|
| |
| |
| |
Problemen met morfemen: voor- en nadelen van de representatie van interne woordstructuur in het mentaal lexicon
Dominiek Sandra
1. Het mentaal lexicon en lexicale representaties
In de psycholinguïstiek wordt de term ‘mentaal lexicon’ gebruikt om te verwijzen naar het geheugengebied waar de lexicale kennis, d.w.z. de kennis van de woorden van een taal, van een taalgebuiker ligt opgeslagen. Met het begrip ‘gebied’ wordt alleen een subsysteem van het geheugen bedoeld. De term draagt geenszins de implicatie dat het om een anatomisch duidelijk te onderscheiden zone in de hersenen zou gaan. Volgens sommige onderzoekers vormen het mentaal lexicon en de processen die de toegang tot de lexicale kennis mogelijk maken echter wel een aparte module binnen het cognitieve systeem (Fodor, 1983; Forster, 1985). Concreet komt dit erop neer dat processen van niet-lexicale aard de toegang tot een woord in het mentaal lexicon niet kunnen beïnvloeden. De vaststelling dat proefpersonen sneller op een woord kunnen reageren als het in hoge mate voorspelbaar is (b.v. Hij stak de sleutel in het sleutelgat en opende de DEUR) of als het in een sterk verwante semantische context voorkomt (brood - BOTER) wijzen in zo een optiek niet op een snellere toegang tot het mentaal lexicon maar op een snellere uitvoering van andere processen (zoals b.v. de semantische integratie van opeenvolgende woorden). Andere onderzoekers gaan er van uit dat cognitieve processen van niet-lexicale aard wel rechtstreeks de toegang tot het mentaal lexicon kunnen beïnvloeden.
De kennis die in het mentaal lexicon is ondergebracht, moet de taalgebruiker in staat stellen om woorden in talige communicatie te kunnen gebruiken. Het gaat dus om linguïstisch relevante, permanente eigenschappen van woorden. Niet-permanente eigenschappen van woorden, zoals het zich herinneren dat men een woord kort geleden gelezen heeft, zijn ook een vorm van kennis betreffende die woorden. Die kennis kan men echter niet aanwenden om de woorden correct te gebruiken. Men neemt aan dat zulke situatie-specifieke kennis niet in het mentaal lexicon is opgenomen maar in een apart geheugensysteem (wat Tulving, 1972, het episodisch geheugen heeft genoemd).
Aangezien een model van het mentaal lexicon een verklaring moet kunnen bieden van wat een taalgebruiker met woorden doet, rijst de vraag wat minimaal tot die abstract-linguïstische kennis gerekend moet worden. Een opsomming van de verschillende wijzen waarop taalgebruikers met woorden omgaan, biedt daarop een antwoord. Woorden kan men uitspreken en verstaan, schrijven
| |
| |
en lezen. Er bestaan m.a.w. een auditieve en een visuele taalmodaliteit en de taalgebruiker kan woorden zowel produceren als waarnemen. Het is evident dat er in niet-pathologische vormen van taalgebruik bij deze processen telkens sprake is van een woordvorm (die men produceert of waarneemt) en van een woordbetekenis. De noodzakelijke en voldoende voorwaarden om voornoemde vier taalactiviteiten te kunnen uitvoeren, kan men weergeven in de vorm van een stelsel linguïstische representaties. Een representatie op het syntactische en semantische niveau is noodzakelijk om woorden te begrijpen en correct te gebruiken, een orthografische representatie is vereist om geschreven woorden te kunnen lezen en schrijven, en een fonologische representatie is noodzakelijk om gesproken woorden te kunnen uitspreken en verstaan. Tesamen vormen ze een voldoende set om de diverse gebruiksmogelijkheden van woorden te verklaren. De verschillende representaties van een woord zijn met elkaar verbonden en de eenheid die daardoor ontstaat, wordt een lexicale representatie genoemd. Lexicale representaties bevatten dus alle informatie die de taalgebruiker nodig heeft om de woorden in alle gebruikssituaties te hanteren.
Aangezien de psycholinguïstische vraagstelling niet enkel de representatie van lexicale kennis betreft maar tevens het gebruik ervan, moet een model van het mentaal lexicon ook een beschrijving bieden van de manier waarop de opgeslagen informatie toegankelijk wordt. Die toegang kan verschillen in functie van de taalmodaliteit (visueel versus auditief) en de ‘rol’ van de taalgebruiker (zender of ontvanger). Bij het lezen zal de lexicale representatie bereikt worden via een orthografische representatie van het woord (tenzij omzetting naar een fonologische representatie vereist zou zijn), bij het luisteren naar gesproken taal via een fonologische representatie en bij spreken en schrijven via een syntactische en semantische representatie.
De representaties die gebruikt worden om de informatie die in een lexicale representatie besloten ligt te ontsluiten, worden door Taft en Forster (1975); toegangscodes genoemd (zie ook Taft, 1985). Die codes hoeven niet noodzakelijk met één van de eerder genoemde types representaties binnen de lexicale representatie samen te vallen. Bij voorbeeld, bij het lezen van het woord donder zou een toegangscode als don of dond gebruikt kunnen worden om de orthografische representatie van het woord te bereiken, waarna meteen ook de fonologische en syntactisch-semantische representaties beschikbaar zouden worden (zie Taft & Forster, 1976; Taft, 1979; voor voorstellen omtrent het gebruik van partiële woordbeschrijvingen als toegangscodes).
| |
2. De voordelen van morfologische representaties in het mentaal lexicon
Binnen de theoretische linguïstiek heeft men nauwelijks aandacht opgebracht voor de orthografische representatie van woorden. Het betreft hier dan ook een perifeer aspect van de taal, dat inderdaad meer van belang is voor het proces van woordherkenning dan voor linguïstische theorieën. Wel hebben veel linguïsten zich beziggehouden met aspecten van de fonologische en de semantische representatie van woorden. Daarnaast is er echter in de linguïstiek ook veel
| |
| |
aandacht uitgegaan naar een hier nog niet genoemde vorm van linguïstische beschrijving: de morfologische representatie. Moeten zulke morfologische beschrijvingen ook opgenomen worden in de lexicale representaties in het mentaal lexicon?
Bij het behandelen van deze problematiek is het wellicht verstandig om het principe te hanteren dat een bepaald type informatie slechts in het mentaal lexicon zal worden opgenomen als de taalgebruiker daar ook enig voordeel kan uit halen. Het zou tegenintuïtief zijn om de representatie van morfologische informatie te verdedigen als daar alleen maar nadelen zouden uit voortvloeien of als kan worden aangetoond dat die nadelen de voordelen veruit overtreffen. Merk daarbij wel op dat zulke voor- en nadelen niet noodzakelijk bewust door de taalgebruiker ervaren moeten worden. Het vooropgesteld criterium is dat de aanwezigheid van een bepaald type informatie in het mentaal lexicon in een verhoogde efficiëntie moet resulteren ten opzichte van een systeem waarin die informatie niet opgenomen is.
Verschillende observaties lijken erop te wijzen dat het voordelig zou zijn om de morfologische structuur van woorden in het mentaal lexicon op te nemen. Ten eerste komen er veel polymorfematische woorden in de taal voor die een doorzichtige formele en semantische relatie tot hun grondwoord(en) onderhouden (fiets - fietser, denk - denker, goed - goedheid, lezen - herlezen, plaatsen - verplaatsen, keuken + stoel - keukenstoel). Aangezien zowel de vorm als de betekenis van het (de) grondwoord(en) onveranderd in de vorm en betekenis van zulke polymorfematische woorden voorkomen, lijkt het onnodig om die informatie ook nog eens in een lexicale representatie van de polymorfematische woorden op te nemen.
Onderzoek naar het gebruik van woordstructuur bij het leren van nieuwe woorden levert een tweede argument ten voordele van de morfologische representatie van woorden in het mentaal lexicon. De resultaten van leerexperimenten (Sandra, 1988, in druk) laten zien dat proefpersonen afgeleide woorden waarvan ze het grondwoord al kennen beter onthouden dan volledig nieuwe woorden. Proefpersonen maken bovendien spontaan gebruik van de relatie tussen het grondwoord en het afgeleide woord, wat blijkt uit vergelijkbare resultaten in een proefpersoongroep die expliciet geïnstrueerd werd om bij het leren van de morfologische relaties gebruik te maken en een groep die deze instructie niet kreeg. Zulke gegevens suggereren dat afgeleide woorden opgeslagen worden in de vorm van een representatie waarin hun grondwoord en affix als aparte eenheden aanwezig zijn. Die interpretatie werd in de experimenten door twee veel voorkomende fouttypes ondersteund: fouten waarbij de proefpersoon zich enkel het grondwoord correct herinnerde (b.v., cooking voor cooker) en fouten waarbij de proefpersoon een betekenisverwant woord als grondwoord produceerde (b.v., lighting voor clearing).
Onderzoek van Freyd en Baron (1982) leidde tot soortgelijke resultaten. Zij stelden vast dat twaalfjarige kinderen reeds gebruik maakten van morfologische verbanden bij het leren van associatieve paren die uit een nonsensvorm en een Engels woord waren opgebouwd. Wanneer de jonge proefpersonen een paar als
| |
| |
skaffist - thief moesten leren, hadden ze daar minder tijd voor nodig als ze reeds eerder skaf - steal hadden geleerd.
Een derde argument dat het nut van morfologische representaties in het mentaal lexicon aangeeft, ligt vervat in het gelijkvormigheidsprincipe dat bij de spelling van Nederlandse woorden gehanteerd wordt (cf. Woordenlijst van de Nederlandse Taal, 1954). Dat principe stipuleert dat de spelling van monomorfematische woorden onveranderd blijft wanneer die woorden in polymorfematische woorden of woordvormen voorkomen, zelfs als de uitspraak een andere spelling suggereert. Voorbeelden zijn: hij lijdt (niet lijt) omwille van lijden, hoed (niet hoet) omwille van hoeden, handtas (niet hantas) omwille van hand, enz. Het gelijkvormigheidsprincipe in de huidige Nederlandse spelling is wellicht geïnspireerd door intuïties van de leden van de spellingcommissie omtrent het belang van morfologische informatie bij het leesproces. Er valt geen enkele reden te bedenken om vormen als hij lijdt boven hij lijt te verkiezen als men weet dat elke generatie jonge en veel generaties minder jonge (!) spellers de grootste moeilijkheden met die vormen ondervinden, behalve het argument dat het herkennen van de stam (lijd) vereist is om lijdt efficiënt te herkennen. Vandaar ook dat de Werkgroep ad hoc Spelling van de Nederlandse Taalunie in 1989 het voorstel formuleerde om in de werkwoordspelling eventueel het analogieprincipe op te geven maar niet het gelijkvormigheidsprincipe (dus hij lijd).
| |
3. Mogelijke representaties van de morfologische structuur in het mentaal lexicon
Bovenstaande argumenten wijzen op het nut van een aparte morfologische representatie binnen de lexicale representatie van woorden. De vraag dient dan gesteld hoe morfologische informatie moet worden gerepresenteerd. Die vraag zal hier alleen voor de categorie van samengestelde woorden worden beantwoord (tot dusver is over polymorfematische woorden in het algemeen gesproken). Wat voor woorden van dit type wordt gesteld, geldt niet noodzakelijk ook voor derivaties en flexievormen.
| |
3.1. Beschrijving van de structurele opbouw van het woord
Een mogelijkheid die in het licht van de hierboven gegeven beschrijving van lexicale representaties het meest voor de hand lijkt te liggen, is dat er naast de orthografische, fonologische, syntactische en semantische representaties nog een vijfde, met name morfologische, representatie aan de lexicale representatie wordt toegevoegd. Zo een representatie zou dan de interne woordstructuur beschrijven door een verwijzing te maken naar de lexicale representaties van de morfologische onderdelen. Figuur 1 maakt dit duidelijk.
Het is echter de vraag welk doel gediend wordt door een dergelijke beschrijving op morfologisch niveau. Het soort representatie dat hier voorgesteld wordt, zou aangeven dat keukenstoel een samengesteld woord is. Dat is nuttige informatie
| |
| |

Figuur 1: De lexicale representatie voor het woord keukenstoel. De morfologische representatie beschrijft de interne structuur van het woord door naar de lexicale representaties van de constituenten te verwijzen.
voor een regel die op samengestelde woorden opereert (b.v. samentrekkingsregel: tuin- en keukenstoelen). De winst is echter zeer minimaal want een verder nut lijkt de representatie niet te hebben. Daartegenover staat als nadeel dat elk samengesteld woord een extra representatie in het mentaal lexicon nodig heeft.
| |
3.2. Beschrijving van de structurele opbouw van het woord met het oog op semantische interpretatie
Men kan de morfologische representatie van een woord echter anders opvatten. Zoals reeds eerder gezegd, zijn sommige samengestelde woorden zowel vormelijk als semantisch een combinatie van hun onderdelen (keukenstoel verwijst naar een stoel die voor een keuken bestemd is). In zulke gevallen maakt een morfologische representatie van het woord de semantische representatie ervan overbodig. Het invoeren van een morfologische representatie resulteert binnen die optiek dus niet in een toevoeging van extra informatie aangezien dit gepaard gaat met het wegvallen van de semantische representatie. Bovendien is de winst dit keer ook niet minimaal aangezien de morfologische beschrijving van het woord nu niet enkel structurele informatie biedt voor regels als de samentrekking maar tevens het dupliceren van semantische informatie in het lexicon overbodig maakt (opnemen van semantische representaties voor keuken en stoel als onderdeel van een semantische representatie voor keukenstoel hoeft niet meer) en op die manier semantische relaties tussen woorden in het lexicon expliciteert. Met andere woorden, een lexicon dat van zulke morfologische representaties gebruik maakt, lijkt te verkiezen boven een lexicon dat de morfologische structuur weergeeft zoals in Figuur 1 en ook boven een lexicon dat geen morfologische informatie bevat: er lijken geen nadelen te zijn (per woord zijn niet méér representaties nodig dan wanneer het woord niet morfologisch gerepresenteerd zou worden; de semantische representatie valt immers weg) maar wel duidelijke voordelen (er wordt méér informatie vastgelegd).
Een morfologische representatie die gebruikt moet worden om de betekenis van een samenstelling af te leiden kan echter niet alleen een verwijzing bevatten naar de lexicale representaties van de constituenten van die samenstelling. De semantische relatie tussen die onderdelen is immers niet in alle samenstellingen dezelfde en om die reden niet voorspelbaar. In een woord als keukenstoel wordt een locatiefrelatie uitgedrukt, in melkfles een container-inhoudrelatie, in
| |
| |
fietswiel een geheel-onderdeelrelatie. Een morfologische representatie kan dus alleen functioneren voor semantische doeleinden als daarnaast ook verwezen wordt naar een regel die het precieze betekenisverband tussen de constituenten specifieert. Jackendoff (1975) noemt dit redundantieregels. Aangezien zulke redundantieregels puur semantische informatie uitdrukken, betekent dit dat de semantische representatie voor woorden als keukenstoel toch niet helemaal kan wegvallen. Toch blijft het een aantrekkelijk voorstel om binnen de lexicale representatie voor een samenstelling als keukenstoel morfologische informatie op te nemen omdat door de verwijzing naar de constituenten de semantische representatie van het woord voor een groot stuk ‘verlicht’ kan worden.
| |
3.3. Geen lexicale representatie van samengestelde woorden
In het hierboven geformuleerde voorstel wordt gebruik gemaakt van de morfologische structuur van samenstellingen om de hoeveelheid informatie binnen hun semantische representatie te reduceren. Die vorm van lexicale representatie werd gemotiveerd vanuit de observatie dat de betekenis van een woord als keukenstoel ten dele redundant is t.o.v. de betekenissen van keuken en stoel (op de precieze aard van hun semantische relatie na). Op het vlak van de woordvorm is er echter eveneens sprake van redundantie. Het woord keukenstoel is als vorm de combinatie van twee reeds in het lexicon voorkomende woorden. Kan die redundantie dan ook niet gebruikt worden bij de lexicale representatie? Als dezelfde logica aangewend wordt als bij de semantische representatie - de representatie van een woord op een bepaalde dimensie kan helemaal of gedeeltelijk worden weggelaten als die representatie redundant is ten opzichte van reeds aanwezige informatie in het lexicon - dan leidt die gedachtengang tot het voorstel om de woordvorm keukenstoel helemaal uit het lexicon te verwijderen. Dat is het meest radicale voorstel dat men kan formuleren: neem het woord keukenstoel helemaal niet in het lexicon op aangezien het vormelijk en semantisch reeds in zijn samenstellende delen besloten ligt.
Eén belangrijke consequentie van dit voorstel is een toenemende mate van complexiteit bij de verwerking van samenstellingen. Tot dusver is uitsluitend over representatiekwesties gesproken omdat alle voorstellen geen implicaties hadden voor toegangsprocessen. Bij het laatste voorstel is dat echter wel het geval. Als samenstellingen immers via hun constituerende delen moeten worden begrepen (‘begrijpen’ is hier een betere term dan ‘herkennen’ aangezien het woord geen lexicale representatie zou hebben), is het nodig dat die delen in het woord worden opgespoord alvorens hun lexicale representaties kunnen worden opgezocht. Dat betekent dat er een procedure moet worden ingevoerd die een morfologische analyse van samenstellingen oplevert. Een essentiële eigenschap van zo een procedure is dat ze zonder lexicale kennis zou moeten opereren. Als de procedure over de kennis zou beschikken dat keuken in keukenstoel een woord is, dan zou het woord keuken reeds lexicaal herkend zijn nog voor het lexicon is geraadpleegd. Dat is natuurlijk uitgesloten aangezien het precies de taak van de morfologische procedure zou zijn om toegang tot het mentaal lexicon mogelijk te maken. Het probleem dat hier aan de orde is, is echter niet
| |
| |
onoverkomelijk (cf. infra). Wat echter binnen een dergelijk voorstel niet oplosbaar blijkt te zijn, is de noodzaak om de semantische relatie tussen de betekenissen van de constituenten lexicaal vast te leggen. Dat kan immers alleen als er een orthografische representatie bestaat waarmee de semantische informatie verbonden kan worden. Een lexicale representatie van het woord is dus een vereiste. Met andere woorden, als men wil besparen op de hoeveelheid gerepresenteerde informatie en de kwaliteit van die informatie wil optimaliseren (explicitatie van morfologische relaties of niet) dan moet dat blijkbaar binnen de lexicale representatie van een woord gebeuren.
| |
3.4. Toegang via de lexicale representatie van een constituent
3.4.1. Het model van Taft en Forster
Toch is er in de psycholinguïstische vakliteratuur bijzonder veel aandacht uitgegaan naar een wijze van representatie waarbij - evenals in het radicale voorstel hierboven - de woordvorm tijdens het proces van lexicale verwerking in constituenten moet worden gesplitst. Binnen dat model, dat door Taft en Forster (1976) werd voorgesteld, is de morfologische decompositie echter niet vereist door het ontbreken van een lexicale representatie voor de samenstelling maar wel door het feit dat die representatie slechts via de eerste constituent toegankelijk kan worden. Bij voorbeeld, een geschreven vorm als keukenstoel wordt niet in één keer op zijn lexicale representatie afgebeeld, maar via een representatie van keuken. Die toegangscode behoort niet tot het eigenlijke lexicon en is dus zelf geen lexicale representatie maar verleent wel toegang tot de lexicale representatie van keuken en alle representaties van woorden waarin keuken in eerste positie voorkomt (keukenstoel, keukenmes, keukenzout). De procedure die de eerste constituent in samenstellingen van de rest van het woord afsplitst, is een parseringsmechanisme dat woorden letter per letter verwerkt en na elke letter verifieert of het afgesplitste deel toegang verleent tot een orthografische representatie in het mentaal lexicon.
Het model van Taft en Forster maakt niet helemaal duidelijk hoe de representaties in het mentaal lexicon er uitzien. In principe zijn er twee mogelijkheden: ofwel zijn het allemaal aparte representaties die via éénzelfde toegangscode bereikt worden (cf. Figuur 2), ofwel gaat het om één representatie waarbinnen alle representaties van samenstellingen in de vorm van een lijst mogelijke tweede constituenten zijn opgenomen (cf. Figuur 3). In dat laatste geval moet voor elke tweede constituent een verwijzing worden gemaakt naar een redundantieregel die de semantische relatie tussen de constituenten specifieert (b.v., stoel, r2 betekent dat de betekenissen van keuken en stoel in een relatie tot elkaar staan die weergegeven wordt door de regel waarnaar r2 verwijst).
| |
| |

Figuur 2: De lexicale representaties voor keuken, keukenstoel, keukenmes en keukenzout. De samenstellingen worden toegankelijk via hun eerste constituent maar hebben geen eigen morfologische representatie.
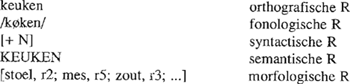
Figuur 3: De lexicale representaties voor keuken, keukenstoel, keukenmes en keukenzout. De samenstellingen worden toegankelijk via de lexicale representatie van hun eerste constituent en hebben tevens een morfologische representatie. Die representatie verwijst tevens naar de redundantieregel die voor semantische interpretatie nodig is.
De laatste vorm van representatie lijkt de enig verdedigbare binnen het model van Taft en Forster. Het alternatief dat in Figuur 2 is weergegeven, heeft immers weinig voordelen te bieden, terwijl het wel duidelijke nadelen heeft. Wat is de zin van een toegangscode als een hele reeks woorden toegankelijk kan worden nadat de code is afgesplitst maar geen enkel woord ook effectief toegankelijk wordt voordat de tweede constituent verwerkt is? Bovendien zou de verwerking van samenstellingen aanzienlijk complexer worden aangezien ze morfologisch gedecomponeerd moeten worden alvorens toegang tot hun lexicale representatie kan worden verkregen. Op het niveau van representatie zijn de problemen even groot. Waarom morfologische decompositie invoeren als het aantal lexicale representaties in het mentaal lexicon hetzelfde blijft? Bovendien zou binnen de lexicale representatie van elke samenstelling toch nog eens een aparte morfologische representatie moeten worden opgenomen als de betekenis van het woord in termen van zijn constituenten zou worden gespecifieerd. Het voordeel is klein: omdat alle samenstellingen met eenzelfde beginconstituent via dezelfde toegangscode toegankelijk worden, blijkt de morfologische verwantschap tussen die woorden uit de structuur van het lexicon.
Een vorm van lexicale representatie waarbij de tweede constituenten van samenstellingen met eenzelfde beginconstituent binnen de lexicale representatie van die eerste constituent worden opgesomd, heeft meer voordelen te bieden. Ten eerste wordt er bespaard op het aantal lexicale representaties. De representaties voor de samengestelde woorden verdwijnen weliswaar niet aangezien ze a.h.w. opgenomen worden binnen de representatie van hun gemeenschappelijke eerste lid, maar de orthografische en fonologische representaties van het eerste lid moeten daardoor slechts één keer gespecifieerd worden. Ten tweede wordt
| |
| |
er ook bespaard op de hoeveelheid semantische informatie in het lexicon. De betekenis van de eerste en tweede constituenten hoeft eveneens slechts één keer te worden opgenomen, meer bepaald bij de lexicale representatie van de woorden zelf. Lexicale redundantieregels zorgen ervoor dat de constituentbetekenissen correct geïntegreerd worden. Het ziet er dus naar uit dat de vorm van representatie van samengestelde woorden zoals in Figuur 3 weergegeven is maximaal gebruik maakt van de redundantie die in dergelijke woorden aanwezig is om te besparen op de hoeveelheid informatie in het lexicon.
| |
3.4.2. Problemen met het model van Taft en Forster
Tegenover de genoemde voordelen staan echter ook nadelen. Ten eerste wordt het proces van lexicale toegang complexer. Alvorens een woord als keukenstoel toegang kan verkrijgen tot zijn lexicale representatie moet het eerst morfologisch gedecomponeerd worden. Een tweede nadeel volgt uit de precieze aard van het vereiste decompositieproces. Aangezien de procedure die de decompositie moet uitvoeren niet over lexicale kennis kan beschikken (zie hierboven), moet ze op verschillende posities binnen het woord een morfologische grens poneren. Dat kan echter niet puur willekeurig omdat er in zo een geval nog een extra geheugen nodig zou zijn om de geteste posities te onthouden. Daarom kan beter voor een systematische procedure geopteerd worden. Zoals reeds gezegd, is dat ook het voorstel van Taft en Forster (1976; zie ook Taft, 1979): een parseringsmechanisme verwerkt woorden letter per letter en stuurt telkens het links afgesplitste deel naar het lexicon door om na te gaan of er lexicale toegang plaatsvindt. Omdat de decompositieprocedure echter onmogelijk kan weten of het te lezen woord mono- of polymorfematisch is, moet ze alle woorden die zich aandienen verwerken. Dat leidt tot fouten in het herkenningsproces van woorden als panter, mantel, pastoor,...en woorden als karton, bolster,...Bij items uit de eerste reeks wordt een bestaand woord (pan, man, pas) ten onrechte afgesplitst van de rest van het woord, waardoor toegang verkregen wordt tot de lexicale representatie van dat deel. Bij inspectie van de lijst mogelijke tweede constituenten blijkt dat de rest van het woord geen tweede constituent van een bestaande samenstelling is. Dat zou voor het proces van lexicale verwerking het signaal kunnen zijn dat een verkeerde parsering gemaakt werd en dat het woord verder geparseerd moet worden. Het zou echter ook kunnen dat de parsering correct was en dat de rest van het woord een tweede constituent
binnen een nieuwe samenstelling is. Daarom is het wellicht aangewezen (nu de mogelijke morfologische grens toch beschikbaar is) om die hypothese meteen te toetsen. Voor woorden als panter blijkt dan snel dat het ook niet om een nieuwe samenstelling gaat. Pas dan kan de prelexicale decompositieprocedure haar werk verder zetten en doorgaan met de parsering (pant, pante, panter) tot uiteindelijk het hele woord verwerkt is en de juiste lexicale representatie toegankelijk wordt.
Voor woorden uit de tweede reeks voorbeelden hierboven (type karton) is de situatie nog problematischer. Daar blijkt in eerste instantie ook dat het afge- | |
| |
splitste woord (kar) geen bestaande samenstelling vormt met de rest van het woord (ton). Bij het verifiëren van de hypothese dat het om een nieuwe samenstelling zou kunnen gaan, blijkt echter dat met karton een ton bedoeld kan zijn die speciaal voor karren ontworpen is. Een dergelijke vorm van lexicale creativiteit vormt op zich natuurlijk geen probleem. Het punt is echter dat wanneer karton niet naar een ton verwijst maar zijn gewone betekenis heeft het proces van lexicale verwerking toch de ton-lezing oplevert! Met andere woorden, binnen het model kan de lexicale representatie van het bestaande woord karton blijkbaar niet bereikt worden. Het voorbeeld van bolster geeft aanleiding tot dezelfde problemen: het woord bolster kan naar een ster verwijzen die de vorm van een (vuur)bol heeft, maar die betekenis zal ook aan het woord worden toegekend wanneer het naar het omhulsel voor een noot verwijst.
Uit de voorbeelden hierboven blijkt dat het invoeren van een decompositieprocedure voor samengestelde woorden (wat onbetwistbare voordelen biedt op het niveau van hun lexicale representatie) de verwerking van een bepaald woordtype (woorden met een korter woord aan het begin, dat echter niet als morfeem functioneert) aanzienlijk vertraagt en de herkenning van woorden van een ander type onmogelijk maakt (woorden die uit twee bestaande woorden zijn opgebouwd en als nieuwe samenstelling geïnterpreteerd kunnen worden). Het laatste probleem kan wel vermeden worden, nl. door geen nieuwvormen te postuleren alvorens er zekerheid over bestaat dat het woord niet in het lexicon voorkomt. Dat lost echter het ene probleem op door een ander te introduceren. Een dergelijke conditie zou immers een bijzonder omslachtig interpretatieproces voor nieuwe samenstellingen met zich meebrengen. Er zouden namelijk twee morfologische decomposities moeten worden gemaakt: de eerste keer om na te gaan of het om een bestaande samenstelling gaat (waarna de vorm als heel woord zou worden verwerkt), de tweede keer om na te gaan of het woord een nieuwe samenstelling is.
Naast de toegenomen verwerkingscomplexiteit en de problemen bij de verwerking van andere woordtypes houdt een vorm van lexicale representatie zoals in Figuur 3 ook mogelijke problemen in voor de categorie van samengestelde woorden zelf. Aangezien de voorgestelde procedure van morfologische decompositie voor samenstellingen is ingevoerd (hoewel ook derivaties met suffixen ermee herkend zouden kunnen worden) is het aannemelijk-dat-ze op de categorie als geheel van toepassing is. Dat is zeker het standpunt van Taft en Forster (1976). Elke samenstelling moet dus morfologisch gedecomponeerd worden om toegang tot haar lexicale representatie te kunnen krijgen.
Binnen een dergelijke visie wordt het belang van linguïstische parameters (b.v. de semantische transparantie van de samenstelling) echter genegeerd. Vanuit linguïstisch standpunt is decompositie immers veel aannemelijker voor vormen als keukenstoel en donderwolk, waar de betekenis van de constituenten volledig behouden is in de betekenis van het hele woord, dan voor woorden als paddestoel en donderdag, waar de betekenis van één of beide constituenten volledig of gedeeltelijk verloren is. Als echter slechts woorden van het semantisch transparante type in gedecomponeerde vorm zouden worden opgeslagen,
| |
| |
dan zouden de problemen die zich bij woorden als karton voordoen ook bij niet-transparante samenstellingen optreden (donderdag zou geïnterpreteerd worden als een dag waarop het dondert). Dat zou tot de toch wel vreemde conclusie leiden dat het streven naar grotere efficiëntie bij één type samenstelling tot grote inefficiëntie leidt bij een ander type samenstelling.
De nadelen van een representatievorm als in Figuur 3 zijn dus ernstig. Globaal gesproken wordt het lexicon moeilijker toegankelijk dan wanneer samenstellingen niet gedecomponeerd zijn opgeslagen. Tenzij natuurlijk de bovengenoemde problemen i.v.m. de verwerking oplosbaar zijn. Aan het probleem dat het verwerkingsproces complexer wordt door de invoering van een decompositieprocedure valt niets te doen. Van zodra een nieuw proces nodig is, wordt het hele proces van lexicale verwerking complexer. Als die toename in complexiteit echter voldoende voordelen op het vlak van representatie oplevert, dan hoeft dat geen nadeel te zijn. Het feit dat tijdens de verwerking van sommige woorden verkeerde lexicale representaties toegankelijk worden, is echter wel een ernstig probleem. Het is immers zonder meer duidelijk dat dit geen kenmerk kan zijn van een efficiënt functionerend mentaal lexicon. Er zijn echter mogelijkheden denkbaar om dat probleem op te lossen.
| |
3.4.3. Oplossingen voor de problemen met het Taft en Forster model
Een eerste mogelijkheid zou zijn om de decompositieprocedure uit te stellen tot gebleken is dat het woord niet als hele vorm in het mentaal lexicon voorkomt (cf. Manelis & Tharp, 1977). Daardoor zouden woorden als panter en karton meteen correct herkend worden aangezien er geen decompositie op uitgevoerd zou worden. Voor woorden die wel in gedecomponeerde vorm gerepresenteerd zijn, zou een dergelijke oplossing dan echter in een vertraagd herkenningsproces resulteren. Tegenover de voordelen op het vlak van lexicale representatie staan dus de nadelen van complexere én vertraagde herkenning. Een vertraging in de herkenningstijd (trager dan het laagst frequente woord van vergelijkbare lengte) kan beter vermeden worden aangezien een snelle herkenning van woorden noodzakelijk is voor een vlot leesproces. Bovendien kan men zich de vraag stellen wat het voordeel van morfologische decompositie zou zijn als de procedure de herkenning van de gedecomponeerde lexicale representaties bemoeilijkt (cf. Taft en Forster, 1975). Decompositie zou voor het bedoelde woordtype (samenstellingen dus) het proces van lexicale toegang niet problematischer maar efficiënter moeten maken in vergelijking met een model waarin zulke representaties niet voorkomen. Daar komt nog bovenop dat uitgestelde decompositie het probleem bij woorden als panter alléén zou oplossen in gevallen waar die woorden monomorfematisch gebruikt worden. Als eerste lid van bestaande samenstellingen die in gedecomponeerde vorm lexicaal gerepresenteerd zouden zijn (panterbroek) en van nieuwe samenstellingen (panterprooi) zouden ze tot precies dezelfde problemen aanleiding geven als bij onmiddellijke decompositie. Aangezien zulke samenstellingen immers gedecomponeerd zouden moeten worden, zou tijdens dat proces toegang tot verkeerde lexicale represen- | |
| |
taties plaatsvinden
(pan/terbroek, pan/terprooi).
Een andere oplossing wordt voorgesteld door Frauenfelder en Schreuder (1991). Binnen het model dat zij verdedigen, zijn twee toegangsprocedures, de ene gebaseerd op het hele woord en de andere op een morfologische decompositie van het woord, parallel operationeel en derhalve met elkaar in competitie om toegang tot het mentaal lexicon te verwerven. Daardoor hoeft de herkenning van woorden die in gedecomponeerde vorm gerepresenteerd zijn niet langer te duren dan de herkenning van even frequente woorden die als heel woord zijn opgeslagen (zoals in een model met uitgestelde decompositie het geval zou zijn), hoewel de hele-woordprocedure vaker de race wint dan de decompositieprocedure (decompositie kost verwerkingstijd). Daardoor wordt ook de kans kleiner dat tijdens het herkenningsproces van woorden als panter toegang wordt verkregen tot de lexicale representatie van woorden die niet als morfeem functioneren (pan). Toch blijft ook binnen een dergelijk ‘race model’ de kans bestaan dat in zulke gevallen een verkeerde lexicale representatie toegankelijk wordt. Dat zou namelijk kunnen gebeuren als een hoogfrequent woord als niet-morfeem aan het begin van een laagfrequent woord voorkomt. De lexicale representatie van een hoogfrequent woord wordt immers sneller toegankelijk dan die van een laagfrequent woord. Natuurlijk zal het verschil tussen de herkenningstijden voor beide woorden dan groter moeten zijn dan de duurtijd van de decompositie. De vraag of het hier alleen om een theoretische mogelijkheid gaat dan wel om een reëel feit hangt af van de tijd die het parseren in beslag neemt en de verhouding tussen de frequentie van het hele woord en de frequentie van het initiële woord. Afhankelijk van deze factoren zal tijdens het herkenningsproces van veel, weinig of geen woorden een verkeerde lexicale representatie toegankelijk worden. Als het om een verwaarloosbaar aantal woorden gaat, stelt dat voor het model
geen probleem. Fouten tijdens de verwerking doen zich immers ook op andere linguïstische niveaus voor, bij voorbeeld in zinnen als The horse raced past the barn...fell en The old train...the young, waar de syntaxis of semantiek tot een verkeerde lezing aanleiding geven. Het optreden van fouten is dus op zich geen reden om een model te verwerpen, omdat foutieve analyses wellicht het natuurlijke nevenprodukt zijn van veel taalprocessen. Als het aantal gevallen dat initieel verkeerd verwerkt wordt echter heel groot is, dan is dat wel een reden om het model te verwerpen. In gevallen waar verschillende procedures tegelijkertijd operationeel zijn, kan men zulke kwesties echter alleen via empirisch onderzoek benaderen.
Een andere mogelijkheid om de eerder genoemde problemen op te lossen werd voorgesteld door Sandra (1990). Een parseringsmechanisme zou een woord van links naar rechts verwerken op de manier voorgesteld door Taft en Forster (1976) en Taft (1979). Als het afgesplitste stuk correspondeert met de orthografische representatie van een woord, dan zou echter slechts toegang tot de lexicale representatie van dat woord worden verworven als geen enkele andere orthografische representatie in het lexicon met het verwerkte woorddeel verenigbaar is. Concreet betekent dit dat na de verwerking van pan in panter of kar in karton er geen toegang verkregen wordt tot de lexicale representatie van
| |
| |
pan en kar omdat op dat ogenblik ook andere orthografische representaties (panter, pantomine,...en karton, karwei,...) met de geparseerde informatie verenigbaar zijn en dus de correcte representaties kunnen zijn. Als tijdens de verwerking van nieuwe of in gedecomponeerde vorm gerepresenteerde samenstellingen blijkt dat de geparseerde informatie met geen enkele orthografische representatie meer verenigbaar is (karwi bij de verwerking van karwiel), wordt de representatie waarvan alle letterposities corresponderen met dezelfde letterposities in het verwerkte woord toegankelijk (kar omdat geen enkele letter uit kar verschilt van de corresponderende letter in karwiel, terwijl alle concurrerende woorden als karwei, karton, karper enz. minstens één niet-corresponderende letter bevatten). Het voorstel biedt een aantal voordelen. Ten eerste, het proces van lexicale verwerking is niet complexer dan het door Taft en Forster (1976) voorgestelde. Ten tweede, er is slechts één proces nodig om monomorfematische en samengestelde woorden te herkennen. Ten derde, de decompositieprocedure verschaft geen toegang tot verkeerde lexicale representaties.
| |
4. Onderzoek naar de lexicale representatie van semantisch transparante en niet-transparante samenstellingen
Aangezien het type lexicale representatie dat in Figuur 3 is voorgesteld de redundante informatie binnen samengestelde woorden maximaal benut en er verwerkingsprocessen denkbaar zijn die de problemen met Taft en Forsters (1976) decompositieprocedure oplossen, is het aangewezen om na te gaan of samenstellingen ook effectief op die manier gerepresenteerd worden. Het is echter wenselijk om bij zo een onderzoek linguïstische beschouwingen te betrekken. In de experimenten waarvan de resultaten hier kort beschreven zullen worden, is de semantische transparantie van de samenstellingen gemanipuleerd. Semantisch transparante (type donderwolk, veldmuis) en niet-transparante (type donderdag, vleermuis) samenstellingen werden als aparte categorieën onderzocht. De hypothese waarvan werd uitgegaan is dat samenstellingen van het transparante type lexicale representaties hebben zoals in Figuur 3 terwijl niet-transparante samenstellingen als hele vormen zijn opgeslagen. Over de precieze aard van de lexicale representaties voor niet-transparante samenstellingen wordt hier geen uitspraak gedaan. Mogelijk is er een morfologische representatie opgenomen, maar in elk geval kan die geen rol spelen bij het bepalen van de betekenis van de samenstelling. Omwille van de niet-transparante aard van de samenstelling moet een volledig gespecifieerde semantische representatie opgenomen worden.
Om voor de twee types samenstellingen na te gaan of hun lexicale representatie slechts via de representatie voor de eerste constituent kan worden bereikt, werd de techniek van semantische priming als diagnostiek gebruikt (Sandra, 1990). Semantische priming is een onderzoekstechniek waarbij een woord onmiddellijk voorafgegaan wordt door een associatief sterk verwant woord (kat - muis). Die techniek leidt tot een snellere herkenning van het tweede woord binnen de context van een lexicale-decisietaak, d.i. een taak waar proefpersonen
| |
| |
zo snel mogelijk moeten te kennen geven of een letterreeks al dan niet een bestaand woord is door één van twee reactieknoppen in te drukken (Meyer & Schvaneveldt, 1971). Als een aantal methodologische voorzorgen genomen wordt (voor een beschrijving, zie Sandra, 1990) kan dat effect in verband gebracht worden met een structurele eigenschap van het mentale lexicon, meer bepaald met het bestaan van paden tussen de lexicale representaties van woorden in sterk associatieve paren. De herkenning van een woord wordt binnen die theorie beschouwd als een proces waarbij ter hoogte van de lexicale representatie activatie wordt opgebouwd tot een kritische drempel (de herkenningsdrempel) overschreden wordt. Het activatieniveau van de representatie daalt snel maar een deel ervan verspreidt zich langs de associatieve paden. Het gevolg daarvan is dat wanneer kort daarop een associatief sterk verwant woord wordt aangeboden de lexicale representatie van dat woord reeds ten dele geactiveerd is, waardoor het sneller herkend wordt dan wanneer een niet-verwant woord eraan voorafgegaan was. Semantische priming kan dus gebruikt worden om na te gaan of de lexicale representatie van het met de prime verwante woord tijdens de herkenning van bij voorbeeld een samenstelling bereikt wordt. Als de lexicale representatie van een woord als donderdag slechts via de lexicale representatie voor donder kan worden bereikt, dan zal dat zich manifesteren in een snellere herkenning van donderdag na de aanbieding van een woord als bliksem, dat met donder sterk verwant is.
Er werden twee reeksen van elk zestien associatieve paren gezocht. In een voorafgaand experiment was eerst aangetoond dat het effect van semantische priming zich binnen die twee reeksen voordeed. Elk tweede lid van zo een paar werd in twee samenstellingen verwerkt, één transparante en één niet-transparante. Voor paren van de ene reeks werden die woorden als eerste constituent gebruikt, voor paren van de tweede reeks als tweede constituent. De positie werd gemanipuleerd omdat vanuit linguïstisch standpunt de finale constituent van een samenstelling belangrijker is dan de eerste (hij bepaalt immers de syntactische categorie van de samenstelling) en dus een betere kandidaat om als toegangscode voor het hele woord te functioneren. Op die manier ontstonden vier types samenstellingen: transparante met het associatieve woord in beginpositie (type bliksem - donderwolk), transparante met het associatieve woord in eindpositie (type rat - veldmuis), niet-transparante met het associatieve woord in beginpositie (type bliksem - donderdag) en niet-transparante met het associatieve woord in eindpositie (type rat - vleermuis). De transparante en niet-transparante samenstellingen werden in aparte lexicale-decisieëxperimenten aangeboden.
De resultaten van het onderzoek kunnen kort worden samengevat. Transparante samenstellingen werden significant sneller herkend als het voorafgaande woord met één van hun constituenten (de eerste of de tweede) associatief verwant was. De herkenning van niet-transparante samenstellingen werd niet beïnvloed als het voorafgaande woord met één van hun constituenten (de eerste of de tweede) associatief verwant was. Voor geen van beide types samenstelling had de positie van het tweede lid uit het associatieve paar invloed op
| |
| |
het effect van semantische priming. Het verschillend effect voor de twee types samenstelling valt niet toe te schrijven aan verschillen in associatiesterkte tussen de leden van de gebruikte woordparen aangezien precies dezelfde paren gebruikt werden.
| |
5. Conclusie
De hypothese dat semantisch transparante samenstellingen via de lexicale representatie voor hun eerste constituent toegankelijk worden (cf. Figuur 3) wordt door experimentele resultaten weerlegd. Blijkbaar vindt toegang plaats tot de lexicale representatie van beide constituenten. Wat dat precies betekent is onduidelijk. Als men van de assumptie vertrekt dat slechts de orthografische representatie van een woord toegankelijk moet worden om een lexicale decisie te maken en dat niet gewacht hoeft te worden op de semantische representatie of interpretatie, dan betekent het wellicht dat de transparante samenstellingen in het experiment geen eigen lexicale representatie hebben. Als men ervan uitgaat dat de betekenis wel een rol speelt bij het maken van een lexicale decisie, dan kan het betekenen dat er binnen de lexicale representatie voor transparante samenstellingen naar de lexicale representaties van hun constituenten verwezen wordt. Die representaties zijn na semantische priming sneller toegankelijk dan in een neutrale conditie.
De bewering dat transparante samenstellingen mogelijk geen lexicale representatie hebben, is in tegenspraak met wat eerder in deze tekst gesteld werd, nl. dat de semantiek van samenstellingen een lexicale representatie noodzakelijk maakt. Toch lijkt het niet uitgesloten dat wanneer de betekenis van het hele woord doorzichtig is taalgebruikers die betekenis telkens kunnen construeren. De betekenisrelatie mag dan al een variabele factor zijn, overwegingen van pragmatische aard en semantische kenmerken van de constituenten (het woord keuken verwijst naar een ruimte, dus keukenstoel zal wellicht een locatiefrelatie uitdrukken) kunnen de mate van ambiguïteit verminderen. De mogelijkheid van verschillende betekenissen hoeft op zich trouwens geen bezwaren in te houden. In de syntaxis kunnen taalgebruikers de structurele ambiguïteit van zinnen immers ook verwerken (Het meisje dat Piet kust).
De resultaten voor de categorie niet-transparante samenstellingen zijn in overeenstemming met de hypothese dat de lexicale representatie van die woorden niet via één van hun constituenten bereikt wordt. Zulke samenstellingen hebben dus een eigen lexicale representatie, los van de representaties van hun constituenten. Dat neemt natuurlijk niet weg dat binnen die lexicale representatie een morfologische representatie opgenomen kan zijn. Die representatie zal dan echter de semantische representatie van het woord niet vervangen, ook niet gedeeltelijk, aangezien de woordbetekenis niet m.b.v. een redundantieregel en een verwijzing naar de constituentbetekenissen kan worden weergegeven.
Uit het onderzoek blijkt dat het belangrijk is om bij een psycholinguïstische benadering van morfologische kwesties oog te hebben voor linguïstische onderscheidingen. De morfologische structuur van samenstellingen blijkt een rol te
| |
| |
spelen bij semantisch transparante samenstellingen maar niet bij niet-transparante samenstellingen. Dat verschil in lexicale representatie van de twee types samenstellingen hoeft geen problemen op te leveren voor de verwerking van de woorden (decompositie in het ene geval, geen decompositie in het andere). Een parseerder die het woord van links naar rechts verwerkt en telkens het afgesplitste deel naar het mentaal lexicon doorstuurt, levert precies het geobserveerde patroon van resultaten op als er een conditie op het mechanisme van lexicale toegang wordt geformuleerd, nl. dat toegang alleen plaatsvindt als slechts één lexicale representatie met de doorgestuurde informatie verenigbaar is (cf. Sandra, 1990).
| |
Bibliografie
| Fodor, J.A. (1983). The modularity of mind: An essay on faculty psychology. Cambridge Mass.: MIT Press. |
| Forster, K.I. (1985). Lexical acquisition and the modular lexicon. Language and Cognitive Processes, 1, 87-108. |
| Frauenfelder, U.H. & R. Schreuder (1991). Constraining psycholinguistic models of morphological processing and representation: the role of productivity. In Booij G. & J. van Marle (red.), Yearbook of Morphology, pp. 165-183. |
| Freyd P. & J. Baron (1982). Individual differences in acquisition of derivational morphology. Journal of Verbal Learning and Verbal Behavoir, 21, 282-295. |
| Jackendoff R. (1975). Morphological and semantic regularities in the lexicon. Language, 51, 639-671. |
| Manelis L. & Tharp, D.A. (1977). The processing of affixed words. Memory & Cognition, 5, 690-695. |
| Meyer, D.E. & Schvaneveldt, R.W. (1971). Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. Journal of Experimental Psychology, 90, 227-234. |
| Sandra, D. (1988). Is morphology used to encode derivations when learning a foreign language? ITL Review of applied linguistics, 79/80, 1-23. |
| Sandra, D. (1990). On the representation and processing of compound words: Automatic access to constituent morphemes does not occur. Quarterly Journal of Experimental Psychology, 42A, 529-567. |
| Sandra, D. (in druk). The use of lexical morphology as a natural mnemonic aid in learning foreign language vocabulary. Proceedings of the first international congress on memory and memorization in acquiring and learning languages. |
| Taft, M. (1979). Lexical access via an orthographic code: The Basic Orthographic Syllable Structure (BOSS). Journal of Verbal Learning and Verbal Behavior, 18,, 21-39. |
| Taft, M. (1985). The decoding of words in lexical access: A review of the morphographic approach. In D. Besner, T.G. Waller & G.E. Mackinnon (Eds.), Reading research: advances in theory and practice (pp. 83-123). London: Academic Press. |
| Taft, M. & Forster, K.I. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior, 14, 638-647. |
| Taft, M. & Forster, K.I. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. Journal of Verbal Learning and Verbal Behavior, 15, 607-620. |
| Tulving, E. (1972). Episodic and semantic memory. In E. Tulving & W. Donaldson (Eds.), Organization of memory (pp. 381-403). New York: Academic Press. |
| Woordenlijst van de Nederlandse Taal (1954). 's-Gravenhage: SDU uitgeverij. |
Adres van de auteur:
Dominiek Sandra, Prinsstraat 13 (kamer D 109), 2000 Antwerpen, België
|
|
