
Tijdschrift voor Taalbeheersing. Jaargang 14
(1992)– [tijdschrift] Tijdschrift voor Taalbeheersing–
[pagina 17]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Leesvaardigheid en contextgebruik bij de visuele woordherkenning
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1 InleidingWeinig onderwerpen in de Cognitieve Psychologie hebben de laatste twee decennia zoveel aandacht gekregen als de visuele woordherkenning. Hiervoor zijn diverse redenen, die deels van praktische en deels van theoretische aard zijn. Kennis van de wijze waarop mensen geschreven woorden herkennen is essentieel bij de theorievorming over de werking van het menselijk brein. Bovendien is deze kennis bijvoorbeeld ook nodig voor het ontwikkelen van ‘lezende’ computer systemen, een toepassing met boeiende perspectieven. Geautomatiseerde visuele woordherkenning is in elk geval ook van essentieel belang bij het leren lezen (Stanovich, 1986; Rayner & Pollatsek, 1989). Technische leesvaardigheid berust voor een belangrijk deel op impliciete kennis van orthografische structuur. Analoog aan de syntaxis, die een beschrijving geeft van mogelijke woordcombinaties, kent de orthografie een grafotaxis, die alle binnen het systeem legale lettercombinaties bevat. Elk alfabetisch schrift bedient zich van een lijst van grafische constituenten, die volgens bepaalde combinatieregels kunnen worden samengevoegd. Kenmerkend voor de grafotaxis is dat het om een soort kennis gaat die voor de gebruiker doorgaans impliciet blijft. Wellicht het meest intrigerende aspect van de grafotaxis is dat geoefende lezers en schrijvers er bij het uitvoeren van lees- en/of schrijfwerk voortdurend gebruik van maken zonder dat zij daarbij hoeven na te denken. Orthografische informatie kan op efficiënte wijze worden verwerkt door gebruik te maken van vaste letterpatronen. Het belang van dergelijke sublexicale orthografische eenheden voor de woordherkenning, speciaal bij het lezen van langere woorden, wordt in recente publicaties benadrukt (Seidenberg, 1989). Impliciete kennis van orthografische structuur stelt de geoefende lezer in staat om de schrijfwijze van zowel bestaande als niet bestaande woorden te beoordelen op hun orthografische ‘legaliteit’. Hoewel in het onderzoek naar gebruik van orthografische structuur bij het lezen flinke vorderingen zijn gemaakt liggen er nog een aantal onbeantwoorde vragen. Ten eerste is door Perfetti (1985) opgemerkt dat er nog onduidelijkheid is over de vraag hoe kennis van orthografische structuur nu eigenlijk precies functioneert tijdens het lezen. Is deze kennis aanwezig in de vorm van een regelsysteem of in de vorm | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 18]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
van letterclusters? Dit laatste zou betekenen dat het geheugen van de ervaren lezer een grote hoeveelheid vaste letterpatronen bevat. Het feit dat sch in het Nederlands een legale combinatie is en shc niet, zou dan gerepresenteerd zijn door de aanwezigheid van sch in het bestand bij afwezigheid van shc. Een tweede punt waarover nog onduidelijkheid bestaat is het verband tussen contextgebruik en het gebruik van orthografische structuur. Volgens Perfetti (1985) hebben goede lezers een vergevorderd stadium van automatisering bereikt en zijn daardoor niet meer zo afhankelijk van context. Anderzijds wijst Stanovich (1986) er op dat goede lezers zich niet zozeer onderscheiden van zwakke lezers door context-afhankelijkheid maar door een grotere flexibiliteit. Zij gebruiken context al naar gelang de eisen die de leestaak stelt. Context effecten zouden daarom vooral taakgebonden zijn. In dit verband merkt Stanovich op dat veel van de in de literatuur gerapporteerde tegenstrijdigheden moeten worden toegeschreven aan een meerduidig gebruik van het begrip ‘context’: Reading researchers generally have not been careful in specifying what level in the processing system was being tapped by the particular contextual manipulation employed in a given experiment... The point is that there can be many types of context. For example, context can act to speed ongoing word recognition during reading. Alternatively, context can be used to facilitate the comprehension of text... Bij de visuele woordherkenning werkt context via associaties, terwijl bij tekstbegrip context primair semantisch werkt. Veel onderzoek naar contextgebruik bij het lezen (bv. Bruck, 1988; De Groot, 1983; Perfetti, 1985) grijpt terug naar het zgn. Interactief-Compensatorische Model van Stanovich (1980). Dit model gaat er van uit dat wanneer een zwakke lezer problemen heeft op woordniveau of lager, hij dat compenseert door het maken van bewuste predicties op grond van het voorafgaande. Dit houdt in dat hij meer afhankelijk wordt van context. Goede lezers kunnen ook gebruik maken van context, maar zij hebben dat minder nodig. Op orthografisch niveau herkennen ze woorden en dat is efficiënter en sneller dan woordherkenning met behulp van context. Goede lezers maken rechtstreeks gebruik van orthografische structuur en hoeven niet of nauwelijks gebruik te maken van context. Zwakke lezers daarentegen compenseren hun minder goed geautomatiseerde woordherkenning door extra steun te zoeken in de zinscontext, en presteren daardoor op het eerste gezicht even goed als goede lezers. De zwakke lezer komt in de problemen bij het verwerken op begripsmatig niveau. Om de sematische contexteffecten te verklaren grijpt Stanovich terug op de ‘Two-Process Theory of Expectancy’ van Posner en Snyder (1975a, 1975b). Volgens deze theorie heeft de semantische context invloed op woordherkenning via twee processen:
De goede lezer herkent woorden snel, zó snel dat het tweede proces niet geactiveerd wordt. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 19]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Er zijn geen processen nodig die de aandacht vergen. De aandacht kan volledig aan het begrijpen van de tekst worden besteed. De zwakke lezer gebruikt ook de context, maar naast de automatische activatie (proces 1), ook de bewuste aandacht (proces 2), en dat vergt wel cognitieve aandachtscapaciteit, zodat minder overblijft voor begripsprocessen. In dit onderzoek wilden wij nagaan of goede en zwakke lezers verschillen in de manier waarop zij tijdens het lezen orthografische informatie verwerken. Daarbij wilden we weten of dit proces context afhankelijk is. Context wordt hier opgevat als de semantische en syntactische omgeving van een gegeven doelwoord. Een context kan in meerdere of mindere mate stereotiep zijn. Een stereotiepe context is hier een grammaticale zin waarin twee woorden associatief sterk gerelateerd zijn, bijvoorbeeld: ‘De bakker bakt iedere dag twintig broden’. Bakker en brood zijn twee woorden waartussen een sterke associatieve relatie bestaat. In ons experiment werd dit type zinnen gecontrasteerd met ‘niet-contexten’, bestaande uit in willekeurige volgorde gezette reeksen woorden. In veel onderzoek naar visuele woordherkenning wordt gebruik gemaakt van taken waarin losse woorden worden aangeboden (bv. Van Rijnsoever, 1988; Rayner, 1988; De Groot, 1983). Hoewel dit type onderzoek methodologisch gezien ongetwijfeld voordelen biedt, kleeft aan het laten lezen van losse woorden het bezwaar dat deze taak tamelijk ver af staat van het ‘natuurlijk’ leesproces. Het verwerken van orthografische informatie bij het lezen van reeksen woorden en zinnen is moeilijk rechtstreeks, dus echt ‘on task’, te meten. Wij kozen voor een simpele taak waarbij met letterverwisselingen werd gewerkt. De gebruikte doelwoorden bevatten steeds één specifieke letterverwisseling, systematisch gekoppeld aan orthografische legaliteit, intra woord letterpositie en lettercluster frequentie. Voor wat betreft de lettercluster frequentie maakten we gebruik van Positionele Bigram Frequenties (PBF). Hiermee worden tweeletter groepen bedoeld die op een gegeven positie in woorden veel voorkomen (Young-Loveridge, 1985). Een voorbeeld is het bigram ‘-en’, dat erg vaak voorkomt aan het woordeinde, bijvoorbeeld in infinitieven en bij meervouden. Hierdoor heeft dit cluster een hoge PBFGa naar eindnoot1. Voor de geoefende lezer fungeren hoogfrequente letterclusters als zelfstandige functionele eenheden bij de woordherkenning. Het blijkt dat dit ten koste gaat van het gemak waarmee de afzonderlijke letters binnen zo'n cluster kunnen worden geïdentificeerd (o.a. Van Rijnsoever, 1988). Op grond van het onderzoek van Van Rijnsoever mag worden verwacht dat hoog PBF clusters een maskerende werking hebben op de letterverwerking. Dit geldt ook voor de rol van de positie binnen het woord: verwisselingen aan het woordeinde zullen vaker worden gemist. Dit is dus in feite het gevolg van leesrichting. Letterverwisseling kunnen zowel in hoog- als in laagfrequente letterclusters, en qua positie zowel aan het begin als aan het eind van een woord zitten. Grafotactisch gezien kunnen letterverwisselingen tot drie verschillende typen schendingen van de visuele woordvorm leiden. Ten eerste kan er een vorm ontstaan die grafotactisch illegaal is, zoals bij stenen in plaats van stenen. Ten tweede kan de ontstane vorm grafotactisch legaal zijn, zoals bij kramten in plaats van kranten. Tenslotte is er nog bij de grafotactisch legale verwisselingen de mogelijkheid dat de resterende vorm in akoestisch opzicht identiek is met de oorspronkelijke vorm, zoals bij brantweer in plaats van brandweer. In de onderzoeksliteratuur (Rayner, 1988) worden deze typen respectievelijk met de termen ‘Shape-Illegal’, ‘Shape-Legal’ en ‘Sound-Legal’ aangeduid. Al deze typen waren in ons onderzoek vertegenwoordigd. Eén van de vragen die wij beantwoord wilden zien was of er een verband was tussen leesvaardigheid en het detecteren van de drie gebruikte | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 20]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
typen verwisselingen. Naar verwachting zullen verwisselingen die leiden tot een illegale lettercombinatie beter worden opgemerkt, omdat ze afwijken van de lettercombinaties die men doorgaans tijdens het lezen tegenkomt. Eerder merkten wij al op dat context op zich geen criterium behoeft te zijn om goede en zwakke lezers te onderscheiden. Zwakke lezers zijn weliswaar meer afhankelijk van context, maar kunnen daardoor ook tot een goede woordherkenning komen. De vraag of context faciliterend dan wel inhiberend werkt op woordherkenning is afhankelijk van de taak die de proefpersoon krijgt. Welk effect van context mag men verwachten bij het verwerken van orthografische informatie? Bij het beantwoorden van deze vraag moet men zich realiseren dat context faciliterend werkt op de snelle semantische verwerking van woorden. De aandacht zal vooral op het zinsniveau zijn gericht, hetgeen ten koste gaat van de verwerking op woordniveau. Hierdoor zullen de individuele letters van een woord minder goed worden bekeken. Daardoor zullen naar verwachting letterverwisselingen in context minder goed worden opgemerkt. Vooral de zwakke lezers zullen hiervan extra hinder ondervinden. Het voorafgaande leidt tot de volgende onderzoekshypothesen:
Om verschillen tussen normale en zwakke lezers beter te kunnen interpreteren werd gebruik gemaakt van een zgn. Reading Level Design (RLD-design) proefopzet. In dit type design worden zwakke lezers vergeleken met jongere normale lezers, gematcht op een standaard leesvaardigheidstest. Het achterliggende idee daarbij is dat de vergelijking hierdoor beter interpreteerbaar wordt. Goede en zwakke lezers van dezelfde leeftijd zullen immers behalve verschil in leesprestatie ook nog allerlei andere, niet te interpreteren verschillen te zien geven, waardoor onduidelijk blijft of het aangetroffen verschil wel in causaal verband met leesvaardigheid staat of niet. Door gelijk te schakelen op leesvaardigheid (Reading Age Level) wordt dit interpretatie-probleem ondervangen. Reading Level Designs zijn bijvoorbeeld gebruikt bij leesonderzoek van jonge kinderen door Bryant & Bradley (1985) en door Reitsma (1983). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2 MethodeProefpersonenAls proefpersonen fungeerde een groep van twintig kinderen uit de groepen 4 en 5 van basisschoolGa naar eindnoot2 ‘De Ichthus’ te Putten (goede lezers) gematched met een groep van twintig kinderen van de LOM-school ‘De Hanze’ te Harderwijk (zwakke lezers). Het matchen op leesvaardigheid gebeurde met de Brustest (Brus & Voeten, 1972). De groep zwakke lezers bestond uit 10 jongens en 10 meisjes met een gemiddelde leeftijd van 12, 1 jaar. De groep goede lezers bestond uit 15 meisjes en 5 jongens met een gemiddelde leeftijd van 8, 9 jaar. Alle kinderen hadden Nederlands als moedertaal. Er waren geen verschillen in etniciteit. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 21]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ExperimenteermateriaalEr werd gebruik gemaakt van associatiewoorden met associatiefrequenties van De Groot (1983). Een zin bevatte altijd een woord (de prime) met het bijbehorend associatiewoord (de target), waarin de letterverwisseling was aangebracht. Het associatiewoord volgde altijd enkele woorden na de prime. In de ‘Geen context’-conditie werden dezelfde zinnen gebruikt, maar dan met de woorden in een willekeurige volgorde. Het totale aantal zinnen bedroeg 128. Enkele voorbeelden worden gegeven in bijlage A. Er werden drie typen verwisselingen gebruikt: c/e (Shape-Illegal, voorbeeld: geweer), m/n (Shape-Legal, voorbeeld: omweer), en t/d (Sound-Legal, voorbeeld, brantweer). De letterverwisseling bevond zich in de eerste of tweede syllabe. Zowel in de context als in de ‘Geen-context’-conditie waren 8 controle-aanbiedingen opgenomen. Dit waren aanbiedingen waarbij geen letterverwisseling voorkwam. De positie van de associatie woorden (primes en targets) in de zin (en de corresponderende willekeurige woordreeks) werd constant gehouden. Het bleek praktisch niet mogelijk om t/d en m/n letterverwisselingen orthogonaal te variëren op de factor PBF. Daarom werden bij die typen alleen verwisselingen in laag PBF clusters gebruikt. Een lijst met alle letterverwisselingen wordt gegeven in bijlage B. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ProcedureHet experiment werd afgenomen in twee sessies. De contextzinnen en de corresponderende ‘Geen-context’ aanbiedingen werden nooit in dezelfde sessie aangeboden. Aanbieding van het leesmateriaal gebeurde via een personal computer met een monochrome beeldscherm en een knoppenkast voor de tijdmeting. Iedere proefpersoon werd in de experimenteerruimte apart genomen. De proefpersoon kreeg eerst instructie. Daarna werden enkele oefenitems doorgewerkt. Het materiaal werd in een willekeurige volgorde aangeboden. De proefpersoon moest eerst de gepresenteerde zin of de reeks woorden lezen. Als hij klaar was moest hij op een knop drukken. De zin verdween dan en de benodigde leestijd werd door de computer geregistreerd. Indien de proefpersoon een verwisseling signaleerde verschenen de woorden nogmaals op het scherm, maar nu in alfabetische volgorde onder elkaar. De proefpersoon moest eerst het betreffende woord aangeven en vervolgens de exacte locatie van de verwisseling. Daarna verschenen twee woorden op het scherm, waaruit hij het woord moest kiezen dat qua betekenis het sterkst met het gelezene was geassocieerd. Over de juistheid van dit oordeel kreeg de proefpersoon feedback. De computer registreerde verder of de letterverwisseling correct werd gelocaliseerd. Het was dus mogelijk dat men een verwisseling had gezien, en desondanks de verkeerde plaats aangaf. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3 ResultatenDe data werden met behulp van covariantie analyses verwerkt. Brusscore en leeftijd werden als covariaat opgenomen. De volgende analyses werden uitgevoerd:
In de analyses werden zowel proefpersoon- als itemgemiddelden als observatie-eenheid genomen (Clark, 1973). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 22]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analyse naar algemene effecten van context en positieHet verwachte context effect werd gevonden, F(1,35)=12.04, p<.001 in de analyse over personen. Ook in de analyse over items was dit effect significant, F(1,80)=5.36, P=.023. Zie figuur 1. Het verwachte differentiële effect van context op groep was niet significant. 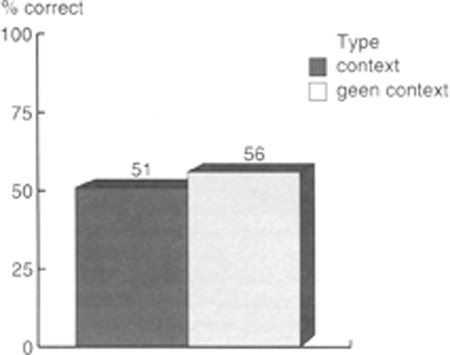
Figuur 1: Hoofdeffect van context
Het positie-effect (syllabe-effect) was significant F(1,35)=20.35, p<.000, in de analyse over personen. In de analyse over items F(1,80)=13.85, p<.000. De letterverwisselingen in de eerste syllabe werden duidelijk beter waargenomen dan in de tweede syllabe. In de analyse over items werd verder nog een interactie gevonden tussen groep en positie, F(1,80)=6.55, p=.012. De goede lezers nemen in de tweede syllabe minder letterverwisselingen waar dan de zwakke lezers. In de eerste syllabe zijn ze vergelijkbaar. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Orthografisch illegale verwisselingen (c/e type)Een multivariate variantie analyse (MANOVA) liet zien dat er in de analyse over personen een effect van groep F(1,33)=5.64, p=.024 optrad in de analyse over personen. In de analyse over items was dit effect niet significant. Tabel 1 geeft een overzicht: (zie tabel 1). Verder was er een significant effect van positie (syllabe) F(1,35)=28.42, p<,001, (zie Figuur 2) en een zwak PBF effect F(1,35)=4.09, p=.051 (analyse over personen). In de analyse over items leverde dit alleen een effect op van positie, F(1,40)=27.07, p<.000. De effecten van syllabe en PBF komen overeen met de in de hypothese gestelde verwachting. Letterverwisselingen in de tweede syllabe worden slechter waargenomen dan in de eerste syllabe en letterverwisselingen in laag PBF clusters worden beter waargenomen dan in hoog PBF clusters. Goede lezers nemen letterverwisselingen in de tweede syllabe over het algemeen iets slechter waar dan zwakke lezers, hoewel dit in de analyse over personen niet significant was; groep x positie, F(1,35)=3.63, p<.065. In de analyse over items was dit wel significant, F(1,40)=7.69, p<.008. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 23]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 1: Gemiddeld aantal detecties in c/e verwisselingen (Maximale score is 6. Standaard deviaties tussen haakjes) 
Figuur 2: Positie effect bij orthografisch illegale verwisselingen (c/e type)
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 24]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Orthografisch legale verwisselingen (m/n en t/d type). Een overzicht van de resultaten wordt gegeven in tabel 2:
Tabel 2: Gemiddeld aantal detecties bij legale verwisselingen (m/n en t/d) (Maximale score is 6. Standaard deviaties tussen haakjes) In de analyse over personen werd een significant effect gevonden van type, F(1.35)= 14,62, p<.001. Zie figuur 3. M/n verwisselingen bleken gemakkelijker localiseerbaar dan overeenkomstige t/d verwisselingen. 
Figuur 3: Vergelijking van de legale typen verwisselingen (m/n en t/d)
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 25]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Toetsing van het type effect gebeurde door vergelijking van de Laag PBF aanbiedingen. Dit leverde, zoals verwacht, op dat illegale verwisselingen veel vaker werden opgemerkt, F(1,35)=153.02, p<.001 over personen. Over items F(1,70)=186.6, p<.001. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analyse van leer- (sessie-)effecten.De resultaten uit de eerste sessie werden vergeleken met die van de tweede sessie. Er werd geen effect van groep gevonden in de analyse over personen, wel een algemeen sessie effect F(1,35)=23.01, p<.001. In de tweede sessie wordt beter gepresteerd door beide groepen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Accuratesse en leestijdenOm na te gaan of de proefpersonen in de tweede sessie nauwkeuriger werkten, en dus geleerd hadden van de eerste sessie, werd een aanvullende analyse uitgevoerd, waarbij gekeken werd naar die gevallen, waarin het juiste woord wèl werd aangewezen, maar waarbij de proefpersoon er vervolgens toch niet in slaagde de juiste letter te localiseren. Over het gehele experiment genomen gebeurde dit in 9% van alle aanbiedingen. In de tweede sessie werden er minder letterverwisselingen verkeerd gelocaliseerd, d.w.z. er werd nauwkeuriger gewerkt, F(1,35)=31.68, p<.000 in de analyse over personen en F(1,80)=25.36, p<.000 in de analyse over items. Dit gold ook voor de c/e letterverwis-selingen afzonderlijk. Het effect van sessie is in de analyse over personen F(1,35)=21.69, p<.001 en in de analyse over items F(1.40)=19.39, p<.001. Het effect van sessie bleef ook bestaan voor de legale typen (m/n en t/d) gezamenlijk, F(1,35)=8.25, p<.007 in de analyse over proefpersonen en F(1,40)=6.19, p<0.017 in de analyse over items. Dit kwam vooral voor rekening van de t/d letterverwisselingen. Het effect van sessie bij t/d was F(1,35)= 13.24, p<.001, bij m/n was dit effect niet significant (analyse over personen). De goede groep presteerde beter dan de zwakke groep (minder verkeerde localisaties), F(1,33)=4.88, p<.034 in de analyse over personen en F(1,80)=12.18, p<.001 in de analyse over items, d.w.z. de goede groep werkte nauwkeuriger of men onthield misschien beter de juiste plaats, zie Figuur 4. Er was geen interactie van groep met sessie. Het effect van groep bleef bestaan wanneer we de c/e letterverwisselingen apart beschouwen, F(1,33)=6.34, p<.017 in de analyse over personen en F(1,40)=14.60, p<.001 in de analyse over items. Bij de m/n en t/d letterverwisselingen waren er geen groepseffecten. In geen van de gevallen was er een interactie van groep met sessie. 
Figuur 4: Accuratesse bij goede en zwakke lezers
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 26]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Een analyse van de leestijden gaf bij alle typen een sterk conditie effect te zien. De benodigde leestijd in de niet-context aanbiedingen was aanmerkelijk langer dan in context. Dit effect was voor goede en zwakke lezers gelijk. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4 DiscussieHet verwachte contexteffect werd gevonden. Letterverwisselingen in de niet-context conditie werden beter waargenomen. Het verwachte differentiële effect van context op groep werd niet gevonden. De zwakke lezers hadden in deze opzet blijkbaar niet méér moeite met het detecteren van letterverwisselingen in de contextsituatie dan de goede lezers. Dit resultaat is dus niet in overeenstemming met de hypothese dat zwakke lezers meer afhankelijk zijn van context. Bij de qua structuur illegale verwisselingen (c/e type) was er een effect van groep. Dit effect was alleen sifnificant in de analyse over personen. Goede lezers bleken zowel beter als accurater te werken dan zwakke lezers. Uit een nadere analyse van de data bleek dat dit verschil vooral ligt op het niveau van de accuratesse. De beide groepen bleken niet te verschillen wat betreft het aantal juist geïdentificeerde woorden maar wèl wat betreft het vinden van de exacte letterverwisseling binnen de woorden. Dit duidt er op dat zwakke lezers beschikken over een minder goede mentale representatie van de visuele woordvorm. Effecten werden verder gevonden voor PBF (zwak en alleen in de analyse over personen) en positie, echter niet in interactie met leesvaardigheid. Dit is in overeenstemming met de algemene verwachting. Volgens Stanovich (1980) onderscheiden goede lezers zich van zwakke lezers op grond van snelle, contextvrije woordherkenning en niet door het gebruik van orthografische structuur: Studies that have examined the effect of orthographic structure on the speed of recognition have consistently found that this variable does not distinguish good from poor readers once the child has passed the initial stages of reading acquisition. (Stanovich, 1980, p.39) Bij de qua structuur legale verwisselingen (m/n en t/d) blijkt een effect van type. Het maakt dus uit wat voor soort letterverwisseling er aangebracht wordt. Er zijn verschillende verklaringen voor dit opvallende verschil. De meest waarschijnlijke is dat alleen bij t/d verwisselingen de fonologische informatie intact blijft. De vraag naar hoe visuele, fonologische, en orthografische kenmerken van woorden precies functioneren bij de visuele woordherkenning staat op dit moment in het onderzoek volop in de aandacht. Een analyse over beide sessies toont een toename in de accuratesse. In de tweede sessie worden er minder letterverwisselingen verkeerd gelocaliseerd. De goede groep doet het wat nauwkeurigheid betreft beter dan de zwakke groep. Er van uitgaand dat goede lezers een betere woordbeeldkwaliteit hebben dan zwakke lezers is dit resultaat logisch verklaarbaar. Het verschil in woordbeeldkwaliteit bepaalt of iemand een goede lezer is. De analyse van de leestijden laat zien dat de proefpersonen in de ‘geen context’ conditie langer over het lees- en detectieproces doen dan in de contextsituatie. Dit kan er mede de oorzaak van zijn dat letterverwisselingen in de ‘geen context’ situatie beter werden waargenomen. Wanneer echter de reactietijden en de scores naast elkaar gelegd worden blijkt dat een langere reactietijd niet met een betere score gepaard gaat. Volgens het Interactief Compensatorisch Model van Stanovich hoeven goede lezers geen gebruik te maken van context. Zwakke lezers daarentegen zijn wèl aangewezen op | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 27]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
context, en zullen daarom bij het ontbreken van context problemen ondervinden. Uit de door ons verzamelde gegevens is voor deze hypothese geen aanwijzing te vinden. Onze eindconclusie is daarom dat in dit onderzoek, dat gericht was op de verwerking van orthografische informatie tijdens het lezen, geen ondersteuning kon worden gevonden voor de voorspelling van het Interactief Compensatorische Model van Stanovich. Daarbij blijft de mogelijkheid open dat de gebruikte meetmethode, waarbij een expliciet orthografisch oordeel werd gevraagd, een rol heeft gespeeld. Een mogelijk bruikbare meer directe meetmethode van contextgebruik is bijvoorbeeld te vinden in de experimenten van Sereno (1991). Hier werd aangetoond dat het mogelijk is om bij ervaren lezers - het onderzoek werd uitgevoerd met studenten als proefpersonen - de woordherkenning te faciliteren door middel van associatieve en syntactische primes. Deze methode is wellicht ook geschikt voor toepassing in experimenten waarin leesvaardigheid en contextgebruik worden gemanipuleerd. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bijlage AVoorbeeldzinnen (primes zijn cursief gedrukt)
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bijlage BLijst van gebruikte letterverwisselingen
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 28]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 29]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||