|
| |
| |
| |
De empirische dimensie
Willem Meijs
1 Inleiding
Deze bijdrage gaat over de empirische dimensie van de (computationele) lexicografie. Aan de hand van recente inzichten en ontwikkelingen in lexicografie, lexicologie en computertaalkunde worden de volgende vragen aan de orde gesteld. Wat zijn empirische taaldata? Hoe komt de lexicograaf aan betrouwbare empirische gegevens over betekenis en gebruik van woorden? Welke woorden komen in aanmerking voor opname in het woordenboek? Op wat voor gronden kunnen deze worden geselecteerd? Hoe kunnen de gegevens het best worden geordend en gepresenteerd? Hoe kunnen moderne electronische en computationele middelen bijdragen aan verbreding van de empirische basis van de lexicografie?
| |
2 Empirische gegevens, methoden en technieken
Het is wellicht nuttig ons eerst af te vragen wat we eigenlijk onder empirische lexicografische gegevens willen verstaan, en wat voor geeigende methoden en technieken er bestaan om aan dat soort gegevens te komen. In de meest letterlijke zin zijn empirische gegevens ‘ervaringsgegevens’, en de meest voordehandliggende manier om dergelijke gegevens te verkrijgen is dus in principe ‘op je ervaring afgaan’. Ervanuitgaande dat we als individuele taalgebruikers onze ervaring met taal ontlenen aan het totaal van de taalgebruikssituaties waarmee we te maken hebben (gehad), dan mogen we stellen dat empirische gegevens over de woorden van ‘de’ taal dus gegevens zijn over hoe die woorden door de taalgemeenschap zijn en worden gebruikt. Daarnaast mogen voor wetenschappelijke doeleinden aan empirische gegevens natuurlijk hoge eisen worden gesteld m.b.t. zaken als consistentie in de wijze van verwerving en beschrijving, controleerbaarheid, eenduidigheid van interpretatie e.d. In de praktijk worden empirische gegevens over taal dan ook vaak vereenzelvigd met ‘betrouwbare taalgebruiksgegevens’. Juist in de moderne taalwetenschap is overeenstemming over wat empirische gegevens zijn echter lange tijd ver te zoeken geweest, met name als gevolg van de opkomst van het generatief-transformationele paradigma in de zestiger jaren. Traditioneel wordt empirische, door ervaring opgedane, kennis vaak geplaatst tegenover theoretische kennis. In de transformationele benadering vervaagde het onderscheid tussen empirie en theorie echter vrijwel geheel. In het ‘competence’-kader van de generatieve benadering vierde de linguistische intuitie, en daarmee de introspectie, hoogtij. Hoewel de introspectieve linguistische intuitie door Chomsky oorspronkelijk alleen
| |
| |
bedoeld was als basis voor grammaticaliteits-oordelen, ging ze in de praktijk allengs tevens als vrijwel de enige bron voor ‘taalfeiten’ fungeren. Waarom via moeizaam graaf- en spit-werk op zoek gaan naar voorbeelden als elke linguist op grond van eigen taalcompetentie deze d.m.v. introspectie zelf kon oproepen? Bijgevolg golden als empirische taalfeiten vooral voorbeeldzinnen die vanuit theoretisch oogpunt interessant waren; met feitelijk taalgebruik hadden deze vaak bar weinig te maken. Typerend in dit opzicht was Chomsky's ‘nul-waarschijnlijkheids’ argumentatie, inhoudende dat elke zin net zo (on)waarschijnlijk is als welke andere zin dan ook. Vanuit theoretisch ‘regeltechnisch’ oogpunt mogelijk een juiste observatie, maar voor inzicht in hoe de taal feitelijk functioneert buitengewoon oninteressant. Het gevolg was dat aan taalgebruiksgegevens in de ‘mainstream’ van de taalwetenschap jarenlang volledig voorbijgegaan werd.
Afgaan op alleen introspectie in kombinatie met een bepaald vooropgezet theoretisch kader als enig kompas heeft, zoals ik lang geleden al eens uitgebreid heb betoogd (Meijs 1975:126-8), het grote nadeel dat dit doorgaans alleen maar leidt tot de ‘ontdekking’ van taalfeiten die zich goed in dat vooraf gekozen kader laten uitdrukken. Introspectie, al dan niet in kombinatie met een vooropgezet theoretisch kader, biedt een te smalle en te eenzijdige basis voor het verkrijgen van betrouwbare empirische gegevens. Het aanboren van de linguistische intuities van taalgebruikers is op zich wel legitiem, maar alleen in combinatie met intersubjectieve validatie. Dat wil zeggen dat de (uitgelokte) linguistische intuities van een representatief aantal informanten t.a.v. een bepaald lexicaal verschijnsel controleerbaar en eenduidig moeten overeenstemmen om als empirische evidentie te worden geaccepteerd (vgl. Greenbaum 1984). Deze methode van gegevens verwerven is echter zeer arbeidsintensief en tijdrovend, en daardoor ook kostbaar. Een voordehandliggend en goedkoper alternatief is dan ook gebruik te maken van bestaande (gesproken of geschreven) teksten. Deze hebben het voordeel dat ze als regel niet met enig vooropgezet linguistisch doel tot stand zijn gekomen en dus in principe theorie-onafhankelijke evidentie bieden. Bovendien zijn teksten in grote hoeveelheden voorhanden, en tegenwoordig als gevolg van de expansieve groei van electronische en computationele hulpmiddelen veel beter toegankelijk dan voorheen. Traditioneel worden verzamelingen tekstbestanden corpora genoemd. In een volgende paragraaf zal nader op de exploratie van corpora voor lexicografische doeleinden worden ingegaan.
Naast veronachtzaming van taalgebruik, bracht de generatief-transformationele benadering een vrijwel exclusieve concentratie op de syntaxis met zich mee. Pas na enige jaren kwam de semantiek weer wat aan bod, en het heeft lang geduurd voordat er ook weer aandacht voor het lexicon kwam. Inmiddels is het besef van het belang van het lexicon binnen de generatieve grammatica overigens weer zo sterk gegroeid dat het in de loop van de tachtiger jaren ‘de centrale plaats binnen het model [heeft] overgenomen van de transformationele component’ (Hulk 1990:29). Ook nu nog is er binnen het generatieve kader naar mijn smaak te weinig aandacht voor concrete lexicale taalgebruiksgegevens als basis voor, en correctief op, theoretische benaderingen, maar het is nu wel zo dat ook het generatieve model inmiddels een
| |
| |
redelijk bruikbaar kader biedt om empirische lexicale gegevens in uit te drukken.
Het is belangrijk om dit laatste punt te benadrukken. Hoewel het empirisme als filosofische stroming ervaring als de enige bron van kennis zag, zal men onder linguisten tevergeefs naar aanhangers van een dergelijk extreem standpunt zoeken. In weerwil van de alledaagse wijsheid dat de feiten ‘voor zichzelf spreken’, gaan linguisten, inclusief lexicografen, ervanuit dat lexicale taalgebruiksfeiten nooit zichzelf verklaren: ze wórden verklaard, en dat kan alleen adekwaat als het systematisch en konsekwent gebeurt. Een theoretisch consistent kader, of dat nu traditioneel-structureel, generatief-transformationeel of functioneel is, is derhalve hoe dan ook onontbeerlijk. Maar dan wel als verklarend uitdrukkingskader achteraf, niet als strikte inperking vooraf van wat men als taalfeiten wil erkennen.
| |
3 Basismateriaal en selectie-criteria
Zgusta (1970) onderscheidt de volgende vier stadia in de produktie van een woordenboek: 1. basismateriaal verzamelen, 2. hoofdwoorden selecteren, 3. lemmata (woordenboekingangen) construeren, en 4. lemmata onderling arrangeren. In deze paragraaf gaat het vooral over de eerste twee stadia. Welke woorden in een woordenboek worden opgenomen is van een groot aantal factoren afhankelijk. Wat is de aard van het beoogde woordenboek, (verklarend monolinguaal, vertaalwoordenboek naar of uit een vreemde taal, etymologisch, algemeen of gespecialiseerd medisch, technisch etc.), wat is de beoogde doelgroep (jeugdigen, volwassenen, mensen met een bepaald verondersteld opleidingsniveau, specialisten etc.), hoe groot is het budget, hoe groot is de beschikbare mankracht, welke technische hulpmiddelen zijn beschikbaar, binnen hoeveel tijd moet het woordenboek op de markt worden gebracht? Enzovoort enzovoort. Het is uiteraard ondoenlijk om hier op alle mogelijke variaties die zich t.a.v. deze factoren kunnen voordoen in te gaan. In het vervolg ga ik daarom in principe uit van een algemeen verklarend monolinguaal woordenboek bedoeld voor een breed publiek met een gemiddeld opleidingsniveau, uit te brengen door een gerenommeerde uitgever met redelijk ruime financiële middelen en een open oog voor moderne inzichten, methoden en technieken. Daarnaast zal ik hier en daar ook aandacht schenken aan aspekten die bij vertaalwoordenboeken een rol spelen.
| |
4 Basiswoordenschat: omvang
Op goede gronden mag worden aangenomen dat de gemiddelde taalgebruiker met een redelijk opleidingsniveau voor de meeste taalgebruikssituaties uitkomt met 20 à 25 duizend woorden (vgl. Diack 1987, De Mezer 1980). Martin (1983, 1988a, 1988b) illustreert dat voor het Engels middels een onderzoek waarbij de ‘objectieve’ frekwenties van woorden ontleend aan zes corpora (waaronder de ‘Brown’, ‘LOB’ en ‘American Heritage’ corpora), opgedeeld in vier frekwentie-rangordes, werden getoetst en bijgesteld aan de hand van de ‘subjectieve’ frekwentie-oordelen van native speakers. Uiteraard
| |
| |
bestaan er juist in de bekendheid met de minder frekwente woorden tussen taalgebruikers onderling grote verschillen, zodat het aantal woorden dat alle taalgebruikers werkelijk met elkaar gemeen hebben eerder in de buurt van de 15 dan de 20 duizend zal liggen. Daarnaast geldt voor de woorden aan de onderkant van het frekwentie-spectrum dat ‘kennen’ lang niet altijd inhoudt dat men ook weet wat ze precies betekenen of hoe ze precies gebruikt kunnen worden. Deze liggen dus in een randgebied van woorden die men weliswaar kent, maar waarvan men niet echt de finesses weet.
Een algemeen verklarend woordenboek stelt zich ten doel voor alle erin opgenomen woorden een ‘verklaring’ te geven wat betreft betekenis en gebruik. Afhankelijk van de reikwijdte en detaillering van het betrokken woordenboek vindt dat dan zijn weerslag in vaste ‘rubrieken’ in de lemmata, voor zaken als spelling, uitspraak, woordsoortinformatie, subcategorisatie, semantiek, ‘usage’ enz. Een woordenboek dat zich zou beperken tot de 10 à 15 duizend woorden die de gemiddelde geschoolde gebruiker al kent zou uiteraard weinig te bieden hebben. Vandaar dat goede verklarende woordenboeken aanzienlijk meer ingangen hebben (met in de praktijk 50 duizend als redelijke ondergrens). In algemene zin mag worden aangenomen dat een verklarend woordenboek tot aan de gekozen frekwentie-grens een afspiegeling zal willen geven van hoe de op te nemen woorden functioneren in het feitelijke taalgebruik. Daarbij dient zich allereerst de vraag aan wat voor bronnen in aanmerking komen om het basismateriaal aan te leveren. In principe is het ‘universum’ waaruit geput kan worden het geheel van taaluitingen in de brontaal. Daarmee is gelijk duidelijk dat het niet mogelijk is dat universum in zijn totaliteit te bestrijken. Het ‘geheel van taaluitingen’ is alleen voorstelbaar in theoretische zin. In de praktijk zal het nooit mogelijk zijn te zeggen van welke verzameling taaluitingen dan ook dat deze volledig is. De verzameling van alle taaluitingen is ‘open-ended’; eindeloos uitbreidbaar. Elke dag komen er miljoenen gesproken en geschreven taaluitingen bij. Dat is ook met de modernste hulpmiddelen met geen mogelijkheid bij te houden.
Bij de meeste soorten verzamelingen waarmee de statistiek zich heeft beziggehouden, ook als ze van grote omvang zijn, is het meestal mogelijk te bepalen hoe men daaruit een representatieve steekproef zou kunnen trekken. Door het principieel open, niet-eindige, karakter van het universum van taaluitingen leent ‘taal’ zich helaas niet voor een dergelijke statistische benadering. Zoals beargumenteerd in Martin (1988a) en Martin e.a. (1986) is wat taal betreft een werkelijk representatief corpus dan ook niet mogelijk, en is een exemplarisch corpus (Bungarten 1979) het hoogst haalbare. Naast het niet-eindige karakter van het taal-universum komt dat vooral doordat taal uitermate heterogeen is. Martin noemt vijf dimensies waarin taal niet homogeen is: de geografische, de sociale, de individuele, de inhoudelijke, en de temporele (leeftijds) dimensie. Daarnaast treedt binnen elk van deze dimensies weer variatie op m.b.t. algemeen, literair en vaktalig taalgebruik. Een belangrijk onderscheid dat deze dimensies doorsnijdt is daarnaast het onderscheid tussen spreektaal en schrijftaal.
Om tot een zo redelijk mogelijk exemplarisch corpus te komen stellen Martin e.a. een benadering voor via de notie ‘standaardtaal’ (ST), gedefinieerd als
| |
| |
een bovenregionale taal die gesproken en geschreven wordt door een sociale en economische elite, maar begrepen in het gehele taalgebied, en die geschikt is voor velerlei communicatieve situaties en allerlei gespreksonderwerpen en vakgebieden. Om hierin de eerder genoemde factoren zoveel mogelijk tot hun recht te laten komen, stellen zij met het oog op de lexicografie een recursieve omschrijving van ‘taal’ voor die de kern van de ST als basis neemt en zich vandaaruit a.h.w. concentrisch uitbreidt van belangrijkere naar minder belangrijke, en van algemene naar meer specifieke communicatieve situaties, en zich daarnaast ook wat regionale, sociale, individuele, inhoudelijke en temporele aspekten betreft uitbreidt van kern naar de meer perifere variatievormen. Het uiteindelijke model dat hieruit resulteert wordt een ‘stratificatiemodel’ genoemd, omdat het beoogt de verschillende strata van de taal zoveel mogelijk tot hun recht te laten komen.
| |
5 Corpustaalkunde
Voor de opkomst van de transformationeel-generatieve grammatica was het verzamelen van corpusgegevens een vast onderdeel van de taalkunde. Zoals een blik op de dikke pillen die zij publiceerden laat zien, waren grote traditionele taalkundigen als Poutsma, Jespersen en Kruisinga voortdurend op zoek naar taalgebruiksvoorbeelden. Dat ging zelfs zo ver dat theoretische regels slechts als zodanig werden geaccepteerd als er voldoende gebruiksvoorbeelden werden bijgeleverd om ze te staven. Hoewel de transformationeel-generatieve vervanging van taalgebruiksgegevens door zelfbedachte voorbeelden weer in een ander uiterste verviel, was een van hun punten van kritiek op de traditionele praktijk wel gegrond, nl. dat deze vooral gericht leek op het vinden van ongebruikelijke en onregelmatige verschijnselen, terwijl aan de meest algemene verschijnselen vaak juist voorbij werd gegaan. In feite waren de traditionele taalkundigen dan ook niet corpustaalkundigen in de moderne betekenis van het woord: ze verzamelden geen teksten, maar voorbeelden, die vervolgens uit hun verband werden gelicht om een bepaald theoretisch punt te schragen. Eigenlijk waren de traditionele grammatici daardoor, netzogoed als later de transformationalisten die introspectief naar voorbeelden zochten, met een gericht zoeklicht, een theoretische ‘bias’, aan het werk.
Zoals gesteld in Aarts & Meijs (1990b:175 e.v.) is een wezenlijk kenmerk van de moderne corpustaalkunde het feit dat uitgegaan wordt van lopende, verbonden teksten, zodat de taalgebruiksfeiten altijd in relatie tot hun oorspronkelijke context kunnen worden bestudeerd. Daarnaast is een niet meer weg te denken aspekt van de moderne corpustaalkunde dat zij werkt met computercorpora, d.w.z. corpora bestaande uit machine-leesbare teksten. Ook dat is een zeer belangrijk verschil met de traditionele corpustaalkunde, want het verschaft de mogelijkheid het subjectieve theoretische zoeklicht voor een hele hoop zaken uit te schakelen, zodat op een minder bevooroordeelde manier naar de taalfeiten kan worden gekeken. En natuurlijk houdt het werken met computercorpora tevens in dat de computer op velerlei manieren bij de verwerking en bewerking van de gegevens kan worden
| |
| |
betrokken, met name ook voor allerlei tellingen en vergelijkingen die anders zeer tijdrovend of zelfs onmogelijk zouden zijn.
Corpustaalkunde op basis van computercorpora is vreemd genoeg tegen de verdrukking in gegroeid. Terwijl de mainstream taalkundigen zich en masse verdiepten in de theoretische abstracties van de transformationeel-generatieve grammatica, zetten Nelson Francis en Henry Kucera (beiden werkzaam aan de Brown Universiteit in Providence) in het begin van de zestiger jaren het eerste computercorpus op, het zogenaamde ‘Brown Corpus’, een Amerikaans-Engels corpus van ongeveer een miljoen woorden in de vorm van 500 stukken verbonden (geschreven) tekst van elk 2000 woorden. Tegen het eind van de zestiger jaren werd door Randolph Quirk het (gesproken Brits-Engelse) Survey of Modern English Educated Usage opgezet, waarvan een deel later ook tot computercorpus werd omgebouwd (het ‘London-Lund’ corpus). In de zeventiger jaren vond de compilatie van het ‘Lancaster-Oslo-Bergen’ corpus (kortweg het LOB corpus) plaats als Brits-Engelse pendant van het ‘Brown’ corpus. In 1980 werd aan de Universiteit van Birmingham onder leiding van John Sinclair een aanvang gemaakt met de compilatie van het eerste specifiek voor lexicografische doeleinden opgezette corpus, het Collins COBUILD corpus, dat zou uitgroeien tot een corpus van 20 miljoen woorden. In Nederland kwam het eerste computercorpus (schrijf- en spreektaal, 720.000 woorden) in de eerste helft van de zeventiger jaren tot stand (het ‘Eindhoven Corpus’ - Uit den Bogaart 1975), terwijl in de loop van de tachtiger jaren aan het Instituut voor Nederlandse Lexicologie in Leiden een lexicografisch corpus werd opgebouwd dat inmiddels meer dan 50 miljoen woorden omvat.
Bestaande corpora beantwoorden over het algemeen slechts gedeeltelijk aan het eerder geschetste stratificatiemodel van Martin. In de meeste gevallen is er echter wel sprake van spreiding over meerdere, op externe gronden als verschillend aangemerkte, tekstcategoriën. Zo is het ‘Brown’-corpus opgedeeld in informatieve teksten enerzijds en fictionele teksten anderzijds in een verhouding van 3:1. Binnen deze twee overkoepelende categoriën zijn de corpusteksten dan weer nader ingedeeld in subcategorieën als respectievelijk ‘pers’, ‘ambtelijk taalgebruik’, ‘wetenschappelijk taalgebruik’ enz., en ‘detectives’, ‘science-fiction’, ‘humor’ enz. Het ‘LOB’-corpus is op het ‘Brown’-corpus geënt en volgt dus dezelfde indeling. Deze beide corpora beperken zich, zoals vermeld, tot schriftelijk taalgebruik. Het ‘London-Lund’-corpus bestaat uit getranscribeerde gesproken teksten, opgedeeld naar type interactie: ‘telefoongesprekken’, ‘radiopraatjes’, ‘lezingen’, ‘heimelijk opgenomen gesprekken’ enz. Het ‘Eindhoven-corpus’ bevat vooral (schriftelijk) journalistieke en ambtelijke taal alsmede (gesproken) parlementair taalgebruik. Hoewel deze corpora niet specifiek voor lexicografische doeleinden werden opgezet, lenen ze zich uiteraard wel voor enig lexicografisch onderzoek. Men zal zich daarbij echter moeten realiseren dat het ideaal van representatieve (laat staan exemplarische) adekwaatheid er slechts zeer ten dele in wordt benaderd.
Hoewel het speciaal voor lexicografische doeleinden opgezette Cobuild Corpus niet uitgaat van een volledig geëxpliciteerd kader als het stratificatiemodel zijn de vrij globale uitgangspunten die aan de samenstelling ervan ten
| |
| |
grondslag lagen tot op zekere hoogte wel vergelijkbaar. Renouf (1984:6) vat ze als volgt samen: ‘(...) we wanted to cover the whole range of current, “normal”, but adult, “educated”, native-speaking English modes and registers’. Een criterium dat in het stratificatiemodel niet als zodanig een rol speelt was verder dat, binnen de bovengenoemde parameters, bij voorkeur teksten werden geselecteerd waarvan mocht worden aangenomen dat ze een groot publiek hadden bereikt: veelgelezen romans en kwaliteitskranten, veelbeluisterde radioprogramma's enz. ‘The argument here was that such texts were more truly representative of the language because they were influential in its evolution.’ (Renouf 1984:5). Anders dan in het stratificatiemodel werd vaktaal (evenals b.v. poezie en toneel) expliciet uitgesloten. Populair-wetenschappelijke teksten daarentegen zijn wel ruim vertegenwoordigd in het Cobuild materiaal.
| |
6 Kwantitatieve aspekten
Zoals eerder gesteld gaat het bij het verzamelen van empirische lexicografische gegevens om het opsporen van betrouwbare gebruiksgegevens. Er is de laatste jaren veel onderzoek verricht op basis van (computer)corpora (verg. b.v. Aarts & Meijs 1984, 1986, 1990a; Meijs 1987), dat nuttige informatie over allerlei aspecten heeft opgeleverd, variërend van nieuwe inzichten in de structuur van zelfstandige naamwoordgroepen of die van relatieve bijzinnen tot studies naar de detectie van Topics en Themes, of de rol van Discourse Tags in verbonden teksten. Zoals Francis in een voor de ontwikkeling van de corpuslinguistiek belangrijk, plaatsbepalend artikel (Francis 1982) al stelde, laten globale (bijvoorbeeld syntactische) verschijnselen zich in een vrij klein corpus van b.v. een miljoen woorden al goed bestuderen, terwijl voor zinvolle bestudering van andere verschijnselen veel grotere corpora nodig zijn. Dat laatste geldt met name voor lexicale verschijnselen.
Aan de orde is hier dus de relatie tussen corpusomvang en gebruikswaarde, het ‘nuttig rendement’. Hieronder verstaan we de verhouding tussen corpusomvang in aantallen woorden (tokens) enerzijds, en de aantallen woordvormen en lemmata (types) anderzijds. Onder ‘woordvorm’ versta ik hier inderdaad letterlijk de vorm van een woord: in een corpus kan een en dezelfde vorm vele malen als los ‘woord’ voorkomen. Een ‘lemma’ is een mogelijke woordenboekingang: het kan zijn dat meerdere woordvormen onder één lemma worden gerangschikt (b.v. enkel- en meervoudsvormen van hetzelfde zelfstandig naamwoord, of de verschillende verbogen vormen van hetzelfde werkwoord), maar het omgekeerde kan ook voorkomen, als b.v. dezelfde woordvorm meerdere woordsoorten dekt die aparte woordenboekingangen vereisen (b.v. recht als bijvoeglijk dan wel als zelfstandig naamwoord).
Corpusonderzoek heeft een aantal ijzeren wetmatigheden aan het licht gebracht met betrekking tot de verhouding tussen woorden, woordvormen, en lemmata, alsmede wat betreft het aantal woordvormen dat maar eenmaal voorkomt (de zogenaamde hapax legomena). Stel dat een bepaald corpus slechts de helft van het aantal woordvormen bevat dat men in een woordenboek wil opnemen en waarvoor het corpus gebruiksvoorbeelden moet
| |
| |
leveren. Men zou nu ietwat simplistisch kunnen overwegen het corpus met inachtneming van de principes van het stratificatiemodel uit te breiden tot tweemaal de oorspronkelijke omvang. Een dergelijke verdubbeling van het corpus levert dan weliswaar tweemaal zoveel woorden (tokens) op, maar het aantal verschillende woordvormen en lemmata (types) zal slechts in zeer beperkte mate blijken te zijn toegenomen. Een uitgebreider corpus levert namelijk vooral ‘meer van hetzelfde’: nog weer meer voorbeelden van de, het, op, dat, is enz. - vooral functiewoorden en wat heel frekwente inhoudswoorden. Zo bevat het 1 miljoen woorden tellende LOB corpus ongeveer 50.000 verschillende woordvormen, terwijl het 7,3 miljoen woorden tellende ‘Birmingham Main Corpus’ (de kern van het Cobuild corpus) zo'n 132.000 woordvormen oplevert. M.a.w. een verzevenvoudiging van het aantal woorden levert hier nog niet eens een verdrievoudiging van het aantal woordvormen op. Bovendien zal blijken dat de meeste nieuw-voorkomende woordvormen als hapax legomena hun intrede doen, en dat is natuurlijk een erg smalle basis om solide gebruiksgegevens voor de desbetreffende woordvormen op te baseren.
Er is dus altijd sprake van ‘diminishing returns bij uitbreiding van corpora. Naarmate het corpus groter wordt neemt het nuttig rendement percentueel af. Zich baserend op Schäder (1976) laten Martin e.a. (1986:65) zien hoe het bruto rendement (de verhouding tussen het aantal woordvormen en het aantal woorden) en het netto rendement (de verhouding tussen het aantal lemmata en het aantal woorden) teruglopen van resp. 12,5 en 8,3 procent bij een corpus van 80.000 woorden tot resp. 1,8 en 1,2 procent bij een corpus van 7.222.000 woorden. Verder ligt het aantal hapax legomena bij een dergelijke vergroting van het corpus toch nog op zo'n 50% van alle woordvormen.
Hoewel de lexicografische benutting van corpora als gevolg van deze statistische wetmatigheden iets weg heeft van een soort Sisyfusarbeid, betekent dat niet dat het daarmee onbegonnen werk is. Ten eerste gaat de ontwikkeling van nieuwe hardware- en software-mogelijkheden zo snel dat de omvang van het materiaal dat in machine-leesbare vorm beschikbaar (te maken) is vrijwel onbegrensd is. Men denke aan zaken als de CD-ROM en OCR (Optical Character Recognition). In de beginjaren van de corpustaalkunde moesten corpusteksten woord voor woord op ponskaarten worden ingetypt: tegenwoordig kan men hele encyclopedieën, de complete Shakespeare en de Bijbel op een CD-ROM kwijt, en adverteert Hewlett Packard met een ScanJet die het hele Guiness Book of Records (inclusief de plaatjes) in een uurtje op een PC kan inlezen. Ten tweede is zelfs een half procent nuttig rendement op een heel groot corpus toch heel veel: 250.000 verschillende woordvormen op een corpus van 50 miljoen woorden, bijvoorbeeld. Als het om een goed uitgebalanceerd corpus gaat levert dit, als we de hapax legomena geheel buiten beschouwing laten, nog altijd nuttig materiaal op voor zo'n 125.000 woordvormen - meer dan genoeg voor de meeste lexicografische doeleinden.
Renouf (1987) laat zien hoe de uitbreiding van het Birminghamse kerncorpus (7 miljoen woorden) met het zgn. ‘reservecorpus’ (13 miljoen woorden) toch veel lexicografisch interessante extra informatie oplevert. Ze doet dit aan de hand van een aantal voorbeelden van woordvormen die in het kerncorpus
| |
| |
niet of nauwelijks voorkomen maar wel redelijk vertegenwoordigd zijn in het reservecorpus, zoals faddish en faddy, moot, off-key, advisedly en laat daarnaast voor een aantal andere woordvormen (faggot, vainly, sorely e.a.), die ook in het kerncorpus al in redelijke aantallen present waren, zien hoe de extra voorkomens in het reservecorpus aanleiding geven tot verfijningen in betekenisonderscheidingen, collocatie-patronen enz. Ze beschrijft haar bevindingen in termen van het begrip ‘lexicale resolutie’, naar analogie met het fotografische begrip ‘resolutie’:
To the smaller data resource, the larger one variously brings evidence where there was none, or sharpens the focus where a vague picture has begun to emerge, or corrects an imbalance, or sometimes highlights an oddity where there appeared to be none. One must assume that a still larger corpus would continue this process of differentiation, of heightening the resolution for the word forms under scrutiny. (Renouf 1987:130)
Een interessant alternatief voor ongelimiteerde corpusexpansie is daarnaast wat men gerichte ‘corpus-evolutie’ zou kunnen noemen. Dit bouwt voort op het door Jeremy Clear en John Sinclair van het Cobuild-team gekoesterde idee van een ‘monitorcorpus’ (verg. Clear 1987). Een monitor-corpus is een corpus dat vanuit een welomschreven uitgangssituatie veranderingen bijhoudt (‘monitort’) binnen een bepaalde, goed te traceren taalvariant - krantentaal bijvoorbeeld. Boven een zekere lexicografisch bepaalde verzadigingsgrens komen nieuwe voorkomens van een woordvorm (met hun directe context) niet bovenop, maar in plaats van, eerder geregistreerde voorkomens van dezelfde woordvorm (waarbij overigens wel de ‘totaalscore’ van alle voorkomens per woordvorm wordt bijgehouden). Daarnaast geldt een bepaalde, automatische ‘vervalwaarde’ voor woordvormen waarvoor geen nieuwe voorkomens worden geregistreerd. Op deze manier wordt het bestand a.h.w. voortdurend ververst, en kan worden bijgehouden welke woordvormen om zich heen grijpen en welke er in onbruik raken. Een dergelijk evoluerend corpus kan bijvoorbeeld worden ontleend aan automatische dagelijkse registratie van de machineleesbare zetbestanden van een aantal dagbladen.
| |
7 Voor- en nadelen van corpora voor lexicografisch gebruik
In een eerdere paragraaf is gesteld dat het bij empirische gegevens gaat om ‘ervaring’ en om ‘gebruik’. Bij een woordenboek was de ervaring afkomstig van de betrokken lexicografen, en die ervaring werd ook in het verleden doorgaans al zoveel mogelijk getoetst aan het taalgebruik door het verzamelen en inspecteren van gebruiksvoorbeelden. Aan die situatie is met de komst van (computer)corpora in wezen niets veranderd: de ervaring (en de vakkennis en kwaliteit) van de lexicograaf blijft de doorslaggevende factor. Een corpus betekent niet dat de lexicograaf overbodig wordt. Integendeel: met de beschikbaarheid van een systematisch gecompileerd exemplarisch corpus kan zij/hij zich veel meer dan voorheen concentreren op het eigenlijke lexicografische werk. Het moeizame verzamelen is al gedaan, en alle aandacht kan nu worden gericht op het kritisch analyseren en vergelijken
| |
| |
van de gevonden gebruiksvoorbeelden en op een systematische en coherente presentatie van de daaruit voortvloeiende inzichten.
In Martin e.a. (1986) wordt een aantal voor- en nadelen van lexicografisch gebruik van corpora opgesomd. Ik vat ze hieronder kort samen:
Voordelen:
| (1) | een corpus is een empirische, objectieve en intersubjectieve databasis; |
| (2) | een corpus richt zich vooral op de performantie, waardoor allerlei, ook afwijkende, elliptische of marginale taalvormen erin zullen voorkomen; |
| (3) | de corpusmethode biedt de mogelijkheid subject (de onderzoeker) en object (de taal) strikt van elkaar te scheiden. |
Nadelen:
| (1) | het is veel moeilijker en bewerkelijker een betrouwbaar corpus samen te stellen dan de eigen introspectie te raadplegen; |
| (2) | taalveranderingen na de definitieve samenstelling van het corpus kunnen niet meer beschreven worden; |
| (3) | corpora abstraheren van reële communicatieve situaties; |
| (4) | voor uiterst zeldzame fenomenen zullen zelfs zeer omvangrijke corpora niet volstaan. |
Ik denk dat er aan de genoemde voordelen nog zeker enige toegevoegd kunnen worden, met name als we het hebben over computercorpora, terwijl bij de genoemde nadelen wel wat kanttekeningen te plaatsen zijn.
Eerst iets over de nadelen. Wat nadeel (1) betreft kan ik kort zijn: natuurlijk is het samenstellen van een betrouwbaar corpus een bewerkelijke zaak, maar na alles wat hierboven al over introspectie gezegd is zal duidelijk zijn dat introspectie niet langer als een serieuze bron voor het aanleveren van betrouwbare en complete gegevens kan worden beschouwd. Nadeel (2) geldt gezien de voortschrijdende technologische mogelijkheden al een stuk minder - men vergelijke de passage over het ‘monitor-corpus’ hierboven. Nadeel (3) is maar zeer ten dele waar - ik kom daar later op terug - en is zeker niet iets waarop introspectieve gegevensverzameling beter zou scoren. Nadeel (4) is reëel, maar de beschouwing in de voorgaande paragraaf heeft al laten zien dat het in ieder geval goed mogelijk is dit te kwantificeren door de beoogde dekking te relateren aan corpusgrootte.
Zoals al eerder gesteld zijn corpora in onze hedendaagse informaticamaatschappij in feite gelijk te stellen met computercorpora. Op grond daarvan zou ik aan de door Martin e.a. genoemde voordelen nog de volgende willen toevoegen:
| (4) | Een corpus biedt de mogelijkheid de woorden in hun oorspronkelijke context te bezien. |
| (5) | Corpusgegevens kunnen op allerlei manieren met elkaar in verband gebracht worden. |
| (6) | Het is mogelijk corpora op allerlei manieren te verrijken. |
Wat (4) aangaat: weliswaar geeft een corpus niet de gehele bij nadeel (3) bedoelde ‘communicatieve situatie’, maar aangezien het is samengesteld uit stukken verbonden tekst biedt het wel de mogelijkheid woorden steeds in hun oorspronkelijke talige context te bekijken, en daaruit valt vaak ook heel wat over de wijdere communicatieve context op te maken. Bovendien is het gebruikelijk gegevens over de bronnen van het materiaal aan het corpus toe
| |
| |
te voegen. Ook daaraan zijn vaak nadere details over de communicatieve situatie te ontlenen.
Voordeel (5) is evident: computerprogramma's bieden de mogelijkheid snel en efficient b.v. alle voorkomens van een bepaalde woordvorm bij elkaar te zetten, na te gaan of een bepaalde woordvorm regelmatig voorkomt in de omgeving van een andere woordvorm; er kunnen tellingen worden verricht, statistische bewerkingen worden uitgevoerd enz. Wat (6) betreft: het is mogelijk de resultaten van betrouwbare bewerkingen aan het corpus toe te voegen, zodat deze te allen tijde in kombinatie met de woordgegevens op te roepen zijn. Zo zijn het Brown en het LOB corpus, alsook het Eindhoven corpus beschikbaar in gelemmatiseerde vorm, d.w.z. alle woorden erin zijn voorzien van woordsoortaanduidingen in de vorm van zgn. ‘code-tags’. Gegeven een voldoende verfijnd en betrouwbaar parseer (analyse) programma, is het in principe mogelijk corpuszinnen van een volledige syntactische analyse te voorzien. Het Nijmeegse CCPP corpus is een voorbeeld van een dergelijk, zij het vrij klein (130.000 woorden), Engelstalig corpus (vgl. Aarts & van den Heuvel 1985). In de praktijk is er nog niet zo veel gebruik gemaakt van grammaticaal verrijkte corpora voor lexicografische doeleinden, maar er zijn wel aanzetten in die richting (zoals b.v. die in Church en Hanks 1990 - zie volgende paragraaf).
| |
8 Exploratie van corpora voor lexicografische doeleinden
De basisgedachte die ten grondslag ligt aan de lexicografische benutting van corpora zou men met een kleine variatie op een bekend gezegde als volgt kunnen samenvatten: ‘zeg mij met welke woorden gij omgaat en ik zal u zeggen wat gij betekent’, of, zoals Wilks (1972:86) het, wellicht met een knipoog naar Sartre, uitdrukte: ‘...meaning is always other words’. Wat dit inhoudt valt het best te illustreren aan de hand van woorden met meerdere betekenissen. In de betekenis van vervoermiddel zal een woord als bus veel voorkomen in kombinatie met woorden als instappen, uitstappen, optrekken, rijden, chauffeur, passagiers enz. In de betekenis doos, trommel zal het vaak associëren met woorden als indoen, opdoen, instoppen, brieven, koekjes, geld, deksel enz. Voorts mogen we aannemen dat bus in de eerste betekenis veel woorden in zijn omgeving gemeen zal hebben met die van b.v. trein, auto, tram, terwijl het in de tweede betekenis veel omgevingswoorden zal delen met woorden als trommel, doos, map enz. Kortom, woorden die kwa betekenis op elkaar lijken, zullen doorgaans ook vrij veel overlapping vertonen in de woorden die zij in hun omgeving aantrekken. En omgekeerd: woorden die aantoonbaar gelijksoortige contextwoorden aantrekken moeten wel ook in betekenis overeenkomst vertonen. Overigens zullen natuurlijk lang niet alle contextwoorden desambiguerende werking hebben: combinaties als een rode bus of de bus was vol zijn op zichzelf met beide betekenissen te rijmen.
Aannemende dat teksten doorgaans met bona fide communicatieve bedoelingen worden geproduceerd, valt te verwachten dat betekeniswoorden in corpusteksten in verreweg de meeste gevallen zinnige verbanden met elkaar hebben: de betekenissen haken als het ware op elkaar in. Lexicografisch onderzoek van corpusteksten is er o.a. op gericht deze verbanden
| |
| |
tussen woorden op te sporen en de impliciete relaties (met name de semantische) expliciet te maken, dan wel te toetsen aan de al bestaande expliciete kennis. Door de voorkomens in een corpus in context en in samenhang met elkaar te bestuderen kan de lexicograaf zich aldus een oordeel vormen over hoe een gegeven woordvorm of lemma in het taalgebruik functioneert. Dit kan er o.a. toe leiden dat meer of minder betekenissen worden onderscheiden, dat meerdere betekenissen worden samengeklapt, dat betekenisomschrijvingen worden verfijnd enz. Op soortgelijke wijze kunnen bestaande inzichten over frekwentie, spreiding over verschillende soorten taalgebruik, syntactische en pragmatische aspekten, collocaties e.d. worden verfijnd op basis van deze confrontatie met corpusgegevens. In hoofdstuk 2 beschrijven Martin e.a. (1986) aan de hand van een aantal ‘case-studies’ hoe dat in zijn werk kan gaan. Het is duidelijk dat de lexicograaf daarbij niet in den blinde opereert: vooronderstellingen, bijvoorbeeld ontleend aan bestaande woordenboeken, worden getoetst aan de aangetroffen voorkomens. Er is derhalve voortdurend sprake van interactie tussen theoretische inzichten en empirische gegevens, waarbij in laatste instantie het inzicht van de lexicograaf doorslaggevend blijft voor de conclusies die uit deze interactie worden getrokken.
Optimale benutting van computercorpora voor lexicografische doeleinden is echter alleen mogelijk in een geïntegreerde computerondersteunde omgeving waarin deze bronnen van empirische gegevens systematisch toegankelijk zijn, en waarin de lexicograaf kan beschikken over ondersteunende softwarefaciliteiten, zoals zoekprogramma's, indexerings- en concordantie-systemen, statistische programmatuur enz. Juist omdat het bij corpora vaak gaat om zeer grote hoeveelheden gegevens, heeft de lexicograaf hulpmiddelen nodig om die gegevens naar waarde te schatten. Er wordt dan ook gestreefd naar de ontwikkeling van betrouwbare, automatische voorbewerkingen, die geheel door de computer worden verricht, waardoor het oordeel van de lexicograaf pas hoeft te worden ingeroepen op het moment dat het materiaal al in hoge mate zinvol geordend en geanalyseerd is.
Church en Hanks (1990) beschrijven een dergelijke automatische voorbewerking die erop gericht is de associatie-sterktes tussen de leden van woordparen te bepalen. De associatie-ratio die zij hanteren is een maat die aangeeft hoe vaak twee (of meer) woordvormen in een corpus in dezelfde volgorde vlak bij elkaar voorkomen (al dan niet met een aantal woorden ertussen), en in hoeverre dit statistisch significant is. De significantie wordt bepaald door de geconstateerde associaties af te zetten tegen de statistische waarschijnlijkheid dat de betrokken woorden bij toeval in elkaars direkte omgeving opduiken. Zo blijken de geconstateerde associaties tussen set en up, set en off, en set en out in een 44 miljoen woorden tellend corpus van Associated Press berichten vele malen groter dan puur op grond van toeval zou mogen worden verwacht, terwijl dat voor b.v. set en on, set en in, en set en about veel minder het geval is.
Hoewel associatie-gegevens gebaseerd op puur sekwentiële nabijheid al een hele hoop bruikbare informatie opleveren, gaat het veelal om grammaticaalsyntactisch bepaalde, c.q. geleide relaties. Preciezere associatie-gegevens zouden derhalve gebaseerd moeten worden op grammaticaal en syntactisch
| |
| |
verrijkte corpora. Church en Hanks demonstreren dit aan de hand van een onderzoek naar werkwoord/lijdend-voorwerp paren ontleend aan een versie van het bovengenoemde Associated Press corpus waaraan door middel van een parser (Hindle 1983a, 1983b) syntactische informatie was toegevoegd. Door het werkwoord constant te houden kan dan worden vastgesteld welke woorden typisch als object daarbij voorkomen, en in welke relatieve frekwentie. Zo blijkt water het meest frekwent als object van drink voor te komen, in aflopende frekwentie gevolgd door beer, alcohol, coffee, wine, milk, beverage, cup, tea enz. Omgekeerd blijkt het meest frekwente werkwoord dat telephone als object heeft answer te zijn, op grote afstand gevolgd door use, receive, return, tap, be on, pick up etc.
Het zal duidelijk zijn dat dit soort gegevens de lexicograaf naast voorbeeld-materiaal ook buitengewoon nuttige gegevens kan opleveren over typisch syntactisch gedrag, distributie en collocaties, betekenisnuances enz. Het zal echter evenzeer duidelijk zijn dat het bij grote corpora al gauw om zoveel gegevens gaat dat de lexicograaf onmogelijk alles kan inspecteren. Het computationeel-statistische instrumentarium moet m.a.w. zodanig verfijnd worden dat de lexicograaf alleen gegevens onder ogen krijgt waarvan bij voorbaat vaststaat dat zij voor nadere inspectie van belang zijn. Hoewel het hierbij in essentie gaat om semantisch-syntactische verbanden suggereren Church & Hanks dat het opsporen van deze verbanden toch grotendeels via algemene, puur op distributieverschijnselen gebaseerde procedures kan verlopen. Er zal echter nog heel wat onderzoek verricht moeten worden voordat dit op werkelijk betrouwbare manier kan worden gedaan.
Church & Hanks' benadering vertoont veel verwantschap met de principes van het door BSO ontwikkelde ‘Distributed Language Translation’ systeem (vgl. Papegaaij 1986). Hierin wordt getracht de keus tussen verschillende mogelijke vertaalekwivalenten zoveel mogelijk automatisch, zonder tussenkomst van expliciete semantische karakterizeringen, te bepalen op basis van distributiegegevens over die vertaalekwivalenten, ontleend aan corpusmateriaal. Sterk vereenvoudigd weergegeven wordt dit bereikt door de computer zuiver rekenkundig te laten vaststellen welke van de mogelijke vertaalekwivalenten in termen van de in het corpus aangetroffen contexten het best aansluit bij de gegeven context van het te vertalen item. Hierbij moet onder ‘context’ wederom niet zomaar adjacentie worden verstaan, maar syntactisch bepaalde relaties zoals tussen werkwoord en lijdend voorwerp, of tussen zelfstandig naamwoord en attributief gebruikt bijvoeglijk naamwoord. Voor de tweede fase voorzag het DLT-project in een ambitieus plan: de ontwikkeling van een ‘Bilingual Knowledge Bank’ (BKB) in de vorm van een aantal parallelle ‘vertaalcorpora’ van elk zo'n 3 miljoen woorden, bestaande uit syntactisch geanalyseerde bronteksten systematisch gekoppeld aan door erkend goede vertalers geleverde, eveneens syntactisch geanalyseerde vertalingen. Hoewel er enige evidentie bestaat voor de lexicografische bruikbaarheid van een dergelijke benadering, waarin corpus en (vertaal) woordenboek in hoge mate geïntegreerd zijn (zie b.v. Harris 1988; Brown et al. 1988), is het bij het BSO-plan, vanwege de enorme investeringen die ermee gemoeid zijn vooralsnog gebleven bij een goedberedeneerd (Sadler 1989) gedachtenexperiment.
| |
| |
| |
9 Empirische lexicografie in de praktijk
Hoewel er, zoals in de vorige paragraaf aangegeven, al uitgebreid nagedacht is over hoe de empirische dimensie van de lexicografie, met name met behulp van systematisch onderzoek van corpusdata, kan worden verrijkt, zijn de aangegeven mogelijkheden in de praktijk tot nu toe nog maar in zeer beperkte mate benut. Het Cobuild woordenboek (Sinclair 1987a) is het eerste voorbeeld van een woordenboek dat geheel op basis van corpusgegevens, en in een sterk computerondersteunde omgeving, tot stand is gekomen. Het basismateriaal voor dit woordenboek bestond, zoals reeds vermeld, uit een kerncorpus van 7 miljoen woorden tekst aangevuld met een reservecorpus van nog eens 13 miljoen woorden tekst. Eerst werd het kerncorpus doorgelicht op de frekwenties van de erin voorkomende woordvormen, welke werden vergeleken met een aantal vooraf aangelegde lijsten, zoals die van de hoofdwoorden in andere ‘Learners' Dictionaries’, woordenlijsten ontleend aan veelgebruikte taalcursussen e.d. Daarna werd het frekwentie-onderzoek uitgebreid naar het reserve-corpus om te zien of de inmiddels opgestelde eerste lijst van mogelijke lemmata moest worden uitgebreid, bijgesteld etc. De bijgestelde lemmata-lijst diende vervolgens als basis voor de samenstelling van een lexicale database waarin de voorkomens van de geselecteerde items geïndexeerd werden opgeslagen. Voor alle kandidaat-lemmata konden de lexicografen aldus via de database beschikken over zogenaamde KWIC- concordantie gegevens (KWIC = Key Word In Context), waarbij, per lemma, de voorkomens van dezelfde woordvormen gecentreerd onder elkaar elkaar gegroepeerd staan met ervoor en erachter een stukje oorspronkelijke context (b.v. zeven voorafgaande en zeven erop volgende woorden). Zie fig. 1 voor een voorbeeld van een stuk KWIC-concordantie ontleend aan het Cobuild corpus.
Bij de minder frekwente woordvormen kregen de lexicografen in principe steeds alle voorkomens op deze wijze voorgeschoteld. Bij zeer frekwente woorden als at, by, but etc. zorgde een computerprogramma voor homogene reductie van het materiaal door steeds het n-de voorkomen te selecteren en de tussenliggende voorkomens over te slaan (waarbij de waarde van n afhankelijk was van de totale frekwentie van de desbetreffende woordvorm). In de meeste gevallen zijn dit soort concordantie-gegevens voldoende om de lexicograaf een goed inzicht te geven in de verschillende betekenissen waarin een woord gebruikt wordt, de syntactische constructies waarin ze kunnen voorkomen, collocatiegedrag e.d. En in gevallen waarbij deze KWIC gegevens toch niet voldoende informatie geven blijft het altijd mogelijk via de verwijzing naar de oorspronkelijke vindplaats de wijdere context in het corpus in aanmerking te nemen. Terugkoppeling naar het corpus bleek daarnaast ook zeer nuttig om het woordenboek te voorzien van realistische, op werkelijk taalgebruik gebaseerde, voorbeeldzinnen, ter illustratie van de verschillende onderscheiden betekenissen.
Bij het verdere lexicografische werk speelde de computer eveneens een centrale rol. Zo werd de computer ingeschakeld om te controleren of de lexicografen voor alle lemmata konsekwent alle benodigde gegevens hadden ingevuld (gegevens over uitspraak, spelling, vervoegingen, woordsoort,
| |
| |

Fig. 1 Deel van een KWIC-concordantie voor mind uit het Cobuild kern-corpus (uit Sinclair 1987b)
betekenis, collocaties enz.). Ook de feitelijke produktie van het woordenboek, dat uiteindelijk 70.000 lemmata zou bevatten, was grootendeels een computerondersteund gebeuren. Een gedetailleerde beschrijving van de
| |
| |
totstandkoming van het Cobuild woordenboek wordt gegeven in Sinclair (1987b).
Ook bij de produktie van Van Dale's Groot Woordenboek Hedendaags Nederlands (van Sterkenburg & Pijnenburg 1984) en, in samenhang daarmee, van de verschillende vertaalwoordenboeken (N-E, E-N, N-F, F-N, N-D, D-N) speelden aan een corpus ontleende gegevens, en het computer-ondersteund gebruik van een lexicale database een belangrijke rol. In deze database werden o.a. voor alle lemmata in het monolinguale verklarende woordenboek zgn. ‘betekenisresumé's’ opgenomen. Bij het samenstellen van de woordenboeken van het Nederlands naar de verschillende vreemde talen werden deze zelfde betekenisresumé's, door de computer automatisch uit de database opgehaald, weer gebruikt om de verschillende vertaalekwivalenten te ordenen. En hoewel, zoals Al (1988) uitlegt, het simpelweg ‘omdraaien’ van b.v. een N-E woordenboek om een E-N woordenboek te verkrijgen niet mogelijk is, leidde de beschikbaarheid van de lexicale database ook voor het samenstellen van de woordenboeken van de vreemde taal naar het Nederlands toe tot besparingen en een grotere interne consistentie.
Samenvattend kan gesteld worden dat gebruik van een goed-gecalibreerd computercorpus de lexicograaf kan ontlasten van allerlei vrij ondankbaar monnikkenwerk, en haar/hem in staat stelt zich volledig te concentreren op het eigenlijke lexicografische werk: het opsporen van betrouwbare empirische gegevens m.b.t. betekenis en gebruik van kandidaat-lemmata, hun frekwentie, collocatie-gedrag, realistische voorbeelden enz. Bovendien kan een daarop aansluitende computer-ondersteunde werkomgeving in zeer belangrijke mate bijdragen aan een konsekwente indeling van de lemmata en de interne samenhang van het gehele woordenboek.
| |
10 Feedback: computationele lexicologie
Aan de empirische dimensie van de lexicografie is de laatste tien jaar nog een ander aspect toegevoegd, nl. gedetailleerde feedback over de lexicografische praktijk, via onderzoek van bestaande machine-leesbare woordenboeken (in de literatuur meestal aangeduid met de Engelse afkorting MRD voor ‘machine-readable dictionary’). Verreweg het meeste onderzoek gedurende de afgelopen jaren heeft zich gericht op de Longman Dictionary of Contemporary English (LDOCE - Procter 1978), een van de eerste Brits-Engelse woordenboeken die in machine-leesbare vorm beschikbaar kwamen (zie Boguraev & Briscoe 1989 voor een uitgebreid overzicht van onderzoek gebaseerd op de LDOCE MRD). De voornaamste drijfveer voor dit soort onderzoek was in de meeste gevallen de wens de grote hoeveelheden lexicale kennis die in woordenboeken liggen opgeslagen geschikt te maken voor gebruik in het kader van projekten op het vlak van de computationele Natuurlijke Taal Verwerking (meestal aangeduid met de Engelse afkorting NLP voor Natural Language Processing). De meeste NLP-systemen moesten zich behelpen met kleine ‘demo-lexicons’ van enkele tientallen, hooguit een paar honderd, woorden, en door benutting van een bestaand MRD, zo was de verwachting, zouden veel grotere, en veel realistischer lexicons kunnen worden ingeschakeld.
| |
| |
Het toegankelijk maken van een MRD bleek in de meeste gevallen overigens niet zo'n eenvoudige opgave. Voordat het zover was moest er meestal flink wat werk (inclusief handwerk) worden verricht. Akkerman et al. (1985; 1988) beschrijven in detail wat er allemaal bij een dergelijke ‘herstructurering’ van een MRD komt kijken. Veel van de problemen en probleempjes die zich voordeden hadden te maken met het feit dat het woordenboek zich (uiteraard) op de normale menselijke gebruiker richt. Die stoort zich er niet aan (en merkt waarschijnlijk niet eens op) dat er b.v. de ene keer Adj staat, met hoofdletter, en een volgende keer adj, of adj. (met punt), dat er soms variatie is in de volgorde van bepaalde gegevens (adj, n of n, adj, soms 10; T1 en dan weer T1; 10 enz.). De menselijke gebruiker begrijpt dat inquire, en- (...)~r staat voor vier vormen, nl. inquire, enquire, inquirer, en enquirer, en dat ~ist in combinatie met het voorafgaande existentialism de vorm existentialist moet opleveren (terwijl strikte naleving van de instructies in het voorwerk van het woordenboek eigenlijk zou uitmonden in de vorm existentialismist!). En hij zal waarschijnlijk ook wel begrijpen hoe de definitie van het lemma AA - (in Britain) (a film) that children under 14 are not admitted to see in a cinema - bedoeld is, hoewel weglating van het laatste van de stukjes tussen haakjes, of van beide stukjes, eigenlijk iets onvolledigs en ongrammaticaals oplevert. Het zal duidelijk zijn dat de computer met dit soort zaken aanzienlijk meer moeilijkheden zal hebben, omdat dat domme apparaat nu
eenmaal graag correcte, konsekwente input binnenkrijgt. Maar natuurlijk is die zwakte van de computer in werkelijkheid juist zijn sterkte. De ijzeren konsistentie die het computermatig doorlichten van MRDs met zich meebrengt, levert naast empirische gegevens over de lexicografische praktijk in bestaande woordenboeken ook nieuwe inzichten op die ongetwijfeld van invloed zullen zijn voor de manier waarop toekomstige woordenboeken tot stand zullen komen.
Terwijl een woordenboek als boek eigenlijk maar op één manier toegankelijk is (nl. via de alfabetische ordening), kan een MRD op allerlei manieren doorzocht en geanalyseerd worden, b.v. aan de hand van uitspraakaanduidingen, uitgangen, spellingsgegevens, woordsoortmarkeringen, synoniemvermeldingen enz. Hierdoor wordt het in principe mogelijk allerlei dimensies van het woordenboek zichtbaar te maken en op hun systematiek en konsistentie te onderzoeken. Woordenboeken bevatten allerlei dwarsverbanden, zowel tussen lemmata onderling als tussen onderdelen van lemmata. Zo zijn de betekenisomschrijvingen van nomina vaak gerelateerd aan die van verba, via tournures als the act of (V)ing, the process of (V)ing etc. Dit soort betekenisverbanden kan parallel lopen met eveneens overvloedig aanwezige morfologische (derivationele) dwarsverbanden, maar noodzakelijk is dat niet. Derivationele affixen markeren vaak inhoudelijke relaties tussen lemmata onderling, zoals tussen agens-nominalisaties en hun basiswerkwoorden, tussen afgeleide adjectiva en hun nominale of verbale bases (greenish ← green, readable ← read) enz.
Binnen lemmata vertonen opeenvolgende betekenisomschrijvingen vaak eveneens allerlei herkenbare dwarsverbanden zoals metonymische of metaforische betekenisuitbreidingen (b.v. diernamen die ook voor personen kunnen worden gebruikt: fox, pig, rat enz.), een aflopend activiteitscurve van
| |
| |
menselijke agens (Peter opened the door) naar materiëel instrument (the key opened the door), causatieve versus niet-causatieve betekenissen van werkwoorden (the door opened) enz. Afhankelijk van het soort relatie kunnen verschillende elementen in de opeenvolgende betekenisdefinities van lemmata deze dwarsverbanden markeren: anaforen (mazurka2 = a piece of music for this), cause (open1 = to (cause to) become open), like (bark2 = a sound like this) etc. Dergelijke (min of meer) systematische uitbreidingen zijn soms terug te vinden bij hele klassen van begrippen: woorden als church, university e.d. vertonen vaak dezelfde opeenvolging van metonymisch gerelateerde betekenissen: concreet (gebouw); abstract (institutie); menselijk (de mensen die de instititutie vertegenwoordigen).
Hoewel de in bestaande woordenboeken vertegenwoordigde dwarsverbanden uiteraard vooral feitelijk gelexicaliseerde gevallen betreffen, is er hier sprake is van een systematiek die daarboven uitstijgt. Zo betoogt Martin (1990) dat veel categoriale verschuivingen die in bestaande woordenboeken simpelweg in opeenvolgende vermeldingen uitmonden, in feite een systematisch en grotendeels voorspelbaar patroon volgen. Hij illustreert dat o.a. aan de hand van de ontwikkeling van het adjectief natural naar het nomen (he's a natural), en presenteert een model waarin dit soort verschuivingsmogelijkheden verantwoord wordt. In Martin's visie op een ‘dynamisch lexicon’ kan een dergelijke benadering leiden tot eliminatie van allerlei redundanties die men in traditionele woordenboeken aantreft.
Martin benadrukt ook het belang van het lexicon (c.q. MRD) als relationele structuur, d.w.z. als een samenhangend, taxonomisch georganiseerd stelsel van conceptueel-semantisch relaties. De impliciete conceptueel-semantische structuur van een woordenboek is bij een MRD in principe te traceren door, beginnend bij de definitie van een specifiek lemma de kern (het ‘genus’- woord) op te sporen, vervolgens het lemma voor dat genus-woord op te zoeken, daar weer de definitie-kern van te bepalen enz., totdat dit recursieve proces uitloopt in heel algemene woorden (zaak, substantie) of in circulariteit (b.v. object = ding, ding = object). Hierdoor ontstaan definitie-ketens die in de hogere regionen veelal bij elkaar komen en die zich aldus samen laten voorstellen als een aantal zich vertakkende omgekeerde boom-structuren. Bij een konsekwente opbouw zijn de niveaus binnen dergelijke bomen in principe hiërarchisch aan elkaar verbonden via hyponymie relaties: aal en schol komen er bijvoorbeeld uit als hyponiemen van vis, ekster en merel als hyponiemen van vogel, vogel en vis op hun beurt weer als hyponiemen van dier enz.
Dergelijke hierarchieën van via hun genus-woorden verbonden definities kunnen vervolgens benut worden om de informatie vervat in de differentiae op de verschillende niveaus toegankelijk te maken en aan elkaar te relateren. De differentiae bevatten vaak systematische informatie over allerlei eigenschappen: kleur, vorm, omvang, samenstelling, doel enz., en dit soort eigenschappen laat zich normaliter van boven naar beneden (‘top-down’) overerven. Als b.v. uit de definitie van vogel blijkt dat ‘kunnen vliegen’ een karakteristieke eigenschap van dat soort dieren is, dan geldt die eigenschap in principe voor (de referenten van) alle woorden die blijkens hun definitie- | |
| |
kern als vogels zijn getypeerd, tenzij dat ergens in de differentiae expliciet wordt tegengesproken (verg. Martin 1990:124-128).
Pionierswerk in het empirisch onderzoek van MRDs is verricht door Amsler (1980, 1981), die de semantisch-taxonomische structuur van de machineleesbare versie van het Merriam-Webster Pocket Dictionary heeft getraceerd. Hij constateert dat de feitelijke netwerk-relaties die uit zijn onderzoek naar voren komen niet zo keurig netjes en hierarchisch in elkaar zitten als in het boven geschetste, gesimplificeerde ideaalbeeld. In het ZWO-project ‘LINKS in the Lexicon’ (Meijs 1986, 1989, 1990; Meijs & Vossen 1990; Vossen 1990a; Vossen e.a. 1989), waarin de semantische-taxonomische structuur van de LDOCE in kaart werd gebracht, bleek dat ook in die MRD de door Amsler gesignaleerde ‘tangled hierarchies’ optreden.
Zo vormen, zoals in fig. 2 te zien is, animal en creature een in elkaar gedefinieerde circulariteit, waar alle definitieketens van dierennamen in uitmonden, terwijl de definitieketens van mensen-aanduidende woorden via person en being in het kringetje object / thing uitmonden, zonder enige directe relatie met de dierentaxonomie. Verder vormen alle woorden die via hun definitieketens uitkomen bij ship of boat (en via deze bij vessel) een ‘eiland’ dat niet met de rest van de taxonomie verbonden is. Aangezien de meeste inconsistenties vrij hoog in die hierarchie optreden zijn ze over het algemeen echter makkelijk te isoleren en eventueel handmatig te herstellen. Het totaalbeeld dat uit het LINKS-onderzoek naar voren komt is toch behoorlijk homogeen
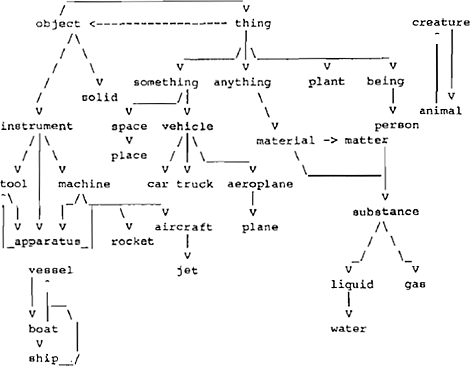
Fig. 2 De top van de taxonomie van zelfstandige naamwoorden ontleend aan LDOCE (uit Vossen 1990a)
| |
| |
en consistent: de globale taxonomisch-hierarchische samenhang is heel duidelijk herkenbaar, en vertoont grote overeenkomst met wat in ander empirisch onderzoek over taxonomieën is geconstateerd (voor details zie Vossen 1990b; vergelijk ook Berlin e.a. 1973; Rosch 1978). Inmiddels is het mogelijk gebleken op basis van de MRD-gegevens een ‘taxonomy-browser’ te ontwikkelen, waarmee men naar gelieven in de aan LDOCE onttrokken taxonomieën kan ‘grasduinen’ (Vossen & Serail 1990). Fig. 3 geeft een voorbeeld van de gedetailleerde informatie die met behulp van deze taxonomy-browser kan worden blootgelegd.
Fig. 3 laat een deel van de taxonomie van abstracte nomina zien; de getallen onder de woorden geven aan hoe vaak het desbetreffende woord voorkomt als definitie-kern, c.q. genus-woord.
Door de impliciete taxonomische structuren, en de verdere informatie die daarmee ontsloten wordt, systematisch toegankelijk te maken, worden MRDs

Fig. 3 Een deel van de taxonomie van abstract nomina in LDOCE (uit Vossen 1990b)
| |
| |
als het ware getransformeerd tot lexicale kennisbanken. In het ESPRIT-project ‘ACQUILEX’ (Acquisition of Lexical Knowledge for Natural Language Processing Systems - Boguraev e.a. 1989), waarin wetenschappers van de Universiteiten van Amsterdam, Barcelona, Cambridge, Dublin en Pisa samenwerken, wordt dit thans grootschalig gedaan voor een aantal monolinguale en bilinguale MRDs.
Het blootleggen van de impliciete semantische structuur van een MRD is overigens bepaald geen eenvoudige opgave. Om de genus-woorden en de voornaamste differentiae te vinden moeten de definitiestructuren op de een of andere manier geanalyseerd worden. In het LINKS-project is dat bereikt door alle woorden in de definities d.m.v. een automatisch coderingsprogramma van grammaticale codes te voorzien, en de aldus gecodeerde definities vervolgens met behulp van een restrictieve, specifiek op definities toegespitste parseer-grammatica te analyseren (Vossen 1990c). Voordat die grammatica kon worden ontwikkeld werden de strukturen die typisch in definities voorkomen uitgebreid met behulp van een ‘patroonherkenningsprogramma’ bestudeerd en in kaart gebracht. Hoewel in de meeste gevallen de syntactische kern van een definitie samenvalt met het semantische genus, komt het ook vaak voor dat die kern een systematische relatie (‘part-whole’, ‘member-group’, ‘quantity-mass’ etc.) uitdrukt, terwijl de eigenlijke genusinformatie verderop in de definitie te vinden is. Het gaat hier om gevallen als a type of dog, a stretch of water, a piece of gold enz. In Vossen e.a. (1989) wordt hierover verslag gedaan, waarbij de meest karakteristieke patronen worden ingedeeld in een aantal hoofdcategorieën. Naast gegevens voor de parseer-grammatica leverde dit inzichten in de karakteristieken van ‘definitietaal’ op, die van nut kunnen zijn voor de ontwikkeling van toekomstige generaties woordenboeken waarbij in een computer-ondersteunde lexicografische werkomgeving ook het schrijven van definities op een systematisch gestructureerde manier kan gebeuren.
Daarnaast is er het levensgrote probleem van de ambiguïteit: de woorden die in de definities gebruikt worden kunnen allemaal zelf meerdere betekenissen hebben. Om betrouwbare ketens op te bouwen moet dus op de een of andere manier worden vastgesteld welke van de mogelijke betekenissen in elk gegeven geval van toepassing is. Anders krijgen we situaties waarbij paling via een van de betekenissen van aal bij aalmoezenier uitkomt, of waarbij schroefdraad via een van de betekenissen van moer wordt gerelateerd aan moeder. Vossen (1990a) en Copestake (1990) beschrijven een aantal heuristische procedures waardoor desambiguëring in veel gevallen semi-automatisch kan verlopen en dit soort desastreuse konsekwenties kan worden vermeden. De empirische les die uit dit aspect van de exploratie van bestaande (machineleesbare) woordenboeken kan worden getrokken is dat bij de produktie van toekomstige woordenboeken de kernwoorden in de definities al bij voorbaat gedesambigueerd moeten worden, d.w.z. dat bij meerduidige woorden die in de definities gebruikt worden bij voorbaat wordt aangegeven in welke betekenis ze bedoeld zijn.
| |
| |
| |
11 Tot slot
Van oudsher hebben lexicografen zich beijverd om wat in een woordenboek wordt opgenomen empirisch te onderbouwen door relevante gebruiksvoorbeelden te verzamelen. Corpora maken het in principe mogelijk die empirische, observationele basis spectaculair te verbreden. In het huidige tijdsgewricht zijn corpora altijd gelijk te stellen met computercorpora. Op grond van onderzoek naar de distributieve en statistische eigenschappen van corpora is het in principe mogelijk de gewenste omvang en samenstelling van corpora voor specifiek lexicografische doeleinden vrij nauwkeurig te bepalen. Zinvolle exploratie en explotatie van grote computercorpora is alleen goed mogelijk in een geïntegreerde, computer-ondersteunde omgeving waarin automatische voor-selectie van materiaal de lexicograaf in staat stelt zich volledig te concentreren op datgene wat voor het beoogde eindprodukt relevant is. Het hiervoor vereiste instrumentarium laat echter nog veel te wensen over, met name wat betreft de voorbewerking en verrijking van het corpusmateriaal. Onderzoek van bestaande machineleesbare woordenboeken heeft veel empirische gegevens opgeleverd over hun impliciete semantisch-conceptuele structurering. Bevindingen ontleend aan dit soort onderzoek kunnen eveneens bijdragen aan de ontwikkeling van een afgewogen computerondersteunde werkomgeving waarin de lexicograaf gedwongen wordt bij elk nieuw in te voeren lemma rekening te houden met de gewenste consistentie en de interne samenhang van het beoogde eindprodukt. Naast ‘traditionele’ woordenboeken zullen dat steeds vaker ook produkten zijn die van die semantisch-conceptuele structurering uitgaan, zoals taxonomisch-thesaurisch georganiseerde lexica, synoniem-woordenboeken e.d. - in standaard boekformaat dan wel in de vorm van softwarebestanden die kunnen worden ingezet bij allerlei NLP-toepassingen.
| |
Bibliografie
| Aarts, J. en T. van den Heuvel, 1985. Computational tools for the syntactic analysis of corpora. Linguistics, 23, 303-35. |
| Aarts, J. en W.J. Meijs (red). 1984. Corpus Linguistics: Recent Developments in the Use of Computer Corpora in English Language Research. Amsterdam: Rodopi. |
| Aarts, J. en W.J. Meijs (red). 1986. Corpus Linguistics II: New Studies in the Analysis and Exploitation of Computer Corpora. Amsterdam: Rodopi. |
| Aarts, J. en W.J. Meijs (red). 1990a. Theory and Practice in Corpus Linguistics. Amsterdam: Rodopi. |
| Aarts, J. en W.J. Meijs, 1990b. Corpustaalkunde. In A. Neijt & D. Bakker (red), Computerlinguistiek: Een Overzicht in Artikelen, Dordrecht: Foris, 173-192. |
| Akkerman, E., P.C. Masereeuw en W.J. Meijs, 1985. Designing a Computerized Lexicon for Linguistic Purposes: ASCOT Report No 1. Amsterdam: Rodopi. |
| Akkerman, E., H.J. Voogt-van Zutphen en W.J. Meijs, 1988. A Computerized Lexicon for Word-level Tagging: ASCOT Report No 2. Amsterdam: Rodopi. |
| Al, B.F., 1988. Langue source, langue cible et metalangue. In R. Landheer (red), Aspects de Linguistique Francaise, Amsterdam: Rodopi, 15-29. |
| Amsler, R.A., 1980. The Structure of the Merriam-Webster Pocket Dictionary, Diss., University of Texas at Austin. |
| |
| |
| Amsler, R.A., 1981. A taxonomy for English nouns and verbs, Proceedings of the 19th Annual Meeting of the Association for Computational Linguistics, Stanford, California, 133-8. |
| Berlin, B., D.E. Breedlove en P.H. Raven, 1973. General principles of classification and nomenclature in folk biology. American Anthropologist, 75:214-42. |
| Boguraev, B., E. Briscoe, N. Calzolari, A. Cater, W. Meijs, E. Picchi en A. Zampolli, 1989. Acquisition of Lexical Knowledge for Natural Language Processing Systems, Project Description and Technical Annexe for ESPRIT Basic Research Action, Pisa. |
| Boguraev, B. en E. Briscoe (red), 1989. Computational Lexicography for Natural Language Processing, London/New York: Longman. |
| Brown, P., J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, J. Lafferty, R. Mercer en P. Roossin, 1988. A Statistical Approach to Machine Translation, IBM Report. |
| Bungarten, T., 1979. Das Korpus als empirische Grundlage in der Linguistik und Literaturwis-senschaft. In H. Bergenholtz & B. Schäder (red) Empirische Textwissenschaft, Kônigstein: Scriptor Verlag, 52-70. |
| Church, K.W. en P. Hanks, 1990. Word association norms, mutual information, and lexicography, Computational Linguistics, 16/1:22-29. |
| Clear, J., 1987. Trawling the language: monitor corpora. In M. Snell-Hornby (red) ZuriLEX 1986 Proceedings, Tübingen: Francke. Copestake, A. 1990: An Approach to building the hierarchical element of a lexical knowledge base from a machine-readable dictionary. ACQUILEX Working Paper. Cambridge: Computer Laboratory, Cambridge University. |
| Diack, H., 1975. Testing your Word-Power, London. Francis, W.N. 1982: Problems of assembling and computerizing large corpora. In S. Johansson (red) Computer Corpora in English Language Research, Bergen: Centre for the Humanities, 7-24. Greenbaum, S. 1984: Corpus analysis and elicitation tests. In Aart, J. & W.J. Meijs, (red): Corpus Linguistics: Recent Developments in the Use of Computer Corpora in English Language Research. Amsterdam: Rodopi, 193-201. |
| Harris, B., 1988. Interlinear Bitext, Translation Technology 7. |
| Hindle, D., 1983a. Deterministic parsing of syntactic non-fluencies. In Proceedings of the 23d Annual Meeting of the Association for Computational Linguistics. |
| Hindle, D., 1983b. User Manual for Fidditch, a Deterministic Parser, Naval Research Laboratory Technical Memorandum #7590-142. |
| Hulk, A., 1990. De rol van het lexicon in de generatieve syntaxis, In R.H. Baayen en G.E. Booij (red), Corpusgebaseerde Woordanalyse. Jaarboek 1990, Amsterdam: Vakgroep Taalkunde, VU, 29-40. |
| Martin, W., 1983. The construction of a basic vocabulary: an objective-subjective approach, Linguistica Computazionale 3:183-197. |
| Martin, W., 1988a. Variation in lexical frequency. In P. van Reenen & K. van Reenen-Stein (red) Spatial and Temporal Distributions, Manuscript Constellations, Amsterdam/Philadelphia: John Benjamins, 139-152. |
| Martin, W., 1988b. Corpora voor woordenboeken. In A. Dees (red) Corpusgebaseerde Woordanalyse. Jaarboek 1988, Amsterdam: Vakgroep Taalkunde, VU, 91-99. |
| Martin, W., 1990. Over de organisatie van (computer)lexica. In R.H. Baayen & G.E. Booij (red), Corpusgebaseerde Woordanalyse. Jaarboek 1990, Amsterdam: Vakgroep Taalkunde, VU, 119- 134. Martin, W., F. Platteau en R. Heymans, 1986. Naar een Corpus voor een Woordenboek Hedendaags Nederlands, Antwerpen: Computerlinguistiek, Universitaire Instelling. |
| Meijs, W.J., 1975. Compound Adjectives in English and the Ideal Speaker-Listener, Amsterdam: North Holland. |
| Meijs, W.J., 1986. Links in the lexicon: The dictionary as a corpus, ICAME News, 10, 26-28. |
| Meijs, W.J., 1989. Spreading the word: knowledge-activation in a functional perspective. In J. Connolly & S. Dik (red) Functional Grammar and the Computer, Dordrecht: Foris, 201-15. |
| Meijs, W.J., 1990. The expanding lexical universe: extracting taxonomies from machine-readable dictionaries. ACQUILEX Working Paper. Amsterdam: Engels Seminarium UvA. |
| Meijs, W.J. (red), 1987. Corpus Linguistics and Beyond. Amsterdam: Rodopi. |
| |
| |
| Meijs, W.J. en P. Vossen, 1990. Het computationele lexicon op ware grootte. TABU 20/2:137-147. |
| de Mezer, M., 1980. L'enrichissement lexical au niveau avance’ de l'enseignement du français, Studia Romanica Posnaniensia, 7. |
| Papegaaij, B.C., 1986. Word Expert Semantics: An Interlingual Knowledge-Based Approach, Dordrecht: Foris. |
| Procter, P. (red), 1978. Longman Dictionary of Contemporary English. Harlow: Longman. |
| Rosch, E., 1978. Principles of categorization. In E. Rosch and B.B. LLoyd (red) Cognition and Categorization, Erlbaum: Hillsdale. |
| Renouf, A., 1984. Corpus development at Birmingham University. In Aarts, J. & W.J. Meijs, (red): Corpus Linguistics: Recent Developments in the Use of Computer Corpora in English Language Research. Amsterdam: Rodopi, 3-39. |
| Renouf, A., 1987. Lexical resolution. In W. Meijs (red) Corpus Linguistics and Beyond, Amsterdam: Rodopi, 121-31. |
| Sadler, V., 1989. Working with Analogical Semantics: Disambiguation Techniques in DLT, Dordrecht: Foris. |
| Schäder, B., 1976. Maschinenlesbare Textcorpora des Deutschen und des Englischen, Deutsche Sprache 4:356-370. |
| Sinclair, J. (red), 1987a. Collins COBUILD English Language Dictionary. London/Glasgow: Collins. |
| Sinclair, J. (red), 1987b. Looking Up. An Account of the COBUILD Project in Lexical Computing. London/Glasgow: Collins ELT. |
| van Sterkenburg, P.G.J. en W.J.J. Pijnenburg (red), 1984. Van Dale Groot Woordenboek Hedendaags Nederlands. Utrecht/Antwerpen: Van Dale Lexicografie. |
| Uit den Bogaart, P.C., 1975. Woordfrequenties in geschreven en gesproken Nederlands, Utrecht: Oosthoek, Scheltema en Holkema. |
| Vossen, P., 1989. The structure of lexical knowledge as envisaged in the LINKS-project. In J. Connolly & S. Dik (red) Functional Grammar and the Computer, Dordrecht: Foris, 177-99. |
| Vossen, P., 1990a. Polysemy and vagueness of meaning descriptions in the Longman Dictionary of Contemporary English. ACQUILEX Working Paper, Amsterdam: Engels Seminarium UvA. Verschijnt ook in J. Svartvik & H. Wekker (red) Topics in English Linguistics, 's-Gravenhage: Mouton/De Gruyter. |
| Vossen, P., 1990b. The end of the chain: Where does decomposition of lexical knowledge lead us eventually? ACQUILEX Working Paper, Amsterdam: Engels Seminarium UvA. Verschijnt ook in: Proceedings of the 4th Conference on Functional Grammar, June 1990, Kopenhagen, (voorlopige titel). |
| Vossen, P., 1990c. A Parser-grammar for the Meaning Descriptions of the Longman Dictionary of Contemporary English. Technical Report, Amsterdam: Engels Seminarium UvA. |
| Vossen, P., W.J. Meijs en M. den Broeder, 1989. Meaning and structure in dictionary definitions. In B. Boguraev & T. Briscoe (red) Computational Lexicography for Natural Language Pro-cessing, London: Longman, 171-92. |
| Vossen, P. en I. Serail, 1990. Devil: A taxonomy-browser for decomposition via the lexicon, ACQUILEX Working Paper, Amsterdam: Engels Seminarium UvA. |
| Wilks, Y., 1972. Grammar, Meaning, and the Machine Analysis of Language, Londen: Routledge. |
| Zgusta, L., 1970. Manual of Lexicography. 's-Gravenhage: Mouton. |
|
|
