|
| |
| |
| |
Verstaanbaarheid en appreciatie. Nederlandse dialekten uit België zoals inwoners van Duffel die ervaren
0. Inleiding.
Deze studie kan gesitueerd worden in het onderzoek naar attitudes tegenover diverse taalvormen, maar wijkt op belangrijke punten af van wat in dit domein al gepresteerd is. Het onderzoeksveld omvat het noordelijk deel van België, en betreft uitsluitend de Nederlandse dialekten die daar gesproken worden. Alle andere taalvormen waarmee de bevolking frekwent gekonfronteerd wordt - vooral algemeen Nederlands met Belgische inslag, maar ook nog steeds Frans en in toenemende mate het Noordnederlands gekleurde AN - blijven buiten beschouwing. De aangeboden taalvariatie is dan ook uitsluitend geografisch; dat impliceert dat voor praktisch alle informanten ten minste een deel van de aangeboden taalvormen vreemd is, en, gezien de ekstreme verbrokkeling van het Nederlandse dialektgebied in België, moeilijk te verstaan.
Een tweede beperking t.o.v. het gangbare attitude-onderzoek is dat niet geprobeerd wordt om oordelen i.v.m. sprekers van de diverse taalvormen te ontlokken: de bedoeling was in de eerste plaats om na te gaan of er een relatie bestaat tussen de verstaanbaarheid van de taalvorm en de appreciatie ervan; de relatieve appreciatie van het verschijnsel ‘dialekt’ (in diverse verschijningsvormen) tegenover bijv. de standaardtaal blijft hier volledig buiten beschouwing.
En marge van dit onderzoek hebben wij wel nog enige aandacht besteed aan wat wij hier noemen de ‘eksterne herkenbaarheid’ van de voorgestelde dialekten, m.a.w. aan de vraag ‘zijn de informanten in staat om de gehoorde dialekten geografisch te situeren?’. Deze vraag is eventueel met de twee andere aspekten te korreleren in zoverre dat t.o.v. verstaanbaarheid en aantrekkelijkheid van bepaalde dialekten vrij vaste vooroordelen bestaan (b.v. Westvlaams is mooi, Gents is afschuwelijk, Limburgs is niet te verstaan), zodat een dialekt dat als b.v. Westvlaams herkend wordt eventueel direkt van het gunstige vooroordeel t.a.v. appreciatie kan profiteren. Dit aspekt kunnen wij echter bij gebrek aan voldoende eenduidig materiaal niet in de studie betrekken.
| |
| |
| |
0.1. De keuze van de taalvormen.
Bij de keuze van de fragmenten die ter beoordeling werden aangeboden hebben wij een zo groot mogelijk evenwicht tussen de dialektgebieden nagestreefd. De praktische noodzaak om de enquête ‘werkbaar’ te houden beperkte zowel de lengte van de fragmenten als het aantal ervan.
a) Met een ‘aanlooptijd’ van 30 sekonden om gewoon te worden aan de stem van de spreker, leek een lengte van anderhalve minuut per fragment gewenst.
b) Om heel het Nederlands sprekende deel van België in het onderzoek te betrekken hebben wij ons gebaseerd op de administratieve indeling in vijf provincies, en op bestaande dialektindelingen; uit de westelijke helft van het gebied (grosso modo de provincies Oost- en West-Vlaanderen), en uit de oostelijke helft (de provincies Antwerpen, Vlaams-Brabant en Limburg) werd een gelijk aantal fragmenten geselekteerd.
Op die manier kwamen wij tot de volgende 14 fragmenten:
- drie uit West-Vlaanderen: het noordoostelijke polderdialekt van Dudzele, en twee uit het zuiden van de provincie: Dikkebus (west) en Menen (oost);
- vier uit Oost-Vlaanderen: twee westelijke dialekten, nl. Oosteeklo in het Meetjesland en Lozere, tussen Gent en Oudenaarde; en twee oostelijke: Belsele uit het Land van Waas en Bambrugge uit het Land van Aalst;
- vijf uit het Brabantse dialektgebied: het Noordkempense grensdialekt van Wuustwezel, verder nog twee dialekten uit de Antwerpse Kempen: Lier (west) en Mol (oost); uit Vlaams-Brabant ten slotte: Grimbergen (west) en Kumtich (oost);
- twee uit Belgisch-Limburg: het Voordkempense van Bree, en het Maaslandse van Uikhoven.
Alle gekozen fragmenten zijn afkomstig van mannen. Ze zijn uitgesproken verhalend van aard: opeenvolgingen van vraag en antwoord komen niet voor. Referenties in het verhaal aan plaatsen, namen, regionaal bepaalde toestanden of gewoonten e.d. werden angstvallig geweerd. Een paar keer kon een dergelijk ideaal fragment niet gevonden worden. Wij hebben ons er dan mee beholpen om de gewraakte passages uit te wissen, uiteraard zonder dat de koherentie van de aangeboden tekst geschaad wordt.
| |
| |
De fragmenten werden in de volgende orde aangeboden:
Uikhoven (L), Dikkebus (WV), Belsele (OV), Kumtich (B), Lozere (OV), Lier (A), Dudzele (WV), Bree (L), Grimbergen (B), Oosteeklo (OV), Mol (A), Menen (WV), Bambrugge (OV), Wuustwezel (A).
| |
0.2. De keuze van de informanten.
In totaal werden 72 mensen geënquêteerd, allen afkomstig van en woonachtig in de Antwerpse gemeente Duffel. Ze zijn gelijk verdeeld op grond van de volgende variabelen:
| - | sekse: 36 mannen en 36 vrouwen; |
| - | vier leeftijdskategorieën: telkens 18 van 20-27, 28-37, 38-50 en 51-65; |
| - | drie sociale groepen: telkens 24 uit:
| a) | de groep van de handarbeiders (geschoolde en ongeschoolde arbeiders en kleine zelfstandigen); |
| b) | de middengroep (bedienden, onderwijzend personeel e.d.); |
| c) | de hoogste groep (dokters, notarissen, advokaten, managers of eigenaars van bedrijven). |
|
Wij krijgen dus een informantenveld dat er als volgt uitziet:
Tabel 1
De informanten
|
|
20-27 |
28-37 |
38-50 |
51-65 |
Totaal |
| soc. kl. A mannen |
3 |
3 |
3 |
3 |
12) 24 |
| vrouwen |
3 |
3 |
3 |
3 |
12) |
| soc. kl. B mannen |
3 |
3 |
3 |
3 |
12) 24 |
| vrouwen |
3 |
3 |
3 |
3 |
12) |
| soc. kl. C mannen |
3 |
3 |
3 |
3 |
12) 24 |
| vrouwen |
3 |
3 |
3 |
3 |
12) |
| Totaal |
18 |
18 |
18 |
18 |
72 |
| |
1. Verstaanbaarheid van de dialekten.
Aangezien de enquête een grote variëteit van dialekten betreft, gespreid over heel het Nederlandse taalgebied in België, mogen wij a priori verwachten dat er bij een aantal ervan problemen rijzen bij de ver- | |
| |
staanbaarheid: aangezien de informanten uit een enkele eng omschreven streek afkomstig zijn, die ongeveer centraal ligt in het taalgebied, kunnen wij een algemene hypotese stellen, dat de verstaanbaarheid gaat afnemen naarmate wij ons in westelijke of oostelijke, resp. in noordelijke of zuidelijke richting van dat vrij centraal gelegen punt verwijderen.
Een tweede, komplekse en moeilijker kontroleerbare hypotese kan zijn dat de verstaanbaarheid sterk afhankelijk is van de mate waarin de informanten met mensen uit andere dialektgebieden in kontakt komen. Hoewel het onmogelijk is om hier een algemene regel te stellen, zal het wel zo zijn dat er meer en intensiever kontakt is naarmate de informant een hogere sociale positie bekleedt; met vrij grote zekerheid kunnen wij bovendien stellen dat met het toenemen van de leeftijd ook het aantal mogelijkheden tot kontakt met ‘niet-streekgenoten’ toeneemt, wat dan zou moeten leiden tot betere verstaanbaarheid van een grote variëteit van dialekten bij ouderen dan bij jongeren. Ten slotte is het zeker zo dat in het geheel van de bevolking mannen door hun beroepsaktiviteit meer met andere mensen in kontakt komen dan thuisblijvende vrouwen; in het hier onderzochte staal van de bevolking moet niet verwacht worden dat dat verschil duidelijk aan het licht komt: ook de meerderheid van de geënquêteerde vrouwen heeft een beroep dat met dat van hun mannelijke kollega's te vergelijken is.
| |
1.1. De fragmenten t.o.v. elkaar.
De informanten werden verzocht voor elk van de fragmenten aan te geven in welke mate ze die verstonden, nl. heel goed (5), goed (4), nogal (3), slecht (2), heel slecht (1). Als wij voor elk opgegeven antwoord de tussen haakjes toegevoegde waarden toekennen, krijgen wij de volgende tabel:
Tabel 2
Verstaanbaarheid van de fragmenten (max. score: 360)
|
| 1. |
Lier (A) |
338 (93.89%) |
| 2. |
Mol (A) |
318 (88.33%) |
| 3. |
Grimbergen (B) |
298 (82.78%) |
| 4. |
Kumtich (B) |
290 (80.56%) |
| 5. |
Uikhoven (L) |
279 (77.50%) |
| |
Dudzele (WV) |
279 (77.50%) |
| 7. |
Wuustwezel (A) |
265 (73.61%) |
| 8. |
Oosteeklo (OV) |
255 (70.83%) |
| 9. |
Bambrugge (OV) |
251 (69.72%) |
| 10. |
Lozere (OV) |
238 (66.11%) |
| 11. |
Dikkebus (WV) |
229 (63.61%) |
| 12. |
Belsele (OV) |
213 (59.17%) |
| 13. |
Menen (WV) |
209 (58.06%) |
| 14. |
Bree (L) |
193 (53.61%) |
Opmerking: de toegevoegde percentages zijn berekend t.o.v. het teoretisch haalbare maksimum (d.w.z. als alle informanten voor het betreffende dialekt waarde 5 hadden toegekend).
| |
| |
Hoewel de tabel zoals hij hier staat al direkt de eerste hypotese bevestigt, zijn er een aantal punten die een gedetailleerde bespreking vereisen:
1. Buiten de inherente eigenschappen van het dialekt (klanken, konstrukties, leksikale items, die eventueel afwijken van wat in Duffel gewoon is), zijn er nog de individuele kenmerken van de spreker, waarvan zeker geen abstraktie kan worden gemaakt: intonatiepatronen en artikulatiegewoonten zijn weliswaar tot op zekere hoogte geografisch bepaald: bekend zijn b.v. het door vele Brabanders als hinderlijk ervaren intonatiepatroon van Oostvlamingen uit het westen van die provincie (door de leek als ‘gekapt spreken’ omschreven), het vlugge spreekritme van ‘de’ Zuidwestvlaming, en het zangerige aksent van de Limburger: allemaal elementen die de verstaanbaarheid voor mensen van buiten die gebieden in zekere mate in het gedrang brengen. Maar bovendien zijn er individuele spreekgewoonten die hetzelfde effekt hebben. Daarom is voor elk dialekt dat de kwotering ‘(heel) slechte verstaanbaarheid’ meekreeg aan de informant een nadere verklaring gevraagd: het ging hier om een gedeeltelijk geleide vraag, waarbij de informant de keuze had tussen:
a) en b): het fragment wordt onduidelijk of te vlug gesproken;
c): het dialekt vertoont klanken, enz. die het verstaan belemmeren;
d): andere redenen (die gespecificeerd dienen te worden).
Op die manier krijgen wij het volgende overzicht:
- Fragmenten waarbij noch de eksterne (a-b), noch de interne (c, gedeeltelijk d) oorzaken meer dan vijf keer als hinderlijk worden opgegeven: Mol (0-1), Lier (0-2), Grimbergen (3-3), Kumtich (4-5).
- Fragmenten waarbij de eksterne oorzaken niet meer dan vijf keer worden opgegeven, de interne wel: Uikhoven (1-6), Dudzele (4-6).
- Fragmenten waarbij de eksterne oorzaken meer dan vijf keer worden opgegeven, de interne niet: Wuustwezel (6-2).
- Fragmenten waarbij zowel de eksterne als de interne faktoren meer dan vijf keer aangewezen worden: Bambrugge (7-6), Oosteeklo (15-6), Lozere (6-17), Menen (14-16), Dikkebus (10-22), Belsele (22-10), Bree (14-24).
Uit dit overzicht blijkt dat eksterne en interne faktoren ongeveer in dezelfde mate verantwoordelijk zijn voor de volgorde vastgesteld in tabel 2: Uikhoven, Dudzele en Wuustwezel staan op gelijke hoogte tussen de vier Brabantse dialekten enerzijds, de zeven overblijvende
| |
| |
niet-Brabantse anderzijds. Bij de laatste reeks staan de Oostvlaamse, met uitzondering van het vlug en onduidelijk gesproken stukje uit Belsele, voor de resterende geografisch-ekstreme Westvlaamse en Limburgse dialekten.
Deze vaststellingen maken het ons mogelijk de eerste hypotese eksakter als volgt te formuleren: Voor zover geen individuele faktoren optreden (in positieve of negatieve zin) wordt de verstaanbaarheid van dialekten geringer naarmate ze verder van de woonplaats van de informanten gesproken worden.
2. De zo geamendeerde hypotese wordt, zoals gezien, over heel de lijn bevestigd: de Brabantse dialekten halen de hoogste scores, met het vlak bij Duffel gelegen Lier op de eerste plaats; de dialekten die op de Noord-Zuid-as het verst verwijderd zijn nemen de laatste plaatsen in in deze groep, waarbij de zuidelijke er nog iets beter afkomen dan het noordelijke Wuustwezel; voor dat laatste fenomeen is in de eerste plaats het snellere spreekritme van de Noordkempense dialekten in vergelijking met de overige Brabantse verantwoordelijk.
De niet-Brabantse dialekten volgen in de te verwachten volgorde, met uitzondering van Uikhoven en Dudzele enerzijds (waarvan de sprekers heel bedachtzaam en duidelijk praatten), en Belsele anderzijds (ongeartikuleerd en vooral vlug).
| |
1.2. Sociale distributie van de verstaanbaarheid.
In 1.1. hebben wij de informanten van het onderzoek als groep zonder verdere differentiaties behandeld. In dit tweede deel nu wordt de linguïstische variatie genegeerd, en gaat de aandacht juist naar de sociale variabelen uit. In de volgende tabel worden opgenomen: de totale som van alle antwoorden (voor alle 14 fragmenten) in elke kategorie, gevolgd door het percentage t.o.v. de maksimaal mogelijke waardering.
Het percentage 72.52 voor de enquête in z'n geheel is uiteraard een gemiddelde voor de verstaanbaarheid van alle 14 fragmenten tezamen. Hetzelfde geldt van de percentages voor alle deelgroepen. In zekere zin worden daardoor de verschillen wel wat afgevlakt: een meer gedetailleerd onderzoek brengt aan het licht dat de dialekten met uitgesproken hoge scores voor verstaanbaarheid (i.c. vooral de Brabantse) nauwelijks verschillen vertonen bij de subgroepen: voor Lier, Mol, Grimbergen en Kumtich samen is de totale score voor dit aspekt 86.39; de enige afwijking van enig belang bij de subgroepen is die van de sociale middengroep (B), die 91.87 haalt; voor de rest bedraagt de grootste afwijking
| |
| |
Tabel 3
De verstaanbaarheid per groep
|
|
20-27 |
28-37 |
38-50 |
51-65 |
Totaal |
Tot. M+V |
| AM |
145 (69.04) |
151 (71.90) |
147 (70.00) |
154 (73.33) |
597 (71.07) |
|
| |
|
|
|
|
|
1189 (70.77) |
| V |
143 (68.09) |
137 (65.24) |
154 (73.33) |
158 (75.24) |
592 (70.48) |
|
| BM |
143 (68.09) |
165 (78.57) |
158 (75.24) |
154 (73.33) |
620 (73.81) |
|
| |
|
|
|
|
|
1292 (76.90) |
| V |
160 (76.19) |
148 (70.84) |
178 (84.76) |
186 (88.57) |
672 (80.00) |
|
| CM |
140 (66.67) |
144 (68.57) |
154 (73.33) |
156 (74.29) |
594 (70.71) |
|
| |
|
|
|
|
|
1174 (69.88) |
| V |
133 (63.33) |
152 (72.38) |
138 (68.71) |
157 (74.76) |
580 (69.05) |
|
| Tot |
864 (68.57) |
897 (71.19) |
929 (73.73) |
965 (76.59) |
3655 (72.52) |
| |
Tot. M 1811 (71.86) |
|
|
|
|
| |
Tot. V 1844 (73.71) |
|
|
|
|
nauwelijks 3%; vgl. nog de scores voor de vier leeftijdskategorieën die resp. 86.11-85.56-88.33 en 85.56 halen.
Erg verwonderlijk is deze vaststelling niet: dialekten uit het eigen gebied vereisen geen speciale training of begaafdheid van de toehoorder; de geringe verschillen in het cijfermateriaal zullen dan ook integraal op rekening komen van de soms waarschijnlijk betwistbare keuze tussen ‘goede’ en ‘heel goede’ verstaanbaarheid.
De verschillen in tabel 3 komen dan ook volledig op rekening van de minder bekende dialekten. Ter illustratie nog de cijfers voor de Limburgse, West- en Oostvlaamse dialekten bij de vier leeftijdskategorieën (mannen en vrouwen samen):
Tabel 4
Verstaanbaarheid van niet-Brabantse dialekten
|
|
20-27 |
28-37 |
38-50 |
51-65 |
| L |
110 (61.11) |
114 (63.33) |
115 (63.89) |
133 (73.89) |
| OV |
222 (61.67) |
232 (64.44) |
245 (68.06) |
258 (71.67) |
| WV |
159 (58.59) |
177 (65.56) |
181 (67.03) |
200 (74.07) |
| |
| |
In de drie rijen van tabel 4 zijn, zoals verwacht, de verschillen heel wat geprononceerder dan in de laatste rij van tabel 3.
Tabel 3 lijkt echter voor het hier gestelde doel heel goed bruikbaar. Wij kunnen er direkt uit afleiden:
1. dat de kapaciteit om vreemde dialekten te verstaan toeneemt met de leeftijd van de proefpersonen; de afwijkingen t.o.v. die tendens in de rijen die de sociale groepen en seksen representeren, hoeven ons niet te verwonderen: die cijfers zijn telkens gebaseerd op de opgaven van hooguit drie proefpersonen: die toevallige afwijkingen worden wel opgevangen in de samenvattende resultaten in de laatste rij (gebaseerd op 18 informanten);
2. dat de gave (of de bereidheid!) om andere dialekten te verstaan uitermate groot is bij de sociale middengroep: van alle individuele percentages van vrouwen en mannen van deze kategorie blijven er maar twee beneden het algemene gemiddelde (mannen van 20-27 en vrouwen van 28-37); de overige zes vakjes scoren hoger. Ter vergelijking: zowel bij de laagste als bij de hoogste klasse blijven vijf groepjes beneden het gemiddelde, en komen er maar drie boven: die laatste behoren telkens tot de twee hoogste leeftijdskategorieën, waarvan wij gezien hebben dat die over het algemeen merkelijk beter presteren dan de jongeren.
Voor een verklaring van deze overtuigende afwijking t.o.v. de gestelde hypotese kunnen wij kiezen tussen o.a. de volgende mogelijkheden:
- ofwel is de hypotese fout in een van zijn premissen, nl. dat kontakt met een brede waaier van mensen in de hoogste klasse in werkelijkheid niet groter is dan in de middengroep;
- ofwel treedt er een storende faktor op bij de hoogste klasse: er is al een paar keer op gezinspeeld dat de opgaven van de proefpersonen in laatste instantie subjektief gekleurd zijn: er is niet alleen de kwestie van het kunnen verstaan, maar ook van de wil om eventueel een (kleine) inspanning te doen als men met een onbekende taalvorm gekonfronteerd wordt. Het lijkt niet onmogelijk dat precies vertegenwoordigers van de hoogste bevolkingsklasse zich boven deze inspanning verheven voelen, zodat hun prestaties (die ten slotte niet objektief kontroleerbaar zijn: wij moeten vertrouwen op de eerlijkheid van de informanten) niet beter zijn dan die van de laagste klasse.
Waarschijnlijk moet de verklaring voor de afwijking t.o.v. de hypotese in een van beide mogelijkheden (of in een kombinatie van de twee) gezocht worden. Verder onderzoek is hier noodzakelijk.
| |
| |
3. Zoals te verwachten was, is er nauwelijks een verschil tussen mannen en vrouwen, en voor zover er een is, wijst het zeker niet op een geringere kapaciteit (of bereidheid) van vrouwen om al dan niet vreemde dialekten te verstaan: mannen 71.86%, vrouwen 73.17%; bovendien blijken in zeven van de twaalf vergelijkbare vakjes de vrouwen een min of meer grote voorsprong te hebben op de mannen (in vijf is de verhouding omgekeerd).
| |
2. Appreciatie van de dialekten.
Aan elke informant werd ook een vraag voorgelegd naar de mate waarin hij de taalvorm apprecieerde. Ook hier was er een vijfpuntschaal, gaande van heel mooi (5), mooi (4), over noch mooi, noch lelijk (3) naar lelijk (2) en heel lelijk (1).
In dit hoofdstukje zullen wij niet alleen een bespreking geven die parallel loopt met die voor de verstaanbaarheid, maar bovendien ook proberen de korrelatie tussen die twee eigenschappen van de diverse taalvormen te bepalen.
Aangezien het hier een uitermate subjektieve aangelegenheid betreft is het erg moeilijk om vooraf hypoteses op te stellen. Bij ons onderzoek hebben wij ons beperkt tot een enkele stelling, nl. dat de appreciatie van dialekten in sterke mate afhankelijk is van de verstaanbaarheid ervan.
De bespreking zal voor de rest uitsluitend het gevonden cijfermateriaal betreffen; uiteraard kan die werkmetode wel tot het a posteriori opstellen van enkele hypoteses leiden, die door verder onderzoek geverifieerd moeten worden.
| |
2.1. De fragmenten t.o.v. elkaar.
De antwoorden van de informanten vertonen een weinig gediversifieerd beeld voor de 14 fragmenten: tussen de hoogste en de laagste gekwoteerde ligt nauwelijks 15% (vgl. bij de verstaanbaarheid: 40%). De hoogste percentages liggen bovendien nog vrij laag: het hoogste (Dudzele) scoort 71% (vgl. bij de verstaanbaarheid: Lier met 94%). Een eerste vaststelling dus: de informanten hebben zich op de vlakte gehouden, en geven in massa de derde kwotering (noch mooi, noch lelijk): van de 1008 antwoorden behoren er niet minder dan 539 tot die kategorie. Voegen wij daar nog aan toe dat de ekstreme antwoorden (‘heel mooi/lelijk’) maar in resp. 41 en 9 antwoorden gekozen zijn, dan is meteen duidelijk dat deze vraag de informant voor zware problemen moet hebben gesteld.
| |
| |
Tabel 5
Appreciatie van de gebruikte taalvormen (max. score: 360)
|
| 1. |
Dudzele (WV) |
257 (71.39%) |
| 2. |
Mol (A) |
246 (68.33%) |
| 3. |
Dikkebus (WV) |
244 (67.78%) |
| 4. |
Lier (A) |
243 (67.50%) |
| 5. |
Uikhoven (L) |
241 (66.94%) |
| 6. |
Oosteeklo (OV) |
237 (65.83%) |
| 7. |
Lozere (OV) |
228 (63.33%) |
| 8. |
Wuustwezel (A) |
224 (62.22%) |
| 9. |
Grimbergen (B) |
223 (61.94%) |
| 10. |
Bambrugge (OV) |
218 (60.56%) |
| 11. |
Kumtich (B) |
215 (59.72%) |
| 12. |
Menen (WV) |
206 (58.89%) |
| 13. |
Belsele (OV) |
205 (57.22%) |
| 14. |
Bree (L) |
202 (56.11%) |
Een vraag die hier direkt rijst is de volgende: In hoeverre mag verwacht worden dat de informanten voor elk fragment afzonderlijk een autonoom oordeel uitgesproken hebben? Een waarde-oordeel uitbrengen kan enkel t.o.v. een norm, en het is wel erg onwaarschijnlijk dat de ondervraagden a priori over een norm van welke aard ook konden beschikken. Indien niet, dan is het gevaar groot dat ze de fragmenten gewoon relatief t.o.v. elkaar gaan afwegen. In se is een oordeel als ‘dialekt x vind ik mooier dan dialekt y’ natuurlijk een (waardevol) gegeven, maar een dergelijke mededeling moet met meer omzichtigheid gehanteerd worden dan b.v. ‘dialekt x waardeer ik op nivo a, en y op nivo b (a ≠ b)’. In het laatste geval hebben wij een konjunktie van twee onafhankelijke oordelen. Een grondige analyse van tabel 5 leert dat dat ideaal niet bereikt is, en dat wij in feite te maken hebben met een relatieve rangschikking: telkens weer wordt vertrokken van een ekstreme (negatieve) appreciatie, om geleidelijk aan omhoog te klimmen, en dan weer met een ruk naar beneden te gaan. Het hele proces is als volgt te rekonstrueren: bij het beluisteren van het eerste fragment op de band (Uikhoven) wordt in grote meerderheid een voorzichtige gunstige kwotering uitgebracht; het volgende fragment (Dikkebus) doet het nog een ietsje beter, maar dan komt er met Belsele een flinke duik; wij gaan dan in opwaartse richting via Kumtich, Lozere, Lier en Dudzele; met Bree krijgen wij een nieuw dieptepunt, te vergelijken met dat van Belsele. De opwaartse beweging begint dan opnieuw (Grimbergen, Oosteeklo en
Mol), totdat Menen weer een bar slechte kwotering krijgt; daarna volgt nog een lichte stijging in appreciatie met Bambrugge en ten slotte Wuustwezel, het laatste fragment.
Opgemerkt mag nog worden dat een dergelijke cirkelbeweging helemaal niet bestaat t.o.v. de verstaanbaarheid.
Het blijkt dus wel overduidelijk dat tabel 5 een relatieve waarde heeft, en zeker geen absoluut oordeel over de opgenomen taalvormen
| |
| |
reflekteert: een andere volgorde zou ook de volgorde kwa appreciatie kunnen beïnvloeden.
| |
2.2. Sociale distributie van de appreciatie.
Zoals in 1.2. wordt in het volgende overzicht geen rekening meer gehouden met verschillen tussen de fragmenten, en beperken wij ons weer tot de sociale variabelen. Voor elke kategorie wordt de som opgegeven van de genoteerde waarden voor de 14 fragmenten, gevolgd door de percentages t.o.v. de maksimale teoretische waardering.
Tabel 6
De appreciatie per groep
|
|
20-27 |
28-37 |
38-50 |
51-65 |
Totaal |
Tot. M+V |
| AM |
137 (65.24) |
140 (66.67) |
132 (62.68) |
137 (65.24) |
546 (65.00) |
|
| |
|
|
|
|
|
1082 (64.40) |
| V |
134 (63.81) |
135 (64.29) |
138 (65.71) |
129 (61.43) |
536 (63.81) |
|
| BM |
129 (61.43) |
153 (72.86) |
134 (63.81) |
126 (60.00) |
542 (64.52) |
|
| |
|
|
|
|
|
1105(65.77) |
| V |
134 (63.81) |
130 (61.90) |
152 (72.38) |
147 (70.00) |
563 (67.02) |
|
| CM |
133 (63.33) |
133 (63.33) |
126 (60.00) |
132 (62.87) |
524 (62.38) |
|
| |
|
|
|
|
|
1009 (60.06) |
| V |
121 (57.62) |
132 (62.86) |
122 (58.10) |
110 (52.38) |
485 (57.74) |
|
| Tot |
788 (62.54) |
823 (65.32) |
804 (63.81) |
781 (61.98) |
3196 (63.41) |
| |
Tot. M 1612 (63.97) |
|
| |
Tot. V 1584 (62.82) |
|
Ondanks de vrij middelmatige waardecijfers (gemiddeld percentage 63.4; vgl. met verstaanbaarheid 72,52%), valt op dat er vrij grote verschillen zijn in de afzonderlijke vakjes: die waarden varieren tussen 52.4 en 72.9%. Toch blijken die individuele verschillen elkaar grotendeels op te heffen als wij de grotere kategorieën onder ogen nemen: tussen mannen en vrouwen is er nauwelijks een verschil wat de appreciatie betreft. Wel signifikant lijkt ons het verschil tussen de twee laagste klassen (A en B) enerzijds, en de hoogste (C) anderzijds. Vooral
| |
| |
de vrouwen van die laatste kategorie geven bijzonder lage waarderingen (dat geldt voor alle vier leeftijdskategorieën). Wat die laatste variabele ten slotte betreft, blijkt er een licht stijgende tendens te zijn van de oudste leeftijdskategorie naar de 28-37-jarigen, die tendens wordt echter afgebroken bij de jongsten, die nauwelijks hogere waarderingscijfers toekennen als de oudste informanten. Rekening houdend met de nogal romantische verering voor alles wat ‘volks’ heet te zijn bij de jeugd, kan dat laatste alleen maar verwondering wekken. Een mogelijke verklaring lijkt ons het volgende: in 2.3. zal blijken dat er een vrij enge band bestaat tussen verstaanbaarheid en appreciatie van taalvormen. Aangezien de kapaciteit om vreemde dialekten te verstaan blijkbaar het geringste is bij de jongste leeftijdskategorie, moet dit logischerwijze ook de appreciatie in negatieve zin beïnvloed hebben. Als wij nu al even rekening houden met de korrelatie tussen verstaanbaarheid en appreciatie, wordt het toch wel mogelijk om zelfs uit de geringe cijferverschillen in tabel 6 af te leiden dat de aangeboden fragmenten relatief minder goed overkomen bij 38-50-jarigen en nog minder bij 51-65-jarigen, dan bij de twee jongste kategorieën.
Samenvattend lijkt ons de volgende algemene konklusie uit tabel 6 verantwoord: De aangeboden dialektfragmenten worden wat hun taalvorm betreft het meest geapprecieerd in de sociale middengroep en grosso modo méér naarmate de informanten jonger zijn.
| |
2.3. Korrelatie tussen verstaanbaarheid en appreciatie.
Onder 2.2. hebben wij er al op gewezen dat geringe verstaanbaarheid over het algemeen resulteert in lage appreciatie voor de taalvorm van het betreffende fragment. Er zijn verschillende manieren om de interrelatie van die twee eigenschappen te illustreren. Een eerste bestaat erin om na te gaan uit welke verstaanbaarheidskategorieën (A, B,..., E) de verschillende appreciaties (Aʹ, Bʹ,..., Eʹ) komen. Als de geponeerde korrelatie inderdaad bestaat, moet het zwaartepunt van de kategorie Aʹ in de hoge verstaanbaarheidskategorieën vallen, dat van Eʹ in de laagste, en moet er bovendien een geleidelijke verschuiving tussen die twee waargenomen worden.
De volgende tabel, die illustreert dat er inderdaad van zo'n verloop sprake is, bestaat uit twee delen:
- de absolute cijfers voor de meldingen met AʹA, AʹB,... EʹE;
- de percentages van het voorkomen van meldingen A, B,... E bij resp. Aʹ, Bʹ,... Eʹ.
| |
| |
Tabel 7
Korrelatie van verstaanbaarheid en apprciatie
|
|
Aʹ |
Bʹ |
Cʹ |
Dʹ |
Eʹ |
| A |
31 |
98 |
101 |
18 |
0 |
| B |
8 |
97 |
198 |
27 |
0 |
| C |
1 |
48 |
179 |
39 |
1 |
| D |
1 |
18 |
57 |
62 |
3 |
| E |
0 |
1 |
4 |
11 |
5 |
|
Aʹ |
Bʹ |
Cʹ |
Dʹ |
Eʹ |
| A |
75.6 |
37.5 |
18.7 |
11.5 |
- - - |
| B |
19.5 |
37.1 |
36.7 |
17.2 |
- - - |
| C |
2.4 |
18.3 |
33.2 |
24.8 |
11.1 |
| D |
2.4 |
6.8 |
10.6 |
39.5 |
33.3 |
| E |
- - - |
0.4 |
0.8 |
7.0 |
55.6 |
De tabel met percentages behoeft nauwelijks kommentaar: de hoogste waardering voor appreciatie (Aʹ) komt praktisch uitsluitend voor bij de fragmenten die ook een A hebben voor verstaanbaarheid; buiten B komt overigens nog nauwelijks iets voor. Bij Bʹ wordt het wat gekompliceerder: B- en C-meldingen nemen sterk in aantal toe, maar A is ook nog heel goed vertegenwoordigd (meer dan C). Voor Cʹ komt C nu op gelijke hoogte met B, maar A verliest duidelijk terrein. Voor Dʹ krijgen wij een vrij regelmatige verdeling: B en C, die allebei nog goed vertegenwoordigd zijn (maar nu met C in de meerderheid) worden voorbijgestreefd door D. Ook A en E zijn nog aanwezig. Ten slotte is er de vrij zeldzame kwotering erg lelijk (Eʹ), die vrijwel uitsluitend voorkomt bij (heel) slecht verstaanbare fragmenten (D en E).
Men kan tabel 7 ook van links naar rechts lezen, en dan telkens de hoogste appreciatiewaarden zoeken voor de fragmenten met verstaanbaarheid A, B,... E; die vindt men dan in de omkaderde vakjes, die zoals verwacht op de diagonaal van boven-links naar beneden-rechts liggen.
De belangrijkste konklusie uit dit hoofdstukje is zeker wel dat subjektieve oordelen over bepaalde taalvormen in sterke mate mede bepaald worden door objektieve gegevens, waarvan de verstaanbaarheid waarschijnlijk niet alleen staat. Het gekke is dat de respondenten zich duidelijk niet bewust (willen?) zijn van de echte motieven waar hun oordeel op berust: Wie mogelijkheid Dʹ of Eʹ aankruiste kreeg ook hier de gelegenheid om die keuze te verantwoorden; 152 keer is van die mogelijkheid gebruik gemaakt; dat de informant moeilijkheden heeft gehad met het verstaan wordt maar 10 keer toegegeven en als reden geëkspli- | |
| |
citeerd; 14 keer wordt de inhoud verantwoordelijk gesteld en 42 maal de onaangename stem van de spreker. In alle andere gevallen (101 keer: sommigen hebben meer dan één reden opgegeven) meent men dat de negatieve appreciatie voortkomt uit eigenschappen van de taalvorm zelf (vooral de zogenaamde ‘platheid’ van de klanken). Eerlijkheidshalve moet hieraan toegevoegd worden dat de hier eerst aangehaalde mogelijkheid niet ekspliciet geformuleerd was op het enquêteformulier, terwijl de overige dat wel waren. Maar zelfs zo kunnen wij met zekerheid besluiten dat de informanten zich uit zichzelf moeilijk de band tussen verstaanbaarheid en appreciatie kunnen voorstellen.
| |
3. Eksterne herkenbaarheid (situeerbaarheid) van de dialekten.
Hoewel het onderzoek zeker niet op de eerste plaats gericht was op de kapaciteit van de Duffelse bevolking om diverse dialekten thuis te brengen, kreeg de informant toch als eerste opgave om d.m.v. een kruisje op een kaart van de Vlaamse provincies aan te duiden waar hij of zij dacht dat elk fragment vandaan kwam.
De bedoeling van dit deel van het onderzoek was om na te gaan of ‘men’ zich bewust is van het bestaan van verschillende dialektgebieden, en of men daar, als dat het geval is, bepaalde dialekten mee kan verbinden.
Voor de verwerking van de 1008 gegevens was een vrij tijdrovend procedé nodig: Vanuit de plaats waar het fragment reëel vandaan kwam werd telkens een assenkruis getrokken dat het hele gebied in vier gewoonlijk erg ongelijke delen verdeelt; de assen lopen parallel met de grenzen van het kaartje, ze zijn m.a.w. een visualisering van de manier waarop de informant het gebied psychisch organiseert.
Vanuit punt x (voor dialekt x) wordt dan voor het door de informant aangeduide punt xʹ de eventuele afstand naar het noorden of zuiden gemeten t.o.v. de oost-west-as, en ook die naar het oosten of westen t.o.v. de noord-zuid-as. Als afspraak stellen wij dat de afwijkingen naar het westen en die naar het noorden een positieve waarde krijgen, die naar zuid en oost een negatieve. Al die gegevens worden verzameld en per fragment samengeteld; de som (die dus positief of negatief kan zijn) gedeeld door 72 geeft de gemiddelde afwijking aan voor de situering van het bepaalde dialekt. Wij kunnen dan de twee waarden die voor elk dialekt gevonden worden als koördinaten op een kaart met dezelfde schaal als de oorspronkelijke brengen: op die manier vinden wij de plaats waar het dialekt door de groep gemiddeld gelokaliseerd wordt.
| |
| |
Natuurlijk roept een dergelijke werkwijze bezwaren op: stel dat het fragment in het Uikhovens dialekt door een aanzienlijk aantal ondervraagden niet met Limburg geassocieerd wordt; er bestaat weinig kans toe dat ze dit erg vreemde dialekt in de onmiddellijke buurt van hun eigen woonplaats, i.c. Duffel, gaan plaatsen (al zijn er in de praktijk toch wel een paar die dat doen). De meeste informanten die echt gaan raden (zelfs al geven ze dat niet toe) zullen dan ook een uitzonderlijk grote afwijking naar het westen opgeven (West- en Oost-Vlaanderen) Die meldingen vervalsen het totale beeld in grote mate. Bovendien heeft het voor die gevallen eigenlijk helemaal geen belang meer hoe groot de eventuele afwijking op de N-Z-as wel is.
Er is uiteraard geen enkele manier om objektief te bepalen hoe dikwijls er voor een bepaald dialekt ‘geraden’ is. Om toch enigszins rekening te houden met dit gegeven, hebben wij een tweede afwijkingsgemiddelde berekend: voor elk dialekt zijn die meldingen apart genomen waarbij althans de provincie juist aangeduid was. Ook deze werkwijze levert moeilijkheden op: wat doe je met aanduidingen die vlak over de grens van de juiste provincie terecht zijn gekomen? Het is nu eenmaal zo dat heel weinig intuïtief bekende dialektgebieden met administratieve indelingen samenvallen. Een paar voorbeelden: de grens tussen Antwerpen en Vl.-Brabant is over geen enkel deeltrajekt een dialektgrens; de de zuidoostelijke hoek van Vl.-Brabant is kwa taal niet te onderscheiden van het zuidwesten van Limburg, en het westelijk deel van dezelfde provincie nauwelijks van het zuidoosten van O.-Vlaanderen, enz. Toch hebben wij gemeend alleen de administratieve grenzen in aanmerking te kunnen nemen: onze ervaring is dat de informanten zich bij de keuze van een plaats allereerst door de algemeen bekende indeling in vijf provincies lieten leiden, en pas in tweede instantie binnen dat gebied zijn gaan elimineren totdat ze hun definitieve keuze in een kruisje lieten blijken. Een bewijs voor de geldigheid van deze redenering is het feit dat een aantal geënquêteerden na het plaatsen van het kruisje nog korrekties aanbrachten (d.m.v. een pijltje naar een andere plaats toe), maar dat geen enkele van die pijlen een provinciegrens kruist.
| |
3.1. De verschillende fragmenten.
Op de bijgevoegde kaart vindt men voor elk fragment drie gegevens: de plaats waar het fragment effektief thuishoort (de nummers komen overeen met de gemeenten vermeld in tabel 2), die waar het gemiddeld door de hele groep van 72 informanten geplaatst wordt, en ten slotte die waar het gesitueerd wordt door degenen die de juiste provincie weten
| |
| |
te bepalen. Het aantal van de informanten die daarin geslaagd zijn vindt men in de volgende bespreking van elk van de 14 fragmenten. De dialekten worden per provincie geordend.
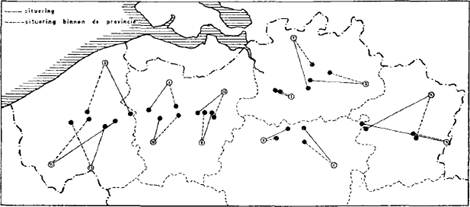
Situering van dialekten
(de nummers van de aangeduide plaatsen korresponderen met de volgorde voor de faktor verstaanbaarheid: tabel 2).
| |
a) West-Vlaanderen
a1. Dudzele: 48 informanten situeren dit fragment in W.-Vl.; een kleine meerderheid daarvan (26) in de noordelijke helft van de provincie; 18 keer wordt een Oostvlaamse plaats aangeduid. Gemiddeld levert dat een situering op in zuid-zuidoostelijke richting; houden wij enkel rekening met de opgaven van degenen die W.-Vl. gekozen hebben, dan blijft de afwijking naar het zuiden toe ongeveer even groot, maar dan in zuid-zuidwestelijke richting.
a2. Dikkebus: 56 situeringen in W.-Vl., met twee duidelijke kernen: de omgeving van Brugge en die van Kortrijk; de streek van Ieper (waar het fragment werkelijk thuishoort) is stiefmoederlijk bedeeld. Praktisch alle andere kruisjes (13) liggen in O.-Vl. Gemiddeld levert dat een afwijking op in noordoostelijke richting, ook als wij enkel rekening houden met de opgaven binnen W.-Vl.
a3. Menen: 54 situeringen in W.-Vl., de overige met twee uitzonderingen in O.-Vl. Binnen de grenzen van de provincie is nauwelijks van een koncentratie sprake. Gemiddeld gaat de afwijking voornamelijk naar het noorden, in licht oostelijke richting als rekening wordt gehouden
| |
| |
met alle opgaven, naar het westen toe als alleen de Westvlaamse lokaliseringen tellen.
Besluit: De Westvlaamse dialekten worden over het algemeen heel goed als zodanig herkend; de interne geleding van dat dialektgebied is bij het onderzochte staal van de Duffelse bevolking vrijwel onbekend. Wel opmerkelijk is dat het langzaam en duidelijk gesproken fragment van Dudzele minder met W.-Vl. geassocieerd wordt dan de twee andere die veel vlugger gesproken worden.
| |
b) Limburg
b1. Uikhoven: 52 informanten weten dit fragment in de juiste provincie te situeren; wat vooral merkwaardig is, is dat de overigen hun opgaven over alle andere provincies (vooral O.-Vl.) uitsmeren. Dit wijst in alle geval op een minder gefikseerd karakter van het Limburgs als een ‘oostelijk’ dialekt (vgl. de Westvlaamse dialekten, die voor zover ze niet in de juiste provincie gesitueerd worden, dan toch in grote meerderheid ten westen van Duffel terecht komen). Het gemiddelde wijst op een meer westelijke situering vlak bij de Limburgs-Brabantse grens; met de opgaven binnen de provinciegrenzen komen wij in de buurt van Hasselt-Genk, trouwens het enige gebied waar van een koncentratie van individuele situeringen sprake is.
b2. Bree: 54 juiste situeringen, met dan nog een achttal opgaven in de oostelijke helft van het Antwerps-Brabantse gebied. Eigenaardig genoeg is er een koncentratie in het zuiden van Limburg (streek van Tongeren). In het algemeen gaat de afwijking in zuidwestelijke richting, binnen de provincie naar het zuid-zuidwesten.
Besluit: De Limburgse dialekten leveren blijkbaar wat meer moeite op dan de Westvlaamse, wat wel op een geringere bekendheid zal wijzen. Ook hier kan globaal niet geponeerd worden dat de Duffelse bevolking op de hoogte is van welke geleding ook in het ‘Limburgs’.
| |
c) Oost-Vlaanderen
c1. Oosteeklo: Het aantal juiste situeringen in de provincie is verbazend klein: met 38 nauwelijks meer dan de helft. De overige zijn met 4 uitzonderingen (in Vl.-Br. en L.) allemaal in West-Vlaanderen, vooral in de noordelijke helft daarvan terechtgekomen. Houden wij met alle opgaven rekening, dan krijgen wij een zuidelijke afwijking tot even ten noorden van Gent; de opgaven binnen de provincie gaan gemiddeld in zuid-zuidoostelijke richting (ongeveer de plaats van Lokeren). Van een
| |
| |
koncentratie binnen de provincie is nauwelijks sprake; wel opvallend is dat het zuidoostelijke kwart van de provincie (Ninove-Aalst-Dendermonde) praktisch niet gekozen wordt.
c2. Lozere: Dit zuidwestelijke dialekt vertoont nagenoeg hetzelfde beeld als het noordwestelijke Oosteeklo: 38 juiste lokaliseringen in de provincie, 29 in W.-Vl. Er is een lichte koncentratie in de omgeving van Gent. Globaal is er een afwijking naar het noorden, binnen de provincie een iets grotere (!) naar het noordoosten (Lokeren).
c3. Belsele: Dit dialekt komt vrij duidelijk als Oostvlaams over: 47 lokaliseringen binnen die provincie, met een koncentratie in het noordoostelijke kwart (Land van Waas); de overige zijn met drie uitzonderingen verdeeld over W.-Vl. en Vl.-Br. Globaal is er een niet al te grote zuidwestelijke afwijking, binnen de provincie een zuid-zuidwestelijke.
c4. Bambrugge: 48 lokaliseringen binnen de Oostvlaamse grenzen, met een belangrijke koncentratie van individuele opgaven tussen Aalst en Dendermonde. De overige lokaliseringen in de vier andere provincies (ook in Antwerpen). Beide gemiddelden gaan naar het noorden toe, met een lichte uitwijking naar het westen.
Besluit: De westelijke Oostvlaamse dialekten worden duidelijk als westelijk, minder overtuigd als Oostvlaams ervaren; de twee oostelijke krijgen een heel andere behandeling; door sommigen worden ze met het Brabants geassocieerd, wat dan wel op rekening moet komen van het overgangskarakter van die dialekten. Daarmee is ook gezegd dat er een vrij ontwikkeld bewustzijn is voor althans een gedeelte van de interne geleding van het Oostvlaams.
| |
d) Vlaams-Brabant
d1. Grimbergen: 45 lokaliseringen in Vl.-Br., de overige op vijf meldingen na (twee in O.-Vl. aan de grens met Brabant, en drie in Limburg) in Antwerpen (vooral in het zuidwesten van die provincie). De individuele opgaven koncentreren zich ten noordwesten van Brussel. Dit alles wijst op een tot nu toe niet geziene nauwkeurigheid. Globaal hebben wij een niet al te grote afwijking naar het noordoosten, binnen de provincie een kleine in dezelfde richting.
d2. Kumtich: 50 lokaliseringen in Vl.-Brabant, de overige weer met 5 uitzonderingen in heel de provincie Antwerpen. Een bijzonder sterke koncentratie tussen Leuven en Tienen. Ook hier dus een vrij nauw- | |
| |
keurige lokalisering. al is zowel de globale als de specifieke gemiddelde afwijking (beide in noordwestelijke richting) iets groter als bij Grimbergen.
Besluit: de dialekten uit Vlaams-Brabant worden duidelijk als zodanig ervaren, al ziet men niet zomaar de scheiding t.o.v. die van het zuiden van de provincie Antwerpen. Bovendien lijkt in het bewustzijn van het onderzochte bevolkingsstaal ook wel een oppositie tussen west en oost te leven.
| |
e) Antwerpen
e1. Wuustwezel: 46 situeringen in Antwerpen, met een vrij dichte koncentratie in de Noorderkempen, en een lichtere in het oosten van de provincie. De overige vooral in Brabant (12) en Limburg (8). Als wij rekening houden met alle opgaven, hebben wij een vrij uitgesproken verschuiving naar het zuid-zuidoosten; de opgaven binnen de provincie leveren een minder grote verschuiving naar het zuidoosten op.
e2. Mol: Het beeld voor Mol wijkt niet zo erg af van het vorige: de koncentratie in het oosten van de provincie is iets dichter; verder is het aantal meldingen buiten de provinciegrenzen geringer (58 informanten hebben de provincie juist). Wij krijgen in beide gemiddelden een belangrijke afwijking naar het westen, die voor zover wij ons tot de opgaven in Antwerpen beperken, wat naar het noorden afbuigt.
e3. Lier: Zoals te verwachten levert dit dialekt uit de buurstad van Duffel niet veel moeilijkheden op: afgezien van vier vergissingen, waarvan een in W.-Vl. (!), twee in Vl.-Br. en een in het Oostvlaamse Land van Waas, komen alle lokaliseringen in het westen van de provincie Antwerpen terecht, merkwaardig genoeg wel in meerderheid meer naar het noorden toe dan de plaats van Lier op de kaart. Dat levert dan een lokalisering op die licht naar het noordwesten afbuigt (uiteraard praktisch zonder verschil naargelang van het al of niet weglaten van niet-Antwerpse lokaliseringen).
Besluit: De dialekten van de provincie Antwerpen worden duidelijk als verschillend van de westelijke gevoeld, maar afgezien van de direkt bekende (i.c. Lier) is de scheiding t.o.v. de Vlaams-Brabantse niet overtuigend gegeven. Hetzelfde fenomeen hebben wij trouwens ook in omgekeerde richting vastgesteld, bij de bespreking van de Vlaams-Brabantse fragmenten. Over de interne geleding van het gebied kan voorlopig het volgende vastgesteld worden: het eigen dialekt wordt verschillend
| |
| |
geacht van het Mechels en alles wat ten zuiden daarvan ligt (vandaar een afwijking naar het noorden); hetzelfde geldt t.o.v. het ‘Kempens’. De twee kwa taalvorm toch erg verschillende representanten van het laatste worden echter vrijwel op dezelfde plaats ondergebracht, niet eens zo ver van de plaats waar Lier in realiteit ligt. Waarschijnlijk dient hier het al of niet voorkomen van /h/ als foneem als herkenningsteken: de grens van dit verschijnsel ligt enkele kilometers ten oosten van Lier, en de psychologische dialektgrens die daarmee samenhangt blijkt bijzonder sterk te zijn: alle dialekten met /h/ kunnen dan ook onmiddellijk ten oosten van de stad gesitueerd worden.
| |
f) Algemeen besluit
Over het algemeen mag gesteld worden dat de Zuidnederlandse dialekten voor het onderzochte bevolkingsstaal in een aantal geografisch bepaalde types uiteenvallen, en dat die typologie meer gediversifieerd wordt naarmate het gebied dichter bij de woonplaats van de informanten ligt: zowel Westvlaams als Limburgs worden goed als zodanig herkend, maar zonder verdere diversifikatie; in het Oostvlaams wordt vrij gemakkelijk de heel reële grens tussen oost en west ervaren, maar eigenaardig is zeker dat er geen verschil wordt gemaakt tussen de dialekten van het Land van Waas en de veel meer Zuidbrabants aandoende streektalen van het zuidoosten van de provincie. Ten slotte is er het eigen Brabantse gebied, waarin heel gemakkelijk onderscheiden wordt tussen de noordelijke taalvormen van het grootste deel van de provincie Antwerpen, en de zuidelijke van Vlaams-Brabant en de aangrenzende strook van Antwerpen. In beide groepen wordt nog een verschil gezien tussen west en oost. Merkwaardig maar goed verklaarbaar (cf. supra) is vooral de gemiddelde lokalisering van de Kempense dialekten niet zo ver ten oosten van Lier (en van Duffel): een overtuigend bewijs van het bestaan van een psychologische dialektgrens tussen het zuidwesten van Antwerpen (Klein-Brabant en aangrenzend gebied) en de Kempen.
| |
3.2. Sociale distributie van de situeerbaarheid.
In de volgende tabel is per deelgroep, per vakje, enz. opgenomen hoe groot de gemiddelde afwijking is t.o.v. de reële lokalisering van de 14 dialekten. De afstanden zijn in kilometers berekend op de volgende manier, geïllustreerd aan de gegevens voor alle mannelijke informanten:
| - | som van alle afwijkingswaarden op de W.-O.-as (in welke richting ook): 13527.43 km. |
| |
| |
| - | som van alle afwijkingswaarden op de N.-Z.-as (idem): 9122.85 km. |
| - | gemiddelde afwijking (voor 36 maal 14 = 504 opgaven): resp. 26.84 en 18.10 km. |
| - | de eigenlijke afwijking wordt nu berekend volgens de formule: 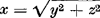 (schuine zijde van een rechthoekige driehoek). Dit levert de waarde 32.37 op. (schuine zijde van een rechthoekige driehoek). Dit levert de waarde 32.37 op. |
Tabel 8
Afwijkingen in de situering van de fragmenten (in km)
|
|
20-27 |
28-37 |
38-50 |
51-65 |
Totaal |
Tot. M + V |
| AM |
36.35 |
62.85 |
37.95 |
24.47 |
40.41 |
40.58 |
| V |
39.46 |
47.84 |
34.74 |
40.96 |
40.75 |
|
| BM |
37.06 |
28.38 |
24.38 |
28.10 |
28.41 |
31.75 |
| V |
37.95 |
37.52 |
28.32 |
32.31 |
34.03 |
|
| CM |
33.52 |
33.62 |
25.63 |
26.18 |
27.24 |
29.16 |
| V |
33.25 |
35.94 |
25.33 |
30.05 |
31.07 |
|
| Tot. |
36.26 |
39.36 |
29.40 |
30.35 |
33.83 |
De tabel is, met een paar weinig belangrijke uitzonderingen, bijzonder eenvoudig te interpreteren:
1. Mannen presteren gemiddeld heel wat beter bij het lokaliseren dan vrouwen: de respektieve afwijkingen bedragen 32.37 en 35.28 km. Of dit vooral met een betere bekendheid met dialekten, dan wel met betere geografische kennis samenhangt, is niet uit te maken.
2. De kapaciteit om dialekten ‘thuis te brengen’ neemt duidelijk toe van de laagste naar de hoogste sociale klasse; de tendens is overduidelijk, ook als wij mannen en vrouwen van de diverse klassen apart beschouwen. Vooral de laagst gesitueerde groep blijft over heel de lijn in gebreke: het blijkt dus wel dat minder goede prestaties samenhangen met geringer ervaring: arbeiders en kleine middenstanders hebben waarschijnlijk minder gelegenheid om sprekers van andere dialekten te ont- | |
| |
moeten, en bovendien in grote meerderheid ook minder kennis van de geografie; de twee hogere klassen (die relatief dicht bij elkaar liggen) zijn op beide punten ongetwijfeld bevoordeeld.
3. De twee oudste leeftijdskategorieën presteren uitgesproken goed in vergelijking met de twee jongere. Eens te meer kan hier de faktor ‘ervaring’ aangehaald worden, maar gezien de betere schoolopleiding van grote groepen uit het bevolkingsstaal waarschijnlijk niet de faktor ‘betere geografische kennis’.
Opmerking: Bij de mannen is er een konsekwent dalende lijn in de gemiddelde afwijkingskoëfficiënt van jong naar oud; de hogere waarden van 28-37-jarigen t.o.v. 20-27, en voor 51-65 t.o.v. 38-50 in tabel 8, zijn te wijten aan de resultaten bij de vrouwen. Of aan deze waarneming veel waarde moet worden gehecht lijkt ons erg twijfelachtig: het aantal informanten per kategorie is vrij gering, en toeval kan dus een grote rol gespeeld hebben.
Over het algemeen lijken een aantal premissen, die i.v.m. de frekwentie van het kontakt met sprekers van vreemde dialekten geponeerd zijn in hoofdstuk 1, door de cijfers voor de situeerbaarheid bevestigd te worden: oudere mannen uit de hoogste sociale klassen hebben blijkbaar van alle onderzochte groepen het meeste kontakt (gehad) met sprekers van een brede waaier van dialekten. Dit feit speelt waarschijnlijk niet alleen een rol bij de eksterne herkenbaarheid van dialekten (situeerbaarheid), maar ook (cf. hoofdstuk 1) bij de interne (verstaanbaarheid). In hoeverre ook het derde onderzochte kenmerk (appreciatie) beïnvloed wordt is minder duidelijk: in alle geval komen vooroordelen zoals b.v.: ‘bewoners van die of die streek zijn sympatiek/antipatiek’ e.d. vrij algemeen voor bij grote delen van de Belgische bevolking. Verder onderzoek is hier noodzakelijk.
Universiteit Antwerpen (UIA)
Herman Boets
Georges De Schutter
|
|
