
Tijdschrift voor Taalbeheersing. Jaargang 28
(2006)– [tijdschrift] Tijdschrift voor Taalbeheersing–
[pagina 220]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Reinier Cozijn
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. InleidingEr is in de gedragswetenschap een toenemende aandacht voor oogbewegingsregistratie als methode voor het doen van onderzoek. Die methode leent zich bij uitstek om de cognitieve aspecten van informatieverwerking en - productie bij mensen in kaart te brengen. Oogbewegingsregistratie wordt bijvoorbeeld gebruikt in taalverwerkings-en taal-productieonderzoek (zie ook Lentz, Mak & Pander Maat in dit nummer), usabilityonderzoek, mens-machine interactie en industrieel ontwerp (zie voor een overzicht Jakob & Karn, 2003). Andere toepassingen van de oogbewegingsregistratie zijn te vinden in de medische wetenschap (bv. diagnostiek en computeraansturing voor mindervaliden) en sinds kort ook in de computerspelindustrie (zie bv. Kenny et al., 2005). Bij taalbeheersers lijkt er nog een aarzeling te bestaan om deze techniek toe te passen, omdat hij complex en bewerkelijk is. Gelukkig is daar de laatste jaren veel in verbeterd zowel op hardware- als op softwaregebied. De verbetering van de techniek heeft niet alleen betrekking op de nauwkeurigheid en de hanteerbaarheid van de apparatuur maar ook op de analyseerbaarheid van de data. In dit artikel wordt ingegaan op het gebruik van de oogbewegingsregistratie in leesonderzoek en in het bijzonder op het analyseren van oogbewegingsdata. Hieronder volgen een schets van de oogbewegingspatronen tijdens het lezen en een bespreking van het probleem van het afleiden van betekenisvolle afhankelijke maten van onderzoek (leestijden). De toepassing van de techniek en de analyse van oogbewegingen wordt uitgelegd aan de hand van een casus en het artikel sluit af met een korte discussie. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. Oogbewegingen en lezenDe populariteit van oogbewegingsregistratie voor het doen van leesonderzoek schuilt in het gegeven dat oogbewegingen van nature voorkomen tijdens het lezen. De meting verstoort het normale leesgedrag niet en de deelnemers aan een leesexperiment hoeven geen | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 221]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
extra taak uit te voeren. Oogbewegingen worden al langere tijd gebruikt voor het doen van onderzoek naar taalprocessen (zie voor een overzicht Rayner, 1998; Rayner & Pollatsek, 1989). De eerste onderzoeken naar oogbewegingen waren gericht op het vaststellen van de specifieke oogbewegingspatronen die plaatsvinden tijdens het lezen. Uit dat onderzoek valt het volgende beeld te destilleren. Wanneer iemand een tekst leest, springen de ogen van één positie in de tekst naar de volgende. De gemiddelde lengte van zo'n sprong, ook wel saccade genoemd, is 8 lettertekens (met een ondergrens van 1 en een bovengrens van 15 lettertekens) die gemiddeld 30 milliseconden duurt. Een uitzondering vormt de sprong van het einde van een regel naar het begin van de volgende regel (return-sweep) die uiteraard langer is en langer duurt (60 tot 80 milliseconden). Tijdens een sprong nemen de ogen geen visuele informatie op (Matin, 1974). Visuele informatie wordt opgenomen in de periode van relatieve rust tussen twee sprongen in. Deze periode wordt een fixatie genoemd. Lezers hebben fixaties van gemiddeld 200 tot 250 milliseconden. Bij normale fontgrootte en leesafstand heeft de lezer tijdens een fixatie een blikveld van ongeveer 3 lettertekens naar links en 15 lettertekens naar rechts (de richting van dit blikveld is natuurlijk taalafhankelijk). In het centrum van het blikveld, de fovea, is de waarneming het scherpst. Dit gebied van grote scherpte reikt meestal niet verder dan 7 lettertekens naar rechts. Lezers lezen niet voortdurend vooruit. Gemiddeld genomen springen lezers in 15% van de gevallen terug in de tekst. Zo'n sprong terug wordt ook wel regressie genoemd. Na de beginperiode waarin is komen vast te staan welke fysieke factoren de visuele waarneming van tekst beïnvloeden, is de aandacht in het oogbewegingsonderzoek verschoven naar de cognitieve factoren die het kijkpatroon sturen. Aan de cognitieve interpretatie van oogbewegingen liggen twee uitgangspunten ten grondslag: de immediacy assumption en de eye-mind assumption (Just & Carpenter, 1980). De eerste assumptie stelt dat alle verwerkingsprocessen die worden uitgevoerd op een woord starten zodra het woord wordt bekeken. De tweede geeft aan dat de ogen op een woord gericht blijven zolang de verwerking van het woord duurt. Ofschoon voor beide assumpties evidentie is gevonden, zijn ze toch niet sluitend. Zo is uit onderzoek gebleken dat niet alle woorden in een tekst worden bekeken. Korte, hoogfrequente en/of zeer voorspelbare woorden, zoals functiewoorden, worden vaak overgeslagen. Dat wil niet zeggen dat ze niet worden verwerkt. Er is aangetoond dat ze worden waargenomen en verwerkt gedurende het kijken naar de woorden die eraan voorafgaan. Dit betekent dat de kijktijd op een woord niet noodzakelijkerwijs een afspiegeling is van de verwerking van alleen het bekeken woord. Een tweede probleem is dat de verwerking van een woord soms doorgaat, terwijl de ogen al verder springen in de tekst. Dit is bijvoorbeeld aangetoond in een studie naar de verwerking van laagfrequente woorden (zie Rayner & Duffy, 1986). Ondanks deze beperkingen heeft de studie van oogbewegingen veel informatie opgeleverd over de verwerking van geschreven taal en het onderzoek naar de invloed van lexicale, syntactische, semantische en tekstuele factoren op de verwerking van tekst op een hoger plan getild. De methode is met name zo geschikt omdat ze inzicht verschaft in de temporele eigenschappen van het leesproces. De ogen verraden niet alleen hoe lang de verwerking van een stuk tekst duurt maar ook wanneer het voor het eerst wordt waargenomen en wanneer er sprake is van een herlezing. Zoals hierboven gesteld, springen lezers regelmatig terug in een tekst en herlezen ze tekstgedeeltes die ze in een eerder stadium al hadden verwerkt. Deze herlezingen kunnen indicatief zijn voor leesproblemen, maar dat hoeft niet. Indien lezers op een probleem in de tekst stuiten, kunnen ze in principe drie dingen doen: ze pau- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 222]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
zeren op de plaats waar het probleem optreedt, ze springen terug in de tekst of ze lezen door en hopen verderop in de tekst het probleem op te lossen. Lukt dat laatste niet, dan wordt de gehele zin veelal nog eens gelezen (Frazier & Rayner, 1982; Liversedge et al., 1998). Regressies en fixatietijden zijn dus indicatief voor de cognitieve processen die zich afspelen tijdens het lezen. Waar de interpretatie van regressies redelijk rechttoe rechtaan is, is de interpretatie van fixatietijden min of meer problematisch. Want hoe moet de leestijd van een woord bepaald worden als het meerdere malen is gefixeerd, of hoe moet de leestijd bepaald worden van grotere teksteenheden zoals een constituent, een deelzin, een zin, of een alinea? En wat als de onderzoeker geïnteresseerd is in vroeg optredende talige processen, zoals lexicale toegang of woordfrequentie-effecten, en wat als de interesse uitgaat naar laat optredende processen, zoals zins- of tekstintegratie? Het mag wel duidelijk zijn dat deze vraag niet eenvoudig te beantwoorden is. De vaststelling van geschikte maten voor leestijden is dan ook lang een belangrijk thema geweest in het leesonderzoek waarbij oogbewegingen geregistreerd worden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Het afleiden van leestijdenZoals hierboven is uiteengezet, bestaan oogbewegingen uit fixaties en saccades. Ofschoon fixaties aangeven wat er verwerkt wordt en fixatietijden iets zeggen over hoe lang iets verwerkt wordt, zijn ze toch niet te gebruiken als leestijden in leesonderzoek. Woorden kunnen namelijk meerdere malen worden gefixeerd en soms is de onderzoeker geïnteresseerd in de verwerking van een regio die bestaat uit meerdere woorden waarop vaak meerdere malen gefixeerd wordt. Enkelvoudige fixaties schieten dan tekort om de verwerkingstijd weer te geven. Dat het bepalen van een leestijd op basis van fixaties niet triviaal is, kan aan de hand van een voorbeeld geïllustreerd worden. Figuur 1 geeft een hypothetisch (maar wel realistisch) fixatiepatroon weer boven een kort stukje tekst. De fixaties zijn in kijkvolgorde genummerd en boven de woorden geplaatst. Boven elke fixatie staat de tijd in milliseconden. De onderzoeker is geïnteresseerd in de verwerking van de regio ‘de oplossing’ (in het voorbeeld onderstreept).
Figuur 1: Voorbeeld van acht fixaties (in de volgorde 1 t/m 8) met daarboven hun tijden (in milliseconden) op een tekstgedeelte met daaronder enkele mogelijke leestijden van een tekstregio (‘de oplossing’, onderstreept).
Het kijkpatroon in het voorbeeld verloopt van fixatie 1 (‘de’) naar 2 (‘de oplossing’) naar 3 (‘de oplossing’) naar 4 (‘klacht’), etc. De vraag is nu: wat is de leestijd van ‘de oplossing’ in | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 223]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
het voorbeeld? Indien de onderzoeker geïnteresseerd is in zeer vroege verwerkingsprocessen (bv. lexicaal), dan zou volstaan kunnen worden met de duur van de eerste fixatie op de regio (fixatie 2). De duur van eerste verwerking zou daarmee op 200 milliseconden komen. Deze fixatie wordt echter gevolgd door nog een fixatie op dezelfde regio (fixatie 3), zodat men ook deze tot de eerste verwerking zou kunnen rekenen. De duur van de eerste verwerking is dan 460 milliseconden. Deze manier om verwerkingstijden te berekenen is als eerste gebruikt door Just en Carpenter (1980). Zij gaven daaraan de naam gaze, die moeilijk in het Nederlands te vertalen is. De gaze is gedefinieerd als de som van alle fixatietijden op een regio tot de regio in voor- of achterwaartse richting wordt verlaten. Indien de onderzoeker echter geïnteresseerd is in latere verwerkingsprocessen, (syntactisch/ semantisch/tekstueel) zouden wellicht fixaties 4 en 5 ook meegeteld kunnen worden. De redenering om fixaties mee te tellen die deel uitmaken van een regressie vanaf een regio, is gebaseerd op de veronderstelling dat de lezer kennelijk op grond van de verwerking van de regio besloot om terug te springen in de tekst. De verwerking van de regio is dus nog niet af en processen die plaatsvinden tijdens de regressie zouden meegeteld moeten worden in een maat van eerste verwerking. Volgens deze redenering is de eerste verwerking van een regio pas voltooid als hij in voorwaartse richting wordt verlaten en de lezer dus nieuwe informatie tot zich neemt (bij fixatie 6). Deze definitie van de leestijd van de regio resulteert in een leestijd van 1010 milliseconden. Weer een andere benadering van de leestijd is om niet de regressies mee te rekenen in de leestijden van de regio's waarvandaan ze starten, maar om simpelweg alle fixatietijden op een regio op te tellen, ongeacht waar ze vandaan komen. Volgens deze visie zouden fixaties 2, 3, 5 en 7 moeten worden opgeteld om de totale verwerkingstijd van de regio te verkrijgen. De leestijd is dan 1230 milliseconden. Hopelijk maakt dit voorbeeld niet alleen duidelijk dat de berekening van leestijden op basis van fixaties complex is, maar ook dat het bepalen van een afhankelijke maat van verwerking een beredeneerde keuze van de onderzoeker moet zijn. De keuze van de afhankelijke maat leidt in het hier gegeven voorbeeld tot leestijden van eenzelfde regio die lopen van 200 tot 1230 milliseconden, hetgeen natuurlijk een enorm verschil is. Het probleem van de leestijdenberekening heeft in de afgelopen decennia niet alleen geleid tot een veelvoud aan afhankelijke maten maar ook tot veel verwarring, omdat dezelfde maten terugkeerden in de literatuur onder andere (vaak zelfverzonnen) namen (Murray, 2000). Onder onderzoekers die zich bezighouden met leesonderzoek is er nu enigszins consensus bereikt over de volgende maten: first-fixation duration, gaze, total-pass reading time en total reading time (respectievlijk eerste fixatie, gaze, regressiepadtijd en totale kijktijd in Figuur 1). Voorgesteld is om in oogbewegingsleesonderzoek in ieder geval de regressiepadtijden en het aantal regressies te rapporteren (zie voor een uitgebreide discussie Cozijn et al., 2003). Zoals gesteld in paragraaf 2 nemen de ogen tijdens een saccade geen visuele informatie op. Dit verschijnsel heeft ertoe geleid dat leesonderzoekers de duur van saccades buiten beschouwing lieten wanneer ze leestijden berekenden. Dit is onjuist. Dat er tijdens saccades geen nieuwe informatie wordt opgenomen betekent nog niet dat er geen informatie wordt verwerkt. Irwin (1998) heeft aangetoond dat weliswaar sommige visuele cognitieve processen worden gehinderd door een saccade, maar dat taalverwerking ongehinderd doorloopt. Daarom moeten, anders dan in het bovenstaande voorbeeld wordt gesuggereerd, saccadetijden meegeteld worden in de berekening van afhankelijke maten van taalverwerking. Het effect van het meetellen van saccadetijden is uiteraard klein maar telt op bij het effect van de eraan gerelateerde fixatietijden (Vonk & Cozijn, 2003). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 224]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De complexiteit van het berekenen van leestijden op basis van oogbewegingen zou menig onderzoeker afschrikken als er inmiddels niet makkelijk te gebruiken programma's zouden zijn om het werk te vereenvoudigen. Aan de hand van een leesonderzoek als casus zal het gebruik van één zo'n programma, namelijk het onder Microsoft Windows werkende programma FixationGa naar eind1, worden besproken. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. De casusDe toepassing van het programma om oogbewegingen over tekst te analyseren, Fixation, wordt geïllustreerd aan de hand van een leesonderzoek naar de invloed van layout-kenmerken op het begrijpen van tekst. Na een korte inleiding op het onderzoek volgt een wat uitgebreidere beschrijving van de methode, gevolgd door de resultaten en de conclusie. Voor de doeleinden van dit artikel wordt slechts een klein gedeelte van de resultaten besproken. In de usability-literatuur (zie Nielsen, 2000 e.a.) en de typografie-literatuur (zie Waller, 1980 e.a.) wordt geadviseerd om belangrijke termen in de tekst vet te maken en om tekstuele informatie in puntsgewijze opsommingen te plaatsen. De idee is dat deze layout-kenmerken fungeren als aandachttrekkers en dat ze de begrijpelijkheid en de leesbaarheid van teksten bevorderen. Naar de invloed van vetgedrukte woorden en opsommingen op het leesproces zelf is weinig onderzoek verricht. In een oogbewegingsexperiment is de invloed onderzocht van vetgedrukte kernwoorden en van puntsgewijze opsommingen op de verwerking van twintig korte, verklarende teksten over consumentenrecht. De verwachtingen waren dat het vetdrukken van kernwoorden en het plaatsen van informatie in een puntsgewijze opsomming zouden leiden tot diepere verwerking en dus tot langere leestijden (Reynolds & Shirey, 1988). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.1 Materiaal.Als materiaal voor deze studie zijn 20 teksten gebruikt over consumentenrecht afkomstig van het Ministerie van Economische Zaken. De oorspronkelijke teksten, die waren geschreven om op een website te plaatsenGa naar eind2, bevatten zelf al opsommingen en vetgedrukte woorden. Om vast te stellen of de juiste woorden vetgedrukt waren is een vooronderzoek onder 72 proefpersonen uitgevoerd waarin is vastgesteld welke woorden als kernwoorden van de teksten werden aangemerkt. De proefpersonen konden maximaal zeven begrippen aanmerken. Van deze zeven begrippen werden de vijf begrippen genomen die door negen of meer proefpersonen waren geselecteerd. Deze procedure resulteerde in vijf kernwoorden per tekst die door gemiddeld 23% van de proefpersonen als belangrijk waren aangemerkt. De opmaak van de teksten werd voor het experiment aangepast door ze te voorzien van een titel, een inleiding, een opsomming en een uitleiding. De vijf vetgedrukte kernwoorden konden voorkomen in de opsomming en de uitleiding. Van de teksten werden vier versies gemaakt door de aan- of afwezigheid van een puntsgewijze opsomming en de aan- of afwezigheid van vetgedrukte kernwoorden te variëren. Wanneer de opsomming niet puntsgewijs werd aangeboden, waren de leden van de opsomming aaneengeschre ven met behulp van komma's en het voegwoord en. Een voorbeeld van een tekst met een puntsgewijze opsomming en vetgedrukte kernwoorden is gegeven in Figuur 2. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 225]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Figuur 2: Voorbeeld van een experimentele tekst in de versie met een puntsgewijze opsomming en vetgedrukte kernwoorden (afbeelding van 800 x 600 pixels).
Voorbeeld van een experimentele De teksten werden in het leesexperiment aangeboden met behulp van de bij de eyetracker meegeleverde software. Voor deze software was het noodzakelijk de teksten om te zetten in afbeeldingen (grootte: 800 × 600 pixels). Omdat het meten van oogbewegingen de betrouwbaarste resultaten geeft in het midden van het scherm, waren de teksten centraal op het scherm geplaatst met een linkermarge van 90 en een topmarge van 95 pixels. De teksten hadden een lichte achtergrond en waren opgemaakt als webteksten in het lettertype Verdana met puntgrootte 10. Het omzetten van de teksten in plaatjes gebeurde met behulp van het programma TSGGa naar eind3. Dit programma maakte van elke tekst tevens een object-bestand, waarin voor elk woord van de tekst de grafische coördinaten zijn opgeslagen. Dit bestand is nodig voor de analyse van de oogbewegingen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.2 Instrumentatie.Naast de leestijden van de vetgedrukte woorden en de opsommingen werd het begrip van een tekst gemeten door middel van beweringen. Na het lezen van een tekst werd een bewering over de tekst aangeboden die beoordeeld moest worden op zijn juistheid. Voor elke tekst werden twee beweringen gemaakt, een juiste en een onjuiste. De juiste bewering over de voorbeeldtekst van Figuur 2 luidde: Een klacht kunt u het beste schriftelijk verwoorden. De onjuiste versie luidde: Door het schrijven van een klachtenbrief maakt u de verkoper duidelijk dat u een discussie aan wilt gaan. Ook van de beweringen werden plaatjes gemaakt met een afmeting van 800 bij 600 pixels. Ze hadden dezelfde achtergrond, hetzelfde lettertype en dezelfde linkermarge als de teksten maar hadden een topmarge van 390 pixels, ongeveer ter hoogte van de plaats waar de laatste regel van de teksten stond. Deze hoogte is gekozen om ervoor te zorgen dat proefpersonen terstond na het lezen van de laatste regel van een tekst verder konden gaan met het beoordelen van de bewering. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.3 Design.De kruising van de variabelen Vet en Opsomming leverde vier condities op: vet/puntsgewijze opsomming, vet/niet-puntsgewijze opsomming, niet-vet/puntsgewijze opsomming en niet - vet/niet - puntsgewijze opsomming. De vier condities werden semi-ran- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 226]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dom verdeeld overde 20 teksten, hetgeen resulteerde in vijf teksten per conditie. Omdat een tekst slechts eenmaal aan een proefpersoon kon worden aangeboden, werden er vier lijsten van 20 teksten gemaakt, waarbij elke tekst op elke lijst in een andere conditie stond. Elke proefpersoon kreeg willekeurig een lijst toegewezen. Ook de verdeling van juiste en onjuiste beweringen was semi-random. Elke proefpersoon zag 10 teksten met een juiste en 10 teksten met een onjuiste bewering. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.4 Proefpersonen.Aan het experiment namen 33 studenten van de Universiteit van Tilburg deel, 16 vrouwen en 17 mannen met een gemiddelde leeftijd van 22,4 jaar. De proefpersonen droegen geen bril of contactlenzen (brillen en contactlenzen kunnen de betrouwbaarheid van de meting negatief beïnvloeden). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.5 Apparatuur.De oogbewegingen werden in een onderzoekslaboratorium geregistreerd met behulp van een SR Research Eyelink II eyetrackerGa naar eind4. De software behorende bij de eyetracker (een in C geschreven bibliotheek van routines) werd gebruikt om de teksten aan te bieden. De teksten werden getoond op een 19-inch monitor met een schermresolutie van 800 bij 600 pixels. Proefpersonen zaten op ongeveer 70 cm van het beeldscherm. Er werd gemeten op het rechteroog (de meting op slechts één oog bleek voldoende betrouwbaar) met een frequentie van 250 Hz (de standaard snelheid van de eyetracker). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.6 Procedure.De proefpersonen werd verteld dat het onderzoek ging over hoe mensen teksten lezen. Ze waren niet op de hoogte van het eigenlijke doel van het experiment. Na het instellen van de apparatuur en het kalibreren van de proefpersoon (kalibreren is het tot stand brengen van een correspondentie tussen de metingen op het oog en de kijkposities op het scherm; zie Lentz, Mak en Pander Maat in dit nummer voor een uitgebreide beschrijving) werd een oefenblok bestaande uit drie teksten getoond. Het eigenlijke experiment startte na het oefenblok. De procedure van de aanbieding van een tekst was als volgt. Voorafgaand aan een tekst werd een scherm getoond met een sterretje. Het sterretje stond precies op de plaats waar de titel van een tekst begon. De proefpersoon moest strak naar het sterretje kijken en op de enter-toets drukken. Het sterretje verdween dan en op de plaats van het sterretje verscheen een tekst. De instructie luidde om de tekst goed en snel door te lezen en wanneer hij begrepen was meteen op de enter-toets te drukken. De tekst verdween en een bewering over de tekst verscheen op de plaats waar de tekst geëindigd was. De opdracht was om de bewering te beoordelen op zijn juistheid op basis van de tekst die net was gelezen. Het oordeel kon worden gegeven door op de ‘z’-toets (onwaar) of de ‘/’-toets (waar) te drukken. Na het drukken verdween de bewering van het scherm en verscheen er een kalibratiepunt midden op het scherm. Dit punt diende om een eventuele lineaire verschuiving in de meting te corrigeren. Na het kalibratiepunt verscheen weer het sterretje op het scherm en herhaalde de procedure zich. Het experiment duurde ongeveer 30 minuten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 227]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Figuur 3: Voorbeeld van een experimentele tekst met daarover geplaatst de genummerde fixaties van een proefpersoon (het kruisje bij fixatie nummer 1 geeft de positie van de cursor in het programma weer).
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.7 Verwerking van de gegevens.De oogbewegingsgegevens zijn geanalyseerd met behulp van het programma Fixation. Het programma leest de oogbewegingsdata van een proefpersoon in ascii-formaatGa naar eind5 in en plaatst de fixaties over de plaatjes die zijn aangeboden in het experiment (zie Figuur 3). Om de fixaties te kunnen koppelen aan de woorden van de tekst heeft het programma de grafische coördinaten van de woorden nodig. Zoals eerder gezegd zijn deze coördinaten opgeslagen in zogenaamde object-bestanden tijdens de vervaardiging van het materiaal. De objecten zijn zo gecodeerd dat ze een eventuele spatie voorafgaand aan een woord bij het woord trekken. De reden daarvoor is dat lezers van links naar rechts lezen en een blikveld hebben dat naar rechts groter is dan naar links (zie paragraaf 2). Wanneer dus een fixatie op een spatie vóór een woord valt, kan ervan uitgegaan worden dat het woord rechts van de spatie gelezen wordt. Het programma koppelt automatisch alle fixaties aan de objecten waarbinnen ze vallen, waarbij de linker- en bovengrens tot een object gerekend worden maar de rechter- en de ondergrens niet. Voor het opnemen van de linkergrens geldt dezelfde redering als voor het opnemen van spaties. Dat de bovengrens tot het woord eronder gerekend wordt, komt omdat lezers vaker boven de regel lezen dan eronder. De automatische koppeling van fixaties aan objecten bespaart de onderzoeker weliswaar veel werk, maar toch zullen alle koppelingen handmatig gecontroleerd moeten worden. Het programma Fixation helpt de onderzoeker ook daarbij. Met behulp van de muis kunnen verkeerd of niet gekoppelde fixaties eenvoudig gecorrigeerd worden door ze op te pakken en naar het juiste object te slepen. Een voorbeeld van een niet-gekoppelde fixatie is fixatie nummer 1 in Figuur 4. Deze fixatie valt duidelijk binnen geen enkel object. Met behulp van het programma is de fixatie handmatig gekoppeld aan het eerste object op de pagina, namelijk het object waarbinnen het woord ‘Een’ valt. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 228]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
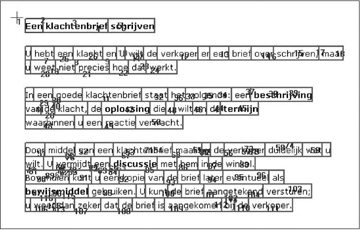
Figuur 4: Voorbeeld van een experimentele tekst met daarover geplaatst de genummerde fixaties van een proefpersoon en de grafische objectgegevens van de woorden van de tekst. Fixatie nummer 1 die ogenschijnlijk niet in een object valt, is handmatig toegekend aan het eerste object op de pagina dat codeert voor het woord ‘Een’.
Op dezelfde wijze zijn alle teksten van alle proefpersonen gecontroleerd en gecorrigeerd. Het programma Fixation laat onmiddellijk zien of een meting op een tekst gelukt of mislukt is en staat op eenvoudige wijze toe fixatietoewijzingen te veranderen of zelfs fixaties van analyse uit te sluiten. Zoals in paragraaf 3 is gesteld, moeten uit de fixaties leestijden worden afgeleid. Daarvoor is het noodzakelijk dat binnen de teksten de regio's zijn gedefinieerd waarover de leestijden moeten worden berekend. In dit experiment waren die regio's de (al dan niet vetgedrukte) kernwoorden, de opsomming en de uitleiding. Het coderen van regio's is gedaan in de object-bestanden door de objecten die tot dezelfde regio behoorden hetzelfde codenummer te geven. De codering in regio's wordt voor alle teksten op gelijke wijze gedaan, zodat bijvoorbeeld regio 2 in alle teksten codeert voor het eerste (al dan niet) vetgedrukte kernwoord. Met behulp van het programma zijn vervolgens per regio de volgende leestijden gegenereerd: eerste fixatie, gaze, regressiepadtijd en totale kijktijd. Deze tijden zijn berekend met inbegrip van de duur van de saccades (zie paragraaf 3 voor een uitleg). Bij de leestijden is aanvullende informatie opgeslagen over het aantal fixaties waaruit een leestijd is opgebouwd, of de leestijd wordt afgesloten met een sprong vooruit of een sprong terug in de tekst, of er in de leestijd een afgewezen fixatie zit en of een leestijd in het begin, het midden of aan het einde een knippering bevat. Met ‘knippering’ wordt bedoeld dat de lezer met de ogen knippert. Tijdens een knippering is er per definitie geen geldige oogmeting (wanneer de ogen dicht zijn, wordt er niets geregistreerd). Dat wil echter niet zeggen dat alle knipperingen van de analyse moeten worden uitgesloten. Wanneer een lezer tijdens het kijken naar een en dezelfde regio knippert, kan de tijd van de knippering meegenomen worden in de bereke- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 229]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ning van de leestijd. Wanneer echter een knippering plaatsvindt aan het begin of het einde van het kijken naar een regio, is de leestijd van deze regio in principe ongeldig, want dan is niet met zekerheid te zeggen wanneer het lezen van deze regio startte respectievelijk eindigde. De leestijden zijn weggeschreven in ascii-formaat en ingelezen in SPSS voor statistische analyse. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.8 Resultaten.Binnen de context van dit artikel is ervoor gekozen om niet alle resultaten van het onderzoek maar slechts een gedeelte te laten zien. Hieronder staan de resultaten van de leestijden van alleen die kernwoorden die in de opsomming stonden (40 kernwoorden in 20 teksten). In het onderzoek ging de belangstelling uit naar de invloed van vetgedruktheid op de verwerking van kernwoorden. De verwachting was dat een kernwoord meer aandacht zou krijgen en dieper verwerkt zou worden als het vetgedrukt is dan wanneer het niet vetgedrukt is. Twee afhankelijke maten die de diepere verwerking weerspiegelen zijn de gaze en de regressiepadtijd (zie paragraaf 3). Het verschil tussen de twee maten is dat de regressiepadtijd in tegenstelling tot de gaze rekening houdt met regressies. Ter illustratie worden hieronder de resultaten van deze twee maten besproken en bediscussieerd.
In oogbewegingsonderzoek is er altijd redelijk veel uitval van data. Daarvoor zijn drie oorzaken aan te wijzen. In de eerste plaats slaan lezers soms regio's in een tekst over en zijn er voor die regio's dus geen metingen. In de tweede plaats vallen er metingen af, omdat lezers met hun ogen knipperen (zie paragraaf 4.7). En in de derde plaats vallen metingen met extreme waarden af, zoals dat in tijdmetingsonderzoek gebruikelijk is. Het is daarom belangrijk om de data op te schonen alvorens over te gaan tot statistische toetsing. In totaal waren er 1320 metingen mogelijk (33 proefpersonen maal 40 kernwoorden). In 15,9% van de gevallen was een kernwoord overgeslagen. Voor de gazetijden gold dat in 3,3% van de gevallen de gazetijd begon of eindigde met een knippering en in 0,9% van de gevallen dat de tijd drie of meer standaarddeviaties afweek van het proefpersonenen itemgemiddelde per conditie. Bij de regressiepadtijden begon of eindigde 3,2% van de gevallen met een knippering en viel 2,0% uit vanwege extreme waarden. De resterende gaze- en regressiepadtijden werden onderworpen aan univariate variantieanalyses over proefpersonen (F1) en over teksten (F2) met de factoren Vet (wel/niet vetgedrukt) en Opsomming (wel/niet puntsgewijs). De gemiddelde gaze- en regressiepadtijden en de bijbehorende percentages regressies staan in Tabel 1.
In de analyses van de gazetijden werden geen effecten gevonden: alle F's waren kleiner dan 1. De analyses van de regressiepadtijden lieten echter een interactie zien tussen Vet en Opsomming: F1(1,116) = 7,19; MSE = 132140; p < 0,01; η2 = 0,058 en F2(1,40) = 5,17; MSE = 69718; p < 0,05; η2 = 0,114. Wanneer er een puntsgewijze opsomming was, waren de regressiepadtijden van de kernwoorden langer als ze vetgedrukt waren dan wanneer ze niet vetgedrukt waren, maar als er geen puntsgewijze opsomming was, was het precies andersom: de regressiepadtijden waren korter als de kernwoorden vetgedrukt waren dan wanneer ze niet vetgedrukt waren. Er waren verder geen effecten van Vet en Opsomming in deze analyses. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 230]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 1: De gemiddelde gaze- en regressiepadtijden (ms) en het aantal regressies (percentages) van de kernwoorden in de opsomming als functie van Vet (wel/niet vetgedrukt) en Opsom ming (wel/niet puntsgewijs).
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.9 Discussie.De interactie tussen Vet en Opsomming in de analyses van de regressiepadtijden suggereert dat de twee layout-factoren elkaar beïnvloeden en dus niet onafhankelijk zijn. Een mogelijke interpretatie is dat als vetgedrukte woorden en puntsgewijze opsommingen tegelijkertijd en op dezelfde plaats in de tekst gebruikt worden, ze elkaar storen. Een volledige bespreking van deze interactie valt echter buiten het bestek van dit artikel. Een interessante en hier meer relevante bevinding is dat de gazetijden geen interactie lieten zien. Een mogelijke verklaring daarvoor schuilt in het relatief hoge aantal regressies en de verdeling van de regressies over de verschillende condities. Als er veel regressies zijn vanuit een regio, zijn de gazetijden van die regio korter. De reden daarvoor is dat als lezers besluiten om terug te springen in de tekst, ze dat besluit vaak al heel snel bij de eerste fixatie maken (Vonk & Cozijn, 2003). De gazetijden geven dan een onderschatting van de werkelijke verwerkingstijd, gegeven dat de tijd die doorgebracht wordt tijdens de regressie bijdraagt aan de verwerkingstijd van de regio. Het relatief hoge aantal regressies (gemiddeld 25,4% tegen 15% bij normaal lezen, zie paragraaf 2) maakt de gazetijden als maat voor verwerking daarom minder betrouwbaar. De scheve verdeling van regressies in Tabel 1 doet verder vermoeden dat de onderschatting van de gazetijden groter is in de conditie puntsgewijs/vet ten opzichte van niet-puntsgewijs/vet (29,0% versus 27,7%) en niet-puntsgewijs/niet-vet ten opzichte van puntsgewijs/niet-vet (25,5% versus 19,5%) en dat daardoor de interactie in de gazetijdenanalyses analyses niet zichtbaar werd.
De verschillende resultaten met de gazetijden en de regressiepadtijden laten zien dat het belangrijk is om de aantallen regressies mee te laten wegen in de keuze voor een van deze maten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5. ConclusieHet mag wel duidelijk zijn dat de hier gepresenteerde casus een onvolledig beeld geeft van het uitgevoerde onderzoek. Het doel van dit artikel is echter om duidelijk te maken dat het inzetten van oogbewegingsregistratie in leesonderzoek binnen ieders bereik ligt. De hardware wordt steeds eenvoudiger te bedienen en in te stellen. Dat geldt bijvoorbeeld voor de | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 231]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
eyetracker die hier is besproken (de EyeLink II van SR Research) maar in nog hogere mate voor bijvoorbeeld de nieuwe eyetracker van TobiiGa naar eind6. Het enige waar de taalverwerkingswetenschapper op moet letten is dat de apparatuur een adequate temporele resolutie heeft, d.w.z. dat hij zeer korte tijden kan meten. In leesonderzoek zijn effecten van 20 milliseconden geen uitzondering. Een apparaat met een temporele resolutie van 60 Hz, dat dus elke 16,6 milliseconden een meting doet, maakt het welhaast onmogelijk een dergelijk verschil aan het licht te brengen, aangezien de grootte van het gezochte effect min of meer gelijk staat aan slechts één enkele meetwaarde. Ook de software is geen belemmering meer om oogbewegingsonderzoek te doen. Software zoals Fixation heeft een enorm bedieningsgemak en een grote flexibiliteit. Het is geen enkel probleem om in leesonderzoek de leestijden te analyseren van woordsegmenten, afzonderlijke woorden, groepen van woorden of alinea's. En dat kan met verschillende afhankelijke maten van verwerking. In het artikel is duidelijk gemaakt dat de onderzoeker hieraan veel aandacht zal moeten besteden. Daarnaast biedt het programma Fixation de mogelijkheid om de verwerking van beeldmateriaal te analyseren. Het genereert daartoe de tijden van de stappen in een kijkpad. Ook experimenten binnen het Visual World Paradigma kunnen worden geanalyseerd. Dit paradigma, dat binnen het taalverwerkingsonderzoek een grote vlucht heeft genomen, maakt gebruik van de eigenaardigheid van mensen om te kijken naar de afbeeldingen van de entiteiten waarover de taaluiting gaat die ze beluisteren. Zo kan simpelweg gezien worden welke entiteit in een zin of tekst in focus is, terwijl een luisteraar taal verwerkt. Tot slot kan nog gezegd worden dat de oogbewegingsregistratie op een toenemend aantal onderzoeksterreinen wordt ingezet. Zo wordt de techniek steeds meer gebruikt in combinatie met neurimaging-technieken om convergerende resultaten te verkrijgen (zie ook Hoeks, Hendriks & Redeker in dit nummer). De verwachting is dat de techniek verder gebruikt zal worden als pretestinstrument (zie bijvoorbeeld Lentz, Mak & Pander Maat en Van den Haak, De Jong & Schellens in dit nummer), om schrijfprocessen te bestuderen (zie bijvoorbeeld Van Waes & Leijten in dit nummer) en om vast te stellen hoe mensen multimodale informatie verwerken zoals hypertext, beeld en tekst, video en tekst en allerlei combinaties met spraak. Programma's zoals Fixation zullen in deze ontwikkelingen meegaan.
* Ik wil scriptiestudente Hellen Megens (doctoraalopleiding Tekst en Communicatie aan de Faculteit Communicatie en Cultuur van de Universiteit van Tilburg) bedanken voor het uitvoeren van het leesonderzoek dat als casus dient in dit artikel. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 232]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||