|
| |
Hoe begrijpelijk is mijn tekst?
De opkomst, neergang en terugkeer van de leesbaarheidsformules
Carel Jansen - Faculteit der Letteren, Radboud Universiteit Nijmegen
Leo Lentz - Afdeling Taalbeheersing, Universiteit Utrecht
Met één druk op de knop vaststellen hoe begrijpelijk je tekst is. Wie wil dat niet? Het kan nu al op diverse manieren, en de komende jaren zullen er alleen maar meer digitale begrijpelijkheidstests verschijnen. Maar wat zijn ze waard? En wie ziet er toe op de naleving van de ambitieuze beloften van de bureaus die hier een boterham mee verdienen?
Schrijvers die proberen hun teksten zo begrijpelijk mogelijk te maken, willen natuurlijk ook graag kunnen vaststellen in hoeverre ze daarin geslaagd zijn. Hoe goed of slecht waren eerdere versies van de tekst te volgen en wat hebben de bewerkingen opgeleverd? Het zou erg handig zijn als deze vragen in een handomdraai beantwoord konden worden dankzij een betrouwbaar instrument dat precies laat zien voor welke lezers een tekst wel en niet begrijpelijk is. Naar zo'n meetinstrument, meestal aangeduid met de term leesbaarheidsformule, wordt intussen al meer dan tachtig jaar gezocht.
In de jaren twintig van de vorige eeuw werden in de Verenigde Staten de eerste leesbaarheidsformules ontwikkeld, om het Amerikaanse docenten gemakkelijker te maken geschikte boeken voor hun leerlingen te kiezen. Al snel daarna volgden er andere met een veel algemener doel. Het beroemdst werd de ‘Reading Ease’-formule van schrijfvaardigheidsdocent en publicist Rudolf Flesch, uit 1948. Toepassing van deze formule vergde niet veel meer dan het tellen van de zinnen, woorden en lettergrepen in een aantal tekstfragmenten. Die getallen moesten in de volgende formule worden ingevoerd: RE = 206,84 - (1,02 maal SL) - (0,85 maal WL). ‘RE’ stond voor ‘Reading Ease’ (leesgemak), ‘SL’ voor het gemiddelde aantal woorden per zin, en ‘WL’ voor het gemiddelde aantal lettergrepen per woord. De uitkomst van de formule was het voorspelde leesgemak van de doorgemeten tekst. Hoe hoger de score, hoe gemakkelijker de tekst.
| |
■Koud kunstje
Eind jaren vijftig kwamen er ook varianten van de formule van Flesch in zwang die speciaal voor het Nederlands ontwikkeld waren. Zo ontstond na aanpassing door de Wageningse socioloog Wouter Douma de formule van Flesch-Douma: RE = 206,83 - (0,93 maal SL) - (0,77 maal WL), met een bijbehorende interpretatieschaal die sprekend leek op die van Flesch. Ook de formule zelf was vrijwel een kopie van het Amerikaanse voorbeeld. De enige verschillen betroffen de constanten waarmee de gemiddelde zinslengte (SL) en de gemiddelde woordlengte (WL) vermenigvuldigd moesten worden. Die werden door Douma voor het Nederlands zó gekozen dat ze, wanneer er 10% bij werd opgeteld, precies gelijk zouden zijn aan de constanten uit de Flesch-formule. Een belangrijke rechtvaardiging voor deze aanpassing was de mededeling van de hoofdredacteur van Het Beste, die liet weten dat hij altijd rekening moest houden met een uitloop van 10% bij het opnemen van vertaalde artikelen uit Reader's Digest.
Opvallend genoeg duurde het een hele tijd, zeker in het Nederlandse taalgebied, voordat er door taalbeheersers vraagtekens werden gezet bij de wetenschappelijke onderbouwing van de leesbaarheidsformules. Maar toen was de kritiek ook niet mis te verstaan: de uitslagen met twee cijfers achter de komma suggereerden ten onrechte dat er heel precies was gemeten, en vooral hekelde men het zwakke onderzoek waarop de formules gebaseerd waren. Een dieptepunt op dat vlak was de test die Douma zelf uitvoerde om na te gaan of zijn formule de juiste voorspellingen opleverde. Toen de uitkomsten tegenvielen, concludeerde Douma niet dat er blijkbaar iets mis was met zijn formule, maar schreef hij dat toe aan de test die hij had gedaan. Maar het belangrijkste bezwaar tegen leesbaarheidsformules
| |
| |
betrof de suggestie die de formules wekken dat het een koud kunstje zou zijn om een tekst begrijpelijker te maken. Je knipt een aantal zinnen doormidden, vervangt hier en daar een komma door een punt, kiest een aantal woorden die korter zijn dan wat er stond, en klaar is Kees. Kijk maar: volgens de formule is je tekst ineens een stuk eenvoudiger te begrijpen geworden.
De fout die hier wordt gemaakt, is dat het onmiskenbare verband dat er bestaat tussen woord- en zinslengte enerzijds en tekstbegrijpelijkheid anderzijds, zonder terughoudendheid wordt beschouwd als een oorzakelijk verband. Die drogreden herkennen we allemaal meteen als een ambitieuze voorzitter van een voetbalclub uit de - ook onmiskenbare - samenhang tussen het aantal plaatsen in een stadion en de prestaties van zijn club zou concluderen dat hij alleen maar een extra toeschouwersring hoeft te laten plaatsen om zijn elftal meer successen te laten behalen. Maar zodra het over teksten gaat, is het kennelijk lastiger om te beseffen dat niet elk verband dat tussen twee verschijnselen wordt gevonden een oorzakelijk verband hoeft te zijn, en dat veranderingen op het ene punt niet automatisch tot veranderingen op het andere punt hoeven te leiden.
| |
■Microsoft

Illustratie: Matthijs Sluiter
De gefundeerde kritiek op de leesbaarheidsformules leidde tot een steeds negatievere houding in de schrijfadviesliteratuur en daarmee tot een sterk teruglopende populariteit. Totdat de computer gemeengoed werd, en het voor de gebruikers van formules niet meer nodig was om zelf berekeningen uit te voeren. In de jaren negentig besloot Microsoft om voor een aantal talen (niet voor het Nederlands) in het tekstverwerkingsprogramma Word twee leesbaarheidsformules in te bouwen als optie in de spelling- en grammaticacontrole. Toen werd het wel heel gemakkelijk en aantrekkelijk om de leesbaarheid van een tekst ‘objectief’ vast te laten stellen. Dat het fundament van die berekeningen er sinds de introductie van de RE-formule van Flesch niet minder wankel op is geworden, onttrekt zich aan het oog van de Word-gebruiker die zijn Engelstalige tekst wil laten doormeten. Die voert de tekst in, zet de spellingen grammaticacontrole aan, zorgt dat ‘grammatica tegelijk met spelling controleren’ is ingeschakeld, vinkt het selectievakje ‘leesbaarheidsstatistieken weergeven’ aan, wacht tot de suggesties voor spelling en stijl de revue zijn gepasseerd, en ziet dan een tabelletje verschijnen met onder meer de Flesch Reading Ease-score (zie figuur 1). Informatie over de schaduwzijden van deze leesbaarheidsmeting ontbreekt.
Wie anno 2008 de leesbaarheid van zijn teksten wil vaststellen, kan ook op internet terecht. Daar vinden we zonder moeite diverse leesbaarheidsformules waarmee direct en gratis kan worden afgelezen wat het begrijpelijkheidsniveau is van teksten (ook in het Nederlands) en zelfs van websites; zie www.squidoo.com/readability. Het ziet er indrukwekkend uit, maar het is oude wijn in nieuwe zakken. De wetenschappelijke basis is, ondanks de moderne technologie, nog net zo pover als in de jaren vijftig. Maar heeft de moderne technologie ook geleid tot nieuwe ontwikkelingen in het begrijpelijkheidsonderzoek die wél de moeite waard zijn?
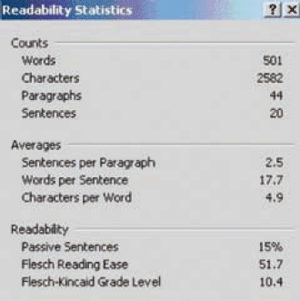
Figuur 1. Een leesbaarheidsmeting in Word.
| |
■Jargonscanner
Dankzij de digitalisering van kranten, tijdschriften en boeken beschikken we tegenwoordig over enorme tekstbestanden. En die zijn weer geordend op diverse genres. Dat is vooral handig met het oog op de vraag welke woorden moeilijk zijn voor lezers. Met de moderne technologie kunnen we tegenwoordig dus veel meer dan het aantal lettergrepen in woorden tellen.
| |
| |

Figuur 2. Voorbeeld van de jargonscanner van Gridline.
De Universiteit Utrecht en het taalsoftwarebureau Gridline werken samen aan de ontwikkeling van een zogenoemde jargonscanner, waarmee de moeilijke woorden in een tekst met één druk op de knop gemarkeerd worden. Op de site van Gridline lezen we over een proefversie van die scanner waarmee ‘rekening wordt gehouden met het taalniveau van het door u beoogde publiek en de vaktermen die u met dit publiek wilt delen’.
In het voorbeeld (figuur 2) zien we moeilijke woorden als vergunningensysteem en parkeercapaciteit, maar daarnaast zijn woorden gemarkeerd als parkeerplaatsen, autogebruik, kantoorgebouw en nieuwbouwprojecten. En ook de Apeldoornselaan is blijkbaar een moeilijk woord. Verderop komen we woorden tegen als kaderwetgebieden en de Binckhorst, die niet gemarkeerd zijn als jargon. Hoe valt dat te begrijpen?
Misschien is juist de geavanceerdheid van het systeem debet aan deze gebreken. De scanner werkt namelijk met een grote verzameling beleidsteksten en een verzameling alledaags taalgebruik. De software berekent van elk woord hoe vaak dat voorkomt in beide verzamelingen en bepaalt vervolgens de verhouding tussen die twee uitkomsten. Als een woord relatief vaak voorkomt in de ‘beleidsverzameling’ (zoals misschien het geval is bij parkeerplaats) en niet zo heel vaak in de ‘alledaagse’ verzameling, dan wordt het gemarkeerd als jargon. Waarom dat ook geldt voor Apeldoornselaan en niet voor de andere eigennaam Binckhorst, is lastig te verklaren.
De ontwikkelingen zijn veelbelovend: dankzij de grote digitale tekstverzamelingen en de geavanceerde software kunnen we veel betere informatie krijgen over moeilijke woorden dan vroeger het geval was. Maar we zijn er nog lang niet. Over de vraag wat precies een moeilijk woord is, en hoe we die moeilijkheid in een formule kunnen vatten, zijn we voorlopig nog niet uitgedacht.
| |
■Texamen
Dankzij geavanceerde taaltechnologie kunnen we niet alleen woorden maar ook zinnen beter op moeilijkheid analyseren, en tangconstructies (woorden die bij elkaar horen, worden gescheiden door een flink aantal andere woorden) en lijdende vormen laten aanwijzen.
Texamen, een analyseprogramma dat het commerciële tekstvereenvoudigingsbedrijf BureauTaal in 2006 presenteerde, werkt onder meer met dit soort tekstkenmerken. Maar de gebruiker moet zelf ook nog een aantal vragen beantwoorden, zoals ‘Staat het belangrijkste van de tekst in het begin?’ en ‘Hoeveel figuurlijke uitdrukkingen komen er in de tekst voor?’
Hoe Texamen precies in elkaar zit en welk gewicht aan de diverse tekstkenmerken wordt toegekend om tot een bepaalde inschatting van de begrijpelijkheid te komen, is bedrijfsgeheim. Misschien begrijpelijk, maar daarmee is onafhankelijke controle op de werking van het systeem onmogelijk. Dat daaraan wel degelijk behoefte bestaat, blijkt bijvoorbeeld als een fragment uit het kinderboek Pinkeltje met Texamen wordt geanalyseerd. Volgens Texamen is Pinkeltje geschreven op het een-na-hoogste taalniveau: Ci. En dat betekent volgens publicaties van BureauTaal dat slechts 15% van de volwassenen deze tekst begrijpt. Opmerkelijk is ook het grote aantal woorden dat Texamen hier markeert als ‘laagfrequent’ (zie ook figuur 3). Volgens ons zou alleen het ouderwetse buisje (kledingstuk) voor die kwalificatie in aanmerking mogen komen.
Volgens Texamen begrijpt slechts 15% van de volwassenen het kinderboek Pinkeltje.
| |
■Samenhang
Een vernieuwende en veelbelovende techniek die inmiddels breed toegankelijk is voor het Engelse taalgebied, is LSA: Latent Semantic Analysis. De term semantische analyse wil zeggen dat woorden en teksten geanalyseerd worden op hun betekenis en onderlinge samenhang. Je zou verwachten dat dit gebeurt met behulp van een groot digitaal woordenboek waarin de betekenis van alle in de tekst gebruikte woorden is gedefinieerd. Maar de techniek gaat heel anders in zijn werk. In dit systeem wordt de moeilijkheid van het woord buisje niet bepaald doordat ergens in zo'n woordenboek deze betekenis als weinig gebruikelijk is omschreven. Evenmin wordt berekend hoe vaak het woord voorkomt in een verzameling teksten. In LSA voer je een berekening uit van de kans dat dit woord samen met de andere woorden in de alinea voorkomt. Hoe lager die kans, des te ongebruikelijker is de combinatie van buisje met woorden als pakken, opvliegen, snavel en bang.
Met dezelfde techniek kan gecontroleerd worden of een korte reeks woorden, zoals de titel van een tekst of het label van een link in een website, de lezer op het juiste spoor zet naar de inhoud van de tekst die daarachter schuilgaat. Met LSA worden bijvoorbeeld heel aardige voorspellingen gedaan over de gebruiksvriendelijkheid van navigatieroutes op websites. Deze techniek is ontwikkeld in de academische wereld en is via het web toegankelijk - zie http://lsa.colorado.edu.
| |
■Stap verder
Een veel omvangrijker programma, dat teksten op ruim vijftig kenmerken analyseert, is Coh-metrix, ontwikkeld aan de universiteit van Memphis en eveneens voor iedereen toegankelijk op het web (http://fedex.memphis.edu/iis/projects/cohmetrix.shtml). We kunnen er teksten invoeren en laten berekenen met vertrouwde maten als de reeds besproken leesbaarheidsformules, passieve zinnen en tangconstructies. Maar Cohmetrix doet meer. De extra's van dit programma zitten in de analyse van factoren die de samenhang van de tekst bepalen. In een eenvoudige tekst bevat elke nieuwe zin niet al te veel nieuwe informatie vergeleken met de voorgaande zin. Er moet voldoende overlap zijn om de tekst als een samenhangend geheel te kunnen begrijpen. Coh-metrix berekent die mate van overlap. En in een verhalende tekst moet de verteller niet in elke zin wisselen van hoofdper- | |
| |
soon, plaats en tijd. Als de hoofdpersoon zich in de eerste zin voorneemt om boodschappen te gaan doen, dan moet dat doel bij voorkeur in de volgende zinnen terugkeren.
Coh-metrix analyseert teksten op zulke abstracte factoren als ‘verteltijd’, ‘intenties’, ‘ruimte’ en ‘personages’, en gaat na in hoeverre de verschillende zinnen in een fragment op die factoren samenhangen. Dat is zowel methodisch als theoretisch een hele stap verder dan een berekening van het aantal woorden en lettergrepen in een zin. Toch zijn de makers van dit programma veel minder pretentieus dan we soms bij andere programma's zien. Coh-metrix voorspelt niet of bepaalde groepen lezers een tekst wel of niet zullen begrijpen, maar geeft een indicatie van de samenhang in de tekst.
| |
■Voorkennis
In de voorbeelden hierboven passeerden drie aspecten van begrijpelijkheid de revue: woordmoeilijkheid, zinsmoeilijkheid en samenhang tussen tekstelementen. Hebben we daarmee alles te pakken? Nee, er zijn beslist moeilijke teksten met gemakkelijke woorden, eenvoudige zinnen en veel samenhang. Wat maakt die teksten dan moeilijk? Voor een antwoord op die vraag is een dieper inzicht nodig in wat tekstbegrip precies is.

Figuur 3. De analyse met Texamen van een fragment uit het kinderboek Pinkeltje.
Ten tijde van de eerste leesbaarheidsformules werd aangenomen dat een goed begrip van een tekst inhield dat de lezer de inhoud van de tekst zo precies mogelijk in zijn hoofd had. In de gangbaarste recente theorieën is daar iets belangrijks aan toegevoegd: een tekst kan alleen maar goed begrepen worden wanneer de lezer zijn eigen voorkennis inzet tijdens het lezen. Elke tekst bevat immers talloze vooronderstellingen en verzwegen relaties tussen onderdelen, die enkel met behulp van voorkennis goed begrepen kunnen worden. En omdat het voor de schrijver bijzonder moeilijk is een juiste inschatting van die voorkennis te maken, kan er op dat punt van alles misgaan tijdens het lezen. In het onderzoek dat de afgelopen decennia is uitgevoerd naar de begrijpelijkheid van folders, brochures, formulieren, websites en handleidingen blijkt telkens weer dat de voornaamste problemen veroorzaakt worden door forse verschillen tussen de veronderstelde en de feitelijke voorkennis. Lezers hebben de meeste moeite met het begrijpen van wat er níét gezegd wordt, met de verzwegen vooronderstellingen van de auteurs.
| |
■Beloftes
De overheid en het bedrijfsleven hebben een grote behoefte aan hanteerbare hulpmiddelen bij het streven naar begrijpelijke teksten. Taaltechnologisch onderzoek houdt zeker grote beloftes in. Met geavanceerde software en grote tekstbestanden kunnen teksten steeds beter worden geanalyseerd. Van sommige tekstkenmerken, een lijdende vorm bijvoorbeeld of een tangconstructie, is bekend dat die een negatieve invloed kunnen hebben op de begrijpelijkheid. Maar de narigheid is dat er altijd situaties zijn waarin een lijdende vorm of een tangconstructie juist volkomen op zijn plaats is, zonder de begrijpelijkheid te schaden. Daarom zal ook toekomstige analysesoftware onvermijdelijk leiden tot foutieve meldingen, zoals parkeerplaats in de jargonscanner en de zogenaamd ingewikkelde zinsconstructies van Pinkeltje in Texamen.

Figuur 4. Texamen waardeert het positieve resultaat van een analyse met een valse belofte.
Het zal ook nog lang duren voordat we met behulp van software een goede inschatting kunnen maken van de voorkennis die nodig is om een tekst te begrijpen. En dat leidt tot onvermijdelijke missers: problemen die lezers in de praktijk ervaren doordat hun voorkennis tekortschiet, maar die door de software over het hoofd worden gezien.
Toch moeten we, alles bij elkaar, blij zijn met de vorderingen in taaltechnologisch onderzoek naar de factoren die tekstbegrip bepalen. We zijn duidelijk verder dan tijdens de hoogtijdagen van de klassieke leesbaarheidsformules. Zorgelijk is wel dat de commerciële belangen de consumentenbelangen soms overschaduwen. Schrijvers zijn niet gebaat bij de valse illusie dat een tekst met een positieve score op een eenvoudige leesbaarheidsformule door de doelgroep begrepen zou worden. Een bureau dat dat suggereert, weet niet wat begrijpen inhoudt.
Controle op de kwaliteit van dit soort software is dringend gewenst. De kans is groot dat er de komende jaren meer van zulke programma's op de markt komen. Om het kaf van het koren te scheiden zou een onafhankelijke instelling een kwaliteitsbrevet moeten kunnen verstrekken. Gebruikers zouden beter geïnformeerd moeten worden over de mogelijkheden en onmogelijkheden van het instrument waarmee ze aan het werk gaan. Aanbieders zouden voorzichtiger moeten worden met hun beloftes, en meer openheid moeten bieden over de criteria waarop teksten geanalyseerd worden.
|
|
