
De Nieuwe Taalgids. Jaargang 9
(1915)– [tijdschrift] Nieuwe Taalgids, De–
[pagina 65]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De statistiek en de taalwetenschap.Als eenige goedwillige geesten wilden helpen, zouden we met betrekkelijk weinig moeite: de wetenschap onzer Nederlandsche taal zóó hoog op kunnen stooten tusschen al hare concurrenten, dat het waarlijk een lust zou zijn het te zien. Terwijl toch van den eenen kant de nieuwe richting onzer taalwetenschap, de oude reeds verre overtreft in breedte van gezichtsveld, zoodat er, om maar iets te noemen, psychologie, sociologie en aesthetica tegenwoordig sàmen bespreken, wat nog onlangs de alleen-zaligmakende schoolmeesterslogica bedisselde; zouden wij dàn ook alle vroegere acribie verre in de schaduw kunnen stellen, door zoover de stof het gedoogt, de nauwkeurigheid der exacte wetenschappen na te volgen: in de precisie van het getal. Het is nu toch langzamerhand voor iedereen wel duidelijk geworden, dat de taalwetenschap een bemiddelend standpunt inneemt: tusschen de historische en de natuurkundige vakken. Van den eenen kant toch wordt de taal beheerscht: door onveranderlijke akoestieke, physiologische en psychologische natuurwetten; en van den anderen kant oefenen de onregelmatige historische en sociale feiten: er een onverbiddelijken, maar steeds wisselenden invloed op uit. Terwijl nu de statistiek voor de natuurwetenschappen: slechts een voorbereidende half-exacte methode kan zijn, die b.v. de nog in kinderschoenen wankele meteorologie heden ten dage voor onweders, zomervlekken enz., en de reeds wat verdergevorderde geneeskunde voor den duur en het verloop der verschillende ziektes, trouw beoefenen, maar die de chemie en de physica reeds lang: door veel eenvoudiger volop exacte deelformules over atoomgewicht, massa, energie enz. hebben vervangen; is de statistiek daarentegen voor het zuiver historisch, politiek en meest-individueel moreel gebeuren, wel voor immer gedoemd een ál te exacte, en dus oppervlakkige ietwat valsche methode te blijven, omdat hier naast eenige regelmaat-strooiende uiterlijke omstandigheden, de bewuste motieven van den zich-verantwoordelijk voelenden mensch - wat ook de deterministen voor de toekomst te bewijzen hopen - aan vaste formules of getallen aldoor maar blijven ont- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 66]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
snappen. Maar juist in het tusschengebied, waar van den eenen kant de vaste wetten der menschelijke samenleving werken, en van den anderen kant toch óók de individuen ingrijpen, b.v. in de economie, de demographie (over geboorten, huwelijken, sterfgevallen, ouderdomsklassen), en de leer der bevolkingsschakeering in beroepen, staten en standen, heeft de statistiek reeds ontzaglijke diensten bewezen. En dat kan zij dus nu ook voor de taal. De statistiek is toch een methode: om door opeenhooping van vele bizondere gevallen, abstractie makende van hunne kleinere onderlinge afwijkingen, en alleen lettend op hun belangrijker overeenkomst, daarin grootere groepen op te merken, en de verhouding dier verschillende groepen in precieze cijfers vast te leggen. Den besten uitleg dezer definitie: geeft de indeeling in de statische en de dynamische statistiek. De statische statistiek wil één complexen toestand beschrijven: b.v. de huidige schakeering en verdeeling van een landsbevolking naar provinciën, seksen, leeftijdsklassen, standen, hoogere en lagere vakken, ontspanningen, tendenzen, geestelijke stroomingen en geestelijke beddingen, kortóm in locale, familiale en sociale kringen. Elk dier grootere kringen met hunne ondergroepen: worden in de balans der statistiek gewogen, en voor dezen bepaalden tijd van dit land, elk met een precies getal geijkt. In tweede instantie kunnen dan de statistische opgaven van verschillende naast elkander levende landsbevolkingen, ter onderlinge verduidelijking neven elkander gelegd worden. Want hier, gelijk overal, is de vergelijking: de moeder van het dieper begrijpen. De dynamische statistiek daarentegen wil de maatschappelijke toestandsveranderingen nagaan, die dezelfde bevolking in den loop van den tijd doorleeft. Zij steunt natuurlijk op de statische methode, die eerst voor de verschillende tijdstippen hare taak zoo veelzijdig mogelijk mag afwerken. De dynamische statistiek moet echter zelf de meest geschikte tijdstippen daartoe uitkiezen, en zoo, als het ware een netwerk breien, waarvan de mazen dan door de statische statistiek moeten worden gevuld. Is dat eenmaal gedaan, dan neemt de dynamische weer zelf het werk in handen, en legt de historische verschuivingen: de nivelleerende assimilaties of integraties, de specifieke differencieeringen of dissimilaties, de uitschakelingen en kerndeelingen dier ééne landsbevolking: in chronologische reeksen van nauwkeurige getallen vast. Ook hier kan en moet, in tweeden aanleg, dan natuurlijk weer de vergelijking tusschen de verschillende historische ontwikkelingen, van min of meer verwante maatschappijen: het eindelijke licht doen opgaan. Wie de twee eerste deelen van het ‘Handboek der Nederlandsche taal’ gelezen heeft, begrijpt hieruit reeds aanstonds, hoe het derde | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 67]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
deel: de contemporaine taalgroepsverschuivingen en de synthese van dat alles in het Algemeen-beschaafd Nederlandsch behandelen zal. Om evenwel te hoog gespannen verwachtingen te matigen, wil ik hier reeds zeggen, dat tot dit werk het voorhanden Nederlandsche statistiekmateriaal der laatste 60, 70 jaren, nog slechts fragmentarisch toereikend kan genoemd worden. Het is evenwel minder de taak der linguisten dan die der sociologen, deze leemte zoo spoedig mogelijk aan te vullen; want het geldt hier nog alleen de sociologische factoren, die óók in de taal een rol spelen. Daarnaast zijn er nu echter een heele reeks zuiver-linguistische elementen, waarop tot nog toe de statistische methode slechts ten halve en gebrekkig is toegepast, hoewel ook hier de éénige zekere oplossing te vinden is, voor allerlei vraagstukken, die ons voortdurend bezighouden. En daar het persoonlijk vrije initiatief: op zuiver taalkundig gebied een nog minder belangrijke rol speelt, dan op het sociologisch terrein, kunnen we hier nog veel veiliger zekerheid en grooter regelmaat verwachten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
I.Er is indertijd heel wat geschreven over Storm's zoogenaamde articulatiebasis, die volgens velen een der diepste oorzaken zou zijn van het uiteenloopend klankverschil: tusschen al de talen en dialecten, die er op Gods wereld gesproken worden. Sommigen legden hierbij vooral nadruk op de mond- en tonghouding in den ruststand (‘Indifferenzlage’); anderen beschouwden de articulatiebasis mijns inziens veel juister, als een associatief complex van nationale articulatiegewoonten. Zoo wees men erop, dat de Engelschen heel weinig hun lippen bewegen, de tong bij het spreken over het algemeen plat en laag houden, maar àls zij ze van voren opheffen, dit graag toch een beetje meer naar achteren doen dan de Franschen, die met hun tong graag zoover mogelijk naar voren werken, of m.a.w. vóór in den mond spreken, en ook hunne lippen veel sterker bewegen. Als men deze beschouwingen, het best door Jespersen: Lehrbuch der Phonetik2 blz. 249-51 bijeengezet, aandachtig naleest, stoot men aanhoudend op vaagheden, zoo b.v. voor het Duitsch: ‘Zischlaute kommen häufig vor - (es) kommen nur wenige ausgeprägt niedere Vokale vor - in schwachen Silben häufig, auch l, m, n, r als Gipfel, doch kommen auch volle Vokale vor - Konsonantengruppen häufig’; voor het Fransch: Stimmbänderverschluss sehr selten. - In schwachen Silben oft volle Vokale - nur wenige Konsonantengruppen nach Vokal - enz. enz. Men ziet het: ‘häufig, oft, wenig, auch, selten, sehr selten’ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 68]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
daar moeten wij het mee doen. En toch het middel om hier tot exacte precisie te komen, ligt voor de hand: tèl ze! En niet in het woordenboek natuurlijk, - daar staan immers allerlei termen die zelden of nooit gebruikt worden, met woordjes die minstens tienmaal in elk gesprek voorkomen, gelijkwaardig naast elkander; en de buigings- en vervoegingsvormen staan er meestal zelfs heelemaal niet in! - maar in een doorloopenden tekst, of liever nog uit den mond van een spreker, en het allerliefst uit de levende gesprekwisseling van het dagelijksch verkeer. Toen Förstemann in 1840-50 het eerst op dit idee kwam (Neues Jahrbuch der Berlinischen deutschen Gesellschaft. Bnd. 7, blz. 83 vlgd. Kuhn's Zeitschrift Bnd. I, blz. 163 vlgd. en II, blz. 35 en 401 vlgd.), was de phonetiek nog niet heel ver gevorderd; en of hij wilde of niet, hij moest toen wel met letters in plaats van klanken werken, wat hij uitdrukkelijk met spijt constateert. Verder was zijn fout, dat hij het zich te gemakkelijk maakte. Hij meende met het tellen van een vier-, vijfhonderd klanken voor elke taal te kunnen volstaan. Hij behandelde zoo het Nieuwhoogduitsch, Middelhgd., Oudhgd., Gotisch, Latijn, de oud Grieksche dialekten en het Sanskrit, en mengde zoo, niet zonder schande en schade de statische door de dynamische statistiek heen. Weldra volgde Schleicher hem ‘letterlijk’ na in zijne Formenlehre der kirchenslawischen Sprache, blz. 17 vlgd. Ondanks deze gebrekkige methode kwamen beiden echter reeds tot interessante resultaten, die door de latere onderzoekingen ten volle bevestigd werden. Zoo bleken in al de onderzochte talen de tandmedeklinkers veelvuldiger voor te komen, dan de lip- en keel-medeklinkers samen, maar de overeenkomstige e- en i-klinkers toch niet altijd in de meerderheid te zijn tegenover de o's en oe's. Whitney: Oriental and linguistic Studies, New-York 1874, was, zoover ik weet, de eerste, die zuiver phonetisch te werk ging, en bovendien begreep, dat de waarde der statistiek, krachtens haar wezen, juist in de groote getallen gelegen is. Hij telde dan voor het deftig uitgesproken literaire Amerikaansch-Engelsch dier dagen 10000 klanken uit, en legde zoo het percentsgewijze voorkomen van elk: tot in 2 decimalen nauwkeurig vast. Hetzelfde deed hij voor het Sanskrit (Journal of the American Oriental Society, vol. 10, en kort samengevat in zijn Indische Grammatik, Leipzig 1879 blz. 29). Het resultaat dezer twee eenvoudige geduldoefeningen was reeds zeer belangrijk. Alleen de lange en korte a: brengen het in het Sanskrit samen tot 28 % van alle klanken, terwijl alle overige klinkers tezamen, r̥ en l̥ inkluis, slechts 15½ % bedragen. Met behulp der onderzoekingen van Förstemann vergelijkt Whitney dan de verhouding tusschen vocalen en consonanten in | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 69]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de verschillende talen (wat natuurlijk voor den silbenbouw zeer belangrijk is) en komt zoo tot dit lijstje van percenten:
Verder telt hij dan natuurlijk eenerzijds de scherpe en zachte glijders en ploffers, de neusklanken en vloeiers, en anderzijds de tand-, lipen medeklinkers samen, en legt al die verhoudingen in percentcijfers vast, evenals dit voor de verschillende soorten van klinkers geschiedt. Na Whitney heeft zich vooral B. Bourdon: L'expression des émotions et des tendances dans le langage, Paris 1892, met de taalstatistiek bezig gehouden. Ook hij begon natuurlijk met voor het Fransch de phonetische klanken uit te tellen (Chap. 6). Het was hem echter, gelijk de titel van zijn werk reeds aanduidt, hierbij vooral ook om den aesthetischen indruk, m.a.w. om de klankexpressie te doen. Hij had daartoe een tiental fragmenten uitgekozen, van geheel verschillende gemoedsstemming, en meende nu, als de dichters met hun beweringen over klankexpressie gelijk hadden, in eens tot opvallende resultaten te moeten komen. Die vond hij niet. En daaruit concludeerde hij nu: dat de klankexpressie een illusie is. Typisch voorbeeld van dwaling, bij de ongeoefende statistici zeer gewoon. Zij meenen door hun uiterlijke cijfers de diepinnige kennis van het onderzoekingsobject te vervangen. Nutteloos pogen! Het eigenlijk wetenschappelijke der statistische methode zit niet in de eenvoudige optel- en deelsommetjes! De moeilijkheid ligt in de verschillende waardeering: der onbeteekenende en der belangrijke cijfers; in het afbakenen der verschillende groepen naar werkelijkkarakteristieke kenmerken, opdat het eindresultaat in z'n abstracte cijfer toch de rijkst-mogelijke concreetheid inhoude. En daartoe is een degelijke deskunde van de onderzochte verschijnselen noodig. Welnu, van aesthetica had de heer Bourdon - zijn linguistisch zeer verdienstelijk boek bewijst het van voren tot achteren - slechts heele flauwe begrippen. Het zou dan ook niet moeilijk vallen, uit | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 70]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dezelfde fragmenten en dezelfde cijfers, waaruit hij tot het niet bestaan der klankexpressie besluit, met alle evidentie het volle bewijs voor een fijn geschakeerde zielsverklanking te voeren. Maar ik meen hier ter plaatse met een paar eenvoudige Nederlandsche voorbeeldjes meer nut te doen. Welnu, men leze nu eens na elkaar de twee bekende sonnetten van Kloos: ‘De zee, de zee klotst voort in eindelooze deining’ en ‘Ik denk altoos aan u, als aan die droomen.’ - Hebt U 't gedaan, en nu wel gemerkt, dat U voor elk dier sonnetten een heel anderen mondstand noodig hadt? Voor ‘De zee’, hebt U een koelen gladden streepmond getrokken: met de lippen plat tegen de tanden, en de tong op den bodem van den mond, bijna alleen met den breeden dunnen voorrand tegen de tanden bewegend. Maar bij het lezen van ‘Ik denk altoos aan U,’ hebt U de lippen ietwat vooruitgestulpt gelijk men bij 't kussen doet, terwijl uw warme tong in malsche beweging, vooral aan den wortel, beurtelings bol werd en slonk. Dat is aesthetische invoeling, waarover ongevoelige naturen zich vroolijk mogen maken, zooveel ze willen. Maar nu komt de statistiek, en die telt uit, dat in het eerste sonnet de ɛ, ɪ, e, ɛi͡, i, ĭ, die alle den eerstbeschreven mondstand vorderen, samen 102 maal voorkomen, terwijl al de andere klinkers en halfklinkers het samen slechts tot 72 brengen; terwijl daarentegen in het tweede sonnet de ə, a, ɑ, ɔ, u, o, ø, ʏ, y, ɔu͡, ʚy͡, u, ŭ, die alleen bij den laatstbeschreven mondstand mogelijk zijn, samen 105 keer terugkomen, terwijl al de andere klinkers samen niet hooger dan 32 halen. Om dit echter goed te begrijpen, moeten wij deze cijfers in percenten omrekenen, en ze met de statistiek van het Algemeen Beschaafd Nederlandsch, en nog een paar andere verzen vergelijken.
Zoo zien wij dus met volle zekerheid, dat Kloos - toch wel onder invloed van zijn gevoel! - in beide sonnetten zeer merkbaar van onze neutrale articulatiebasis is afgeweken. En dit is exacte wetenschap, waarmee zelfs de stugste prozamensch niet meer lachen kan. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 71]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Verder konden Bourdon en Whitney de conclusie van Förstemann betreffende de overgroote meerderheid der dentale medeklinkers voor een heele groep van talen bevestigen, zoodat dit van toen af voor het Sanskrit, Grieksch, Latijn, Italiaansch, Spaansch, Fransch, Gotisch, Hoogduitsch, Engelsch, Welsh, Russisch, Hebreeuwsch en Hongaarsch wetenschappelijk vast stond. Tot welke mooie praktische conclusies zulke constateeringen leiden kunnen, toonde Faddegon op het 6de Ned. Philologencongres, Handelingen blz. 101, 104. Bourdon vulde verder ook de bovengegeven lijst van Whitney: over de verhouding der vocalen tot de consonanten, in de opgenoemde talen aan; en knoopte daaraan een paar ingenieuze opmerkingen vast: over het muzikaal karakter der talen met veel en lange klinkers, en het grooter activiteitsgevoel der volken wier talen veel medeklinkers rijk zijn. Dit laatste zouden we, meen ik, gemakkelijk eveneens op aesthetisch gebied kunnen overbrengen, door b.v. Helmers met Hélène Swarth, of den oproerszang der Luciferisten met de eerste beschouwende rei uit Lucifer, statistisch te vergelijken. Als men nu echter uit het materiaal van Bourdon en Whitney, onze boven geschetste articulatiebasis wilde afleiden; zou men natuurlijk ook dáártoe met de onderlinge verhouding der ɛ- en ə-rij moeten beginnen. Zoover de verschillende wijze van bewerking toeliet heb ik uit beide bronnen de gemiddelde verhouding berekend: en kwam tot een weliswaar bevredigend, maar toch ook in menig opzicht bevreemdend resultaat, dat ik onder alle voorbehoud meedeel, al was het alleen om tot verder onderzoek aan te sporen. In het Fransch zou dan de ɛ-rij 47 % en in het Engelsch 53 % bedragen. Bevredigend noem ik dit, omdat het Engelsch dus inderdaad koeler blijkt dan het Fransch, maar bevreemdend, omdat het Nederlandsch met z'n 34 % zoo ontzaglijk veel warmer dan het Engelsch en Fransch zou blijken te zijn. Er zullen hier wel particuliere opvattingen en fouten schuilen. Zeer geschikte teksten om al deze vraagstukken opnieuw, aan een degelijk onderzoek te onderwerpen, lijken mij: F. Franke: Phrases de tous les jours9, (met Ergänzungsheft7 1910) Berlin, Reisland 1906, prijs 1 M. 60; E. True-O. Jespersen: Spoken English7 (met Ergänzungsheft7 1910) ibidem 1908, pr. 1 M. 60; E. Meijer: Deutsche Gespräche. Ibidem 1906, pr. 1 M. 50; P. Passy: Le français parlé6. Ibidem 1908, pr. M. 0,80. Voor sommige fijnere resultaten, zal men echter eerst de zoo gewonnen, op het alphabet der Association phonétique internationale gebaseerde statistiek, in het analphabetisch systeem van Jespersen óm moeten rekenen: door namelijk elken klank in zijn elementen te ontleden, en daarna elk dier elementen weer afzonderlijk op te | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 72]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
tellen. Dat men, dit moeilijk ideaal beoogende, er natuurlijk van het begin der statistiek af, op bedacht moet zijn: voor sommige klanken twee of drie hulpteekens aan te nemen, zal ieder die Jespersen heeft bestudeerd gemakkelijk inzien; maar aan het prachtige resultaat zoo te bereiken, zal ook wel geen enkel deskundige kunnen twijfelen. En wat is er nu tot nog toe voor het Nederlandsch gedaan? Een jong begaafd onderwijzer, de heer J. Geerts te Amsterdam heeft op mijn verzoek de phonetische teksten achter in Dijkstra uitgeteld, nadat Jac. van Alphen deze van de Friesche eigenaardigheden gezuiverd, en ook op eenige andere punten verbeterd had. Het resultaat van die statistiek, die ik onlangs zelf tot 10000 klanken heb aangevuld en afgerond, zal ik in mijn Handboek publiceeren. Maar het zou mij zeer welkom zijn, als hetzelfde eens op eenige andere teksten werd toegepast. Het langste stuk in Dijkstra, is een scène uit De Koo's Kandidatuur van Van Bommel: dus ietwat deftig Algemeen-Beschaafd Nederlandsch. Daarnaast zouden nu op de eerste plaats uit een roman of tooneelstuk: de gesprekken van menschen uit de lagere volksklasse in aanmerking komen, mits ze niet al te sterk dialect spreken; maar daarnaast zijn ook statistieken over allerlei soorten van teksten wellekom. Als nu de onderwijzers aan dit alles eens een handje wilden meehelpen. Maar zij moeten goed de klankleer kennen, en aanvankelijk zeker de teksten eerst in phonetisch schrift transcribeeren. Later gaat dat al tellende van zelf. Het alphabet der Association phonétique internationale is natuurlijk aangewezen, liefst in nauwe aansluiting bij Dijkstra, wiens systeem après tout verreweg het beste en bruikbaarste is. Zij, die een dialect kennen, kunnen zich natuurlijk nog verdienstelijker maken. Alleen zou ik hun dan willen aanraden, zich bij de vaststelling der dialectklanken te houden aan een eventueel reeds bestaande dialectgrammatica, - of daarvoor eerst een phonetische specialiteit te raadplegen, want daar hangt natuurlijk alles van af. Dat ook hier interessante resultaten als voor het grijpen liggen, wil ik even met één voorbeeld bewijzen. Voor de dialecten heb ik zelf telkens 2000 klanken geteld: uit de phonetische teksten van Sipma voor het Landfriesch, van Colinet voor het Aalstersch en van Grootaers voor het Tongersch. Misschien dat ik ook Smout voor het Antwerpsch en Goemans voor het Leuvensch nog zal natellen. Maar dan is mijn materiaal voorloopig ook uitgeput. Het is nu bekend, dat de Friezen en Hollanders in overeenstemming met hun koeler karakter meestal de lippen glad tegen de tanden houden; terwijl de Brabanders, al wat warmer van temperament, de lippen beginnen te plooien, en de | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 73]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Limburgers ten slotte, die heete Italianen van het Noorden, meestal met vooruitgestulpte lippen spreken. Welnu, volgens onze statistieken uit de teksten van Sipma, Colinet en Grootaers komen we tot de volgende getallen.
Als wij deze cijfers met die van het staatje op blz. 70 vergelijken; zien we dus, dat het Algemeen-Nederlandsch in stemtemperatuur met het Landfriesch op dezelfde lijn staat, terwijl de Zuid-Limburgers altijd even warm spreken als Kloos toen hij het Sonnet: ‘Ik denk altoos aan U’ dichtte, en de Zuid-Brabanders met René de Clercq het midden houden. Als dus verder ook de fijne verzenproevers zich tot dit slaafsche klankentellen wilden leenen - van hen wordt niet zooveel gevraagd: in een uurtje komt men, na eenige oefening, best met een sonnet klaar! - dan zou uit deze samenwerking heel wat nieuw licht kunnen opgaan over problemen die anders noodzakelijkerwijze in het halfdonker moeten blijven schemeren. Woorden wekken maar voorbeelden trekken. Wat uit een lange beschrijving niet duidelijk wordt, verklikt één staaltje vanzelf. Daarom laat ik hier een mijner papiertjes afdrukken. Eerst het sonnet ‘De Zee’ in phonetische transcriptie.
də ze
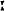 də ze
də ze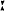 klɔtst fo
klɔtst fo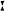 rt ɪn ɛɪ͡ rt ɪn ɛɪ͡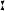 ndəlo ndəlo zə dɛɪ͡ zə dɛɪ͡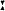 nɪŋ nɪŋ
də ze
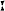 warɪm warɪm ɛɪ͡n zi ɛɪ͡n zi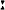 l zɪxsɛlf werspi l zɪxsɛlf werspi gəlt sit gəlt sit
də ze
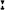 ɪzɑls mɛɪ͡n zi ɪzɑls mɛɪ͡n zi l ɪn we l ɪn we zən ɛn vərsxɛɪ͡ zən ɛn vərsxɛɪ͡ nɪŋ nɪŋ
zɛɪ͡ĭɪz e
 n le n le vənt sxo vənt sxo n ɛn kɛnt sɪxsɛlvə nit n ɛn kɛnt sɪxsɛlvə nit
zɛɪ͡ wɪst sɪxsɛlvən ɑf ɪn e
 wɪgə ver wɪgə ver ɛɪ͡ ɛɪ͡ nɪŋ nɪŋ
ɛn wɛnt sɪg ɑltɛɪ͡t um ɛŋ ke
 rt we rt we r wa r wa r zɛɪ͡ vlit r zɛɪ͡ vlit
zɛɪ͡ drʏkt sɪxsɛlvən ʚy͡
 t ɪn dʚy͡ t ɪn dʚy͡ zəndərlɛɪ͡ lɛɪ͡ zəndərlɛɪ͡ lɛɪ͡ nɪŋ nɪŋ
ɛn zɪŋt en e
 wɪg blɛɪ͡ wɪg blɛɪ͡ ĭɛn e ĭɛn e wɪx kla wɪx kla gənt lit. gənt lit.
o ze
 wɑz ɪk ɑls xɛɪ͡ wɑz ɪk ɑls xɛɪ͡ ĭ ɪn al yw umbəwʏsthɛɪ͡t ĭ ɪn al yw umbəwʏsthɛɪ͡t
dɑn zɔu͡
 ŭ ɪk e ŭ ɪk e rst xəhe rst xəhe l l ɛn gro ɛn gro t xəlʏkəx sɛɪ͡ t xəlʏkəx sɛɪ͡ n n
dɑn hɑt ɪk e
 rst xe rst xe n lʏst na n lʏst na r mɛnsləkə bəlʏsthɛɪ͡t r mɛnsləkə bəlʏsthɛɪ͡t
up mɛnsələkə vrø
 xt ɛn mɛnsələkə pɛɪ͡ xt ɛn mɛnsələkə pɛɪ͡ n n
dɑn wɑs mɛɪ͡n zi
 l en ze l en ze ɛn ha ɛn ha rə zɛlfxərʏsthɛɪ͡t rə zɛlfxərʏsthɛɪ͡t
zɔu͡
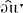 wɛɪ͡ wɛɪ͡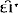 l zɛɪ͡ gro l zɛɪ͡ gro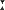 tər ɪz dɑn gɛɪ͡ tər ɪz dɑn gɛɪ͡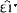 nɔx nɔx ro ro tər zɛɪ͡ tər zɛɪ͡ n n
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 74]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Nu ga ik tellen. Aan den eenen kant staan de klinkers, aan den anderen kant de medeklinkers. Ik ga het stuk twee keer door. Den eersten keer voor de vocalen, daarna voor de consonanten. Telkens als ik een klank ontmoet zet ik een streepje achter het overeenkomstig phonetisch teeken. Telkens als ik zie dat het den vijfden keer is, maak ik het streepje wat dikker of wat langer. Dan is later het uittellen zooveel te zekerder. 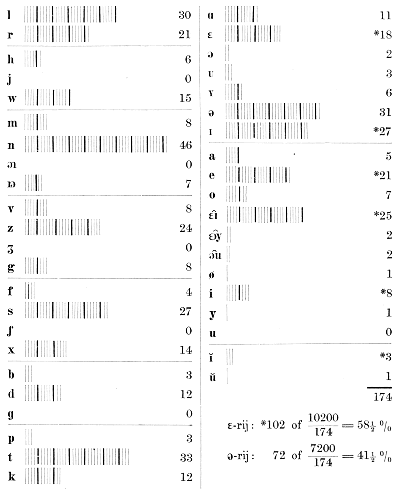 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 75]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Natuurlijk heeft ten slotte de dynamische statistiek der losse klanken: niet bij het Algemeen-Beschaafd, maar met de dialecten te beginnen. In veel gevallen zal dit moeilijk zijn, daar ons natuurlijk uit het verleden geen phonetische teksten ten dienste staan. Maar onmogelijk is het niet. Alleen mogen zich hier natuurlijk alleen hoogstaande krachten aan wagen. Zoo zie ik niet in, waarom wij op een goeden dag niet zouden verrast kunnen worden: met een dynamische klankstatistiek van het Brugsch, Gentsch of Antwerpsch, van het Zuid-Limburgsch, Geldersch-Cleefsch, Delftsch of Land-Friesch loopend over een vijf- of zestal eeuwen. En dat daarvan de resultaten pas echt grandioos zouden zijn, dat kan elk Neerlandicus gemakkelijk op zijn vingers uitrekenen. Dàn toch pas zouden wij voor de wisseling der klanktendenzen in het Algemeen-Beschaafd Nederlandsch vasten grond onder de voeten hebben, en met behulp der vergelijkende en combineerende dynamische statistiek zouden wij voet voor voet terrein winnen, altijd verder! tot de heele historische Nederlandsche klank-ontwikkeling, en daarmee tevens een majestueus brok hoogland: van nationaal karakteren zieleleven voor ons openlag. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
II.Maar met het tellen van de afzonderlijke klanken is de lange reeks der statistische taalonderzoekingen pas begonnen. Het eerstvolgende probleem is de silbenbouw. Whitney heeft zich althans inzooverre hiermee ingelaten, dat hij voor z'n Engelsche teksten van zamen 10000 klanken: ook het aantal silben heeft geteld, en toen dat getal door het aantal consonanten heeft gedeeld. Hij kwam zoo tot het resultaat, dat één Engelsche silbe gemiddeld 17/10 of juister 1,682 consonanten noodig heeft. Dit globale resultaat is echter niet heel belangrijk, omdat het weer te weinig concrete inhoud heeft overgehouden. Bourdon (t.a.p. Chap. XI) is de eerste geweest, die voor het Fransch begon uit te tellen, hoe dikwijls alle klanken achter elkaar voorkomen: zonder pauze ertusschen. Hij begon met de groepen van twee klanken, en maakte daarvan een klimmende reeks, naargelang ze: nooit, ééns, tweemaal, driemaal, enz. tot 54 maal toe in eenige bladzijden tekst voorkwamen. Het merkwaardige nu van deze statistiek is, dat verreweg de meeste in zich mogelijke combinaties: onder de nul ressorteeren. Van de ca. 1100 klankparen komen er 560 absoluut nóóit voor, 140 éénmaal, 90 tweemaal, 57 driemaal, 52 viermaal, 38 vijfmaal, 19 tot 11 van zes tot dertien maal, 9 tot 2 van veertien tot negentienmaal, en bijna telkens slechts 1 groep van de twintig tot vierenvijftig maal voor. Er bestaat | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 76]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dus tusschen sommige klanken een ontzaglijke affiniteit, en tusschen andere een onverzoenlijke afstooting. Toen nu Bourdon de nooitvoorkomende groepen nader begon aan te kijken, bleek het hem aanstonds, dat de reden dezer onderlinge afstooting in hun algeheele of gedeeltelijke gelijkenis moet gezocht worden: il y a une tendance manifeste à éviter les successions de sons semblables ou analogues. Wanneer dus deze tellingen voor een groote reeks talen hetzelfde resultaat opleveren - en aan de waarheid van dit vermoeden kan nauwelijks getwijfeld worden - zullen deze eenvoudige statistiekjes een weliswaar negatief, maar tòch ook veel algemeener bewijs: voor de diepe taalneiging der differentieering geleverd hebben, als al onze met zooveel moeite en zorg bijeengezochte dissimilatie-voorbeeldjes samen. De fout van Bourdon was echter weer, dat hij uit gebrek aan algemeene taalkennis niet de juiste stempels wist te kiezen, om uit zijn statistisch materiaal de noodige munt te slaan. Zoo profiteerde hij ternauwernood van het begrip der klankaffiniteit, om b.v. allerlei analogische uitbreidingen der klankwetten te verklaren. Verder maakte hij geen onderscheid tusschen de initiale en finale consonantparen, of m.a.w. tusschen de medeklinkergroepen die een silbe openen en sluiten. Anders had hij onmiddellijk het geheele geheim van den silbenbouw: de gestadig rijzende en dalende sonoriteitsgolf ontdekt, en meteen de typische golfstructuren van verschillende Europeesche talen kunnen vaststellen. Zie Principes de linguistique psychologique, p. 432, 399, 461. Ten slotte bleef hij, moe van het tellen, bij de groepen van twee klanken staan, en gaf uit de grootere groepen, slechts eenige verdwaalde voorbeeldjes. Voor het Nederlandsch en zijne dialekten zou een klankengroepstatistiek mijns inziens: als volgt moeten worden opgezet. Eerst moeten de onafhankelijke begingroepen onderzocht worden. Hiertoe behooren: al de medeklinkers die voor den eersten klinker komen, mèt dien eersten klinker zelf. Hier doet zich natuurlijk aanstonds de moeilijkheid op: Wat is een onafhankelijk begin, m.a.w. mogen we eenvoudig het begin van elk woord nemen? Nee, natuurlijk. In ‘vader en moeder’ heeft b.v. en geen onafhankelijk begin. Over het algemeen dunkt mij echter, dat wij met het aannemen van lieering of sandhi streng zullen moeten zijn, en al deze gevallen in een aparte categorie moeten opnemen. Gelijk we zien zullen, worden die dan later bij de tusschengroepen gemakkelijk verrekend. En nu de techniek. Men kan daartoe een lijst aanleggen, juist als voor de losse klanken: aan de ééne helft klinkers en aan de andere helft de medeklinkers. Alleen kan | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 77]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de kant der klinkers natuurlijk tamelijk smal genomen worden, maar die der medeklinkers heel breed of ver uit elkaar. Want alles wordt gerangschikt naar den eersten klank. Achter de vocalen kan dus niets meer komen. Maar achter elken medeklinker kunnen 1o. alle vocalen, en 2o. soms nog een of zelfs twee medeklinkers komen, en daarna weer elke vocaal. De groep der s b.v. neemt ontzaglijke verhoudingen aan: Eerst sɑ, sɛ, sɔ, enz. met alle klinkers; dan sl- met alle klinkers, misschien sr-, evenzoo sj- (zal meest wel ʃ zijn) dito, dan sm-, sn-. Nu komt echter sx-, met 1o. weer alle vocalen, en 2o. sxr- met alle vocalen, dan sp- 1o. dito, 2o. spr- dito, 3o. spl- dito, en eindelijk st-, 1o. dito, 2o. str- dito. En achter elk van die mogelijke groepen moet plaats zijn voor telstreepjes. Ik herhaal hier opnieuw: het woordenboek kan ons helpen, om zoo ongeveer te zien, wat er zoo al zijn kan; maar voor de eigenlijke statistiek is het volstrekt onbruikbaar. Wie op deze wijze alleen de begingroepen: in de kindertaal of in de verschillende Nederlandsche dialecten aan 't onderzoeken ging, zou reeds aanstonds merkwaardige resultaten aan het licht brengen; vooral als hij er ter vergelijking b.v. het Fransch en een Slavische of Maleische taal bijnam. Men moet evenwel goed beseffen, dat juist omdat het aantal verschillende groepen zooveel grooter is als het aantal losse klanken, het onderzochte materiaal ook des te grooter moet zijn: 10000 groepen zijn bijlange na niet genoeg. Ik geloof dat we minstens tot 100000, misschien zelfs tot 1000000 groepen zullen moeten gaan, eer we op vaste verhoudingen komen van de verschillende combinaties. We zouden echter, daar het hier vooral om de medeklinkers te doen is, voorloopig van de verschillende klinkers na de medeklinkers af kunnen zien, en dan zijn 100000 groepen zeker meer dan voldoende. Als we dan maar beseffen, dat het zoo een voorloopig werk blijft, en er dus de verwaarloosde klinkers tòch bijnoteeren, opdat we later zelf, of andere statistici, op ons begonnen 100000 tot de 1000000 door kunnen tellen. Op de tweede plaats komen de eindgroepen. Daartoe behooren de laatste klinker en alle medeklinkers die er achter komen. De moeilijkheid: wat we als een einde beschouwen, wordt op dezelfde wijs als bij de begingroepen geregeld. Wat de techniek betreft, rangschikken wij hier alles naar den laatsten klank. Het rijmwoordenboek kan ons toonen, wat we zooal te verwachten hebben, maar is voor het werk zelf onbruikbaar. De medeklinkerzijde wordt dus weer even druk als bij de begingroepen. Ter vergelijking zouden hier een paar der andere Germaansche talen allernuttigst blijken, maar natuurlijk eerst weer de Nederlandsche autochtone en heterochtone dialecten zelf. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 78]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ten derde komt dan het allerbelangrijkste, maar ook verreweg het moeilijkste onderzoek: der tusschengroepen. Onder een tusschengroep versta ik al de klanken tusschen twee klinkers, mèt die klinkers zelf. Dus b.v. in den juist neergeschreven zin undə, ʏsə, əgru, ərsta, ɑŋkə, ʏsə, ɪŋkə, ɪŋkə. Ook met het verbinden der woorden onderling moeten we hier weer streng te werk gaan. En het best van al zou zijn, al de tusschengroepen op de woordgrens: apart te noteeren, dus b.v. voor denzelfden zin əre, aɪ, ɪkɑ, ɑldə, əklɑ, ətwe, eklɪ, ɛti, iklɪ, ərsɛ. Grelijk men ziet, bestaat elke tusschengroep: uit een eindgroep + begingroep. We moeten dus in geen enkele taal de tusschengroepen gaan onderzoeken: eer er de begin- en eindgroepen geschakeerd en geteld zijn. Ook de techniek moet bij de twee vorige statistieken aansluiten in dier voege, dat elke tusschengroep tweemaal genoteerd wordt: ééns als eindgroep voor de eerste silbe, waarbij dus de eindklank de indeeling geeft; en eens als begingroep voor de tweede silbe, onder het hoofd van den beginklank. Hier vooral zijn zeker een 1000000 groepen noodig om tot definitieve resultaten te komen, maar kan men voorloopig, als men alleen met de medeklinkers rekent, ook met een 100000 al heel wat bereiken. Bij het opmaken nu van de allerbelangrijkste verschillen tusschen de onafhankelijke begin- en eindgroepen, en de begin- en eindgroepen der tusschengroepen, nemen we ten slotte alle genoteerde lieering- en sandhi-gevallen: als bemiddelende overgangsverschijnselen in onze conclusies op. Ik heb met opzet deze heele techniek eerst volgens het statistisch turfsysteem uitgewerkt, om den lezer zelf op het idee te doen komen, dat wij ook hier de demographen zullen moeten navolgen: en bij meer ingewikkelder statistisch werk, tot het kaartsysteem moeten overgaan. Elke begingroep (van de klinkers afgezien) krijgt een aparte kaart. Evenzeer de eindgroepen. De tusschengroepen krijgen elk een gekleurde kaart, die eerst bij de begingroepen dienst doen, en daarna zonder overschrijven bij de eindgroepen kunnen worden gerangschikt. Bij al deze begin-, eind- en tusschengroepen zal het verder z'n nut hebben bij de vereenvoudigde consonantverbindingen: tevens de oorspronkelijke te noteeren, als die ten minste nog gevoeld worden. Zoo zou het b.v. voor de tegenwoordige taal verkeerd zijn: voor thans (eindgroep ɑns) ook het oudere thands dus ɑnts aan te teekenen; maar voor Hollandsch (eindgroep ɑns) is dat wel noodig, omdat dit woord nog wel degelijk als afleiding van Holland: həlɑnt gevoeld wordt. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 79]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
III.Na den silbenbouw komt de verhouding van het getal silben tot het woord aan de beurt. Ook dit is door Bourdon onderzocht voor het Latijn, Grieksch, Fransch, Duitsch en Engelsch, maar telkens weer met veel te klein materiaal: van slechts 300 tot 1500 silben per taal. Toch kreeg hij zoo reeds eenige resultaten, die althans merkwaardig genoeg zijn om ze hier mee te deelen, al was het alleen maar om te laten zien, waartoe bij gunstige materiaalkeuze deze eenvoudige optelsommetjes weer leiden kunnen. Hij nam een stuk van Cicero, een van Plato, een van Bossuet, een van Thierry, een van Heine, en een uit het populair Engelsche ‘Tom Brown's School-days’. Daarin vond hij nu: (ik zet ter vergelijking Whitney's resultaten van 3729 getelde silben in de laatste kolom er bij)
Gelijk men aanstonds ziet, zijn deze cijfers niet exact vergelijkbaar, omdat de som der silben voor elken schrijver niet juist dezelfde is. Bourdon meende: dat let zoo nauw niet; maar dat is valsch, d.w.z. tegen het heele wezen der statistiek in. Waarom toch zouden wij ons met een tennaastenbij tevredenstellen, als we met bijna dezelfde moeite exacte verhoudingen kunnen vinden? Zoo ón-ge-véér wisten we dat trouwens ook wel zónder statistiek! Maar ondanks al deze fouten blijkt eruit, dat: was in het Latijn het aantal woorden van twee silben nog grooter dan van één silbe, en in het Grieksch slechts een beetje kleiner, in onze moderne kultuurtalen daarentegen: de éénsilbige woorden alleen bijna tweemaal zoo talrijk zijn dan al de meersilbige te zamen. Nu zal men zeggen, dat hierbij een heele boel lidwoordjes, voornaamwoorden en andere enclitische vormwoordjes zijn meegerekend; maar | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 80]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
datzelfde is in het Latijn en Grieksch, hoewel misschien in iets mindere mate, het geval. Als wij daar dus voor een oogenblik van afzien, heeft het althans voorloopig den schijn, dat wij druk op weg zijn naar het Chineesche monosyllabisme. Dat hangt natuurlijk samen met ons vlugger denken en spreken, ons intensiteitsaccent en nog zooveel meer. Maar eer we deze en dergelijke conclusies gaan trekken, moeten op groote schaal deze statistiekjes worden verbeterd en aangevuld. En daarbij zal het dan nuttig zijn vooral rekening te houden met den nadruk of het intensiteitsaccent, en verder met de verschillende woordsoorten. Dat toch de ongeaccentueerde eenlettergrepige woordjes bijna even goed met het hoofdwoord waaromheen ze gegroepeerd zijn, zouden aanééngeschreven kunnen worden: gelijk het trouwens in veel gevallen bij ons in het Middelnederlandsch gebruik was, en in verschillende Romaansche talen nog thans geschiedt, is wel voor iederen deskundige duidelijk. Ik zou dus willen voorstellen deze uit één hoofdwoord en een of meer enclitische woordjes bestaande accenteenheden, weer als overgangsgroepen apart in rekening te brengen. Onder de geaccentueerde monosyllaba echter zouden we verder onderscheid kunnen maken tusschen de verschillende rededeelen. En dan zou blijken, gelijk reeds Bourdon bevroedde, dat ten eerste de voornaamwoorden, echte bijwoorden (en voorzetsels), m.a.w. de zoogenaamd demonstratieve stammen, onder de monosyllaba het drukst vertegenwoordigd zouden zijn; maar dat ten tweede onder de naamwoorden en werkwoorden juist die vooral éénsilbig zijn, die verreweg het vaakste voorkomen. Zoo vinden we in Bourdon's materiaal voor het Grieksch: ἦν, δεῖ, χρὴ, enz. voor het Latijn par, sis, rem, est, vis, sit, enz. Ik herinner voor het Idg. aan de éénlettergrepige woorden voor lichaamsdeelen e.a. Zou deze tweede constateering, vraagt Bourdon, niet tevens de reden geven van de eerste? m.a.w. zouden de vroegere etymologen wel altijd gelijk hebben gehad, toen ze de demonstratieve wortels als een soort primitieve monosyllaba aanzagen, tegenover de meersilbige nominale en verbale wortels? Of zouden niet veeleer die demonstratieven, alleen door 't veelvuldig gebruik éénsilbig geworden zijn? De studies van het Eskimo, de Kaukasische en de Semito-Chamitische talen: komen voorloopig dit vermoeden alweer volop bevestigen. Men ziet wederom, tot welke breeduitvademende conclusies: zulk een paar eenvoudige optelsommetjes aanleiding kunnen geven. En is het dan geen schande voor de linguisten, dat zij deze allereenvoudigste methode tot nu toe bijna heelemaal ongebruikt hebben gelaten? En zullen we hen nu zoo maar laten voortsukkelen? Maar bovendien ook de stijlleer en de aesthetica kunnen hier weer | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 81]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
aan 't grasduinen gaan. Korte woordjes hooren bij vlug, lange woorden bij langzaam spreken. Vooral op de verschillende letterkundige genres zou deze statistiek dus moeten worden toegepast. Kullmann heeft onlangs in het Zeitschrift für Psychologie 1909, Bnd. 54 blz. 209, voor het Duitsch bewezen, dat hoe meer het letterkundig genre de dagelijksche omgangstaal naderbij komt, des te meer éénsilbige woorden het bevat: dus het meest in tooneelstukken, iets minder in brieven, nòg minder in verhalen, en het allerminst in wetenschappelijke verhandelingen. Maar hij meende bovendien, nog een anderen factor der woordverkorting op het spoor te zijn: in de gevoelsbetoning. Hoe meer gevoel er ligt in een tekst, des te meer éénsilbige woorden vindt men er. Deze laatste conclusie vooral interesseerde mij. En daarom heb ik voor de taal van eenige mijner vrienden, die ik dóór en door ken, een zelfde onderzoek ingesteld. Over het algemeen is het toch, in kwesties waar het gevoel bij te pas komt, aan te raden: met experimenten in subjecto vivo te beginnen. Welnu, het resultaat kwam over 't algemeen zeer goed uit. Alleen lijkt mij de term ‘gefühlsbetont’ te vaag gekozen. Het is meen ik, vooral de intensiteit van het gevoel, dat ons eensilbig maakt. Daartegenover staat dan de plechtige koelheid van al de vele lange, langzaam-gerekte samenstellingen in de verzen van Ten Kate, den koning der cantate. Verder zouden vooral de werken van Bilderdijk, hiervoor een gunstig proefveld zijn, daar deze bij al z'n intense ontboezemingslust toch ook, gelijk wij uit De Jager zien kunnen, vaak een geweldigen dorst had naar nieuwe lange woorden. Als deze, juist in de koelere passages frequent bleken voor te komen, zou dit tot een bij uitstek klaar bewijs kunnen dienen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
IV.Een vierde probleem biedt ons de lengte van den zin. Bourdon heeft zich dit vraagstuk gesteld in dezen vorm: hoeveel woorden telt de zin? Onder zin verstaat hij daarbij, behoudens onvoorziene gevallen waarin het gezonde verstand beslist: elk rijtje woorden dat in den druk wordt geopend en gesloten, door een punt, een dubbelpunt en een kommapunt - waarschijnlijk zal hij de vraagteekens en uitroepteekens ook wel als zinslot gerekend hebben, maar hij zegt het niet uitdrukkelijk. Daar natuurlijk de aandacht hier aanstonds op de verschillende genres viel, nam hij twee oratorische stukken van Bossuet, twee observeerende passages uit de Caractères van La Bruyère en een | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 82]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
bedrijf van Molières Le Bourgeois gentilhomme (alleen het proza). Daarnaast telde hij nog een passage van Wilhelm Wundt, den psycholoog, en een Duitsche klucht van Jacobson; waarvan hij echter alleen het slotcijfer geeft.
Hieruit blijkt dus reeds aanstonds, wat trouwens te verwachten was, dat mannen met veel ideeën, of die m.a.w. een groot gemak hebben van synthese, assimilatie, productie en associatie, ook van zelf veel grootere zinnen bouwen, dan de gewone alledaagsche sterveling, die meest in het blijspel aan het woord is. Na deze proeve van eenvoudige statische statistiek, ging hij nu tot de dynamische over, om den Franschen zinbouw der drie laatste eeuwen te vergelijken. Hij nam daartoe de bloemlezing van Marcou: Morceaux choisis des Classiques français, en telde van elk der voornaamste schrijvers minstens ongeveer 40 regels af. En zoo vond hij dat de gemiddelde zinslengte voor de 17de eeuw: 20,5 woorden, voor de 18de eeuw: 14,8 woorden, voor de 19de eeuw: 21 woorden was. Dit aanvankelijk eenigszins bevreemdend resultaat - daar toch de 17de eeuwsche Fransche klassieken bekend zijn om hun periodenstijl, die thans niet zoo uitsluitend meer in den smaak valt - verklaart hij dan verder, waarschijnlijk met recht: door onderscheid te maken tusschen perioden en perioden. Ook thans schrijven de Franschen dikwijls nog lange zinnen genoeg, maar het zijn aaneenkoppelingen van hoofdzinnen, hoogstens door een paar relatiefzinnen onderbroken, m.a.w. het zijn niet meer de kunstig samengestelde Ciceroniaansche zinstructuren vooral uit ondergeschikte leden bestaande, maar echte nevenschikkende perioden. Deze heele redeneering komt echter in | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 83]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
een bedenkelijk licht, als wij ons herinneren, dat Bourdon ook veel bijzinnen voor zinnen rekent. Men ziet, het resultaat is vooral daarom de moeite waard genoteerd, wijl het tot controleering uitlokt. Ik voor mij zoek de reden van de lengte der zinnen: dan ook nog in heel andere gronden dan in rijkdom van ideeën; namelijk in den rompstand en het temperament. Of is Frederik van Eeden dan b.v. zoo verre de mindere van Jacob van Lennep in voorstellings- en gedachtenrijkdom? En toch meende ik niet zonder reden, dat zij ook in hetzelfde genre van verhaal, volstrekt niet even lange zinnen bouwen. Daaruit zal men begrijpen, dat ik niet de woorden, maar de silben van den zin ga tellen. Deze geven toch ten eerste: een veel zuiverder lengtemaat dan de voortdurend varieerende woordenlengte; en hangen ten tweede meer onmiddellijk van de halfbewuste rompstand- en temperamentsneigingen af: want of wij een woord meer of minder kiezen is zeker evenveel aan de gedachte als aan het gevoel te wijten; maar of wij meer of minder onbetoonde silben elideeren, uitstooten of inslikken, dat is een zaak van adem, en van gevoel. Juist echter omdat dit weer met allerlei dingen samenhangt, die dikwijls niet met zekerheid uit de gewone spelling zijn op te maken, is hier vóór alles weer de statistiek op het levende woord: het gehoorde materiaal aangewezen. Niet in de boeken, maar naar de voorlezing van den schrijver zelf moeten deze telsommen worden opgemaakt. Dan heeft men bovendien het voordeel, dat men met een stopwatch (Fünftelsekundenuhr) den geheelen duur van periodes of alinea's kan opnemen. Het spreekt echter vanzelf: dat men niet zoo gauw de silben tellen kan als de schrijver ze uitspreekt. Daarom ga ik daarbij als volgt te werk. Ik studeer eerst goed den tekst in, en noteer vooral de twijfelachtige gevallen (waar ik niet weet hoeveel de schrijver uitspreekt of inslikt), op zulk een wijze, dat ik met een enkel potloodstreepje zijn ware uitspraak vast kan leggen. Pas daarna ga ik mijn dus-bewerkten tekst uittellen. Maar verder kan ik ook geen vrede hebben met Bourdon's zinsafbakening. Ik reken toch geen tusschengeschoven bijzinnen, inleidende zinnen of halve zinnen voor een zin tout court. Alle kommapunten en dubbelpunten ga ik dus voorbij. En voor mij is de zin pas uit, als er een heusche punt staat. En soms aarzel ik ook dan zelfs. De vraagteekens en uitroepteekens behandel ik met onderscheid. Bij het afhooren luister ik, of de schrijver een pauze maakt. Bij teksten, die ik niet te hooren kan krijgen, let ik er op, of de schrijver er een hoofdletter op laat volgen; maar beslist in twijfelachtige gevallen natuurlijk: m'n invoeling in schrijver en tekst. Welnu, om althans een paar van m'n resultaten hier mee te deelen, vond ik in | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 84]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
een fragment uit Oltmans' Het slot Loevesteyn, 131 zinnen, met te zamen 7962 silben, dus gemiddeld 61 silben per zin; Van Lennep's De gestoorde Bruiloft, 285 zinnen, met te zamen 14215 silben, dus gemiddeld 50 silben per zin;Ga naar voetnoot1) Koetsveld's De Haan v.d. Burgemeester en Het Bezoek, 183 zinnen, met te zamen 6765 silben, dus gemiddeld 37 silben per zin; Beets' Camera-fragmenten, 318 zinnen, met te zamen 9136 silben, dus gemiddeld 29 silben per zin; diverse verhaalstukjes uit Van Eeden, 527 zinnen, met te zamen 11358 silben, dus gemiddeld 22 silben per zin. Dat zijn toch feiten, die te denken geven, naar ik meen. Het zijn de eerste stukjes, die ik uittelde, en dus volstrekt geen uitgekozen brokjes pour le besoin de la cause. In deze gemiddelde ligt nu echter nog een realiteit verborgen, die wij er met eene nieuwe berekening uit kunnen halen, namelijk de gemiddelde afwijking. Twee schrijvers toch kunnen een zelfde gemiddelde zinslengte hebben, en toch inderdaad zinnen van heel verschillende lengte schrijven. Zoo komt b.v. A met 50 zinnen van 60, en 50 zinnen van 20 op hetzelfde gemiddelde als B met 50 zinnen van 45 en 50 van 35, namelijk op 40. En dat maakt toch in werkelijkheid een groot verschil! Daarom ga ik nu, nadat de gemiddelde gevonden is, voor elken zin de afwijking van het gemiddelde vaststellen: door bij grootere zinnen het gemiddelde getal van hun aantal silben af te trekken, en omgekeerd bij kleinere zinnen hun getal silben af te trekken van het gemiddelde. Al deze verschillen worden dan weer bijeengeteld, en de som gedeeld door het aantal zinnen. In ons geval b.v. heeft A (50 × 20) + (50 × 20)/100 = 20 en B (50 × 5) + (50 × 5)/100 = 5 tot gemiddelde variatie. Waarom zou binnenkort, voor al onze grootere schrijvers, de gemiddelde zinslengte (m) mèt de gemiddelde variatie (v), niet als thermometer kunnen dienen voor een gewichtigen factor: in hun zieleleven en temperament? Maar ik hoor U mompelen, dat ik bij Frederik van Eeden: z'n voorliefde voor het sprookjesgenre vergeet, en dat ik bij Van Lennep en Oltmans niet denk aan de litteraire mode dier dagen. Maar ik vraag het u: zou die sprookjesliefhebberij in Van Eeden dan weer | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 85]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
louter uiterlijk toeval zijn, of moet die niet innerlijk samenhangen met heel zijn wijze van voelen en denken? En die litteraire modes: zijn - van prullerige epigonen afgezien - toch ook weer niet als etiketten de schrijvers van buiten, op de schouders geplakt. Elke litteraire mode, die althans geen ephemeer vlindertje is, beantwoordt aan een denk- en voelgewoonte van een groep hoogstaande leiders; en niemand, die in dien kring opgroeit, ontkomt aan den invloed van hun temperament, en dat niet slechts voor z'n spreek- of schrijfmanier, maar óók en misschien nog meer, voor z'n innerlijke denken en voelen. Ik ontken dus volstrekt niet, dat we voor de zinslengte, zoowel met het genre, als met de litteraire modes en manieren rekening moeten houden, en dat we dus éérst Beets en pas daarna v. Eeden met Van Lennep moeten vergelijken; maar alles te zamen zijn dat correcties, gelijk elke nauwkeurige thermometer er noodig heeft, zij compliceeren het verschijnsel, maar vernietigen de diepere causaliteit volstrekt niet. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
V.Over het accent zijn in de laatste jaren verschillende statistische studiën verschenen, vooral voor het Duitsch en Engelsch. K. Marbe gaf in 1904 te Giessen een voordracht ‘Über den Rhythmus der Prosa’ uit. Hij voelde bij het lezen van Goethe's Sankt Rochusfest zu Bingen, ‘subjectief-aesthetisch’ een heel andere bewustzijnsdispositie als bij de lectuur van Heine's Harzreise. Hij besloot: dit statistisch te onderzoeken, en begon de beide teksten te accentueeren, en vroeg Prof. Roetteken hetzelfde te doen. Zij letten hierbij alleen op het intensiteitsaccent of den nadruk, en maakten voor het gemak: ook geen onderscheid tusschen hoofd- en bijaccenten. Nu ging hij na: hoeveel ongeaccentueerde silben telkens tusschen twee geaccentueerde silben instonden (en noemde deze cijfers ‘z-Werte’ naar Zahl). Deze telde hij nu tezamen, deelde ze door het aantal accentintervallen en kwam zoo tot de gemiddelde z-waarde (mz). Op dezelfde wijze als boven aangegeven: berekende hij daarna hun gemiddelde variatie of vz. Het bleek nu dat volgens beider accentueering in de fragmenten uit Goethe's reisbeschrijving, zoowel mz als vz tamelijk konstant: kleiner waren dan in de Harzreise van Heine. Hij ging toen verder, ook met Prof. Dürr, andere passages uittellen, en kwam zoo langzamerhand tot het inzicht, dat vz gedeeld door mz een ongeveer constante waarde had. Dit moest naar zijn meening met diepe rhythmische eigenaardigheden van het Duitsche karakter samenhangen, en zoo werd hem | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 86]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de gemiddelde constante vz/mzwaarde: 0,464 tot typisch kenmerk van het Duitsche prozarhythme. Om dit uit te laten komen vroeg hij Prof. Schneegans op dezelfde wijze een paar Fransche teksten te behandelen. Ter betere oriënteering laat ik hier zijn staatje afdrukken.
Men ziet al aanstonds, wat ook Marbe zich niet verheelt, dat de mysterieuze breuk vz/mz voor het Fransch nu juist niet zoo'n bizonder constanten indruk maakt. H. Unser: Über den Rythmus der deutschen Prosa, Heidelberg 1906, zette Marbe's onderzoek voort over de letterkundige genres; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 87]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
en vond dat de z-waarde het grootst is in verhalend proza, minder groot in den ‘affektlosen’ brief, nog kleiner in den ‘affektvollen’ brief, en eindelijk het kleinst in het dagelijksch gesprek, m.a.w. hoe meer gestyleerd de taal, des te grooter is het gemiddeld aantal ongeaccentueerde silben tusschen twee accenten. Daarop volgde spoedig: A. Lipsky: Rhythm as a distinguishing Characteristic of Prose Style. Archives of Psychology, New-York 1907, nr. 4, die een rechte evenredigheid vond tusschen de z-waarde en het gemiddelde aantal lettergrepen der woorden (ms). Daarop volgde toen, de reeds op blz. 81 genoemde studie van Kullmann, die o.a. óók uitrekende dat hoe grooter de gemiddelde z-waarde (mz), hoe kleiner het getal monosyllaba wordt. Eindelijk kwam Max Beer: Zeitschrift für Psychologie, Bnd. 56, 1910 blz. 264 vlgd., betoogen, dat hoe kleiner de gemiddelde z-waarde is: de leestijd des te grooter wordt, in proza althans, niet in poëzie. Welnu, ik heb voor het Nederlandsch bijna al deze constateeringen gecontroleerd, aan passages, mij voorgelezen door vijf schrijvers zelf, die ik door jarenlangen omgang zeer goed ken. En wat blijkt nu? Wat Lipsky (voor het Engelsch) meent te vinden komt bij mij volstrekt niet uit. Integendeel. Bij het dalen van mz stijgt juist ms! Wat Kullmann daarop (voor het Duitsch) verder bouwt, dat mz evenredig stijgt als het aantal monosyllaba daalt, en omgekeerd, komt bij mij niet uit, veeleer het tegendeel. Wat ten slotte Max Beer vond over den leestijd, komt al wederom bij mijn onderzoek volstrekt niet uit: eer is 't juist omgekeerd, maar dit toch ook weer niet constant. Ik zal later al mijn cijfers publiceeren. Wat volgt hieruit? Dat er natuurlijk een fout is in de methode. En deze is trouwens makkelijk aan te wijzen: ‘voor het gemak’ houden al deze leerlingen van Marbe, juist als hij zelf, geen rekening met de bijaccenten, zoo zeggen ze ten minste. Maar wat is het gevolg daarvan? Men kan het zelf, in de door hen betrekkelijk karig meegedeelde geaccentueerde teksten aanstonds zien, en trouwens uit eigen ervaring weet ik, dat men er toe gedwongen wordt: nu eens rekenen ze een sterk bijaccent wèl als hoofdaccent, en dan weer eens rekenen ze het niet. M.a.w.: er wordt hier gerekend met cijfers, berustend op subjectieve willekeur, zonder éénig houvast in de taalrealiteit. Het eerste beginsel der statistiek: dat men alleen gelijke gevallen mag optellen, of althans slechts dingen die in veel meer overeenkomen dan ze van elkaar afwijken, wordt hier met voeten getreden. Bovendien wordt hier overal, wat ik belief te noemen, statistisch gemierd; d.w.z. twee radeloos oppervlakkig gestelde problemen (over accent en woordlengte) worden op de vlijtigste wijze gecombineerd en in leege cijfers dooreengehaspeld; er wordt | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 88]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
met getallen ijverig gegoocheld, mysterieuze breuken worden naarstig opgesteld zonder eenig contact met de werkelijkheid, en zoo verwordt de statistiek tot een krioelende hokuspokus, jammer genoeg. Of dan al de resultaten dezer school louter verzinsel zijn? Neen. Wat Unser en Kullmann over de genres vonden, zal wel voor een groot deel waarheid blijken, zelfs heeft Marbe's breuk vz/mz ook bij mijn 5 Nederlandsche proefpersonen slechts een kleine en regelmatige schommeling tusschen 0,47 en 0,51; best mogelijk, dat hier dus toch waarheidskiemen schuilen. Maar om daaruit de volwassen waarheid op te telen, zal men in de accent-statistiek, gelijk trouwens overal, het materiaal moeten nemen gelijk het is: dus met al zijn trappen van nadruk. Juist om de contrôle gemakkelijk te maken, heb ik hierboven het staatje van Marbe overgenomen. Tischer: Philosophische Studien I, blz. 495-543, heeft bewezen, dat wij, binnen de perken van gewoon kamergeluid, op den duur niet meer dan vijf graden van geluidskracht kunnen onderscheiden. Daarop steunde nu S. Behn: Der deutsche Rhythmus und sein eigenes Gesetz, Strassburg 1912, bij het aannemen van 5 graden van taalintensiteit. Den laagsten graad, een silbe ə noemt hij 1, het hoofdaccent 5, het gewone bijaccent 3, het sterke 4, het zwakke 2. En als er iets is, dat dit nuttige boek afdoende bewijst,Ga naar voetnoot1) dan is het juist het objectief bestaan in het Duitsch van deze vijf intensiteitsgraden, en van hun practische onderscheidbaarheid. Welnu, dientengevolge moeten al de teksten door Marbe, Unser, Lipsky, Kullmann, Beer en Prandtl, opnieuw worden geaccentueerd, en nu niet met één enkel accentstreepje, maar met minstens vijf teekens. En dan, ik meen het zeer stellig, zal men tot definitieve resultaten komen. Waarom ik hier zoo zeker van ben? Wijl ik, na lezing van Behn, zelf opnieuw voor het Nederlandsch aan het accentueeren en het tellen ben getogen, en reeds prachtige resultaten verkregen heb. Wijl ik bovendien met een 65-tal mijner leerlingen, op de 3de klas van Gymnasium en Hoogere Burgerschool daaromtrent aan 't oefenen gegaan ben; en ca. 50 onder hen, reeds na eenige klassen, in de onderscheiding dier vijf trappen een verwonderlijke vaardigheid hebben verkregen. Alleen moet men geen aparte woordjes nemen, maar gesprekken en zinnen of zinnetjes uit een interessanten tekst. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 89]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VI.Een der schoonste weldaden, door de statistiek aan de taalwetenschap bewezen: is het boek van Th. Zielinski: Das Klauselgesetz in Ciceros Reden. Grundzüge einer oratorischen Rhythmik, Leipzig 1904. Dat men - in verzorgden stijl vooral - let op het rhythme der zinstaarten is algemeen-, en dat vooral de redenaars hierin sterk zijn - is wel niet minder bekend. Cicero heeft daar zelf lang en breed over geschreven. Alleen zijn de termen die hij gebruikt: voor ons niet altijd zoo heel duidelijk, en is bovendien de bedoelde tekst nog op menige plaats corrupt. Reeds verschillende geleerden hadden er zich nu aan gewaagd: het rhythme van Cicero's periodestaarten te onderzoeken, maar hoe zeker zij allen ook waren van hun resultaten, onderling weken zij op de wonderbaarlijkste wijzen af. Toen kwam Zielinski op het tamelijk snugger idee: ze eenvoudig allemaal te gaan tèllen. Dit bleek nu toch nog zoo héél gemakkelijk niet, daar wij dikwijls niet met volle zekerheid weten: wat Cicero als een periode beschouwde. Door langdurige lezing meent echter Zielinski, dank z'n litterairesthetische invoeling: daar tamelijk zeker van geworden te zijn; en al blijft dit het zwakke puntje in z'n werk (waarover men L. Laurand S.J.: Etudes sur le style des discours de Cicéron, Paris 1907, Livre II, p. 107-222 kan nalezen) over het eindresultaat zal wel geen twijfel meer wezen. Van de 17902 periode-staarten in Cicero's redevoeringen: behooren er 10845 of 60,3 % tot de volgende 5 grondtypen.
Van de overige behooren er 4776 of 26½ %, tot de afgeleide vormen, d.w.z. dat in een der grondtypen: een lange silbe door twee korte is vervangen. Zoo ontstaan b.v.
Zulke afgeleide vormen zijn er 18, grondtypen maar 5. Brengen we dat in rekening, dan beslaat elk der 5 grondtypen in doorsneeGa naar voetnoot1) c.a. 12 %; en elk der afgeleide vormen slechts 1½ %. Hieruit volgt | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 90]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
toch wel onmiskenbaar, dat Cicero eenige vaste rhythmen in oor en mond had hangen, die hij met bizondere voorliefde te pas bracht. Dat dit samenhangt met z'n litteraire manier, en z'n Grieksch-Rhodische leermeesters, daar is herhaaldelijk op gewezen; maar of dit ook misschien samenhangt met 's mans temperament en rompstand, dat is een vraag, die ik nog nergens gesteld vond. Toch waag ik het in dezen, iets te vermoeden. Want Cicero is niet de eenige, die er typische zinstaarten op na houdt. De Grieken waren hem daarin voorgegaan: vooral Isokrates, maar toch ook Demosthenes muntten erin uit. En die Grieksche zinstaarten: mogen bij oppervlakkig aankijken veel op die van Cicero lijken; in hun typische vormen, en vooral in de frequentie der onderscheiden typen: is er een merkbaar verschil. Men vergelijke b.v.K. Münscher: Die Rhythmen in Isokrates Panegyrikos. Programm Ratibor 1908 en C. Josephy: Der oratorische Numerus bei Isokrates und Demosthenes, Diss. Zürich 1887. Maar zoowel de Oud-Grieksche als de Latijnsche prozarhythmen berustten bijna uitsluitend op de kwantiteit. Dat werd sinds de 4de eeuw na Christus anders. En zoo werden b.v. in het oude kerklatijn
allemaal dus louter intensiteits-clausulen. Volgens W. Meyer: Der accentuirte Satzschluss in der griechischen Prosa vom 4. bis 16. Jahrhundert, Göttingen 1891 - wiens resultaten ten onrechte door een overvaren statisticus C. Litzica: Das Meyersche Satzschlussgesetz in der byzantizischen Prosa. Diss. München 1898 zijn betwist - ontwikkelden zich ook in het Grieksch van dien tijd, eenige sterk gelijkende intensiteits-clausulen:
H.v. Wilamowitz: Hermes Bnd. 34 blz. 214 vlgd. en D. Serruys: Mélanges offerts à L. Havet. Paris 1909 blz. 473 vlgd. bewezen | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 91]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
later, dat ook déze vormen reeds onder de oudere kwantiteitsclausulen voorkwamen. Gelijk men ziet, komen dus in het Byzantijnsche Grieksch altijd: twee ongeaccentueerde silben vóór het laatste accent. Naast deze drie grondtypen zijn er nu weer een heele reeks afgeleide, die zich echter alleen hierdoor onderscheiden, dat zich vóór het laatste accent meer dan twee dus b.v. drie, vier of vijf ongeaccentueerde silben bevinden. Het schijnt dus: dat het kleiner of grooter getal ongeaccentueerde silben slechts een bijkomstigen invloed op het geheel uitoefent. Met deze feiten voor oogen lette ik sinds jaren op het rhythme der Nederlandsche zinstaarten. (Zie Studiën. Deel 74 blz. 533). Maar al m'n toevallige konstateeringen en mooie voorbeeldjes: hadden mij waarschijnlijk nooit veel verder gebracht, als ik niet na kennismaking met Behn's bovengenoemd boek, stelselmatig aan het accentueeren en tellen was gegaan. Weldra kwam de regelmaat aan den dag, en bleek ook mijn vermoeden van vijf jaar geleden bewaarheid: dat juist als in het Byzantijnsche Grieksch, en ietwat dichterbij in volkomen overeenstemming met onze Middelnederlandsche versmaat, in het rhythme onzer tegenwoordige zinstaarten: wat meer of minder ongeaccentueerde silben tusschen de verschillende toppen, aan de typische vormen weinig afdoen. Aanvankelijk was een mijner grootste moeilijkheden: waar begint de staart. Onder den invloed der Latijnsche en Grieksche clausulen zocht ik hem aanvankelijk tot 5, 6, 7 of 8 silben te beperken. Weldra echter bemerkte ik zoo de feiten geweld aan te doen, en ik besloot tot regel te nemen: alle woorden die staan tusschen de laatste kleine pauze en de punt, m.a.w. de heele laatste constructie. Deze stukjes accentueerde ik nu met cijfers: naar de vijf graden van intensiteit, en nu merkte ik, dat deze opnieuw in overeenstemming met het Mnl. vers, meestal juist vier toppen telden; slechts zelden komt een 2 of 3 tweemaal voor. Men moet daartoe natuurlijk weer beginnen met te luisteren naar een schrijver die zijn eigen werk voorleest. Ik neem dus een stukje uit een studie van mijn vriend en collega: Mr. Dr. Charles Raaymakers (descendentiestand-koele variëteit) dat hij me zelf heeft voorgelezen: Ieder individualistisch kiesrechtstelsel | moet onverbiddelijk komen tot algemeen stemrecht 2 1 1 5 1 1 3 1 1 4 1 1 2 1. De ondervinding leert het | daar is geen ontkomen aan 1 2 3 1 5 1 4. Ook hier in ons land | zijn we reeds aardig op weg 3 1 2 5 1 1 4. Is dat eenmaal bereikt | dan moet de Eerste Kamer verdemocratiseerd 1 3 1 2 1 5 1 1 1̀ 1 1̀ 1 4. Dat is de historische lijn 2 3 1 1 5 1 1 4. En als dan ook het parlementaire stelsel | tot het uiterste is gedreven | dan heeft het individualisme | zijn hoogste ontwikkeling bereikt 1 5 1 1 4 1 2 1 3. En wat hebben we | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 92]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dan gewonnen 1 4 2 1 1 3 1 5 1? Dat het heil van den staat | blijvend en uitsluitend gesteld is | in handen van de klasse die numeriek de sterkste is | in handen van de arbeiders en het proletariaat 1 3 1 1 1 5 2 1 1 1 2 1 1 4. Dan viert het stelsel van de helft plus één | zijn hoogsten triomf | maar dan toont het zich ook | in al zijn absurditeit 1 5 1 2 3 1 4. Ik betreur ten zeerste | dat de werkman zoolang | van allen invloed op staatkundig gebied verstoken is geweest | ik gevoel veel voor den arbeidenden stand | ik heb eerbied voor den oppassenden arbeider | ik wil met den vromen abt van Cusans | de ruwe hand van den werkman kussen | maar voor den werkman knielen dat nooit 2 1 1 2 1 5 1 4 3. En dat is het toch | wat het individualistische stelsel ten slotte eischt | doordat het in zijn laatste consequentie | den gewonen onontwikkelden werkman | oppermachtig maakt | en als een god | voor wien alle knie zich buigen moet | ten troon verheft | enkel en alleen | omdat hij numeriek de sterkste is 1 2 1 1 1 5 1 4 1 3. Op dezelfde wijze heb ik nu verder, na nog eenige mondelinge proeven met andere personen, uit allerlei stukken van onze groote schrijvers: de zinstaarten geaccentueerd. Zoo b.v. van Hooft, Brandt, Justus van Effen, van der Palm, Potgieter, Beets, Broere, Douwes-Dekker, Schaepman, van Eeden, Kloos, Couperus en Lodewijk van Deijssel enz. Gaandeweg drongen zich nu vijf typen met karakteristieken gevoelsindruk aan mij op. Type 1. Kenmerk: Sierlijk, zacht, vlug en vloeiend. Aard: top voorop (of althans in de eerste helft)Ga naar voetnoot1) daarna in de lagere toppen nog een nieuwe daling en rijzing. Einde slepend. Voorbeelden: 1 1 5 1 3 1̀ 1 4 1̀ 1 2 1 Type 2. Kenmerk: krachtig ingehouden. Aard: top voorop (of althans in de eerste helft). Einde staand. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 93]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Voorbeelden: 1 1 4 1 1 5 1 1 1 3 1 2 Type 3. Kenmerk: Langzaam, plechtig, gerekt. Aard: Top voorop (of althans in de eerste helft). Daarna geleidelijke daling der toppen. Einde slepend. Voorbeelden: 1 1̀ 1 5 1 1 4 1 1 1̀ 1 3 1 1 Type 4. Kenmerk: stootend kort. Aard: Top in de tweede helft, maar niet op het einde. Einde meestal slepend. Voorbeelden: 1 2 1 3 1 5 1 4 1 Type 5. Kenmerk: Scherp, raak (of uitroepend en vragend). Aard: Top achterop. Einde meestal staand. Voorbeelden: 2 1 1 4 1 3 1 2 1 5 Daarna ben ik een statistiek gaan maken: van de frequentie dier typen bij al die verschillende schrijvers, en meen treffende dingen gevonden te hebben: over den samenhang van deze typen met de rompstanden van Rutz. Daar ik echter graag mijn materiaal eerst nog wil vervolledigen, en liever ook anderen eens in dezelfde richting zoeken zag, verklap ik daar voorloopig nog niets van. Alleen nog dit. Wie mijne typen eerst met de Laat-Latijnsche en daarna met de klassieke clausulae vergelijkt, merkt al spoedig een treffende overeenkomst. Ik wijt die echter niet aan historische maar aan psychischelementaire verwantschap. Om dit kort in het licht te stellen, kies ik eenige voorbeelden uit de Praefatio Apostolorum in het Missale Romanum, waarvan wij | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 94]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dank zij de Gregoriaansche muziek vrijwel de waarschijnlijke accentuatie kunnen vaststellen:
Hieruit is nu misschien ook te verklaren, waarom de cursus dispondaicus van lieverlede verdween. Praktisch was hij met den cursus velox samengevallen. Hoe ten slotte ook in het mhgd. en nhgd. het ags., mengl. en nengl. (meer of min onder invloed van den Latijnschen cursus?) dergelijke zinstaarten voorkwamen, kan men nazien bij K. Burdach: Über den Satzrhytmus der deutschen Prosa. Sitz. Ber. d. preus. Ak. d. Wiss. 1909 blz. 520-535. Fr. Wenzlau: Zwei- und Dreigliedrigkeit der deutschen Prosa des 14en und 15en Jahrhunderts. Halle 1909 en A. Schönbach: Sitz. Ber. d. kk. Wiener Akad. Bnd. 160 blz. 51 vvlg. J. Shelley: The Church Quarterly Review. April Number 1912, A. Clark: Prose Rhythm in English, London 1913. F. Fijn van Draat: Voluptas aurium. Englische Studien 1914? Idem: The Cursus in Old English Poetry. Anglia 1914 blz. 377 vlgd. Ik citeer deze studies om zoo volledig mogelijk de literatuur te geven, niet alsof ik met alles instemde. Trouwens vooral in zulke zaken: waag ik me niet aan halfbekende talen. En hiermee sta ik aan het einde van de klankleer: in haar verhouding tot de statistische methodes. Het onderwerp dat ik als titel boven dit opstel schreef, is dus nog op geen derde afgehandeld. Ook voor de prosodie en het verzenrhythme, voor de woordvorming, de naamgeving, de beteekenisontwikkeling en de beeldspraak, kan en moet langs statistischen weg, nog o zoo veel gedaan worden. En dan ten slotte de stylistiek, de grammatica en de syntaxis! Den Hertog en Terwey wisten natuurlijk altijd hoe alles precies was, maar de boeken van v. Wijk, Holtvast en Reynders staan vol woordjes als soms, vaak, zelden, ook, wel eens enz. Wie goed uit z'n oogen ziet merkt hier slag op slag: hoe diep waar de kijk is van Ronjat: Essai de syntaxe des parlers provençaux modernes, Macon 1913, | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 95]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
die, na de voornaamste Provençaalsche afwijkingen kort gerecapituleerd te hebben, zegt: ‘Les traits 1, 2, 3, 4, 5, 6, 7, 8, 9 consistent essentiellement en possibilités linguistiques au demeurant non seulement applicables aux oeuvres littéraires, mais appliquées avec une extension plus ou moins considérable même dans la conversation courante. Les traits 10, 11, 12, 13, 14, 15, 16, 17 reflètent le goût de la langue pour certaines tournures qui sont préféreés à d'autres également correctes, mais moins idiomatiques. Les traits 11, 12, 13, 14, 15, 16 sont au moins pour une grande part de véritables règles grammaticales sans l'application desquelles les phrases ne sont plus senties comme correctes.’ Wat een frissche levenswaarheid waait ons uit die woorden tegen, als we ze ontmoeten na een kwartier vervelens in Den Hertog! En tòch, hoeveel verder kunnen wij niet komen in volle, parelende, sappige levenswaarheid door.... de dorre statistiek! Hoe ìs die vergelijking ook al weer van de okkernoot, over de bast en de pit? Want ook deze verdeeling in drieeën is toch weer maar een benadering, en zoolang wij niet de juiste verhoudingen kennen, moeten wij, juist als Ronjat, weer met ‘au moins pour une grande part’ en andere achterdeurtjes: voor ons wetenschappelijk geweten den aftocht dekken. Ik ben dit artikel begonnen met te zeggen, dat als wij wilden, we de Nederlandsche taalwetenschap hoog konden opwerken, onder al hare concurrenten. Ik dacht daarbij vooral aan de kleinheid van ons landje, het geringe aantal onzer dialecten, en onze betrekkelijk kleine literatuur. Want als wij het met de statistiek aanleggen, weten we wel het begin, maar nog niet het einde. Wat voor de Fransche, de Engelsche, de Duitsche taal en letteren: een onbegonnen werk ware, kan voor Nederland in eenige jaren zijn volbracht. Als er medewerkers komen opdagen, ben ik daarom graag bereid deze artikelenreeks voort te zetten. Ik vraag niet zoozeer om materiaal of toezending van manuscripten, als wel om overdrukjes van zelf gepubliceerde onderzoekingen en resultaten. Er zijn immers zooveel onderwijzersbladen met absoluut gebrek aan degelijke kopie over Nederlandsche taal! Vooral verzoek ik toch vooral matig begunstigd te worden met uitvoerige correspondentie; maar een briefje, om te verhoeden dat we met tweeën of drieeën juist hetzelfde zouden ondernemen, zal ten allen tijde zeer welkom zijn. Canisius-College, Nijmegen. Jac. van Ginneken. |
|