|
| |
| |
| |
De luchtbibliotheek
Hoe bouw je zelf een digitale bibliotheek? En wat kun je ermee?
Ewoud Sanders
Ik moet een jaar of twaalf zijn geweest toen ik me voor het eerst verbaasde over iets wat me nog altijd op een kinderlijke manier verbazen kan: de inhoud van de lucht. Als ik indertijd, ruim dertig jaar geleden, aan mijn vriendjes vroeg wat zij zagen als zij naar de lucht keken, dan kreeg ik als antwoord: wolken, de toppen van bomen, de zon, en hé kijk daar, een vliegtuig.
Ja, die dingen zag ik ook, maar mijn verbazing betrof het onzichtbare in de lucht. Ik heb het niet over engelen, God of Allah, maar over de radiosignalen die op een of andere manier de weg van Lopik naar de transistorradio op onze keukentafel wisten te vinden. Daar kwamen ze voornamelijk tevoorschijn als muziek. Ik zag die stralen dan ook voor me als compacte bundels vol muzieknoten.
Later kwamen daar nog televisiebeelden bij: eerst Nederland 1, toen Nederland 2 en 3, het werd steeds drukker. De lucht moet vol stralen zitten, bedacht ik me, bundels met informatie die overal doorheen beuken: door gebouwen, door bomen, door onze hond en door mijn lichaam. Ik kon ze niet zien of voelen, maar ik was diep onder de indruk van wat daar allemaal door de lucht raasde, op weg naar onze antennes.
Inmiddels is het nog veel gekker: ga met een laptop met een draadloze internetverbinding op een bankje in het park zitten en u heeft - onder veel meer - toegang tot de inhoud van honderdduizenden boeken. De prachtige digitale collecties van de Bibliothèque Nationale in Parijs, van de Library of Congress in Washington, van het British Museum in Londen, ruim 350.000 pagina's bij de Digitale Bibliotheek voor de Nederlandse Letteren (dbnl), de krantencollectie op de website van de Koninklijke Bibliotheek - het is bóven Nederland nog veel drukker geworden dan tijdens het spitsuur in de Randstad.
En die drukte zal nog verder toenemen, want alleen Google al gaat de komende drie jaar ruim zeven miljoen boeken op internet zetten.
Het is iets wat ik niet goed kan bevatten, zoals ik nooit écht heb begrepen hoe radio en televisie werken. Maar het blijft onverminderd verbazingwekkend: door de lucht zweeft, in de vorm van nulletjes en eentjes, binnen afzienbare tijd de grootste bibliotheek die ooit door mensenhanden is gebouwd.
Dat is allemaal goed en wel, maar is dit iets waar de welmenende, niet al te technisch onderlegde particulier zelf iets aan toe kan voegen? Kunnen u en ik meebouwen aan deze digitale toren van Babel? Of nog beter: kunnen wij misschien zélf onze eigen digitale bibliotheek bouwen, met net zoveel smaak en zorg ingericht als de bibliotheek in ons huis?
Ja, dat kan, dat ligt inmiddels binnen handbereik. Het kost tijd en geld, maar het kan.
Voor diegenen die nu denken, há, hier kan ik afhaken, want ik heb geen zin om tijd en geld te steken in het digitaliseren van boeken, heb ik goed nieuws, want er zijn ook mogelijkheden om het gratis te laten doen, met een minimale tijdsinspanning. Maar daarover later meer.
Eerst een beschrijving van hoe je zelf een digitale bibliotheek kunt bouwen, wat je ervoor
| |
| |
nodig hebt aan hard- en software, wat je ermee kunt en wat de voor- en nadelen zijn van zo'n papierloze boekerij.
| |
Wat heb je nodig?
Je hebt er, kort gezegd, drie dingen voor nodig: een scanner (een apparaat, dus hardware), een softwarepakket om de computer een scan te laten omzetten in digitale tekst, en een programma om pdf's te bewerken (waarbij pdf staat voor Portable Document Format). Voor al deze zaken is de concurrentie groot: er zijn heel veel verschillende scanners en zogenoemde ocr-programma's (ocr staat voor Optical Character Recognition, optische tekenherkenning), en er zijn allerlei programma's waarmee je pdf's kunt bewerken. Tamelijk toevallig ben ik terechtgekomen bij een zwart-wit, flatbed Fujitsu-scanner (afgeprijsd €500), bij het ocr-programma FineReader 8.0 (€142) en bij pdf Converter Professional 4 (€99). Daarnaast gebruik ik Adobe Reader, dat je gratis kunt downloaden van internet.
scanners
Wat voor scanner heb je nodig? Dat ligt aan je eisen. Als je de tijd hebt om op je dooie gemakje af en toe een niet al te dik boek te scannen, kun je al uit de voeten met een flatbed hp-scanner van onder de €200. Als je veel en vooral veel sneller wilt scannen, heb je een ‘middenklasse productiescanner’ nodig (dat is de aanduiding die scannerverkopers gebruiken). Dergelijke productiescanners zijn veel sneller (het scannen van een pagina op het flatbed kost dan zo'n drie seconden) en ze kunnen veel meer scans per dag aan dan zo'n goedkope machine. Er komen voordurend nieuwe scanners op de markt, maar momenteel verdienen aanbeveling de Fujitsu fi-5220C (€1448 ex. btw) en de Canon dr2580C (€1399 ex. btw). Voor details over de prestaties van deze scanners, zie www.scannerstore.nl en ga daar via de hyperlink ‘scanners’ naar de optie ‘scannermatrix’.
Overigens is er een flinke markt voor tweedehands scanners. Zoek bijvoorbeeld via www.veilingkijker.nl. Bij de aankoop van een tweedehands scanner is het wel zaak te onderzoeken of ze werken binnen bijvoorbeeld Windows xp. Veel technische informatie over scanners is bovendien te vinden op de websites van de fabrikanten.
Het heeft mij vrij veel tijd gekost om te doorgronden hoe een en ander werkt, want gek genoeg ligt die informatie niet voor het grijpen, en ook de handleidingen bij de software blinken niet uit door duidelijkheid. Ik maak het niet al te technisch, maar het lijkt me toch handig om even kort samen te vatten hoe je te werk moet gaan.
Om een boek te scannen ga je - tenzij je de bladzijden lossnijdt - net zo te werk als bij een kopieerapparaat. Je legt het boek op de glasplaat, maakt een ‘afdruk’ (die als digitaal plaatje wordt opgeslagen), je slaat de bladzijde om en maakt nog een ‘afdruk’, en zo verder tot je klaar bent.
Duurt dat lang? Dat ligt aan de snelheid van je scanner, maar bij een wat zwaardere pro- | |
| |
ductiescanner haal je vrij makkelijk zo'n driehonderd pagina's per uur. In die tijd is het boek gescand, zijn dubbele pagina's automatisch gesplitst, zijn zwarte randen weggesneden en zijn de scans gelezen door de ocr-software. Dat lezen door de ocr-software houdt in dat de door het scannen gemaakte afbeelding van de originele tekst - vergelijkbaar met een fotokopie - is omgezet in doorzoekbare en bewerkbare digitale tekst, vergelijkbaar met een Word-bestand.
Bij losse bladen - bijvoorbeeld een kopie van een artikel, of losgesneden bladen uit een boek of tijdschrift - gaat dit allemaal veel sneller. De automatische invoer van een niet al te dure scanner ligt op zo'n vijftig pagina's per minuut; dure scanners kunnen al zo'n tweehonderd pagina's per minuut aan, dubbelzijdig.
Hoe ziet zo'n scan met ocr er nu uit? Het gescande document wordt met de ocr opgeslagen in een pdf-document. De standaard is tegenwoordig om de tekst onder het paginabeeld te bewaren. De pdf bestaat dus uit twee lagen: wat wij zien is een getrouwe kopie van het origineel. Daaronder, op de tweede laag, ligt de ocr. In die ocr is het origineel zo getrouw mogelijk nagemaakt: grote letters staan groot in de ocr, kleine letters klein, kortom, de uitgetikte tekst volgt het origineel zo precies mogelijk en ligt er precies onder.
Er was een tijd dat de pdf slechts uit één laag bestond; je keek dan naar de ocr. Dat is bijvoorbeeld gebeurd bij het tijdschrift De Navorscher, die geweldige vraagbaak die van 1851 tot 1960 heeft bestaan. Je ziet daar geen facsimile van de oorspronkelijke bladzijde, maar een reconstructie van de pagina zoals die is gemaakt door de computer.
Technisch kon het toen nog niet anders, maar deze aanpak had een groot nadeel. Als er nu een leesfout in de ocr staat - en die zijn ruimschoots aanwezig - dan kun je op die reconstructie niet zien hoe het in het origineel staat. Kortom, om De Navorscher correct te citeren of om bij twijfelgevallen te kijken wat er nu precies staat, moet je toch terug naar de papieren versie. De Navorscher moet nog eens opnieuw worden gescand.
Tegenwoordig kennen we dat probleem niet meer. Er worden nog steeds leesfouten gemaakt in de ocr, maar je kijkt naar een exacte kopie van het origineel. Je kunt daar de tekst zo afscheppen, met de functie ‘tekst selecteren’. Als je de tekst nu in bijvoorbeeld Word plakt en je ziet een leesfout staan, dan heb je het origineel bij de hand om die leesfout te corrigeren. Dit kan zelfs in de ocr - maar daarover later meer, want ik had beloofd het niet al te technisch te maken.
Heeft het zin om op deze manier zelf aan de slag te gaan? Hierboven schreef ik al dat alleen al op de website van de dbnl ruim 350.000 bladzijden zijn gedigitaliseerd. De dbnl is al sinds 1999 bezig en ontvangt jaarlijks een subsidie van €288.000. Wat zou een particulier of een kleine instelling zonder veel geld daar nu aan kunnen toevoegen?
In de eerste plaats: de dbnl scant geen boeken, maar laat de boeken integraal uittikken op de Filipijnen. Het voordeel van deze aanpak is dat de uitgetikte teksten nagenoeg foutloos zijn. Het nadeel is dat deze aanpak erg duur is (ongeveer €2 per pagina).
Een ander groot nadeel vind ik dat er weinig overblijft van de beleving van het oorspronkelijke boek. Ik ben een groot voorstander van het digitaliseren van boeken, maar ik wil het boek wel graag als boek blijven herkennen - het zetsel, de oorspronkelijke letters, de opmaak, de afbeeldingen, desnoods de vlekken.
Bij sommige boeken in de collectie van de dbnl zijn afbeeldingen van het origineel bijgevoegd, maar bij de meeste zit je te kijken naar een steriele uitgetikte tekst.
Een nog veel groter bezwaar vind ik dat 350.000 pagina's misschien wel veel lijkt, maar
| |
| |
gezien de tijd en de kosten die ermee gemoeid zijn, eigenlijk niet zo veel is. Onlangs heeft het eenmansbedrijf Arik in een paar maanden tijd honderd jaargangen van het tijdschrift De Gids gescand. Alleen die honderd jaargangen - van 1837 tot 1937 - tellen al 206.896 pagina's. Mijn eigen digitale bibliotheek is, door eigen scanwerk maar vooral door scanwerk door derden te initiëren, inmiddels veel groter dan de dbnl. En een stuk eenvoudiger te doorzoeken, want sinds 1999 is het de dbnl niet gelukt om een betrouwbare zoekfunctie te maken.
| |
Vlees en bloed
Voordat ik nog iets zeg over het bewerken van de scan en de ocr - eerst de kernvraag van dit stuk: wat is nu het voordeel van een digitaal boek boven een boek van vlees en bloed?
Dit tijdschrift wordt gelezen door boekenliefhebbers. Ik ken de geneugten van het boek. In mijn bibliotheek staan duizenden boeken uit de achttiende, negentiende en de eerste helft van de twintigste eeuw. Ik ken de genoegens van het zoeken naar en het bezitten van boeken, van het voelen en ruiken aan boeken en - niet te vergeten - van het lézen van boeken.
Maar toch: veel boeken zijn voor mij grondstof voor de dingen die ik zelf wil schrijven. Het zijn bronnen van schoonheid, maar in de eerste plaats bronnen van informatie. En hoe meer boeken je hebt, hoe meer tijd het kost om die informatie te vinden en hoe meer ruimte die boeken in beslag nemen.
Zie daar het eerste immense voordeel van het digitale boek. Honderd jaargangen van De Gids beslaan zo'n twintig a vijfentwintig meter in de boekenkast. Ik heb de set die nu is gedigitaliseerd zien staan, ze komen van een bevriende letterkundige. Mooie, vuistdikke leren banden, soms vier per jaargang, grotendeels uniform ingebonden, met een fraai rugschild. Maar ook met leerrot, zodat je handen bruinrood kleurden als je een band uit de kast pakte. En ondanks een stapeltje registers nauwelijks écht te raadplegen.
Ik heb de afgelopen vijftien jaar hele reeksen taalkundige tijdschriften bladzijde voor bladzijde doorgebladerd. Ik vond er de schitterendste dingen in. De aantekeningen die ik maakte, verwerkte ik in een database. Dat werkt niet slecht, maar het is niks vergeleken bij het digitaal doorzoeken van een tijdschrift.
Aan het oude bronnenmateriaal waar wij mee werken - ieder op zijn eigen vakgebied - verandert niet veel. Maar onze onderzoeksvragen veranderen voortdurend. Als ik nu opnieuw al die tijdschriften zou doorbladeren - wat me maanden werk zou kosten - zou ik heel andere dingen noteren dan toen.
Gelukkig is dat niet meer nodig. Je kunt, als je wilt, met een paar muisklikken een index maken op de boeken, artikelen en tijdschriften die je hebt gescand. Dat kun je doen met pdf Converter Professional of bijvoorbeeld met Adobe Acrobat. Die indexen kun je allemaal centraal (vanuit een zoekvenster) benaderen. Ik doe veel aan taalkundig onderzoek en ik heb de afgelopen twee jaar de belangrijkste taalkundige tijdschriften laten scannen (door Arik, waar ik overigens geen enkel zakelijk belang in heb). Als ik nu op zoek ga naar een woord of uitdrukking, dan vink ik in zo'n zoekvenster aan door welke indexen ik wil zoeken. Dat kunnen de volgende bronnen zijn:
| · | De Gids 1837-1937 (206.896 pagina's); |
| · | De Navorscher 1851-1960 (50.622 pagina's); |
| |
| |
| · | De Taalgids 1859-1867 of de Taal & Letterbode 1870-1875 (samen met de vorige titel 4926 pagina's); |
| · | Noord en Zuid 1877-1907 (16.565 pagina's); |
| · | Tijdschrift voor Nederlandse taal- en letterkunde 1881-1990 (tntl, 34.861 pagina's); |
| · | Onze Volkstaal 1882-1890 (aantal pagina's onbekend); |
| · | Taal en letteren 1891-1906 (7995 pagina's); |
| · | Onze Taal 1932-2000 (8190 pagina's); |
| · | Taal en Tongval 1949-2004 (15.195 pagina's); |
| · | een collectie van de belangrijkste spreekwoordenboeken van 1840 tot 1950 (8178 pagina's); |
| · | alle spellinggidsen en Groene Boekjes van 1804 tot 1995 (7822 pagina's); |
| · | Amstelodamum 1900-2000, plus alle jaarboeken en maandbladen (37.705 pagina's); |
| · | de eerste editie van de Winkler Prins 1870-1882. |

De titelpagina van deel 1 van de eerste editie van de ‘Winkler Prins’. Ook dit invloedrijke naslagwerk, uitgegeven door C.L. Brinkman, is inmiddels gedigitaliseerd. In de loop van 2007 komen de eerste negen drukken ervan digitaal beschikbaar
| |
| |
| |
Tijd
Kost dit veel tijd? De computer zelf is slechts enkele seconden bezig om via de (gecomprimeerde) indexen zo'n 400.000 à 450.000 pagina's te doorzoeken. Hoe lang jij vervolgens bezig bent met het lezen, hangt af van het aantal ‘hits’, het aantal vindplaatsen. En van je zoekvraag: je kunt instellen dat je alleen hele woorden zoekt, of een exacte combinatie van woorden, dan wel een deel van een woord. Zoeken op een woorddeel levert natuurlijk meer vindplaatsen op, die een langere leestijd vergen. Maar alles bij elkaar is het ongekend om zo razendsnel door zo'n kolossale hoeveelheid tekst te kunnen zoeken.
En dit was slechts een kleine selectie van de reeksen die intussen een plekje hebben gevonden in mijn digitale bibliotheek en die - door hun overstap van papier naar pdf - tientallen meters ruimte in mijn boekenkasten hebben opgeleverd. Er zijn ook enkele grote aardrijkskundige en biografische woordenboeken beschikbaar, waaronder het tiendelige Nieuw Nederlandsch biografisch woordenboek (1911-1937), het veertiendelige Aardrijkskundig woordenboek der Nederlanden (1839-1854) van A.J. van der Aa, het 21-delige Biographisch woordenboek der Nederlanden van dezelfde auteur en het 35-delige Vaderlandsch woordenboek (1785-1797) van Jacobus Kok.
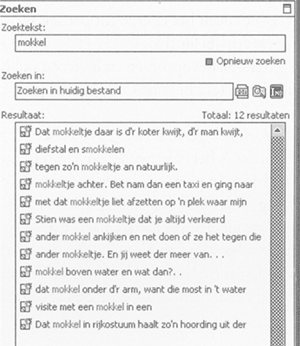
Zoeken in scans op delen van woorden levert meer resultaten op. Hier de resultaten van de zoekopdracht ‘mokkel’ in Tibbe Bosch, Bet van Beeren, Koningin van de Zeedijk, Amsterdam 1977. Niet alleen mokkel en mokkeltje worden gevonden, maar ook smokkelen
Dit gaat om grote reeksen die door derden zijn gescand. Met sommige titels heb ik iets te maken gehad, met andere helemaal niks. De meeste reeksen zijn te koop, sommige - zoals het tntl en Taal en Tongval - (nog) niet vanwege potentiële auteursrechtelijke problemen. Juist op dit terrein wordt het auteursrecht, dat uit 1912 dateert, links en rechts ingehaald door de werkelijkheid. In de praktijk maken auteurs en uitgevers slechts zelden bezwaar tegen het scannen van teksten. Voor de auteursrechtelijke kanten van deze kwestie, zie http://tinyurl.com/se78r (Taskforce Archieven).
| |
| |
in aantocht
Er zijn al veel grote naslagwerken gedigitaliseerd, maar welke komen er binnenkort nog aan? Uitgeverij Het Spectrum zal in 2007 een reeks dvd's uitbrengen met daarop in gedigitaliseerde vorm de eerste negen drukken van de Winkler Prins Encyclopedie. Er komt een digitale versie van de Militaire Spectator, een tijdschrift dat sinds 1832 bestaat. Uitgeverij Kok heeft plannen om de eerste twee edities van de Christelijke Encyclopaedie uit te brengen, mogelijk samen met de twee edities van de Katholieke Encyclopaedie - werken van enorm cultuurhistorisch belang.
| |
Meer voordelen
Zijn ruimtewinst en snelle doorzoekbaarheid nu de enige voordelen van het gescande boek? Nee, er zijn nog véél meer voordelen.
Veel boekenliefhebbers vinden het een gruwel om een boek op het scherm te moeten lezen. Ik lees vrijwel nooit een boek op het computerscherm. Ik lees een boek in mijn stoel of in mijn bed en als ik er mee klaar ben en ik vind het de moeite waard, dan leg ik het op de scanner. Niet alleen het citeren uit boeken wordt op die manier veel makkelijker - de tekst is immers vrijwel foutloos uitgetikt door het ocr-programma - maar bij boeken met een kleine letter óók het opzoeken en herlezen van bepaalde passages. Als je aan het wieltje van je muis draait terwijl je de Ctrl-toets ingedrukt houdt, kun je teksten naar believen groter of kleiner maken.
Als ik een boek heb gescand, kies ik of ik het per se wil houden - want zo goed, mooi of belangrijk - of dat ik het een tweede leven gun in het antiquarische circuit. De inhoud is en blijft bewaard op mijn pc en op diverse back-ups. Wie twijfelt aan de duurzaamheid van pdf in vergelijking met papier: volgens een recent verschenen studie over de duurzaamheid van digitale opslagmiddelen (Networking for Digital Preservation: Current Practice in 15 National Libraries van Ingeborg Verheul) is pdf zo'n standaardformaat en zó wijdverbreid, dat het tot in lengte van dagen leesbaar zal blijven, al was het maar doordat er in de toekomst software ontwikkeld zal worden om pdf-bestanden te converteren naar nieuwe formaten.
| |
Serendipiteit
Het gescande boek bevordert de ongezochte vondst, de serendipiteit. Ik weet niet of het u lukt om alles te lezen wat u zou willen lezen, mij niet. Ik scan ook wel eens een boek dat ik nog niet heb gelezen. Nu leest de computer het voor mij. Als ik vervolgens mijn computer doorzoek - via indexen of bijvoorbeeld met Google Desktop, dat ook pdf's indexeert - vind ik soms informatie in publicaties waar ik nooit aan zou hebben gedacht.
Voor historisch en letterkundig onderzoek is het vaak van belang om je bronnen in chronologische volgorde te lezen. Dat is voor mij een reden om de titel van een gescand boek altijd te beginnen met een jaartal. Bijvoorbeeld: 1906-M.J. Brusse-Landlooperij. Dit prachtige boek, waarin Brusse verslag doet van zijn avonturen als stroper, jutter en landloper, bevat veel dialect en platte volkstaal. Als ik nu mijn pc doorzoek op een bepaalde term en het komt in zeven boeken voor, dan staan die meteen in chronologische volgorde in de zoekresultaten.
| |
| |
Maar stel nu dat ik het belangrijk zou vinden om alle boeken van M.J. Brusse bij elkaar te zetten - en dat zijn er tientallen, de meeste zeer de moeite van het lezen waard. Dan kopieer ik simpelweg de scan en verander de naam bijvoorbeeld in Brusse-M.J.-Landlooperij (1906).
Anders gezegd: bij gescande boeken is het niet nodig om dubbele exemplaren te kopen. Binnen twee seconden is een gescand boek gedupliceerd. Wilt u alle boeken van een bepaalde uitgeverij bij elkaar zetten? Maak een apart mapje, kopieer wat u nodig heeft en klaar is kees. Alle boeken met het werk van een bepaalde illustrator bij elkaar? Idem. Hoort een boek in verschillende rubrieken - mapjes op de pc - thuis, bijvoorbeeld boekhistorie en geschiedenis algemeen? Kopieer en plak en het is gedaan.
Dit kan natuurlijk ook met alleen hoofdstukken uit een boek. Of met alleen inhoudsopgaven en/of registers - als u geen zin of tijd heeft om hele boeken te scannen. Twintig jaar geleden heb ik nog vele kaartenbakken gevuld met fiches, maar een goed ingerichte gescande bibliotheek maakt die geheel overbodig.

Omslag van het boek Landlooperij van M.J. Brusse. Het boek werd in 1906 uitgegeven door W.L. en J. Brusse in Rotterdam. De tekening op het omslag is van Pieter Dupont
| |
| |
Heeft u verschillende convoluten in de kast staan, banden of bandjes met boeken van bijvoorbeeld verschillende schrijvers uit verschillende jaren? De band kan een goede reden zijn om ze bij elkaar te houden, maar in gescande vorm maakt dat niks uit. U kunt de convoluten nu makkelijk opdelen en de bestanddelen op verschillende plaatsen opbergen.
Werkt u wel eens met anderen samen, of op verschillende plekken - thuis en op de universiteit, in Nederland en in het vakantiehuisje? De gescande bibliotheek is supermobiel. Op mijn pc staat een kastje ter grote van een gemiddelde Nederlandse roman. Het is een externe harde schijf met 300 gigabyte geheugen - ruimte voor tienduizenden gescande boeken. Wilt u nog lichter reizen? Je staat versteld hoeveel er al op een usb-stick past.
De gescande bibliotheek is makkelijk deelbaar. Stel, u wilt een aantal bronnen met anderen doornemen, met deskundigen die in Nederland of aan het andere eind van de wereld wonen. Eenmaal gescand is een boek of een reeks boeken zo verspreid, per e-mail, per cd of per dvd - afhankelijk van de hoeveelheid bits en bytes die de titel in beslag neemt. Om u een idee te geven, een boek van 220 bladzijden met enkele foto's beslaat ongeveer 8 mb. De omvang hangt ook af van de resolutie waarmee u scant. De huidige standaard is 300 dpi (dots per inch), maar bij klein of ‘moeilijk’ zetsel wordt dit 400 dpi, waardoor het aantal bytes omhoog vliegt. Je hebt dus wel wat geheugenruimte op je pc nodig, maar extra werkgeheugen is niet nodig.
Ik heb verschillende boeken in mijn bibliotheek staan die in geen enkele openbare collectie in Nederland aanwezig zijn. Dat is leuk voor de verzamelaar, maar slecht voor de boekwetenschap. En het boek is kwetsbaar. Een gescand en verspreid zeldzaam boek is niet langer zeldzaam en daardoor minder waard, maar het is ook minder kwetsbaar en door meer mensen te bestuderen.
Er zijn trouwens ook zeldzame exemplaren van algemeen gangbare boeken, bijvoorbeeld doordat ze kanttekeningen bevatten van de auteur. Als die kanttekeningen duidelijk zijn, zijn ze ook te lezen op een scan. Hetzelfde geldt bijvoorbeeld voor handgeschreven correcties in het exemplaar dat aan de auteur heeft toebehoord.
Al jarenlang voeg ik extra informatie aan boeken toe. Kopieën van besprekingen, uit aanbiedingsfolders, advertenties, soms een necrologie van de auteur. Dit alles kan ook bij een gescand boek. Met een programma als pdf Converter Professional kun je de gemaakte scan op ieder moment bewerken. Bij ongedateerde boeken voeg ik het jaartal toe (in het rood, zodat duidelijk is dat het niet op de originele titelpagina staat), soms de jaartallen van de auteur of een opmerking over de drukgeschiedenis (eerder verschenen in die en die krant, tweede herziene druk in dat jaar, enzovoort).
Maar je kunt ook hele pagina's aan de scan toevoegen. Bijvoorbeeld met een bespreking die je gevonden hebt in de digitale krantencollectie van de Koninklijke Bibliotheek - 350.000 pagina's uit de periode 1910-1945 - of in het digitale archief van de Groene Amsterdammer (1877-1940).
| |
Nadelen
Dit klinkt allemaal geweldig, althans ik vind het zelf geweldig. Maar zijn er ook nadelen verbonden aan het scannen van boeken? Natuurlijk, die zijn er ook. Een boek kan beschadigd raken of zelfs uit elkaar vallen als je het bladzijde voor bladzijde op de scanner moet
| |
| |
leggen, zeker als je het een beetje op de glasplaat moet drukken. Er zijn speciale boekscanners waarbij dit niet nodig is, zoals de scanners van Bookeye, maar die zijn peperduur - vanaf ongeveer €25.000.
Overigens is het scannen van een kwetsbaar boek slechts eenmaal belastend. Nadien kun je het veilig in de kast zetten en het voortaan op de pc raadplegen. Men vergeet wel eens dat gewoon lezen ook schadelijk kan zijn voor een boek.
Een ander nadeel is dat de ocr niet foutloos is, wat vooral van belang is als je uit het boek wilt citeren. Afhankelijk van de kwaliteit van de scanner en van het zetwerk - modern zetsel of loodzetsel - beloven de verkopers van ocr-software tegenwoordig dat zo'n 98 tot 99,8 procent van de tekst foutloos is. Zeker voor boeken die na circa 1890 gedrukt zijn, komt dit overeen met mijn ervaring. Bij oudere boeken ligt het foutpercentage hoger (je kunt het wel omlaag krijgen door je ocr-software te trainen; dit kan ook bij FineReader).
Ik vind de foutjes die overblijven niet zo erg. Als je scans met bijvoorbeeld Acrobat Reader leest, kun je niks meer in de achterliggende ocr veranderen. Als je pdf Converter Professional gebruikt (of een vergelijkbaar programma) kun je foutjes in de ocr meteen herstellen: je tikt de verbetering in, klikt op ‘save’ en daarmee is de kous af.
Dat je op deze manier kunt ‘inbreken’ in de ocr geeft trouwens ook interessante mogelijkheden. Stel u heeft het plan, zoals ik, om nog eens een boek te maken over vergeten woorden. En een bloemlezing over de zelfkant van de samenleving in de Nederlandse literatuur. De ervaring leert datje op de onmogelijkste momenten, als je er helemaal geen tijd of ruimte voor hebt, dingen tegenkomt die interessant zouden kunnen zijn voor dergelijke projecten. Vroeger zou ik een aantekening op een fiche hebben gemaakt, of - erger - op een papiertje in het boek. Nu maak ik simpelweg een krabbel in de ocr, bijvoorbeeld [vergeten woord] of [bloemlezing zelfkant].
Ik hoef hier dus straks maar naar te zoeken, en de vergeten woorden en de literaire beschrijvingen van de zelfkant springen tevoorschijn. Voor de duidelijkheid: die verwijzingen staan niet op de gescande pagina, maar op de achterliggende ocr. Niemand heeft er last van - je moet weten dat ze er zijn om ze te vinden. Je kunt die aantekeningen natuurlijk ook op de bovenste laag maken; je kunt ze ook zo weer weggooien of je houdt bijvoorbeeld een schone kopie.
Zo zijn er meer mogelijkheden. Ik ben al jaren bezig met een Historisch Bargoens Woordenboek. Daarvoor las ik laatst Het spionnetje. Roman uit de Jordaan van G.P. Smis - een boek dat ik voor de verandering niemand kan aanraden. Smis zat met het probleem hoe hij het platte Jordaans zou weergeven. Hij koos voor een fonetische weergave die zijn boek vrijwel onleesbaar maakt. Zo wordt gozer bij hem gausir, heibel wordt haabil, heitje wordt haaitje, en gribus is omgetoverd tot griebese.
Leuk, maar het zijn geen woordvormen waar je snel op zou gaan zoeken. Nu zou je in de ocr bij gausir kunnen toevoegen [= gozer]. Dit kun je een keer doen, of met ‘zoek en vervang’ door de hele tekst. Nu kom je het woord gozer toevallig in heel veel spellingvarianten tegen, namelijk ook als gauser, goasser, gooser, goosser, goozer, goser, gosert, gouser en gozerd. Dat zijn erg veel spellingvarianten om op te zoeken, maar als je de ocr heb ‘verrijkt’ hoef je alleen te zoeken op ‘[= gozer]’, en alle spellingvarianten komen vanzelf tevoorschijn.
In het vakjargon spreekt men in dit geval van het toevoegen van tags of metadata.
| |
| |

Omslag van Het Spionnetje. Roman uit de Jordaan uit 1939 van G.P. Smis. Het boek, uitgegeven door de Wereldbibliotheek, is vrijwel onleesbaar door de curieuze fonetische weergave van het plat-Amsterdams. Wie de tekening op het omslag heeft gemaakt is niet bekend
Maar goed, ik was bezig met de nadelen van scannen. Hier is er nog een: niet alle boeken lenen zich voor het scannen op een eenvoudige machine thuis. Atlassen en boeken in groot formaat met uitklapbare kaarten vergen duurdere scanners die grotere formaten kunnen verwerken. Nog altijd zeer de moeite waard, maar niet voor iedereen te betalen.
Nog een nadeel: omdat het vooral bij seriewerken geen doen is om bladzijde voor bladzijde om te slaan, wordt hier gewerkt met scanners met automatische documentinvoer (adf). Daarvoor moet een boek worden losgesneden. In theorie kan zo'n seriewerk daarna weer worden ingebonden, maar in de praktijk wordt er vaak een set opgeofferd. Die 20 à 25 meter van De Gids, met leerrot en rugschildjes - ze bestaan niet meer. Ze zijn uit elkaar gehaald, geofferd, vernietigd. Het vernietigen van boeken doet natuurlijk altijd pijn, ook voor de grootste voorstander van de digitale, gescande bibliotheek. Het is vanzelfsprekend zaak om alleen reeksen te offeren die ruimschoots voorhanden zijn in openbare collecties. Of boekjes die antiquarisch geen stuiver meer opbrengen.
| |
Ruilbeurs
Ik had de lezers die geen geld en tijd willen besteden aan het scannen van boeken in het vooruitzicht gesteld dat verder lezen in dit artikel zou worden beloond met informatie over
| |
| |
een manier om gratis en zonder tijdsinvestering boeken te laten scannen. Die manier is er inderdaad. In Apeldoorn is een bedrijf dat boekopcd heet. De formule is simpel. Je kunt daar een boek brengen - voorheen kwamen ze het halen, nu moet je er zelf naartoe - dat zij voor je scannen. Jij krijgt gratis en voor niks een gescand exemplaar terug op een cd'tje, plus het oorspronkelijke boek natuurlijk, dat wordt gescand op een grote en dure scanner, die ook grote formaten aankan. Boekopcd biedt de scan vervolgens op internet te koop aan - de afspraak is dat u de scan niet verhandelt.
De scans van boekopcd zijn niet zo mooi als die van Arik (ze worden bijvoorbeeld niet schoongemaakt) en aanvankelijk was het boekaanbod bedroevend (veel incomplete sets bijvoorbeeld). Maar het laatste halfjaar is de voorraad geschoond, zijn incomplete reeksen aangevuld of verwijderd en weten steeds meer particulieren, archieven, bibliotheken en andere instellingen de weg naar Apeldoorn te vinden. Er zijn daar nu werkelijk interessante boeken te koop, voor relatief weinig geld, en als zij de boeken interessant vinden die u wilt laten scannen, dat gebeurt dan kosteloos.
Zelf zie ik echter het meest in iets anders: een ruilbeurs voor gescande boeken, op internet. Inmiddels heb ik twee jonge jongens voor mij werken, die in totaal tien uur in de week bij mij scannen (als ze kunnen kiezen tussen vakken vullen bij de supermarkt en boeken scannen, blijkt de keuze snel gemaakt). Wekelijks worden hier zo'n zeventig tot tachtig boeken gescand en die productie zal nog verder toenemen. Bovendien ben ik van plan om hier nog jaren mee door te gaan. Ik heb nu al honderden boeken en artikelen op mijn pc staan en hoewel ik die niet gratis ga weggeven, wil ik best scans ruilen tegen andere goede scans van interessante boeken.
Dus: wie voelt zich aangesproken? Wie gaat de scanner die hij al in huis heeft op deze manier gebruiken? Of wie koopt een nieuwe scanner plus toebehoren en gaat aan de slag?
Er komt de komende jaren veel bij op internet, dat is waar. De universiteitsbibliotheken van Amsterdam en Leiden en de Koninklijke Bibliotheek in Den Haag hebben drie miljoen euro gekregen om hun collectie boeken en pamfletten uit de periode 1781-1800 te digitaliseren. De dbnl heeft eenmalig €800.000 extra gekregen om duizend sleutelteksten uit de Nederlandse cultuurgeschiedenis te laten uittikken.
Maar zitten daar de boeken tussen die u zo graag digitaal zou willen doorzoeken, en liefst op korte termijn? In mijn geval is die kans heel klein. En hoe dan ook: ik heb geen zin om jaren te wachten. Scannen kost tijd en geld, maar ik vind de baten veel groter dan de kosten: plankruimte, een mobiele bibliotheek en ongekende zoekmogelijkheden.
webverwijzingen
| · | http://demo.zylab.com/dga/ (De Groene Amsterdammer 1877-1940) |
| · | http://kranten.kb.nl/ |
| · | http://www.scansoft.nl/ (producent pdf Converter Professional) |
| · | www.arik.nl |
| · | www.boekopcd.nl |
| · | www.dbnl.org/ |
| · | www.easydata.nl/ (distributeur FineReader) |
Met dank aan Jaap Engelsman
|
|
