
Spektator. Jaargang 14
(1984-1985)– [tijdschrift] Spektator. Tijdschrift voor Neerlandistiek–
[pagina 101]
| ||||||||||||||||||
Automatisch vertalen in NederlandGa naar eind*
| ||||||||||||||||||
1. Historie1949 is het geboortejaar van het automatische vertalen. Na een enthousiast rondschrijven van Warren Weaver aan 200 Amerikaanse collega's over de mogelijkheden van automatisch vertalen werd een groot aantal onderzoeksgroepen opgericht. Een succesvolle demonstratie van IBM en de onderzoeksgroep van de Georgetown University in 1954 deed de regering besluiten grote sommen geld ter beschikking te stellen aan onderzoek naar het automatisch vertalen. Tien jaar later is het enthousiasme geluwd. Vertaalmachines zijn er nog steeds niet, ondanks de prachtige beloftes uit de jaren vijftig. Twee publikaties, Bar-Hillel (1960) en het ALPAC rapport (1966), smoorden uiteindelijk alle enthousiasme over het onderzoek naar automatisch vertalen. Bar-Hillel wees er op dat volledig automatische vertalingen nooit van hoge kwaliteit kunnen zijn, aangezien bij het vertalen kennis van zaken nodig is en het onmogelijk is om alle wetenswaardigheden in de computer op te slaan. Met een heel eenvoudig voorbeeld wist Bar-Hillel (1960, appendix III) zijn stelling duidelijk te maken. Bekijk:
Het gaat in (1) om de vertaling van het schuingedrukte zinnetje, en dan met name om pen, dat zowel ‘ding om mee te schrijven’ kan betekenen als ‘omheining om peuters in te laten spelen’. In de gegeven context levert de vertaling van pen geen enkel probleem op voor de mens, maar een computer is pas in staat om pen goed te vertalen wanneer die beschikt over kennis van de relatieve grootte van een doos, een schrijfpen en een speelbox. Dit ene voorbeeld kan natuurlijk met talloze andere voorbeelden uitgebreid worden, waaruit blijkt dat een enorme hoeveelheid encyclopedische kennis vereist is, waarvan niet duidelijk is hoe die georganiseerd moet worden. De conclusie van Bar-Hillel was dan ook, dat het streven naar volledig automatische vertalingen van goede kwaliteit gestaakt diende te worden. Als realistische alternatieven noemde Bar-Hillel automatische vertalingen van matige kwaliteit, en samenwerking van mens en machine bij het vertalen, in een ‘machine - post-editor partnership’. Vertalers zouden als post-editors van de machinale vertalingen moeten optreden. Wellicht zou de taak van de post-editors in de toekomst kleiner worden, omdat de kwaliteit van het machinale vertalen steeds zou toenemen. | ||||||||||||||||||
[pagina 102]
| ||||||||||||||||||
De ALPAC commissie (Automatic Language Processing Advisory Committee) werd ingesteld door de US National Academy of Sciences om de resultaten van Amerikaans onderzoek naar automatisch vertalen te beoordelen. Het rapport van de commissie was uitermate negatief: de kosten van het ontwikkelen van vertaalsystemen zouden de baten verre overtreffen, en in aansluiting op wat Bar-Hillel al beweerd had: het is een waanidee dat de machine een vertaling van goede kwaliteit zou kunnen leveren. Bar-Hillel's suggestie om van een machine - post-editor partnership uit te gaan, werd niet overgenomen, waarschijnlijk omdat uit een tussentijdse evaluatie van één van de projekten (het Georgetown projekt) in 1962 al gebleken was dat een vertaler minder tijd nodig had voor het regelrecht vertalen dan voor het corrigeren van de door de machine vertaalde tekst (ALPAC 1966, p. 19). De gevolgen van deze negatieve publikaties waren groot. In de jaren '70 ontplooiden slechts enkele universiteiten werkzaamheden op het gebied van het automatische vertalen (m.n. de universiteiten van Grenoble, Heidelberg, Saarbrücken, Texas, Montreal en Hongkong). Buitenuniversitair werd slechts een handjevol systemen ontwikkeld (o.a. LOGOS, New York; SYSTRAN, La Jolla, Californië; TITUS, Parijs, Düsseldorf, cf. Bruderer (1978), p. 71-155). Belangstelling van academische zijde voor dit soort projekten (of ze nu universitair of buitenuniversitair zijn) was er nauwelijks. Aan het einde van de jaren '70 kwam hierin verandering. In 1978 verscheen Bruderer: een 800 pagina's tellende inventarisatie van vertaalmachines in ontwikkeling en apparaten die voor de vertaler van nut kunnen zijn (automatische woordenboeken e.d.). De publikatie van dit omvangrijke werk kan als signaal van hernieuwde belangstelling beschouwd worden. In 1978 ook werd door een commissie van de EEG een permanente werkgroep opgericht met als doel een vertaalsysteem (Eurotra genaamd) voor de talen van de EEG te ontwikkelen. De belangrijkste reden voor de hernieuwde interesse in vertaalmachines is ongetwijfeld de groeiende behoefte aan vertalingen door de toenemende wereldhandel. Naast correspondentie die vertaald moet worden zijn er ook grote hoeveelheden technische documenten, zoals handleidingen bij apparaten. Een andere reden is wellicht, dat er een aantal bruikbare vertaalmachines kon worden gemaakt: SYSTRAN en TAUM-Meteo onder andere. SYSTRAN, ontwikkeld in een industriële omgeving (LATSEC Inc. en World Translation Center Inc., La Jolla, Californië) kent verschillende versies. De Russisch-Engelse versie werd gebruikt door de NASA bij het Apollo-Sojoez ruimtevaartprojekt. De Engels-Franse versie, in eerste instantie gemaakt met het oog op de Canadese markt, werd in 1975 door de EEG aangeschaft. Later werden ook de Frans-Engelse en de Engels-Italiaanse versies verkocht aan de EEG (Wheeler, 1984). De aankoop van deze systemen betekende overigens niet dat ze ook direkt gebruikt konden worden. Er moesten talloze verbeteringen aangebracht worden, zodat nous avions bijvoorbeeld niet langer vertaald werd in we aeroplanes. Pas sinds 1981, na enkele jaren voortgezette ontwikkeling, is het soms zinvol voor vertalers bij de EEG om SYSTRAN een vertaling te laten maken. Maar helaas, soms is de vertaling zo slecht dat die in z'n geheel weggegooid moet worden. ‘It is learning all the time’ is de optimistische conclusie van Wheeler (1984), die geholpen heeft SYSTRAN te verbeteren. De kans is echter groot dat het systeem het nooit echt zal leren. Een geheel andere ontstaansgeschiedenis heeft TAUM-Meteo doorgemaakt. De TAUM-groep (Traduction Automatic Université Montréal) heeft vanaf onge- | ||||||||||||||||||
[pagina 103]
| ||||||||||||||||||
veer 1970 aan automatisch vertalen gewerkt. Binnen het prototypische vertaalsysteem dat door de groep ontwikkeld is, werd in twee jaar tijd door vier mensen TAUM-Meteo gemaakt, een machine voor het vertalen van weerberichten uit het Engels in het Frans. Dit systeem wordt algemeen als het meest succesvolle vertaalsysteem beschouwd: ruim 80% van de zinnen vertaalt de machine correct. In de overige zinnen zit een probleem waar de machine geen raad mee weet, en die zinnen worden automatisch doorgestuurd naar menselijke vertalers. Het succes van TAUM-Meteo is vooral te danken aan de beperktheid van het onderwerp, en de eenvoud van de zinsbouw bij weerberichten. Er hoeft bijvoorbeeld geen regelsysteem te worden gemaakt voor de subjonctief, de passé defini, en andere tijdsaanduidingen in het Frans, die geen regelrechte parallel kennen in het Engels. Een voorbeeld (cf. Isabelle 1984, app. I):
Op basis van het percentage dat behaald is met TAUM-Meteo, voor een zeer beperkt type tekst, is het irreëel om gespannen verwachtingen te koesteren ten aanzien van vertaalsystemen voor normale teksten. Menselijke vertalers zullen altijd nodig blijven voor correcties en aanvullingen. Vanuit die meer bescheiden verwachtingen kan het ontwerpen van een vertaalmachine zowel in commercieel als in wetenschappelijke opzicht een zinvolle onderneming zijn. Het commerciële belang behoeft geen toelichting; wetenschappelijk zijn vertaalmachines interessant, omdat ze licht zullen werpen op taalverwantschap, en onderzoek naar vorm-betekenisrelaties afdwingen. | ||||||||||||||||||
2. Theoretische achtergrondHelaas, wellicht door het stigma dat het automatische vertalen heeft opgelopen in het prille begin van zijn ontwikkeling, is er weinig theoretisch onderzoek verricht dat als uitgangspunt kan dienen bij het ontwerpen van vertaalsystemen. Er worden vier ‘generaties’ vertaalsystemen onderscheiden. Woord-voorwoord-vertalers, met uitsluitend morfologische analyse, behoren tot de eerste generatie. Zulke vertaalmachines zijn, als het goed is, wel in staat te ontdekken dat het in het huis anders vertaald moet worden dan het in het regent. De tweede generatie vertaalmachines maakt gebruik van een morfologische en syntaktische analyse als tussenstap. Zulke systemen zouden subjecten van objecten kunnen onderscheiden, en dus in staat zijn de politie is ongelukkig te vertalen in the police are unhappy, met de juiste getalsovereenkomst van persoonsvorm en subject. De derde generatie is toegerust met morfologische, syntaktische en semantische analyse. De kwaliteit van deze systemen is beter, zoals geïllustreerd kan worden met de vertaling van de appel die Jan eet. Alleen op grond van semantische kenmerken kan het systeem beslissen dat de vertaling moet zijn the | ||||||||||||||||||
[pagina 104]
| ||||||||||||||||||
apple John eats en niet the appel that eats John. Doordat in dit geval aan de machine bekend is dat appels eetbaar zijn, en niet zelf kunnen eten, of dat aan de machine bekend is dat Jan oneetbaar is, maar wel zelf kan eten, wordt een onlogische vertaling voorkomen. Is de analyse zo grondig dat alle kenmerken van de brontaal verdwenen zijn, dan is het toppunt van analyse bereikt, en spreekt men van een interlinguaal vertaalsysteem: generatie 4. Geen enkele van de nu in gebruik zijnde systemen werkt met een interlingua. Deze 4 soorten vertaalsystemen, samengevat in het volgende schema, vormen de theoretische basis voor vrijwel alle huidige vertaalsystemen (Bruderer 1978, 23):
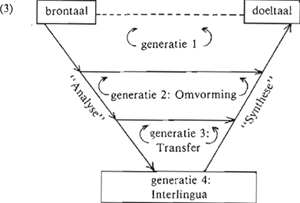 De tussentaal dient in eerste instantie als middel om de kwaliteit van de vertaling te verhogen, evenals de morfologische, syntaktische, en semantische analyse dat doen. Dat daarbij naar diepe semantische representaties gezocht wordt, hoeft geen verwondering te wekken. Bij het vertalen staat niet het relateren van brontaalvormen aan doeltaalvormen centraal, maar het betekenisbehoud bij die omzetting. Het verschil bijvoorbeeld tussen het lidwoord de en het lidwoord het correspondeert niet met enig betekenisverschil. Dat onderscheid kan dan ook gevoeglijk uit de tussentaal worden weggelaten. Het verschil tussen het categoriaal en indefiniet gebruik van het lidwoord een daarentegen, is wel voor de betekenis van belang: de interlingua zou dat verschil moeten kunnen weergeven. Schema (3), een gebruikelijke manier om het vertaalproces weer te geven, suggereert dat de interlingua (IL) aan de volgende eisen zal voldoen:
Niet iedereen beschouwt elk van deze drie karakteristieken als wezenlijk. Andreyev (1967) bijvoorbeeld, hecht de meeste waarde aan (c). Hij stelde voor een vertaalmachine te bouwen voor de 15 meest gebruikte talen, en de tussentaal speciaal voor deze talen samen te stellen, op basis van een isomorfieprobabiliteitsscore. Wanneer het merendeel van de talen een toekomende tijd kent, dan moet de tussentaal ook een toekomende tijd kennen, enz. De tussentaal mag niet te zeer op één van de talen lijken: ‘It is however, impossible to move the IL in the direction of the Russian language, for example, without at | ||||||||||||||||||
[pagina 105]
| ||||||||||||||||||
the same time moving it away from the structure of Chinese, and vice versa. We are, therefore, obliged to seek a middle course, that is, to minimize the average number of incongruences for the translational field of the PL's (paralanguages, de bron- en doeltalen, A.N.) taken as a whole. By appropriately weighing each language of the field, we are able to calculate the properties of the IL for the international system (...)’ (Andreyev, 1967, 25). Kwaliteit van vertaling en haalbaarheid, de punten (4a) en (4b), komen in Andreyevs betoog nauwelijks aan bod. Andreyev lijkt geheel over het hoofd te zien, dat talen oppervlakkige overeenkomsten kunnen hebben, terwijl de betekenis die bij die oppervlaktevormen hoort, per taal verschilt. De door Andreyev genoemde toekomende tijd, bijvoorbeeld, wordt in het Nederlands anders gebruikt dan in het Engels. Hoe een tussentaal met de toekomende tijd daarvoor een oplossing zal bieden is onduidelijk. Ongetwijfeld is onderzoek naar semantische representaties van groot belang voor de toekomst van het automatisch vertalen. Het ideaal van de ‘universele betekenis’ ligt nu echter nog in het zeer verre verschiet, ten eerste omdat universele betekenis een nog vrijwel oningevulde notie is, en ten tweede, omdat die universele betekenis, wanneer die al gevonden zou zijn, automatisch van de vorm van de taal moet kunnen worden afgeleid. Vanzelfsprekend brengt diepe analyse het risico van mislukken met zich mee. Velen menen daarom dat een vertaalsysteem een transfercomponent moet bevatten (Eurotra o.a.), of dat de interlingua voor een beperkt aantal talen moet worden ontworpen, en dat die dus niet noodzakelijk bron- en doeltaalonafhankelijk moet zijn (Rosetta). | ||||||||||||||||||
3. Nederlandse aktiviteitenLiteratuuronderzoek leert, dat vóór 1980 niemand in Nederland het automatisch vertalen tot zijn terrein van onderzoek rekende. Wie zou ook aan automatisch vertalen durven denken, nadat Battus bevolen had dat zo iemand eerst zou zeggen waarom hij Bar-Hillel niet gelooft (Battus 1973, herdrukt in 1983, p. 128). Nog steeds is er niets tegen Bar-Hillels betoog in te brengen, en dus beschouwden taalkundigen automatisch vertalen als een onderwerp waarmee een oprecht wetenschapper zich niet moest inlaten. De inaugurele rede van Sciarone (uitgesproken op 29 oktober 1980), Over automatisch vertalen, kan als pionierswerk binnen Nederland beschouwd worden. In zijn rede plaatst Sciarone het ALPAC-rapport in de context van de jaren '80: ‘De vraag die zich opdringt is in hoeverre de bezwaren van de commissie, nu, 15 jaar later, nog gelden. Voor wat betreft het kostenaspect kan opgemerkt worden dat computergebruik nog slechts een fractie kost van vroeger, terwijl de kosten van menselijke arbeid verveelvoudigd zijn. De kosten nodig voor het ontwikkelen van een automatisch vertaalsysteem zijn vooral kosten ten behoeve van taalkundig onderzoek en het aanwenden van onderzoeksresultaten voor een praktisch doel. Zolang men bereid is taalkundigen te financieren voor het verrichten van algemeen taalkundig onderzoek, is weinig extra geld noodzakelijk. Wel zal in een aantal gevallen dit onderzoek meer gericht moeten worden op een praktisch bruikbaar doel.’ (p. 10). Onderzoek naar automatisch vertalen lijkt in Nederland weer te ‘mogen’, en het onderwerp wint terrein binnen het vakgebied van de computerlinguïstiek (vergelijk de hoeveelheid tekst over machinaal vertalen in de overzichtsartikelen van Landsbergen (1977), een halve pagina, en Van Bakel (1983), vier pagina's). Tussen 1980 en nu zijn er in Neder- | ||||||||||||||||||
[pagina 106]
| ||||||||||||||||||
land drie projekten van de grond gekomen: Eurotra, Rosetta en DLT die hieronder in deze volgorde worden besproken. | ||||||||||||||||||
3.1 EurotraNa een viertal jaren voorbereiding is het Eurotraprojekt van start gegaan in 1982, toen de Europese ministerraad besloot een onderzoeks- en ontwikkelingsprogramma te steunen met als doel ‘the creation of a machine translation system of advanced design (Eurotra) capable of dealing with all the official languages of the Community’ (King en Perschke 1984). Het research projekt moet aan het einde van de jaren '80 een vertaalsysteem opleveren in prototypische vorm, dat verder ontwikkeld kan worden in een industriële omgeving. Het Eurotraprojekt heeft niet alleen tot doel zelf een vertaalsysteem te ontwerpen, maar ook moet het een stimulans vormen voor automatisch vertalen (en computerlinguïstiek) in het algemeen, zodat de landen in de EEG zich op dat gebied zullen ontwikkelen. Daarom is Eurotra decentraal georganiseerd: op dit moment zijn er zeven taalgroepen (in de Nederlands-Belgische taalgroep werken de afdeling Toegepaste Taalkunde van de KU Leuven, de vakgroep Toegepaste Taalkunde van de TH Delft, en het instituut voor Algemene Taalwetenschap van de RU Utrecht samen), alsmede enige internationale groepen die verantwoordelijk zijn voor het creëren van een gemeenschappelijk beschrijvingskader en voor de organisatie en coördinatie van de verschillende groepen. Het Eurotrasysteem moet aan een aantal eisen voldoen: multilingualiteit, uitbreidbaarheid, kwaliteit, het systeem moet verbeterd kunnen worden, en in ‘batch mode’ kunnen werken. We zullen deze kort toelichten. De belangrijkste voorwaarde is dat Eurotra een multilinguaal vertaalsysteem wordt, dat uitbreidbaar is in het geval anderstalige landen zich bij de EEG aansluiten. De EEG kent nu 7 officiële talen, maar het is niet denkbeeldig dat het er in de toekomst 9 zullen zijn. Het grote aantal talen is er de oorzaak van, dat het ondoenlijk is taalpaargewijze vertaalsystemen te ontwikkelen. Voor de zeven talen zou dat inhouden dat er 42 bilinguale systemen gemaakt zouden moeten worden. Het toevoegen van één nieuwe taal aan zo'n systeem betekent het ontwerpen van 14 nieuwe bilinguale systemen. Het andere uiterste, een interlinguaal vertaalsysteem, is eenvoudiger uitbreidbaar: voor elke taal die aan het systeem toegevoegd wordt, zijn twee regelcomponenten nodig: één voor het vertalen vanuit de nieuwe taal naar de interlingua, en één voor de vertaling vanuit de interlingua naar de nieuwe taal. Echter: zo'n interlingua bestaat nog niet, en er wordt zelfs aan getwijfeld of een interlingua theoretisch mogelijk is. Daarom heeft Eurotra gekozen voor de transfer-variant (cf. schema (3)), waarbij de vertaling plaats heeft na morfologische, syntaktische, en semantische analyse. Eurotra heeft dus twee tussentijdse resultaten van het vertaalproces, brontaal- en doeltaalinterface genaamd, vgl.: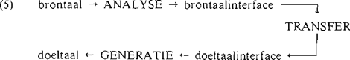 Analyse en generatie (generatie is een ander woord voor synthese) zijn strikt monolinguaal: bij het ontwerpen van deze componenten wordt geen rekening | ||||||||||||||||||
[pagina 107]
| ||||||||||||||||||
gehouden met de doeltalen. Het is, bijv., niet de bedoeling dat degene die de Engelse analyse ontwerpt, regels gaat schrijven om wall te disambigueren voor de twee mogelijke vertalingen in het Nederlands (muur/wand). Monolinguaal wordt wél want (zelfstandig naamwoord) en want (voegwoord) onderscheiden, omdat dat onderscheid doeltaalonafhankelijk is. Zoals uit deze voorbeelden al blijkt, zijn er monolinguale woordenboeken nodig, die disambigueren tijdens analyse en vormvarianten beregelen tijdens generatie, en bilinguale woordenboeken voor de juiste vertaling tijdens transfer. In een situatie zoals geschetst bij (5), is het van groot belang dat de transfercomponent zo klein mogelijk gehouden wordt: er zijn immers ‘slechts’ 7 analyse en 7 generatiecomponenten, terwijl er 42 transfercomponenten zijn (één transfercomponent vanuit en naar iedere taal). Wanneer een bepaald fenomeen dus in de monolinguale componenten kán worden behandeld, dan moet het daar worden behandeld. Het streven is dus wel degelijk naar een zo interlinguaal mogelijke representatie, zeker voor die onderdelen van de grammatika waarvoor zo'n benadering haalbaar lijkt. Als voorbeeld kan de vertaling van de tijden genoemd worden: wanneer het mogelijk is in de analysefase aan de Nederlandse zinnen van (6) een interlinguale tijdswaarde toe te kennen (gesimplificeerd: ‘progressief’, ‘presens’ en ‘futurum’, in deze volgorde), dan kunnen de verschillende Engelse vormen daarbij in de synthesefase worden beregeld, en kan transfer op dit punt ontlast worden.
Wanneer het onmogelijk is, een interlinguale representatie te vinden voor de tijden, dan zullen contextgevoelige transferregels geschreven moeten worden. Ook meer gecompliceerde transferregels zijn overigens nodig, voor strukturele verschillen tussen de talen, cf. Krauwer en Des Tombe (1984). De kwaliteit van de Eurotra-vertalingen moet die van de SYSTRAN-vertalingen overtreffen. Kwaliteit is niet eenvoudig meetbaar. Post-editors verbeteren in SYSTRAN-vertalingen ongeveer 35%, en in menselijke vertalingen ongeveer 10%. Eurotra mikt op een correctiepercentage tussen de 30 en 10%. (Uit zulke foutenpercentages blijkt ook, dat het waarschijnlijk niet verstandig is een willekeurige EEG-taal tot interlingua te verheffen, want de kwaliteit zou dan al gauw beneden het SYSTRAN-peil liggen.) Het Eurotrasysteem moet in de loop der jaren verbeterd kunnen worden, bijvoorbeeld door gebruik te maken van ontwikkelingen binnen de linguïstiek en de informatica. Een uitgebreid netwerk van aparte modules moet daarvoor garant staan. Aan Eurotra is de eis opgelegd dat het systeem in ‘batch mode’ kan werken, d.w.z. zonder interaktie met de gebruiker. Deze eis impliceert, dat de vertaling hoe dan ook geleverd moet worden, ook bij een inputtekst die zelf matig van kwaliteit is, en ook wanneer de inputtekst woorden of constructies bevat die toevallig niet in de vertaalcomputer zijn opgenomen. Om deze reden wordt binnen Eurotra aandacht besteed aan ‘fail-safe’ strategieën, waarmee op slinkse wijze een mislukte vertaling toch nog gered kan worden, bijvoorbeeld door lagere niveaus van representatie via nieuwe transfercomponenten te laten | ||||||||||||||||||
[pagina 108]
| ||||||||||||||||||
kortsluiten, cf.:
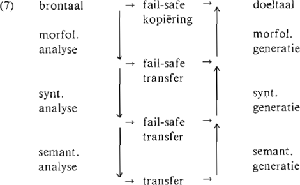 Wanneer de analyse op een bepaald niveau zou stranden, dan wordt er toch een vertaling geproduceerd maar via een lager transferniveau. Is analyse geheel onmogelijk (het woord is onbekend), dan wordt er domweg gecopieerd van bronnaar doeltaal. De nadelen van het ontwerpen van fail-safe strategieën zijn uit (7) direct al afleesbaar: de fail-safe transfercomponenten kosten ontwikkelingstijd (wanneer ze tenminste interessanter werk doen dan domweg kopiëren), en de uitkomst van een klein gedeelte ‘mislukte’ vertaling moet ingepast kunnen worden in de rest van het ‘normale’ vertalen, wat geen eenvoudige zaak is. Hoe Eurotra zich verder zal ontwikkelen is onduidelijk. De organisatorische problemen en de problemen rond de besluitvorming binnen een dergelijk internationaal gezelschap zijn niet onaanzienlijk. ‘Vrijheid in gebondenheid’ is de manier waarop aan verschil in ideeën tegemoet gekomen wordt, cf. ‘The project contains linguists coming from many different backgrounds and with experience with a variety of earlier systems; leaving them freedom to develop their own strategies uses their background to maximum profit, allows freedom for experimentation and permits different languages to be treated differently.’ (King en Perschke 1984). Op internationaal niveau worden afspraken gemaakt die de bilinguale componenten betreffen, met name afspraken over de vorm van de interfacestrukturen. Hoe via analyse van de brontaal zo'n interfacestruktuur berekend wordt, is de verantwoordelijkheid van elke afzonderlijke taalgroep. | ||||||||||||||||||
3.2 RosettaRosetta is ontwikkeld in het Natuurkundig Laboratorium van Philips. Tot 1984 werd er door twee mensen aan gewerkt, nu is dat aantal verdubbeld. Over het systeem zijn twee artikelen geschreven (Landsbergen 1982 en 1984), op welke de hiernavolgende uiteenzetting gebaseerd is. Rosetta is een interlinguaal vertaalsysteem, gebaseerd op de Montague Grammatika, waarmee niet bedoeld wordt dat het systeem een op de intensionele logica geënte interlingua heeft, noch dat het van categoriale grammatika's gebruik maakt. Uit de Montague Grammatika zijn afkomstig het compositionaliteitsprincipe (‘de betekenis van een complex geheel is opgebouwd uit de betekenis van de onderdelen van dat geheel’), en de notie derivatieboom, waarover hieronder meer. Kenmerkend voor Rosetta is het gebruik van isomorfe grammatika's, een noviteit binnen het machinevertalen. De grammatika's van ver- | ||||||||||||||||||
[pagina 109]
| ||||||||||||||||||
schillende talen zijn isomorf wanneer iedere syntaktische regel of basisexpressie in de ene taal qua betekenis correspondeert met minstens één syntaktische regel of basisexpressie in de andere taal. Zinnen vormen elkaars vertaling wanneer ze dezelfde betekeniseenheden hebben en dezelfde derivatie doorlopen hebben (‘a sentence s' is considered as a possible translation of a sentence s, if s' and s have not only the same meaning, but if they also have similar derivational histories, which implies that their meanings are derived in the same way from the same basic meanings.’ (Landsbergen 1984)). Een goede vertaling zou dus tot stand komen wanneer regels met hetzelfde betekeniseffect in de verschillende talen worden toegepast op basisexpressies met dezelfde betekenis. Het volgende voorbeeld kan verduidelijken hoe dit in zijn werk gaat (Landsbergen, 1982). Als het Engelse the Italian girl vertaald moet worden in het Italiaanse la ragazza italiana, dan corresponderen de basisexpressies Italian en italiano (de neutrale vorm), en girl en ragazza met elkaar. Laten we de betekenis B1 en B2 noemen. In beide zinsdelen zijn regels met hetzelfde semantische effect gebruikt: een regel voor de betekenis van Adj-Nomen-combinaties (M1), en een regel voor de betekenis van het definiete lidwoord bij een nominale constituent (M2). Het definiete lidwoord is zelf geen basisexpressie, vandaar de logische derivatieboom (8). 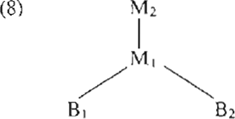 Zo'n representatie fungeert als interlingua in Rosetta. Merk op dat de Engelse regels qua vorm verschillen van de Italiaanse: de volgorde van adjektief en nomen verschilt, en in het Italiaans houden de regels rekening met overeenkomst van getal en geslacht. Voor de interlinguale representatie zijn deze vormverschillen irrelevant. In de Engelse analyse (we werken het voorbeeld verder uit voor de vertaling Engels - Italiaans) wordt de interlinguale representatie via een aantal tussenstappen van de oppervlaktevorm afgeleid; in de Italiaanse generatie wordt de oppervlaktevorm middels gelijksoortige tussenstappen van de interlinguale representatie (8) afgeleid. Figuur (9) op de volgende bladzijde geeft het gehele proces weer in schematische en vereenvoudigde vorm. De taak van de morfologische analysecomponent is onder meer het toekennen van de woordsoorten en het analyseren van de opbouw van complexe woorden met behulp van een stammenwoordenboek. De S-parser maakt van de string woorden een oppervlaktestruktuur. De M-parser zet deze om in een derivatieboom, met de Engelse regels R1 en R2 voor resp. de adjektief-nomen combinatie en het definiete lidwoord. De Engelse betekenis van de basisexpressies wordt weergegeven met b1 en b2. Analyse-transfer zet deze Engelse derivatieboom om in de interlinguale. Generatie-transfer zet de interlinguale derivatieboom om in de Italiaanse derivatieboom, met de Italiaanse regels R1' en R2', en de Italiaanse basisexpressies b1' en b2'. (In dit voorbeeld hebben simpele omzettingsregels in de beide transfercomponenten gewerkt.) M-generator maakt van de Italiaanse derivatieboom een oppervlaktestruktuur; ‘leaves’ is de component waarin alles, behalve de eindknopen gedeleerd wordt, en morfologische generatie maakt daarvan het Italiaanse zinsdeel la ragazza italiana, in de juiste vorm. | ||||||||||||||||||
[pagina 110]
| ||||||||||||||||||
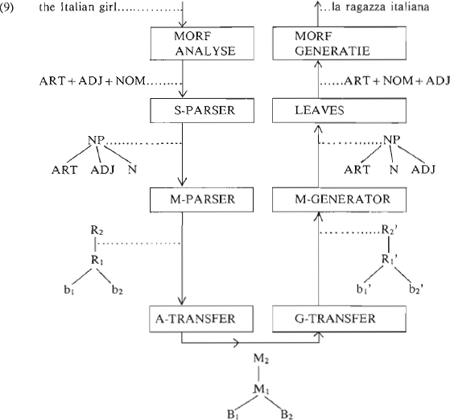 Vertaalbaarheid middels de notie isomorfe grammatika wordt gegarandeerd door zo'n grammatika aan een aantal eisen te laten voldoen. De meest in het oog lopende conditie is die van de omkeerbaarheid: elke regel is omkeerbaar, zodat elke analyseerbare zin gegenereerd kan worden, en dus voor elke analyseerbare zin een vertaling gevonden kan worden, wanneer de grammatika's van de talen isomorf zijn. Analyse en generatie zijn dan ook, zoals uit (9) blijkt, elkaars spiegelbeeld. In Rosetta wordt de interlingua door het ontwikkelen van de isomorfe grammatika's, en dus niet a priori gedefinieerd. Dat impliceert, dat de vertaling vanuit en naar de interlingua mogelijk is wanneer het ontwikkelen van isomorfe grammatika's mogelijk is. Als nadeel kan genoemd worden, dat het schrijven van isomorfe grammatika's een moeilijker taak is dan het schrijven van een grammatika voor één taal. Onmogelijk lijkt dit echter niet, terwijl de omschrijving van een a priori gedefinieerde interlingua misschien onhaalbaar is. Eén van de problemen waarmee de computerlinguïstiek in het algemeen kampt is ambiguïteit. Berucht is het voorbeeld Time flies like an arrow, dat bij automatische analyse veelvoudig ambigu bleek te zijn, terwijl geen mens dat verwacht had. Het basisontwerp van Rosetta is zodanig, dat in geval van ambiguïteit alle mogelijke vertalingen door het systeem worden opgeleverd. Dit is echter slechts één van de mogelijke manieren waarop het systeem gebruikt kan worden. Een andere gebruiksmogelijkheid is de interaktieve, waarbij het systeem | ||||||||||||||||||
[pagina 111]
| ||||||||||||||||||
aan de gebruiker in het geval van ambiguïteiten vragen kan stellen, bijv. over de betekenis van door hem gebruikte woorden. Een derde gebruiksmogelijkheid is die waarbij het systeem zelf tracht te desambigueren, o.a. door het gebruik van een semantisch type-systeem, dat meer en minder waarschijnlijke vertalingen van elkaar onderscheidt. Deze twee gebruiksvarianten zijn in het huidige systeem overigens nog slechts rudimentair ontwikkeld (Landsbergen 1984, § 3). Rosetta is verder ontwikkeld dan Eurotra: al in 1981 bestond een geïmplementeerde versie van Rosetta, terwijl die van Eurotra nog moet verschijnen. Het plan is, Rosetta eerst voor drie talen te ontwikkelen: Engels, Nederlands en Italiaans of Spaans. | ||||||||||||||||||
3.3 Distributed Language Translation (DLT)DTL is ontworpen bij BSO (Buro voor Systeemontwikkeling) te Utrecht. Recent is een 350 pagina's tellend rapport over DLT gepubliceerd (Witkam 1983). De naam ‘Distributed Language Translation’ is afkomstig van het idee de feitelijke vertaling van bron- naar doeltaal te distribueren over de deelnemers aan het communicatieproces. Tijdens het typen van de brontaaltekst op een moderne tekstverwerker die met DLT uitgerust is, wordt een interlinguale representatie gemaakt; die representatie wordt naar een aangesloten DLT-ontvanger gezonden, en aldaar omgezet in de doeltaal. DLT-verzendende en DLT-ontvangende apparatuur beschikt slechts over informatie van één taalpaar: brontaal - interlingua, of interlingua - doeltaal. De ‘offices-of-the-future’ zullen er met DLT dus uitzien als in (10) geschetst. 
| ||||||||||||||||||
[pagina 112]
| ||||||||||||||||||
Uit de opzet, de vertaling deels bij de zender en deels bij de ontvanger te laten geschieden, volgt dat DLT een interlinguaal vertaalsysteem moet worden. De keus is gevallen op een gemodificeerd Esperanto. Omdat tijdens het intypen van de brontekst op een DLT-machine de vertaling van die brontekst in het gemodificeerde Esperanto gemaakt wordt, kan de machine eventuele problemen bij die vertaling voorleggen aan de gebruiker. DLT wordt dan ook een half-automatisch vertaalsysteem genoemd; problemen met dubbelzinnige brontekst bijv. moeten door de gebruiker worden opgelost. Overigens hoeft de gebruiker daarvoor niet een uitgebreide taalkundige scholing te hebben genoten. Bij de zin: Hij zag de man met de verrekijker kan de machine vragen:
Voor het juist beantwoorden van deze vraag is natuurlijk wel enig taalgevoel nodig. Witkam motiveert op verschillende plaatsen in het rapport zijn keuze voor het Esperanto, en weegt die keus af tegen het gebruik van een mathematisch geconstrueerde interlingua. Een voordeel van een natuurlijke taal (en het gemodificeerde Esperanto wordt als zodanig beschouwd) is dat natuurlijke talen meer aan elkaar verwant zijn dan aan enig systeem uit de logica (p. III-2). Bovendien zijn vertaalexperimenten, gebaseerd op zuiver abstracte, ‘logische’ interlingua's weinig succesvol geweest (p. IV-1). Als tweede argument wordt de compactheid van natuurlijke talen genoemd (p. IV-1). Omdat in het DLT-systeem de interlinguale representatie moet worden doorgeseind naar de ontvanger, kan het mogelijk van belang zijn dat de representatie niet al te groot wordt. De meer specifieke keuze voor het Esperanto is begrijpelijk, omdat het Esperanto ontworpen is als ‘ideale combinatie’ van eigenschappen van natuurlijke talen. Van oorsprong staat het Esperanto dus al tussen een aantal talen in. Voordelen zouden zijn dat het Esperanto morfologisch transparanter is, eenvoudiger, en minder ambigu dan gewone natuurlijke talen. Helaas is er geen literatuur beschikbaar waarin het Esperanto taalkundig met een natuurlijke taal wordt vergeleken. Er is wel een proefschrift (Manders 1947) waarin een vijftal kunsttalen met elkaar vergeleken worden. De conclusie van Manders is, dat het Esperanto (voor menselijke communicatie natuurlijk) de beste kunsttaal is, al is de syntaxis van het Esperanto het ‘zwakke punt’ (p. 345). Dat laatste is niet zo verwonderlijk, want het Esperanto is ontworpen aan het einde van de vorige eeuw, in een tijd dus dat taalkundigen slechts belangstelling hadden voor historische taalkunde, fonologie en morfologie. Opmerkelijk is, dat de tussentaal in DLT geen constituentenstruktuur zal zijn. Er wordt wél een constituentenstruktuur gemaakt bij de omzetting van brontaal in tussentaal, maar die constituentenstruktuur wordt weer afgebroken (p. III-48). De tussentaal zelf bevat dus geen abstracte elementen, gelabelde haken e.d., maar is net zo leesbaar als een gewone tekst (p. IV-92). Dat zou van nut zijn bij het oplossen van problemen bij het ontwikkelen en verbeteren van het systeem. Het gevaar is, natuurlijk, dat tijdens de vertaling van tussentaal naar doeltaal een andere constituentenstruktuur wordt gecreëerd, met een andere betekenis. Het DLT-projekt is qua omvang vergelijkbaar met Eurotra. De haalbaar- | ||||||||||||||||||
[pagina 113]
| ||||||||||||||||||
heidsstudie, waarvan Witkam (1983) het verslag is, heeft 4 manjaar gevergd. Als volgende fase is een verkennend onderzoek van ongeveer 15 manjaar gepland, waarbij ook de implementatie van onderdelen van DLT op het programma staan. | ||||||||||||||||||
4. ConclusieNa een lange periode van rust op het gebied van automatisch vertalen, heerst er nu weer bedrijvigheid. Nederland neemt aktief deel aan dit soort onderzoek, met medewerking van Eurotra en twee projekten van eigen bodem: Rosetta en DLT. Schematisch kan het belangrijkste verschil tussen deze projekten als volgt weergegeven worden: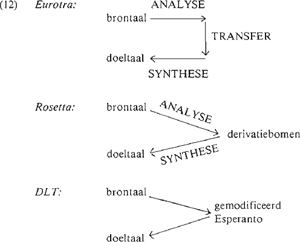 De transfercomponent in Eurotra betekent, dat de vertaalproblemen taalpaargewijs opgelost zullen worden. De vraag is natuurlijk of die oplossing mogelijk is, wanneer eenmaal de analyse- en synthesecomponenten door de verschillende taalgroepen gemaakt zijn. In Rosetta worden analyse en synthese taalpaarsgewijs (of taalgroepsgewijs) ontwikkeld, en daarmee worden de vertaalproblemen opgelost. De vraag is, hoe groot de groep talen kan zijn. In DLT wordt a priori een tussentaal gedefinieerd: het gemodificeerd Esperanto. Die tussentaal lijkt toch nog zoveel op een natuurlijke taal dat er in feite een dubbel vertaalsysteem gemaakt wordt. Of het Esperanto een eenvoudige, onambigue en transparante taal is, doet daarbij niet ter zake. Zulke eigenschappen zullen misschien de analyse en synthese van het Esperanto vereenvoudigen, maar niet de transferfase van brontaal naar Esperanto, noch die van Esperanto naar doeltaal. Alle projekten zijn omvangrijk, en dat kan ook niet anders, want voor het ontwikkelen van een vertaalautomaat moeten grammatika's, monolinguale en bilinguale woordenboeken ontwikkeld worden. Het is dan ook vrijwel onmogelijk dat er op korte termijn volledige vertaalmachines zullen worden opgeleverd. Dat betekent niet dat daarom maar moet worden afgezien van de onderneming. | ||||||||||||||||||
[pagina 114]
| ||||||||||||||||||
Integendeel: onderzoek naar automatisch vertalen dwingt antwoorden af op een aantal vragen. Welke soorten verschillen zijn er tussen talen? Moet de vertaling van historisch verwante talen, zoals het Nederlands en Duits, anders verlopen dan de vertaling van niet verwante talen? Impliceert historische verwantschap eenvoudige vertaling? Welke bestaande taaltheorie of welke onderdelen van bestaande taaltheorieën zijn geschikt voor gebruik bij automatisch vertalen? Welke aspekten van talen zijn principieel onvertaalbaar? Waarom zijn ze onvertaalbaar? Antwoorden op deze vragen kunnen gevonden worden in de praktijk, door het ontwikkelen van vertaalmachines, en in theorie, door de contrastieve bestudering van talen. | ||||||||||||||||||
Bibliografie
|
| |||||||||||||||||