|
| |
| |
| |
Leesstrategieën in hypertext
J.J. Beishuizen en E.T. Stoutjesdijk
Samenvatting
Het bestuderen van lange teksten is een cyclisch proces, bestaande uit selectie en verwerking van de stof. Bij de keuze voor hypertext spelen naast de kwaliteit van de hypertext, de aard van het kennisdomein, de leestaak, de domeinkennis van de lezer en zijn leerstijl een rol. Onderzocht werd of er verschillende leesstrategieën zijn bij het werken met hypertext en of deze samenhangen met de leerstijl (i.c. regulatie- en verwerkingsstijl) van de lezer. Er bleken zeer verschillende leesstrategieën gehanteerd te worden. Deze verschillen hingen niet significant samen met verschillende verwerkingsstijlen. Wel was er een relatie tussen regulatiestijl en leesstrategie. Stuurlozen konden het slechtst met de hypertext overweg; zij gingen weinig systematisch te werk. Een grote mate van zelfsturing bleek echter, tegen de verwachting, niet bij te dragen aan een gestructureerde aanpak. Mogelijke verklaringen worden gegeven en kort wordt op vervolgonderzoek ingegaan.
| |
1 Inleiding
Hypertext is een betrekkelijk jong produkt van informatica en informatiewetenschap. Beschouwt men een tekst in een boek als een lineaire reeks van alinea's, dan is het belangrijkste kenmerk van een hypertext dat de alinea's niet in een volgorde staan. Het is aan de lezer om alinea's uit te kiezen door gebruik te maken van navigatiemiddelen. Een computerprogramma loodst de lezer op diens aanwijzingen door de hypertext. Op het eerste gezicht lijkt een dergelijke faciliteit heel geschikt voor lezers die op zoek zijn naar specifieke informatie, bijvoorbeeld in de gebruiksaanwijzing van een apparaat of in een verzameling afbeeldingen van 19e eeuwse schilderijen. Voorts zou een hypertext goed tegemoet kunnen komen aan verschillen tussen lezers, bijvoorbeeld in kennis van het betreffende domein of in lees- en studeergewoonten. Hoewel deze veronderstellingen aannemelijk lijken, kunnen ze nog niet met empirische gegevens worden ondersteund: er is nog weinig onderzoek gedaan naar de manier waarop een hypertext wordt gelezen. In dit artikel worden leesstrategieën in hypertext geanalyseerd, deels op grond van wat bekend is over het bestuderen van normale teksten, deels op grond van eigen onderzoek naar het bestuderen van een hypertext. In deze inleiding wordt eerst ingegaan op het bestuderen van normale teksten. Vervolgens worden kenmerken van hypertext besproken en komen overeenkomsten en verschillen met normale teksten aan de orde. Daarna wordt de vraagstelling van ons eigen onderzoek naar de samenhang tussen studiegewoonten en wijze van hypertextgebruik verder uitgewerkt.
| |
1.1 Het bestuderen van lange teksten
Het bestuderen van een lange tekst, zoals een hoofdstuk uit een studieboek, is een voorbeeld van een algemeen proces van informatie opnemen uit de omgeving. Dit proces bestaat uit een zich herhalende cyclus van selectie en verwerking van informatie. Onder selectie wordt hier verstaan het oriënteren op de omgeving en het opnemen van informatie uit de omgeving, op basis van een signalement of criterium. Onder verwerking wordt de | |
| |
interne afhandeling van opgenomen informatie verstaan. In Neissers (1976) algemene model van informatieverwerking registreert de waarnemer niet alles wat aan zijn oog voorbij trekt, maar neemt hij voortdurend steekproeven uit het aanbod van informatie op basis van verwachtingen. De geselecteerde informatie wordt geïnterpreteerd; ze krijgt betekenis in termen van bestaande kennis (assimilatie). Zonodig wordt de bestaande kennis gewijzigd (accommodatie). Deze verwerking levert nieuwe verwachtingen op waarmee de volgende ronde van start gaat.
Baker en Brown (1984) onderscheidden selectie- en verwerkingsprocessen bij het bestuderen van teksten. Het is duidelijk dat de aard van de leestaak bepaalt of selectie danwel verwerking op de voorgrond staat. Het opzoeken van een telefoonnummer in het telefoonboek is vooral een selectietaak. De lezer controleert per regel of de naam van de abonnee klopt met het signalement. Is er overeenstemming, dan wordt de regel (inclusief het telefoonnummer) verder verwerkt. Het lezen van een roman is voor de meeste mensen een verwerkingstaak. Er is geen dwingende reden om af te wijken van de aangeboden volgorde van zinnen. De lezer besteedt alle aandacht aan de interpretatie van de tekstinhoud.
Dit laatste neemt niet weg dat mensen lezen of studeren verschillend kunnen opvatten. Veel mensen lezen een roman in de volgorde waarin de auteur de tekst heeft gepubliceerd. Anderen kijken eerst hoe het boek afloopt of bladeren de tekst door en nemen kris kras informatie op, waarmee ze een interne representatie van de tekst opbouwen. Diverse onderzoekers hebben met behulp van vragenlijsten bij studenten getracht te achterhalen hoe ze gewend zijn te studeren (Schmeck, 1983,1991; Entwistle, 1988; Marton & Säljö, 1984). In Nederland ontwikkelden Vermunt en Van Rijswijk (1987) op basis van Schmecks werk de Inventaris Leerstijlen. Deze bevat diverse schalen, waarmee aspecten van studeergewoonten worden gemeten. Drie van de schalen hebben vooral betrekking op het reguleren van het studeren. Sommige mensen hebben de gewoonte zelf te bepalen op welke manier en in welke volgorde ze een tekst bestuderen. Anderen laten zich bij voorkeur leiden door externe adviezen. Een derde categorie geeft helemaal geen blijk van enige vorm van regulatie en lijkt vrij stuurloos te werk te gaan.
Drie andere schalen hebben betrekking op verwerking van (schriftelijke) informatie. Sommige studenten zijn gewoon om verbanden in de tekst op te sporen en op alle mogelijke manieren relaties te leggen met al aanwezige kennis. Deze activiteiten zijn kenmerkend voor diepe verwerking van informatie. Andere studenten gebruiken vooral de structuur van de tekst om stapsgewijs een interne weergave van de informatie te maken. De derde schaal - vooral op toepassing gerichte, ‘concrete’ verwerking - werd in deze studie buiten beschouwing gelaten. Deze verwerkingsstijl is niet duidelijk te onderscheiden van diepe verwerking. In dit stadium van het onderzoek leek het verstandiger om de aandacht te concentreren op het contrast tussen diepe en stapsgewijze verwerking. Het ligt voor de hand dat verwerking en regulatie met elkaar samenhangen: diepe verwerking met zelfregulatie en stapsgewijze verwerking met externe regulatie (Vermunt & Van Rijswijk, 1988).
Samenvattend kan het bestuderen van lange teksten worden opgevat als het selecteren en verwerken van teksteenheden (alinea's) waarbij sommige lezers zelf bepalen op welke manier ze de teksteenheden selecteren en bij de interne weergave allerlei dwarsverbanden leggen, terwijl andere lezers stapsgewijs de van buiten aangegeven volgorde van teksteenheden aanhouden en de informatie dienovereenkomstig representeren.
| |
| |
| |
1.2 Hypertext
Een hypertext is een verzameling teksteenheden (alinea's, aantekeningen over een bepaald onderwerp) die met elkaar verbonden zijn via diverse relaties. Dit kunnen associatieve relaties zijn (tekst A heeft iets te maken met tekst B) of relaties van een bepaald type (uitleg, empirische evidentie, tegenstelling, etc.). De lezer van een hypertext selecteert een teksteenheid hetzij lokaal vanuit de laatst gelezen eenheid via een van de mogelijke relaties, hetzij globaal vanuit een overzicht van alle teksteenheden, de inhoudsopgave of begrippenkaart. Als de hypertext geen inhoudsopgave of begrippenkaart bevat, kan selectie alleen op lokaal niveau plaatsvinden en bestaat het gevaar dat de lezer verdwaalt. De aanwezigheid van een goed georganiseerde inhoudsopgave voorkomt dit.
| |
1.3 Tekst en hypertext: overeenkomsten in verwerking; verschillen in selectie
Het lezen van een hypertext lijkt op het lezen van een tekst. In beide gevallen is sprake van selectie en verwerking van informatie. Vooral in de verwerkingsfase zijn de overeenkom-sten pregnant. In beide aanbiedingsvormen moeten teksteenheden verwerkt worden, dat wil zeggen intern gerepresenteerd in een tekstbasis en een situatiemodel (Van Dijk & Kintsch, 1983). Verschillen in presentatievorm zouden de wijze van verwerking kunnen beïnvloeden. Ten eerste wordt elektronische tekst verticaal gepresenteerd (op een beeldscherm) en gedrukte tekst horizontaal (in een boek op tafel bijvoorbeeld). Belangrijker zijn de mogelijkheden voor markering. Elektronische tekst kan wel gemarkeerd worden met onderstrepingen en aantekeningen in de kantlijn, maar deze handelingen zijn met pen en papier dikwijls eenvoudiger uit voeren. Dit relatieve gebruiksgemak kan een voordeel zijn bij de verwerking van tekst in vergelijking met hypertext (zie Van Hout Wolters, 1986; zie echter Van Oostendorp, 1989; Van Oostendorp & Peeck, 1990). In boeken schrijft men echter ook niet altijd en voor het beeldscherm kan natuurlijk aanvullend met pen en papier gewerkt worden.
Er is wel vergelijkend onderzoek gedaan naar verschillen in tekstbegrip bij elektronische en schriftelijke teksten (Mills & Weldon, 1987; Dillon, McKnight & Richardson, 1988), maar over het algemeen betrof dit relatief korte teksten (tot ca. 2000 woorden). Van Oostendorp (1989) constateerde in een vergelijkend experiment met een vrij korte tekst dat de prestatie in een computerconditie, waar men de tekst op beeldscherm kreeg aangeboden en aantekeningen op de pc maakte, vrijwel niet achterbleef bij de pen-en-papiercondities. Reinking (1988) vond dat lezers in een computerconditie meer tijd besteedden aan het studeren en onder andere daardoor méér tekstbegrip verwierven dan lezers van gewone tekst. Hij concludeerde dat computers tekstbegrip kunnen bevorderen, mits ze doelbewust gebruikt worden om actieve opname van informatie en diepe verwerking van de tekst te stimuleren. Voor verdere literatuurverwijzingen op het gebied van de vergelijking tussen electronische en traditionele presentatie van tekst, zie onder-meer de artikelen van Van Oostendorp en Van Kruiningen in dit nummer.
De noodzaak bij hypertext om na elke teksteenheid actief een volgende teksteenheid te selecteren en de rijkdom aan middelen hiertoe, hebben tot gevolg dat het selectieproces bij het lezen van hypertext in het algemeen veel meer op de voorgrond staat dan bij het lezen van tekst. Vooral in de selectiefase verschillen de beide aanbiedingsvormen.
Welke hulpmiddelen om te selecteren biedt een gewone gedrukte tekst? In de eerste plaats wordt elke teksteenheid gevolgd door een nieuwe teksteenheid. De lineaire
| |
| |
volgorde die door de auteur van de tekst is bedacht, suggereert een voorkeursordening van de teksteenheden. De lezer kan zich bij deze suggestie aansluiten en aan de hand van de auteur de teksteenheden selecteren en verwerken. Vervolgens bieden overzichten als inhoudsopgave, registers van zaken of personen en een verklarende woordenlijst, de gelegenheid om een nieuwe teksteenheid te selecteren. Tenslotte kan de lezer gebruik maken van de tekstopmaak, of kan hij via zelf aangebrachte markering belangrijk geachte passages nog eens terugzoeken en herlezen. Met uitzondering van de lineaire volgorde, bezit een hypertext deze oriëntatie- en selectiehulpmiddelen ook. Een hypertext biedt dikwijls, maar niet per definitie, meer selectiehulpmiddelen op woordniveau of op het niveau van (relaties tussen) de teksteenheden. Een tekst met veel, en een hypertext met weinig selectiehulpmiddelen hoeven elkaar in dit opzicht echter niet ver te ontlopen. Belangrijker is dat een lezer bij een hypertext steeds moet kiezen en bij een lineaire tekst nooit hoeft te kiezen.
| |
1.4 Factoren die een rol spelen bij de keuze voor hypertext
De vraag welke presentatievorm de voorkeur verdient, tekst of hypertext, kan in zijn algemeenheid niet beantwoord worden. Vier factoren zijn van grote invloed op een eventuele voorkeur: de aard van het kennisdomein, de aard van de leestaak, de domein-kennis van de lezer en de studeergewoonten van de lezer.
In sommige kennisdomeinen liggen de ordening van begrippen en hun onderlinge relaties vast, terwijl in andere kennisdomeinen allerlei ordeningen mogelijk zijn. Pask (1976) vergelijkt het begrippennetwerk in dergelijke domeinen met een visnet. Als men een bepaald knooppunt omhoog trekt, ontstaat er een hiërarchische ordening van begrippen. Keuze van een ander knooppunt leidt tot een heel andere ordening, zonder dat overigens knooppunten ten opzichte van elkaar van plaats verwisselen. Spiro, Vispoel, Schmitz, Samarapungavan & Boerger (1987) stellen, dat het bestuderen van een dergelijk kennisdomein vanuit verschillende perspectieven zou kunnen leiden tot een meer flexibele en gemakkelijk toepasbare representatie (zie ook Spiro, Feltovich, Jacobson, & Coulson, 1991).
In sommige leestaken ligt het accent op selectie, terwijl andere leestaken juist veel verwerkingsactiviteiten vergen. Het is van belang te benadrukken dat de aard van de leestaak door verschillende lezers op verschillende manieren kan worden opgevat. Het is de taakopvatting van de lezer die bepaalt welke leeractiviteiten worden ondernomen (Willems, 1991) en dus welke presentatievorm het meest geschikt is.
Hoe meer domeinkennis de lezer heeft, hoe meer hij kan profiteren van de extra selectiemogelijkheden van hypertext. Men kan dus veronderstelen dat een beginner in het domein meer gebaat is bij een tekst en een ervaren lezer meer profijt heeft van een hypertext.
Tenslotte bepaalt de leerstijl van de lezer mede of hij betere resultaten zal behalen met een tekst of een hypertext. Het valt te verwachten dat een aanbiedingsvorm zonder dwingende of gesuggereerde leesvolgorde beter past bij lezers die gewend zijn zelf te bepalen wat ze lezen en in welke volgorde. Lezers die bij voorkeur een beroep doen op suggesties van buiten of helemaal niet gericht lezen, zullen beter af zijn met een lineaire tekst. Een lezer die gewend is om informatie diep te verwerken, zal om verbanden te exploreren uitgebreid gebruik maken van alle oriëntatie- en selectiehulpmiddelen die een tekst en een hypertext bieden, zowel op globaal niveau (inhoudsopgave, registers, schema's) als op lokaal niveau (verwijzingen van het type ‘Zie ook ...’, verklarende | |
| |
woordenlijsten). Bij stapsgewijze verwerking van informatie in een hypertext sluiten selectiehulpmiddelen op lokaal niveau goed aan bij de gewoonte om teksteenheden lineair af te werken. Ook de lineaire ordening van een tekst wordt eerder gevolgd door een stapsgewijze dan door een diepe verwerker. Al met al lijkt hypertext beter geschikt voor diepe verwerkers die zelf hun weg bepalen, en tekst beter te passen bij stapsgewijze verwerkers die graag gebruik maken van externe adviezen.
| |
1.5 Vraagstelling
De samenhang tussen domeinkenmerken, leestaak, domeinkennis en leerstijl van de lezer enerzijds en de manier van studerend lezen en het studieresultaat anderzijds is tot nu toe uitsluitend onderzocht bij tekst als presentatievorm en niet bij hypertext. Daarbij komt dat in het onderzoek bijna altijd met korte teksten is gewerkt van minder dan 2000 woorden. Dat is jammer, want daardoor heeft het selectieaspect van studerend lezen relatief weinig aandacht gekregen. In ons onderzoek wilden we (1) de bestaande inzichten toepassen op hypertext als aanbiedingsvorm en toetsen op hun geldigheid en (2) onze kennis van studerend lezen uitbreiden door het selectieaspect op de voorgrond te plaatsen. Gestreefd werd naar beschrijving van het leesproces bij bestudering van een lange hypertext van ongeveer 20.000 woorden. Het proces werd vastgelegd in een protocol van interacties met het hypertextprogramma.
Bij de analyse van de leesprotocollen ging het vooral om twee vragen: (1) Hoe gebruiken beginners in een domein een lange hypertext; zijn er bepaalde leesstrategieën volgens welke ze te werk gaan bij het studeren? en (2) Wat is de invloed van verwerkingsstijl (diepe en stapsgewijze verwerking) en regulatiestijl (zelfsturing, externe sturing en stuurloosheid) op het leesgedrag?
De eerste kwestie werd aangepakt door met behulp van het leesprotocol na te gaan hoe een lezer onderwerpen van de zogenaamde begrippenkaart bestudeerde: met of zonder oriëntatie vooraf en door uitputtend lezen van alle bij het onderwerp behorende tekst-eenheden of door steekproeven van teksteenheden te nemen. Verder gingen we na of de opeenvolging van geselecteerde onderwerpen verklaard kon worden doordat de ordening van onderwerpen op de begrippenkaart was gevolgd, doordat de lezer relaties tussen onderwerpen had nagetrokken, of anderszins.
Wat betreft de tweede vraag bepaalden we om te beginnen de effecten van planmatigheid (zelf- of extern gestuurde leerstijl) en stuurloosheid. Van planmatig werkende lezers werd een goed te interpreteren leesprotocol verwacht; stuurloze lezers zouden meer doelloos zwalken door de hypertext. Zelfsturende lezers zouden efficiënter om moeten gaan met de hypertext dan de extern gestuurde lezers omdat de laatstgenoemden onvoldoende aanwijzingen kregen waaruit een leesvolgorde kon worden afgeleid en de betreffende hypertext ook nauwelijks selectiemiddelen op lokaal niveau bood. Wellicht zouden ze gebruik maken van de volgorde waarin de onderwerpen werden afgebeeld op de zogenaamde begrippenkaart.
In de tweede plaats onderzochten we het effect van diepe en stapsgewijze verwerking. Van de meer diepe verwerkers werd verwacht dat ze de selectie van een teksteenheid uitvoerig zouden overwegen door zich te oriënteren op de inhoud van een teksteenheid en de plaats ervan binnen het geheel, alvorens met lezen te beginnen. Uitgesproken stapsgewijze verwerkers zouden minder oriëntatie vooraf verrichten en bij het lezen wellicht gebruik maken van de volgorde waarin de onderwerpen werden afgebeeld op de begrippenkaart. Verder werd van diepe verwerkers verwacht dat ze onderwerpen uitputtend zouden | |
| |
bestuderen alvorens een nieuw onderwerp aan te snijden, terwijl stapsgewijze verwerkers sneller van onderwerp zouden wisselen om zoveel mogelijk verschillende onderwerpen op de begrippenkaart te kunnen afzoeken.
| |
2 Methode
Als proefpersonen werkten 48 letterenstudenten (zonder voorkennis over het domein van de hypertext) in individuele sessies mee aan een studeerexperiment. Na een korte introductie werden de werking van de computer en het programma gedemonstreerd en las men de leestaak. Daarin werd een onderwerp omschreven waarop gestudeerd moest worden: de veranderingen die informatie bij opslag in en ophalen uit het lange-termijn geheugen ondergaat. Aan de proefpersonen werd duidelijk gemaakt dat de beschikbare tijd niet toereikend was om de hele tekst grondig te bestuderen. De leestaak moest als selectiecriterium worden gebruikt. De proefpersoon werd twee uur alleen gelaten om te studeren, met beschikking over de computer, de instructies, de leestaak, een klok, pen en papier, waarna men 20 minuten kreeg om de natoets te maken. Tenslotte beantwoordde men van de Inventaris Leerstijlen voor het Hoger Onderwijs (Vermunt & Van Rijswijk, 1987) de vragen over verwerkings- en sturingsgewoonten. Hiermee werden scores bepaald voor diepe en stapsgewijze verwerking, en zelfsturing, externe sturing en stuurloosheid.
| |
2.1 De hypertext
Als basis voor de hypertext werd het hoofdstuk over het geheugen uit een inleidend boek in de cognitieve psychologie (Gleitman, 1986) gebruikt. Voor deze tekst van ongeveer 20.000 woorden was een niet-lineaire structuur gecreëerd (Samarapungavan & Beishuizen, in press) door middel van domeinanalyse. Vier perspectieven van waaruit onderwerpen in het domein van het geheugen benaderd kunnen worden, vormden het uitgangspunt van het onderliggende conceptuele model. Van kleine teksteenheden, zoals een alinea, was beoordeeld of ze een fenomeen, een theorie, een model of een experiment beschreven. Binnen elk van deze perspectieven waren hoofd- en subonderwerpen onderscheiden en benoemd. Tenslotte was voor elk hoofdonderwerp vastgesteld met welke andere hoofd-onderwerpen het verband hield.
De hypertext was gestructureerd met behulp van deze analyse en geschreven in een Hypercard-omgeving op een Macintosh Hei. Een A4 scherm was verdeeld in twee vensters: een overzichts- en een tekstvenster. In het overzichtsvenster was een begrippenkaart (Figuur 1) van het hele domein afgebeeld, bestaande uit vier velden, die de perspectieven representeerden: Phenomena, Theories, Models en Experiments. In elk veld waren de hoofdonderwerpen weergegeven. Deze begrippenkaart bleef gedurende de hele leestijd zichtbaar. Via dit venster vond selectie van teksteenheden plaats door gebruik van de commando's boven de begrippenkaart. Hulpmiddelen bij het maken van keuzen waren de functies SHORT INFO en RELATIONS. Short info bestond uit korte, oriënterende informatie over elk veld, hoofd- of subonderwerp: een omschrijving van het betreffende concept en/of informatie over de substructuur van een hoofdonderwerp. Relaties konden alleen van elk hoofdonderwerp worden opgevraagd; middels lijnen werden dan de relaties met andere hoofdonderwerpen afgebeeld.
| |
| |
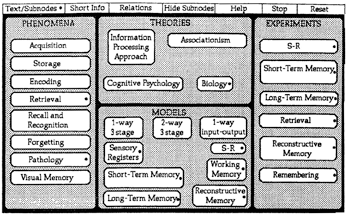
Figuur 1: De begrippenkaart op de bovenste helft van het scherm. De onderwerpen (bijvoorbeeld: short term memory) zijn geplaatst in één of meer van de vier velden (perspectieven): fenomenen, theorieën, modellen en experimenten
Het onderste venster was het tekstvenster. Via dit venster konden 72 verschillende teksteenheden worden gelezen: 4 algemene tekstkaarten over de velden, 12 tekstkaarten bij niet onderverdeelde hoofdonderwerpen en 56 bij de subonderwerpen. Om deze kaarten te selecteren, klikte men met een muis op het gekozen onderwerp op de begrippenkaart en vervolgens op TEXT. In het tekstvenster verscheen dan het betreffende stukje tekst. Als het hoofdonderwerp uit subonderwerpen bestond, kwam men niet rechtstreeks bij een teksteenheid, maar verscheen eerst de substructuur van het onderwerp op de begrippenkaart in de vorm van subnodes. Men kon dan een keuze voor een subonderwerp maken (eventueel na short info's over de subonderwerpen te hebben gelezen). De titel van ieder geselecteerd onderwerp, werd in reverse video gemarkeerd op de begrippenkaart. Men kon terugbladeren door de eerder opgevraagde tekstkaarten en deze herlezen, door op het tekstscherm te klikken op de pijl naar links (terug) of de pijl naar rechts (weer vooruit).
| |
2.2 De leestaak en de toets
De leestaak was voor alle proefpersonen gelijk en bestond uit een omschrijving van het deel van het domein waarover men na afloop zou worden getoetst: de veranderingen die informatie ondergaat bij opslag in en ophalen uit het lange-termijn geheugen. Bij tekstanalyse bleek dat 22 van de tekstkaarten relevant waren voor de leestaak. De omschrijving bood veel aanknopingspunten met de begrippenkaart, maar was voor beginners in het domein niet zo duidelijk dat men gemakkelijk de betreffende tekstkaarten kon opsporen. De natoets bestond uit 22 open vragen over de relevante tekst, waarop korte antwoorden gegeven moesten worden.
| |
| |
| |
2.3 Procesmetingen
Het programma registreerde alle handelingen van een proefpersoon en het tijdstip waarop deze werden uitgevoerd in een protocol. Om te beginnen werden vijf eenvoudige frequentiematen correlationeel geanalyseerd: de aantallen opgevraagde relaties, de daarvan gebruikte relaties om een nieuw onderwerp te kiezen, opgevraagde korte informaties, gelezen relevante kaarten voor de leestaak en gelezen kaarten in het algemeen.
Bovendien werd een codeersysteem ontwikkeld om de protocollen gedetailleerder op handelingssequenties te onderzoeken. Het coderen bestond uit het opdelen van de protocollen in segmenten en het categoriseren van elk segment en van elke overgang tussen twee segmenten. Een segment werd gedefinieerd als één of meer achtereenvolgende handelingen die op hetzelfde hoofdonderwerp betrekking hadden. Dit criterium voor segmentatie was gekozen omdat een hoofdonderwerp voor de proefpersoon een logische eenheid lijkt te zijn. De permanente representatie van het domein via de begrippenkaart was immers op het niveau van hoofdonderwerpen.
Classificatie van de segmenten vond plaats op grond van twee soorten activiteiten: oriënteren vooraf en lezen. Oriëntatie was het opvragen van short info voordat men tekst koos. Wat betreft lezen kon men de tekst van alle subonderwerpen hebben opgevraagd, of hieruit een selectie hebben gemaakt, of men kon teruggebladerd hebben naar eerder opgevraagde tekst. Door combinatie van deze mogelijkheden ontstonden zes categorieën:
| 1 | Uitputtend lezen: geen short info vooraf, alle subnodes gelezen. |
| 2 | Selectief lezen: geen short info vooraf, een deel van de subnodes gelezen. |
| 3 | Oriëntatie + uitputtend lezen: short info en alle subnodes gelezen. |
| 4 | Oriëntatie + selectief lezen: short info en een deel van de subnodes gelezen. |
| 5 | Alleen oriëntatie: short info, geen tekst opgevraagd. |
| 6 | Bladeren: eerder opgevraagde tekst opnieuw bekeken. |
De overgangen tussen segmenten werden geclassificeerd naar het waarschijnlijk door de proefpersoon gelegde verband tussen twee na elkaar gekozen onderwerpen. De vraag was: hoe kwam iemand bij de keuze van onderwerp y na de verwerking van (een deel van) onderwerp X? Zes categorieën werden gedefinieerd. In volgorde van de sterkste naar de zwakste verbinding tussen twee segmenten zijn dit A tot en met F:
| A via relaties: Gebruik van de opgevraagde relaties met X om een nieuw onderwerp y te kiezen. (Y is een van de onderwerpen waarmee X een relatie heeft.) |
| B binnen een veld: Een nieuw onderwerp y kiezen binnen hetzelfde veld als X. |
| C veld na relaties: Terug gaan naar een veld voor keuze y, nadat vanuit een eerder onderwerp in dat veld alleen relaties gevolgd zijn. |
| D opvullen van een veld: Na X terug gaan naar een veld waar eerder een of meer onderwerpen zijn gelezen (en dus gemarkeerd), terwijl y zelf een nog niet gemarkeerd onderwerp is en wordt gevolgd door tenminste een onderwerp uit datzelfde veld. |
| E nieuw veld: Beginnen in een nieuw veld (waar nog niets gemarkeerd is). |
| F onduidelijk: Iedere overgang die niet kan worden verklaard door A tot en met E. |
De segmentatie en de classificatie van segmenten en overgangen konden worden geautomatiseerd. Met dit codeersysteem kon elk protocol worden beschreven in termen van relatieve frequenties van elk segment- en overgangtype.
| |
| |
| |
3 Resultaten
3.1 Handelings frequenties
In de kwantitatieve analyse werden in eerste instantie simpele tellingen van de geregistreerde acties en de toetsresultaten geanalyseerd op onderlinge samenhang en op samenhang met de scores op de ILS, evenals relatieve frequenties van segment- en overgang- typen in de protocollen. De toetsresultaten worden hier buiten beschouwing gelaten.
Men las gemiddeld 35 tekstkaarten, waarvan 9 relevante. (Precisie: .26). In twee uur benutte men gemiddeld drie maal een relatie door naar een van de gerelateerde tekstkaarten te gaan en oriënteerde men zich 39 maal met behulp van short info's.
Samenhang tussen de afhankelijke variabelen onderling en met de ILS-scores werd onderzocht door middel van correlatieanalyse. Positieve correlaties werden gevonden tussen het aantal gelezen relevante kaarten en het totaal aantal gelezen kaarten (.76; p<.00 1), en tussen de aantallen opgevraagde short info's en relaties (.42; p<.01). Het lezen van veel kaarten verhoogde dus sterk de kans op het vinden van relevante kaarten (in tegenstelling tot bijvoorbeeld short info's, die hier niet aan bijdroegen). En het gebruik van meer relaties als navigatiemiddel om te selecteren ging samen met het vaker op vragen van short info's.
Tussen de ILS-scores op de vijf schalen en de afhankelijke variabelen was één correlatie significant. Stuurloosheid bleek negatief samen te hangen met het gebruik van short info's; hoe meer het iemand aan sturing ontbrak, hoe minder short info's er werden opgevraagd.
| |
3.2 Protocolanalyse
De protocollen werden gesegmenteerd. De gemiddelde serielengte van elk protocol werd berekend als een maat voor de continuïteit in het gedrag. Een serie segmenten is een aantal opeenvolgende onderwerpen, met elkaar verbonden door slechts directe veld- of relatie-overgangen (A, B of C). In Tabel 1 zijn naast de gemiddelde relatieve categoriefrequenties ook het gemiddeld aantal segmenten per protocol en de gemiddelde lengte van segment-series weergeven.
Tabel 1: Overzicht van de protocolgegevens (N=48)
| Segmenttypen; percentages |
M |
sd |
Overgangtypen; percentages |
M |
sd |
| 1 (Uitputtend lezen) |
36.2 |
21.8 |
A (Relaties) |
11.3 |
10.1 |
| 2 (Selectief lezen) |
7.1 |
6.9 |
B (Binnen veld) |
53.8 |
17.7 |
| 3 (Oriënteren + uitputtend lezen) |
10.6 |
9.9 |
c (Veld na relaties) |
2.5 |
3.5 |
| 4 (Oriënteren + selectief lezen) |
9.1 |
7.5 |
D (Opvullen van een veld) |
4.5 |
3.8 |
| 5 (Alleen oriënteren) |
35.4 |
19.2 |
E (Nieuw veld) |
12.9 |
5.7 |
| 6 (Bladeren) |
1.6 |
3.5 |
F (Onduidelijk) |
15.0 |
11.6 |
| |
_____ |
|
|
_____ |
|
| |
100% |
|
|
100% |
|
| |
| Protocollengte: aantal segmenten |
38.1 |
15.41 |
Serielengte: aantal segmenten |
3.7 |
1.6 |
| |
| |
Om eventuele systematische samenhang in categoriegebruik op te sporen, werd ook op de segment- en overgangtypen een correlatieanalyse gedaan. Het onderscheid tussen oriënteren en niet oriënteren bleek van groter belang dan het onderscheid tussen uitputtend en selectief lezen. De relatieve frequenties van de segmenttypen 3 en 4 (beide met oriëntatie, maar verschillend in selectiviteit) waren positief gecorreleerd: .53 (p<.001), terwijl type 1 (zonder oriëntatie) juist negatief correleerde met de segmenttypen met oriëntatie 3,4 en 5 (resp. -.49, -.53 en -.74; p<.001). Tussen het voorkomen van segmenten met en zonder oriëntatie bestond dus een negatief verband, terwijl de categorieën met oriëntatie onderling positief samenhingen.
Wat betreft de overgangen waren de relatieve frequenties van A en C sterk positief gecorreleerd (.68; p<.001). Dit is niet verwonderlijk, aangezien de aanwezigheid van A één van de voorwaarden was om de overgang die volgde ‘C’ te noemen. A en c hadden beide een negatief verband met B (-.59; p<.001 en -.42; p<.01 respectievelijk). Het vaker gebruiken van relaties om over te gaan op een nieuw onderwerp ging dus ten koste van de overgangen binnen hetzelfde veld.
Een patroon van positieve correlaties werd geconstateerd tussen onduidelijke overgangen, bladeren, selectief lezen zonder oriëntatie en korte series aan de ene kant en stuurloosheid volgens de ILS aan de andere kant. Het relatieve aantal niet door het model verklaarde overgangen (F) vertoonde een positieve samenhang met het aantal keren dat een proefpersoon bladerde (segment type 6) door de eerder gelezen kaarten (.53; p<.001). Beide zouden kunnen worden opgevat als tekenen van ongeorganiseerd handelen. De sterk negatieve correlatie van F met de (zeer systematische) B-categorie (-.70; p<.001) was hiermee in overeenstemming. F hing bovendien positief samen met het segmenttype dat bestond uit selectief lezen zonder oriëntatie vooraf (type 2) (.43; p<.01). Dit soort segmenten roept de vraag op: op welke gronden selecteerde men subonderwerpen als men niet oriënteerde? De selectie zou willekeurig geweest kunnen zijn. Het verband met het aantal F-overgangen ligt dan voor de hand. De relatieve F-frequentie bleek namelijk inderdaad positief samen te hangen met stuurloosheid (.3 8; p<.01). Behalve dat stuurloosheid zich uitte in de vorm van F-overgangen, bleek er een negatief verband met serielengte te zijn. (-.50; p<.001). Proefpersonen met gebrek aan regulatie, maakten kortere series en sprongen dus meer van het ene naar het andere, niet direct ermee verbonden onderwerp.
Behalve stuurloosheid correleerde geen van de ILS-scores significant met de uit de protocolanalyse resulterende gedragsmaten. Wel bleek variantieanalyse inzichten toe te voegen. Hiertoe werden de protocollen van proefpersonen met hoge en lage scores op de subschalen voor sturing en verwerking met elkaar vergeleken. Als hoog werd beschouwd een boven gemiddelde score op de betreffende schaal; de scores onder het gemiddelde werden als matig of laag opgevat.
De maten van diepe en stapsgewijze verwerking hadden geen significante effecten op het gebruik van de verschillende segmenten en overgangen. Wat betreft sturing resulteerden zowel een hoge stuurloosheid (N=25) als een hoge zelfsturing (N=25) in kortere series segmenten - oftewel in vaker iets afbreken - dan een lage stuurloosheid (N=23) of een lage zelfsturing (N=25). (Hoge stuurloosheid: gemiddeld 3.2 segmenten, tegenover 4.3 bij een lage stuurloosheid (F(l)=6.37; p<.05); hoge zelfsturing: gemiddeld 3.3 segmenten, tegenover 4.2 bij een lage zelfsturing (F(1)=4.14; p<.05).
De lage zelfstuurders maakten bijna tweemaal zoveel gebruik van het segmenttype met oriëntatie en selectief lezen (11.8%) als de hoge zelfstuurders (6.6%) (F(1)=5.95; p<.05). Proefpersonen die veel gebrek aan sturing toonden in de ILS lazen eveneens minder vaak | |
| |
uitputtend, maar zij oriënteerden zich daarbij ook minder dan de niet-stuurlozen. (Segmenten met oriëntatie en uitputtend lezen: 6.9% bij hoge stuurloosheid, tegenover 14.6% bij lage stuurloosheid (F(l)=7.31; p<.01).
Juist omdat de correlatieanalyse niets opleverde, zou een indeling van de proefpersonen in drie groepen voor elke subschaal interessanter kunnen zijn dan deze tweedeling. Omdat het aantal proefpersonen per groep echter te klein was en zij niet waren geselecteerd op extreme ILS-scores, waren de gevonden verschillen met deze methode niet significant. De data vertoonden niettemin een zeer consistente tendens: wat betreft alle subschalen, behalve die voor stuurloosheid, leek de middengroep steeds de beste aanpak te vertonen, door gebruik van meer directe overgangen en dus langere series segmenten, minder F- overgangen en relatief meer segmenten met oriëntatie en/of met selectief lezen. Dit verklaart waarom er in een aantal gevallen wel gedragsverschillen werden gevonden tussen ‘hoog’ en ‘laag’ scorende proefpersonen op een ILS-schaal, terwijl er geen correlatie was tussen de scores op de schaal en de gedragsmaat.
| |
4 Discussie
Proefpersonen hanteerden verschillende werkwijzen. Zo handelden ze meer of minder systematisch, lazen ze veel of juist weinig, en oriënteerden ze zich meestal voor het lezen of deden ze dit in het algemeen niet. Stuurlozen bleken duidelijk slechter overweg te kunnen met deze hypertext dan zelf of extern gestuurden. (Deze verschillen kwamen overigens niet tot uitdrukking in de toetsresultaten. Alle groepen scoorden op de natoets ongeveer gelijk.)
Dat verschillende werkwij zen van elkaar te onderscheiden waren (de eerste onderzoeksvraag), werd bevestigd door correlatieanalyses. Positieve correlaties werden gevonden tussen het gebruik van de navigatiemiddelen short info's en relaties, en tussen bepaalde segment- en overgangtypen. Zo bleken de proporties van de segmenttypen met oriëntatie onderling positief samen te hangen (3, 4 en 5), net als de twee overgangtypen waarin relaties een rol speelden (A en C), de onduidelijke overgangen, de bladersegmenten en de segmenten waarin selectief werd gelezen zonder oriëntatie vooraf (F, 6 en 2). Deze positieve correlaties wijzen op iets gemeenschappelijks (respectievelijk: oriëntatie, relaties en willekeur) in de betreffende categorieën, waarvoor bepaalde proefpersonen een voorkeur hadden.
Negatieve correlaties maakten de tegenpolen van deze werkmethoden zichtbaar: het gebruik van categorieën zonder oriëntatie tegenover die met oriëntatie, overgangen binnen velden (B) tegenover het gebruik van relaties om overgangen te vormen (A en C), en B-overgangen tegenover onduidelijke overgangen (F).
Waardoor werd bepaald wie welke aanpak hanteerde? Welke rol speelde de leerstijl? (Dit was de tweede onderzoeksvraag.) De scores op de subschalen voor verwerking bleken geen relatie te hebben met de aanpak, zoals geregistreerd in de protocollen. De handelingen die in deze studie zijn onderzocht hadden voornamelijk betrekking op het voorkomen en de wijze van selectie: sturingsactiviteiten. De invloed van verwerkingsstijl hierop is hooguit indirect. Verwerkingsactiviteiten zouden bestudeerd kunnen worden door het uitgebreider onderzoeken van de aantekeningen.
Sturingsgewoonten hadden wel enig verband met het voorkomen van bepaalde categorieën segmenten en overgangen. Gebrek aan regulatie hing samen met het maken van onduidelijke overgangen (F) en met het maken van kortere series segmenten (‘van de hak op de tak springen’). Ook uit de variantieanalyse bleek dat de niet-stuurlozen relatief | |
| |
meer directe overgangen maakten (A, B en C) en dus langere series. Zij lazen bovendien vaker uitputtend met oriëntatie (type 3).
Hoewel deze hypertext vooral mogelijkheden bood om op globaal niveau te selecteren en minder op lokaal niveau, bleken zelfgestuurden er niet beter mee uit de voeten te kunnen dan extern gestuurden. Integendeel, een hoge zelfsturing leidde net als gebrek aan sturing tot kortere series en minder oriënteren en selectief lezen. De mate van externe sturing had geen effecten. Zelfsturing zou een vorm van regulatie kunnen zijn die, in tegenstelling tot externe sturing, voor een buitenstaander soms moeilijk te volgen is. Aangezien het categoriesysteem juist was gebaseerd op van buitenaf interpreteerbare handelingen, werden door zelfsturing gereguleerde acties er wellicht te weinig in onderkend. Bovendien zou het zo kunnen zijn dat flexibiliteit effectiever is dan teveel zelfsturing. Op de meeste subschalen, ook die voor de positief gewaardeerde gewoonten van zelfsturing en diepe verwerking, leken gemiddelde of matig hoge scores gunstiger voor het aanpakgedrag van de studietaak dan extreem hoge scores.
De conclusie van het onderzoek is in de eerste plaats dat er inderdaad verschillende strategieën voorkomen bij lezers die een lange hypertext bestuderen. Sommigen lezen bedachtzaam, anderen gaan willekeurig te werk. In de tweede plaaats hangen deze verschillen samen met de sturingsgewoonten van de lezers: stuurloze lezers zeggen niet alleen onsystematisch te werk te gaan bij het bestuderen van gewone tekst, ze vertonen bij een hypertext ook kenmerken van willekeur: veel onduidelijke overgangen, veel van de hak op de tak springen. De protocollen van planmatig werkende lezers zijn veel beter te interpreteren. In tegenstelling tot de verwachting blinken lezers met een hoge mate van zelfsturing niet uit door efficiënt werken. Als een gematigde score op de schalen voor zelfsturing en externe sturing een kenmerk is van flexibiliteit, dan lezen flexibele lezers efficiënter dan sterk zelfgestuurde lezers. Deze bevinding komt overeen met Pask's (1976) opvatting dat flexibele lezers beter toegerust zijn dan lezers met een meer uitgesproken holistische of serialistische leesstrategie. In de derde plaats blijkt verwerkingsstijl, in tegenstelling tot onze verwachtingen, geen directe invloed op de leesstrategie in de hypertextomgeving te hebben. Dit is des te verbazingwekkender, omdat we juist grote overeenstemming tussen tekst en hypertext veronderstelden bij de verwerking van tekst, meer dan bij de selectie van tekst. In onze leesomgeving wordt verwerking van informatie door de lezer niet in het protocol vastgelegd. De enige indicatie voor verschillen in verwerkingsdiepte zou kunnen worden ontleend aan de tijd die aan elk onderwerp werd besteed. Ook hier vonden we geen verschillen tussen proefpersonen met verschillende verwerkingsstijlen. De enige verklaring die we achteraf kunnen geven, is dat het kennisdomein voor de lezers in het onderzoek volstrekt nieuw was. Alle informatie was dus onbekend en moest op dezelfde grondige wijze verwerkt worden. Stapsgewijze verwerkers besteden in principe aan alle onderwerpen evenveel aandacht. Diepe verwerkers concentreren zich op belangrijke of onbekende onderwerpen. Omdat het domein zo onbekend was voor de proefpersonen (letterenstudenten) konden diepe verwerkers zich niet onderscheiden door diepe verwerking van belangrijke of onbekende onderwerpen: alle onderwerpen waren voor hen even belangrijk en onbekend. Ook bij het selecteren van onderwerpen hebben diepe verwerkers geen aanknopingspunten om hun aandacht speciaal te richten op belangrijke tekstdelen.
In vervolgonderzoek zal worden gewerkt met studenten die sterker van elkaar verschillen wat betreft hun leerstijlen. Ook wordt het hypertext-programma uitgebreid met navigatiemiddelen die waarschijnlijk beter aansluiten bij de verschillende studenttypen en zodoende meer tussen hen zullen differentiëren. Zo wordt op lokaal niveau een optie | |
| |
toegevoegd die het vanuit elke tekstkaart mogelijk maakt verder te lezen in de oorspronkelijke boekvolgorde (voor de externe stuurders?) en een ‘Zie ook...’ optie met verwijzingen naar aanverwante tekstkaarten waarin nader op het betreffende onderwerp wordt ingegaan (voor de diepe verwerkers?). Tenslotte zal de tekst niet meer worden voorgelegd aan absolute leken, maar aan eerstejaars psychologiestudenten die de tekst al eens voor een tentamen bestudeerd hebben.
| |
Bibliografie
| Baker, L. & Brown, A.L. (1984). Metacognitive skills and reading. In P.D. Pearson, Handbook of reading research, (pp.353-394). New York: Longman. |
| Dillon, A., McKnight, C., & Richardson, J. (1988). Reading from paper versus reading from screen. The Computer Journal, 31, 457-464. |
| Entwistle, N. (1988). Motivational Factors in Students' Approaches to Learning. In R.R. Schmeck (Ed.), Learning Strategies and Learning Styles, (pp.21-51). New York: Plenum Press. |
| Gleitman, H. (1986). Psychology. New York: Norton and Company. |
| Marton, F. & Saljö, R. (1984). Approaches to learning. In F. Marton, D.J. Hounsell & N.J. Entwistle (Eds.), The experience of learning, (pp.36-55). Edingburgh: Scottish Academic Press. |
| Mills, C.B., & Weldon, L.J. (1987). Reading text from computer screens, ACM Computer Surveys, 50, 597-624. |
| Neisser, U. (1976). Cognition and reality. Principles and implications of cognitive psycholoy. San Francisco: W.H. Freeman and Company. |
| Pask, G., (1976). Conversational techniques in the study and practice of education. British Journal of Educational Psychology, 45, 12-25. |
| Reinking, D. (1988). Computer-mediated text and comprehension differences: The role of reading time, reader preferences, and estimation of learning. Reading Research Quarterly, 23, 484-499. |
| Samarapungavan, A. & Beishuizen, J.J. (in press). Domain Expertise and Knowledge Acquisition from ‘Non-Linear’ Expository Text. Journal Computers in Human Behavior. |
| Schmeck, R.R. (1983). Learning Styles of College Students. In R.F. Dillon & R.R. Schmeck (Eds.), Individual Differences in Cognition, Vol.1. (pp. 233-278). New York: Academic Press. |
| Schmeck, R.R., Geisler-Brenstein, E. & Cercy, S.P. (1991). Self-Concept and Learning: the revised inventory of learning processes. Educational Psychology, 11, 343-362. |
| Spiro, R.J., Feltovich, P.L., Jacobson, M.J., & Coulson, R.L. (1991). Cognitive Flexibility, Constructivism, and Hypertext: Random Access Instruction for Advanced Knowledge Acquisition in Ill-Structured Domains. Educational Technology, 31, 24-33. |
| Spiro, R.J., Vispoel, W., Schmitz, J., Samarapungavan, A, & Boerger, A. (1987). Knowledge acquisition for application: Cognitive flexibility and transfer in complex content domains. In B.C. Britton (Ed.), Executive control processes, (pp.177-199). Hillsdale, NJ: Erlbaum. |
| Van Dijk, T.A., & Kintsch, W. (1983). Strategies in Discourse Comprehension. New York: Academic Press. |
| Van Hout Wolters, B.H.A.M. (1986). Markeren van kerngedeelten in studieteksten: een proces-produkt benadering. Lisse: Swets & Zeitlinger. |
| Van Oostendorp, H. (1989). Studeren en aantekeningen maken achter de computer. Voordracht Congres Nederlandse Vereniging voor Psychonomie. Noordwijkerhout, 18-19 september. |
| Van Oostendorp, H., & Peeck, J. (1990). Taking notes while studying texts on a computer with different windowing systems. Paper presented at APPLICA '90, 2nd Congress European Multi-Media, Artificial Intelligence and Training. |
| |
| |
| Vermunt, J.D.H.M. & Van Rijswijk, F.A.W.M. (1987). Inventaris Leerstijlen voor het Hoger Onderwijs. Tilburg: Katholieke Universiteit Brabant. |
| Vermunt, J.D.H.M. & Van Rijswijk, F.A.W.M. (1988). Analysis and Development of students' skill in selfregulated learning. Higher Education, 17, 647-682. |
| Willems, J.M.H.M. (1989). Sturen van leerprocessen met behulp van studietaken. In Span, P., De Corte, E. & Van Hout Wolters, B. (Eds.), Onderwijsleerprocessen. Strategieën voor de verwerking van informatie, (pp.l 13-121). Lisse: Swets & Zeitlinger. |
|
|
