|
| |
| |
| |
De selectie en digitalisatie van dialecten en woorden uit de reeks Nederlandse dialectatlassen
Wilbert Heeringa
1. Inleiding
In Nerbonne, Heeringa, van den Hout, van der Kooi, Otten en Van de Vis (1996) werd voor het eerst beschreven hoe met behulp van de notie Levenshtein-afstand de dialectologische afstanden tussen Nederlandse dialecten kunnen worden gemeten. Dit onderzoek vond plaats op basis van 20 dialecten die geselecteerd werden uit de Reeks Nederlandse Dialectatlassen (RND, Blancquaert en Peé, 1925-1982). Nerbonne en Heeringa (1997) is een vervolg op dit onderzoek beschreven. Hierbij is het aantal dialecten verdubbeld tot 40 dialecten. In Nerbonne en Heeringa (1998) wordt een verder vervolg beschreven. Het aantal dialecten is nu gelijk aan 104. In alle gevallen zijn per dialect 100 worden gekozen. In dit laatste artikel schreven we: ‘De dichtheid van de 104 plaatsen is laag, en de spreiding nog niet helemaal regelmatig. In de toekomst willen we rond tweehonderd plaatsen in de studie opnemen die samen een regelmatig patroon vormen.’
Inmiddels is een nieuwe elektronische gegevensverzameling gereed gekomen die gegevens bevat voor 350 dialecten van 347 plaatsen uit het Nederlandse taalgebied, 1 Plautdietsch dialect, het Standaard Nederlands en het standaard Duits. 238 dialecten komen ook voor in de Fonologische atlas van de Nederlandse dialecten (FAND, Goossens, Taeldeman en Verleyen 1998). Van de Nederlandse dialecten zijn er voor 122 dialecten transcripties van een langere woordenlijst bestaande uit 166 woorden, en voor 228 dialecten transcripties van een kortere woordenlijst bestaande uit 125 woorden. De 125 woorden vormen een deelverzameling van de 166 woorden. Alle 125 woorden komen ook voor in de FAND. Voor het Plautdietsch en de beide standaardtalen is de lange woordenlijst gebruikt. De data is beschikbaar via:
http://www.let.rug.nl/~heeringa/dialectology/rnd
In dit artikel geven we een beschrijving van de manier waarop deze nieuwe elektronische gegevensverzameling tot stand is gekomen. We beschrijven de keuze van dialecten en woorden, de opstelling van de transcripties van de woordenlijsten voor het standaard Nederlands en het standaard Duits, en de omzetting van transcripties naar elektronisch formaat.
| |
2. Keuze van de dialecten
2.1 Spreiding
We maakten eerst een selectie uit die plaatsen die zowel in de RND als in de FAND voorkomen. Uit deze selectie markeerden we op de kaart al die plaatsen waarvan, volgens opgave van de RND, het inwoneraantal meer dan 5000 en minder dan 10.000 bedroeg. Het idee hierachter is dat in kleinere plaatsen de dialectologische situatie minder stabiel is. Het overlijden van een spreker of de verhuizing van een heel gezin is
| |
| |
binnen een kleine gemeenschap van grote invloed. Voor grotere plaatsen geldt dat er binnen die plaats meerdere tamelijk sterk van elkaar afwijkende dialecten kunnen zijn. Bijvoorbeeld voor Amsterdam worden in de RND voor meerdere wijken dialectteksten gegeven.
De selectie op basis van inwoneraantal gaf een niet geheel bevredigende situatie. Te kale gebieden ontstonden in Groningen en Drenthe, Noord-Holland, het noorden van Zuid-Holland, Utrecht, de grensstrook langs Duitsland van Groesbeek naar Tegelen, het zuid-westen van West-Vlaanderen en Frans Vlaanderen, een gebied linksonder Klein-Brabant, en sommige van de Zeeuwse eilanden. De kale gebieden hebben we aangevuld met kleinere plaatsen, dus plaatsen met minder dan 5000 inwoners. Om een regelmatig patroon te krijgen, was het soms nodig plaatsen uit de vorige stap te deselecteren en te vervangen door één of meer kleinere plaatsen.
Voor Friesland hebben we alleen ten aanzien van Friese plaatsen gestreefd naar een regelmatig patroon met een dichtheid die vergelijkbaar is met de rest van het gebied dat de RND bestrijkt. Vervolgens voegden we daaraan alle in de RND aanwezige Stadsfriese plaatsen toe. De Stadsfriese plaatsen op het vasteland vormen taaleilanden. Van de Stadsfriese dialecten is alleen Heerenveen niet in de FAND aanwezig.
Op deze wijze kregen we een selectie van 192 dialecten die zowel in de RND als in de FAND voorkomen. Omdat in sommige gebieden, met name in Drenthe, de dichtheid van de plaatsen uit de RND erg laag is, kozen we in die gebieden plaatsen die zowel geografisch als dialectologisch dicht in de buurt liggen van een plaats uit de FAND. Het betrof in totaal 9 dialecten. Op die manier onstond een net van 201 plaatsen die zonder de stadfriese taaleilanden en enkele gemarkeerde plaatsen in Noord-België een regelmatig patroon vormen. De opnamen die ten behoeve van de FAND van de dialecten in Friesland zijn gemaakt, zijn helaas nog niet zodanig verwerkt dat ze elektronisch beschikbaar gesteld kunnen worden.
Uiteindelijk is het niet bij deze 201 dialecten gebleven omdat er nogal wat materiaal was dat we niet ongebruikt wilden laten liggen. De oude selectie van 104 dialecten bevatte een aantal dialecten die niet in de FAND voorkwamen. Deze hebben we aan de nieuwe selectie toegevoegd. Daarnaast beschikten we over materiaal van alle in de RND aanwezige Duitse dialecten. Dit materiaal was ontstaan door een aparte studie over dialecten in en rondom de graafschap Bentheim. Verder vond de omzetting van geschreven of gedrukte vorm naar elektronische vorm (het coderen) plaats terwijl de selectie nog niet helemaal afgerond was. Daardoor ontstond nogal wat materiaal dat buiten de uiteindelijke selectie van 201 plaatsen viel. Tenslotte voegden we een aantal bijzondere plaatsen toe, namelijk Hoogkerk en Zandeweer (om persoonlijke redenen), Donkerbroek en Tjalleberd (in elk van deze plaatsen zijn twee dialecten evenals in Appelscha), en Aubel en Raeren (plaatsen buiten het ‘officiële’ Nederlandse taalgebied evenals Baelen en Eupen). Daarmee kwamen we op totaal 350 dialecten. In Tabel 1 (zie Appendix) wordt de complete lijst van alle 350 dialecten gegeven. In Figuur 1 wordt een beeld gegeven van de spreiding en dichtheid van de plaatsen.
| |
| |
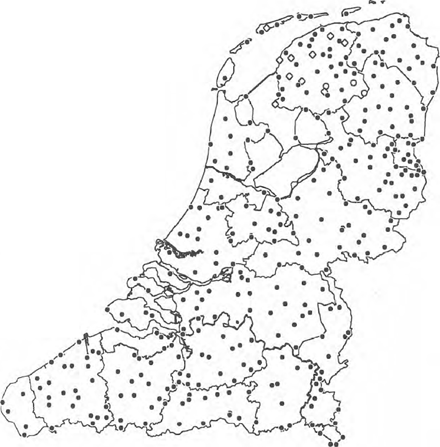
Figuur 1. Beeld van de spreiding en dichtheid van de 347 plaatsen. De ruiten geven taaleilanden weer. Het betreft een deel van de Stadsfriese plaatsen. De cirkels geven plaatsen waar twee dialecten gesproken worden, en één van beide dialecten een taaleiland vormt.
| |
2.2 Variatie
Bij de keuze van de Friese plaatsen hebben we ons onder meer laten leiden door een indelingskaart van P. Breuker (1993). Daarop wordt het taalgebied in Friesland verdeeld in het Bildts, het Kleifries, het Woudfries, het Zuidhoeks en het Stellingwerfs. We hebben een zodanige selectie gemaakt dat al deze groepen vertegenwoordigd zijn. Verder zijn er de Stadsfriese dialecten, en een aantal speciale dialecten: Hindeloopen, West-Terschelling, Oosterend, Schiermonnikoog.
Ten aanzien van het Stadsfries geldt dat Leeuwarden als Friese hoofdstad waarschijnlijk erg bepalend is voor het karakter van de andere stadstalen in dit gebied.
| |
| |
De variatie tussen Leeuwarden, Franeker, Harlingen, Bolsward, Sneek, Slaveren en Dokkum is minimaal. Het Bildt, Midsland en Ameland wijken daar merkbaar van af. Het westelijke Amelands is in verschillende opzichten behoudender dan het oosten. Om op de kaart een compleet beeld van dialectologische variatie te geven, en de Stadsfriese plaatsen als eilanden in het Friese continuum liggen, namen we alle beschikbare Stadsfriese dialecten op, ongeacht de variatie binnen deze dialecten. Hierbij beschouwen we Kollum ook als een Stadsfries taaleiland in het Friese continuüm, hoewel deze plaats volgens de kaart van Daan (1969) zou behoren tot het Kollummerlands, en de kleur groen van dit gebied op deze kaart suggereert dat het behoort tot het Saksisch taalgebied.
Voor drie plaatsen in Friesland zijn in de RND twee teksten gegeven: Appelscha, Donkerbroek en Tjalleberd. In Appelscha wordt zowel Stellingwerfs als Fries gesproken. In de RND wordt gemeld dat voor 135 gezinnen het Fries de huiselijke omgangstaal is, voor 129 het Stelllingwerfs en voor 19 het Nederlands. Daarbij houdt ieder zich aan zijn eigen dialect. Tweetaligen vormen een uitzondering. Tegenwoordig is Appelscha voor ongeveer 25% Fries, en de rest Stellingwerfs en Nederlands. Het Stellingwerfse Appelscha maakt deel uit van het Stellingwerfse continuüm. Het Friese Appelscha ligt hier als taaleiland middenin. Het Stellingwerfs is ouder dan het Fries, maar beide dialecten mogen als even autochtoon beschouwd worden. Het Fries werd geïntroduceerd door Friese arbeiders die in Appelscha kwamen wonen ten tijde van verveningen.
Voor 1850 sprak de meerderheid in Donkerbroek het Stellingwerfs. Volgens de RND bediende ten tijde van de opnamen wel de helft van de bevolking zich van een Fries dialect. Vooral de ouderen spreken een Stellingwerfs dialect. Voor ongeveer 20 gezinnen is het Nederlands de huiselijke omgangstaal. We hebben het Friese Donkerbroek beschouwd als behorend tot het Friese dialectcontinuüm, en het Stellingwerfse Donkerbroek als een taaleiland in het Friese dialectcontinuüm. Veel inwoners van deze plaats beheersen beide dialecten.
Het Tjalleberds (of ‘Gietersk’) werd geïntroduceerd door (laag)veenarbeiders uit Noordwest Overijssel (Giethoorn en omstreken). De RND meldt dat in Tjalleberd 90% van de bevolking Fries spreekt, en 10% het Tjalleberds. Enkele gezinnen spreken Nederlands. Vaak spreken ouders onderling nog Tjalleberds, maar tegen hun kinderen Fries. Het Tjalleberds vomt hier een Saksisch taaleiland in het Friese dialectcontinuüm.
Voor de vertegenwoordiging van het Twents kozen we de steden Almelo, Hengelo en Oldenzaal. Hoewel deze plaatsen meer dan 10.000 inwoners hebben zijn ze heel bepalend voor dit gebied. Ten zuiden daarvan kozen we Delden en Groenlo, beide belangrijke plaatsen in hun omgeving. Groenlo ligt in een ander dialectgebied dan de Twentse steden. Het is een oude en belangrijke plaats in de Achterhoek en ligt vlak bij de Duitse grens die enkele kilometers oostelijk dwars door Zwilbroek/Zwilbrock gaat. Het is bovendien een Rooms-katholieke enclave.
Voor de vertegenwoordiging van de oostkant van Limburg kozen we naast enkele kleinere plaatsen de steden Venlo, Sittard en Kerkrade. Hoewel deze drie steden meer dan 10.000 inwoners hadden, kozen we ze toch omdat ze heel bepalend zijn in dit gebied. In het zuiden van Limburg kozen we 's-Gravenvoeren als Vaals. Beide plaatsen liggen weliswaar relatief dicht bij elkaar, maar Vaals ligt ten oosten van isoglosse 13 op de kaart van Daan (1969), war een belangrijke scheidslijn is.
Voor Vlaanderen geldt dat een aantal steden een zeer gemarkeerd dialect hebben. Het gaat om Oostende, Brugge, Gent, Roeselare, Kortrijk, Aalst en Ronse. Het
| |
| |
Gents bijvoorbeeld heeft zeer veel verschijnselen die rond de stad niet voorkomen. De Gentse fonologie wijkt niet op enkele, maar op de meeste punten af van die van het omliggende platteland. In Gent zijn bijvoorbeeld alle klinkers lang terwijl ze in de omgeving van Gent allemaal halflang zijn. Op de kaart van Daan (1969) zien we dat de Stadsfriese plaatsen wel als taaleilanden zijn gemarkeerd, maar deze Vlaamse steden niet. De indeling van het Belgische deel van de kaart berust op dialectsprekende taalkundigen. Kennelijk contrasteren naar hun oordeel de genoemde steden niet dusdanig met de omgeving dat ze op de kaart als taaleilanden weergegeven werden. In navolging van hun keuze beschouwen ook wij deze steden niet als taaleilanden.
| |
2.3 Uitbreiding
In het Groningse taalgebied hebben we als gemeld de dialecten van Zandeweer en Hoogkerk toegevoegd. De opnamen werden gemaakt in de herfst van 2000. We interviewden voor Zandeweer één zegsvrouw (hierna aangeduid als z1), en één zegsman (z2). Voor Hoogkerk interviewden we één zegsman (hierna aangeduid als h1), en één zegsvrouw (h2).
We gebruikten de complete vragenlijst van 141 zinnen uit het Groninger deel van de RND (deel 16). Uit zin 1 t/m 139 knipten we de 166 woorden die we ook uit de bestaande teksten van de RND selecteerden en digitaliseerden (zin 140 en 141 zijn feitelijk geen echte zinnen, bij zin 140 worden de locale landmaten, en bij zin 141 worden de locale waternamen opgevraagd). Op deze manier kregen we voor Zandeweer en Hoogkerk telkens twee woordenlijsten. Voor het maken van transcripties namen we voor Hoogkerk de woordenlijst van Bedum en voor Zandeweer de woordenlijst van Roodeschool als uitgangspunt en pasten die aan. Dit geeft een zo groot mogelijke garantie dat de nieuwe transcripties consistent zijn met de transcripties in de RND. De nieuwe transcripties werden gecontroleerd door Marcus Bergman. De twee lijsten van Zandeweer werden gecombineerd tot één lijst, en de twee lijsten van Hoogkerk werden gecombineerd tot één lijst. Bij het combineren namen we steeds alle verschillende vormen over die door de zegslieden voor hetzelfde item gegeven werden. Bij verwerking van de data telt een vorm die door meerdere informanten gegeven werd niet zwaarder dan een vorm die door precies één informant gegeven werd.
| |
2.3.1 Zegslieden Zandeweer
Zegsvrouw z1 was 68 jaar en geboren in Zandeweer. Haar vader was geboren in Zandeweer, en haar moeder in Uithuizermeeden. De zegsvrouw verhuisde op 32-jarige leeftijd naar Hoogkerk. In Hoogkerk gebruikte ze het Zandeweerster dialect zelden, zodat aangenomen mag worden dat ze het Zandeweerster dialect, zoals dat gesproken werd in de zestiger jaren, vrij goed heeft bewaard. De opname werd gemaakt op 9 november 2000. Zegsman z2 was 78 jaar en geboren in Doodstil, een gehucht vlakbij Zandeweer. Zijn vader was geboren in Zandeweer, en zijn moeder in Pieterburen. De zegsman spreekt meestal dialect. De opname werd gemaakt op 11 november 2000. De verschillen tussen beide zegslieden waren klein.
| |
| |
| |
2.3.2 Zegslieden Hoogkerk
Zegsman h1 was 75 jaar en geboren te Hoogkerk. Zijn vader was geboren te Dordrecht. Door het vroeg overlijden van zijn vader heeft de zegsman zijn vader niet gekend. Zijn moeder was geboren te Hoogkerk. De zegsman heeft het grootste deel van zijn leven in Hoogkerk gewoond. De zegsman spreekt regelmatig dialect. De opname werd gemaakt op 31 oktober 2000. Zegsvrouw h2 was 61 jaar en geboren vlakbij Hoogkerk in de gemeente Roden. Zij ging naar kerk en school in Hoogkerk. Zowel haar vader als haar moeder waren geboren in Hoogkerk. De zegsvrouw spreekt regelmatig dialect. De opname werd gemaakt op 6 november 2000.
De dialecten zoals die gesproken werden door de beide zegslieden waren relatief sterk vernederlandst. Opvallend dat door de sprekers niet steeds dezelfde woorden werden vernederlandst. Onder vernederlandsing verstaan we dat een Gronings woord vervangen werd door een Nederlands woord (bv. ‘zoepm’ [zupm] wordt ‘karnemelk’ [karnəmɛlk]), of dat een Gronings woord vervangen werd door een vergroningst Nederlands woord (bijvoorbeeld ‘kopstubber’ (kɔpstʏbər) wordt ‘ragebol’ [rυˑɣbɔl]). Nu wilden we materiaal krijgen dat inpasbaar is in het materiaal van de RND. Het RND-materiaal werd verzameld in de periode 1956-1961. Verondersteld mag worden dat de dialecten in die tijd nog aanmerkelijk minder vernederlandst waren. Om ons materiaal inpasbaar te maken in het materiaal van de RND, hebben we de meeste woorden waarvan de beide zegslieden een vertaling gaven die ongeveer gelijk was aan het Standaard Nederlands, een tijd later nog eens afzonderlijk afgevraagd. In de meeste gevallen gaven de zeglieden dan een vertaling die als een duidelijk Groningse vorm herkend kan worden.
| |
3. Keuze van de woorden
Over de vragenlijst in de RND schrijft Blancquaert: ‘Wat nu de inhoud van de vragenlijst betreft, deze werd opgevat als een reeks zinnetjes met woorden die bepaalde klanken zouden illustreren; er werd voor gezorgd dat bvb. de mogelijke ontwikkelingen van de oudgermaanse vocalen, tweeklanken en consonanten in de vragenlijst vertegenwoordigd waren’. Uit de zinnen van deze vragenlijst werd in eerste instantie een woordenlijst opgesteld van 100 woorden waarin zo ongeveer alle klinkers (monoftongen en diftongen) en medeklinkers terug te vinden zijn. Ook de consonantencombinatie [sx] komt erin voor, die in sommige dialecten als [sk] en in andere als [sj] wordt uitgesproken.
Na verloop van tijd is deze lijst aangepast omdat bij een aantal woorden problemen aan de orde bleken te zijn. De woorden werden uit de lijst verwijderd. De data hiervan werden helaas niet bewaard. De 20 woorden werden vervangen door 20 andere, zodat de woordenlijst in totaal uit 100 woorden bleef bestaan. In hoofdstuk 4 worden de woorden, tezamen met de problemen die ze gaven, besproken.
Nadat een nieuwe selectie werd gemaakt van uiteindelijk 201 plaatsen, werd de woordenlijst uitgebreid met 66 woorden uit de FAND, zodat het totaal aantal woorden dat ook in de FAND te vinden is gelijk werd aan 125. Het totaal aantal woorden kwam daarmee op 166. Voor de meeste dialecten die na die tijd gedigitaliseerd werden, werden alleen de woorden gecodeerd die ook in de FAND te vinden zijn. Daardoor bevatten 122 dialecten transcripties voor 166 woorden terwijl 228 dialecten transcripties voor 125 woorden bevatten. In Tabel 2 wordt de complete woordenlijst van 166
| |
| |
woorden gegeven. In Tabel 3 wordt de verdeling weergegeven van de woorden over de woordsoorten. Voor een aantal woorden geldt dat er iets speciaals mee aan de hand is of dat ze helaas zelfs minder goed bruikbaar zijn. De betreffende woorden komen in hoofdstuk 4 aan de orde.
Wanneer onderzoek gedaan wordt zowel op basis van de RND als de FAND, en in beide gevallen dezelfde plaatsen en woorden worden gebruikt, zullen de resultaten maximaal vergelijkbaar zijn. Volledig vergelijkbaar zullen ze echter niet zijn:
| 1. | De woorden uit de RND werden opgevraagd in en dus beïnvloed door het zinsverband. Dit kan gevolgen hebben voor de keuze van het lexeem. Bijvoorbeeld: zin 1 luidt: ‘Mijn vriend is de bloemen gaan gieten.’ Zin 17 luidt: ‘Ik heb het niet gedaan, hoor, vriend.’ In zin 17 heeft ‘vriend’ een andere gevoelswaarde dan in zin 1 en wordt daarom soms ook anders vertaald. In de FAND werden woorden voor het grootste deel geïsoleerd opgevraagd. |
| 2. | Opvragen in zinsverband heeft ook gevolgen voor de uitspraak, met name voor de begin- en eindklank. In de FAND speelt dit probleem niet. |
| 3. | De RND geeft niet alleen fonologische/fonetische variatie weer, maar ook lexicale variatie. ‘Vriend’ kan vertaald zijn als ‘vriend’, ‘makker’, ‘maat’, ‘kameraad’ of ‘kennis.’ Voor meerdere woorden komt het voor dat voor plaatsen waar in de RND een ander lexeem gegeven wordt, in de FAND hetzelfde lexeem gebruikt wordt als die in de vragenlijst, bijvoorbeeld: stuk (zelfstandig naamwoord), knuppel, kar, krom. In de FAND wordt voor sommige woorden bij sommige plaatsen ‘gg’ (geen gegevens) vermeld, vermoedelijk ook in die gevallen waar in plaats van het lexeem in de vragenlijst beslist een ander lexeem gebruikt wordt. |
| 4. | Opvragen in zinsverband geeft een grotere garantie dat het woord semantisch steeds hetzelfde is. Bijvoorbeeld ‘rijkdom’ betekent meestal ‘de verzameling goederen die iemand rijk maakt’, en een heel enkele keer ‘de groep van personen die rijk zijn’. Bij opvraging in zinsverband komt dit semantisch verschil eerder aan het licht dan bij opvraging in isolatie. In de RND vind we dit woord in zin 85: ‘De mensen zochten niet anders dan geld en rijkdom’. |
| 5. | Diachroon dialectonderzoek door vergelijking van RND-materiaal met FAND-materiaal is niet helemaal betrouwbaar omdat het RND-materiaal gedurende een vrij lange tijdspanne tot stand kwam (1925-1982). Het materiaal voor de FAND werd in veel kortere tijd verzameld (1979-1996). |
| |
4. Verwerking van de woorden
De vertaling van een item werd geaccepteerd indien de vertaling dezelfde betekenis heeft als het item. De vertaling kan een lexicale variant zijn van het item, maar kan ook een synoniem zijn van het item. Wanneer schip bijvoorbeeld vertaald wordt met boot, accepteren we boot als vertaling. Een vertaling werd niet geaccepteerd indien de vertaling niet dezelfde betekenis heeft, ook al betreft het een lexicale variant van het item. Bijvoorbeeld met rijkdom wordt normaal gesproken de verzameling goederen bedoeld die iemand rijk maken. Echter in één dialect verstond men onder ‘rijkdom’ de groep van rijke mensen. In dat geval wordt ‘rijkdom’ niet als vertaling geaccepteerd.
| |
| |
Alle vertalingen voor eenzelfde item moesten afkomstig zijn uit steeds dezelfde context. Indien het woord in een context niet voorkomt, mag het woord uit een andere context gehaald worden, indien het zeker is dat de vertaling in die andere context precies dezelfde betekenis heeft als dat het gehad zou hebben als het gebruikt was in de default context. De invloed van die andere context op de vertaling moet vergelijkbaar zijn met de invloed van de default context op de vertaling.
In 4.1 en 4.2 worden woorden, waarmee iets speciaals aan de hand was en/of die minder goed bruikbaar waren, besproken. Woorden die gemarkeerd zijn met een * komen niet meer in de gegevensverzameling voor, terwijl van woorden zonder * de data wel bewaard gebleven is.
| |
4.1 Verschillende vragenlijsten
4.1.1 Nederlands
In ieder deel van de RND is een vragenlijst afgedrukt. De vragenlijsten blijken niet allemaal gelijk te zijn, maar zijn vaak in meer of minder sterke mate aangepast aan de taalkundige situatie van het gebied. Omdat een vragenlijst informanten kan beïnvloeden, geven we hier een overzicht van woorden uit de (voormalige) woordenlijst die niet in alle vragenlijsten hetzelfde waren.
kippen (zin 1)
Deel 1 t/m 8: kiekens, deel 9 t/m 16: kippen.
*bang (zin 2)
Deel 1 t/m 8: schrik, deel 9 t/m 16: bang.
*kersen (zin 11)
Deel 1 t/m 8, 10 t/m 12,14 t/m 16: krieken, deel 9: morellen, deel 13: kersen.
knuppel (zin 13)
Deel 1 t/m 8: klippel, deel 9 t/m 16: knuppel
*spinnewebben (zin 19)
Deel 1, 6 t/m 8, 13 t/m 15: spinneweb(ben), deel 9 en 11: spinneweb, deel 2 t/m 5, 10, 12 en 16: spinnewebben.
ragebol (zin 19)
Deel 1: raagborstel, deel 2 t/m 16: ragebol.
duivel (zin 28)
Deel 1 t/m 8, 10, 13 en 15: Lucifer, deel 9, 11, 12, 14 en 16: duivel.
graag (zin 31)
Deel 1 t/m 8: gaarne, deel 9 t/m 16: graag.
optillen (zin 45)
Deel 1 t/m 8: opheffen, deel 9: oplichten, deel 10 t/m 16: optillen.
| |
| |
metselaar (zin 46)
Deel 1 t/m 8: metser, deel 9 t/m 16: metselaar.
boterham (zin 51)
In deel 1 t/m 4 wordt dit item niet opgevraagd. Deel 5 en 7 t/m 16: boterham, deel 6: stuite.
jongetje (zin 69)
Deel 1 t/m 9: mannetje, deel 10 t/m 16: jongetje.
*wagenmaker (zin 77)
Deel 1 t/m 8: boogmaker, deel 9 t/m 16: wagenmaker.
krom (zin 87)
Deel 1 t/m 12 en 14 t/m 16: krom, deel 13: met een bocht.
*schaduw (zin 91)
Deel 1 t/m 9: lommer, deel 10 t/m 16: schaduw.
ossenbloed (zin 96)
Deel 1 t/m 6, 8 t/m 12 en 14 t/m 16: ossenbloed, deel 7: ossebloed. In deel 13 is ‘ossenbloed’ vervangen door ‘melk’. Vervolgens worden ‘bloed’ en ‘twee ossen’ afzonderlijk afgevraagd.
*voer (zin 97)
Deel 1 t/m 8: voeder, deel 9: voer, deel 10 t/m 12, 15 en 16: (vee)voeder, deel 13 en 14: veevoer.
karnemelk (zin 100)
Deel 1 t/m 8: botermelk, deel 9 t/m 16: karnemelk.
duwen (zin 105)
Deel 1 t/m 11, 13, 15 en 16: duwen, deel 12 en 14: drukken.
je (zin 116)
Deel 1 t/m 8: gij, deel 9 t/m 16: je.
spuit (zin 127)
Deel 1 t/m 8: spat, deel 9 t/m 16: spuit
*kruisen (zin 128)
‘Kruisen’ werd niet in alle delen op dezelfde manier opgevraagd. In deel 1 t/m 4, in deel 5 (soms), in deel 6 t/m 8 en deel 15 (de Nederlandse vragenlijst) vinden we ‘kruisen’ in de zin ‘De koster luidt voor de kruisen’. Het betref hier de Kruisprocessie. In deel 2 t/m 7 staat er in een noot bij: ‘bepaalde processie bij de R.K.’ In deel 5 (soms), in deel 9 t/m 14, in deel 15 (Friese vragenlijst) en in deel 16 wordt ‘kruisen’ als los item opgevraagd als meervoud van ‘kruis’. ‘Kruisen’ heeft dus niet altijd dezelfde semantiek, wat ook gevolgen heeft voor de vertaling.
| |
| |
duitsers (zin 130)
In deel 1 t/m 4 is dit item te vinden in zin 126: ‘De Duitschers hebben ons oud huis afgebrand’. In deel 5 t/m 16 is dit item te vinden in zin 130: ‘De twee Duitsers kwamen naar buiten.’
soldaten (136)
In deel 1 t/m 4 is dit item te vinden in zin 52: ‘De soldaten hebben (dat vrouwmensch) heur haar afgesneden’. In deel 5 t/m 16 wordt ‘de soldaten’ afzonderlijk afgevraagd in zin 136.
| |
4.1.2 Frans
In deel 6 (West-Vlaanderen en Fransch-Vlaanderen) wordt gemeld dat bij het interviewen bleek dat de zegslieden diverse woorden uit de vragenlijst niet kenden. Het probleem werd opgelost door ze te vervangen door de Franse equivalenten. We geven hieronder een overzicht van de substituties die betrekking hebben op onze woordenlijst. Voor de ‘/’ staat de Nederlandse vorm, na de ‘/’ de Franse vorm. De Franse woorden zijn gespeld zoals ze ook gespeld zijn in de RND.
| pet / casquette (zin 20) |
| paddestoel / champignon (zin 20) |
| stenen / briques (zin 25) |
| standbeeld / monument, statue (zin 26) |
| kaars / bougie (zin 59) |
| goed / bon (zin 92) |
| brug / pont (zin 106) |
| koster/ bedeau, suisse (zin 128) |
| kruiwagen / brouette (zin 129) |
| Duitsers/ Allemands(ch)e (zin 130) |
| dopen / baptiseren (zin 137) |
| |
4.1.3 Fries
In deel 15 (Friesland) zijn twee vragenlijsten afgedrukt, namelijk een Nederlandse en een Friese lijst. De Nederlandse lijst werd, na overleg met de informanten, gebruikt in De Blesse (F 44), Grijpskerk (B 42), Hindeloopen (F 2), Scherpenzeel (F 53), op het eiland Terschelling en in Zoutkamp (B17). De Friese vragenlijst werd in de overige en daarmee de meeste plaatsen gebruikt. De woorden uit de Nederlandse vragenlijst waren meestal wel terug te vinden in de Friese vragenlijst. We geven hieronder een overzicht van bijzondere gevallen die betrekking hebben op onze woordenlijst. Voor de ‘/’ staat de Nederlandse vorm, na de ‘/’ de Friese vorm. De Friese woorden zijn gespeld zoals ze ook gespeld zijn in de Friese vragenlijst in de RND.
beschimmeld / biskimmele (skimmelige) (zin 5)
In de Nederlandse vragenlijst is beschimmeld een bijvoeglijk naamwoord bij een hetwoord, namelijk ‘het brood’. In de Friese vragenlijst is biskimmele (skimmelige) een bijvoeglijk naamwoord bij een de-woord, namelijk ‘de bôle’. Hierbij zijn ‘brood’ en
| |
| |
‘bôle’ woorden die duiden op niet-telbare zaken. Bijvoeglijke naamwoorden die voorafgaan aan de-woorden die duiden op niet-telbare zaken worden gewoonlijk verlengd met een sjwa. We accepteerden de vertaling voor het bijvoeglijk naamwoord alleen wanneer deze voorafging aan een het-woord.
*krieken / kersen (zin 11)
Dit verschil is ook tussen de Nederlandse vragenlijsten van de verschillende RND-delen te vinden.
*vastenavond / Sinteklaezjen (zin 15)
Beide woorden zijn niet semantisch identiek en daarom uit de woordenlijst verwijderd.
Lucifer / duvel (Lucifer) (zin 28)
Dit verschil is ook tussen de Nederlandse vragenlijsten van de verschillende RND-delen te vinden.
*beesten / bargen, kij (zin 31)
Beide woorden zijn niet semantisch identiek en daarom uit de woordenlijst verwijderd.
keelpijn / pine (pyn) yn 'e keel (zin 32)
We accepteerden beide vormen, omdat ze allebei opgebouwd zijn uit de elementen ‘keel’ en ‘pijn’ of ‘pine’ of ‘pyn’.
metselaar / timmerman (zin 46)
Beide woorden zijn niet semantisch identiek. We hebben het woord wel gehandhaafd in de woordenlijst, maar in de dialecten waar timmerman gegeven is, opgegeven dat de vertaling voor metselaar ontbreekt.
boterham / bêlle (zin 51)
In Pebesma en Zantema (1994) wordt als vertaling voor boterham gegeven: brogge, stik iten. Veel Friezen vertalen het ook als ‘stik bôle’. In de RND wordt ‘een boterham’ (met lidwoord) vertaald met bôlle (zonder lidwoord). We hebben bôlle als vertaling voor boterham geaccepteerd.
veel / folle (zin 56)
De Nederlandse zin luidt: ‘Aarden potten zijn niet veel waard.’ De Friese zin luidt: ‘Stiennen potten binnen neat wurdich. Keulse potten.’ In de Friese zin kan dus geen vertaling gevonden woorden voor veel. Voor de Friese dialecten kozen we daarom uit zin 15 een vertaling voor veel. Indien de vertaling ook daar niet gevonden kon worden, kozen we de vertaling uit zin 55.
*pater / dûmny (pastoar) (zin 62)
Deze woorden zijn niet semantisch identiek en daarom uit de woordenlijst verwijderd.
*kaarten / damjen (zin 65)
Beide woorden zijn niet semantisch identiek en daarom uit de woordenlijst verwijderd.
| |
| |
spannen / slagge (zin 74)
In Pebesma en Zantema (1994) wordt als vertaling voor spannen gegeven: spanne. Het woord slagge als vertaling voor spannen is heden ten dage minder gebruikelijk, maar geldt wel als synoniem.
krom / mei in bocht (zin 87)
De omschrijving met een bocht acccepteerden we niet. Wanneer met een bocht wordt afgevraagd, zal de informant(e) niet gauw krom zeggen, ook al kent de informant(e) het woord krom wel degelijk, ook in de context van zin 87 uit de RND. We hebben het woord wel gehandhaafd in de woordenlijst, maar in de dialecten waar mei in bocht gegeven is, opgegeven dat de vertaling voor krom ontbreekt.
*(vee)voeder / kûle (zin 97)
Het Friese woord kûle wordt in Pebesma en Zantema (1994) vertaald met ‘kuil’. Het Friese woord ‘foer’ is de vertaling voor het Nederlandse woord ‘voer’. Daaruit blijkt dat (vee)voeder en kûle semantisch niet identiek zijn. Ze zijn daarom uit de woordenlijst verwijderd.
*pastoor / pastoar (dûmny) (zin 125)
Deze woorden zijn niet semantisch identiek en daarom uit de woordenlijst verwijderd.
saus / sjeu (zin 132)
Het Nederlandse woord saus wordt in Pebesma en Zantema (1994) vertaald met het Friese woord sjeu. Het Friese woord sjeu wordt in Pebesma en Zantema (1994) vertaald met het Nederlandse woord ‘jus’ of saus. Het Friese sjeu is dus een goed vertaling voor het Nederlandse saus.
flauw / flutterich (zin 132)
Het Friese woord flutterich wordt in Pebesma en Zantema (1994) vertaald met ‘dun’ of ‘slap’. Het Friese woord ‘flau’ of ‘sleau’ is de vertaling voor het Nederlandse woord flauw. Daaruit blijkt dat flauw en flutterich semantisch niet identiek zijn. We hebben het woord wel gehandhaafd in de woordenlijst, maar in de dialecten waar flutterich gegeven is, opgegeven dat de vertaling voor flauw ontbreekt.
| |
4.2 Probleemwoorden
4.2.1 Vrije vertaling
*glazen (zin 10)
In zin 10 wordt ‘vier glazen bier’ ook vaak vertaald als ‘vier glaasjes bier’, of kortweg ‘vier glaasjes’.
keelpijn (zin 32)
Zin 32 luidt: ‘Hij kan niet gaan werken, hij heeft keelpijn’. We noteren steeds wat volgt op ‘hij heeft’. Soms is dat precies één woord (bijvoorbeeld ‘keelpijn’) en soms is dat een omschrijving (bijvoorbeeld ‘pijn in de keel’). Wanneer een omschrijving is gegeven, noteren we de woorden uit de omschrijving aan elkaar vast en beschouwen dit als één woord.
| |
| |
*beschermen (zin 41)
‘De man moet zijn vrouw beschermen’ wordt ook vaak vertaald als ‘de man moet voor zijn vrouw opkomen’. ‘Beschermen’ en ‘opkomen voor’ zijn niet goed vergelijkbaar.
*schaduw (zin 91)
‘Schaduw’ wordt in sommige dialecten ook vertaald als ‘uit de zon’.
*eik (zin 120)
Soms wordt een vertaling voor ‘eik’ en soms wordt een vertaling voor ‘eikeboom’ gegeven.
*uier(zin 127)
‘De melk spuit uit de uier van de koe’ wordt soms ook vertaald als ‘de melk spuit uit de spenen van de koe’.
*eeuwigheid (zin 134)
‘Eeuwigheid werd ook vaak vertaald als ‘een hele tijd’. ‘Eeuwigheid’ en ‘een hele tijd’ zijn minder goed vergelijkbaar.
| |
4.2.2 Fonologie
mijn (zin 2)
De kans bestaat hier dat soms ‘mijn’ en soms ‘m'n’ vertaald wordt. Er blijkt inderdaad variatie te zijn tussen [ɪ] als klinker en de [ə] als klinker. Deze variatie lijkt echter niet willekeurig, maar geografisch gebonden te zijn.
ik (zin 14)
‘Ik heb zijn knie gezien’ wordt vaak vertaald als ‘'k heb zijn knie gezien’. Deze reductie blijkt echter niet willekeurig, maar geografisch gebonden te zijn. De toepassing van deze reductie is het sterkst in het zuidwesten van het Nederlands taalgebied waar zelfs ‘ik kan...’ (zin 30 en 73) vertaald wordt als ‘kan...’ of ‘ke kan’.
| |
4.2.3 Semantiek
Bij vergelijking van de dialecttekst met de vragenlijst is het, zonder kennis van het betreffende dialect, moeilijk om te bepalen of de vertaling semantisch identiek is aan dat wat in de vragenlijst gegeven is. Woorden die lexicaal verschillend zijn, kunnen semantisch identiek zijn. Bijvoorbeeld het Groningse ‘kopzeer’ is semantisch identiek aan het Nederlandse ‘hoofdpijn’ (woord niet uit de RND). Wanneer echter in een zeker dialect het Nederlandse mond (zin 86) vertaald wordt met ‘bek’, is het, wanneer men geen spreker is van dat dialect, moeilijk te zeggen of ‘bek’ in dat dialect dezelfde gevoelswaarde heeft als het Nederlandse ‘mond’. Het kan ook voorkomen dat woorden die lexicaal identiek zijn semantisch verschillend zijn. Bijvoorbeeld met *rijkdom (zin 85) wordt normaal gesproken de verzameling goederen bedoeld die iemand rijk maken. Bij één dialect echter bleek dat men onder ‘rijkdom’ de groep van rijke mensen verstond.
| |
| |
Het veiligste zou het zijn om voor alle 347 dialecten sprekers te zoeken en hen de vertalingen te laten controleren. Echter er is dan wel een groot tijdsverschil tussen het tijdstip waarop de opnamen gemaakt werden en het moment waarop de vertalingen gecontroleerd worden. Verder zou dit, gezien het tamelijk grote aantal dialecten, voor ons ondoenlijk zijn. We zagen daarom van deze conrole af. Het is daarom heel waarschijnlijk dat resultaten van onderzoek op basis van deze gegevensverzameling behept zullen zijn met ruis. Zolang echter deze ruis ook echt ‘ruis’ is, zal dit niet leiden tot systematische vertekening.
Hieronder bespreken we nog een aantal woorden die qua semantiek als speciale gevallen beschouwd kunnen worden.
brood (zin 5)
Het Nedersaksische woord ‘brood’ komt overeen met het Nederlandse woord ‘roggebrood’, terwijl het Nederlandse woord ‘brood’ overeenkomt met het Nedersaksische woord ‘stoet’. Het woord wordt opgevraagd in de zin ‘op dat schip kregen ze beschimmeld brood’. Meestal wordt ‘brood’ dan vertaald met ‘brood’, mogelijk omdat roggebrood de meest gangbare en gebruikte broodsoort was, mogelijk ook door voorkeur voor hetzelfde lexeem.
Het verschillend en veranderd gebuik van ‘brood’ zagen we ook in een onderzoekje naar 17 dialecten in en rondom Bentheim. De RND-opnamen zijn gemaakt in 1974/1975. In 1999 maakten we zelf nieuwe opnamen (Heeringa, 2000). Het bleek dat in 2 dialecten (Coevorden en Lage) het woord ‘brood’ gehandhaafd bleef. Mogelijk is de betekenis wel verschoven van roggebrood naar brood in Nederlandse betekenis. In 12 dialecten (Bergentheim, Gramsbergen, Hoogstede, Itterbeck, Langeveen, Neuenhaus, Nieuw Schoonebeek, Nordhorn, Radewijk, Uelsen, Vasse en Wilsum) werd ‘brood’ vervangen door ‘stoet’, waarschijnlijk omdat roggebrood niet meer de meest gangbare en gebruikte broodsoort is. In 1 dialect (Lattrop) bleef ‘stoet’ gehandhaafd. De sprekers van dit dialect waren in 1974/1975 hun tijd dus al ver vooruit. In 2 dialecten (Emlichheim en Schoonebeek) werd ‘stoet’ vervangen door ‘brood’. Dit betekent waarschijnlijk niet dat de sprekers van deze dialecten weer meer roggebrood zijn gaan eten, maar dat deze twee dialecten vernederlandsen en het oude woord ‘stoet’ door het woord ‘brood’ in Nederlandse betekenis is vervangen. Omdat in de RND ‘brood’ meestal met ‘brood’ is vertaald, menen we daaruit te kunnen afleiden dat het woord op tamelijk vergelijkbare manier door de informanten is geïnterpreteerd en vertaald.
breder (zin 25)
‘Breder’ wordt soms ook vertaald als ‘bredere’ of ‘brederen’. We weten niet of ‘bredere’ of ‘brederen’ vertalingen zijn die semantisch identiek zijn aan ‘breder’, of dat de informant het woord ‘breder’ in gedachten vanuit een context vertaalde, bijvoorbeeld ‘de bredere stenen’ of ‘de brederen’. We gaan er vanuit dat ‘breder’ wel steeds op dezelfde manier is opgevraagd en de verschillende varianten daarom vergelijkbaar met elkaar zijn.
breedste (zin 25)
‘De breedste’ wordt soms ook vertaald als ‘de breedsten’. We weten niet of ‘breedsten’ semantisch identiek is aan ‘breedste’. Voor al die gevallen waarin het bepaalde lidwoord ‘de’ gebruikt is gaan we er vanuit dat ‘breedste’ steeds op dezelfde manier is opgevraagd en de verschillende varianten daarom vergelijkbaar met elkaar zijn.
| |
| |
| |
4.2.4 Morfologie
beschimmeld (zin 5)
‘Beschimmeld’ gaat meestal vooraf aan een het-woord (brood), en soms aan een dewoord (bôle, stoet). Hierbij zijn ‘brood’, ‘bôle’ en ‘stoet’ woorden die duiden op niet-telbare zaken. Bijvoeglijke naamwoorden die voorafgaan aan de-woorden die duiden op niet-telbare zaken worden gewoonlijk verlengd met een sjwa. We accepteerden de vertaling voor het bijvoeglijk naamwoord alleen wanneer deze voorafging aan een hetwoord.
duivel (zin 28)
‘De duivel’ (met lidwoord) wordt ook vaak vertaald met Lucifer (zonder lidwoord). We hebben Lucifer als vertaling voor duivel geaccepteerd.
boterham / bôlle (zin 51)
‘Een boterham’ (met lidwoord) wordt ook vertaald met woorden als brood en bôlle (zonder lidwoord, omdat het bij die vertalingen om niet-telbare zaken gaat). We hebben woorden als brood en bôlle als vertaling voor boterham geaccepteerd.
*dopen (zin 80)
‘Het kindje was dood, voordat ze het konden dopen’ wordt ook vertaald als ‘het kindje was dood voordat het gedoopt kon worden’.
*weddenschap (zin 47)
‘Ze springen om het verst voor een weddenschap’ wordt ook vaak vertaald als ‘ze hebben gewed wie het verste springen kan’.
| |
4.2.5 Knippen uit zinsverband
Soms worden woorden aan elkaar vast uitgesproken en dus in de RND aan elkaar vast genoteerd. Wanneer we uit zo'n woordgroep één bepaald woord willen knippen, is het niet altijd onmiddelijk duidelijk waar het ene woord eindigt, en het andere woord begint. Hieronder volgen de woorden die soms problemen gaven.
keelpijn (zin 32)
[hɛftɪndəkeˑl] kan opgesplitst worden als [hɛf][t]ɪndəkeˑl], [hɛft][t][ɪndəkeˑl] en [hɛft][ɪndəkeˑl]. We losten dit op door naar dialecten vlak in de buurt te kijken waar de woorden wel los van elkaar genoteerd zijn.
ossebloed (zin 96)
Uit [ɔsəbludrɪŋkən] knippen we [ɔsəblud], en uit [ɔsəblutrɪŋkən] knippen we [ɔsəblut].
drinken (zin 96)
Uit [ɔsəbludrɪŋkən] knippen we [drɪŋkən], en uit [ɔsəblutrɪŋkən] knippen we [trɪŋkən].
| |
| |
veulen (zin 107)
In de zin ‘Ge moet ons veulen eens komen keuren’ wordt het zinsdeel ‘veulen eens’ in deel 1, 2, 3, 4, en 6 dikwijls vertaald met [føˑlnəkɪr] of een variant hiervan. Dit kan opgesplitst worden als [føˑl][nəkɪr], [føˑln][nəkɪr] of [føˑln][əkɪr]. We losten dit op door naar dialect en vlak in de buurt te kijken waar de woorden wel los van elkaar genoteerd zijn, of waar [føˑl(n)] vervangen is door [kɑxtl̘] en/of [(n)əkɪr] vervangen is door [iʃ].
buigen (zin 129)
In de zin ‘De bomen van de kruiwagen buigen door onder 't gewicht’ wordt het zinsdeel ‘buigen door’ soms vertaald met [byːɣ døːr] of [byːɣdøːr]. In deze gevallen kiezen we als vertaling voor buigen [byːɣ]. Soms wordt het zinsdeel ‘buigen door’ vertaald met [byːɣt døːr] of [byːɣtøːr]. In deze gevallen kiezen we als vertaling voor buigen [byːɣt]. In alle gevallen gaan we ervan uit dat de vorm [byːɣd] wat minder voor de hand ligt.
| |
4.2.6 Verbinding met voltooid deelwoord
Bepaling van de woordgrens is soms moeilijk wanneer een willekeurig woord en een voltooid deelwoord aan elkaar vastgeschreven zijn. Stel bijvoorbeeld dat in de zinsnede ‘Het is een warme dag geweest’ (in zin 68) ‘dag’ en ‘geweest’ aan elkaar vastgeschreven zijn als [dɑɣəυɛst]. Bij opsplitsing kan ‘dag’ twee vormen hebben: [dɑɣ] en [dɑɣə]. Tevens kan ‘geweest’ drie vormen hebben: [ɣəυɛst], [əυɛst] en [υɛst].
Problemen van deze aard doen zich, voor wat betreft de woorden uit onze woordenlijst, voor bij gezien (zin 14), zee (zin 29), geroepen (zin 35), dag (zin 68), geweest (zin 76), brug (zin 106), gras (zin 111), blauw (zin 131), geslagen (zin 131) en gebonden (zin 139).
We maken een keuze door in dezelfde dialecttekst na te gaan of er meer woorden zijn die met een [ə] verlengd zijn, en door na te gaan of andere voltooide deelwoorden beginnen met [ɣə], [ə] of [ ]. Stel nu dat ‘dag geweest’ is getranscribeerd als [dɑɣəυɛst]. We splitsen dan overeenkomstig het volgende schema:
| Achtervoegsel van andere woorden in de tekst |
Voorvoegsel van andere voltooide deelwoorden in de tekst |
|
|
| [ ] |
[ɣə] |
[dɑɣ] |
[ɣəυɛst] |
| [ ] |
[ɣə] of [ə] |
[dɑɣ] |
[ɣəυɛst] |
| [ ] |
[ə] |
[dɑɣ] |
[əυɛst] |
| [ ] |
[ə] of [ ] |
[dɑɣ] |
[əυɛst] |
| [ ] |
[ ] |
[dɑɣ] |
[υɛst] |
| [ ] of [ə] |
[ɣə] |
[dɑɣ] |
[ɣəυɛst] |
| [ ] of [ə] |
[ɣə] of [ə] |
[dɑɣə] |
[ɣəυɛst] |
| [ ] of [ə] |
[ə] |
[dɑɣə] |
[əυɛst] |
| [ ] of [ə] |
[ə] of [ ] |
[dɑɣə] |
[əυɛst] |
| [ ] of [ə] |
[ ] |
[dɑɣə] |
[υəst] |
| |
| |
Wanneer ‘dag geweest’ getranscribeerd is als [dɑɣəυɛst], moet in het schema voor een eventuele [ə] na [dɑɣ] of voor [υɛst] een [ə] worden gelezen.
Ook de andere gevallen betreffende de woorden uit onze woordenlijst losten we analoog aan het voorfoeeld voor [dɑɣəυɛst] op. We onderkennen dat deze aanpak leidt tot een transcriptie die niet altijd overeenkomst met hoe het woord in werkelijkheid in isolatie wordt uitgesproken. Het is echter niet mogelijk voor elk probleemgeval informanten op te sporen en te vragen hoe het woord in isolatie wordt uitgesproken. Het is dan niet gek te kiezen voor een oplossing waarin weerspiegeld wordt wat in vergelijkbare situaties in de rest van de tekst gebeurt.
| |
5. Codering van de woorden
5.1 De tekens van het fonetisch schrift
In Blancquaert (1948) lezen we: ‘Het door ons gebezigde fonetisch schrift is dit van de International Phonetic Association van Paul Passy en Daniel Jones, voor een paar punten aangepast aan de noodwendigheden van het Nederlands...’. In elk deel wordt het systeem weergegeven. Het aantal gebruikte tekens voor klanken en diacritische tekens is niet altijd gelijk, maar zal bepaald zijn door wat nodig was om de klanken van de dialecten in het betreffende deel correct weer te geven.
De [ɒ] (als in Eng. ‘law’) komt alleen in deel 1, 2 en 4 voor. De [c] (als in Ned. ‘rietje’) komt alleen in deel 16 voor. De [t] (als in Ned. ‘tak’) wordt in de delen 7, 8, 10, 11 en 12 niet vermeldt in het overzicht van het ‘Fonetisch Schrift’, maar wel in de transcripties gebruikt. De [υ] (als in Ned. ‘water’, labiodentaal) komt alleen voor in de delen 3, 5 en 7 t/m 16. De [ɡ] wordt alleen in deel 16 vermeldt als een apart teken dat een stemloze occlusief representeert (als in Ned. ‘wasgoed’). De glottisslag [ʔ] komt alleen voor in deel 2 t/m 16.
De [ˌ] (vocalisering) komt alleen voor in de delen 2 t/m 8 en 10 t/m 16. De [⋺] (halve ronding) en de [⋲] (halve ontronding) vinden we alleen in de delen 3 t/m 16. De [⊢] (meer naar voren) vinden we alleen in de delen 3 t/m 16, en de [⊣] (meer naar achteren) vinden we alleen in de delen 1 en 3 t/m 16. De [.] (palatalisering) komt alleen voor in de delen 1 t/m 11, 13 en 15. De [^] (sleeptoon of tweetoppig zwak gesneden accent of tweetoppig dalend accent) vinden we alleen in de delen 2 t/m 11, 13 en 15. In deel 8 heeft de sleeptoon in een deel van de dialecten een fonetische betekenis en wordt genoteerd als [^], en bij het andere deel van de dialecten een fonologische betekenis en wordt aangegeven door de betreffende klank de onderlijnen. Bij digitalisatie wordt zowel voor de [ ] als voor de onderlijning hetzelfde symbool gebruikt. De [\] (stoottoon of scherp gesneden accent) wordt alleen in de delen 8 en 13 gebruikt De [∪] (leniskarakter) en de [∩] (fortiskarakter) vinden we alleen in deel 13.
Bij digitalisatie van de transcripties werden alle diacritische tekens overgenomen. Echter bij verwerking van de data is het belangrijk rekening te houden met het feit dat niet alle diacritische tekens in alle atlasdelen voorkomen, en vermoedelijk ook niet door alle transcribenten (even scherp) worden waargenomen. Het lijkt daarom beter om bij verwerking van de data alleen die diacritische tekens te verwerken die in de
| |
| |
meeste delen voorkomen en duidelijk waarneembaar zijn. In navolging van Hoppenbrouwers (1988) beperken we ons tot de diacritische tekens voor half lang, lang, vocalisering, nasalering, palatalisering.
Niet altijd werden dezelfde klanken door middel van dezelfde tekens gerepresenteerd. De [ᴣ] (als in Ned. ‘gelei’) wordt in deel 1 weergegeven door een [z] en een schrijfletter [j] aan elkaar vast, en in de delen 2 t/m 16 als [ᴣ]. De [æ] (als in Eng. ‘bad’) wordt in deel 1 weergegeven door en schrijfletter [x], en in de delen 2 t/m 16 als [æ]. De [a] (als in Ned. ‘baak’) wordt in deel 1 weergegeven door een [ɛ] en een [L] aan elkaar vast, en in de delen 2 t/m 16 als [a]. De [ɔ] (als in Ned. ‘ros’) wordt in de delen 1 en 2 weergegeven als [2], en in de delen 3 t/m 16 als [ɔ]. De [ʌ] (in IPA: [y], als in Ned. ‘bus’) wordt in deel 1 weergegeven als [Ω], en in de delen 2 t/m 16 als [ʌ]. De [œ] (als in Ned. ‘freule’) wordt in de delen 1 en 2 weergegeven als [ω], en in de delen 3 t/m 16 als [œ]. De [χ] (als in Ned. ‘lachen’) wordt in de delen 1 en 3 t/m 16 weergegeven als [χ], en in deel 2 als [x]. Wanneer nu voor dezelfde klank in het ene atlasdeel een ander teken wordt gebruikt dan in het andere atlasdeel, worden bij digitalisatie beide tekens vastgelegd door middel van hetzelfde symbool.
Het overzicht van het ‘Fonetisch Schrift’ is in deel 1 handgeschreven, in deel 2 getypt en in de delen 3 t/m 16 gedrukt. De transcripties zijn in deel 1, 7, 8, 10 en 15 handgeschreven, in deel 2 getypt, en in de delen 3 t/m 6, 9, 11 t/m 14, en 16. Door deze verschillende manieren van weergeven, kunnen er kleine verschillen zijn in de weergave van tekens. Met name in handgeschreven teksten wordt soms het schrijfletter-equivalent voor de corresponderende blokletter gebruikt. Het feit dat een klank minder sterk wordt gehoord, wordt in handgeschreven teksten aangegeven door die klank in superschrift weer te geven, in getypte teksten door die klank kleiner weer te geven of door er een schuin streepje dwars doorheen of erboven te plaatsen, en in gedrukte teksten door die klank kleiner weer te geven. Deze verschillen in notatie zijn in de gedigitaliseerde data niet meer terug te vinden. Omdat ze allen hetzelfde betekenen, werden ze ook allen door middel van hetzelfde symbool vastgelegd.
| |
5.2 Gebruik van de fonetische tekens
5.2.1 Fonetische overzichten
In het overzicht van het fonetische schrift wordt steeds aangegeven wat de symbolen representeren, door een Nederlands woord te geven waarin de betreffende klank voorkomt. Het voorbeeld dat voor een symbool gegeven wordt, kan soms per atlasdeel verschillen. Meestal betekent dit geen verschil in betekenis. In deze paragraaf geven we een overzicht van die klanken waarbij door verschil in voorbeelden mogelijk verschil in betekenis kan ontstaan. Die gevallen waarbij dat zeker is, worden besproken in 5.2.2 en 5.2.3. Hieronder geven we per klank voor alle atlasdelen weer hoe die vermeld wordt in het fonetische overzicht.
| De [e]-klank |
| |
| eˑ |
in Ned. ‘bede’ |
deel 1, 2 |
| |
| |
| eˑ |
in Ned. ‘beek’ |
|
deel 3 t/m 10, 12, 14 t/m 16 |
| e |
in Ned. ‘beek’ |
(geen lengteteken) |
deel 11 |
| eː |
in Ned. ‘zeer’ |
|
deel 12, 14, 16 |
| ɪˑ |
in Ned. ‘zeer’ |
|
deel 13 |
| |
| De [a]-klank |
|
| |
| aː |
in Ned. ‘jaar’ |
|
deel 1, 2, 13 |
| aˑ |
in Ned. ‘baak’ |
|
deel 3 t/m 10, 10 t/m 16 |
| a |
in Ned. ‘baak’ |
(geen lengteteken) |
deel 11 |
| |
| De [o]-klank |
|
| |
| oː |
in Ned. ‘zoon’ |
|
deel 1, 2 |
| oː |
in Ned. ‘boos’ |
|
deel 3 t/m 5, 15 |
| oː |
in Ned. ‘boos’ |
|
deel 6 t/m 10, 12 t/m 14, 16 |
| o |
in Ned. ‘boos’ |
(geen lengteteken) |
deel 11 |
| oː |
in Ned. ‘boor’ |
|
deel 16 |
| ʊː |
in Ned. ‘boor’ |
|
deel 13 |
| |
| De [u]-klank |
|
| |
| u |
in Ned. ‘zoet’ |
(kort) |
deel 1, 2 |
| u |
in Ned. ‘boek’ |
(kort) |
deel 3 t/m 10, 12, 14 t/m 16 |
| u |
in Ned. ‘boek’ |
(geen lengteteken) |
deel 11, 13 |
| uː |
in Ned. ‘boer’ |
|
deel 13 |
| |
| De [y]-klank |
|
| |
| y |
in Ned. ‘duwen’ |
(kort) |
deel 1, 2 |
| y |
in Ned. ‘nu’ |
(kort) |
deel 3 t/m 10, 12, 14 t/m 16 |
| y |
in Ned. ‘nu’ |
(geen lengteteken) |
deel 11, 13 |
| yː |
in Ned. ‘zuur’ |
|
deel 13 |
| |
| De [ø]-klank |
|
| |
| ωˑ |
in Ned. ‘jeugd’ |
|
deel 1, 2 |
| ø |
in Ned. ‘beuk’ |
(kort) |
deel 3 t/m 10, 15 |
| ø |
in Ned. ‘beuk’ |
(geen lengteteken) |
deel 11 t/m 14, 16 |
| øː |
in Ned. ‘beur’ |
|
deel 16 |
| ʌː |
in Ned. ‘deur’ |
|
deel 13 |
| |
| |
| De [œ]-klank |
|
| |
| œ |
in Ned. ‘duif’ |
(geen lengteteken,
1e lid tweeklank) |
deel 1, 2 |
| œ |
in Ned. ‘freule’ |
(geen lengteteken) |
deel 3 t/m 5, 7 t/m 12, 14 t/m 16 |
| œ |
in Ned. ‘lui’ |
(geen lengteteken,
1e lid tweeklank) |
deel 3 t/m 5, 7 t/m 12, 14 t/m 16 |
| œ |
in Ned. ‘freule’ |
(halflang) |
deel 6, 13 |
| œ |
in Ned. ‘lui’ |
(geen lengteteken,
1e lid tweeklank) |
deel 6, 13 |
| |
5.2.2 De lengte
In de inleiding van deel 3 schrijft Blancquaert dat de weergave van de teksten naar zijn gevoelen nauwkeuriger is dan die van de beide eerste atlassen, ondermeer omdat voor het weergeven van de duur het onderscheid tussen kort, halflang en lang juister werd waargenomen, ‘en wel zóó dat van het dubbel lengteteeken minder kwistig gebruik werd gemaakt’.
Het valt op dat volgens de delen 3 t/m 5 en deel 15 de [o] in Ned. ‘boos’ lang is, en volgens de delen 6 t/m 10, 12 t/m 14 en deel 16 halflang. Voor de [œ] in Ned. ‘freule’ wordt in de delen 3 t/m 5, 7 t/m 12, en 14 t/m 16 niets over de lengte gezegd. Echter in de delen 6 en 13 wordt gemeldt dat de [œ] in Ned. ‘freule’ halflang is..
Opvallend in het Fonetisch Overzicht in deel 11 is dat voor geen enkele vocaal aangegeven is wat de lengte is in het voorbeeldwoord. In de inleiding schrijft van Oyen onder andere:
‘Minder met mijn Zuidhollanderschap te maken heeft, meen ik, het feit dat ik slecht hoor of een klank halflang dan wel lang genoemd dient te worden, al geloof ik buitendien dat werkelijk lange klanken in het gebied van deze atlas vrij zeldzaam zijn. Ik heb daar gaandeweg steeds meer de konsekwentie uit getrokken, en slechts die klanken met het betrokken diakritiese teken aangegeven die zich als opvallend lang aan mij voordeden.’
Gezien de genoemde problemen lijkt het raadzaam om bij de verwerking van de data slechts onderscheid te maken tussen kort en lang, en alle halflange klanken te verwerken als zijnde lang. We vinden deze aanpak ook terug in de featuretabel van Hoppenbrouwers (1988).
| |
5.2.3 Ee, oo en eu voor r
In de inleiding van deel 13 lezen we dat de opnamen voor Amsterdam door Blancquaert zijn gedaan. Jo Daan merkt hierover op dat ze zelf een aantal verschijnselen anders genoteerd zou hebben. Het betreffen zeven verschijnselen, en onder punt 6 meldt ze:
‘In de positie voor r noteerde Blancquaert, overeenkomstig zijn spellingsvoorschriften oˑ en eˑ in plaats van ʊˑ en ɪˑ (bv. Zin 27 : keˑrǝl - seːr 74 foːr 75
| |
| |
koːrs). In verband met de relevantie van oˑ|ʊˑ en eˑ|ɪˑ in sommige Noordhollandse dialekten heb ik in alle opnamen nauwkeuriger fonetisch genoteerd dan in de Amsterdamse opnamen is gebeurd.’
Even verderop in de inleiding vinden we een toelichting op het fonetisch schrift. We lezen daar onder andere:
‘Ik heb de klinkers oo en ee in de positie voor r altijd aangeduid met de tekens ʊ en ɪ, als deze tekens tenminste de gebruikte klank weergaven. Het lijkt me onjuist om in fonetisch schrift de ee van zee en de oo van boos kwalitatief gelijk te stellen met die van zeer en door, zoals Blancquaert doet op blz. 59 en 60 van de bovengenoemde publicatie.’
Met ‘bovengenoemde publicatie’ bedoelt de auteur Na meer dan 25 jaar Dialect-onderzoek op het Terrein (Blancquaert, 1948).
In de inleiding van deel 16 schrijft A. Sassen:
‘In sommige Groninger dialekten worden woorden als oren (no 81) en aren (mv. van aar), woord (79) en baard met dezelfde of vrijwel dezelfde vocaal uitgesproken, nl. ʊː. In die dialekten is de opposite /oˑ/ - /ʊˑ/ als bv. In /roˑt/ “rood” - /rʊˑt/ “raad” vóór r geneutraliseerd. De r vóór een andere, “korte” of “sonantische” consonant wordt meestal niet duidelijk hoorbaar gearticuleerd. In gevallen als hier bedoeld is meestal [oːr] gespeld als het desbetreffende woord beantwoordt aan een met o(o) gespeld Nederlands equivalent (oren, woord, doornen), daarentegen met [ʊː] wanneer het Nederlandse equivalent a(a) heeft (gevaarlijk, kaarten, gevaren). Een overeenkomstige gedragsregel is gevolgd in geval van [eː] en [oː] vóór r waar veelal ook [ɪː] en [ʌː] mogelijk waren geweest, bv. [peːrt] “paard” en [vøːr] “voor”. In al de drie gevallen (oor, eur, eer) is de in klein corpus gedrukte r vóór consonant, fonetisch niet of nagenoeg niet of ook wel als een lichte “naslag” met ə gerealiseerd (vʊːə̘ “varen”), dus (tevens) teken voor het timbre van de voorafgaande vocaal. Hoewel deze wijze van spellen de waargenomen klankstructuur meer fonologisch dan fonetisch verantwoordt, heb ik me in dezen graag aangepast bij de transcriptie die Blancquaert zelf voor Rottum C 33* bleek te hebben gevolgd.’
Bij de verwerking van de data zouden we graag willen dat verschillende notaties die dezelfde betekenis hebben, niet als verschillend worden beschouwd. Als eerste stap zouden we iedere [e] voor [r] of [ʀ] kunnen vervangen door [ɪ], iedere [o] voor [r] of [ʀ] door [ʊ], en iedere [ø] voor [r] of [ʀ] door [ʌ]. Zoals Sassen aangeeft, kan een [r] ook verzwakken tot [ə]. Ook in die gevallen kan dus de voorafgaande [e] worden vervangen door [ɪ], de [o] door [ʊ], en de [ø] door [ʌ]. Hier ontstaan echter problemen. Het is niet altijd duidelijk of een [ə] die volgt op [e], [o] of [ø] een afgezwakte [r] representeert. Indien niet, dan moet [e] een [e], de [o] een [o], of de [ø] een [ø] blijven. We zouden dus voor ieder keer dat een [e] wordt gevolgd door een [ə] moeten
| |
| |
controleren wat ermee bedoeld wordt. Veel informanten zullen echter niet meer in leven zijn, en bovendien is het, gezien het grote aantal dialecten, voor ons ondoenlijk. We hebben er daarom voor gekozen om alle [ɪ]'s te vervangen door [e]'s, alle [ʊ]'s te vervangen door [o]'s, en alle [ʌ]'s (in IPA: [ʏ]'s) te vervangen door [ø]'s. Id de IPA-klinkerdriehoek liggen de vervangen waarden telkens dicht in de buurt van de hier genoemde vervangers. Toch blijft gelden dat hiermee bepaalde contrasten verloren gaan. We verkiezen dat echter boven de situatie dat contrasten worden geïntroduceerd die zuiver het gevolg zijn van verschil in notatie en geen werkelijk contrast representeren. Wellicht correleert het op deze manier verloren gegane contrast voldoende met één of meer van de overgebleven contrasten die in de data gevonden kunnen worden.
| |
5.2.4 Notatie van de en-syllabe zonder sjwa
Deel 12 werd verzorgd door H. Entjes en A.R. Hol. In de inleiding bespreekt Entjes de verschillen in schrijfwijze tussen mej. Hol en zichzelf. Hij schrijft onder meer:
‘Een tweede verschil tussen de notatie van mej. Hol en die van mij betreft gevallen als kʌnn̩ en kʌnˑ voor Ndl. kunnen. De eerste notatie is die van mej. Hol, de tweede is van mij. Ik zou alleen maar dan kʌnn̩ schrijven, als ik twee maal de klank n waarnam en de tweede n syllabische waarde had. Ik ben tot de notatie kʌnˑ gekomen, omdat ik maar één n en die van langere duur meende te horen. Voor mijn gehoor bestond dus, om een ander voorbeeld te noemen, het verschil tussen kʊm en kʊmˑ voor Ndl. kom en komen alleen maar in lengteverschil van de slot-m. Afgaande op wat ik meende te horen heb ik daarom Ndl. krijgen dus ook genoteerd als kriːgən, kriːgn̩, kriːgŋ, kriːɡŋ of kriːŋ.’
Uit hetgeen Entjes schreef, blijkt dat de en-syllabe waarin de sjwa ontbreekt niet altijd op dezelfde manier wordt genoteerd. Dit is niet altijd het gevolg van verschil in transcribenten. Soms komt het ook voor dat dezelfde transcribent verschillende notaties gebruikt. De en-syllabe zonder sjwa vinden we met name in Vlaanderen (delen 2, 3 en 6), Gelderland (deel 12), Overijssel (delen 12 en 14), Drenthe (delen 14 en 16), Groningen (deel 16) en Friesland (deel 15). Hieronder geven we een overzicht van de gevallen waarin notaties niet altijd hetzelfde zijn en geven daarbij aan hoe we daarmee omgaan bij de verwerking van de data.
| |
Syllabe -en als in Ned. zwemmen
Voor Vlaanderen vinden we voor zwemmen (zin 42) onder andere de volgende transcripties: [zwɛˑmn] (Ronse), [zwæˑmn] (Assenede), [zwæm̩ː] (Damme). De vraag is of de uitgangen [mn], [mn] en [m̩ː] verschillende uitspraken representeren. In het dialect van Zelzate vinden we [zwæˑmn] (zwemmen) en (blʊˑmː] (bloemen). In deel 12 wordt bloemen (zin 2) door Hol genoteerd als [blumn̩] (Spankeren) en door Entjes als [bloːmˑ] (Laren).
| |
| |
| |
Syllabe -en als in Ned. spinnen
Voor Vlaanderen vinden we voor spinnen (zin 3) onder andere de volgende transcripties: [spɪnː] (Damme), [spɪn̩] (Reninge), [spɛn̩ː] (Alveringem). Naast [nː], [n̩] of [n̩ː] vonden we in Vlaanderen nooit [nn] of [nn]. In deel 12 werd stenen (zin 25) door Hol genoteerd als [steˑnn̩] (Spankeren) en door Entjes als [steːnˑ] (Groenlo).
| |
Syllabe -en als in Ned. springen
Voor Vlaanderen vinden we voor springen (zin 47) onder andere de volgende transcripties: [sprɪŋn] (Ronse), [sprɪŋn] (Damme). Voor brengen (zin 39) vinden we onder andere de volgende transcripties: [briŋən] (Brugge), [briŋn] (Oostkamp), [briŋː] (Damme). In het dialect van Damme vinden we [sprɪŋn] en [briŋː]. Het is de vraag of de uitgangen [ŋn] en [ŋː] verschillende uitspraken representeren. In deel 12 wordt brengen (zin 39) door Hol genoteerd als [brɛŋn̩] (Spankeren), en door Entjes als [brɛŋ].
Wanneer verschillende notaties hetzelfde bedoelen te representeren, moeten we bij de verwerking van de data ervoor zorgen dat ze niet als verschillend beschouwd worden. De combinatie klinker+[mn] of klinker+[ŋn] lijkt moeilijk uitspreekbaar. We zouden de notaties voor de en-syllabe kunnen vervangen door respectievelijk [mm] en [ŋŋ], of door respectievelijk [m̘] en [ŋ]. Kiezen we voor [mm] en [ŋŋ], dan moeten we ook [nn] handhaven. We zouden dan een (half)lange en/of syllabische [m], [n] of [ŋ] ook moeten vervangen door [mm], [nn] of [ŋŋ]. Dit is echter riskant omdat het niet altijd duidelijk is of een (half)lange [m], [n] of [ŋ] (half)lang is vanwege een ontbrekende sjwa, of vanwege iets anders. Bijvoorbeeld door de verbinding met het volgende woord worden medeklinkers soms ook lang. In navolging van Entjes kiezen we daarom voor [m̩], [n̩] en [ŋ̩].
Wanneer nu een woord eindigt op [mn],[mn̩], [mn] of [mn̩], vervangen we dat bij verwerking door [m̩]. Wanneer een woord eindigt op [nn], [nn̩], [nn] of [nn̩], vervangen we dat door [n̩]. Wanneer een woord eindigt op [ŋn], [ŋn̩], [ŋn] of [ŋn̩], vervangen we dat door [ŋ]. De overige diacritische tekens van het eerste of tweede element laten we weg. Wanneer het tweede element een [m] (na [m]) of [ŋ] (na [ŋ]) zou zijn, volgen we een vergelijkbare aanpak als hierboven voor de n als tweede element gegeven is.
| |
Syllabe -en als in Ned. geroepen
Voor Vlaanderen vinden we voor geroepen (zin 35) onder andere de volgende transcripties: [gəroˑpn] (Ronse), [gəruˑpn] (Bottelare), [g̘əro̞p̬m̩] (Damme), [gəroˑpm] (Oostkamp). In deel 12 wordt dopen (zin 137) door Hol genoteerd als [døːpn̩] (Spankeren) en door Entjes als [døːpm̩] (Groenlo).
| |
| |
| |
Syllabe -en als in Ned. hebben
Voor Vlaanderen konden we de combinaties [bn] en/of [bn] niet vinden. In deel 12 wordt hebben (zin 106) door Hol genoteerd als [hɛbn̩] (Spankeren). In de dialecten die door Entjes zijn getranscribeerd konden we de combinatie [bm] niet vinden. In deel 16 vinden we als transcriptie: [hɛbm̩] (Bellingwolde).
| |
Syllabe -en als in Ned. bakken
Voor Vlaanderen vinden we voor bakken (zin 113) onder andere de volgende transcripties: [baˑkn] (Nukerke), [bɑkŋ] (Alveringem). In deel 12 wordt bakken (zin 113) door Hol genoteerd als [bɑ̝kn̩] (Spankeren) en door Entjes als [bɑk̬ŋ] (Laren).
| |
Syllabe -en als in Duits. geschlagen
De combinatie [ɡn] vonden we alleen in Dokkum en Peize. Voor Dokkum wordt geslagen (zin 131) genoteerd als [slɑ̙ˑɡn̩]. Voor Peize wordt kregen (zin 5) genoteerd als [kreˑɡn̩]. De combinatie [ɡŋ] vonden we onder andere in Schoonebeek en Bedum. Voor Schoonebeek wordt geslagen (zin 131) genoteerd als [sla̙ːɡŋ]. Voor Bedum wordt kregen (zin 5) genoteerd als [kreˑɡŋ].
Het komt ons, in navolging van Entjes, voor, dat na [p] en [b] een [m] en geen [n] moet volgen, en dat na [k] en [ɡ] een [ŋ] en geen [n] moet volgen (zie ook Wörterbuch der deutschen Aussprache, 1996). Bij verwerking van de data vervangen we daarom [pn̩] door [pm̩], [bn̩] door [bm̩], [kn̩] door [kŋ] en [ɡn̩] door [ɡŋ]. De diacritsche tekens van beide elementen laten we ongewijzigd.
| |
5.3 Omzetting naar ASCII
De teksten in de RND zijn weergegeven in een IPA-achtige notatie. Blancquaert nam het IPA als uitgangspunt en paste dit, tot zover naar zijn oordeel noodzakelijk, aan het Nederlands aan. Uit iedere dialecttekst selecteerden we de transcripties van de vertalingen van steeds dezelfde woorden. De keuze van de dialecten bespraken we in hoofdstuk 2, en de keuze van de woorden bespraken we in hoofdstuk 3.
Om de transcripties te kunnen verwerken door de computer, moeten die gedigitaliseerd worden. De programmatuur die wij gebruiken begrijpt alleen tekens uit de zogenaamde ASCII-set, een verzameling van 128 basistekens. Voor ieder fonetisch teken kiezen we nu een ASCII-teken dat in de computerbestanden dat fonetisch teken representeert. In de tabellen 4, 5 en 6 wordt voor respectievelijk de vocalen, consonanten en diacritische tekens aangegeven door welk ASCII-symbool een RND-symbool gerepresenteerd wordt.
Het gebruik van schrijfletters in enkele delen van de RND leidt soms tot het gebruik van tekens die we om technische redenen in de tabellen 4, 5 en 6 niet kunnen afdrukken. Het betreft de [æ] die soms als schrijfletter [x] wordt weergegeven, de [a] die soms wordt weergegeven als een [ɛ] en een [L] aan elkaar vast, de [y] die als schrijfletter [y] wordt weergegeven, de [t] die als schrijfletter [t] wordt weergegeven, de
| |
| |
[r] die als schrijfletter [r] wordt weergegeven, de [v] die ook als schrijfletter als [v] wordt weergegeven (dus zoals bij een drukletter), de [υ] die als schrijfletter [v] wordt weergegeven (dus enigszins rond), de [ʒ] die wordt weergegeven als schrijfletter [z] en schrijfletter [j] aan elkaar vast.
Diacritische tekens hebben meestal betrekking op precies één segment. Bij codering worden de codes voor de diacritische tekens achter de code van de klank van het betreffende segment geplaatst. Aan de volgorde waarin de diacritische tekens in de bestanden gegeven zijn kan geen betekenis worden ontleend. De enige diacritsche tekens die soms ook betrekking kunnen hebben op twee segmenten, zijn die voor de sleeptoon en de stoottoon. Wanneer een sleeptoon of stoottoon betrekking heeft op een tweeklank, is bij codering de ^ of \ alleen achter het eerste segment geplaatst. In de RND-teksten wordt voor de sleeptoon gewoonlijk de ^ gebruikt. Echter in deel 8 wordt in een deel van de teksten de sleeptoon weergegeven door de één- of tweeklank waar die betrekking op heeft, te onderstrepen.
Tekens in superschrift weergegeven in handgeschreven teksten, of tekens kleiner weergegeven of met een schuin streepje er dwars doorheen of erboven in getypte teksten, of tekens kleiner weergegeven in gedrukte teksten worden in het gecodeerde materiaal gevolgd door een 9. Bij het coderen hebben we ook de ‘aanvulling bij de teksten’ (deel 1), ‘verbeteringen en aanvullingen’ (deel 2), ‘errata’ (deel 6, 7, 8, 10, 11 en 13), ‘corrigenda’ (deel 9) en ‘verbeteringen en toevoegingen’ (deel 12, 14 en 16) verwerkt.
| |
6. Opzoeken van de woorden
6.1 Ontbreken van een vertaling
Bij het opzoeken van de woorden in de 141 zinnen bleek dat soms een vertaling voor een woord ontbrak. Hieronder worden de oorzaken gegeven voor het ontbreken van een vertaling voor een woord.
| 1. |
Het woord is niet opgevraagd. Dit komt vaak voor als het woord deel uitmaakt van opsommingen van woorden en/of uitdrukkingen. |
| |
| 2. |
Doordat de zin heel vrij is vertaald, bevat deze geen vertaling voor het woord. |
| |
| |
Voorbeeld zin 90: |
| |
Nederlands: |
Zijn liedje was kort maar toch goed |
| |
Dialect: |
Hij heeft niet lang gezongen, maar het was wel mooi |
| 3. |
Doordat de zin heel vrij is vertaald, bevat deze een morfologisch andere vorm van het woord. |
| |
| |
Voorbeeld zin 47: |
| |
| |
Nederlands: |
Ze springen om het verst voor een weddenschap. |
| |
dialect: |
Ze hebben gewed wie het verste springen kan. |
| |
| |
| 4. |
Het gebruik van het woord is voor de betekenis van de zin onnodig en wordt in het betreffende dialect gewoonlijk weggelaten. |
| |
| |
Voorbeeld zin 10: |
| |
| |
Nederlands: |
Baas, tap ons vier glazen bier. |
| |
dialect: |
Baas, vier bier alstublieft! |
| |
| 5. |
Het woord is niet bekend omdat het specifiek is voor een bepaalde religie, cultuur of beroepstak. Er wordt een vertaling gegeven die niet synoniem is met het woord. |
| |
| |
Voorbeeld zin 15: |
| |
| |
Nederlands: |
Vastenavond wordt niet veel meer gevierd. |
| |
dialect: |
Sinterklaas wordt niet veel meer gevierd. |
| |
| 6. |
Het woord is niet bekend in de streek waar het dialect gesproken wordt. Bijvoorbeeld in deel 16 (Groningen en Noord-Drenthe) luidt zin 24: ‘Hij heeft ooit eens een beet (v.e. hond) gekregen’. Echter nergens in deel 16 vinden we het woordje ooit terug. In het gebied van dit atlasdeel was het gebruik van ooit in niet-polaire betekenis destijds niet bekend (Hoeksema, 1999). |
Uit het ontbreken van een woord kan dus niet altijd de conclusie getrokken worden dat het woord in het betreffende dialect echt niet bestaat. We probeerden eerst of een vertaling voor het woord gevonden kon worden in één of meer van de andere zinnen. Indien een vertaling in meerdere zinnen gevonden kon worden, kozen we de vertaling uit de zin die qua context het meest vergelijkbaar was. Dat kan per dialect verschillend zijn. Wanneer ook geen vertaling gevonden kon worden in één van de andere zinnen, werd op de betreffende regel in het bestand een ‘|’ afgedrukt. Wanneer bij verwerking van de data bij een dialect een vertaling voor een woord ontbreekt, wordt dat woord niet in de beschouwing betrokken.
| |
6.2 Meerdere vertalingen
Soms bleek dat voor een woord meerdere vertalingen werden gegeven. Wanneer de vertalingen werden gescheiden door ‘of,’ ‘of ook’ of ‘of’ namen we al die vertalingen over. Soms stond daarbij achter elke vertaling tussen haakjes het nummer/de nummers of de naam/de namen van de zegslieden. Bij verwerking van de data telt een vorm die door meerdere informanten gegeven werd niet zwaarder dan een vorm die door precies één informant gegeven werd.
Wanneer bij een vertaling (soms tussen haakjes) ‘oud’ of ‘verouderd’ was vermeld, namen we die niet over. Echter wanneer bij de ene vorm (soms tussen haakjes) ‘nieuw’ was vermeld, en bij de andere vorm (soms tussen haakjes) ‘oud’ was vermeld, namen we niet alleen de nieuwe, maar ook de oude vorm over. De indruk wordt gewekt dat tegelijkertijd een nieuwe en een oude vorm in omloop waren. Vertalingen waarbij (soms tussen haakjes) ‘ouder’ was vermeld namen we wel over. De indruk wordt gewekt dat de oudere vorm nog steeds gebruikt wordt naast de nieuwe vorm. Vertalingen
| |
| |
waarbij (soms tussen haakjes) ‘nieuwer’ was vermeld namen we wel over. De indruk wordt gewekt dat de nieuwere vorm gebruikt wordt naast de oude vorm. Wanneer bij de ene vorm (soms tussen haakjes) ‘vroeger’ was vermeld,
en bij de andere vorm (soms tussen haakjes) ‘nu’ was vermeld, namen we alleen de vorm van ‘nu’ over. De indruk wordt gewekt dat de vorm van ‘nu’ nu alleen nog maar in omloop is. Wanneer (soms tussen haakjes) ‘opkomend’ is vermeld, namen we ook die vorm over.
Wanneer bij de ene vorm (soms tussen haakjes) ‘in het dorp’ was vermeld, en bij de andere vorm (soms tussen haakjes) ‘bij de boeren’ was vermeld, namen we beide vormen over. Vertalingen waarbij (soms tussen haakjes) ‘plat’ of ‘boers’ was vermeld, namen we niet over. Vertalingen waarbij (soms tussen haakjes) ‘iets ruwer’ of ‘platter’ was vermeld, namen we wel over.
Wanneer (soms tussen haakjes) ‘zeldzaam’ was vermeld, namen we die vorm niet over. Vertalingen die tussen haakjes waren gegeven namen we gewoonlijk niet over. Dit lijken minder gangbare vormen te zijn. Alleen wanneer duidelijk aangegeven was dat de vorm vrij gangbaar is naast, of in plaats gekomen is van de niet tussen haakjes vermelde vorm, kan die vorm respectievelijk naast of in plaats van de niet tussen haakjes vermelde vorm worden gegeven. Wanneer een vorm in de gegeven zin niet gevonden kon worden als gevolg van een vrije vertaling, maar de vorm gegeven was tussen haakjes, namen we die wel over.
Soms werden vormen gegeven tussen enkele of dubbele verticale strepen. Deze namen we gewoonlijk niet over. Het betrof woorden die in de gegeven context niet bij voorkeur worden toegepast, of het gaat om semantisch of lexicaal verwante woorden. Wanneer een vorm tussen enkele of dubbele verticale strepen voorafgegaan werd door ‘ook veel’ namen we die wel over. Wanneer een vorm in de gegeven zin niet gevonden kon worden als gevolg van een vrije vertaling, maar de vorm gegeven was tussen enkele of dubbele verticale strepen, namen we die wel over.
Soms stonden binnen een vertaling één of meer tekens tussen haakjes. We gaven dan alle vormen die we daaruit kunnen afleiden. Bijvoorbeeld: indien ‘veulen’ was vertaald als [føːl(ən)], gaven we zowel [føːl] als [føːlən].
Bij meerdere vertalingen werden die vertalingen op de betreffende regel in het bestand gescheiden door een ‘/’. Bij verwerking van de data hangt het af van de gekozen methode hoe meerdere vertalingen voor hetzelfde woord verwerkt worden.
| |
6.3 Opsplitsen en concateneren van woorden
Soms worden twee opeenvolgende woorden zodanig uitgesproken, dat de laatste klank van het eerste woord tevens de eerste klank van het laatste woord is. Bijvoorbeeld in ‘ik moest ossebloed drinken’ (zin 96) kunnen de laatste twee woorden worden uitgesproken als [ɔsəbludrɪŋkə]. Wanneer beide woorden in de woordenlijst voorkomen, worden ze gecodeerd als [ɔsəblud] respectievelijk [drɪŋkə].
Wanneer niet duidelijk is waar de woordgrens ligt, kijken we naar vergelijkbare woorden in dezelfde dialecttekst, of naar hetzelfde zinsdeel in teksten van dialecten die vlak in de buurt liggen.
Wanneer de vertaling van een item bestaat uit meerdere woorden, worden de woorden niet gescheiden door spaties, maar aan elkaar geschreven. Wanneer bijv. keelpijn (zin 32) wordt vertaald als [pɛˑɪn ɪn də keːl], noteren we [pɛˑɪnɪndəkeːl].
| |
| |
| |
7. Standaardtalen
Ten behoeve van onderzoek naar de relatie tussen dialecten en standaardtalen is het nodig om ook transcripties van de woorden in die standaardtalen te hebben. We maakten transcripties voor het Nederlands en het Duits. Daarbij moet erop gelet worden dat de transcripties van de standaardtalen consistent zijn met de RND-transcripties van de dialecten.
| |
7.1 Nederlands
Voor de Nederlandse transcriptie vormde het Tekstboekje van Blancquaert (1939) de basis. Het fonetisch systeem dat daarin gebruikt wordt is hetzelfde als die in de RND gebruikt wordt, met uitzondering van enkele uitbreidingen die we hieronder noemen. Bij gebruik van dit tekstboekje krijgen we transcripties die consistent zijn met het RND-materiaal, daar Blancquaert een groot aantal delen van de RND geheel of gedeeltelijk verzorgde, en de andere auteurs, op één na, allemaal door Blancquaert waren ingewerkt en allen op vergelijkbare wijze transcribeerden (tenzij door henzelf anders aangegeven).
De woorden uit de woordenlijst werden zoveel mogelijk opgezocht in de teksten in het tekstboekje, en indien de context niet significant verschilde, werd de transcriptie overgenomen. Wanneer een woord niet gevonden kon worden, werd gezocht naar een vergelijkbaar woord en werd aan de hand daarvan de transcriptie bepaald.
Zowel in het tekstboekje als in de RND wordt een [ɔ] die voorgaat aan één van de nasale medeklinkers [m], [n] of [ŋ] genoteerd als [υ] (bv in: <Tom>, <ton>, <tong>). Terwille van de consistentie gebruikten wij in onze woordenlijst dezelfde conventie.
In het textboekje gebruikt Blancquaert alleen de [r], en nooit de [r]. In de RND wordt de [r] echter wel gebruikt. Omdat in het Nederlands beide realisaties zijn toegestaan, wordt voor ieder woord in de woordenlijst waarin één of meer <r>'s voorkomen ook een variant gegeven waarin de <r>'s uitgesproken worden als [r]. Verder transcribeert Blancquaert zowel de labiodentale als de bilabiale <w> als [w]. In de RND-delen 3, 5 en 7 t/m 16 wordt wel onderscheid gemaakt tussen beide consonanten. In onze woordenlijst transcriberen we de <w> aan het begin van een lettergreep als [υ], en de <w> aan het eind van een lettergreep of na de <u> (bijvoorbeeld: <nieuwe>, <duwen>, <brouwer>) als [w]. De [ɣ] wordt genoteerd aan het begin van een lettergreep, en de [x] aan het eind van een letttergreep.
In de teksten van Blancquaert wordt een onderscheid gemaakt tussen [v] and [f], bijvoorbeeld: <vier> is [vi.r] en <fier> is [fi:r]. Het lijkt zo te zijn dat zowel in het tekstboekje als in de RND meestal een [v] wordt getranscribeerd wanneer een <v> is gespeld, en een [f] wordt getranscribeerd wanneer een <f> is gespeld. Bij het beluisteren van nieuwe opnamen die gemaakt werden op basis van de RND-vragenlijst constateerden we dat meestal alleen nog de [f] werd gebruikt, ook daar waar een <v> wordt gespeld. Voor hedendaags standaard Nederlands geldt hetzelfde: zowel de <v> als de <f> worden uitgesproken als een [f]. Echter terwille van de consistentie met het RND-materiaal transcribeerden we <v> als [v], en <f> als [f].
| |
| |
Blancquaert noteert <tj> als [tj], bijvoorbeeld: <tuintjes> is [tœ.yntjəs], <kindje> is [kɪntjə]. Dit is gelijk aan de notatie in de meeste RND-delen. Alleen in deel 16 (Groningen en Noord-Drenthe) wordt <tj> genoteerd als [c]. Wanneer een woord eindigt op de lettergreep <en> (bijvoorbeeld: <komen>, <rozen>, <open>), transcribeert Blancquaert die lettergreep altijd als [ən]. Echter in onze woordenlijst laten we de slot-n steeds weg (bijvoorbeeld: [ko.mə], [ro:zə], [o.pə]). Dit is in overeenstemming met de transcripties die gegeven worden in CELEX en in Paardekooper (1998). Blancquaert gaf niet aan op welke lettergreep de klemtoon valt. Wij deden dat eveneens niet.
| |
7.2 Duits
Voor de Duitse transcripties gebruikten we het Würterbuch der deutschen Aussprache (1969). Bij gebruik van dit woordenboek is het belangrijk om ervan bewust te zijn dat de IPA [ɑ] wordt genoteerd als [a], terwijl IPA [a] wordt genoteerd als [ɑ]. The IPA [υ] wordt genoteerd als [v]. Omdat de RND [ʊ] niet hetzelfde is als de [ʊ] die in dit woordenboek wordt gebruikt, vervingen we de [ʊ] in het woordenboek steeds door [u]. Evenals in de Blancquaert/RND-notatie noteerden we een [ɔ] die voorafgaat aan de [m], [n] of [ŋ] als [ʊ].
In het woordenboek wordt de <r> steeds genoteerd als [r], nooit als [ʀ]. In de RND wordt de [ʀ] echter wel gebruikt. Omdat in het Duits beide realisaties zijn toegestaan, wordt voor ieder woord in de woordenlijst waarin één of meer <r>'s voorkomen ook een variant gegeven waarin de <r>'s uitgesproken worden als [ʀ]. In de RND wordt de [ç], ook aangeduid als ‘de zachte g’, niet gebruikt, hoewel men deze zou verwachten in de transcripties van Brabantse en Limburgse dialecten. In plaats daarvan werd de [x] gebruikt. Om het materiaal consistent te houden, noteerden wij eveneens de [x] waar de [ç] wordt uitgesproken en was gegeven in het woordenboek. In het woordenboek wordt de [ɤ] niet gebruikt. Verder gebruikt het woordenboek alleen de [f]. De [v] representeert de labiodentale approximant die gewoonlijk in Nederlandse transcripties genoteerd wordt als [υ].
In het woordenboek worden drie diftongen genoemd: <au> getranscribeerd als [ao], <eu> of <äu> getranscribeerd als [ɔø], en <ei> of <ai> getranscribeerd as [ae]. Onder de beide segmenten wordt een boogje afgedrukt. Echter, deze notatie is niet consistent met die van de RND. Volgens het woordenboek is de <ou> in het Nederlandse <Gouda>, <Oosterhout> en <brouwer> gelijk aan de Duitse <au>. Derhalve gebruiken we de Blancquaert/RND notatie voor de Duitse <au>: [ɔ.u]. Sommige mensen zijn echter van mening dat de Duitse <au> meer open is dan de Nederlandse <ou> of <au>. De Duitse <eu> of <äu> is gelijk aan de Nederlandse <oi> als in <spoiler>. We noteerden deze diftong als [ɔ.i]. The Duitse <ei> of <ai> is gelijk aan de Nederlandse <ai> als in <mais>. We noteerden deze diftong als [ɑ.i].
Volgens Koenraads (1967), die dezelfde notatie gebruikt als die in het Wörterbuch der deutschen Aussprache, zijn Duitse diftongen dalende diftongen. Het eerste
| |
| |
segment wordt sterker beklemtoond dan het tweede segment. In het tekstboekje van Blancquaert en in de RND wordt dit aangegeven door het eerste element halflang te noteren, en het tweede element te noteren als zijnde een klank die minder sterk wordt gehoord. Om consistentie te waarborgen noteerden we de Duitse diftongen op dezelfde manier.
In het woordenboek wordt aangegeven dat bij woorden die eindigen op <en> of <em> de [ə] mag worden weggelaten na [f], [υ], [s], [z], [ʃ], [ʒ], [ç], [x], [pf] en [ts] in bepaalde situaties (bij hoge spreeksnelheden, in bepaalde fonogische omgevingen). Echter in de diminutieve uitgang <chen> moet de [ə] altijd worden uitgesproken. In onze transcripties geven we voor de betreffende woorden na [f], [υ], [s], [z], [ʃ], [ʒ], [ç], [x], [pf] of [ts] een tweede variant waarin de [ə] is vervangen door [n̩].
In woorden die eindigen op <en> mag de [ə] worden weggelaten na [p], [b], [t], [d], [k] en [g]. Dat is niet toegestaan bij de uitgangen <igen> en <em>. In slot-lettergreep-accumulaties (bijvoorbeeld <rettenden>) mag alleen in de eerste <en> de [ə] weggelaten worden. In onze transcripties geven we voor de betreffende woorden na [t] of [d] een tweede variant waarin de [ən] vervangen is door [n̩], na [p] of [b] door [m̩], en na [k] of [g] door [ŋ].
In woorden die eindigen op <el> (bijvoorbeeld <Knüppel>) mag de [ə] worden weggelaten, behalve na een klinker of na [g], [l] or [r]. In onze transcripties geven we voor de betreffende woorden een tweede variant waarin de [əl] is vervangen door [l̩].
In woorden die eindigen op <er> (bijvoorbeeld <Lehrer>) moet de <er> uitgesproken worden als een mid-vocaal. We transcriberen die lettergreep als [ə̞]. In woorden die eindigen op <r> waarbij de <r> voorafgegaan wordt door een lange vocaal (bijvoorbeeld <vier>), moet de <r> uitgesproken worden als een donkere midvocaal. We transcriberen in dat geval de <r> als [ə]. In woorden met één van de voorvoegsels <er>, <her>, <ver> or <zer> (bijvoorbeeld <Versuch>) moet de <r> worden uitgesproken als een donkere mid-vocaal. We zouden de <r> dan transcriberen als [ə]. Echter in onze woordenlijst komen zulke woorden niet voor.
| |
8. Slot
In Na meer dan 25 jaar Dialect-onderzoek op het Terrein schrijft Blancquaert:
‘Geplaatst voor het dilemma, onzen tijd vóór alles te besteden aan het dringend werk van de materiaalverzameling, ofwel ook al eens stil te blijven staan bij onmiddellijk te bereiken, maar nog steeds partiële resultaten, hebben wij de eerste gedragslijn verkozen al weten wij ook dat er méér geschitterd kan worden door het volgen van de tweede. Voor ons heeft namelijk het persoonlijk succes minder belang dan de voortgang van de gemeenschappelijke taak: de beoefening van de Nederlandse Taalkunde-in-optimale voorwaarden. En mogen wij dan ook maar wat werken voor “de naneef”, zoals van Ginneken het (l.c.) heeft geformuleerd, dan vinden wij dit reeds eervol genoeg. Wij menen in geweten te moeten doen wat het meest dringend is, zij het dan ook voor ons persoonlijk het minst lonend.’ (1948: 13)
| |
| |
Jo Daan (1976, blz. 199) schrijft onder meer:
‘Het is jammer dat Blancquaert niet meer geweten heeft met hoeveel vrucht zijn atlassen gebruikt worden, het is gelukkig dat zijn medewerker en opvolger, die met zo mogelijk nog groter hardnekkigheid de voltooiing heeft nagestreefd, het wel weet.’
We zijn blij over het omvangrijke materiaal van de RND te kunnen beschikken en hiervan een relatief klein gedeelte in digitale vorm beschikbaar te kunnen stellen. Moge hierdoor het vruchtbaar gebruik door de ‘naneven’ nog fors toenemen.
| |
Erkenning
Wij danken Jo Daan, Arjen Versloot (Friesland), Siebren Dyk (Friesland), dhr. G.H. Kocks (Drenthe), Jacques van Keymeulen (Frans-, West-, Oost- en Zeeuws-Vlaanderen) en Joep Kruijsen (Brabant en Limburg) voor hun waardevolle adviezen tijdens de selectie van de dialectplaatsen. Wij danken Saakje van Dellen, Rogier Nieuweboer en Marcus Bergman voor het monnikenwerk dat zij verricht hebben, namelijk het digitaliseren van de transcripties. Wij danken Marcus Bergman voor de controle van de transcripties van woorden uit de opnamen van de dialecten van Hoogkerk en Zandeweer. Wij danken Rogier Nieuweboer voor de transcriptie van de woordenlijst in het Plautdietsch. Wij danken Jo Daan voor kopieën van enkele pagina's uit het Tekstboekje van Blancquaert (1939). Wij danken Peter Kleiweg voor het beschikbaar stellen van zijn cartografische programma's en Frits Steenhuisen voor het aanleveren van coördinaten.
| |
Literatuur
Blancquaert, E.
[1925] |
Dialect-atlas van Klein-Brabant, De Sikkel, Antwerpen. |
| [1935] |
Dialect-atlas van Noord-Oost-Vlaanderen en Zeeuwsch-Vlaanderen (Reeks Nederlandsche Dialect-atlassen, deel 3), De Sikkel, Antwerpen. |
| 1939 |
Tekstboekje, 2e druk (Nederlandse Fonoplaten van Blancquaert en van der Plaetse, Eerste Reeks), De Sikkel, Antwerpen. |
Blancquaert, E, P.J. Meertens
[1939] |
Dialect-atlas van de Zeeuwsche eilanden (Reeks Nederlandsche Dialect-atlassen, deel 5), De Sikkel, Antwerpen. |
Blancquaert, E.
1948 |
Na meer dan 25 jaar Dialect-onderzoek op het Terrein. Koninklijke Vlaamse Academie voor Taal en Letterkunde, Reeks III, nr. 28, Drukkerij George Michiels N.V., Tongeren. |
Blancquaert. E., J.C. Claessens, W. Goffin, A. Stevens
1962 |
Dialektatlas van Belgisch-Limburg en Zuid Nederlands-Limburg (Reeks Nederlandse Dialektatlassen, deel 8), De Sikkel, Antwerpen. |
| |
| |
Breuker, P.
1993 |
Normaspecten fan it hjoeddeiske Frysk, proefschrift Rijksuniversiteit Groningen, Stichting FFYRUG, Groningen. |
Boelens, K., G. van der Woude m.m.v. K. Fokkema en E. Blancquaert
1955 |
Dialect-atlas van Friesland (Nederlandse en Friese dialecten) (Reeks Nederlandse Dialect-atlassen, deel 15), De Sikkel, Antwerpen. |
Daan, Jo
1969 |
Dialektatlas van Noord-Holland (Reeks Nederlandse Dialektatlassen, deel 13), De Sikkel, Antwerpen. |
| 1976 |
‘De RND en de ANKO’, in: Taal en Tongval 28, 192-199. |
Entjes, H.
1982 |
Dialektatlas van Zuid-Drenthe en Noord-Overijsel (Reeks Nederlandse Dialektatlassen, deel 14), De Sikkel, Antwerpen. |
Entjes, H., A.R. Hol
1973 |
Dialektatlas van Gelderland en Zuid-Overijssel (Reeks Nederlandse Dialektatlassen, deel 12), De Sikkel, Antwerpen. |
Heeringa, W., J. Nerbonne, H. Niebaum, R. Nieuweboer, P. Kleiweg
2000 |
‘Dutch-German Contact in and around Bentheim’, in: D.G. Gilbers, J. Nerbonne, J. Schaeken (eds.), Languages in Contact (Studies in Slavic and General Linguistics), Amsterdam en Atlanta, Rodopi, 145-156. |
Hoeksema, J.
1999 |
‘Aantekeningen bij ooit, deel 2: de opkomst van niet-polair ooit’, in: TABU 29-4, 147-172. |
Hol, A.R. en J. Passage
1966 |
Dialectatlas van Oost-Noord-Brabant[,] de Rivierenstreek en Noord-Nederlands-Limburg (Reeks Nederlandse Dialektatlassen, deel 10), De Sikkel, Antwerpen. |
Hoppenbrouwers, C. en G. Hoppenbrouwers
1988 |
‘De featurefrequentiemethode en de classificatie van Nederlandse dialecten’, in: TABU 18-2, 51-92. |
Koenraads, W.H.A.
1967 |
Deutsche Laut- und Aussprachlehre für Niederländer. P. Noordhoff, Groningen. |
Oyen, L. m.m.v. E. Blancquaert† en Chr.J. Voet
1968 |
Dialektatlas van Zuid-Holland en Utrecht (Reeks Nederlandse Dialektatlassen, deel 11), De Sikkel, Antwerpen. |
Paardekooper, P.C.
1998 |
ABN-uitspraakgids, 3e druk, Sdu Uitgevers, Den Haag. |
Pée, Willem, m.m.v. E. Blancquaert
1946 |
Dialect-atlas van West-Vlaanderen en Fransch-Vlaanderen (Reeks Nederlandsche Dialect-atlassen, deel 6), De Sikkel, Antwerpen. |
Pée, Willem
1958 |
Dialektatlas van Antwerpen (Reeks Nederlandse Dialektatlassen, deel 7), De Sikkel, Antwerpen. |
Pebesma, H. en A. Zantema
1994 |
Van Goors' klein Fries woordenboek: Nederlands-Fries en Fries-Nederlands, 7e druk, Ljouwert: afûk, Elsevier, Amsterdam. |
| |
| |
Sassen, A.
1967 |
Dialektatlas van Groningen en Noord-Drenthe (Reeks Nederlandse Dialektatlassen, deel 16), De Sikkel, Antwerpen. |
Vangassen, H.
[1930] |
Dialect-atlas van Zuid-Oost-Vlaanderen (Reeks Nederlandsche Dialect-atlassen, deel 2), De Sikkel, Antwerpen. |
| [1938] |
Dialect-atlas van Vlaamsch-Brabant (Reeks Nederlandsche Dialect-atlassen, deel 4), De Sikkel, [Antwerpen]. |
Weijnen, A.
1952 |
Dialect-atlas van Noord-Brabant (Reeks Nederlandse Dialect-atlassen, deel 9), De Sikkel, Antwerpen. |
Wörterbuch der deutschen Aussprache
1969 |
Wörterbuch der deutschen Aussprache. München: Max Hueber Verlag. |
| |
| |
| |
Appendix
Tabel 1.
Overzicht van de gedigitaliseerde dialecten. Dialecten waarvan de naam voorafgegaan wordt door een * worden verwerkt als taaleilanden. Donkerbroek 1, Tjalleberd 1 en *Appelscha 2 zijn Friese varianten, en *Donkerbroek 2, *Tjalleberd 2 en Appelscha 1 zijn Saksische varianten. Voor dialecten met een ! zijn 166, en voor dialecten zonder ! zijn 125 woorden gedigitaliseerd. In de kolom ‘Deel’ wordt voor ieder dialect aangegeven in welk deel van de RND de dialecttekst gevonden kan worden. Als het deelnummer wordt gevolgd door een *, komt het dialect ook voor in de FAND.
| Code |
Plaats |
Deel |
| A 001 |
*Midsland |
15* ! |
| A 002 |
West-Terschel. |
15* ! |
| A 003 |
Oost-Vlieland |
13 ! |
| A 008 |
Den Burg |
13 ! |
| B 001a |
Hollum |
15* ! |
| B 002 |
Nes |
15 ! |
| B 004 |
Schiermonnikoog |
15* ! |
| B 006 |
Oosterend |
15 |
| B 007 |
Ferwerd |
15 ! |
| B 009 |
Holwerd |
15* ! |
| B 013b |
Anjum |
15* |
| B 017 |
Zoutkamp |
15* ! |
| B 019 |
St. Annaparochie |
15* |
| B 023 |
Hallum |
15* |
| B 024 |
Stiens |
15 ! |
| B 030 |
*Dokkum |
15* ! |
| B 034b |
Westergeest |
15* |
| B 035 |
*Kollum |
15 ! |
| B 042 |
Grijpskerk |
15* |
| B 043 |
Sexbierum |
15* ! |
| B 045 |
*Harlingen |
15* ! |
| B 048 |
*Franeker |
15* ! |
| B 056 |
*Leeuwarden |
15* ! |
| B 058 |
Tietjerk |
15* |
| B 060 |
Veenwouden |
15* |
| B 062 |
Bergum |
15 ! |
| B 068 |
Surhuisterveen |
15 ! |
| B 082 |
Spannum |
15* |
| B 094 |
Grouw |
15* ! |
| B 096 |
Oudega |
15* |
| B 098 |
Rottevalle |
15* |
| B 100 |
Ureterp |
15 ! |
| B 101 |
Marum |
15* |
| B 106 |
Makkum |
15* ! |
| B 110 |
*Bolsward |
15* ! |
| B 112 |
*Sneek |
15* ! |
| B 114 |
IJlst |
15* |
| B 123a |
Beets |
15 |
| B 127 |
Bakkeveen |
15* |
| B 130 |
1 Donkerbroek 1 |
15 |
| B 130 |
2 *Donkerbroek 2 |
15 |
| C 001a |
Roodeschool |
16* ! |
| C 026 |
Eenrum |
16* |
| C 037 |
Zandeweer |
! |
| C 043 |
Bierum |
16 ! |
| C 070 |
Bedum |
16 ! |
| C 074 |
Stedum |
16* |
| C 085 |
Wagenborgen |
16* |
| C 100 |
Niekerk |
16 |
| C 107 |
Hoogkerk |
! |
| C 108 |
Groningen |
16 ! |
| C 128 |
Scheemda |
16* |
| C 147 |
Peize |
16 |
| C 149 |
Eelde |
16* |
| C 152 |
Hoogezand |
16 ! |
| C 159 |
Veendam |
16* |
| C 161 |
Winschoten |
16 ! |
| C 165 |
Bellingwolde |
16* |
| C 176 |
Norg |
16* ! |
| C 184 |
Eext |
16* |
| C 189 |
Stadskanaal |
16* ! |
| D 006 |
Wateringen |
11* |
| E 003a |
Den Oever |
13* ! |
| E 009 |
Schagen |
13* ! |
| E 014a |
Opperdoes |
13* |
| E 028a |
Heerhugowaard |
13 ! |
| E 040 |
Enkhuizen |
13* |
| E 041 |
Egmond aan Zee |
13* |
| E 058 |
Hoorn |
13* |
| E 066 |
Heemskerk |
13 ! |
| E 069 |
De Rijp |
13* |
| E 085 |
Koog aan de Zaan |
13 |
| E 091b |
Volendam |
13* |
| E 092 |
Monnickenwerf |
13* |
| E 097 |
Haarlem |
13 ! |
| E 117 |
Aalsmeer |
11* |
| E 127 |
Huizen |
11* ! |
| E 133 |
*Katwijk aan Zee |
11* |
| E 138a |
Warmond |
11 |
| E 142a |
Langeraar |
11 |
| |
| |
| Code |
Plaats |
Deel |
| E 144 |
Nieuwveen |
11 ! |
| E 155 |
Loenen |
11* |
| E 164 |
Soest |
11 ! |
| E 173 |
Koudekerk |
11* |
| E 192 |
Utrecht |
11* |
| E 198 |
Delft |
11 ! |
| E 200 |
Zoetermeer |
11* ! |
| E 215 |
Oudewater |
11* |
| E 225 |
Vreeswijk |
11* |
| E 233 |
Driebergen |
11 |
| F 001 |
Workum |
15* |
| F 002 |
*Hindeloopen |
15* |
| F 004 |
Langweer |
15 ! |
| F 010 |
1 Tjalleberd 1 |
15 |
| F 010 |
2 *Tjalleberd 2 |
15 |
| F 013 |
*Heerenveen |
15 ! |
| F 017 |
Oudeschoot |
15* |
| F 020 |
Jubbega |
15* |
| F 026 |
*Staveren |
15* |
| F 028 |
Koudum |
15* |
| F 038 |
Lemmer |
15* |
| F 047 |
Noordwolde |
15* |
| F 052 |
Kuinder |
14* |
| F 056 |
Oldemarkt |
14* |
| F 060 |
Steenwijk |
14* ! |
| F 066 |
Vollenhove |
14* |
| F 076 |
Koekange |
14* |
| F 077 |
Urk |
14* |
| F 085 |
Hasselt |
14* |
| F 086 |
Rouveen |
14* |
| F 087 |
Staphorst |
14 |
| F 089 |
IJsselmuiden |
14* |
| F 090 |
Kampen |
14* ! |
| F 095 |
Zalk |
14* |
| F 098 |
Dalfsen |
14* |
| F 102 |
Oldebroek |
14 |
| F 103 |
Hattem |
14* |
| F 111 |
Nunspeet |
12* |
| F 119 |
Wijhe |
12* ! |
| F 121 |
Spakenburg |
12* |
| F 124 |
Putten |
12* ! |
| F 129 |
Vaassen |
12* ! |
| F 138 |
Batmen |
12* |
| F 156 |
Wilp |
12* |
| F 165 |
Amersfoort |
12* |
| F 169 |
Woudenberg |
12* |
| F 170 |
Barneveld |
12* |
| F 173 |
Hoenderlo |
12* |
| F 187 |
Doorn |
11 |
| F 191 |
Veenendaal |
12* ! |
| F 199 |
Spankeren |
12 ! |
| F 200 |
Dieren |
12* |
| F0205 |
Bronkhorst |
12* |
| G 001b |
1 Appelscha 1 |
15* |
| G 001b |
2 *Appelscha 2 |
15* |
| G 004 |
Assen |
16 ! |
| G 008 |
Grolloo |
16 |
| G 015a |
Wessingtange |
16 ! |
| G 024 |
Dwingelo |
16* |
| G 028 |
Beilen |
16 |
| G 031 |
Orvelte |
16 |
| G 034 |
Odoorn |
16 |
| G 039 |
Roswinkel |
16* ! |
| G 048 |
Ruinen |
14* ! |
| G 058 |
Emmen |
14 ! |
| G 060 |
Zuidbarge |
14* |
| G 076 |
Hollandseveld |
14* |
| G 077 |
Zwinderen |
14* |
| G 081 |
Schoonebeek |
14* |
| G 091 |
Dedemsvaart |
14* |
| G 094 |
Gramsbergen |
14 |
| G 095 |
Coevorden |
14* |
| G 099 |
Emlichheim |
14 |
| G 100 |
Hoogstede |
14 ! |
| G 102 |
Nw. Schoonebeek |
14* |
| G 112 |
Ommen |
14 ! |
| G 113 |
Hardenberg |
14* ! |
| G 115 |
Bergentheim |
14* |
| G 118 |
Radewijk |
14 |
| G 119 |
Itterbeck |
14 |
| G 120 |
Wilsum |
14 |
| G 138 |
Lemele |
14* ! |
| G 143a |
Langeveen |
14 |
| G 143* |
Vasse |
14 |
| G 145 |
Uelsen |
14 |
| G 147 |
Neuenhaus |
14 |
| G 150 |
Lage |
14 |
| G 153 |
Lattrop |
14 |
| G 161 |
Nordhorn |
14 ! |
| G 171 |
Vriezenveen |
12* |
| G 172 |
Wierden |
12* |
| G 173 |
Almelo |
12 ! |
| G 174 |
Tubbergen |
12* |
| G 177 |
Ootmarsum |
12* |
| G 177b |
Tilligte |
12* |
| G 197 |
Rijssen |
12* |
| G 203 |
Delden |
12* |
| G 204 |
Hengelo |
12 ! |
| G 207 |
Oldenzaal |
12* |
| G 221 |
Laren |
12* ! |
| |
| |
| Code |
Plaats |
Deel |
| G 233 |
Usselo |
12* |
| G 246 |
Lochem |
12* |
| G 255 |
Eibergen |
12* |
| G 257 |
Haaksbergen |
12* |
| G 278 |
Zelhem |
12* |
| G 280 |
Groenlo |
12* |
| H 003 |
Blankenberge |
6* |
| H 014 |
Damme |
6 ! |
| H 015 |
Middelkerke |
6 |
| H 016 |
Oostende |
6* |
| H 036 |
Brugge |
6* |
| H 054 |
Gistel |
6* |
| H 062 |
Bekegem |
6 ! |
| H 069 |
Oostkamp |
6* |
| H 084 |
Veurne |
6* |
| H 097 |
Oostkerke |
6 |
| H 100 |
Alveringem |
6 ! |
| H 119 |
Wingene |
6* |
| I 009 |
Brielle |
11* |
| I 025 |
Middelharnis |
5* |
| I 030 |
Renesse |
5 ! |
| I 049 |
Zierikzee |
5* ! |
| I 057 |
Steenbergen |
5* |
| I 058 |
Westkapelle |
5* |
| I 069 |
Goes |
5* |
| I 081 |
Middelburg |
5* ! |
| I 096 |
Kapelle |
5 ! |
| I 108 |
Breskens |
3* ! |
| I 116b |
Lamswaarde |
3 ! |
| I 116d |
Groenendijk |
3 |
| I 118 |
Ossendrecht |
3* |
| I 119 |
Zandvliet |
3* |
| I 144 |
Clinge |
3 |
| I 147 |
Kieldrecht |
3 ! |
| I 152 |
Moerkerke |
3* |
| I 161 |
Assenede |
3* |
| I 165 |
Zelzate |
3 ! |
| I 170 |
Moerbeke |
3* |
| I 178 |
Beveren |
3* |
| I 192 |
Zomergem |
3* |
| I 203 |
Lochristi |
3* |
| I 221 |
Hingene |
1 |
| I 241 |
Gent |
3* |
| I 252 |
Kalken |
3* |
| I 264a |
Lebbeke |
1 ! |
| I 270 |
Lippelo |
1 ! |
| I 273 |
Buggenhout |
1* |
| K 008 |
Berkel |
11* |
| K 021 |
Polsbroek |
11 ! |
| K 030 |
Vianen |
11 ! |
| K 054 |
Lekkerkerk |
9* |
| K 078 |
Deil |
9* |
| K 087 |
Klaaswaal |
9* ! |
| K 094a |
Papendrecht |
9* |
| K 098 |
Hardinxveld |
9* |
| K 101 |
Almkerk |
9* ! |
| K 128 |
Dussen |
9 ! |
| K 133a |
Drongelen |
9 ! |
| K 152 |
Fijnaart |
9* |
| K 155 |
Zevenbergen |
9* |
| K 157 |
Oudenbosch |
9 |
| K 163 |
Dongen |
9* |
| K 164 |
Loon op Zand |
9* |
| K 174 |
Roosendaal |
9* ! |
| K 184 |
Goirle |
9* ! |
| K 187 |
Oirschot |
9* |
| K 189 |
Essen |
7* |
| K 190 |
Zundert |
7* |
| K 201 |
Kalmthout |
7* |
| K 210 |
Rijkevorsel |
7* |
| K 237a |
Zevendonk |
7 ! |
| K 239 |
Gierle |
7* |
| K 240 |
Arendonk |
7* |
| K 253 |
Wijnegem |
7 ! |
| K 257 |
Oelegem |
7* |
| K 277 |
Balen |
7* |
| K 287 |
Boom |
7* |
| K 299 |
Itegem |
7* |
| K 307 |
Geel |
7* ! |
| K 312 |
Meerhout |
7* |
| K 322 |
Thisselt |
1 |
| K 330 |
Mechelen |
1* ! |
| K 348 |
Herselt |
4* |
| K 361 |
Zolder |
8* |
| L 001 |
Wk. b. Duurstede |
10* |
| L 014 |
Renkum |
10* |
| L 033 |
Zevenaar |
10* |
| L 037 |
Doetinchem |
12* ! |
| L 054 |
Druten |
10* |
| L 063 |
Oosterhout |
10 ! |
| L 084 |
's-Herenberg |
12* |
| L 088 |
Herewaarden |
10* |
| L 102 |
Ravenstein |
10 ! |
| L 119 |
Groesbeek |
10* |
| L 148 |
Den Dungen |
10* |
| L 157 |
Zeeland |
10* |
| L 187a |
Rijkevoort |
10* |
| L 200 |
Sint Oedenrode |
10* |
| L 207 |
Gemert |
10 ! |
| L 208 |
Bakel |
10* |
| |
| |
| Code |
Plaats |
Deel |
| |
| L 210 |
Venray |
10 ! |
| L 214 |
Wanssum |
10* |
| L 237 |
Helmond |
10* ! |
| L 240 |
Geldrop |
10* |
| L 258 |
Riethoven |
10 ! |
| L 265 |
Meiel |
10* |
| L 270 |
Tegelen |
10 ! |
| L 271 |
Venlo |
10* |
| L 285 |
Budel |
8* |
| L 314 |
Overpelt |
8* |
| L 325 |
Horn |
8* |
| L 360 |
Bree |
8* |
| L 369 |
Kinrooi |
8 ! |
| L 381 |
Echt |
8* |
| L 414 |
Houthelen |
8 ! |
| L 428 |
Born |
8 ! |
| L 432 |
Susteren |
8* |
| M 009 |
Aalten |
12* ! |
| M 042 |
Ulft |
12* |
| N 006 |
Warhem |
6* |
| N 026 |
Reninge |
6 ! |
| N 028a |
Houthulst |
6* |
| N 033 |
Gits |
6 ! |
| N 038 |
Roeselare |
6* |
| N 065 |
Woesten |
6* |
| N 078 |
Moorslede |
6* |
| N 108 |
Hondegem |
6* |
| N 141 |
Kortrijk |
6* |
| N 145 |
Bellegem |
6* |
| N 153 |
Steenbeek |
6 ! |
| N 163 |
Nieuwkerke |
6* |
| O 018 |
Nazareth |
2* |
| O 026 |
Bottelare |
2 ! |
| O 061 |
Aalst |
1* |
| O 080 |
Waregem |
6* |
| O 139 |
Heldergem |
2* |
| O 153 |
Hekelgem |
2 ! |
| O 165 |
Wemmel |
4* |
| O 179 |
Zwevegem |
6 |
| O 181 |
Ingooigem |
6 ! |
| O 202 |
Nukerke |
2* |
| O 228 |
Geraardsbergen |
2* ! |
| O 255 |
Lot |
4* |
| O 265 |
Ronse |
2* |
| P 002 |
Humbeek |
1* |
| P 004 |
Grimbergen |
1 ! |
| P 018 |
Kampenhout |
4* |
| P 025 |
Aarschot |
4* |
| P 026 |
Werchter |
4 ! |
| P 041 |
Diest |
4* |
| P 102 |
Boutersem |
4* ! |
| P 133 |
Overijse |
4* |
| P 143a |
Vertrijk |
4 |
| P 145 |
Tienen |
4* ! |
| P 174 |
Ve1m |
4* |
| Q 019 |
Beek |
8 ! |
| Q 020 |
Sittard |
8* |
| Q 071 |
Diepenbeek |
8* |
| Q 099 |
Meerssen |
8* |
| Q 121 |
Kerkrade |
8* ! |
| Q 183 |
Vreren |
8 ! |
| Q 200 |
's-Gravenvoeren |
8* |
| Q 222 |
Vaals |
8* |
| Q 240 |
Lauw |
8* |
| Q 249 |
Aubel |
8 ! |
| Q 263 |
Raeren |
8 ! |
| Q 279 |
Baelen |
8 ! |
| Q 284 |
Eupen |
8 ! |
| b 012 |
Kapelle-Broek |
6 ! |
| b 015 |
Bollezeele |
6* |
| |
Protasovo |
! |
| |
| |
| |
Tabel 2.
Woordenlijst. In de kolom ‘Klasse’ wordt voor ieder woord door middel van een afkorting de woordsoort eengegeven. Hierbij geldt: zn = zelfstandig naamwoord, bn = bijvoeglijk naamwoord, ot = onbepaald telwoord, bt = bepaald telwoord, tt = werkwoord tegenwoordige tijd, vt = werkwoord verleden tijd, vd = voltooid deelwoord, pv = persoonlijk voornaamwoord, bw = bijwoord, vz = voorzetsel ij = interjectie. In de kolom ‘RND’ wordt voor ieder woord het zinnummer in de RND-vragenlijst uit deel 16 vermeld. In de kolom ‘FAND’ wordt voor ieder woord het item- of zinnummer in de FAND-vragenlijst vermeld (indien aanwezig in de FAND).
| Woord |
Klasse |
RND |
FAND |
| kippen |
zn |
1 |
|
| mijn |
pv |
2 |
1779 |
| vriend |
zn |
2 |
689 |
| bloemen |
zn |
2 |
|
| spinnen |
tt |
3 |
|
| machines |
zn |
3 |
|
| werk |
zn |
4 |
700 |
| op |
vz |
5 |
1740 |
| schip |
zn |
5 |
534 |
| kregen |
vt |
5 |
1286 |
| beschimmeld |
bn |
5 |
|
| brood |
zn |
5 |
89 |
| timmerman |
zn |
6 |
|
| splinter |
zn |
6 |
|
| vinger |
zn |
6 |
666 |
| fabriek |
zn |
8 |
|
| vier |
bt |
10 |
1750 |
| bier |
zn |
10 |
49 |
| twee |
bt |
11 |
1746 |
| drie |
bt |
12 |
1721 |
| hij |
pv |
13 |
1536 |
| knuppel |
zn |
13 |
299 |
| ik |
pv |
14 |
1077 |
| knie |
zn |
14 |
296 |
| gezien |
vd |
14 |
1565 |
| ragebol |
zn |
19 |
|
| pet |
zn |
20 |
|
| paddestoel |
zn |
20 |
|
| kerel |
zn |
21 |
271 |
| brede |
bn |
25 |
|
| stenen |
zn |
25 |
583 |
| breder |
bn |
25 |
771 |
| breedste |
bn |
25 |
|
| standbeeld |
zn |
26 |
|
| duivel |
zn |
28 |
139 |
| gebleven |
vd |
28 |
1104 |
| meester |
zn |
29 |
372 |
| zee |
zn |
29 |
726 |
| graag |
bw |
31 |
1725 |
| keelpijn |
zn |
32 |
|
| steel |
zn |
33 |
581 |
| bezem |
zn |
33 |
45 |
| neen |
ij |
34 |
|
| geroepen |
vd |
35 |
1364 |
| peer |
zn |
36 |
988 |
| rijp |
bn |
36 |
886 |
| geld |
zn |
38 |
173 |
| ver |
bn |
39 |
929 |
| brengen |
tt |
39 |
1131 |
| vrouw |
zn |
41 |
|
| zwemmen |
tt |
42 |
1588 |
| sterk |
bn |
43 |
|
| bed |
zn |
45 |
22 |
| optillen |
tt |
45 |
|
| metselaar |
zn |
46 |
|
| springen |
tt |
47 |
1430 |
| boterham |
zn |
51 |
|
| vader |
zn |
53 |
1812 |
| zes |
bt |
53 |
1760 |
| jaar |
zn |
53 |
239 |
| school |
zn |
53 |
540 |
| laten |
tt |
53 |
1304 |
| gaan |
tt |
53 |
1189 |
| water |
zn |
54 |
|
| potten |
zn |
56 |
480 |
| zijn |
tt |
56 |
1597 |
| veel |
ot |
56 |
926 |
| maart |
zn |
58 |
1730 |
| nog |
bw |
58 |
1733 |
| koud |
bn |
58 |
845 |
| kaars |
zn |
59 |
241 |
| geeft |
tt |
59 |
1204 |
| licht |
zn |
59 |
346 |
| paard |
zn |
60 |
431 |
| tegen |
vz |
63 |
1742 |
| zwaluwen |
zn |
64 |
|
| kaas |
zn |
66 |
244 |
| motor |
zn |
67 |
|
| dag |
zn |
68 |
970 |
| avond |
zn |
68 |
13 |
| |
| |
| Woord |
Klasse |
RND |
FAND |
| |
| jongetje |
zn |
69 |
|
| barst |
zn |
70 |
21 |
| brief |
zn |
71 |
82 |
| hart |
zn |
72 |
202 |
| spannen |
tt |
74 |
1416 |
| nieuwe |
bn |
74 |
1020 |
| kar |
zn |
74 |
1020 |
| zoon |
zn |
76 |
743 |
| koning |
zn |
76 |
311 |
| ook |
bw |
76 |
1738 |
| geweest |
vd |
76 |
1599 |
| rozen |
zn |
78 |
|
| lange |
bn |
78 |
970 |
| woord |
zn |
79 |
710 |
| kindje |
zn |
80 |
284 |
| was |
vt |
80 |
1602 |
| dochtertje |
zn |
82 |
120 |
| bos |
zn |
82 |
77 |
| ladder |
zn |
83 |
333 |
| mond |
zn |
86 |
978 |
| droog |
bn |
86 |
784 |
| dorst |
zn |
86 |
129 |
| weg |
zn |
87 |
697 |
| krom |
bn |
87 |
847 |
| liedje |
zn |
90 |
351 |
| goed |
bn |
92 |
806 |
| kelder |
zn |
95 |
270 |
| voor |
vz |
95 |
1753 |
| moest |
vt |
96 |
1338 |
| ossenbloed |
zn |
96 |
|
| drinken |
tt |
96 |
1169 |
| broer |
zn |
98 |
87 |
| moe |
bn |
98 |
867 |
| karnemelk |
zn |
100 |
|
| dun |
bn |
100 |
788 |
| zuur |
bn |
100 |
964 |
| put |
zn |
101 |
484 |
| uur |
zn |
101 |
645 |
| Italie |
zn |
104 |
|
| bergen |
zn |
104 |
|
| vuur |
zn |
104 |
692 |
| spuwen |
tt |
104 |
|
| duwen |
tt |
105 |
1181 |
| hebben |
tt |
106 |
1287 |
| stuk |
zn |
106 |
605 |
| brug |
zn |
106 |
92 |
| veulen |
zn |
107 |
659 |
| komen |
tt |
107 |
1262 |
| deur |
zn |
109 |
110 |
| naaien |
tt |
110 |
|
| gras |
zn |
111 |
186 |
| brouwer |
zn |
112 |
|
| bakken |
tt |
113 |
1075 |
| je |
pv |
116 |
1593 |
| eieren |
zn |
116 |
148 |
| krijgen |
tt |
116 |
1291 |
| markt |
zn |
116 |
|
| waren |
vt |
119 |
1605 |
| vijf |
bt |
119 |
1751 |
| eikels |
zn |
120 |
|
| hooi |
zn |
122 |
226 |
| is |
tt |
122 |
1594 |
| groen |
bn |
122 |
812 |
| boompje |
zn |
124 |
73 |
| wijn |
zn |
125 |
705 |
| huis |
zn |
126 |
1071 |
| melk |
zn |
127 |
374 |
| spuit |
tt |
127 |
1435 |
| koe |
zn |
127 |
300 |
| koster |
zn |
128 |
320 |
| kruiwagen |
zn |
129 |
|
| buigen |
tt |
129 |
1135 |
| Duitsers |
zn |
130 |
|
| blauw |
bn |
131 |
756 |
| geslagen |
vd |
131 |
1394 |
| saus |
zn |
132 |
522 |
| flauw |
bn |
132 |
801 |
| sneeuw |
zn |
133 |
559 |
| stad |
zn |
135 |
|
| doen |
tt |
136 |
1640 |
| dopen |
tt |
137 |
1152 |
| doopvont |
zn |
137 |
|
| soldaten |
zn |
137 |
|
| dorsen |
tt |
138 |
1153 |
| binden |
tt |
139 |
1096 |
| gebonden |
vd |
139 |
|
| |
| |
Tabel 3. Verdeling van de woorden over woordsoorten.
|
| Woordsoort |
125 woorden |
166 woorden |
| |
| Zelfstandig naamwoord |
64 |
95 |
| meervoud |
3 |
12 |
| verkleinvorm |
4 |
5 |
| Bijvoeglijk naamwoord |
15 |
19 |
| vergrotende trap |
1 |
1 |
| overtreffende trap |
0 |
1 |
| Onbepaald telwoord |
1 |
1 |
| Bepaald telwoord |
5 |
5 |
| Werkwoord |
30 |
35 |
| tegenwoordige tijd |
21 |
25 |
| verleden tijd |
4 |
4 |
| voltooid deelwoord |
5 |
6 |
| Persoonlijk voornaamwoord |
4 |
4 |
| Bijwoord |
3 |
3 |
| Voorzetsel |
3 |
3 |
| Interjectie |
0 |
1 |
| |
| |
Tabel 4. Codering vocalen.
|
| RND |
IPA |
ASCII |
als in: |
opmerking |
| |
| i |
i |
i |
Ned. bieden |
|
| ɪ |
ɪ |
I |
Ned. bidden |
|
| eˑ |
eˑ |
e. |
Ned. beek |
|
| eː/ɪˑ |
eː/ɪˑ |
e:/I. |
Ned. zeer |
|
| ɛ |
ɛ |
E |
Ned. bek |
|
| æ |
æ |
Q |
Eng. bad |
|
| aˑ |
aˑ |
a. |
Ned. baak |
|
| ɑ |
ɑ |
A |
Ned. bak |
|
| ɒ |
ɒ |
D |
Eng. law |
|
| ɔ/2 |
ɔ |
) |
Ned. ros |
|
| ʊ |
ʊ |
O |
Ned. Tom/ton/tong |
|
| oˑ |
oˑ |
o. |
Ned. boos |
|
| oː/ʊˑ |
oː/ʊˑ |
o:/O. |
Ned. boor |
|
| u |
u |
u |
Ned. boek |
|
| y |
y |
y |
Ned. nu |
|
| ø/ω |
ø |
0 |
Ned. beuk |
|
| øː/ωː/ʌˑ |
øː |
0:/U. |
Ned. beur |
|
| œ |
œ |
Y |
Ned. freule |
|
| œ |
œ |
Y |
Ned. lui |
eerste lid tweeklank |
| ʌ/Ω |
y |
U |
Ned. bus |
|
| ə |
ə |
@ |
Ned. de |
|
| |
| |
Tabel 5. Codering consonanten.
|
| RND |
IPA |
ASCII |
als in: |
opmerking |
| |
| c |
c |
c |
Ned. rietje |
|
| p |
p |
p |
Ned. paard |
|
| b |
b |
b |
Ned. bal |
|
| t |
t |
t |
Ned. tak |
|
| d |
d |
d |
Ned. dak |
|
| k |
k |
k |
Ned. kar |
|
| g |
g |
K |
Eng. goal |
|
| m |
m |
m |
Ned. maart |
|
| n |
n |
n |
Ned. nacht |
|
| ŋ |
ŋ |
N |
Ned. tingeling |
|
| ɲ |
ɲ |
J |
Ned. oranje |
|
| l |
l |
l |
Ned. les |
|
| r |
r |
r |
Ned. rear |
d.m.v. tongpunt |
| r |
r |
R |
Ned. raar |
d.m.v. huig |
| f |
f |
f |
Ned. fout |
|
| v |
v |
v |
Ned. vat |
|
| υ |
υ |
W |
Ned. water |
labiotendaal |
| w |
w |
w |
Eng. wow |
bilabiaal |
| s |
s |
s |
Ned. som |
|
| z |
z |
z |
Ned. zout |
|
| ʃ |
ʃ |
S |
Ned. kruisje |
|
| ʒ |
ʒ |
Z |
Ned. gelei |
|
| j |
j |
j |
Ned. jaar |
|
| χ/x |
x |
x |
Ned. lachen |
|
| g |
ɣ |
g |
Ned. geven |
|
| g/ɡ/ɡ̂ |
x |
G |
Ned. wasgoed |
stemloze fricatief |
| h |
h |
h |
Ned. hoed |
|
| ʔ |
ʔ |
? |
|
glottisslag |
| |
| |
Tabel 6. Codering diacritische tekens
|
| RND |
positie |
IPA |
ASCII |
betekenis |
| |
| ˑ |
achter klank |
ˑ |
. |
halflang |
| ː |
achterklank |
ː |
: |
lang |
| ˋ |
achter klank |
ʰ |
ˋ |
aspiratie |
| ˌ |
onder klank |
ˌ |
, |
vocalisering waardoor |
| |
l, m, n, ŋ en r vaak |
| |
syllabische waarde |
| |
verkrijgen |
| ⊃ |
achter klank |
˒ |
1 |
ronding van niet-geronde of overronding van geronde |
| ⋺ |
achter klank |
|
2 |
halve ronding |
| ⊂ |
achter klank |
˓ |
3 |
ontronding of minder dan normale ronding van geronde |
| ⋲ |
achter klank |
|
4 |
halve ontronding |
| ˔ |
achter klank |
˔ |
{ |
meer gesloten |
| ˕ |
achter klank |
˕ |
} |
meer open |
| ⊢ |
achter klank |
⊢ |
> |
meer naar voren |
| ⊣ |
achter klank |
⊣ |
< |
meer naar achtcren |
| ˇ |
onder consonant |
ˇ |
5 |
geheel of gedeeltelijk stemhebbend |
| ̯ |
onder consonant |
˳ |
6 |
geheel of gedeeltelijk stemloos |
| ~ |
boven klank |
~ |
~ |
nasalering |
| ~/ |
boven klank |
|
7 |
halve nasalering |
| ˙ |
boven klank |
ʲ |
8 |
palatalisering die tevens |
| . |
onder klank |
ʲ |
8 |
een indruk van |
| ˳ |
onder klank |
ʲ |
8 |
mouillering geeft |
| ^ |
boven vocaal |
|
^ |
sleeptoon of tweetoppig |
| ˍ |
onder vocaal |
|
^ |
zwakgesneden accent of tweetoppig dalen accent |
| \ |
boven vocaal |
|
\ |
stoottoon of scherp gesneden accent |
| ∪ |
boven consonant |
|
" |
leniskarakter |
| ∩ |
boven consonant |
|
! |
fortiskarakter |
| ' |
voor lettergreep |
|
' |
beklemtoning lettergreep |
| ' |
voor lettergreep |
|
' |
beklemtoning lettergreep |
| |
9 |
zachtere uitspraak |
| |
| |
| |
Adres auteurs
Informatiekunde
Faculteit der Letteren
RU Groningen
Postbus 716
9700 AS Groningen
|
|
