
Forum der Letteren. Jaargang 1978
(1978)– [tijdschrift] Forum der Letteren–
[pagina 72]
| |||||||||||||||
Geïnstitutionaliseerde lexicologie W.J.J. Pijnenburg H. van der Hulst M. MoortgatSamenvatting | |||||||||||||||
Historisch overzichtDe grote woord- en tekstarchieven zijn gewoonlijk vanuit de lexicologisch - lexicografische zijde opgezet. De reden hiervoor lijkt ons voor de hand te liggen. Om de woordinventaris van een taal te beschrijven heeft de lexicoloog niet genoeg aan een corpus van beperkte omvang of aan zijn eigen intuïties t.a.v. de kennis van de woordenschat van zijn taal. Dat is onmiddellijk vast te stellen aan de hand van willekeurig welk woordenboek. Het Woordenboek der Nederlandsclie taal, de grootste onderneming op dit terrein binnen ons taalgebied, mist in de letters A alleen al enorm veel, vaak heel gewone woorden, zoals elders in deze bundel is aangetoond door Van Sterkenburg op basis van een vergelijking met ‘Hollands Heilig Woordenboek’ (W.F. HermansGa naar voetnoot(1)); leggen we naast de Van Dale weer de Koenen (ten onrechte door Hermans niet genoemd als ‘het redelijk alternatief’), dan blijken ook daarin weerde nodige lacunes - vaak heel gewone woorden - op te vallen: Om eens een andere letter te nemen; Koenen heeft 57 woorden meer dan Van Dale bij de woorden die met RA beginnen, waaronder bijv.: Raadsvrouwe, racestuur, radiotoestel, radiobode, raketgeleerde, ranja, rassengelijkheid, rayondirecteur. Het is duidelijk, dat hoe goed ook opgezet, een woordenboek nooit compleet kan zijn. Kruyskamp, de bewerker van de 7e t/m 10e druk van Van Dale, gaat in zijn inleiding op de 10e druk in op het aspect van de volledigheid, waarbij hij een ruwe schatting maakt van het aantal woorden die in het Nederlands gebruikt worden; hierbij komt hij | |||||||||||||||
[pagina 73]
| |||||||||||||||
tot een raming van 2 à 5 miljoen woorden. Deze getallen maken duidelijk dat het juist de lexicografie is geweest die met het oog op het volledigheidsaspect met steeds grotere tekstcorpora moest werken - of steeds langere rijen boeken moest excerperen - zodat van daaruit een behoefte aan het sneller en efficiënter opzetten van een corpus of een woordarchief zich deed gevoelen. Een volledige verzameling die de complete woordenschat beoogde te bevatten en te beschrijven is bekend onder de naam Thesaurus en in het begin van de 16e eeuw onder invloed van het humanisme ontstaan. De woordenboeken tot in het midden van de 19e eeuw gaan in hoofdzaak terug op deze verzamelingen. We kunnen dus in de 16e eeuw, waar de lexicografische breuk met het verleden met name tot uitdrukking komt in dit streven naar volledigheid, de oorsprong zien van de moderne verzamelingen die hier aan de orde zijn. Over de breuk zegt ClaesGa naar voetnoot(2), ‘In de zestiende eeuw ontstonden onder invloed van de humanistische beweging uitvoerige vertaalwoordenboeken in de volkstaal, die vrijwel geheel onafhankelijk stonden van de oudere traditie. De middeleeuwse vocabularia (...) konden (...) niet meer zijn dan bijkomende hulpmiddelen voor de zestiende- eeuwse lexicografen, die de volledige woordenschat te boek wilden stellen (...)’. De eerste aanzet hiertoe is het Dictionaire francoislatin (1539) van Robert Estienne († 1559) waar voor het eerst de volkstaal en niet het Latijn als uitgangspunt werd gekozen. In Engeland is vergelijkbaar Richard Huloet's Abcedarium Anglico Latinum (1552), voor het Duitse taalgebied Die Teütsch Spraach of Dictionarium Germanicolatinum nouum (1561), van de Zwitser Josua Maaler. Het eerste vertaalwoordenboek dat van het Nederlands uitging is het Naembouck van allen natuerlicken ende ongeschuumde vlaemsche woorden, ghestelt in ordene bij abc, ende twalsch daer by ghevought (1546) van de Gentenaar Joos LambrechtGa naar voetnoot(3). De Nederlandse lexicografische traditie vindt vervolgens haar voorlopige hoogtepunt in de vorm van Kiliaan's Etymologicum Teutonicae Linguae (1574; 1588; 1599). Via het bekende procédé, dat gewoonlijk met ‘plagiat par ordre alphabétique’, wordt aangeduid zijn vanhieruit de meeste moderne hand-, zak- enz. woordenboeken tot stand gekomen. Sedert 1862 is er tevens de mogelijkheid geweest de nomenclatuur (makrostruktuur) te relateren aan het sedertdien verschijnende Woordenboek der Nederlandsche Taal (WNT), dat een wetenschappelijke opzet had in de zin van de historisch-vergelijkende taalwetenschap. Ook hier zien we soortgelijke ondernemingen in de buurlanden: Duitsland's Deutsches Wörterbuch (1852-1961); Engelands Oxford English Dictionary (1884-1928); het woordenboek van de Académie Française, gevolgd door Littré (1863-1873) (toen de eerste 30.000 woorden bevatte, had Littré er al ongeveer 85.000)Ga naar voetnoot(4). Het streven naar volledigheid blijkt uit de woorden van De Vries uit zijn Ontwerp dat ‘alles wat ooit of ergens Nederlandsch was ... verzameld, gerangschikt en tot een volkomen geheel bearbeid (moest) worden’Ga naar voetnoot(5). | |||||||||||||||
[pagina 74]
| |||||||||||||||
Ten behoeve van al deze woordenboeken werden enorme woordarchieven (bewijsplaatsarchieven) aangelegd die hun diensten verricht hadden als de woordenboeken waren voltooid. Bekend is de tragedie met het materiaal van het WNT dat werd vernietigd tot en met de bewerking van deel XVIII (1958). Men leest op p. VII: ‘Met het oog op dit Centrale Instituut voor Nederlandsche Lexicographie der toekomst (d.i. het tegenwoordige Instituut voor Nederlandse Lexicologie, W.P.) wordt thans het volledige woordenboekmateriaal ... op ons Scriptorium bewaard’. Dat is dan 100 jaar na de start van het WNT. Zo heeft telkens een moment van bezinning de lexicografen ertoe gebracht te overwegen wat met hun materiaalverzamelingen aan te vangen, als het woordenboek voltooid zou zijn, of mogelijk al tijdens de bewerking hiervan. Duidelijk was in ieder geval dat het materiaal een zelfstandig leven kreeg, waarmee bovendien los van de lexicografie gewerkt moest kunnen worden. Het was natuurlijk bruikbaar voor morfologisch onderzoek, maar eigenlijk zou het dan tevens retrograad gerangschikt moeten kunnen worden; voor valentie-onderzoek, maar eigenlijk zou je dan meer context en meer zinnen bij de bewijsplaatsen moeten aantreffen; voor semantisch onderzoek, maar dan zou een ideologische rangschikking (d.i. een rangschik- king naar begrippen, niet naar alfabet) beter zijn, voor etymologisch onderzoek maar dan zou een alfabetisch-ideologische (d.w.z. dat bij een kernwoord eveneens de afleidingen en samenstellingen worden behandeld ook al zouden ze alfabetisch op een andere plaats thuishoren; bijv. bij tuin ook kloostertuin, voortuin enz.) rangschikking de voorkeur verdienen, (als in het DEAF): kortom het materiaal was nuttig maar te weinig manipuleerbaar. Het beschikbaar komen van de computer ook voor taalkundig onderzoek heeft de mogelijkheden van veelsoortige manipulatie van een materiaalverzameling in zicht gebracht. Belangrijke impulsen tot het gebruik van de computer voor niet-lexicografische arbeid kwamen uit hoek van de bijbelvorsers, filosofen, rechtsgeleerden en al diegenen die zich met concordanties en indices bezig hielden; hun uitgangspunt was één werk (de bijbel), één auteur (Wittgenstein) of één vakgebied (de rechten) die zij toegankelijk wilden maken door concordanties en indices. De Italiaanse Jezuiet Roberto Busa te Gallarate heeft voor dit werk dat tot dan toe met de hand werd verricht voor het eerst kaartponsmachines gebruikt, nl. in 1951 ten behoeve van een concordantie op Thomas van Aquino, een project dat zou uitmonden in de Index Thomisticus, een complete index op het werk van Thomas. Van hieruit was de stap naar een computer-gestuurd woordarchief niet ver meer; ook het werk voor het woordarchiefen de Thesaurus kon worden gemechaniseerd. En een aldus ontstaan Corpus zou benut kunnen worden voor grammaticaal onderzoek, omdat het, in tegenstelling tot traditionele lexicografische verzamelingen, flexibel is. Als het Corpus maar groot, rijk, uitgebreid, verscheiden naar tekstgenre enz. genoeg is, kan het lexicografisch én grammaticaal onderzoek uit één corpus gedaan worden. | |||||||||||||||
FrankrijkIn 1957 had B. Quemada, voortbouwend op de ervaringen van Busa, in Frankrijk het Centre d'Etude du Vocabulaire Français te Besançon opgezet dat zich officieel bezig- | |||||||||||||||
[pagina 75]
| |||||||||||||||
hield met het langs automatische weg bijeenbrengen van de woordenschat der 16e- en 17e- eeuwse Franse poëten. Deze taak is echter spoedig uitgebreid met het verzamelen van de gehele woordenschat uit Franse woordenboeken en van oude bewijsplaatsen uit publicaties en etymologische woordenboeken, kortom meer en meer werd de gehele Franse woordenschat in een woord- en tekstarchief vastgelegd. Deze gehele verzameling en de ‘met de hand’ aangelegde collectie van het Inventaire général de la langue française van Mario Roques in Parijs werd met enige buitenlandse collecties samengevoegd ten behoeve van het in 1960 onder leiding van Paul Imbs te Nancy gestarte project van de Trésor de la langue française (TLF), een project dat later ook onder toezicht van B. Quemada komt, en waaruit een tweetal woordenboeken moeten resulteren: een van ongeveer 8 banden voor de taal tot ca. 1575 en een van 12 à 15 banden voor de tijd daarna tot heden. De beide series zijn zelf weer onderverdeeld in zgn. periodewoordenboeken, waarin per eeuw, of per afgerond tijdperk de woordenschat wordt beschreven. Dit project brengt als nieuwe elementen ‘the exceptional richness of research data it contains and ... the minuteness of the analysis which these data will make possible’Ga naar voetnoot(6). Hier voegt Quemada in een voetnoot aan toe, dat deze rijkdom bestaat in ‘250,000,000 uses taken from the data of 2,500 texts of 100,000 words’Ga naar voetnoot(7). Dit werk, bij de opzet waarvan min of meer de klassieke methode wordt gevolgd zal ook ‘take advantage of the results of the most recent works of historical semantics and the development of French lexicology’Ga naar voetnoot(8). Deze laatste ontwikkeling stelt de lexicograaf in staat ‘thanks to the subtlety of its general data, ... to show what, through all stages of its development, distinguishes one word from another with respect to form, meaning, “stylistic” shades and “syntactical” uses’Ga naar voetnoot(9). De omvang en de toegankelijkheid van het materiaal ligt hier duidelijk aan deze opzet ten grondslag. | |||||||||||||||
ItaliëAnders dan in Frankrijk waar de mechanische lexicografie van het Centre d'Étude du Vocabulaire Français (Besançon) althans wat de lexicografische output betreft via een ‘personele unie’ verbonden werd met het Centre de la Recherche pour un Trésor de la Langue Française is in Italië de volgende verhouding ontstaan tussen twee vergelijkbare instituten: het Centro Nazionale Universitario di Calcolo Elettronico (CNUCE) te Pisa en de Accademia della Crusca te Florence. Het eerste fungeert als databank van de laatstgenoemde: ‘A la différence de presque tous les autres grands Centres de recherche lexicologique ou lexicographique (Besançon, Nancy, Liège, Cambridge, Prague etc.), qui disposent de leur propre installation électronique et de leur propre laboratoire mécanographique, avec une équipe de techniciens sous leurs ordres directs, la Crusca ne dispose que d'une seule poinçonneuse de fiches; la perforation des textes est accomplie | |||||||||||||||
[pagina 76]
| |||||||||||||||
en service non seulement hors du siège de l'Académie mais hors de Florence; et pour toutes les élaborations électroniques, elle est tributaire du CNUCE de Pise’Ga naar voetnoot(10). Het CNUCE is ontstaan als gevolg van een overeenkomst tussen de universiteit van Pisa en IBM-Italië, en is in het kader van de werkzaamheden aan het Woordenboek van de Crusca en die van de Index Thomisticus (zie p. 75) begonnen met automatisch excerperen van teksten. Als eerste verschenen de indices en concordanties op de Divina Comoedia, maar spoedig werden ook de werkzaamheden t.b.v. het Dizionario Storico della Lingua Italiana van de Crusca verricht. DaarnaastGa naar voetnoot(11) werd er een ‘documentation lexicographique’ aangelegd t.b.v. bijv. het Dizionario di testi storici dell' eteo cuneiforme (Woordenboek van de historische teksten van het spijkerschrift-hittitisch) en Dizionario storico della lingua rumena del XIV secolo (Historisch woordenboek van het 14e-eeuws Roemeens); dan t.b.v. vakwoordenboeken: Vocabulario Giuridico della Lingua Italiana, het Lessico Intellettuale Europeo, voorts indices en concordanties op de opera omnia van een auteur bijv. de al genoemde Index Thomisticus; of t.b.v. bepaalde werken met het oog op grammaticale, metrische, stylistische, thematische analyse: Goethe, Pindaros, Gide, of de Tabulae Iguvinae, de Gotische Bijbel. In 1971 verscheen het Lessico di Frequenza della lingua italiana contemporanea (Frequentiewoordenboek van het hedendaagse Italiaans) door U. Bostolini, C. Tagliavini en A. ZampolliGa naar voetnoot(12), gebaseerd op 500.000 bewijsplaatsen uit de periode 1927-1968Ga naar voetnoot(13). Na ongeveer 7 jaar ervaring met dit soort werk op het CNUCE kon Zampolli in 1973Ga naar voetnoot(14) ‘a series of procedures’ aanbieden ‘which are applicable to texts in any language’. Zo werkt men te Pisa aan een machine-woordenboek, het Dizionario italiano di macchina (Italiaans machine-woordenboek), een automatisch lexicon, dat bij de lemmata gegevens over taalsfeer, homografie, etymologie, fonematische transscriptie, en grammaticale classificatie bevat, naast een reeks flexie-algorithmen die automatisch de buigingsvormen bij de ingangen opleveren. Dit heeft als doel te helpen bij (1) (semi-) automatisch lemmatiseren; (2) de automatisering van de fonematische transcriptie; (3) linguistisch onderzoek op basis van een op te stellen inventaris van taaleenheden. Met behulp van dit machine-woordenboek worden verder de volgende typen onderzoek verricht: (1) Fonetisch onderzoek: het opstellen van algorithmen voor semi-automatische fonetische transscriptie, syllabificatie, het onderkennen van clusters en fonetische patronen. (2) Statistische bewerkingen als het tellen van verschillende taalkundige eenheden (gra- | |||||||||||||||
[pagina 77]
| |||||||||||||||
femen, morfemen, woorden, clusters) en het uitvoeren en rangschikken van allerlei berekeningen, die de verspreiding, het gebruik, de entropie (mate van onvoorspelbaarheid), correlaties e.d. van de verschillende eenheden weergeven. (3) Filologische bewerkingen, als het verzorgen van een kritische editie en het bijeenplaatsen van varianten. Opgemerkt moet nog worden dat ook bij de franse Trésor weliswaar ‘dictionaires de machine’ worden vervaardigd maar in een andere conceptie dan in Italië of bij het INL (zie hieronder): de Franse dictionaires de machine zijn bijv. lijsten van de flexievormen van het werkwoord, van homografen, van grammaticale formaties en van woorden met zeer hoge frequenties als ‘a, à, afin, ailleurs, aussi, alors’ etc. Het wetenschappelijk onderzoek in de computerlinguistiek, de linguistische statistiek, de waarschijnlijkheidsleer met tekstpopulaties, mechanische vertaling en wiskundige modellen van talen is in de taalkundige sectie van het CNUCE samengebracht, waar A. Zampolli als hoogleraar leiding geeft aan een viertal teams, waaronder een research team. Dit element heeft tot op heden aan de hele opzet van het Nederlandse Woordarchief ontbroken. Onderzoek als hierboven wordt, los van onze databank-in-aanbouw, verricht door het Mathematisch Centrum in Amsterdam waar een aantal programma's voor automatische taalkundige analyse van het Nederlands zijn ontwikkeld en wellicht t.z.t. door het in 1975 ingestelde Utrechtse Instituut voor toegepaste taalkunde en computerlinguistiek. Niettemin moeten we bedenken, dat Zampolli in 1973 al kon schrijven: ‘While the computers are becoming more and more rapid, and the programs more and more sophisticated, the lexicographers cannot benefit in proportion because present methodology already produces far more data than an editing team of reasonable size can analyze when working with present procedures’Ga naar voetnoot(15). Indien, zoals we mogen aannemen, na de nodige versterking van de sectie computerlinguistiek, de nederlandse taalbank binnen afzienbare tijd van de grond komt, dan zijn op basis van de Italiaanse ervaringen twee dingen aan de orde, die we reeds hier noemen:
Dit veronderstelt onderzoek naar machinewoordenboeken, thesauri, inter-actieve man-machine technieken en automatische syntaktische analyse (‘parsing’-systems). Bij de bespreking van het Instituut voor Nederlandse Lexicologie (INL) aan het slot van dit artikel zullen we op een aantal van deze aspecten nader ingaan. | |||||||||||||||
Engeland en AmerikaIn het Engelse taalgebied blijkt zich gelijkaardige ontwikkeling voor te doen naar een gecentraliseerde databank. Het model voor moderne corpora ‘The Standard Corpus of Present-Day Edited American English’ (het zgn. Brown-Corpus) kreeg in Engeland een | |||||||||||||||
[pagina 78]
| |||||||||||||||
pendant in het ‘Computer Archive of Modern English Texts’ (CAMET); tezamen met een databank van gesproken taal (te Londen) zullen beide corpora samengevoegd worden als een ‘International Computer Archive of Modern English’ (te Bergen, Noorwegen). Een informele start met dit project is in februari 1977 gemaakt door G. Leech en W.N. FrancisGa naar voetnoot(16). Meer specifiek lexicografisch gericht zijn twee projecten op het gebied van het oudere Engels die we slechts noemen: het Dictionary of Old English (DOE Toronto) o.l.v. A. Cameron en het ‘Michigan Early Modern English Materials’ archief (MEMEM), op basis waarvan in de toekomst een vroeg modern Engels woordenboek geschreven zal worden (na de voltooiing van het conventioneel vervaardigde Middle English Dictionary); In deze projecten wordt gewerkt met teksten in ‘computer-readable form’ die een tekstbank vormen die ook toegankelijk is voor niet-lexicografisch onderzoek. Een corpus dat vergelijkbaar is met de hierboven genoemde corpora is dat van het Schots (Edinburgh), speciaal gericht op het Dictionary of the Older Scottish Tongue. | |||||||||||||||
DuitslandDe Duitse situatie is vergelijkbaar met die in het Engelse taalgebied. Het materiaal van het Duitse moderne taalarchief is verdeeld over een drietal subcorpora die vervaardigd worden door de afdelingen van het Institut für Deutsche Sprache (IdS)Ga naar voetnoot(17) (De sectie Linguistische Datenverarbeitung van het IdS houdt zich bezig met verschillende aspecten van de automatische analyse van dit materiaal):
Hiernaast functioneren zgn. ‘Clearingstellen’ die het onderzoek op de verschillende deelgebieden coördineren in die zin dat zij overbodig (= dubbel) werk trachten te voorkomen. Voor het moderne Duits zijn deze ‘Clearinghouses’ in Mannheim en Manitoba (Canada), ten behoeve van het onderzoek aan deze en de andere zijde van de oceaan. Parallel daarmee heeft het oudere Duits zijn Clearinghouses in Bonn en in Los Angeles. Een voorstel van een in Mannheim gehouden conferentie (1971) om ook voor het oudere Duits een centrale databank van teksten te creëren (of eventueel twee: één in Duitsland en één in de Verenigde Staten) is op moeilijkheden gestoten die deels van financiële aard zijn, deels veroorzaakt worden door de onwil van onderzoekers om hun teksten ter beschikking te stellen. Zoals de situatie nu ligt, heeft R. Wisbey een aanzienlijk Corpus van vroegmiddeleeuws materiaal (ambtelijke teksten) terwijl het laatmiddelhoogduitse onderzoek zich in Bonn situeertGa naar voetnoot(18). De hierboven besproken projecten zijn specifiek op tekstverwerking gericht. Aan de | |||||||||||||||
[pagina 79]
| |||||||||||||||
Universiteit van Saarbrücken (H. Eggers) en te Bonn in het Institut für Kommunikationsforschung und Phonetik, worden nieuwe methoden van tekstverwerking onderzocht zoals automatische syntaktische en morfologische analyse, taalstatistiek en vertaling met de computer. | |||||||||||||||
ZwedenIn Zweden waren in 1965 kranten-teksten met 1.000.000 woorden verponst in computer-readable form t.b.v. een Frequency Dictionary of Present Day Swedish door de Research-groep voor modern Zweeds, waaruit zich de afdeling voor computerlinguistiek ‘Språkdata’ ontwikkelde aan de universiteit van Göteburg. In 1972 is deze groep geïnstitutionaliseerd, waarna in 1975 een Logotheek als dienstverlenend orgaan ging functioneren. Het doel van deze Logotheek is
De logotheek staat ter beschikking van alle gebruikers op het gebied van onderzoek en onderwijs, administratie en industrie, voor niet-commerciële doeleinden zoveel mogelijk gratis. De logotheek betrekt haar materiaal op de eerste plaats van uitgeverijen en kranten, terwijl ook elders opgezette corpora zoveel mogelijk daarin worden ondergebracht. Ga naar voetnoot(19) | |||||||||||||||
De taken van de lexicoloog?Uit het voorgaande blijkt dat de invoering van de computer in het taalkundig onderzoek verschuivingen teweeggebracht heeft in de werkzaamheden die de lexicoloog in de praktijk als zijn arbeidsterrein beschouwt. We willen één en ander toelichten aan het bijgaande schema, dat het meerledige karakter van het verschijnsel lexicologie illustreert. 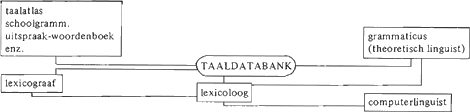 | |||||||||||||||
[pagina 80]
| |||||||||||||||
Historisch gezien is de relatie tussen lexicoloog en lexicograaf, zoals die in de linkeronderhelft van het schema tot uitdrukking komt, het oudst: dit verband stelt ook het minst problemen. Als men de lexicografie ziet als ‘het handwerk bestaande in het schrijven van woordenboeken’Ga naar voetnoot(20), d.i. ‘a special technique rather than a branch of linguistics’Ga naar voetnoot(21), dan is de lexicoloog degene die de theorievorming betreffende het samenstellen van woordenboeken, en daarmee de theoretische studie van de woordenschat, voor zijn rekening neemt. Het onderscheid dat we hier aantreffen, is er een tussen toegepaste vs. theoretische wetenschapsbeoefening: de term ‘theoretische lexicografie’ waaraan sommigen voor dit onderdeel van de taak van de lexicoloog de voorkeur gevenGa naar voetnoot(22), is in dit opzicht dan ook verdedigbaar. In de praktijk zijn lexicograaf en lexicoloog - in de beperkte zin die we tot dusver hanteerden - de Dr. Jekyll en Mr. Hyde van de woordenschat: het is doorgaans de schrijver van een woordenboek die zich theoretisch bezint over dit (technisch) bedrijfGa naar voetnoot(23). De theorievorming met betrekking tot de lexicografische arbeid houdt in dat de onderzoeker zich op de hoogte stelt van de bevindingen van de theoretische linguistiek inzoverre die voor de leer van de woordenschat van belang zijnGa naar voetnoot(24); dit zijn met name de resultaten van semantisch en morfologisch onderzoek. Het lijkt ons nuttig een misverstand uit de weg te ruimen, waartoe niet zelden aanleiding is gegeven, nl. dat de lexicoloog de taken van morfoloog en semanticus voor zich zou willen opeisen. Morfologie en semantiek beschouwen wij hier als theoriegebonden deelgebieden van een wellicht axiomatisch en geformaliseerd grammaticaal model, bijvoorbeeld dat van de transformationeel-generatieve grammatika of de generatieve semantiek. Het lexicon (in tegenstelling tot het woordenboek) is dan eveneens ‘een theoretische grootheid, die deel uitmaakt van een grammatica en waarvan de inrichting afhankelijk is van het soort grammatica dat men als een adequate beschrijving van taal beschouwt’Ga naar voetnoot(25). Zo heeft een lemma in de TGG de vorm van een matrix, die de fonologische, syntactische en semantische kenmerken van een lexicaal item weergeeft, terwijl de semantisch-syntactische informatie van lemmata in het generatief-semantisch model er als een boomstructuur uitziet. Een lexicoloog die deskundige van het lexicon zou zijn, zoals de fonoloog de specialist is van de fonologische component binnen een grammaticale theorie, blijkt nu niet te bestaan. De reden waarom dit denkbare wezen in feite denkbeeldig blijft, ligt ons inziens hierin, dat het lexicon als opsommende lijst van uitzonderingen van de taal niet verder bestudeerbaar is: voor zover de lexicale items voorspelbare d.i. beregelbare eigenschappen hebben, zijn deze immers reeds door de semanticus en morfoloog beregeld (in de TGG in de vorm van zgn. redundantieregels); wat overblijft is een lijst van | |||||||||||||||
[pagina 81]
| |||||||||||||||
taalspecifieke, idiosyncratische bouwstenen, arbitraire verbindingen van vorm en betekenis, die zich aan verdere beregeling onttrekken. De lexicoloog kan zich dus wel de bevindingen van het onderzoek naar de morfologische en semantische componenten van de grammatica eigen maken, maar hij doet dat met het oog op zelfstandige studie van de woordenschat, waarbij men deze ‘leer van de woordenschat’ mag beschouwen als een buiten het transformationeel of elk ander theoriegebonden paradigma vallende discipline met eigen bestaansrecht. De termen ‘lexical morphology’ en ‘lexical semantics’Ga naar voetnoot(26), als onderscheiden van morfologie en semantiek binnen een bepaald theoretisch taalmodel, verschaffen misschien enig inzicht in dit verband. Het ontstaan en de ontwikkeling van de zgn. taaldatabank, die in ons schema een centrale plaats inneemt, illustreert andermaal de tussenpositie die de lexicoloog inneemt tussen toegepaste wetenschappen als de lexicografie en theoretische bezigheden als het opstellen van een expliciete grammatica. Het schema, voor zover nog niet behandeld, geeft uitdrukking aan het samenkomen van verschillende faktoren, waaronder de intrede van de computer in het taalkundig bedrijf en het feit dat elke vorm van taalkunde op de een of andere manier gepaard gaat met verzameling van talige gegevens. Dit samenkomen heeft geresulteerd in de eerder genoemde nieuwe werkzaamheden voor de lexicoloog (zie p. 74). Hieronder willen we nog eens stapsgewijs nagaan hoe een en ander in zijn werk is gegaan. Vóór de invoering van de computer in de menswetenschappen werkt de lexicograaf met een conventioneel corpus, dat hij inductief benadert om de woordenschat van de taal te beschrijvenGa naar voetnoot(27). De automatiseringsmogelijkheden die de computer biedt, zijn dan ook in de eerste plaats aangewend om de lexicografische slavenarbeid te verrichten: concordanties en indices worden vervaardigd, berustend op meer of minder gesofisticeerde alfabetiseringsprogramma's (zie p. 74). Een voor de hand liggende voorwaarde voor het op deze wijze vervaardigen van dergelijke lijsten, nl. het feit dat de teksten verponst moeten worden, opent nu echter ‘nieuwe wegen’: het traditioneel corpus van fiches wordt een computergestuurd tekstarchiefGa naar voetnoot(28), dat meteen ook interessant wordt voor de niet-lexicograaf (zie p. 74). Een theoretisch linguist die een grammatica opstelt als een deductief axiomatisch systeem vindt in een computergestuurde taalbank de mogelijkheid tot algorithmische toetsing van zijn theorie. Anderzijds zal een linguist, | |||||||||||||||
[pagina 82]
| |||||||||||||||
die er de voorkeur aan geeft generalisaties over zijn taal te bereiken op basis van een corpus, door de taalbank rijkelijk voorzien wordenGa naar voetnoot(29). De historische taalkundige zal idealiter kunnen nagaan, vanzelfsprekend via een interpretatie van spellingssystemen, hoe het fonologisch systeem van een taal zich heeft ontwikkeld aan de hand van vele, automatisch opvraagbare, bewijsplaatsen van woorden waaraan zich een ontwikkeling heeft voltrokken. Meer mogelijkheden van gebruik laten zich gemakkelijk bedenken. Met deze verandering van conventioneel corpus naar computergestuurd taalarchief gaat een uitbreiding gepaard van het takenpakket van de lexicoloog- ‘theoretisch lexicograaf’: hij is nu ook ‘taalarchivaris’. De lexicoloog, die door de automatisering en wijziging in de lexicografische methodologie tot stand heeft gebracht, gaat nu een stap verder zetten en het produkt van de geautomatiseerde lexicografie (taaldatabanken) toegankelijk maken voor elke taalkundige die van de diensten van een taalbank gebruik meent te moeten maken. Dit zal in eerste instantie de theoretische linguist zijn, maar ook voor de vervaardiger van taalatlassen, schoolgrammatica's, frekwentielijsten e.d. zijn er mogelijkheden. Dit veronderstelt echter dat de lexicoloog een nieuwe interdisciplinaire lijn opent, en zich de bevindingen van de computer-linguistiek eigen maakt, om de specifieke eisen die de linguist stelt aan een taalbank, te kunnen opvangen. Tegenover het ‘gemak’ waarmee mogelijkheden van gebruik van een taalbank opkomen, staat het feit dat een computergestuurd taalarchief niet zomaar voor elke linguist toegankelijk is. De wijze waarop een dergelijk archief bruikbaar kan zijn voor verschillende typen onderzoek dienen onderzocht en uitgebouwd te worden: de lexicoloog als taaldatabankbeheerder heeft er een taak bijgekregen, die strikt genomen niet meer valt binnen het terrein van de lexicologie! Het spreekt vanzelf dat de taalbank een theorie-vrij gebruiksmiddel is, waarvan de opbouw en inrichting niet per se ter hand genomen moet worden door de lexicoloog. Hij bevindt zich echter, gezien de historische ontwikkeling van zijn werkzaamheden, in de meest aangewezen positie om dit te doen: hij is ‘van huis uit’ betrokken bij het inrichten van een taalarchief (gericht op het lexicografisch produkt: een woordenboek) en hij heeft zich gespecialiseerd in automatische tekstverwerkingGa naar voetnoot(30). Bezien wij nu hoe bovenstaande ontwikkeling past in het INL en zijn opdracht. De ge ïnstitutionaliseerde lexicologie in Nederland dateert van 1969 toen de Stichting Instituut voor Nederlandse Lexicologie (INL) haar werkzaamheden begon. De opdracht van deze Stichting was tweeledig nl. ‘het Woordenboek der Nederlandsche Taal ... volgens de traditionele methoden met spoed ... voltooien’ en ‘met behulp van machines een permanente woordinventaris der Nederlandse taal op ponskaarten (aanleggen en op peil houden)’. In deze opzet week de Nederlandse Stichting weinig af van de buitenlandse instellingen op hetzelfde terrein. Het ‘lexicografische’ woordarchief krijgt door de ontwikkeling van de automatisering in de taalkunde een nieuwe dimensie; de hierop volgende theoretische beschouwingen over lexicografie en woordarchief leiden tot meer klaarheid over het begrip lexicologie. De lexicoloog die aldus met een geauto- | |||||||||||||||
[pagina 83]
| |||||||||||||||
matiseerd woord- en tekstarchief wordt opgescheept staat nu voor de keus: of terug naar zijn status als ‘theoretisch lexicograaf’ en onderzoeker van de woordenschat, in welk geval hij als linguist gebruik kan maken van de taaldatabank, of zijn vakgebied uitbreiden met de computerlinguistiek, in welk geval hij de taaldatabank kan beheren t.b.v. de lexicograaf (en de lexicoloog - oude-stijl), de grammaticus en de verschillende theoretische en toegepaste disciplines. Of een dergelijke uitbreiding waardevast zal blijken zal de toekomst uitwijzen. In ieder geval is bij de Stichting de opbouw van een taaldatabank der Nederlandse taal met kracht ter hand genomenGa naar voetnoot(31). Hierbij zijn een paar opmerkingen op hun plaats. De zinsnede uit de opdracht van de Stichting die gewijd was aan het samenstellen van een woordarchief - een taak die door de afdeling Thesaurus zal worden volvoerd - behoeft in het licht van de ontwikkelingen op het gebied van de computerlinguistiek enige preciseringGa naar voetnoot(32). ‘Met behulp van machines’ dient zo begrepen te worden, dat naar de mate van het (financieel)-mogelijke steeds via de modernste apparatuur, taalmateriaal op informatiedragers (magneetband, disc) in een databank wordt ondergebracht. Zolang de Stichting niet over een eigen computer beschikt, wordt voor verdere bewerking gebruik gemaakt van de computer (IBM 370/158 model 3) van het CRI van de Rijksuniversiteit Leiden, waarmee de Thesaurus d.m.v. een beeldstation on-line is verbonden. Uiteraard wordt naast een corpus oud- en middelnederlands ook reeds een corpus modern Nederlands op de Stichting verwerkt. Alle historisch èn modern materiaal dat elders reeds verwerkt is kan evt. na conversie in de taaldatabank worden ondergebracht, indien dit door onderzoekers van buiten het INL ter beschikking wordt gesteld. Modern materiaal, zou - als in Zweden - rechtstreeks via de Nederlandse en Belgische drukkerijen in de vorm van zgn. drukkertapes ter beschikking van de taaldatabank gesteld kunnen worden. Een werkgroep-informatiedragersGa naar voetnoot(33), die zich over deze problematiek heeft gebogen, en waarin ook Van Sterkenburg, de directeur van het INL, zij het à titre personel, zitting had, heeft tot nog toe niet de gewenste resultaten opgeleverd. Een tweede zinsnede uit de opdracht, t.w. ‘permanente woordinventaris’ dient thans zo begrepen te worden, dat geen woordinventaris, maar een taalarchief, een taaldatabank wordt aangelegd, waaruit, als dat voor de lexicografische afdeling(en) van het INL dienstig is, een woordarchief van elke gewenste taalperiode in allerlei rangschikkingen gelicht kan worden. Ten derde, en dat is inmiddels uit het voorgaande genoegzaam gebleken wordt niet op ‘ponskaarten’ verzameld, maar op magnetische informatiedragers. De opdracht is nu, na 8 jaar werken, aan herformulering toe: ‘met behulp van de computer en perifere apparatuur een taaldatabank van de Nederlandse taal op informatiedragers aanleggen en op peil houden’. Hoewel in de oude formulering alleen impliciet uitgesloten, willen wij hier expliciet aan toe voegen, dat in onze visie niet alleen de geschreven taal object van onze zorg zal zijn. Evenwel heeft een archief van gesproken | |||||||||||||||
[pagina 84]
| |||||||||||||||
Nederlands in computer-readable form voor ons nu niet de hoogste prioriteit. Op dit moment is in het Nederlandse taalarchief ondergebracht:
Onderzoek wordt momenteel verricht naar:
Het ligt in de bedoeling om ons in de nabije toekomst te buigen over de opnamecriteria die een rol spelen bij het inrichten van de taaldatabank, dit zowel van de historische als van de eigentijdse taalperiodeGa naar voetnoot(36). Voorts dienen de hierboven genoemde mogelijkheden tot het gebruik van de taaldatabank van linguistisch onderzoek nader uitgewerkt te worden. Het spreekt vanzelf dat dit onderzoek sterk bepaald wordt door de taaltheoretische achtergrond en interesse van de INL-medewerkers die zich hiermee bezighouden. Op dit moment wordt gewerkt aan de toetsingsmogelijkheden van fonologische en semantisch-syntaktische theorieën. | |||||||||||||||
BesluitWanneer we de Nederlandse situatie vergelijken met de buitenlandse zijn een aantal punten op te merken: Buitenlandse lexicologische ondernemingen zijn over het algemeen met meer mensen - en vaak ook met meer geld (Italië: IBM!) gestart. De reden hiervan ligt voor de hand: grote(re) taalgebieden beschikken over meer geld. Bovendien hebben landen met een agressievere cultuur-politiek hier ook meer voor over. Evenwel zijn ook zonder extreem grote financiële injecties op ons taalgebied redelijke resultaten te bereiken. Veel hangt hier af van de coördinatie en organisatie van het onderzoek, de bereidheid van de drukkerijen om hun zettapes en van de individuele onderzoeker om zijn materiaalverzame- | |||||||||||||||
[pagina 85]
| |||||||||||||||
ling ter beschikking te stellen. Indien de geschetste ontwikkeling binnen het INL doorzet zal er een sterke behoefte bestaan aan de uitbouw van de afd. automatisering, die een theoretisch gerichte linguistische sectie zal omvatten, naast de technische met systeemontwerpers, systeemanalysten, programmeurs en soft-ware deskundigen. Wij hopen in regelmatige rapportages de belangstellende vakgenoten van onze vorderingen op de hoogte te houden.
Instituut voor Nederlandse Lexicologie Leiden |
|