: een indicatie van een begripsveld, waarbinnen een structuur van gerela- | |||||||||||||||||||||||||||||||||
[pagina 168]
| |||||||||||||||||||||||||||||||||
teerde elementen ligt.Ga naar eind44. Die begripsvelden bestaan niet onafhankelijk en los van elkaar, maar begrenzen elkaar onderling, evenals dat het geval is met de betekenissen en zelfs de vormen van de morfemen.Ga naar eind45. Informatief, maar ook semantisch en formeel, is er dus een hechte gestructureerdheid van elkaar begrenzende elementen en velden, waarbij één wijziging verschuivingen in het hele stramien kan veroorzaken (vergelijkbaar met de Lautgesetze uit de fonologie). In eerste instantie is men geneigd hieruit te concluderen, dat het totale betekenisveld van taal A verschilt van het totale betekenisveld van taal B, doordat er althans op onderdelen verschillen zijn waar te nemen. En hetzelfde schijnt te gelden voor de begripsvelden, al moet men een uitzondering maken voor de ‘termen’ zoals die bij een vertaalmachine in het zogenaamde micro-glossarium zijn opgenomen.Ga naar eind46. Zelfs woorden als per en il uit tekst A kunnen niet onveranderlijk met voor en de/het worden weergegeven in tekst B en een identieke vertaling van taal A naar taal B, met dien verstande dat de informatie identiek ‘overkomt’, lijkt dan ook illusoir. Aangezien informatie een structuur van begrippen is, schijnt men dichter bij het niveau van gelijkwaardigheid (III) te komen in de vertaling, naarmate men dichter bij de informatie blijft. Maar hebben vorm en betekenis zo gezien nog een andere dan een zuiver intermediaire functie, en moet vertalen zich toch niet primair concentreren op ‘het aangeduide’? Dan is het inderdaad zo, dat vertalen ‘niet meer is dan een activiteit waarbij het denotatum, dat door de betekenis van een gegeven taal wordt aangewezen, weergegeven wordt door de betekenissen van de taal waarin de vertaling geschiedt’.Ga naar eind47. Moeten we, simplificerend, het vertaalproces terugvoeren tot een schema: code A → het aangeduide → code B?Ga naar eind48. Het is duidelijk, dat althans de enit in genen dele volgens dit schema gewerkt heeft; simplificerend kan men zeggen, dat daarbij vertaald is via de zuiver formele aspecten, waarbij de betekenis en zeker de begripsstructuur secundair geweest zijn. Er is voor taal B gewerkt zoals de computer dat doet, ook al heeft die extra-mogelijkheden en al kan daarvoor ‘begrips-inhoud’ geformaliseerd worden, die bij de enit niet of te weinig heeft meegespeeld. We noteren nu twee tegenstrijdige resultaten bij de enit-vertaling, zoals dat m.m. ook bij de machinale vertaling het geval is: a) ten aanzien van taal B is gewerkt op formele gronden, dus afgaand op de woord- en constructievormen. De betekenis evenzeer als het aangeduide begrip zijn daarbij in zoverre secundair geweest, dat ze of niet mede betrokken zijn in het proces van herschrijving A → B, of dat ze van A geleend zijn en onveranderd aan de vormen van B zijn toegekend. In feite is hiermee het schema van Antal weerlegd, dat trouwens niet meer is dan een notionele interlingua. Men kan blijkbaar zelfs in hoge | |||||||||||||||||||||||||||||||||
[pagina 169]
| |||||||||||||||||||||||||||||||||
mate abstraheren van de begripsstructuur, al tonen de vele ongrammaticale zinnen van de enit - evenals die van de computer in zijn huidige stadium - dat zonder betekenis en begrip een volledig adequate vertaling niet te bereiken is. b) Het feit dat er zo'n groot percentage ongrammaticale zinnen in de B-tekst voorkomt wijst er op, dat men op een of andere wijze niet alleen de betekenis, maar ook begripselementen betrekken moet in het vertaalproces. In hoeverre men met name de laatste kan formaliseren, kunnen we hier niet aangeven; wel willen we in de volgende paragraaf enkele middelen noemen. Over de verhouding van begrip en betekenis, zoals die met name in het vertaalproces werkzaam blijkt, concluderen we voorlopig het volgende:
| |||||||||||||||||||||||||||||||||
§ 7. Interpretatie en betekenis.De twee voorafgaande paragrafen hebben in feite meer problemen opgeworpen dan opgelost. Met name het feit, dat de betekenissen te algemeen, te weinig gespecificeerd zijn om binnen het begrip te differentiëren, vraagt een verdergaande analyse van de informatieve functionaliteit. De erkenning van ‘specificators’ die buiten de woordbetekenis om informatief werkzaam zijn - ook al heeft men hierbij meer op de praktijk van het vertalen gelet dan gezocht naar een linguïstische achtergrond - is gemeengoed onder de computer-taalkundigen. Al in 1955 heeft Kaplan een onderzoek gepubliceerd, waarbij de context betrokken werd in het nader preciseren van het door een | |||||||||||||||||||||||||||||||||
[pagina 170]
| |||||||||||||||||||||||||||||||||
woord aangeduid begrip. Als we het woord W noemen en de voorafgaande en volgende woorden x, kunnen we in een schema de graad van nauwkeurigheid aangeven: W - xW - Wx - xxW - Wxx - xWx - xxWxx. De context xWx is dus nauwkeuriger dan Wxx of xxW, terwijl xxWxx evenzeer informatief is als een hele zin.Ga naar eind49. Wat vertellen ons deze gegevens nu over de verhouding van de betekenis en de mechanismen die deze betekenis nauwkeuriger schijnen te richten? We bepalen ons weer tot enkele uitingen uit de enit: de bragozzi [vissersschepen] met bontgekleurde zeilen verstrooien de haar voorafgaande waters (38). De romaanse Toskane verschafte de tenietgedaan Etrurië haar genoegdoening (48). We zouden hier kunnen spreken van sentoïden: verschillende grondpatronen (deep structures - Chomsky) die in een (toevallig) gelijke gebruiksvorm (surface structure) zijn gerealiseerd. Dat die gelijkheid hier mede te wijten is aan een slechte beheersing van de code van taal B, is niet relevant. De constructionele homonymieGa naar eind50. biedt hier echter informatieve moeilijkheden, doordat noch uit de situatie, noch uit de context af te leiden is wat subject en wat object is in zin 1 en wat subject en wat indirect object is in zin 2. We concluderen hieruit: de intentie van de taalgebruiker heeft de hoorder niet bereikt. Wat moeten we nu verstaan onder intentie? Intentie is de bedoelde differentiatie binnen het door de betekenis van een woord(groep) aangeduide begripsveld, zoals die afleesbaar is uit contextuele en/of situationele verschijnselen. In zin 2 b.v. weten we door de context en wel uitsluitend daardoor, hoe we de nog betrekkelijk vage notie ‘tenietgedaan’ (opgeroepen door de betekenis van tenietgedaan) moeten interpreteren, namelijk als ‘verwoest’ (niet als ‘opgeheven’, ‘verdwenen’ b.v.). En in ons meergebruikte voorbeeld Wijdbekend is ons land herbergzaam leren ons de contextuele verschijnselen (ons, is ... herbergzaam, voorafgaande zin) dat hier niet ‘aarde’, ‘bouwland’, ‘streek’ geïntendeerd is binnen de notie ‘land’, maar ‘natie’. Het is duidelijk dat de interpretatie secundair is ten opzichte van de betekenis, ook al speelt ze een rol bij het opbouwen van een informatief beeld. Ze is dan ook geen gecodificeerd gegeven, geen regel, maar een gesystematiseerd aspect van het taalgebruik. Terwijl de betekenis van land onveranderlijk ‘land’ is, evenals de betekeniswaarde van het morfeem / land /, kan men niet zeggen dat de (gecodificeerde) betekenis van ons de intentie ‘natie’ behelst. Overigens wordt het belang van de intentie hierdoor niet geringer en het wordt nu duidelijk waarom we in § 2 voor het derde niveau (gelijkwaardigheid) behalve correlatie van de betekenissen in taal A en taal B, ook correlatie eisten van de intentie | |||||||||||||||||||||||||||||||||
[pagina 171]
| |||||||||||||||||||||||||||||||||
en dus de interpretatiemechanismen. Voordat we deze laatste aan de orde stellen, vatten we samen:
Het bovenstaande heeft al de richting aangewezen, waarin de intentie werkt: met de intentie correspondeert namelijk de interpretatie en de formele brug tussen beide hebben we genoemd de interpretatiemechanismen. Die mechanismen kunnen situationeel zijn en contextueel; aangezien we ons hier echter bezighouden met de vertaling van teksten, kunnen we de situationele interpretatiemechanismen buiten beschouwing laten: ze gelden niet voor taal A en dus evenmin voor taal B. Een tekst biedt, naast de betekenismechanismen waarmee ruwweg een informatief schema wordt gepresenteerd, een aangepaste toevoeging van informatiemechanismen. Hiermee wordt binnen het algemene betekenisschema gedifferentieerd en wel zo ver, als nodig is om de intentie van de spreker gestalte te geven. Anders gezegd: de intentie werkt via een aantal interpretatiemechanismen - en veelal worden die niet bewust gekozen, maar zijn ze al werkzaam door de combinaties van betekenissen - zodanig, dat de hoorder de aangeboden tekst gedetailleerd kan interpreteren.Ga naar eind51. In de twee bovengenoemde enit-uitingen is de informatie verstoord, doordat de interpretatiemechanismen niet in voldoende mate aanwezig zijn om de geïntendeerde specificaties binnen de betekenisstructuur over te dragen. Hoe belangrijk de functie van de interpretatiemechanismen is voor een volledig toereikende informatie, zien we in de volgende spraakgroep: hier moeten we, zoals in § 4 bij de betekenis, door de spraak heen het taalgebruik opsporen met zijn betekenismechanismen èn zijn interpretatiemechanismen. (Wijdbekend is ons land herbergzaam - en dat ook tot zijn nut - en) nogal met voldoende inrichtingen welgesteld. De informatie die hierbij uiteindelijk tot stand komt, verloopt volgens het volgende schema: 1) formele klankreeks → 2) betekenisstructuur → 3) interpretatie → 4) informatie. Eventueel moeten we in dit geval een tussenschakel 3a) invoegen, te weten die van de herinterpretatie, in verband met de afwijkingen van de code. | |||||||||||||||||||||||||||||||||
[pagina 172]
| |||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||
§ 8. Vertalen en vertolken.In deze paragraaf willen we enkele voorlopige conclusies trekken na een voorlopige terreinverkenning. Onze probleemstelling in § 1 betrof de zinvolle wisselwerking tussen vertalen als een praktische handeling en de taalkunde als een wetenschappelijke systematisering van taalverschijnselen. Zonder exact aan te kunnen geven waar en in hoeverre beide ‘systemen’ zinvol kunnen zijn voor elkaar, mogen we toch een aantal raakvlakken signaleren, waarbij de contacten tot nieuwe inzichten of tot een heroriëntatie leidden. Het vertalen als proces hebben we scherper kunnen afbakenen dankzij een linguïstische analyse van enkele resultaten. Van essentieel belang is gebleken het feit, dat taal A en taal B als volledig autonome structuren gezien worden, zowel in hun mechanische functionaliteit alsook in hun | |||||||||||||||||||||||||||||||||
[pagina 173]
| |||||||||||||||||||||||||||||||||
informatieve ‘outputs’. Zelfs waar het vertaalproces in optimale zin werkzaam is, krijgen we aldus een schema van gescheiden circuits:  Het vertaalproces als een herschrijven van identieke informatie verwerpen we hiermee categorisch: er bestaat geen objectieve informatie (althans niet in relatie met natuurlijke talen), maar uitsluitend linguïstisch gestructureerde informatie. Het vertaalproces dient zich daarom te concentreren op de functionele mechanismen betekenis en interpretatie met hun formele representanten, in het besef dat deze autonoom en inwendig gestructureerd zijn, en uniciteit bezitten voor de eigen taal. Twee zaken relativeren deze strakke voorstelling van zaken. Enerzijds is er het vormcomplex waarin de informatiemechanismen hun ‘veruiterlijking’ zoeken; anderzijds is er het ‘mede-weten’ van taalgebruikers binnen één taalgemeenschap. Het vormcomplex biedt de mogelijkheid in optimaal objectieve zin de informaties ‘a’ en ‘b’ tot elkaar te brengen: in en aan dit materiële aspect kan gezocht worden naar een zo groot mogelijke verfijning, zodat althans de bedoeling (dat is niet hetzelfde als intentie of interpretatie) gelijkwaardig kan worden in vele gevallen. Daar staat tegenover dat het (al of niet linguïstisch voorgevormde) denkpatroon elementen in het proces van informatie-overdracht invoert, die niet formeel uitgedrukt zijn. En vooral dit laatste kan een materieel onvatbaar element vormen in de functionaliteit van de taal, waardoor het vertaalproces sterk gehinderd wordt. De divergentie van taal A en taal B valt daardoor ten dele buiten de beide stelsels van mechanismen, die we hier onder de termen betekenis en interpretatie hebben samengebracht.Ga naar eind52. Strikt genomen ligt de informatie buiten de orde van de taal, hetgeen het vertalen kan bemoeilijken. Die informatie wordt echter linguaal begrensd, is een veld waarbinnen de betekenis- en interpretatiemechanismen als coördinaten binnendringen; dat opent de mogelijkheid tot vertalen, maar dan uiteraard ook in en via de inwendige en uitwendige structuurprincipes waarover de taal beschikt. Vertalen is daarom voor ons: een herschrijven van de informatie ‘a’ uit taal A tot de informatie ‘b’ uit taal B door de onderling samenwerkende betekenis- en informatiemechanismen van B in optimale overeenstemming te brengen met de mechanismen van A en te coderen in het organisch ermee verbonden vormcomplex van taal B. | |||||||||||||||||||||||||||||||||
[pagina 174]
| |||||||||||||||||||||||||||||||||
Dat de rol van een computer in een dergelijk proces discutabel is, spreekt vanzelf. Men moet zelfs constateren, dat de machinale vertaling nooit volledig op het optimale niveau zal kunnen komen (het niveau van gelijkwaardigheid), omdat het ‘mede-weten’ niet gecodeerd is en niet volledig gesystematiseerd kan worden. Daar staat tegenover, dat in teksten - vooral wetenschappelijke, waarin het modale aspect ondergeschikt is - principieel de voor-kennis en het mede-weten zoveel mogelijk uitgeschakeld zijn. Voor dergelijke teksten zijn er zeker mogelijkheden voor de machinale vertaling.Ga naar eind53. Het komt ons voor, dat men daarbij rekening zal moeten houden met de uitkomsten die de linguïstiek biedt en wel in die zin, dat de codering (algoritmen) en programmering ook als het ware in twee fasen verloopt: eerst voor de betekenismechanismen en in tweede instantie voor de interpretatiemechanismen. Of een eenvoudig vertaalschema als van Yngve daarvoor een juist beeld geeft, valt om meer dan een reden te betwijfelen. Ook als men de betekenismechanismen alleen splits in een glossarium en een grammatica (respectievelijk de tweede en de eerste box), blijf de vraag of men de woorden (morfemen?) los moet zien van hun distributieregels. Met andere woorden, het schijnbaar voor de hand liggende onderscheid tussen regels en materiaal zou wel eens een nodeloze verzwaring kunnen betekenen van de ‘opgeslagen kennis’, omdat men daardoor verplicht is in aparte algoritmen uit te werken, wat zich veelal als een geïntegreerd geheel presenteert. Dat de codering van de secundair werkende interpretatiemechanismen het gehele proces uitermate verzwaart, behoeft geen betoog. Men moet voor de machine coderen wat niet in de taalcode geborgen ligt, maar alleen gesystematiseerd optreedt in het taalgebruik; daarbij mag men niet streven naar 100% juistheid, aangezien dat op z'n minst een contextuele analyse zou impliceren van iedere voorafgaande en iedere volgende zin voor elk te interpreteren woord! Een statistisch vooronderzoek van deze materie is dus een eerste vereiste.Ga naar eind54. Tenslotte enkele opmerkingen over de verhouding van mens en machine in het vertaalproces:
| |||||||||||||||||||||||||||||||||
[pagina 175]
| |||||||||||||||||||||||||||||||||
Mol (België) F.G. Droste |
|