|
| |
| |
| |
Hoe krijg je ‘ter’ en ‘ten’ onder de knie?
Een ERP-onderzoek naar de verwerking van de syntactische structuur van vaste uitdrukkingen
Nienke Meulman & Laurie Stowe
1. Inleiding
Vaste uitdrukkingen zijn een frequent fenomeen, Fellbaum (1999) schat dat maar liefst 40% van onze lexicale representaties vaste uitdrukkingen zijn in plaats van individuele woorden. De bekendste typen vaste uitdrukkingen zijn idiomen, spreekwoorden en gezegdes, zoals:
| (1) |
a. |
Iets onder de knie krijgen. |
| |
b. |
Hoge bomen vangen veel wind. |
| |
c. |
Voor spek en bonen. |
Echter, combinaties van woorden die als geheel verwijzen naar een specifiek concept beperken zich niet alleen tot de hierboven besproken figuurlijke uitdrukkingen. Er zijn ook meer letterlijke combinaties die tot de categorie vaste uitdrukkingen worden gerekend. Voorbeelden zijn vaste samenstellingen, vaste voorzetselverbindingen en andere vaste woordcombinaties:
| (2) |
a. |
openbaar vervoer, officier van justitie, zwarte koffie |
| |
b. |
dol op, denken aan, |
| |
d. |
een verdrag sluiten, een contract afsluiten |
| |
e. |
min of meer |
Deze samenstellingen zijn bijzonder, omdat ze als woordgroep moeten worden geleerd en ook als zodanig worden gebruikt. Men zegt bijvoorbeeld niet ‘donkerbruine koffie’, terwijl dat wel een goede beschrijving zou zijn. Verder zijn bijvoorbeeld de combinaties ‘dol aan’, ‘een verdrag afsluiten’ en ‘meer of min’ niet acceptabel. Ook voor de figuurlijke uitdrukkingen zijn er beperkingen. Men kan bijvoorbeeld niet ‘iets onder de knieën krijgen’ en wanneer iemand voor ‘spek, bonen en aardappelen’ naar de winkel gaat, verliest de uitdrukking zijn figuurlijke betekenis. De figuurlijke boodschap in de bovenstaande uitdrukkingen is niet simpelweg afhankelijk van de betekenis van de individuele woorden. In de uitdrukking voor spek en bonen hebben de letterlijke betekenis van zowel ‘spek’ als ‘bonen’ niets te maken met de figuurlijke betekenis van het geheel (‘nutteloos, zonder winst of kost’). Toch moeten beide aanwezig zijn, en in deze specifieke vorm, om de figuurlijke betekenis op te roepen.
Het niet-compositionele karakter en de vaste vorm lijken te indiceren dat deze uitdrukkingen een lexicale eenheid vormen, en ook op deze manier zullen zijn opgeslagen in ons Mentale Lexicon. De volgende voorbeelden laten echter
| |
| |
zien dat de zaak iets gecompliceerder ligt:
| (3) |
a. |
Hij heeft de taal bijzonder snel onder de knie gekregen. |
| |
b. |
De baby had het kruipen al snel onder de knie. |
Hier is zowel lexicale als syntactische variatie in het idioom ‘iets onder de knie krijgen’ te zien. In het eerste voorbeeld staat het werkwoord in de voltooide tijd, in het tweede voorbeeld is ‘krijgen’ vervangen door ‘hebben’ en staat het werkwoord op een andere plaats in de zin. Het lijkt alsof de uitdrukkingen samen gaan met een set van regels, die de structuur van de uitdrukking specificeren. Enkele van die regels voor bovenstaand voorbeeld zijn dat de prepositionele constituent ‘onder de knie’ gecombineerd kan worden met zowel het werkwoord ‘krijgen’ als ‘hebben’ en dat het naamwoord ‘knie’ perse in het enkelvoud moet staan en vooraf moet worden gegaan door de determinator ‘de’. Deze syntactische beperkingen binnen vaste uitdrukkingen volgen niet uit de normale grammaticale regels van onze taal. Waarom ‘onder de knieën krijgen’ niet correct is kunnen we noch op basis van grammaticale regels, noch aan de hand van semantische of pragmatische redeneringen verklaren. Blijkbaar hebben we hier te maken met speciale eenheden. Opmerkelijk is de enorme variatie tussen uitdrukkingen in hun vrijheid en beperkingen, en nog opmerkelijker is het feit dat moedertaalsprekers deze uitstekend beheersen en er nauwelijks fouten in maken.
Waar worden deze syntactische beperkingen voor vaste uitdrukkingen gespecificeerd? Jan Koster stelt in 1986 dat deze informatie in het lexicon moet zijn opgeslagen, maar vraagt zich tegelijkertijd af hoe deze informatie dan zou zijn gecodeerd:
‘It seems to me that the most natural place for such interpretation (e.g. kick the bucket = “die”) is not D-structure but the lexicon. The crucial fact then, is that some idioms can be scattered and some cannot. But of course, the most natural place for that information is also the lexicon. The question is how this information must be coded.’ (Koster, J., 1986, pagina 48).
De huidige studie gaat hier verder op in. Cutting & Bock (1997) kwamen als eerste met een model van het Mentale Lexicon waarin de syntactische structuur van vaste uitdrukkingen werd gespecificeerd, zie figuur 1. Ze baseerden dit model op hun studie naar idioom mengsels. Hier kregen proefpersonen twee idiomen tegelijkertijd visueel aangeboden, en moesten vervolgens één van beide benoemen. De competitie tussen de idiomen zorgde ervoor dat proefpersonen vaker per ongeluk een mengsel van beide produceerden. Deze mengsels bleken niet zomaar willekeurig te zijn: dezelfde syntactische structuur bleek sneller te mengen en de fouten volgden grammaticale regels. Hieruit concludeerden de onderzoekers dat er syntactische analyse plaatsvindt tijdens de verwerking van idiomen. Om dit te kunnen verklaren introduceerden Cutting en Bock het begrip
| |
| |
phrasal frame. Dit frame bevat de syntactische structuur van het idioom, bijvoorbeeld het idioom ‘het loodje leggen’ wordt geassocieerd met een VP constructie. Verder heeft een idioom zijn eigen lexicale concept knoop. Wanneer een idioom geactiveerd wordt, stroomt er activiteit in verschillende richtingen: naar het concept, naar de individuele lemma's, en naar het phrasal frame. Hoewel idiomen op het lexicaal concept niveau als geheel zijn gerepresenteerd zijn ze ook in zekere mate compositioneel, omdat de individuele lemma's aan de hand van het phrasal frame op de juiste manier samengevoegd worden.
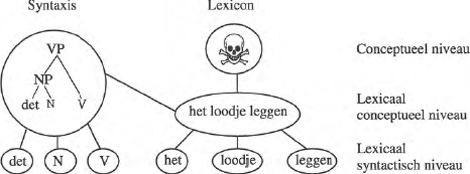
Figuur 1: Representatie van een idioom volgens Cutting & Bock (1997).
Het probleem van dit model is dat er niet ingegaan wordt op hoe de specifieke beperkingen binnen het idioom die niet volgen uit de normale grammatica gerepresenteerd zijn. In het voorbeeld gelden de beperkingen dat het naamwoord niet in het meervoud kan staan (‘de loodjes leggen’) en dat er geen indefiniete determinator gebruikt mag worden (‘een loodje leggen’). Waar worden deze lexicale beperkingen en syntactische eigenschappen van de lemma's zelf gespecificeerd? Cutting en Bock gaan hier niet op in. Om het model te kunnen handhaven zouden we enkele aanvullende aannames moeten maken. We zouden ervan uit kunnen gaan dat het lexicale concept van het idioom alleen de juiste woordvormen op het lexicaal syntactisch niveau selecteert. In ‘iets onder de knieën krijgen’ is dan de verkeerde woordvorm geselecteerd, we zouden hier kunnen spreken van een lexicale schending. Lastiger wordt het om te verklaren waarom werkwoorden wel vervoegd mogen worden, maar bijvoorbeeld een passief constructie vaak niet is toegestaan (‘het loodje werd door hem gelegd’) en het feit dat in veel idiomen toch meerdere woordvormen mogelijk zijn.
Volgens Sprenger, Levelt, en Kempen (2006) ligt de informatie die relevant is voor het syntactische gebruik van een idioom opgeslagen in het lexicon. In hun model wordt het lexicale concept van een idioom geassocieerd met een superlemma op het lexicaal syntactische niveau. Dit superlemma is de
| |
| |
representatie van de syntactische eigenschappen van het idioom, verbonden met de individuele lemma's van zijn constituenten (zie figuur 2). Het superlemma specificeert de syntactische relaties tussen de individuele lemma's en blokkeert de operaties die niet geaccepteerd zijn. Volgens Sprenger e.a. gedraagt een idioom zich syntactisch afwijkend, niet volgens algemene grammaticale regels en derhalve moeten deze syntactische eigenaardigheden wel gespecificeerd zijn in het lexicon.
Het Superlemma model gaat ervan uit dat een syntactische operatie van het idioom ofwel wordt toegestaan, of wordt geblokkeerd, de regels liggen immers vast in het lexicon. Tabossi, Wolf en Koterle (2009) geven echter aan dat context vaak een rol speelt bij het bepalen of een syntactische operatie binnen een idioom is toegestaan. Ze gebruiken het voorbeeld van de Engelse uitdrukking ‘to bury the hatchet’, waarvan de
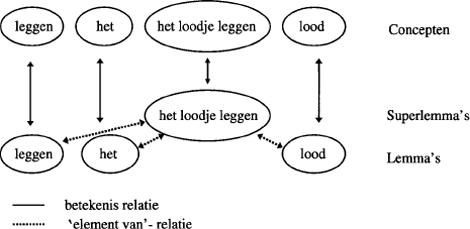
Figuur 2: Representatie van een idioom volgens Sprenger e.a. (2006).
passiefconstructie (‘the hatchet is buried’) op het eerste gezicht onaanvaardbaar lijkt. Echter, in de juiste context blijkt deze operatie toch acceptabel, zoals in ‘After years of murderous warfare, the hatchet was finally buried once and for all’. Verder geven Tabossi e.a. aan dat wanneer mensen uitdrukkingen moeten beoordelen op hun accepteerbaarheid, ze niet simpelweg antwoorden met ‘ja’ of ‘nee’, maar een operatie ‘volkomen acceptabel’, ‘enigszins vreemd’ of ‘zeer vreemd’ vinden. Op basis van deze argumenten nemen ze aan dat de toegestane syntactische operaties worden bepaald door pragmatische principes. De syntactische beperkingen liggen niet opgeslagen in het lexicon, maar volgen uit de eigenschappen van het idioom en zijn figuurlijke interpretatie. Mensen gebruiken hun beheersing van de taal om te bepalen of een operatie is toegestaan. De algemene principes die gelden voor letterlijke taal zijn ook van toepassing op de idiomen, de toegestane syntactische operaties zijn dus principieel, en niet
| |
| |
idiosyncratisch. Volgens Tabossi e.a. wordt de syntaxis van idiomen zodoende bepaald door dezelfde syntactische en pragmatische principes die gelden voor letterlijk taalgebruik.
Er bestaan dus verschillende visies op de representatie van de syntactische beperkingen binnen idiomen. In het model van Cutting en Bock (1997) worden de beperkingen bepaald door de selectie van specifieke woordvormen. Sprenger e.a. (2006) stellen echter dat de unieke syntactische eigenschappen van elk idioom op een lexicaal niveau zijn gerepresenteerd. Tot slot gaan Tabossi e.a. (2009) ervan uit dat er geen verschil is tussen de verwerking van de syntactische structuur van idiomen en die van letterlijke zinnen, beide zijn gebaseerd op algemene syntactische en pragmatische principes. De huidige studie heeft zich daarom gericht op de volgende vraag: is de syntactische structuur van idiomen lexicaal (idiosyncratisch) gerepresenteerd of is de verwerking van de syntactische structuur principieel en vergelijkbaar met normale zinnen?
Eerdere studies hebben bewijs geleverd voor syntactische verwerking binnen idiomen (Peterson, Burgess, Dell, & Eberhard, 2001; Cutting & Bock, 1997). Om de aard van deze verwerking te onderzoeken kan er gekeken worden naar wat er in het brein gebeurt tijdens het verwerken van de syntactische structuur van idiomen. In de huidige studie is hiervoor gebruik gemaakt van de Event Related brain Potential (ERP) techniek, waarbij hersenpotentialen tijdens zinsverwerking werden gemeten. In de volgende paragraaf volgt een korte uitleg van de techniek en hoe deze is toegepast in de huidige studie.
Voor onze onderzoeksvraag waren we geïnteresseerd in de verwerking van de syntactische beperkingen binnen een idioom, die niet volgen uit de normale regels van de grammatica. We hebben daarom gebruik gemaakt van schendingen in de interne syntactische structuur van een idioom, die op basis van algemene grammatica regels geen schending opleveren, zoals:
| (4) |
a. |
De loodjes leggen. |
| |
b. |
Een loodje leggen. |
De reactie die het brein vertoont op bovenstaande schendingen kan dan worden vergeleken met de reactie op normale syntactische schendingen die wel volgen uit algemene grammaticale regels:
| (5) |
a. |
*Ik lopen. |
| |
b. |
*Wij loopt. |
Tot slot zijn er in de huidige studie ook letterlijke vaste uitdrukkingen meegenomen, omdat deze evenals idiomen als woordgroep geleerd en gebruikt moeten worden. Hier speelt echter de extra figuurlijke betekenis geen rol, waardoor de verschillend met de idioom schendingen ons een indicatie kunnen geven van de breinprocessen geassocieerd met figuurlijk taalgebruik. Er is hier een versteende woordvorm gebruikt, namelijk de vormen ‘ter’ en ‘ten’. Deze
| |
| |
oude naamvalsuitgangen worden in het hedendaags Nederlands zelden meer gebruikt, maar ze zijn bewaard gebleven in enkele vaste uitdrukkingen. De keuze voor één van beide alternatieven (‘ter’ of ‘ten’) wordt niet langer gebaseerd op een algemene syntactische regel, maar op een beperking binnen de vaste uitdrukking:
| (6) |
a. |
*ten wereld |
| |
b. |
*ter onder |
Door hersenresponsen op bovenstaande verschillende typen schendingen met elkaar te vergelijken, is het mogelijk de aard van de syntactische structuur van vaste uitdrukkingen te onderzoeken. Indien reacties in het brein op de schendingen van de vaste uitdrukkingen (letterlijk of figuurlijk) sterk verschillen van die op normale syntactische schendingen, moeten we aannemen dat de unieke syntactische kenmerken idiosyncratisch zijn en op een lexicaal niveau liggen opgeslagen. Indien de reacties sterk overeen komen kunnen we stellen dat de syntactische structuur van vaste uitdrukkingen gebaseerd is op dezelfde principes als normaal taalgebruik en dat vaste uitdrukkingen niet op een bijzondere manier gerepresenteerd zijn.
| |
2. De ERP techniek
Event Related Potentials zijn de elektrofysiologische reacties van het brein op bepaalde stimuli. Tijdens een experiment wordt het ruwe EEG (elektroencefalogram) signaal gemeten door middel van een cap met elektroden die op het hoofd geplaatst wordt, terwijl een proefpersoon bijvoorbeeld zinnen leest op een scherm. ERPs verkrijgt men vervolgens door een grote hoeveelheid segmenten uit het EEG signaal na een bepaalde soort stimulus op te tellen en te middelen. Voor de huidige studie is deze techniek bijzonder relevant, omdat er verschillende hersenresponsen gevonden zijn voor verschillende processen binnen taalverwerking. Een aantal componenten zijn voor dit onderzoek interessant. De P600 (een positieve uitschieter in het signaal 600 ms na aanbieding van de stimulus) wordt geassocieerd met syntactische verwerking. Daarentegen wordt de N400 (negatieve uitschieter na 400 ms) in verband gebracht met semantische verwerking. In figuur 2 zijn deze componenten weergegeven (N.B. het is gebruikelijk om negatieve waarden omhoog te plotten). We zien dat het signaal bij een semantische schending rond 400 ms negatiever wordt dan bij de controlezin, terwijl bij een syntactische schending het signaal rond 600 ms positiever wordt. Beide effecten zien we over een groot gedeelte van de elektroden, met name aan de achterkant van het hoofd. In sommige studies wordt na een syntactische schending ook een LAN effect (left anterior negativity, een vroege negatieve uitschieter in het signaal van de voorste elektroden aan de linkerkant) aangetroffen. Een LAN wordt echter niet altijd waargenomen bij een syntactische schending, en het is nog niet geheel duidelijk wat dit effect precies
| |
| |
reflecteert (Hoen en Dominey, 2000, bijvoorbeeld relateren dit effect aan een algemener, niet talig, proces nodig voor het voorspellen van structuren in bepaalde sequenties).
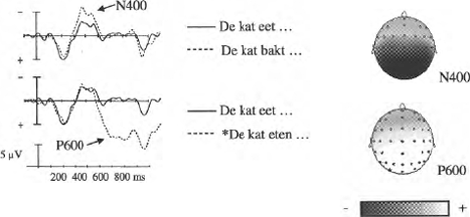
Figuur 3: Verschillende componenten in het ERP signaal voor semantische (N400) en syntactische (P600) schendingen. Links: het gemiddelde ERP signaal. Rechts: de schedelverdeling van de effecten: het verschil tussen de correcte en de schending conditie voor elk van de elektroden (bovenaanzicht van het hoofd). (Vrij naar Osterhout & Nicol, 1999.)
Omdat syntactische en semantische schendingen verschillende componenten laten zien in het ERP signaal, is deze techniek bij uitstek geschikt om naar de huidige onderzoeksvraag te kijken. Indien de syntactische structuur van vaste uitdrukkingen gebaseerd is op dezelfde syntactische principes als die van normale zinnen (Tabossi e.a.) zouden we voor alle typen schendingen een P600 (eventueel in combinatie met een LAN) in het signaal zien. Is de syntactische schending echter het gevolg van de selectie van een verkeerd woord (Cutting & Bock), dan is er sprake van een lexicale schending en zullen we een N400 verwachten (Moreno, Federmeier & Kutas, 2002). Ook wanneer de syntactische structuur van vaste uitdrukkingen gespecificeerd wordt op een lexicaal niveau (Sprenger e.a.) zouden we een N400 kunnen verwachten, onder andere op basis van een studie van Osterhout, Poliakov, Inoue, McLaughlin, Valentine, Pitkanen, Frenck-Mestre en Hirschensohn (2008). Zij vonden bij tweedetaalleerders dat ingewikkelde syntactische structuren in sommige gevallen als semantische eenheid werden opgeslagen. Wanneer deze structuur geschonden werd zagen ze een N400 in het signaal optreden. Het is mogelijk dat we een dergelijk effect zien in de huidige studie. Het is niet moeilijk voor te stellen dat we de syntactische structuur van vaste uitdrukkingen op een soortgelijke manier opslaan.
| |
| |
| |
3. Methode
Er zijn twee experimenten uitgevoerd. In het eerste experiment hebben we gekeken naar schendingen in figuurlijke vaste uitdrukkingen (idiomen). Hieronder staan enkele voorbeelden van de gebruikte schendingen, de target woorden (het punt van de schending) zijn onderstreept:
| (7) |
a. |
De mooie blondine sloeg een rijke miljonair aan de haken die haar vader had kunnen zijn. |
| |
b. |
Het huwelijk liep op de klip, omdat de man was vreemdgegaan. |
Elke proefpersoon las 40 idioom zinnen, waarvan de helft in de correcte vorm en de overige met schending, aangevuld met een groot aantal fillers. Er waren twee lijsten zodat een proefpersoon elke zin maar in één van de twee condities aangeboden kreeg. Alle schendingen waren schendingen van getal. Items waarin de schending een meervoudsvorm opleverde (zoals in 7a) en items waarin de schending een enkelvoudsvorm opleverde (zoals in 7b) waren gelijkwaardig verdeeld, om een lengte effect te voorkomen. Het target woord was altijd aan het einde van het idioom, zodat proefpersonen de figuurlijke idioombetekenis op dat moment reeds geactiveerd hadden. Alle materialen waren gepretest om ervoor te zorgen dat alleen bekende idiomen werden gebruik en na elke testsessie was er een begripstaak waarin de proefpersoon moest aangeven of hij/zij ook daadwerkelijk bekend was met de aangeboden idiomen. De data van proefpersonen die hierop slecht scoorden werd niet in de analyse meegenomen.
In het tweede experiment werd gekeken naar letterlijke vaste uitdrukkingen, de eerder beschreven versteende woordvormen met ‘ter’ en ‘ten’. Hieronder volgen enkele voorbeelden van de gebruikte schendingen:
| (8) |
a. |
*De jongens kwamen ter val toen ze tegen een boom reden. |
| |
b. |
*De sollicitant bracht het onderwerp voetbal ten sprake om de sfeer wat te verbeteren. |
Het punt van de schending (hierboven onderstreept) is in dit geval logischerwijs op het woord na ‘ter’ of ‘ten’. Er waren 44 versteende woordvorm zinnen per lijst (22 correct en 22 incorrect), waarbij ‘ter’ en ‘ten’ gelijkmatig verdeeld waren. In een pretest was onderzocht of mensen de gebruikte schendingen ook daadwerkelijk ‘incorrect’ beoordeelden. Naast de zinnen met versteende woordvormen en een groot aantal fillers zijn er in het tweede experiment ook normale grammaticale schendingen van getal meegenomen (20 correcte zinnen en 20 zinnen met schendingen per lijst). Het ging om schendingen van het volgende type:
| |
| |
| (9) |
a. |
*Sigrid gebruikt de winter om te schaatsen en jij sleeën liever van hoge heuvels af. |
| |
b. |
*De pianist streeft naar een glanzend parket en wij dweil zijn vloer met een speciale azijn. |
De data van 62 proefpersonen werd meegenomen in de analyse, 30 daarvan hadden meegedaan aan experiment één en 32 in experiment twee. De gemiddelde leeftijd van de proefpersonen was 21 jaar, ze hadden allen Nederlands als moedertaal en waren rechtshandig. Verder had geen van hen neurologische, psychiatrische of taalstoornissen. Het EEG signaal werd gemeten aan de hand van 64 elektroden, terwijl de proefpersonen zinnen lazen op een computerscherm. De zinnen werden woord voor woord gepresenteerd, dit om oogbewegingen die het signaal kunnen beïnvloeden zoveel mogelijk te voorkomen. Elk woord werd 240 ms aangeboden, gevolgd door 240 ms wit scherm. Een derde van de zinnen werd gevolgd door een vraag die betrekking had op de inhoud van de zin, dit om ervoor te zorgen dat de proefpersonen actief de zinnen bleven lezen. Een testsessie duurde ongeveer een uur, inclusief vier korte pauzes.
| |
4. Resultaten
De grand average ERP's vanaf het punt van de schending en de schedelverdeling van de effecten zijn te zien in figuur 4. Het signaal van de correcte zinnen laat een patroon van pieken en dalen zien dat kenmerkend is voor het lezen van zinnen. Tot ongeveer 300 ms zijn de signalen voor de correcte zinnen en hun schendingen vrijwel identiek aan elkaar. Voor de idioom schendingen (A) zien we vervolgens een langdurige frontale positiviteit optreden gevolgd door een, zowel qua latentie als qua schedelverdeling, klassieke P600. Voor de schendingen in de versteende woordvormen (B) zien we na ongeveer 400 ms een negativiteit in de linker posterieure elektroden. Daarna volgt een P600 in combinatie met een late LAN. Tot slot laten de normale syntactische schendingen van getal (C) een klassiek patroon zien dat ook in eerdere onderzoeken naar voren is gekomen: een LAN en een P600.
| |
| |
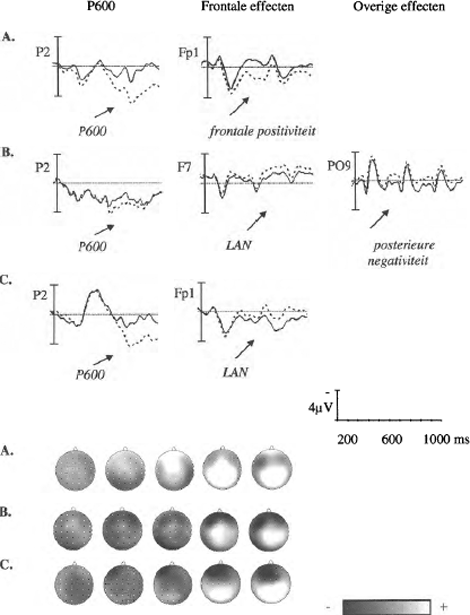
Figuur 4: Boven: Het gemiddelde ERP signaal vanaf het punt van de schending. Onder: De schedelverdeling van de effecten: het verschil tussen de correcte en de schending conditie voor elk van de elektroden (bovenaanzicht van het hoofd).
A: De idioomschendingen (‘Het huwelijk liep op de klip’) laten een langdurige frontale positiviteit en een P600 zien. B: De schendingen in de versteende woordvormen (‘*De jongens kwamen ter val’) worden geassocieerd met een posterieure negativiteit, gevolgd door een P600 in combinatie met een late LAN. C: Syntactische schendingen van getal in normale zinnen (‘*Jij snoeien de struiken’) veroorzaken een LAN en een P600.
| |
| |
De effecten zijn statistisch getoetst aan de hand van een herhaalde metingen design met drie factoren: conditie (correct / schending), gebied (anterieur / middenvoor / middenachter / posterieur) en hemisfeer (links / rechts), in drie verschillende tijdssegmenten: 200-400, 400-600 en 600-1000 ms. De resultaten zijn weergegeven in tabel 1. In het eerste tijdssegment (200-400 ms) waren er geen significante effecten. In het volgende tijdssegment (400-600 ms) zien we voor de idioom schendingen een hoofdeffect voor conditie als gevolg van anterieure positiviteit en voor de schendingen in de versteende woordvorm interacties veroorzaakt door de links gelateraliseerde posterieure negativiteit. Tot slot zien we in het tijdssegment voor een klassieke P600 (600-1000 ms) voor alle schendingen significante effecten; enkel de P600 voor de versteende woordvorm lijkt enigszins gelateraliseerd.
Tabel 1: Toetsresultaten van een herhaalde metingen design met 3 factoren: conditie (correct / schending), gebied (anterieur / midden-voor / midden-achter / posterieur) en hemisfeer (links / rechts).
|
| Schending |
Segment (ms) |
Effect |
F(df) |
p-waarde |
| Idiomen |
400-600 |
cond |
9,88 (1,29) |
.004 |
| |
600-1000 |
cond |
17,77 (1,29) |
<.001 |
| |
|
cond × geb |
10,64 (1,62;46,91) |
.005 |
| |
|
cond × hem |
7,01 (1,29) |
.013 |
| Versteende woordvorm |
400-600 |
cond × hem |
5,42 (1,31) |
.027 |
| |
|
cond × geb × hem |
4,43 (2,41;74,77) |
.011 |
| |
600-1000 |
cond × geb × hem |
4,17 (2,34;72,47) |
.015 |
| Normale getal schendingen |
600-1000 |
cond |
6,06 (1,31) |
.020 |
| |
|
cond × geb |
5,25 (2,05;63,49) |
.007 |
| |
5. Discussie
Vaste uitdrukkingen hebben syntactische beperkingen, ze kunnen niet alle operaties ondergaan die normale zinnen wel kunnen ondergaan. De huidige studie richtte zich op de vraag hoe deze syntactische beperkingen binnen vaste uitdrukkingen zijn opgeslagen. Er zijn drie theorieën besproken. In het model van Cutting en Bock (1997) zouden we moeten aannemen dat de beperkingen worden bepaald door de selectie van specifieke woordvormen, alleen exact de juiste
| |
| |
elementen vormen samen de vaste uitdrukking. Sprenger e.a. (2006) stellen echter dat de unieke syntactische eigenschappen van elk idioom op een lexicaal niveau zijn gerepresenteerd door middel van een superlemma. Het feit dat een vaste uitdrukking zich syntactisch eigenaardig gedraagt suggereert volgens Sprenger e.a. dat de syntactische beperkingen idiosyncratisch zijn opgeslagen: elk idioom heeft zijn eigen beperkingen, vastgelegd in het lexicon. Tot slot gaan Tabossi e.a. (2009) ervan uit dat er geen verschil is tussen de verwerking van de syntactische structuur van idiomen en die van letterlijke zinnen, beide zijn gebaseerd op algemene syntactische en pragmatische principes. De syntactische beperkingen van een vaste uitdrukking volgen uit de gezamenlijke restricties die worden opgelegd door de idiomatische reeks en zijn figuurlijke interpretatie. Volgens Tabossi e.a. gebruiken mensen hun beheersing van de taal om te bepalen of een operatie is toegestaan.
Er werden schendingen in de syntactische structuur van zowel letterlijke als figuurlijke vaste uitdrukkingen aangeboden en de reactie van het brein hierop werd onderzocht aan de hand van ERP's. De effecten werden vergeleken met schendingen van getal in normale zinnen. Op basis van twee van deze modellen hadden we redenen om een N400 te verwachten voor de schendingen in de vaste uitdrukkingen. Beide theorieën gaan ervan uit dat vaste uitdrukkingen speciale eenheden zijn die op een unieke manier in ons lexicon zijn opgeslagen. De gebruikte schendingen zouden hierdoor geïnterpreteerd worden als lexicale schendingen, door selectie van een verkeerd woord (Cutting & Bock) of door een schending in een semantische eenheid met zijn eigen specifieke beperkingen (Sprenger e.a.). In beide gevallen zouden we een N400 verwachten, omdat dit effect gezien wordt in reactie op semantische of lexicale fouten. In het signaal van de schendingen in de vaste uitdrukkingen was echter geen N400 aanwezig. Er was een posterieure negativiteit zichtbaar voor de versteende woordvorm, maar deze was slechts in een klein gedeelte van de achterste elektroden aanwezig, terwijl we een klassieke N400 gewoonlijk over een groot gedeelte van het posterieure en middengebied zien. Een andere schedelverdeling laat zien dat een ander deel van de neurale schors betrokken is en er zich dus een ander proces in de hersenen afspeelt.
Wel was er voor zowel de schendingen in de figuurlijke en letterlijke vaste uitdrukkingen, als in de normale syntactische schendingen een P600 effect zichtbaar. Het effect was qua latentie en qua schedelverdeling zeer vergelijkbaar voor de verschillende condities. Het P600 effect wordt geassocieerd met syntactische verwerking. Ook was er voor zowel de versteende woordvorm schendingen als de normale getal schendingen een LAN effect aanwezig. De afwezigheid van dit effect bij de idioomschendingen is mogelijk te verklaren door het feit dat er in hetzelfde tijdssegment een sterke frontale positiviteit aanwezig is die een eventueel aanwezige negativiteit opheft. Deze resultaten ondersteunen het standpunt van Tabossi e.a. Zij stellen dat er aan de syntactische structuur van vaste uitdrukkingen dezelfde principes ten grondslag liggen als aan die van normale zinnen. Het feit dat het P600 effect voor alle drie de condities
| |
| |
aanwezig is wijst in deze richting. Het spreekt het idee dat er voor vaste uitdrukkingen bijzondere representaties zijn tegen.
In de resultaten zijn verder verschillen te zien tussen de figuurlijke en letterlijke vaste uitdrukkingen. In het signaal voor de idiomen vinden we naast de P600 een frontale positiviteit, terwijl er voor de versteende woordvorm naast de P600 er zowel frontaal als posterieur een negativiteit te zien is. Deze resultaten zijn moeilijk te verklaren binnen een theorie die aanneemt dat de beperkingen in het lexicon gespecificeerd worden. Men zou immers geen verschillen verwachten tussen de verwerking van de syntactische structuur van letterlijke en figuurlijke vaste uitdrukkingen, wanneer de kenmerken van deze structuur idiosyncratisch in het lexicon liggen opgeslagen.
Hoewel het noodzakelijk is in de toekomst een verklaring te vinden voor de verschillen tussen de soorten schendingen in het ERP signaal, kunnen we niet om de overduidelijke overeenkomst heen. De aanwezigheid van een P600 en de afwezigheid van een N400 voor drie in de huidige studie gebruikte typen schendingen is voldoende om uitspraken te kunnen doen over de in dit artikel besproken onderzoeksvraag en hypotheses. Duidelijk is dat de resultaten niet verklaart kunnen worden aan de hand van een model waarin de syntactische structuur van vaste uitdrukkingen in het lexicon ligt opgeslagen. Hoewel een vaste uitdrukking zich syntactisch eigenaardig gedraagt, blijkt dat het taalverwerkingssysteem zijn interne structuur toch op een vergelijkbare manier verwerkt als normale zinnen.
Deze resultaten dwingen ons om op een andere manier naar het lexicon te kijken, bijvoorbeeld volgens Jackendoffs (1995, 2009) visie op de compositionaliteit van taal. Hij stelt dat een groot deel van het lexicon bestaat uit specifieke syntactische structuren gekoppeld aan betekenissen, in feite bestaat een groot deel van onze taal dus uit vaste uitdrukkingen. Er is volgens hem geen strikte scheiding tussen lexicon en grammatica, woorden en regels zijn allemaal stukjes linguïstische structuur opgeslagen in het lange termijn geheugen. Hierin is sprake van een continuüm, met aan het ene uiterste woorden, en aan het andere uiterste algemene syntactische regels. Ergens daartussenin liggen dan de figuurlijke en letterlijke vaste uitdrukking die in dit artikel zijn besproken. In de huidige studie zagen we dat het taalverwerkingssysteem schendingen in syntactische regels van normale zinnen en syntactische schendingen in meer woordachtige eenheden (vaste uitdrukkingen) op een vergelijkbare manier verwerkt. Dit is in overeenstemming met Jackedoffs continuüm. Het fenomeen van de vaste uitdrukkingen laat zien dat het onderscheid tussen lexicon en grammatica misschien niet zo duidelijk is als we denken. De figuurlijke betekenis van een vaste uitdrukking is alleen verbonden met een select aantal mogelijke vormen van de uitdrukking. Het hoeft echter niet zo te zijn dat deze beperkingen daarom een speciale representatie hebben in het lexicon. De resultaten van de huidige studie laten geen grote verschillen zien tussen de verwerking van de eigenaardige syntactische eigenschappen van een vaste uitdrukking en die van normale syntactische structuur. Misschien is er een
| |
| |
glijdende schaal van hoe specifiek de beperkingen van een constructie zijn.
| |
Referenties
Cutting, J.C., & Bock, K.
1997 |
‘That's the way the cookie bounces: Syntactic and semantic components of experimentally elicited idiom blends.’ Memory and Cognition, 25, 1, 57-71. |
Fellbaum, C., ed.
1998 |
WordNet: An Electronic Lexical Database, Cambridge, MA: MIT Press. |
Hoen, M., & Dominey, P.
2000 |
‘ERP analysis of cognitive sequencing: A left anterior negativity related to structural transformation processing.’ NeuroReport: For Rapid Communication of Neuroscience Research, 11(14), 3187-3191. |
Jackendoff, R.
1995 |
‘The Boundaries of the Lexicon.’ In M. Everaert, E.J. van der Linden, A. Schenk, & R. Schreuder (Eds.), Idioms: Structural and Psychological Perspectives, 133-165. Hillsdale, NJ: Erlbaum. |
Jackendoff, R.
2009 |
‘Compounding in the Parallel Architecture and Conceptual Semantics,’ in R. Lieber & P. Štekauer (Eds.), The Oxford Handbook of Compounding, 105-28, Oxford University Press. |
Koster, J.
1986 |
Domains and Dynasties: the Radical Autonomy of Syntax. Foris, Dordrecht |
Moreno, E.M., Federmeier, K.D. & Kutas, M.
2002 |
Switching Languages, Switching Palabras (Words): An Electrophysiological Study of Code Switching. Brain and Language 80, 188-207. |
Osterhout, L., & Nicol, J.
1998 |
On the distinctiveness, independence, and time course of the brain responses to syntactic and semantic anomalies. Language and Cognitive Processes, 14, 283-317. |
Osterhout, L., Poliakov, A., Inoue, K., McLaughlin, J., Valentine, G., Pitkanen, I., Frenck-Mestre., & Hirschensohn, J.
2008 |
‘Second-language learning and changes in the brain.’ Journal of Neurolinguistics, 21, 6, 509-521. |
Peterson, R.R., Burgess, C., Dell, G.S., & Eberhard, K.M.
2001 |
‘Dissociation between syntactic and semantic processing during idiom comprehension.’ Journal of Experimental Psychology: Learning, Memory and Cognition, 27, 5, 1223-1237. |
Sprenger, S., Levelt, W.J.M., & Kempen, G.
2005 |
‘Lexical access during the production of idiomatic phrases.’ Journal of Memory and Language, 54, 161-184. |
Tabossi, P., Wolf, K., & Koterle, S.
2009 |
‘Idiom syntax: Idiosyncratic or principled?’ Journal of Memory and Language, 61, 77-96. |
|
|
