
Queeste. Tijdschrift over middeleeuwse letterkunde in de Nederlanden. Jaargang 2010
(2010)– [tijdschrift] Queeste–
[pagina 1]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[Nummer 1]Velthem et al.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 2]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
continuation, Velthem included a lengthy account of the Battle of the Golden Spurs, which is - as far as we know - the earliest extant and most exhaustive Middle Dutch narrative source on the Courtrai battle. The text has attracted considerable scholarly attention, from the field of philology as well as from social and military history, including a recent translation and re-edition of the text.Ga naar voetnoot5 In this contribution I will argue that contrary to widespread belief, the attribution of the account of the battle of the Golden Spurs to Velthem is not without problems: chances even exist that the original version of the vernacular account should not be attributed to Velthem at all. To re-assess the authorship of the account, I will turn to a stylometric analysis of the rhyme words found in it. This stylistic aspect of Middle Dutch texts has recently been demonstrated to be a valuable aid in medieval authorship verification. First, I will briefly sketch the context of this contribution. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ContextThe context for the present contribution was a recent study into the possibility of discriminating Middle Dutch historiographical authors on the basis of their rhyme words.Ga naar voetnoot6 This study focused on the Spiegel historiael, a popular rhymed adaptation of the Latin chronicle Speculum historiale by Vincent of Beauvais. Around 1280, Jacob of Maerlant - undoubtedly one of the most successful and most prolific authors in Dutch literary history - undertook the initiative for the monumental Spiegel historiael.Ga naar voetnoot7 Maerlant was the architect of the project and anticipated four major text shares or parts (partieën), in which the entire history of the world from Genesis onwards would be related. Following the elegant construction of his Latin source text, Maerlant moreover anticipated that each part would be divided into smaller books (boeken), which in turn would be divided into even smaller chapters (kapittels). When accompanied by a full-scale table of contents, the Spiegel historiael could likewise become a powerful arsenal of vernacular knowledge, readily consultable by subsequent readers.Ga naar voetnoot8 The Spiegel historiael did indeed become a very popular and highly-esteemed text, rapidly spreading over the medieval Low Countries in numerous manuscripts.Ga naar voetnoot9 Maerlant wrote the first, the third and the beginning of the fourth part of the Spiegel historiael. It is generally assumed that he wrote them at the end of his life and that health reasons, possibly even his death, prevented him from finishing the text. The fourth part was continued and finished in the early fourteenth century by Lodewijk van Velthem, a Brabantine priest actively involved in contemporary Middle Dutch literature.Ga naar voetnoot10 In 1315, his text narrates, he finished the fourth part of the Spiegel his- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 3]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
toriael and dedicated it to Mary of Berlaar, a local noblewoman who had requested him to continue the chronicle. In the final passage of this part, he informs us about the anterior history of the work. In the beginning of the first part, Maerlant told us that he had dedicated the Spiegel - or at least his share - to Floris v, count of Holland. Strangely enough, Maerlant seems to have skipped the second part and seems to have started the third part right after finishing the first one. Velthem tells us why: the second part was written by Filip Utenbroeke, who seems to have lived and worked around 1300 near Damme, a suburb of Bruges. According to Velthem, Utenbroeke had already died in 1315. The nature of the relationship between Maerlant and Utenbroeke has fascinated many scholars. Although Utenbroeke's name is mentioned neither by Maerlant nor Utenbroeke himself, they seem to have known each other reasonably well.Ga naar voetnoot11 Both Western Flemish poets would have lived and worked at the end of the thirteenth century, near Damme. It is often believed that Maerlant was a shipping clerk there and some have argued that Utenbroeke, who descended from an important local family, might have succeeded him in that position. Apart from this proximity in time and space, other reasons exist to presume a close relationship between both: in the third part of the Spiegel historiael, Maerlant refers to Utenbroeke's second part three times and thus seems to display considerable knowledge of Utenbroeke's contribution to the Spiegel. Some researchers have even argued that Maerlant would have ‘outsourced’ the second part of the Spiegel historiael to a younger colleague, much like a medieval master-painter would have outsourced specific parts of a pictorial work to one of his younger trainees. It seems likely, then, that few Middle Dutch poets were as close in professional background, dialect and schooling as Maerlant and Utenbroeke. Many Middle Dutch scholars have long believed that medieval poets would have had unique and distinguishable styles. The manner in which Middle Dutch poets styled their texts would be very personal, according to this view, allowing scholars to differentiate between authors on stylistic grounds.Ga naar voetnoot12 Especially the use of rhyme words, as a salient stylistical ‘fingerprint’, would easily lend itself to stylometric analysis for the purpose of authorial discrimination.Ga naar voetnoot13 The often-heard claim that style and more specifically rhyme vocabulary would contain robust indications of authorship is an interesting hypothesis but one that until recently was never empirically tested. Because there is much discussion concerning the authorship of many Middle Dutch texts, the verification of this hypothesis is highly desirable. In the field of computational philology (part of Humanities computing or Digital humanities) there is currently a great deal of interest in computer-aided stylistic research into authorial identity. The many insights from this particular research area are increasingly being used in Middle Dutch studies.Ga naar voetnoot14 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 4]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
I have recently investigated the applicability of the ‘authorship-rhyme theory’ to those parts of the Spiegel historiael that are traditionally attributed to Maerlant and Utenbroeke.Ga naar voetnoot15 My starting point was some of the recent achievements from computational philology, many of which go back to a methodology borrowed from Computational Linguistics (see below). I investigated whether a relatively simple computational model or ‘profile’ could be extracted from the rhyme words in these texts, allowing us to differentiate between authors or ‘recognize’ them, so to speak. The pair Maerlant-Utenbroeke provided an ideal test case: computational researchers in the field of authorship attribution continually stress that it is important to limit oneself to attribution cases in which author, topic, language, genre, etc. are kept as stable as possible.Ga naar voetnoot16 If it proves possible to extract a meaningful stylistical difference between the oeuvres of two authors, one has to make sure that these differences are only related to authorial differences and not to other misleading, contextual factors such as genre. As illustrated above, an experimental set-up with Maerlant and Utenbroeke seemed to offer an excellent test case to verify the claim whether Middle Dutch poets can indeed be distinguished on the basis of their rhyme words. From this investigation, it became clear that even with a simple technique it was indeed possible to distinguish between Utenbroeke (second part) and Maerlant (third part) on the basis of rhyme words, provided enough example data was available per author. After finishing this research, the question emerged whether the positive results from these experiments could be extrapolated to other cases and moreover, if the attribution algorithm would continue to perform relatively accurately if more than two authors were considered in an attribution experiment. Therefore, I decided to include another author in the comparison; given the history of the Spiegel historiael the most evident candidate for this was Velthem. As mentioned, this author continued the Spiegel historiael and concluded the fourth and unfinished part of the chronicle. Moreover, Velthem added an extra, final fifth part to the Spiegel in which he described the most recent historical developments (especially in the Low Countries) up to his own days. Because Velthem's share in the fourth part has survived only in fragments, I chose to include Velthem's fifth part and compare it with Utenbroeke's second and Maerlant's third part. The original experiments were repeated under the exact same conditions, only this time with three authors instead of two. The first results showed that Velthem's inclusion was not problematic at all: Velthem seemed to have used quite a recognizable style and could readily be distinguished from Maerlant and Utenbroeke. At first, the inclusion of a third author therefore seemed to improve on the attribution results. However, this was not true for the fourth book of the fifth part of the Spiegel historiael. Quite the contrary, this book rapidly seemed to be problematic in our experiments, since the attribution algorithm would never attribute either the whole book or samples from it to the ‘correct’ author, namely Velthem. The attribution algorithm always preferred to attribute the majority of samples from this book to Maerlant or Utenbroeke. It did not come as a surprise | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 5]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
that smaller and thus less representative samples of this work were apparently misattributed. However, the fact that a whole book was invariably ‘misattributed’, seemed a far more troubling issue. Why did Velthem's fourth book, containing the famous account of the Battle of the Golden Spurs, behave so differently from the rest of his work? Was this fourth book actually written by Velthem?, was the question that emerged clearly and is the provocation for the present contribution. Concerning the fifth part of the Spiegel historiael, there is one lucky coincidence. It is already known that Velthem did not write all of this fifth part. In the first three books of the fifth part, Velthem interpolated many, sometimes only slightly reworked passages from an existing historiographical text in rhyming couplets: the Battle of Worringen. This extensive poem dealt with the eponymous battle in 1288, between two main protagonists, John I, the duke of Brabant and the archbishop of Cologne. The poem was written by John of Heelu, a Brabantine poet who was probably working for the ducal court between 1288 and 1290.Ga naar voetnoot17 Velthem borrowed substantial portions of text from Heelu's poem. However, this is something that scholars have had to work out for themselves, since Velthem never explicitly mentions his borrowings from this text or author. At the end of his fifth part, Velthem does mention that he has called upon various reports by eyewitnesses throughout his continuation; possibly, he implicitly considered Heelu's report to be one of these.Ga naar voetnoot18 That we know Heelu's work so well, comes from the fact that his Battle of Worringen has survived independently from Velthem as well. Because of this independent manuscript tradition, it is possible to demarcate and study Velthem's ‘plagiarisms’ - if the tern is not too anachronistic - in great detail.Ga naar voetnoot19 Velthem seems to have interpolated Heelu's text in three parts: (a) book 1, vs. 2824-3543 = chapters 40 to 46, (b) book 2, vs. 3220-4032 = chapters 44 to 55, (c) book 3, vs. 71-1388 = chapters 2 to 21.Ga naar voetnoot20 What is vital for the present contribution, is that these textual regions offer valuable comparative material for the style and authorship of the fifth part of the Spiegel historiael. One would expect that these textual regions in which the author is demonstrably drawing heavily from another author will be characterized by a significant ‘contamination’ of Velthem's ‘stylome’, a term sometimes used to denote an author's personal writing style.Ga naar voetnoot21 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
DataMedieval texts such as the Spiegel historiael are often not extant in autographs and often only survive in much younger copies (of copies) of the original exemplar. The texts on which we are forced to work, as such seem to be at the end of a long and complex copying chain with subsequent scribes introducing all kinds of variations in the texts. It is commonly known that medieval scribes often altered texts when co- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 6]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
pying them, by adjusting dialect and spelling to their own liking or even changing certain words and wordings to accommodate the text to their own or their patron's stylistic preferences.Ga naar voetnoot22 Recent research has stressed that this situation seriously challenges the practice of medieval authorship attribution, since there is a real danger that the stylome of the original author of a text has dramatically faded in later copies and suffered severe scribal interventions.Ga naar voetnoot23 Concerning our stylometric research into the authorship of the Spiegel historiael, we would like to ensure, however, that the stylistic aspects on which we work are related only to the original authors and not to later scribes of the texts. This is one of the reasons why in the remainder of this article, we shall continue to work with rhyme words. Apart from the traditional opinion that rhyme words seem to be a reliable indicator of authorial style, rhyme words are also considered a rather stable factor in the handwritten transmission of medieval texts. This category of words, the skeleton of the epic text, is extremely resistant to scribal change, because copyists generally refrained from altering rhyme words. A scribe could easily intervene in the words inside the verse line but regarding words in rhyme position, scribes were largely ‘stuck’ with their exemplar. If a scribe was to alter a word in rhyming position, the scribe would also have to re-work a substantial share of the rest of their exemplar text, for example because of syntactic shifts that would thus be introduced in the course of the text. It seems that scribes for this reason generally refrained from re-rhyming their exemplar, with the result that words in rhyme position often seem to be ‘intact’, reflecting authorial rather than scribal style. In this study, we will work with highly frequent rhyme words in the works of Velthem. Research has shown that especially highly frequent words are attractive for stylometric research into authorship attribution.Ga naar voetnoot24 These items are well-spread throughout an oeuvre and a language and seem rather reliable variables from a quantitative point of view. Highly frequent rhyme words are often considered ‘stopgaps’ in stylistic research: they are similar to mnemonics, being semantically vague rhyme words that poets of longer epic texts used as helpful aids in the cumbersome process of rhyming their long epic texts. The data used in this study are the rhyme words from the second part (Utenbroeke), the third part (Maerlant) and the fourth and fifth part (Velthem) of the Spiegel historiael. Regarding the second and third part, our data set is identical to the one used in our previous study, the sole difference being that we restrict our analysis to the first 103 chapters for these authors.Ga naar voetnoot25 This limitation is a result of the fragmentary survival of the fourth part, of which only fractions, scattered over numerous manuscripts, survive. If we collect what is left of the fourth part - most chapters can be digitally harvested from the Cd-rom Middelnederlands - we end up with a data set containing 103 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 7]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
more or less complete chapters.Ga naar voetnoot26 In an appendix, we provide a legend to justify our data's origin. After the publication of this article, the entire data set will be made available for download from a website in the public domain.Ga naar voetnoot27 In order not to favour or disfavour any of the authors under scrutiny, each of their share in the dataset is therefore artificially limited to 103 chapters. Concerning the fifth part - almost completely extant in the codex Leyden, University Library, bpl E14 - we will work with the complete digital standard edition from the text, as it can be harvested from the Cd-rom Middelnederlands. The rhyme words contained in the chapters of this data set have been linguistically enriched with lemmas, meaning that every token in rhyme position has been assigned a uniform label indicating its normalized form.Ga naar voetnoot28 This normalized form is similar to a dictionary headword, spelled according to present-day Dutch spelling rules. Our measurements below are restricted to counts performed on these lemmas, so that we can abstract from superficial textual variation (for instance in spelling and spacing but also inflection). In a number of cases, tokens were not assigned a traditional lemma: proper nouns, numerals and foreign words were not assigned a true lemma label but rather a vague part-of-speech tag (respectively PrName, Numb and Foreign). These words are often very content-specific and can be expected to reveal much more about a text's topic than the style of its author. To prevent the rather specific content of these words from disturbing our experiments - which after all focus on authorial style rather than topic detection - we assigned these words a more generic label and thus ‘bleached’ their content. Below, we listed a ranking of Velthem's thirty most frequent rhyme words (after lemmatization, as counted in the fourth part) and their (generic) English translation. These semantically vague and largely context-independent ‘stopgaps’ will be the basis for our experiments. The thirty top frequent items are often used in stylometric authorship studies and generally seem to yield acceptable results.Ga naar voetnoot29 1 ‘PrName’, 2 ‘zijn’ (to be), 3 ‘mede’ (also), 4 ‘stad’ (place, city), 5 ‘doen’ (to do), 6 ‘zaan’ (swiftly), 7 ‘gereed’ (readily), 8 ‘dat’ (that), 9 ‘daar’ (there), 10 ‘verstaan’ (understand), 11 ‘daarnaar’ (thereafter, thereat), 12 ‘godweet’ (God knows), 13 ‘groot’ (large), 14 ‘gaan’ (to go), 15 ‘ding’ (thing), 16 ‘voorwaar’ (for sure), 17 ‘komen’ (to come), 18 ‘man’ (man), 19 ‘waan’ (delusion), 20 ‘heer’ (lord), 21 ‘nu’ (now), 22 ‘niet’ (not), 23 ‘gij’ (you), 24 ‘gene’ (part of demonstrative pronouns), 25 ‘met’ (with), 26 ‘stond’ (time, hour), 27 ‘al’ (all), 28 ‘deze’ (these), 29 ‘dood’ (death, dead), 30 ‘dan’ (then) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 8]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
MethodologyThe methodology we will adopt below is ‘text classification’, a dominant approach in computational stylometric research into authorship attribution.Ga naar voetnoot30 In text classification for authorship attribution, the author is considered a class label that needs to be assigned to a given portion of text or ‘sample’. Below, such a sample will consist of a variable number of chapters in the Spiegel historiael. The class labels that will be assigned to these samples will naturally be ‘Maerlant’, ‘Utenbroeke’ or ‘Velthem’. The assignment of such class labels is done by a ‘classifier’, a program borrowed from the field of Machine Learning that is ‘trained’ to label or classify similar samples of text. This is comparable to so-called ‘spam filters’ or software services in, for example, email-clients that will decide whether incoming emails should be labelled spam or not. The concept of ‘training’ refers to the fact that a classifier cannot build up real-world knowledge from scratch. Before the actual labelling in the classification phase, the classifier gets trained during the training phase. In the training phase, the classifier is presented with a number of previously labelled example samples (the training data). On the basis of this data, the classifier can ‘learn’ which type of sample (e.g. chapters) are linked to which class (e.g. the author). Once the algorithm is trained, it is possible to evaluate the performance of the classifier.Ga naar voetnoot31 For evaluation purposes, scholars in Machine Learning often turn to simulations or ‘scenarios’, in which a classifier is asked to label a sample that it has not seen until then. Of course, the machine doesn't know which label should be assigned to this new, unknown sample, but we do. Through this simulation, one can check whether the classifier assigns the unknown test sample to the right class. A popular simulation scenario is leave one out validation. Consider, for instance, a data set containing 30 novels; 15 written by author A and 15 by author B. During leave one out validation, we will train the classifier 30 times on 29 novels. Each time another novel is put aside as a test exemplar. After training, the classifier is asked to label or classify the test exemplar - the one novel which the classifier did not see during training. After thirty rounds or ‘folds’, one should now have a quite accurate view of the performance of the classifier. If the classifier made mostly correct predictions (e.g. 29 out of 30) or rather mostly false predictions (6 out of 30), we have an empirically founded estimation of how well the classifier will perform in the future, should it be asked to label similar unknown samples, also in cases in which even the researcher is not sure of the correct class of the samples. The most important difficulty is of course the internal workings of the classifier. To prevent the situation in which a classifier is used or considered as a ‘black box’, we shall work with a rather intuitive classification method: memory-based learning.Ga naar voetnoot32 In memory-based learning, the training phase is exceptionally simple: the classifier will | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 9]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
simply store the training samples in its memory, without any far-reaching interventions in the data. The power of memory-based learning is associated with the actual classification phase: when the classifier is presented with a new, unlabelled sample, it will search through its memory for the unknown sample's ‘nearest neighbour’ or that labelled sample which is most similar to the unlabelled sample currently under scrutiny.Ga naar voetnoot33 Subsequently, the classifier will extrapolate the class label of the labelled sample to the unlabelled sample and assign the test exemplar the same class as its nearest neighbour. This is why we need a metric that is able to determine the ‘distance’ between samples, since a sample's nearest neighbour is of course the sample in memory at a minimal distance.Ga naar voetnoot34 The implementation of a distance metric is strongly related to the way in which samples are represented in the machine's memory. Below, we shall represent samples in terms of the relative frequency of the rhyme words in them. In our case, we will work with floating-point numbers, representing the relative frequency of rhyme words in a sample, a usually small number between 0 and 1. One simple way in which a memory-based algorithm could work, is as follows. If two samples are compared, the algorithm will go through the list of rhyme words and calculate the absolute difference between the frequencies for each rhyme. Subsequently, this difference in frequency between samples per rhyme word, can be scaled between the extreme (maximal and minimal) values for that specific rhyme in all samples in memory. Finally, the resulting differences are simply summed.Ga naar voetnoot35 The resulting value approximates the distance between two samples: it will be large in the case of two highly dissimilar samples and small in the case of highly similar samples. Below is a naive visualization of nearest neighbour classification. Central in the picture is the new, unlabelled test sample. The classifier will assign this sample the same class as its nearest neighbour, or the instance in memory at a minimal distance from the new sample. In this two-dimensional, somewhat naive visualization, the nearest neighbour of the unknown sample belongs to the class V (for instance, ‘Velthem’), at the minimal distance δ1. The first item of the other class ‘X’ is at a far larger distance δ2 from the test sample and will definitely not be considered a nearest neighbour of the unlabelled instance. This particular sample will thus be labelled as belonging to the V-class. 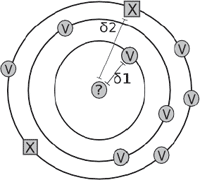 Figure 1 Naive two-dimensional visualization of an example of nearest neighbour classification. The unlabelled test instance (central, marked with a question mark) will be classified as belonging to the class V, because its nearest neighbour belongs to that class. The nearest neighbour (class V) is at the minimal distance δ1 from the test instance; the nearest instance of the class X is at the far larger distance of δ2.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 10]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Below is a tabular representation of how training samples are stored in memory. This representation is based on the relative frequencies of five frequent rhyme words. The case study presented in this table are the complete books of the second (Utenbroeke) and third (Maerlant) part of the Spiegel historiael. These books are each represented according to the relative frequencies of five highly frequent rhyme words in them.Ga naar voetnoot36 From this table, we can read which sample would be the nearest neighbour for each sample during leave one out validation and what the exact distance would be between these two samples, according to the simple distance metric described above. Notice that even with such a simple distance metric, only one book would be misattributed. In our experiments we shall adopt a slightly more complex distance metric (explained in the appendix), but this example should illustrate how one can implement a concrete distance metric.
Table 1 Illustration of nearest neighbour classification applied to the actual books of the second (Utenbroeke) and third (Maerlant) part of the Spiegel historiael. On the basis of the difference in frequencies between the five rhyme words considered in this table and the extreme (minimal and maximal) values for each rhyme word in the training data, one can calculate the distance between samples. For each sample, this table indicates which other sample in memory would be its nearest neighbour during leave one out validation. Even with this simple distance metric, only one book (part 2, book 7) is misattributed (to Maerlant instead of Utenbroeke). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Experimental set up: double deltaFor the present stylometric investigations into the authorship in the fifth part of the Spiegel historiael we will use a slightly more complex, powerful variant of the simple classification technique described above. The details of these modifications are dis- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 11]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
cussed in the appendix. In our experiments we will contrast Velthem's work with the work of another control author, Maerlant or Utenbroeke. Although our analysis would definitely benefit from including more control authors in our training data, this is currently not possible because enriched medieval corpora that are similar to the Spiegel historiael are rare and time-consuming to produce. Our main starting point in the experiments will be the samples in our data set, representing Velthem's fourth part and the parts by the control authors. In a first phase, we perform a leave one out experiment with the 103 chapters from the fourth part and contrast them with an equal number of chapters from the second or third part. This first step is important to assess the performance of our classifier: if the classifier is adept at distinguishing Velthem from the control authors in these experiments, we can expect the same classifier to yield trustworthy results when analyzing the style and authorship of the fifth part. An important factor in assessing performance is of course accuracy: the average number of samples that were attributed to the correct author during leave one out simulation. The higher the accuracy, the more robust our classifier. Nevertheless, there are also other interesting measures that can be derived from these results, such as, for instance, the average distance between Velthem's test samples and their nearest neighbours in classification. This is why, during the leave one out experiments, we keep track of the following values for each Velthem sample: (a) the distance between the Velthem sample and the nearest other Velthem sample and (b) the distance between the Velthem sample and the nearest non-Velthem sample. Our expectation is of course that the average distance between Velthem samples and other Velthem samples will be smaller than between the Velthem samples and the samples attributed to the control authors. In a second phase, we apply the trained (and ‘tested’) classifier to the fifth part. First, we divide the fifth part into equal-sized samples, each of them representing a number of consecutive chapters throughout the fifth part (see below). The sampling procedure applied to the chapters from the fifth is thus equal to the sampling procedure for the training samples from the second, third and fourth part. Subsequently; we ‘window’ through the fifth part and present all samples to the classifier. For each sample, we have the classifier return the distances between the sample from the fifth part and (a) the nearest Velthem sample from the fourth part and (b) the nearest sample from the control author in the experiment. Therefore, we consistently work with two classes in these experiments: ‘Velthem’ or ‘not Velthem’. It is of course interesting to see to which of these classes the classifier attributes the samples from the fifth part. However, it is regrettable that such a binary outcome reveals little more about the classifier's confidence for a given attribution. To deepen our insight in the classifier's confidence for each attribution we therefore propose an ad hoc stylometric measure, which we will call ‘double delta’ - because this metric is in many ways reminiscent of the Delta procedure introduced by J. Burrows.Ga naar voetnoot37 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 12]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
As is clear from Figure 1, there are always two competing classes when classifying a test sample in our experiments: ‘Velthem’ and ‘not Velthem’. Choosing between these classes comes down to a comparison of two values: δ1 or the distance to the nearest Velthem sample and δ2 or the distance to the nearest control author sample. Whichever distance is smaller wins. Whatever may be the outcome of the attribution, the relative difference between δ1 and δ2 is of the utmost importance. If the nearest Velthem sample is much closer to the unlabelled sample than the nearest sample in memory attributed to the control author, the classifier's confidence in attributing the sample to Velthem would be relatively high - and vice versa. To capture this nuance, we propose ‘double delta’ (δδ), a value that we consistently equate with (δ1/δ2)-1.Ga naar voetnoot38 For some samples, δδ can take on a positive value: in that case the distance from a particular test sample to the nearest training sample attributed to the control author, is smaller than the distance to the nearest Velthem chapter. The test chapter, therefore, would be attributed to the control author and the higher the δδ value in this case, the more confident this attribution would be. If δδ takes on a negative value for a particular sample, things would be the other way round: in that case, a Velthem chapter would be a ‘nearer neighbour’ than any of the samples attributed to the control author. The lower the value of δδ, the more confident the classifier is in attributing the test sample to Velthem. As such, ‘double delta’ is a confidence measure that looks at the ‘difference in differences’ between the competing samples in the test sample's immediate neighbourhood.Ga naar voetnoot39 Readers should take some time to convince themselves of the effect of the δδ value; a visualization of its properties is offered in the illustrations below. 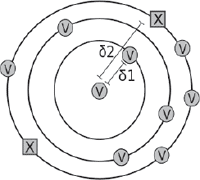 Figure 2a δ1 << δ2; δδ >> 0 (test sample attributed to Velthem with relatively high confidence)
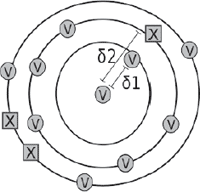 Figure 2b δ1 < δ2; δδ > 0 (test sample attributed to Velthem but with modest confidence)
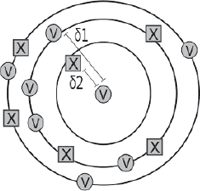 Figure 2c δ1 > δ2; δδ < 0 (test sample attributed to control author with modest confidence)
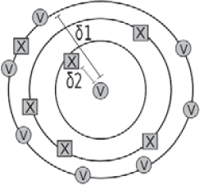 Figure 2d δ1 >> δ2; δδ 0 (test sample attributed to control author with relatively high confidence)
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 13]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Experimental results on the reference corporaWe have experimented with different settings in our classification task. The main parameter of concern was the size of the samples used. From previous research, it is known that it is more difficult to extract reliable style markers from smaller, less representative samples of an author's oeuvre. One would therefore be inclined to use larger samples. On the other hand, we are necessarily working with a limited set of example data per author and using larger samples will inevitably lead to having fewer samples per author in the data set. Adopting too large a sample size, might therefore not be advisable either. Below is a visualization of the results in leave one out validation for different sample sizes, both in the reference corpus with Utenbroeke and Velthem, as well as the reference corpus with Maerlant and Velthem. The graphs show the classification results (attribution accuracy) for different sample sizes.Ga naar voetnoot40 Note that using a larger sample size leads to having fewer chapters available.Ga naar voetnoot41 From this graph, it is clear that our classification technique seems to be able to successfully distinguish between the two pairs of authors, starting from samples that contain 12 chapters or more (cf. the dotted vertical line in the figure above). Using smaller sample sizes generally seems to lead to less robust or less stable classification results in leave one out validation. Note that it seems slightly more difficult to distinguish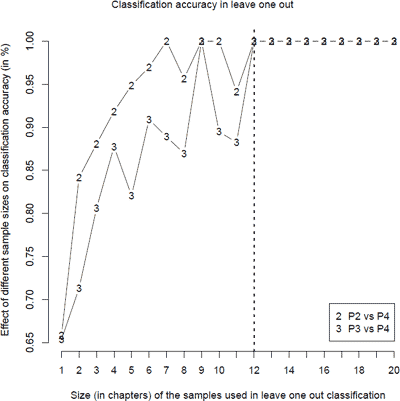 Figure 3 Graph visualizing the results (attribution accuracy) after leave one out validation for the reference corpus with Velthem and Utenbroeke (P2 vs. P4) and the reference corpus with Velthem and Maerlant (P3 vs. P4). The features used are Velthem's thirty most frequent rhyme words. The results are displayed for increasing sample sizes: starting from samples representing 12 consecutive chapters, it is possible to distinguish between Velthem and the two control authors in the training corpora (100% correct attributions).
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 14]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Maerlant from Velthem than Utenbroeke from Velthem. This observation is consistent with the claim that Maerlant seems to have had a profound stylistic and linguistic influence - especially regarding rhyme words - on his epigone Velthem.Ga naar voetnoot42 Also note that, although we use a more complex learning technique, it seems easier to distinguish Velthem from Utenbroeke and Maerlant than Utenbroeke from Maerlant.Ga naar voetnoot43 This is of course largely due to Velthem's rather recognizable style, which has been characterized in the past as extremely rich in ‘stopgaps’.Ga naar voetnoot44 This explains why it is relatively easier to distinguish Velthem from his colleagues when inspecting the frequency of Velthem's thirty top frequent rhyme words, which are of course all stopgaps. Apart from inspecting plain accuracy, we have also looked at the double delta value for the Velthem samples in these experiments. In the graphs below, we have plotted for each of the sample sizes we have inspected what the effect was on the δδ values for the Velthem chapters during the same leave one out experiments. In each graph (Velthem versus Utenbroeke and Velthem versus Maerlant) we have plotted the mean δδ value in the experiments for each sample size, as well as the standard variation of the δδ value, by the addition and subtraction of the standard variation for each mean value. 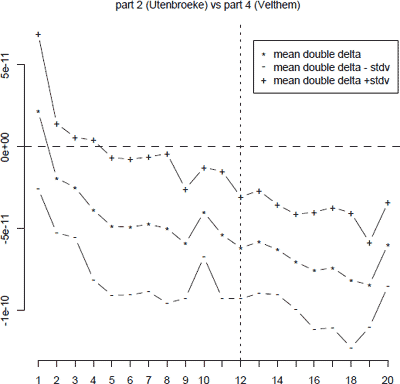 Figure 4 Graph visualizing the effect of using increasing sample sizes during leave one out validation on the training corpus in which Velthem's fourth part is contrasted with Utenbroeke's second part. Using a sample of 12 chapters leads to an acceptably negative mean double delta score, indicating a safe margin between Velthem's samples and the control author's samples in the training corpus.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 15]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
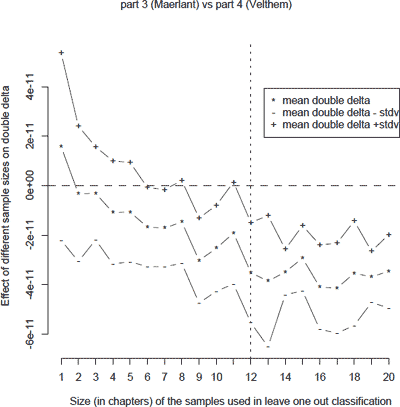 Figure 5 Graph visualizing the effect of using increasing sample sizes during leave one out validation on the training corpus in which Velthem's fourth part is contrasted with Maerlant's third part. As in figure 4, using a sample of 12 chapters leads to an acceptably ‘negative’ mean double delta score, indicating a safe margin between Velthem's samples and the control author's samples in the training corpus.
In these graphs we have also indicated the value of zero (horizontal dashed lines). As explained above, this is an important value, since a negative δδ value for a Velthem sample indicates that the classifier will indeed attribute the sample to Velthem. Regarding the robustness of our classifier, we therefore want to minimize the δδ values for the Velthem chapters: a larger margin between zero and the mean δδ value indicates that the attributions were more confident and robust. Again, we see that a sample size of 12 chapters (vertical dotted lines) seems to yield a relatively robust outcome. The general trend in those graphs is again that it is slightly more difficult to distinguish Maerlant from Velthem than Utenbroeke from Velthem, which is consistent with the accuracy figures discussed in the previous paragraphs. In the rest of our contribution, we shall therefore restrict ourselves to an analysis of the fifth part in which we limit ourselves to samples containing 12 chapters. This sample size seems to yield acceptable results during the leave one out validation on the control corpora and seems to constitute an optimal trade-off between classification accuracy (the efficiency of the classifier), granularity (larger samples will result in a less clear or fine-grained image of the texts analyzed) and the margin between zero and the mean δδ values (the overall confidence in classification). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Experimental results on the fifth part: a ‘palimpsest’?The two graphs above represent our stylometric analysis, applied on the fifth part of the Spiegel historiael. We divided this fifth part into consecutive samples, each consisting of 12 chapters. Each of these samples was presented to a classifier, trained on a | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 16]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
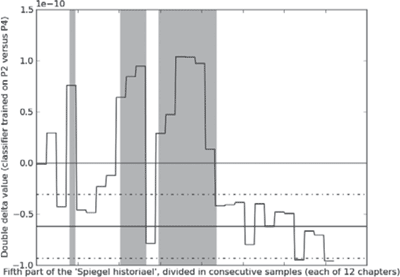 Figure 6 Graph visualizing the first experimental outcome of the stylometric analysis of the fifth part. The fifth part is divided in samples of 12 consecutive samples and these samples are presented to the classifier trained on the reference corpus with 12 chapter samples of Velthem's fourth part and Utenbroeke's second part. The graph indicates the double delta values returned by the classifier for each of the samples from the fifth part. The more negative these values, the more confident the classifier is in attributing a particular sample to Velthem (and vice versa). The upper horizontal line indicates ‘zero confidence’. The lower horizontal lines indicate the mean of double delta values during leave one out validation on the training corpus (cf. Figure 4), with the addition and subtraction of the standard deviation (dotted lines). The two first grey zones indicate Velthem's interpolations of Heelu's text; the final grey zone indicates the fourth book with the account of the Battle of the Golden Spurs.
reference corpus containing samples of the exact same size (12 chapters). We applied two classifiers: one trained on the reference corpus with Utenbroeke's second part as a control author and one with Maerlant's third part. From our previous leave one out experiments on these corpora, we know that our classifier was rather successful during leave one out validation on this corpora: it yielded correct attributions as well as confident attributions for this sample size, with ample margins between 0 and the mean δδ for the Velthem chapters in these reference corpora. For each of the samples from the fifth part which we fed to the classifier, we registered the δδ value the classifier returned for this sample. These values are visualized in the graphs above, together with - as a point of reference - the mean δδ values (with the standard deviation added and subtracted) we observed for this classifier and settings during the leave one out experiments on the reference corpora. Note that our two graphs contain three textual regions (marked in grey) that are of particular relevance. The first grey region is the first time Velthem interpolates a portion from Heelu's Battle of Worringen.Ga naar voetnoot45 The second grey area marks Velthems second and third interpolations from this text.Ga naar voetnoot46 The | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 17]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
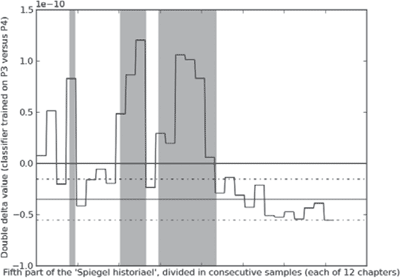 Figure 7 Graph visualizing the second experimental outcome of the stylometric analysis of the fifth part. The fifth part is divided in samples of 12 consecutive samples and these samples are presented to the classifier trained on the reference corpus with 12 chapter samples of Velthem's fourth part and Maerlant's third part. The graph indicates the double delta values returned by the classifier for each of the samples from the fifth part. The more negative these values, the more confident the classifier is in attributing a particular sample to Velthem (and vice versa). The upper horizontal line indicates ‘zero confidence’. The lower horizontal lines indicate the mean of double delta values during leave one out validation on the training corpus (cf. Figure 5), with the addition and subtraction of the standard deviation (dotted lines). The two first ‘grey zones’ indicate Velthem's interpolations of Heelu's text; the final grey zone indicates the fourth book with the account of the Battle of the Golden Spurs.
third grey zone coincides with the fourth book of the fifth of the Spiegel historiael, being the main focus of this contribution. The most striking aspect of these figures is that both show subtle differences but seem to agree on the general trends in the data - they ‘share their curves’. Consider the first two grey regions in the text: the areas in the fifth part where we know that Velthem heavily draws from an existing text written by another author. Here the values of double delta are strongly positive, indicating that both classifiers are quite confident in rejecting Velthem's authorship for these passages. On the other hand, if we look at the three final books of the fifth part at the right far-end of the graphs, we notice that the value for double delta is highly negative, meaning that the classifier is quite confident in attributing these books to Velthem on stylistic grounds. In these last two books, Velthem leaves the genre of pure, non-fictional history writing in his chronicle and turns to the genre of fortunetelling.Ga naar voetnoot47 It is interesting to note that, although the tone and content of these last two books are very different from the tone and content of the fourth part, both classifiers agree that these samples are in fact surprisingly similar in style to Velthem's samples from the fourth part, since the δδ val- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 18]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ues are well tinder zero, safely within the range of deviation that was present in our training data. Our analysis, therefore, offers no reasons to doubt that Velthem was indeed the original author of the last three books of the fifth part - although this has of course never been doubted. In general, it seems that our algorithm safely detects the authorial ‘take-overs’ between Velthem and Heelu in the left regions of figures 7 and 8.Ga naar voetnoot48 The attribution to Velthem of the white regions in between the first two grey regions is initially slightly less confident than in our training data, but the main trend is definitely clear.Ga naar voetnoot49 Even though Velthem has superficially manipulated Heelu's citations to make them fit for insertion into his own chronicle, our classifier's δδ can still reasonably well detect the ‘switch in styles’ between the white, Velthem zones (relatively low δδ's) and the first two grey, Heelu zones (relatively high δδ's). If we inspect the double delta values in third grey zone, the δδ returned by the classifier is surprisingly positive, sometimes even higher than the δδ values we observed for those parts of which we indeed know that Velthem was not the original author. Within this particular experimental set-up, our classifiers are thus remarkably confident in rejecting the attribution of this text to Velthem. The observation seems especially true for the middle of the fourth book (coinciding with the account of the actual Battle of the Golden Spurs), since the values at the outer ends of the third grey region seem to be less extreme. The result of these experiments is straightforward: a classification technique that was successful in distinguishing Velthem's fourth part from those of two control authors is extremely confident that Velthem did not write the majority of the fourth book of his fifth part, much in the same way in which the classifier successfully detected that Velthem has not written the passages in which he ‘cites’ from Heelu. How to interpret this result? Is it really possible that Velthem did not write ‘his’ account of the Battle of the Golden Spurs, as this analysis suggests? We should be cautious not to blindly ‘over-trust’ the results of this quantitative analysis: even though our result is rather definite, one should not forget that the discipline of stylometry is still in its infancy and, indeed, largely controversial outside the field itself, as J. Rudman has noted on many occasions. Rudman, rightly, emphasizes that the results from stylometric, non-traditional authorship attribution can only be validated in close collaboration with studies from the field of traditional literary research.Ga naar voetnoot50 Therefore, I will now explore in greater detail whether other arguments could indeed support the hypothesis that the marked difference in style in the fourth book which our analysis has shown can indeed be explained by a shift of authorship or other factors. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 19]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Non-stylometric argumentsAn important reference is this context is an article by Evert van den Berg (1992) in which he reported the results of a stylistic analysis of a large corpus of Middle Dutch narrative poetry. The author of the text in the fourth book of the Spiegel historiael, Van den Berg noted, used many fewer stopgaps and epithets than Velthem normally used in his other works. Van den Berg's attempt to interpret this difference is rather brief but interesting. He did not immediately think of a difference in authorship, but suggested another interpretation: maybe the Battle of the Golden Spurs had made such an impression on the priest that the author tried to style his text in a more refined way by using, for example, many fewer stopgaps.Ga naar voetnoot51 As such, Van den Berg seemed to assume that Velthem (deliberately?) changed his style in the fourth book. This early detection and interpretation of the stylistic deviations in the fourth book are fascinating but, as yet, difficult to assess. One problem is that we have very little insight into the stylistic deviations and developments that could occur within the oeuvres of Middle Dutch authors. Another interesting explanation is, moreover, that Velthem was indeed drawing on a pre-existing text in his fourth book, but that he himself had written this text earlier in his career. It should not be forgotten that Velthem indeed often travelled to Flanders around this period, which is why this explanation should not be put aside too easily.Ga naar voetnoot52 Another problem is that we have very little information on the freedom with which authors could dynamically adapt their style to the topic of a text, as Van den Berg suggests. for Velthem, however, one could raise serious doubts as to whether he could flexibly adapt his rhyming style to the topic of a text, let alone his attitude towards it. Consider for instance Velthem's discussion of Bernard of Clairvaux, with a erudite anthology of his works in the fourth part. Velthem must have been a true admirer of Bernardus and dedicates an unusually high number of lines to his person. It is clear, moreover, that Velthem is trying to adopt a more refined style in certain passages. However, these endeavours seem to have had no effect at all on the relative stopgap-richness of his text.Ga naar voetnoot53 It seems questionable therefore, whether the stylistic deviations in the fourth book can really be ascribed to a change in topic or Velthem's attitude towards that topic. However, one interesting matter should be addressed here. In the graphs in figures 7 and 8, I have claimed that the δδ scores were rather successful in detecting the shift between the original Velthem-passages and the passages he borrowed from Heelu. We can indeed see that most of the time the classifier returns a negative value outside the grey areas, indicating an attribution to Velthem. However, this is not true for the beginning of the fifth part, where a limited number of chapters seem to be attributed either to Velthem with extremely low confidence or even to the control author - this effect seems more prominent in the experiment with Maerlant as a control author. It is inter- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 20]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
esting to note that the text actually contains indications as to the classifier's remarkable choice, since the de-attributed area largely seems to coincide with chapters 4 to 19 in the first book, which are a faithful translation from the Speculum historiale.Ga naar voetnoot54 The problem is that this ‘misattribution’ confronts u s with the issue of whether our method is in fact only doing authorship attribution and is not affected by other factors, such as the availability of a (vernacular or Latin) source text or the content of the text (geographic description). The text itself suggests a partial possible explanation for this situation. In these chapters, Velthem is dealing with Middle Eastern history, in which detailed and diverse geographical descriptions take up an important place. One immediately notices that a good number of the geographical place names related to the Orient appear in rhyme position, so that this portion of text seem to be characterized by a relatively high frequency of rhymes with proper name tags (PrName). This might well be the reason why these passages are apparently difficult to attribute: not only these passages become highly similar to portions in Maerlant's or Utenbroeke's part - that sometimes also contain a lot of proper nouns - but also that the high frequency of proper nouns seems to have left little room for other typically ‘Velthemish’ stopgaps. In other words, it could well be that the content of the text (rather detailed geographical description) has left little room for the author's stylome to manifest itself in any conclusive manner, causing the classifier to be ‘misguided’. This example serves to illustrate that stylometry is not necessarily conclusive and its results should be handled with care. Although it should therefore be emphasized that currently other options cannot be ruled out, it remains quite possible however that Velthem is in fact not the author of the bulk of the fourth book. This hypothesis is especially tempting if we compare the high double delta values in the fourth book with those equally high values in the previous parts of his text where Velthem is known to be ‘plagiarizing’ Heelu. As such, one could argue that the fourth book is a sort of ‘palimpsest’, in the metaphorical sense that Velthem has superficially adapted a pre-existing text by another anonymous author and integrated it into his chronicle. In the rest of this contribution I will expand on this hypothesis and investigate whether other, non-stylistic arguments could support it. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Velthem, the compilerIn Middle Dutch studies, Velthem is known to be an enthusiast ‘compiler’.Ga naar voetnoot55 In the fifth part we have already seen the case of Heelu but also from his involvements in the Merlin Continuation we know that he did not shun some advanced copy-pasting.Ga naar voetnoot56 Often he simply omits to cite his source.Ga naar voetnoot57 It is generally assumed that we may identify Velthem with the famous compiler behind the Middle Dutch Lancelot compilation.Ga naar voetnoot58 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 21]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In this mysterious codex, a compiler - probably Velthem - collected an enormous anthology of Middle Dutch Arthurian literature by combining pre-existing texts. The original authors of the source texts are never mentioned. If it were to turn out that Velthem, known to be a ‘literary master thief’, was drawing on a pre-existing text in the case of book four, this would not come as a surprise. Another aspect of the debate involves chronology. We know that Velthem completed the first 23.000 verse lines of his fifth part in little more than one year.Ga naar voetnoot59 For this part, Velthem no longer had a Latin source text available: he himself had to collect all the necessary information and combine it into a single, coherent text. Scholars have often wondered how authors such as Velthem and Maerlant managed to complete similar projects on such short notice.Ga naar voetnoot60 In this respect too, it would not come as a surprise that Velthem managed to finish the fifth part in such a limited time span by borrowing considerable parts of that text from elsewhere. It is interesting, moreover, that book four is exceptionally long compared to the other books: with its 5329 lines, it is substantially longer than the next longest, namely the first book, counting 4307 lines.Ga naar voetnoot61 In this case too, it would make sense to assume the following: at a given moment, Velthem suddenly had a pre-existing source text on the Battle of the Golden Spurs available and the avid incorporation into his chronicle caused the exceptional length of the fourth book. Another issue has been discussed by historians: Velthem, a Brabantine priest writing more than a decade after the actual battle, is suspiciously well informed about the details on the battlefield, even the weather conditions on July 11, 1302.Ga naar voetnoot62 Historians have wondered how and where Velthem could possibly have gotten such specific information.Ga naar voetnoot63 Was he, for instance, able to interview Flemish veterans of the battle? Again, these givens seem to emphasize the possibility that there is an anonymous source text in the game, maybe even a source text which was written shortly after 1302. For the author of such a (Flemish?) text it is much more likely that he had been an eyewitness of the battle he described - just like Heelu - or at least that he had available reliable first-hand information.Ga naar voetnoot64 A close reading of the text reveals other elements that might be interesting in the debate around the authenticity of Velthem's account of the Battle of the Golden Spurs. In the account, one can hardly overlook the many intertextual links to Carolingian epics, such as:Ga naar voetnoot65 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 22]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
En bleven niet in Alisant
te genen vuige daer Rolant vacht
te Roncevale spet groter tracht,
alsi vor Cortrike daden.Ga naar voetnoot66
The horse of the count of Artois is called Morel, a Carolingian naming.Ga naar voetnoot67 Elsewhere, the blood of the French is called ‘Saracen blood’ which seems yet another Carolingian element.Ga naar voetnoot68 A little further, we read: Men seit vele van Roncevale,
maer dits die jammerlixste tale,
daermen yegeren af mag tellen.Ga naar voetnoot69
A number of lines after this Carolingian reference, we find an interesting illustration of the impact of such references on the medieval public. Consider the following little detail in the Leyden manuscript of the fifth part of the Spiegel historiael (codex Leyden, University Library, bpl E14. At the top of the third column on folio 49r, we read (in a diplomatic edition): The first line in the quote mentions Roelant (Charlemagne's famous nephew, Roland) as a speaker.Ga naar voetnoot71 Content-wise, however, it would make much more sense if John of Rinesse, one of the main commanders of the Flemish troops, was talking here. Most recent editions have indeed emended Roelant into Rinesse.Ga naar voetnoot72 Because this passage appears only a few lines after the Carolingian reference cited in the previous paragraph, it seems that the scribe of the manuscript was puzzled (daydreaming?) by the reference and associatively confused John of Rinesse and Roelant.Ga naar voetnoot73 What might strike the reader of these ‘Carolingian’ passages is that, until now, these have never been reported to be an essential characteristic of Velthem's poetics.Ga naar voetnoot74 What we do know, is that Velthem was a great admirer of Arthurian epics. In other texts, Velthem seems deeply fascinated by Arthurian material, even to the extent that he often | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 23]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Figure 8 Enlarged reproduction of the top part of the third column on folio 49r in the complete manuscript of the fifth part (Leyden, University Library, bpl E14). The scribe writes Roelant where we would expect Rinesse; this seems a slip of the pen under the influence of a Carolingian reference a couple of lines earlier.
‘colours’ his non-fictional writing with fictional elements from this particular subgenre.Ga naar voetnoot75 It is striking therefore, that precisely in the fourth book the author continually refers to Carolingian material without any reference to Arthurian legend, whereas Velthem's writings elsewhere tend to display a far larger admiration for Arthurian lore. Again, this observation in itself does not prove anything: we know that Velthem favoured Arthurian material, but we do not know whether he favoured it over Carolingian material. Nevertheless, it is striking that this shift in the nature of the epic intertextuality in his fourth book, seems to coincide with the marked stylistic differences we observed. Another conspicuous element that does not really fit our traditional view of Velthem is the use of entire French lines between the Middle Dutch rhymes: Artoys riep met groten dangiere:
‘Fudies meldaelge, treis ariere,
fans clercs die pileer,
rende vus saus reposeer.’
Dus hadde Guulke grote porsse.Ga naar voetnoot76
Similar phrases - a clear indication, moreover, of a bilingual poet and audience - seem to deviate from our traditional view of Velthem. So far, I have not encountered them elsewhere in his work. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
A source text?As argued above, we cannot rule out the possibility that Velthem's fourth book is a ‘palimpsest’, whereby the author superficially adapted a pre-existing text, plausibly but not necessarily written by another author, and included it in his own text. It is certainly clear that Velthem's fourth book deviates significantly in style and tone from the rest of Velthem's oeuvre written around 1315-1316, although these differences do | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 24]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
not necessarily imply that the pre-existing text would have been written by another author. Assuming that there was indeed a pre-existing source text, functioning as the main blueprint for Velthem's account of the Battle of the Golden Spurs, it might be interesting to speculate about what this source text might have looked like.Ga naar voetnoot77 If we look at the battle from the point of view of French historiography, it seems possible to expand on the hypothesis of a source text. Immediately after the defeat near Courtrai, the French king, Philip le Bel, was planning to undertake serious crackdowns in order to erase the humiliating memory of the battle - the news of the defeat was rapidly spreading through Europe. For these expeditions, the crown needed funding, but public opinion was increasingly turned against Philip: French tax payers were disappointed in his politics and hesitated to sponsor new expeditions, now that the French nobiliary army had been so shamefully defeated in Flanders. Seeking to restore trust in his politics, Philip turned to the ‘pr machine’ at his court. Already by the fall of 1302, he sent out an official explanation for what happened in Flanders. The Flemish had fought in a dishonest, unknightly manner, according to the court. On the battlefield they had deliberately dug treacherous ditches. According to the court, these crafty ruses had tricked the French army into defeat. In sources anterior to this public statement, however, such ‘treacherous tricks’ were never mentioned. The first French historiographical source, the Chronique Artésienne (ca. 1304-1305), followed Philip's pamphlet-like statements and attempted to re-confirm them. A few years later, from 1304-1307, Guillaume Guiart, a citizen from Orléans, wrote the rhymed chronicle La branche des royaus lignages, which he later dedicated to the French king. The citizen went to the abbey of Saint-Denis to document his work. It is striking that he attacks a biased Flemish version of the facts in 1302. According to Guiart, the Flemish version is tendentious and untruthful, since it omits to mention all the defeats by the French army that the Flemish suffered before 1302.Ga naar voetnoot78 It is striking however, that the well-informed author of the Orléans chronicle explicitly mentions the presence of many small brooks and ditches on the battlefield, but he never suggests that these were ‘treacherous’ or that these would have been dug ‘deliberately’ by the Flemish troops.Ga naar voetnoot79 If we look at the version presented in Velthem's text, we have to account for the possibility that some other author wrote the underlying blueprint for the fourth book. This author might have been writing shortly after 1302 - this is suggested by the detail of his account - and, interestingly, takes a stand in the discussion surrounding the mendacious twaddle which circulates in France: Nu doet u selc logen verstaen,
ende secgen van dere gracht saen
datse die Fransoyse en wisten niet,
ende datsi daerombe hadden tverdriet.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 25]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Dat es sceren ende groet spel.
Si wisten alle dese wacht wel.Ga naar voetnoot80
This author denies the French versions of the story, as initiated by the royal statements at the end of 1302. As a sort of pamphleteer, he clearly takes a stand in issues heavily debated in the period between the royal statements in the fall of 1302 and Guiart's reaction to the Flemish twaddle around 1307. If Velthem's fourth book is indeed drawing on a pre-existing vernacular account, it would seem that we can assume that this account vvas written in this time span, rather shortly after the battle. It remains too difficult to assess, however, to what extent we can attribute the quote above to the source text or to Velthem, who could easily have intervened in his exemplar. What does remain striking is that historians have noted that ‘Velthem's’ account of the battle itself on July 11, 1302 seems extremely detailed and faithful, but that his account of the events from before and after the battle is full of errors.Ga naar voetnoot81 Again, the assumption that Velthem was drawing on a pre-existing source text dealing with the battle (and only the battle), would provide an interesting explanation for these observations.Ga naar voetnoot82 If these assumptions are true, the unattested Flemish source text will have been highly similar to Heelu's account of the Battle of Worringen. In his case too, we see an extremely biased, rhymed account of a recent battle victory, maybe written by an eyewitness as well. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ConclusionIn this contribution we have presented the results of a stylometric analysis of the fifth part of the Spiegel historiael based of highly frequent rhyme words. We have especially focussed on the authorship on the fourth book in this text, traditionally attributed to Lodewijk of Velthem. A technique, borrowed from Machine Learning, that could successfully distinguish between Velthem and two control authors (Jacob of Maerlant and Philip Utenbroeke) in two reference corpora and could moreover clearly detect Velthem's ‘plagiarisms’ of John of Heelu, was highly confident in rejecting Velthem's authorship for the bulk of the fourth book. It was demonstrated that the use of rhyme words in the account of the Battle of the Golden Spurs shows a significant deviation from Velthem's style in his share of the fourth part of the Spiegel historiael. The stylistic differences that were demonstrated are paralleled by various non-stylistic observations and indicate that there is indeed a marked shift in style and tone in the fourth book, | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 26]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
as Evert van den Berg already noted in 1992. If we consider the fact that Velthem is traditionally indeed known to be an enthusiastic ‘compiler’, this makes it attractive to assume that Velthem indeed largely based his text on a pre-existing, vernacular rhymed account of the battle in 1302. So far, the question whether Velthem is the author of this pre-existing source text cannot be answered in a conclusive manner. Although our results clearly do not point in Velthem's direction, one should be careful not to over-estimate the potential of current stylometric methods, which are after all still in their infancy. Another complicating factor is that there has been little consistent research into the diachronic or genrological stability of style within medieval oeuvres. Although Middle Dutch authors, such as Velthem and Maerlant, seem to display stylistic steadfastness, the lack of research on this topic makes it difficult to assess the matter. For the time being, we cannot exclude the possibility that Velthem re-used an earlier text of his, perhaps one of the earliest works in his career. Our argument has clearly shown that there is, however, ample reason to doubt Velthem's authorship in the case of the fourth book but it would be premature to definitely de-attribute it. Nevertheless, there is rarely smoke without fire. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
SummaryThe fifth part (Vijfde Partie, ca. 1316) is the last part of the continuation of the Spiegel historiael, a Middle Dutch rhymed chronicle initiated in the thirteenth century by Jacob van Maerlant and Filip Utenbroeke. Historians agree that one of the most interesting accounts of the famous Battle of the Golden Spurs (Guldensporenslag, 1302) is to be found in the fourth book of this fifth part, which is traditionally attributed to Lodewijk of Velthem. This contribution claims, however, that there is ample reason to doubt the attribution of the account of the battle to Velthem. A stylometric analysis (Machine Learning) of the rhyme words demonstrates that the bulk of the fourth book shows a significant deviation from Velthem's style. The author seems to have borrowed many a passage from a pre-existing vernacular source text, possibly written by another unidentified author. This hypothesis is backed up by various non-stylistic arguments. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
SamenvattingDe Vijfde Partie (ca. 1316) is het laatste deel van de voortzetting van de Spiegel historiael, een Middelnederlandse rijmkroniek die in de dertiende eeuw werd begonnen door Jacob van Maerlant en Filip Utenbroeke. Historici zijn het erover eens dat een van de meest interessante verslagen van de bekende Guldensporenslag (1302) is te vinden in het vierde boek van de Vijfde Partie dat traditioneel toegeschreven wordt aan Lodewijk van Velthem. Ik zal beargumenteren dat de toeschrijving van liet relaas van de veldslag aan Velthem niet zonder problemen is. Een stylometrische analyse (Ma- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 27]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
chine Learning) van de rijmwoorden toont aan dat het leeuwendeel van het vierde boek significant afwijkt van Velthems stijl. De auteur lijkt passages te hebben overgenomen uit een bestaande, volkstalige brontekst, mogelijk zelfs geschreven door een andere ongeïdentificeerde auteur. Deze hypothese wordt ondersteund door verscheidene niet-stilistische argumenten.
Address of the author: University of Antwerp, city campus Prinsstraat 13, room d. 118 b-2000 Antwerp mike.kestemont@ua.ac.be | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 28]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Appendix 1: Inspirations from the fields of Machine learning and StylometryThe memory-based learnerFor our implemention of a memory-based learner, we were largely dependent on an external software package, the Tilburg Memory Based Learner (Timbl, version 6.3.0). The software and detailed documentation are freely available from http://ilk.uvt.nl/. Most of the formulas listed below are taken from the reference guide; many of them are more thoroughly discussed in a recent book publication.Ga naar voetnoot83 The classification techniques we have used in this study are adaptations of IB 1, one of the original k nearest neighbours algorithms proposed by Aha, Kibler and Albert in 1991. In our classification experiments, k is consistently kept at 1. Note that in Timbl's kernel implementation, k refers to the k nearest distances and not (necessarily) the k nearest neighbours. The simplest distance between two samples X and Y - as presented in the example in Table 1 - is equal to the summation of the (absolute) differences between their n features (Equation 1). 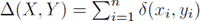 (1)
In the case of the (Manhattan-like, scaled) distance metric illustrated in figure two - only meant as an intuitive illustration of our approach - the difference between two features can be defined as in Equation 2. 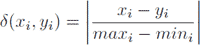 (2)
Note that memory-based learning - at least IB 1 - beats striking resemblances to the Delta-procedure originally proposed by Burrows, as was recently shown by Shlomo Argamon, who proposed a (both mathematical and conceptual) simplification of the Delta metric.Ga naar voetnoot84
Regarding the metrics which we have actually used in our experiments, we made use of a Information Gain, a well-known weighting metric from information theory, used to assess the informativity of each feature i in a given data set. Some features contain more interesting information than others for a certain classification task and thus should be considered more relevant in classification. Information Gain can be calculated using the formula in Equation 3. 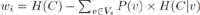 (3)
with C as the set of class labels, Vi the set of values for each feature i and H(C) as the entropy of class labels in C. Consult the reference guide for more details on this calculation, since Information Gain is actually dependent on an important temporary discretization of numeric features such as ours - we used the default discretization settings. The weighting procedure was subsequently used in calculating the actual distance between two samples. Rather than using a plain Manhattan distance, we used timbl's implementation of the cosine distance, arguably one of the best performing distance metrics used in nearest neighbour text classification. The cosine distance between sample X and Y can be defined as in Equation 4. 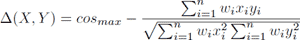 (4)
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 29]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Note that the weighting factor (Information Gain) for each feature is actually included in this formula. Cosine distance is an extension of the plain dot product between two feature vectors and is known to have a beneficiary normalization effect regarding document length in text classification tasks (consult the Timbl manual for more information). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Double deltaIn a previous version of this article we originally proposed another implementation of double delta (δδ), namely simply as δδ=δ2-δ1, with δ1=Δ (test sample by Velthem, nearest Velthem sample) and δ2=Δ (test sample by Velthem, nearest control author sample). A reviewer, however, was kind enough to remark that this calculation does not keep track of the actual δ1 and δ2 values (it only considers the difference between them) and could therefore be misleading. Consider case (a) with δ1=100, δ2=101, and δδ, thus, equal to 1 and case (b) with δ1=1 and δ2=2 and δδ, thus, also equal to 1. Clearly, there is major difference between case (a) and (b), a difference that a simple subtraction (δ2-δ1) would fail to capture. The anonymous reviewer therefore proposed another implementation of δδ, namely as (δ1 / δ2)-1. In case (a), this yields a δδ of -0.0099, close to zero confidence, whereas for case (b), the result is a δδ of -0.5, a relatively higher confidence score. This implementation is clearly far better apt at capturing and appreciating the fact that the attribution confidence in case (a) should be far lower than in case (b), since both samples are relatively far from the test sample. We thank the anonymous reviewer for this remark and have gratefully integrated his suggestion into our code. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Appendix 2: Data from the fourth partBelow is given a legend for the chapters used from Velthem's fourth part. Maerlant's final chapter was part 4. book 3, chapter 34. All subsequent chapters from the fourth part are traditionally attributed to Velthem.Ga naar voetnoot85 for Velthem's share in this part, we work with a continuous ‘dummy’ numbering, because of the complex and fragmentary nature of the extant material. If chapters survive in multiple parallel manuscripts, only one of these text witnesses is included in the data set. The manuscripts are listed in the same order as they can be found on the Cd-rom Middelnederlands, from which our data was digitally harvested. An exception are the Bruges fragments, which were added to the data set based on a file generously put at my disposal by Dirk Geinaert.Ga naar voetnoot86 Incomplete verse lines were silently removed from the data set. After the chapter's title we indicate between round brackets the number of (surviving) rhyme words taken from it. The lemmatized data set will be available from http://www.mikekestemont.org after the publication of this article.
Brussels, Royal Library, iv 827, 1
[Last two chapters were not included because of an overlap] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 30]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Mainz, Bischöfliches Priesterseminar, without signature
Ghent, University Library, 1374
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 31]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Leyden, University Library, Ltk. 1020, iii-iv
Wroclaw, Biblioteka Uniwersytecka, iv F 88e-ii
Ghent, University Library, 2541, 9
Ghent, University Library, 2541, 10
Ghent, University Library, 2541, 11
Vienna, Österreichische Nationalbibliothek, Cod. 13708
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 32]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Berlin, Geheimes Staatsarchiv Preussischer Kulturbesitz, xx. ha sta. Königsberg, Hs. 33, 20
Bruges, City archives, Oud Archief reeks 538, fragmenten van handschriften
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliography
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 33]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 34]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|