
Nederlandse Letterkunde. Jaargang 10
(2005)– [tijdschrift] Nederlandse Letterkunde–
[pagina 212]
| |||||||||||||||||
De list van het lexicon
| |||||||||||||||||
[pagina 213]
| |||||||||||||||||
methoden ten grondslag liggen. Wat er in de praktijk nodig is om het onderzoek ook uit te kunnen voeren wordt beschreven in paragraaf 4. Ter illustratie gebruik ik voorlopige onderzoeksresultaten van Joris van Zundert en mijzelf aangaande de Middelnederlandse Roman van Walewein. De tekst van deze Arturroman vermeldt dat er twee auteurs aan gewerkt hebben en geeft zelfs aan in welk deel van de tekst de tweede het overgenomen heeft van de eerste. Als auteursonderscheidingsmethoden de situatie in de Walewein kunnen bevestigen, levert dit wellicht meer informatie op over hoe auteurs van Middelnederlandse Arturromans van elkaar verschillen. Als dat zo is, dan zouden deze methoden een veelbelovend hulpmiddel kunnen zijn bij het beantwoorden van een aantal andere bestaande, auteursgerelateerde vragen uit de (medio)neerlandistiek. Hierop wordt ingegaan in paragraaf 5. Een bespreking van alle aspecten van dit onderzoek is niet mogelijk in één artikel. Een onderbouwing van de door ons genomen stappen in het onderzoek en onze interpretatie van de resultaten komt binnenkort in andere publicaties aan de orde. | |||||||||||||||||
2 AuteursherkenningGa naar eind5Voor het vaststellen van de identiteit van een onbekende auteur gebruiken onderzoekers verschillende argumenten. Als extern argument voor auteurschap geldt bijvoorbeeld de op een titelpagina van een werk gegeven auteursnaam. Dit is in feite een claim van de uitgever of van een auteur - de toeschrijving hoeft immers niet correct te zijn. Verder kan er in de tekst zelf een auteur genoemd worden, kan de ontstaansgeschiedenis van een tekst voor een bepaalde auteur pleiten, en kunnen biografische gegevens iemands auteurschap aannemelijk maken. Interne argumenten betreffen zaken als genre, thema's en motieven, filosofische en ethische aspecten van de tekst, kwaliteit van het werk en stijl. Met name dat laatste aspect, stijl, omvat heel wat zaken: metrum, ritme (ook in het geval van proza kunnen we van ritme spreken), rijm, het gebruik van bepaalde woorden of woordcombinaties, de keuze uit synoniemen voor eenzelfde begrip, spelling, interpunctie - en zo is er ongetwijfeld nog meer te bedenken. Deze aspecten kunnen zowel kwalitatief als kwantitatief benaderd worden. Met kwalitatief bedoel ik een beargumentering op grond van vooral externe gegevens en op een intuïtieve beoordeling van interne aspecten. De kwantitatieve benadering omvat een beoordeling van vooral interne aspecten op grond van concrete getallen en een berekening van percentages, gemiddelden, en mate van afwijking van wat statistisch verwacht mocht worden. Met name de toegenomen computermogelijkheden hebben het gebruik en het belang van de kwantitatieve benadering sterk vergroot. Kwalitatieve argumentatie blijft echter nog steeds een rol spelen. Het is van groot belang om te benadrukken dat het interpreteren van kwantitatieve gegevens te allen tijde een kwalitatieve bezigheid blijft. De uiteindelijke conclusies worden dan ook op grond van een combinatie van de beide benaderingswijzen getrokken. | |||||||||||||||||
[pagina 214]
| |||||||||||||||||
Niet alle aspecten van een tekst kunnen worden gekwantificeerd. Ethiek en filosofie zijn lastig te tellen. Maar veel stijlaspecten kunnen wel geconcretiseerd worden. In het huidige auteursherkenningsonderzoek wordt gestreefd naar het meten van frequent voorkomende elementen, omdat de frequentie min of meer onbewust tot stand is gekomen. Om een voorbeeld te geven: een auteur kan heel bewust het gebruik van synoniemen met elkaar afwisselen om zijn stijl niet al te saai te laten zijn, maar de mate waarin hij bijvoorbeeld gebruik maakt van voegwoorden, lidwoorden, aanwijzend voornaamwoorden en dergelijke - functiewoorden dus - is eerder intuïtief dan bewust. En aangezien elke auteur uniek is, zal die intuïtie per persoon verschillen en bieden hoogfrequente elementen dus de beste kans om het unieke van een auteur te ontdekken. Wel moet dan worden bepaald wanneer een verschil tussen auteurs significant is, dus wanneer het verschil groot genoeg is om van verschillende auteurs te mogen spreken. | |||||||||||||||||
3 Analyse van het lexiconAls een letterkundig onderzoeker concreet wil kunnen zien in welk opzicht een auteur uniek en onderscheidbaar is, kan hij dat het best doen op grond van onderzoek op woordniveau. Er zijn ook wel methoden waarbij programma's worden losgelaten op strings - letterreeksen waarbij woordgrenzen genegeerd worden - maar het zal duidelijk zijn dat het dan erg lastig kan worden om verschillen tussen auteurs van een voor letterkundigen betekenisvolle omschrijving te voorzien.Ga naar eind6 Het materiaal kan op verschillende manieren worden onderzocht. Enkele gangbare methoden zijn factor analyse, cluster analyse, gebruik van neurale netwerken, ‘principle component analysis’, het berekenen van ‘lexicale rijkdom’ en het onderzoek van de meest frequente woorden. Alleen de laatste twee zijn doorzichtig genoeg om vervolgonderzoek naar hoe de verschillen precies liggen mogelijk te maken. Ik zal kort op deze twee methoden in gaan. Voor het berekenen van de lexicale rijkdom van een tekst is de aanname dat elke auteur een eigen, individuele woordvoorraad tot zijn beschikking heeft, waarin hij sommige woorden bevoorrecht boven andere. De mate van woordherhaling in een tekst kan zichtbaar worden gemaakt met behulp van Udney Yule's Characteristic K, kort: Yule's K (Afb. 1). De formule wordt toegepast op alle woorden van de onderzochte tekst(en) en stelt de verhouding vast tussen het totaal aantal woorden (tokens) en het aantal verschillende woorden (typen). Hoe hoger het getal is dat de formule oplevert, hoe minder variatie de auteur in zijn woordgebruik vertoont. Van de bestaande formules voor het meten van lexicale rijkdom wordt die van Yule als de beste beschouwd. Er wordt echter aanbevolen om deze meting nooit als enige meting te gebruiken.Ga naar eind7 Wij hebben ervoor gekozen om ter ondersteuning hoogfrequente woorden nader te analyseren. Momenteel is ‘Burrows' Delta’ het | |||||||||||||||||
[pagina 215]
| |||||||||||||||||
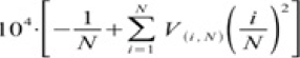 Afb. 1: Formule voor Yule's K. N is de tekstlengte in tokens. V(i,N) is het aantal typen dat i keer voorkomt in de tekst van lengte N. 104 is een vergrotingsfactor die de resultaten leesbaarder maakt (een resultaat is niet 0,0004223 maar 4,223).
populairst bij onderzoekers die zich met auteursherkenning bezighouden.Ga naar eind8 Het materiaal voor Burrows' Delta bestaat uit de 150 meest frequente woorden in een groep teksten. Om na te gaan wie de mogelijke auteur is van een bepaalde tekst, verzamelt de onderzoeker een groep teksten van auteurs die in aanmerking zouden kunnen komen voor het auteurschap, bijvoorbeeld op grond van onderwerp, genre, stijl, of datering van hun wel bij naam bekende werk. De groep wordt zo groot mogelijk gemaakt. De gemiddelde frequentie van elk woord in de hele set wordt vergeleken met zijn frequentie in elk van de teksten in de set. Dan volgt de berekening van de z-scores - het gemiddelde per woord in een van de testteksten wordt afgetrokken van het gemiddelde in de hele set; het resultaat wordt gedeeld door de standaarddeviatie van het woord in de hele set. Vervolgens wordt het gemiddelde van de absolute z-scores berekend; het resultaat is de ‘Delta’ (D, voor ‘difference’), het gemiddelde van de absolute verschillen tussen de z-scores van een set woorden in een groep en de z-scores van dezelfde set woorden in de testtekst. Op deze manier is het gebruik van woorden met een verschillende (hoge) frequentie op een verantwoorde manier vergelijkbaar gemaakt binnen de groep teksten die als uitgangspunt zijn genomen. Wat is nu het listige aan een analyse van het lexicon ten behoeve van auteursherkenning? Het lijkt veel logischer om als onderzoeker te kijken naar dat wat opvalt. Maar het menselijk oog interpreteert over het algemeen alleen dat wat relatief gezien niet vaak voorkomt als opvallend. Zodra het hoogfrequente zaken betreft, komt de onderzoeker niet verder dan intuïties, als hij niet aan het tellen slaat. Onbewust veroorzaakte sporen van de werkelijke auteur worden op het oog niet vaak herkend, maar kunnen door lexiconanalyse wel getraceerd worden. En doordat de metingen op woordniveau blijven, is op grond van de resultaten weer verder te zoeken naar de verschillen op microniveau. Daarbij moet in gedachten worden gehouden dat de vergelijking van teksten over hetzelfde onderwerp of uit hetzelfde genre de duidelijkste resultaten levert: hier hoeft de onderzoeker niet te vrezen dat de verschillen mogelijk worden bepaald door een verschil in onderwerp van de bestudeerde teksten. | |||||||||||||||||
[pagina 216]
| |||||||||||||||||
4 Op zoek naar Penninc en Vostaert, de twee auteurs van de Roman van Walewein4.1 InleidingVoor zover wij weten zijn de in paragraaf 3 beschreven methoden nog niet toegepast op middeleeuwse teksten. Vanuit de vraag die in de meeste auteursherkenningsstudies wordt gesteld, is dit ook niet zo vreemd. De methoden zijn ontwikkeld vanuit de grootst mogelijke ambitie: hoe kunnen we aan een tekst een auteur toekennen met uitsluiting van mogelijke andere auteurs? Voor teksten uit de vroegste eeuwen van onze schriftelijke cultuur is slechts bij uitzondering de naam van de auteur bekend. Toch leven er bij onderzoekers genoeg vragen die met behulp van auteursherkenningsmethoden dichter bij een antwoord kunnen komen. Onderzoekers realiseren zich dat ook wel, maar toegankelijke hulpmiddelen voor het toepassen van de methoden ontbreken, evenals voldoende kennis over de methodologische aspecten en de implicaties daarvan. Dat wil ik laten zien aan de hand van ons lopend onderzoek naar de twee auteurs van de Roman van Walewein. Ik houd daarbij de volgorde aan van de stappen in het onderzoek. | |||||||||||||||||
4.2 TekstkeuzeDe Middelnederlandse Arturistiek kent een aantal onopgeloste auteurskwesties die de gemoederen nog steeds (en recentelijk zelfs meer dan ooit) bezighouden. Het corpus van teksten omvat twaalf romans in paarsgewijs rijmende verzen: de Roman van Walewein, de Ferguut, Jacob van Maerlants Historie van den Grale en Boek van Merline, Lodewijc van Velthems Merlijn-continuatie, en zeven verkorte en bewerkte romans die zijn opgenomen in de zogeheten Lancelot-compilatie, een van de topstukken van de Koninklijke Bibliotheek in Den Haag. Deze compilatietekst kan in feite als de dertiende roman gezien worden. Het is nog steeds niet helemaal duidelijk wie deze compilatie heeft gecomponeerd, en of degene die de structuur van het geheel heeft bedacht ook verantwoordelijk is voor de praktische uitwerking ervan, voor toegevoegde hoofdstukken, verbindende teksten, en bewerkingen op microniveau. De Oudfranse tekst die als basis diende voor de Lancelot-compilatie heeft daarnaast minimaal twee andere vertalingen in het Middelnederlands opgeleverd, te weten de Lantsloot vander Haghedochte, ook een verstekst, en de ‘Rotterdamse prozafragmenten’. Alle romans zijn in slechts één (volledig) handschrift overgeleverd. Van de meeste van deze teksten zijn wel enkele fragmenten van andere handschriften overgeleverd, in een aantal gevallen zelfs van de mogelijke bron van de verkorte, bewerkte versie. Met name die laatste gevallen zijn uiterst interessant: is het mogelijk om met behulp van auteursonderscheidingsmethoden na te gaan | |||||||||||||||||
[pagina 217]
| |||||||||||||||||
hoe groot de veranderingen in de bewerkingen zijn ten opzichte van de mogelijke brontekst? Worden de bewerkte teksten door de moderne methoden aan dezelfde auteur toegeschreven als de aan de compilatie toegevoegde hoofdstukken? Heeft de bewerker wellicht ook in een van de teksten eigen eerder werk herzien? De genoemde romans zijn alle geschreven en overgeleverd in de dertiende en veertiende eeuw.Ga naar eind9 Ons startpunt is de Roman van Walewein. Dit is namelijk een van de weinige Arturromans in het corpus waarvan we (denken te) weten door wie hij geschreven is. In de tekst zelf staat namelijk dat Penninc de roman uitdacht en startte, en dat Pieter Vostaert de onafgemaakte tekst van een eind voorzag. Vostaert schrijft dat hij ‘ongeveer 3300 verzen’ heeft toegevoegd. Buiten deze roman komen we de namen van Penninc en Vostaert niet tegen. Ik zal op deze plaats niet in de details van het onderzoek treden - dat zal in andere publicaties nader aan de orde worden gesteld - maar me hier concentreren op de methodologische stappen en hun praktische uitwerking. Hier volstaat het om te vermelden dat de onderzoekers die zich in het verleden met de auteurskwestie hebben beziggehouden de overgang tussen het werk van Penninc en van Vostaert zo'n veertig tot vijftig verzen eerder in de tekst veronderstellen dan Vostaerts eigen opmerking aan het eind van de roman impliceert en dat diezelfde onderzoekers concrete verschillen in stijl en ‘karakter’ van de tekstdelen hebben geconstateerd.Ga naar eind10 De vraag die wij met behulp van methoden voor auteursherkenning willen beantwoorden is: kunnen wij een punt in de tekst aanwijzen waar dat wat voorafgaat het meest contrasteert met dat wat volgt? Deze vraag proberen we te beantwoorden door het meten van verschillende lexicale aspecten, vanuit de gedachte dat overeenkomstige resultaten van verschillende metingen de waarschijnlijkheid van dat resultaat - en de waarde van de gebruikte methoden - aanzienlijk zou versterken. | |||||||||||||||||
4.3 De digitale tekstMetingen zijn pas mogelijk wanneer we de tekst in machineleesbare vorm ter beschikking hebben. Nu is de Medioneerlandistiek wat dat betreft goed bedeeld. De cd-rom Middelnederlands, vervaardigd door het Instituut voor Nederlandse Lexicologie, deels met subsidie van NWO, en gepubliceerd in 1998 bevat behalve het volledige Middelnederlandsch woordenboek van Jakob Verdam en Eelco Verwijs meer dan 300 teksten uit een grote verscheidenheid aan genres en vrijwel alle literaire en ambtelijke teksten tot het jaar 1301. Ook de Roman van Walewein komt erop voor (Afb. 2): | |||||||||||||||||
[pagina 218]
| |||||||||||||||||
 Afb. 2: Het begin van de Roman van Walewein op de cd-rom Middelnederlands.
De andere Arturromans zijn eveneens op de cd-rom te vinden. En inmiddels heeft de Digitale bibliotheek voor de Nederlandse letteren al heel wat Middelnederlandse teksten op haar website beschikbaar, waaronder op http://www.dbnl.nl/tekst/penn002jees01/ ook de Roman van Walewein. (Afb. 3) Een blik op de twee digitale tekstversies maakt echter duidelijk dat er nog het één en ander moet gebeuren voordat de tekst geschikt is voor het uitvoeren van metingen. Op de cd-rom Middelnederlands is de tekst in stukken gehakt en over verschillende bestanden verdeeld. Op de dbnl loopt de tekst wel door, maar wordt deze onderbroken door de pagina-aanduiding uit de papieren bron. Het voetnotenapparaat ontbreekt op de cd-rom Middelnederlands maar is wel opgenomen in de dbnl. Afhankelijk van onze onderzoeksvraag moeten we die noten echter apart coderen of moeten we ze verwijderen. Opgeloste afkortingen zijn in beide edities cursief weergegeven; hierover moet de meetgrage onderzoeker besluiten om die cursivering te vervangen door een explicietere codering in het bestand of om de cursivering te laten vervallen. Wat verder nog opvalt is dat in beide digitale edities de regelnummering nog impliciet is: elk vijfde vers wordt genummerd. | |||||||||||||||||
[pagina 219]
| |||||||||||||||||
 Afb. 3: Het begin van de Roman van Walewein op de website van de dbnl.
Geen van beide digitale teksten kan zonder aanpassingen worden gebruikt voor metingen. Voordat hij aan de slag kan, moet de onderzoeker dus op basis van een van deze bestanden een eigen versie van de tekst maken in een formaat dat gebruikt kan worden voor de metingen die hij wil toepassen. Voor ons onderzoek hebben wij gekozen voor een praktische oplossing. We hebben de tekst op de cd-rom Middelnederlands als uitgangspunt gekozen. Met behulp van de op de cd geboden opslagfunctie is het bestand als één geheel weggeschreven in tekstformaat (.txt). Met behulp van een eenvoudig script is de tekst vervolgens voorzien van een doorlopende regelnummering. Bij deze bewerkingen gingen de cursiveringen die opgeloste afkortingen aanduiden verloren, maar dat was geen probleem in het kader van metingen van de woordenschat - we vertrouwen erop dat de editeur van de Middelnederlandse tekst de afkortingen zodanig heeft opgelost dat ze resulteren in de woorden die de auteur of kopiist ook bedoelde. De tijdsinvestering voor het formatteren van het materiaal was minimaal: ongeveer 30 minuten. Het digitale bestand van de ‘kale’ tekst voldoet echter nog steeds niet aan de eisen voor het geplande onderzoek. De tekst moet namelijk nog verrijkt worden met relevante aanvullende gegevens. | |||||||||||||||||
[pagina 220]
| |||||||||||||||||
4.4 TekstverrijkingDe metingen die we willen doen betreffen de woordenschat; dus moeten we ons beraden over wat een woord is. We willen de lexicale rijkdom bepalen met de formule ‘Yule's K’ voor de mate van woordherhaling en we willen de frequentie van het gebruik van de honderdvijftig meest voorkomende woorden analyseren met ‘Burrows' Delta’. Beide wensen maken lemmatisering van de tekst noodzakelijk. Lemmatiseren is het abstraheren van spellingvariatie en verbuiging en vervoeging door het toekennen van een normaalvorm aan elk woord in het tekstmateriaal. Een ontwikkeling naar een enigszins vaste spelling komt voor het Nederlands pas vanaf 1800 op gang; het Middelnederlands kende, in al zijn dialecten, een zeer gevarieerde spelling. Ook individuele scribenten varieerden schijnbaar naar willekeur. Als we dus onderzoek willen doen naar woordenschat en niet naar spelling, dan dienen we het materiaal op woordniveau te coderen met een normaalvorm. De eerste twee verzen van de Roman van Walewein, Vanden coninc Arture / Es bleven menighe avonture, krijgen de volgende tags:
Het liefst willen we dan ook het werkwoord zijn van het bezittelijk voornaamwoord zijn onderscheiden door er een code ter aanduiding van de woordsoort aan toe te voegen. Eerdere onderzoekers hebben gemeld dat abstraheren naar vorm geen noemenswaardige invloed op de meetresultaten heeft. Uit hun werk wordt echter niet duidelijk in hoeverre zij bij hun tests uitsluitend normalisatie van spelling hebben toegepast of dat zij ook werkwoordsvervoegingen en de verbuigingen van zelfstandige en bijvoeglijke naamwoorden hebben gereduceerd tot een normaalvorm. Wij wilden zelf voor het Middelnederlands testen wat de resultaten zouden zijn op een ongelemmatiseerde en een gelemmatiseerde tekst. We hebben een test gedaan met een van de kleinere Arturromans, Walewein ende Keije, van zo'n 3600 verzen. De metingen van Yule's K voor de ongelemmatiseerde en de gelemmatiseerde versie weken inderdaad weinig van elkaar af. Dit is echter voor ons niet voldoende reden om lemmatisering achterwege te laten. Als we namelijk ook willen nagaan waarop de resultaten van de metingen uiteindelijk terug te voeren zijn, hebben we een beter handvat aan lemmatisering - het is immers gemakkelijker praten over voorkeuren voor woorden dan over voorkeuren voor bepaalde strings.Ga naar eind11 | |||||||||||||||||
[pagina 221]
| |||||||||||||||||
Lemmatiseren van teksten is een in de lexicografie en de corpuslinguïstiek geaccepteerde en vaak uitgevoerde bewerkingsslag voor het geschikt maken van onderzoeksmateriaal. Er zijn echter voor onderzoekers uit andere disciplines (of werkzaam aan instellingen die niet in corpusbouw participeren) geen hulpmiddelen beschikbaar die het lemmatiseren van een tekst vergemakkelijken. En handmatig lemmatiseren - woordvorm voor woordvorm door de tekst heen lopen en aan elke woordvorm een lemma toekennen door dat in het digitale bestand tussen afgesproken codes in te typen - kost erg veel tijd. Wij hebben getracht het werk voor onszelf én voor anderen efficiënter te maken door een computer-ondersteunde lemmatiseeroptie aan te bieden binnen een webapplicatie die wij aan het ontwikkelen zijn, Autonom. De doelstelling van Autonom is om onderzoekers de mogelijkheid te bieden om zonder enige kennis van tekstformaten en tagstructuren of zonder programmeercapaciteiten teksten te verrijken met codes volgens hun eigen inzichten en ten behoeve van hun eigen onderzoeksvragen (in een recent artikel in Literary and Linguistic Computing zijn wij nader op Autonom ingegaan).Ga naar eind12 We hebben het Walewein-bestand in tekst-formaat in de Autonom-repository geplaatst. Een druk op de knop ‘frequencies’ leverde vervolgens de alfabetische lijst van alle in de tekst voorkomende woordvormen op, waarvan op de afbeelding een deel van de letter A is te zien (Afb. 4). In het midden zijn de verschillende woordvormen te zien. In de kolom rechts daarvan staat het aantal voorkomens van de vorm. De symbooltjes voor de getallen geven aan of de onderzoeker de betreffende vindplaatsen al bekeken heeft en hoeveel van de vindplaatsen hij van een gewijzigde annotatie heeft voorzien. Een voorbeeld: aan de vorm ‘ave’, die viermaal voorkomt, is door de onderzoeker voor drie vindplaatsen hetzelfde lemma toegekend (te weten - het voorzetsel - ‘af’). De vierde vindplaats kreeg een afwijkend lemma (te weten - Latijn - ‘ave’). Het annoteren en analyseren gebeurt met behulp van de knoppen in de linker kolom. Een klik op de knop ‘contexts’ voor de woordvorm avonture levert een scherm op met een KWIC-presentatie (keyword in context) van de zeven vindplaatsen (Afb. 5). Ze worden getoond in de volgorde van voorkomen in de tekst. Een druk op de knop ‘expand’ rechts in het concordantiescherm vergroot de gepresenteerde context tot de gewenste omvang. In de rechterkolom bevindt zich de ‘help’-informatie voor de gebruiker. De woordvormen kunnen alle in één keer van dezelfde tag (of van meer tags tegelijk) worden voorzien vanuit de alfabetische lijst die we net zagen, maar zijn ook per voorkomen te coderen. Dit gebeurt met de knop ‘Annotate’, waarmee een invulformulier voor de tagging wordt geopend (Afb. 6).
In het voorbeeld hebben we de context van de allereerste vindplaats van avonture in de Roman van Walewein vergroot en het annotatieblok opgeroepen. De applicatie heeft op ons verzoek automatisch dezelfde vorm ingevuld in het veld lemma zodat we alleen bij afwijkingen iets in het veld hoeven te wijzigen. Voor het Mid- | |||||||||||||||||
[pagina 222]
| |||||||||||||||||
 Afb. 4: Een deel van de alfabetische lijst met woordvormen uit de Roman van Walewein.
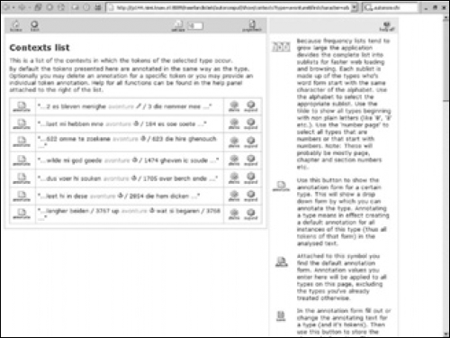 Afb. 5: De voorkomens van de woordvorm avonture in hun context in de Roman van Walewein.
| |||||||||||||||||
[pagina 223]
| |||||||||||||||||
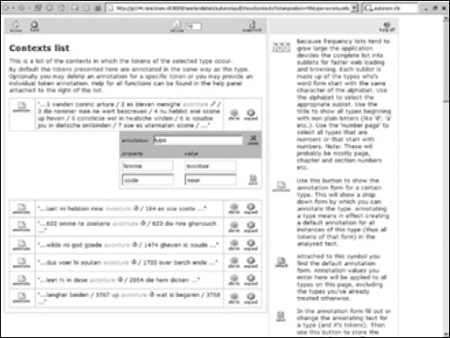 Afb. 6: De voorkomens van de woordvorm avonture in context en met een vergrote context en opengeklapt annotatieformulier voor de eerste vindplaats in de Roman van Walewein.
delnederlands moet er echter meestal wel iets gewijzigd worden; in de toekomst hopen we deze optie te verfijnen door de suggestie van het lemma te baseren op eerder gelemmatiseerde teksten. Wij hebben de vorm avonture genormaliseerd tot Modern Nederlands ‘avontuur’. De in te vullen velden zijn naar believen uit te breiden. Een tweede veld kan ingevuld worden met (bijvoorbeeld) een aanduiding van de woordsoort, hier met als waarde ‘noun’, zelfstandig naamwoord. We hebben de woordsoortcodering voor ons onderzoek voorlopig achterwege gelaten en de 11.202 verzen van de Roman van Walewein uitsluitend gelemmatiseerd. Dit heeft ongeveer 100 uur gekost, wat aanzienlijk sneller is dan wanneer we het volledig handmatig gedaan zouden hebben. We werken nog aan een filter waarmee op basis van de lemmatisering eventuele volgende codeerrondes aanzienlijk versneld kunnen worden.Ga naar eind13 | |||||||||||||||||
[pagina 224]
| |||||||||||||||||
4.5 De metingenPas na verrijking van de tekst kunnen we beginnen met het doen van de metingen. De Roman van Walewein heeft 11.202 versregels. Als we willen zoeken naar het punt van het grootste contrast - de waarschijnlijke plaats in de tekst waar de tweede auteur het overgenomen heeft van de eerste - zouden we de metingen het liefst vers voor vers door de hele roman willen laten lopen, bijvoorbeeld: vergelijk de 2000 regels voor vers 2000 met de 2000 erna Om deze schuivende meting toe te kunnen passen hebben we ons voor de meting van lexicale rijkdom geconcentreerd op dat deel van de tekst waarin we de overgang konden verwachten. In de grafiek in Afb. 7 verwijst de horizontale as naar het gedeelte van de Walewein waarin we de overgang van de eerste naar de tweede auteur - gezien de informatie die we hebben - zouden kunnen verwachten: ergens tussen vers 7800 en 7900. De curve ‘abs(dK)’ geeft voor de individuele versregels in de tekst het verschil tussen Yule's K vóór en Yule's K ná die versregel, ofwel: de curve geeft weer hoe groot het verschil is in lexicale rijkdom voor en na elk vers. Hoe groot het verschil moet zijn om significant, dus betekenisvol (en niet meer toevallig), genoemd te mogen worden, bepalen we met behulp van statistische regels. In de grafiek zijn deze grenzen van ‘betekenisvolheid’ aangegeven. De horizontale lijn getiteld ‘mean’ geeft het gemiddelde verschil in lexicale rijkdom voor en na een vers voor de hele tekst weer. De twee horizontale lijnen getiteld ‘+/- 1 st dev’ begrenzen het gebied waarbinnen resultaten statistisch gezien niet relevant zijn. Een resultaat (punt) uit de curve ‘abs(dK)’ dat binnen dit gebied valt, kan dus net zo goed door toeval bepaald zijn als door zaken van werkelijk belang. Resultaten buiten dit gebied zijn statistisch gezien wél significant; daar betekent het verschil in lexicale rijkdom iets waar we een verklaring voor hopen te vinden. Nu is in één oogopslag te zien dat er wel meer punten zijn in de grafiek die in dat opzicht interessant kunnen zijn. Als we aannemen dat een groot verschil in lexicale rijdom een indicatie is voor de overgang van de ene auteur naar de andere, hoe kiezen we dan uit de vier kandidaten die deze grafiek ons biedt voor het overgangsgebied? Hiervoor berekenen we de trend die de meetresultaten te zien geven; deze is weergegeven met de curve ‘6 per. Mov. Avg.(abs(dK))’. Deze berekening ‘dempt’ de grilligheid van de curve ‘abs(dK)’ waardoor relatief kleine uitslagen in de curve ‘abs(dK)’, die weinig betekenisvol zijn, als ruis uit het grafiekbeeld wegvallen. We zien daarna beter welke uitslagen werkelijk afwijken van het algemene | |||||||||||||||||
[pagina 225]
| |||||||||||||||||
beeld. Wanneer we zo kijken naar de trendcurve zien we globaal genomen een dal met tegen de rechterzijde van het dal plotseling een steile geïsoleerde piek. Dat is statistisch gezien opmerkelijk. De grafiek vertoont dus een golvende tendens, die een duidelijke trendbreuk laat zien waar hij wordt doorbroken door een piek. De piek concentreert zich rond vers 7881. 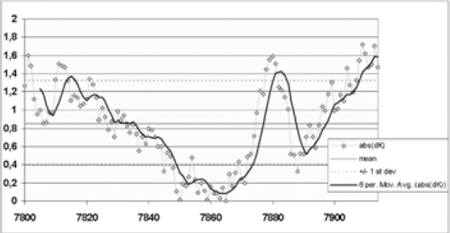 Afb. 7: Contrasten in Yule's K voor en na de weergegeven versregels.
Om Burrows' Delta toe te kunnen passen hebben we de tekst in verschillende, deels overlappende tekstdelen verdeeld. Dit was nodig omdat Burrows' Delta de mate van overeenkomst in het gebruik van woorden in teksten vergelijkt met het gemiddelde in een groep teksten. Omdat we in dit geval te maken hebben met ‘maar’ één tekst, moeten we die verschillende teksten creëren. Dit doen we door tekstdelen van arbitraire grootte uit de volledige tekst te lichten en die als de te vergelijken teksten te beschouwen. In dit geval werden er tien deels overlappende tekstdelen van elk 2000 verzen uit de complete tekst genomen. Tekstdeel 1 bestond uit de verzen 1001-3001, deel 2 uit vers 2001-4001, het derde deel uit 3001-5001 enzovoort. Als vergelijkingsbasis werd vervolgens de ‘groep teksten’ bestaand uit vers 2000-6000 genomen; we hebben voor dit tekstgedeelte gekozen omdat het buiten de proloog valt en in zijn geheel aan Penninc kan worden toegeschreven. Op deze wijze emuleren we de situatie waarin Burrows' Delta berekend kan worden: een aantal teksten van onbekende auteurs en voldoende vergelijkingsmateriaal van bekende hand. Aan de kleine set meetpunten hebben we er enkele toegevoegd binnen het ‘verdachte’ gebied. | |||||||||||||||||
[pagina 226]
| |||||||||||||||||
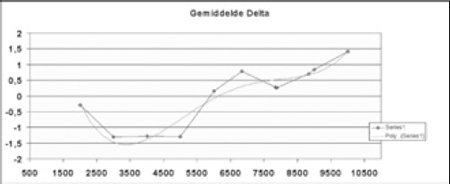 Afb. 8: Afwijkingen ten opzichte van de gemiddelde Delta voor en na de weergegeven versregels.
In Afb. 8 is de afwijking van het gemiddelde gebruik van de 150 hoogstfrequente woorden weergegeven. Ook hier heeft vers 7881 de opvallendste breuk in het gebied waarin we het afwisselen van de auteurs kunnen veronderstellen. In een volgende fase zullen we deze meting nog fijnmaziger uitvoeren om het resultaat steviger te maken, maar deze voorlopige uitkomst wekt al voldoende vertrouwen om alvast hierop verder te bouwen. De geconstateerde plaats in de tekst komt trouwens overeen met de locatie die de woorden van de tweede auteur zelf ongeveer suggereren en spreekt de mening van eerdere onderzoekers dus tegen.Ga naar eind14 Vanuit de blik van de ontwikkelaars van deze methoden zouden deze resultaten wellicht het eindpunt in het onderzoek zijn: er is een heel concreet resultaat te zien. Maar voor de onderzoeker van de tekst begint het nu pas echt. Er blijkt een duidelijk punt van grootste contrast te zijn. Dat punt, zo zien we als we de tekst erbij nemen, valt middenin een lange episode in het verhaal. Het lijkt aannemelijk dat de tweede auteur, Pieter Vostaert, zijn invloed vanaf vers 7881 duidelijk laat gelden. Maar waarop is het geconstateerde contrast nu te herleiden? Ofwel: hoe verschillen de twee tekstdelen - hoogstwaarschijnlijk de twee auteurs - nu precies van elkaar? En om een stap verder naar de literaire analyse te zetten: wat zeggen de verschillen over hun bijdrage aan de tekst, hun opvattingen over het verhaal of hun ideeën over wat een Arturroman moet zijn? Omdat er, zoals hierboven duidelijk geworden zal zijn, nog zoveel praktische problemen te overwinnen waren bij het vaststellen van de digitale tekst en het verrijken daarvan, zijn wij nog niet toegekomen aan al de vervolgstappen die zich nu aandienen en die noodzakelijk zijn om de gegeven vragen te beantwoorden. Ik ga hier in op de voorbereidingen voor de eerstvolgende stap in het onderzoek, om daarna terug te keren naar de perspectieven die dit onderzoek lijkt te bieden. We hebben een serie nieuwe metingen gedaan op grond van het lexicon van de tekst als geheel en van het deel tot aan vers 7881 en het deel van 7881 tot het eind. Hier wordt ook duidelijk waarom de lemmatisering van zo groot belang is voor de vervolgstappen: op grond van de lemmata hebben we berekend wat het | |||||||||||||||||
[pagina 227]
| |||||||||||||||||
gemiddelde voorkomen van elk lemma is in de gehele tekst en vervolgens hoe de gemiddelde frequentie van de lemmata in beide tekstdelen zich verhoudt tot het gemiddelde in de complete tekst. We hebben een lijst gemaakt van de per tekstdeel meest opvallende afwijkingen ten opzichte van het gemiddelde, waarvan we hier het bovenste deel van de lijst laten zien. Het lemma dat in het eerste deel van de tekst het meest afwijkt van het gemiddelde en zeer nadrukkelijk significant vaker voorkomt dan in het tweede deel van de tekst is zijn. En hier is onmiddellijk duidelijk dat voor deze stap van het onderzoek codering op woordsoort relevant wordt. Want betreft het opvallend frequenter voorkomen de vormen van het werkwoord, of van het bezittelijk voornaamwoord? 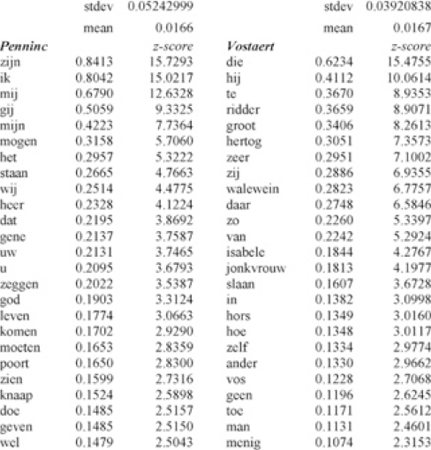 Afb. 9: Lemmata die opvallend vaker voorkomen in het deel van Penninc (linker kolom) en lemmata die opvallend vaker voorkomen in het deel van Vostaert (rechter kolom). De z-scores geven de mate van afwijking van het gemiddelde aan: 1 betekent een afwijking met 1 × de standaarddeviatie (afwijkingen van 1 × de standaarddeviatie en meer zijn statistisch relevant); het persoonlijk voornaamwoord ik bijvoorbeeld met een z-score van 15.0217 (dus 15(!) maal de standaarddeviatie) heeft duidelijk een onderscheidend vermogen waar het de twee tekstdelen, en dus waarschijnlijk de twee auteurs betreft.
| |||||||||||||||||
[pagina 228]
| |||||||||||||||||
We hebben getracht de significantste afwijkingen van het gemiddelde in groepen te verdelen. Dan vallen een aantal zaken op, waarvan ik er hier slechts twee noem. Het meest opvallend is het verschil in het gebruik van persoonlijke voornaamwoorden. In het eerste deel van de tekst worden de eerste en tweede persoon, dus ik, jij en afgeleiden, veel vaker gebruikt dan gemiddeld, terwijl het tweede deel een significant hoger gebruik van de derde persoon, hij en zij en afgeleiden, vertoont. Verder komen modale werkwoorden - zullen, moeten, mogen e.d. - significant vaker voor in het eerste deel. Maar wat zegt dit over de werkwijze en over de tekstdelen van de twee auteurs? Ofwel: in welke context komen deze woorden voor, en hoe verschillen die contexten van elkaar? De eerste hypothese die wij willen testen is dat de verschillen in het gebruik van persoonlijke voornaamwoorden en van modale werkwoorden terug te voeren zijn op een verschil in het gebruik van dialoog in de twee tekstdelen. Eerdere onderzoekers hebben er namelijk op gewezen dat Penninc, de eerste auteur, veel meer dialoog gebruikt dan zijn opvolger Vostaert. Als we willen nagaan of dat klopt en hoe hun woordenschat eruit ziet binnen en buiten dialoogtekst, dan moeten we het bestand van de tekst aan een nieuwe codeerronde onderwerpen met een afbakening van tekst in dialoogvorm - eventueel met onderscheiding van directe rede, indirecte rede en erlebte rede. Vervolgens kunnen we de metingen die we eerder hebben gedaan opnieuw uitvoeren voor de volgende onderdelen: -Lexicale rijkdom in alleen de tekstpassages in directe rede Hierbij zullen we opnieuw nagaan of er per teksttype een breuk in de tekst gevonden kan worden. En als dat het geval is, zal duidelijk worden of vers 7881 in de tekst opnieuw als punt van grootste contrast aangewezen wordt door de metingen. De resultaten van die metingen werpen ongetwijfeld weer nieuwe vervolgvragen op, zodat het op dit moment nog moeilijk in te schatten is welke koers ons onderzoek daarna precies zal nemen. Een codering van tekst in directe en erlebte rede ter onderscheiding van de rest van de tekst overstijgt het woordniveau en kan nog niet efficiënt worden aangebracht met behulp van onze webapplicatie. Zodra deze functionaliteit is opgeleverd, gaan we hiermee aan de slag. | |||||||||||||||||
[pagina 229]
| |||||||||||||||||
5 PerspectievenHet onderzoek is nog lang niet zover dat we al definitieve antwoorden op sommige van onze vragen kunnen geven. Wat is dan het nut van deze nieuwe methoden? Ik ben ervan overtuigd dat deze sterk kwantitatieve aanpak de logische volgende stap is in onderzoek dat raadsels rond auteurschap wil oplossen. Van Es, in zijn inleiding tot de Roman van Walewein uit 1957, presenteerde karakterschetsen van Penninc en Vostaert op grond van uitgebreid taalonderzoek. Hij betreurde het dat hij niet de kans had om een volledig overzicht van het woordmateriaal te geven; ‘Hoe belangrijk zou dit toch zijn, ja noodzakelijk bijna, voor een diepgaande analyse van taal en stijl van onze middeleeuwse dichters’.Ga naar eind15 In de tijd waarin dit soort stijlonderzoek nog handmatig werd gedaan, was een volledige behandeling uitgesloten. De taalelementen die werden bestudeerd, moesten altijd als min of meer intuïtieve keuzes beschouwd worden. De onderzoeker moest voorzichtig blijven in zijn conclusies, want wie weet zou het analyseren van ándere elementen wel in een heel andere richting wijzen (of in geen enkele richting). Door uit te gaan van het volledige woordmateriaal en gebruik te maken van kwantitatieve auteursonderscheidingsmethoden kan precies die onzekerheid voor een groot deel uitgesloten worden. Álles wordt bekeken, en de elementen die binnen dat woordmateriaal onderscheidend lijken te zijn, worden nader onderzocht (ook om die reden is het handig wanneer teksten uit hetzelfde genre of over dezelfde onderwerpen met elkaar vergeleken worden - dat scheelt een aanvullend onderzoek naar in hoeverre inhoudelijke verschillen verantwoordelijk zijn voor de significantie van de meetresultaten). Op grond van kwalitatieve argumenten wordt vervolgens steeds verder toegewerkt naar een conclusie waarvan de onderzoeker wél zal kunnen zeggen dat hij daarvoor de gehele woordvoorraad van een tekst of auteur onderzocht heeft. Zoals ik aan het begin van deze bijdrage heb vermeld, willen we de kennis die wij opdoen bij het bestuderen van de Roman van Walewein gebruiken als startpunt voor onderzoek naar de andere Middelnederlandse Arturromans. Het eerst is Walewein ende Keije aan de beurt. Ook voor deze tekst speelt namelijk een interessante auteurskwestie. Onlangs heeft Marjolein Hogenbirk in haar proefschrift over deze tekst op grond van kwalitatieve overwegingen aannemelijk gemaakt dat een aantal hoofdstukken van deze tekst geen bewerking zijn van een - helaas niet overgeleverde - eerdere Middelnederlandse versie van de tekst, maar een toevoeging zijn van de hand van de compilator van het handschrift waarin deze tekst is geïncorporeerd in het grotere geheel dat de Lancelot-compilatie wordt genoemd.Ga naar eind16 Zij kondigt nader taalkundig onderzoek aan waarmee de tekst beter gelokaliseerd zal kunnen worden.Ga naar eind17 Ik denk dat onderzoek van de taal, en wel de woordenschat, ook goede diensten kan bewijzen in vervolgonderzoek naar de door haar voorgestelde auteurssituatie. Wij willen Hogenbirks hypothese graag testen door het toepassen van Yule's K en Burrows' Delta. Voor enkele andere Arturromans uit de Lancelotcompilatie zijn fragmenten voor- | |||||||||||||||||
[pagina 230]
| |||||||||||||||||
handen van de tekst die ten grondslag ligt aan de bewerking in de compilatie. Voor deze teksten willen we nagaan in hoeverre de oorspronkelijke auteur zichtbaar blijft in de bewerking. Ook willen we onderzoeken of de beschreven auteursherkenningsmethoden wellicht meer inzicht verschaffen in bijvoorbeeld de mate van bewerking of de aard ervan. Worden bepaalde woorden (en onderwerpen) systematisch overgeslagen? Wijst dat op een bepaalde al dan niet bewuste richting van de bewerking? Vinden we veel verschillende auteurs terug, of zijn er teksten te groeperen en aan slechts enkele auteurs toe te schrijven? Kan dit onderzoek leiden tot handvatten bij het beschrijven van de mate van bewerking of omwerking in een (afschrift van een) tekst? Ongetwijfeld levert het onderzoek naar de Roman van Walewein en naar Walewein ende Keije nog meer nieuwe vragen op. De wegen die we zullen volgen zijn echter nog heel onvoorspelbaar en kronkelen alle kanten op, met onvermoede beloningen en onverwachte én verwachte hindernissen op de route. Dat past trouwens bijzonder goed bij dit genre vol van ridders op queeste en jonkvrouwen in nood. De winst voor de Arturistiek en voor andere letterkundige deeldisciplines kan echter groot zijn, en dat maakt het computer-ondersteunde auteursonderscheidingsonderzoek zo uitdagend. Het zal trouwens duidelijk zijn dat dit type onderzoek een combinatie van kennis en competenties vergt die vrijwel nooit in één letterkundig georiënteerde onderzoeker wordt aangetroffen. Er is kennis nodig van de stand van zaken en van de levende vragen binnen een bepaald onderzoeksgebied, ervaring in het ontwikkelen en programmeren van nog nergens beschikbare technische hulpmiddelen, en relevante kennis van wiskunde en statistiek. Om al deze competenties binnen één onderzoek samen te brengen is samenwerking tussen onderzoekers met verschillende competenties noodzakelijk. In het voorgaande heb ik verder laten zien wat er moet gebeuren voordat het onderzoeksmateriaal, de teksten, ook werkelijk gebruikt kan worden. De teksten moeten beschikbaar zijn (of gemaakt worden) in digitale vorm, en zijn (of worden) bij voorkeur gelemmatiseerd en op woordsoort gecodeerd. Bovendien moet de onderzoeker de mogelijkheid hebben om zonder technische kennis eigen coderingen aan een bestand toe te voegen, het liefst via een webapplicatie met een zeer gebruiksvriendelijke interface.Ga naar eind18 Mijn ideaal zou een website zijn waarin een onderzoeker zijn tekst kan aanbieden en vervolgens door alle ‘hoepels’ kan laten springen die maar nodig zijn voor (bijvoorbeeld) auteursonderscheidingonderzoek. Lemmatisering, codering, vervolgens automatisch een overzicht van metingen van lexicale rijkdom, Burrows' Delta, en wat dies meer nog zal zijn. Met als eindpunt een suggestie van auteurschap of van afbakening van tekstgedeelten die aan verschillende auteurs moeten worden toegeschreven. Zover is het nog lang niet. Maar ik wil graag een tafelronde oprichten om op zoek te gaan naar deze ‘digitale’ graal.Ga naar eind19 | |||||||||||||||||
[pagina 231]
| |||||||||||||||||
Literatuuropgave
|
|