|
| |
| |
| |
Leo Lentz, Pim Mak en Henk Pander Maat
Oogbewegingsregistratie en gebruikersonderzoek
Samenvatting
Welke mogelijkheden biedt oogbewegingsregistratie ons vakgebied om op het spoor te komen van problemen die lezers ervaren met teksten? In een experiment is aan proefpersonen een tekst voorgelegd van een financiële bijsluiter. Deze werd in verschillende condities gelezen: wel of geen commentaar geven en wel of niet hardoplezen. Na afloop werd een begripstoets afgenomen op een aantal moeilijke woorden in de tekst. De resultaten maken duidelijk dat zowel de opdracht hardop te lezen als de opdracht om na het lezen commentaar te geven gevolgen heeft voor het leesproces zelf in vergelijking met proefpersonen die de tekst stillezen. Voor het opsporen van lexicale begripsproblemen biedt de gebruikte techniek nog weinig steun. In een slotbeschouwing wordt gereflecteerd op de problemen en de mogelijkheden van oogbewegingsregistratie voor evaluatie-onderzoek.
| |
1. Inleiding
Er zijn allerlei manieren om teksten te pretesten op kwaliteit. Zo kan onderscheid worden gemaakt tussen synchrone en retrospectieve methoden, en tussen methoden die de nadruk leggen op tekstbeoordeling en op het daadwerkelijk gebruiken van de tekst. In eerder onderzoek hebben we vastgesteld dat het lezersprotocol een sterke methode is om begripsproblemen te identificeren (Pander Maat & Lentz, 2003). Het lezersprotocol is een variant van de hardopdenkmethode waarbij lezers tijdens het hardoplezen van een tekst commentaar leveren. Het sterke punt van de methode lijkt er vooral in te liggen dat lezers het verbaliseren van problemen nauwelijks hoeven uit te stellen, anders dan bijvoorbeeld bij de plus-enminmethode het geval is. Pander Maat & Lentz concluderen dat deze methode veel meer probleemsignaleringen oplevert bij zin-voor-zin commentaar geven dan bij alinea-voor-alinea commentaar geven.
Het is mooi dat het hardopdenken veel informatie levert over begripsproblemen, maar het is wel de vraag of de opdracht om commentaar te leveren het leesproces beïnvloedt. Leest een lezer anders wanneer hij weet dat er straks commentaar moet worden gegeven? We hebben op dit punt geen hypotheses, omdat we geen eerder onderzoek naar het effect van commentaartaken op het leesproces kennen.
In Pander Maat en Lentz (2003) bleek het voor de hoeveelheid commentaar niet uit te maken of de tekst hardop dan wel stil gelezen werd. Wij vroegen ons af welke invloed hardoplezen op het leesproces zou kunnen hebben. Het meest voor de hand liggende effect is natuurlijk dat hardoplezen het leesproces vertraagt (zie Rayner, 1998). Maar het is ook denkbaar dat bij hardoplezen de lezer in veel hogere mate lineair door de tekst heen gaat | |
| |
dan bij stillezen het geval is. Omdat hij gedwongen is het ‘voorlezen’ voort te zetten, kan hij immers niet vrijelijk terugkijken naar eerdere tekstgedeelten, ook wanneer hij dat normaal gesproken wel zou doen. Dit soort vragen kan eigenlijk alleen worden beantwoord wanneer het leesproces rechtstreeks geregistreerd wordt. Daarom hebben we in dit onderzoek met oogbewegingsregistratie gewerkt.
Maar onze interesse in oogbewegingsregistratie ging verder dan de hierboven genoemde vragen. We hebben de methode niet alleen gebruikt bij het onderzoek naar het effect van commentaar geven en hardoplezen op het leesproces, we zijn ook geïnteresseerd in de mogelijkheid om oogbewegingsregistratie zelf als pretestmethode te gebruiken, met name bij het opsporen van begripsproblemen. Onze redenering is dat deze problemen vaak zichtbaar kunnen zijn in verstoringen van het leesproces. Wanneer bijvoorbeeld een woord extreem lang gelezen wordt, of er wordt later nog eens naar teruggekeken, of er wordt aan het eind van de zin vrij lang gewacht, dan zou dat kunnen duiden op begripsproblemen. Rayner (1998) geeft allerlei onderzoek weer waaruit blijkt dat met name herlezen gerelateerd is aan problemen bij het opbouwen van mentale representaties van de tekstinhoud. Daarnaast is bekend dat minder frequente woorden langere fixaties krijgen; en moeilijke woorden behoren vaak tot de minder frequente woorden.
Daarom hebben we in dit onderzoek verkend in hoeverre oogbewegingen indicaties voor begripsproblemen kunnen bevatten. Het zou natuurlijk heel mooi zijn als begripsproblemen konden worden opgespoord met een methode die niet of nauwelijks ingrijpt in het leesproces, in die zin dat de lezers niets ‘extra's’ hoeven te doen naast het lezen van de tekst. We hebben ons hier beperkt tot een specifieke categorie begripsproblemen, namelijk problemen met moeilijke woorden.
Samenvattend zijn er drie onderzoeksvragen:
| • | Welke invloed heeft de instructie om commentaar te leveren op het leesproces van een zakelijke tekst? |
| • | Welke invloed heeft de instructie om een tekst hardop (in plaats van stil) te lezen op het leesproces? |
| • | Kan registratie van oogbewegingen indicaties opleveren voor lexicale begripsproblemen bij het lezen van zakelijke teksten? |
Het onderzoek naar de eerste twee vragen is experimenteel te noemen, dat naar de derde vraag exploratief.
| |
2. Methode
Om de eerste twee vragen te beantwoorden is een experiment opgezet met als onafhankelijke variabelen commentaar geven en manier van lezen. Aldus ontstonden vier condities:
| • | stillezen en geen commentaar geven; |
| • | hardoplezen en geen commentaar geven; |
| • | stillezen en commentaar geven; |
| • | hardoplezen en commentaar geven. |
| |
| |
Ten behoeve van de verkennende onderzoeksvraag naar indicaties voor leesproblemen vulden alle proefpersonen na afloop van de leesactiviteit een digitale vragenlijst in waarin gevraagd werd naar de betekenis van tien woorden die in de tekst voorkwamen. Op die manier wilden we nagaan of er op de een of andere manier een relatie te vinden was tussen het niet begrijpen van specifieke woorden en het leesgedrag in passages waarin die woorden voorkwamen.
| |
2.1 Proefopstelling.
De proefopstelling was als volgt. In het laboratorium van het UiL-OTS is een cabine waarin een eyetracker is opgesteld. Figuur 1 biedt een weergave van de opstelling.

Figuur 1: Proefopstelling met de eye-tracker.
Deze opstelling bestaat uit de volgende componenten. Voor de registratie van oogbewegingen wordt gebruikgemaakt van de SMI Eyelink I. Dit is een systeem met een hoofdset waar twee camera's aan gemonteerd zijn, die zodanig worden ingesteld dat ze de bewegingen van de pupillen kunnen registreren. Dit systeem maakt gebruik van infrarood-technologie en meet met een frequentie van 250 Hz, binnen een bereik van dertig graden horizontaal en twintig graden verticaal, de pupilpositie met een nauwkeurigheid van 0.5 tot 1 graad. Twee computers maken deel uit van het systeem: op de ene pc draait de SMI eye-tracker en worden dus de data geregistreerd; op de andere pc draait het stimulusmateriaal waar de proefpersoon mee geconfronteerd wordt. Aan deze pc zijn twee monitors gekoppeld, een voor de proefpersoon zelf en een in de ruimte van de proefleider. Voor dit specifieke experiment maakten we gebruik van het softwareprogramma Gazetracker waarmee het mogelijk is onder Windows stimulusmateriaal aan te bieden en data te registeren.
| |
2.2 Materiaal.
Het materiaal bestaat uit een financiële bijsluiter Rendemix zoals we die op het Internet hebben aangetroffen op de site van de Rabobank. Sinds 2002 zijn banken verplicht voor hun financiële producten een bijsluiter te maken die het publiek in staat moet | |
| |
stellen een keuze te maken tussen verschillende producten en de risico's goed in te schatten. De Autoriteit Financiële Markten heeft regels opgesteld waar deze bijsluiters aan moeten voldoen.
De Rendemix bijsluiter is eerder object van onderzoek geweest (Kippersluis, 2005) met als doel na te gaan of er problemen waren met moeilijke woorden in de tekst. Daartoe werd een digitale versie gemaakt waarin proefpersonen de mogelijkheid kregen woorden die zij niet begrepen aan te klikken, waarna uitleg op het scherm verscheen. Aldus werd een indicatie verkregen van de woorden waar proefpersonen moeite mee hadden. Deze tekst is enigszins herzien, om zo op elk scherm voor de proefpersoon een afgeronde passage te kunnen presenteren. Aldus ontstond een versie van de bijsluiter die in tien schermen gepresenteerd werd. Figuur 2 biedt een weergave van de uiteindelijke presentatievorm.

Figuur 2: Weergave van een scherm in de proefopstelling.
FINANCIËLE BIJSLUITER RENDEMIX
Deze financiële bijsluiter geeft geen informatie die op uw persoonlijke situatie is toegesneden en geeft geen uitputtende beschrijving van de voor u geldende rechten en plichten. Verdere details over RendeMix vindt u in het prospectus dat kosteloos op aanvraag beschikbaar is. Het beleggingsfonds RendeMix raadt u aan ook hiervan kennis te nemen. De financiële bijsluiter wordt actueel gehouden.
Vanwege de gewenste nauwkeurigheid van meting werd gekozen voor een regelafstand die groter is dan normaal. En om de verhoudingen in balans te houden, werd ook gekozen voor een wat groter lettertype. Per scherm werden aldus maximaal negen regels tekst aangeboden met een regelafstand van 1,5 centimeter (36 pt.) en een lettergrootte van 16,5 pt. Aldus ontstond een scherm dat zeker niet gebruikelijk is voor de financiële bijsluiter op het web. Hier hebben we dus een concessie moeten doen ten gunste van de kwaliteit van de meting. Verderop zal blijken dat we hierin misschien nog niet ver genoeg gegaan zijn.
De interface van de proefopstelling zag er als volgt uit. In een beginscherm stond de toewijzing aan een van de condities (hardop of stil werken en wel of geen commentaar geven op elk scherm) en een link naar het eerste scherm. De interface verschilde per conditie, omdat de commentaargevers onder elk scherm een link commentaar aantroffen, die zij aan moesten klikken alvorens commentaar te geven. Daarna verscheen precies hetzelfde scherm met rechtsonder in rood de opdracht: geef commentaar. Daaronder stond een link Verder, die leidde | |
| |
naar de volgende passage van de bijsluiter. Op deze manier konden we de registratie van de oogbewegingen tijdens de eerste lezing en die tijdens het commentaar geven van elkaar scheiden. Proefpersonen werden geacht hun commentaar uit te stellen tot na afronding van het lezen van de passage. De interface dwong dus de volgende volgorde af: lezen - klikken op commentaar - commentaar geven op de passage - klikken op verder - lezen van de volgende passage. De interface van de hardoplezers verschilde niet van die van de stillezers.
| |
2.3 Proefpersonen.
De proefpersonen werden geworven via een site van het UiL-OTS waar vooral studenten op afkomen. Zij konden zich daar digitaal inschrijven voor een sessie en ontvingen na afloop een vergoeding van 5 euro. Aan de proefpersonen werden enkele specifieke voorwaarden gesteld die voortvloeien uit de technologie. Zo waren brildragers bij voorbaat uitgesloten omdat de registratie bij hen tot onvoldoende resultaten leidt. Proefpersonen die mascara droegen, moesten dit verwijderen voordat de sessie kon beginnen, omdat mascara tot gevolg heeft dat het systeem de pupil niet goed kan detecteren. Daartoe was materiaal in het laboratorium aanwezig. Proefpersonen mogen niet langer dan 30 minuten over de taak doen, omdat dan langzamerhand de ogen uitdrogen, wat tot extra knipperen leidt, hetgeen ook weer leidt tot verhoogde onnauwkeurigheid. Onze taak kostte de proefpersonen vijf tot tien minuten. In totaal namen 26 proefpersonen deel aan dit onderzoek. Na controle van de data vielen er twee af, omdat de nauwkeurigheid van de registratie te gering bleek te zijn.
| |
2.4 Procedure.
De procedure was als volgt. Na binnenkomst werd de proefpersonen kort uitgelegd dat het om een onderzoek ging naar de kwaliteit van een financiële bijsluiter, waar hun feedback voor nodig was. Daarna werd de proefpersonen gevraagd goed te gaan zitten, zodanig dat de muis goed bereikbaar was en het scherm goed zichtbaar was. Als ze eenmaal goed zaten, werd de hoofdset opgezet, werden de camera's goed op de pupil gericht, en werd gecontroleerd of de hoofdset goed stevig zat. Ook dit is van groot belang voor de kwaliteit van de meting. Onverwachte bewegingen met het hoofd kunnen namelijk leiden tot een verschuiving van de hoofdset en een slechtere kwaliteit van de meting.
Daarna startte de eerste kalibratie. De proefpersoon werd gevraagd zich goed te concentreren op een zwarte stip die op negen plaatsen in het scherm verscheen en daar zichtbaar bleef totdat de proefpersoon goed fixeerde. De proefleider-pc registreerde de positie van de pupil en gaf een score in termen van failed, poor of good calibration. In het eerste geval werd deze procedure herhaald. Vervolgens werd de Gazetracker software geactiveerd en doorliep de proefpersoon een procedure die vergelijkbaar was met de kalibratie. Hij of zij moest telkens met de muis op de zojuist verschenen stip klikken, waarna een volgende stip verscheen. Deze procedure werd aan het eind van de sessie nogmaals uitgevoerd. Op die manier konden we controleren in hoeverre de data aan het begin en het eind van de sessie met dezelfde mate van nauwkeurigheid geregistreerd waren. Bovendien konden we op basis van deze procedure eventuele afwijkingen in de metingen achteraf corrigeren.
Na het lezen en eventueel commentaar geven werd de opname van geluid en oogbewegingen gestopt. De hoofdset werd afgenomen en vervolgens werd de korte digitale vragenlijst op het scherm getoond met tien meerkeuzevragen over moeilijke woorden. Na elke vraag kwam een vraag waarin op een vijfpuntsschaal feeling of knowing werd bevraagd. De vraag luidde: In hoeverre bent u zeker van het antwoord dat u gaf.
| |
| |
| |
2.5 Analyse.
De analyse van de data begon voor elke proefpersoon met een controle van de betrouwbaarheid van de meting. Daartoe werden de door ons ingevoegde twee extra kalibraties gebruikt. Figuur 3 biedt een weergave van zo'n kalibratie.
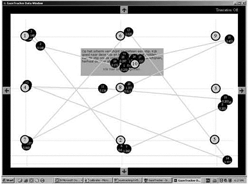
Figuur 3: Weergave van de kalibratie in Gazetracker.
In de figuur zien we de negen stippen die na elkaar op het scherm verschijnen met daarop (in groen) weergegeven een rondje dat aangeeft dat daar geklikt is door de proefpersoon. De nummers geven de volgorde van de kliks aan. De zwarte rondjes zijn weergaven van de fixaties van de proefpersoon. In elk rondje staat een nummer dat weergeeft de hoeveelste fixatie het betreft en een getal dat de duur van de fixatie weergeeft. Met behulp van deze output kunnen we nagaan in hoeverre Gazetracker een fixatie heeft geregistreerd op het punt waar geklikt werd. De applicatie is door ons zo gebouwd dat de proefpersoon goed moet mikken in het midden van het rondje. Dat kan niet zonder een duidelijke fixatie. Wanneer de fixatie dus naast de klik getoond wordt, is er sprake van een meetfout. Zo zien we in Figuur 3 dat de meting in de linker bovenhoek precies op de juiste plaats is, terwijl de meting in de rechter benedenhoek naar boven gecorrigeerd zou moeten worden, omdat de fixatie enigszins onder het te fixeren punt is weergegeven. Aan dit scherm is goed te zien dat de fout niet op het hele scherm gelijk is, en dat de mate van correctie dus afhankelijk zou moeten zijn van de positie op het scherm.
Nu biedt de software van Gazetracker de mogelijkheid om de registratie achteraf te corrigeren met een functie Shift data (zie ook de bespreking van Fixation door Cozijn in dit nummer). De proefleider verplaatst dan het fixatiepunt met de muis - in het geval van Figuur 3 - een klein stukje naar boven. Wanneer dit voor alle negen punten gedaan wordt, herberekent Gazetracker met een algoritmische functie de data voor de gecorrigeerde registratie. Figuur 4 toont het resultaat van de correctie voor het kalibratiescherm. De correctie wordt vervolgens ook toegepast op de data van de schermen met tekst.
| |
| |

Figuur 4: Kalibratiescherm na correctie van de data.
Wij hebben op deze manier alle data gecontroleerd en gecorrigeerd door voor de eerste vijf schermen uit te gaan van de eerste kalibratie en voor de laatste vijf schermen uit te gaan van de laatste kalibratie. Hoewel dit een prachtige functie is, gegeven de onnauwkeurigheid waar we nu eenmaal mee moeten leven, is deze toepassing niet zonder risico's. Wanneer we de data van de schermen 6 tot en met 10 namelijk corrigeren op basis van de kalibratie die plaatsvond na het tiende scherm, veronderstellen we dat de onnauwkeurigheid die we aldaar corrigeren ook van toepassing is op eerdere schermen. We corrigeren immers achterwaarts, zonder precies te weten op welk moment de toenemende onnauwkeurigheid optrad. Gesteld dat het probleem zich pas voordeed in het zevende scherm, dan heeft deze operatie voor het zesde scherm eerder een verslechtering dan een verbetering tot gevolg. Idealiter vindt na elk scherm een kalibratie plaats, maar daarmee zouden we het leesgedrag wel heel erg verstoren. Daarom beperkten we ons tot een extra kalibratie aan het begin en het eind van het leesproces, wetend dat in het algemeen de waarde van de correctie daalt naarmate je verder van de kalibratiepagina komt.
Ten behoeve van de analyse hanteerden we de volgende afhankelijke variabelen:
| • | de totale leestijd van de gehele tekst; |
| • | de terugleestijd (de tijd die wordt besteed aan het lezen van reeds eerder gelezen regels in de tekst); |
| • | de vooruitleestijd (de leestijd minus de terugleestijd); |
| • | het aantal keren teruglezen. |
| |
3. Resultaten
De eerste stap bij de analyse van de data was het exploratief bekijken van de oogbewegings-patronen. Een belangrijke constatering hierbij was dat de data ook na correctie niet voldoende betrouwbaar waren om op woordniveau te kunnen vaststellen waar fixaties hadden | |
| |
plaatsgevonden. Er kon daarom geen analyse van de leestijden per woord worden uitgevoerd. In de volgende paragraaf gaan we dieper op dit punt in.
Bij het analyseren van de effecten van de onafhankelijke variabelen op het leesgedrag werden vier maten gebruikt. De eerste maat was de totale leestijd op de pagina. Daarnaast waren we geïnteresseerd in hoe eventuele effecten van de onafhankelijke variabelen tot uitdrukking zouden komen in het leespatroon. De verwachting daarbij was dat het effect van hardoplezen zou zijn dat proefpersonen meer ‘lineair’ zouden lezen, d.w.z. dat ze minder vaak dan bij stillezen terug zouden springen naar eerder gelezen gedeelten van de tekst. Een andere verwachting was dat commentaar geven juist zou leiden tot meer terugspringen in de tekst dan wanneer geen commentaar hoefde te worden gegeven.
Vanwege het feit dat de fixatiegegevens niet betrouwbaar genoeg waren om op woordniveau de fixaties toe te kennen, werd er voor de analyse van het leespatroon uitgegaan van de leestijden per regel. Hierbij werd onderscheid gemaakt tussen de vooruitleestijd en de terugleestijd. Om deze twee maten te definiëren werd bijgehouden tot welke regel in de tekst een proefpersoon was gevorderd. Alle fixaties op deze regel werden gerekend bij de vooruitleestijd, fixaties op eerdere regels werden gerekend bij de terugleestijd. We hebben hier voor deze vrij grove maat van terugleestijd gekozen omdat we, vanwege het gebrek aan precisie van de metingen niet konden vaststellen of een fixatie die links van een voorafgaande fixatie terechtkwam, een sprong terug was naar een eerder woord (en het bij terugleestijd gerekend moest worden) of een tweede fixatie was op hetzelfe woord (en het bij vooruitleestijd gerekend moest worden).
Naast de terugleestijd hebben we ook gekeken naar het aantal keren dat de lezer tijdens het lezen van de tekst terugsprong naar eerdere regels.
Op deze data werden variantie-analyses uitgevoerd. De resultaten van de verschillende afhankelijke maten zijn weergegeven in Tabel 1. De variantie-analyse over de totale leestijd liet hoofdeffecten zien van commentaar (F(1,20) = 8.66, p <. 01) en van manier van lezen (F(1,20) = 11.87, p <. 005). De proefpersonen deden langer over het lezen van een pagina wanneer ze na het lezen commentaar moesten geven dan wanneer ze geen commentaar hoefden te geven, en ze deden langer over het lezen van een pagina wanneer ze hardop lazen dan wanneer ze stil lazen. Er was geen interactie tussen beide onafhankelijke variabelen.
In de vooruitleestijd was alleen een hoofdeffect te zien van manier van lezen (F(1,20) = 9.30, p <. 01). Wanneer proefpersonen hardop lazen was de vooruitleestijd langer dan wanneer ze stil lazen. In de terugleestijd was alleen een hoofdeffect te zien van commentaar (F(1,20) = 8.32, p <. 01). In de conditie met commentaar besteedden de proefpersonen meer tijd aan het herlezen van eerdere delen van de tekst dan in de conditie zonder commentaar. In het aantal keren teruglezen was hetzelfde patroon te zien, dit effect was echter niet significant (F(1,20) = 3.01, p =. 09)
Er waren grote verschillen in de aantallen commentaren die de proefpersonen gaven. De aantallen commentaren op de tien pagina's liepen uiteen van in totaal 3 tot 20, met een gemiddelde van 8.1. Er was geen verschil in aantal commentaren tussen de hardoplezers en de stillezers. Ook was er geen correlatie tussen het aantal commentaren en de leestijdmaten.
| |
| |
Tabel 1: Totale leestijd, Vooruitleestijd en Terugleestijd per conditie (in seconden per gelezen scherm) en Aantal keren terug lezen per scherm
|
|
Totaal |
Vooruit |
Terug |
Aantal keren terug |
| Stillezen |
Geen commentaar |
14.2 |
10.3 |
4.0 |
1.4 |
| |
Wel commentaar |
19.3 |
11.4 |
7.9 |
3.4 |
| Hardoplezen |
Geen commentaar |
20.1 |
15.6 |
4.6 |
2.5 |
| |
Wel commentaar |
25.1 |
16.2 |
8.9 |
3.3 |
| |
4. Discussie
Het experiment had twee doelen. Het eerste doel was te onderzoeken welke invloed het hardoplezen van een tekst of het geven van commentaar na het lezen van een tekst hebben op het leespatroon. Uit het experiment werd duidelijk dat beide taken een effect hebben op het leespatroon, alleen wel een verschillend effect. Hardoplezen had alleen een effect op het leestempo. Hardoplezers lazen langzamer dan stillezers. In tegenstelling tot wat we verwachtten hadden hardoplezers niet meer dan stillezers de neiging om ‘lineair te lezen’. Hardoplezers keken niet minder vaak of minder lang dan stillezers terug naar eerdere delen van de tekst. Commentaar geven had juist alleen een effect op het teruglezen in de tekst. De vooruitleestijd van commentaargevers was niet langer dan die van proefpersonen die geen commentaar moesten geven, wel besteedden de commentaargevers meer tijd aan reeds eerder gelezen delen van de tekst. Let wel, dit terugkijken trad niet op tijdens het commentaar geven, maar reeds in het eerste deel van het leesproces.
Wat betekent dit resultaat nu voor de validiteit van pretesten waarin proefpersonen hardop moeten lezen of commentaar moeten geven op teksten? Uit het feit dat proefpersonen in de commentaarconditie meer en vaker teruglezen mogen we afleiden dat zij intensiever lezen, en vermoedelijk een hogere ambitie hebben om de tekst te begrijpen dan mensen die niet deelnemen aan een pretest en dezelfde tekst gewoon thuis lezen. Dat kan ertoe leiden dat we in een pretest problemen op het spoor komen die zich in de praktijk niet voordoen, omdat mensen buiten de pretest met een lagere ambitie lezen. Zij lezen als het ware over de problemen heen. Maar het omgekeerde is ook denkbaar: in de praktijk zullen mensen meer problemen ervaren, omdat zij minder cognitieve energie steken in de constructie van een mentale representatie. Er lijkt dus een validiteitsbedreigende factor in het geding te zijn, maar we weten niet precies wat het effect daarvan is. Er is echter ook een derde redenering denkbaar die de validiteitsbedreigende factor nuanceert. De proefpersonen in dit onderzoek hadden zelf geen initiatief genomen om een tekst te lezen over een beleggingsproduct. Zij waren niet echt met beleggen bezig. Vermoedelijk zullen lezers die overwegen in te stappen in het beschreven fonds een hogere ambitie hebben om de tekst te lezen dan de proefpersonen die deelnamen aan de pretest. En daarmee zou hun ambitieniveau goed kunnen lijken op dat van de proefpersonen aan wie gevraagd werd commentaar op de tekst te leveren. Het lijkt ons wenselijk dat in de toekomst meer onderzoek gedaan wordt met oogbewegingsregistratie naar leespatronen van mensen die in verschillende pretestcondities dezelfde tekst lezen.
| |
| |
Een daarmee verbonden discussiepunt is de vraag of we het leesgedrag zoals dat thuis plaatsvindt als norm moeten stellen. Gesteld dat lezers daar nauwelijks problemen ervaren, terwijl we als experts toch sterke vermoedens hebben dat lezers niet weten wat woorden als benchmark en bewaarloon betekenen, welk criterium leggen we dan aan voor ‘adequaat begrip’? De norm die voortvloeit uit een functionele analyse (mensen kunnen alleen begrijpen wat het doel van het fonds is als zij weten wat een benchmark is) of het meer descriptieve criterium dat het gros van de lezers het niet nodig vindt om dat te begrijpen als zij overwegen geld in een beleggingsfonds te storten?
Tijdens de afname van de test hadden we de indruk dat de proefpersonen niet erg gul waren met commentaar. Gemiddeld produceerden zij in totaal acht commentaren met een probleemdetectie over de tien getoonde schermen. Dat is dus minder dan één commentaar per scherm. Als we dat vergelijken met commentaren die geproduceerd werden bij teksten over veilig vrijen en de gevaren van alcohol, zoals door De Jong (1998) verzameld, dan is er echter nauwelijks verschil. De teksten zijn ongeveer even lang en de gemiddelde hoeveelheid commentaar is bij De Jong tussen de 6 en de 9 commentaren per proefpersoon. Het is denkbaar dat onze indruk een gevolg is van de opstelling in het laboratorium. De proefleider en de proefpersoon bevinden zich in een aparte ruimte, verbonden door een deur (die we meestal open lieten staan) en een glazen ruit. De proefpersoon moest vooral stil zitten en naar het scherm kijken. Die twee factoren - de ruimtelijke opstelling en de gerichtheid op een beeldscherm - hadden tot gevolg dat er nauwelijks interactie was tijdens de sessie tussen proefleider en proefpersoon. Dat was uitdrukkelijk ook de opzet, omdat elke interactie het risico inhoudt dat de proefpersoon het hoofd ineens naar de proefleider wendt, waardoor de hoofdset verschuift en de data verloren gaan. Hoewel de hoeveelheid geproduceerd commentaar dus misschien niet eens tegenvalt, trekken we toch de conclusie dat voor een pretest interactie wel degelijk wenselijk is, en oogbewegingsregistratie alleen een optie is als dat zonder hoofdset gebeurt. Het voornaamste argument voor die conclusie is het gebrek aan diagnostische kwaliteit van veel commentaar. Proefpersonen merken bijvoorbeeld op dat de tweede zin in het fragment best moeilijk is en klikken dan door naar het volgende scherm. Een proefleider heeft dan behoefte om een vraag te stellen over de aard van die moeilijkheid. Staan er moeilijke woorden in die zin of is de constructie lastig?
Het derde doel van het experiment was inzicht te krijgen in de vraag in hoeverre oogbewegingsregistratie kan helpen bij het detecteren van moeilijke woorden in de tekst. Helaas waren de data niet nauwkeurig genoeg om hierover uitspraken te kunnen doen. Het gebrek aan nauwkeurigheid in de data heeft te maken met het feit dat we gebruik maakten van een webomgeving, waarin de proefpersonen met behulp van muiskliks door de pagina's moesten navigeren. Het eyelink systeem is te gevoelig voor de bewegingen van het hoofd die hiermee gepaard gaan, zodat het niet mogelijk bleek om op woordniveau te meten. Om wel de juiste nauwkeurigheid in de metingen te bereiken hebben we twee opties: ofwel de proefpersonen minder laten bewegen en dus geen muis meer te laten gebruiken, ofwel een eye-tracking systeem te gebruiken dat minder gevoelig is voor de bewegingen die gepaard gaan met het gebruik van muis en toetsenbord.
Het is mogelijk om de bewegingen van de proefpersoon te beperken, door bijvoorbeeld in plaats van de muis een ander display met slechts twee toetsen of een knop op het toetsenbord te gebruiken. In het huidige experiment was dat mogelijk geweest, maar wanneer het | |
| |
normale gedrag van mensen tijdens het surfen op internet moet worden vastgelegd, is dat een te grote beperking, zeker wanneer de proefpersoon ook de mogelijkheid moet hebben om te typen tijdens de meting van de oogbewegingen. Onze conclusie is dat in die gevallen een systeem moet worden gebruikt dat een zekere mate van beweging van de proefpersoon toestaat.
| |
5. Hoe verder?
Wat kunnen we nu verwachten van deze techniek en wat zijn onze plannen voor de toekomst om met oogbewegingsregistratie problemen met teksten op te sporen? We hebben de hoop nog niet opgegeven dat lexicale begripsproblemen met oogbewegingsregistratie opgespoord kunnen worden. Daartoe zijn we inmiddels overgestapt op een nieuw systeem, ontwikkeld door Tobii, waarmee proefpersonen alle vrijheid hebben om te bewegen terwijl de kalibratie heel nauwkeurig is. In feite hebben proefpersonen met dit systeem nauwelijks meer in de gaten dat hun oogbewegingen geregistreerd worden. Zij kunnen zelfs opstaan, weglopen en weer terugkeren naar de computer, waarna automatisch de blik weer gevangen wordt. Het nadeel van dit systeem is dat de frequentie daalt van 250 Hz in het tot nu toe gehanteerde systeem naar 50 Hz, waardoor een verlies in nauwkeurigheid ontstaat van de meting van fixatietijden en saccades. Met dit systeem zullen wij het hier gerapporteerde onderzoek repliceren om na te gaan of langere leestijden indicaties zijn voor lexicale begripsproblemen. Uit Fins onderzoek is steun gekomen voor dat idee. Hyrskykari e.a. (2003) rapporteren over een proactief systeem dat in staat is om op grond van oogbewegingen te voorspellen dat een lezer een begripsprobleem ervaart, waarna een toelichting op de betekenis van dat woord automatisch in beeld verschijnt. Dit systeem is ontwikkeld in de context van het lezen van teksten in een vreemde taal; die toelichting is dus in feite een vertaling van de term. Het is natuurlijk goed denkbaar dat zoiets ook voor teksten in de moedertaal ontwikkeld wordt.
Voor het opsporen van andere problemen met teksten dan lexicale problemen achten wij oogbewegingsregistratie zeker ook kansrijk. In eerste instantie denken we dan aan problemen met de structuur van de tekst. Voorspelbaar is dat goed gestructureerde teksten de lezer minder noodzaken heen en weer te springen in de tekst, en dat zoekopdrachten in goed gestructureerde teksten gerichter en sneller uitgevoerd kunnen worden dan in slecht gestructureerde teksten. De frequentie van teruglezen en de duur van de terugleestijd zouden dus goede indicatoren kunnen zijn voor problemen met de structuur van een document. Er zijn ook plannen om oogbewegingsregistratie in te zetten om indicaties op te sporen voor persuasieve effecten van teksten. Recent uitgevoerd onderzoek van Kamalski et al. (in voorbereiding) wijst erop dat proefpersonen gevoelig zijn voor signalen in de tekst die wijzen op een persuasief doel, hetgeen zich vertaalt in een langere leestijd.
Voor de evaluatie van websites lijkt oogbewegingsregistratie een zeer aantrekkelijke methode. In bescheiden mate hebben we hier ervaring mee opgedaan. De grote kracht van deze methode is dat we precies na kunnen gaan of bezoekers van een site een bepaalde cruciale link voor verdere navigatie negeren omdat zij hem niet waargenomen hebben, of omdat ze hem verkeerd geïnterpreteerd hebben. We kunnen zien of een bezoeker waarneemt dat | |
| |
het menu voor hoofdnavigatie van een site ergens onderweg veranderd is in een domeinspecifiek menu. Nauwkeurig kan vastgesteld worden of de banners op een site wel of niet bekeken worden. Aansluitend bij Cooke (2005) concluderen we dat het ‘lezen’ op een site in hoge mate ook ‘kijken’ is, daarom leent oogbewegingsregistratie zich goed om in een evaluatie-onderzoek problemen op het spoor te komen die bezoekers van websites ervaren.
| |
Bibliografie
| Cooke, L. (2005). Eye Tracking: How it works and how it relates to usability. Technical Communication, 52(4), 456-463. |
| Hyrskykari, A., Majaranta, P., & Räihä K. (2003). Proactive response to eye-movements. In M. Rautenberg e.a. (eds.), Human-computer interaction - Interact '03. IOS Press - IFIP, 129-136. |
| Jong, M. de (1998). Reader feedback in text design: Validity of the plus-minus method for the pretesting of public information brochures. Amsterdam/Atlanta: Rodopi. |
| Kamalski, J., Lentz. L., Sanders, T., & Zwaan R. (in voorbereiding). The fore-warning effect of coherence markers in persuasion: Off-line and on-line evidence. |
| Kippersluis, B. van (2005). De financiële bijsluiter: Experimenteel onderzoek naar het begrip van jargon. Eindwerkstuk Bachelor. Universiteit Utrecht. |
| Pander Maat, H., & Lentz, L. (2003). Waarom het lezersprotocol zo'n goede pretestmethode is. Tijdschrift voor Taalbeheersing, 25(3), 202-220. |
| Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124(3), 372-422. |
|
|
