
Spektator. Jaargang 18
(1988-1989)– [tijdschrift] Spektator. Tijdschrift voor Neerlandistiek–
[pagina 44]
| |||||||||||||
Rosetta: Synonymie en VertalingGa naar eind*
| |||||||||||||
[pagina 45]
| |||||||||||||
talen. In paragraaf 3 wordt een beknopte inleiding in het Rosetta-kader gegeven, in paragraaf 4 gevolgd door een meer gedetailleerde bespreking van de rol van het Isomorfieprincipe voor het behoud van betekenis. De complicaties van de Rosetta-grammatica zullen nader toegelicht worden in paragraaf 5 aan de hand van de bespreking van enkele niet-triviale vertalingen die Rosetta geacht wordt aan te kunnen. Tenslotte is paragraaf 6 toegespitst op de relevantie van het Rosetta-kader vanuit een meer algemeen linguïstisch standpunt. | |||||||||||||
2. De notie synonymieNeem de volgende drie beweringen.
Deze uitdrukkingen hebben identieke waarheidscondities. Elk van de beweringen is waar dan en slechts dan als zeven meer is dan drie. Maar ondanks het feit dat zij corresponderende elementen bevatten die equivalent zijn, is hier geen sprake van drie synoniemen. Een paarsgewijze vergelijking laat dat zien. Als zeven meer is dan drie, dan zijn de uitdrukkingen (2) en (3) beide waar. Bij een overgang van (2) naar (3), of omgekeerd, blijft daarom in extensionele (i.e. niet-intensionele) conteksten de betekenis behouden. In intensionele conteksten leidt het feit dat het aantal basisexpressies voor (2) en (3) verschillend is tot een cruciaal verschil: in intensionele conteksten zijn ze niet vrij verwisselbaar. Zo betekent Wij geloven dat 2 + 5 = 7 niet hetzelfde als Wij geloven dat 7= 7. De beweringen (1) en (2) hebben identieke betekenissen en, zoals Carnap dat noemt, L-(ogisch)-equivalente, met elkaar corresponderende delen. Bovendien zijn ze opgebouwd uit hetzelfde aantal basisexpressies en operaties. De verschillen in de oppervlaktestructuur corresponderen hier niet met betekenisverschil. In intensionele conteksten zijn ze vrij verwisselbaar. Of zoals Carnap zegt: (3) heeft een intensionele structuur die niet isomorf is met die van (1) en (2). If two sentences are built in the same way out of designators [...] such that any two corresponding designators are L-equivalent, then we say that the two sentences are intensionally isomorphic (o.c.: p. 56). Bewering (3) bevat een argument dat niet isomorf is met het corresponderende deel van (1) en (2). Om deze redenen voldoen het paar (1) en (3) en het paar (2) en (3) niet aan Carnaps voorwaarde voor isomorfie. Omdat uitsluitend isomorfe uitdrukkingen als echte synoniemen beschouwd worden, is (3) geen synoniem van (1) of (2). In het rekenkundige voorbeeld hierboven hoeven de semantische systemen waaraan gerefereerd wordt niet langs empirische weg gereconstrueerd te | |||||||||||||
[pagina 46]
| |||||||||||||
worden. Zij zijn onafhankelijk gegeven. De equivalentie van de uitdrukkingen in kwestie is duidelijk. Binnen de contekst van zulke voorbeelden is de beslissing omtrent het al dan niet bestaan van synonymie bijna triviaal. Carnap: We find that [these expressions] are isomorphic by establishing the L-equivalence of corresponding signs. (o.c.:p. 58) Als richtlijn bij de ontwikkeling van automatische vertaalsystemen is dit echter niet voldoende. Allereerst bestaat er geen unanimiteit met betrekking tot de grammaticale structuur van natuurlijke talen: er bestaat geen welgedefinieerd principe dat a priori bepaalt welke strings beschouwd moeten worden als basisexpressies, welke als complexe uitdrukkingen, en welke strings betekenisloos zijn. Op het niveau van de oppervlaktestructuur zijn er bovendien talrijke incongruenties, zelfs in verwante talen als het Nederlands en het Engels. Het is daarom niet duidelijk welke uitdrukkingen beschouwd kunnen worden als ‘corresponding signs’. Een formele verantwoording van synonymie tussen natuurlijke talen veronderstelt eerder de stipulatie van synonymie: uitdrukkingen zijn isomorf wanneer wij ze als zodanig behandelen. In paragraaf 5 zullen we aan de hand van voorbeelden laten zien dat er soms gestipuleerde synonymie nodig is bij de behandeling van de omvangrijke fragmenten waarvoor het Rosetta-systeem bedoeld is. De aan paragraaf 5 voorafgaande paragrafen omvatten een inleiding in het Rosetta kader (paragraaf 3), en in de manier waarop in dit kader behoud van betekenis wordt gerealiseerd (paragraaf 4). | |||||||||||||
3. Het Rosetta-kaderHet linguïstische werk binnen het kader van Rosetta wordt gestuurd door een aantal richtlijnen, in de praktijk meestal aangeduid als de ‘principes’. Het Isomorfieprincipe is hier slechts één van. Dit principe zal in de volgende paragraaf uitgebreider ter sprake komen. Deze paragraaf bevat een globale beschrijving van het Rosetta-kader. Behalve enkele Rosetta-principes worden hier ook de linguïstisch relevante representatieniveaus geïntroduceerd. | |||||||||||||
3.1 Enkele Rosetta-principesDe hier te bespreken principes zijn bedoeld als leidraad bij het systematische onderzoek naar de mogelijkheden tot automatische vertaling en als ondersteuning bij de bouw van de systemen.
| |||||||||||||
[pagina 47]
| |||||||||||||
| |||||||||||||
3.2 Representaties in RosettaHet vertaalproces is op te delen in een analytisch deel en een generatief deel. Beide worden gedefinieerd door de drie componenten van de compositionele grammatica's van het Rosetta-systeem (die M-grammatica's genoemd worden): de morfologische component, de syntactische component en de semantische component. Als toelichting op de manier waarop de hierboven geschetste principes elkaar beïnvloeden en ook met het oog op de leesbaarheid van de volgende paragrafen volgt hier een kort overzicht van de in Rosetta gebruikte representatieniveaus. We beperken ons daarbij tot de representaties van de syntactische en semantische componenten van de M-grammatica's. De volgende drie niveaus, waarvan de eerste twee door de syntactische component en het derde niveau door de semantische component gedefinieerd worden, zijn van belang. (Figuur 2 aan het eind van deze paragraaf geeft een schematisch overzicht van het Rosetta vertaalproces.)
De syntactische oppervlaktebomen (S-bomen) zijn constituentstructuren gedefinieerd door de regels van de syntactische component, de zogenaamde M-regels. De S-bomen geven de syntactische structuur van complexe uitdrukkingen weer. De derivatie van een oppervlakteboom vanuit basisexpressies loopt via de recursieve toepassing van syntactische combinatieregels (M-regels), en dit proces wordt weergegeven in een syntactische derivatieboom (syntactische D-boom) waarvan de terminale elementen bestaan uit basisexpressies en waarbij de niet-terminale knopen de namen van de toegepaste regels dragen. Met elke knoop van de derivatieboom correspondeert een S-boom. In Rosetta wordt het onderscheid tussen betekenisvolle operaties en zuiver syntactische bewerkingen weerspiegeld in het onderscheid tussen respectievelijk regels (in de syntactische derivatiebomen weergegeven met Rn) en transformaties (in de syntactische derivatiebomen als Tn weergegeven). Het linkerdeel van Figuur 1 bevat een specificatie van de syntactische derivatieboom en van de tussenliggende S-bomen voor de zin Oscar slaapt.Ga naar eind3 Zinnen van de brontaal (of delen ervan), die natuurlijk altijd taalspecifieke | |||||||||||||
[pagina 48]
| |||||||||||||
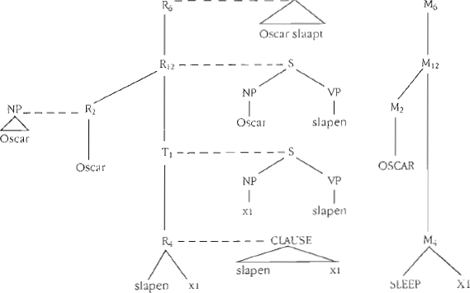 Figuur 1. Syntactische en semantische derivatie voor Oscar slaapt.
eigenschappen hebben, worden via de representatie van hun gemeenschappelijke betekenis afgebeeld op uitdrukkingen van de doeltaal. Volgens het Compositionaliteitsprincipe correspondeert het proces dat tot welgevormde oppervlaktestrings leidt met de derivatie van de betekenis van de gegenereerde string. Daarom kan de betekenis van een complexe uitdrukking worden weergegeven in een semantische derivatieboom (semantische D-boom): een boom met de namen van de betekenissen van de basisexpressies als terminale elementen, en de namen van de betekenissen van de syntactische regels als niet-terminale knopen (weergegeven met Mn).Ga naar eind4 Het rechterdeel van Figuur 1 is een voorbeeld van een semantische derivatieboom. Omdat puur syntactische bewerkingen per definitie geen effect hebben voor de semantiek, zijn de transformaties bij de bepaling van de synonymie irrelevant. Ze zijn om zo te zeggen niet vertaalrelevant. Voor een uitgebreide bespreking van het formele onderscheid tussen regels en transformaties, zie Appelo, Fellinger & Landsbergen (1987). Voor de rol van de semantische derivatiebomen als interlingua, zie Appelo & Landsbergen (1986). Voor de toekenning van een gemeenschappelijke semantische derivatieboom aan twee synonieme strings die tot verschillende talen behoren en die verschillende oppervlaktestructuren hebben, is een parallelle afleiding vereist. Het deel van de derivatie dat als ‘betekenisloos’ gemarkeerd is, namelijk het deel dat door transformaties wordt gedefinieerd, kan daarbij buiten beschouwing blijven. De inhoud van de syntactische regels, de M-regels is taalspecifiek. Bovendien kunnen M-regels complexe syntactische operaties definiëren. Daarom is een zorgvuldige opdeling van de syntactische inhoud over de verschillende stappen nodig. In het vervolg zullen syntactische derivaties overigens in gereduceerde vorm | |||||||||||||
[pagina 49]
| |||||||||||||
worden weergegeven. Slechts het betekenisvolle deel van de derivatie wordt gegeven. Syntactische transformaties worden dus weggelaten. (Als gevolg hiervan hebben de syntactische D-bomen dezelfde geometrie als de hiermee corresponderende semantische D-bomen). Bovendien worden enkele voor dit betoog minder belangrijke betekenisvolle regels buiten beschouwing gelaten. Bijvoorbeeld de regel die de NP-knoop boven eigennamen definieert, en soms ook de regels die de argumentvariabelen vervangen door volledige NP's. Samenvattend: de syntactische regels en basisexpressies definiëren wat de betekeniseenheden zijn, en taalspecifieke syntactische generalisaties worden door de oppervlaktebomen tot uitdrukking gebracht. Het verband tussen syntactische en semantische derivatie wordt in de volgende paragraaf uitgebreid toegelicht. Deze paragraaf besluit met een schematische weergave van het Rosetta-vertaalproces (Figuur 2). 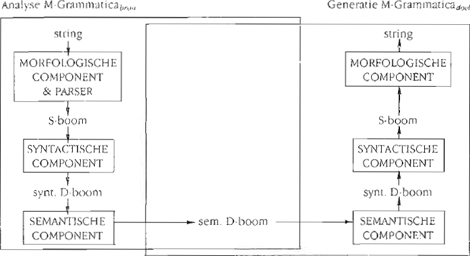 Figuur 2. Het Rosetta-vertaalproces.
| |||||||||||||
4. IsomorfieVolgens het ‘Isomorfieprincipe’ moeten zinnen die als elkaars vertalingen beschouwd worden, op vergelijkbare manier worden afgeleid, dat wil zeggen door middel van volledig parallelle processen. Om deze reden zullen hun gereduceerde syntactische derivatiebomen dezelfde geometrie vertonen. Om er zeker van te zijn dat voor equivalente uitdrukkingen een vertaalrelatie wordt gedefinieerd, moeten de verschillende stappen in de derivatie zorgvuldig gekozen worden, en wel zodanig dat elke basisexpressie op zijn (gestipuleerde) equivalent kan worden afgebeeld en dat er voor elk van de regels een gelijkwaardige tegenhanger bestaat. Dit ontwerpproces wordt dus gekenmerkt door afstemming van (de regels van) de grammatica's. In Rosetta wordt informatie over de feitelijke inhoud van syntactische bewerkingen niet in de derivatiebomen weergegeven. De derivatiebomen | |||||||||||||
[pagina 50]
| |||||||||||||
drukken dus verschillen als die tussen (1) en (2) alleen indirect uit. Dit is in overeenstemming met de analyse van Carnap: [...] the use of a functor preceding the two argument signs instead of one standing between them may be regarded as an inessential syntactical device. (o.c.: p. 56) In de volgende paragraaf komen afbeeldingen aan de orde die aanzienlijk minder triviaal zijn dan die van (1) en (2). Dat de afstemming van grammatica's geen triviaal proces is wordt toegelicht aan de hand van enkele gevallen van incongruentie tussen twee talen. Sommige hiervan vereisen zelfs het stipuleren van synonymie van basisexpressies waar er op het eerste gezicht geen sprake is van betekenisidentiteit. | |||||||||||||
5. IncongruentiesStel dat woordvolgorde of de volgorde van constituenten vanuit semantisch standpunt irrelevant is, zoals Carnap zegt. Dan hoeft de afbeelding van synonieme uitdrukkingen uit verschillende talen niet bemoeilijkt te worden door incongruenties ten gevolge van verschillen in oppervlaktevolgorde. Deze kunnen worden toegeschreven aan taalspecifieke aspecten van de grammatica's, bijvoorbeeld aan transformaties of de inhoud van betekenisvolle regels. Incongruenties kunnen echter ook met andere aspecten dan volgorde samenhangen. Om met een betrekkelijk eenvoudig voorbeeld te beginnen:
Deze twee zinnen hebben verschillend georganiseerde predikaten: (5) bevat een hulpwerkwoord om de ‘progressive tense’ uit te drukken, terwijl in (4) uitsluitend het tegenwoordige-tijdmorfeem voorkomt. Om isomorfe derivaties voor deze zinnen af te leiden moet uitgemaakt worden of het Engelse hulpwerkwoord al dan niet een basisexpressie is. Een basisexpressie heeft een basisbetekenis. Maar aangezien het concept van de ‘progressive tense’ intuïtief eerder wordt verbonden met sententiële eigenschappen dan met het werkwoord be, lijkt het voor de hand liggend is in (5) te behandelen als een syncategorematisch ingevoerde expressie zonder onafhankelijk gedefinieerde basisbetekenis. Als we aannemen dat het tegenwoordige-tijdmorfeem in het Nederlands eveneens door middel van een regel ingevoerd wordt, kunnen (4) en (5) ondanks hun verschillen, toch op isomorfe wijze worden afgeleid. Figuur 3 toont de vereenvoudigde syntactische derivatiebomen voor (4) en (5). Zij laten de hier gevolgde strategie duidelijk zien: isomorfe syntactische derivaties worden verkregen door zowel voor de Nederlandse als voor de Engelse zin uit te gaan van twee basisexpressies in de derivaties. De regels R5 en R5′ combineren de beide basisexpressies, zodat een predicatieve structuur ontstaat, terwijl R6 en R6′ tempus toekennen. | |||||||||||||
[pagina 51]
| |||||||||||||
Het verschil tussen de oppervlaktestrings (4) en (5) vloeit voort uit een verschil in de inhoud van R6 en R6′. 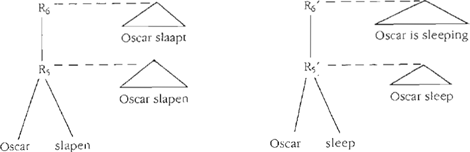 Figuur 3. Syntactische derivatiebomen voor (4) en (5)
Andere incongruenties hebben een minder triviaal karakter omdat zij tot analyses en/of afbeeldingen nopen die in zekere zin tegen de intuïtie ingaan. In deze paragraaf bespreken we drie voorbeelden. Allereerst twee voorbeelden van incongruenties van grammaticale relaties. Het derde voorbeeld heeft betrekking op de afbeelding van een bijwoord op een werkwoord.
1. Genitief-s ten opzichte van postnominale modificatie. Neem de volgende twee NP's:
In (6) wordt de possessieve modificatie door een genitieve NP tot uitdrukking gebracht. In (7) bevat de prenominale structuur een bepaald lidwoord terwijl de possessieve modificatie uitgedrukt wordt door een postnominale PP; (6) en (7) laten zien dat in het Nederlands en het Spaans de possessieve relatie met verschillende syntactische middelen wordt uitgedrukt, namelijk een determinator in het Nederlands en een complement in het Spaans. Figuur 4 bevat isomorfe syntactische derivatiebomen voor (6) en (7).Ga naar eind5 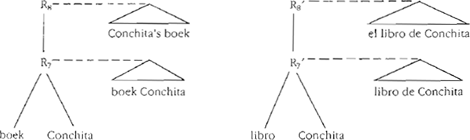 Figuur 4. Syntactische derivatiebomen voor (6) en (7).
| |||||||||||||
[pagina 52]
| |||||||||||||
De derivaties in Figuur 4 zijn gebaseerd op de volgende veronderstellingen.
De synonymie van (6) en (7) wijst erop dat grammaticale relaties (of categorieën) zoals determinator en modificator op zichzelf niet vertaalrelevant zijn. Bovendien illustreren (6) en (7) de stelling dat de afbeelding van derivatiebomen niet altijd vanzelf spreekt, maar eerder het resultaat is van een nauwgezet afstemproces dat - met betrekking tot de vraag wat als basisexpressie beschouwd moet worden - met minder voor de hand liggende beslissingen gepaard kan gaan. Het voorbeeld dat in de volgende paragraaf besproken wordt is zelfs nog gecompliceerder omdat het daar gaat om de afbeelding van basisexpressies die intuïtief geen synoniemen van elkaar zijn.
2. Omwisseling van argumenten: bevallen versus like. Neem de zinnen (8) en (9). Deze worden intuïtief beschouwd als vertalingen van elkaar: beide brengen tot uitdrukking dat de film Amadeus Jane aanspreekt:
In (8) is Amadeus het grammaticale subject en Jane het indirect object. Daarentegen is in (9) Amadeus het directe object en Jane het subject. De oppervlaktevolgorde van de argumenten in (8) en (9) is dus verschillend, mogelijk omdat bevallen een zogenaamd ergatief werkwoord is, terwijl like dat niet is. Toch lijken (8) en (9) dezelfde waarheidscondities te hebben. Isomorfe derivatiebomen voor deze zinnen krijgen we alleen als bevallen en like als elkaars vertalingen worden gezien. Uitgedrukt in formeel seman- | |||||||||||||
[pagina 53]
| |||||||||||||
tische termen: er dient gestipuleerd te worden dat zij hetzelfde tweeplaatsige predikaat aanduiden, hier weergegeven als LIKE. Het argument van dit tweeplaatsige predikaat LIKE bestaat uit een paar, in dit geval de denotata van Jane en Amadeus. Met andere woorden: de betekenis van (8) en (9) dient een logische expressie te zijn langs de lijnen van (10). (De volgorde van de argumenten is in feite willekeurig.)
Om (10) af te kunnen leiden als resultaat van een compositioneel proces, wordt een semantische derivatie als in Figuur 5 verondersteld. Geen enkele syntactische derivatie die ten opzichte van de derivatie uit Figuur 5 verschilt in het aantal stappen voor de vorming van het propositionele niveau kan als basis dienen voor isomorfe syntactische derivatiebomen. 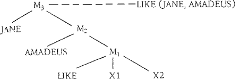 Figuur 5. Semantische derivatieboom voor (8) en (9).
In Figuur 6 zijn de (gereduceerde) syntactische derivatiebomen voor (8) en (9) opgenomen die isomorf zijn met de semantische derivatieboom uit Figuur 5: de taalspecifieke syntactische regels R1 en R1′, die corresponderen met de gemeenschappelijke semantische regel M1, specificeren de syntactische configuraties voor respectievelijk bevallen en like. 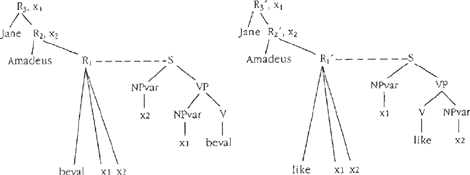 Figuur 6. Deel van de syntactische derivatiebomen voor (8) en (9) en afgeleide S-bomen.
| |||||||||||||
[pagina 54]
| |||||||||||||
Drie aspecten van deze analyse zijn van belang:
3. Het afbeelden van bijwoorden op werkwoorden. Een klassiek vertaalprobleem heeft betrekking op de vertaling van de Engelse zin (11) en zijn Nederlandse equivalent (12).Ga naar eind7
Het probleem is dat like beschouwd moet worden als vertaalsynoniem van graag, ondanks de verschillen tussen de categorieën waartoe deze twee basisexpressies behoren: like is een werkwoord en graag is een bijwoord. Dit verschil in categoriestatus dwingt tot de aanname van verschillende oppervlaktestructuren: de oppervlaktestructuur van (11) bevat een sententieel complement, terwijl (12) een enkelvoudige zin zonder ingebedde zin is. De isomorfie van het relevante deel van de grammatica kan als volgt gerealiseerd worden. Het tweeplaatsige predikaat like wordt afgebeeld op graag dat per stipulatie eveneens beschouwd wordt als een tweeplaatsig predikaat. De inhoud van de syntactische regels verantwoordt het verschil in oppervlaktevolgorde. Zie Figuur 7. Om de synonymie van (11) en (12) aan te kunnen, moet het bijwoord graag als tweeplaatsig predikaat geanalyseerd worden. Overigens kan het relationele karakter van graag ook op monolinguale gronden verdedigd worden. De aanwezigheid van graag veronderstelt een levend subject: *het regent graag (cf. *it likes to rain). Het sterke verband tussen graag en het subject van | |||||||||||||
[pagina 55]
| |||||||||||||
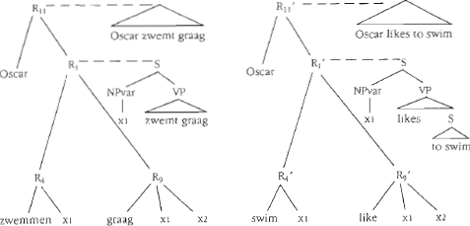 Figuur 7. Syntactische derivatiebomen voor (11) en (12)
de zin blijkt eveneens uit de onmogelijkheid een zin met graag met behoud van waarheidswaarde in de lijdende vorm te zetten. Net als in de voorafgaande voorbeelden van incongruentie illustreert de synonymie van (11) en (12) de beperkte relevantie van oppervlakte-syntactische concepten vanuit het oogpunt van vertaling. Het Rosetta-kader biedt een adequate methode voor dit gegeven omdat betekenisbehoud wordt verwezenlijkt via de derivationele geschiedenis en niet via een oppervlakteanalyse. | |||||||||||||
6. DiscussieIn de voorafgaande paragrafen is gedemonstreerd hoe intuïtieve oordelen over de synonymie van uitdrukkingen uit verschillende talen de opzet van de Rosetta-grammatica's kunnen sturen. Wat wij tot nu toe hebben willen benadrukken, zijn de consequenties van het feit dat de grammatica's in belangrijke mate beïnvloed zijn door het afstemproces, en slechts ten dele onafhankelijk gemotiveerd zijn. Het werk dat voorafgaat aan het afstemproces behoort tot de contrastieve linguïstiek. Het afstemmen zelf kan in sommige opzichten beschouwd worden als eclectisch: wanneer er incongruenties tussen de talen bestaan, kan er een keuze tussen conflicterende analyses worden gemaakt zonder aan welk principe dan ook te refereren. Naast de ontwikkeling van een automatisch-vertaalsysteem bestaat er binnen Rosetta een meer empirisch perspectief: het biedt een kader voor het onderzoek naar de vraag of uitdrukkingen uit verschillende talen behandeld kunnen worden als behorend tot één en hetzelfde semantische systeem en, meer in het bijzonder, naar de vraag of synonymie verantwoord kan worden binnen een op compositionaliteit gebaseerd kader. Deze laatste paragraaf is bedoeld om enig licht te werpen op het aandeel van empirisch gemotiveerde linguïstische analyses binnen Rosetta, en daarmee op de relevantie | |||||||||||||
[pagina 56]
| |||||||||||||
van die analyses voor het onderzoek naar de semantiek van natuurlijke talen in het algemeen en naar linguïstische universalia. Allereerst moet hier benadrukt worden dat het Rosetta-kader onderscheid maakt tussen verschillende analyseniveaus. Zoals reeds in paragraaf 3.2 is aangegeven bestaan er twee soorten representaties die relevant zijn: oppervlaktebomen en derivatiebomen. Voor de compositionele afbeelding van uitdrukkingen op hun semantische interpretatie, en dus ook op hun pendant in de doeltaal, vormt de derivatieboom het cruciale niveau. De oppervlaktebomen representeren niet alleen het resultaat van betekenisvolle stappen in de derivatie, maar ook de taalspecifieke kenmerken van een taal. Daarom kunnen S-bomen configuraties bevatten die voor een bepaalde taal onafhankelijk gemotiveerd zijn. Als zodanig zijn zij van belang voor het onderzoek naar de syntaxis van natuurlijke talen. De taalafhankelijkheid van S-bomen heeft ook een praktisch voordeel: in het ontwerpproces is het cruciaal dat er een apart niveau bestaat voor de representatie van monolinguale generalisaties: om de greep op de gegenereerde structuren niet te verliezen moeten de linguïsten die de M-regels formuleren kunnen refereren aan taalspecifieke syntactische generalisaties. Zo kan het Nederlands gemakkelijker beschreven worden wanneer het als een SOV-taal in plaats van als een SVO-taal beschouwd wordt. Daarom is SOV de onderliggende volgorde in de S-bomen voor het Nederlands. Een ander interessant effect van de formalisering van synonymie tussen talen is al ter sprake gekomen in paragraaf 5: het op elkaar afstemmen van grammatica's kan tot analyses leiden die vanuit monolinguaal standpunt niet voor de hand liggen, maar die in feite toch een monolinguale generalisatie uitdrukken, bijvoorbeeld de getrapte analyse van possessieve genitieven waarbij de bepaaldheid werd ‘losgeweekt’ uit de possessieve determinator, en de analyse van het bijwoord graag als tweeplaatsig predikaat. De hierboven geclaimde relevantie van Rosetta in verband met onderzoek naar linguïstische universalia is gebaseerd op de volgende veronderstellingen: (a) de semantiek van natuurlijke taal dient het intuïtieve oordeel van de taalgebruiker over synonymie te verantwoorden, en (b) de verschillende natuurlijke talen moeten door hetzelfde semantische model beschreven worden. Daarom dient de intuïtieve synonymie van uitdrukkingen die tot verschillende talen behoren verantwoord te worden door er identieke betekenisrepresentaties aan toe te kennen. Gegeven het hierboven beschreven kader, veronderstelt dit parallelle derivaties voor synonieme uitdrukkingen. Zoals boven is aangevoerd, kan de afstemming van grammatica's leiden tot willekeurige keuzes, bijvoorbeeld tussen een analyse gebaseerd op taal A en een analyse gebaseerd op taal B. Omdat Rosetta voor een beperkt aantal talen ontworpen is, kan er op basis van één derivatieboom niets geconcludeerd worden met betrekking tot de universaliteit van een bepaalde analyse. Uitgaande van een systeem voor een minder beperkt aantal talen worden de te maken keuzes minder willekeurig omdat er dan meer feiten zullen zijn om rekening mee te houden. Eén suggestie omtrent universaliteit is reeds geïmpliceerd door het voorafgaande: gegeven de analyse van like en bevallen als synonieme predikaten moet de notie VP beschouwd worden | |||||||||||||
[pagina 57]
| |||||||||||||
als een oppervlakte-syntactisch concept, semantisch irrelevant, en in die zin wellicht niet behorend tot de gemeenschappelijke universele linguïstische categorieën. Deze conclusie wordt gesteund door een analyse van het Moderne Iers: zoals gesteld in McCloskey (1979) kan het Moderne Iers als een VSO-taal beschouwd worden, dat wil zeggen als een taal met een onderliggende structuur zonder syntactische VP. Een meer algemene conclusie die getrokken kan worden op basis van de specifieke manier waarop Rosetta de synonymie tussen talen behandelt, is het feit dat de bepaling van het evenwicht tussen syntactische en semantische analyses aanleiding kan zijn tot het onderscheiden van meer representatieniveaus dan in het algemeen gebruikelijk is. Naast de representatie van de oppervlakte-syntactische generalisaties is er een niveau nodig dat de derivationele geschiedenis weergeeft. Onder die aanname moet de verantwoording van de correspondentie tussen syntaxis en semantiek niet gezocht worden in de specificatie van een correspondentie tussen oppervlaktesyntactische structuren en semantische representaties. Oppervlaktestructuur hoeft derhalve ook niet door overwegingen van semantische aard gecompliceerd worden. In dit opzicht zouden de critici van Montague (1974) gelijk kunnen hebben. Als echter een onderscheid wordt gemaakt tussen oppervlaktestructuur enerzijds, en de afleiding ervan anderzijds, waarbij beide onafhankelijk gemotiveerd zijn, dan kan de relatie tussen oppervlaktestructuur en semantische representatie zwakker zijn dan vaak beweerd is. Aangenomen dat Montague niet de bedoeling heeft gehad syntactische welgevormdheid te verantwoorden, dan zou de hier beschreven verklaring van synonymie zelfs als steun beschouwd kunnen worden voor het feit dat Montague oppervlaktestructuur volledig buiten beschouwing heeft gelaten. | |||||||||||||
[pagina 58]
| |||||||||||||
Bibliografie
|
| ||||||||||||