|
| |
| |
| |
Het type ontzadelen:
denominaal of deverbaal?
Harald Baayen
1 Inleiding
Het prefix ont- hecht zich aan adjectiva, nomina en verba. Bij formaties van het type ontzadelen leidt dit tot het probleem dat de woordsoort van het grondwoord niet zonder meer vast te stellen is. Aan deze structureel ambigue afleidingen kan zowel een nomen als een verbum ten grondslag liggen. De Vries (1975:172-173) kiest voor een denominale disambiguëring, een keuze die hij motiveert met een beroep op de produktiviteit van dit type afleiding. Volgens De Vries sluit het produktieve type ontzadelen - hij noemt zelf formaties als ontnieten, ontkaften en ontverven als voorbeelden van recente nieuwvormingen - zich wat haar produktiviteit betreft aan bij de ondubbelzinnig denominale produktieve afleidingen van het type ontvlezen, en onderscheidt het zich in dit opzicht van improduktieve deverbale afleidingen als ontbranden en ontvluchten. Op grond hiervan concludeert De Vries dat het type ontzadelen denominaal is.
In Baayen (1990) heb ik erop gewezen dat althans een aantal door De Vries als denominaal opgevoerde formaties (ontkleden, ontstemmen, ontwortelen) op grond van hun betekenis eerder voor een deverbale analyse in aanmerking komen dan voor een denominale analyse. In deze bijdrage laat ik zien dat het type ontzadelen zich ook kwantitatief als deverbale afleiding gedraagt.
Daar de kwantitatieve analyse is gebaseerd op een semantische classificatie van de deverbale ont- afleidingen, ga ik in § 2 kort in op de verschillende semantische typen die we bij de deverbale ont- formaties aantreffen. In § 3 ontwikkel ik een methode om verschillen in produktiviteit tussen semantische typen te onderzoeken aan de hand van de corresponderende kansverdelingen van gebruiksfrekwenties. In § 4 wordt deze methode op de frekwentiedistributies van de verschillende semantische typen ont- afleidingen toegepast.
| |
2 Afleidingen met ont-: semantische typen
De categorie van met ont- geprefigeerde verba valt in een drietal semantische typen uiteen. In aansluiting bij De Vries (1975:127-129) onderscheiden we inchoatieve ont- formaties als ontbranden, ontploffen en ontkiemen, separatieve formaties als ontduiken, ontvallen en ontsnappen, en reversatieve formaties als ontmagnetiseren, onthechten en onttoveren. De inchoatieve en separatieve typen zijn wat hun semantiek betreft nauw verwant. De inchoatieve lezing verschijnt hier als een abstractere variant van de separatieve lezing, net zoals dit bij het
| |
| |
werkwoord gaan het geval is (vergelijk zij gaat naar huis, separatief, met zij gaat aan het werk, inchoatief). De Vries (1975:129) acht geen van deze categorieën produktief, dit ondanks de nauwe semantische verwantschap van het reversatieve type (ontmagnetiseren) met het produktieve denominale type ontvlezen.
Beschouw nu reversatieve verba van het type ontzadelen. Aan ontzadelen kunnen we een denominale structuur toekennen, maar een deverbale analyse behoort evengoed tot de mogelijkheden. De denominale analyse is onafhankelijk gemotiveerd voor verba als ontvlezen, non-reversatieve verba waar geen sprake kan zijn van het omkeren of ongedaan maken van een eerdere handeling. De deverbale analyse is eveneens onafhankelijk gemotiveerd voor verba als ontmagnetiseren, verba waar het grondwoord onmiskenbaar een werkwoord is. Welke analyse verdient voor verba als ontzadelen de voorkeur? De Vries (1975) opteert voor de denominale analyse op grond van een tweetal overwegingen. In de eerste plaats merkt hij op dat denominale ont- formaties zich van de deverbale afleidingen onderscheiden op grond van hun produktiviteit. In de tweede plaats acht hij het mogelijk om bij verba van het type ontzadelen op grond van de semantiek een denominale structuur toe te kennen.
Het is mij niet geheel duidelijk hoe zwaar de tweede overweging telt. Verba als ontkleden, ontstemmen en ontwortelen zijn mijns inziens op grond van hun semantiek eerder deverbaal dan denominaal (zie Baayen 1990), en bij verba als ontwapenen, ontkoppelen en ontgrendelen is het mij evenmin duidelijk hoe op semantische gronden ondubbelzinnig tot een denominale afleiding besloten kan worden. Het sterkste argument voor een denominale analyse is daarmee de overweging dat de deverbale ont- afleidingen in het algemeen niet produktief zijn. Dit argument is echter niet meer dan een plausibiliteitsargument. Uit de omstandigheid dat de inchoatieve en separatieve deverbale ont- afleidingen improduktief zijn kunnen we niet met zekerheid besluiten tot de improduktiviteit van het reversatieve type. Het is immers denkbaar dat de produktiviteit van het deverbale ont- zich nu juist manifesteert bij het reversatieve type. Om deze mogelijkheid op haar waarde te schatten moeten we de verschillende typen ont- afleidingen nader op hun produktiviteit onderzoeken, waarbij we gebruik kunnen maken van de relatie tussen de produktiviteit van een morfologische categorie en de gebruiksfrekwenties van haar leden (zie Baayen 1992, 1993).
| |
3 Produktiviteit en frekwentieverdelingen
In Baayen (1989, 1990, 1992, 1993) heb ik een aantal kwantitatieve maten voor produktiviteit voorgesteld die allen gebaseerd zijn op een kanstheoretisch model waarin de in een steekproef geobserveerde grootte van de woordenschat beschouwd wordt als een functie van de grootte van de steekproef. De snelheid waarmee de woordenschat in de steekproeftijd toeneemt blijkt uitgedrukt te kunnen worden als de ratio van het aantal woorden dat slechts eenmaal in de steekproef is geobserveerd - de zogenaamde hapaxen - en de
| |
| |
steekproefgrootte zelf. Op basis van deze kanstheoretische modellering van de woordenschat als functie van de steekproeftijd kunnen verschillende produktiviteitsmaten ontwikkeld worden (zie Baayen 1993). Voor een gedetailleerde analyse van de produktiviteit van de verschillende semantische typen afleidingen met het prefix ont- zijn deze kwantitatieve maten minder goed bruikbaar, en wel om twee redenen. In de eerste plaats observeren we dat verbale prefigering in het Nederlands niet bijzonder produktief is (zie De Vries 1975, Baayen 1990). Dit leidt tot aantallen hapaxen in de frekwentiedistributies die zo gering zijn dat er geen betrouwbare statistische toetsen op uitgevoerd kunnen worden. In de tweede plaats is er een praktisch probleem. Het corpus Uit den Boogaart (1975), dat de frekwentiegegevens volledig expliciteert, is te klein voor het hier beoogde vergelijkend onderzoek. Het INL corpus is hiervoor beter geschikt, maar helaas zijn de frekwentiegegevens die onder CELEX on-line beschikbaar zijn onvolledig in die zin dat nu juist de hapaxen niet verwerkt zijn. Op hapaxen gebaseerde produktiviteitsmaten kunnen op de CELEX-INL gegevens dus niet toegepast worden.
Omdat de CELEX bestanden ondanks het ontbreken van de hapaxen veel meer ont- formaties bevatten dan het corpus Uit den Boogaart, verdient een op de databank van CELEX gebaseerde analyse de voorkeur. Met deze keuze worden we dan wel gedwongen om een nieuwe statistische methode te ontwikkelen voor de analyse van produktiviteit. Eén mogelijkheid is om, voorwaardelijk werkend op een zekere minimale gangbaarheid van de onderzochte formaties in geschreven Nederlands - de voorwaarden voor opname in de CELEX databank zijn een minimale dispersie van 2 dan wel een minimale frekwentie van 2 - de frekwentiedistributies van de verschillende semantische typen als geheel te onderzoeken.
Linguistisch gezien laat de bij een morfologische categorie behorende frekwentiedistributie zich wellicht het beste interpreteren als de resultante van twee tegengestelde krachten, produktiviteit enerzijds en lexicale individuatie, met als extreem semantische idiosyncraticiteit, anderzijds. Voor produktieve categorieën zijn grote aantallen laagfrekwente woorden kenmerkend. Voor categorieën met een hoge mate van semantische individuatie zijn hoger frekwente formaties typerend. In de nu volgende analyses speelt de factor van semantische individuatie in haar extreemste vorm - semantische opaciteit - geen rol, omdat ik semantisch niet transparante formaties niet in de analyse betrokken heb. Het is immers bij veel opake formaties niet goed mogelijk ze bij een van de semantische typen onder te brengen. Voorts is het ook verre van duidelijk of zulke formaties aan het synchrone taalsysteem een functionele bijdrage leveren. De hier beschreven analyses zijn derhalve in tweeërlei opzicht voorwaardelijk: we beperken ons tot een analyse van die transparante formaties die een minimale gangbaarheid in geschreven Nederlands bezitten.
Nu is het voor het onderzoek van morfologisch en/of semantisch gedefinieerde lexicale typen handig om frekwentiedistributies te kunnen visualiseren. Hiertoe leent zich bij uitstek de zogenaamde kansdichtheidsfunctie. Kansdichtheidsfuncties kan men beschouwen als veredelde histogrammen, waarbij het belangrijkste voordeel van de kansdichtheidsfunctie ten opzichte van het
| |
| |
histogram is dat de kansdichtheidsfunctie minder arbitrair en dus betrouwbaarder is dan een histogram (zie Haerdle 1991).
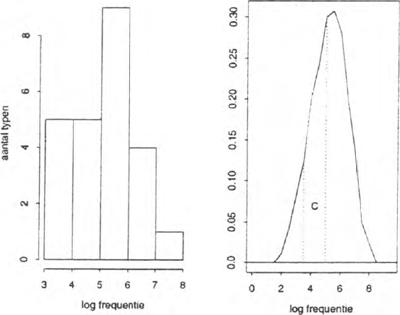
Figuur 1: Histogram en geschatte kansdichtheidsfunctie voor van adjectiva afgeleide woorden met het prefix be- in het CELEX-INL corpus.
In figuur 1 vindt men links een histogram en rechts een geschatte (zie Haerdle 1991 voor details) kansdichtheidsfunctie voor het prefix be-. Op de horizontale as is in beide gevallen de tokenfrekwentie in een logaritmische schaal uitgezet. De lengte van een staaf in het histogram, of precieser, de oppervlakte van zo'n staaf, is proportioneel met de steekproeffractie van typen die met (logaritmisch getransformeerde) gebruiksfrekwenties in het met de staaf corresponderende interval op de X-as voorkomen. Hetzelfde geldt mutatis mutandis voor de kansdichtheidsfunctie. Hier is de grootte van bijvoorbeeld het oppervlak C in figuur 1 gelijk aan de kans dat een de-adjectivale formatie met be- een gebruiksfrekwentie f heeft zodanig dat log f valt in het interval [3.5, 5.0]. Het histogram geeft hier een vertekend beeld van de kans op laagfrekwente soorten. De geschatte kansdichtheidsfunctie laat zien dat deze kans door het histogram overschat wordt.
In de nu volgende paragraaf gebruik ik grafieken van geschatte kansdichtheidsfuncties om verschillen en overeenkomsten tussen morfologische categorieën te traceren. De achterliggende gedachte is dat verschillen tussen morfologische categorieën terug te vinden zijn als verschillen tussen kansdichtheidsfuncties. Of de op basis van visuele inspectie vermoedde verschillen statistisch significant zijn kunnen we vervolgens met behulp van non-parametrische toetsen als die van Kolmogorov-Smirnov of Mann-Whitney (Siegel 1956) vaststellen.
| |
4 De produktiviteit van het reversatieve ont-
Figuur 2 geeft een beeld van de kansdichtheidsfuncties van de reversatieve, inchoatieve en separatieve deverbale formaties met ont-, alsmede de kansdichtheidsfunctie
| |
| |
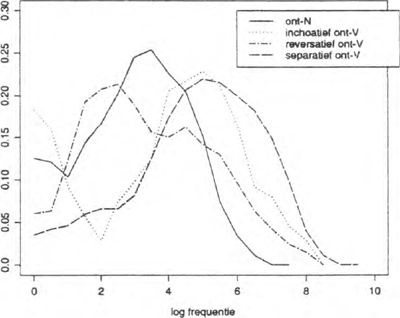
Figuur 2: Kansdichtheidsfuncties van vier semantische typen derivaties met het prefix ont-. De kansdichtheden zijn geschat met behulp van de WARP techniek met een Epanechnikov kern.
van de denominale ont- formaties. Voor de deverbale inchoatieven en separatieven ligt de kansmassa voornamelijk bij de hogere frekwenties. Voor de deverbale reversatieven constateren we daarentegen een opvallende overlapping met de kansdichtheidsfunctie van de - produktieve - denominale formaties. Ten opzichte van de denominale verba met ont- verschijnen de deverbale reversativa met een iets grotere kans op hogere (log) tokenfrekwenties, maar dit verschil is lang zo groot niet als bij de deverbale separativa en inchoativa.
Tabel 1: Overschrijdingskansen behorende bij paarsgewijze homogeniteitstoetsen voor vier klassen van met ont- geprefigeerde verba (tweezijdige Mann-Whitney U toets). Een χ2 toets voor vier onafhankelijke steekproeven laat zien dat de homogeniteitsaanname onwaarschijnlijk is (χ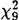 = 30.17, p < 0.01). = 30.17, p < 0.01).
|
|
separatief ont-V |
reversatief ont-V |
inchoatief ont-V |
| reversatief ont-V |
p < 0.05 |
|
| inchoatief ont-V |
p > 0.35 |
p < 0.05 |
|
| ont-N |
p < 0.01 |
p > 0.50 |
p < 0.10 |
Interessant is ook dat de nauwe semantische verwantschap van de separativa en inchoativa in figuur 2 is terug te vinden als een vergaande overeenkomst tussen de kansdichtheidsfuncties. Al met al suggereert figuur 2 (i) dat het deverbale reversatieve ont- zich quantitatief aansluit bij het denominale ont-, en (ii) dat de deverbale separativa en inchoativa zich quantitatief identiek gedragen. Deze hypotheses kunnen we toetsen met bijvoorbeeld de Mann-Whitney U-test (zie bijv. Siegel 1956). Uit een paarsgewijze vergelijking van de verschillende typen ont- afleidingen (tabel 1) blijkt dat de deverbale reversativa en de denominale ont- formaties niet significant van elkaar
| |
| |
verschillen. Hetzelfde geldt voor de deverbale inchoativa en separativa. Alle andere verschillen zijn wel significant. We concluderen dat de deverbale reversatieve formaties niet als improduktief moeten worden gekenmerkt, en dat we de deverbale separativa en inchoativa op grond van hun semantische verwantschap en hun ononderscheidbare kansdichtheidsfuncties als één morfologisch type - het improduktieve deverbale non-reversatieve ont- - mogen beschouwen.
Met de vaststelling dat aan de deverbale reversativa een zekere produktiviteit niet kan worden ontzegd ontvalt ons de mogelijkheid om met De Vries (1975) het produktiviteitscriterium te gebruiken om de derivationele oorsprong van het structureel ambiguë type ontzadelen vast te stellen. Maar de analyse kan nog verder aangescherpt worden door de denominale ont- formaties nader te onderzoeken. Veel van de door CELEX als denominaal geanalyseerde formaties kunnen met evenveel recht als deverbale afleidingen beschouwd worden. Nader inzicht in de samenhang tussen de produktiviteit van het denominale ont- en die van de deverbale reversativa kunnen we verkrijgen door de denominale afleidingen te splitsen in twee klassen, een strikt denominale klasse, gekenmerkt door een niet-reversatieve lezing, en een klasse waar een deverbale afleiding, gegeven de beschikbaarheid van een conversiewerkwoord, tot de mogelijkheden behoort.
We verkrijgen zo een nieuwe classificatie van typen ont- afleidingen:
| 1. | deverbale non-reversativa (ontbranden, ontvluchten), |
| 2. | deverbale reversativa (ontmagnetiseren), |
| 3. | denominale non-reversativa (ontvlezen), en |
| 4. | structureel ambiguë reversativa van het type ontzadelen. |
Nu hebben we reeds geobserveerd dat het type ontzadelen zich wat haar frekwentiekarakteristieken betreft aansluit bij de denominale afleidingen als geheel. Het is echter waarschijnlijk dat deze aansluiting met name tot stand komt door de aanwezigheid van als denominaal geanalyseerde reversatieve ont- formaties in de verzameling van denominale afleidingen van het type 4. De vraag is of deze afleidingen niet als deverbaal moeten worden geanalyseerd. Om deze vraag te kunnen beantwoorden onderzoeken we wederom de bij deze vier typen behorende kansdichtheidsfuncties.
De geschatte kansdichtheidsfuncties in figuur 3 suggereren dat de structureel ambiguë afleidingen van het type ontzadelen zich aansluiten bij de denominale reversativa. De non-reversatieve typen verschijnen als extremen, de denominale non-reversativa bij de lagere frekwenties, de deverbale non-reversativa bij de hogere frekwenties. De denominale en deverbale reversativa nemen een tussenpositie in, waarbij de deverbale reversativa een enigzins grotere spreiding vertonen. Dit doet vermoeden dat we in feite met drie typen afleidingen te maken hebben: denominale non-reversativa (ontvlezen), deverbale non-reversativa (ontbranden, ontvluchten), en reversativa (ontmagnetiseren, ontkurken, ontzadelen). Dit vermoeden wordt bevestigd door de uitkomsten van de paarsgewijs uitgevoerde Mann-Whitney U-toetsen.
| |
| |
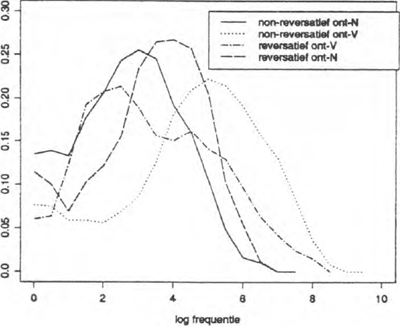
Figuur 3: Kansdichtheidsfuncties van denominale en deverbale reversativa en non-reversativa met het prefix ont-. De kansdichtheden zijn geschat met behulp van de WARP techniek met een Epanechnikov kern.
Uit tabel 2 blijkt dat de denominale en deverbale reversativa inderdaad niet significant van elkaar verschillen (p > 0.40). Omgekeerd verschillen de non-re-
Tabel 2: Overschrijdingskansen behorende bij paarsgewijze homogeniteitstoetsen voor vier klassen met ont- geprefigeerde verba (tweezijdige Mann-Whitney U toets). Een x2 toets voor vier onafhankelijke steekproeven laat zien dat de homogeniteitsaanname onwaarschijnlijk is (x = 32.08, p < 0.001).
|
|
reversatief ont-N |
non-reversatief ont-N |
reversatief ont-V |
| non-reversatief ont-N |
p < 0.04 |
|
| reversatief ont-V |
p > 0.40 |
p = 0.13 |
|
| non-reversatief ont-V |
p < 0.01 |
p < 0.001 |
p < 0.02 |
versatieve denominale afleidingen wel significant (p < 0.05) van de reversatieve denominale ont- formaties. Ondanks het ontbreken van een significant verschil tussen de deverbale reversativa en de denominale non-reversativa (p = 0.13 bij tweezijdige toetsing) neem ik aan dat we de denominale en deverbale reversativa kunnen samenbrengen in één ongedeelde morfologisch type.
Figuur 4 vat de kansdichtheidsfuncties van de drie uit deze analyse resulterende semantische typen samen. Uit een homogeniteitstoets voor drie onafhankelijke steekproeven blijkt dat de denominale non-reversativa, de deverbale non-reversativa en de reversativa zelf niet één en hetzelfde morfologische type representeren ( x = 27.86, p < 0.001). Ook paarsgewijs verschillen ze significant op het 5% nivo (tweezijdige Mann-Whitney U-toetsing).
Figuur 4 laat zien dat de reversatieve verba door enigzins hogere frekwenties worden gekarakteriseerd dan de non-reversatieve denominale afleidingen. Deze verschuiving in de richting van hogere gebruiksfrekwenties doet een ietwat geringere graad van produktiviteit voor de reversatieve verba vermoeden. Deze geringere produktiviteitsgraad kunnen we wellicht herleiden tot de
| |
| |
wezenlijk complexere lexicaal-conceptuele structuur van reversatieve verba ten opzichte van denominale non-reversativa. Bij denominale non-reversatieve afleidingen
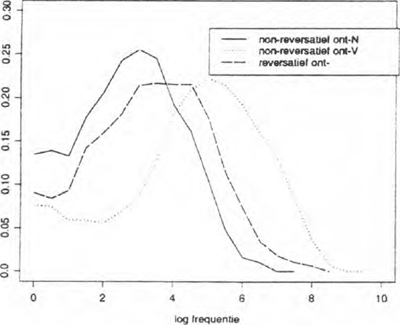
Figuur 4: Kansdichtheidsfuncties van de denominale non-reversativa, de deverbale non-reversativa en de (deverbale) reversativa.
is de integratie van de nominale basis in de lexicaal-conceptuele structuur van het prefix ont- relatief eenvoudig. Het nominale grondwoord kan hier zonder meer ingevoegd worden in de lexicaal-conceptuele structuur van het prefix. Voor een formatie als ontvlezen verkrijgen we zo, gebruik makend van het theoretisch kader van Jackendoff (1991), de volgende structuur (Lieber 1992):
| (1) |
[cause ([ ], [inch [be ([vlees], |
| |
[at-end-of [from [on ([ ])]]])]])]. |
De door Jackendoff (1991) voorgestelde complexe functie at-end-of from on formaliseert hier de notie van ‘volledige verwijdering’. In (1) verschijnt het grondwoord eenvoudigweg als eerste argument van de be functie in de lexicaal-conceptuele structuur van ont-.
De afleiding van deverbale reversativa is wezenlijk complexer. Hier moet namelijk de op zich reeds complexe lexicaal-conceptuele structuur van het verbale grondwoord in die van het prefix ont- geïntegreerd worden. Voor ontmagnetiseren leidt dit tot een structuur als
| (2) |
[cause ([ ]α [inch [be |
| |
([cause ([ ]β, [inch [be ([magnetisme], [atd ([ ]γ)])]])], |
| |
[at-end-of [from [atd ([γ])]]])]])]. |
waarin nu de lexicaal-conceptuele structuur van het grondwoord magnetiseren als eerste argument van de be functie van het prefix verschijnt. Dat we hier met een wezenlijk complexer integratieproces te maken hebben blijkt ook uit de noodzaak van preciese co-indicering van de argumenten van grondwoord en prefix met behulp van de indices α, β, γ. De grotere complexiteit van de
| |
| |
functionele integratie bij het deverbale reversatieve ont- leidt, zo mogen we veronderstellen, tot een hogere graad van lexicale individuatie en in samenhang hiermee tot een lagere graad van produktiviteit.
We keren terug tot het probleem van de structurele ambiguïteit van het type ontzadelen. We hebben gezien dat dit type zich, wat zijn produktiviteit betreft, aansluit bij de - zeker niet improduktieve -deverbale reversativa van het type ontmagnetiseren. De combinatie van een nauwe semantische verwantschap en eenzelfde frekwentiële karakteristiek legitimeert de voorgestelde samenvoeging van de types ontzadelen en ontmagnetiseren in één deverbale categorie. Is deze disambiguïsering juist, dan kunnen integratieprocessen in het mentale lexicon begrepen worden als een de produktiviteit van een type mede bepalende factor. Immers, met de keuze voor een deverbale oorsprong voor het type ontzadelen veronderstellen we dat de vorming van een reversatief werkwoord niet plaatsvindt zonder de reeds aanwezige kennis over de handeling waarvan de omkering geprediceerd wordt, te integreren in de semantische representatie van het afgeleide werkwoord. Dankzij deze integratie liggen de reversatieve ont- afleidingen hechter verankerd in het netwerk van semantische relaties in het lexicon dan de non-reversatieve denominale afleidingen. Laatstgenoemde afleidingen zijn vanuit deze optiek innovatiever maar tegelijk incidenteler en marginaler. In tegenstelling tot de reversativa, die zich hechten aan een vrij beperkte verzameling van doorgaans reeds bestaande (plaatsings)verba, hechten zij zich aan een breed scala van nomina. Dit heeft tot gevolg dat de kans op nieuwvormingen en daarmee de produktiviteitsgraad bij het denominale non-reversatieve type hoger is dan bij het reversatieve type.
| |
Bibliografie
| Baayen, R.H. (1989), A Corpus-Based Approach to Morphological Productivity. Statistical Analysis and Psycholinguistic Interpretation. Diss. Vrije Universiteit, Amsterdam. |
| Baayen, R.H. (1990), Corpusgebaseerd Onderzoek naar Morfologische Produktiviteit, Spektator 19, 213-233. |
| Baayen, R.H. (1992), Quantitative Aspects of Morphological Productivity. In G.E. Booij & J. van Marle (Eds.), Yearbook of Morphology 1991 (pp. 109-149). Dordrecht: Kluwer. |
| Baayen, R.H. (1993), On Frequency, Transparency and Productivity. In G.E. Booij & J. van Marle (Eds.), Yearbook of Morphology 1992 (pp. 227-254). Dordrecht: Kluwer. |
| Baayen, R.H. & Lieber, R. (1991), Productivity and English Derivation: A Corpus-Based Study. Linguistics 29, 801-843. |
| Haerdle, W. (1991), Smoothing Techniques With Implementation in S. Berlin: Springer Verlag. |
| Jackendoff, R. (1991), Semantic Structures, Cambridge, Mass.: The MIT Press. |
| |
| |
| Lieber, R. (1992), Dutch Verbal Prefixation: Lexical Conceptual Structure, Argument Structure and Productivity. Lezing gehouden op het Max-Planck Instituut voor Psycholinguistiek, Nijmegen, Augustus 1992. |
| Siegel, S. (1956), Non-parametric statistics for the behavioral sciences. Tokyo: McGraw-Hill Kogakusha. |
| Vries, J.W. de (1975), Lexicale Morfologie van het Werkwoord in Modern Nederlands. Leiden: Universitaire Pers. |
Max Planck-Instituut voor Psycholinguistiek,
Wundtlaan 1
6521 XD Nijmegen
|
|
