
Spektator. Jaargang 14
(1984-1985)– [tijdschrift] Spektator. Tijdschrift voor Neerlandistiek–
[pagina 319]
| |||||||||||||||||||||||||||||||||||||||||
Ambisyllabiciteit en de structuur van Nederlandse lettergrepen
| |||||||||||||||||||||||||||||||||||||||||
2. De distributie van korte vocalen en lettergreepstructuurEen aloude observatie met betrekking tot de distributie van Nederlandse vocalen is dat de korte vocalen niet kunnen voorkomen in woordfinale positie, enkele uitzonderingen daargelaten. Aparte aandacht verdient de vocaal schwa, die (evenals de vocaal in zijn naam uitzonderlijk) regelmatig woordfinaal voorkomt. De beperkte distributie van korte vocalen kan men verklaren in termen van lettergreepstructuurregels, en wel op twee manieren. Men kan stellen dat hier een beperking in het geding is op de compositie van woordfinale lettergrepen of men kan stellen dat er sprake is van een algemene beperking op de bouw van lettergrepen in het Nederlands. Uitgaande van het idee dat lettergrepen gestructureerd zijn als in (1) kunnen beide verklaringen weergegeven worden als in (2):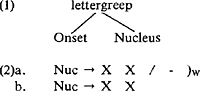 | |||||||||||||||||||||||||||||||||||||||||
[pagina 320]
| |||||||||||||||||||||||||||||||||||||||||
(2a) zegt dat een woordfinale nucleus bestaat uit twee posities en (2b) zegt dat elke nucleus bestaat uit twee positiesGa naar eind1. Een goede reden om de eerste verklaring te kiezen zou natuurlijk zijn dat niet-woordfinale lettergrepen wel degelijk op een korte vocaal kunnen uitgaan. In bepaalde gevallen lijkt dit inderdaad zo te zijn, namelijk in woorden van het type (3):
De conclusie dat hier een korte vocaal in open lettergreep voorkomt berust op twee veronderstellingen. Op de eerste plaats moeten we ervan uitgaan dat de dubbelgespelde consonanten niet alleen op fonetisch nivo, maar ook op fonologisch nivo een enkel segment representeren (4a) en op de tweede plaats moeten we er van uit gaan dat in een sequentie /...vcv.../ de consonant altijd tot de onset behoort van de twee lettergreep (4b):
De lineaire notatie en het lettergreepsymbool ‘$’ gebruik ik hier kortheidshalve. In de ‘correcte’ representatie, waarop ik later zal overschakelen en die hierarchisch van aard is, spelen bij dit soort grenzen geen rol. Het is betrekkelijk eenvoudig om aan te tonen dat de verklaring, weergegeven in (2a), onbevredigend is. In het Nederlands komen geen woorden voor met een niet-finale lettergreep die uitgaat op een korte vocaal en gevolgd wordt door een lettergreep die begint met een vocaal. Laten we tijdelijk de conventie aannemen dat korte vocalen op fonologisch nivo gerepresenteerd worden d.m.v. één symbool en lange d.m.v. twee:
Dus: lettergrepen eindigend op een korte vocaal kunnen alleen voorkomen wanneer de volgende lettergreep met een consonant begint. Dit betekent dat (2a) in elk geval vervangen moet worden door (6):
De afwezigheid van de woorden in (5a) vormt uiteraard geen probleem voor de tweede verklaring voor de afwezigheid van woordfinale korte vocalen, weergegeven in (2b). Voor (2b) zijn de vormen in (3) problematisch, tenzij we een van beide (of beide) veronderstellingen verwerpen, weergegeven in (4). In (7a) neem ik aan dat (4a) fout is (en dat bijgevolg geldt: <cc> ~ /cc/) en in (7b) nemen we aan dat (4b) fout is (en dat bijgevolg /...vc$v.../ mogelijk is): | |||||||||||||||||||||||||||||||||||||||||
[pagina 321]
| |||||||||||||||||||||||||||||||||||||||||
Er zijn strikt fonologische redenen om (7b) te verwerpen. Het intervocalische segment wordt hier gepresenteerd als een enkele lettergreepfinale consonant. Zoals bekend zal zijn bestaat er in het Nederlands een regel van verstemlozing (final devoicing, FIDE), die stemhebbende obstruenten in lettergreepfinale positie blokkeert (cf. Kooij 1978, Van der Hulst 1980). Door de representatie in (7b) aan te houden voorspellen we nu dat FIDE van toepassing zal zijn en tot verstemlozing zal leiden van de intervocalische consonant. Deze voorspelling is onjuist, getuige de uitkomst van de derivatie in (8)
We zouden in de formulering van FIDE kunnen opnemen dat er geen vocaal mag volgen, maar dat lijkt me eerder een vingerwijzing om naar een andere ana-analyse te zoeken dan een oplossing. (7b) heeft hierbij nog een ander nadeel. Woordinitiële lettergrepen in het Nederlands beginnen nooit met een schwa. Gesteld dat we hier opnieuw niet te maken hebben met een positie-afhankelijke beperking op de bouw van lettergrepen, dan zou de lettergreepopsplitsing in (7b) op onafhankelijke gronden uitgesloten zijn. (7a) Is niet problematisch voor de regel van eindverstemlozing, omdat deze regel in zijn toepassing wordt geblokkeerd door de regressieve assimilatieregel (REVO) zoals voorspeld door het principe van Proper Inclusion Precedence (zie Van der Hulst 1980 voor een bespreking van dit punt):
De structurele descriptie van FIDE is ‘properly included’ in die van REVO. Aan (7b) kleeft nog een bezwaar nl. dat de opsplitsing in lettergrepen ‘tegenintuitief’ is, in flagrante strijd met de oordelen van taalgebruikersGa naar eind2. Soortgelijke bezwaren zou men ook kunnen hebben tegen (7a). Het bezwaar tegen (7a) zou kunnen zijn dat ten onrechte geïmpliceerd is dat er een dubbelgearticuleerde (of tenminste lange) consonant aanwezig is en het bezwaar tegen (7b) zou kunnen zijn dat het volstrekt onjuist is aan te nemen dat de tweede lettergreep begint met een vocaal. Tegen beide bezwaren kan (m.i. terecht) ingebracht worden dat sprekers-oordelen betrekking hebben op fonetische representaties en dat wij hier te maken hebben met fonologische representaties. In een poging om niettemin tegemoet te komen aan de meer intuitieve (of fonetische) bezwaren tegen (7a) is het denkbaar een tot nu toe verzwegen veronderstelling overboord te zetten, de vooronderstelling namelijk dat een intervocalische enkel consonant niet tegelijkertijd deel kan uitmaken van twee opeenvolgende lettergrepen. Wanneer we dat wel toelaten dan kan een enkele consonant de ene lettergreep sluiten (en zodoende 2b honoreren) en de erop volgende openen (zodat ook aan 4b wordt voldaan): | |||||||||||||||||||||||||||||||||||||||||
[pagina 322]
| |||||||||||||||||||||||||||||||||||||||||
De gekozen notatie (een grenssymbool ‘boven’ een consonant’) laat duidelijk zien dat het binnen een lineaire benadering niet mogelijk is om ambisyllabische consonanten te karakteriseren. De gebruikelijke opvatting omtrent de structuur van segmenten laat niet toe dat een grens ‘in’ een segment valt. De representaties in (7a), (7b) (waarin ik kortheidshalve een lineaire benadering koos) worden zonder gebruikmaking van grenssymbolen, niet-lineair gerepresenteerd als in (11):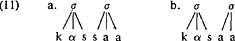 De onverhuld niet-lineaire representatie van (10) vinden we in Kahn (1976) en, toegepast op het Nederlands, in Booij (1979), waar een ambisyllabische consonant als volgt wordt weergegeven: 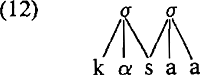 Met de representatie in (12) lijken de intuitieve of fonetische bezwaren, zoals we die konden hebben tegen (10a) en (10b) te verdwijnen. De niet-lineaire weergave van ambisyllabische consonanten heeft echter tot gevolg dat de formulering van FIDE gewijzigd moet worden: 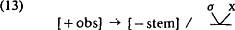 De notatie x/ staat voor ‘niet geassocieerd naar rechts’ en voorkomt dat de regel werkt op syllabe-initiële obstruenten. Hierdoor wordt de ambisyllabische consonant vanzelf uitgesloten. Drie manieren om een woord als kassa te representeren zijn nu besproken (11a, 11b en 12). Alleen wanneer we (11a) kiezen is het onnodig en regels als FIDE te herformuleren en ik concludeer daarom dat de representatie in termen van korte ambisyllabische consonanten ongewenst is. Door ‘ambisyllabische’ consonanten als lang te representeren en vervolgens als kort te interpreteren op fonetisch nivo, voorspellen we nu dat talen geen oppositie kunnen hebben tussen lange consonanten en ambisyllabische consonanten. Het Nederlands is alvast geen tegenvoorbeeld. Interessanter is dat in Vogel (1977:91) wordt beweerd dat genoemde voorspelling in zijn algemeenheid juist is. Dit betekent dat er geen behoefte bestaat aan een aparte entiteit (de ambisyllabische consonant) en zo vormt de afwezigheid van bovengenoemde oppositie een extra argument ten gunste van de beslissing kassa te representeren met een mediale lange consonant. | |||||||||||||||||||||||||||||||||||||||||
[pagina 323]
| |||||||||||||||||||||||||||||||||||||||||
3. CV-fonologieOntwikkelingen binnen de autosegmentele fonologie hebben geleid tot de introduktie van een laag, bestaande uit segmenten weergegeven als ‘C’ en ‘V’ die enerzijds als referentiepunt gelden voor de associatie van kenmerken of kenmerkbundels die de klankaspecten van uitingen representeren en anderzijds als referentiepunt voor de hierarchische organisatie van de uiting. Deze laag wordt veelal aangeduid met de term ‘CV-skeleton’ (cf. Clements en Keyser 1983). De aanwezigheid van het CV-skeleton verschaft ons de mogelijkheid de voordelen van (11a) en (12) te combineren. Het voorstel om zgn. ambisyllabische consonanten te representeren als lange consonanten impliceert voor kassa de representatie in (14):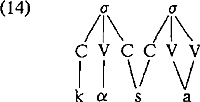 Op het nivo van het skeleton is de intervocalische consonant dubbel, maar toch is er slechts één segment /s/. Door zijn ‘dubbelheid’ kan de intervocalische consonant de eerste lettergreep sluiten en de tweede openen. Door de representatie in termen van één segment /s/ wordt tegemoet gekomen aan de intuitieve en fonetische bezwaren. Als mogelijk nadeel van deze representatiewijze noemen Van der Hulst en Smith (1982), waar voorgesteld wordt zogenaamde ambisyllabische consonanten aldus weer te geven, dat binnen de autosegmentele fonologie ‘multiple association’ automatisch ‘lengte’ aangeeft: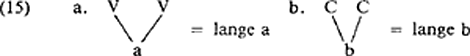 Hier stellen zij tegenover dat het al dan niet ‘lang’ zijn van een dubbelgeassocieerd segment een zaak is van de fonetische interpretatie. Een segment kan zich fonologisch gezien lang gedragen, terwijl het fonetisch gezien kort is. Hoe zit het nu met FIDE? Hoe kunnen we FIDE blokkeren wanneer we aannemen dat (14) correct is? De oplossing voor dit probleem wordt aangereikt in Borowski et al (1983). In deze publicatie wordt eveneens voorgesteld ambisyllabische consonanten te representeren als in (14). De evidentie wordt ontleend aan het Deens. In de analyse figureert een regel die qua SD vergelijkbaar is met FIDE, namelijk Consonant Gradation: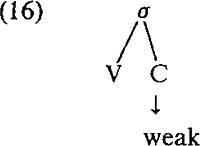 ‘Weak’ houdt in dat lettergreepfinale stemloze obstruenten stemhebbend wor- | |||||||||||||||||||||||||||||||||||||||||
[pagina 324]
| |||||||||||||||||||||||||||||||||||||||||
den en stemhebbende fricatief. Voorkomen moet worden dat deze regel werkt op de ‘linkerhelft’ van een lange obstruent. Borowski et al. doen een beroep op een algemeen principe, aangeduid als de Geminate Constraint:
Borowski et al. wijzen erop dat een principe dat de integriteit van geminaten waarborgt in verschillende vormen is voorgesteld ter verklaring het gedrag van gegemineerde segmenten vis-a-vis fonologische regels. Terecht stellen zij dat de constraint ook van toepassing is op ambisyllabische consonanten als het juist is dat ambisyllabische consonanten structureel identiek zijn aan geminaten. Gegeven (17) wordt voorspeld dat FIDE net als Consonant Gradation niet zal werken op de linkerhelft van een lange obstruent. | |||||||||||||||||||||||||||||||||||||||||
4. Een probleem tot slotTot slot van deze squib wil ik een probleem aan de orde stellen met betrekking tot de distributie van ‘lange’ consonanten. Ik benadruk dat dit probleem neutraal is met betrekking tot het hier voorgestelde. We beginnen met (2a) in herinnering te roepen in de vorm van (17a). Aan de eis dat een lettergreepkern twee posities dient te bevatten wordt voldaan door ofwel een lange vocaal ofwel een korte vocaal-consonant opeenvolging. Nu kunnen lettergrepen in het Nederlands complexer zijn, in de zin dat een vertakkende nucleus nog gevolgd kan worden door één extra consonant (17b):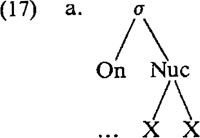 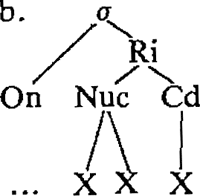 Trommelen (1983) wijst erop dat woordintern lettergrepen met een complexere structuur betrekkelijk ongebruikelijk zijn:
Gegeven het bestaan van woorden waarin wel ‘superzware’ lettergrepen voorkomen in niet-finale positie, kan niet gesproken worden van een echte wetmatigheid. Niettemin lijkt het mij correct te stellen dat (17a) niet alleen een ondergrens stelt aan de omvang van lettergrepen, maar tevens een geprefereerde bovengrens. Uit (18) kunnen we afleiden dat voor een mediale consonantcluster lange vocalen ongebruikelijk zijn indien de eerste consonant van het cluster de voorafgaande lettergreep sluit (zoals dat in 18 het geval is). De mediale clusters in (18) | |||||||||||||||||||||||||||||||||||||||||
[pagina 325]
| |||||||||||||||||||||||||||||||||||||||||
delen de eigenschap dat ze vallen buiten de ‘main template’, waarmee in Van der Hulst (1984) de Nederlandse lettergreepstructuur getypeerd wordt. Ze zijn ofwel volstrekt uitgesloten als syllabe-initiële clusters (dit geldt voor mp, tl en kt) ofwel worden uitgedrukt met behulp van ‘auxiliary templates’ (dit geldt voor sm en st). Dit betekent dat de lettergreepgrens in de clusters valt. De syllabificatieregels creëren geen ‘gemarkeerde’ lettergrepen. Wat blijkt nu het geval te zijn wanneer mediaal meerdere consonanten voorkomen die volgens het ‘main template’ wel in syllable-initiële positie kunnen staan (kortweg obstruent + sonorant)? In zulke gevallen zijn er geen voorbeelden te vinden van een voorafgaande korte vocaal wanneer de desbetreffende lettergreep het hoofdaccent draagt! Dus de woorden in (19a) komen voor, maar niet die van het type in (19b)Ga naar eind3:
Voorbeelden waar een korte vocaal, die niet in de lettergreep met hoofdklemtoon staat, gevolgd wordt door een ongemarkeerde lettergreepinitiele clusters komen overigens wel voor:
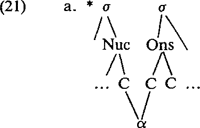 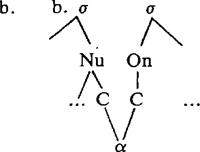 Het is niet direct duidelijk hoe we dit moeten verklaren. Geen van de hier besproken benaderingen van ‘ambisyllabiciteit’ leidt ertoe dat deze configuratie wordt uitgesloten. | |||||||||||||||||||||||||||||||||||||||||
[pagina 326]
| |||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
| ||||||||||||||||||||||||||||||||||||||||