|
| |
| |
| |
Lexicale decisie en hardop lezen door normale en zwakke lezers
W.H.J. van Bon, P.H. Tooren en C.W.J.M. van Eekelen
Samenvatting
Deze bijdrage rapporteert over de relatie tussen hardop lezen en lexicale decisie bij een groep van overwegend zwak lezende LOM-leerlingen en een jongere groep basisschoolleerlingen met hetzelfde niveau van leesvaardigheid. Omdat de Nederlandse orthografie tamelijk transparant is werd een discrepantie tussen beide taken verwacht, maar lexicale-decisie bleek in beide groepen sterk gecorreleerd te zijn aan het hardop lezen van dezelfde woorden. Dat gold ook voor de vergelijking van een semantische decisietaak (‘namentaak’) met hardop lezen. Deze uitkomst laat zich goed rijmen met de opvatting dat een belangrijk deel van de onderzochte leesactiviteiten bestaat uit fonologisch decoderen, ook als de taak vraagt om raadpleging van het mentale lexicon. De resultaten suggereren ook dat de gebruikte groepsgewijze lexicale-decisietoets een goed alternatief is voor de individuele hardop-leestoets.
Er werden geen wezenlijke verschillen gevonden tussen de beide groepen lezers. De zwak lezende LOM-leerlingen hebben dus kennelijk eerder een leerachterstand dan dat ze anders lezen dan kinderen die een normale leesontwikkeling doormaken.
| |
1 Inleiding
De gebruikelijke manier om iemands leesvaardigheid te bepalen is door haar of hem een tekst of losse woorden hardop te laten lezen en daarbij snelheid en juistheid van de verklanking vast te stellen. Zo gebeurt dat bijvoorbeeld in de AVI-toetsen en in de Een-Minuut-Toets, of in de nieuwere variant van de laatste, de Drie-Minuten-Toets. Men kan tegen deze handelwijze als bezwaar aanvoeren dat het bij lezen uiteindelijk altijd gaat om begrip van tekst of woord, en dat dit ‘begrip’ niet tot uitdrukking komt in zulke hardopleestoetsen. Bepaling van leesvaardigheid zou daarom beter kunnen gebeuren met toetsen voorbegrijpend lezen. Daar is weer tegen in te brengen dat de ‘technische leesvaardigheid’ die men met de hardopleestoets probeert vast te stellen zeer waarschijnlijk een eigen en belangrijke rol speelt in het geheel van competenties die tezamen het tekstbegrip bepalen (Hoover & Gough, 1990), en daarom aparte toetsing verdient.
Een argument tegen de validiteit van hardop lezen als indicator van leesvaardigheid is voorts dat het gangbare lezen niet vraagt om de productie van een gesproken woord. In het leesonderwijs wordt wel hardop gelezen, maar vermoedelijk alleen omdat het alternatief, stillezen, de leesactiviteit aan de waarneming van leerling en leerkracht onttrekt en moeilijk onderwijsbaar maakt. (De bevordering van de kunst van het voorlezen wordt vermoedelijk niet als een belangrijk doel van het onderwijs beschouwd.) Ook de gedachte dat de identificatie van de woorden in een tekst essentieel is voor tekstbegrip veronderstelt slechts de vaststelling van hun fonologie of hun betekenis en niet de productie van de overeenkomstige uitspraak. Deze constatering is niet triviaal, omdat de productie van die uitspraak zijn eigen moeilijkheden met zich meebrengt. Dat laatste ligt alleen al voor de hand omdat bij het spreken zelf versprekingen kunnen voorkomen. Zulke versprekingen kunnen bestaan uit het min of meer toevallig falen van de besturing en de uitvoering van | |
| |
de spraakproductie, maar kunnen ook berusten op een structureel spraakprobleem.
Dat er een discrepantie is tussen woordidentificatie en woorduitspraak is voor het lezen aannemelijk gemaakt door een onderzoek van Kusters (1987). Goede en zwakke lezers lazen een reeks zinnen of losse woorden. Na lezing van een tevoren geselecteerd doelwoord moest de lezer steeds uit vier alternatieven die de proefleider voorlas het woord kiezen dat er het meest mee te maken had. Hier is belangrijk dat de zwakke lezers na fout gelezen doelwoorden het correcte alternatief toch vaker kozen dan toeval (25%) zou doen verwachten, zowel in geval van woorden in zinnen (52%) als in geval van losse woorden (48%); de goede lezers lazen te weinig fouten om zo'n vergelijking te maken. Waar het bij de productie van het gesproken woord fout ging, bij de vaststelling van fonologie van het woord of in stadia daarna, leert ons dit experiment niet. Duidelijk is wel dat de zwakke lezers in de regel meer van de woordbetekenis achterhaald hadden dan te horen was aan het hardop gelezen woord.
Een alternatieve manier om woordherkenning te toetsen, die niet vraagt om uitspraak, is lexicale decisie. Hoewel de methode gebruikt kan worden met gesproken woorden, wordt hij doorgaans toegepast met geschreven woorden. In een volgorde die voor de proefpersoon onvoorspelbaar is worden bestaande woorden en pseudowoorden gepresenteerd. De proefpersoon moet van elk woord vaststellen of het bestaat of niet. De juistheid en de snelheid van de beslissingen (behoort het woord tot het lexicon van mijn taal of niet?) worden bepaald. De eisen die de beslissingsprocedure stelt aan de bekendheid met het woord zijn betrekkelijk ruim: in beginsel voldoen voor een juiste keuze zowel (on)bekendheid met het letterpatroon, met het klankpatroon als met de betekenis.
In dit artikel wordt gerapporteerd over een onderzoek naar de relatie tussen hardop lezen en lexicale decisie. Daarbij is lexicale decisie - anders dan gebruikelijk - vastgesteld met een klassikale potlood-en-papier-toets. Bij twee groepen leerlingen in de basisschoolleeftijd - een groep basisschoolleerlingen en een groep LOM-leerlingen met hetzelfde gemiddelde niveau van leesvaardigheid, maar verschillend in gemiddelde leeftijd - is onderzocht hoe beide toetsprocedures zich tot elkaar verhouden.
De mogelijkheid dat de uitspraak een aparte foutenbron is die alleen bij hardop lezen voorkomt doet al verwachten dat de uitkomsten van beide toetsvormen niet perfect met elkaar overeenkomen. Ook de redenering van Frost, Katz en Bentin (1987; zie ook Katz & Feldman, 1983) voorspelt voor het Nederlands een niet-perfecte relatie tussen het hardop lezen (‘benoemen’) van losse woorden en lexicale decisie. Naar hun opvatting wordt de mate van samenhang tussen hardop lezen en lexicale decisie bepaald door de orthografie van de taal in kwestie. Als de taal een transparante orthografie heeft - fonemen en grafemen dus een een-op-een-relatie hebben - dan kan de articulatoire code voor het uitspreken van geschreven woorden op een doelmatige manier uit de grafemische code worden afgeleid en is er een minimale rol weggelegd voor het mentale lexicon bij het hardop lezen (‘benoemen’) van woorden. Bij talen met een minder doorzichtige orthografie en veel woordspecifieke spellingpatronen, kan de uitspraak minder doeltreffend uit de grafemen worden afgeleid; daar zal de aanwezigheid van een lexicale representatie van de woord-orthografie van voordeel zijn bij het bepalen van de uitspraak. Frost e.a. zien deze opvatting ondermeer bevestigd in de constatering dat zowel in het Servo-Kroatisch, als in het Engels en het Hebreeuws, talen met een orthografie die varieert van respectievelijk zeer transparant naar tamelijk ondoorzichtig, de lexicale decisietijd bepaald wordt door de lexicale status van de stimulus: de oordelen over hoogfrequente woorden vragen minder tijd dan die over laagfrequente en die weer minder dan de oordelen | |
| |
over pseudowoorden. Een vergelijkbaar effect op de benoemtijd vonden ze echter alleen voor het Hebreeuws en (in mindere mate) voor het Engels. Ondersteunende evidentie zien ze ook in de bevinding van Katz en Feldman (1983) dat zowel in het Servo-Kroatisch als in het Engels benoemen sneller gaat dan lexicale decisie, maar dat het verschil tussen die twee het grootst is voor de meest transparante taal, het Servo-Kroatisch. Als deze verschillen voortkomen uit een door de orthografie bepaalde anderssoortige taakuitvoering, dan zou er ook in het Nederlands, een taal met een orthografie die transparanter is dan die van het Engels, een discrepantie moeten zijn tussen de twee taken.
Voor dit onderzoek zijn woorden geselecteerd die geschikt zijn voor kinderen aan de onderkant van de leesvaardigheidsverdeling: orthografisch regelmatige eenlettergrepige woorden met een betrekkelijk eenvoudige structuur (CVCC en CCVC; C staat voor consonant, V voor vocaal). Anders dan onregelmatige woorden lenen regelmatige woorden zich zowel voor herkenning door toepassing van grafeem-foneem-omzettingsregels als voor identificatie op grond van hun specifieke letterpatroon (‘woordbeeld’). Ze zijn daardoor bij uitstek geschikt om aan de hand van overeenkomst of verschil tussen benoeming en lexicale decisie vast te stellen of (groepen van) individuen van elkaar verschillen in de toepassing van deze twee veronderstelde identificatieprocedures.
Het onderzoek dat we hier rapporteren had tot doel zwakke lezers te vergelijken met normale lezers van hetzelfde leesniveau. De omstandigheden lieten echter geen volledige selectie- en matchingsprocedure toe. Daarom is de groep zwakke lezers eenvoudig samengesteld uit LOM-leerlingen. We mogen immers aannemen dat deze populatie voor een belangrijk deel uit zwakke lezers bestaat. De groep normale lezers is samengesteld uit basisschoolleerlingen. Als er zich inderdaad een aanmerkelijk aantal zwakke lezers onder de LOM-leerlingen bevindt, dan zal deze groep bij een gelijk leesniveau gemiddeld een hogere didactische leeftijd en een hogere kalenderleeftijd moeten hebben.
Indien deze lezersgroepen in procedureel opzicht van elkaar verschillen (verschillende strategieën hanteren), dan zou dat zichtbaar moeten zijn in een verschillende relatie tussen de twee taken. Zo'n verschil zou men bijvoorbeeld kunnen verwachten vanwege de fonologische problematiek die regelmatig is aangetroffen bij kinderen met leesproblemen en die zich uit in zwakke prestaties op allerlei taken waarbij spraakklanken moeten worden verwerkt of gemanipuleerd (van Bon, 1994). Deze problematiek is misschien ook de oorzaak van de discrepantie tussen woordidentificatie en woorduitspraak die Kusters (1987) constateerde. Als deze redenering juist is, dan zouden de zeer zwakke lezers hogere lexicale-decisiesscores moeten hebben dan de normale lezers van hetzelfde hardopleesniveau. Als echter het tegenovergestelde verschil in lexicale decisie wordt gevonden (de normale lezers leveren betere prestaties dan de zeer zwakke), dan wijst dat (zie Frost e.a., 1987) op betere beschikbaarheid van de woord-orthografie bij de normale lezers. Bij de zwakke lezers heeft dan kennelijk de ontwikkeling van de lexicaal-orthografische representaties geen gelijke tred hebben gehouden met de woord-identificatie door grafeem-foneem-omzetting. Overeenstemming tussen beide groepen in het verschil tussen lexicale decisie en hardop lezen suggereert dat de ontwikkeling van de zwakke lezers niet anderssoortig is dan die van de normale lezers, maar slechts vertraagd.
Hoewel de uitkomsten van dit experiment theoretische implicaties hebben, heeft het onderzoek mogelijk ook praktische consequenties. Als de twee toetsprocedures equivalent zijn dan heeft dat het praktische voordeel dat de lexicale decisie-toets gebruikt kan worden als een klassikaal alternatief voor de hardop-leestoets, die vraagt om individuele afname.
| |
| |
Om de equivalentie van de toetsvormen te bepalen wordt de correlatie tussen beide taken bepaald bij gebruik van dezelfde woorden en pseudowoorden. Het voorafgaande doet echter verwachten dat die correlatie voor het Nederlands slechts beperkt zal zijn en dat de samenhang bij de zwakke lezers misschien anders is dan bij de normale lezers. Als additioneel validiteitscriterium werd een toets voor tekstbegrip in het onderzoek opgenomen. Voor exploratieve doeleinden is bovendien een semantische categorisatietaak in het onderzoek betrokken. Die taak vraagt eveneens een betekenisbeslissing, maar een die ‘dieper’ gaat, niet of het woord bestaat, maar of het woord een voornaam is of niet. Men zou verwachten dat een diepere beslissing meer tijd zou vergen.
| |
2 Methode
2.1 Proefpersonen
Op twee LOM-scholen en twee Basisscholen werden de ‘klassegroepen’ geselecteerd waarin de leerlingen te vinden zouden zijn waarvan de score op de Een-Minuut-Test (EMT; Brus & Voeten, 1972) vermoedelijk niet hoger zou zijn dan 59. Uit de leerlingen van deze klassen werden twee groepen van 60 proefpersonen samengesteld met een zo goed mogelijk overeenkomende gemiddelde EMT-score (de groepsgrootte is bepaald door de verdere opzet van het onderzoek). Overeenkomst in leesniveau zou uiteraard tot gevolg hebben dat de normale lezers op de Basisschool jonger waren dan de zwakke lezers op de LOM-scholen. Tabel 1 laat zien dat de zwakke lezers iets betere EMT-scores hebben dan de normale lezers. De tabel laat ook het gebruikelijke verschil in geslachtelijke samenstelling en de verwachte verschillen in kalender- en didactische leeftijd zien.
Tabel 1: Gemiddelde leeftijd, aantal maanden leesonderwijs en toetsscores van de zwakke en de normale lezers (standaarddeviaties tussen haakjes), en de uitkomsten van de betreffende t-toetsen (tweezijdig), alsmede de groepssamenstelling naar geslacht.
|
|
Zwakke |
lezers |
Normale |
lezers |
t(118) |
p |
| Leeftijd (maanden) |
114.30 |
(15.39) |
93.51 |
(8.33) |
9.14 |
<.01 |
| Didactische |
|
|
|
|
|
|
| leeftijd (maanden) |
27.97 |
(11.95) |
14.22 |
(5.24) |
8.16 |
<.01 |
| EMT (aantal goed) |
33.15 |
(12.47) |
28.72 |
(14.61) |
2.06 |
.08 |
| Hardop lezen |
|
|
|
|
|
|
| aantal gelezen |
39.30 |
(16.22) |
33.78 |
(17.62) |
1.79 |
.08 |
| aantal goed |
34.60 |
(16.21) |
30.47 |
(17.51) |
1.34 |
NS |
| Lexicale decisie |
|
|
|
|
|
|
| aantal gelezen |
26.82 |
(12.45) |
21.58 |
(12.37) |
2.35 |
<.05 |
| aantal goed |
24.47 |
(12.47) |
18.55 |
(12.72) |
2.62 |
<.01 |
| Namentoets |
|
|
|
|
|
|
| aantal gelezen |
31.30 |
(16.80) |
26.20 |
(17.55) |
.93 |
NS |
| aantal goed |
29.42 |
(15.61) |
23.38 |
(16.60) |
1.09 |
NS |
| Schriftelijke Opdrachten |
2 |
|
|
|
|
|
| aantal goed |
18.63 |
(7.24) |
15.95 |
8.12 |
1.91 |
.06 |
| Aantal jongens/meisjes |
45/15 |
|
27/33 |
|
|
|
| |
| |
| |
2.2 Toetsen
De lexicale-decisietoets bestond uit 60 CCVC- en CVCC-woorden, zelfstandige naamwoorden die volgens Kohnstamm, Schaerlaekens, de Vries, Akkerhuis & Froonincksx (1981) bij 6-jarigen bekend mogen worden verondersteld, en 20 pseudowoorden, die gevormd waren door van willekeurig uit de unaniemenlijst van Kohnstamm e.a. gekozen woorden van dezelfde typen een letter te wijzigen. Van dit woordmateriaal werden 60 verschillende volgorden gemaakt door eerst vaste maar willekeurige posities te bepalen voor de pseudowoorden en voor de bestaande woorden, en daarna de woorden en de pseudowoorden volgens een Latijns vierkant over de beschikbare posities te variëren. Elk van de 60 woorden kwam daardoor in de 60 lijsten een keer voor op een bepaalde, voor woorden bestemde plaats, en slechts een keer na hetzelfde andere woord. Elk van de 20 pseudowoorden kwam daardoor in de 60 lijsten drie keer voor op een bepaalde, voor pseudowoorden bestemde plaats, en hooguit drie keer na hetzelfde andere pseudowoord. De 80 woorden werden in drie kolommen op een A4-vel afgedrukt. De proefpersonen kregen de opdracht de ‘onzin-woorden’ door te strepen. Na een minuut zei de proefleider ‘streep’ en zetten de leerlingen een streep onder het laatst gelezen woord. De werkwijze werd op het bord voorgedaan met een aantal oefenitems.
De namentoets had dezelfde opzet als de lexicale decisietaak en maakte gebruik van dezelfde woorden. De pseudowoorden waren echter vervangen door jongensnamen met een mmkm- of een mkmm-structuur en waarvan we verwachtten dat ze bekend zijn. De opdracht was nu elke jongensnaam door te strepen. De jongensnamen werden begrijpelijkerwijs niet met een beginhoofdletter geschreven.
Voor de hardopleestoets werden dezelfde woordenlijsten gebruikt als voor de lexicaledecisietoets.
Als toets voor tekstbegrip fungeerde Schriftelijke Opdrachten 2 (Brus & van Bergen, 1971) die bestaat uit 32 geschreven opdrachten die moeten worden uitgevoerd door in een tekstboekje een streep, een cijfer of een kruisje te plaatsen, een eenvoudige tekening te maken, enzovoorts.
| |
2.3 Procedure
Het onderzoek vond plaats in de maanden maart tot juli. Eerst werden in één groepsgewijze sessie de namentoets, de lexicale-decisietoets en Schriftelijke Opdrachten 2 afgenomen. Vervolgens werd de hardop-leestoets individueel afgenomen.
| |
3 Resultaten en discussie
Om eerst een globaal antwoord te vinden op de vraag of de scores op de lexicale decisietoets corresponderen met die op de hardop-leestoets, werden correlatiecoëfficiënten tussen de aantallen goede responsies op de verschillende toetsen bepaald. Tabel 2 geeft deze voor beide groepen afzonderlijk en voor alle proefpersonen tezamen.
De correlatiematrices van de twee groepen komen sterk met elkaar overeen, zij het dat de coëfficiënten voor de zwakke lezers op één uitzondering na lager zijn dan die voor de normale lezers. Dat zou kunnen duiden op een geringere toetsbetrouwbaarheid of (hetgeen misschien op hetzelfde neerkomt) op een geringere samenhang in het gedrag van de zwakke lezers.
| |
| |
Tabel 2: De correlatie tussen het aantal goed op de verschillende toetsen
|
| Alle proefpersonen |
|
|
|
|
|
| |
| |
EMT |
HL |
LD |
NT |
SO2 |
| |
| EMT |
- |
|
|
|
|
| Hardop lezen (HL) |
.91 |
- |
|
|
|
| Lexicale decisie (LD) |
.82 |
.78 |
- |
|
|
| Namentoets (NT) |
.81 |
.74 |
.78 |
- |
|
| Schriftelijke Opdrachten 2 (SO2) |
.66 |
.51 |
.61 |
.61 |
- |
| |
| Zwakke lezers |
|
|
|
|
|
| |
| |
EMT |
HL |
LD |
NT |
SO2 |
| |
| EMT |
- |
|
|
|
|
| Hardop lezen (HL) |
.90 |
- |
|
|
|
| Lexicale decisie (LD) |
.79 |
.78 |
- |
|
|
| Namentoets (NT) |
.76 |
.70 |
.75 |
- |
|
| Schriftelijke opdrachten 2 (SO2) |
.57 |
.40 |
.47 |
.53 |
- |
| |
| Normale lezers |
|
|
|
|
|
| |
| |
EMT |
HL |
LD |
NT |
SO2 |
| |
| EMT |
- |
|
|
|
|
| Hardop lezen (HL) |
.92 |
- |
|
|
|
| Lexicale decisie (LD) |
.85 |
.78 |
- |
|
|
| Namentoets (NT) |
.86 |
.77 |
.81 |
- |
|
| Schriftelijke Opdrachten 2 (SO2) |
.71 |
.58 |
.71 |
.68 |
- |
De hardop-leestoets heeft een erg hoge correlatie met de EMT. Dat wijst erop dat de hardop-leestoets ondanks zijn beperkt woordmateriaal als maatstaf voor hardop-leesvaardigheid kan worden gebruikt; het verschil in samenstelling (de EMT bestaat uit woorden van uiteenlopende fonologische structuur en orthografische regelmaat) heeft kennelijk slechts een beperkt effect op de hardop-leesprestaties. De lexicale-decisietoets heeft in beide groepen een hoge correlatie (.78) met het hardop lezen van dezelfde woorden. Deze correlatie is hoger dan men op grond van de redenering van Frost e.a. (1987) vanwege de transparante orthografie van het Nederlands (zie hierboven) zou verwachten. Dat verband is blijkbaar niet geforceerd door de opname van pseudowoorden in de hardop-leestoets, want het verband van de decisietoets met de EMT is niet zwakker. Bovendien zou men dan juist een lage correlatie verwachten omdat de opname van pseudowoorden in een woordenlijst het gebruik van lexicale informatie bij het benoemen tegengaat (Bryant & Bradley, 1980). Ook het verband met de toets voor tekstbegrip geeft geen aanleiding om de lexicale-decisietoets als inferieur te beschouwen; integendeel, zij is zelfs nauwer aan de begripstoets gerelateerd dan de hardop-leestoets.
| |
| |
Tabel 1 laat zien dat in dit onderzoek - zoals bijvoorbeeld ook bij Katz en Feldman (1987)- lexicale decisie meer tijd vergt dan benoeming. Een variantie-analyse met groep (zwakke vs. normale lezers) als tussen- en toets (hardop vs. lexicale decisie) als binnenproefpersonen-factor geeft een significant effect van het type toets (F(1,118)=l30.32, p<.01). Dat is uit te leggen als het gevolg van de extra tijd die het kost om in het geval van lexicale decisie het mentale lexicon te raadplegen. Uit het correlatiepatroon (tussen de twee toetsen en van de twee toetsen met andere toetsen) blijkt echter dat het gedrag in beide taken sterk overeenkomt en dat deze raadpleging dus maar een beperkte eigen rol speelt. De verklaring die voor de hand ligt is dat de woord-identificatie bij beide toetsprocedures langs dezelfde weg verloopt en in beide gevallen resulteert in de specificatie van een fonologisch patroon vóór een eventuele betekenisidentificatie. In het ene geval is dat patroon het uitgangspunt voor de uitspraak, in het andere voor de toetsing of het woord in het mentale lexicon voorkomt. We moeten dan echter wel aannemen dat deze toetsing gecoueleerd is met de afleiding van het fonologische patroon, danwel nauwelijks tussen proefpersonen differentieert.
Het tijdsverschil tussen beide taken (of liever het verschil in het aantal woorden dat men in dezelfde tijd correct kan afhandelen) discrimineert niet tussen zwakke en normale lezers (F(1,118)=.85). Men kan ook daarin een argument zien voor de equivalentie van beide taken. Dat veronderstelt echter dat er feitelijk geen verschil is tussen de groepen proefpersonen. Het is natuurlijk mogelijk dat er wel zo'n verschil is, maar dat de toetsen ongevoelig zijn voor dit verschil.
Er blijkt een significant algemeen verschil tussen de groepen te bestaan (F(1,118)=3.97, p<.05) ten gunste van de zwakke lezers, maar een MANOVA met de beide toetsen als afhankelijke variabelen en de EMT-score als covariaat laat zien dat het verschil een gevolg is van het feit dat de groepen niet volledig vergelijkbaar waren. Als men zo corrigeert voor het verschil in EMT-scores, is het verschil tussen de groepen niet meer significant (F(2, 115)=.44). Er is geen significante interactie van groep en EMT-score in het effect op de toetsresultaten (F(2,15)=.47).
Een andere aanwijzing voor de overeenkomst tussen de groepen is de uitkomst van een variantie-analyse met de hardop-leesscore als afhankelijke variabele, de lexicaledecisiescore en het groepslidmaatschap als factoren. Daarbij bleek noch het groepslidmaatschap, noch de interactie daarvan met de lexicaledecisiescore een significante bijdrage te leveren aan de verklaring van de hardop-leesscore (F(1,116)=.35 resp. F(1,116)=.38). Het verband tussen beide toetsen in de twee groepen kan dus als hetzelfde worden beschouwd. Verdere analyse laat zien dat het verband adequaat wordt weergegeven door een intercept en een rechte lijn; de data geven geen aanleiding om een (eenvoudig) kromlijnig verband te veronderstellen: de hardop-leesscore is te voorspellen als .91 maal de lexicaledecisiescore plus 11.44. Figuur 1 geeft een afbeelding van deze samenhang.
Totnogtoe zijn beide taken en beide proefpersoongroepen vergeleken naar het nettoresultaat, het aantal correcte responsies. Het is echter denkbaar dat vergelijkbare aantallen goede antwoorden tot stand komen op grond van onderscheiden strategieën, zij het dat de hoge correlatie tussen de taken zoiets in dit geval onwaarschijnlijk maakt. Het is bijvoorbeeld mogelijk dat de ene groep zijn aantal goede responsies behaalt ten koste van een groter aantal fouten dan de andere. Zeker de lexicale decisietaak zou zich lenen voor enig risicogedrag.
Uit Tabel 1 is af te leiden dat beide groepen weinig fouten maakten. Op het aantal gelezen woorden is de proportie fouten gering (hardop lezen: .13, lexicale decisie: .14).
| |
| |
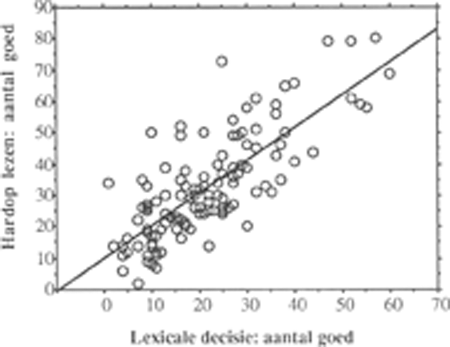
Figuur 1: De samenhang tussen het aantal goede responsies op de lexicale-decisie- en de hardop-leestaak
Deze proporties zijn voor de twee taken niet significant verschillend (t(119)= 1.11), wat niet wijst op meer gokgedrag bij lexicale decisie. Wel blijken de proefpersoongroepen in dit opzicht te verschillen (zie Figuur 2). Terwijl ze zich niet van elkaar onderscheiden in de proportie hardop-leesfouten (t(118)=1.04), maken normale lezers meer lexicale decisiefouten dan zwakke lezers (t(l18)=3.29, p<.01). Splitsen we de proportie lexicaledecisiefouten op in ten onrechte doorgestreepte bestaande woorden en ten onrechte nietdoorgestreepte pseudowoorden dan zien we (Figuur 2) alleen een significant verschil in het eerste (t(118)=3.65, p<.01), niet in het tweede (t(118)=.52). Het verschil is dus dat de normale lezers minder bestaande woorden als zodanig herkennen, wat niet zo vreemd is omdat zij jonger zijn en dus minder woorden zullen kennen. Nemen we de proportie fouten tegen pseudowoorden als index voor de neiging tot gokgedrag, dan zien we dat er slechts weinig gegokt wordt en dat beide groepen daarin niet van elkaar verschillen.
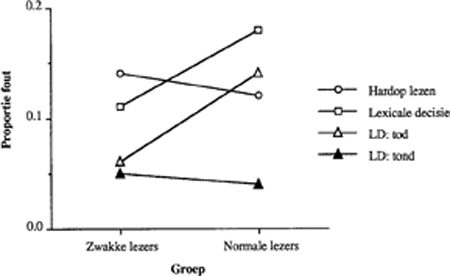
Figuur 2: Proportie hardop-leesfouten en lexicale-decisiefouten, de laatste ook gesplitst in ten onrechte doorgestreepte woorden (LD: tod) en ten onrechte nietdoorgestreepte pseudowoorden (LD: tond), steeds als proportie van het aantal gelezen woorden.
| |
| |
De onderzoeksopzet geeft ook de mogelijkheid de beoordeling van de afzonderlijke woorden te bestuderen. Door de manier waarop de (pseudo) woorden over de decisielijsten waren verdeeld, werd elk (pseudo)woord immers ongeveer even vaak beoordeeld als de andere. Voor elk (pseudo)woord kan nu de proportie goede responsies over alle beoordelingen worden bepaald. Een weergave van deze proporties voor de beide groepen zou te veel plaats vragen, daarom vatten we de betreffende resultaten hier kort samen. Nemen we 80 tot willekeurige scheidslijn, dan zien we dat de jongere normale lezers inderdaad met meer woorden moeite hebben dan de zwakke lezers: List, harp en rasp zijn voor beide groepen moeilijk, maar ondere de jongere lezers lijkt ook een zekere onbekendheid te bestaan met kans, blaar, graaf, groet, kluif, kraam, kruit, ploeg, snik, vlot. Er zijn weliswaar pseudowoorden die bij de normale lezers meer dan 20% fouten opleverden en niet bij de zwakke lezers, maar het omgekeerde geldt ook. Sommige pseudowoorden worden echter door nogal wat kinderen in beide groepen als woorden beschouwd: smap, grik, knoep en spur. Het zou interessant zijn te onderzoeken door welke factoren deze onjuiste beslissingen worden bepaald. Het is denkbaar dat de overeenkomst met een of meer bestaande woorden (‘buren’) daarin een belangrijke rol speelt.
De responsie in de lexicale decisietaak kan in beginsel op twee manieren tot stand komen: door vast te stellen of de vorm bekend voorkomt (of men het woord eerder gezien of gehoord heeft) of door na te gaan of het woord een betekenis heeft. Als de betekenisidentificatie een belangrijke rol speelt, dan zou dat te zien moeten zijn bij vergelijking van de lexicale-decisietaak en de namentaak, omdat die van elkaar verschillen in de eisen die ze op dat punt stellen. Voor de ene taak volstaat beantwoording van de globale vraag of het woord een betekenis heeft; de andere taak gaat ervan uit dat het woord een betekenis heeft en vraagt vaststelling of die betekenis tot een bepaalde categorie (jongensnamen) behoort.
Vergelijking van de gemiddelden in Tabel 1 laat zien dat de aard van de beslissing (woord of pseudowoord versus woord of jongensnaam) inderdaad van belang is. Paarsgewijze t-toetsing van het verschil tussen beide taken in het aantal gelezen en het aantal goed beoordeelde woorden geeft voor beide groepen significante effecten (p<.01) in het voordeel van de namentaak. Het aantal fouten is kennelijk geen eenvoudige functie van het aantal beoordeelde woorden, want op de lexicale decisietaak worden significant (p<.01) meer fouten gemaakt dan op de namentaak (2.69 vs.2.03). Men kan dus doeltreffender en sneller onderscheiden tussen woorden en jongensnamen dan tussen dezelfde woorden en pseudowoorden.
Ondanks dit verschil hebben de twee beslissingstaken een hoge onderlinge correlatie en komen ze sterk overeen in hun verband met andere toetsen (Tabel 2). De aard van de beslissing is dus nauwelijks van invloed op de wijze waarop de taken tussen proefpersonen differentiëren. In aansluiting op de eerdere vergelijking tussen lexicale decisie en hardop lezen ligt de verklaring voor de hand dat de leestaak bij de drie toetsprocedures langs dezelfde weg verloopt en resulteert in de specificatie van een fonologisch patroon vóór een eventuele betekenisidentificatie. De toetsresultaten zouden dan vooral worden bepaald door dat fonologisch decoderen en bij de onderhavige vergelijking minder door de betekenisbeslissing. Wellicht is dat laatste bevorderd door bij beide beslissingstaken twijfelachtige items zoveel mogelijk te vermijden: bij de namentaak waren de foutenproporties van de woorden zelfs lager dan bij de lexicale-decisietaak; we vonden daar geen foutenproporties hoger dan .20, hetgeen leidt tot de opvallende constatering dat de lezers soms - zie boven - gemakkelijker aannemen dat een item een nonsensewoord is dan een | |
| |
naam. De meeste namen leverden ook geen problemen op. Beide groepen proefpersonen hadden kennelijk moeite om in harm, klaas, steef, flip en dries jongensnamen te herkennen. Het is in overeenstemming met hun beperkter ‘kennis van de wereld’ dat de jongere normale lezers daarnaast ook moeite hadden met bart, dirk, niels, twan, bram en sjaak.
Ons onderzoek is beperkt tot een klein bereik van geringe of aanvankelijke leesvaardigheid. Het is zeker niet uitgesloten dat de overeenkomst tussen en de samenhang van de toetsprocedures geringer is bij gevorderde lezers. Ook het gebruikte woordmateriaal (orthografisch regelmatige eenlettergrepige woorden) was beperkt. Dat diene als caveat bij de volgende conclusies, waarbij we beginnen met de praktische consequenties.
Klassikale beslissingstaken van de soorten die in dit onderzoek werden gebruikt vormen een goed alternatief voor het individuele hardop lezen van dezelfde losse woorden. De negatieve verwachtingen die men dienaangaande zou kunnen hebben op grond van theoretische overwegingen, zijn blijkbaar onjuist.
Als men kiest voor zo'n beslissingstaak, dan kan men kiezen tussen lexicale decisie en een toets als de namentaak. Omdat het onderzoek geen reden geeft om de ene boven de andere te verkiezen, kan men het beste de lexicale-decisietaak gebruiken aangezien er meer geschikte pseudowoorden te construeren zijn als afleiders dan bruikbare woorden van een bepaalde semantische categorie zoals namen, gebruiksvoorwerpen of groentesoorten.
De equivalentie van de drie taken wijst op grote overeenkomst in de taakuitvoering; dit in tegenstelling tot de suggestie van Frost e.a. (1987). De resultaten laten zich goed rijmen met de opvatting dat een belangrijk deel van de onderzochte leesactiviteit bestaat uit fonologisch decoderen, ook als het gaat om taken waarbij het mentale lexicon moet worden geraadpleegd.
Als er zich onder de zwakke lezers in het LOM-onderwijs een substantieel aantal dyslectici bevindt en als dyslectici essentieel anders lezen dan normale lezers van hetzelfde leesniveau, dan zou men verwachten dat beide groepen lezers in dit onderzoek zich van elkaar zouden onderscheiden. De LOM-leerlingen onderscheidden zich in de aard van hun leesvaardigheid echter niet van de jongere Basisschool-leerlingen van hetzelfde leesniveau. De zwakke lezers in dit onderzoek lijken dus niet zozeer anders te lezen dan normale lezers van hetzelfde niveau als wel een leesachterstand te hebben. Het is natuurlijk niet uitgesloten dat de uitkomst bepaald is door de manier waarop de groep zwakke lezers werd samengesteld. Een eenvoudige berekening die de relatie tussen kalenderleeftijd en EMT-scores bij de Basisschoolleerlingen tot uitgangspunt had laat zien dat er enkele LOM-leerlingen aan het onderzoek hebben meegedaan die in overeenstemming met hun kalenderleeftijd lazen. Herhaling van het onderzoek met een selectieprocedure waardoor alleen echte zwakke lezers in de vergelijking worden betrokken, is daarom zeker gewenst. De uitkomsten van het onderhavige onderzoek geven echter weinig reden van zo'n onderzoek wezenlijk andere resultaten te verwachten.
Ten aanzien van de equivalentie van hardop lezen en lexicale decisie is tenslotte een kanttekening op zijn plaats. De correlatie tussen deze toetsen is wel zeer hoog, maar niet maximaal. Dat hij niet maximaal is, is niet te wijten aan test-onbetrouwbaarheid. Uit nog ongepubliceerd vervolgonderzoek weten we dat de split-half- en de hertest-betrouwbaarheid van beide typen taken groot zijn. Er is dus een beperkte discrepantie tussen de scores op beide taken die geen gevolg is van onbetrouwbaarheid. Die discrepan | |
| |
tie is, zo blijkt uit hetzelfde vervolgonderzoek, betrouwbaar. Er zijn kinderen die bij herhaling beter blijken te zijn in hardop lezen dan men op grond van hun lexicale decisie zou verwachten. Er zijn daarnaast kinderen die bij herhaling slechter zijn in hardop lezen dan in lexicale decisie. Deze laatste groep is interessant omdat zij kennelijk bestaat uit kinderen voor wie de uitspraakcomponent van de hardop-leestaak uitzonderlijke problemen oplevert. Een vraag die ons nu bezighoudt, is wat de aard is van de uitspraak-problemen waardoor het hardop lezen een negatiever beeld geeft van hun leesvaardigheid dan de lexicale-decisietoets.
| |
Bibliografie
| Bon, W.H.J. van (1994). Fonemische segmentatie (v/h auditieve analyse). In W.H.J. van Bon, E.C.D.M. van Lieshout & J.T.A. Bakker (Red.). Gewoon, ongewoon, buitengewoon. Rotterdam: Lemniscaat. |
| Brus, B.Th. & van Bergen, J.B.A.M. (1972). Schriftelijke opdrachten. Nijmegen: Berkhout. |
| Brus, B.Th. & Voeten, M.J.M. (1973). Een-Minuut-Test. Nijmegen: Berkhout. |
| Bryant, P.E. & Bradley, L. (1980). Why children sometimes write words which they cannot read. In U. Frith (Red.), Cognitive processes in spelling (blz. 355-370). Londen: Academic Press. |
| Frost, R., Katz, L. & Bentin, S. (1987). Strategies for visual word recognition and orthographical depth. A multilingual comparison. Journal of Experimental Psychology: Human Perception and Performance, 13, 157-166. |
| Hoover, W.A, & Gough, P.B. (1990). The simple view of reading. Reading-and-Writing, 2, 127-160 |
| Katz, L. & Feldman, L.B. (1983). Relation between pronunciation and recognition of printed words in deep and shallow orthographies. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9, 157-166. |
| Kohnstamm, G.A., Schaerlaekens, A.M., de Vries, A.K., Akkerhuis, G.W. & Froonincksx, M. (1981). Nieuwe streeflijst woordenschat voor 6-jarigen. Lisse: Swets & Zeitlinger. |
| Kusters, E.D.M. (1987). Self-corrections in oral reading. Some aspects of the reading process of good and poor readers. Unpublished doctoral dissertation, University of Brabant. |
|
|
