De Nieuwe Taalgids. Jaargang 61
(1968)– [tijdschrift] Nieuwe Taalgids, De–
[pagina 12]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Trema of koppelteken?
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 13]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Nu is het inderdaad mogelijk om de invloed van alternatieve spellingssystemen op het ‘snel en zonder fouten lezen’ experimenteel en quantitatief na te gaan op een wijze, die zich voor directe toepassing der mathematische statistica leent, zodat de uitkomsten objectief in getalmaat kunnen worden uitgedrukt en geïnterpreteerd. Het leek ons daarbij gewenst om in eerste instantie slechts éen variabele te introduceren, t.w. de invloed van de keuze tussen het trema en het koppelteken voor de scheiding van opeenvolgende klinkers. Bij toepassing van matched pairs heeft men dan een onderzoeksysteem, waarin de volgende factoren constant zijn: 1e de lettersamenstelling; 2e de fonemen; 3e de morfemen; 4e de informatie-inhoud in de zin der informatietheorie. Het enige kenmerk, waarin de woordbeelden dan verschillen, is de wijze van codering van éen informatie-eenheid, nl. het alternatieve gebruik van het symbool boven, resp. - ná een letter voor de decoderingsopdracht: ‘Lees de volgende letter gescheiden van de geïndiceerde’. Bij de samenstelling van de proef moet dan nog rekening worden gehouden met de mogelijke invloed van het al dan niet vertrouwd zijn met een bestaand woordbeeld, al zou dit volgens de fonologische theorie geen rol mogen spelen. Een dergelijke invloed kon echter eenvoudig geheel worden uitgeschakeld, door er voor te zorgen, dat in beide te gebruiken lijsten even veel woordbeelden voorkomen, die in de huidige spelling gangbaar zijn, terwijl anderzijds de woorden zoveel mogelijk gekozen werden, die men niet regelmatig onder ogen krijgt. Verder is ervoor gezorgd, dat alle in aanmerking komende opeenvolgingen van klinkers vertegenwoordigd zijn. De opgestelde lijst, zoals deze in de proef gebruikt werd, omvatte 100 woorden, waarvan er in de lijst met tremata 38 waren, die geheel overeenkwamen met de huidige spelling, en in de lijst met koppeltekens 36. De frequenties van de te scheiden klinkeropvolgingen waren: aaa -1, aa - 6, ae - 6, ao - 2, au -1, ea - 3, ee - 22, eee - 5, ei - 5, eo - 4, ie - 7, iee - 3, ieo -1, ieu -1, ii - 2, ij -1 (scheiding nodig waar ij gelezen zou kunnen worden i.p.v. -i j-), ijee -1, ioe - 2, ioo - 1, iou -1, oa - 2, oe - 3, oi - 2, oo - 21, ooe - 2, uu -1. Deze relatieve frequenties zijn niet opzettelijk gezocht, maar deden zich automatisch voor bij willekeurige keus van woorden onder inachtneming van de eis van gelijke frequentie van bekende woordbeelden in beide matched pair lijsten. Teneinde de invloed van gewenning uit te schakelen, werden de woorden in de beide lijsten aselect verdeeld, zodat geen enkele maal dezelfde opeenvolging voorkwam. Verder werd elke lijst tweemaal hardop voorgelezen, waarbij elke proefpersoon steeds eindigde met dezelfde lijst als waarmee hij of zij begonnen was, zodat de gemiddelde gewenningsfactor bij beide alternatieven gelijk was. Ten overvloede werd bovendien steeds gewisseld in de beginlijst, dwz. als de eerste proefpersoon gelezen had in de volgorde abba, dan kreeg de volgende de volgorde baab, en zo vervolgens. Tabel i geeft een representatieve samenvatting van de gebruikte woorden (35 uit het totaal van 100) ter oriëntatie. Deze zijn hier alfabetisch gerangschikt ter wille van de overzichtelijkheid, maar waren dus over de proeflijsten willekeurig door elkaar verdeeld. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 14]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
TABEL I
Representatieve steekproef uit de gebruikte woordpopulaties
Het totale aantal proefpersonen bedroeg 40, in leeftijd variërend van 7 tot en met 67 jaar en in opleiding van 1 jaar l.o. tot gymnasiale opleiding gevolgd door een afgesloten universitaire studie. De kennis van vreemde talen der proefpersonen variëerde van 0 tot 7. De proefpersonen kregen de opdracht de woordenlijsten op snel leestempo voor te lezen, waarbij de proefleider het startsein gaf, onmiddellijk na de overhandiging van het blad, zodat à prima vista met lezen werd begonnen. De leestijd werd nauwkeurig gemeten (ten dele met stopwatches, ten dele met een elektrische tijdmeter) en de | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 15]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
mislezingen werden met behulp van een handtallycounter geregistreerd, zodat ‘de tel kwijt raken’ werd uitgeschakeld. Als mislezing werd iedere hapering opgevat, waarbij de proefpersoon opnieuw met het woord begon en iedere foutieve weergave van de objectieve woordinhoud, d.w.z. van de alléén op grond van de spelling adaequaat te achten klankweergave, dus zonder op daaraan niet herkenbare uitspraak- en klemtoondetails te letten, mits deze in het gegeven woordbeeld mogelijk zijn. De oe in dioestrus werd dus geaccepteerd bij uitspraak als oe, eu, è of ee, aangezien deze alle mogelijk zijn en de keuze afhangt van de opleiding en het milieu van de proefpersoon. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. ResultatenIn Tabel ii wordt een overzicht gegeven van de verkregen uitkomsten, uitgedrukt als de verhouding van de leestijd, die benodigd was voor de lijst met trema-spelling tot die van de lijst met koppeltekenspelling, en dito voor de verhouding tussen het bij deze beide lijsten geconstateerde aantal mislezingen. Waar de verhouding groter is dan 1, is dit voor het snelle overzicht nog nader aangeduid door een + teken, waar de verhouding kleiner is dan 1, door een - teken. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.1. Invloed van de spellingswijze op de leestijdBij 36 van de 40 proefpersonen was de benodigde leestijd voor de lijst met tremaspelling langer dan voor die met koppeltekens. De kans, dat deze uitkomst toevallig zou zijn, blijkt bij parametervrije toetsing met de tekentoets kleiner te zijn dan 1 op 100 millioen (P= 0.9 × 10-8). (ter toelichting voor niet statistisch georiënteerde lezers moge worden opgemerkt, dat de tekentoets geen enkele vooronderstelling vereist betreffende de vorm van de statistische verdeling). De gemiddelde verhouding (‘grand average’) over alle proefpersonen bedroeg 1,19 ± 0.04 (s.e.) (s.d. = ± 0.23), dat wil dus zeggen, dat voor het lezen van een met trema geschreven woord gemiddeld 19% meer tijd nodig was dan voor het lezen van hetzelfde woord, geschreven met een koppelteken, maar uit geheel dezelfde lettersamenstelling opgebouwd. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.2. Invloed van de spellingswijze op de misleeskansAlle 40 proefpersonen maakten méér fouten bij het lezen van de lijst met tremata dan bij de lijst met koppeltekens. De tekentoets geeft aan, dat de kans, dat deze uitkomst bij toeval zou kunnen worden verkregen, kleiner is dan 1 op billioen (P < 10-12) oftewel minder dan 1 op ongeveer 70000 × de totale bevolking van Nederland...! De gemiddelde verhouding is bovendien nog groter ten nadele van het trema dan bij de vergelijking van de leestijden, nl. 3,09 ± 0,31 (s.e) (s.d. = ± 1.98). Gemiddeld werden dus met het trema ruim 3 × zoveel leesfouten gemaakt als met het koppelteken. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.3. Invloed van de talenkennis der proefpersonenUit de eensluidendheid van de verschillen tussen de beide vergeleken spellingswijzen voor álle proefpersonen wat het optreden van mislezingen betreft, blijkt dat er op dit punt geen qualitatief verschil is tussen personen met verschillende ontwikkeling. Het is evenwel een voor de hand liggende hypothese, dat de quantitatieve uitkomsten nog wel zouden kunnen variëren met de intellectuële status van de proefpersonen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 16]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
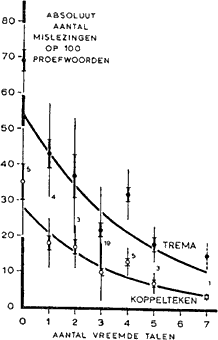
Teneinde dit na te gaan, werden de verkregen gegevens ingedeeld in klassen op basis van het aantal vreemde talen, dat de proefpersonen in geschreven vorm bekend was (ongeacht op welk niveau, aangezien het niet mogelijk is verschillen hierin objectief in rekening te brengen, en het voor de eenvoudige proef slechts gaat om de mogelijke invloed van een grotere vertrouwdheid met afwijkende woordbeelden). Voor elke klasse werd het gemiddelde met standaarddeviatie en standaardfout berekend en voor elk kenmerk de regressie voor dit kenmerk als functie van de talenkennis. Voor beide schrijfwijzen bleek de gemiddelde leestijd af te nemen met toenemende talenkennis, maar over de gehele linie liggen de gemiddelde tijden hoger voor de trema-spelling dan voor die met het koppelteken. Het verband is exponentiëel, zoals blijkt wanneer de gegevens worden uitgezet op een semi-logarithmische grafiek (abscis lineair, ordinaat logarithmisch). Wegens plaatsgebrek zijn deze grafieken niet hierbij opgenomen, maar alleen de uitkomsten vermeld.
TABEL II Uitkomsten van het vergelijkend onderzoek naar de leesefficiency bij gebruik van tremata of koppeltekens
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 17]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Zeer duidelijk komt de invloed van bekendheid met woordbeelden van vreemde talen ook tot uiting ten aanzien van het absolute aantal mislezingen (Fig. 1). Ook dit verband is exponentiëel, hetgeen populair gezegd betekent, dat pas bij kennis ovan een oneindig aantal talen (oneindig in de strikt wiskundige zin!) absoluut foutloos lezen verwacht zou mogen worden. Uit de cartesische grafiek blijkt zeer evident hoe zeer de leesefficiency toeneemt met uitbreiding van de talenkennis en hoe armzalig het resultaat is, wanneer alléén maar bekendheid met de moedertaal aanwezig is. Door een pragmatisch inadaequate schrijfwijze wordt dit dan nog slechter dan bij toepassing van een ten aanzien van de informatieverwerking optimaal coderingssysteem mogelijk zou zijn. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Diskussie van de verkregen uitkomstenDe in de voorgaande paragrafen vermelde uitkomsten van het proefondervindelijk onderzoek tonen onomstotelijk aan dat koppeltekens een betere leesbaarheid, zowel wat snelheid als perceptie betreft, van de woorden geven dan tremata. In tegenstelling tot de niet nader gemotiveerde voorkeur van de Nederlands-Belgische commissie voor de spelling van de bastaardwoorden voor het trema, moet dus uit utiliteitsoverwegingen reeds gekozen worden voor een zoveel mogelijke toepassing van koppeltekens in alle gevallen, waar er geen dringende reden zou bestaan voor tremata. Bij eenvoudige woorden, en woorden die uit korte lettergrepen bestaan, zoals aäron, naäpen, zal men in het algemeen waarschijnlijk niet zoveel behoefte gevoelen aan een verbetering van de leesbaarheid, hoewel deze óók hierbij duidelijk aan de dag treedt. Woordbeelden als chloroösmaat blijken echter reeds zoveel mislezingen te veroorzaken, dat aan het koppelteken zonder enig voorbehoud de voorkeur zal moeten worden gegeven. Feitelijk is de betere leesbaarheid van met koppeltekens geschreven woorden reeds van oudsher aan taaldidaktici bekend: Sinds Jan Ligthart of misschien reeds vroeger begint men in eerste leesboekjes op de lagere school met het scheiden van alle lettergrepen door kop- | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 18]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
peltekens. Natuurlijk wordt dit later, wanneer een voldoende leesvaardigheid is verkregen, eerder hinderlijk dan helpend, maar voor de opeenvolging van de meeste klinkers kan in het Nederlands, in tegenstelling tot verschillende vreemde talen, een scheidingsaanduiding niet worden gemist. Bij de beoordeling van de consequenties moet men er ook aan denken, dat bij aanvaarding van de voorstellen van de commissie op het punt van weglating van de zgn. ‘tussen’-n (in vele gevallen een meervouds-n) in samengestelde woorden, het aantal woorden, waarin klinkerscheiding nodig is, aanzienlijk zal toenemen. Dit is reeds het geval geweest bij de thans geldende spellingsvoorschriften: Men denke aan de verandering van kippenei in kippeëi. Het zou in dit verband interessant kunnen zijn, om een analoge proef uit te voeren ten aanzien van de relatieve efficiency van een spelling met ‘tussen’-n's in vergelijking tot een alternatieve waarin deze is verdwenen en daarvoor in de plaats òf koppeltekens òf tremata zullen zijn toegevoegd. Het alternatief: ‘Trema of koppelteken’ betekent een klein verschil in de voor schrijven en drukken benodigde papierruimte, aangezien het trema geen letterspatie beslaat, en het koppelteken wel. Wanneer men hieruit echter zou willen concluderen, dat een spelling met tremata ‘besparing op drukkosten’ zou geven, dan vergist rnen zich deerlijk. Wanneer zich nl. in een zetregel slechts éen woord bevindt, dat verkeerd gezet wordt, dan moet bij het tegenwoordige machinale zetprocédé de gehele regel opnieuw worden gezet. Bij een gemiddeld 3 × grotere kans op fout lezen van een woord met trema, neemt de kans op het optreden van een zetfout in evenredige mate toe, maar de toeneming van correctiekosten wordt hiervan nog een veelvoud! Het is een volslagen misvatting, te menen, dat papier duurder zou zijn dan zetloon. Elke argumentatie, die uit het verkleinen van het aantal letterspaties, dat voor een woord gemiddeld nodig is, wil afleiden dat deze automatisch gepaard zou gaan met een verlaging van drukkosten, gaat uit van valse praemissen. Het uitgevoerde onderzoek toont aan, dat het inderdaad op betrekkelijk eenvoudige wijze mogelijk is om efficiencykenmerken van een spelling quantitatief na te gaan en te toetsen, zonder dat daarbij andere dan strikt rationele factoren in het geding worden gebracht. Gezien de eclatante uitkomsten voor een schijnbaar zo ondergeschikt detail als de klinkerscheiding met tremata of koppeltekens, komt het ons voor, dat het hoogst gevaarlijke consequenties kan hebben, wanneer zonder nader onderzoek van andere kenmerken van bestaande en voorgestelde alternatieve spellingssystemen, veranderingen zouden worden ingevoerd of opgelegd, die niet rationeel verantwoord zouden kunnen blijken te zijn. c. van duijn jr. |
|