
Riskante gewoonten en zorg voor eigen welzijn
(1963)–I. Gadourek–
[pagina 361]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.7 Statistische bewerkingZowel klassieke (parametrische) als verdelingsvrije methoden werden toegepast om significante verbanden tussen de afzonderlijke variabelen aan te tonen. Het materiaal leende zich hier goed voor: leeftijd, intensiteit der rookgewoonten, intensiteit en frequentie der drinkgewoonten, gebruik van koffie, van versnaperingen konden zonder meer als kwantitatieve variabelen worden beschouwd. Het bleek mogelijk door middel van de analyse der covariantie de gemiddelde waarde (mediaan) van deze variabelen te berekenen voor allerlei kwalitatieve categorieën zoals kerkgenootscha, woonstreek, positieve of negatieve houding, gemeente. Het verschil tussen de gemiddelden binnen de categorie alsmede de variantie van de gemiddelden in twee of meerdere categorieën kon worden onderzocht en de significantie hiervan berekend. Op deze wijze is ook het clustering-effect gecorrigeerd, dat door de opbouw van de steekproef in twee stappen was veroorzaakt. Hiervoor heeft Drs. Ch.A.G. Nass ons twee formules gegeven die het mogelijk maken de standaarddeviatie van een proportie te schatten met inachtneming van de invloed van de woongemeente; dit zowel voor de steekproef getrokken uit de grote steden (met 100.000 inwoners en meer), als voor de steekproef getrokken uit de 71 kleinere gemeenten. Voor de steden (A-gemeenten) luidde de formule als volgt:(1) 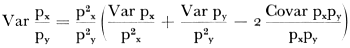 Hier is:
x index voor een onderzocht aspect, b.v.: ‘roker’; y index voor een ander aspect, b.v.: ‘boven 20 jaar’; px/py schatting van het aantal personen in alle A-gemeenten met eigenschap y. Als eigenschap x eigenschap y insluit dan is dit een schatting van de fractie x-personen onder alle y-personen. Verder: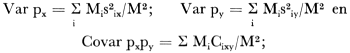 waarbij Cixy is covariantie van de eigenschappen x en y in gemeenten i. Hij wordt als volgt berekend: 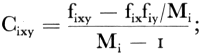 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 362]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
indien de eigenschap x de eigenschap y insluit dan wordt deze laatste formule:
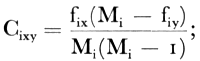 waarbij
Mi is het aantal proefpersonen per gemeente, dat uit de dossiers moest worden getrokken;
fix is het aantal personen met eigenschap x onder de Mi personen uit de gemeente i;
pix = fix/Mi de fractie voor de personen met eigenschap x in de gemeente i;
M is het aantal personen te kiezen uit de grote steden, nl. 742 personen; fx = 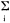 fixhet aantal personen met eigenschap x onder M (742 potentiële respondenten); fixhet aantal personen met eigenschap x onder M (742 potentiële respondenten);
s2ix = fix(Mi - fix)/Mi(Mi - 1) is de variantie van eigenschap x in gemeente i.
fixy is het aantal personen in gemeente i die zowel eigenschap x als eigenschap y hebben. Als iedere persoon met eigenschap x (boven 20 jaar en roker) noodzakelijk ook eigenschap y (boven 20 jaar) heeft, dan geldt fixy = fix. Voor de kleinere plaatsen, waar immers een vaste quota per gemeente werd getrokken (20 personen), gold eveneens de formule voor de variantie van proportie (1). De onderscheiden leden werden echter als volgt berekend: 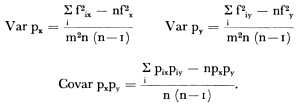 Notaties:
n = 71 kleinere gemeenten: m = 20 personen, het aantal personen per gemeente; i = 1, 2, ..., 71; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 363]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
fix = het aantal personen met eigenschap x onder de m proefpersonen van gemeente i;
pix = fix/m; px = fx/nm = Σ pix/n. Tenslotte kon de informatie verkregen door middel van beide methoden worden gecombineerd met gebruik van de formule waar (2) 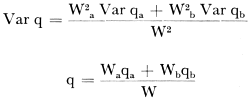 een proportie in beide steekproeven te zamen; dus aantal rokers gedeeld door aantal personen boven 20 jaar onder de 1.297 proefpersonen; W is dan het aantal proefpersonen in beide steekproeven; Wa en Wb het aantal proefpersonen in elke steekproef afzonderlijk; Var qa en Var qb: variantie van de proportie in elke steekproef afzonderlijk.
Met behulp van deze methode was het ons mogelijk om voor de gevonden proporties de overschrijdingskansen te bepalen en op deze wijze tot verantwoorde uitspraken te komen niet slechts over de 1.297 personen in onze steekproef, maar over de ganse Nederlandse bevolking. Hiernaast werd het ons mogelijk reeds tot de opsporing van causale verbanden over te gaan, door de gevonden proporties met de desbetreffende standaardfouten met elkaar statistisch te vergelijken. Dit alles, men vergeve ons de herhaalde beklemtoning, met de correctie voor de steekproeffout ontstaan door het trekken van de steekproef uit de (eveneens getrokken) Nederlandse gemeenten, in plaats vanuit het ganse universum. Laten we de toepassing van de bovenvermelde formules aan een enkel voorbeeld illustreren. De vraag waarop wij door middel van de variantie-analyse een antwoord hopen te verkrijgen, betreft de schatting van de proportie van de niet-rokers onder de volwassen Nederlandse bevolking; als hypothese nemen wij aan dat er in de grote steden significant meer rokers zijn dan in de gemeenten met minder dan 100.000 inwoners. Wij stellen in de eerste plaats twee tabellen op bevattende de percentages rokers en het te interviewen aantal personen in de afzonderlijke gemeenten, alsmede andere nodige cijfers, die wij zullen gebruiken in de variantieformule. Eén tabel is opgesteld voor de kleinere, een andere voor de grotere gemeenten: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 364]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Daar het gevonden percentage rokers in de steekproef getrokken uit de grote steden 60,7% was, kunnen we stellen dat het werkelijke percentage rokers onder de volwassen bevolking in de gemeenten met meer dan 100.000 inwoners tussen 56,2% en 65,2% is. De kans dat het buiten dezen grenswaarden ligt is kleiner dan 5%. Voor de kleinere gemeenten hebben we de volgende tabel samengesteld: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 365]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 366]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
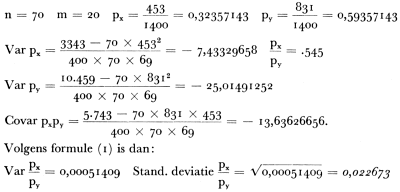 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 367]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Passen we dit reusltaat op onze bevindingen toe, dan kunnen we stellen dat het percentage rokers onder de volwassen bewoners van de gemeenten met minder dan honderdduizend inwoners ongeveer tussen 50 en 59 percent ligt. De kans dat er meer rokers zijn dan 59% of minder dan 50% is kleiner dan 5%. We zien dat het percentage rokers volgens onze schatting in de kleinere gemeenten inderdaad lager ligt, het verschil bedraagt immers 6,2%. Is dit verschil toevallig of kunnen we hieraan een zekere significantie toeschrijven? Volgens de bekende formule is de standaardfout van het verschil tussen twee proporties uit onafhankelijke steekproeven
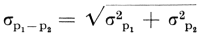 met de berekende waarden: 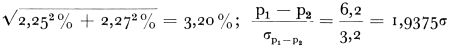 Het verschil is bijna significant bij het 0,05%-niveau van waarschijnlijkheid (P is ca. .054). Om de proportie van rokers in de gehele volwassen bevolking in Nederland (q) te schatten, gebruikten wij de formule (2) met de door ons berekende waarden voor afzonderlijke steekproeven. Dan verkregen wij 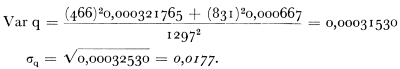 De foutenmarge voor de beide steekproeven te zamen ligt aanzienlijk lager dan voor de steekproeven afzonderlijk, zodat wij kunnen stellen dat er onder de volwassenen in Nederland 56,7% ± 3,6% rokers zijn. Bij het significantieniveau van P < .05 ligt het percentage rokers tussen 53,1% en 60,3%Ga naar voetnoot1. In plaats van x en y (in ons geval ‘boven 20 jaar’ en ‘roker boven 20 jaar zijn’) kunnen andere eigenschappen gebruikt worden. Zo hebben wij b.v. voor x genomen ‘vrouwelijke niet-roker boven 20 jaar’ en voor y ‘niet-roker boven 20 jaar’. De standaardfout voor beide steekproeven te zamen bedroeg 0,03364. Een corresponderende standaardfout voor de mannen onder de nietrokers bedroeg 1,75%. Daar het verschil tussen de percentages niet-rokers bij de mannen en vrouwen in onze steekproef hoger was dan 50%, is het duidelijk dat de hypothese dat een zo hoog verschil op toeval berust, ver- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 368]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
worpen mag worden. De standaardfout van het verschil (3,8%) is meer dan 13 × kleiner dan het verschil zelf, zodat we bijna zekerheid hebben dat het roken niet toevallig meer bij mannen dan bij vrouwen voorkomt. Aan deze min of meer evidente voorbeelden kunnen we de mogelijkheden zien die de methode van covariantie biedt voor het toetsen van hypothesen met betrekking tot de gehele populatie bij de steekproeven die aan het z.g. clustering-effect onderhevig zijn. Eveneens kunnen we zien dan de methode bijzonder omslachtig is en niet geschikt voor een diepergaande analyse van het materiaal. Bij het inschakelen van meer dan twee variabelen (in de vorm van proporties) zou de methode nog bewerkelijker worden, terwijl een analyse van de interactie in een gehele matrix van variabelen onmogelijk zou zijn. Een andere reden waarom we hebben besloten bij de meeste variabelen het effect van clustering te verwaarlozen, was de betrekkelijk geringe waarde die aan de natuurlijke groepering van de respondenten in de woonplaatsen kon worden toegeschreven. Voor zeven variabelen of proporties hebben we de standaardfout berekend volgens de bovenbeschreven methode en volgens de formule die wordt toegepast op aselecte, normaal verdeelde steekproeven: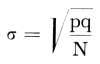 De resultaten kunnen in de volgende tabel worden samengevat:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 369]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wij bemerken dat t.o.v. de belangrijkere afhankelijke variabelen de vertekening veroorzaakt door de natuurlijke groepering der respondenten voor de gehele steekproef onder de waarde van 1% blijft, waar slechts een proportie van de steekproef wordt beschouwd (‘mannen onder de respondenten’) is de vertekening uiteraard groter. Ook hier echter bleef de waarde van deze vertekening onder de 2%. Al hadden wij geen zekerheid dat t.o.v. andere door ons onderzochte variabelen de foutenmarge niet groter zou uitvallen, wij hebben toch besloten de clustering-correctie slechts tot de in Tabel 2.7.3 opgenomen variabelen te beperken. Doorslaggevend voor onze beslissing was het feit dat wij ten tijde van de bewerking van onze gegevens niet over een adequate methode beschikten die deze correctie zou mogelijk maken ook voor de correlatieberekening, noch over andere technieken die zich leenden voor de analyse van een groot aantal variabelenGa naar voetnoot1. Nadat de beslissing werd genomen om van de minder bewerkelijke technieken gebruik te maken, werden voor de analyse van afzonderlijke hypothesen zowel de parametrische (het verschil tussen de twee gemiddelden, correlatie- en variantieanalyse) als non-parametrische (vooral de Chi-kwadraat berekening) toetsingstechnieken aangewend. Reeds spoedig stuitten we echter op het probleem van de interrelatie van de onderzochte variabelen, die de aanwending van statistisch toetsen op de afzonderlijke hypothesen van ons heterogeen materiaal moeilijk zo niet onmogelijk heeft gemaakt. Wilden wij de veronderstelling toetsen of mensen die veel deelnemen aan het verenigingsleven vaker of meer roken dan personen met lagere sociale participatie (hetgeen uit de theorie omtrent de sociale functie van de rookgewoonten kon worden afgeleid), dan zagen we ons met het feit geconfronteerd, dat zowel de sociale participatie als de rookgewoonten waarschijnlijk gecorreleerd waren met een aantal andere variabelen in overeenkomstige richting; wij verwachtten immers meer rokers in de hogere inkomstengroepen (en deze zijn tevens de groepen met meer opleiding) en bij mannen (en alweer hebben de mannen onder de bevolking meer opleiding en hogere inkomsten). Uit een voorgaand onderzoek leerden wij dat zowel mannen als personen met hogere status tevens hoge scores behaalden op de sociale-participatieschaal die wij gebruiktenGa naar voetnoot2. Door middel van non-parametrische tests bemerken wij | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 370]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dat inderdaad ook de inkomsten en de opleiding in onze steekproef met de sociale participatie zijn gecorreleerd. De vraag doet zich dan voor: indien wij een positieve correlatie tussen de sociale participatie en de intensiteit van de rookgewoonten vaststellen (hetgeen inderdaad geschiedde, zie de Matrix van Intercorrelaties, op blz. 384A), hoe moet deze correlatie worden uitgelegd? Mogen wij aannemen dat de sociale participatie als zodanig oorzaak is van het roken in onze samenleving, of is deze correlatie met de participatie slechts een bijprodukt van de samenhang tussen het roken en andere factoren (c.q. het man- of vrouw-zijn, opleiding, inkomsten)? Teneinde een antwoord te geven op deze vraag zouden wij deze correlatie moeten trachten terug te vinden in de kunstmatig homogene groeperingen van mensen met dezelfde opleidingsgraad, van dezelfde inkomsten en hetzelfde geslacht. De beperkte omvang van onze steekproef liet nauwelijks een dergelijke opsplitsing in vier of meer categorieën (waarvan de meeste met meer dan twee subcategorieën) toe. Bovendien werd de analyse nog verzwaard door het feit dat wij bij andere verbanden geheel in het duister tastten over de mogelijke factoren die de gezochte samenhang konden verstoren en dat wij niet (als in het aangehaalde voorbeeld het geval is geweest) beschikten over de kennis verzameld in voorafgaande onderzoekingen. Al deze overwegingen deden ons zoeken naar een techniek die het mogelijk zou maken de gelijktijdige werking (interactie) van een groot aantal variabelen te onderzoeken zonder al te groot verlies van informatie door de voortdurende inkrimping van onze steekproef. Nu beschikt men vooral in het psychologisch gerichte onderzoek sedert jaren over een methode die bij uitstek geschikt is om structuur aan te brengen in het materiaal bestaande uit responsies van een groot aantal individuen op een groot aantal ‘tests’ (c.q. vragen): de factoranalytische bewerking van de correlatiecoëfficiënten. Zo groot was het nadeel van de causale interpretatie van het afzonderlijk beschouwde statistische verband tussen telkens slechts twee variabelen, dat we besloten deze methode te gebruiken ondanks de bezwaren die kleven aan de toepassing van de correlatietechnieken op de enquêtegegevens: de nu en dan voorkomende afwijking van de normale verdeling bij vele variabelen en de onvoldoende quantificatie der gegevens; strikt genomen, laten immers zelfs de Guttman-schalen slechts de rangmethode toe, terwijl het gebruik van dichotome variabelen met risico's en het gebruik van de slechts nominale variabelen (als ‘kerkgenootschap’) met onzekerheid gepaard gaan. Wij besloten de factoranalyse der correlatiecoëfficiënten niet als de enige methode aan te wenden, doch slechts als een methode die de afzonderlijk verkregen informatie zou trachten te synthetiseren. Daar waar het ging om de sterkte van de gesignaleerde samenhang, zou men zowel de spreiding als de mate | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 371]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
van quantificatieGa naar voetnoot1 van de variabele in beschouwing nemen teneinde de adequate test van de hypothese te kiezen. Voor het voornaamste factoranalytische schema zijn in de eerste plaats 34 variabelen uit ons materiaal gekozen. Om onderzoektechnische redenen (de elektronische machine die wij voor de bewerking zouden kiezen, liet uitgebreider schema's niet toe) en methodologische overwegingen (het was bedenkelijk zelfs in de groep van 34 heterogene sociologische variabelen naar de gemeenschappelijke factoren te gaan zoeken) moest een groot gedeelte van het door middel van onze enquête verzamelde materiaal worden weggelaten. De selectie van variabelen werd geheel gedicteerd door onze wetenschappelijke belangstelling, hoewel systematische overwegingen (het opnemen van de basisvariabelen als geslacht, opleiding, inkomsten, burgerlijke staat enz.) een zekere beperking legden op de vrijheid van keuze. Behalve de selectie van variabelen is ook de selectie van subcategorieën aansprakelijk geweest voor de reductie van informatie. Er zijn tweedelige categorieën gebruikt (geslacht, woonplaats, aard van beroep) naast driedelingen (vooral met betrekking tot de verandering) en variabelen bestaande uit een groter aantal subcategorieën (hieronder vallen ook de echte kwantitatieve variabelen in gegroepeerde vorm: gemeentegrootte, inkomsten, leeftijd, intensiteit rook- en drinkgewoonten enz.). Voor de goede orde geven wij in Tabel 2.7.4 deze 34 variabelen weer, te zamen met de gebruikte subcategorieën gerangschikt in dezelfde richting waarin deze ook in de correlatiematrix zijn opgenomen.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 372]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 373]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 374]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 375]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 376]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 377]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Het is niet moeilijk om uit Tabel 2.7.4 de inlichtingen te distilleren die wij nodig hebben om de correlatiecoëfficiënten te interpreteren die voor elk van de omschreven variabelen paarsgewijs met alle overige variabelen zijn berekend. De subcategorieën geven immers de richting van de associaties aan, daar de volgorde (aangeduid door de Romeinse cijfers) bij het coderen van het materiaal is aangehouden. Uit de laatste kolom leren wij welke subcategorieën bij de berekening van de coëfficiënt buiten beschouwing zijn gelaten. Het ging hier om betrekkelijk kleine aantallen mensen die hetzij geen opinie hadden, hetzij geen adequaat antwoord op onze vraag hebben gegeven. Daar waar het zinvol was (de categorie ‘niet van toepassing’ bij de mensen die geheel geen alcohol gebruiken), werden deze mensen aan de neutrale of andere corresponderende subcategoric gevoegd. In geen van de onderscheiden gevallen daalde het N (totaal aantal respondenten wier antwoorden werden gecorreleerd) onder 1000 personen. Slechts een kleine toelichting willen wij hier geven, betreffende de reden waarom sommige variabelen werden opgenomen en betreffende de wijze waarop het quantificatieproces zich voltrok. De eerste vier variabelen behoeven wellicht geen commentaar; wat variabele 5, beroepsgroep, betreft, hebben wij besloten om van de gebruikelijke classificatie der beroepen in sociale rangstanden af te zien; wij meenden dat zowel ‘inkomsten’ als ‘opleiding’ reeds belangrijke informatie in dit opzicht verschaften en dat door het beroep uitsluitend te zien als indicator van de sociale status een | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 378]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
stuk van de sociale realiteit teloor zou gaan. Als kleine aanduiding van ‘de aard van het werk’ namen we de verdeling van beroepen berustend op de werkzaamheden buitens- en binnenshuis. Variabele 8, gezinsbinding, ontstond door samentrekken van informatie, verkregen op twee vragen. We meenden dat de instelling en het geestelijke evenwicht in belangrijke mate worden beïnvloed door het feit of de mens deel uitmaakt van een gezinsgroep en de intieme sfeer kent van een ‘man-vrouw’- of een ‘ouder-kind’-verhouding. Vandaar dat we een eenvoudige schaal opstelden die de verloofden boven de niet-verloofden en ongehuwden zonder kinderen plaatste, de gehuwden zonder kinderen boven de verloofden en, met enige aarzeling, ongehuwden met kinderen nog hierboven. Deze laatste categorie omvatte nl. vooral de weduwen met kinderen, hiernaast ook gescheiden moeders of vaders met kinderen; slechts in enkele gevallen ging het om moeders met buitenechtelijke kinderen. Veronderstellend dat bij de weduwen het proces van de persoonlijkheidsvorming zich reeds heeft voltrokken en dat in hun psychisch referentiekader toch een ‘partner’ heeft bestaan, meenden we deze categorie een hogere score te moeten geven. Het kleine aantal (72 personen) excuseert een mogelijke vergissing; de correlaties zullen waarschijnlijk voornamelijk bepaald worden door de laatste categorie (gehuwd met kinderen: 852 personen) duidelijk meer scorend dan ‘de rest’. Sociale participatie (variabele 9) is gebaseerd op de Stuart Chapin-schaal, die wij voor Nederland hebben vertaald en bij een kleine steekproef in een voorgaand onderzoek geijktGa naar voetnoot1: voor elke respondent werd nagegaan het lidmaatschap in verenigingen en instellingen (o.a. kerkgenootschap) alsmede de intensiteit van zijn deelname aan het leven en het functioneren van de vereniging (c.q. instelling). De som van de behaalde punten bepaalde de mate van de formele sociale participatie van de individu. Cultuuraanvaarding (variabele 10) is gebaseerd op de reeds aangehaalde schaal van Guttmans type. Contacten met communicatiemedia (variabele 11) is een eenvoudige cumulatieve index; regelmatige toegang tot een krant, een of meer weekbladen, een radio vormen de basis van de index; het geregeld luisteren naar lezingen en voorlichting werd hieraan als nieuwe categorie toegevoegd. Kerkgenootschap bleek een der moeilijkst te quantificeren categorieën. Na enige aarzeling besloten wij twee aspecten hiervan door de rangschikking van subcategorieën tot uiting te brengen: A. de mate van maatschappelijke binding en collectief gezag die een bepaald kerkgenootschap voorstelt; wij meenden in de organisatie van de Rooms-Katholieke kerk een hechtere binding en een meer conformiteit vereisende structuur te vinden | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 379]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
dan in een der Gereformeerde kerken; en bij de Nederlands Hervormde kerk een iets hechtere binding en sterker collectief gezag dan bij de Remonstranten of Doopsgezinden. B. het verschil tussen de ethiek van het protestantisme en van het rooms-katholicisme; de groepering personen zonder godsdienstige binding werd bij deze tweede variabele (no. 32) tussen beide belangrijkste aftakkingen van de christelijke godsdienst in Nederland geplaatst; volgens de informatie die wij verkregen uit de publikaties van het C.B.S.Ga naar voetnoot1 worden de onkerkelijken in Nederland niet uitsluitend uit de protestante of rooms-katholieke gezinnen gerekruteerd, zodat ook t.o.v. ‘de nawerking’ van de ethos der kerkgenootschappen in generaties onkerkelijken de personen zonder kerkgenootschap tot een gemengde, dus in statistische termen: neutrale, groepering behoren. Houding t.o.v. het roken (var. 14) is de schaal verkregen door het zoeken van de langste correlatie-as van een aantal vragen omtrent roken (zie bespreking op blz. 357 vlg.). Sociale instelling (var. 20) is ‘een semantische schaal’; de onderscheiden responsiemogelijkheden werden geanalyseerd naar de mate van behulpzame of ‘asociale’ houdingselementen, zonder enige empirische toets van unidimensionaliteit. Wel werden er meerdere beoordelaars ingeschakeld bij de classificatie van ‘items’. De ‘unfolding technique’ van Coombs, die we oorspronkelijk op dit soort vraag hoopten toe te passen, bleek te omslachtig te zijn om de latente structuur in de responsiepatronen te ontdekken. Daar we zelf bezwaren hadden tegen de constructie van schalen uitsluitend aan de hand van semantische analyse van de stimuli, beperkten wij de oorspronkelijke 7-gradenschaal tot een schaal met vier subcategorieën. Deze bevatte de mensen die de volgende uitspraken kozen.
Tevredenheid (vr. 21) was alweer een eenvoudige combinatie-index, verkregen door het samentrekken van antwoorden op de vier ‘satisfactie- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 380]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
vragen’ in onze vragenlijst: tevredenheid met werk, gezondheid, huisvesting en eigen levensloop .Deze vragen bleken in de factoranalyse van de tetrachorische r-coëfficiënten van 12 houdingsvragen met de eerste factor bijzonder hoog geladen (zie Tabel 2.8.4 en Tabel 2.8.5 op blz. 396). Wij hebben afgezien van een scoringprocédé dat met de intensiteit der ladingen rekening zou houden, daar twee variabelen zowel met Factor I' als Factor II' bleken te zijn geladen; om semantische redenen werden deze afzonderlijk in ons breder factoranalytisch schema opgenomen (var. 24 en 25: zie verder). Bezorgdheid (var. 22): eveneens een combinatie-index. De zorgen over geldzaken, gezondheid, dood enz. werden als quantitatief equivalent beschouwd en het aantal levensgebieden waarop men zorgen koesterde werd eenvoudig voor elke respondent opgeteld. Normenbeleving (var. 23) is waarschijnlijk de meest zorgelijke variabele van ons schema. Als grondslag lag de veronderstelling dat de bevolking kan worden verdeeld langs de scheidslijn van de collectivistische, maatschappijbeschermende en de meer individualistische, minder traditionele moraal. Daar vraag 108, evenals de reeds besproken vraag 126, die de bron vormde van onze variabele ‘sociale instelling’, was van het type ‘order 2 en reject 2’, in de termen van Coombs terminologieGa naar voetnoot1, het bleek alweer moeilijk aan de hand van de tegenwoordige kennis van de schaalconstructie hier een empirische schaal te construeren. Wij besloten tot de classificatie van de responsies volgens de in Tabel 2.7.4 aangeduide wijze. Abortus (vanwege het belang van de voortplantingsfunctie voor de maatschappij) wordt als meer ‘collectivistisch’ gezien dan andere inbreuken op de normen van seksueel gedrag (prostitutie); de religieuze norm werd boven de politieke norm geplaatst, deze beide boven de economische; en deze alweer boven de zuiver individualistische normen als de zorg voor eigen gezondheid. Persoonlijkheidsevenwicht (var. 24) werd gebaseerd op de informatie die de respondenten verstrekten over hun eigen psychische toestanden, als ‘onder spanning of druk leven’, ‘angsten hebben’, ‘zich vervelen’, ‘het doel van eigen leven niet inzien’, enz. Een eenvoudige combinatie-index werd opgesteld, waarbij de kwalitatieve verschillen tussen deze ‘symptomen’ werden verwaarloosd en slechts de groepen mensen met en groepen mensen zonder ‘symptomen’ in het correlatieschema werden opgenomen, terwijl aan mensen met meer dan één ‘symptoom’ nog hogere scores werden gegeven, evenredig met het aantal symptoomresponsies dat zij gaven. Van de overige variabelen behoeft slechts var. 31, woonstreek enig com- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 381]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
mentaar: de gebruikelijke verdeling van ons land langs de lijn aangegeven door de grote rivieren werd door ons gevolgd bij de verdeling van de personen uit de 85 gemeenten in onze steekproef in de twee groepen van ‘Zuiderlingen’ en ‘Noorderlingen’. Deze categorie werd opgenomen daar we van tevoren grote verschillen in gedrag en levensstijl in beide onderdelen van ons land verwachtten en geïnteresseerd waren o.a. in de vraag in hoeverre deze geografische verschillen door structurele (vooral godsdienstige) verschillen waren veroorzaakt. Tenslotte nog een beschouwing van dit schema van 34 variabelen als geheel. Het valt niet te ontkennen dat bij de samenstelling hiervan, bij de selectie van de categorieën, het subjectieve element, in de vorm van de belangstelling van de onderzoekers of de opdrachtgever een sterke rol heeft gespeeld. Wij kunnen de opgenomen variabelen classificeren ongeveer in dezelfde groepen als de hoofdstukken van het eerste deel van ons rapport. Bij de onafhankelijke variabelen hebben wij naast de gebruikelijke ‘basisfactoren’ (zoals leeftijd, sekse, inkomsten, enz.) ook enkele nieuwe concepten toegevoegd: de mate van cultuuraanvaarding of -ontwijking, sociale participatie, gezinsbinding, frequentie contact huisarts, contacten met communicatiemedia, traumatische ervaringen, evaluering van eigen jeugd, algemene normbeleving en tevens de dynamische aspecten (levensstandaardverandering). Het spreekt vanzelf dat dank zij het algemene referentiekader van deze studie, gebaseerd op de hypothese der sociale interdependentie, de scheiding tussen de onafhankelijke en afhankelijke factoren niet systematisch is doorgevoerd: de correlatiematrix hielp ons ook de causale relaties tussen de onafhankelijke variabelen onderling vinden. Een kritische bedenking moet ons in dit verband van het hart: hoewel we zoveel mogelijk ernaar streefden om bij het opstellen van het correlatieschema aan de eis van de begripsmatige onafhankelijkheidGa naar voetnoot1 te voldoen, is het evident dat niet alle variabelen als onderling onafhankelijk in semantische of operationele zin kunnen worden beschouwd. Zowel kerkgenootschap A als kerkgenootschap B zijn immers van dezelfde feitelijke basis afgeleid, nl. van de vraag tot welk kerkgenootschap de respondent zich rekende. Met beide variabelen is tevens var. 9 begripsmatig verbonden: het is a priori uitgesloten dat de leden van een kerkgenootschap de score van o punten behalen, daar wij bij onze inventarisatie van instellingen en verenigingen waarvan men lid was tevens aan de kerk hebben gedacht. Een correlatie tussen variabelen 6 en 31 is ook betrekkelijk | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 382]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
weinig zeggend, daar beide variabelen op dezelfde feitelijke basis terug te brengen zijn. Voor de resterende concepten kunnen wij echter stellen dat zij wederzijds a priori onafhankelijk zijn en dat het daarom zinvol kan zijn naar de empirische onderlinge verbanden te speuren. Plaatsen we de zojuist omschreven variabelen in een matrix, dan bemerken wij dat er in principe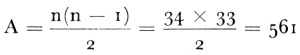 correlatieberekeningen moeten gebeuren teneinde alle statistische samenhangen te vinden, die de variabelen onderling verbinden. (Langs de hoofddiagonaal verwachtten wij nl. correlaties 1, terwijl de tweede helft van de matrix symmetrisch is). Wij prijzen ons gelukkig dat dank zij de medewerking van het Mathematisch Instituut van de Rijksuniversiteit te Groningen, op ons verzoek een apart programma voor de berekening van correlaties (Pearsons produkt-momentcoëfficiënten) uit de gegroepeerde gegevens werd ontworpen voor de elektronische rekenmachine (de zebra). Op deze wijze werden de Hollerith-lijsten, afkomstig van de afdeling Statistiek van het N.I.P.G. door ons slechts samengetrokken in de gewenste categorieën en op de band geponst. De correlatierekening geschiedde machinaal. Tabel 2.7.5 geeft de resultaten van deze fase van de bewerking weer. Teneinde ruimte te besparen hebben we in de cellen van de matrijs slechts de getallen achter de komma opgenomen, rekening houdend met de richting van de correlatiecoëfficiënt (negatief of positief). Op deze wijze kon een decimale plaats gewonnen worden voor nauwkeuriger weergave van de coëfficiënten. Cursief gedrukte getallen duiden de coëfficiënten aan die volgens onze berekening een significantieniveau behalen van .01 of meer. We volgden hierin de door De Jonge opgegeven methodeGa naar voetnoot1. 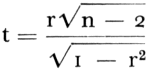 voor n = 1.297 en r = .06 vonden wij P < 0.05 > 0.02. Met andere woorden: r = .056 bleek nog net significant bij .05 niveau van waarschijnlijkheid, terwijl de drempelwaarde voor het .02 niveau lag bij r = .064. De inkrimping van n bleek van veel minder invloed te zijn, de tabel van ‘Fractielen van de verdeling van de correlatiecoëfficiënt r voor ρ = o’ (Tabel E, de Jonge, deel I, blz. 298) die de Jonge ontleent aan Walker | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 383]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
en Lev geeft voor n - 2 = 1000 de volgende waarden op: r0,95 ... 0,052 r0,975 ... 0,062; r0,99 ... 0,073; r0,995 ... 0,081. Daar bij elke correlatieberekening in ons schema n kleiner was dan 1000 respondenten, kunnen wij aannemen dat de grenswaarde van r = .065 voor de nog significante verbanden gehandhaafd kan worden. Teneinde de kans op toevallige verbanden te verminderen, hebben we de waarde van r = .075 als kritieke waarde gekozen, die met P < .01 correspondeert. Een niet te verwaarlozen aantal significante samenhangen kan van onze basismatrix van intercorrelaties worden afgelezen. Deze vormen de eerste stap op zoek naar causale samenhangen, daar we veronderstellen dat oorzaak en gevolg werkelijk moeten samengaan, hetzij structureel of in de loop der tijd, wil er van een oorzakelijk verband sprake zijn. Op grond van onze vroegere onderzoekervaring waren we echter voorzichtig om de gesignaleerde verbanden zonder meer causaal te gaan interpreteren. In overeenstemming met het theoretisch denken over de echte en onechte verbanden dat vooral door Herbert A. Simon pregnant is geformuleerdGa naar voetnoot1, kan een statistisch verband tussen twee variabelen van een sociologische enquête dan causaal worden geïnterpreteerd indien het de toets van het systematisch invoeren van de mogelijk interveniërende variabelen heeft doorstaan. Indien wij deze stelling consequent doordenken, dan zal ook de intensiteit van het verband, de waarde van de correlatiecoëfficiënt, niet doorslaggevend zijn voor de beslissing of wij met een causaal echte of onechte samenhang te maken hebben. Toegepast op onze matrix van intercorrelaties vindt deze redenering haar bevestiging. Nemen wij een der belangrijkste variabelen van ons onderzoek, de intensiteit der rookgewoonten, in beschouwing, dan vinden wij naast een verwachte, vanzelfsprekende correlatie met het geslacht, ook een correlatie met de aard van het werk. Deze correlatie hebben wij niet verwacht; wij konden niet zonder meer theoretisch verklaren waarom personen buitenshuis werkend significant meer rookten dan personen binnenshuis (r = .30!). Wij waren eerder geneigd te denken dat de industriële arbeid en het leven in de steden het gebruik van stimulantia in de hand zou werken. Toen we echter variabele 1 (geslacht) als een testfactor invoerden, verdween het verband geheel. Simon volgend hebben wij voor de toets de partiëlecorrelatiemethode gebruikt: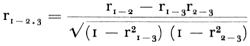 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 384]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Lezen wij voor 1 = aard van beroep (var. 5); voor 2 = intensiteit rookgewoonten (var. 13); en voor 3 = geslacht (var. 1), dan kunnen we in de corresponderende cellen van de matrix rechtstreeks de waarden voor onze formule vinden. Na het invullen verkrijgen wij
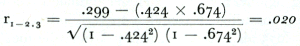 De oorspronkelijke coëfficiënt van .30 wordt hier op .02 gereduceerd. Duidelijk wordt hier aangetoond dat het gesignaleerde verband, hoewel significant bij het niveau P < .0001, causaal gezien een schijnverband voorstelt, dat geheel ‘weg kan worden verklaard’ uit andere associaties: vrouwen roken opvallend minder dan mannen en vrouwen werken tevens opvallend meer binnenshuis dan mannen. Hierin hebben wij dan een statistisch instrument gevonden dat het ons mogelijk maakt om structuur aan te brengen in de honderden statistische significante verbanden die wij hebben berekend. Door middel van de partiële correlatie indien het om correlatiecoëfficiënten gaat, door middel van de combinatie van de significantietoetsen daar waar b.v. nonparametrische statistieken worden berekendGa naar voetnoot1, kunnen wij immers de schijnverbanden scheiden van de statistische associaties die niet kunnen worden toegeschreven aan een of ander interveniërende factor en die ons een stapje nader kunnen brengen tot de oorzaken van de bestudeerde verschijnselen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 384A]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 2.7.5 Basis correlatiematrix
|
| 1 | Geslacht: man - vrouw |
| 2 | Leeftijd: 21-25 jaar - ouderen |
| 3 | Inkomsten: - ƒ 40,- - hogere |
| 4 | Opleiding: geen - L.O. - hogere |
| 5 | Aard van het werk: buitenwerk - binnenwerk |
| 6 | Gemeentegrootte: -3.000 - groter |
| 7 | Migratie-index: 0, 1 × - meerdere keren |
| 8 | Gezinsbinding: ongehuwd z.k. - gehuwd m.k. |
| 9 | Sociale participatie: - 2 p. - 4 p. → |
| 10 | Cultuuraanvaarding: o (laag) - hoog |
| 11 | Contact met communicatiemedia: geen - meer |
| 12 | Kerkgenootschap A: geen - And. - N.H. - Ger. - R.-K. |
| 13 | Intensiteit roken: geen, - 1 → veel |
| 14 | Houding t.o.v. roken: tolerant → intolerant |
| 15 | Roken oorzaak longziekten: gelooft niet - wel |
| 16 | Intensiteit drinken: niets - vaak (veel) |
| 17 | Houding t.o.v. drinken: o (tolerant) → 5 (intolerant) |
| 18 | Intensiteit koffiegebruik: niets - veel |
| 19 | Snoepgewoonten: niet - elke dag veel |
| 20 | Sociale instelling: asociaal - behulpzaam |
| 21 | Tevredenheid: tevreden - ontevreden |
| 22 | Bezorgdheid: geen zorgen - vele zorgen |
| 23 | Normenbeleving: collectief (seksueel) - individueel |
| 24 | Persoonlijkheidsevenwicht: geen symptomen - wel symptomen |
| 25 | Traumatische ervaringen: geen - vele |
| 26 | Jeugdherinneringen: prettig - onprettig |
| 27 | Optimisme: optimistisch - pessimistisch |
| 28 | Inkomstenverandering: thans meer - thans minder |
| 29 | Rookpatroonverandering: thans meer - thans minder |
| 30 | Drinkpatroonverandering: thans meer - thans minder |
| 31 | Woonstreek: Noorden - Zuiden |
| 32 | Kerkgenootschap B: N.H. - Ger. - And. - Geen - R.-K. |
| 33 | Frequentie doktersbezoek: vaak - nooit |
| 34 | Aantal werkuren: geen, - 5 → veel |
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 1.00 | .022 | -.111 | -.113 | .424 |
| 2 | .022 | 1.00 | -.104 | -.187 | .003 |
| 3 | -.111 | -.104 | 1.00 | .289 | .067 |
| 4 | -.113 | -.187 | .289 | 1.00 | .122 |
| 5 | .424 | .003 | .067 | .122 | 1.00 |
| 6 | .035 | .075 | .079 | .106 | .155 |
| 7 | .016 | -.211 | .155 | .194 | .080 |
| 8 | -.041 | .249 | .334 | -.163 | -.007 |
| 9 | -.163 | .006 | .193 | .138 | -.036 |
| 10 | .010 | -.007 | .022 | .139 | .047 |
| 11 | .003 | .011 | .197 | .134 | .061 |
| 12 | .009 | -.059 | -.077 | -.062 | -.023 |
| 13 | -.674 | -.061 | .149 | .094 | -.299 |
| 14 | .008 | .084 | -.117 | -.119 | -.052 |
| 15 | .037 | -.008 | .034 | .108 | .037 |
| 16 | -.273 | -.097 | .089 | .119 | -.105 |
| 17 | .129 | .239 | -.029 | -.047 | .086 |
| 18 | -.137 | -.116 | .115 | -.032 | -.113 |
| 19 | .162 | -.009 | .119 | .096 | .183 |
| 20 | -.023 | .042 | -.018 | .071 | -.014 |
| 21 | -.034 | .049 | -.049 | .009 | -.009 |
| 22 | .120 | -.016 | .000 | -.008 | .073 |
| 23 | -.121 | .136 | -.030 | -.046 | -.079 |
| 24 | .115 | .080 | -.037 | -.006 | .094 |
| 25 | .002 | .027 | .054 | -.028 | -.018 |
| 26 | .049 | .101 | .013 | -.078 | .004 |
| 27 | .054 | .051 | -.004 | -.045 | .012 |
| 28 | -.025 | .185 | -.119 | -.105 | -.064 |
| 29 | -.101 | .020 | .023 | .046 | -.047 |
| 30 | -.192 | .151 | .001 | -.084 | -.162 |
| 31 | -.041 | -.080 | -.058 | -.093 | -.045 |
| 32 | -.045 | -.104 | .054 | -.003 | -.019 |
| 33 | -.098 | -.066 | .063 | .087 | -.043 |
| 34 | -.107 | -.316 | .206 | .049 | -.129 |
| 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|
| 1 | .035 | .016 | -.041 | -.163 | 0.10 |
| 2 | .075 | -.211 | .249 | .006 | -.007 |
| 3 | .079 | .155 | .334 | .193 | .022 |
| 4 | .106 | .194 | -.163 | .138 | .139 |
| 5 | .155 | .080 | -.007 | -.036 | .047 |
| 6 | 1.00 | .110 | .072 | -.170 | .005 |
| 7 | .110 | 1.00 | .007 | -.059 | .012 |
| 8 | .072 | .007 | 1.00 | .058 | -.101 |
| 9 | -.170 | -.059 | .058 | 1.00 | .282 |
| 10 | .005 | .012 | -.101 | .282 | 1.00 |
| 11 | .100 | .044 | .055 | .145 | .107 |
| 12 | -.269 | -.126 | -.114 | .293 | .269 |
| 13 | .004 | .025 | .034 | .097 | -.063 |
| 14 | .078 | -.038 | .015 | -.046 | .024 |
| 15 | -.037 | .020 | -.034 | .054 | .089 |
| 16 | -.015 | .034 | -.097 | .050 | -.046 |
| 17 | .071 | -.062 | .120 | .056 | .097 |
| 18 | -.066 | -.018 | .034 | -.019 | -.112 |
| 19 | .196 | .110 | .054 | .098 | .124 |
| 20 | -.140 | .009 | -.069 | .194 | .251 |
| 21 | .096 | .079 | .041 | -.114 | -.064 |
| 22 | .106 | .051 | .098 | -.024 | .140 |
| 23 | .064 | -.021 | -.039 | -.069 | -.036 |
| 24 | .177 | .084 | .021 | -.137 | .045 |
| 25 | .160 | .202 | .059 | -.054 | -.005 |
| 26 | .108 | .065 | .085 | -.114 | .007 |
| 27 | .005 | -.022 | .048 | -.021 | .005 |
| 28 | -.022 | -.024 | .083 | -.075 | -.030 |
| 29 | -.001 | .100 | .043 | -.033 | -.059 |
| 30 | .003 | .006 | .107 | -.029 | -.007 |
| 31 | -.329 | -.139 | -.072 | .051 | .004 |
| 32 | -.030 | -.031 | -.057 | .021 | -.104 |
| 33 | -.112 | -.059 | -.085 | .011 | -.017 |
| 34 | -.098 | .010 | .031 | .111 | .025 |
| 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|
| 1 | .003 | .009 | -.674 | .008 | .037 |
| 2 | .011 | -.059 | -.061 | .084 | -.008 |
| 3 | .197 | -.077 | .149 | -.117 | .034 |
| 4 | .134 | -.062 | .094 | -.119 | .108 |
| 5 | .061 | -.023 | -.299 | -.052 | .037 |
| 6 | .100 | -.269 | .004 | .078 | -.037 |
| 7 | .044 | -.126 | .025 | -.038 | .020 |
| 8 | .055 | -.114 | .034 | .015 | -.034 |
| 9 | .145 | .293 | .097 | -.046 | .054 |
| 10 | .107 | .269 | -.063 | .024 | .089 |
| 11 | 1.00 | -.097 | .023 | -.041 | -.008 |
| 12 | -.097 | 1.00 | -.022 | -.074 | -.005 |
| 13 | .023 | -.022 | 1.00 | -.066 | -.110 |
| 14 | -.041 | -.074 | -.066 | 1.00 | .176 |
| 15 | -.008 | -.005 | -.110 | .176 | 1.00 |
| 16 | -.010 | .033 | .308 | -.069 | -.044 |
| 17 | .087 | -.135 | -.152 | .157 | .042 |
| 18 | .017 | .009 | .273 | .015 | -.055 |
| 19 | .114 | -.156 | -.173 | .012 | .074 |
| 20 | .034 | .144 | -.035 | .007 | .045 |
| 21 | -.041 | -.124 | .073 | .080 | .022 |
| 22 | .043 | -.053 | -.070 | .127 | .069 |
| 23 | -.045 | -.197 | .104 | .040 | .013 |
| 24 | .071 | -.152 | -.045 | .140 | .100 |
| 25 | .089 | -.146 | .037 | .101 | -.004 |
| 26 | .029 | -.119 | -.043 | .047 | .002 |
| 27 | .002 | -.025 | -.047 | -.056 | .035 |
| 28 | -.021 | .014 | .000 | .015 | -.021 |
| 29 | .053 | -.057 | .076 | .018 | -.039 |
| 30 | -.024 | .011 | .144 | .073 | -.024 |
| 31 | -.175 | .459 | .036 | -.070 | -.024 |
| 32 | -.044 | .339 | .092 | -.054 | .005 |
| 33 | -.021 | .052 | .076 | -.097 | .003 |
| 34 | .019 | .072 | .106 | .032 | -.006 |
| 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | |
|---|---|---|
| 1 | -.273 | .129 |
| 2 | -.097 | .239 |
| 3 | .089 | -.029 |
| 4 | .119 | -.047 |
| 5 | -.105 | .086 |
| 6 | -.015 | .071 |
| 7 | .034 | -.062 |
| 8 | -.097 | .120 |
| 9 | .050 | .056 |
| 10 | -.046 | .097 |
| 11 | -.010 | .087 |
| 12 | .033 | -.135 |
| 13 | .308 | -.152 |
| 14 | -.069 | .157 |
| 15 | -.044 | .042 |
| 16 | 1.00 | -.250 |
| 17 | -.250 | 1.00 |
| 18 | .091 | -.136 |
| 19 | -.033 | .175 |
| 20 | -.068 | .056 |
| 21 | .003 | -.044 |
| 22 | -.035 | .112 |
| 23 | .064 | .002 |
| 24 | -.069 | .063 |
| 25 | -.006 | .116 |
| 26 | -.045 | .040 |
| 27 | -.066 | .064 |
| 28 | -.060 | .016 |
| 29 | -.018 | -.015 |
| 30 | -.062 | -.024 |
| 31 | .041 | -.299 |
| 32 | .124 | -.243 |
| 33 | .058 | -.040 |
| 34 | .048 | -.045 |
| 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | |
|---|---|---|---|---|---|
| 1 | -.137 | .162 | -.023 | -.034 | .120 |
| 2 | -.116 | -.009 | .042 | .049 | -.016 |
| 3 | .115 | .119 | -.018 | -.049 | .000 |
| 4 | -.032 | .096 | .071 | -.009 | -.008 |
| 5 | -.113 | .183 | -.014 | -.009 | .073 |
| 6 | -.066 | .196 | -.140 | .096 | .106 |
| 7 | -.018 | .110 | .009 | .079 | .051 |
| 8 | .034 | .054 | -.069 | .041 | .098 |
| 9 | -.019 | .098 | .194 | -.114 | -.024 |
| 10 | -.112 | .124 | .251 | -.064 | .140 |
| 11 | .017 | .114 | .034 | -.041 | .043 |
| 12 | .009 | -.156 | .144 | -.124 | -.053 |
| 13 | .273 | -.173 | -.035 | .073 | -.070 |
| 14 | .015 | .012 | .007 | .080 | .127 |
| 15 | -.055 | .074 | .045 | .022 | .069 |
| 16 | .091 | -.033 | -.068 | .003 | -.035 |
| 17 | -.136 | .175 | .056 | -.044 | .112 |
| 18 | 1.00 | -.152 | -.015 | -.075 | -.051 |
| 19 | -.152 | 1.00 | -.018 | -.006 | .059 |
| 20 | -.015 | -.018 | 1.00 | -.044 | .008 |
| 21 | -.075 | -.006 | -.044 | 1.00 | .206 |
| 22 | -.051 | .059 | .008 | .206 | 1.00 |
| 23 | .028 | -.013 | -.048 | .001 | -.062 |
| 24 | -.066 | .086 | -.002 | .308 | .406 |
| 25 | -.011 | .089 | -.052 | .129 | .146 |
| 26 | -.031 | .008 | -.080 | .145 | .107 |
| 27 | -.021 | .081 | .030 | .037 | .173 |
| 28 | -.030 | -.064 | -.032 | .043 | .055 |
| 29 | .000 | -.004 | .009 | .100 | .002 |
| 30 | -.012 | -.095 | -.013 | .095 | -.004 |
| 31 | .070 | -.312 | .026 | -.071 | -.140 |
| 32 | .062 | -.149 | -.066 | .026 | -.099 |
| 33 | .084 | -.105 | -.031 | -.211 | -.154 |
| 34 | .110 | -.074 | .030 | -.063 | .052 |
| 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | |
|---|---|---|---|---|---|
| 1 | -.121 | .115 | .002 | .049 | .054 |
| 2 | .136 | .080 | .027 | .101 | .051 |
| 3 | -.030 | -.037 | .054 | .013 | -.004 |
| 4 | -.046 | -.006 | -.028 | -.078 | -.045 |
| 5 | -.079 | .094 | -.018 | .004 | .012 |
| 6 | .064 | .177 | .160 | .108 | .005 |
| 7 | -.021 | .084 | .202 | .065 | -.022 |
| 8 | -.039 | .021 | .059 | .085 | .048 |
| 9 | -.069 | -.137 | -.054 | -.114 | -.021 |
| 10 | -.036 | .045 | -.005 | .007 | .005 |
| 11 | -.045 | .071 | .089 | .029 | .002 |
| 12 | -.197 | -.152 | -.146 | -.119 | -.025 |
| 13 | .104 | -.045 | .037 | -.043 | -.047 |
| 14 | .040 | .140 | .101 | .047 | -.056 |
| 15 | .013 | .100 | -.004 | .002 | .035 |
| 16 | .064 | -.069 | -.006 | -.045 | -.066 |
| 17 | .002 | .063 | .116 | .040 | .064 |
| 18 | .028 | -.066 | -.011 | -.031 | -.021 |
| 19 | -.013 | .086 | .089 | .008 | .081 |
| 20 | -.048 | -.002 | -.052 | -.080 | .030 |
| 21 | .001 | .308 | .129 | .145 | .037 |
| 22 | -.062 | .406 | .146 | .107 | .173 |
| 23 | 1.00 | -.022 | .007 | -.028 | .013 |
| 24 | -.022 | 1.00 | .221 | .216 | .105 |
| 25 | .007 | .221 | 1.00 | .306 | .077 |
| 26 | -.028 | .216 | .306 | 1.00 | .046 |
| 27 | .013 | .105 | .077 | .046 | 1.00 |
| 28 | .014 | .066 | -.023 | -.020 | .040 |
| 29 | -.009 | .026 | .007 | -.035 | -.010 |
| 30 | .032 | .030 | 0.69 | .016 | .021 |
| 31 | -.152 | -.187 | -.181 | -.080 | -.055 |
| 32 | -.111 | -.049 | -.064 | -.020 | -.112 |
| 33 | .045 | -.171 | -.084 | -.065 | -.007 |
| 34 | -.032 | -.058 | .027 | -.032 | .018 |
| 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | 32 | |
|---|---|---|---|---|---|
| 1 | -.025 | -.101 | -.192 | -.041 | -.045 |
| 2 | .183 | .020 | .151 | -.080 | -.104 |
| 3 | -.119 | .023 | .001 | -.058 | .054 |
| 4 | -.105 | .046 | -.084 | -.093 | -.003 |
| 5 | -.064 | -.047 | -.162 | -.045 | -.019 |
| 6 | -.022 | -.001 | .003 | -.329 | -.030 |
| 7 | -.024 | .100 | .006 | -.139 | -.031 |
| 8 | .083 | .043 | .107 | -.072 | -.057 |
| 9 | -.075 | -.033 | -.029 | .051 | .021 |
| 10 | -.030 | -.059 | -.007 | .004 | -.104 |
| 11 | -.021 | .053 | -.024 | -.175 | -.044 |
| 12 | .014 | -.057 | .011 | .459 | .339 |
| 13 | .000 | .076 | .144 | .036 | .092 |
| 14 | .015 | .018 | .073 | -.070 | -.054 |
| 15 | -.021 | -.039 | -.024 | -.024 | .005 |
| 16 | -.060 | -.018 | -.062 | .041 | .124 |
| 17 | .016 | -.015 | -.024 | -.299 | -.243 |
| 18 | -.030 | .000 | -.012 | .070 | .062 |
| 19 | -.064 | -.004 | -.095 | -.312 | -.149 |
| 20 | -.032 | .009 | -.013 | .026 | -.066 |
| 21 | .043 | .100 | .095 | -.071 | .026 |
| 22 | .055 | .002 | -.004 | -.140 | -.099 |
| 23 | .014 | -.009 | .032 | -.152 | -.111 |
| 24 | .066 | .026 | .030 | -.187 | -.049 |
| 25 | -.023 | .007 | .069 | -.181 | -.064 |
| 26 | -.020 | -.035 | .016 | -.080 | -.020 |
| 27 | .040 | -.010 | .021 | -.055 | -.112 |
| 28 | 1.00 | .065 | .108 | -.005 | -.016 |
| 29 | .065 | 1.00 | .093 | -.033 | .064 |
| 30 | .108 | .093 | 1.00 | .035 | .069 |
| 31 | -.005 | -.033 | .035 | 1.00 | .371 |
| 32 | -.016 | .064 | .069 | .371 | 1.00 |
| 33 | -.036 | -.037 | -.044 | .096 | .045 |
| 34 | -.051 | -.034 | -.022 | .051 | .087 |
| 28 | 29 | 30 | 31 | 32 |
| 33 | 34 | |
|---|---|---|
| 1 | -.098 | -.107 |
| 2 | -.066 | -.316 |
| 3 | .063 | .206 |
| 4 | .087 | .049 |
| 5 | -.043 | -.129 |
| 6 | -.112 | -.098 |
| 7 | -.059 | .010 |
| 8 | -.085 | .031 |
| 9 | .011 | .111 |
| 10 | -.017 | .025 |
| 11 | -.021 | .019 |
| 12 | .052 | .072 |
| 13 | .076 | .106 |
| 14 | -.097 | .032 |
| 15 | .003 | -.006 |
| 16 | .058 | .048 |
| 17 | -.040 | -.045 |
| 18 | .084 | .110 |
| 19 | -.105 | -.074 |
| 20 | -.031 | .030 |
| 21 | -.211 | -.063 |
| 22 | -.154 | .052 |
| 23 | .045 | -.032 |
| 24 | -.171 | -.058 |
| 25 | -.084 | .027 |
| 26 | -.065 | -.032 |
| 27 | -.007 | .018 |
| 28 | -.036 | -.051 |
| 29 | -.037 | -.034 |
| 30 | -.044 | -.022 |
| 31 | .096 | .051 |
| 32 | .045 | .087 |
| 33 | 1.00 | .064 |
| 34 | .064 | 1.00 |
| 33 | 34 |
| 1 | Sex: man - woman |
| 2 | Age: young - old |
| 3 | Incomes: low - high |
| 4 | Education: low level - high level |
| 5 | Kind of work: outdoors - indoors |
| 6 | Size of residence place: small - big |
| 7 | Migration index: low - high frequency |
| 8 | Family integration: single without children - married with children |
| 9 | Social participation index: low scores - high scores |
| 10 | Culture involvement: low scores - high scores |
| 11 | Contacts with mass communication media: none - many |
| 12 | Church-affiliation A: none - smaller churches - Dutch Reformed - Calvinist - Roman Catholic |
| 13 | Smoking habits: does not smoke - smokes much |
| 14 | Attitude to smoking: tolerant - intolerant |
| 15 | Smoking as cause of lung-illness: does not believe it - believes it |
| 16 | Drinking habits: does not drink - drinks much |
| 17 | Attitude to drinking: tolerant - intolerant |
| 18 | Coffee drinking habits: does not drink - drinks much |
| 19 | Habit of eating sweets: non-existent - intensive |
| 20 | Social attitude: asocial - altruistic, helpful |
| 21 | General satisfaction: content - discontent |
| 22 | Worries: no worries - many worries |
| 23 | Normative pattern: collectivistic - individualistic |
| 24 | Symptoms of lack of well-being: no symptoms - many symptoms |
| 25 | Traumatic youth experiences: none - more than one kind |
| 26 | Youth-reminiscences: warm - unpleasant |
| 27 | Optimism: optimistic - pessimistic |
| 28 | Change in incomes: now higher - now lower |
| 29 | Change in smoking pattern: now more - now less |
| 30 | Change in drinking pattern: now more - now less |
| 31 | Residential region: the North - the South |
| 32 | Church-affiliation B: Protestant - Without - Roman Catholic |
| 33 | Contacts with family-doctor: frequent - none |
| 34 | Working-hours: none, short - long |
- voetnoot*
- Door een machinale fout zijn de gemeenten no. 7 (Best) en 70 (Zutphen) op deze tabel samengevoegd. Daar het in het geval van Best slechts om 8 personen ging, achtten wij het niet nodig om de tabel over te doen.
- voetnoot1
- Als rokers beschouwden wij bij deze berekening personen die meer dan 1 sigaret (of 1 g tabak) per dag rookten, niet de personen die geheel niets rookten. De tabellen 2.7.1 en 2.7.2 werden opgemaakt voor de revisie der ponsingen.
- voetnoot1
- Het is de verdienste van professor Leslie Kish geweest dat de sociale onderzoekers attent zijn gemaakt op de gevaren van overbrengen van technieken bestemd voor aselecte steekproeven op gegevens uit ‘clustered samples’ (zie vooral zijn ‘Confidence intervals for clustered samples’) in American Sociological Review, Vol. 22 (1957) blz. 154-165). Professor Kish vermeldde in zijn publikatie (op. cit. blz. 164) dat hij werkte aan de ontwikkeling van een techniek die de schatting van gecorrigeerde variantie voor verschillende statistische waarden mogelijk zou maken. Op onze schriftelijk vraag kon prof. Kish ons echter nog geen resultaten van zijn speuren in deze richting geven. Wel hoopte hij in de loop der tijd de werkzaamheden op dit gebied te hervatten.
- voetnoot2
- I. Gadourek, A Dutch Community, blz. 432.
- voetnoot1
- Wij denken hier aan de classificatie van schaaltechnieken zoals ontworpen door S.S. Stevens en Clyde H. Coombs. Zie ook W.S. Torgerson, Theory and Methods of Scaling, New York, 1958, hfdst. 2.
- voetnoot2
- For English text see Summary, p. 432.
- voetnoot1
- A Dutch Community, 1955, blz. 271-273.
- voetnoot1
- Uit de Statistische Zakboeken van 1948 en 1958 vernemen we dat de toename van ‘onkerkelijkheid’ niet slechts in de noordelijke of westelijke doch ook in de zuidelijke provinciën valt waar te nemen. Deze toename is in absolute percentages in het geïndustrialiseerde westen veel groter; het verhoudingsgetal blijft zeker voor N.-Brabant en Limburg onder het Rijksgemiddelde.
- voetnoot1
- Clyde H. Coombs, ‘Theory and methods of social measurement’ in Leon Festinger, Daniel Katz, Research Methods in the Behavioral Sciences, New York, 1953, blz. 499-508.
- voetnoot1
- Zie voor de definitie van dit begrip ons artikel ‘Interne en externe relaties. Enkele kentheoretische problemen der sociologie’ in Algemeen Nederlands Tijdschrift voor Wijsbegeerte en Psychologie, 53e jrg., 3e Afl. (april, 1961), blz. 134.
- voetnoot1
- H. de Jonge, Inleiding tot de medische statistiek, II, Leiden 1960, blz. 522 en volg.
- voetnoot1
- Zie zijn ‘Spurious Correlation: a Causal Interpretation’, in the Journal of the American Statistical Association, vol. 49, September, 1954; later opgenomen tevens met ‘Causal Ordening and Identifiability’ and andere stukken in Models of Man; Social and Rational, New York, 1957.
- voetnoot1
- Zie ons artikel ‘A substitute for randomization designs in sociological research’ in the Indian Journal of Social Research, III, no. 1 (1962) en de literatuur daar aangehaald.